UPCaD: A Methodology of Integration Between Ontology-Based Context-Awareness Modeling and Relational Domain Data

 ,
,
Abstract
:1. Introduction
2. Conceptual Foundation
2.1. Context-Awareness
- Key-value model;
- Markup schemes;
- Object-oriented models;
- Graphical models;
- Models based on logic;
- Models based on ontologies.
2.2. Linking Context-Awareness and Relational Data
- Use of visions in data modeling: uses context information to avoid ambiguities in data interpretation under different conditions, allowing entities to assume different values according to context. Into this category are included the works proposing extensions for the data model and extensions of query operators to create visions according to the context information [11];
- Database partitioning: uses context information to classify groups of entities according to the context information. It is a strategy considered old and used only by the first proposals [30];
- Information filtering: uses context information to select relevant data in databases. This type of approach is related to recommendation systems, usually with the implementation of techniques that allow users to associate classifications to a context-based recommendation, and if a classification is considered acceptable similar recommendations are made when the context is similar to the one reported previously. This type of approach is the most used in CAR systems and are generally proposed as extensions of query languages that uses context information [13,17,31].
- Modeling phase: The context model is defined according to scenarios that describe the possible contexts where the application will be inserted. Afterwards, the context model is associated with domain model and they are related to contexts of interest. The domain model describes the specific knowledge of an application, for example, entities in a database, business rules, relevant services, among others;
- Execution phase: The system recognizes the current context of the environment and if this context corresponds to one of the contexts of interest of the application. If the current context corresponds to a previously modeled context, the knowledge associated with the context is used by the system.
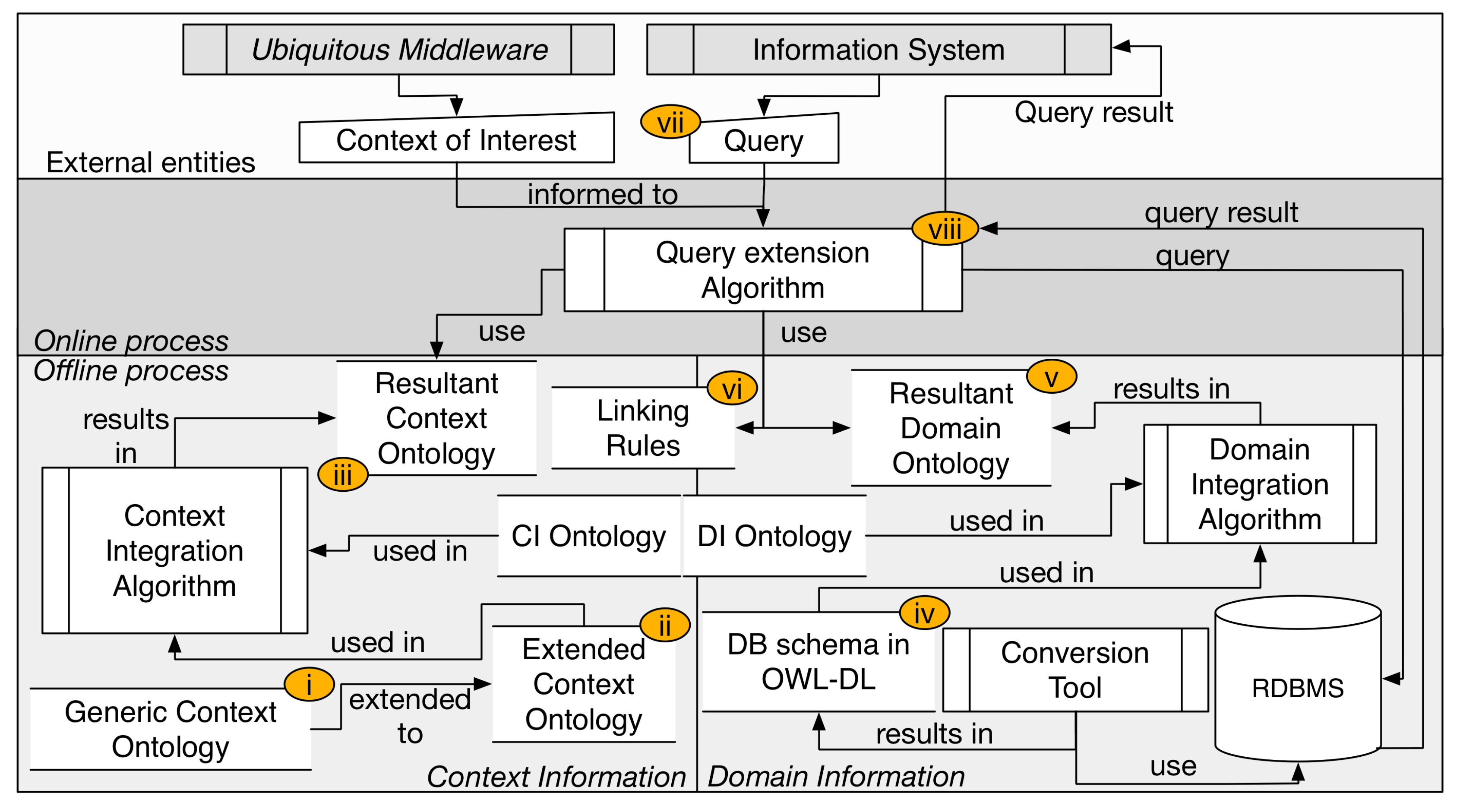
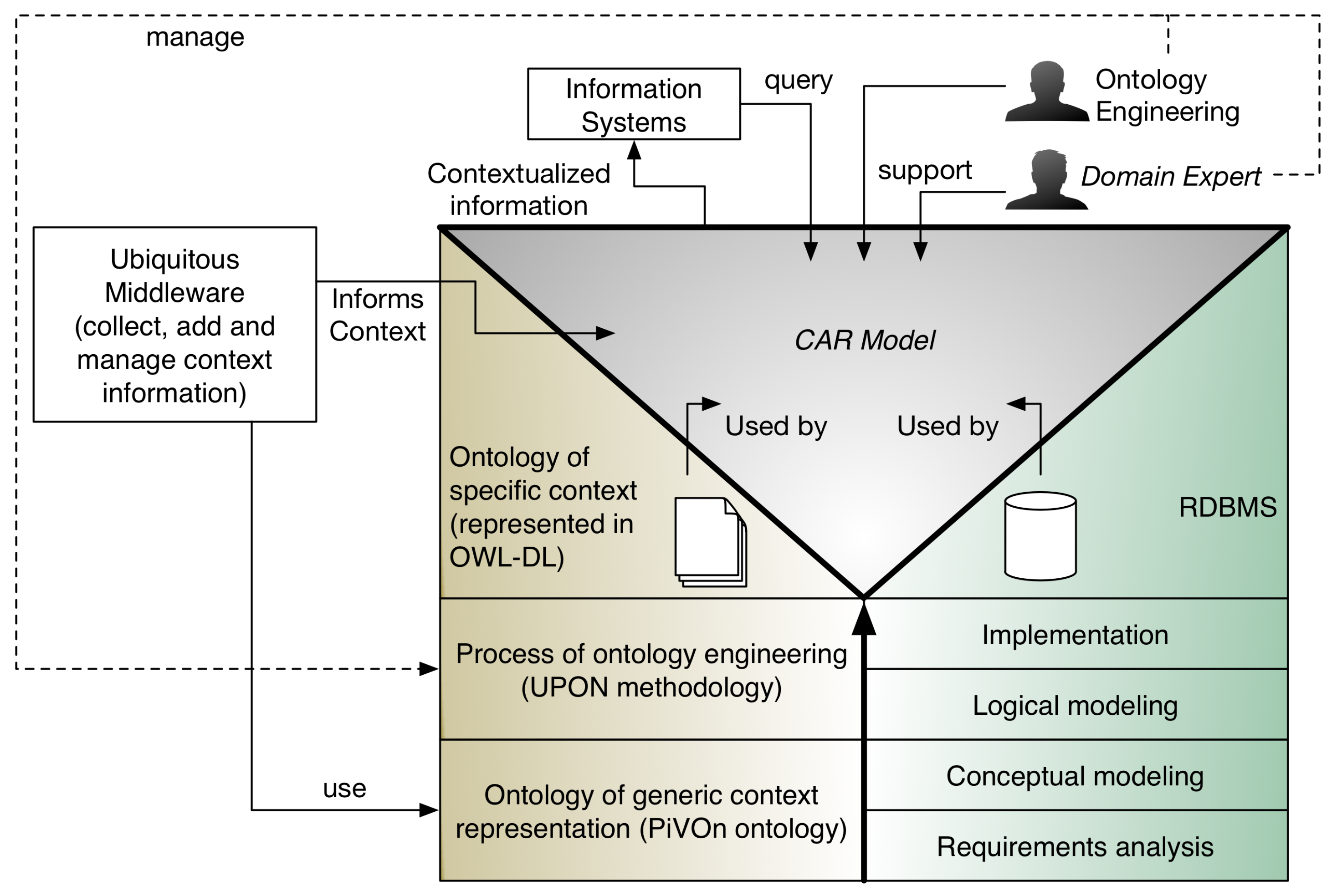
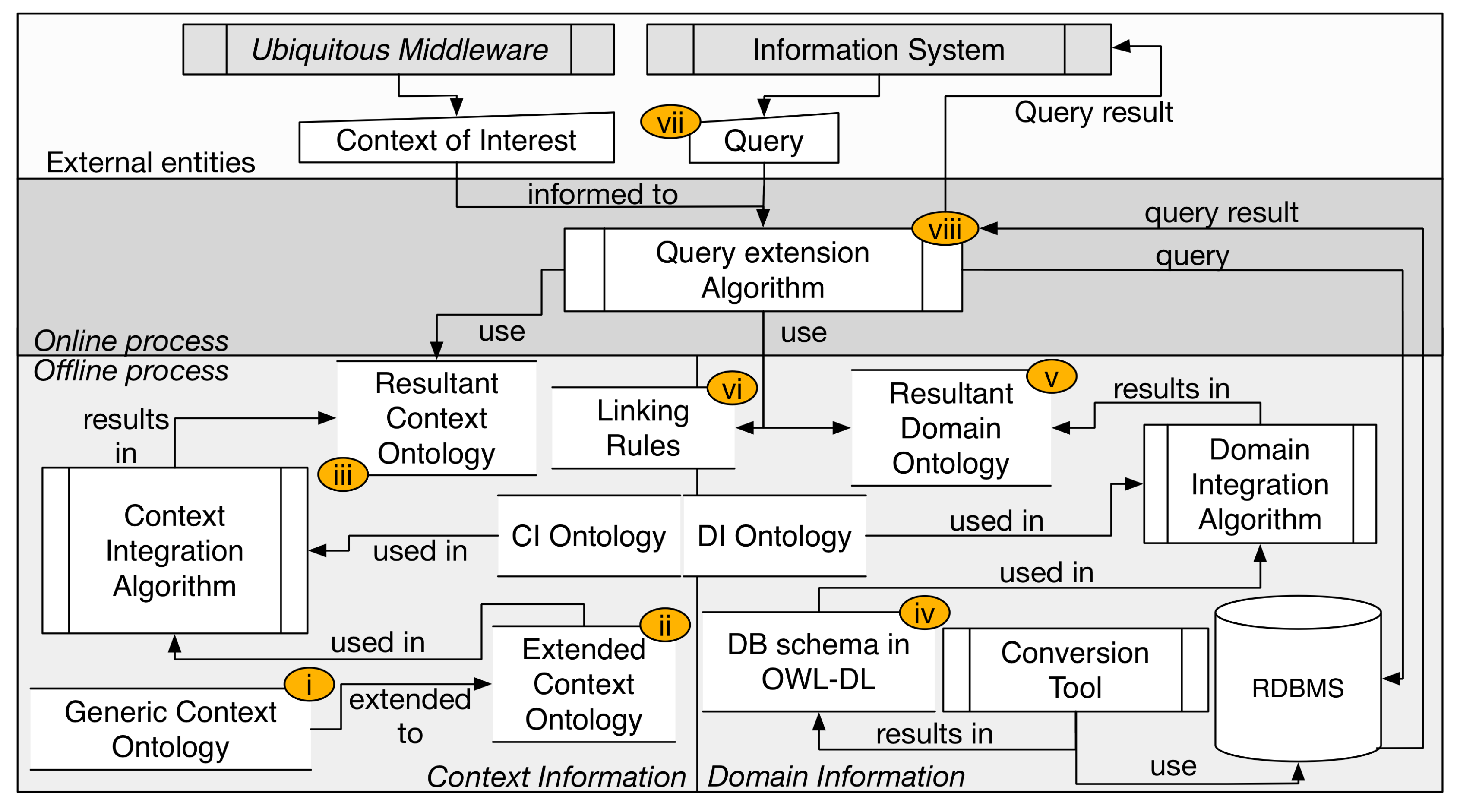
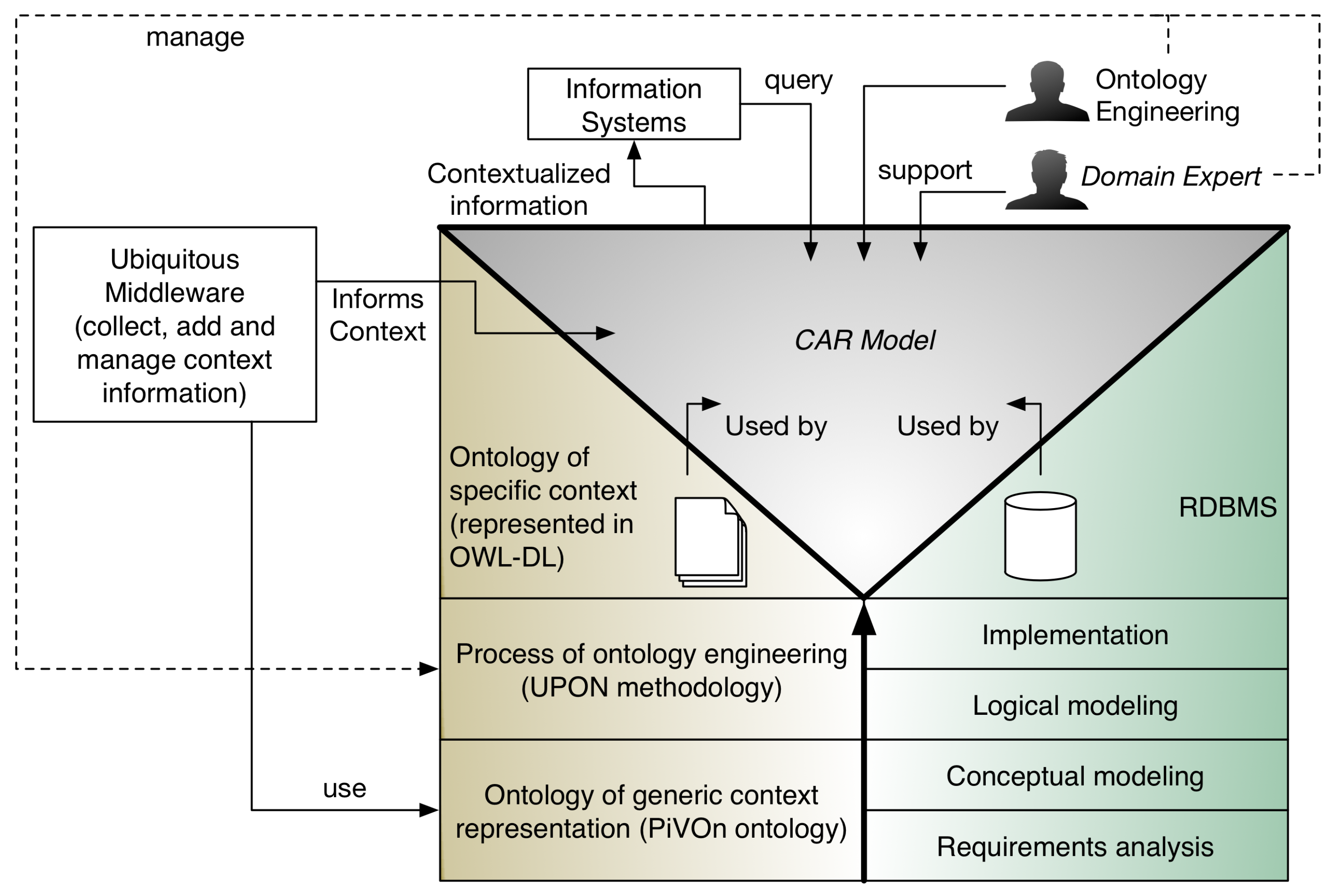
2.3. A CAR Model
- Provides the support to ontology-based context models, even with models of context in use (without the necessity to redefine the context model);
- Provides support to legacy IS, through the use of linking rules that are used with the relational queries predefined in the IS;
- Provides support to a semi-automatized form of linking between context and domain information.
