An Architecture to Manage Incoming Traffic of Inter-Domain Routing Using OpenFlow Networks

Abstract
1. Introduction
- Presenting and describing an architecture that uses OF networks and is compatible with current inter-domain routing protocol (BGP);
- Exploring OF features for network traffic engineering tasks in inter-domain routing; and
- Analyzing how the incoming traffic can be managed using the proposed architecture and BGP.
2. Related Works
3. The Architecture Proposal
3.1. Network Architecture Overview
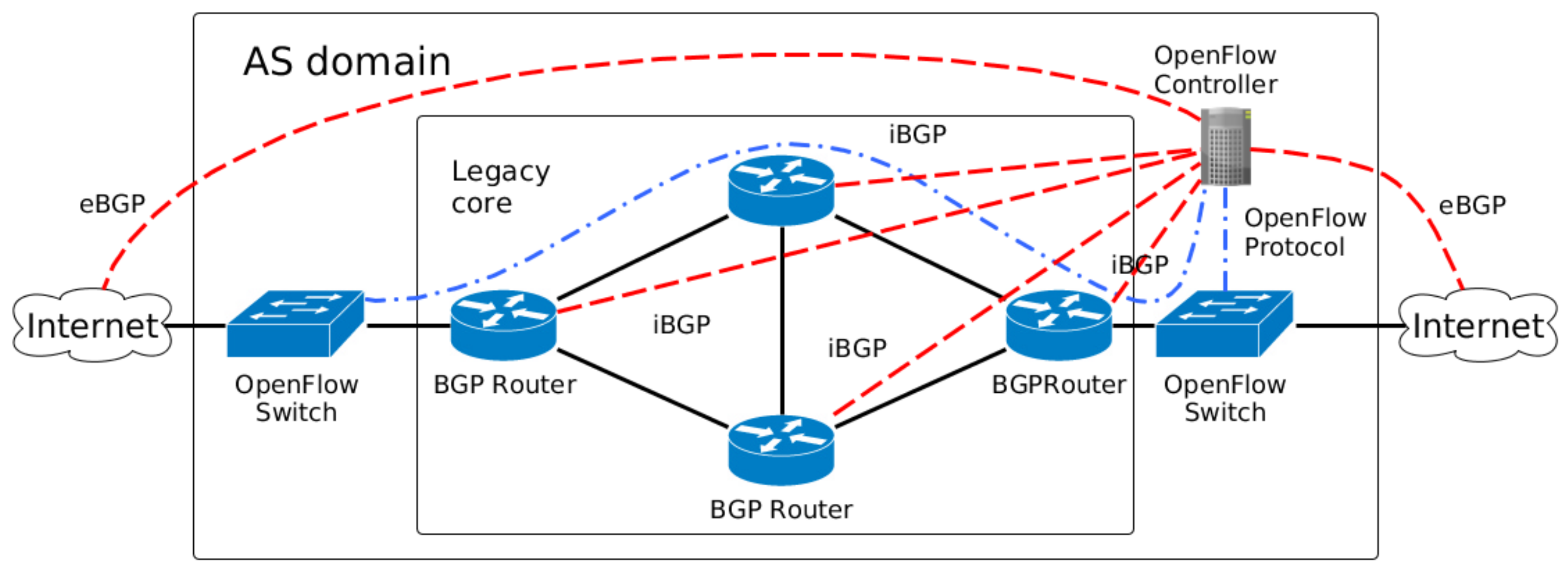
- Legacy network: With the legacy network in the core, the SDN controller is the centralization logic that acts as Route Server for the BGP routers. Figure 1 depicts a scheme for mixing OpenFlow switches and legacy network appliances. The legacy core is connected through internal BGP (iBGP) sessions to the OpenFlow Controller, which distributes external routes to the internal BGP routers. The infrastructure routes continue to be distributed with the interior gateway protocols (such as OSPF) executed in the Legacy core perimeter.
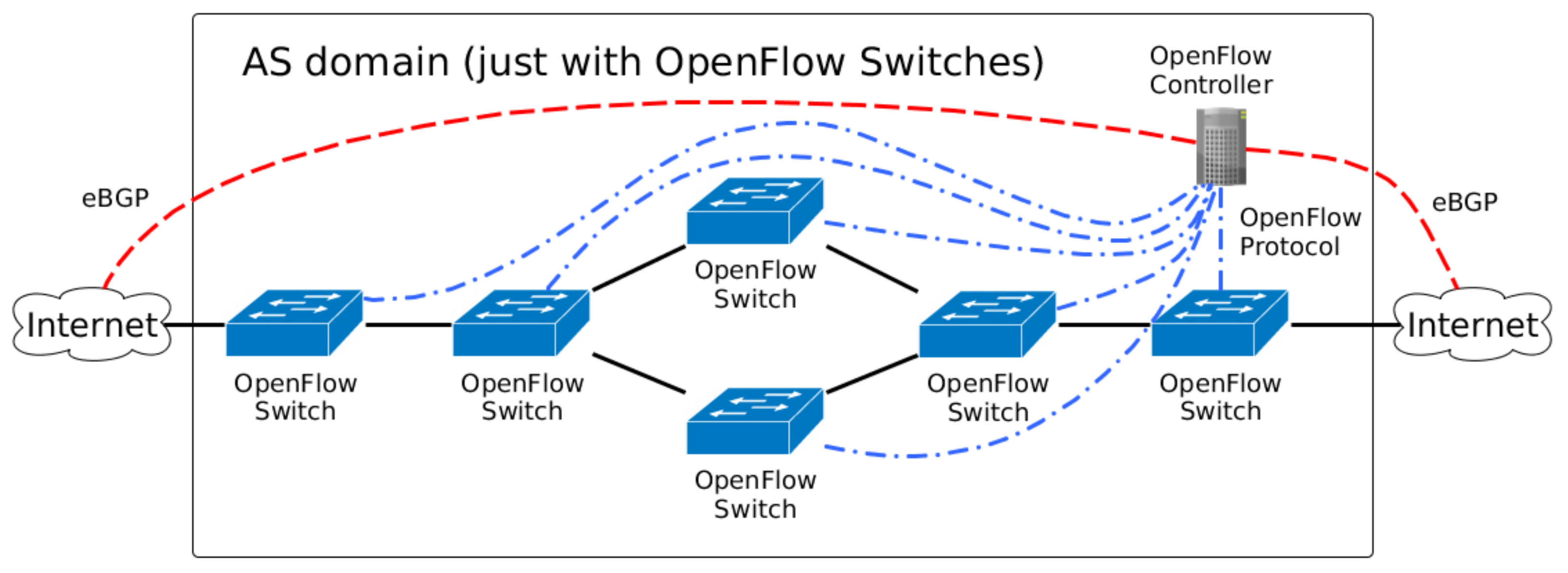
- OpenFlow network: In the future, it is expected that all network devices will have some SDN technology embedded inside an AS. Thus, a domain with SDN technology (OpenFlow devices) is straightforward, and Figure 2 depicts this scenario. All OpenFlow switches are connected to the OpenFlow Controller, which manage the flows inside the AS domain.
