#europehappinessmap: A Framework for Multi-Lingual Sentiment Analysis via Social Media Big Data (A Twitter Case Study)


Abstract
1. Introduction & Literature Review
- Data collection methods have not been mentioned in the studies. Generally, researchers mention the collected data but not how to collect.
- Generally English language used in the studies. Also, if English is not used, then researchers use only one dictionary and analyze only one language and one country.
1.1. Cultural Well-Being and Life Satisfaction Studies
1.2. Ethics on Social Media Studies
1.3. Results of Literature Review
- There is not a multi-lingual framework for Twitter sentiment analysis.
- Lexicon-based (dictionary-based) sentiment analysis is still most popular instead of machine learning, classification and clustering.
- Multicultural comparison of social media data on sentiment analysis has not been done yet.
- Data collection is the least mentioned part in articles, while proposing a novel method for this issue can be very supportive for the academics.
- The user Twitter features such as follower count, friends count, Twitter age, number of Tweets have not been taken into account yet in terms of possible relations of them.
- Whereas business effect and value are mentioned in several studies, the result of a multicultural sentiment analysis and GNH map of a continent have not considered by the researchers yet.
- Some of the dictionaries aimed to be used in this study are mentioned in some studies but have not been used all together yet (possibly because of huge work requirement).
- Big data studies are becoming very popular on sentiment analysis but have not been defined well yet.
- English is very popular and people usually use the LICW dictionary, but except for a few local small scale studies, other languages have not been examined with big data analysis to detect sentiments.
- Validation and accuracy of findings is not a concept for sentiment analysis studies while it should be.
- Anonymizing users’ information, converting the info with other texts and filtering out results to conclude a general result are the frequent methods for ethical consideration on social media studies.
2. Research Questions and Scientific Value
“Is the social media big data appropriate for the sentiment analysis (instead of surveys or interviews) to draw a happiness map of Europe?”
“To design, develop, implement and evaluate a framework for multi-lingual sentiment analysis via social media big data for calculating Gross National Happiness (GNH) levels of European Countries”
- Is there face validity when the polarities determined by sentiment analysis framework are compared with Stock Market Index and Exchange Rates?
- Is there convergent validity when the GNH results of the sentiment analysis framework and GNH survey results of Organization for Economic Cooperation and Development (OECD) report are compared?
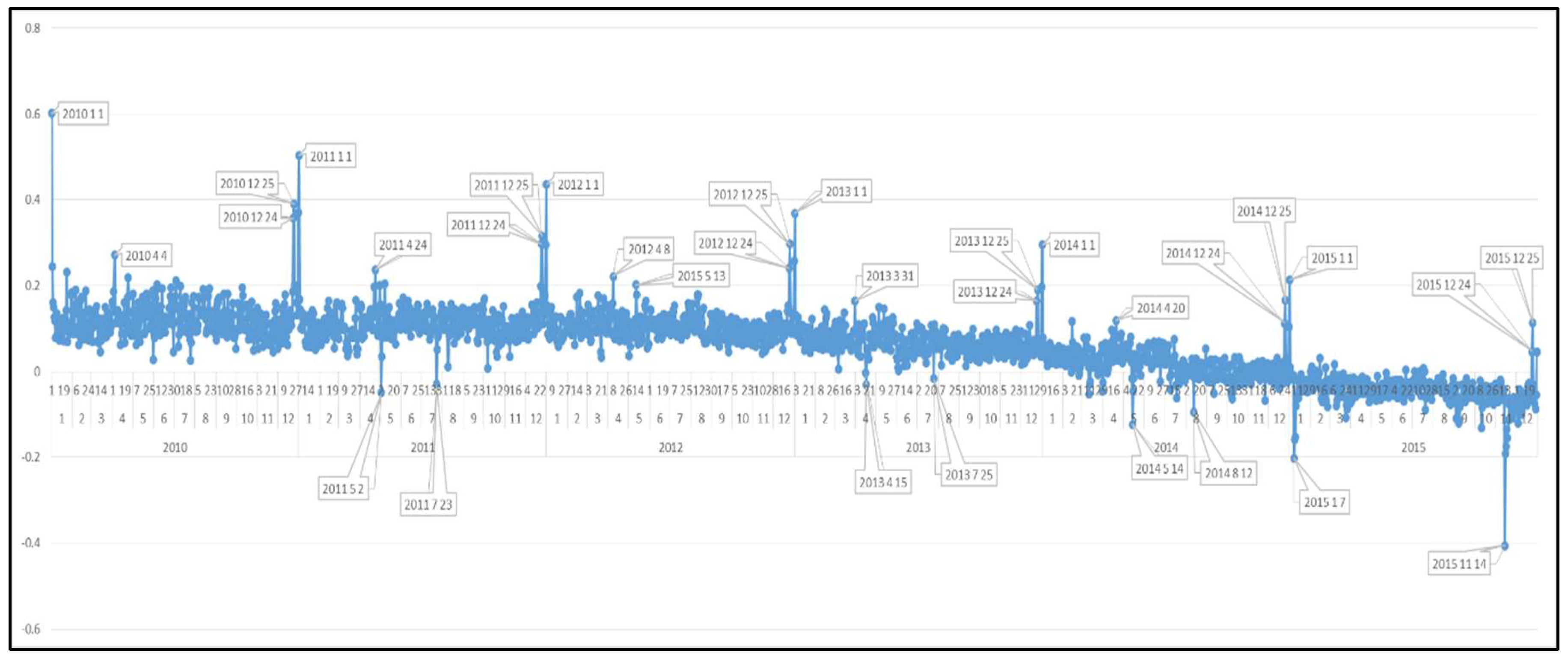
- Is there data reliability when the peaks/troughs of the graphs of sentiment analysis framework are compared with specific dates obtained from news archives?
- What are the GNH polarities of European countries in accordance with the proposed Twitter sentiment analysis framework?
3. Materials and Methodology
3.1. Design of Sentiment Analysis Algorithm
3.2. GNH Calculation for Countries
3.3. Gross National Happiness Calculation Algorithm
3.4. Design of Social Media Big Data Collection Method
3.5. Accessing and Collecting Trend Topics (TT)
- Accepting users’ self-declared profiles for location
- Aggregating geo-tags attached with users’ tweets
- Choosing the most frequent city involved in the geotags
- Choosing the first valid geotag, and convert it to an administrative region, a cell, or coordinates
- Choosing the geometric median of the geo-tags
- TT name,
- TT created at,
- TT search query,
- TT URL values.
