Local Patch Vectors Encoded by Fisher Vectors for Image Classification

 ,
,
Abstract
1. Introduction
2. Description of the Proposed Approach
2.1. Constructing Local Patch Vectors
2.2. The Fisher Vector
2.3. Incorporating Spatial Information
2.4. Feature Selection Based on MI
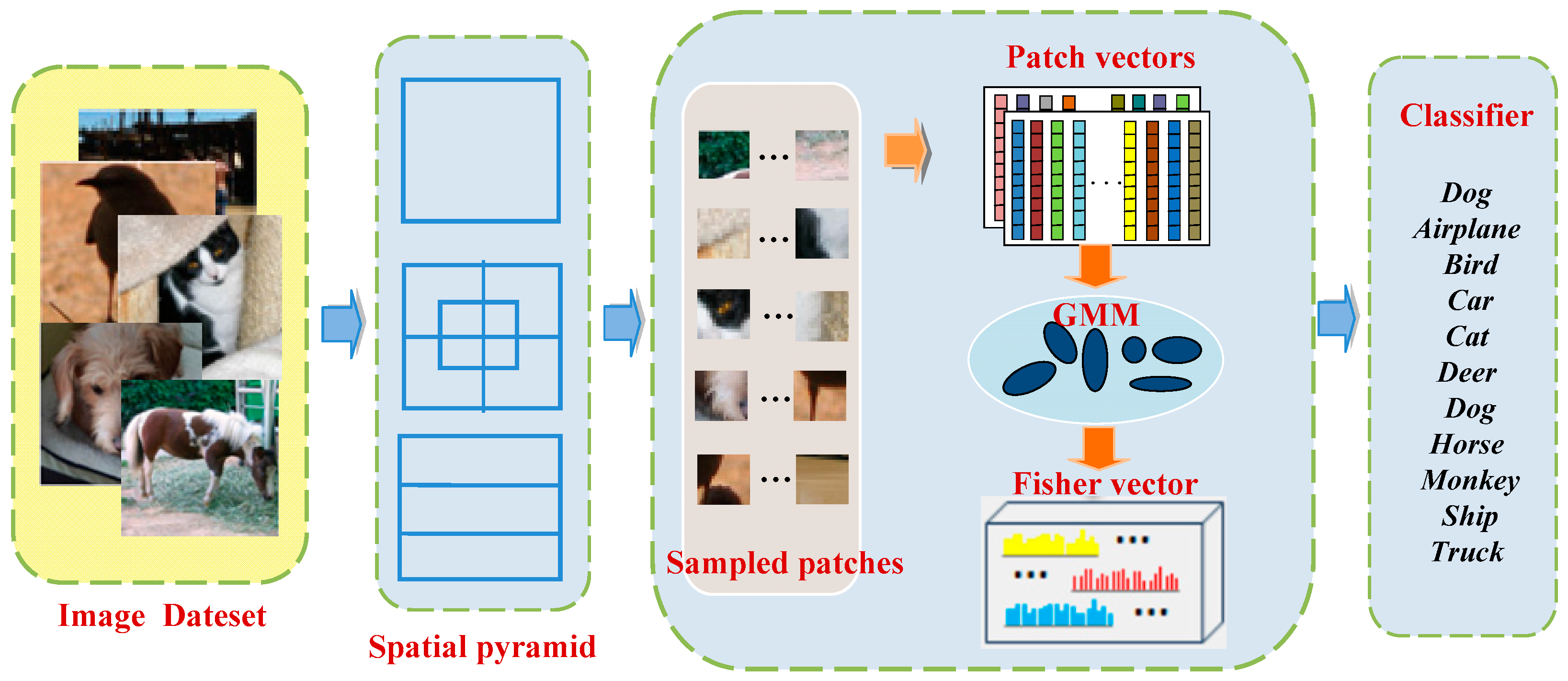
3. Image Classification Framework
- Extract patches. With the images as the input, the outputs of this step are image patches. This process is implemented via sampling local areas of images. Here we use three sampling manners (e.g., dense sampling using fixed grids, random sampling, and saliency-based sampling) to select a compact but representative subset of images. This step is the core part of our work.
