A Semantic Model for Selective Knowledge Discovery over OAI-PMH Structured Resources


Abstract
:1. Introduction
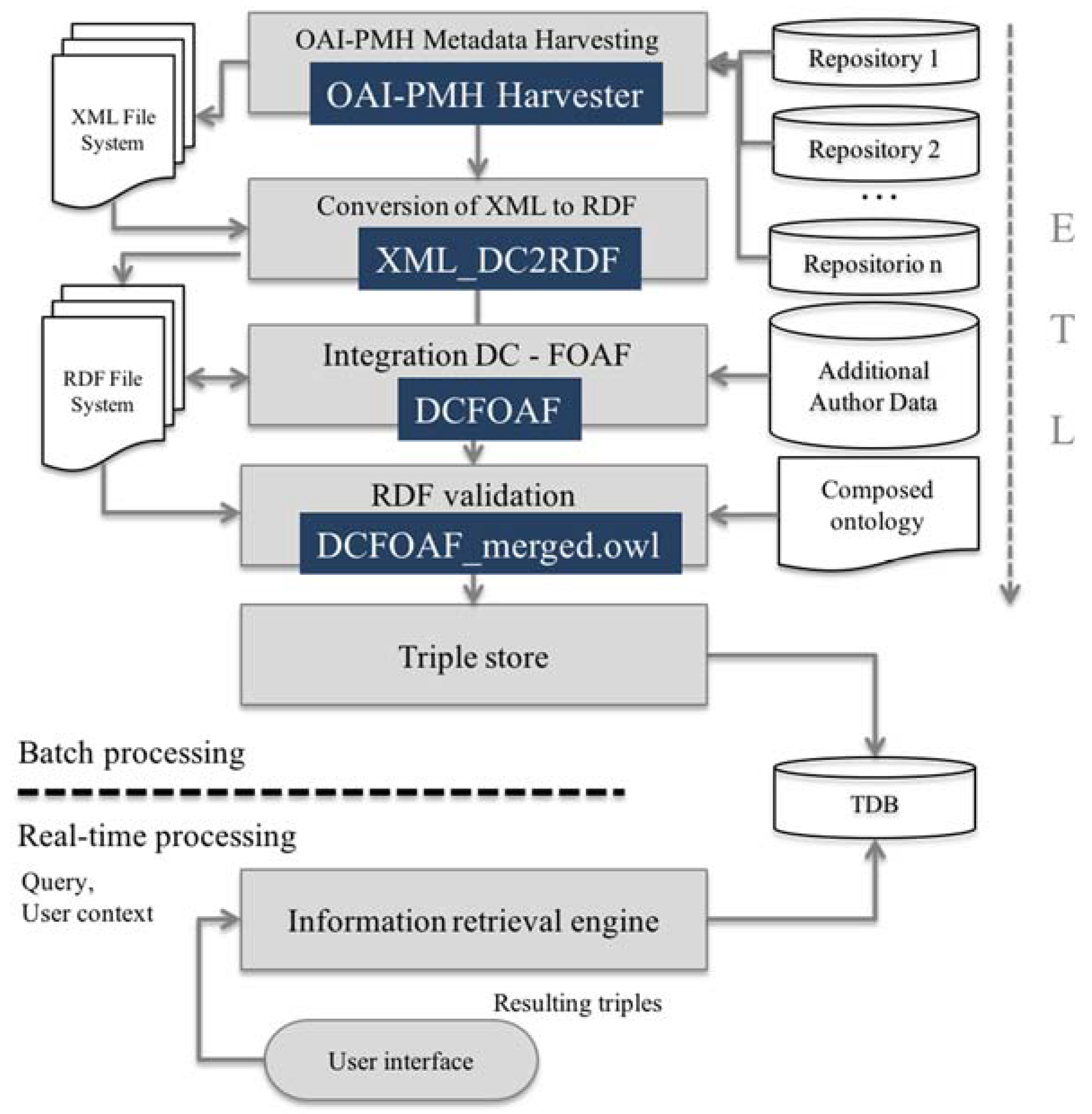
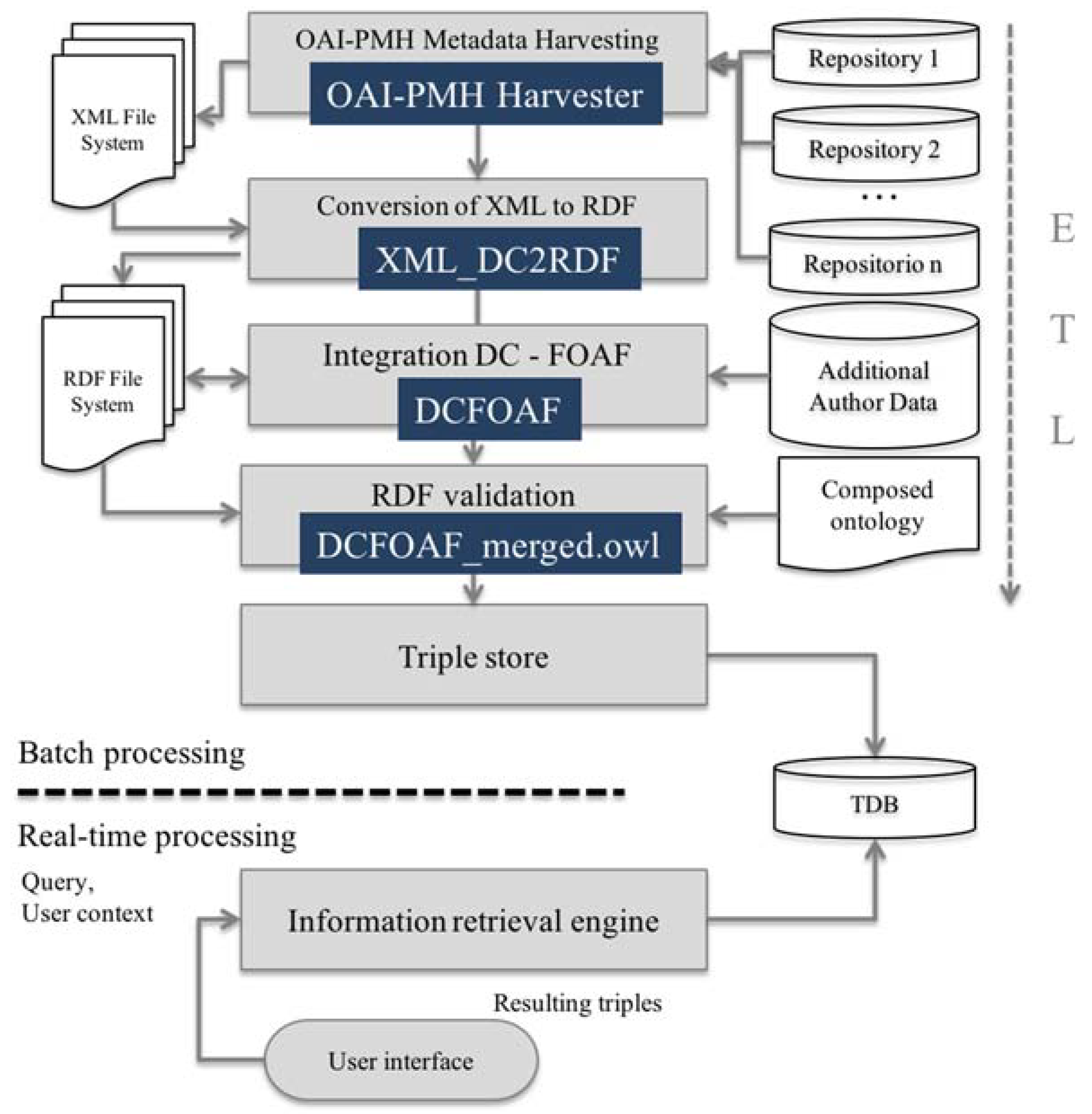
2. Materials and Methods
- Harvesting of resource metadata that are available through repositories that implement OAI-PMH.
- The conversion of the results obtained in XML to RDF.
- The enrichment of statements (obtained in Dublin Core) with additional information from authors (FOAF).
