Genetic Algorithm with an Improved Initial Population Technique for Automatic Clustering of Low-Dimensional Data


Abstract
:1. Introduction
- The selection of the initial population combining the improved K-means++ and density estimation with a low complexity (see Section 2.2).
- The AGA is used to prevent the SeedClust from getting stuck at a local optimal and to maintain population diversity (see Section 2.4).
- The SeedClust worked on low-dimensional taxi GPS data sets (see Section 3.1).
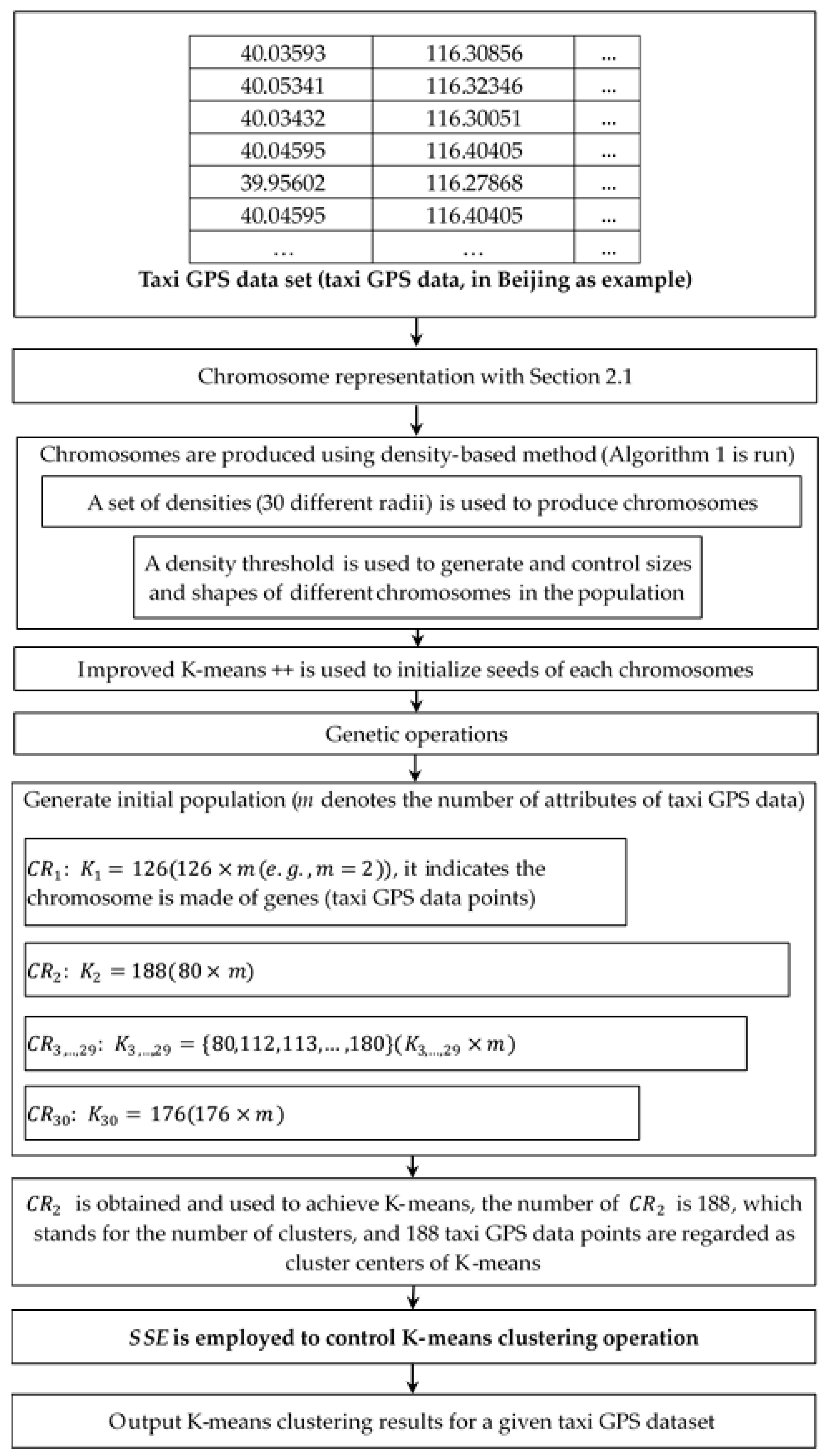
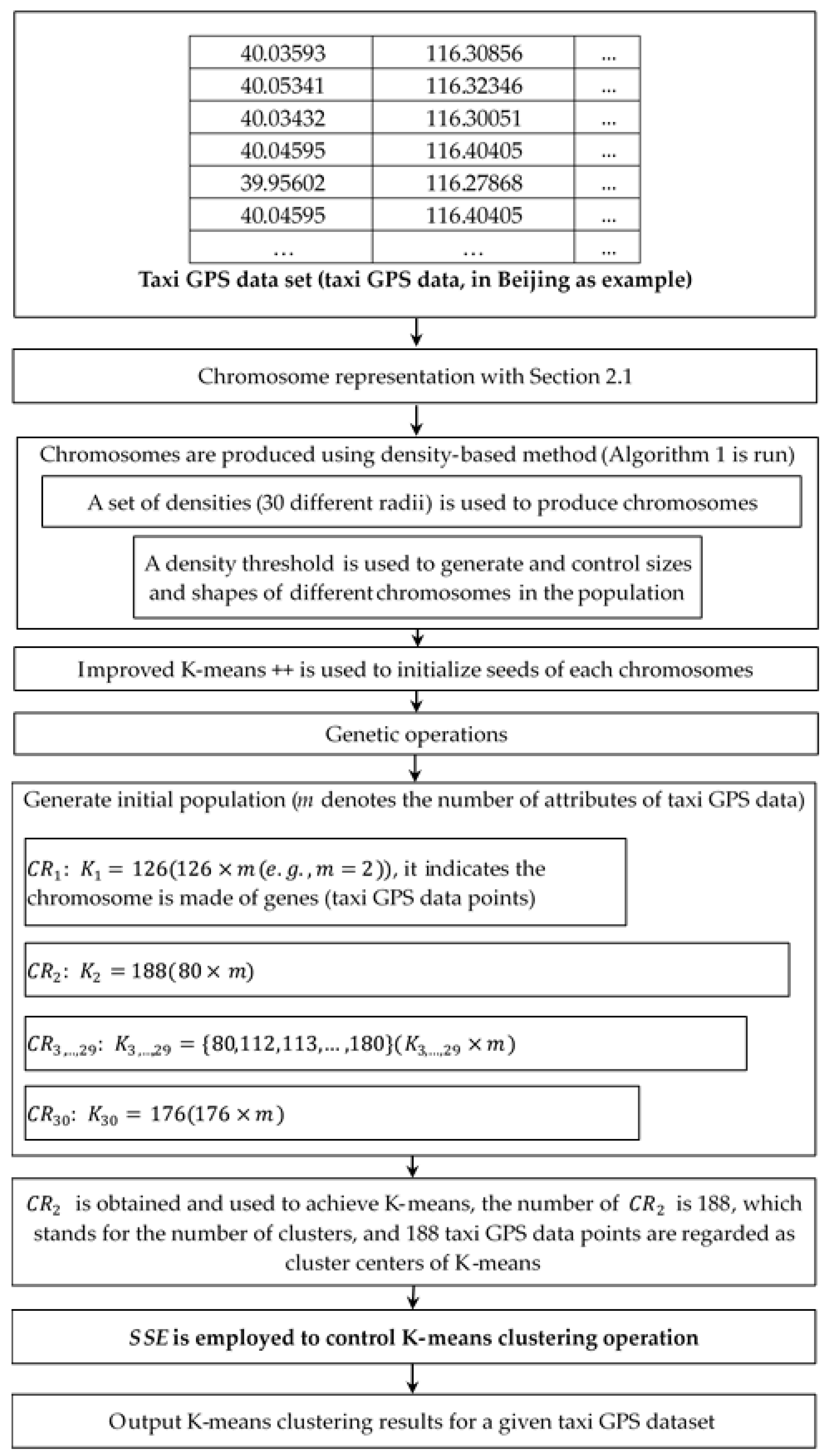
2. The Proposed SeedClust Clustering Algorithm
2.1. Chromosome Representation
2.2. Population Initialization
2.2.1. Initial Operation Using a Density Method
| Algorithm 1. Population generation using density estimation method |
| Input: a given data set data, |
| Output: population results |
| Procedure: |
| Initial parameters |
| Define a set of radius ; |
| Define m is dimension of the given a data set; |
| the normalized data of the given dataset; |
| the initial population matrix DM; |
| threshold T; |
| FOR to NIND |
| //NIND denotes the size of population which is defined by a user, and radius . |
| FOR y = 1 to n |
| Compute distances dist between data points using the normalized data (); |
| DM←dist ≤ POP (data, NIND, , ); |
| //POP is fitness of density estimation, and the results are stored in DM. |
| IF |
| Generate chromosomes ; |
| ELSE |
| Return and run next radius value until is null (WHILE loop is end); |
| END IF |
| END FOR |
| END FOR |
2.2.2. Initial Seeds Using an Improved K-Means++ Method
| Algorithm 2. Initial seeds with an improved K-means++ |
| Input: a set of densities and the normalized data |
| Output: the initial population POP including initial seeds |
| Procedure: |
| Define m is dimension of the given a data set; |
| Compute the number of seeds of each chromosome in Algorithm.1; |
| FOR to NIND |
| FOR to |
| FOR y = 1 to n // n denotes number of the taxi GPS data points |
| // Randomly take one seed from chromosome , |
| // denotes chromosome of the initial seeds |
| // Take a new seed in uniformly chromosome , |
| // choose gene with density as probability, |
| // Seed denotes a function of seed selection, which is used to initialize seeds of each chromosome |
| // denotes chromosomes of the initial seeds in uniformly |
| END FOR |
| END FOR |
| Repeat operation until and seeds altogether have been taken |
| END FOR |
| FOR 1 to NIND |
| Randomly generate NIND chromosomes; |
| Randomly select seeds of each chromosome; |
| END FOR |
