Conceptions of Artificial Intelligence and Singularity


Abstract
:1. Introduction
- Many claims about what AI (artificial intelligence) will be able to do are obtained using naive extrapolation of the past progress, without addressing the conceptual and technical difficulties in the field.
- Many claims about what AI will not be able to do are derived from traditional conceptions on how a computer system should be built and used, as well as an anthropocentric usage of notions such as “intelligence” and “cognition”.
2. Notions Distinguished and Clarified
2.1. Different Types of AI
- A computer system that behaves exactly like a human mind
- A computer system that solves certain problems previously solvable only by the human mind
- A computer system with the same cognitive functions as the human mind
2.2. Presumptions of Singularity
- The intelligence of a system can be measured by a real number.
- AI should be able to increase its intelligence via learning or recursive self-improvement.
- After the intelligence of AI passes the human-level, its entire future will be perceived as a single point, since it will be beyond our comprehension.
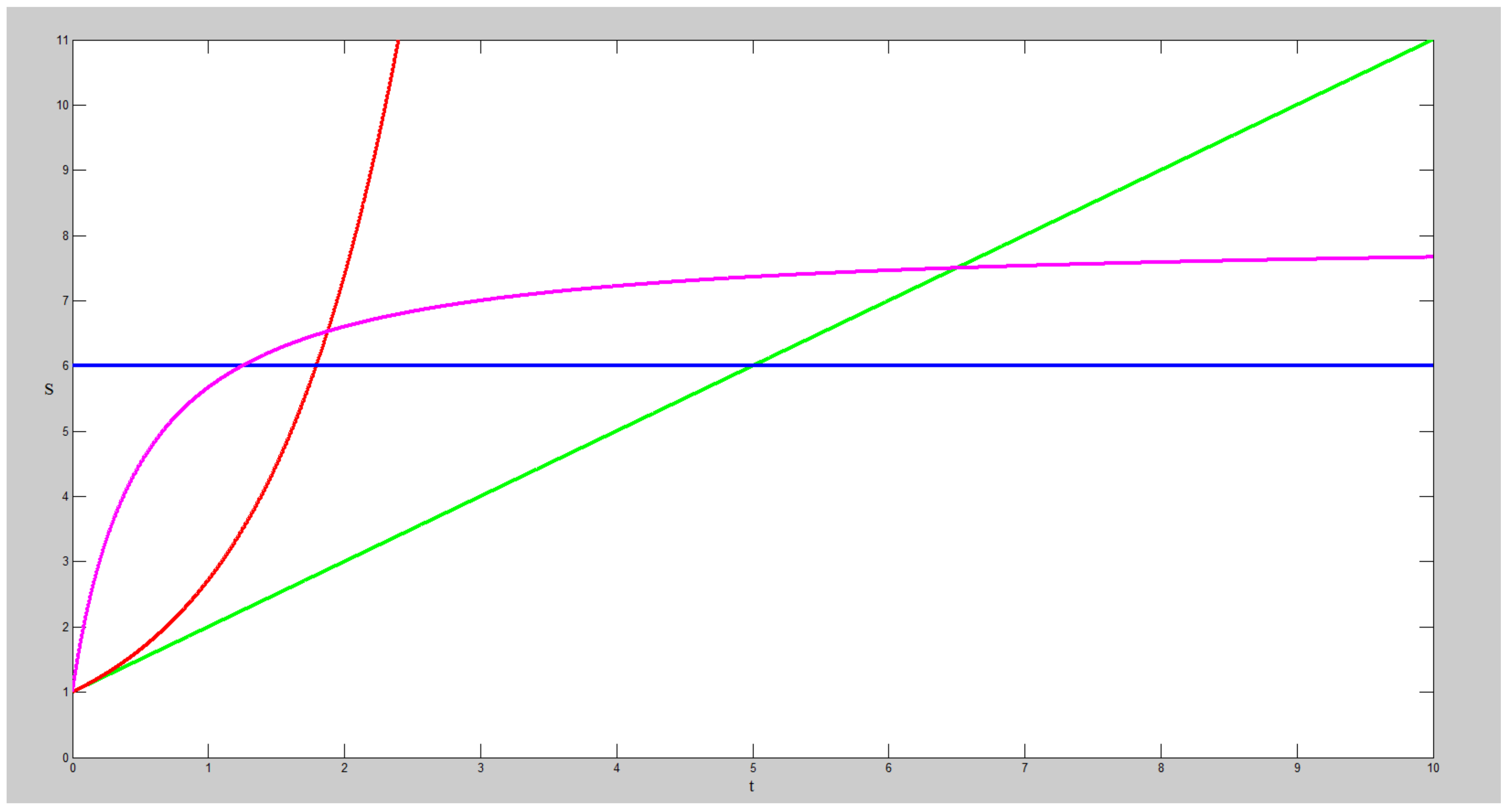
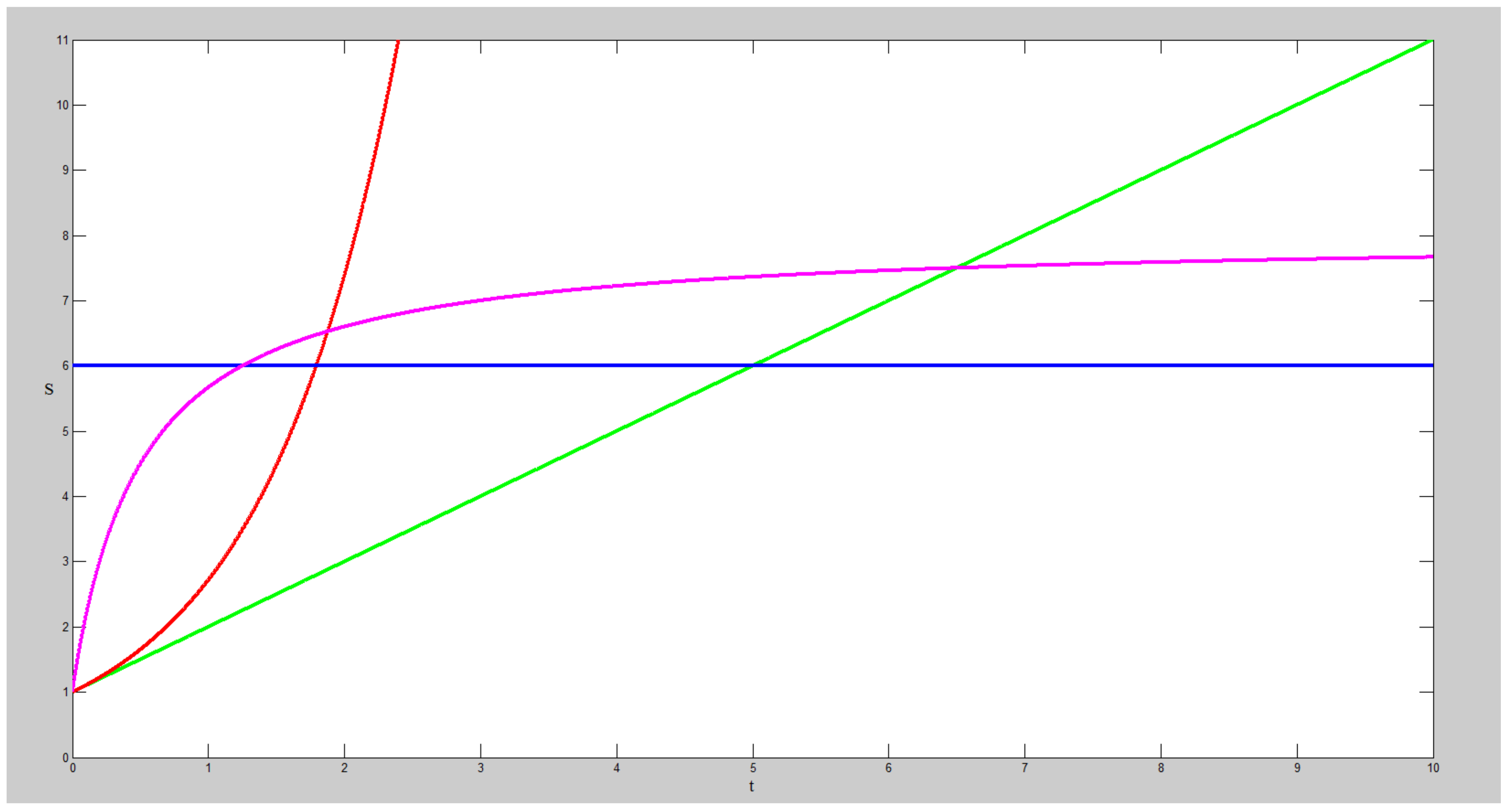
- B-type: The blue line corresponds to a system with constant problem-solving capability—what the system can do is completely determined at the beginning, i.e., . All traditional computation systems belong to this type, and some of them are referred to as “AI”.