- Represent patches. Given image patches, the outputs of this step are their feature vectors. We represent each image patch as a vector of pixel intensity values, and then pre-process these image patch vectors, subsequently, PCA is usually applied to these local patch vectors.
- Generate centroids. The inputs of this step are local image patch vectors extracted from all train images and the outputs are centroids. In our work, the centroids are generated by applying GMM over these local vectors. All centroids compose a discriminative codebook which can be used for feature encoding.
- Encode futures. In this step, the set of local feature descriptors are quantized with learned codebook of 64–512 centroids. For these features quantized to each centroid, we can aggregate first and second order residual statistics. Last, the final FV representation is obtained by concatenating the residual statistics from each centroid.
- Classification. This last step assigns a semantic class label to each image. This step usually relies on some trained classifier (e.g., SVM and soft-max). FV vectors are usually very high dimensional, especially in the case of employing the spatial pyramid structure. There exist many off-the-shelf SVM solvers, such as SVMperf [34], or LibSVM/LIBLINEAR [35]. Limited by our main memory size, these are not feasible for such huge training features. Hence, in our work, we use the soft-max classifier for this discriminative stage.
4. Experiments
4.1. STL-10 Dataset
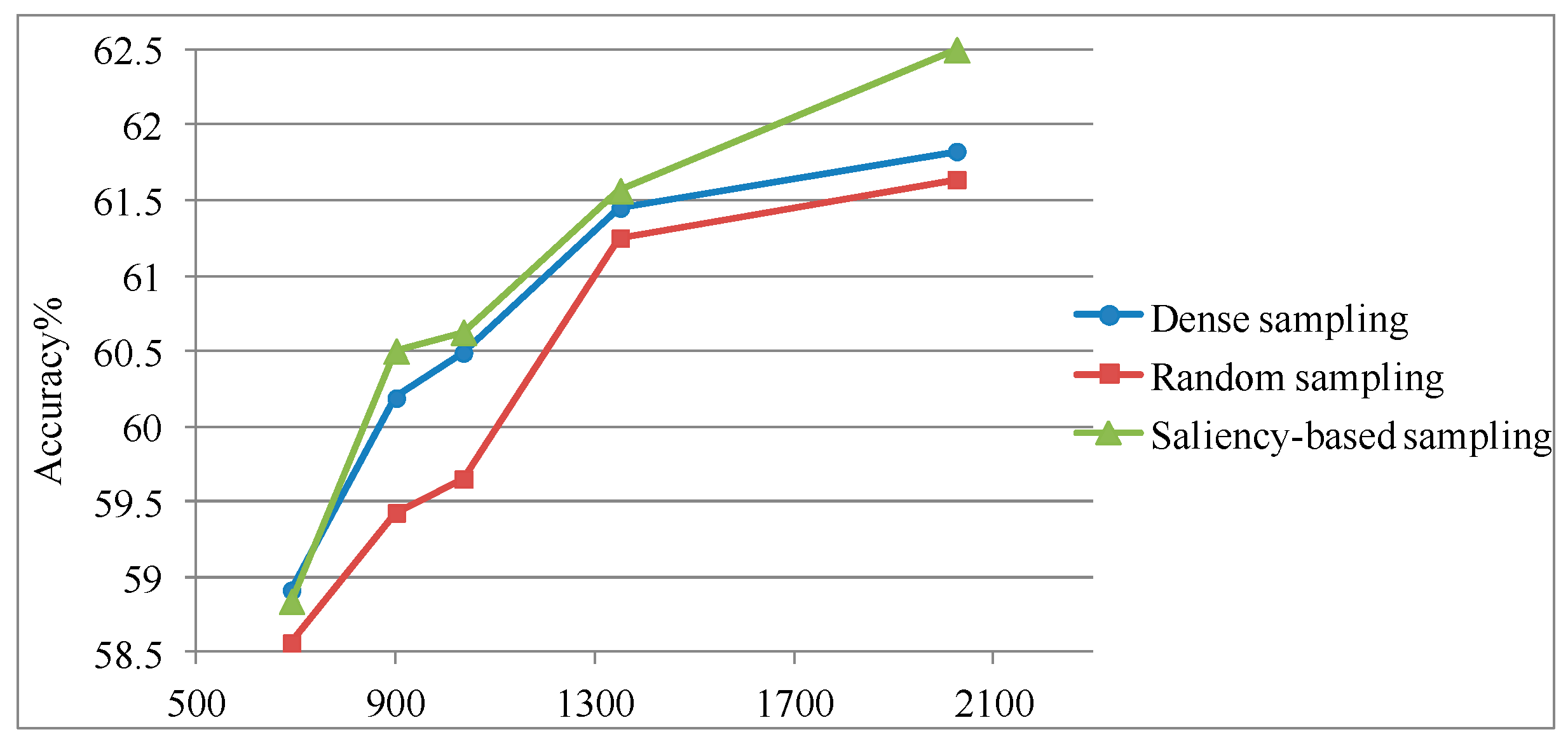
4.1.1. Evaluating the Sampling Performance
4.1.2. Main Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Vailaya, A.; Figueiredo, M.A.T.; Jain, A.K.; Zhang, H.J. Image classification for content-based indexing. IEEE Trans. Image Process. 2001, 10, 117–130. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.K.; Ross, A.; Prabhakar, S. An introduction to biometric recognition. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 4–20. [Google Scholar] [CrossRef]
- Kosala, R.; Blockeel, H. Web mining research: A survey. ACM Sigkdd Explor. Newsl. 2000, 2, 1–15. [Google Scholar] [CrossRef]
- Collins, R.T.; Lipton, A.J.; Kanade, T.; Fujiyoshi, H.; Duggins, D.; Tsin, Y.; Tolliver, D.; Enomoto, N.; Hasegawa, O.; Burt, P. A System for Video Surveillance and Monitoring; VSAM Final Report; The Robotics Institute, Carnegie Mellon University: Pittsburgh, PA, USA, 2000; pp. 1–68. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded Up Robust Features. Comput. Vis. Image Underst. 2006, 110, 404–417. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 21–23 September 2005; pp. 886–893. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikäinen, M. Face Recognition with Local Binary Patterns. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 469–481. [Google Scholar]