| Generate an initial population (2*NIND chromosomes) including initial seeds of each chromosome |
2.3. Fitness Function
2.4. Adaptive Genetic Operation
| Algorithm 3. Selection operation algorithm of GAG |
| Input: an initial population POP using Algorithm 2; |
| Output: // selection operation population; |
| Procedure: |
| Initial parameters |
| Define the number of iterations G of the adaptive genetic algorithm; |
| Define m is dimension of the given a data set; |
| // denotes the set of selected chromosomes, initially set to null |
| / / Selection operation |
| FOR 1 to 2*NIND |
| // FitF is used to compute fitness values each chromosome in the initial population POP |
| // Sort function is used to sort the 2*NIND chromosomes in the descending order of their fitness values and then choose NIND number of best chromosomes using fitness value. |
| END FOR |
| // is a chromosome that has the maximum fitness value in the descending order of their fitness values in and is used to compute similarity between chromosomes. |
| Algorithm 4. Adaptive genetic operation |
| Input: |
| Output: the best chromosome |
| Procedure: |
| Initial parameters |
| Define the number of iterations G of the adaptive genetic algorithm; |
| Define m is dimension of the given a data set; |
| // denotes the set of offspring chromosomes (crossover), initially set to null |
| // denotes the set of mutation chromosomes, initially set to null |
| // denotes the set of elitist chromosomes, initially set to null |
| // Step 1: Adaptive crossover operation |
| FOR 1 to G |
| // select a pair of chromosomes from using roulette wheel |
| // is calculated as . Here, is the fitness of the pair // of chromosomes . |
| // are regarded as parent chromosomes in crossover operation of GA |
| // Calculate a set of the adaptive crossover probability of each chromosome in |
| // |
| FOR to DO |
| // Select the best chromosome as reference chromosome using cosine similarity |
| // Perform gene rearrangement in term of work in [10] |
| // Perform crossover operation between using single point crossover |
| // and is also used to handle crossover operation |
| // Two offspring chromosomes are produced |
| // insert in to generate crossover population |
| // remove from |
| END FOR |
| // Step 2: Adaptive mutation operation |
| // Calculate a set of the adaptive mutation probability of each chromosome in |
| // |
| // Calculate a set of the normalization value of each chromosome |
| // |
| FOR to DO |
| // Produce a uniform distribution for mutation operation in |
| IF |
| // Perform mutation on and then get mutate chromosome |
| // insert mutate chromosome in |