- Validation of the resulting knowledge.
- Triple storage.
- Information retrieval based on inference, which will provide service to the end user. One may note that the required information input from a user interface matches the query and the contextual user information.
- OAI-PMH harvester
- XML_DC2RDF
- DCFOAF
- DCFOAF_merged.owl
2.1. Sources of Information
2.2. OAI-PMH Metadata Harvesting
2.3. XML to RDF Conversion
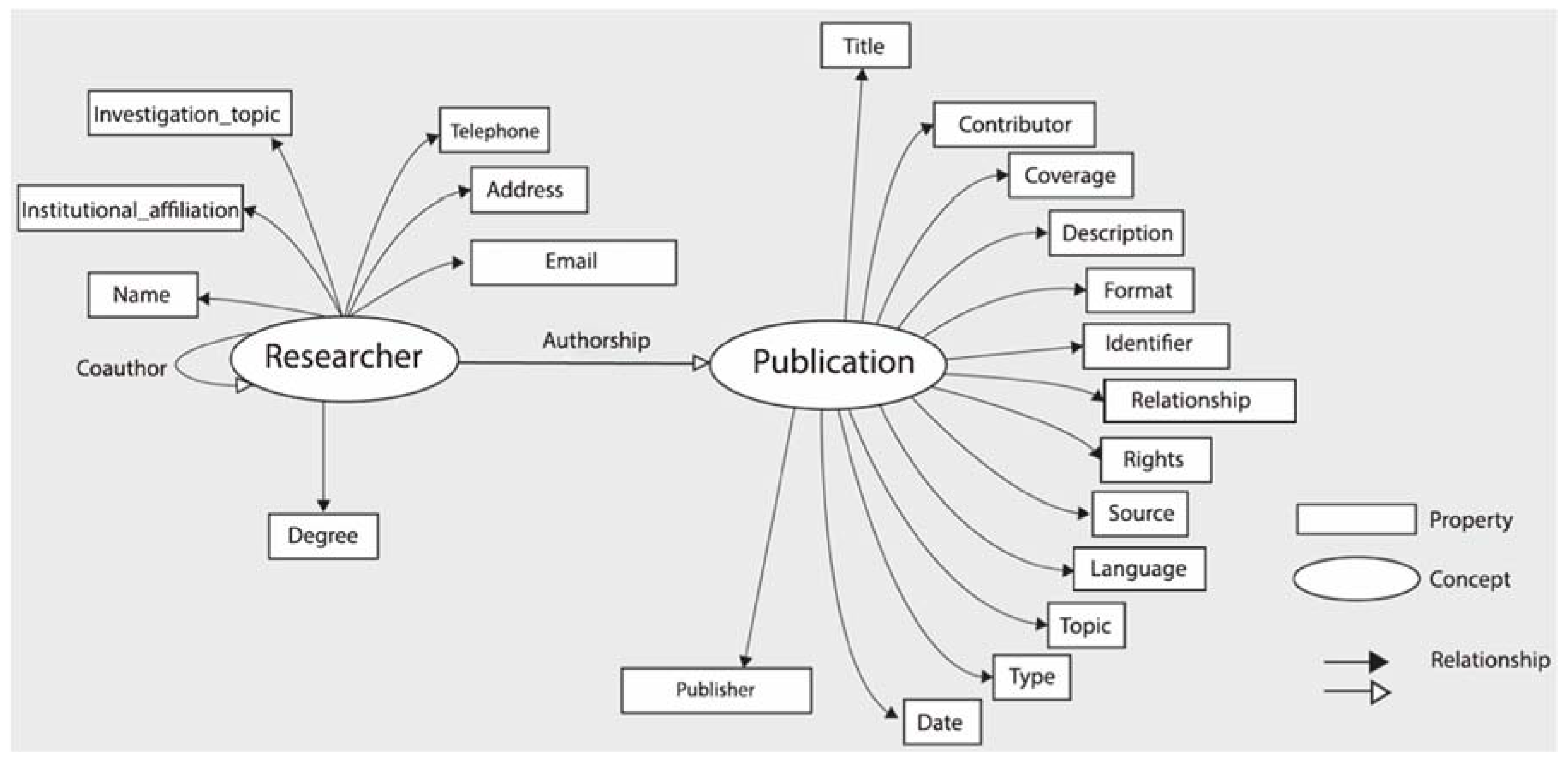