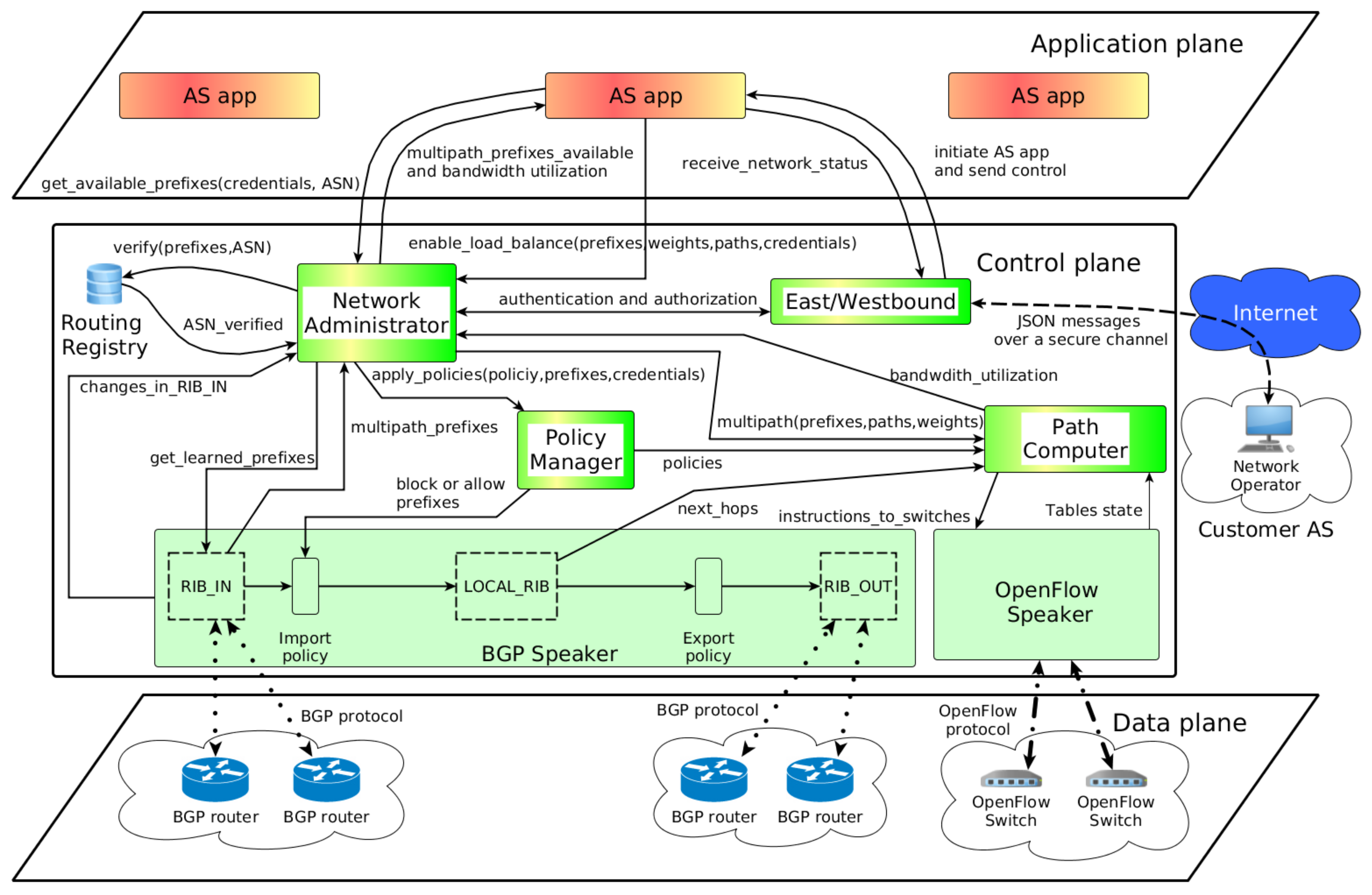
3.2. Architecture Components
3.2.1. Network Administrator
3.2.2. Policy Manager
3.2.3. Path Computer
3.2.4. East/Westbound
3.3. Dynamic of the Proposed Architecture
4. Controlling Inbound Traffic
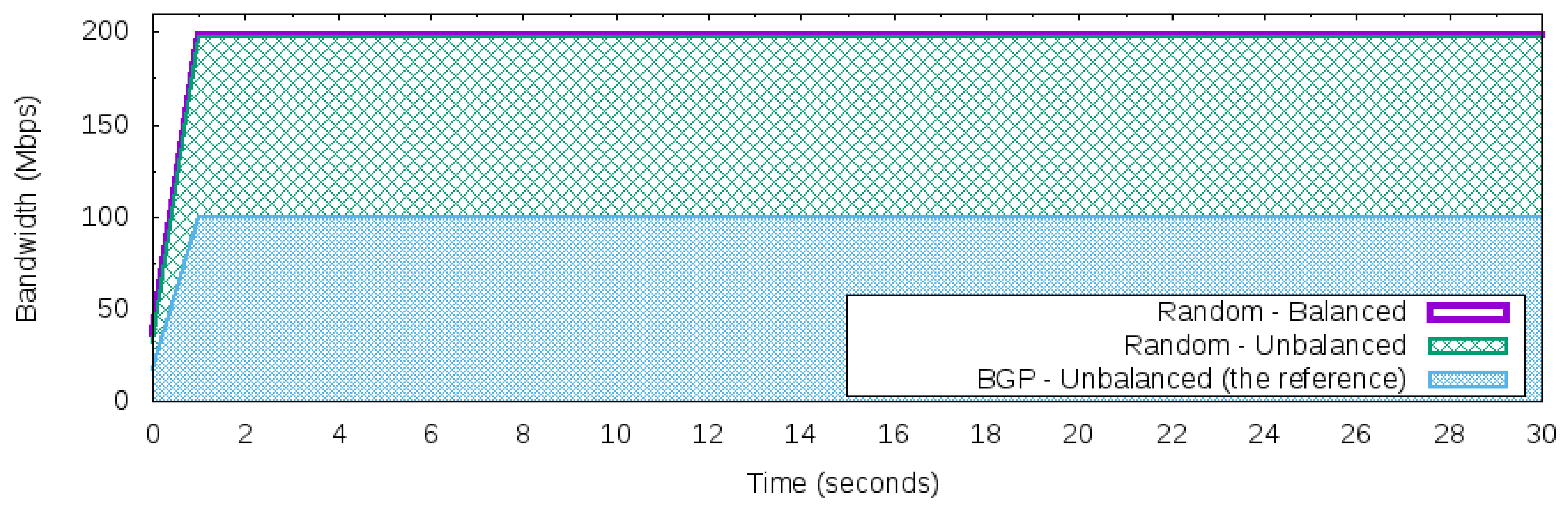
- Reactive Random Load Balancer (Random)
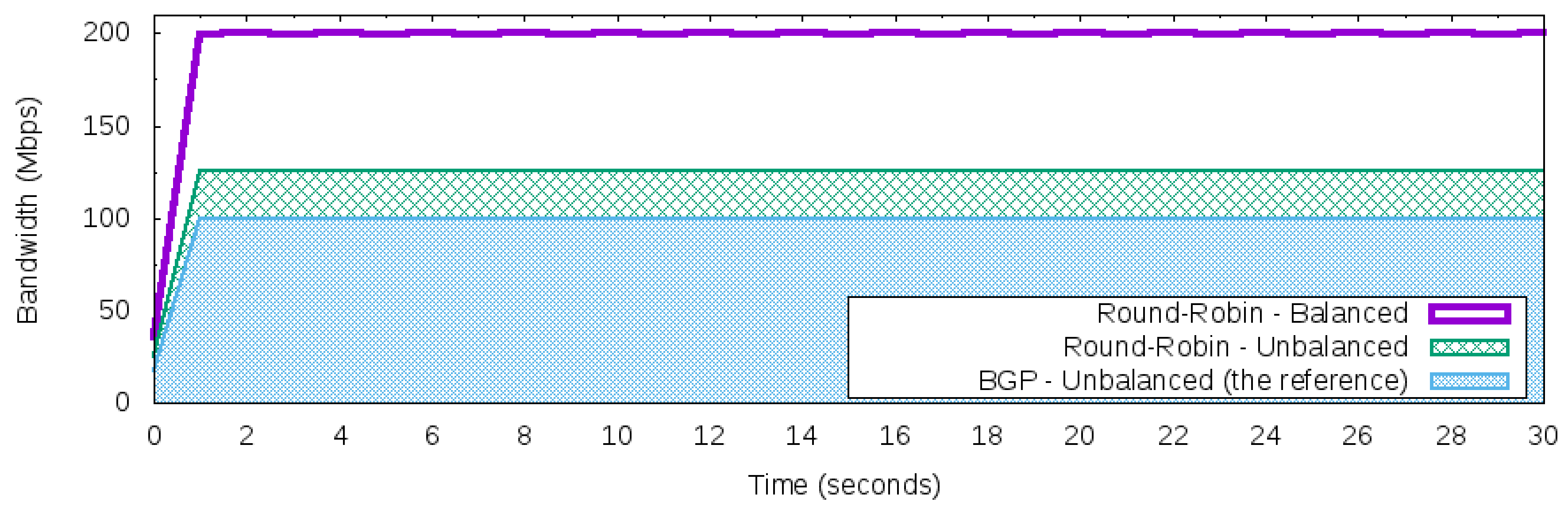
- Reactive Round-Robin Load Balancer (RR)
- Reactive Round-Robin Load Balancer with Threshold (RRT)
4.1. Reactive Random Load Balancer (Random)
| Algorithm 1 Reactive Random Load Balancer |
|
4.2. Reactive Round-Robin Load Balancer (RR)
