A Machine Learning Filter for the Slot Filling Task

Abstract
:1. Introduction
1.1. Example of a Slot Filling System’s Structure
1.2. Research Objective
- RQ1:
- What are the most important features for the filtering step?
- RQ2:
- Is there a generic method to increase the precision of slot filling systems without significantly degrading their recall (overall performance across several relations)?
- RQ3:
- Are some relations more sensitive to our filter?
1.3. Outline and Organization
2. Related Work
2.1. Relation Extraction and Slot Filling
2.2. System Enhancement
3. Proposed Work
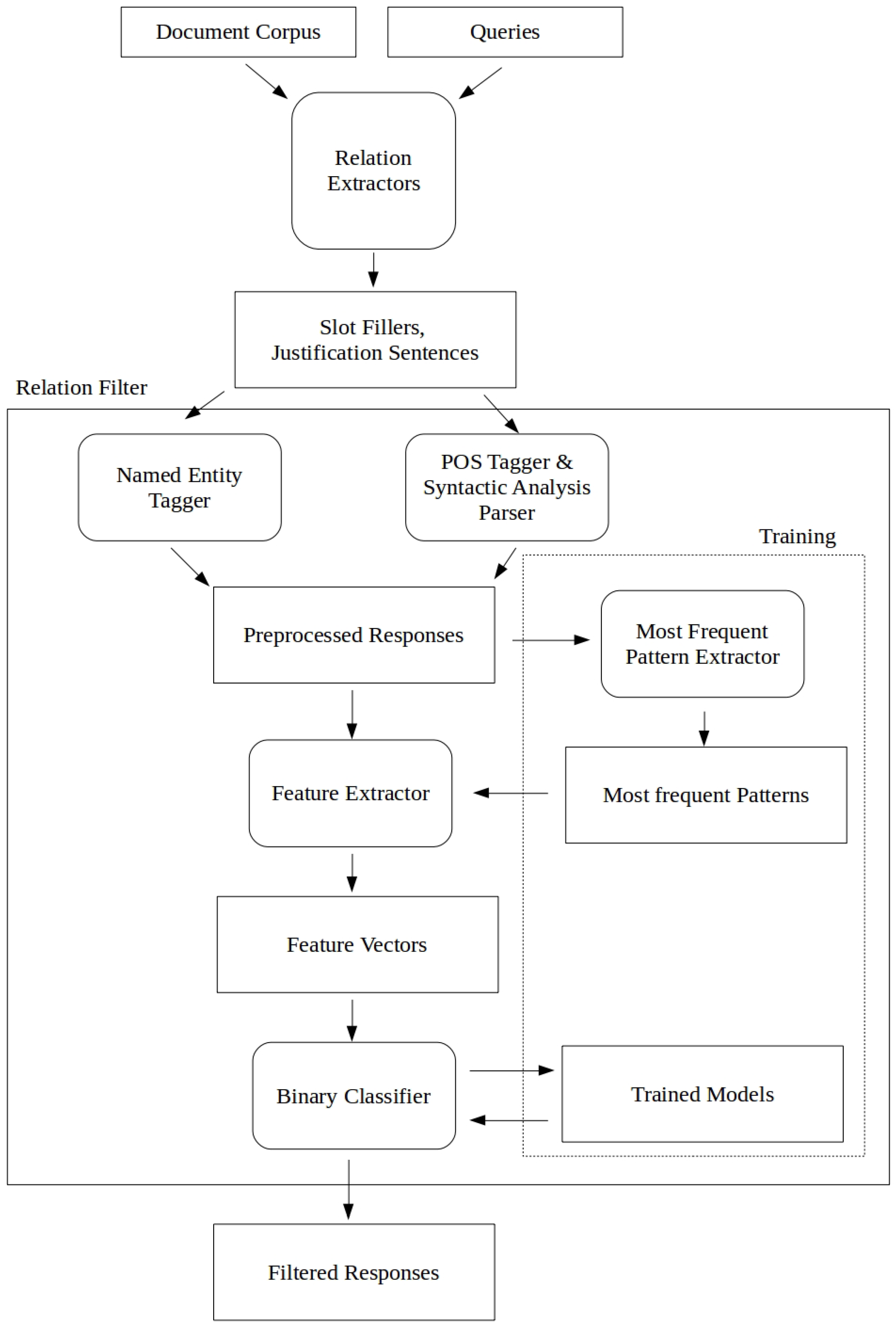
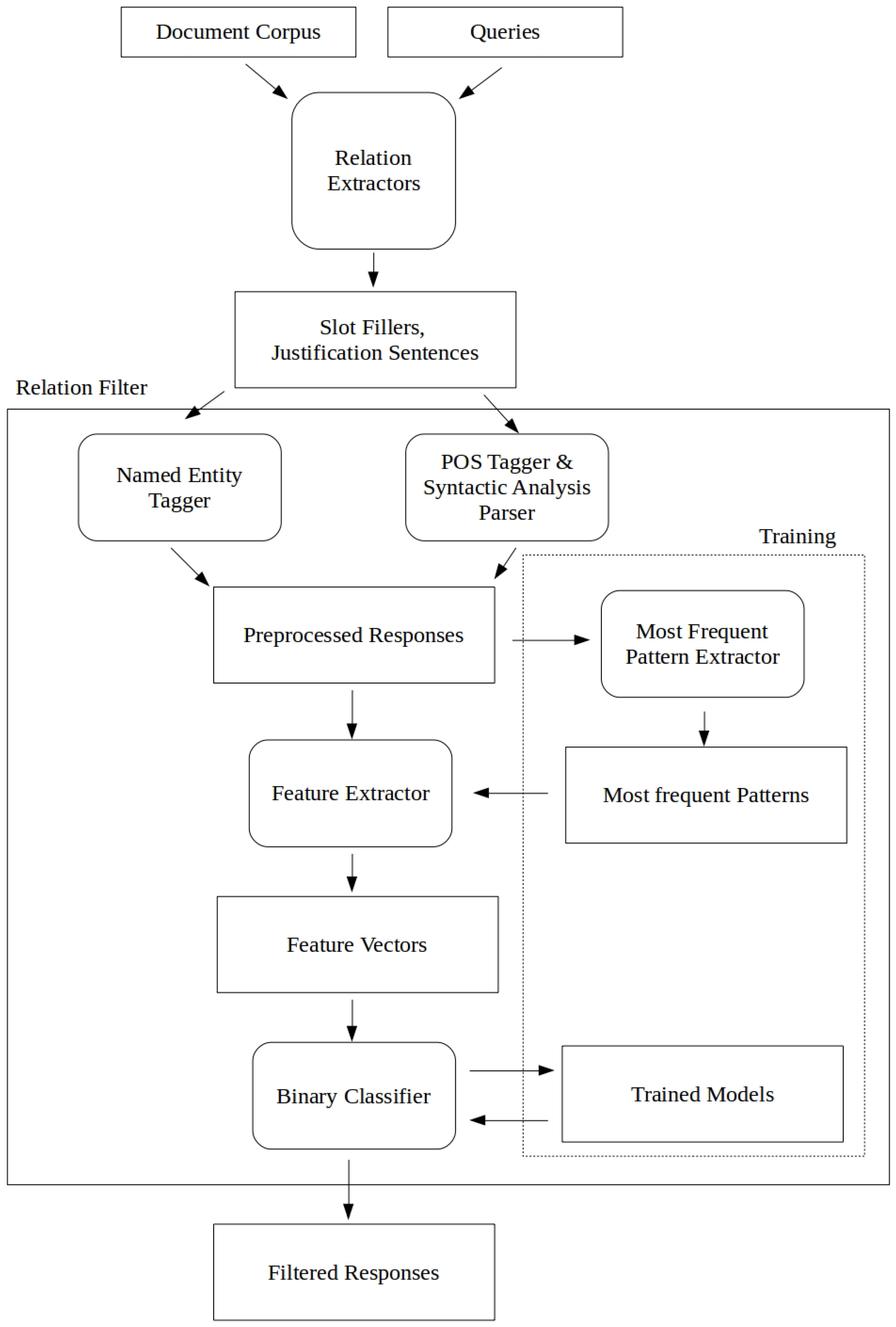
3.1. System Architecture
3.2. Preprocessing
3.2.1. Background
3.2.2. Dataset Cleaning and Partition
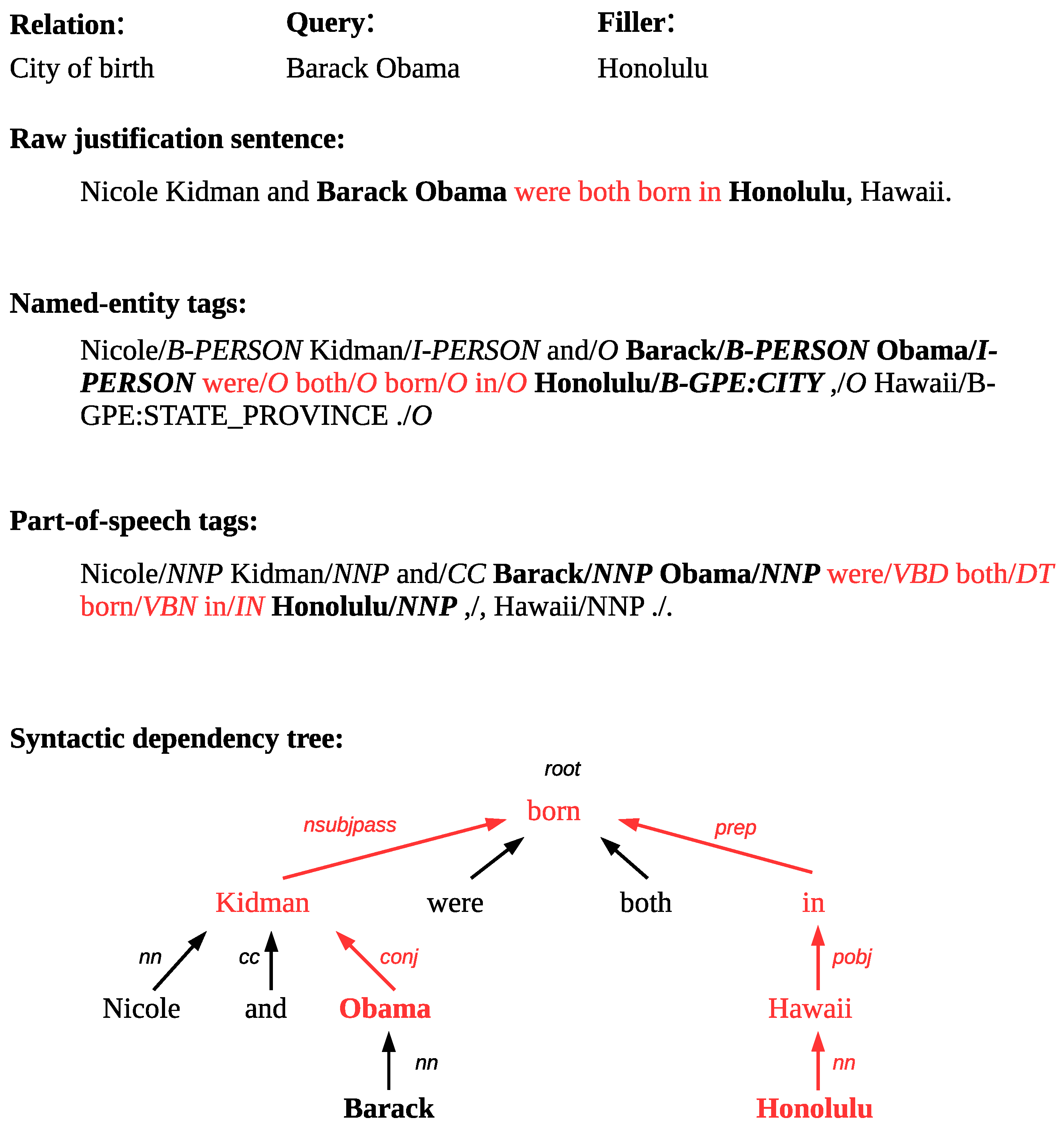
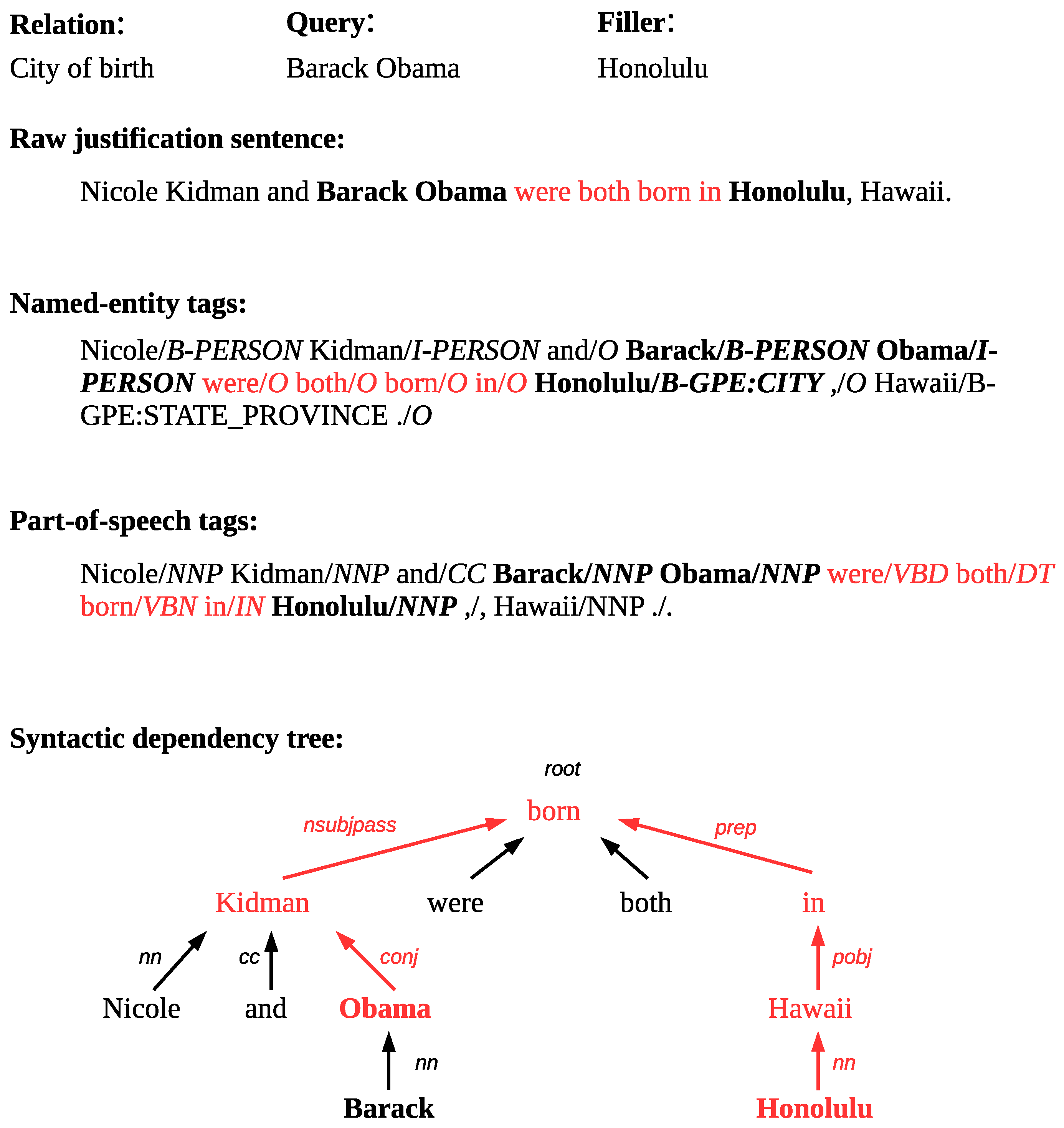
3.2.3. Linguistic Processing of Justifications
3.2.4. Down-Sampling and Selective Filtering
3.3. Features
3.3.1. Statistical Features
3.3.2. Named Entity Features
3.3.3. Lexical (POS) Features
3.3.4. Syntactic features
3.4. Classifiers
4. Experiments
4.1. Experiment Overview
4.2. Evaluation by Relation
4.3. Evaluation by Feature Subset
4.4. Filtering All System Runs
5. Discussion
6. Conclusion
Author Contributions
Funding
Conflicts of Interest
References
- Singhal, A. Introducing the Knowledge Graph: Things, Not Strings. In Official Google Blog; Google Blog: Mountain View, CA, USA, 2012. [Google Scholar]
- Bizer, C.; Lehmann, J.; Kobilarov, G.; Auer, S.; Becker, C.; Cyganiak, R.; Hellmann, S. DBpedia—A Crystallization Point for the Web of Data. Web Semant. Sci. Serv. Agents World Wide Web 2009, 7, 154–165. [Google Scholar] [CrossRef]
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked Data—The Story so Far. Int. J. Semant. Web Inf. Syst. 2009, 5, 205–227. [Google Scholar] [CrossRef]
- Surdeanu, M. Overview of the TAC2013 Knowledge Base Population Evaluation: English Slot Filling and Temporal Slot Filling. In Proceedings of the Sixth Text Analysis Conference (TAC 2013), Gaithersburg, MA, USA, 18–19 November 2013. [Google Scholar]
- Surdeanu, M.; Ji, H. Overview of the English Slot Filling Track at the TAC2014 Knowledge Base Population Evaluation. In Proceedings of the Text Analysis Conference Knowledge Base Population (KBP) 2014, Gaithersburg, MA, USA, 17–18 November 2014. [Google Scholar]
- Ellis, J. TAC KBP Reference Knowledge Base LDC2009E58; Linguistic Data Consortium: Philadelphia, PA, USA, 2013. [Google Scholar]
- Angeli, G.; Gupta, S.; Jose, M.; Manning, C.D.; Ré, C.; Tibshirani, J.; Wu, J.Y.; Wu, S.; Zhang, C. Stanford’s 2014 Slot Filling Systems. In Proceedings of the Text Analysis Conference Knowledge Base Population (KBP) 2014, Gaithersburg, MA, USA, 17–18 November 2014. [Google Scholar]
- Roth, B.; Barth, T.; Wiegand, M.; Singh, M.; Klakow, D. Effective Slot Filling Based on Shallow Distant Supervision Methods. arXiv, 2014; arXiv:1401.1158. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant Supervision for Relation Extraction without Labeled Data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Suntec, Singapore, 2–7 August 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; Volume 2, pp. 1003–1011. [Google Scholar]
- Jiang, J. Domain Adaptation in Natural Language Processing; ProQuest: Ann Arbor, MI, USA, 2008. [Google Scholar]
- Fader, A.; Soderland, S.; Etzioni, O. Identifying Relations for Open Information Extraction. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 1535–1545. [Google Scholar]
- Nguyen, T.H.; He, Y.; Pershina, M.; Li, X.; Grishman, R. New York University 2014 Knowledge Base Population Systems. In Proceedings of the Text Analysis Conference Knowledge Base Population (KBP) 2014, Gaithersburg, MA, USA, 17–18 November 2014. [Google Scholar]