2.3.1. Context Modeling
2.3.2. Domain Modeling
2.3.3. Linking Rules
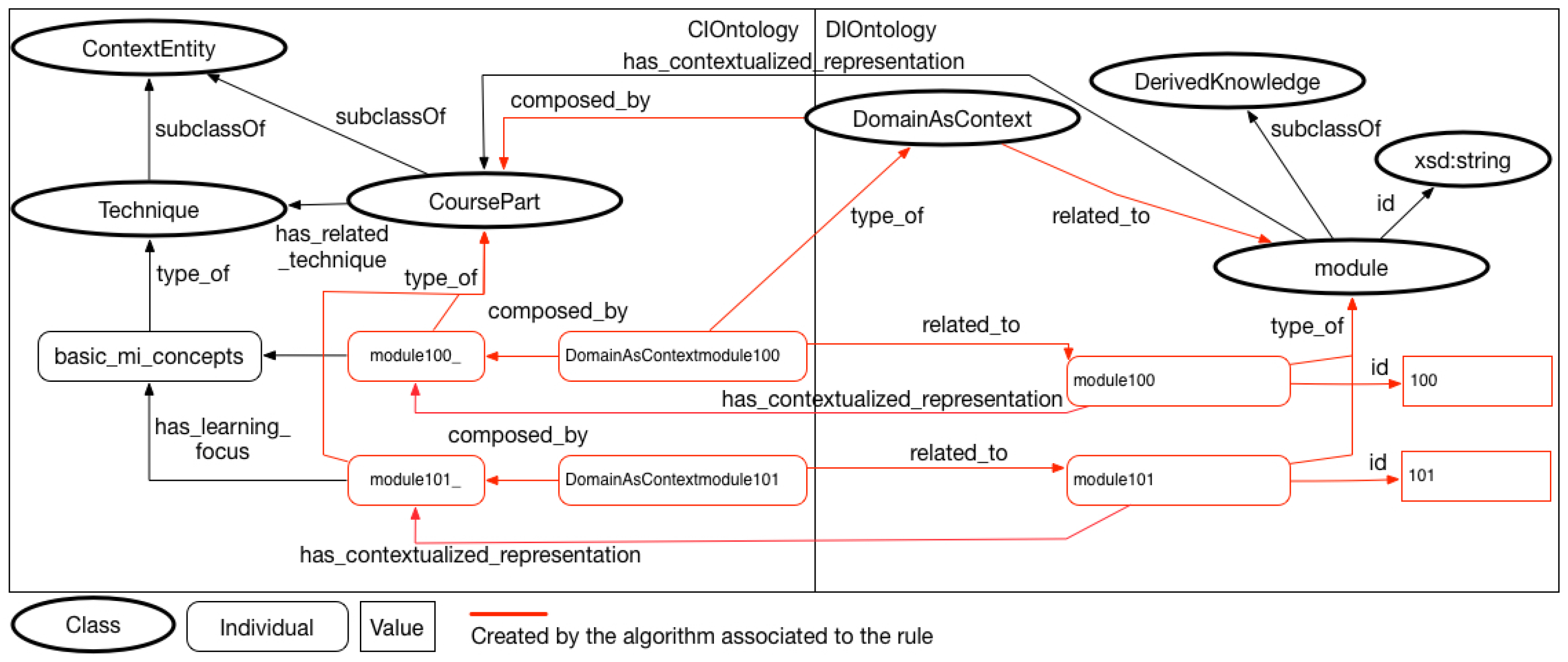
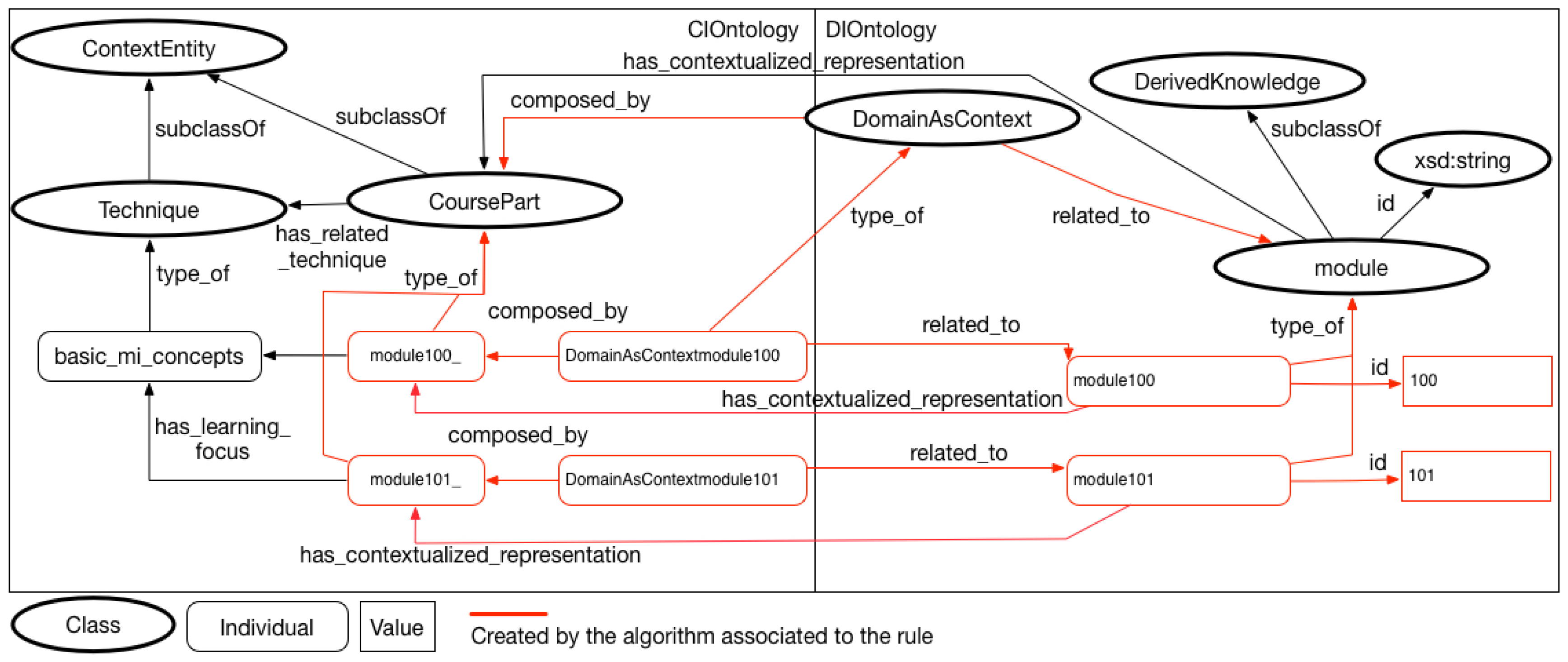
- The Domain and Context (↔) rule implies that domain information can be also considered as a context information by an IS. The rule implies that an individual will be created in the ontology to represent the information related to the tuple of domain schema. The domain information may be considered as a context information.
- The Domain for a Specific Value of Context (⇝) rule was created to relate an expression in relational algebra with a data property of a class that represent a context entity in the ontology of context. The expression is similar to .
- The Domain for a Specific Context Element (↠) rule was created to associate an expression of relational algebra with a specific element of context, represented by an individual in the context ontology. The expression defines that rae(R) is incorporated to the original query when the context individual ci_i is part of the informed context of interest.
3. Research Motivation—Recommendation of Resources in Smart Universities
Motivational Scenario
“A university uses an ubiquitous middleware to manage the educational resources present. This middlware uses an ontology as a context representation model. This ontology contains a set of axioms that, together with a set of processes managed by the middleware and allows data collected from the environment to be aggregated, and after inferences, considered as context information. Thus, the context management of interest in this ubiquitous middleware infers the situations in which students and teachers are. This university also has a recommendation system that presents warnings to students about educational resources that may be of interest. Therefore, the context of interest of each student and teacher is inferred and send to the recommendation system, which recommends to the student or teacher an interesting resource available at the university.A MOOC in the area of psychology and medicine is composed of cases of Motivational Interview (MI). Motivational Interview is a patient-centered approach to demonstrate behavioral changes to increase effectiveness in treating diseases such as obesity, smoking, and depression. The group of techniques that make up a MS has been constantly studied in a wide range of health-related behaviors [39]. To prepare the MOOC on motivational interview, the technical staff assembled the course with a structure composed of topics, where each topic consists of a supporting material (video, document or presentation) and a set of questions. If the student correctly answer the questions related to that topic, the progression to the next one is allowed and new motivational interview situations are introduced. The student completes the course when has finished all the tasks related to the basic concepts and has finished more than 50% of the exercises related to the specific motivational interview cases applied to different contexts (illness to be treated, motivation, among others).Johan is a student of the university’s collective health course who has the ubiquitous middleware and resource recommendation system. At the time of enrollment, Johan registered his smartphone in the system of the university and from there began to receive recommendations of resources. Johan lives in the city of Smartville. Currently, Johan attends the semester, and in a class of Applied Psychology to Health, the system of recommendation used by the university sends an alert to Johan in his smartphone recommending to enroll in the MOOC on Motivational Interviews. During the break of class, John visualizes the alert and enrolls in the Motivational Interview MOOC. At this point, the MOOC asks Johan for permission to receive context information managed by the university’s ubiquitous middleware. Johan authorizes and the MOOC begins to receive constant updates of contexts of interest.”
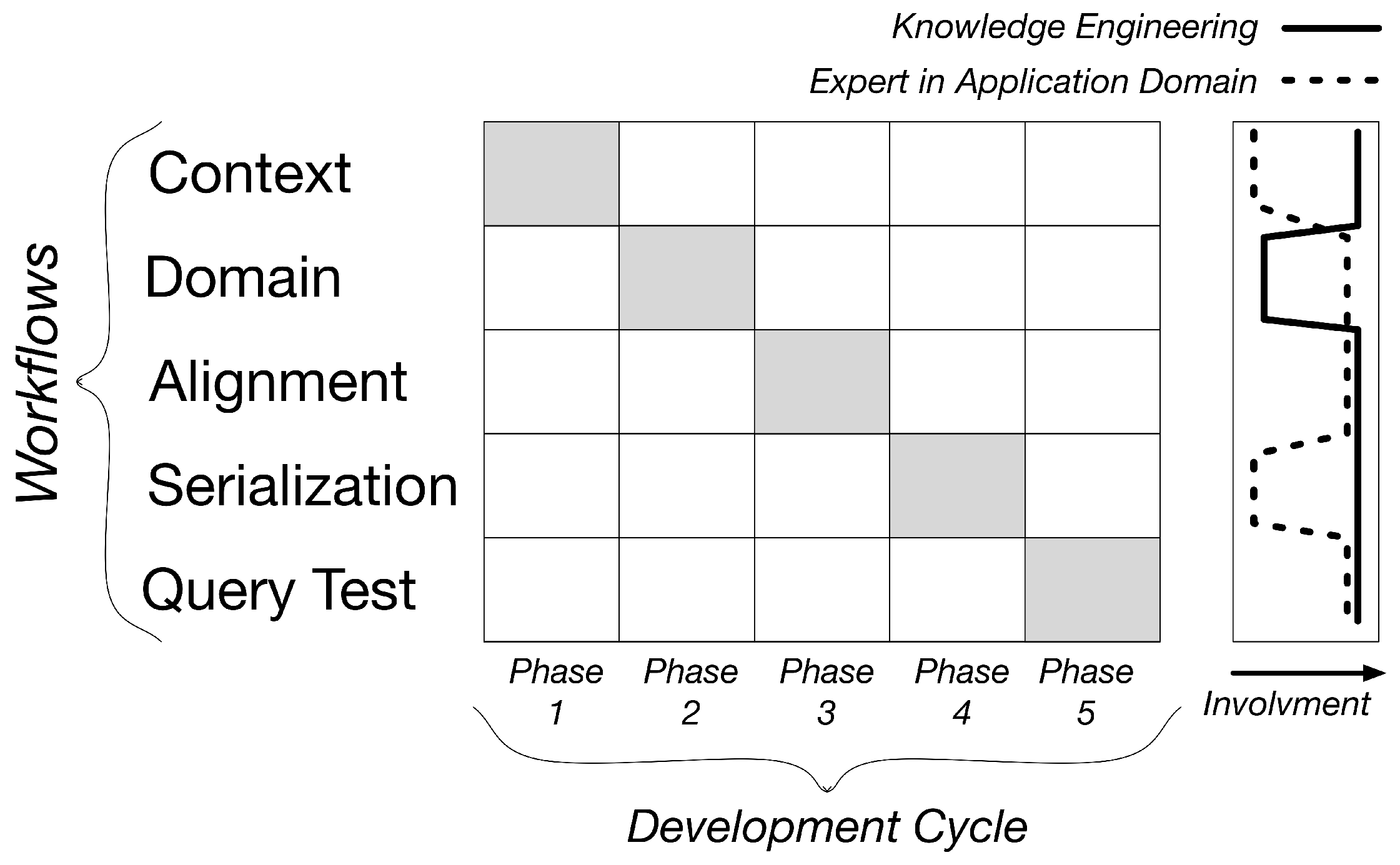
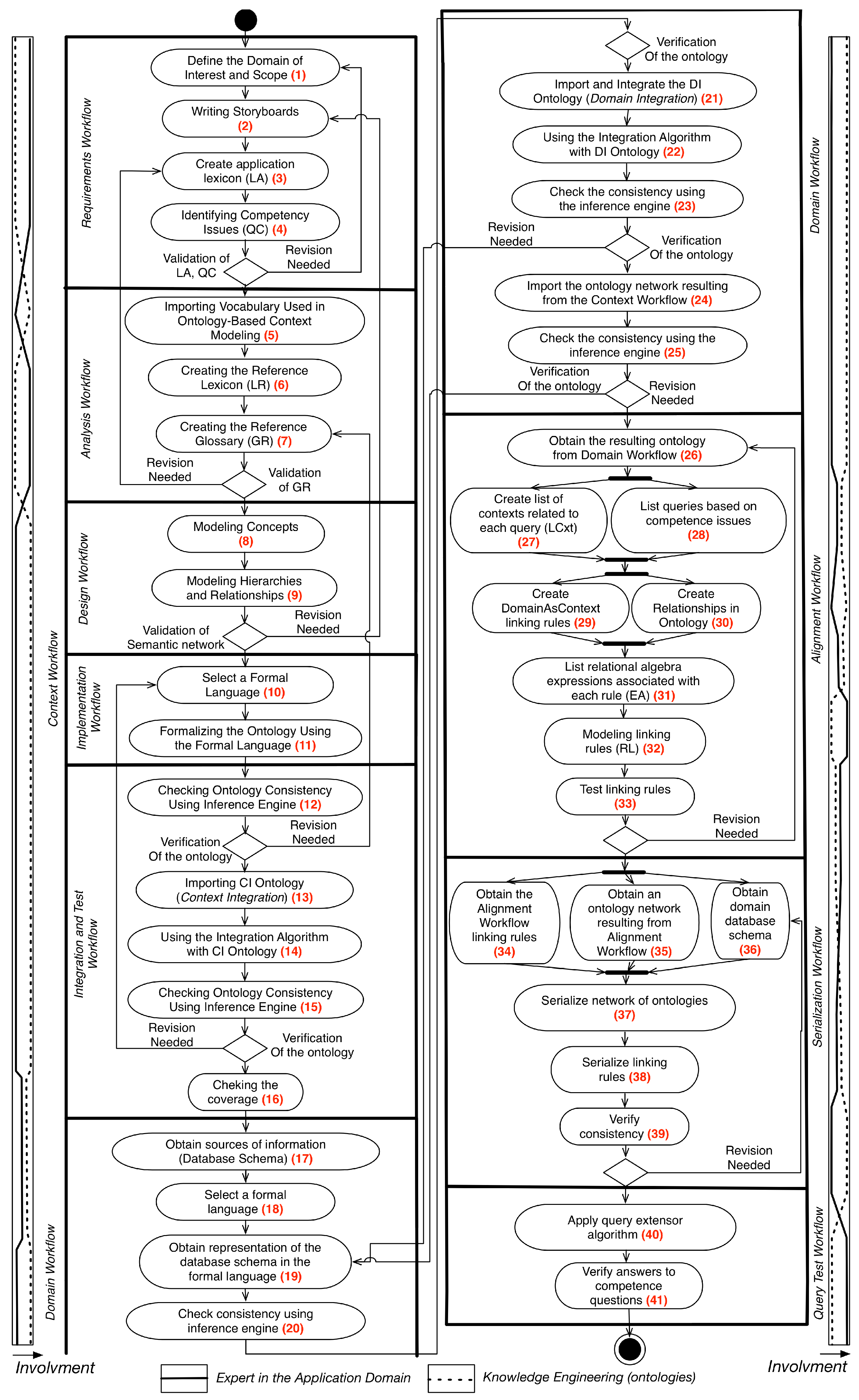
4. UPcad Methodology
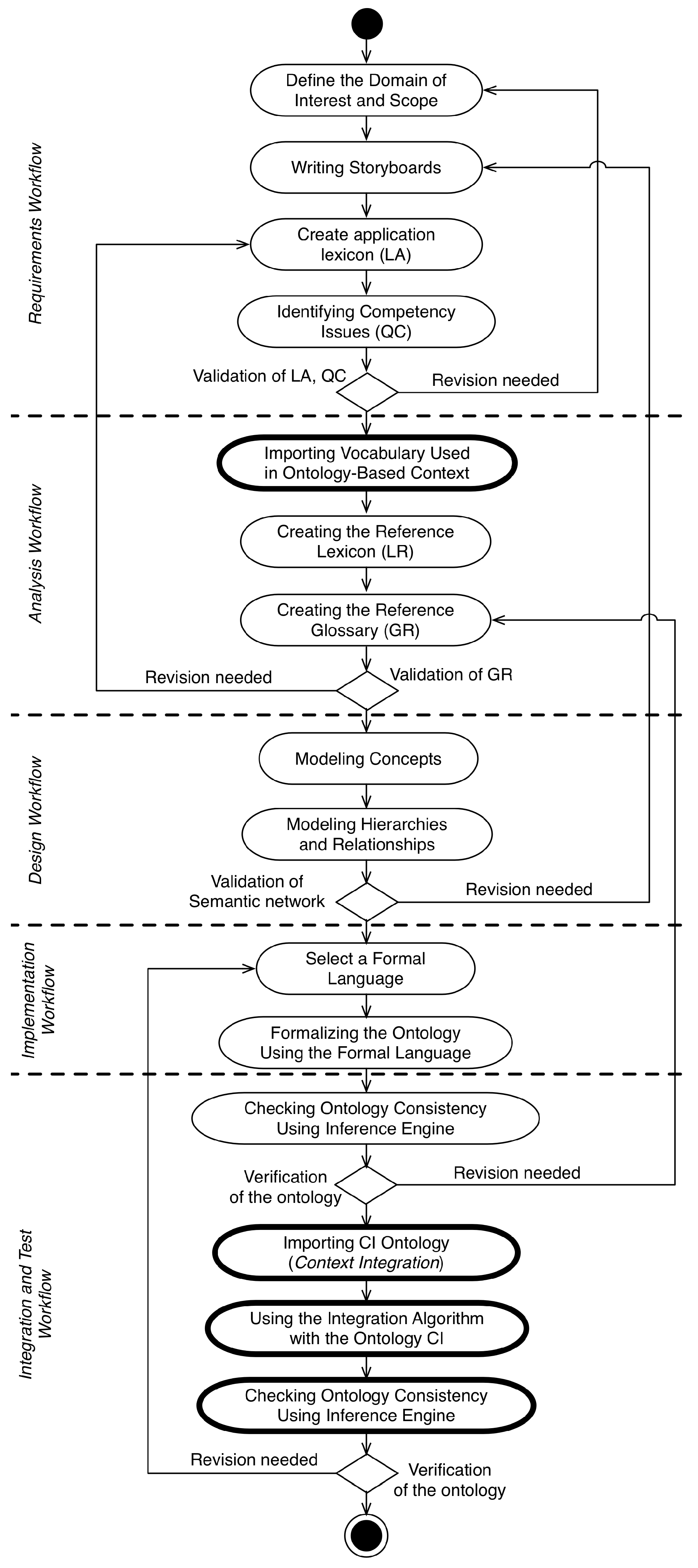
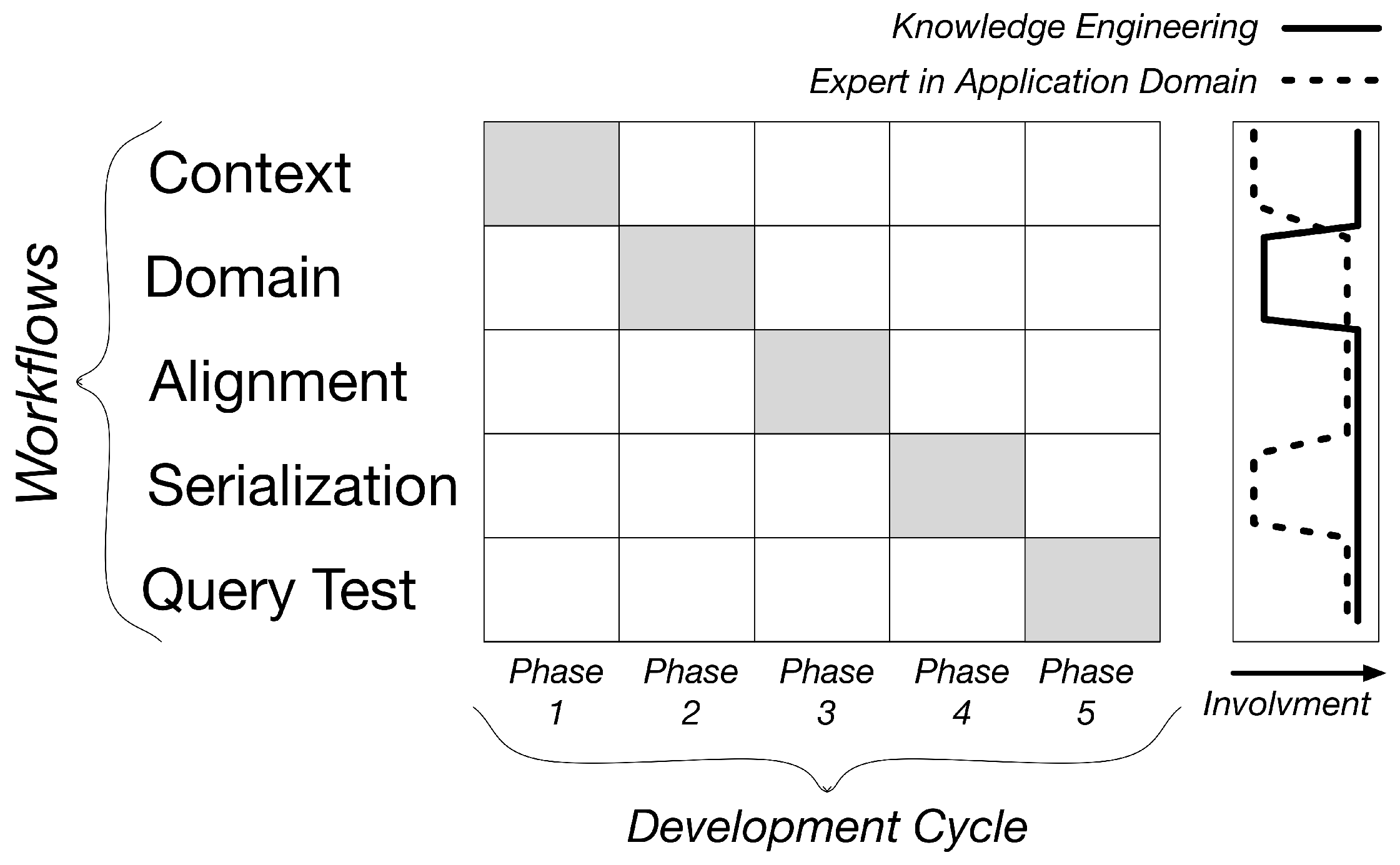
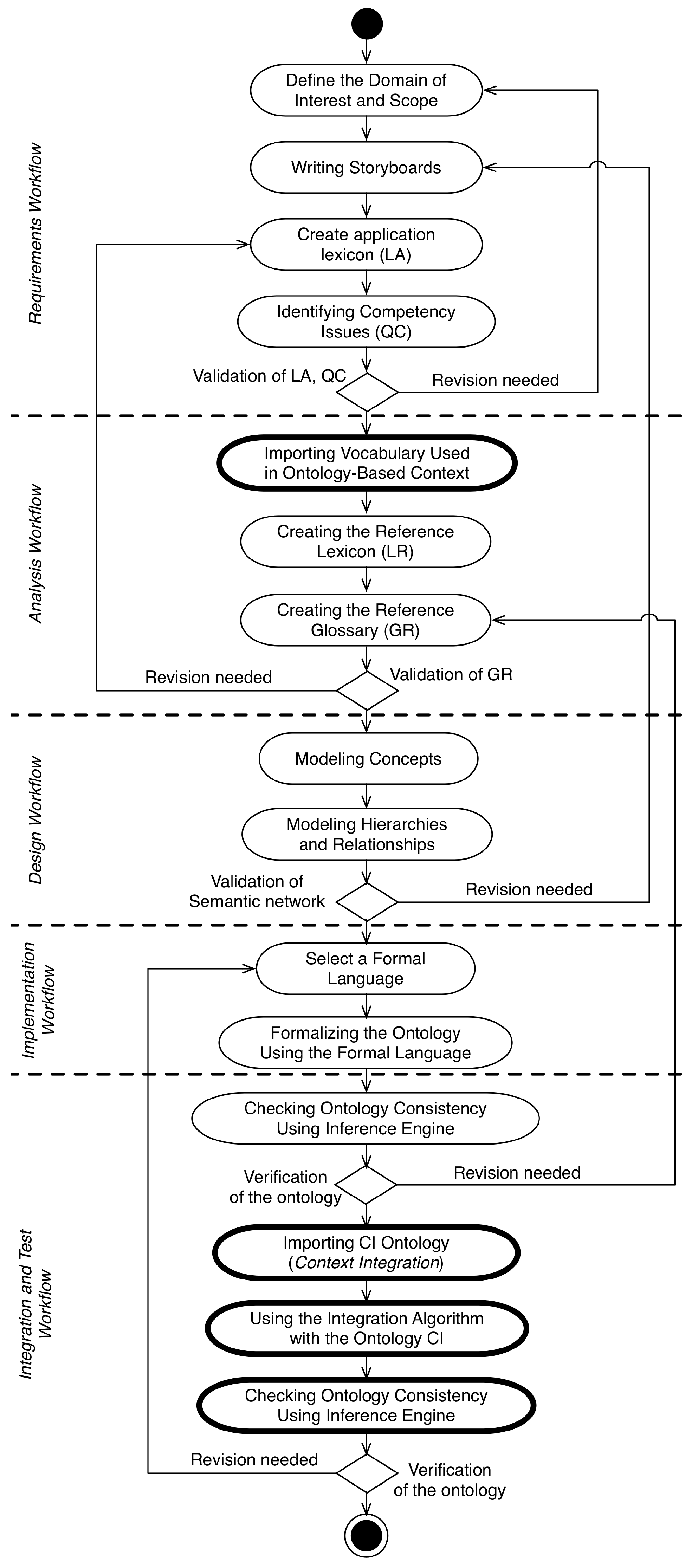
4.1. Methodology Overview
4.2. Context Workflow
- Definition of the Domain of Interest and Scope: It consists of the identification of the main concepts that must be represented, their characteristics and the definition of the domain’s scope that will be represented. For this, ontological commitments must be made in the process.
- Writing Storyboards: In this step the application domain expert wrote one or a series of Storyboards that describe sequences of activities in a given scenario. This scenario describes a set of application scenarios and contexts;