- Wang, Z.; Fan, B.; Wu, F. Local Intensity Order Pattern for feature description. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 603–610. [Google Scholar]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE Features. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 214–227. [Google Scholar]
- Yin, H.; Jiao, X.; Chai, Y.; Fang, B. Scene classification based on single-layer SAE and SVM. Expert Syst. Appl. 2015, 42, 3368–3380. [Google Scholar] [CrossRef]
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Compressed Fisher Vectors for Large-Scale Image Classification; Research Report RR-8209; HAL-Inria: Rocquencourt, France, 2013. [Google Scholar]
- Shi, H.; Zhu, X.; Lei, Z.; Liao, S.; Li, S.Z. Learning Discriminative Features with Class Encoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2016; pp. 46–52. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Gao, B.B.; Wei, X.S.; Wu, J.; Lin, W. Deep spatial pyramid: The devil is once again in the details. arXiv, 2015; arXiv:1504.05277. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Chandrasekhar, V.; Lin, J.; Morère, O.; Goh, H.; Veillard, A. A practical guide to CNNs and Fisher Vectors for image instance retrieval. Signal Process. 2016, 128, 426–439. [Google Scholar] [CrossRef]
- Jurie, F.; Triggs, B. Creating Efficient Codebooks for Visual Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; pp. 604–610. [Google Scholar]
- Nowak, E.; Jurie, F.; Triggs, B. Sampling Strategies for Bag-of-Features Image Classification. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 490–503. [Google Scholar]
- Zhang, J.; Marszałek, M.; Lazebnik, S.; Schmid, C. Local Features and Kernels for Classification of Texture and Object Categories: A Comprehensive Study. Int. J. Comput. Vis. 2007, 73, 213–238. [Google Scholar] [CrossRef]
- Hu, J.; Xia, G.S.; Hu, F.; Sun, H. A comparative study of sampling analysis in scene classification of high-resolution remote sensing imagery. In Proceedings of the Geoscience and Remote Sensing Symposium, Milan, Italy, 13–18 July 2015; pp. 14988–15013. [Google Scholar]
- Zhang, Y.; Wu, J.; Cai, J. Compact Representation of High-Dimensional Feature Vectors for Large-Scale Image Recognition and Retrieval. IEEE Trans. Image Process. 2016, 25, 2407. [Google Scholar] [CrossRef] [PubMed]
- Shi, F.; Petriu, E.; Laganiere, R. Sampling Strategies for Real-Time Action Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Portland, OR, USA, 25–27 June 2013; pp. 2595–2602. [Google Scholar]
- Salah, A.A.; Alpaydin, E.; Akarun, L. A selective attention-based method for visual pattern recognition with application to handwritten digit recognition and face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 420–425. [Google Scholar] [CrossRef]
- Borji, A.; Itti, L. State-of-the-Art in Visual Attention Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 185–207. [Google Scholar] [CrossRef] [PubMed]