- Brin, S. Extracting Patterns and Relations from the World Wide Web. In The World Wide Web and Databases; Springer: Berlin/Heidelberg, Germany, 1999; pp. 172–183. [Google Scholar]
- Agichtein, E.; Gravano, L. Snowball: Extracting Relations from Large Plain-text Collections. In Proceedings of the Fifth ACM Conference on Digital Libraries, San Antonio, TX, USA, 2–7 June 2000; ACM: New York, NY, USA, 2000; pp. 85–94. [Google Scholar]
- Li, Y.; Zhang, Y.; Doyu Li, X.T.; Wang, J.; Zuo, N.; Wang, Y.; Xu, W.; Chen, G.; Guo, J. PRIS at Knowledge Base Population 2013. In Proceedings of the Sixth Text Analysis Conference (TAC 2013), Gaithersburg, MA, USA, 18–19 November 2013. [Google Scholar]
- Roth, B.; Chrupala, G.; Wiegand, M.; Singh, M.; Klakow, D. Generalizing from Freebase and Patterns Using Distant Supervision for Slot Filling. In Proceedings of the Fifth Text Analysis Conference (TAC 2012), Gaithersburg, MA, USA, 5–6 November 2012. [Google Scholar]
- Chen, Z.; Tamang, S.; Lee, A.; Li, X.; Passantino, M.; Ji, H. Top-Down and Bottom-Up: A Combined Approach to Slot Filling. In Proceedings of the 6th Asia Information Retrieval Societies Conference, AIRS 2010, Taipei, Taiwan, 1–3 December 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 300–309. [Google Scholar]
- Schlaefer, N.; Ko, J.; Betteridge, J.; Pathak, M.A.; Nyberg, E.; Sautter, G. Semantic Extensions of the Ephyra QA System for TREC 2007. In Proceedings of the Sixteenth Text REtrieval Conference, TREC 2007, Gaithersburg, MA, USA, 5–9 November 2007; Volume 1, p. 2. [Google Scholar]
- Moro, A.; Li, H.; Krause, S.; Xu, F.; Navigli, R.; Uszkoreit, H. Semantic Rule Filtering for Web-scale Relation Extraction. In The Semantic Web–ISWC 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 347–362. [Google Scholar]
- Angeli, G.; Tibshirani, J.; Wu, J.Y.; Manning, C.D. Combining Distant and Partial Supervision for Relation Extraction. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Surdeanu, M. Slot Filler Validation at TAC 2014 Task Guidelines; TAC: Geelong, Australia, 2014. [Google Scholar]
- Wang, I.J.; Liu, E.; Costello, C.; Piatko, C. JHUAPL TAC-KBP2013 Slot Filler Validation System. In Proceedings of the Sixth Text Analysis Conference (TAC 2013), Gaithersburg, MA, USA, 18–19 November 2013; Volume 24. [Google Scholar]
- Rajani, N.F.; Viswanathan, V.; Bentor, Y.; Mooney, R.J. Stacked Ensembles of Information Extractors for Knowledge-Base Population. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics (ACL-15), Beijing, China, 26–31 July 2015; Volume 1, pp. 177–187. [Google Scholar]
- Ellis, J. TAC KBP 2013 Slot Descriptions; TAC: Geelong, Australia, 2013. [Google Scholar]
- De Marneffe, M.C.; MacCartney, B.; Manning, C.D. Generating Typed Dependency Parses from Phrase Structure Parses. In Proceedings of the 2006 LREC, Genoa, Italy, 28 May 2006; Volume 6, pp. 449–454. [Google Scholar]
- Chrupała, G.; Klakow, D. A Named Entity Labeler for German: Exploiting Wikipedia and Distributional Clusters. In Proceedings of the Conference on International Language Resources and Evaluation (LREC), Valletta, Malta, 17–23 May 2010; pp. 552–556. [Google Scholar]
- Chawla, N.V. Data Mining for Imbalanced Datasets: An Overview. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2005; pp. 853–867. [Google Scholar]