- Creation of the Application Lexicon (LA): The lexicon of the application is a set of the main terms contained in documents, collected from the storyboards developed in the previous process;
- Identifying Competency Issues (QC): Competency issues are conceptual-level issues that the resulting ontology must be able to respond to. They are defined based on interviews with domain experts, users, and developers. They define the coverage and depth of the ontology representation scope over the modeled domain. In the UPON Methodology, there are two types of Competency Issues defined: (i) oriented to the discovery of resources or content; and (ii) semantic interoperability between different schemes. In the developed methodology only questions of the first type are considered;
- Importing Vocabulary Used in Ontology-Based Context Modeling: It is envisaged to import the vocabulary from a context representation ontology at this stage to avoid the redundancy of concepts in the modeling phase;
- Creating the Reference Lexicon (LR): The reference lexicon is defined from the set of concepts described in the application lexicon, in the imported vocabulary of the context ontology and in the information of the documents used in the previous stages;
- Creating the Reference Glossary (GR): The reference glossary is defined by adding informal definitions (sentences about the concept) to the LR using natural language;
- Modeling Concepts: Each concept is categorized through the association of type with the concept. The concepts are categorized using the context ontology as top ontology;
- Modeling Hierarchies and Relationships: At this stage the categorization of concepts described in a taxonomy is complemented with domain-specific relations, aggregation relations and generalization;
- Formalization of the Ontology Using the Formal Language: In this step the concepts and relationships modeled in the design workflow are formalized in the OWL-DL language. This formalization is accomplished through the definition of an ontology, which imports the concepts of the context ontology, forming a network of ontologies.To perform the ontology validation a check-list must be performed, according to different characteristics: (i) Syntactic quality; (ii) Semantic quality; (iii) Pragmatic quality and (iv) Social quality [15];
- Checking Ontology Consistency Using Inference Engine: Checking the consistency of the ontology must be performed using an inference engine. Here the existence of contradictions in the definition of the ontology are discovered. If there is any contradiction, the inference engine informs the ontology engineer, who should review the process of creating the ontology;
- Importing CI Ontology: In addition to importing the context ontology, it is necessary to import the CI ontology. Thus, the concepts created in the extended context ontology should be sub-concepts of the classes of the CI ontology;
- Using the Integration Algorithm with CI Ontology: After the importation of the ontologies’ vocabularies, the designers must integrate these ontologies, generating a net of ontologies. This network of ontologies will be used in the next steps of the workflow.
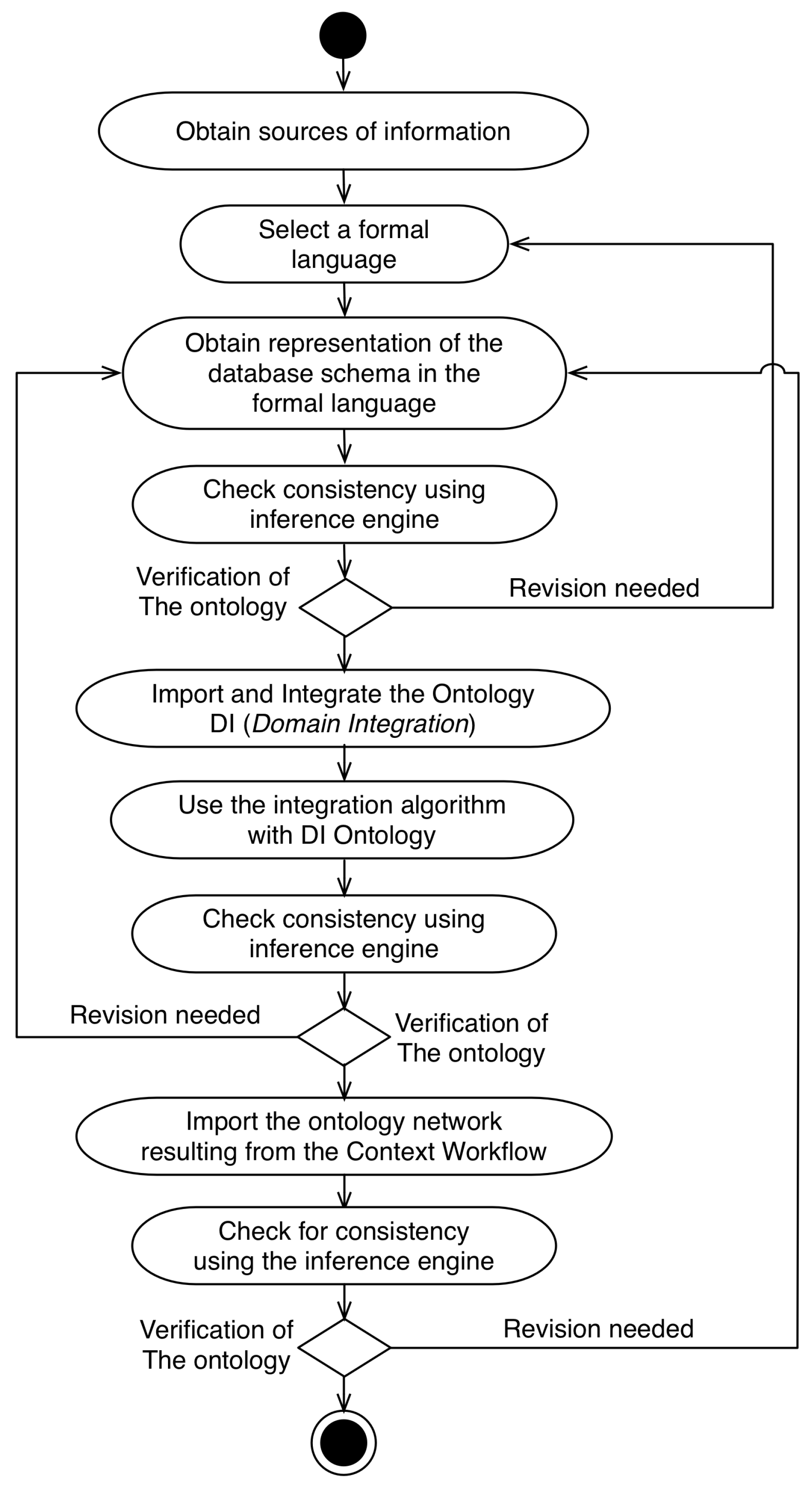
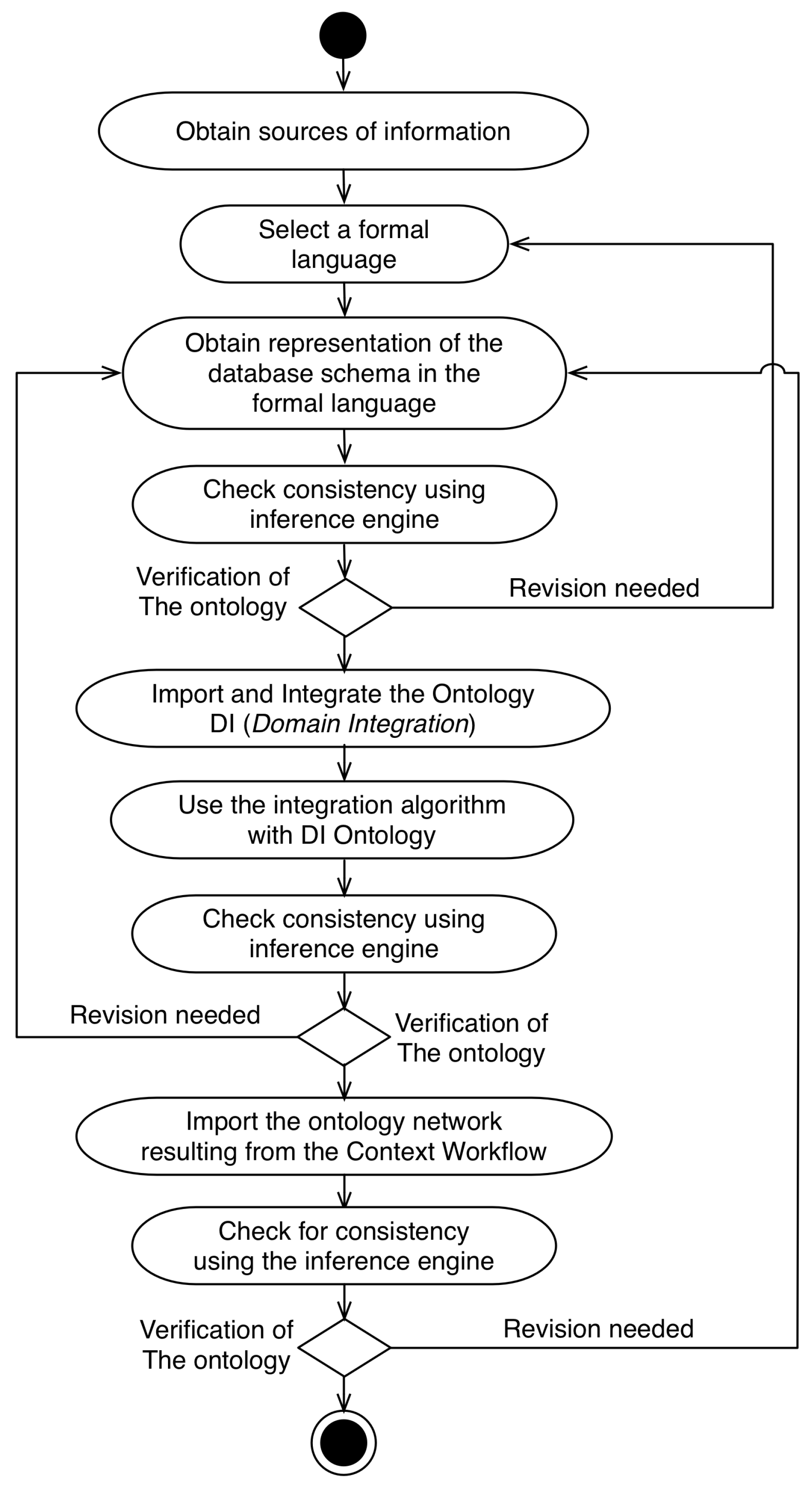
4.3. Domain Workflow
- Obtain sources of information: At this stage the domain expert must obtain the information sources that will be used in the model development. As the focus of this research is the query extension model, a database schema must be employed as the source of information in this step;
- Select a formal language: In this step, the ontology engineer makes the choice of a formal language that will represent the database schema. As the ontology network generated in Context Workflow is represented in the OWL-DL language, it is recommended to choose the OWL-DL or RDF languages in this step for compatibility purposes;
- Obtain representation of the database schema in the formal language: Because the context representation in the model is made in the OWL-DL language, the database schema used in the model must be represented in the same language. Currently, there are tools capable of converting relational schemes to OWL-DL files through R2RML mappings. RDBToOnto is an example of a tool that is used in several projects to do this [33];
- Check consistency using inference engine;
- Import and Integrate the DI Ontology: After the first verification, the ontology engineer imports the DI ontology;
- Check the consistency using the inference engine;
- Import the ontology network resulting from the Context Workflow: The ontology network generated in the Context Workflow is imported and integrated in the ontology network generated in the Domain Workflow;
- Check for consistency using the inference engine.
