An Anti-Collision Algorithm for RFID Based on an Array and Encoding Scheme

Abstract
:1. Introduction
2. Problem Identification
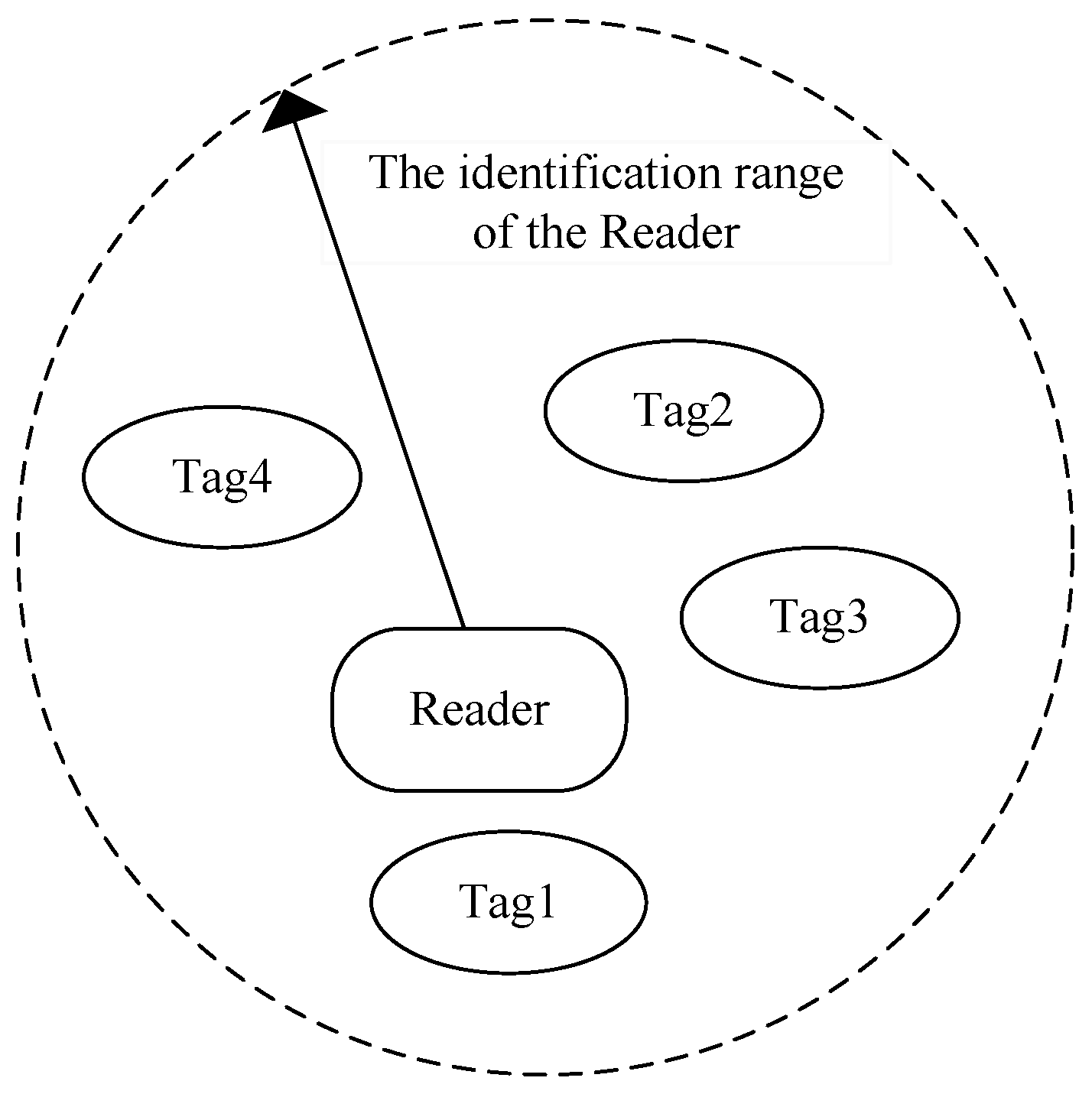
2.1. Tag-Tag Collision
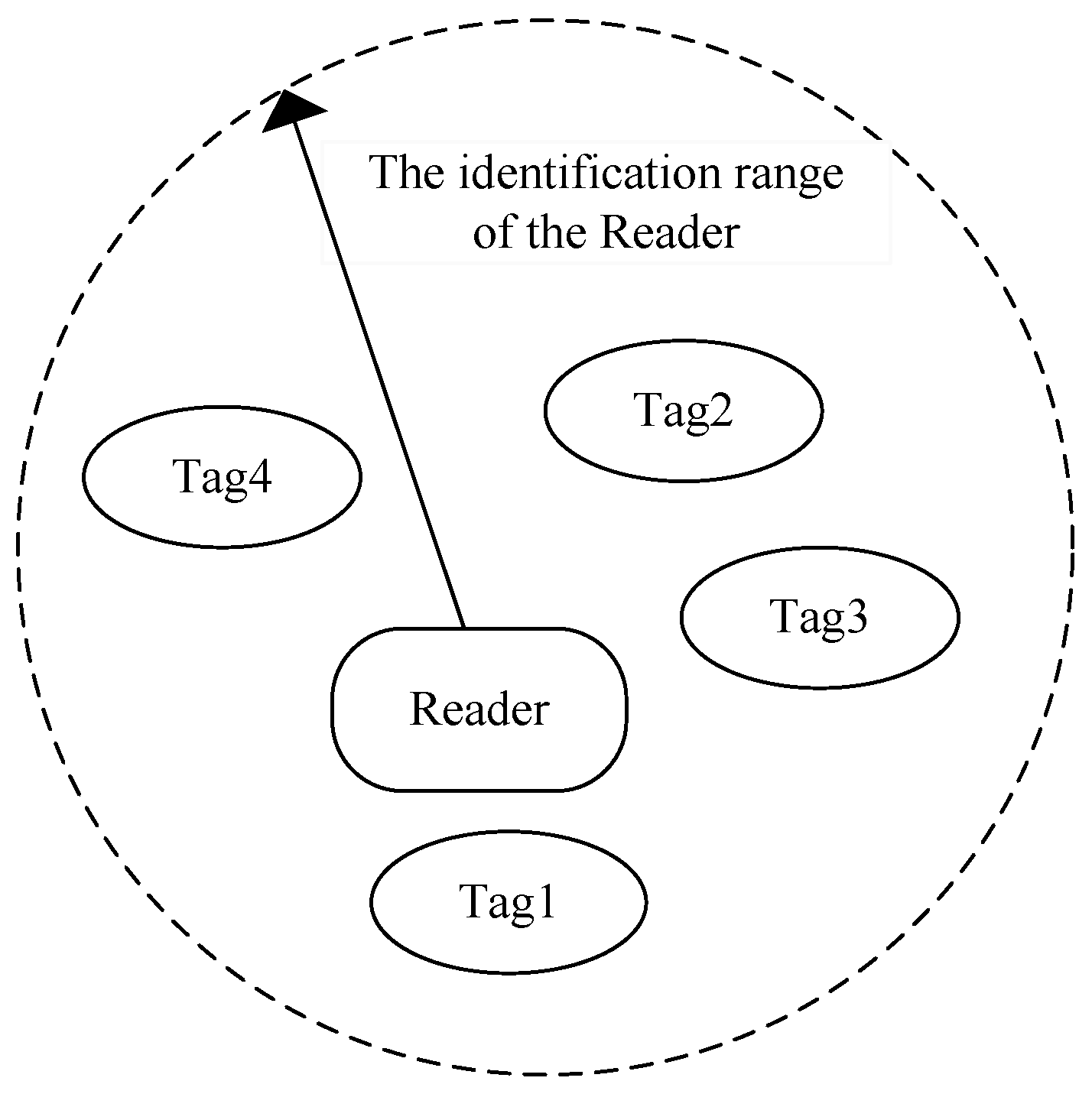
2.2. Tag-Reader Collision
2.3. Reader-Reader Collision
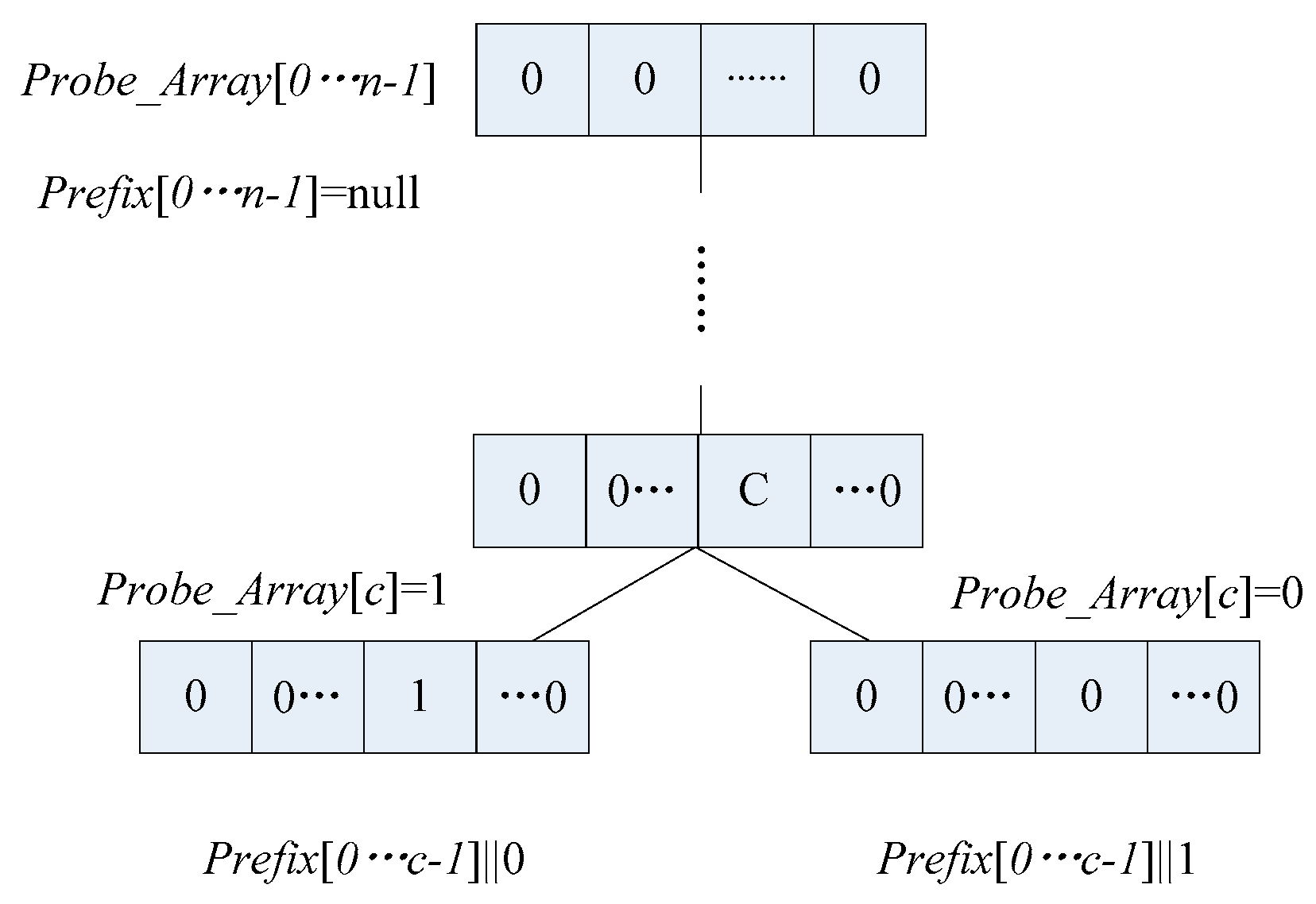
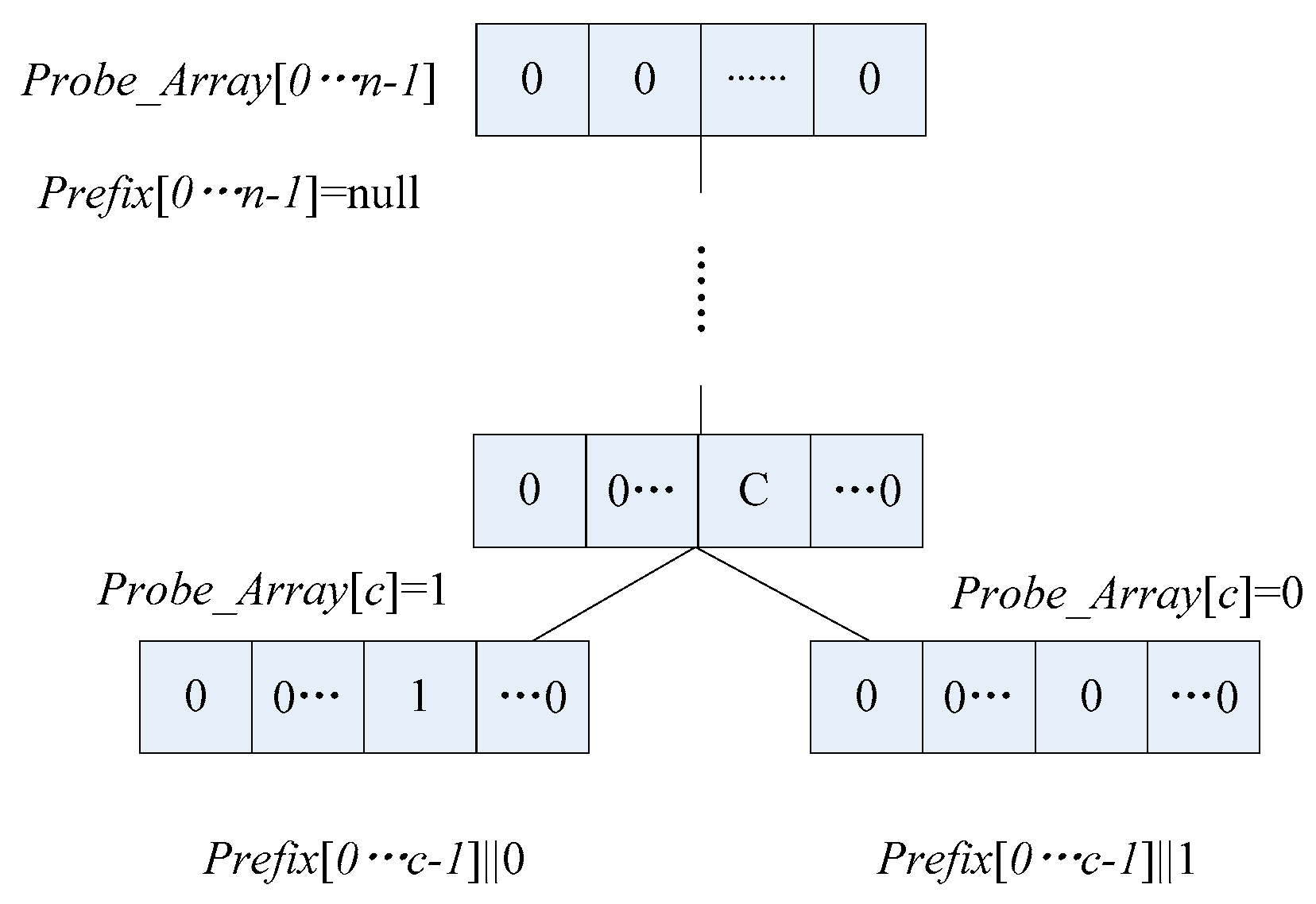
3. Array Storage Scheme
3.1. Description of the Array Storage Scheme
3.2. Example and Comparison of Schemes
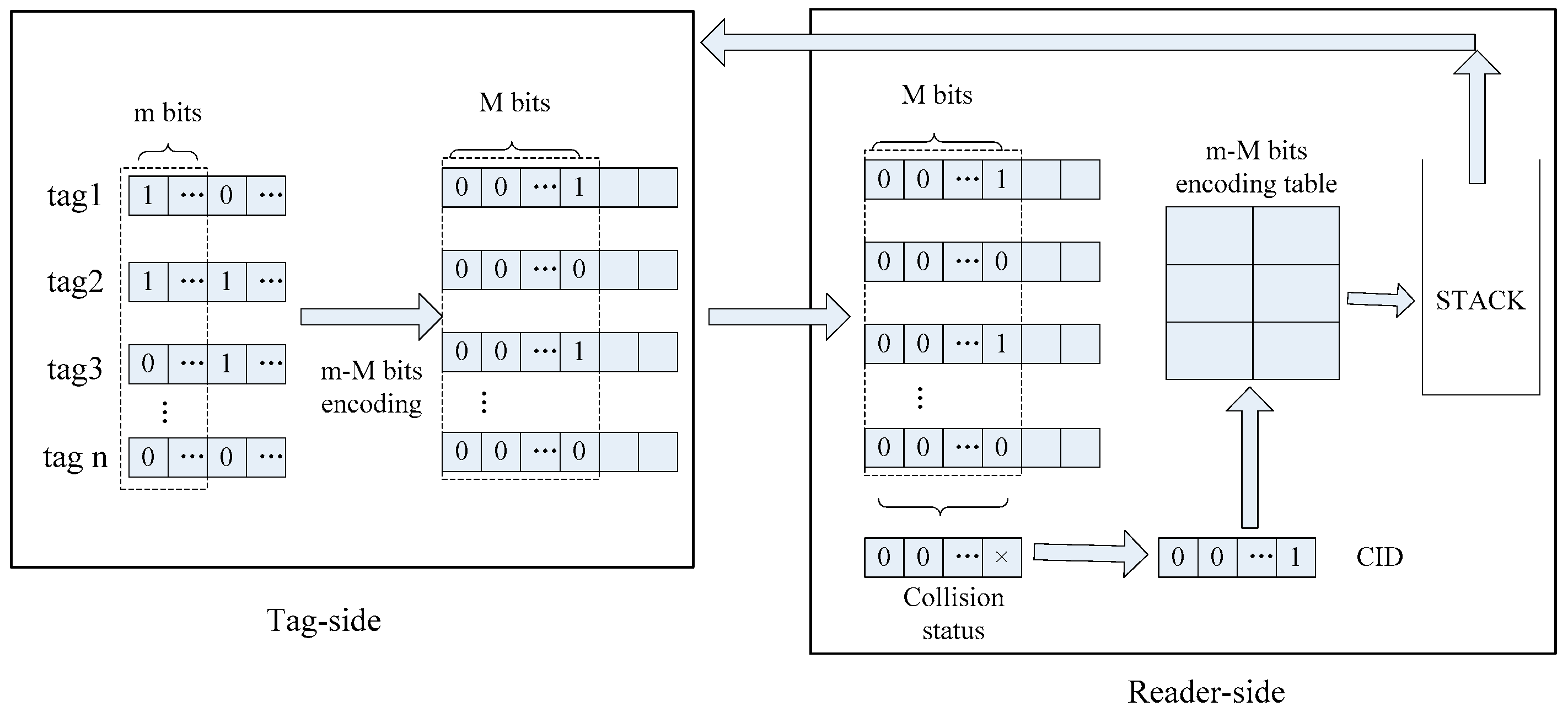
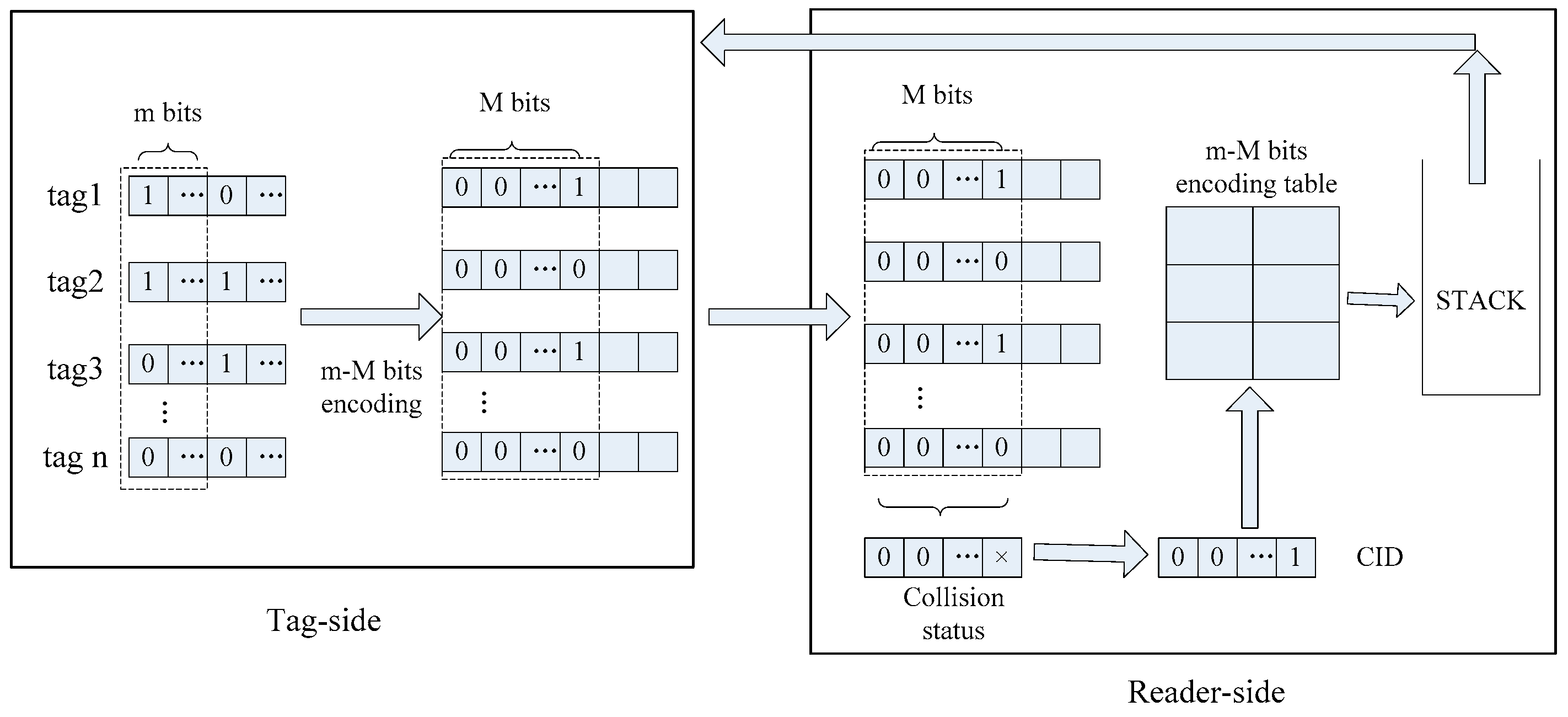
4. Tag Encoding Scheme
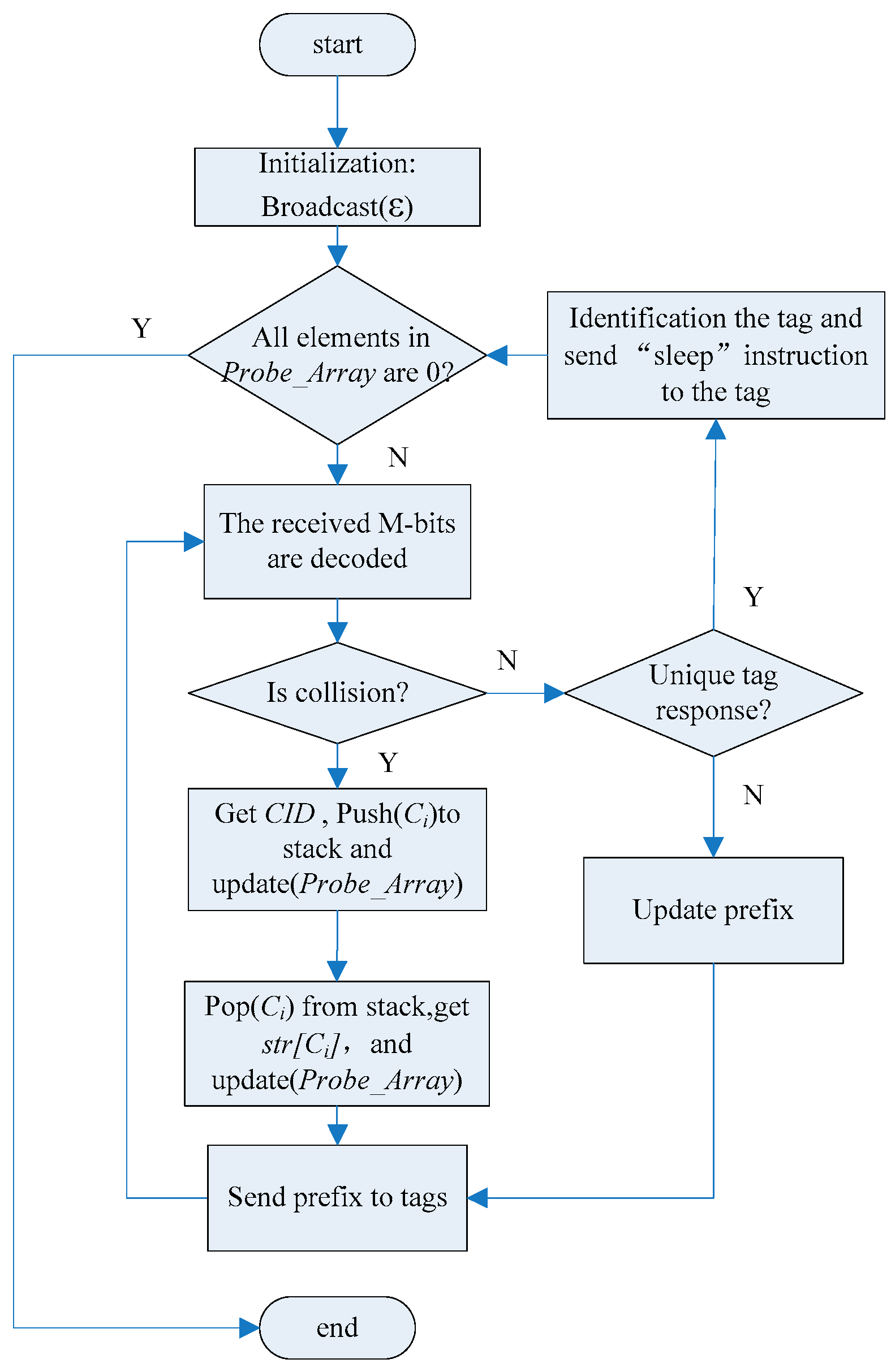
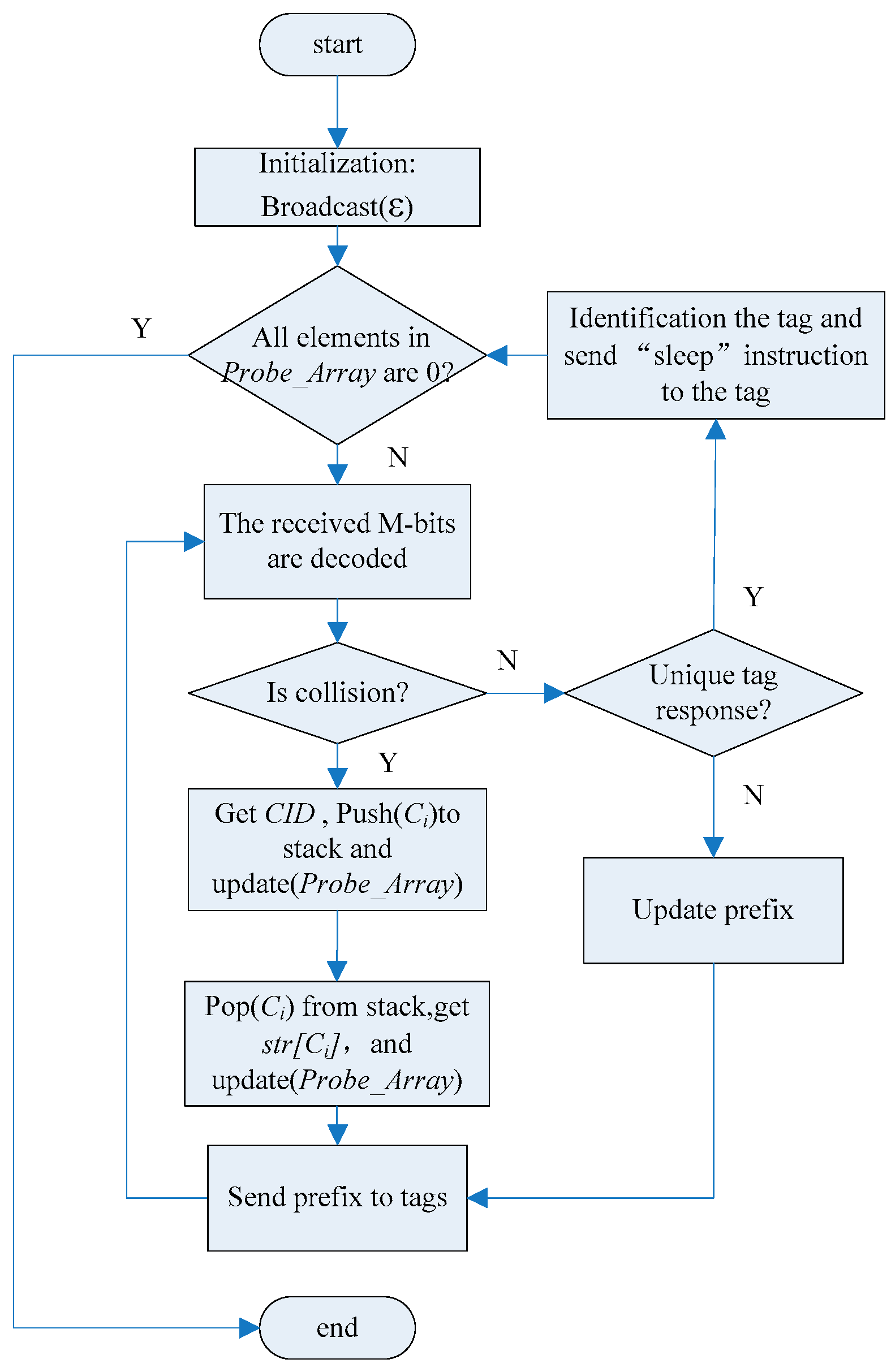
5. An Anti-Collision Algorithm Based on an Array and Encoding Scheme
5.1. Algorithm Description
5.2. Example of Algorithm
5.3. Analysis of Algorithm Performance
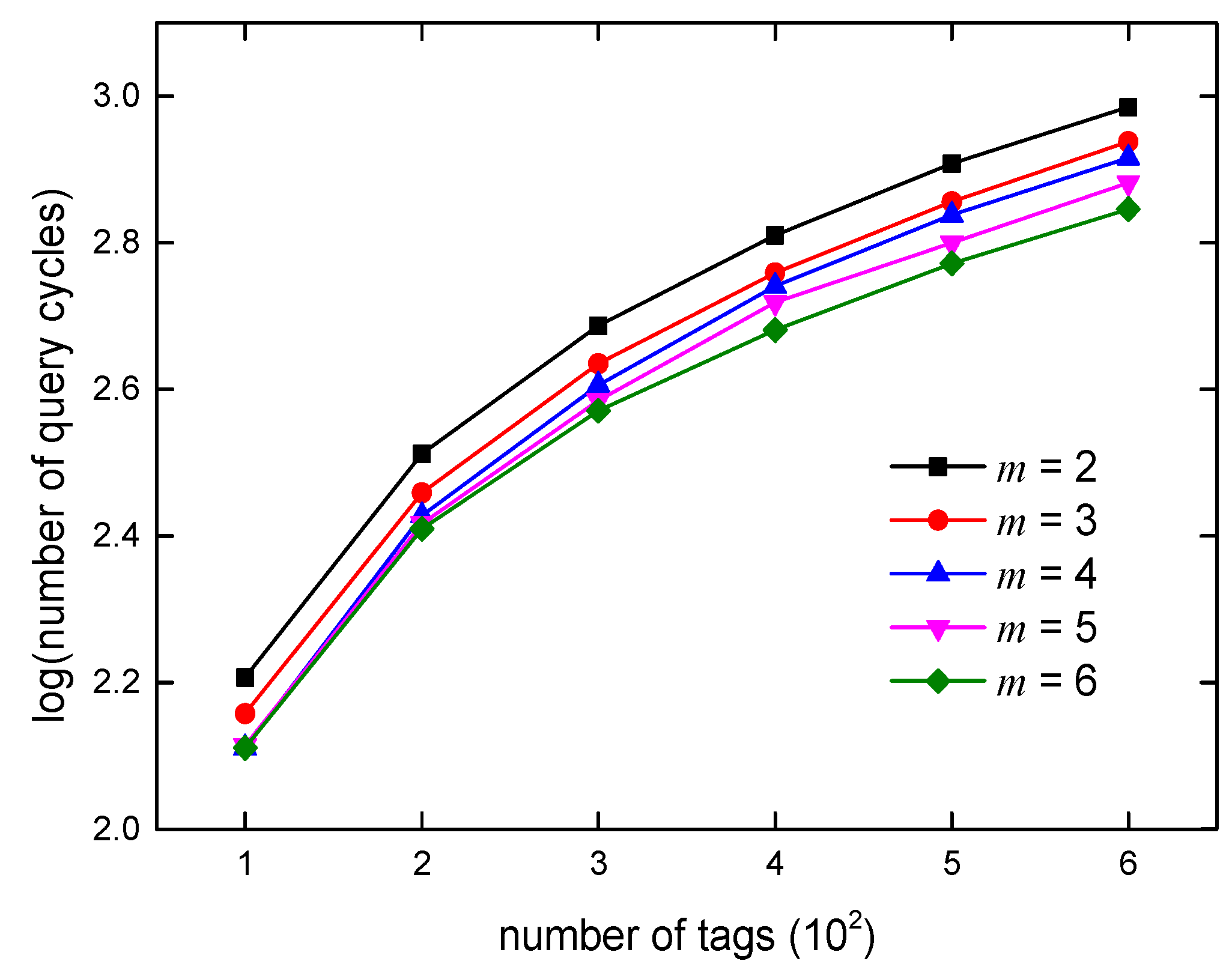
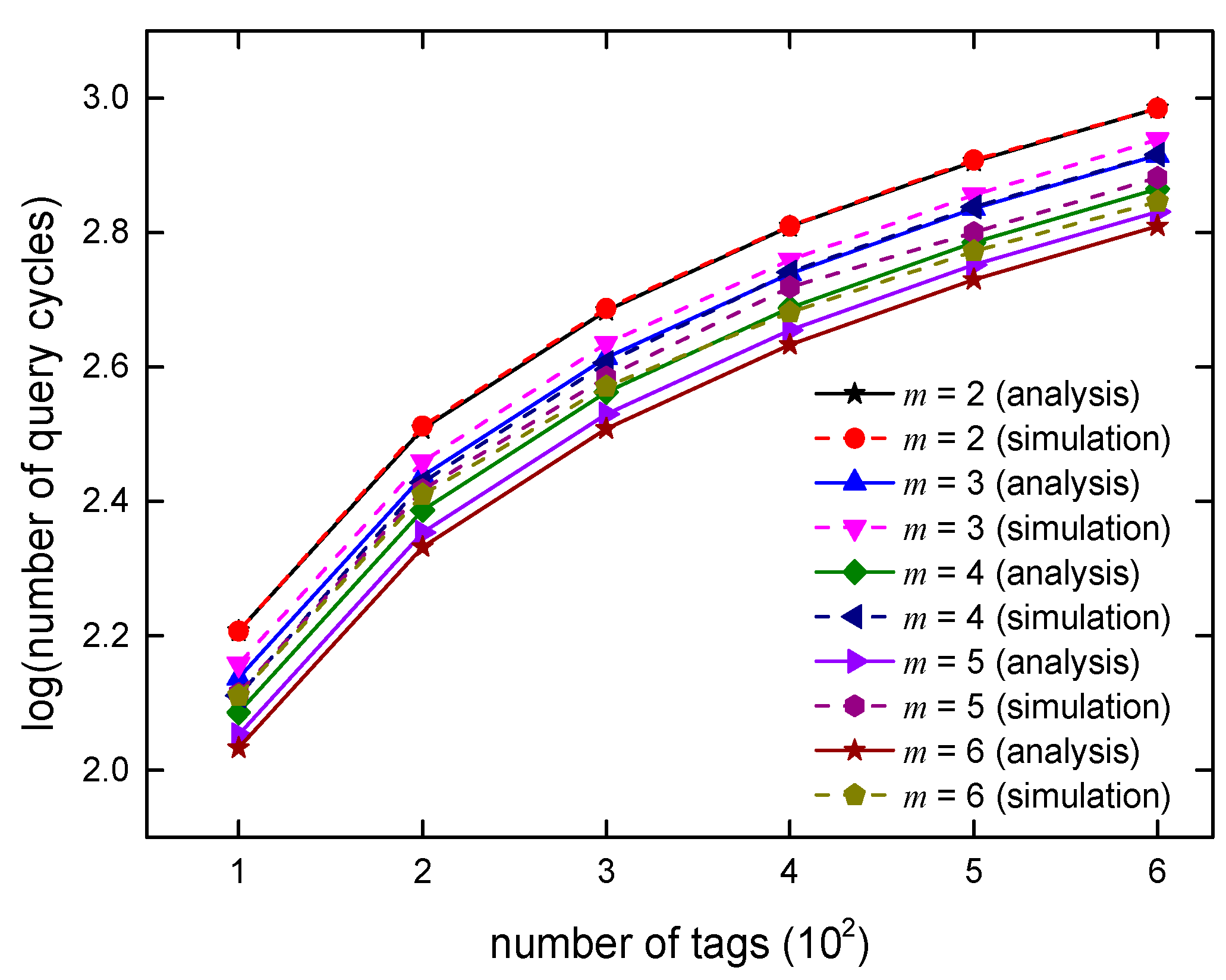
5.3.1. Time Complexity Analysis
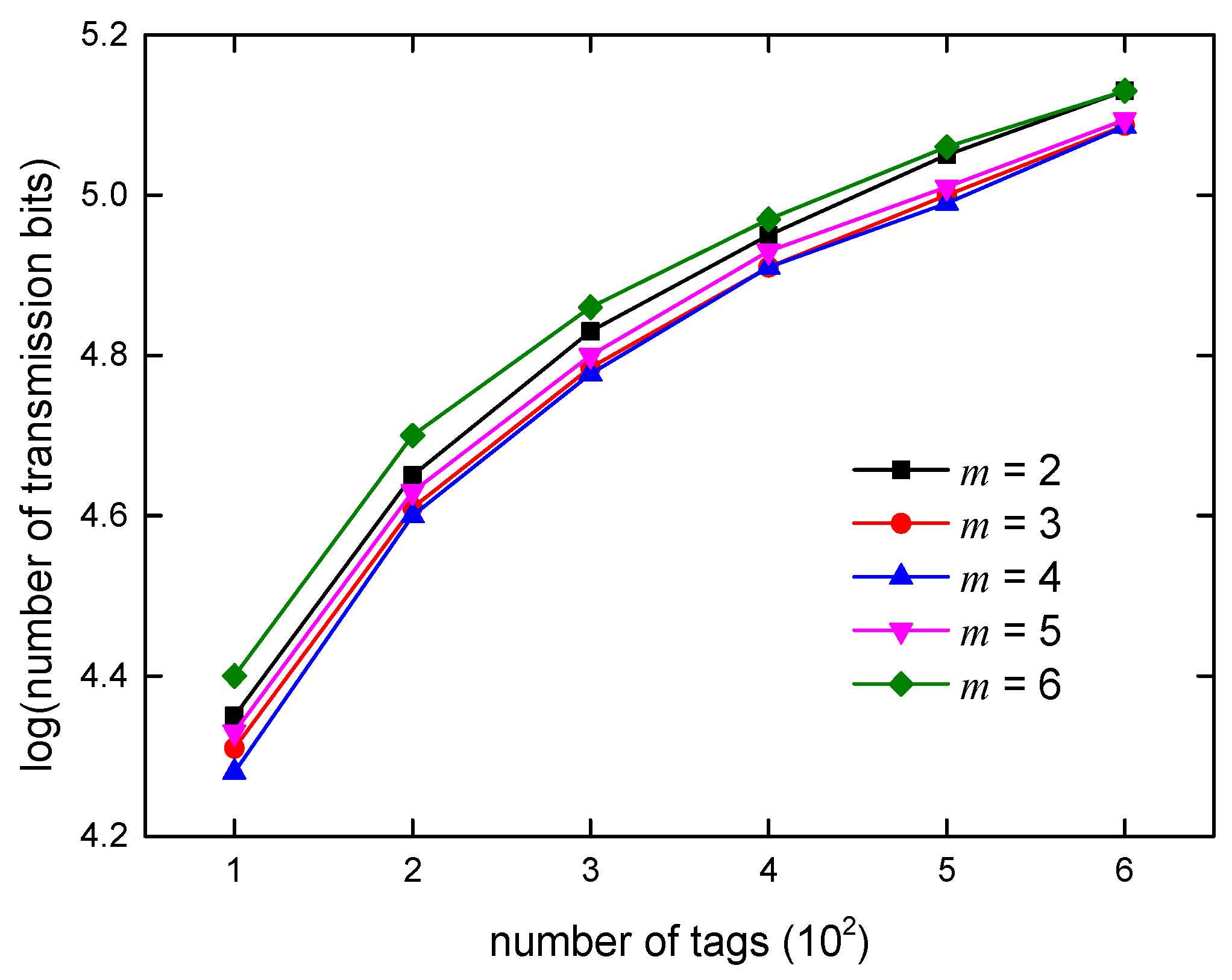
5.3.2. Communication Complexity Analysis
5.3.3. Identification Efficiency Analysis
5.3.4. Reader-Side Memory Complexity Analysis
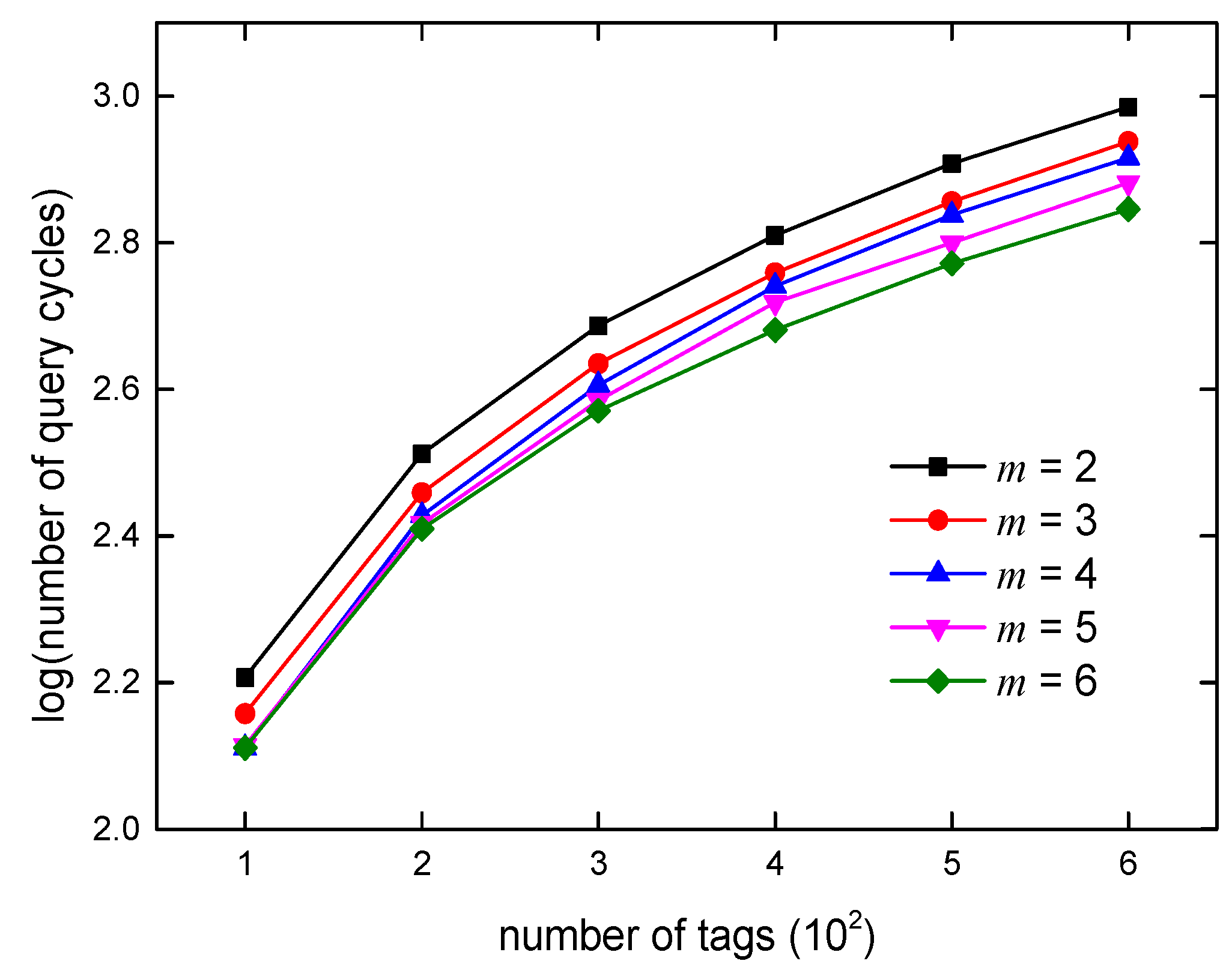