| ELSE |
| // insert un-mutate chromosome in |
| END IF |
| END FOR |
| // Calculate the maximum fitness value of chromosome in |
| // Step 3: Elitism operation |
| IF fitness of the worst chromosome of < fitness value of |
| // Replace the worst chromosome of by |
| END IF |
| IF fitness of the best chromosome of > fitness value of |
| // Replace the by best chromosome of |
| END IF |
| // Continue to perform adaptively genetic operation until G is ended |
| END FOR |
| // Step 4: Obtain the best chromosome |
| // Capture best chromosome with maximum fitness value in |
| // is used to perform K-means clustering operation |
| Algorithm 5. K-means clustering using the best chromosome |
| Input: the best chromosome |
| Output: clustering results of taxi GPS dataset |
| Procedure:Obtain the number of clusters (K) from best chromosome |
| Obtain seeds/cluster centers of clustering operation from best chromosome |
| // K-means clustering |
| ClustRest←ClusteingKM () |
| // K is equal to the number of genes of the best chromosome and seeds/cluster centers are genes of the best chromosome; The minimum of the SSE is used to achieve K-means clustering and is termination condition of K-means clustering |
2.5. Complexity Analysis
3. Experiments and Clustering Evolution
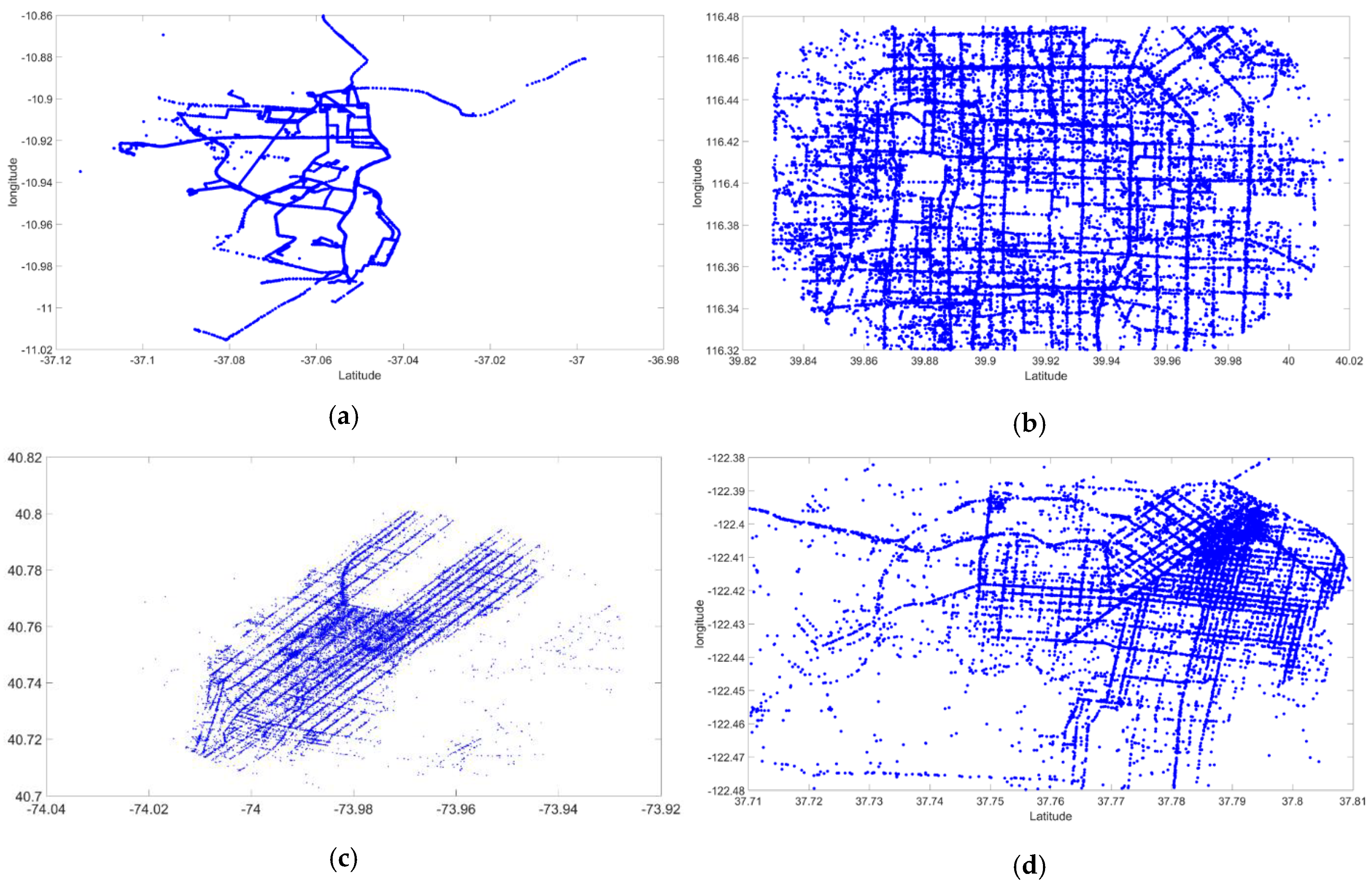
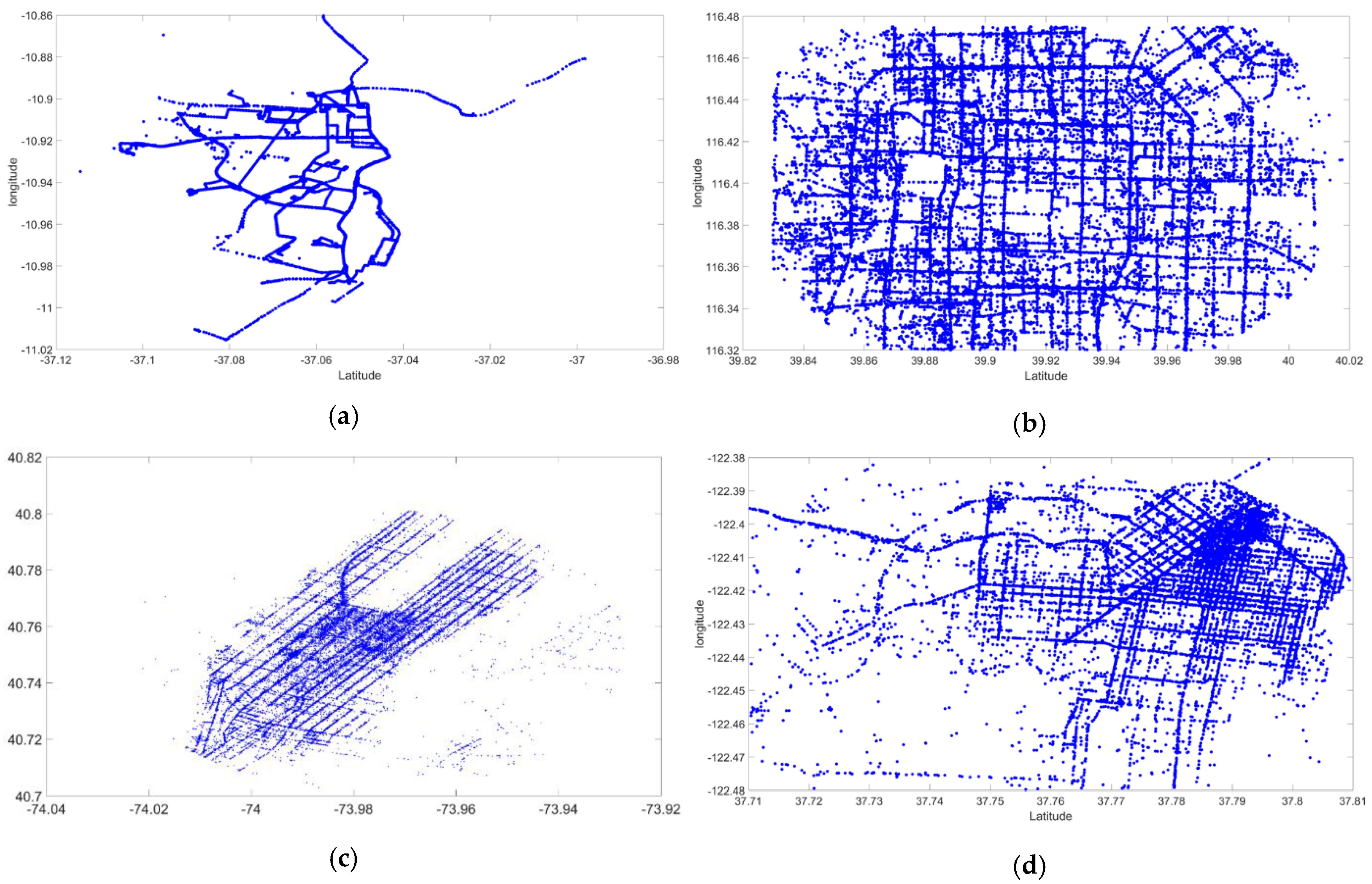
3.1. Description of Taxi GPS Data Sets on Experiments
- (a)
- (b)
- According to [50,51], this GPS trajectory data set was collected in the (Microsoft Research Asia) Geolife project by 182 users during a period of over three years (from April 2007 to August 2012). However, we only extracted the taxi GPS data points of two minutes (9:00–9:02, 2008.02.02) from Beijing, China.
- (c)
- According to [47], in New York City, 13,000 taxis carry over one million passengers and make 500,000 trips, totaling over 170 million trips a year. However, we extracted the taxi GPS data sets of the two minutes from New York, USA.
- (d)
- In [52]: This data set contained mobility traces of taxi cabs in San Francisco, USA. It contained the GPS coordinates of approximately 500 taxis collected over 2 min in the San Francisco Bay Area.
3.2. Clustering Results Evaluation Criteria
3.3. Parameter Setting of Experiments for Comparison Algorithms
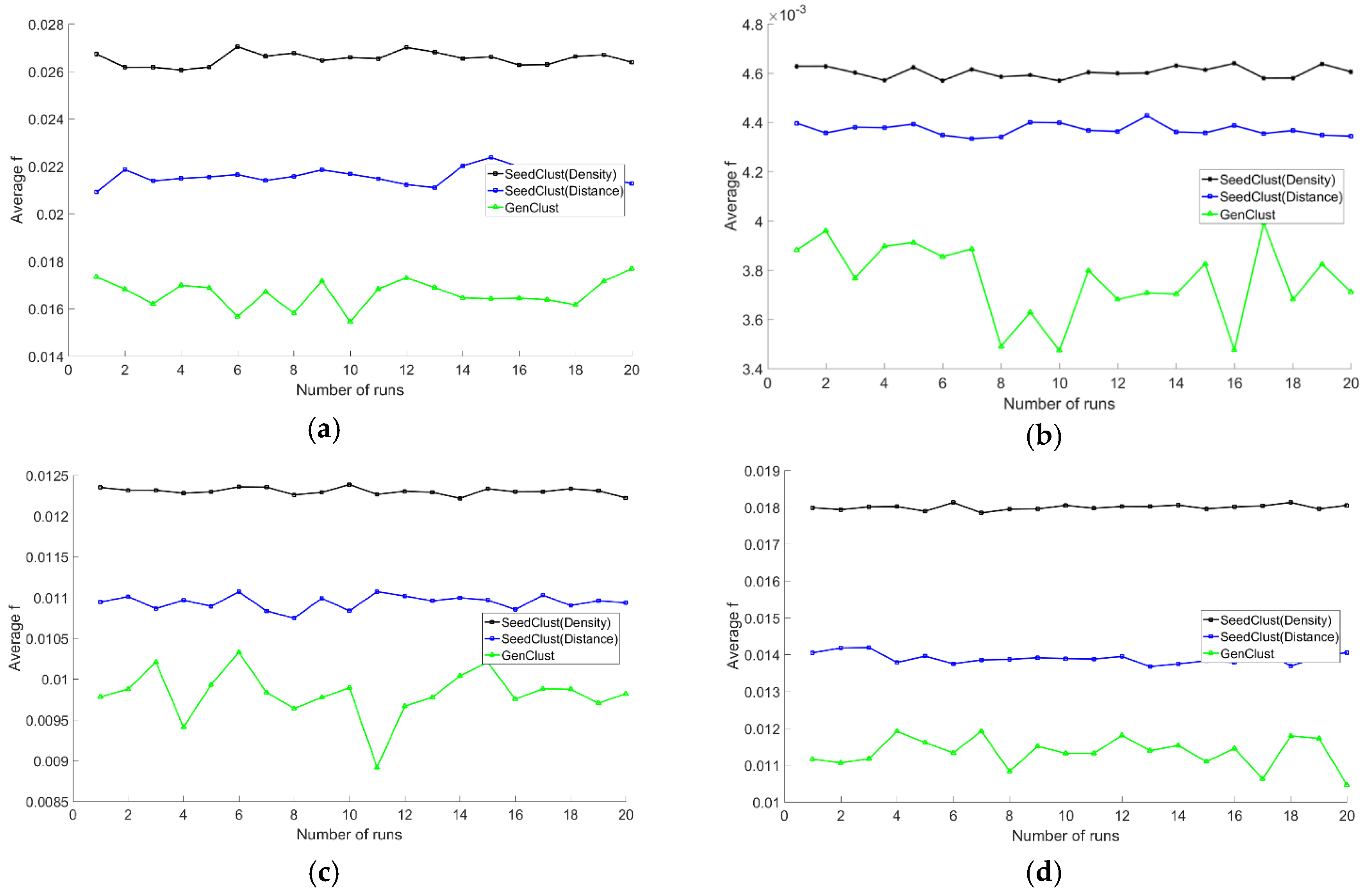
3.4. Experiment Results
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: New York, NY, USA, 2011. [Google Scholar]
- Jain, A.K. Data clustering: 50 years beyond k-means. Pattern Recog. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Kumar, K.M.; Reddy, A.R.M. An efficient k-means clustering filtering algorithm using density based initial cluster centers. Inf. Sci. 2017, 418, 286–301. [Google Scholar] [CrossRef]