- P-type: The pink line corresponds to a system that increases its problem-solving capability until it infinitely approximates an upper bound. For such a system, , but converges to 0. Most machine learning algorithms belong to this type.
- G-type: The green line corresponds to a system where its problem-solving capability increases without an upper bound and is a positive constant. Many AGI projects, including ours, belong to this type.
- R-type: The red line corresponds to a system where both and increase exponentially. We do not think such a system is possible to be actually built, but list it here only as a conceptual possibility to be discussed.
- Although the distinction between object-level and meta-level exists in many AI systems, its exact standard depends on the design of the system, such that the functions carried out as meta-learning in one system may correspond to a type of object-level learning in another system.
- Some proposed “meta-learning” approaches basically suggest trying various designs and keeping the best, but this is usually unrealistic because of the time–space resources it demands and the risks it brings.
- A common misunderstanding is to equalize “recursive self-improving” with “modifying the system’s own source-code”. Certain programming languages, such as Lisp and Prolog, have provided the source-code modification and generation functions for many years; however, the use of these functions does not cause a fundamental difference, as the same effects can be achieved in another programming language by changing certain data, as the “data vs. code” distinction is also based on implementation considerations, not a theoretical boundary.
- The learning of meta-level knowledge and skills cannot be properly handled by the existing machine learning techniques, which are designed for object-level tasks [12]. The same difference happens in the human mind: as an individual, our mental mechanisms are mostly innate, and can be adjusted slowly in limited ways; it is only when discussed at the scale of the species that they are “learned” via evolution, but that happens at a much slower speed and a much higher price (a bad change is usually fatal for an individual). Given this fundamental difference, it is better to call the meta-level learning processes in a species “evolution”, reserving the word “intelligence” for the object-level learning processes of an individual.
3. What an AGI Can Do
3.1. NARS Overview
- Judgment: A judgment is a statement with a given truth-value, as a piece of new knowledge to be absorbed into the system’s beliefs. The system may revise the truth-value of a judgment according to its previous belief on the matter, add it into the conceptual network, and carry out spontaneous inference from it and the relevant beliefs to reveal its implications, recursively.
- Goal: A goal is a statement to be realized by the system. To indicate the extent of preference when competing with other goals, an initial “desire-value” can be given. When the desire-value of a goal becomes high enough, it will either directly trigger the execution of the associated operation, or generate derived goals according to the relevant beliefs.
- Question: A question can ask the truth-value or desire-value of a statement, which may contain variable terms to be instantiated. A question can be directly answered by a matching belief or desire, or generate derived questions according to the relevant beliefs.
- Select a concept in the system’s memory probabilistically, biased by the priority distributions among concepts. Every concept has a chance to be selected, although concepts with high priority have higher chances.
- Select a task and a belief from the concept, also probabilistically as above. Since the two share the same term identifying the concept, they must be relevant in content.
- Carry out a step of inference using the selected task and belief as premises. Based on the combination of their types, the corresponding inference rules will be triggered, which may provide immediate solutions to the task, or (more likely) derived tasks whose solutions will contribute to the solution of the original task.
- Adjust the priority values of the processed items (belief, task, and concept) according to the available feedback from this inference step.
- Process the new tasks by selectively adding them into the memory and/or reporting them to the user.
3.2. Properties of NARS
4. Conclusions
- Their understanding of “intelligence” is highly anthropocentric. As few AGI researcher aims at such an objective, the “AGI research” they criticize does not exist [2].
- Their understanding of computer is oversimplified and reductionist, and only corresponds to a special way of using computer. Even though this is indeed the most common way for a computer system to be built and used at the present time, it is not the only possible way [34].