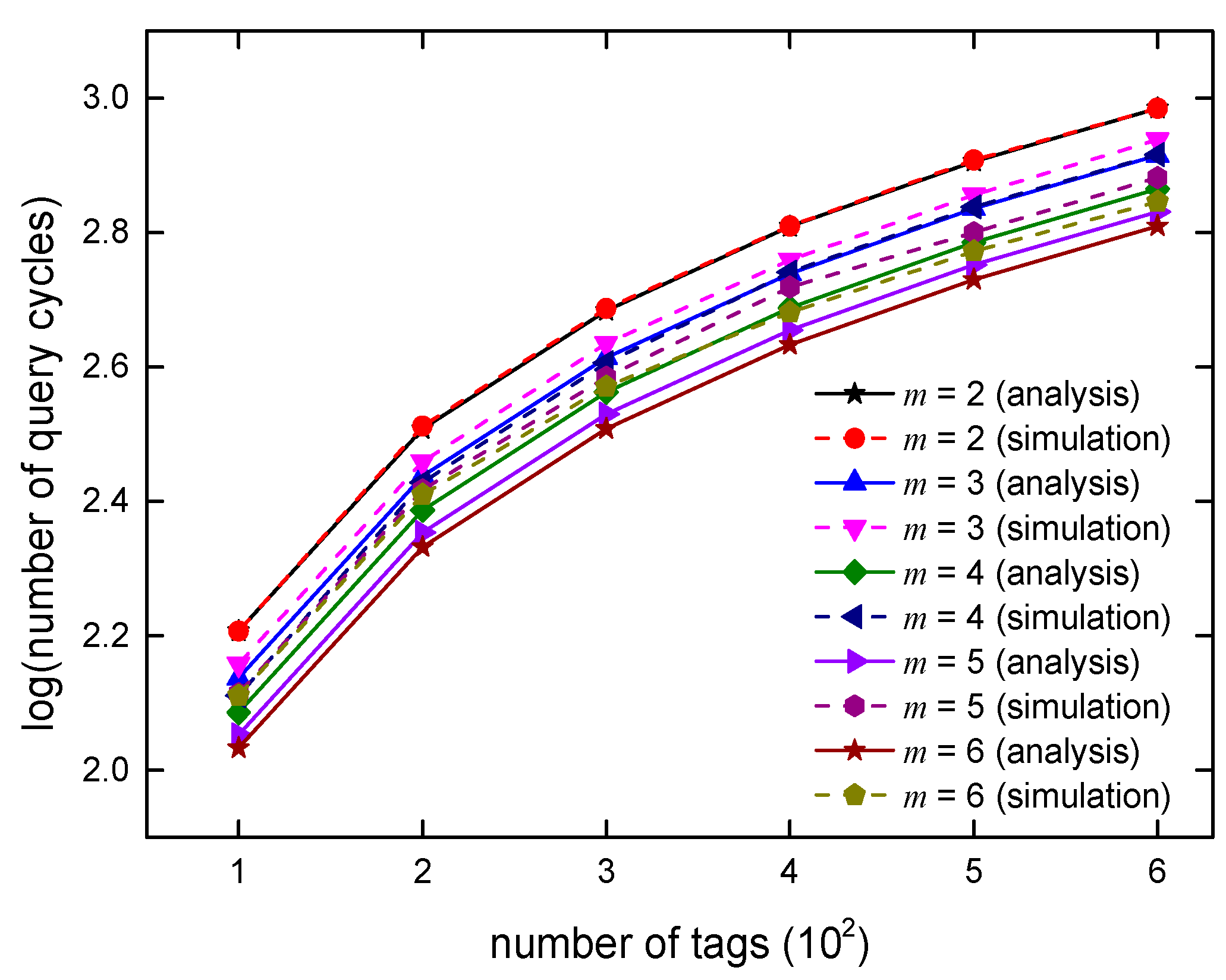
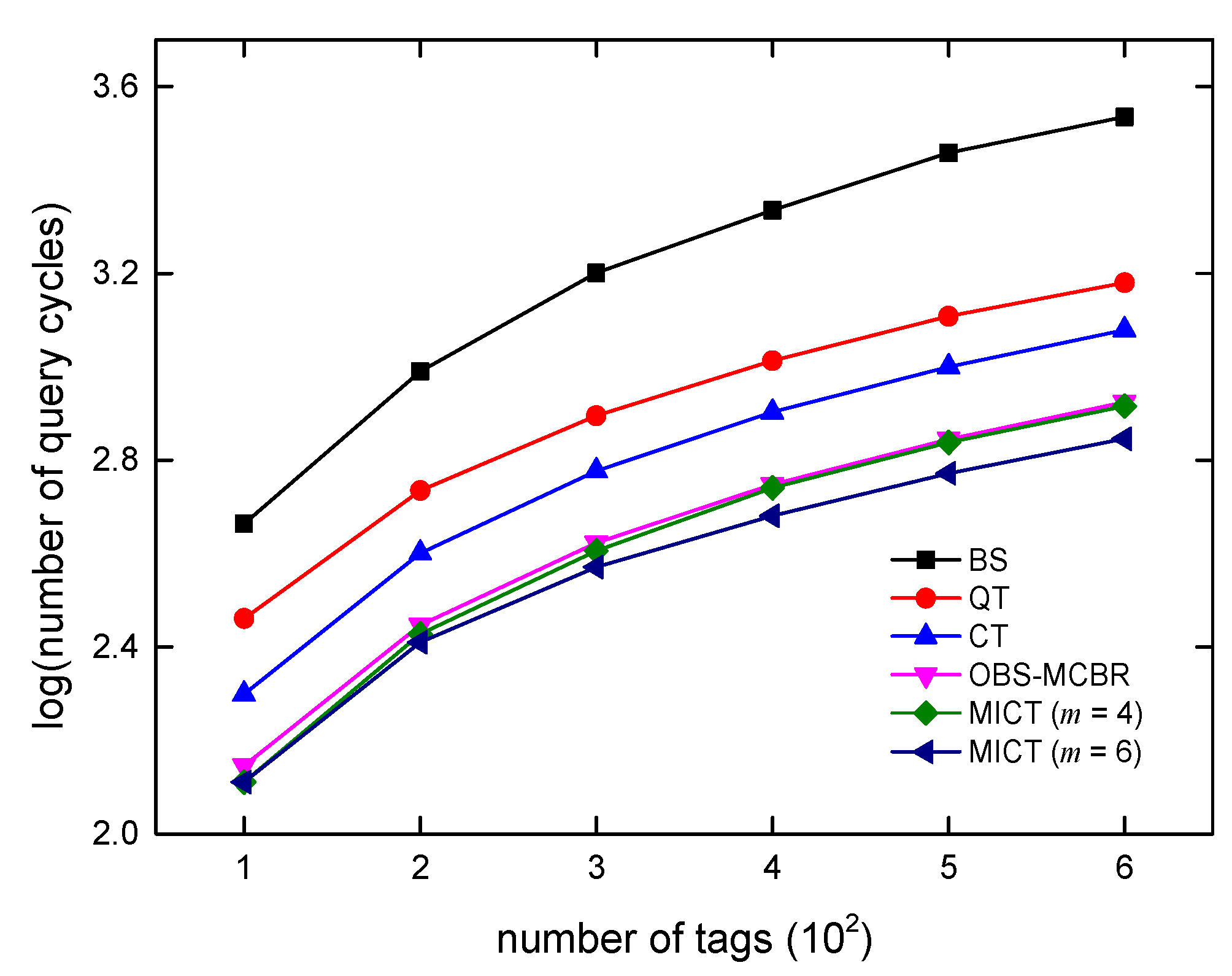
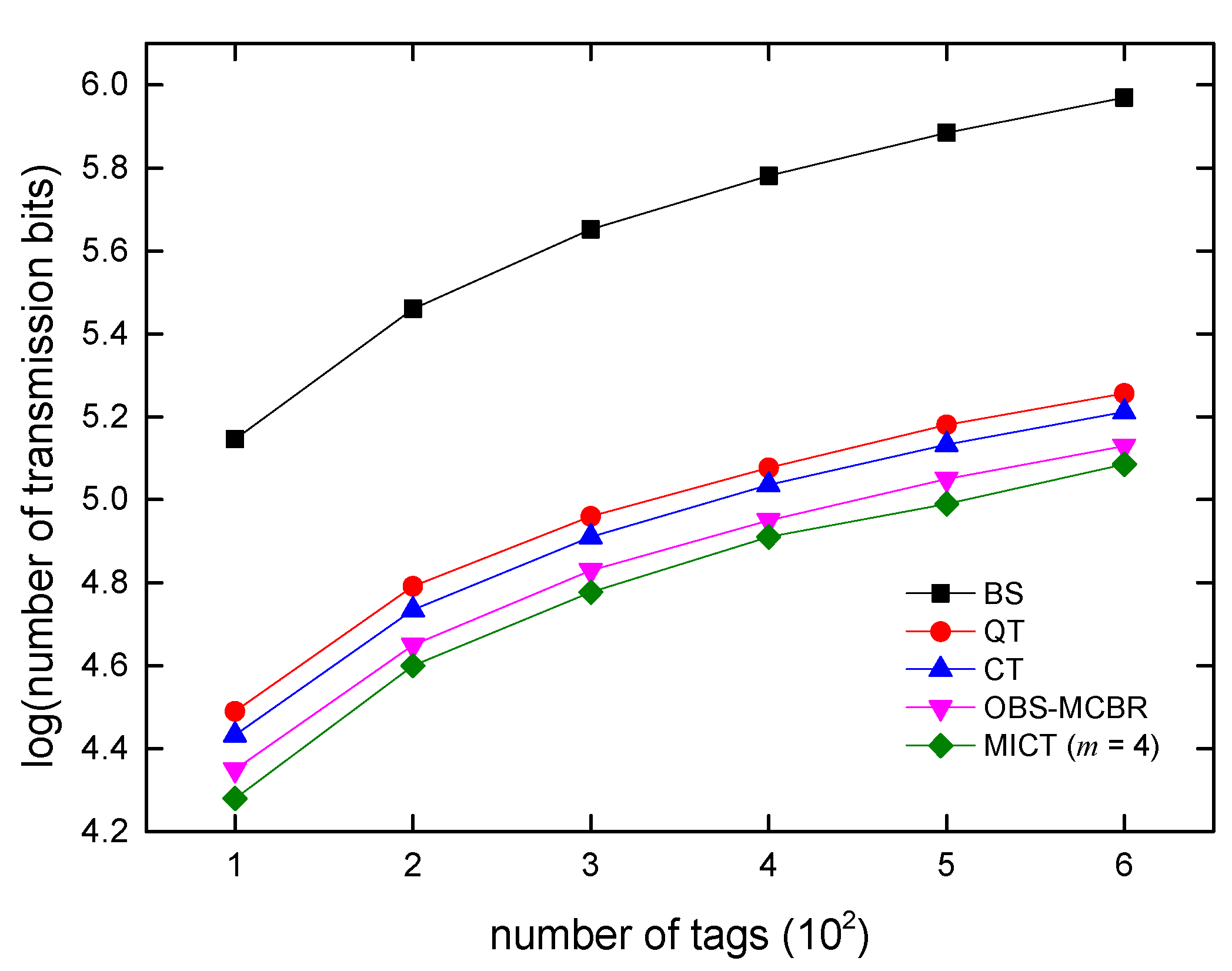
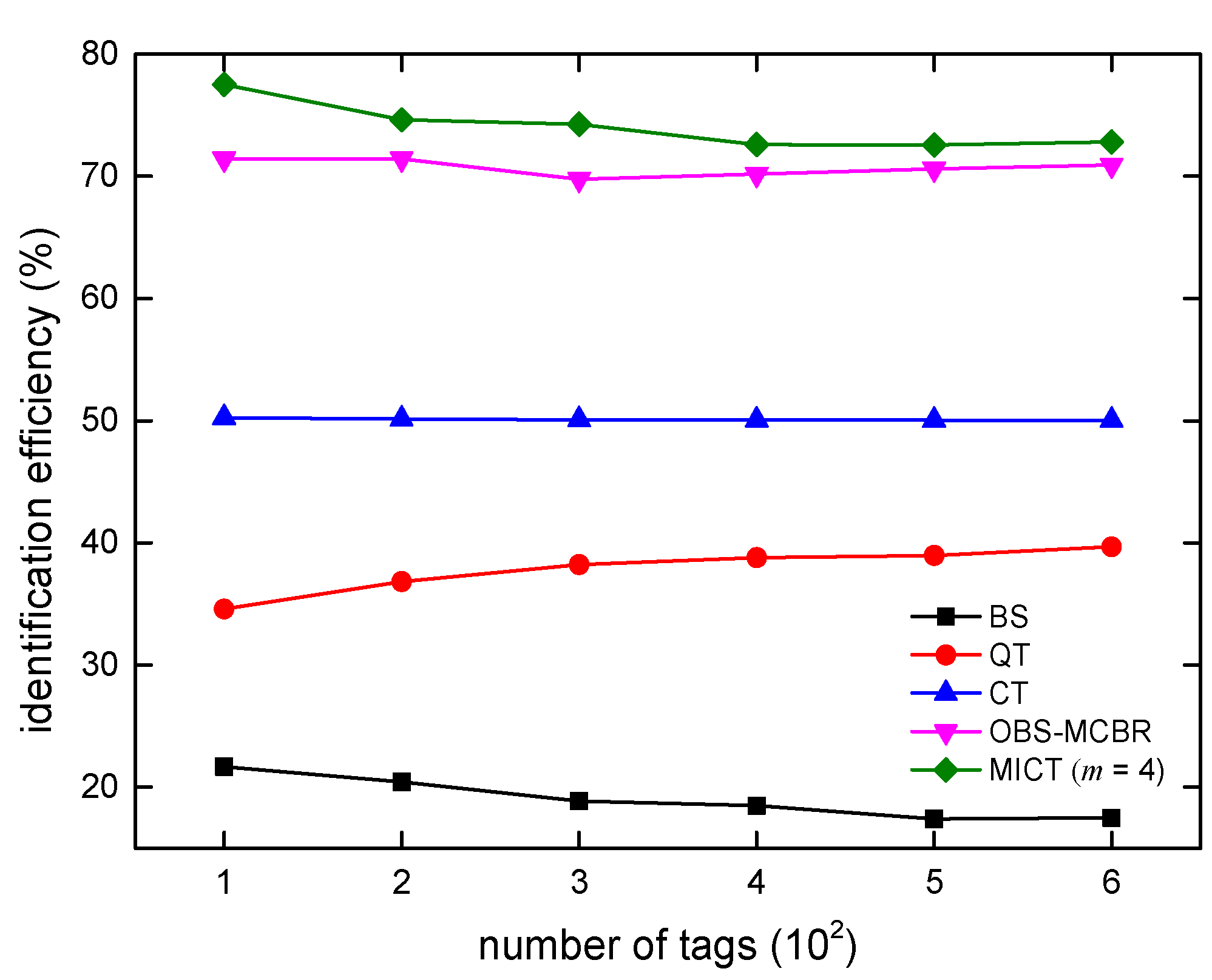
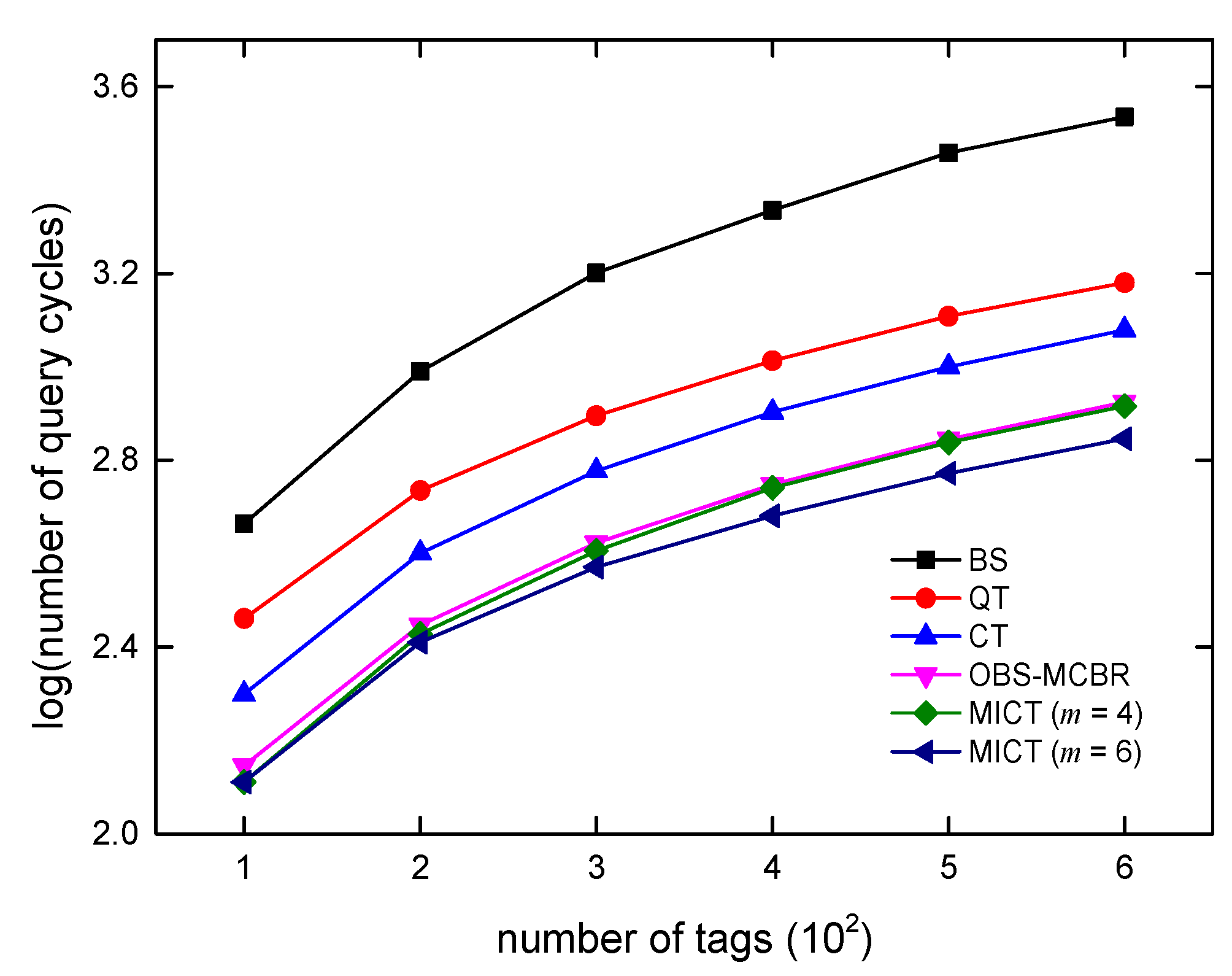
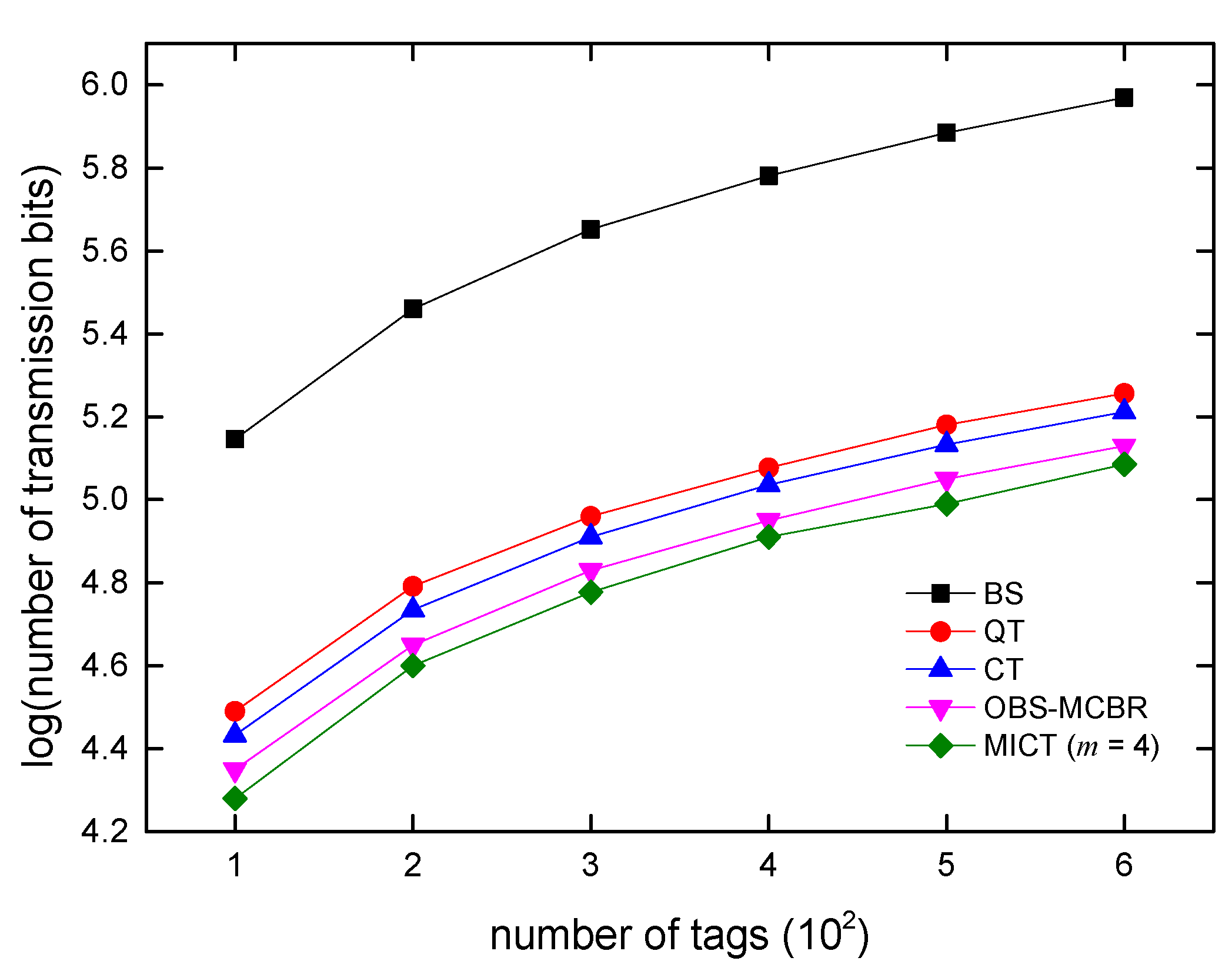
6. Algorithm Simulations and Analysis
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- He, M.; Horng, S.-J. A fast RFID tag identification algorithm based on counter and stack. Expert Syst. Appl. 2011, 38, 6829–6838. [Google Scholar] [CrossRef]
- An, J.; Wu, J.X. Improved RFID binary search anti-collision algorithm. Comput. Eng. Appl. 2009, 45, 229–235. [Google Scholar]
- Tsai, S.-C.; Min, Y. Efficient tag reading protocol for large-scale RFID systems with pre-reading. Comput. Commun. 2016, 88, 73–83. [Google Scholar] [CrossRef]
- Myung, J.; Lee, W. Tag-splitting: Adaptive collision arbitration protocols for RFID tag identification. IEEE Trans. Parallel Distrib. Syst. 2007, 18, 763–775. [Google Scholar] [CrossRef]
- Jung, H. A memory efficient anti-collision protocol to identify memoryless RFID tags. J. Inf. Process. Syst. 2015, 11, 95–103. [Google Scholar]