- Voskarides, N.; Meij, E.; Tsagkias, M.; de Rijke, M.; Weerkamp, W. Learning to Explain Entity Relationships in Knowledge Graphs. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast Algorithms for Mining Association Rules. In Proceedings of the 20th International Conference on Very Large Data Bases; Morgan Kaufmann Publishers, Inc.: Burlington, MA, USA, 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Vapnik, V.N.; Kotz, S. Estimation of Dependences Based on Empirical Data; Springer: New York, NY, USA, 1982; Volume 40. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; ACM: New York, NY, USA, 1992; pp. 144–152. [Google Scholar]
- Burges, C.J. A Tutorial on Support Vector Machines for Pattern Recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Platt, J. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines; Technical Report MSR-TR-98-14; Microsoft Research: Redmond, WA, USA, 1998. [Google Scholar]
- Kohavi, R. Scaling Up the Accuracy of Naive-Bayes Classifiers: A Decision-Tree Hybrid. In Proceedings of the Second International Conference on Knoledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 202–207. [Google Scholar]
- John, G.H.; Langley, P. Estimating Continuous Distributions in Bayesian Classifiers. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, Morgan Kaufmann, Montreal, QC, Canada, 18–20 August 1995; pp. 338–345. [Google Scholar]
- Kohavi, R. The Power of Decision Tables. In Machine Learning: ECML-95; Springer: Berlin/Heidelberg, Germany, 1995; pp. 174–189. [Google Scholar]
- Russell, S.; Norvig, P.; Intelligence, A. A Modern Approach; Artificial Intelligence; Prentice Hall: Egnlewood Cliffs, NJ, USA, 1995; Volume 25, p. 27. [Google Scholar]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: New York, NY, USA, 2014. [Google Scholar]
- Cleary, J.G.; Trigg, L.E. K*: An Instance-based Learner Using an Entropic Distance Measure. In Proceedings of the 12th International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 2016; pp. 108–114. [Google Scholar]
- Sharma, T.C.; Jain, M. WEKA Approach for Comparative Study of Classification Algorithm. Int. J. Adv. Res. Comput. Commun. Eng. 2013, 2, 1925–1931. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Mantel, N. Chi-square tests with one degree of freedom; extensions of the Mantel-Haenszel procedure. J. Am. Stat. Assoc. 1963, 58, 690–700. [Google Scholar]
- Yang, Y.; Pedersen, J.O. A Comparative Study on Feature Selection in Text Categorization. In Proceedings of the Fourteenth International Conference on Machine Learning (ICML 1997), Nashville, TN, USA, 8–12 July 1997; Volume 97, pp. 412–420. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Type | Relation | Content | Quantity | #Correct | #Wrong | Total |
|---|---|---|---|---|---|---|
| ORG | org:alternate_names | Name | List | 100 | 157 | 257 |
| ORG | org:city_of_headquarters | Name | Single | 62 | 118 | 180 |
| ORG | org:country_of_headquarters | Name | Single | 73 | 114 | 187 |
| ORG | org:date_dissolved | Value | Single | 0 | 15 | 15 |
| ORG | org:date_founded | Value | List | 36 | 48 | 84 |
| ORG | org:founded_by | Name | List | 49 | 127 | 176 |
| ORG | org:member_of | Name | List | 5 | 195 | 200 |
| ORG | org:members | Name | List | 49 | 195 | 244 |
| ORG | org:number_of_employees_members | Value | Single | 19 | 28 | 47 |
| ORG | org:parents | Name | List | 34 | 270 | 304 |
| ORG | org:political_religious_affiliation | Name | List | 1 | 39 | 40 |
| ORG | org:shareholders | Name | List | 15 | 255 | 270 |
| ORG | org:stateorprovince_of_headquarters | Name | Single | 47 | 76 | 123 |
| ORG | org:subsidiaries | Name | List | 46 | 259 | 305 |
| ORG | org:top_members_employees | Name | List | 392 | 612 | 1004 |
| ORG | org:website | String | Single | 79 | 17 | 96 |
| PER | per:age | Value | Single | 226 | 22 | 248 |
| PER | per:alternate_names | Name | List | 58 | 114 | 172 |
| PER | per:cause_of_death | String | Single | 127 | 110 | 237 |
| PER | per:charges | String | List | 58 | 149 | 207 |