3.6. Accessing Users from TT and Filtering Bot (Automatic) Accounts
- Account ID
- User name
- Screen name
- Number of followers
- Number of friends (followees, number of people s/he follows)
- Number of tweets
- Number of “favorited” tweets
- Account description
- Language
- Account creation time
3.7. Collecting Tweets of Chosen Users
4. Implementation and Evaluation of the Framework
4.1. Choosing Countries for Sample and Collecting Tweets
- the country should be open to Twitter usage with no bans or censorship
- there should be only one national language spoken within the country and that language must exist in our sentiment analysis dictionaries.
4.2. Sentiment Analysis Algorithm and GNH-TD Calculation
5. Analysis
6. Results
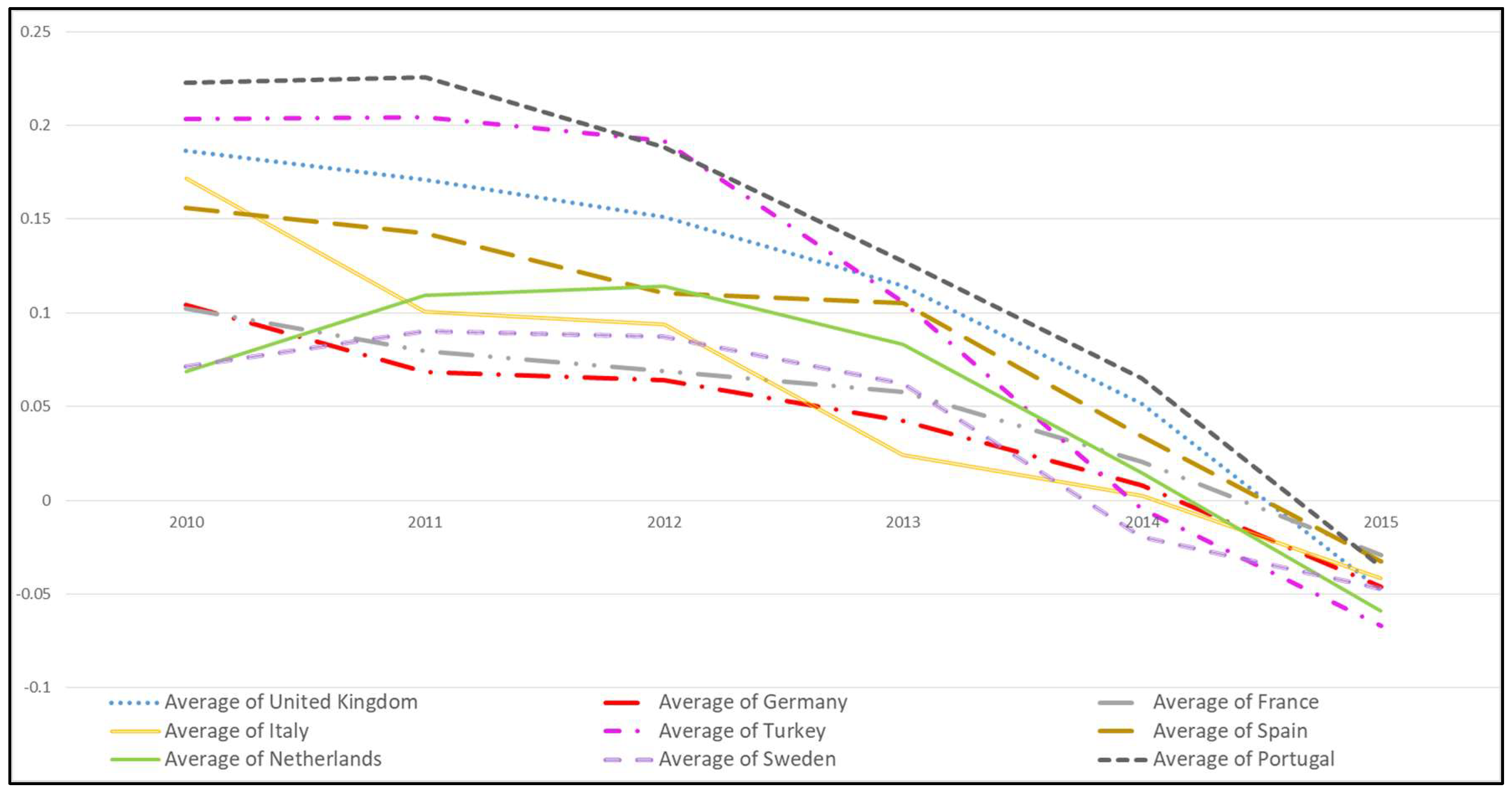
- A negativity trend appears in social media happiness of all countries through the six years period. This result is also approved by OECD Life Satisfaction results of countries, because those values are decreasing also year by year.
- France has changed its positive happiest level from 3rd unhappiest through six years.
- One of the most impressive results of the study, while Turkey starts with second highest (happiest) position in 2010 and in the second position in aggregate results (Table 8); it is the unhappiest country among all at the end of 2015.