- Mohammed, U.S.; Salah, M. Tag anti-collision algorithm for RFID systems with minimum overhead information in the identification process. Radio Eng. 2011, 20, 61–68. [Google Scholar]
- Shin, J.; Jeon, B. Multiple RFID tags identification with M-ary query tree scheme. IEEE Commun. Lett. 2013, 17, 604–607. [Google Scholar] [CrossRef]
- Agrawal, T.; Biswas, P.K. An optimized query tree algorithm in RFID inventory tracking-a case study evidence. Int. J. Comput. Sci. 2012, 9, 85–93. [Google Scholar]
- Kim, S.; Kim, Y. A tag prediction anti-collision algorithm using extra bits for RFID tag identification. Int. J. Ad Hoc Ubiquitous Comput. 2012, 10, 164–174. [Google Scholar] [CrossRef]
- Jiao, C.-H.; Wang, K.-R. Multi-branch query tree protocol for solving RFID tag collision problem. J. China Univ. Posts Telecommun. 2008, 15, 51–54. [Google Scholar] [CrossRef]
- Jia, X.L.; Feng, Q.Y. An efficient anti-collision protocol for RFID tag identification. IEEE Commun. Lett. 2010, 14, 1014–1016. [Google Scholar] [CrossRef]
- Safa, H.; El-Hajj, W. A distributed multi-channel reader anti-collision algorithm for RFID environments. Comput. Commun. 2015, 64, 44–56. [Google Scholar] [CrossRef]