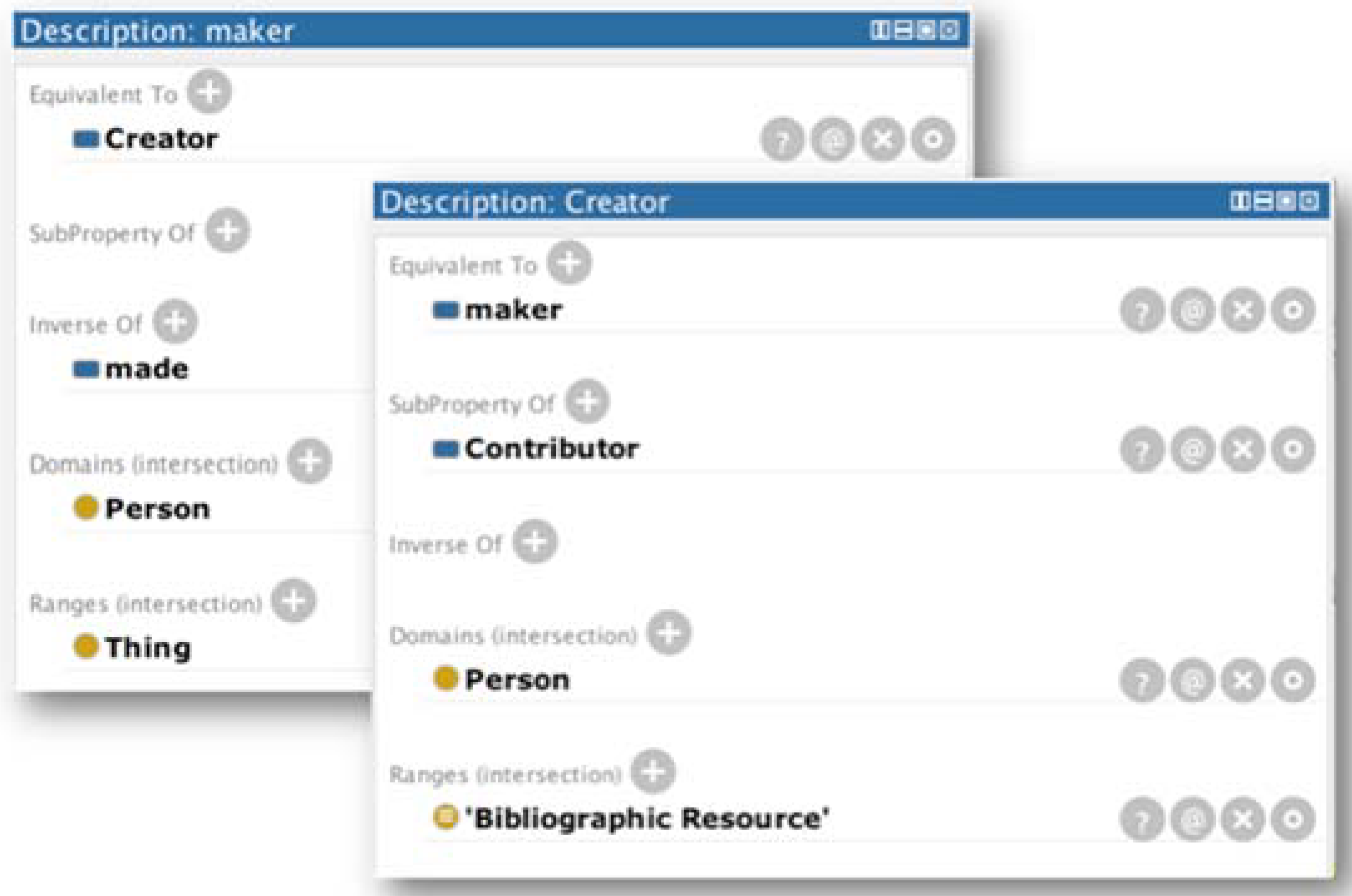
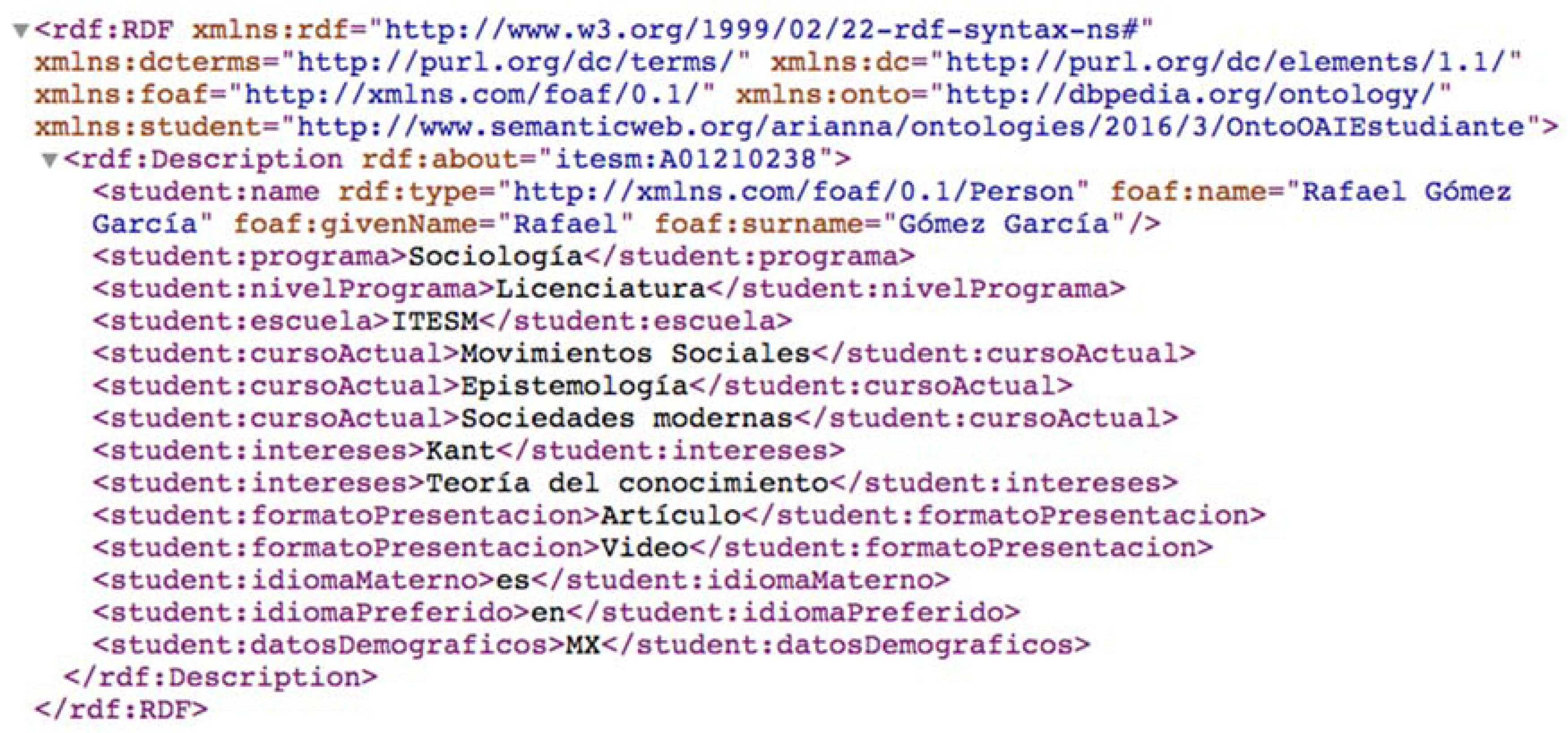
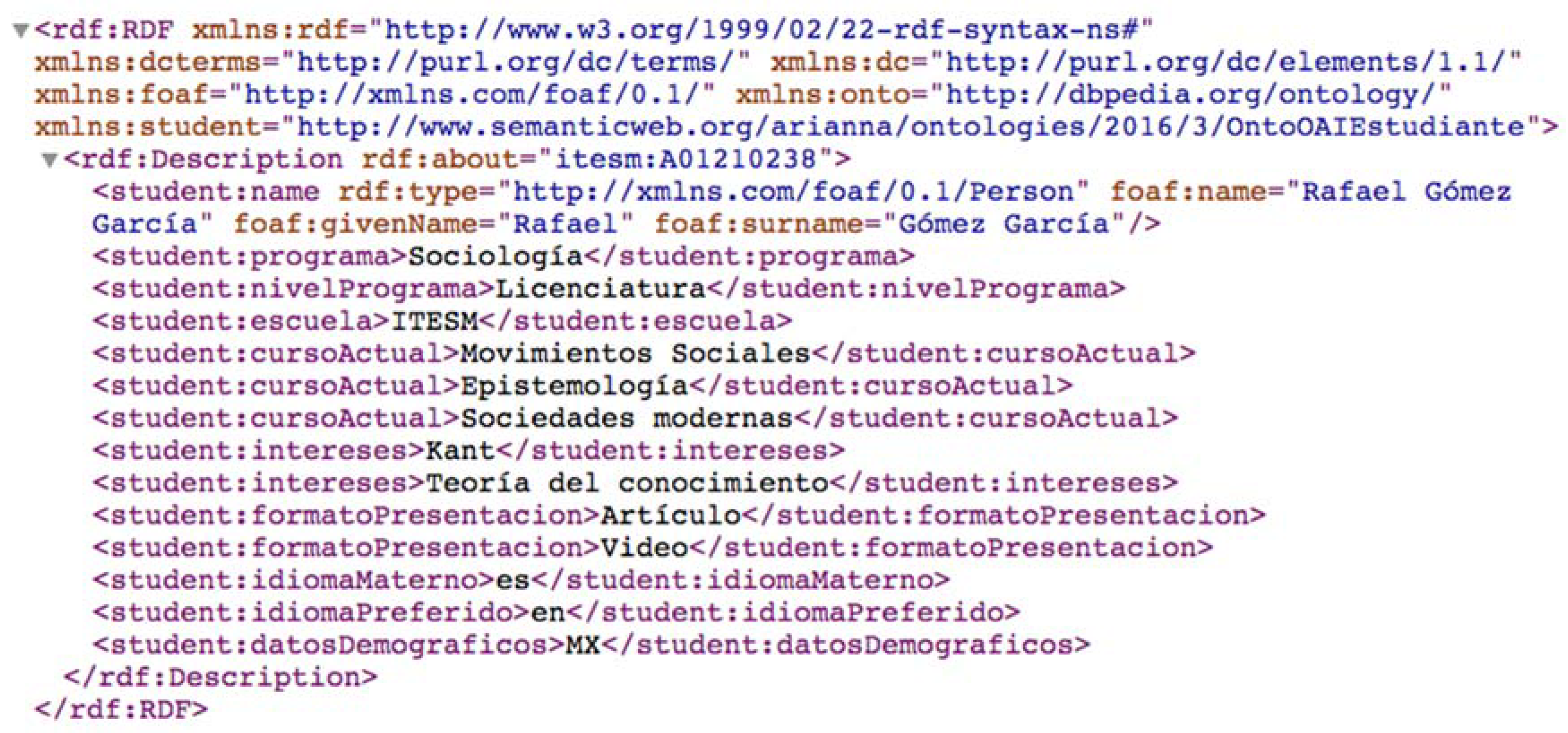
2.4. Integration of DC XML with FOAF
<dc:creator rdf:type = [http://xmlns.com/foaf/0.1/Person] foaf:name = [full name] foaf:givenName = [name] foaf:surname = [last name] foaf:knows = [known person or co-author] foaf:topic_interest = [topic of interest] dc:description = [occupation, grade, etc.] onto:birthDate = [birthdate]/>