| PER | per:children | Name | List | 169 | 202 | 371 |
| PER | per:cities_of_residence | Name | List | 71 | 356 | 427 |
| PER | per:city_of_birth | Name | Single | 44 | 56 | 100 |
| PER | per:city_of_death | Name | Single | 105 | 97 | 202 |
| PER | per:countries_of_residence | Name | List | 77 | 164 | 241 |
| PER | per:country_of_birth | Name | Single | 11 | 23 | 34 |
| PER | per:country_of_death | Name | Single | 26 | 50 | 76 |
| PER | per:date_of_birth | Value | Single | 63 | 22 | 85 |
| PER | per:date_of_death | Value | Single | 123 | 124 | 247 |
| PER | per:employee_or_member_of | Name | List | 257 | 554 | 811 |
| PER | per:origin | Name | List | 120 | 320 | 440 |
| PER | per:other_family | Name | List | 19 | 184 | 203 |
| PER | per:parents | Name | List | 80 | 167 | 247 |
| PER | per:religion | String | Single | 9 | 44 | 53 |
| PER | per:schools_attended | Name | List | 78 | 93 | 171 |
| PER | per:siblings | Name | List | 43 | 154 | 197 |
| PER | per:spouse | Name | List | 169 | 266 | 435 |
| PER | per:stateorprovince_of_birth | Name | Single | 27 | 48 | 75 |
| PER | per:stateorprovince_of_death | Name | Single | 57 | 62 | 119 |
| PER | per:statesorprovinces_of_residence | Name | List | 50 | 176 | 226 |
| PER | per:title | String | List | 888 | 1277 | 2165 |
| Total | 3962 | 7359 | 11321 |
| ID | Name | Description |
|---|---|---|
| Statistical features | ||
| C1 | Sentence length | Number of tokens in sentence |
| C2 | Answer/query length | Number of tokens within answer and query references |
| C3 | Entity order | Order of appearance of query and answer references |
| C4 | #tokens left/between/right | Number of tokens left/right or between entities in the sentence |
| C5 | Confidence score | Score given by the relation extractor [4] |
| Named-entity features | ||
| N1 | #person left/between/right | Number of person left/right or between entities in the sentence [28] |
| N2 | #gpe left/between/right | Number of Geo-political entities left/right or between entities in the sentence [28] |
| N3 | #orgs left/between/right | Number of organizations left/right or between entities in the sentence [28] |
| Lexical (POS) features | ||
| L1 | POS fractions left/between /right/sentence | Fraction of nouns, verbs, adjectives and others left/right/between answer and query references or in the whole sentence [9] |
| L2 | POS subsets | Most frequent subsets of POS tags between query and answer references in the sentence. (boolean feature indicating the presence of the subset) |
| L3 | Word subsets | Most frequent subsets of word (excluding stop-words and named entities) in the sentence. (boolean feature indicating the presence of the subset) |
| L4 | POS bigram subsets | Most frequent subsets of POS tag bigrams (excluding stop-words) between query and answer references in the sentence. (boolean feature indicating the presence of the subset) |
| L5 | Word bigram subsets | Most frequent subsets of word bigrams between query and answer references in the sentence. (boolean feature indicating the presence of the subset) |
| Syntactic features | ||
| S1 | Distance between entities | Distance between entities at the syntactic dependency tree level |
| S2 | Entity level difference | Level difference within syntactic dependency tree between query and answer references |
| S3 | Ancestors | One entity is ancestor of the other at the syntactic dependency tree level |
| S4 | Syntactic dependencies subsets | Most frequent subsets of syntactic dependencies between query and answer references at the syntactic dependency tree level (boolean feature indicating the presence of the subset) |