- Lai, Y.C.; Hsiao, L.Y. An RFID anti-collision algorithm with dynamic condensation and ordering binary tree. Comput. Commun. 2013, 36, 1754–1767. [Google Scholar] [CrossRef]
- Klair, K.; Chin, W. A survey and tutorial of RFID anti-collision protocols. IEEE Commun. Surv. Tutor. 2010, 12, 400–421. [Google Scholar] [CrossRef]
- Yan, X.Q.; Liu, Y. A memoryless binary query tree based Successive Scheme for passive RFID tag collision resolution. Inf. Fusion 2015, 22, 26–38. [Google Scholar] [CrossRef]
- Guo, H.B.; He, C. PSR: A novel high-efficiency and easy-to-implement parallel algorithm for anti-collision in RFID systems. IEEE Trans. Ind. Inform. 2016, 12, 1134–1143. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, F. An anti-collision algorithm for RFID-based robots based on dynamic grouping binary trees. Comput. Electr. Eng. 2018, in press. [Google Scholar] [CrossRef]
- Ma, Y.M.; Jin, D. Anti-collision algorithm based on Multi-threaded RFID lock position. Int. J. Hybrid Inf. Technol. 2013, 6, 95–102. [Google Scholar]
- Landaluce, H.; Perallos, A. Managing the number of tag bits transmitted in a bit-tracking RFID collision resolution protocol. Sensors 2014, 14, 1010–1027. [Google Scholar] [CrossRef] [PubMed]
- Jung, Y.; Kim, D. Optimized binary search with multiple collision bits resolution anti-collision algorithm for efficient RFID tag identification. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2016, 99, 1494–1498. [Google Scholar] [CrossRef]
- Wang, Y.H.; Liu, Y. A multi-bit identification protocol for RFID tag reading. IEEE Sens. J. 2013, 13, 3527–3535. [Google Scholar] [CrossRef]
- Su, X.H.; Liu, B.L. An investigation on tree-based tags anti-collision algorithms in RFID. In Proceedings of the International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 23–25 September 2017; pp. 5–11. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Query Cycles | Prefix | Probe_Array[0…7] Reader’s Decoding Status | Response Tags | Identification Status | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||
| 1 | ε | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 110100100011011010101101 | collision |
| × | - | - | - | - | - | - | - | ||||
| 2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0110110 | Tag B is identified |