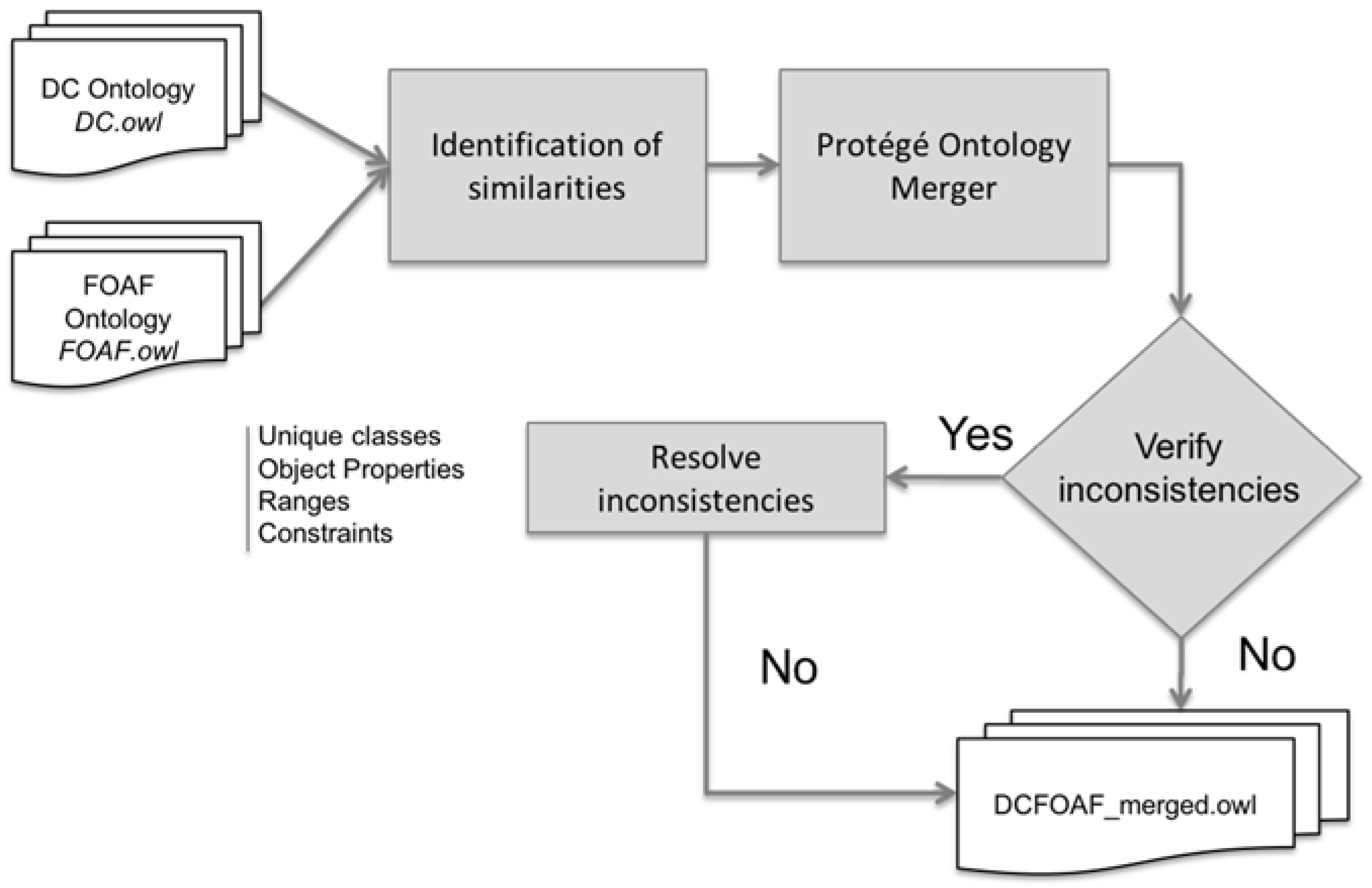
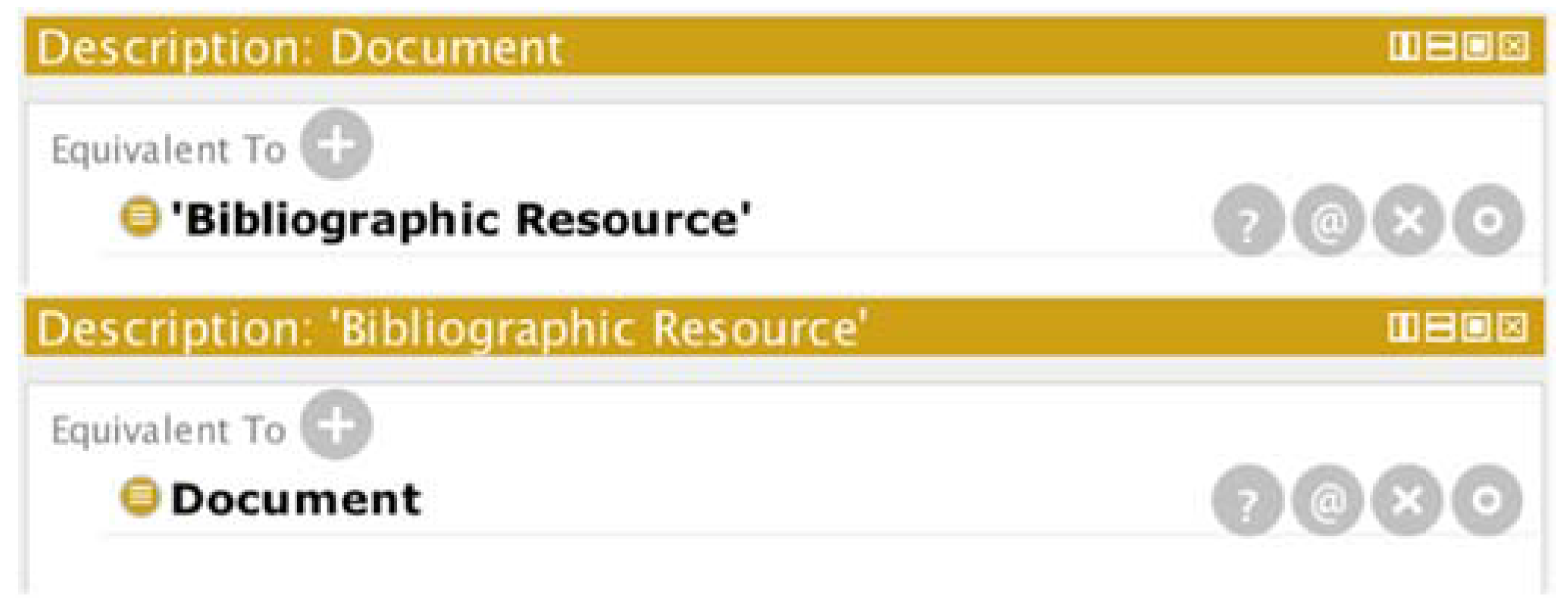
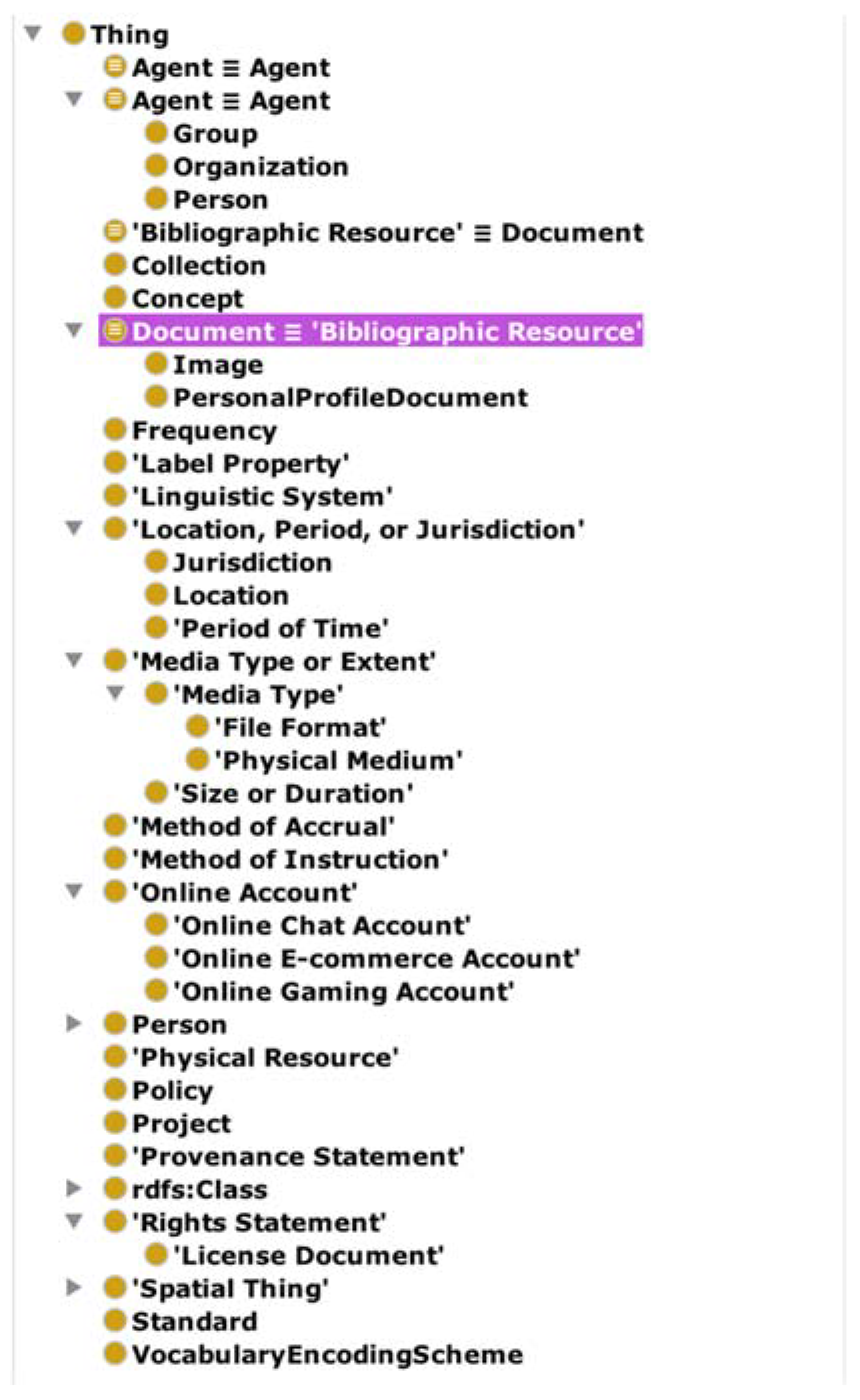
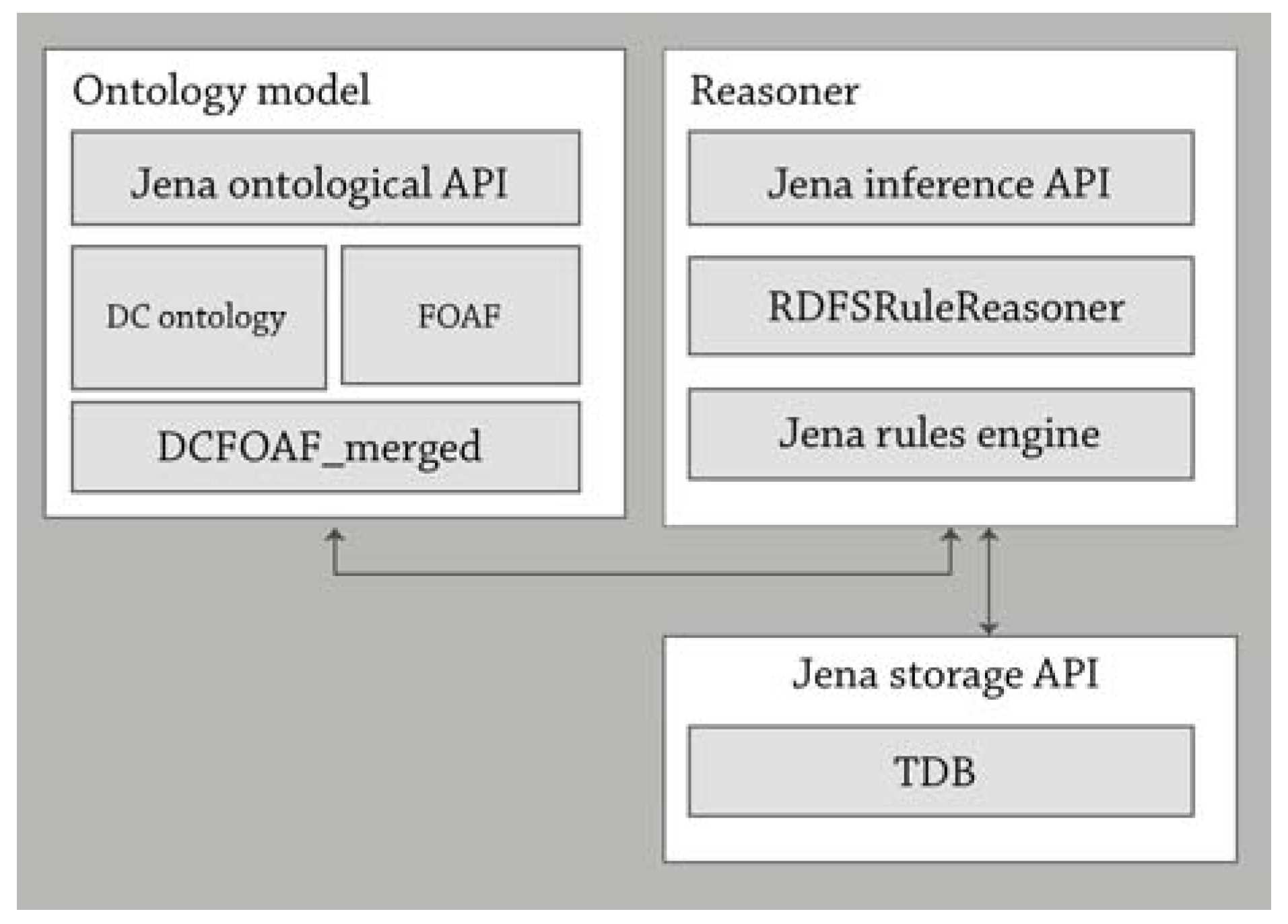
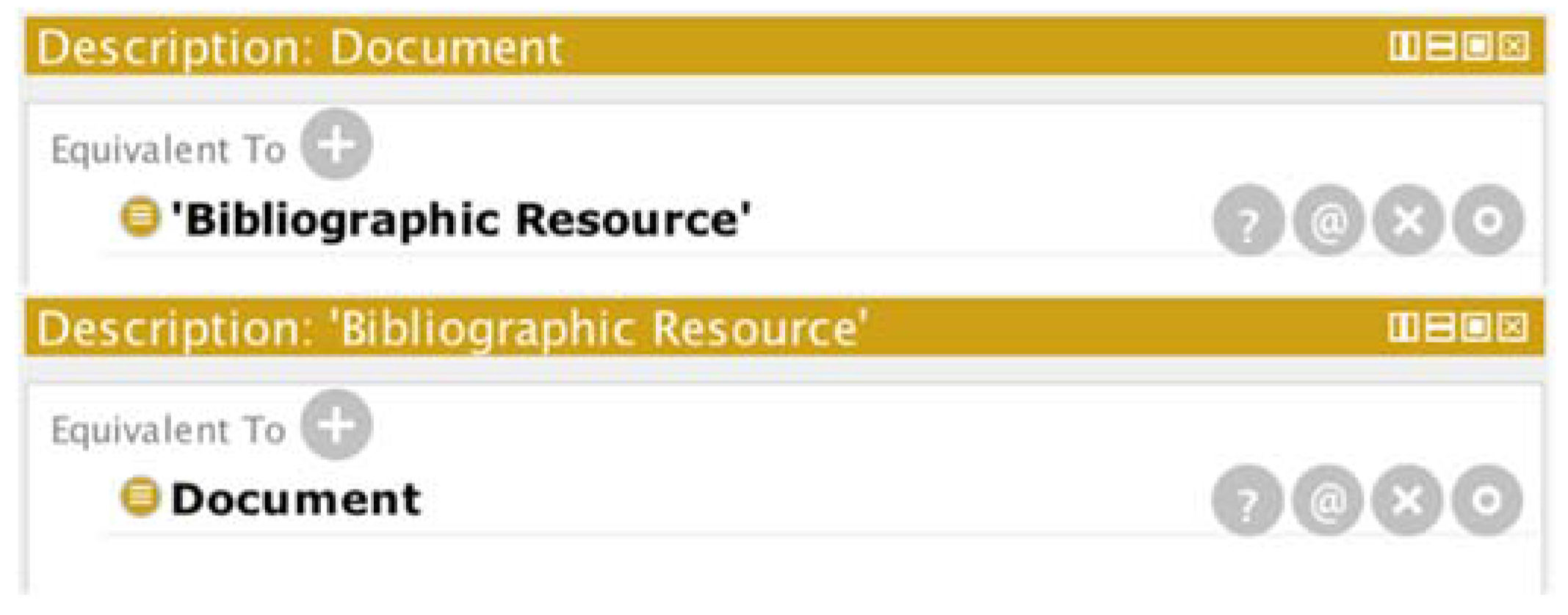
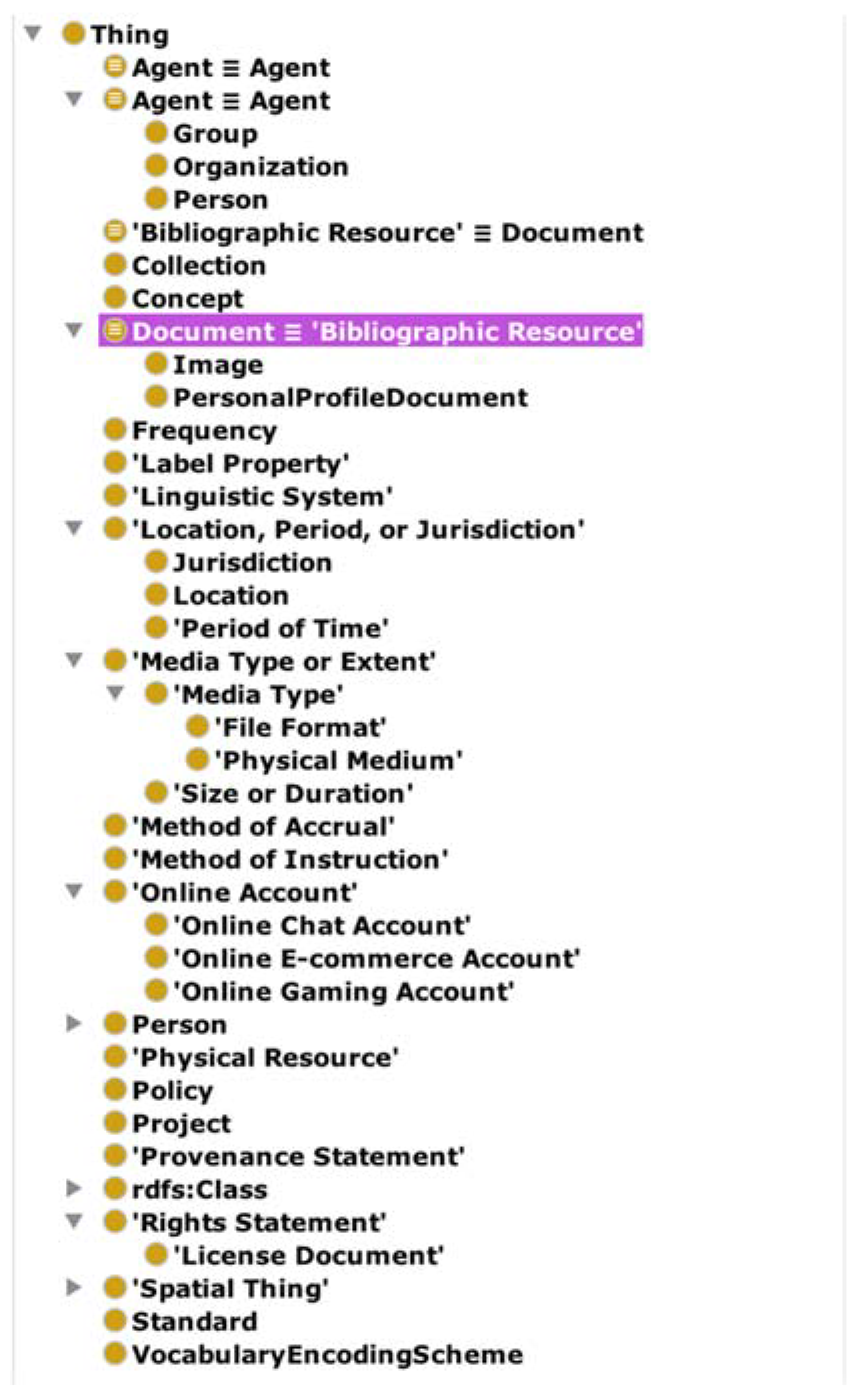
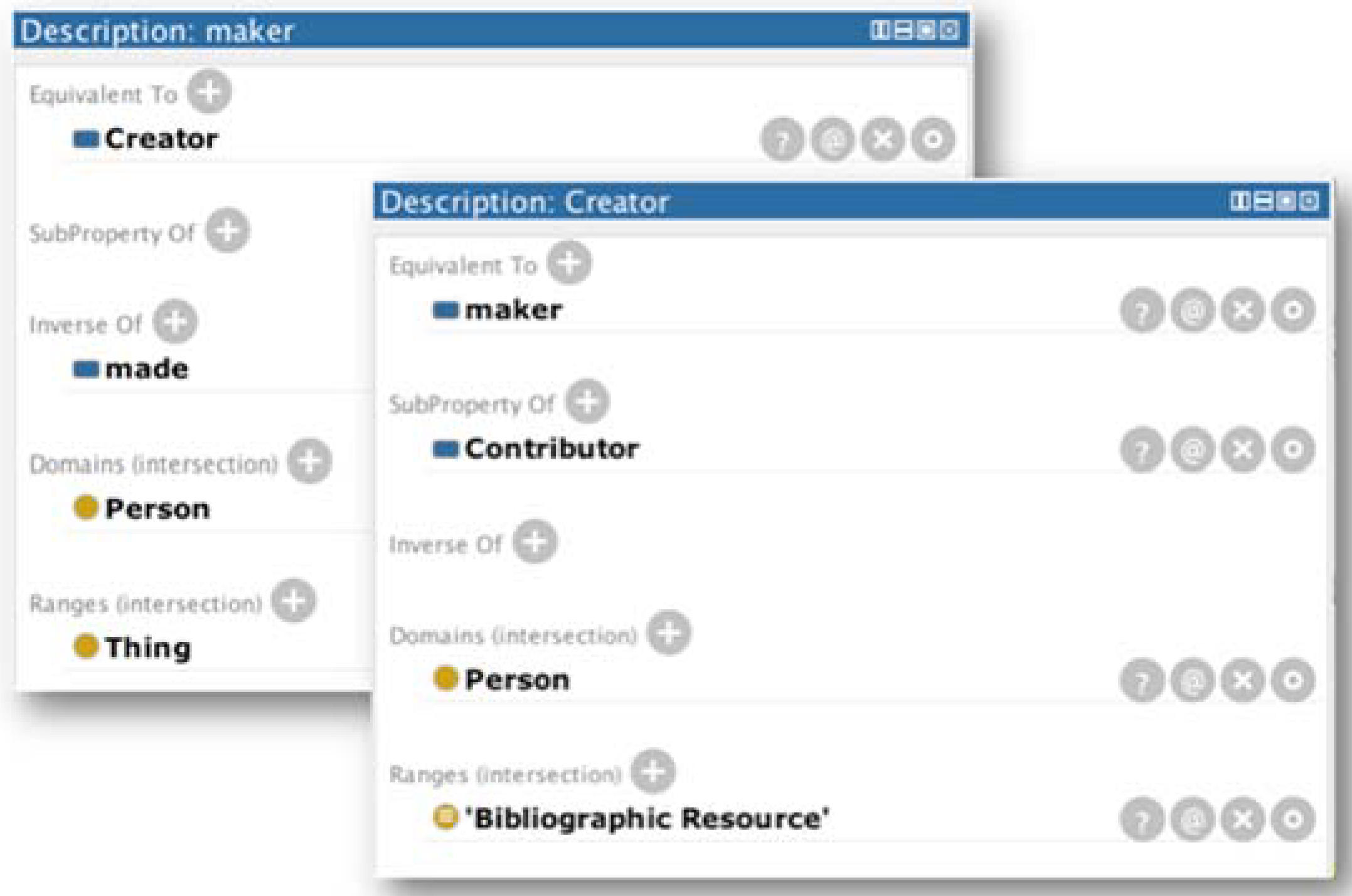
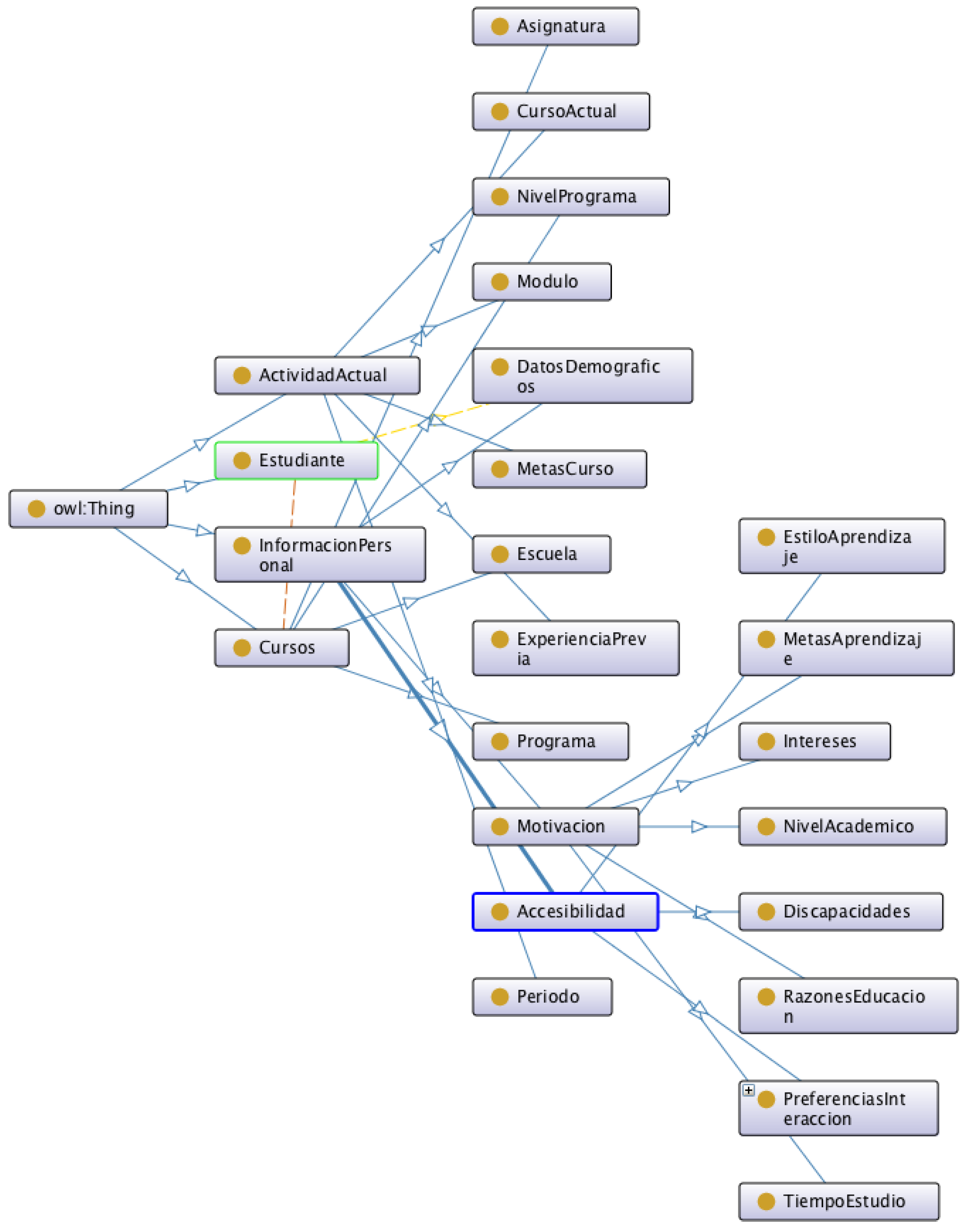
2.5. Ontological Engineering
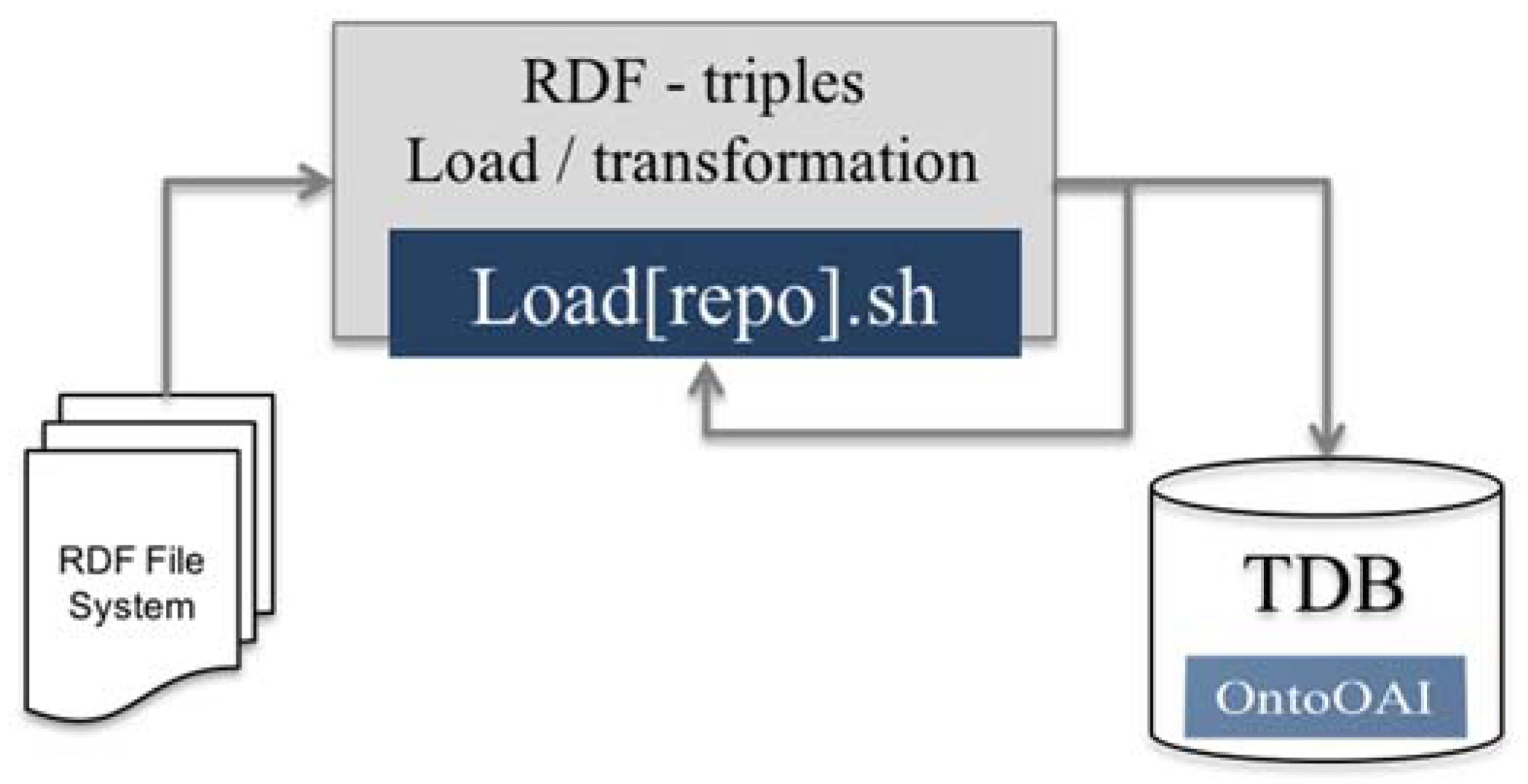
2.6. Storage
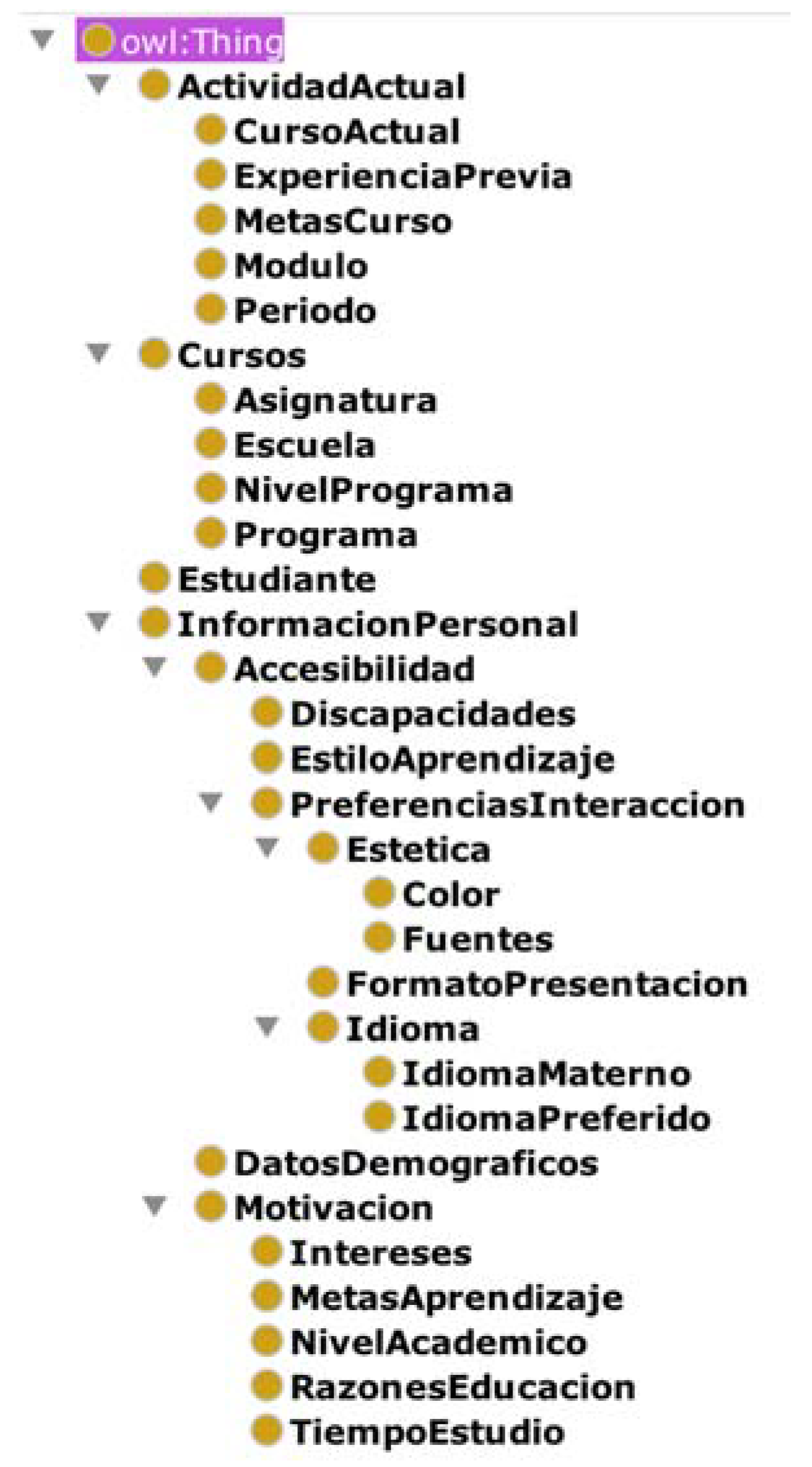