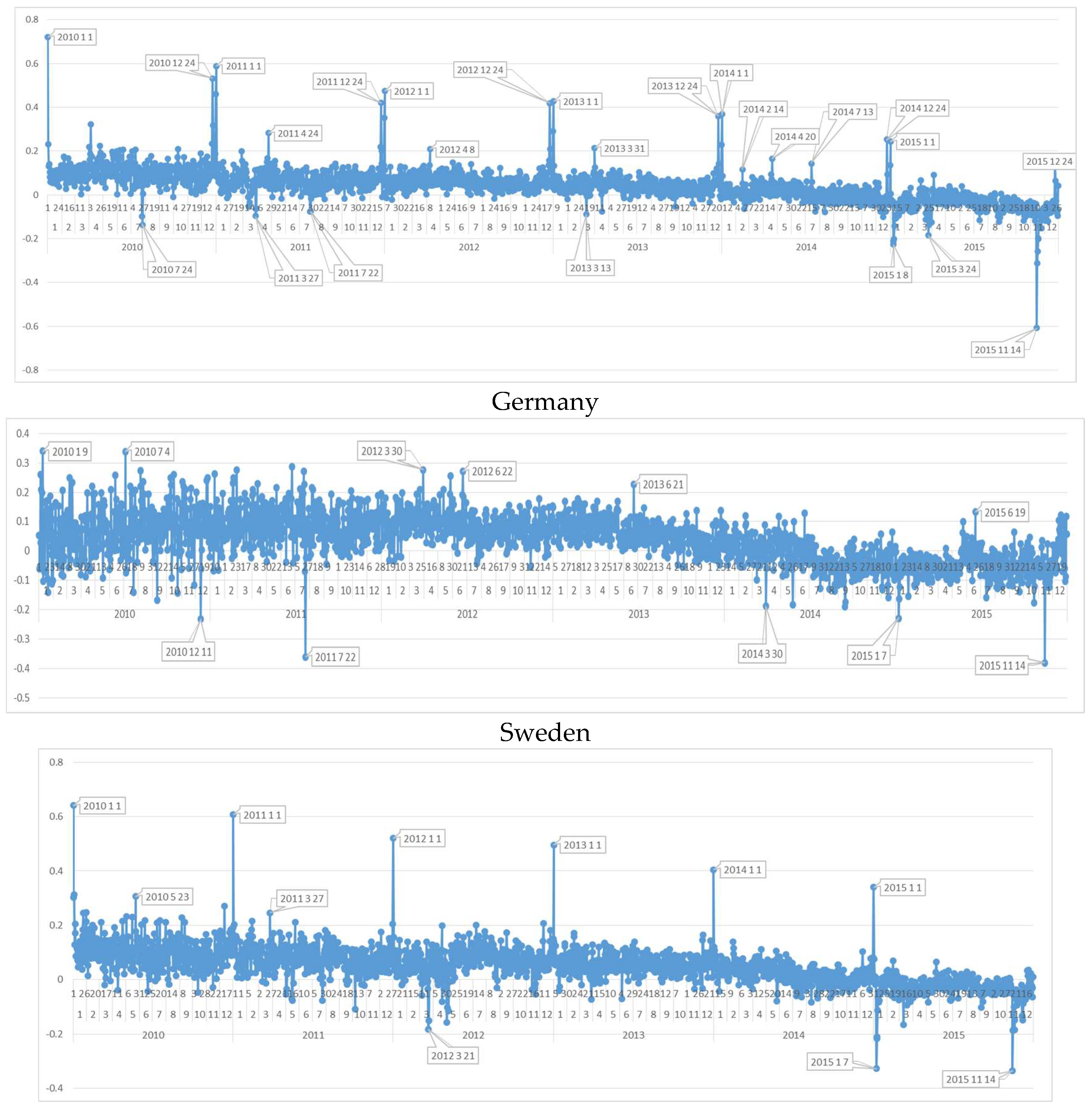
6.1. EU Countries Daily Sentiment Analysis
6.2. Daily Sentiment Analysis for Germany
6.3. Daily Sentiment Analysis for Sweden
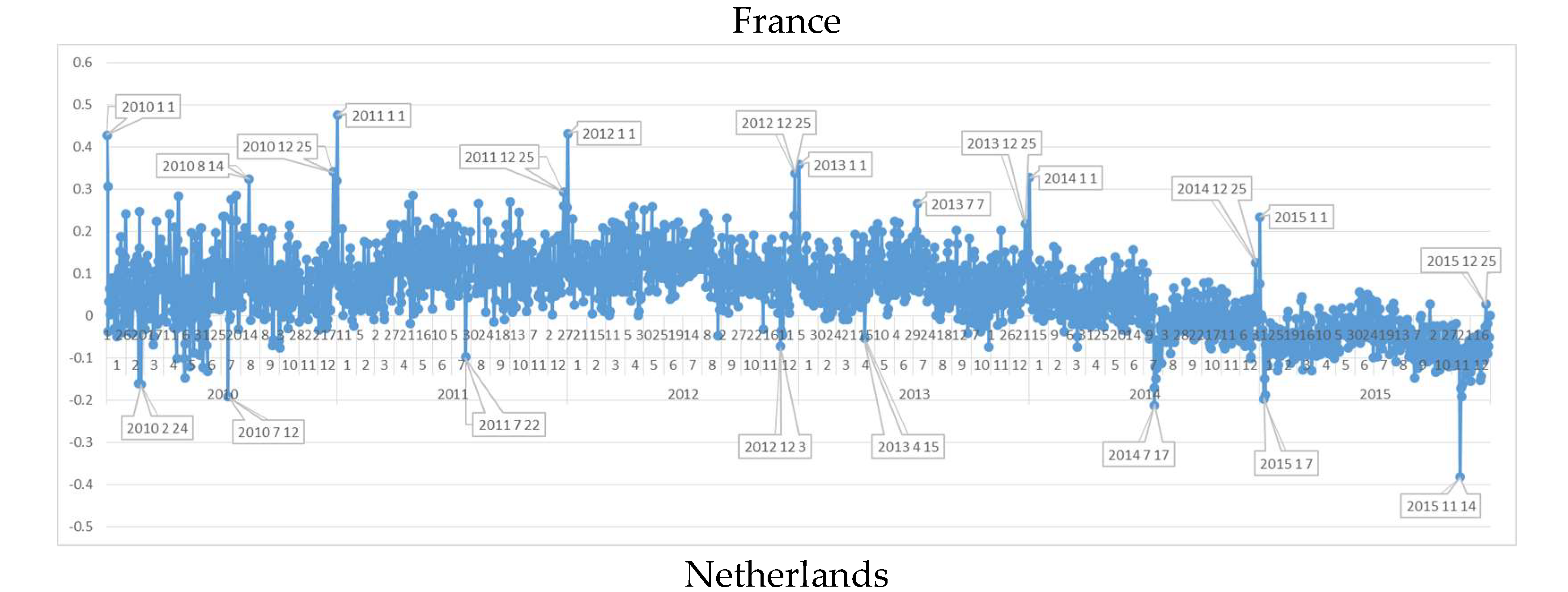
6.4. Daily Sentiment Analysis for France
6.5. Daily Sentiment Analysis for The Netherlands
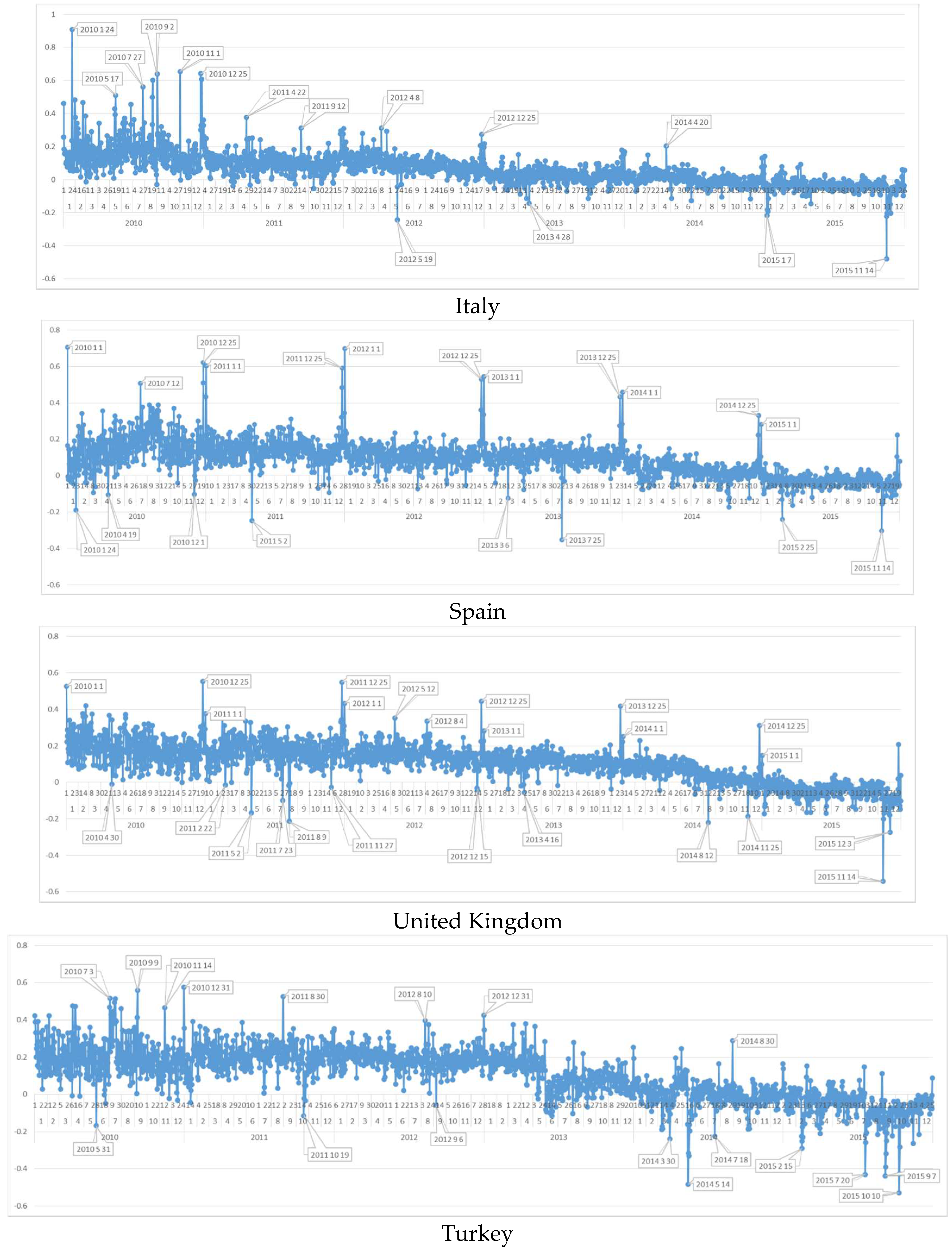
6.6. Daily Sentiment Analysis for Italy
6.7. Daily Sentiment Analysis for Spain
6.8. Daily Sentiment Analysis for United Kingdom
6.9. Daily Sentiment Analysis for Turkey
6.10. Daily Sentiment Analysis for Portugal
7. Discussion and Conclusions
- Lastly, it can be stated that comparing to the survey based methodology of GNH calculation by the global institutions (e.g., OECD), time series results (daily, monthly etc.) can be drawn and explained with this proposed framework. Thus this promising framework can contribute the researchers for related specific social psychology studies.
8. Future Study Recommendations
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A. Daily Sentiment Polarity Graphs of Countries




References
- Hanna, B.; Kee, K.F.; Robertson, B.W. Positive impacts of social media at work: Job satisfaction, job calling, and Facebook use among co-workers. In Proceedings of the SHS Web of Conferences, Kuala Lumpur, Malaysia, 18–20 September 2016. [Google Scholar]
- Fuchs, C. Social Media: A Critical Introduction; SAGE: Thousand Oaks, CA, USA, 2017. [Google Scholar]
- Lenhart, A. Adults and Social Network Websites; Pew Research Center: Washington, DC, USA, 2009. [Google Scholar]
- Lenhart, A.; Madden, M. Social Networking Websites and Teens: An Overview; Pew Research Center: Washington, DC, USA, 2007. [Google Scholar]
- Lenhart, A. Teens and Social Media: The Use of Social Media Gains a Greater Foothold in Teen Life as They Embrace the Conversational Nature of Interactive Online Media; Pew Internet & American Life Project: Washington, DC, USA, 2007. [Google Scholar]
- Bello-Orgaz, G.; Jung, J.J.; Camacho, D. Social big data: Recent achievements and new challenges. Inf. Fusion 2016, 28, 45–59. [Google Scholar] [CrossRef]
- Quan-Haase, A.; Young, A.L. Uses and gratifications of social media: A comparison of Facebook and instant messaging. Bull. Sci. Technol. Soc. 2010, 30, 350–361. [Google Scholar] [CrossRef]
- Mayr, P.; Weller, K. Think before you collect: Setting up a data collection approach for social media studies. In The SAGE Handbook of Social Media Research Methods; SAGE: Thousand Oaks, CA, USA, 2017; p. 107. [Google Scholar]
- Ellison, N.B.; Steinfield, C.; Lampe, C. The benefits of Facebook “friends”: Social capital and college students’ use of online social network sites. J. Comput. Mediat. Commun. 2007, 12, 1143–1168. [Google Scholar] [CrossRef]
- Abdullah, S.; Murnane, E.L.; Costa, J.M.R.; Choudhury, T. Collective smile: Measuring societal happiness from geolocated images. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015; ACM: New York, NY, USA, 2015; pp. 361–374. [Google Scholar]
- Bravo-Marquez, F.; Frank, E.; Pfahringer, B. From unlabelled tweets to twitter-specific opinion words. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; ACM: New York, NY, USA, 2015; pp. 743–746. [Google Scholar]
- Quercia, D.; Ellis, J.; Capra, L.; Crowcroft, J. Tracking gross community happiness from tweets. In Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work, Seattle, WA, USA, 11–15 February 2012; ACM: New York, NY, USA, 2012; pp. 965–968. [Google Scholar]
- Gutierrez, F.J.; Poblete, B. Sentiment-based user profiles in microblogging platforms. In Proceedings of the 26th ACM Conference on Hypertext & Social Media, Guzelyurt, Northern Cyprus, 1–4 September 2015; ACM: New York, NY, USA, 2015; pp. 23–32. [Google Scholar]
- Beasley, A.; Mason, W. Emotional states vs. Emotional words in social media. In Proceedings of the ACM Web Science Conference, Oxford, UK, 28 June–1 July 2015; ACM: New York, NY, USA, 2015; p. 31. [Google Scholar]
- Saif, H.; He, Y.; Fernandez, M.; Alani, H. Contextual semantics for sentiment analysis of twitter. Inf. Process. Manag. 2016, 52, 5–19. [Google Scholar] [CrossRef]
- Akgül, E.S.; Ertano, C.; Banu, D. Twitter verileri ile duygu analizi. Pamukkale Üniv. Müh. Bilim. Derg. 2016, 22, 106–110. [Google Scholar]
- Kalamatianos, G.; Mallis, D.; Symeonidis, S.; Arampatzis, A. Sentiment analysis of greek tweets and hashtags using a sentiment lexicon. In Proceedings of the 19th Panhellenic Conference on Informatics, Athens, Greece, 1–3 October 2015; ACM: New York, NY, USA, 2015; pp. 63–68. [Google Scholar]