- Bai, L.; Cheng, X.; Liang, J.; Shen, H.; Guo, Y. Fast density clustering strategies based on the k-means algorithm. Pattern Recognit. 2017, 71, 375–386. [Google Scholar] [CrossRef]
- Taherdangkoo, M.; Bagheri, M.H. A powerful hybrid clustering method based on modified stem cells and fuzzy c-means algorithms. Eng. Appl. Artif. Intell. 2013, 26, 1493–1502. [Google Scholar] [CrossRef]
- Wishart, D. K-Means Clustering with Outlier Detection, Mixed Variables and Missing Values; Springer: Berlin/Heidelberg, Germany, 2003; pp. 216–226. [Google Scholar]
- Jianjun, C.; Xiaoyun, C.; Haijuan, Y.; Mingwei, L. An enhanced k-means algorithm using agglomerative hierarchical clustering strategy. In Proceedings of the International Conference on Automatic Control and Artificial Intelligence (ACAI 2012), Xiamen, China, 3–5 March 2012; pp. 407–410. [Google Scholar]
- Akodjènou-Jeannin, M.-I.; Salamatian, K.; Gallinari, P. Flexible grid-based clustering. In Proceedings of the 11th European Conference on Principles of Data Mining and Knowledge Discovery, Warsaw, Poland, 17–21 September 2007; pp. 350–357. [Google Scholar]
- Zhao, Q.; Shi, Y.; Liu, Q.; Fränti, P. A grid-growing clustering algorithm for geo-spatial data. Pattern Recognit. Lett. 2015, 53, 77–84. [Google Scholar] [CrossRef]
- Rahman, M.A.; Islam, M.Z. A hybrid clustering technique combining a novel genetic algorithm with k-means. Knowl. Based. Syst. 2014, 71, 345–365. [Google Scholar] [CrossRef]
- Celebi, M.E.; Kingravi, H.A.; Vela, P.A. A comparative study of efficient initialization methods for the k-means clustering algorithm. Expert Syst. Appl. 2013, 40, 200–210. [Google Scholar] [CrossRef]
- Rahman, A.; Islam, Z. Seed-detective: A novel clustering technique using high quality seed for k-means on categorical and numerical attributes. In Proceedings of the Ninth Australasian Data Mining Conference, Ballarat, Australia, 1–2 December 2011; Australian Computer Society Inc.: Sydney, Australia, 2011; Volume 121, pp. 211–220. [Google Scholar]
- Rahman, M.A.; Islam, M.Z. Crudaw: A novel fuzzy technique for clustering records following user defined attribute weights. In Proceedings of the Tenth Australasian Data Mining Conference, Sydney, Australia, 5–7 December 2012; Australian Computer Society Inc.: Sydney, Australia, 2012; Volume 134, pp. 27–41. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007; pp. 1027–1035. [Google Scholar]