- Their understanding of AGI mostly comes from outsiders’ speculations, rather than from the actual research activity in the field. Although it is perfectly fine for an outsider to criticize AGI research, such a criticism is valid only when it is based on the reality of the field.
- AGI should be conceived as a computer system that is similar to human intelligence in principles, mechanisms, and functions, but not necessarily in internal structure, external behaviors, or problem-solving capabilities. Consequently, as another form of intelligence, AGI will roughly be at the same level of competence as human intelligence, neither higher nor lower. As in concrete problem-solving capability, AGI is not always comparable to human intelligence, since they may deal with different problems in different environments.
- To achieve AGI, new theories, models, and techniques are needed. The current mainstream AI results will not naturally grow in this direction, because they are mainly developed according to the dogma that intelligence is problem-solving capability, which does not correspond to AGI, but a fundamentally different objective, with different theoretical and practical values.
- Even when AGI is achieved, it does not lead to a singularity beyond which intelligent computer systems become completely incomprehensible, unpredictable, and uncontrollable. On the contrary, the achieving of AGI means the essence of intelligence has been captured by humans, which will further guide the use of AGI to meet to human values and needs.
Author Contributions
Conflicts of Interest
References
- Braga, A.; Logan, R.K. The Emperor of Strong AI Has No Clothes: Limits to Artificial Intelligence. Information 2017, 8, 156. [Google Scholar] [CrossRef]
- Wang, P. What do you mean by “AI”. In Proceedings of the First Conference on Artificial General Intelligence, Memphis, TN, USA, 1–3 March 2008; pp. 362–373. [Google Scholar]
- Turing, A.M. Computing machinery and intelligence. Mind 1950, LIX, 433–460. [Google Scholar] [CrossRef]
- McCarthy, J.; Minsky, M.; Rochester, N.; Shannon, C. A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence, 1955. Available online: http://www-formal.stanford.edu/jmc/history/dartmouth.html (accessed on 4 April 2018).
- Feigenbaum, E.A.; Feldman, J. Computers and Thought; McGraw-Hill: New York, NY, USA, 1963. [Google Scholar]
- Newell, A.; Simon, H.A. GPS, a program that simulates human thought. In Computers and Thought; Feigenbaum, E.A., Feldman, J., Eds.; McGraw-Hill: New York, NY, USA, 1963; pp. 279–293. [Google Scholar]
- Fuchi, K. The significance of fifth-generation computer systems. In The Age of Intelligent Machines; Kurzweil, R., Ed.; MIT Press: Cambridge, MA, USA, 1990; pp. 336–345. [Google Scholar]
- Roland, A.; Shiman, P. Strategic Computing: DARPA and the Quest for Machine Intelligence, 1983–1993; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Luger, G.F. Artificial Intelligence: Structures and Strategies for Complex Problem Solving, 6th ed.; Pearson: Boston, MA, USA, 2008. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Flach, P. Machine Learning: The Art and Science of Algorithms That Make Sense of Data; Cambridge University Press: New York, NY, USA, 2012. [Google Scholar]
- Pennachin, C.; Goertzel, B. Contemporary approaches to artificial general intelligence. In Artificial General Intelligence; Goertzel, B., Pennachin, C., Eds.; Springer: New York, NY, USA, 2007; pp. 1–30. [Google Scholar]
- Wang, P.; Goertzel, B. Introduction: Aspects of artificial general intelligence. In Advance of Artificial General Intelligence; Goertzel, B., Wang, P., Eds.; IOS Press: Amsterdam, The Netherlands, 2007; pp. 1–16. [Google Scholar]
- Searle, J. Minds, brains, and programs. Behav. Brain Sci. 1980, 3, 417–424. [Google Scholar] [CrossRef]
- Kurzweil, R. The Singularity Is Near: When Humans Transcend Biology; Penguin Books: New York, NY, USA, 2006. [Google Scholar]