- Yamamoto, Y.; Kumamoto, T.; Nadamoto, A. Role of emoticons for multidimensional sentiment analysis of Twitter. In Proceedings of the 16th International Conference on Information Integration and Web-based Applications & Services, Hanoi, Viet Nam, 4–6 December 2014; ACM: New York, NY, USA, 2014; pp. 107–115. [Google Scholar]
- Yu, Y.; Wang, X. World cup 2014 in the Twitter world: A big data analysis of sentiments in us sports fans’ tweets. Comput. Hum. Behav. 2015, 48, 392–400. [Google Scholar] [CrossRef]
- Poblete, B.; Garcia, R.; Mendoza, M.; Jaimes, A. Do all birds tweet the same?: Characterizing Twitter around the world. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011; ACM: New York, NY, USA, 2011; pp. 1025–1030. [Google Scholar]
- Wang, C.-J.; Wang, P.-P.; Zhu, J.J.H. Discussing occupy wall street on Twitter: Longitudinal network analysis of equality, emotion, and stability of public discussion. Cyberpsychol. Behav. Soc. Netw. 2013, 16, 679–685. [Google Scholar] [CrossRef] [PubMed]
- Fu, K.-W.; Chan, C.-H. Analyzing online sentiment to predict telephone poll results. Cyberpsychol. Behav. Soc. Netw. 2013, 16, 702–707. [Google Scholar] [CrossRef] [PubMed]
- Correa, J.C.; Camargo, J.E. Ideological consumerism in Colombian elections, 2015: Links between political ideology, Twitter activity, and electoral results. Cyberpsychol. Behav. Soc. Netw. 2017, 20, 37–43. [Google Scholar] [CrossRef] [PubMed]
- Rice, T.W.; Steele, B.J. Subjective well-being and culture across time and space. J. Cross-Cult. Psychol. 2004, 35, 633–647. [Google Scholar] [CrossRef]
- Minkov, M. Nations with more dialectical selves exhibit lower polarization in life quality judgments and social opinions. Cross-Cult. Res. 2009, 43, 230–250. [Google Scholar] [CrossRef]
- Helliwell, J.F.; Barrington-Leigh, C.P.; Harris, A.; Huang, H. International Evidence on the Social Context of Well-Being; National Bureau of Economic Research: Cambridge, MA, USA, 2009. [Google Scholar]
- Diener, E.; Napa-Scollon, C.K.; Oishi, S.; Dzokoto, V.; Suh, E.M. Positivity and the construction of life satisfaction judgments: Global happiness is not the sum of its parts. J. Happiness Stud. 2000, 1, 159–176. [Google Scholar] [CrossRef]
- Angelini, V.; Cavapozzi, D.; Corazzini, L.; Paccagnella, O. Do danes and italians rate life satisfaction in the same way? Using vignettes to correct for individual-specific scale biases. Oxf. Bull. Econ. Stat. 2014, 76, 643–666. [Google Scholar] [CrossRef]
- Exton, C.; Smith, C.; Vandendriessche, D. Comparing Happiness Across the World: Does Culture Matter? OECD Statistics Working Papers; OECD Publishing: Paris, France, 2015. [Google Scholar]
- Braithwaite, S.R.; Giraud-Carrier, C.; West, J.; Barnes, M.D.; Hanson, C.L. Validating machine learning algorithms for Twitter data against established measures of suicidality. JMIR Ment. Health 2016, 3. [Google Scholar] [CrossRef] [PubMed]
- Lv, M.; Li, A.; Liu, T.; Zhu, T. Creating a Chinese suicide dictionary for identifying suicide risk on social media. PeerJ 2015, 3, e1455. [Google Scholar] [CrossRef] [PubMed]
- O’Dea, B.; Wan, S.; Batterham, P.J.; Calear, A.L.; Paris, C.; Christensen, H. Detecting suicidality on Twitter. Internet Interv. 2015, 2, 183–188. [Google Scholar] [CrossRef]
- Coppersmith, G.; Dredze, M.; Harman, C.; Hollingshead, K. From ADHD to SAD: Analyzing the language of mental health on Twitter through self-reported diagnoses. In Proceedings of the 2nd Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, Denver, CO, USA, 5 June 2015; pp. 1–10. [Google Scholar]
- Guan, L.; Hao, B.; Cheng, Q.; Yip, P.S.; Zhu, T. Identifying Chinese microblog users with high suicide probability using internet-based profile and linguistic features: Classification model. JMIR Ment. Health 2015, 2. [Google Scholar] [CrossRef] [PubMed]
- Tsugawa, S.; Kikuchi, Y.; Kishino, F.; Nakajima, K.; Itoh, Y.; Ohsaki, H. Recognizing depression from Twitter activity. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; ACM: New York, NY, USA, 2015; pp. 3187–3196. [Google Scholar]
- Liu, P.; Tov, W.; Kosinski, M.; Stillwell, D.J.; Qiu, L. Do Facebook status updates reflect subjective well-being? Cyberpsychol. Behav. Soc. Netw. 2015, 18, 373–379. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Kim, I.; Lee, S.W.; Yoo, J.; Jeong, B.; Cha, M. Manifestation of depression and loneliness on social networks: A case study of young adults on Facebook. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015; ACM: New York, NY, USA, 2015; pp. 557–570. [Google Scholar]