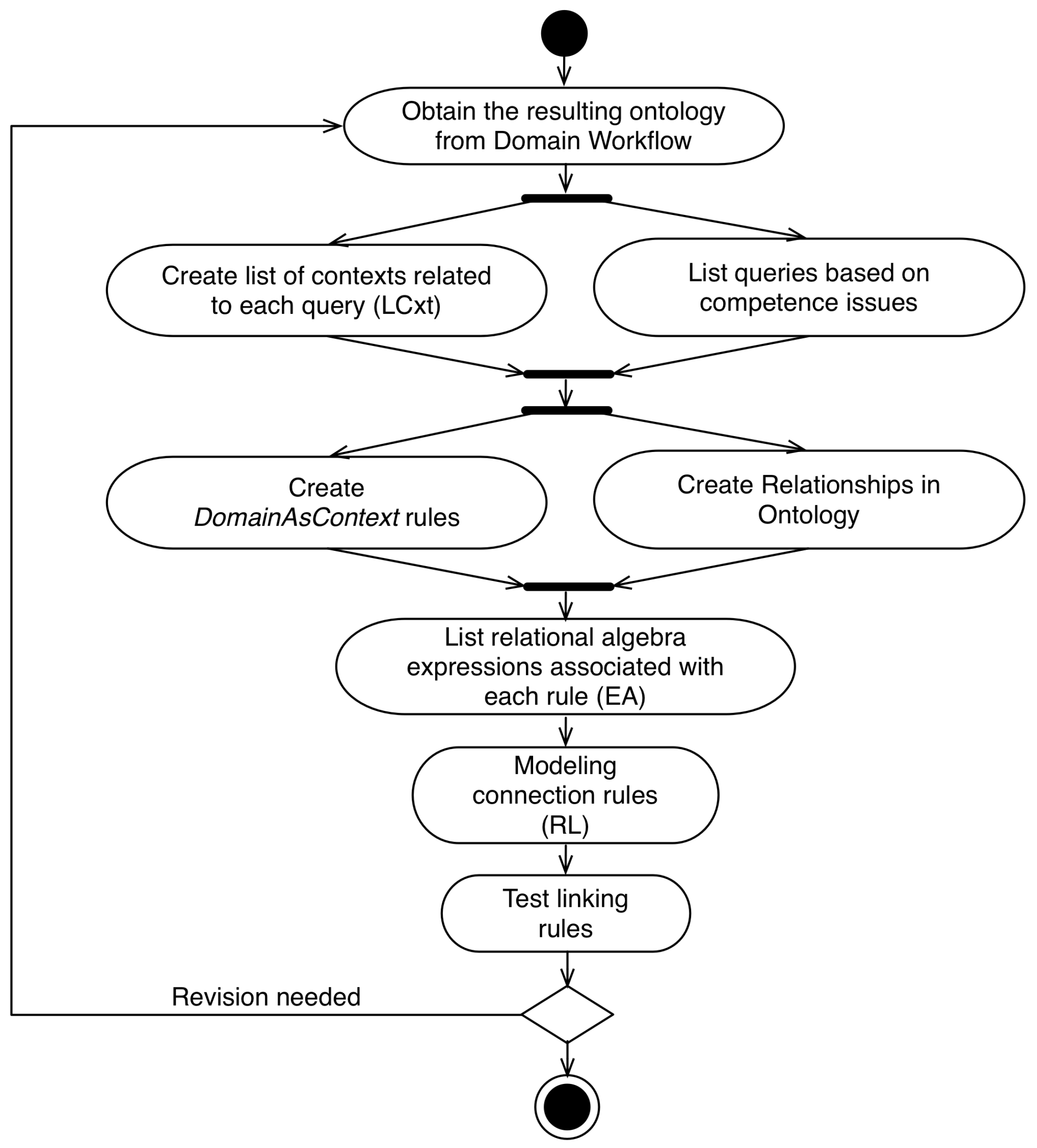
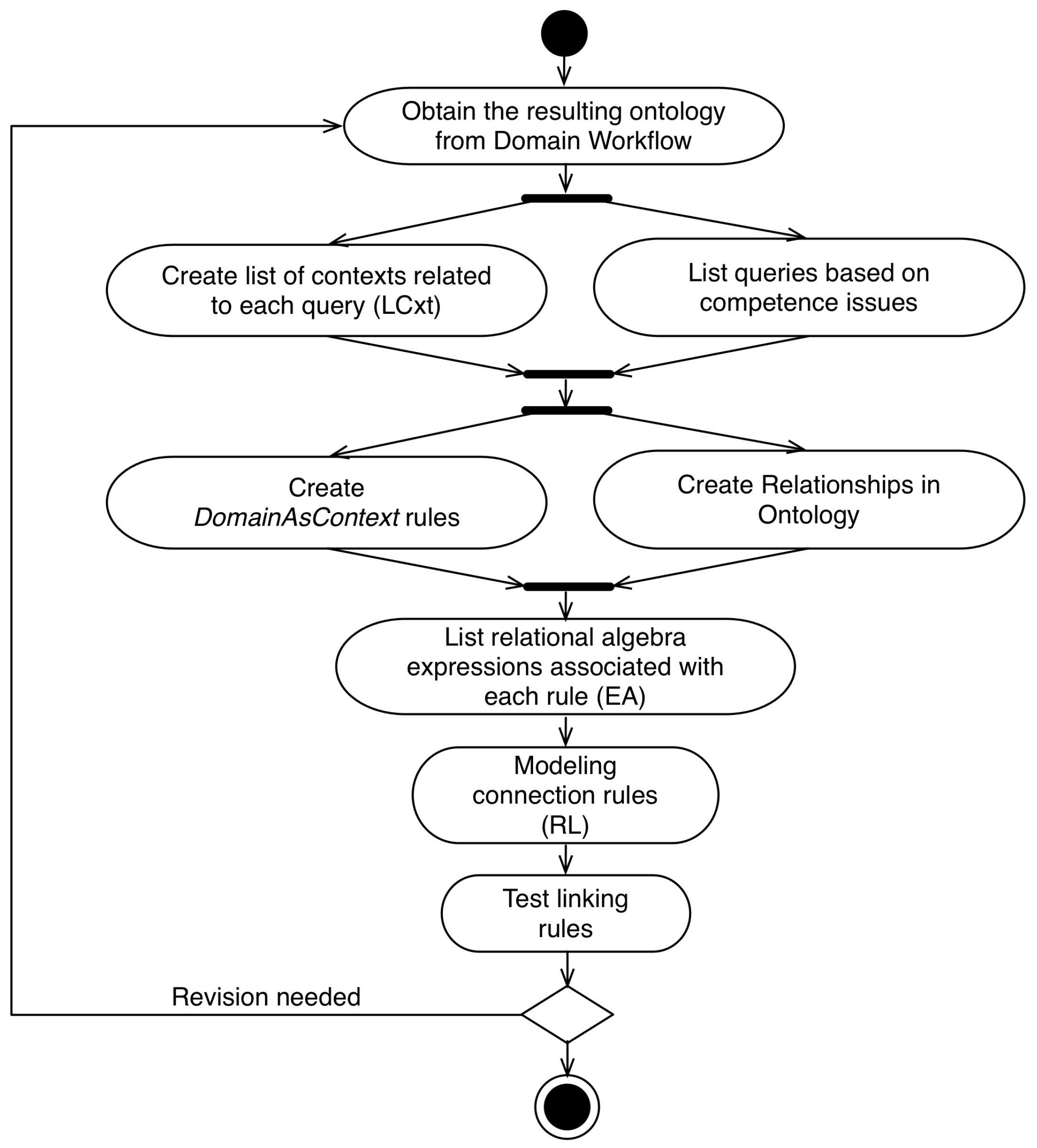
4.4. Alignment Workflow
- Obtain the resulting ontology from Domain Workflow;
- Create list of contexts related to each query (LCxt): Based on the competence issues, the application domain expert and the ontology engineer create a list of: (i) context entities; (ii) context attributes and (iii) semantic contextual relations, which are related to the competence issues defined earlier. These elements will be used in the definition of linking rules;
- List queries based on competence issues: In this step, the expert in the application domain will create a list (LC), the set of queries that are used in the system and that may be contextualized;
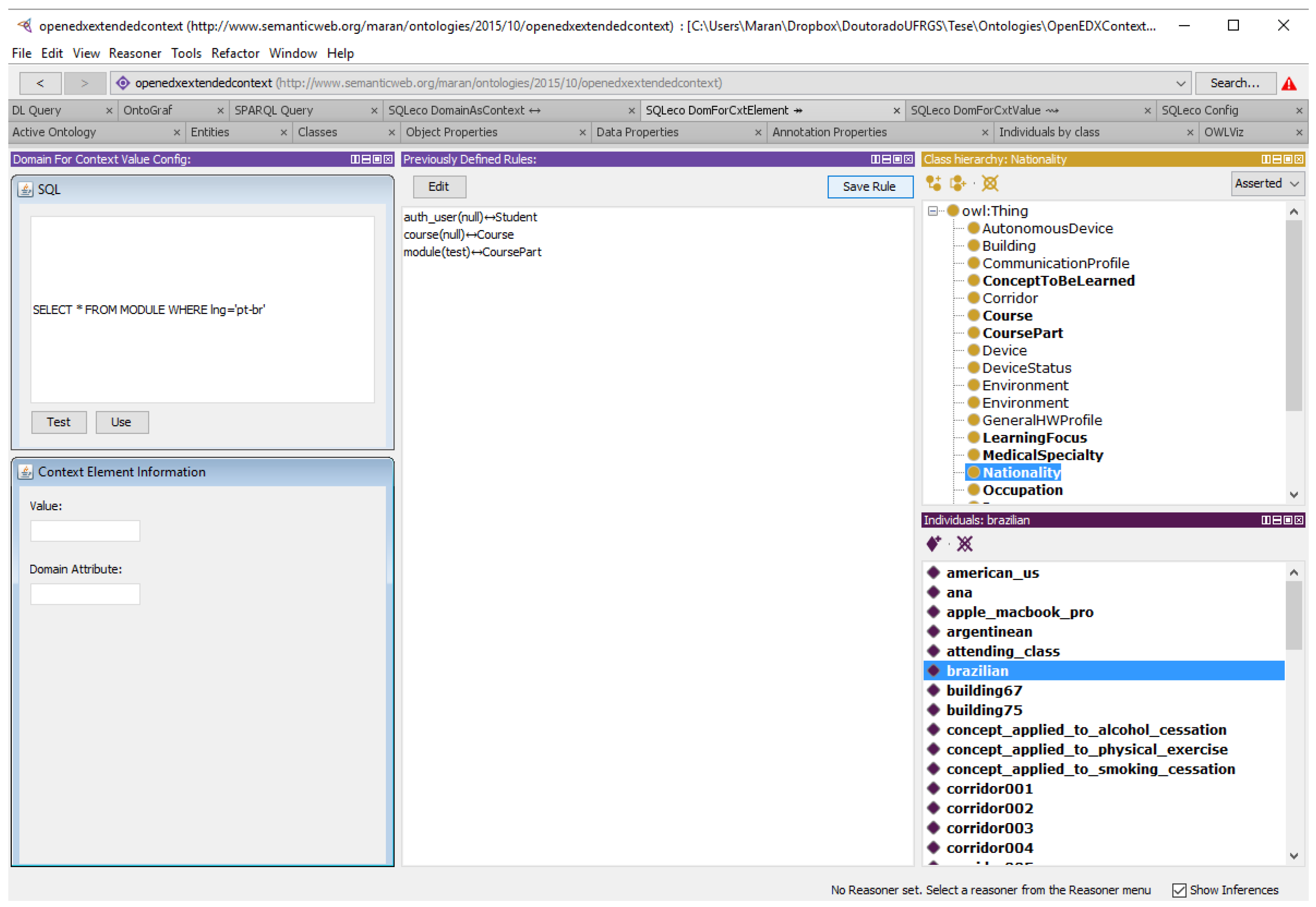
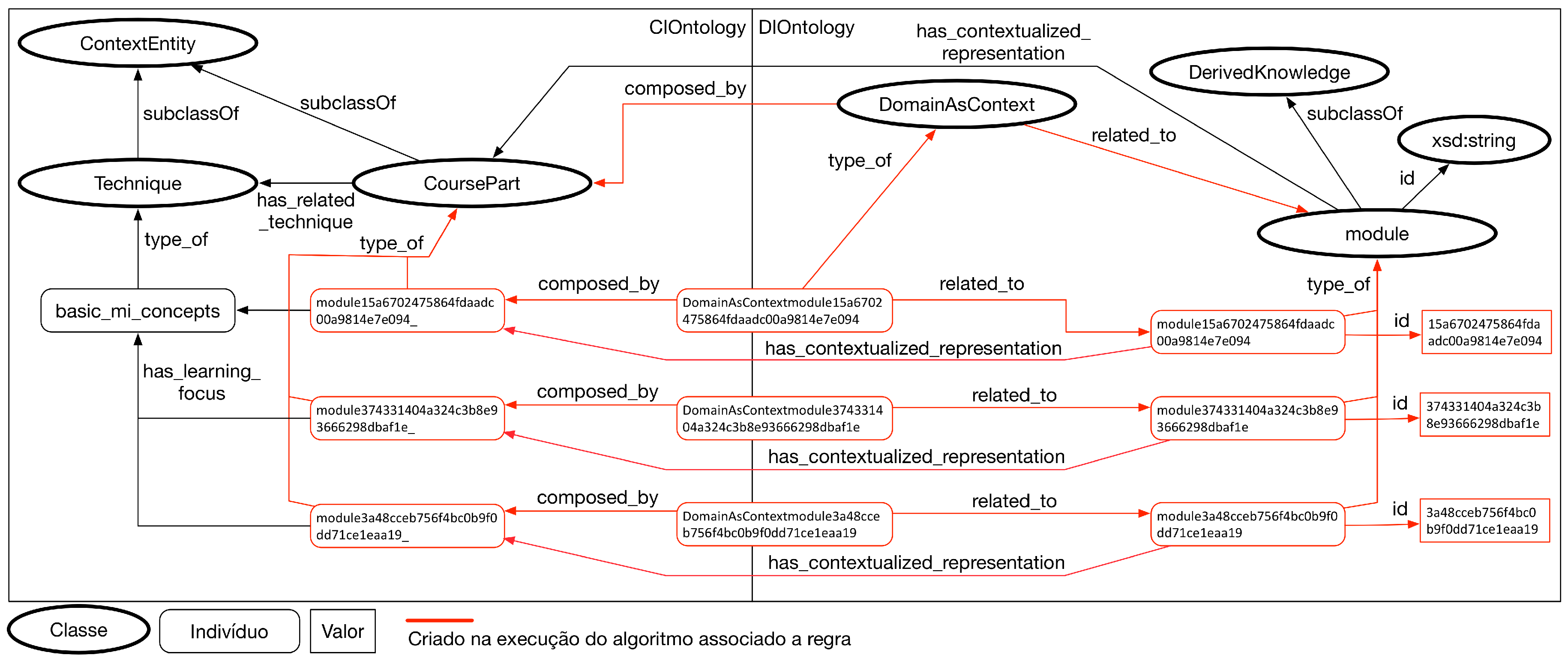
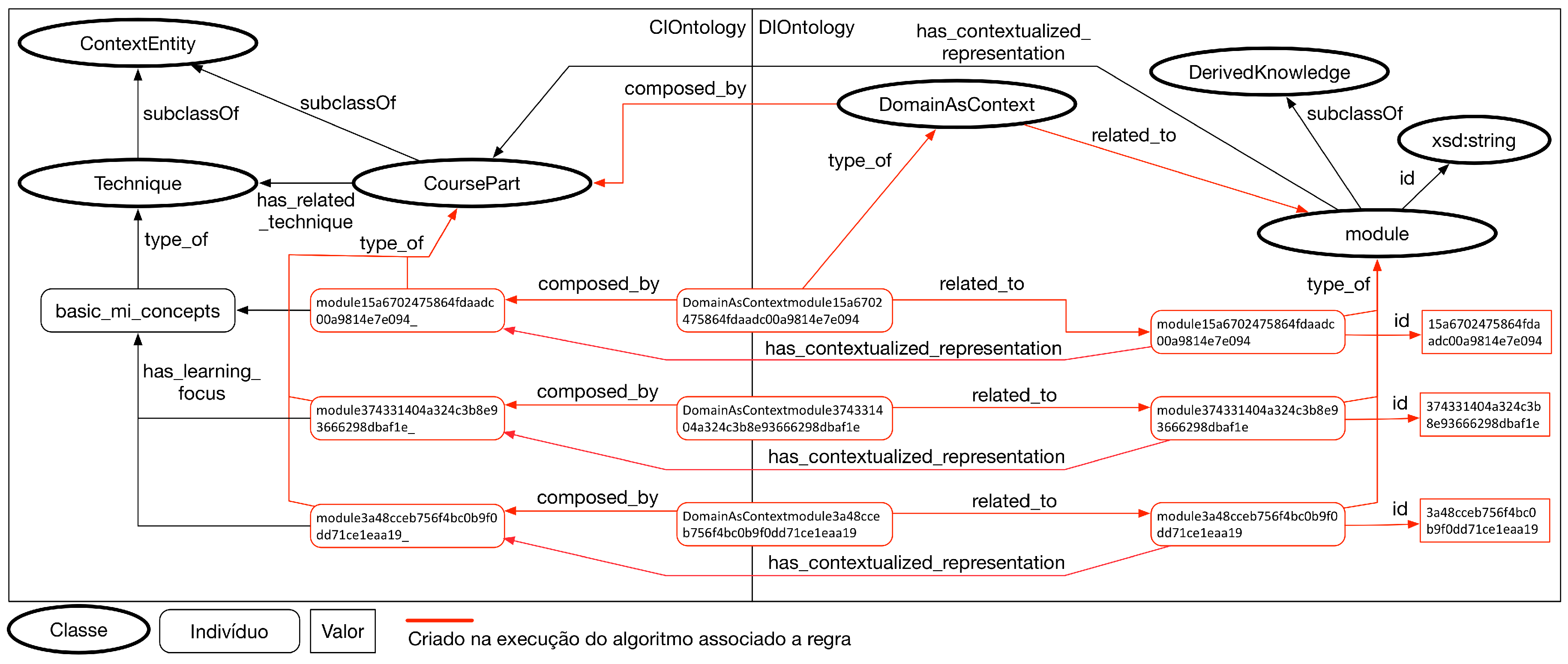
- Create DomainAsContext linking rules: In this step, if necessary, the modeler creates the rules of DomainAsContext type. These rules are different in relation to other rule types because they create new individuals in the network of ontologies, allowing new semantic relationships to be created;
- Create Relationships in Ontology: If domain and context rules are created, new individuals are created in the ontology network. After the creation of these individuals, new semantic relationships can be defined in the network of ontologies with these new individuals;
- List relational algebra expressions associated with each rule (EA): From LCxt and LC, the expert in the application domain defines a series of relational algebra (EA) expressions that represent the filtering that must be performed according to each context element, for each query;