- Gu, Z.; Zhang, L.; Li, H. Learning a blind image quality index based on visual saliency guided sampling and Gabor filtering. In Proceedings of the IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 186–190. [Google Scholar]
- Zhang, L.; Gu, Z.; Li, H. SDSP: A novel saliency detection method by combining simple priors. In Proceedings of the IEEE International Conference on Image Processing, Paris, France, 27–30 October 2014; pp. 171–175. [Google Scholar]
- Wu, J.; Yu, Z.; Lin, W. Good practices for learning to recognize actions using FV and VLAD. IEEE Trans. Cybern. 2016, 46, 2978–2990. [Google Scholar] [CrossRef] [PubMed]
- Ma, B.; Su, Y.; Jurie, F. Local Descriptors Encoded by Fisher Vectors for Person Re-identification. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 413–422. [Google Scholar]
- Sánchez, J.; Perronnin, F. Image Classification with the Fisher Vector: Theory and Practice. Int. J. Comput. Vis. 2013, 105, 222–245. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, J.; Cai, J. Compact representation for image classification: To choose or to compress? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 907–914. [Google Scholar]
- Jégou, H.; Douze, M.; Schmid, C. Product quantization for nearest neighbor search. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 117–128. [Google Scholar] [CrossRef] [PubMed]
- Sanchez, J.; Perronnin, F. High-dimensional signature compression for large-scale image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1665–1672. [Google Scholar]
- Joachims, T. Training linear SVMs in linear time. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 217–226. [Google Scholar]
- Fan, R.E.; Chang, K.W.; Hsieh, C.J.; Wang, X.R.; Lin, C.J. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Vedaldi, A.; Fulkerson, B. VLFeat: An open and portable library of computer vision algorithms. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1469–1472. [Google Scholar]
- Miclut, B. Committees of deep feedforward networks trained with few data. In Proceedings of the German Conference on Pattern Recognition, Münster, Germany, 2–5 September 2014; pp. 736–742. [Google Scholar]
- Coates, A.; Ng, A.Y. Selecting receptive fields in deep networks. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–17 December 2011; pp. 2528–2536. [Google Scholar]
- Du, B.; Xiong, W.; Wu, J.; Zhang, L.; Zhang, L.; Tao, D. Stacked convolutional denoising auto-encoders for feature representation. IEEE Trans. Cybern. 2017, 47, 1017–1027. [Google Scholar] [CrossRef] [PubMed]
- Zou, W.Y.; Ng, A.Y.; Zhu, S.; Yu, K. Deep learning of invariant features via simulated fixations in video. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 3203–3211. [Google Scholar]
- Romero, A.; Radeva, P.; Gatta, C. No more meta-parameter tuning in unsupervised sparse feature learning. arXiv, 2014; arXiv:1402.5766. [Google Scholar]