- Beg, A.; Islam, M.Z.; Estivill-Castro, V. Genetic algorithm with healthy population and multiple streams sharing information for clustering. Knowl. Based Syst. 2016, 114, 61–78. [Google Scholar] [CrossRef]
- Bandyopadhyay, S.; Maulik, U. An evolutionary technique based on k-means algorithm for optimal clustering in RN. Inf. Sci. 2002, 146, 221–237. [Google Scholar] [CrossRef]
- Maulik, U.; Bandyopadhyay, S. Genetic algorithm-based clustering technique. Pattern Recognit. 2000, 33, 1455–1465. [Google Scholar] [CrossRef]
- Chang, D.-X.; Zhang, X.-D.; Zheng, C.-W. A genetic algorithm with gene rearrangement for k-means clustering. Pattern Recognit. 2009, 42, 1210–1222. [Google Scholar] [CrossRef]
- Agustı, L.; Salcedo-Sanz, S.; Jiménez-Fernández, S.; Carro-Calvo, L.; Del Ser, J.; Portilla-Figueras, J.A. A new grouping genetic algorithm for clustering problems. Expert Syst. Appl. 2012, 39, 9695–9703. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, X.; Shen, Y. Automatic clustering using genetic algorithms. Appl. Math. Comput. 2011, 218, 1267–1279. [Google Scholar] [CrossRef]
- Hruschka, E.R.; Campello, R.J.; Freitas, A.A. A survey of evolutionary algorithms for clustering. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2009, 39, 133–155. [Google Scholar] [CrossRef]
- He, H.; Tan, Y. A two-stage genetic algorithm for automatic clustering. Neurocomputing 2012, 81, 49–59. [Google Scholar] [CrossRef]
- Wei, L.; Zhao, M. A niche hybrid genetic algorithm for global optimization of continuous multimodal functions. Appl. Math. Comput. 2005, 160, 649–661. [Google Scholar] [CrossRef]
- Martín, D.; Alcalá-Fdez, J.; Rosete, A.; Herrera, F. Nicgar: A niching genetic algorithm to mine a diverse set of interesting quantitative association rules. Inf. Sci. 2016, 355, 208–228. [Google Scholar] [CrossRef]
- Deng, W.; Zhao, H.; Zou, L.; Li, G.; Yang, X.; Wu, D. A novel collaborative optimization algorithm in solving complex optimization problems. Soft Comput. 2017, 21, 4387–4398. [Google Scholar] [CrossRef]
- Pirim, H.; Ekşioğlu, B.; Perkins, A.; Yüceer, Ç. Clustering of high throughput gene expression data. Comput. Oper. Res. 2012, 39, 3046–3061. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, A.; Das, S. Automatic shape independent clustering inspired by ant dynamics. Swarm Evolut. Comput. 2012, 3, 33–45. [Google Scholar] [CrossRef]
- Krishna, K.; Murty, M.N. Genetic k-means algorithm. IEEE Trans. Syst. Man Cybern. Part B (Cyber.) 1999, 29, 433–439. [Google Scholar] [CrossRef] [PubMed]
- GitHub. Real-World Taxi-GPS Data Sets. Available online: https://github.com/bigdata002/Location-data-sets (accessed on 20 April 2018).