- Test linking rules: After the definition of the linking rules by the modeler, the set of defined rules and the network of ontologies generated in the process are serialized in a DB instance. In this step, the modeled rules are tested. In this testing step, rules are tested only in terms of syntax and semantics. These tests are done through contexts of interest, entered manually, and verification of the return of the queries by the domain expert.
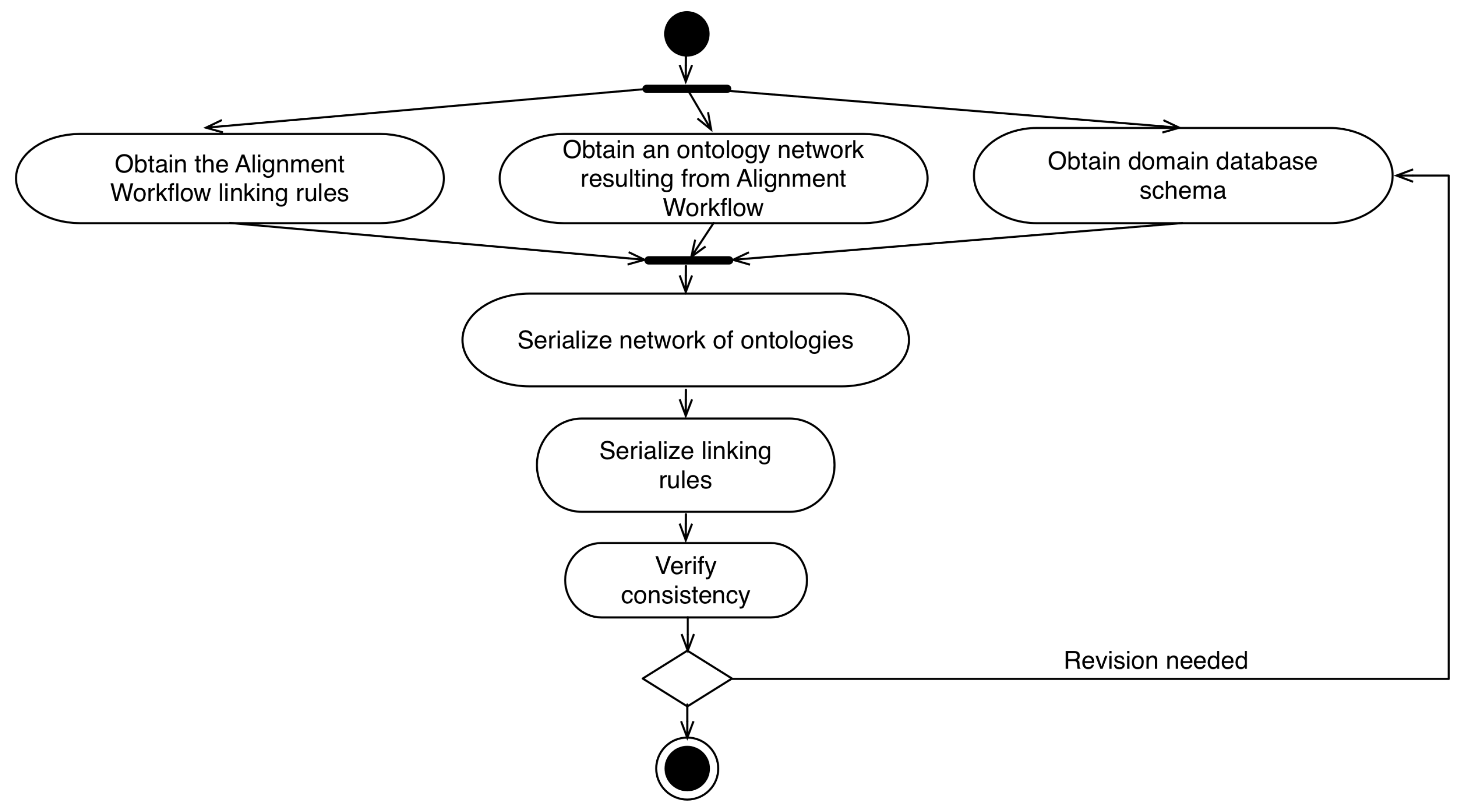
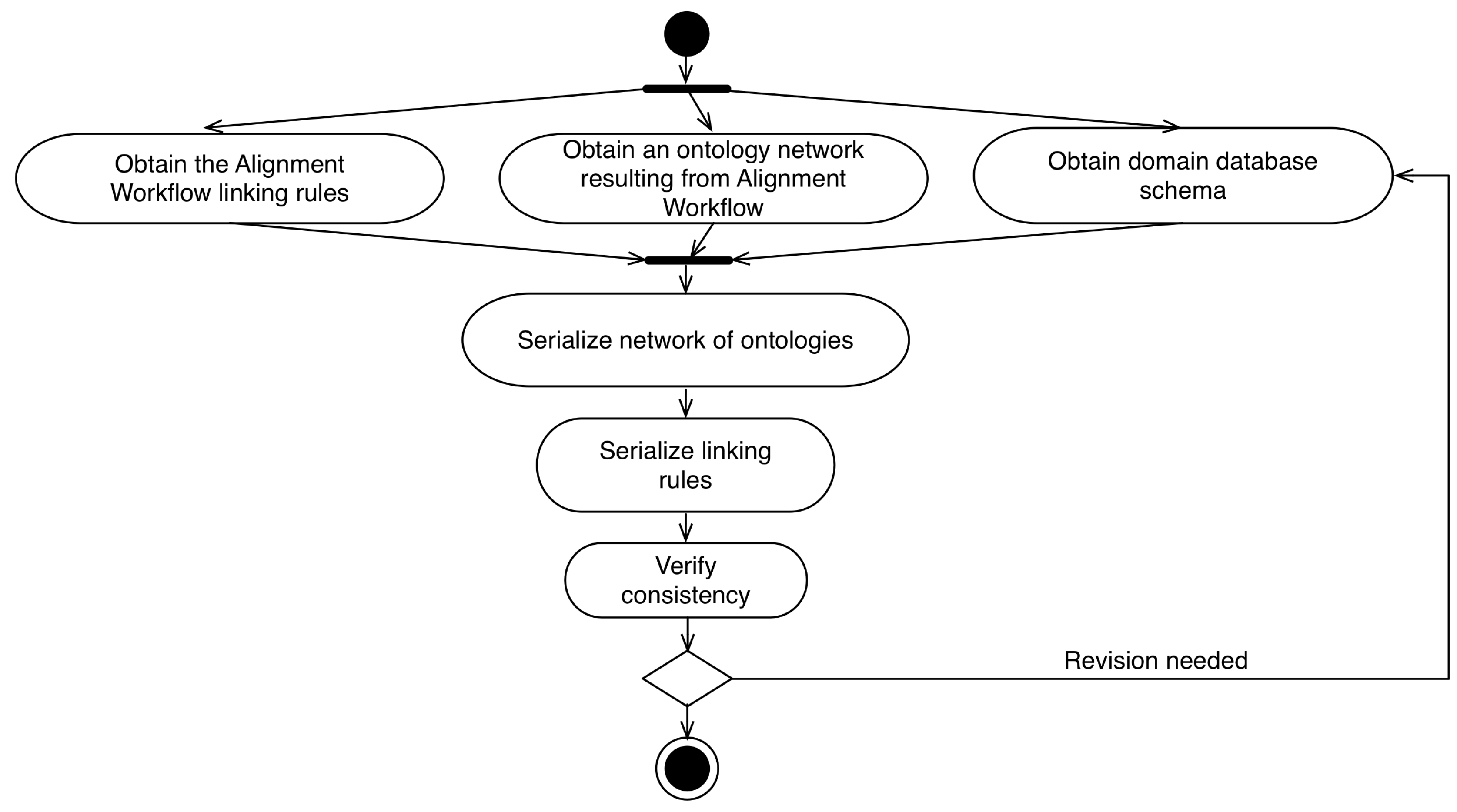
4.5. Serialization Workflow
- Obtain the Alignment Workflow linking rules;
- Obtain an ontology network resulting from Alignment Workflow;
- Obtain domain database schema;
- Serialize network of ontologies: After the step of collecting the information generated in previous processes, the network of ontologies is serialized in a format compatible with the model. In the prototypes developed to support the model, we used the serialization of ontologies in the JSON-LD format;
- Serialize linking rules: The serialization of binding rules occurs in the execution of the algorithms associated with each rule. Each of the algorithms generates a JSON-LD file that is persisted in the same instance of the relational database that stores the domain information;
- Verify consistency: After realizing the persistence of the ontology network used by the model, one must verify the consistency of the information. To perform this check, it is recommended to use an inference engine.