| 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | ||||
| 3 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 10100100101101 | collision |
| 1 | × | - | - | - | - | - | - | ||||
| 4 | 10 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 101101 | Tag C is identified |
| 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | ||||
| 5 | 11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 010010 | Tag A is identified |
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | ||||
| Number of Tags | Stack (bits) | Array (bits) |
|---|---|---|
| 100 | 6.46 | 0.96 |
| 200 | 7.55 | 0.48 |
| 300 | 8.12 | 0.32 |
| 400 | 8.54 | 0.24 |
| 500 | 8.82 | 0.19 |
| 600 | 9.15 | 0.16 |
| Prefix Bits (m = 2) | Encoded Bits (M = 4) |
|---|---|
| 00 | 0001 |
| 01 | 0010 |
| 10 | 0100 |
| 11 | 1000 |
| Prefix Bits (m = 3) | Encoded Bits (M = 8) |
|---|---|
| 000 | 00000001 |
| 001 | 00000010 |
| 010 | 00000100 |
| 011 | 00001000 |
| 100 | 00010000 |
| 101 | 00100000 |
| 110 | 01000000 |
| 111 | 10000000 |
| Str[0] | 0 | 0 |
|---|---|---|
| Str[1] | 0 | 1 |
| Str[2] | 1 | 0 |
| Str[3] | 1 | 1 |