| S5 | Multilevel subsets | Most frequent subsets, where each token is composed of a POS tag, syntactic dependency and direction, between query and answer references at the syntactic dependency tree level (boolean feature indicating the presence of the subset) |
| S6 | Syntactic dependencies bigram subsets | Most frequent subsets of syntactic dependencies bigram between query and answer references at the syntactic dependency tree level (boolean feature indicating the presence of the subset) |
| S7 | Multilevel bigram subsets | Most frequent subsets, where each token is composed of a POS tag, syntactic dependency and direction bigram, between query and answer references at the syntactic dependency tree level (boolean feature indicating the presence of the subset) |
| System ID | Pre-Filtering | Post-Filtering | ||||
|---|---|---|---|---|---|---|
| Recall | Precision | F1 | Recall | Precision | F1 | |
| Uwashington | 0.103 | 0.634 | 0.177 | 0.079 | 0.725 | 0.143 |
| BIT | 0.232 | 0.511 | 0.319 | 0.185 | 0.668 | 0.290 |
| CMUML | 0.107 | 0.323 | 0.161 | 0.082 | 0.553 | 0.142 |
| lsv (Relation Factory) | 0.332 | 0.425 | 0.373 | 0.276 | 0.630 | 0.384 |
| TALP_UPC | 0.057 | 0.131 | 0.080 | 0.048 | 0.262 | 0.082 |
| NYU | 0.168 | 0.538 | 0.256 | 0.139 | 0.620 | 0.227 |
| PRIS2013 | 0.276 | 0.389 | 0.323 | 0.211 | 0.535 | 0.303 |
| Stanford | 0.279 | 0.357 | 0.314 | 0.208 | 0.491 | 0.293 |
| UNED | 0.093 | 0.176 | 0.122 | 0.061 | 0.249 | 0.098 |
| Umass_IESL | 0.185 | 0.109 | 0.137 | 0.153 | 0.159 | 0.156 |
| SAFT_Kres | 0.150 | 0.157 | 0.153 | 0.095 | 0.167 | 0.122 |
| CUNY_BLENDER | 0.290 | 0.407 | 0.339 | 0.221 | 0.519 | 0.310 |
| utaustin | 0.081 | 0.252 | 0.123 | 0.050 | 0.310 | 0.087 |
| ARPANI | 0.275 | 0.504 | 0.355 | 0.215 | 0.600 | 0.316 |
| Average | 0.188 | 0.351 | 0.231 | 0.144 | 0.463 | 0.211 |
| Relation | Algorithm | Accuracy (%) | F1 (Correct) | F1 (Wrong) |
|---|---|---|---|---|
| org:alternate_names | NBTree | 94.7368 | 0.933 | 0.957 |
| org:city_of_headquarters | RandomForest | 74.7368 | 0.755 | 0.739 |
| org:country_of_headquarters | NBTree | 78.6207 | 0.739 | 0.819 |
| org:date_founded | NBTree | 77.4648 | 0.704 | 0.818 |
| org:founded_by | RandomForest | 92.9412 | 0.936 | 0.921 |
| org:members | SMO | 90 | 0.879 | 0.915 |
| org:number_of_employees_members | SMO | 84.375 | 0.828 | 0.857 |
| org:parents | SMO | 80.7692 | 0.808 | 0.808 |
| org:shareholders | SMO | 68.9655 | 0.69 | 0.69 |
| org:stateorprovince_of_headquarters | RandomForest | 81.25 | 0.747 | 0.851 |
| org:subsidiaries | SMO | 86.3636 | 0.847 | 0.877 |
| org:top_members_employees | RandomForest | 76.799 | 0.698 | 0.812 |
| per:alternate_names | SMO | 92.4528 | 0.917 | 0.931 |
| per:cause_of_death | J48 | 84.2932 | 0.84 | 0.845 |
| per:charges | SMO | 73.7864 | 0.743 | 0.733 |
| per:children | RandomForest | 82.6087 | 0.797 | 0.848 |
| per:cities_of_residence | SMO | 75.8929 | 0.765 | 0.752 |
| per:city_of_birth | SMO | 77.0115 | 0.744 | 0.792 |
| per:city_of_death | J48 | 81.6092 | 0.814 | 0.818 |
| per:countries_of_residence | SMO | 73.1343 | 0.746 | 0.714 |
| per:country_of_death | SMO | 82.2222 | 0.818 | 0.826 |
| per:date_of_birth | J48 | 84 | 0.895 | 0.667 |
| per:date_of_death | NBTree | 63.8498 | 0.703 | 0.539 |
| per:employee_or_member_of | NBTree | 66.4269 | 0.689 | 0.635 |
| per:origin | RandomForest | 79.1045 | 0.806 | 0.774 |
| per:other_family | J48 | 87.5 | 0.846 | 0.895 |
| per:parents | J48 | 91.8033 | 0.918 | 0.918 |
| per:schools_attended | RandomForest | 79.1367 | 0.785 | 0.797 |
| per:siblings | RandomForest | 86.9565 | 0.877 | 0.862 |
| per:spouse | RandomForest | 79.2105 | 0.727 | 0.832 |
| per:stateorprovince_of_birth | J48 | 84.058 | 0.766 | 0.879 |
| per:stateorprovince_of_death | SMO | 83.8095 | 0.825 | 0.85 |