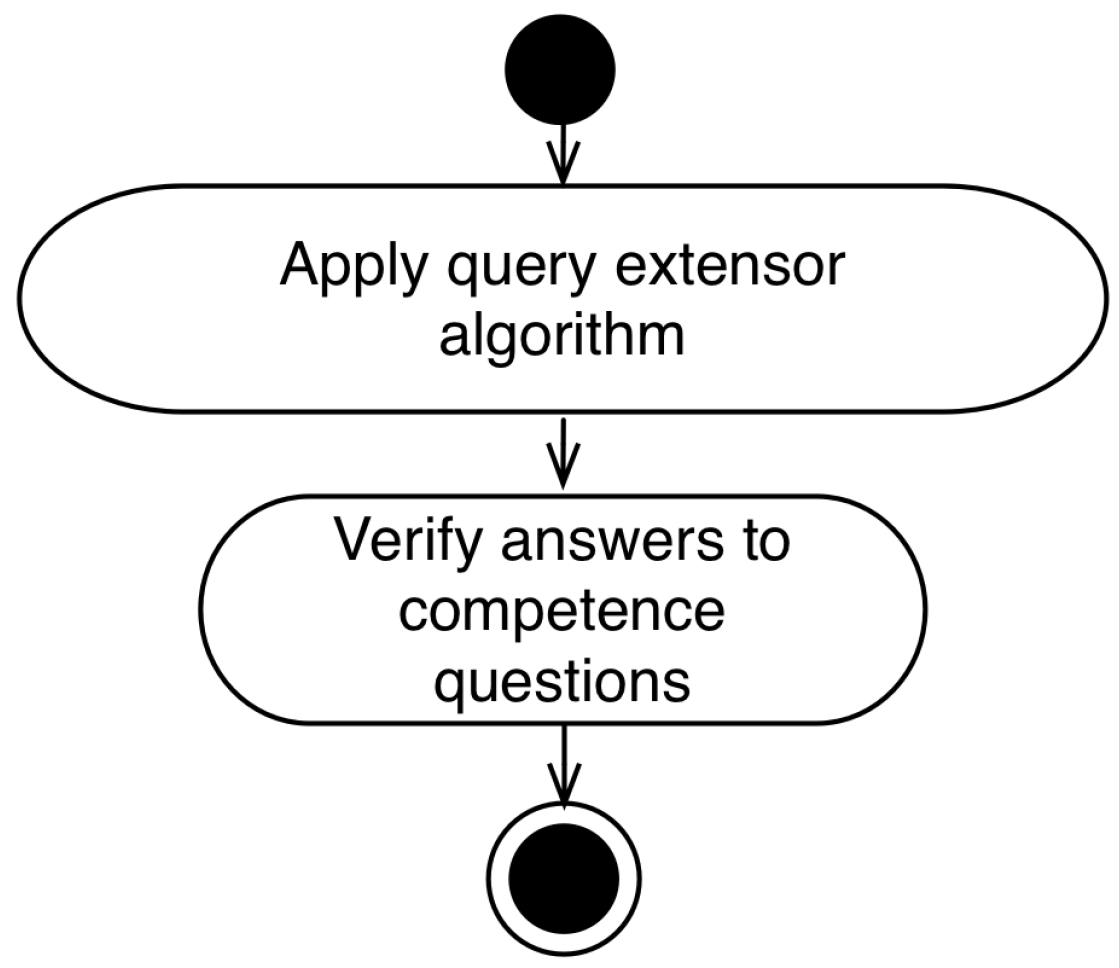
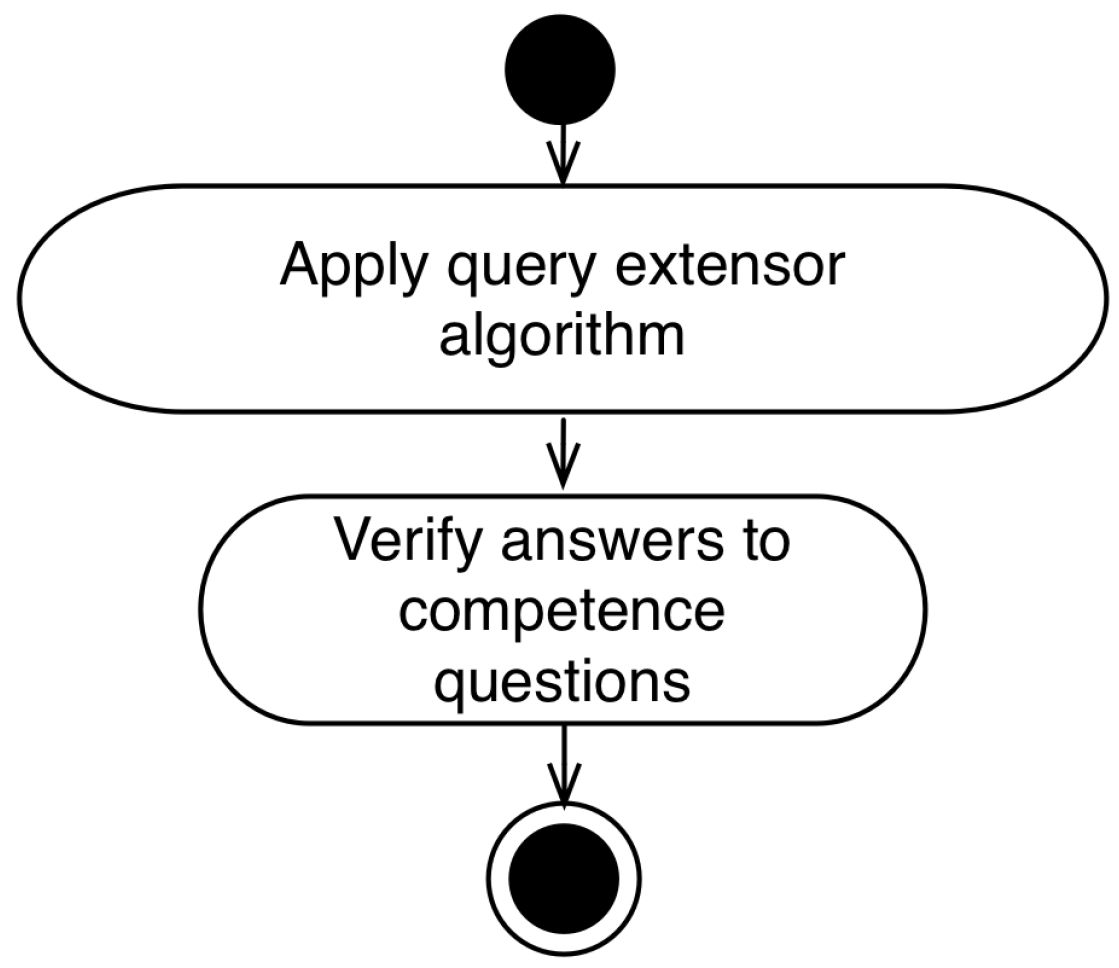
4.6. Query Test Workflow
- Apply query expansion algorithm: The application of the query expansion algorithm is performed by associating the integrator module with the information system;
- Verify answers to competence questions: In this step, the expert in the application domain verifies, through the accomplishment of queries or verification with the users, if the queries answer the questions of competence listed in the first stage of the methodology.
5. Evaluation
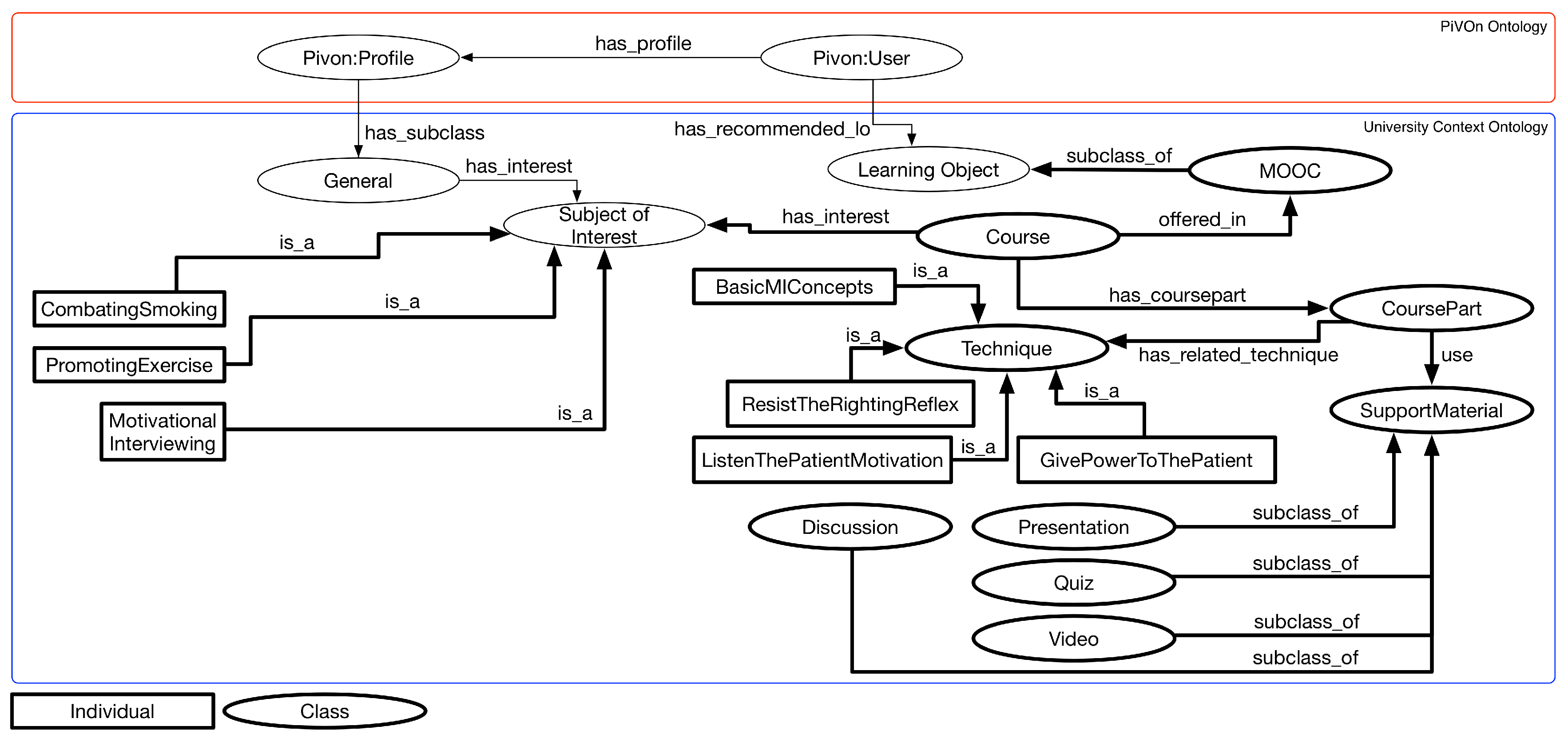
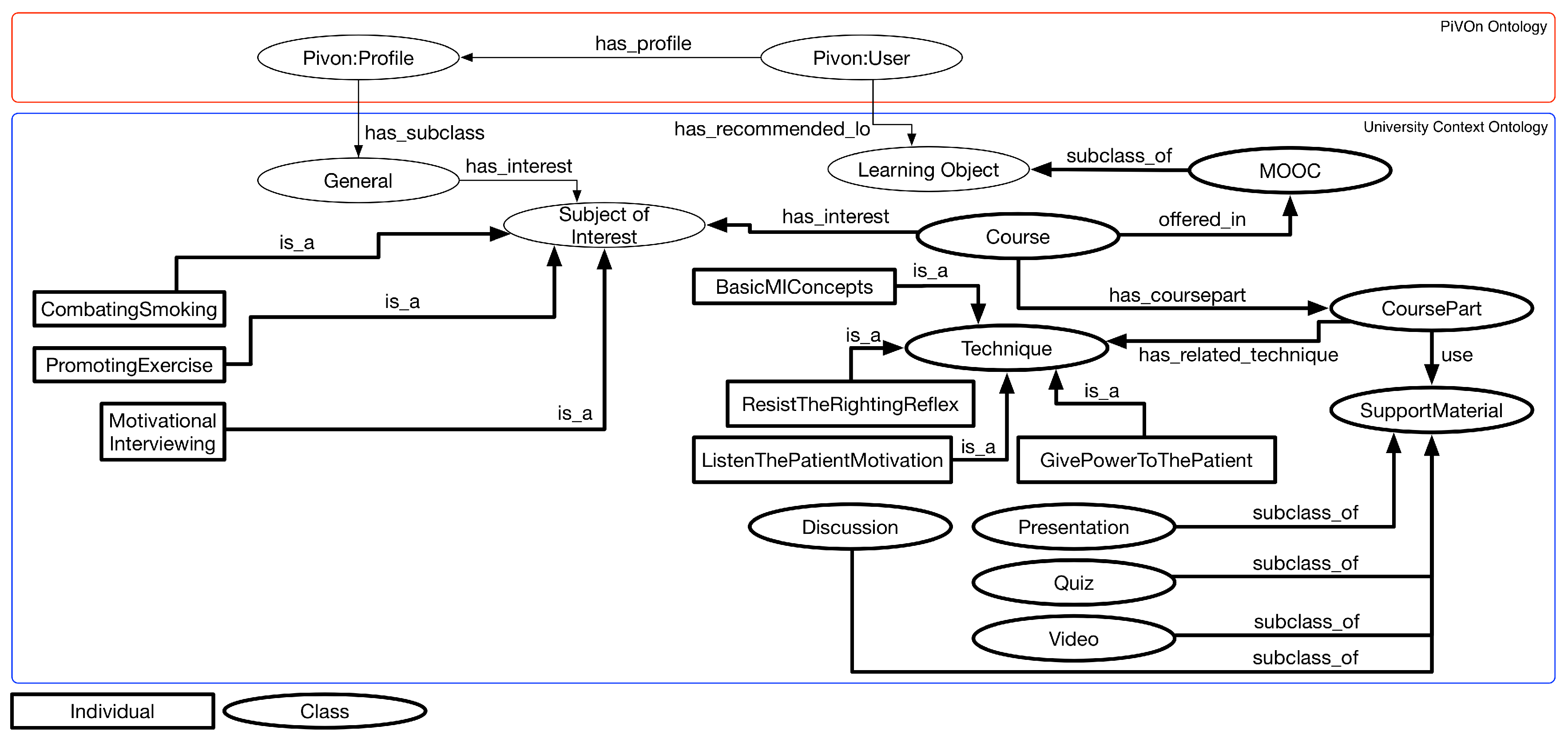
5.1. Application of the Context Workflow
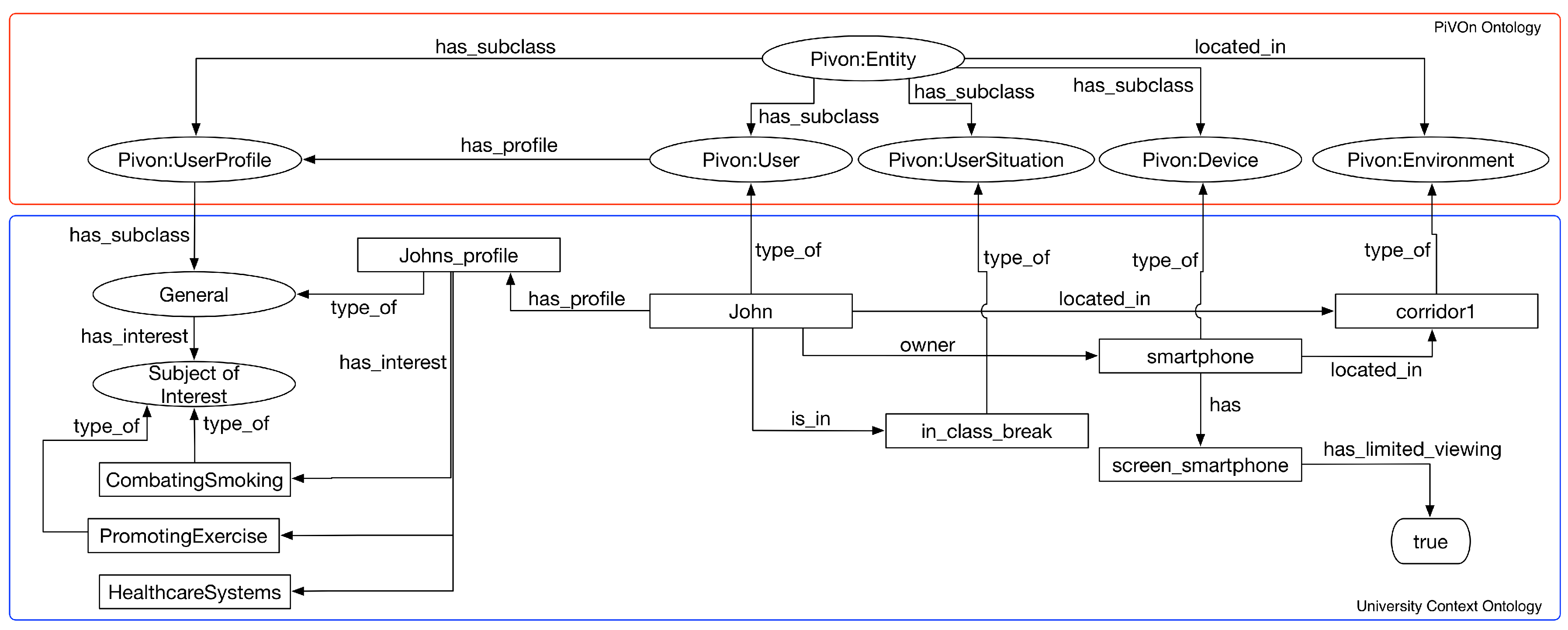
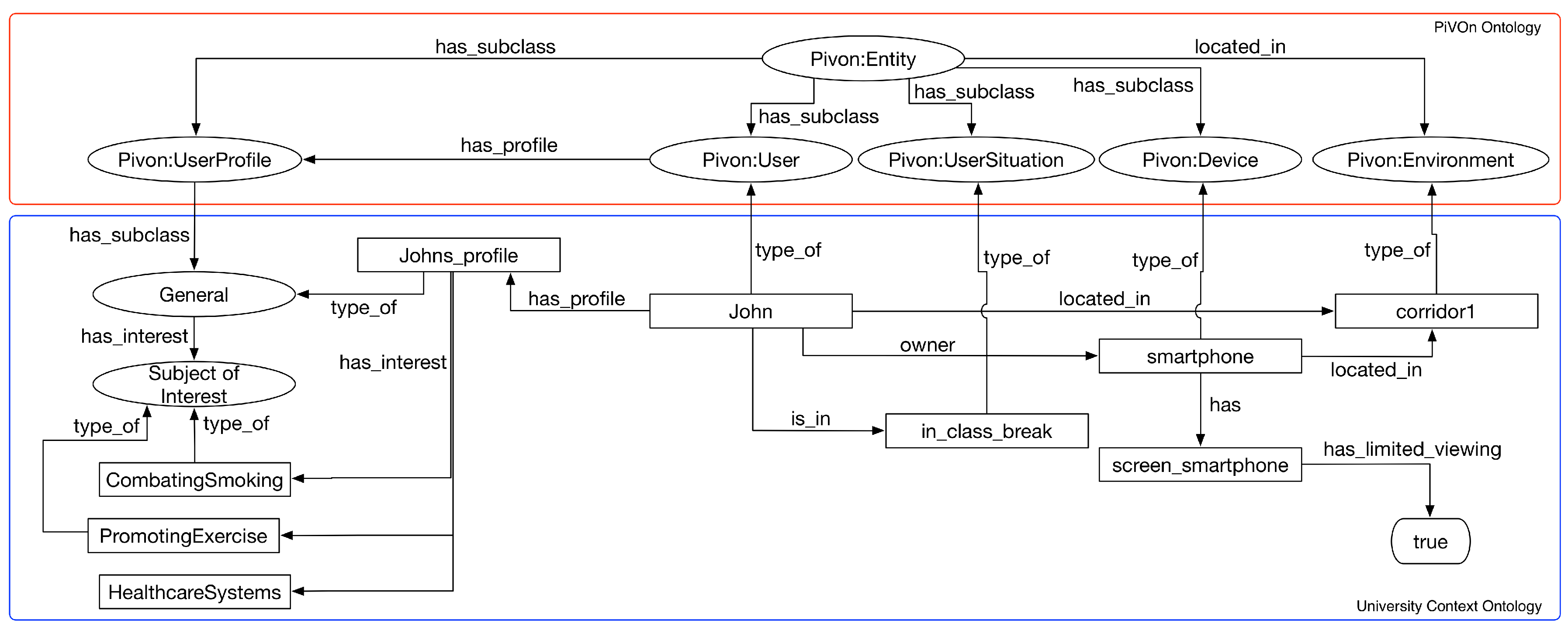
- Storyboard 1: Johan is a public health student at the university campus. He registers and accesses the motivational interview MOOC during the break of one of the classes through his smartphone while staying at the cafeteria. As Johan enrolled in the course and makes the first access, he is presented only to course modules related to learning basic concepts of motivational interviewing. Since Johan is in the range of classes, he uses a device with limited viewing capabilities and the range is 15 min, no backing material with videos longer than 10 min is displayed;