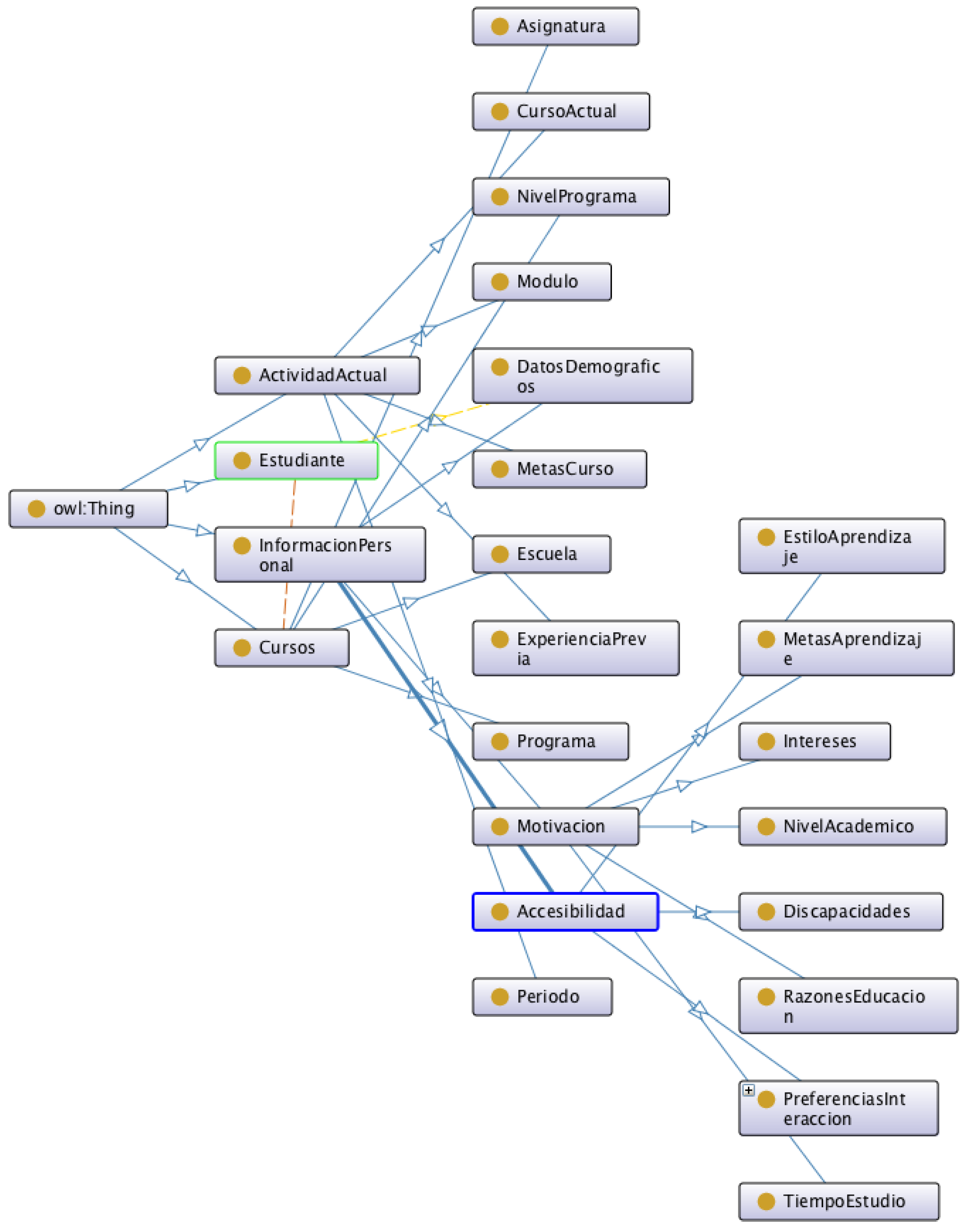
2.7. Context Awareness
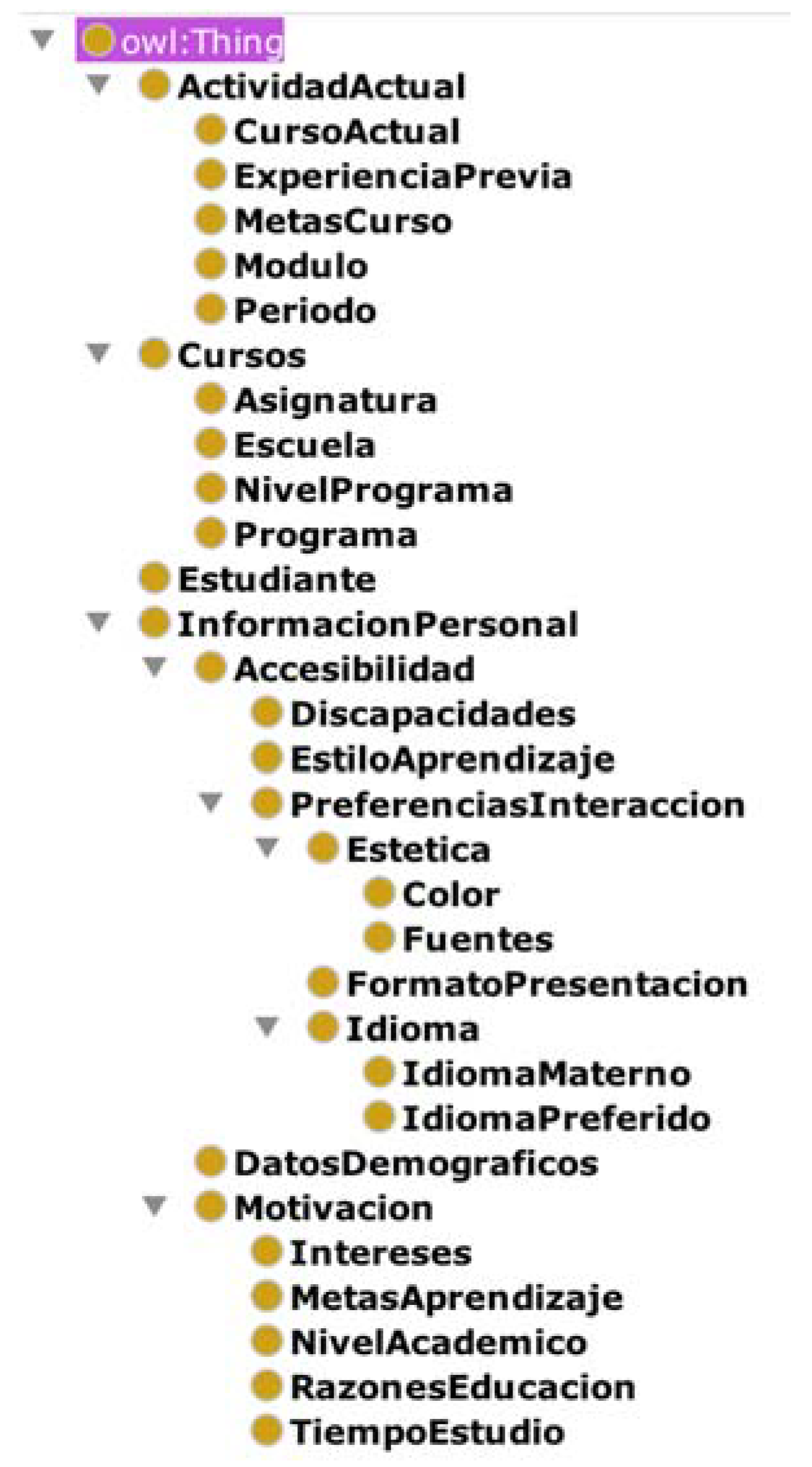
- “Student”, which identifies any student.
- “StudentCourseInformation”, which includes information relevant to the educational process, such as modules for the program of study, school, homework, tests, and so on.
- “StudentCurrentActivity”, which refers to the details of the academic activity of the course year.
- “StudentPersonalInformation”, which is the static and permanent student information.
- “Estudiante”, which represents a student.
- “Cursos”, which describes the classes that the student takes, the school where the student is enrolled, and the program and program level (BA, MA, PhD).
- “ActividadActual”, which describes the current period that the student is enrolled in, previous experience, course goals, module, and period.
- “InformacionPersonal”, which represents accessibility, demographics, and student motivation.