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Pakhira, M.K.; Bandyopadhyay, S.; Maulik, U. Validity index for crisp and fuzzy clusters. Pattern Recognit. 2004, 37, 487–501. [Google Scholar] [CrossRef]
- Zhou, X.; Gu, J.; Shen, S.; Ma, H.; Miao, F.; Zhang, H.; Gong, H. An automatic k-means clustering algorithm of GPS data combining a novel niche genetic algorithm with noise and density. ISPRS Int. J. Geo-Inf. 2017, 6, 392. [Google Scholar] [CrossRef]
- Lotufo, R.A.; Zampirolli, F.A. Fast multidimensional parallel Euclidean distance transform based on mathematical morphology. In Proceedings of the XIV Brazilian Symposium on Computer Graphics and Image Processing, Florianopolis, Brazil, 15–18 October 2001; pp. 100–105. [Google Scholar]
- Juan, A.; Vidal, E. In Comparison of four initialization techniques for the k-medians clustering algorithm. In Proceedings of the Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR), Alicante, Spain, 30 August–1 September 2000; pp. 842–852. [Google Scholar]
- Celebi, M.E. Improving the performance of k-means for color quantization. Image Vis. Comput. 2011, 29, 260–271. [Google Scholar] [CrossRef]
- Spaeth, H. Cluster Dissection and Analysis, Theory, FORTRAN Programs, Examples; Ellis Horwood: New York, NY, USA, 1985. [Google Scholar]
- Cao, F.; Liang, J.; Bai, L. A new initialization method for categorical data clustering. Expert Syst. Appl. 2009, 36, 10223–10228. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; CRC Press: Boca Raton, FL, USA, 1986; Volume 26. [Google Scholar]
- Patwary, M.M.A.; Palsetia, D.; Agrawal, A.; Liao, W.-K.; Manne, F.; Choudhary, A. Scalable parallel optics data clustering using graph algorithmic techniques. In Proceedings of the 2013 International Conference for High Performance Computing, Networking, Storage and Analysis (SC), Denver, CO, USA, 17–22 November 2013; pp. 1–12. [Google Scholar]
- Bai, L.; Liang, J.; Dang, C. An initialization method to simultaneously find initial cluster centers and the number of clusters for clustering categorical data. Knowl. Based Syst. 2011, 24, 785–795. [Google Scholar] [CrossRef]
- Bahmani, B.; Moseley, B.; Vattani, A.; Kumar, R.; Vassilvitskii, S. Scalable k-means++. Proc. VLDB Endow. 2012, 5, 622–633. [Google Scholar] [CrossRef]
- Xiao, J.; Yan, Y.P.; Zhang, J.; Tang, Y. A quantum-inspired genetic algorithm for k-means clustering. Expert Syst. Appl. 2010, 37, 4966–4973. [Google Scholar] [CrossRef]
- Tang, J.; Liu, F.; Wang, Y.; Wang, H. Uncovering urban human mobility from large scale taxi GPS data. Phys. A Stat. Mech. Appl. 2015, 438, 140–153. [Google Scholar] [CrossRef]
- Ekpenyong, F.; Palmer-Brown, D.; Brimicombe, A. Extracting road information from recorded GPS data using snap-drift neural network. Neurocomputing 2009, 73, 24–36. [Google Scholar] [CrossRef]
- Lu, M.; Liang, J.; Wang, Z.; Yuan, X. Exploring OD patterns of interested region based on taxi trajectories. J. Vis. 2016, 19, 811–821. [Google Scholar] [CrossRef]
- Moreira-Matias, L.; Gama, J.; Ferreira, M.; Mendes-Moreira, J.; Damas, L. Time-evolving OD matrix estimation using high-speed GPS data streams. Expert Syst. Appl. 2016, 44, 275–288. [Google Scholar] [CrossRef]
- Ferreira, N.; Poco, J.; Vo, H.T.; Freire, J.; Silva, C.T. Visual exploration of big spatio-temporal urban data: A study of new york city taxi trips. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2149–2158. [Google Scholar] [CrossRef] [PubMed]
- Cruz, M.O.; Macedo, H.; Guimaraes, A. Grouping similar trajectories for carpooling purposes. In Proceedings of the 2015 Brazilian Conference on Intelligent Systems (BRACIS), Natal, Brazil, 4–7 November 2015; pp. 234–239. [Google Scholar]
- Dua, D.; Karra, T.E. Machine Learning Repository (UCI). 731. Available online: https://archive.ics.uci.edu/ml/datasets.html (accessed on 20 April 2018).
- Zheng, Y.; Liu, Y.; Yuan, J.; Xie, X. Urban computing with taxicabs. In Proceedings of the 13th International Conference on Ubiquitous Computing, Beijing, China, 17–21 September 2011; pp. 89–98. [Google Scholar]
- Yuan, J.; Zheng, Y.; Xie, X.; Sun, G. Driving with knowledge from the physical world. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 316–324. [Google Scholar]
- Piorkowski, M.; Natasa, S.D. Matthias Grossglauser. Crawdad Dataset Epfl/Mobility (v. 2009-02-24). 2009. Available online: http://crawdad.org/epfl/mobility/20090224 (accessed on 20 April 2018).