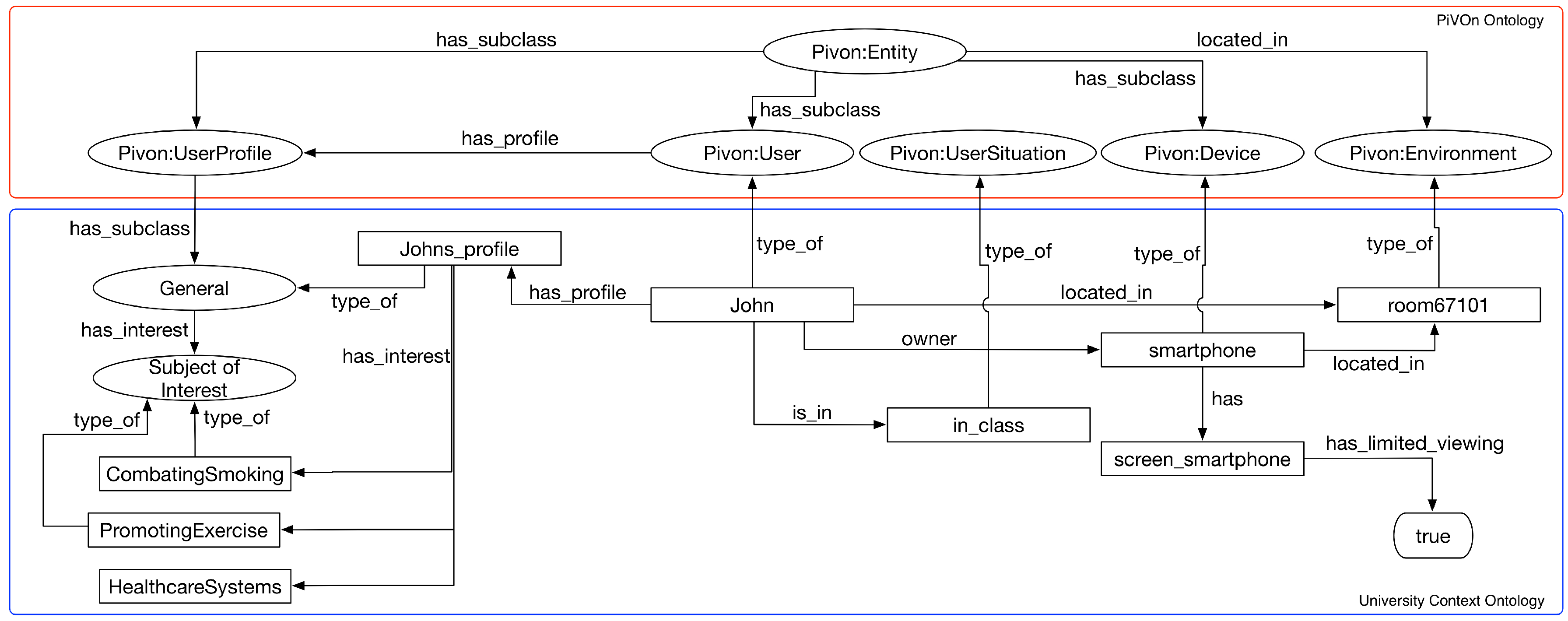
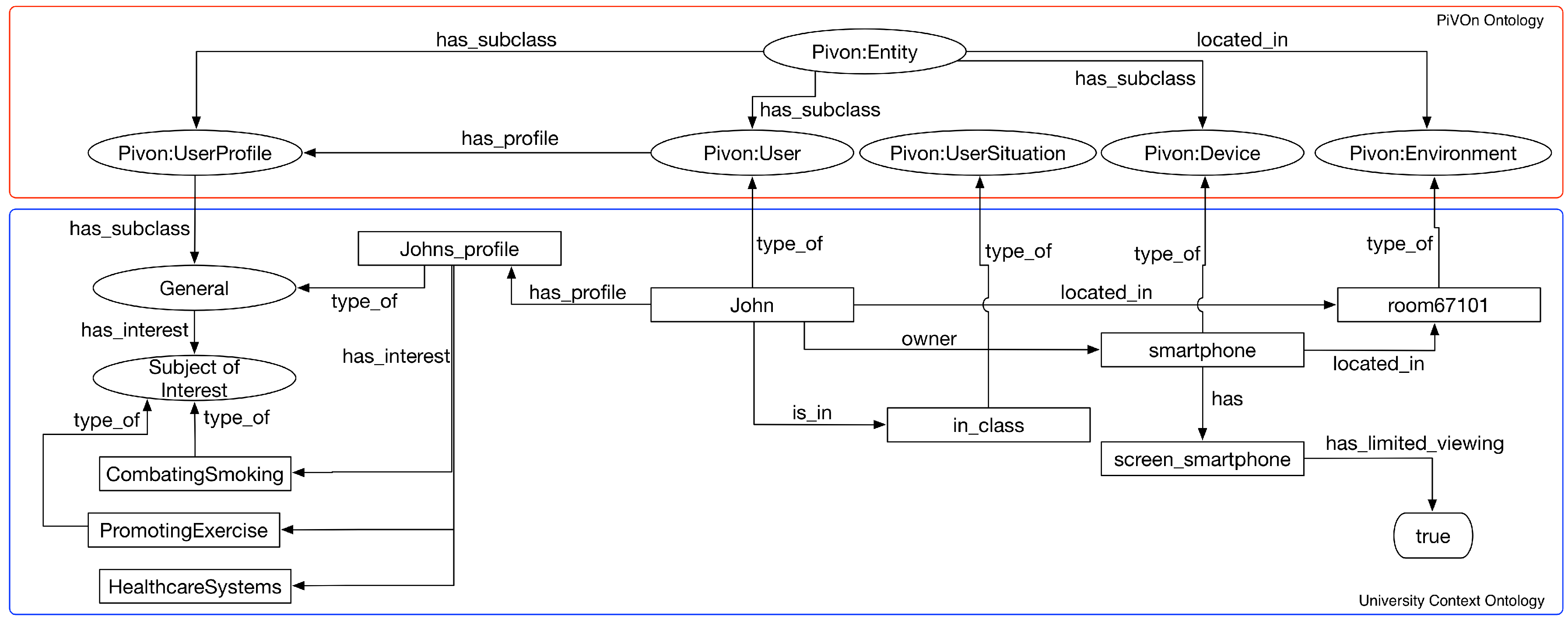
- Storyboard 2: Johan is a public health student on the university campus. He enrolled in the MOOC on motivational interviewing, and during one of his undergraduate classes, he introduced the MOOC to some of his colleagues. As Johan is in class, the MOOC presents only general information about the course, such as the presentation about the course and the discussion forum;
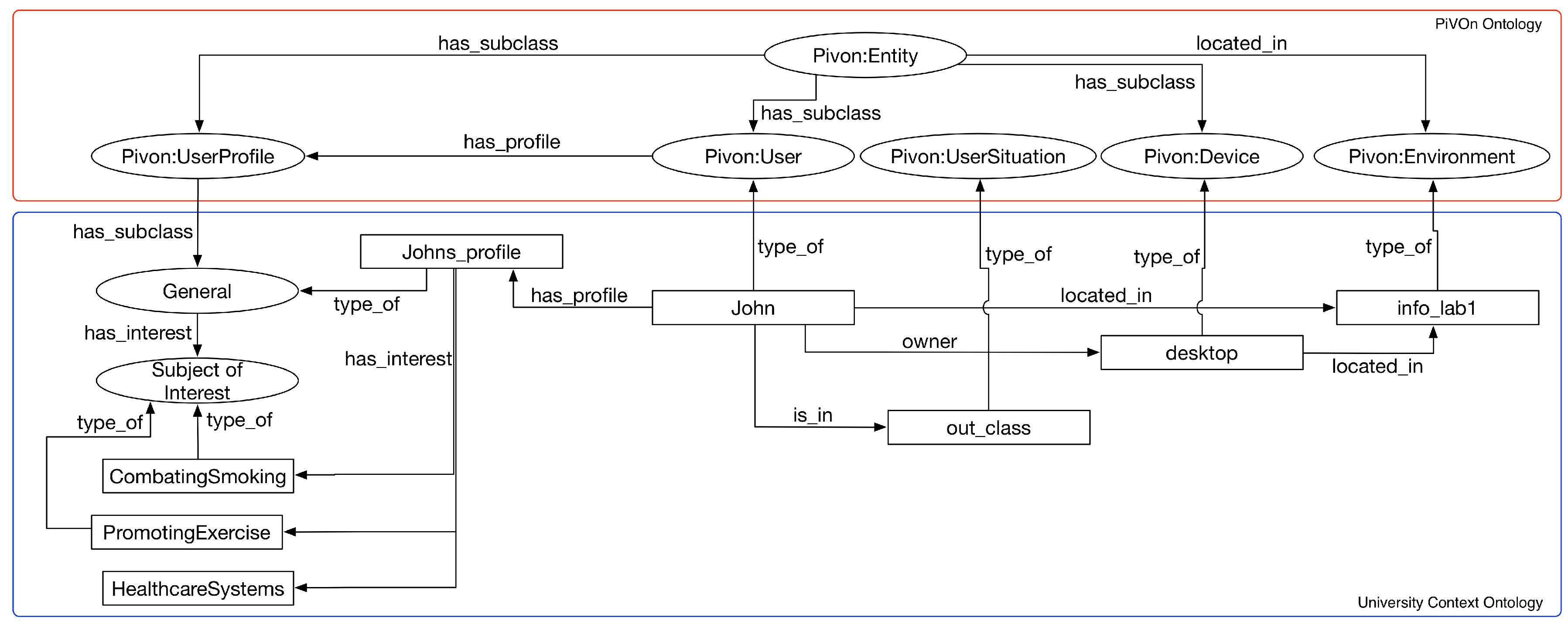
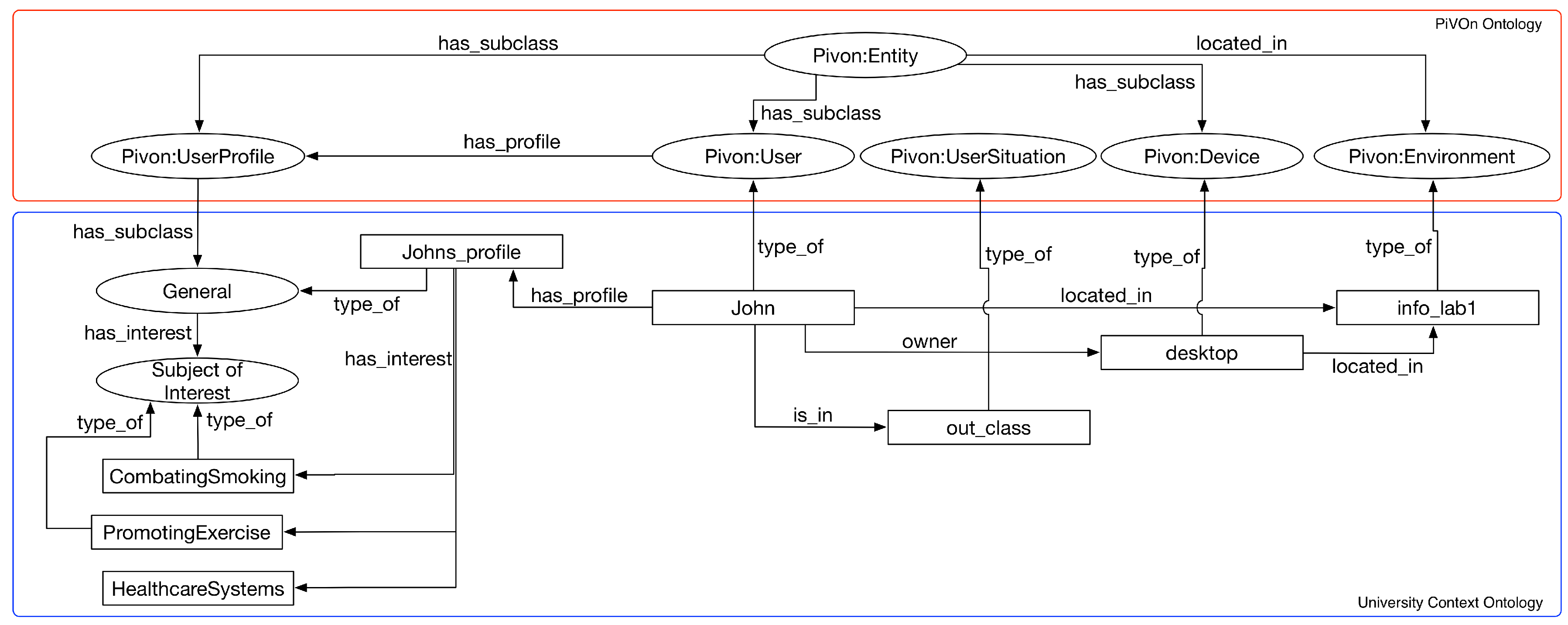
- Storyboard 3: Johan is a public health student on the university campus. Johan is interested in areas such as promoting physical activities for patients and combating smoking. This interest is due to two main factors: (i) Johan’s father smokes; and (ii) John has a close friend with behavioral obesity. Johan goes to the computer lab after lunch and accesses the motivational interview MOOC through one of the lab computers. Johan has already completed activities related to learning basic concepts of motivational interviewing. Thus, the parts of the course related to the concepts of “listening to patient’s motivation", “resistance to correction reflex" and “empowering the patient" are presented to John. We present only the cases where the focus is the promotion of physical exercises or the fight against smoking.