| Algorithm 2 Reactive Round-Robin Load Balancer |
|
4.3. Reactive Round-Robin Load Balancer with Threshold (RRT)
| Algorithm 3 Reactive Round-Robin Load Balancer with Threshold |
|
5. Proof of Concept
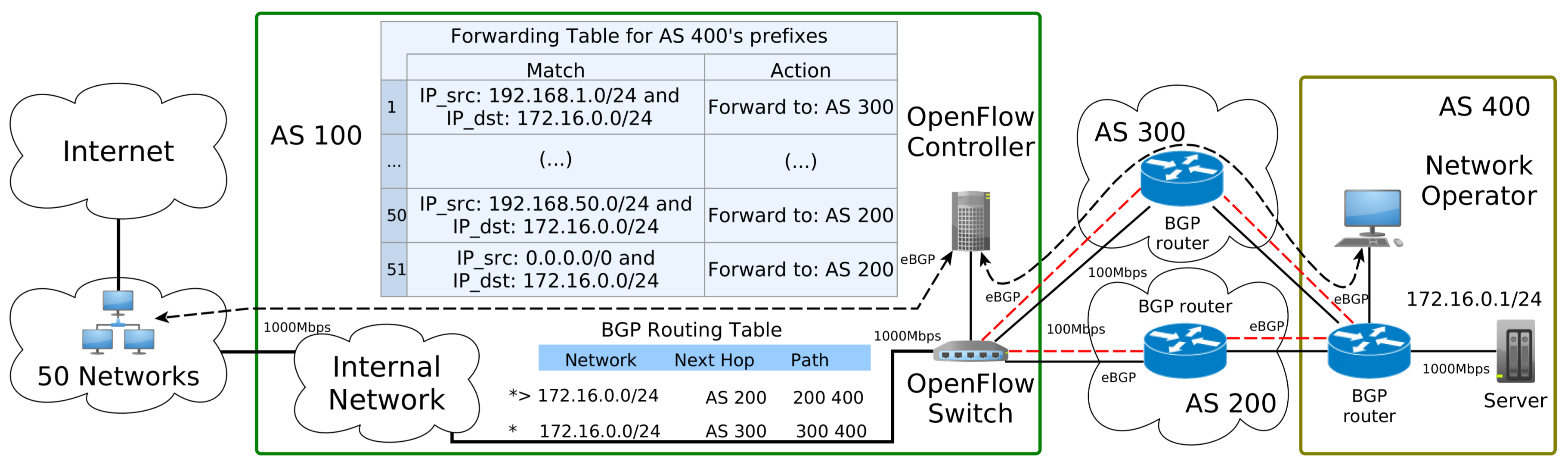
5.1. Topology Adopted
5.2. Prototype Environment
5.3. Workloads
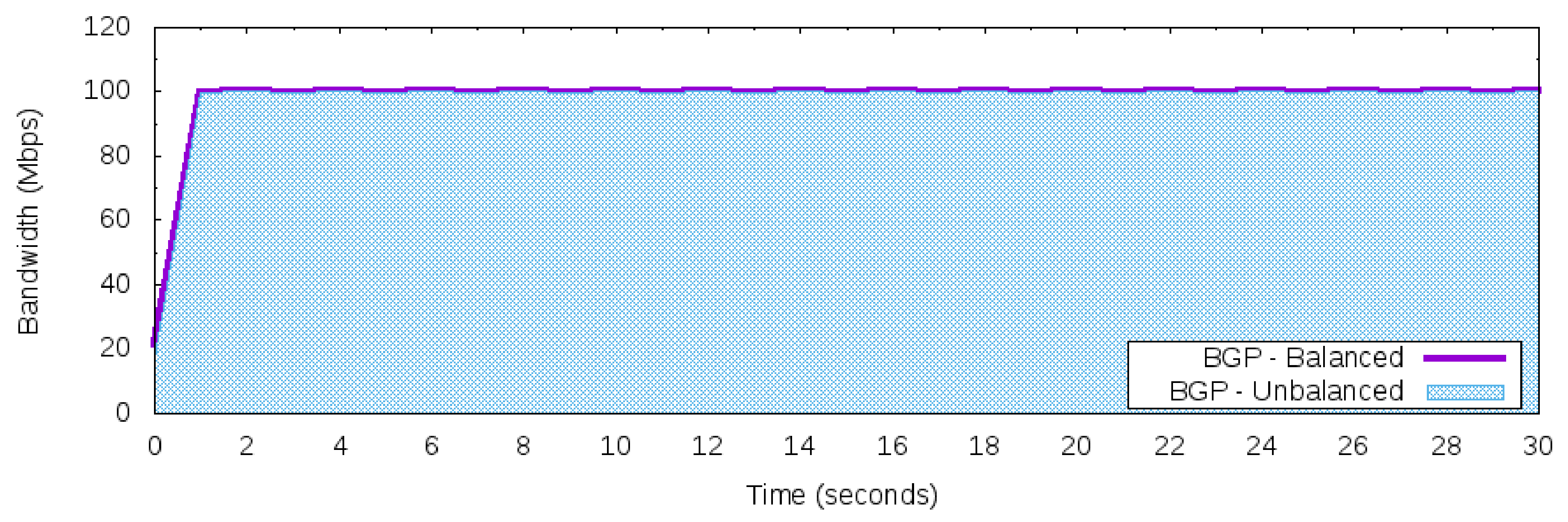
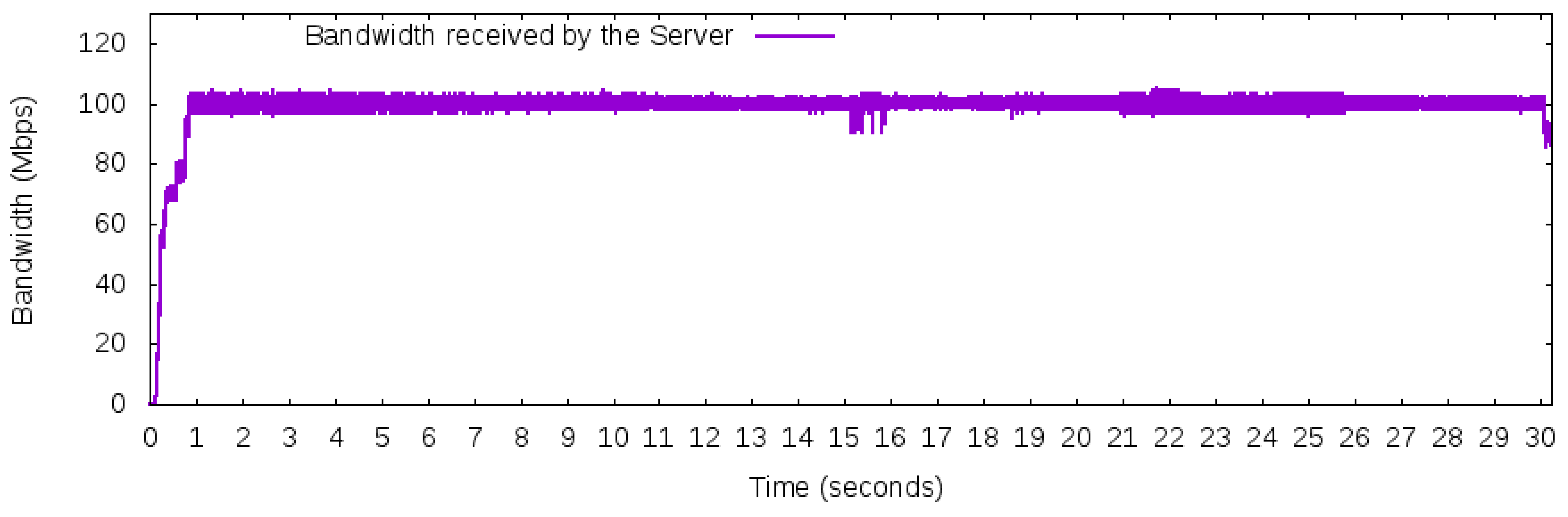
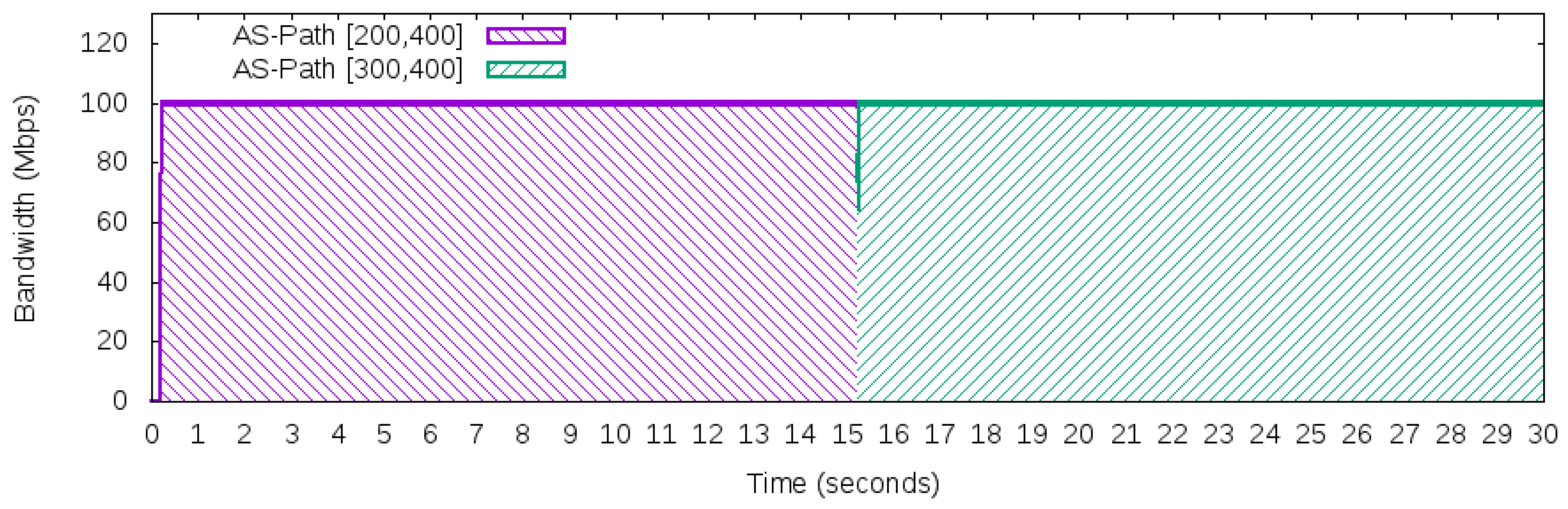
- Maximum constant network traffic for BGP behavior: This workload produces 100 Mbps of bandwidth usage during the 50 Networks 30 s of use iperf in client