| per:statesorprovinces_of_residence | SMO | 77.5281 | 0.773 | 0.778 |
| per:title | RandomForest | 70.96 | 0.644 | 0.755 |
| Relation | Pre-Filtering | Post-Filtering | ||||
|---|---|---|---|---|---|---|
| Instances | Precision | F1 | Precision | F1 | Classifier | |
| org:country_of_headquarters | 30 | 0.267 | 0.250 | 0.636 | 0.311 | NBTree |
| org:date_founded | 7 | 0.714 | 0.500 | 1.000 | 0.556 | NBTree |
| org:number_of_employees_members | 11 | 0.273 | 0.273 | 0.375 | 0.316 | SMO |
| org:parents | 16 | 0.25 | 0.276 | 0.364 | 0.333 | SMO |
| org:subsidiaries | 22 | 0.364 | 0.291 | 0.700 | 0.326 | SMO |
| org:top_members_employees | 153 | 0.386 | 0.417 | 0.663 | 0.505 | RandomForest |
| per:alternate_names | 19 | 0.632 | 0.293 | 0.667 | 0.296 | SMO |
| per:cause_of_death | 29 | 0.759 | 0.710 | 0.880 | 0.759 | J48 |
| per:charges | 8 | 0.375 | 0.113 | 0.600 | 0.120 | SMO |
| per:children | 28 | 0.429 | 0.282 | 0.733 | 0.306 | RandomForest |
| per:city_of_birth | 13 | 0.615 | 0.640 | 0.875 | 0.700 | SMO |
| per:city_of_death | 25 | 0.800 | 0.702 | 0.909 | 0.741 | J48 |
| per:countries_of_residence | 7 | 0.571 | 0.160 | 0.800 | 0.167 | SMO |
| per:date_of_death | 27 | 0.037 | 0.032 | 0.040 | 0.033 | NBTree |
| per:schools_attended | 22 | 0.364 | 0.314 | 0.615 | 0.381 | RandomForest |
| per:siblings | 11 | 0.545 | 0.522 | 0.600 | 0.545 | RandomForest |
| per:spouse | 22 | 0.500 | 0.400 | 0.750 | 0.400 | RandomForest |
| per:stateorprovince_of_birth | 3 | 0.667 | 0.308 | 1.000 | 0.333 | J48 |
| per:statesorprovinces_of_residence | 11 | 0.455 | 0.256 | 0.625 | 0.278 | SMO |
| per:title | 345 | 0.348 | 0.417 | 0.580 | 0.445 | RandomForest |
| org:alternate_names | 62 | 0.710 | 0.583 | 0.722 | 0.545 | NBTree |
| org:city_of_headquarters | 24 | 0.458 | 0.468 | 0.571 | 0.432 | RandomForest |
| org:founded_by | 8 | 0.625 | 0.345 | 0.800 | 0.308 | RandomForest |
| org:stateorprovince_of_headquarters | 8 | 0.625 | 0.357 | 0.750 | 0.250 | RandomForest |
| per:cities_of_residence | 50 | 0.22 | 0.214 | 0.375 | 0.174 | SMO |
| per:employee_or_member_of | 70 | 0.257 | 0.185 | 0.360 | 0.120 | NBTree |
| per:origin | 19 | 0.526 | 0.339 | 1.000 | 0.298 | RandomForest |
| per:parents | 21 | 0.524 | 0.478 | 0.692 | 0.474 | J48 |
| per:stateorprovince_of_death | 12 | 0.667 | 0.533 | 0.750 | 0.462 | SMO |
| org:members | 1 | 0.000 | 0.000 | 0.000 | 0.000 | SMO |
| per:date_of_birth | 7 | 0.857 | 0.600 | 0.857 | 0.600 | J48 |
| per:other_family | 1 | 1.000 | 0.125 | 1.000 | 0.125 | J48 |
| per:country_of_death | 3 | 1.000 | 0.462 | 1.000 | 0.333 | SMO |
| Relation Group | R | P | F1 | #Relations |
|---|---|---|---|---|
| List | 0.183 | 0.009 | 22 | |
| Single | 0.135 | 11 | ||
| Name | 0.173 | 26 | ||
| String | 0.193 | 0.028 | 3 | |
| Value | 0.000 | 0.098 | 0.025 | 4 |
| #train ≥ 300 | 0.233 | 0.015 | 5 | |
| 300 > #train ≥ 100 | 0.193 | 12 | ||
| 100 > #train | 0.124 | 0.005 | 16 | |
| Recall ≥ 0.5 | 0.155 | 0.040 | 5 | |
| 0.5 > Recall ≥ 0.25 | 0.161 | 14 | ||
| 0.25 > Recall | 0.174 | 0.003 | 14 | |
| Precision ≥ 0.65 | 0.105 | 9 | ||
| 0.65 > Precision ≥ 0.4 | 0.197 | 12 | ||
| 0.4 > Precision | 0.181 | 0.024 | 12 |
| Feature Set | R | P | F1 | ↑↑ | ↑↓ | ↓↓ | – | NT |
|---|---|---|---|---|---|---|---|---|
| Baseline 1: Relation Factory (best F1 run) | 0.332 | 0.425 | 0.373 | |||||
| Baseline 2: Relation Factory (best precision run) | 0.259 | 0.509 | 0.343 | |||||
| Statistical | 0.256 | 0.574 | 0.354 | 12 | 13 | 4 | 4 | 8 |
| Statistical + NE | 0.260 | 0.579 | 0.359 | 13 | 11 | 5 | 4 | 8 |
| Statistical + Lexical/POS | 0.266 | 0.614 | 0.371 | 16 | 10 | 4 | 3 | 8 |
| Statistical + Syntactic | 0.253 | 0.582 | 0.352 | 9 | 18 | 1 | 5 | 8 |