- De Choudhury, M.; Counts, S.; Horvitz, E.J.; Hoff, A. Characterizing and predicting postpartum depression from shared Facebook data. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, MD, USA, 15–19 February 2014; ACM: New York, NY, USA, 2014; pp. 626–638. [Google Scholar]
- Park, S.; Lee, S.W.; Kwak, J.; Cha, M.; Jeong, B. Activities on Facebook reveal the depressive state of users. J. Med. Internet Res. 2013, 15. [Google Scholar] [CrossRef] [PubMed]
- Youyou, W.; Kosinski, M.; Stillwell, D. Computer-based personality judgments are more accurate than those made by humans. Proc. Natl. Acad. Sci. USA 2015, 112, 1036–1040. [Google Scholar] [CrossRef] [PubMed]
- Chancellor, S.; Lin, Z.; Goodman, E.L.; Zerwas, S.; De Choudhury, M. Quantifying and predicting mental illness severity in online pro-eating disorder communities. In Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work & Social Computing, San Francisco, CA, USA, 27 February–2 March 2016; ACM: New York, NY, USA, 2016; pp. 1171–1184. [Google Scholar]
- Coppersmith, G.; Ngo, K.; Leary, R.; Wood, A. Exploratory analysis of social media prior to a suicide attempt. In Proceedings of the 3rd Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, San Diego, CA, USA, 16 June 2016; pp. 106–117. [Google Scholar]
- Burnap, P.; Colombo, W.; Scourfield, J. Machine classification and analysis of suicide-related communication on Twitter. In Proceedings of the 26th ACM Conference on Hypertext & Social Media, Guzelyurt, Northern Cyprus, 1–4 September 2015; ACM: New York, NY, USA, 2015; pp. 75–84. [Google Scholar]
- Coppersmith, G.A.; Harman, C.T.; Dredze, M.H. Measuring Post Traumatic Stress Disorder in Twitter. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Huang, X.; Zhang, L.; Chiu, D.; Liu, T.; Li, X.; Zhu, T. Detecting suicidal ideation in Chinese microblogs with psychological lexicons. In Proceedings of the 2014 IEEE 11th International Conference on Ubiquitous Intelligence and Computing and IEEE 11th International Conference on Autonomic and Trusted Computing and IEEE 14th International Conference on Scalable Computing and Communications and Its Associated Workshops (UTC-ATC-ScalCom), Bali, Indonesia, 9–12 December 2014; pp. 844–849. [Google Scholar]
- Ertugrul, A.M.; Onal, I.; Acarturk, C. Does the strength of sentiment matter? A regression based approach on Turkish social media. In Natural Language Processing and Information Systems, Proceedings of the 22nd International Conference on Applications of Natural Language to Information Systems (NLDB 2017), Liège, Belgium, 21–23 June 2017; Frasincar, F., Ittoo, A., Nguyen, L.M., Métais, E., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 149–155. [Google Scholar]
- Wongkoblap, A.; Vadillo, M.A.; Curcin, V. Researching mental health disorders in the era of social media: Systematic review. J. Med. Internet Res. 2017, 19, e228. [Google Scholar] [CrossRef] [PubMed]
- Ferraro, J. The Strategic Project Leader: Mastering Service-Based Project Leadership; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Duncan, W.R. A Guide to the Project Management Body of Knowledge; Project Management Institute: Newtown Square, PA, USA, 1996. [Google Scholar]
- Ahmad, K.; Almas, Y. Visualising sentiments in financial texts? In Proceedings of the Ninth International Conference on Information Visualisation, London, UK, 6–8 July 2005; pp. 363–368. [Google Scholar]
- Chaovalit, P.; Zhou, L. Movie review mining: A comparison between supervised and unsupervised classification approaches. In Proceedings of the 38th Annual Hawaii International Conference on System Sciences (HICSS’05), Big Island, HI, USA, 6 January 2005. [Google Scholar]
- Xu, D.J.; Liao, S.S.; Li, Q. Combining empirical experimentation and modeling techniques: A design research approach for personalized mobile advertising applications. Decis. Support Syst. 2008, 44, 710–724. [Google Scholar] [CrossRef]
- Yuan, S.-T. A personalized and integrative comparison-shopping engine and its applications. Decis. Support Syst. 2003, 34, 139–156. [Google Scholar] [CrossRef]
- Jain, G.; Ginwala, A.; Aslandogan, Y.A. An approach to text classification using dimensionality reduction and combination of classifiers. In Proceedings of the 2004 IEEE International Conference on Information Reuse and Integration (IRI 2004), Las Vegas, NV, USA, 8–10 November 2004; pp. 564–569. [Google Scholar]