mode to generate the UDP packets. The workload was designed to explore the BGP behavior of using just one “best” next hop (per prefix). Thus, based on the adopted topology in Figure 5, this workload will only use one path to carry this traffic, either path [200,400] or path [300,400], but not both to reach prefix 172.16.0.0/24 of AS 400.
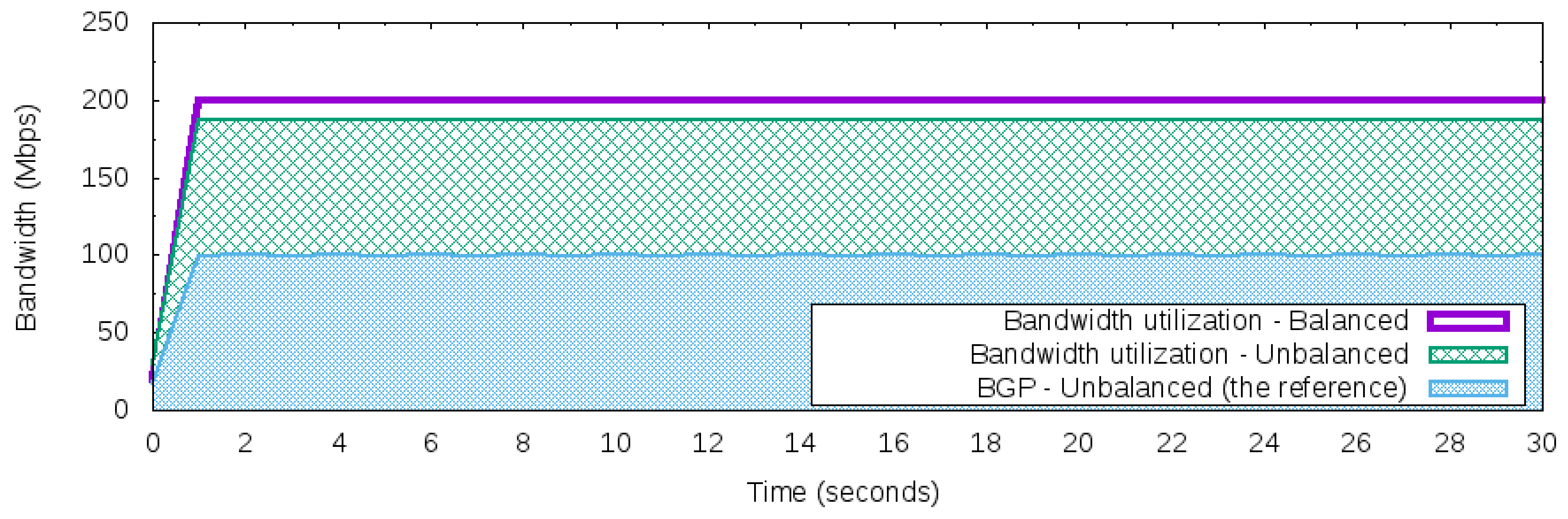
- Constant network traffic with balanced rate: Different from the Maximum constant network traffic for BGP behavior, this workload produces 200 Mbps of bandwidth from the 50 Networks. The total volume of traffic is split equally into each network. Hence, each one will be responsible for producing 4 Mbps of network traffic using UDP packets during the 30 s.
- Constant network traffic with unbalanced rate: Similar to constant network traffic with a balanced rate workload, however, with network traffic it will be configured to become unbalanced. Thus, the 50 Networks is split in half, and 25 of the 50 Networks will generate 7 Mbps and the other 25 will generate 1 Mbps of network traffic using UDP packets for 30 s, where the total number of bandwidth produced is 200 Mbps in this interval.