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. On clustering validation techniques. J. Intell. Inf. Syst. 2001, 17, 107–145. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Islam, M.Z.; Estivill-Castro, V.; Rahman, M.A.; Bossomaier, T. Combining k-means and a genetic algorithm through a novel arrangement of genetic operators for high quality clustering. Expert Syst. Appl. 2018, 91, 402–417. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Taxi GPS Data Set | Land Area | The Number of GPS Taxi Data Points | The Number of Clusters | ||
|---|---|---|---|---|---|
| GA-Clustering, GAK, K-means | GenClust | NoiseClust | |||
| Aracaju (Brazil) | 0.14 × 0.16 | 16,513 | 100, 120 | 128 | 128 |
| Beijing (China) | 1.20 × 0.16 | 35,541 | 100, 180 | 188 | 188 |
| New York (USA) | 0.12 × 0.12 | 32,786 | 100, 174 | 173 | 181 |
| San Francisco (USA) | 0.10 × 0.10 | 21,826 | 100, 140 | 147 | 147 |
| Aracaju (Brazil) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 120 | K = 100 | K = 120 | K = 100 | K = 120 | K = 128 | K = 128 | |
| Max | 0.9437 | 0.9507 | 0.9521 | 0.9586 | 0.9531 | 0.9590 | 0.9666 | 0.9628 |
| Mean | 0.9404 | 0.9471 | 0.9492 | 0.9560 | 0.9512 | 0.9577 | 0.9581 | 0.9608 |
| Min | 0.9337 | 0.9452 | 0.9437 | 0.9538 | 0.9491 | 0.9554 | 0.9500 | 0.9555 |
| Beijing (China) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 180 | K = 100 | K = 180 | K = 100 | K = 180 | K = 188 | K = 188 | |
| Max | 0.8935 | 0.9211 | 0.9044 | 0.9318 | 0.9047 | 0.9322 | 0.9339 | 0.9342 |
| Mean | 0.8910 | 0.9199 | 0.9031 | 0.9306 | 0.9036 | 0.9312 | 0.9332 | 0.9332 |
| Min | 0.8880 | 0.9188 | 0.9019 | 0.9291 | 0.9024 | 0.9304 | 0.9268 | 0.9306 |
| New York (USA) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 174 | K = 100 | K = 174 | K = 100 | K = 174 | K = 173 | K = 181 | |
| Max | 0.9035 | 0.9279 | 0.9139 | 0.9367 | 0.9136 | 0.9366 | 0.9359 | 0.9382 |
| Mean | 0.9012 | 0.9255 | 0.9121 | 0.9358 | 0.9125 | 0.9358 | 0.9337 | 0.9370 |
| Min | 0.8990 | 0.9226 | 0.9108 | 0.9343 | 0.9110 | 0.9351 | 0.9323 | 0.9322 |
| San Francisco (USA) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 140 | K = 100 | K = 140 | K = 100 | K = 140 | K = 147 | K = 147 | |
| Max | 0.9121 | 0.9241 | 0.9211 | 0.9345 | 0.9224 | 0.9352 | 0.9424 | 0.9373 |
| Mean | 0.9089 | 0.9223 | 0.9192 | 0.9317 | 0.9207 | 0.9340 | 0.9348 | 0.9349 |
| Min | 0.9062 | 0.9199 | 0.9151 | 0.9296 | 0.9180 | 0.9319 | 0.9242 | 0.9309 |
| Aracaju (Brazil) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 120 | K = 100 | K = 120 | K = 100 | K = 120 | K = 128 | K = 128 | |
| Max | 56.8006 | 28.6244 | 26.4467 | 21.4416 | 23.6935 | 20.6527 | 20.2802 | 19.8027 |
| Mean | 30.9206 | 27.6284 | 23.4685 | 20.3335 | 22.4054 | 19.2817 | 19.4706 | 17.7361 |
| Min | 28.4969 | 25.6110 | 22.3300 | 19.2218 | 21.4344 | 18.5617 | 18.5425 | 16.8413 |
| Beijing (China) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 180 | K = 100 | K = 180 | K = 100 | K = 180 | K = 188 | K = 188 | |
| Max | 243.2074 | 177.8441 | 192.6010 | 139.9668 | 190.9683 | 135.9318 | 131.4806 | 134.4856 |
| Mean | 233.2443 | 174.7318 | 189.4489 | 135.8667 | 188.5583 | 134.3636 | 130.3514 | 129.5278 |
| Min | 225.5980 | 170.0283 | 186.4393 | 133.2682 | 187.0371 | 132.8659 | 128.9393 | 127.2393 |
| New York (USA) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 174 | K = 100 | K = 174 | K = 100 | K = 174 | K = 173 | K = 181 | |
| Max | 78.0328 | 61.3344 | 64.4638 | 48.0037 | 64.4147 | 46.9724 | 47.5163 | 49.0167 |
| Mean | 75.8746 | 59.4166 | 63.6905 | 46.7535 | 63.1929 | 46.5250 | 46.6981 | 45.0523 |
| Min | 56.8006 | 57.7481 | 62.6907 | 46.0476 | 62.4050 | 46.0851 | 45.5141 | 44.6943 |
| San Francisco (USA) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 140 | K = 100 | K = 140 | K = 100 | K = 140 | K = 147 | K = 147 | |
| Max | 56.8006 | 47.8046 | 45.2107 | 38.1780 | 43.7369 | 36.2862 | 36.0487 | 35.8719 |
| Mean | 54.0564 | 46.2612 | 43.3810 | 36.9472 | 42.2978 | 35.3876 | 34.5929 | 34.3558 |
| Min | 51.8257 | 44.9277 | 42.1251 | 35.6759 | 41.3467 | 34.2106 | 33.7309 | 33.3992 |
| Aracaju (Brazil) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 120 | K = 100 | K = 120 | K = 100 | K = 120 | K = 128 | K = 128 | |
| Max | 13.9231 | 33.6573 | 0.6754 | 0.6904 | 0.6613 | 0.6438 | 0.6449 | 0.6488 |