- Huang, R.; Hansen, J.H. Dialect classification on printed text using perplexity measure and conditional random fields. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2007), Honolulu, HI, USA, 15–20 April 2007; pp. IV-993–IV-996. [Google Scholar]
- Li, N.; Wu, D.D. Using text mining and sentiment analysis for online forums hotspot detection and forecast. Decis. Support Syst. 2010, 48, 354–368. [Google Scholar] [CrossRef]
- Turney, P.D.; Littman, M.L. Measuring praise and criticism: Inference of semantic orientation from association. ACM Trans. Inf. Syst. (TOIS) 2003, 21, 315–346. [Google Scholar] [CrossRef]
- Thelwall, M.; Buckley, K.; Paltoglou, G. Sentiment strength detection for the social web. J. Assoc. Inf. Sci. Technol. 2012, 63, 163–173. [Google Scholar] [CrossRef]
- Thelwall, M.; Buckley, K.; Paltoglou, G.; Cai, D.; Kappas, A. Sentiment strength detection in short informal text. J. Assoc. Inf. Sci. Technol. 2010, 61, 2544–2558. [Google Scholar] [CrossRef]
- Thelwall, M.; Buckley, K. Topic-based sentiment analysis for the social web: The role of mood and issue-related words. J. Assoc. Inf. Sci. Technol. 2013, 64, 1608–1617. [Google Scholar] [CrossRef]
- Vural, A.G.; Cambazoglu, B.B.; Senkul, P.; Tokgoz, Z.O. A framework for sentiment analysis in Turkish: Application to polarity detection of movie reviews in Turkish. In Computer and Information Sciences III; Springer: London, UK, 2013; pp. 437–445. [Google Scholar]
- Kucuktunc, O.; Cambazoglu, B.B.; Weber, I.; Ferhatosmanoglu, H. A large-scale sentiment analysis for yahoo! Answers. In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, Seattle, WA, USA, 8–12 February 2012; ACM: New York, NY, USA, 2012; pp. 633–642. [Google Scholar]
- Garas, A.; Garcia, D.; Skowron, M.; Schweitzer, F. Emotional persistence in online chatting communities. Sci. Rep. 2012, 2, 402. [Google Scholar] [CrossRef] [PubMed]
- Grigore, M.; Rosenkranz, C. Increasing the willingness to collaborate online: An analysis of sentiment-driven interactions in peer content production. In Proceedings of the Thirty Second International Conference on Information Systems, Shanghai, China, 4–7 December 2011. [Google Scholar]
- Giannopoulos, G.; Weber, I.; Jaimes, A.; Sellis, T. Diversifying user comments on news articles. In Proceedings of the International Conference on Web Information Systems Engineering, Paphos, Cyprus, 28–30 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 100–113. [Google Scholar]
- Zheludev, I.; Smith, R.; Aste, T. When can social media lead financial markets? Sci. Rep. 2014, 4, 4213. [Google Scholar] [CrossRef] [PubMed]
- Durahim, A.O.; Coşkun, M. #iamhappybecause: Gross national happiness through Twitter analysis and big data. Technol. Forecast. Soc. Chang. 2015, 99, 92–105. [Google Scholar]
- Pfitzner, R.; Garas, A.; Schweitzer, F. Emotional divergence influences information spreading in Twitter. In Proceedings of the Sixth International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–8 June 2012; Volume 12, pp. 2–5. [Google Scholar]
- Rudra, K.; Chakraborty, A.; Ganguly, N.; Ghosh, S. Understanding the usage of idioms in the Twitter Social Network. In Pattern Recognition and Big Data; World Scientific: Singapore, 2017; pp. 767–788. [Google Scholar]
- Priesner, S. Gross national happiness—Bhutan’s vision of development and its challenges. Indig. Universality Soc. Sci. South Asian Response 1999, 2, 212–233. [Google Scholar] [CrossRef]
- Kramer, A.D. An unobtrusive behavioral model of gross national happiness. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; ACM: New York, NY, USA, 2010; pp. 287–290. [Google Scholar]
- Zheng, X.; Han, J.; Sun, A. A survey of location prediction on Twitter. arXiv, 2017; arXiv:preprint/1705.03172. [Google Scholar]
- Vieweg, S.; Hughes, A.L.; Starbird, K.; Palen, L. Microblogging during two natural hazards events: What Twitter may contribute to situational awareness. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; ACM: New York, NY, USA, 2010; pp. 1079–1088. [Google Scholar]
- Krejcie, R.V.; Morgan, D.W. Determining sample size for research activities. Educ. Psychol. Meas. 1970, 30, 607–610. [Google Scholar] [CrossRef]
- Stats, I.L. Number of Internet Users. Available online: http://www.internetlivestats.com/internet-users (accessed on 24 August 2017).