- Hui, K.Y. Direct modeling of complex invariances for visual object features. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 352–360. [Google Scholar]
- Bo, L.; Ren, X.; Fox, D. Unsupervised feature learning for RGB-D based object recognition. In Proceedings of the 13th International Symposium on Experimental Robotics; Springer: Cham, Switzerland, 2013; pp. 387–402. [Google Scholar]
- Zhao, J.; Mathieu, M.; Goroshin, R.; Lecun, Y. Stacked What-Where Auto-encoders. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.T.; Riedmiller, M. Discriminative unsupervised feature learning with convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 766–774. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average Accuracy | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| None | 67.94 | 68.03 | 66.78 | 67.39 | 66.86 | 67.06 | 67.09 | 65.56 | 67.79 | 67.41 | 67.19 ± 0.72 |
| c = 90% | 67.94= | 68.19↑ | 66.65↓ | 67.55↑ | 66.65↓ | 66.94↓ | 66.94↓ | 65.78↑ | 67.88↑ | 67.30↓ | 67.18 ± 0.74 |
| c = 80% | 67.85↓ | 68.08↑ | 66.59↓ | 67.44↑ | 66.65↓ | 66.98↓ | 66.73↓ | 65.73↑ | 67.63↓ | 67.35↓ | 67.10 ± 0.71 |
| c = 70% | 67.76↓ | 67.88↓ | 66.43↓ | 67.39= | 66.56↓ | 67.14↑ | 66.49↓ | 65.50↓ | 67.71↓ | 67.23↓ | 67.01 ± 0.75 |
| c = 60% | 67.56↓ | 67.43↓ | 65.99↓ | 67.35↓ | 66.59↓ | 66.89↓ | 66.38↓ | 65.59↑ | 67.54↓ | 67↓ | 66.83 ± 0.68 |
| Method | Accuracy |
|---|---|
| Convolutional K-means Network [38] (2011) | 60.1 ± 1.0 |
| SCDAE 2 layer [39] (2017) | 60.5 ± 0.9 |
| Slowness on videos [40] (2012) | 61.0 |
| Sparse feature learning [41] (2014) | 61.10 ± 0.58 |
| View-Invariant K-means [42] (2013) | 63.7 |
| HMP [43] (2013) | 64.5 ± 1 |
| Stacked what-where AE [44] (2016) | 74.33 |
| Examplar CNN [45] (2014) | 75.4 ± 0.3 |
| Ours (c = 70%) | 67.01 ± 0.75 |
| Level | Level 0 | Level 0–1 | Level 0–2 |
|---|---|---|---|
| Mean Accuracy | 60.69 ± 0.7 | 66.53 ± 0.5 | 67.01 ± 0.75 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Liu, H.; Zeng, X.; Qian, S.; Wei, W.; Wu, G.; Duan, B. Local Patch Vectors Encoded by Fisher Vectors for Image Classification. Information 2018, 9, 38. https://doi.org/10.3390/info9020038
Chen S, Liu H, Zeng X, Qian S, Wei W, Wu G, Duan B. Local Patch Vectors Encoded by Fisher Vectors for Image Classification. Information. 2018; 9(2):38. https://doi.org/10.3390/info9020038
Chicago/Turabian StyleChen, Shuangshuang, Huiyi Liu, Xiaoqin Zeng, Subin Qian, Wei Wei, Guomin Wu, and Baobin Duan. 2018. "Local Patch Vectors Encoded by Fisher Vectors for Image Classification" Information 9, no. 2: 38. https://doi.org/10.3390/info9020038
APA StyleChen, S., Liu, H., Zeng, X., Qian, S., Wei, W., Wu, G., & Duan, B. (2018). Local Patch Vectors Encoded by Fisher Vectors for Image Classification. Information, 9(2), 38. https://doi.org/10.3390/info9020038