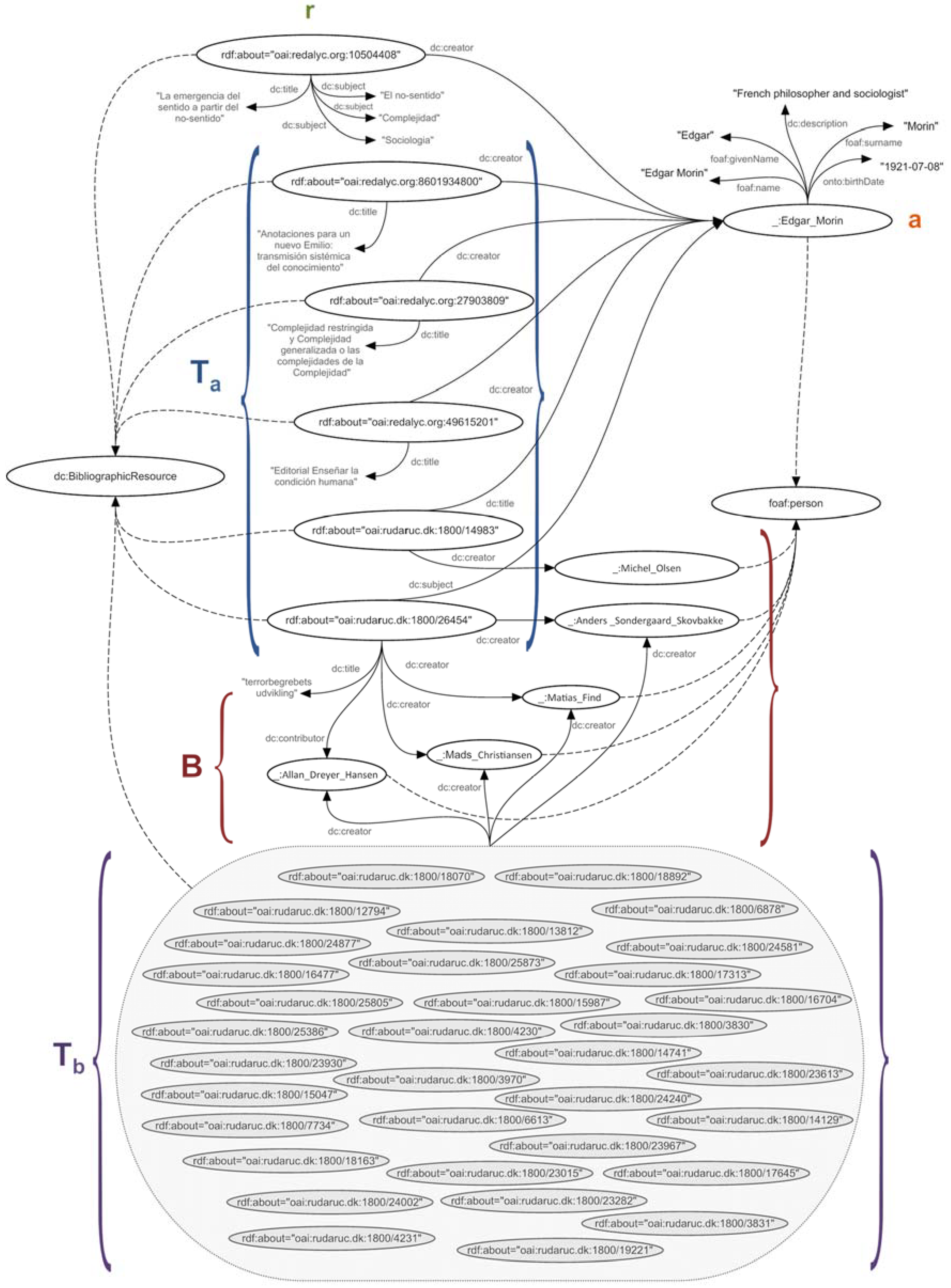
2.8. Inference Engine and Knowledge Discovery
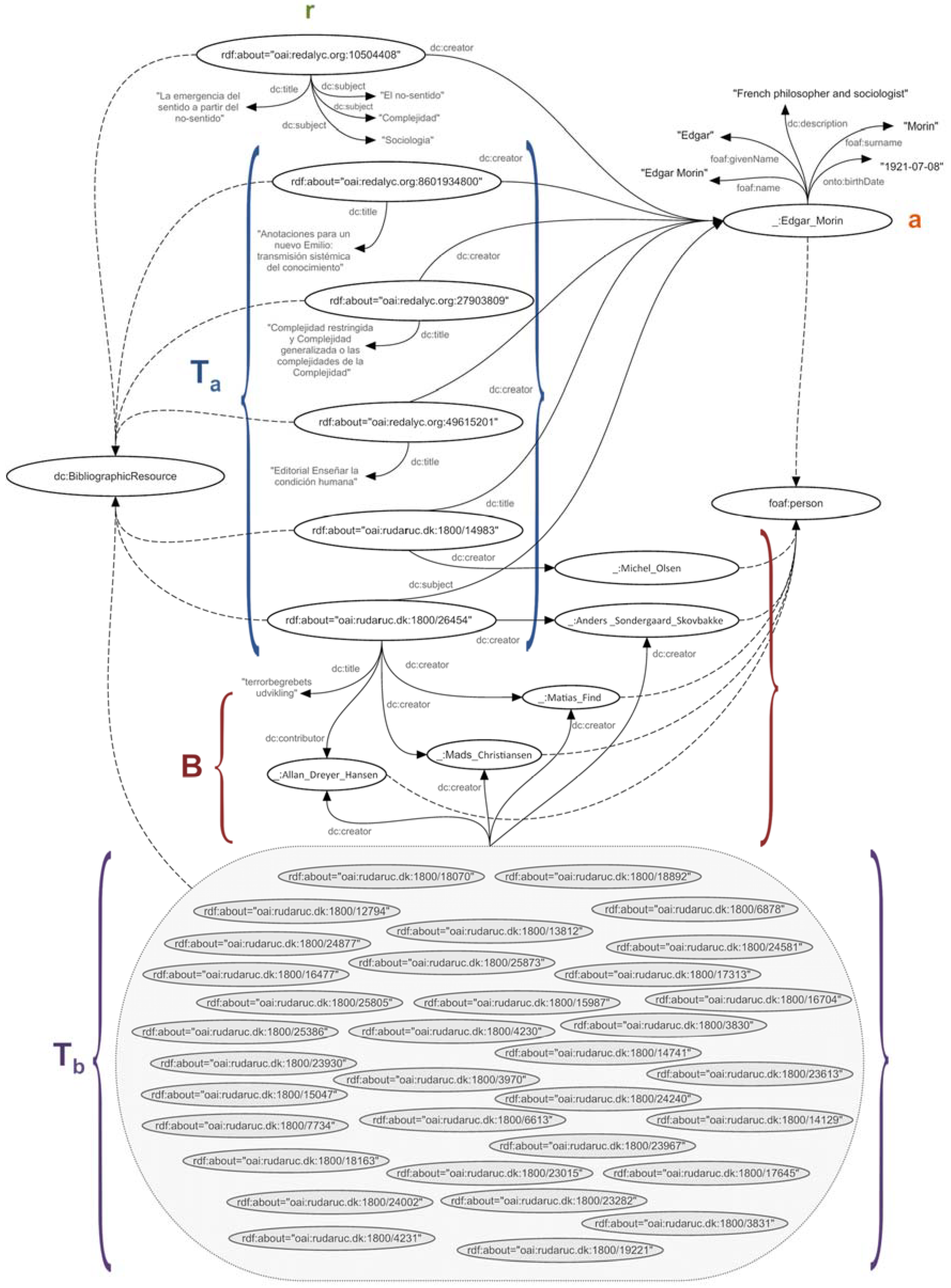
- f (a) = Ra, which defines the authorship or authorial contribution of a resource r written by an author a,
- f (a) = Ta, which defines the participation of an author a in a resource t, where participation means that the author is the subject, title, or resource author,
- f (b) = Tb, which defines the participation of an author b in a resource t, where participation means that the author is the subject, title or resource author,
- R = {r|r ∊ R}, defined by the information resources contained in the knowledge base,
- A = {a|a ∊ A}, defined by the authors or collaborators of information resources contained in the knowledge base,
- T = {t|t ∊ T}, defined by the information resources contained in the knowledge base that were written by a certain group of authors,
- B = {b|b ∊ B}, defined by the authors or collaborators of a given group of information resources contained in the knowledge base,
2.9. Batch Processing and Real-Time Processing
- (a)
- Metadata harvest time depends on the response times of individual repositories. Additionally, the total metadata collection time is subject to the operation mode of the harvester, either sequential or parallel, for all repositories that are to be harvested. Thus, for the first mode, it will be the sum total of the response times of all repositories, and for the parallel mode, it depends on the number of repositories that are being harvested simultaneously and the slower response time of each processing thread.
- (b)
- The availability of repositories at the time of metadata collection processes can prevent a repository from being located. Thus, in a batch, it is possible to perform attempts to reconnect to the repository without impacting the end time.
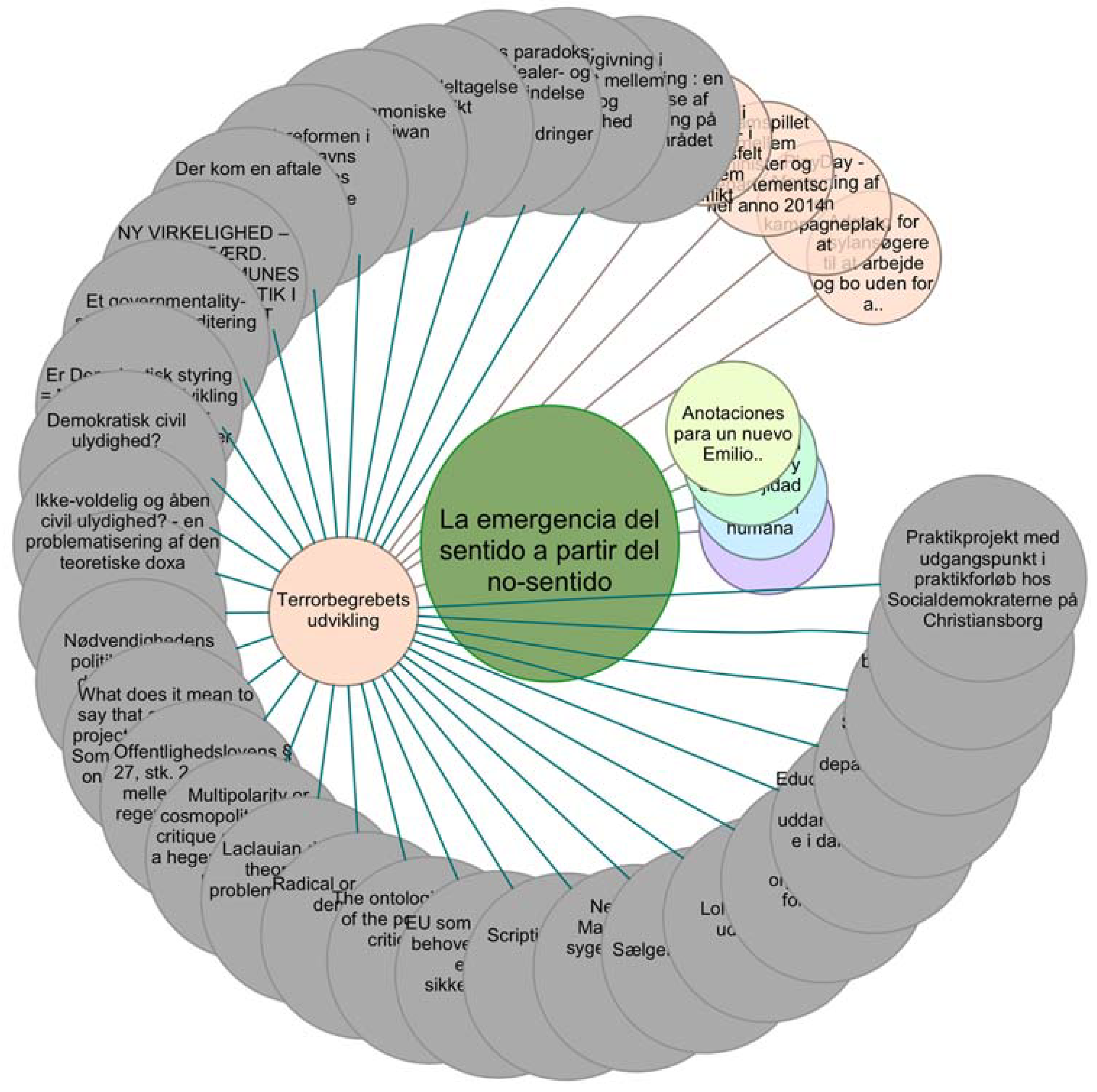
3. Experimental Results
Sources of Information
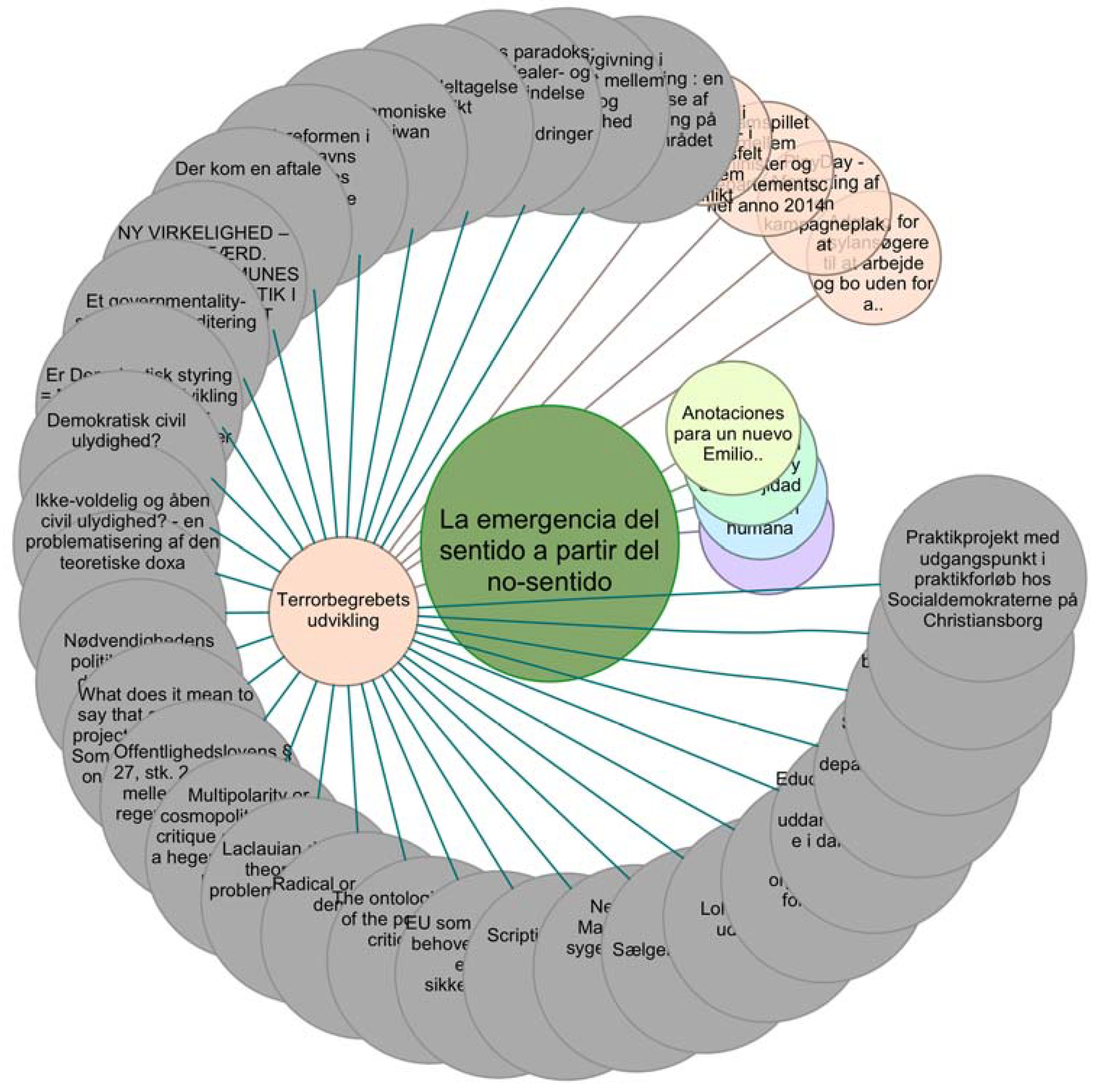
- r = “oai:redalyc.org:10504408”,
- a = “Edgar Morin”,
- Ta = {“oai:redalyc.org:8601934800”, “oai:redalyc.org:27903809”, “oai:redalyc.org:49615201”, “oai:rudar.ruc.dk:1800/14983”, “oai:rudar.ruc.dk:1800/26454”},
- B = {“Michel Olsen”, “Anders Sondergaard Skovbakke”, “Matias Find”, “Mads Christiansen”, “Allan Dreyer Hansen”}
- Tb = {“oai:rudaruc.dk:1800/12794”, “oai:rudaruc.dk:1800/24877”, “oai:rudaruc.dk:1800/16477”, “oai:rudaruc.dk:1800/25805”, “oai:rudaruc.dk:1800/25386”, “oai:rudaruc.dk:1800/23930”, “oai:rudaruc.dk:1800/15047”, “oai:rudaruc.dk:1800/7734”, “oai:rudaruc.dk:1800/18163”, “oai:rudaruc.dk:1800/18070”, “oai:rudaruc.dk:1800/18892”, “oai:rudaruc.dk:1800/13812”, “oai:rudaruc.dk:1800/24240”, “oai:rudaruc.dk:1800/25873”, “oai:rudaruc.dk:1800/15987”, “oai:rudaruc.dk:1800/4230”, “oai:rudaruc.dk:1800/4231”, “oai:rudaruc.dk:1800/24002”, “oai:rudaruc.dk:1800/6878”, “oai:rudaruc.dk:1800/24581”, “oai:rudaruc.dk:1800/17313”, “oai:rudaruc.dk:1800/3831”, “oai:rudaruc.dk:1800/3830”, “oai:rudaruc.dk:1800/3970”, “oai:rudaruc.dk:1800/6613”, “oai:rudaruc.dk:1800/23967”, “oai:rudaruc.dk:1800/14741”, “oai:rudaruc.dk:1800/23613”, “oai:rudaruc.dk:1800/14129”, “oai:rudaruc.dk:1800/23282”, “oai:rudaruc.dk:1800/17645”, “oai:rudaruc.dk:1800/19221”, “oai:rudaruc.dk:1800/16704”, “oai:rudaruc.dk:1800/23015”}
4. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Keßler, C.; d’Aquin, M.; Dietze, S. Linked Data for Science and Education. Semant. Web J. 2013, 4, 1–2. [Google Scholar]
- Allemang, D.; Hendler, J. Semantic Web for the Working Ontologist, 3rd ed.; Morgan Kaufmamm: Waltham, MA, USA, 2011; ISBN 978-0123859655. [Google Scholar]
- Chan, L.; Cuplinskas, D.; Eisen, M.; Friend, F.; Genova, Y.; Guédon, J.-C.; Hagemann, M.; Harnad, S.; Johnson, R.; Kupryte, R.; et al. Budapest Open Access Initiative. 2002. Available online: http://www.soros.org/openaccess/read.shtml (accessed on 8 June 2018).
- Max Planck Society. Berlin Declaration on Open Access to Knowledge in the Sciences and Humanities. 2003. Available online: http://openaccess.mpg.de/Berlin-Declaration (accessed on 8 June 2018).
- Brown, P.; Cabell, D.; Chakravarti, A.; Cohen, B.; Delamothe, T.; Eisen, M.; Grivell, L.; Guédon, J.-C.; Hawley, R.S.; Johnson, R.K.; et al. Declaración de Bethesda sobre Publicación de Acceso Abierto. 2003. Available online: http://ictlogy.net/articles/bethesda_es.html (accessed on 8 June 2018).
- Albert, P.; Holmes, K.; Börner, K.; Conlon, M. Research Discovery through Linked Open Data. In Proceedings of the 12th ACM/IEEE-CS Joint Conference on Digital Libraries, Washington, DC, USA, 10–14 June 2012; ACM: New York, NY, USA, 2012; pp. 429–430. [Google Scholar]