- Rost, B.; Sander, C. Prediction of protein secondary structure at better than 70% accuracy. J. Mol. Boil. 1993, 232, 584–599. [Google Scholar] [CrossRef] [PubMed]
- Helliwell, J.F.; Huang, H.; Wang, S. The Distribution of World Happiness; World Happiness Report; The Earth Institute Columbia University Press: New York, NY, USA, 2016; Volume 8, ISBN 978-0-9968513-3-6. [Google Scholar]
- Tole, A.A. Big data challenges. Database Syst. J. 2013, 4, 31–40. [Google Scholar]
- Nakov, P.; Rosenthal, S.; Kiritchenko, S.; Mohammad, S.M.; Kozareva, Z.; Ritter, A.; Stoyanov, V.; Zhu, X. Developing a successful SemEval task in sentiment analysis of Twitter and other social media texts. Lang. Resour. Eval. 2016, 50, 35–65. [Google Scholar] [CrossRef]
- Nakov, P.; Ritter, A.; Rosenthal, S.; Sebastiani, F.; Stoyanov, V. SemEval-2016 task 4: Sentiment analysis in Twitter. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016. [Google Scholar]
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 task 4: Sentiment analysis in Twitter. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017. [Google Scholar]
- Giachanou, A.; Crestani, F. Like it or not: A survey of Twitter sentiment analysis methods. ACM Comput. Surv. (CSUR) 2016, 49. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing, Philadelphia, PA, USA, 6–7 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; Volume 10. [Google Scholar]
- Poria, S.; Cambria, E.; Howard, N.; Huang, G.-B.; Hussain, A. Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing 2016, 174, 50–59. [Google Scholar] [CrossRef]
- Chaturvedi, I.; Cambria, E.; Vilares, D. Lyapunov filtering of objectivity for Spanish sentiment model. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | Language | |
|---|---|---|
| 1 | Germany | German |
| 2 | The Netherlands | Dutch |
| 3 | France | French |
| 4 | Greece | Greek |
| 5 | Italy | Italian |
| 6 | Portugal | Portuguese |
| 7 | Sweden | Swedish |
| 8 | Poland | Polish |
| 9 | Spain | Spanish |
| 10 | Turkey | Turkish |
| 11 | United Kingdom | English |
| Country | Internet Users [75] (A) | Total Country Population [75] (B) | Number of Trend Topics Accessed | Total Accessed Users | Using National Language and Created Before 01/01/2010 (C) | Ratio to Total Population (B)/5000 |
|---|---|---|---|---|---|---|
| Germany | 71,727,551 | 82,652,256 | 1688 | 1,208,375 | 19,868 | 16,530 |
| United Kingdom | 57,075,826 | 63,489,234 | 789 | 119,335 | 15,856 | 12,698 |
| France | 55,429,382 | 64,641,279 | 3750 | 1,679,862 | 15,414 | 12,928 |
| Italy | 36,593,969 | 61,070,224 | 2660 | 1,308,952 | 14,487 | 12,214 |
| Turkey | 35,358,888 | 75,837,020 | 6189 | 1,075,541 | 17,709 | 15,167 |
| Spain | 35,010,273 | 47,066,402 | 1611 | 446,803 | 13,058 | 9413 |
| Poland | 25,666,238 | 38,220,543 | 1669 | 1,161,760 | 1139 | 7644 |
| The Netherlands | 16,143,879 | 16,802,463 | 288 | 194,570 | 5663 | 3360 |
| Sweden | 8,581,261 | 9,631,261 | 1488 | 1,119,278 | 2777 | 1926 |
| Portugal | 7,015,519 | 10,610,304 | 142 | 180,674 | 3370 | 2122 |
| Greece | 6,438,325 | 11,128,404 | 1060 | 792,048 | 721 | 2226 |
| TOTAL | 355,041,111 | 481,149,390 | 21,334 | 9,287,198 | 110,062 | 96,230 |
| Country | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 |
|---|---|---|---|---|---|---|
| Germany | 1,594,312 | 2,167,848 | 3,446,841 | 5,579,979 | 11,038,771 | 14,500,870 |
| United Kingdom | 264,460 | 696,529 | 1,987,674 | 4,127,235 | 10,243,911 | 26,893,481 |
| France | 442,461 | 976,445 | 2,594,032 | 4,762,945 | 9,608,994 | 19,044,399 |
| Italy | 430,638 | 1,027,982 | 3,371,571 | 5,547,187 | 8,791,952 | 14,411,831 |
| Turkey | 141,592 | 595,032 | 2,162,091 | 5,097,690 | 7,707,706 | 11,430,470 |
| Spain | 174,285 | 626,509 | 1,748,940 | 3,613,995 | 8,966,293 | 25,190,433 |
| The Netherlands | 330,863 | 907,171 | 1,543,801 | 2,384,925 | 4,686,031 | 7,841,054 |
| Sweden | 131,119 | 258,425 | 689,734 | 1,190,342 | 2,031,537 | 2,114,549 |
| Portugal | 116,946 | 250,063 | 390,444 | 840,847 | 2,372,739 | 6,754,129 |
| GNH-TD National Market Index | GNH-TD EUR-USD | GNH-TD GBP-USD | GNH-TD GBP-EUR | ||
|---|---|---|---|---|---|