5.4. Scenario I—Manage Incoming Traffic Using Different Strategies
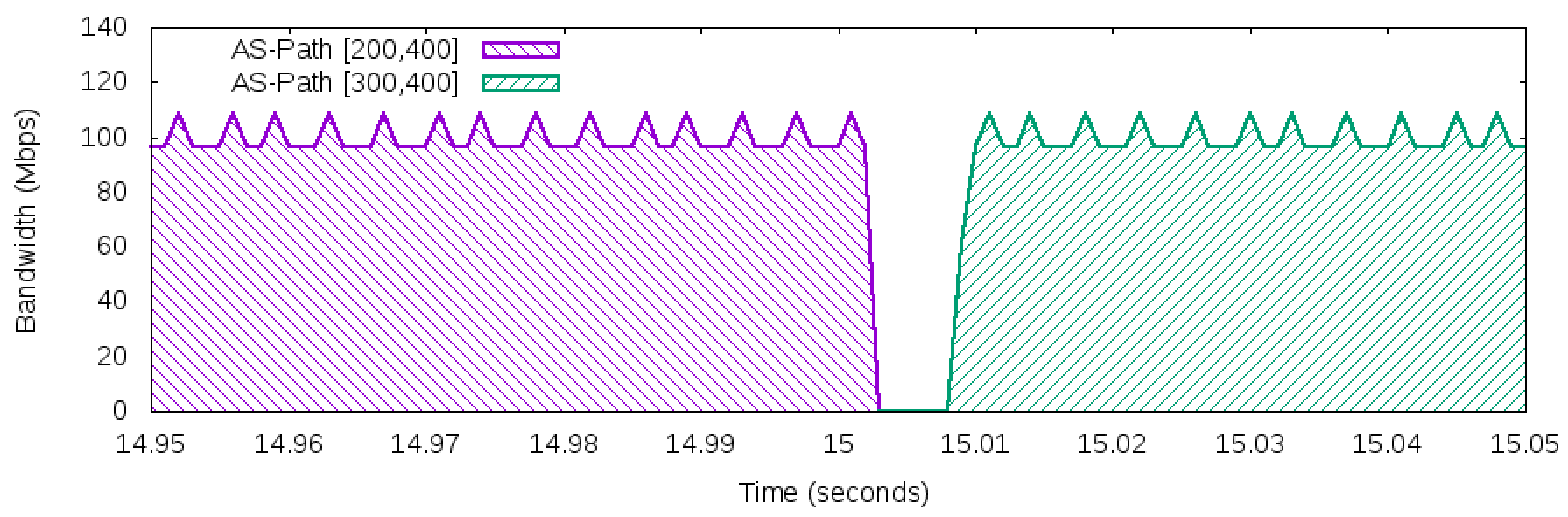
5.5. Scenario II—External Link Failure
5.6. Signaling Overhead
6. Further Discussion
6.1. Number of Network Rules
6.2. Adopting a Routing Registry
6.3. East/Westbound Discussion
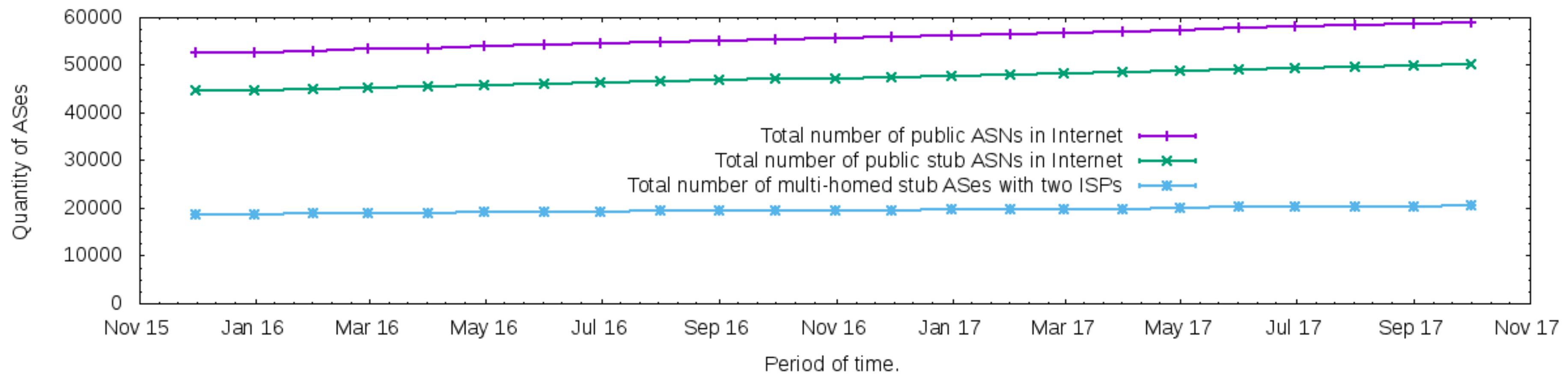
6.4. The Proposed Architecture in the Internet
6.5. Future Works and Limitations
7. Conclusions
Conflicts of Interest
References
- Rekhter, Y.; Li, T.; Hares, S. A Border Gateway Protocol 4 (BGP-4), Network Working Group. 2006. Available online: https://www.rfc-editor.org/rfc/pdfrfc/rfc4271.txt.pdf (accessed on 10 April 2018).
- O’Donnell, R. A Survey of BGP Security Issues and Solutions. Proc. IEEE 2010, 98, 100–122. [Google Scholar] [CrossRef]
- Silva, W.J.A.; Sadok, D.F.H. Control Inbound Traffic: Evolving the Control Plane Routing System with Software Defined Networking. In Proceedings of the 18th International Conference on High Performance Switching and Routing (HPSR), Campinas, Brazil, 18–21 June 2017. [Google Scholar]
- Mendiola, A.; Astorga, J.; Jacob, E.; Higuero, M. A Survey on the Contributions of Software-Defined Networking to Traffic Engineering. IEEE Commun. Surv. Tutor. 2017, 19, 918–953. [Google Scholar] [CrossRef]
- Nunes, B.A.A.; Mendonca, M.; Nguyen, X.N.; Obraczka, K.; Turletti, T. A survey of software-defined networking: Past, present, and future of programmable networks. IEEE Commun. Surv. Tutor. 2014, 16, 1617–1634. [Google Scholar] [CrossRef]
- Kreutz, D.; Ramos, F.M.V.; Veríssimo, P.E.; Rothenberg, C.E.; Azodolmolky, S.; Uhlig, S. Software-Defined Networking : A Comprehensive Survey. Proc. IEEE 2015, 103, 14–76. [Google Scholar] [CrossRef]
- Silva, W.J.A. Avoiding Inconsistency in OpenFlow Stateful Applications Caused by Multiple Flow Requests. In Proceedings of the International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; pp. 543–548. [Google Scholar]
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling Innovation in Campus Networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Wang, N.; Ho, K.H.; Pavlou, G.; Howarth, M. An overview of routing optimization for internet traffic engineering. IEEE Commun. Surv. Tutor. 2008, 10, 36–56. [Google Scholar] [CrossRef]
- Lee, S.J.; Banerjee, S.; Sharma, P.; Yalagandula, P.; Basu, S. Bandwidth-aware routing in overlay networks. In Proceedings of the IEEE INFOCOM, Phoenix, AZ, USA, 13–18 April 2008; pp. 2405–2413. [Google Scholar]
- Quoitin, B.; Bonaventure, O. A cooperative approach to interdomain traffic engineering. In Proceedings of the NGI 2005- Next, Generation Internet Networks: Traffic Engineering, Rome, Italy, 18–20 April 2005; Volume 2005, pp. 450–457. [Google Scholar]
- Yang, X.; Clark, D.; Berger, A.W. NIRA: A new inter-domain routing architecture. IEEE/ACM Trans. Netw. 2007, 15, 775–788. [Google Scholar] [CrossRef]
- Herrmann, D.; Turba, M.; Kuijper, A.; Schweizer, I. Inbound Interdomain Traffic Engineering with LISP. In Proceedings of the IEEE 39th Conference on Local Computer Networks (LCN), Edmonton, AB, Canada, 8–11 September 2014; pp. 458–461. [Google Scholar]
- Qin, D.; Yang, J.; Liu, Z.; Wang, H.; Zhang, B.; Zhang, W. AMIR: Another multipath interdomain routing. In Proceedings of the International Conference on Advanced Information Networking and Applications, AINA, Fukuoka, Japan, 26–29 March 2012; pp. 581–588. [Google Scholar]
- Xu, W.; Rexford, J. MIRO : Multi-path Interdomain ROuting. In Proceedings of the 2006 conference on Applications, technologies, architectures, and protocols for computer communications, Pisa, Italy, 11–15 September 2006; pp. 171–182. [Google Scholar]
- Chen, Z.; Bi, J.; Fu, Y.; Wang, Y.; Xu, A. MLV: A Multi-dimension Routing Information Exchange Mechanism for Inter-domain SDN. In Proceedings of the 2015 IEEE 23rd International Conference on Network Protocols (ICNP), San Francisco, CA, USA, 10–13 November 2015; pp. 438–445. [Google Scholar]
- ONOS. A New Carrier-Grade SDN Network Operation System Designed for High Availability, Performance, Scale-out. 2017. Available online: http://onosproject.org/ (accessed on 10 April 2018).