| Query Cycles | Prefix | Probe_Array[0…7] Decoding State | Response Tags | Stack | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | ε | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 000101101011111111010100110111001011×××××× | 0,1,2,3 |
| × | × | ||||||||||
| 2 | 00 | 0 | 3 | 0 | 3 | 0 | 0 | 0 | 0 | 000101101011111111×××××1 | 0,2,3,1,2,3 |
| 0 | 0 | × | × | ||||||||
| 3 | 0000 | 0 | 3 | 0 | 2 | 0 | 0 | 0 | 0 | Tag A is identified | 2,3,1,2,3 |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | ||||
| 4 | 0010 | 0 | 3 | 0 | 1 | 0 | 0 | 0 | 0 | Tag B is identified | 3,1,2,3 |
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | ||||
| 5 | 0011 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | Tag C is identified | 1,2,3 |
| 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | ||||
| 6 | 01 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | Tag D is identified | 2,3 |
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | ||||
| 7 | 10 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | Tag E is identified | 3 |
| 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | ||||
| 8 | 11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | Tag F is identified | NULL |
| 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | ||||
| The Value of m | Number of Tags | |||
|---|---|---|---|---|
| 100 | 500 | 2000 | 5000 | |
| 2 | 62.11% | 62.11% | 62.07% | 62.07% |
| 3 | 72.99% | 72.99% | 72.99% | 72.97% |
| 4 | 81.97% | 81.97% | 81.90% | 81.89% |
| 5 | 88.50% | 88.50% | 88.50% | 88.51% |
| 6 | 93.46% | 93.11% | 93.02% | 93.02% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Su, X. An Anti-Collision Algorithm for RFID Based on an Array and Encoding Scheme. Information 2018, 9, 63. https://doi.org/10.3390/info9030063
Liu B, Su X. An Anti-Collision Algorithm for RFID Based on an Array and Encoding Scheme. Information. 2018; 9(3):63. https://doi.org/10.3390/info9030063
Chicago/Turabian StyleLiu, Baolong, and Xiaohao Su. 2018. "An Anti-Collision Algorithm for RFID Based on an Array and Encoding Scheme" Information 9, no. 3: 63. https://doi.org/10.3390/info9030063
APA StyleLiu, B., & Su, X. (2018). An Anti-Collision Algorithm for RFID Based on an Array and Encoding Scheme. Information, 9(3), 63. https://doi.org/10.3390/info9030063