| Statistical + Lexical/POS + Syntactic | 0.271 | 0.616 | 0.377 | 16 | 10 | 4 | 3 | 8 |
| Statistical + Lexical/POS + Syntactic + NE | 0.264 | 0.591 | 0.365 | 15 | 12 | 3 | 3 | 8 |
| Statistical + Lexical/POS (bigrams) + Syntactic (bigrams) | 0.272 | 0.623 | 0.379 | 16 | 9 | 4 | 4 | 8 |
| Statistical + Lexical/POS (bigrams) | 0.276 | 0.630 | 0.384 | 20 | 9 | 1 | 3 | 8 |
| Statistical + Syntactic (bigrams) | 0.255 | 0.597 | 0.357 | 9 | 16 | 5 | 3 | 8 |
| Statistical + Lexical/POS (bigrams) + Syntactic (bigrams)+ NE | 0.268 | 0.591 | 0.369 | 14 | 13 | 3 | 3 | 8 |
| Statistical + Lexical/POS (bigrams)+ Syntactic (bigrams)+ Specific | 0.266 | 0.600 | 0.369 | 13 | 15 | 3 | 2 | 8 |
| Statistical + Lexical/POS (bigrams) + Syntactic (bigrams) + NE + Specific | 0.267 | 0.597 | 0.369 | 15 | 13 | 3 | 2 | 8 |
| Statistical + Lexical/POS (bigrams) + Syntactic (unigrams) | 0.272 | 0.607 | 0.376 | 16 | 11 | 3 | 3 | 8 |
| Statistical + Lexical/POS (POS bigrams only) | 0.272 | 0.582 | 0.370 | 15 | 12 | 2 | 4 | 8 |
| Statistical + Lexical/POS (word bigrams only) | 0.266 | 0.618 | 0.372 | 18 | 11 | 2 | 2 | 8 |
| Statistical + Lexical/POS (POS bigrams only) + Syntactic (unigrams) | 0.274 | 0.617 | 0.379 | 15 | 13 | 3 | 2 | 8 |
| Statistical + Lexical/POS (word bigrams only) + Syntactic (unigrams) | 0.270 | 0.608 | 0.374 | 16 | 12 | 2 | 3 | 8 |
| Statistical + Lexical/POS (bigrams) + Syntactic (syntactic dependencies unigrams only) | 0.269 | 0.603 | 0.372 | 16 | 13 | 2 | 2 | 8 |
| Statistical + Lexical/POS (bigrams) + Syntactic (multilevel unigrams only) | 0.279 | 0.614 | 0.383 | 19 | 9 | 3 | 2 | 8 |
| Feature Subset | Recall | Precision | F1 |
|---|---|---|---|
| Pre-Filtering | 0.188 | 0.351 | 0.231 |
| Statistical + Lexical/POS + Syntactic | 0.147 | 0.439 | 0.211 |
| Statistical + Lexical/POS + Syntactic (bigrams) | 0.144 | 0.453 | 0.209 |
| Statistical + Lexical/POS (bigrams) | 0.144 | 0.463 | 0.211 |
| Statistical + Lexical/POS (bigrams) + Syntactic (unigrams) | 0.146 | 0.457 | 0.212 |
| Statistical + Lexical/POS (POS bigrams only) + Syntactic (unigrams) | 0.146 | 0.453 | 0.211 |
| Statistical + Lexical/POS (word bigrams only) + Syntactic (unigrams) | 0.141 | 0.446 | 0.206 |
| Statistical + Lexical/POS (bigrams) + Syntactic (multilevel unigrams only) | 0.145 | 0.458 | 0.211 |
| System ID | Run | Pre-Filtering | Post-Filtering | ||||
|---|---|---|---|---|---|---|---|
| Recall | Precision | F1 | Recall | Precision | F1 | ||
| Uwashington | F1 | 0.103 | 0.634 | 0.177 | 0.079 | 0.725 | 0.143 |
| Precision | 0.086 | 0.646 | 0.152 | 0.067 | 0.742 | 0.122 | |
| Alternate | 0.076 | 0.633 | 0.136 | 0.057 | 0.694 | 0.106 | |
| BIT | F1 | 0.217 | 0.613 | 0.321 | 0.176 | 0.751 | 0.286 |
| Recall | 0.260 | 0.234 | 0.246 | 0.197 | 0.395 | 0.263 | |
| Alternate 1 | 0.225 | 0.539 | 0.318 | 0.181 | 0.693 | 0.287 | |
| Alternate 2 | 0.232 | 0.511 | 0.319 | 0.185 | 0.668 | 0.290 | |
| Alternate 3 | 0.251 | 0.258 | 0.254 | 0.192 | 0.445 | 0.268 | |
| CMUML | F1 | 0.107 | 0.323 | 0.161 | 0.082 | 0.553 | 0.142 |
| Precision | 0.053 | 0.443 | 0.095 | 0.042 | 0.633 | 0.079 | |
| Alternate | 0.097 | 0.303 | 0.147 | 0.073 | 0.525 | 0.128 | |
| lsv (Relation Factory) | F1 | 0.332 | 0.425 | 0.373 | 0.276 | 0.630 | 0.384 |
| Precision | 0.259 | 0.509 | 0.343 | 0.216 | 0.637 | 0.322 | |
| Recall | 0.378 | 0.351 | 0.364 | 0.304 | 0.560 | 0.394 | |
| Alternate 1 | 0.366 | 0.369 | 0.368 | 0.295 | 0.591 | 0.393 | |
| Alternate 2 | 0.358 | 0.381 | 0.369 | 0.286 | 0.595 | 0.386 | |
| TALP_UPC | F1 | 0.098 | 0.077 | 0.086 | 0.078 | 0.148 | 0.102 |
| Precision | 0.020 | 0.291 | 0.038 | 0.016 | 0.387 | 0.031 | |
| Alternate | 0.057 | 0.131 | 0.080 | 0.048 | 0.262 | 0.082 | |