- Quagga. Quagga Routing Suite. 2017. Available online: http://www.nongnu.org/quagga/ (accessed on 10 April 2018).
- Ryu. A Component-Based Software Defined Networking Framework- Ryu. 2016. Available online: https://osrg.github.io/ryu/ (accessed on 10 April 2018).
- Feamster, N.; Rexford, J.; Shenker, S.; Clark, R.; Hutchins, R.; Levin, D.; Bailey, J. SDX: A Software-Defined Internet Exchange, Open Networking Summit. 2013, pp. 2–3. Available online: http://www.cs.princeton.edu/ jrex/papers/sdx-ons13.pdf (accessed on 10 April 2018).
- Gupta, A.; MacDavid, R.; Birkner, R.; Canini, M.; Feamster, N.; Rexford, J.; Vanbever, L. An Industrial-Scale Software Defined Internet Exchange Point. In Proceedings of the 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16), Santa Clara, CA, USA, 16–18 March 2016; pp. 1–14. [Google Scholar]
- Wang, Y.; Bi, J.; Zhang, K.; Wu, Y. A Framework for Fine-Grained Inter-Domain Routing Diversity Via SDN. In Proceedings of the 2016 Eighth International Conference on Ubiquitous and Future Networks (ICUFN), Vienna, Austria, 5–8 July 2016; pp. 751–756. [Google Scholar]
- Kotronis, V.; Gamperli, A.; Dimitropoulos, X. Routing centralization across domains via SDN: A model and emulation framework for BGP evolution. Comput. Netw. 2015, 92, 227–239. [Google Scholar] [CrossRef]
- Saltzer, J.H.; Reed, D.P.; Clark, D.D. End-to-end arguments in system design. ACM Trans. Comput. Syst. 1984, 2, 277–288. [Google Scholar] [CrossRef]
- Ager, B.; Chatzis, N.; Feldmann, A.; Sarrar, N.; Uhlig, S.; Willinger, W. Anatomy of a large european IXP. In Proceedings of the ACM SIGCOMM 2012 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Helsinki, Finland, 13–17 August 2012; Volume 42, pp. 163–174. [Google Scholar]
- Liu, X.; Mohanraj, S.; Pioro, M.; Medhi, D. Multipath Routing From a Traffic Engineering Perspective: How Beneficial is It? In Proceedings of the 22nd IEEE ICNP, Raleigh, NC, USA, 21–24 October 2014; pp. 21–23. [Google Scholar]
- Singh, S.K.; Das, T.; Jukan, A. A Survey on Internet Multipath Routing and Provisioning. IEEE Commun. Surv. Tutor. 2015, 17, 2157–2175. [Google Scholar] [CrossRef]
- Silva, W.J.A.; Dias, K.L.; Sadok, D.F.H. A Performance Evaluation of Software Defined Networking Load Balancers Implementations. In Proceedings of the International Conference on Information Networking (ICOIN), Da Nang, Vietnam, 11–13 January 2017. [Google Scholar]
- Silva, W.J.A. Performance Evaluation of Flow Creation Inside an OpenFlow Network. In Proceedings of the XXXV Simpósio Brasileiro de Telecomunicações e Processamento de Sinais- SBrT2017, São Pedro, SP, Brazil, 3–6 DE SETEMBRO DE 2017; pp. 102–106. [Google Scholar]
- CAIDA. Center for Applied Internet Data Analysis- CAIDA. 2016. Available online: http://data.caida.org/datasets/as-relationships/serial-2/ (accessed on 10 April 2018).
- OpenvSwitch. Open vSwitch. 2016. Available online: http://openvswitch.org/ (accessed on 10 April 2018).
- VirtualBox. Virtualization—Oracle VM VirtualBox. 2016. Available online: https://www.virtualbox.org/wiki/Virtualization (accessed on 10 April 2018).
- Iperf. Iperf- Perform Network Throughput Tests. 2016. Available online: http://iperf.sourceforge.net/ (accessed on 10 April 2018).
- Niven-Jenkins, B.; Brungard, D.; Betts, M.; Sprecher, N.; Ueno, S. Requirements of an MPLS Transport Profile. 2009. Available online: https://tools.ietf.org/html/draft-ietf-mpls-tp-requirements-10 (accessed on 10 April 2018).