| Mean | 6.1980 | 8.2378 | 0.6346 | 0.6322 | 0.6281 | 0.6206 | 0.6328 | 0.6003 |
| Min | 2.2146 | 2.1467 | 0.6200 | 0.5911 | 0.5917 | 0.5912 | 0.6127 | 0.5689 |
| Beijing (China) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 180 | K = 100 | K = 180 | K = 100 | K = 180 | K = 188 | K = 188 | |
| Max | 2.6258 | 4.4956 | 0.8242 | 0.8014 | 0.8190 | 0.7981 | 0.8097 | 0.7916 |
| Mean | 1.7945 | 2.5357 | 0.8006 | 0.7844 | 0.7989 | 0.7845 | 0.7957 | 0.7747 |
| Min | 1.3916 | 1.6638 | 0.7793 | 0.7685 | 0.7804 | 0.7724 | 0.7821 | 0.7582 |
| New York (USA) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 174 | K = 100 | K = 174 | K = 100 | K = 174 | K = 173 | K = 181 | |
| Max | 3.0959 | 3.7681 | 0.8256 | 0.8033 | 0.8485 | 0.8091 | 0.8055 | 0.8090 |
| Mean | 1.9552 | 2.2682 | 0.8043 | 0.7868 | 0.8052 | 0.7913 | 0.7944 | 0.7881 |
| Min | 1.5101 | 1.5862 | 0.7852 | 0.7731 | 0.7852 | 0.7788 | 0.7816 | 0.7691 |
| San Francisco (USA) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 140 | K = 100 | K = 140 | K = 100 | K = 140 | K = 147 | K = 147 | |
| Max | 5.3488 | 6.0387 | 0.8103 | 0.8119 | 0.8224 | 0.8065 | 0.8084 | 0.8013 |
| Mean | 2.5521 | 3.0217 | 0.7940 | 0.7915 | 0.7988 | 0.7877 | 0.7845 | 0.7794 |
| Min | 1.7659 | 2.0931 | 0.7681 | 0.7723 | 0.7816 | 0.7753 | 0.7676 | 0.7598 |
| Aracaju (Brazil) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 120 | K = 100 | K = 120 | K = 100 | K = 120 | K = 128 | K = 128 | |
| Max | 0.0248 | 0.0228 | 0.0311 | 0.0301 | 0.0324 | 0.0319 | 0.0308 | 0.0328 |
| Mean | 0.0218 | 0.0209 | 0.0296 | 0.0284 | 0.0310 | 0.0302 | 0.0298 | 0.0312 |
| Min | 0.0197 | 0.0190 | 0.0197 | 0.0267 | 0.0292 | 0.0280 | 0.0288 | 0.0300 |
| Beijing (China) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 180 | K = 100 | K = 180 | K = 100 | K = 180 | K = 188 | K = 188 | |
| Max | 0.0167 | 0.0125 | 0.0195 | 0.0156 | 0.0194 | 0.0155 | 0.0151 | 0.0156 |
| Mean | 0.0156 | 0.0119 | 0.0191 | 0.0151 | 0.0191 | 0.0153 | 0.0150 | 0.0153 |
| Min | 0.0147 | 0.0116 | 0.0187 | 0.0147 | 0.0187 | 0.0149 | 0.0148 | 0.0149 |
| New York (USA) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 174 | K = 100 | K = 174 | K = 100 | K = 174 | K = 173 | K = 181 | |
| Max | 0.0091 | 0.0068 | 0.0106 | 0.0083 | 0.0105 | 0.0085 | 0.0083 | 0.0086 |
| Mean | 0.0084 | 0.0064 | 0.0101 | 0.0082 | 0.0102 | 0.0083 | 0.0082 | 0.0083 |
| Min | 0.0077 | 0.0060 | 0.0098 | 0.0079 | 0.0099 | 0.0081 | 0.0081 | 0.0079 |
| San Francisco (USA) | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
| K = 100 | K = 140 | K = 100 | K = 140 | K = 100 | K = 140 | K = 147 | K = 147 | |
| Max | 0.0113 | 0.0096 | 0.0128 | 0.0113 | 0.0137 | 0.0117 | 0.0123 | 0.0125 |
| Mean | 0.0100 | 0.0087 | 0.0124 | 0.0110 | 0.0128 | 0.0111 | 0.0116 | 0.0114 |
| Min | 0.0088 | 0.0075 | 0.0118 | 0.0101 | 0.0123 | 0.0105 | 0.0109 | 0.0105 |
| Taxi GPS Data Set | GA-Clustering | K-Means | GAK | GenClust | SeedClust | |||
|---|---|---|---|---|---|---|---|---|
| K = 100 | K = 120 | K = 100 | K = 180 | K = 100 | K = 174 | |||
| Aracaju (Brazil) | 1.4928 | 2.0000 | 0.0510 | 0.0587 | 1.4836 | 2.0715 | 43.6278 | 3.2718 |
| Beijing (China) | 3.2828 | 6.2304 | 0.1120 | 0.2011 | 3.2828 | 6.8314 | 114.2480 | 11.9476 |
| New York (USA) | 3.4886 | 6.6053 | 0.1019 | 0.1773 | 3.9429 | 7.0315 | 129.5530 | 10.9130 |
| San Francisco (USA) | 2.1734 | 3.2701 | 0.0736 | 0.0944 | 2.1391 | 3.2730 | 65.3391 | 5.3727 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Miao, F.; Ma, H. Genetic Algorithm with an Improved Initial Population Technique for Automatic Clustering of Low-Dimensional Data. Information 2018, 9, 101. https://doi.org/10.3390/info9040101
Zhou X, Miao F, Ma H. Genetic Algorithm with an Improved Initial Population Technique for Automatic Clustering of Low-Dimensional Data. Information. 2018; 9(4):101. https://doi.org/10.3390/info9040101
Chicago/Turabian StyleZhou, Xiangbing, Fang Miao, and Hongjiang Ma. 2018. "Genetic Algorithm with an Improved Initial Population Technique for Automatic Clustering of Low-Dimensional Data" Information 9, no. 4: 101. https://doi.org/10.3390/info9040101
APA StyleZhou, X., Miao, F., & Ma, H. (2018). Genetic Algorithm with an Improved Initial Population Technique for Automatic Clustering of Low-Dimensional Data. Information, 9(4), 101. https://doi.org/10.3390/info9040101