- Wiederhold, G. Foreword: On the barriers and future of knowledge discovery. In Advances in Knowledge Discovery and Data Mining; Fayyad, U., Piatetsky-Shapiro, G., Smyth, P., Uthurusamy, R., Eds.; AAAI Press: Menlo Park, CA, USA, 1996. [Google Scholar]
- Frawley, W.J.; Piatetsky-Shapiro, G.; Matheus, C.J. Knowledge Discovery in Databases: An Overview. AI Mag. 1992, 13, 57–70. [Google Scholar]
- IBM. Knowledge Discovery and Data Mining. Available online: http://researcher.watson.ibm.com/ researcher/view_group.php?id=144 (accessed on 8 June 2018).
- Becerril Garcia, A.; Lozano Espinosa, R.; Molina Espinosa, J.M. Semantic Approach to Context-Aware Resource Discovery over Scholarly Content Structured with OAI-PMH. Comput. Sist. 2016, 20, 127–142. [Google Scholar] [CrossRef]
- Becerril Garcia, A.; Lozano Espinosa, R.; Molina Espinosa, J. Modelo para consultas semánticas sensibles al contexto sobre recursos educativos estructurados con OAI-PMH. In Proceedings of the Encuentro Nacional de Ciencias de la Computación, ENC 2014, Oaxaca, Mexico, 3–5 November 2014; pp. 1–15. [Google Scholar]
- Ministerio para la Ciencia e Innovación de España. Informe Modelos de Metadatos para Contenidos Multimedia. Available online: http://omediadis.udl.cat/html/deliverables/215-Modelos_Metadatos_Contenidos_Multimedia/ (accessed on 10 November 2017).
- Haslhofer, B.; Schandl, B. The OAI2LOD Server: Exposing OAI-PMH Metadata as Linked Data. In Proceedings of the International Workshop on Linked Data on the Web (LDOW2008), Beijing, China, 22 April 2008. [Google Scholar]
- Bizer, C.; Cyganiak, R. D2R Server—Publishing Relational Databases on the Semantic Web. 2006. Available online: http://wifo5-03.informatik.uni-mannheim.de/bizer/pub/Bizer-Cyganiak-D2R-Server-ISWC2006.pdf (accessed on 8 June 2018).
- SIMILE. OAI2RDF. 2006. Available online: http://simile.mit.edu/repository/RDFizers/oai2rdf/ (accessed on 8 June 2018).
- Ameen, A.; Rahman Khan, K.; Rani, B. Semi-Automatic Merging of Ontologies using Protégé. Int. J. Comput. Appl. 2014, 85, 35–42. [Google Scholar]
- Panagiotopoulos, I.; Kalou, A.; Pierrakeas, C.; Kameas, A. An Ontology-Based Model for Student Representation in Intelligent Tutoring Systems for Distance Learning. In Artificial Intelligence Applications and Innovations; Lazaros Iliadis, I.M., Ed.; Springer: Halkidiki, Greece, 2012. [Google Scholar]
- Apache Software Foundation. Available online: http://jena.apache.org/about_jena/about.html (accessed on 8 June 2018).
- Dentler, K.; Cornet, R.; Teije, A.; de Keizer, N. Comparison of Reasoners for large Ontologies in the OWL 2 EL Profile. Semant. Web 2011, 2, 71–78. [Google Scholar]
- Becerril-García, A.; Aguado-López, E.; Rogel-Salazar, R.; Garduño-Oropeza, G.; Zúñiga-Roca, M. De un modelo centrado en la revista a un modelo centrado en entidades: La publicación y producción científica en la nueva plataforma Redalyc.org. Aula Abierta 2012, 40, 53–64. (In Spanish) [Google Scholar]
- Segaran, T.; Evans, C.; Taylor, J. Programming the Semantic Web, 1st ed.; O’Reilly: Sebastopol, CA, USA, 2009; p. 302. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | 42 |
| Object properties | 66 |
| Data properties | 40 |
| Repository | Total XML Files Obtained | Total Dublin Core Resources | Harvest Time | Harvest Size |
|---|---|---|---|---|
| Redalyc | 19,027 | 380,540 | 45.6 h | 762.9 MB |
| RUDAR | 154 | 15,400 | 1.2 h | 28.7 MB |
| Total | 19,181 | 395,940 | 46.8 h | 791.6 MB |
| Repository | Resources Described | Resources with Authors in DBPedia | Authors Localised |
|---|---|---|---|
| Redalyc | 380,534 | 52,251 (13.7%) | 57,918 |
| RUDAR | 14,885 | 2550 (17.13%) | 3009 |
| Total | 395,419 | 54,801 (13.8%) | 60,927 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Becerril-García, A.; Aguado-López, E. A Semantic Model for Selective Knowledge Discovery over OAI-PMH Structured Resources. Information 2018, 9, 144. https://doi.org/10.3390/info9060144
Becerril-García A, Aguado-López E. A Semantic Model for Selective Knowledge Discovery over OAI-PMH Structured Resources. Information. 2018; 9(6):144. https://doi.org/10.3390/info9060144
Chicago/Turabian StyleBecerril-García, Arianna, and Eduardo Aguado-López. 2018. "A Semantic Model for Selective Knowledge Discovery over OAI-PMH Structured Resources" Information 9, no. 6: 144. https://doi.org/10.3390/info9060144
APA StyleBecerril-García, A., & Aguado-López, E. (2018). A Semantic Model for Selective Knowledge Discovery over OAI-PMH Structured Resources. Information, 9(6), 144. https://doi.org/10.3390/info9060144