- Bostrom, N. Superintelligence: Paths, Dangers, Strategies; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- Wang, P.; Li, X. Different Conceptions of Learning: Function Approximation vs. Self-Organization. In Proceedings of the Ninth Conference on Artificial General Intelligence, New York, NY, USA, 16–19 July 2016; pp. 140–149. [Google Scholar]
- Wang, P. Rigid Flexibility: The Logic of Intelligence; Springer: Dordrecht, The Netherlands, 2006. [Google Scholar]
- Wang, P. Non-Axiomatic Logic: A Model of Intelligent Reasoning; World Scientific: Singapore, 2013. [Google Scholar]
- Wang, P. Theories of Artificial Intelligence—Meta-theoretical considerations. In Theoretical Foundations of Artificial General Intelligence; Wang, P., Goertzel, B., Eds.; Atlantis Press: Paris, France, 2012; pp. 305–323. [Google Scholar]
- Wang, P. The Assumptions on Knowledge and Resources in Models of Rationality. Int. J. Mach. Conscious. 2011, 3, 193–218. [Google Scholar] [CrossRef]
- Wang, P. Experience-grounded semantics: A theory for intelligent systems. Cognit. Syst. Res. 2005, 6, 282–302. [Google Scholar] [CrossRef]
- Peirce, C.S. Collected Papers of Charles Sanders Peirce; Harvard University Press: Cambridge, MA, USA, 1931; Volume 2. [Google Scholar]
- Hopcroft, J.E.; Motwani, R.; Ullman, J.D. Introduction to Automata Theory, Languages, and Computation, 3rd ed.; Addison-Wesley: Boston, MA, USA, 2007. [Google Scholar]
- Wang, P.; Li, X.; Hammer, P. Self in NARS, an AGI System. Front. Robot. AI 2018, 5, 20. [Google Scholar] [CrossRef]
- Freud, S. The Interpretation of Dreams; Translated by James Strachey from the 1900 Edition; Avon Books: New York, NY, USA, 1965. [Google Scholar]
- Dresp-Langley, B. Why the Brain Knows More than We Do: Non-Conscious Representations and Their Role in the Construction of Conscious Experience. Brain Sci. 2012, 2, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Wang, P. Motivation Management in AGI Systems. In Proceedings of the Fifth Conference on Artificial General Intelligence, Oxford, UK, 8–11 December 2012; pp. 352–361. [Google Scholar]
- Bach, J. Modeling Motivation and the Emergence of Affect in a Cognitive Agent. In Theoretical Foundations of Artificial General Intelligence; Wang, P., Goertzel, B., Eds.; Atlantis Press: Paris, France, 2012; pp. 241–262. [Google Scholar]
- Franklin, S.; Madl, T.; D’Mello, S.; Snaider, J. LIDA: A Systems-level Architecture for Cognition, Emotion, and Learning. IEEE Trans. Auton. Ment. Dev. 2014, 6, 19–41. [Google Scholar] [CrossRef]
- Rosenbloom, P.S.; Gratch, J.; Ustun, V. Towards Emotion in Sigma: From Appraisal to Attention. In Proceedings of the Eighth Conference on Artificial General Intelligence, Berlin, Germany, 22–25 July 2015; pp. 142–151. [Google Scholar]
- Wang, P.; Talanov, M.; Hammer, P. The Emotional Mechanisms in NARS. In Proceedings of the Ninth Conference on Artificial General Intelligence, New York, NY, USA, 16–19 July 2016; pp. 150–159. [Google Scholar]
- Wang, P. Three fundamental misconceptions of artificial intelligence. J. Exp. Theor. Artif. Intell. 2007, 19, 249–268. [Google Scholar] [CrossRef]

{kind=link}
| Type | Deduction | Induction | Abduction |
|---|---|---|---|
| Premise 1 | |||
| Premise 2 | |||
| Conclusion |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; Liu, K.; Dougherty, Q. Conceptions of Artificial Intelligence and Singularity. Information 2018, 9, 79. https://doi.org/10.3390/info9040079
Wang P, Liu K, Dougherty Q. Conceptions of Artificial Intelligence and Singularity. Information. 2018; 9(4):79. https://doi.org/10.3390/info9040079
Chicago/Turabian StyleWang, Pei, Kai Liu, and Quinn Dougherty. 2018. "Conceptions of Artificial Intelligence and Singularity" Information 9, no. 4: 79. https://doi.org/10.3390/info9040079
APA StyleWang, P., Liu, K., & Dougherty, Q. (2018). Conceptions of Artificial Intelligence and Singularity. Information, 9(4), 79. https://doi.org/10.3390/info9040079