| NYU | F1 | 0.168 | 0.538 | 0.256 | 0.139 | 0.620 | 0.227 |
| PRIS2013 | F1 | 0.276 | 0.389 | 0.323 | 0.211 | 0.535 | 0.303 |
| Recall | 0.335 | 0.267 | 0.297 | 0.240 | 0.395 | 0.298 | |
| Alternate 1 | 0.324 | 0.227 | 0.267 | 0.232 | 0.341 | 0.276 | |
| Alternate 2 | 0.266 | 0.221 | 0.242 | 0.181 | 0.319 | 0.231 | |
| Alternate 3 | 0.257 | 0.218 | 0.236 | 0.170 | 0.319 | 0.222 | |
| Stanford | F1 | 0.284 | 0.359 | 0.317 | 0.215 | 0.498 | 0.300 |
| Precision | 0.267 | 0.382 | 0.314 | 0.204 | 0.530 | 0.295 | |
| Alternate 1 | 0.279 | 0.357 | 0.314 | 0.208 | 0.491 | 0.293 | |
| Alternate 2 | 0.267 | 0.351 | 0.303 | 0.200 | 0.483 | 0.283 | |
| Alternate 3 | 0.256 | 0.353 | 0.297 | 0.189 | 0.494 | 0.274 | |
| UNED | F1 | 0.093 | 0.176 | 0.122 | 0.061 | 0.249 | 0.098 |
| Alternate | 0.089 | 0.167 | 0.116 | 0.058 | 0.234 | 0.093 | |
| Umass_IESL | F1 | 0.185 | 0.109 | 0.137 | 0.153 | 0.159 | 0.156 |
| SAFT_Kres | F1 | 0.150 | 0.157 | 0.153 | 0.095 | 0.167 | 0.122 |
| Precision | 0.088 | 0.277 | 0.133 | 0.051 | 0.439 | 0.092 | |
| Alternate | 0.078 | 0.122 | 0.096 | 0.054 | 0.119 | 0.074 | |
| CUNY_BLENDER | F1 | 0.292 | 0.396 | 0.336 | 0.224 | 0.500 | 0.310 |
| Precision | 0.268 | 0.443 | 0.334 | 0.207 | 0.543 | 0.300 | |
| Alternate 1 | 0.275 | 0.400 | 0.326 | 0.212 | 0.498 | 0.297 | |
| Alternate 2 | 0.290 | 0.407 | 0.339 | 0.221 | 0.519 | 0.310 | |
| Alternate 3 | 0.258 | 0.435 | 0.324 | 0.196 | 0.555 | 0.290 | |
| utaustin | F1 | 0.081 | 0.252 | 0.123 | 0.050 | 0.310 | 0.087 |
| Alternate | 0.076 | 0.186 | 0.108 | 0.043 | 0.228 | 0.072 | |
| ARPANI | F1 | 0.275 | 0.504 | 0.355 | 0.215 | 0.600 | 0.316 |
| Average | 0.206 | 0.349 | 0.239 | 0.156 | 0.472 | 0.223 | |
| System Configuration | Pre-Filtering | Post-Filtering | ||||
|---|---|---|---|---|---|---|
| Recall | Precision | F1 | Recall | Precision | F1 | |
| F1-tuned | 0.190 | 0.354 | 0.231 | 0.147 | 0.460 | 0.213 |
| Precision-tuned | 0.167 | 0.398 | 0.218 | 0.129 | 0.510 | 0.194 |
| Recall-tuned | 0.201 | 0.313 | 0.224 | 0.152 | 0.420 | 0.211 |
| Confidence Score Threshold | Recall | Precision | F1 |
|---|---|---|---|
| ine Pre-filtering (baseline) | 0.332 | 0.425 | 0.373 |
| Using our filter | 0.276 | 0.630 | 0.384 |
| ine 0.1 | 0.319 | 0.452 | 0.374 |
| 0.2 | 0.292 | 0.473 | 0.361 |
| 0.3 | 0.275 | 0.494 | 0.353 |
| 0.4 | 0.262 | 0.515 * | 0.347 |
| 0.5 | 0.252 | 0.535 * | 0.343 |
| 0.6 | 0.210 | 0.528 * | 0.300 |
| 0.7 | 0.196 | 0.539 * | 0.287 |
| 0.8 | 0.171 | 0.532 * | 0.259 |
| 0.9 | 0.160 | 0.529 * | 0.246 |
| 1.0 | 0.147 | 0.539 * | 0.231 |
| Algorithm | Recall | Precision | F1 |
|---|---|---|---|
| Pre Filtering | 0.332 | 0.425 | 0.373 |
| Decision table | 0.263 | 0.556 | 0.357 |
| J48 | 0.271 | 0.621 | 0.377 |
| Kstar | 0.272 | 0.605 | 0.376 |
| NBTree | 0.254 | 0.572 | 0.352 |
| Random Forest | 0.274 | 0.622 | 0.380 |
| SMO | 0.256 | 0.596 | 0.358 |
| Combination | 0.276 | 0.630 | 0.384 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lange Di Cesare, K.; Zouaq, A.; Gagnon, M.; Jean-Louis, L. A Machine Learning Filter for the Slot Filling Task. Information 2018, 9, 133. https://doi.org/10.3390/info9060133
Lange Di Cesare K, Zouaq A, Gagnon M, Jean-Louis L. A Machine Learning Filter for the Slot Filling Task. Information. 2018; 9(6):133. https://doi.org/10.3390/info9060133
Chicago/Turabian StyleLange Di Cesare, Kevin, Amal Zouaq, Michel Gagnon, and Ludovic Jean-Louis. 2018. "A Machine Learning Filter for the Slot Filling Task" Information 9, no. 6: 133. https://doi.org/10.3390/info9060133
APA StyleLange Di Cesare, K., Zouaq, A., Gagnon, M., & Jean-Louis, L. (2018). A Machine Learning Filter for the Slot Filling Task. Information, 9(6), 133. https://doi.org/10.3390/info9060133