| Germany | Pearson Correlation | −0.731 ** | 0.498 ** | 0.059 * | 0.589 ** |
| DAX | Sig. (2-tailed) | 0 | 0 | 0.019 | 0 |
| n | 1527 | 1565 | 1565 | 1565 | |
| United Kingdom | Pearson Correlation | −0.603 ** | 0.627 ** | 0.124 ** | 0.714 ** |
| FTSE100 | Sig. (2-tailed) | 0 | 0 | 0 | 0 |
| n | 1514 | 1565 | 1565 | 1565 | |
| France | Pearson Correlation | −0.537 ** | 0.494 ** | 0.079 ** | 0.572 ** |
| CAC40 | Sig. (2-tailed) | 0 | 0 | 0.002 | 0 |
| n | 1537 | 1565 | 1565 | 1565 | |
| Italy | Pearson Correlation | −0.183 ** | 0.417 ** | −0.044 | 0.545 ** |
| FTSEMIB | Sig. (2-tailed) | 0 | 0 | 0.081 | 0 |
| n | 1538 | 1565 | 1565 | 1565 | |
| Turkey | Pearson Correlation | −0.548 ** | 0.506 ** | −0.004 | 0.631 ** |
| BIST100 | Sig. (2-tailed) | 0 | 0 | 0.888 | 0 |
| n | 1511 | 1565 | 1565 | 1565 | |
| Spain | Pearson Correlation | −0.268 ** | 0.503 ** | 0.054 * | 0.597 ** |
| IBEX35 | Sig. (2-tailed) | 0 | 0 | 0.033 | 0 |
| n | 1535 | 1565 | 1565 | 1565 | |
| The Netherlands | Pearson Correlation | −0.687 ** | 0.551 ** | 0.184 ** | 0.584 ** |
| AEX | Sig. (2-tailed) | 0 | 0 | 0 | 0 |
| n | 1537 | 1565 | 1565 | 1565 | |
| Sweden | Pearson Correlation | −0.641 ** | 0.469 ** | 0.056 * | 0.551 ** |
| OMX30 | Sig. (2-tailed) | 0 | 0 | 0.026 | 0 |
| n | 1506 | 1565 | 1565 | 1565 | |
| Portugal | Pearson Correlation | 0.344 ** | 0.585 ** | 0.118 ** | 0.664 ** |
| PSI20 | Sig. (2-tailed) | 0 | 0 | 0 | 0 |
| n | 1440 | 1565 | 1565 | 1565 |
| OECD-Better Life Index | GNH-TD | ||
|---|---|---|---|
| OECD-Better Life Index | Pearson Correlation | 1 | 0.854 ** |
| Sig. (2-tailed) | 0.000 | ||
| n | 36 | 36 | |
| GNH-TD | Pearson Correlation | 0.854 ** | 1 |
| Sig. (2-tailed) | 0.000 | ||
| n | 36 | 36 | |
| Country | Mean (Negative) | Standard Deviation (Negative) | Negative Threshold | Mean (Positive) | Standard Deviation (Positive) | Positive Threshold |
|---|---|---|---|---|---|---|
| Germany | −1.2192 | 0.6364 | <−2.492 | 1.3684 | 0.6307 | >2.6298 |
| United Kingdom | −1.4522 | 0.8271 | <−3.1064 | 1.5253 | 0.7507 | >3.0267 |
| France | −1.4936 | 0.8214 | <−3.1364 | 1.2965 | 0.5799 | >2.4563 |
| Italy | −1.1926 | 0.549 | <−2.2906 | 1.2906 | 0.5678 | >2.4262 |
| Turkey | −1.1579 | 0.5092 | <−2.1763 | 1.2656 | 0.5526 | >2.3708 |
| Spain | −1.4155 | 0.79 | <−2.9955 | 1.6825 | 0.9871 | >3.6567 |
| The Netherlands | −1.3444 | 0.6957 | <−2.7358 | 1.2974 | 0.613 | >2.5234 |
| Sweden | −1.2122 | 0.5478 | <−2.3078 | 1.293 | 0.5725 | >2.438 |
| Portugal | −1.3959 | 0.7635 | <−2.9229 | 1.3422 | 0.6323 | >2.6068 |
| Country | Number of Event Days in Wikipedia Pages | Number of Matching Days from GNH-TD | Detection Accuracy |
|---|---|---|---|
| Germany | 105 | 74 | 70.48% |
| United Kingdom | 121 | 104 | 85.95% |
| France | 137 | 112 | 81.75% |
| Italy | 112 | 83 | 74.11% |
| Turkey | 163 | 146 | 89.57% |
| Spain | 72 | 52 | 72.22% |
| The Netherlands | 84 | 59 | 70.24% |
| Sweden | 69 | 57 | 82.61% |
| Portugal | 58 | 42 | 72.41% |
| Country | Average Sentiment Polarity |
|---|---|
| Germany | 0.040165 |
| Sweden | 0.040715 |
| France | 0.050131 |
| The Netherlands | 0.055155 |
| Italy | 0.058553 |
| Spain | 0.085874 |
| United Kingdom | 0.104333 |
| Turkey | 0.105635 |
| Portugal | 0.132342 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coşkun, M.; Ozturan, M. #europehappinessmap: A Framework for Multi-Lingual Sentiment Analysis via Social Media Big Data (A Twitter Case Study). Information 2018, 9, 102. https://doi.org/10.3390/info9050102
Coşkun M, Ozturan M. #europehappinessmap: A Framework for Multi-Lingual Sentiment Analysis via Social Media Big Data (A Twitter Case Study). Information. 2018; 9(5):102. https://doi.org/10.3390/info9050102
Chicago/Turabian StyleCoşkun, Mustafa, and Meltem Ozturan. 2018. "#europehappinessmap: A Framework for Multi-Lingual Sentiment Analysis via Social Media Big Data (A Twitter Case Study)" Information 9, no. 5: 102. https://doi.org/10.3390/info9050102
APA StyleCoşkun, M., & Ozturan, M. (2018). #europehappinessmap: A Framework for Multi-Lingual Sentiment Analysis via Social Media Big Data (A Twitter Case Study). Information, 9(5), 102. https://doi.org/10.3390/info9050102