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. Enabling Fast Failure Recovery in OpenFlow Networks. In Proceedings of the 8th International Workshop on the Design of Reliable Communication Networks, DRCN 2011, Krakow, Poland, 10–12 October 2011; pp. 164–171. [Google Scholar]
- Lin, Y.D.; Teng, H.Y.; Hsu, C.R.; Liao, C.C.; Lai, Y.C. Fast failover and switchover for link failures and congestion in software defined networks. In Proceedings of the 2016 IEEE International Conference on Communications, ICC 2016, Kuala Lumpur, Malaysia, 22–27 May 2016. [Google Scholar]
- Wang, T.; Shi, X.; Yin, X.; Wang, Z. Quantifying the Propagation Behavior of BGP Routing Update. Bull. Netw. Comput. Syst. Softw. 2015, 4, 18–20. [Google Scholar]
- Godfrey, P.B.; Caesar, M.; Haken, I.; Singer, Y.; Shenker, S.; Stoica, I. Stabilizing route selection in BGP. IEEE/ACM Trans. Netw. 2015, 23, 282–299. [Google Scholar] [CrossRef]
- RouteViews. Dataset Contains IPv4/IPv6 Prefix-to-Autonomous System (AS) Mappings Derived from RouteViews Data. 2017. Available online: http://data.caida.org/datasets/routing/routeviews-prefix2as/ (accessed on 10 April 2018).
- Lin, P.; Bi, J.; Chen, Z.; Wang, Y.; Hu, H.; Xu, A. WE-bridge: West-east bridge for SDN inter-domain network peering. In Proceedings of the IEEE INFOCOM, Toronto, ON, Canada, 27 April–2 May 2014; pp. 111–112. [Google Scholar]
- Hong, C.Y.; Kandula, S.; Mahajan, R.; Zhang, M.; Gill, V.; Nanduri, M.; Wattenhofer, R. Achieving high utilization with software-driven WAN. In Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM—SIGCOMM ’13, Hong Kong, China, 12–16 August 2013; p. 15. [Google Scholar]
- Wang, Y.; Bi, J.; Lin, P.; Lin, Y.; Zhang, K. SDI: A multi-domain SDN mechanism for fine-grained inter-domain routing. Ann. Telecommun. 2016, 71, 625–637. [Google Scholar] [CrossRef]
- Nguyen, X.N.; Saucez, D.; Barakat, C.; Turletti, T. Rules Placement Problem in OpenFlow Networks: A Survey. IEEE Commun. Surv. Tutor. 2016, 18, 1273–1286. [Google Scholar] [CrossRef]
- Bosshart, P.; Varghese, G.; Walker, D.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; et al. P4: Programming Protocol-Independent Packet Processors. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Bianchi, G.; Bonola, M.; Capone, A.; Cascone, C. OpenState: Programming Platform-independent Stateful OpenFlow Applications Inside the Switch. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 44–51. [Google Scholar] [CrossRef]
- Alshamrani, H.; Ghita, B. IP prefix hijack detection using BGP connectivity monitoring. In Proceedings of the IEEE International Conference on High Performance Switching and Routing, HPSR, Yokohama, Japan, 14–17 June 2016; pp. 35–41. [Google Scholar]
- IRR. Internet Routing Registry. Available online: https://www.arin.net/resources/routing/ (accessed on 10 April 2018).
- Kreutz, D.; Ramos, F.M.; Verissimo, P. Towards secure and dependable software-defined networks. In Proceedings of the Second ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking- HotSDN ’13, Hong Kong, China, 16 August 2013; p. 55. [Google Scholar]
- Seedorf, J.; Burger, E. Application-layer traffic optimization (ALTO) problem statement. Netw. Work. Group 2009, 5693, 1–14. [Google Scholar]
- Nascimento, M.R.; Rothenberg, C.E.; Salvador, M.R.; Corrêa, C.N.A.; de Lucena, S.C.; Magalhães, M.F. Virtual routers as a service: The RouteFlow Approach Leveraging Software-Defined Networks. In Proceedings of the 6th International Conference on Future Internet Technologies -CFI ’11, Seoul, Korea, 13–15 June 2011; p. 34. [Google Scholar]
- Nobre, J.C.; Melchiors, C.; Marquezan, C.C.; Tarouco, L.M.R.; Granville, L.Z. A Survey on the Use of P2P Technology for Network Management. J. Netw. Syst. Manag. 2018, 26, 189–221. [Google Scholar] [CrossRef]
- CAIDA. AS Rank: AS Ranking - CAIDA. 2017. Available online: http://as-rank.caida.org/ (accessed on 10 April 2018).
- Wolf, T.; Griffioen, J.; Calvert, K.; Dutta, R.; Rouskas, G.; Nagurney, A. ChoiceNet : Toward an Economy Plane for the Internet. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 58–65. [Google Scholar] [CrossRef]
- Zargar, S.T.; Joshi, J.; Tipper, D. A survey of defense mechanisms against distributed denial of service (DDOS) flooding attacks. IEEE Commun. Surv. Tutor. 2013, 15, 2046–2069. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Match Fields | Instruction |
|---|---|
| IP_src:192.168.1.0/24 and IP_dst:172.16.0.0/24 | Group1 |
| IP_src:192.168.2.0/24 and IP_dst:172.16.0.0/24 | Group1 |
| (...) | Group1 |
| IP_src:192.168.50.0/24 and IP_dst:172.16.0.0/24 | Group1 |
| IP_dst:172.16.0.0/24 | Group2 |
| Group Identifier | Group Type | Action Buckets |
|---|---|---|
| Group1 | Fast Failover | Watch: AS 200 port; Outport: AS 200 |
| Watch: AS 300 port; Outport: AS 300 | ||
| Group2 | Fast Failover | Watch: AS 200 port; Outport: AS 200 |
| Interval | Uncompressed (in Kbps) | Compressed (in Kbps) |
|---|---|---|
| 0–1 | 4472 | 292 |
| 0–5 | 894 | 58 |
| 0–10 | 447 | 29 |
| 0–15 | 298 | 19 |
| 0–20 | 223 | 14 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva, W.J.A. An Architecture to Manage Incoming Traffic of Inter-Domain Routing Using OpenFlow Networks. Information 2018, 9, 92. https://doi.org/10.3390/info9040092
Silva WJA. An Architecture to Manage Incoming Traffic of Inter-Domain Routing Using OpenFlow Networks. Information. 2018; 9(4):92. https://doi.org/10.3390/info9040092
Chicago/Turabian StyleSilva, Walber José Adriano. 2018. "An Architecture to Manage Incoming Traffic of Inter-Domain Routing Using OpenFlow Networks" Information 9, no. 4: 92. https://doi.org/10.3390/info9040092
APA StyleSilva, W. J. A. (2018). An Architecture to Manage Incoming Traffic of Inter-Domain Routing Using OpenFlow Networks. Information, 9(4), 92. https://doi.org/10.3390/info9040092