5.2. Application of the Domain Workflow
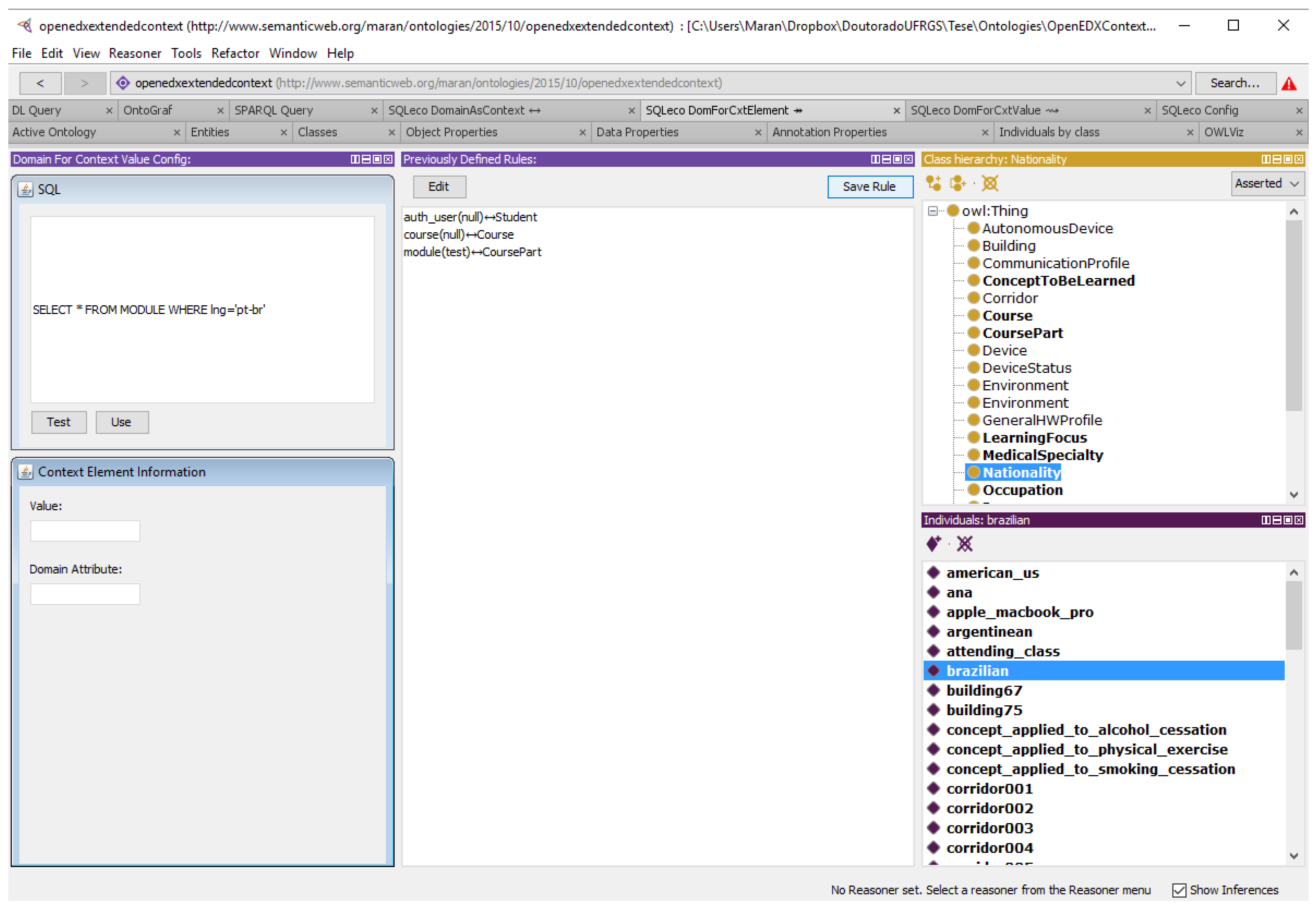
5.3. Application of the Alignment Workflow
5.4. Application of Serialization Workflow
5.5. Application of Query Test Workflow
6. Conclusions and Future Work
- The strength of the proposed approach lies in the UPCaD being a methodology based on well known process, provided by UP and UPON methodologies, to guide the implementation of recent CAR models;
- The definition of the methodology based on workflows provided the possibility of multidisciplinary teams to work together, with the involvement of each team varying in each workflow;
- The implementation of the workflow was supported by existing and common used tools. Examples of tools were cited in the evaluation, as Pellet reasoner, SQLeCO plugin, R2RML tool, Protege and UML;
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Weiser, M. The computer for the 21st century. Sci. Am. 1991, 265, 94–104. [Google Scholar] [CrossRef]
- Dey, A.K.; Abowd, G.D.; Salber, D. A conceptual framework and a toolkit for supporting the rapid prototyping of context-aware applications. Hum. Comput. Interact. 2001, 16, 97–166. [Google Scholar] [CrossRef]
- Chalmers, D. Contextual Mediation to Support Ubiquitous Computing. Ph.D. Thesis, University of London, London, UK, 2002. [Google Scholar]
- Bettini, C.; Brdiczka, O.; Henricksen, K.; Indulska, J.; Nicklas, D.; Ranganathan, A.; Riboni, D. A survey of context modelling and reasoning techniques. Pervasive Mob. Comput. 2010, 6, 161–180. [Google Scholar] [CrossRef]
- Makris, P.; Skoutas, D.N.; Skianis, C. A survey on context-aware mobile and wireless networking: On networking and computing environments’ integration. IEEE Commun. Surv. Tutor. 2013, 15, 362–386. [Google Scholar] [CrossRef]
- Perera, C.; Zaslavsky, A.; Christen, P.; Georgakopoulos, D. Context aware computing for the internet of things: A survey. IEEE Commun. Surv. Tutor. 2014, 16, 414–454. [Google Scholar] [CrossRef]
- Zhang, X.; Hou, X.; Chen, X.; Zhuang, T. Ontology-based semantic retrieval for engineering domain knowledge. Neurocomputing 2013, 116, 382–391. [Google Scholar] [CrossRef]
- Lee, M.H.; Rho, S.; Choi, E.I. Ontology based user query interpretation for semantic multimedia contents retrieval. Multimed. Tools Appl. 2014, 73, 901–915. [Google Scholar] [CrossRef]
- Samwald, M.; Freimuth, R.; Luciano, J.S.; Lin, S.; Powers, R.L.; Marshall, M.S.; Adlassnig, K.P.; Dumontier, M.; Boyce, R.D. An RDF/OWL knowledge base for query answering and decision support in clinical pharmacogenetics. Stud. Health Technol. Inf. 2013, 192, 539. [Google Scholar]
- Forte, M.; de Souza, W.L.; do Prado, A.F. Using ontologies and Web services for content adaptation in Ubiquitous Computing. J. Syst. Softw. 2008, 81, 368–381. [Google Scholar] [CrossRef]
- Bolchini, C.; Quintarelli, E.; Tanca, L. CARVE: Context-aware automatic view definition over relational databases. Inf. Syst. 2013, 38, 45–67. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Context-aware recommender systems. In Recommender Systems Handbook; Springer: New York, NY, USA, 2011; pp. 217–253. [Google Scholar]
- Maran, V.; Machado, A.; Machado, G.M.; Augustin, I.; Lima, J.C.L.; de Oliveira, J.P.M. Database Ontology- Supported Query for Ubiquitous Environments. In Proceedings of the 23rd Brazillian Symposium on Multimedia and the Web, Gramado, Brazil, 17–20 October 2017; ACM DL: New York, NY, USA, 2017. [Google Scholar]
- Jacobson, I.; Booch, G.; Rumbaugh, J.; Rumbaugh, J.; Booch, G. The Unified Software Development Process; Addison-Wesley: Reading, MA, USA, 1999; Volume 1. [Google Scholar]
- De Nicola, A.; Missikoff, M.; Navigli, R. A software engineering approach to ontology building. Inf. Syst. 2009, 34, 258–275. [Google Scholar] [CrossRef]
- Maran, V.; de Oliveira, J.P.M.; Pietrobon, R.; Augustin, I. Ontology Network Definition for Motivational Interviewing Learning Driven by Semantic Context-Awareness. In Proceedings of the 2015 IEEE 28th International Symposium on Computer-Based Medical Systems (CBMS), Sao Carlos, Brazil, 22–25 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 264–269. [Google Scholar]
- Maran, V.; Machado, A.; Augustin, I.; de Oliveira, J.P.M. Semantic Integration between Context-awareness and Domain Data to Bring Personalized Queries to Legacy Relational Databases. In Proceedings of the 18th International Conference on Enterprise Information Systems (ICEIS 2016), Rome, Italy, 25–28 April 2016; Volume 1, pp. 238–243. [Google Scholar]
- Chen, G.; Kotz, D. A Survey of Context-Aware Mobile Computing Research; Technical Report TR2000-381; Department of Computer Science, Dartmouth College: Hanover, NH, USA, 2000. [Google Scholar]
- Strang, T.; Linnhoff-Popien, C.; Frank, K. CoOL: A context ontology language to enable contextual interoperability. In Distributed Applications and Interoperable Systems; Springer: Berlin, Germany, 2003; Volume 2893, pp. 236–247. [Google Scholar]
- Knappmeyer, M.; Kiani, S.L.; Reetz, E.S.; Baker, N.; Tonjes, R. Survey of context provisioning middleware. IEEE Commun. Surv. Tutor. 2013, 15, 1492–1519. [Google Scholar] [CrossRef]
- W3C OWL Working Group. {OWL} 2 Web Ontology Language Document Overview. Available online: https://www.w3.org/TR/owl2-overview/ (accessed on 30 January 2018).
- Berners-Lee, T. Linked Data, in Design Issues: Architectural and Philosophical points. Available online: https://www.w3.org/DesignIssues/ (accessed on 30 January 2018).
- Maran, V.; de Oliveira, J.P.M. Uma Revisão de Técnicas de Distribuição e Persistência de Informações de Contexto e Inferências de Situações em Sistemas Ubíquos. Cad. Inform. 2014, 8, 1–46. [Google Scholar]
- Rodríguez, N.D.; Cuéllar, M.P.; Lilius, J.; Calvo-Flores, M.D. A survey on ontologies for human behavior recognition. ACM Comput. Surv. (CSUR) 2014, 46, 43. [Google Scholar] [CrossRef]
- Hervás, R.; Bravo, J.; Fontecha, J. A Context Model based on Ontological Languages: A Proposal for Information Visualization. J. UCS 2010, 16, 1539–1555. [Google Scholar]
- Hervás, R.; Bravo, J. COIVA: Context-aware and ontology-powered information visualization architecture. Softw. Pract. Exp. 2011, 41, 403–426. [Google Scholar] [CrossRef]
- Poveda Villalon, M.; Suárez-Figueroa, M.C.; García-Castro, R.; Gómez-Pérez, A. A Context Ontology for Mobile Environments. Available online: http://ceur-ws.org/Vol-626/regular3.pdf (accessed on 30 January 2018).
- Brown, P.J.; Jones, G.J. Context-aware retrieval: Exploring a new environment for information retrieval and information filtering. Pers. Ubiquitous Comput. 2001, 5, 253–263. [Google Scholar] [CrossRef]
- Orsi, G.; Tanca, L. Context modelling and context-aware querying. Datalog Reloaded 2011, 1, 225–244. [Google Scholar]
- Colace, F.; De Santo, M.; Moscato, V.; Picariello, A.; Schreiber, F.A.; Tanca, L. Data Management in Pervasive Systems; Springer: Berlin, Germany, 2015. [Google Scholar]
- Martinenghi, D.; Torlone, R. A logical approach to context-aware databases. In Management of the Interconnected World; Springer: Berlin, Germany, 2010; pp. 211–219. [Google Scholar]
- Dıaz, A.; Motz, R.; Rohrer, E. Making ontology relationships explicit in a ontology network. AMW 2011, 1, 749. [Google Scholar]
- Laclavık, M. RDB2Onto: Relational database data to ontology individuals mapping. In Proceeding of Ninth International Conference of Informatics; Slovak Society for Applied Cybernetics and Informatics: Bratislava, Slovak, 2007; Available online: http://nazou.fiit.stuba.sk/home/files/itat_nazou_rdb2onto.pdf (accessed on 30 January 2018).
- Cooper, S. MOOCs: Disrupting the university or business as usual? Arena J. 2013, 39, 182. [Google Scholar]
- Dillenbourg, P.; Fox, A.; Kirchner, C.; Mitchell, J.; Wirsing, M. Massive Open Online Courses: Current state and perspectives. In Proceedings of the Dagstuhl Perspectives Workshop 14112, Dagstuhl Manifestos, 10–13 March 2014; Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik: Wadern, Germany, 2014; Volume 4. [Google Scholar]
- Gutiérrez-Rojas, I.; Alario-Hoyos, C.; Pérez-Sanagustín, M.; Leony, D.; Delgado-Kloos, C. Scaffolding self-learning in MOOCs. In Proceedings of the Second MOOC European Stakeholders Summit, EMOOCs, Lausanne, Switzerland, 10–12 February 2014; pp. 43–49. [Google Scholar]
- Bueno-Delgado, M.; Pavón-Marino, P.; De-Gea-Garcia, A.; Dolon-Garcia, A. The smart university experience: An NFC-based ubiquitous environment. In Proceedings of the 2012 Sixth International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (IMIS), Palermo, Italy, 4–6 July 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 799–804. [Google Scholar]
- Machado, G.M.; de Oliveira, J.P.M. Context-aware adaptive recommendation of resources for mobile users in a university campus. In Proceedings of the 2014 IEEE 10th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Larnaca, Cyprus, 8–10 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 427–433. [Google Scholar]
- Cole, S.; Bogenschutz, M.; Hungerford, D. Motivational interviewing and psychiatry: Use in addiction treatment, risky drinking and routine practice. Focus 2011, 9, 42–54. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tuple | ID | Display_Name | Graded | Parent | Format | Type |
|---|---|---|---|---|---|---|
| 1 | 100 | Clinical Case 1 | 1 | NULL | html | main |
| 2 | 101 | Clinical Case 2 | 1 | NULL | html | main |
| Names | |||
|---|---|---|---|
| Student | Course | Device | MOOC |
| Motivational Interview | Classroom | Interval | Building |
| Classroom | Class | Laboratory | Course Part |
| Smartphone | Desktop | Computer | Video |
| Empowering the Patient | Device | Duration | Smoking Combat |
| Correction Reflection Resistance | Hall | Presentation | Discussion |
| Promotion of Physical Activity | Forum | University | Basic concepts |
| Listen to the patient’s motivation | Campus | Quiz | Support material |
| Question ID | Description |
|---|---|
| QC1 | What support materials from the motivational interview course should be presented to students when they are in the class interval? |
| QC2 | What support materials from the motivational interview course should be presented to students when they are accessing the course using smartphones? |
| QC3 | Which cases of the motivational interview course should be presented to students who are interested in the topics “combating smoking” and “incentive to exercise”? |
| QC4 | Which course cases should be presented to the student when he/she is accessing the course during a face-to-face class? |
| QC5 | Which cases of the motivational interview course should be presented to the student in the first three months of the course? |
| Imported Concepts | |||
|---|---|---|---|
| Ability | Activity | Contact | Device |
| Entity | Publication | System | User |
| Work | Role | Learning Object | Expertise |
| GPS | Organization | Academic | |
| Term | Description |
|---|---|
| MOOC | Online courses made available to a large audience, which is generally not geographically limited. |
| Course | Course offered on a MOOC platform. |
| Course Part | A part of course offered on a MOOC platform. Parts of courses are composed of support elements defined on the platform |
| Motivational Interviewing | Main course topic used in the application scenario |
| Basic Concepts | Student’s learning focus on the course during the first access |
| Smoking Combat | Subject of interest of the student about cases of motivational interview that present situations of combat to smoking |
| Promotion of Physical Activity | Subject of interest of the student about cases of motivational interview that present situations promotion of physical activity |
| Correction Reflection Resistance | One of the techniques used in motivational interviews |
| Listen to the patient’s motivation | One of the techniques used in motivational interviews |
| Empowering the Patient | One of the techniques used in motivational interviews |
| Presentation | One of the types of support material associated with a part of the course on the MOOCs platform |
| Movie | One of the types of support material associated with a part of the course on the MOOCs platform |
| Discussion Forum | One of the types of support material associated with a part of the course on the MOOCs platform |
| Quiz | One of the types of support material associated with a part of the course on the MOOCs platform |
| Classes | Object Properties | Data Properties | Axioms |
|---|---|---|---|
| 130 | 262 | 620 | 3654 |
| Competence Question | Elements of Context of Interest | Context Element Classification |
|---|---|---|
| QC1 | in_class_break | Individual of UserSituation class |
| QC2 | limited_viewing = true | Data property of Device class |
| QC3 | smoking_cessation, exercise_promotion | Individuals of SubjectOfInterest class |
| QC4 | in_class | Individual of UserSituation class |
| QC5 | basic_MI_concepts | Individual of Technique class |
| Competence Question | Related SQL Query | Query ID |
|---|---|---|
| QC1, QC2 | SELECT t1.idmodule AS lev1, t2.idmodule AS lev2, | Query1 |
| t3.idmodule AS lev3, t4.idmodule AS lev4, def.definition | ||
| AS lev4definition FROM module_child AS t1 | ||
| LEFT JOIN module_child AS t2 ON t2.idmodule = t1.idchild | ||
| LEFT JOIN module_child AS t3 ON t3.idmodule = t2.idchild | ||
| LEFT JOIN module_child AS t4 ON t4.idmodule = t3.idchild | ||
| JOIN module ON t4.idmodule = module.id JOIN module_definition | ||
| AS def ON module.definition=def.id | ||
| WHERE t1.idmodule = ‘57bb8878e4efae083b63c157’ | ||
| QC3, QC4, QC5 | SELECT course.id, t1.idmodule AS lev1, | Query2 |
| t2.idmodule AS lev2, module_definition.definition | ||
| FROM auth_user JOIN student_courseenrollment ON | ||
| (auth_user.id = student_courseenrollment.user_id) | ||
| JOIN course ON (student_courseenrollment.course_id = course.id) | ||
| JOIN module_child AS t1 ON (t1.idmodule = course.module_id) | ||
| LEFT JOIN module_child AS t2 ON (t2.idmodule = t1.idchild) | ||
| JOIN module ON (t2.idmodule = module.id) | ||
| JOIN module_definition ON module.definition = module_definition.id | ||
| WHERE auth_user.id = 5 AND | ||
| course.id = ‘course-v1:UnivTest + EM101+2016_1’ |
| Linking Rule | Function of the Rule |
|---|---|
SELECT module.*,FROM module JOIN module_definition ON (module.definition = module_definition.id) WHERE module_definition.definition-> “.block_type” <> ‘video’ OR module_definition.definition-> “.block_info.duration” <600 | Return all the modules with videos with less then 10 min |
SELECT module.*,FROM module JOIN module_definition ON (module.definition = module_definition.id) WHERE module_definition.definition-> “.block_type” <> ‘video’ | Return all the modules with no videos |
SELECT module.*, FROM module JOIN module_definition ON (module.definition = module_definition.id), WHERE module_definition.definition-> “.block_type” = ‘overview’ OR module_definition.definition ->“.block_type” = ‘vertical’ OR module_definition.definition->“.block_type” = ‘course’, OR module.id = ‘3a4ce1eaa19’ | Return all the modules related to smoking cessation |
SELECT module.*,FROM module JOIN module_definition ON (module.definition = module_definition.id), WHERE module_definition.definition ->“” = ‘overview’ OR module_definition.definition -> “” = ‘course’,OR module.id = ‘3a4ce1eaa19’ OR module.id = ’3e9a6124059c62’ | Return only the modules related to course main structure |
| Competence Question | Related SQL Query | Context of Interest | Query Result |
|---|---|---|---|
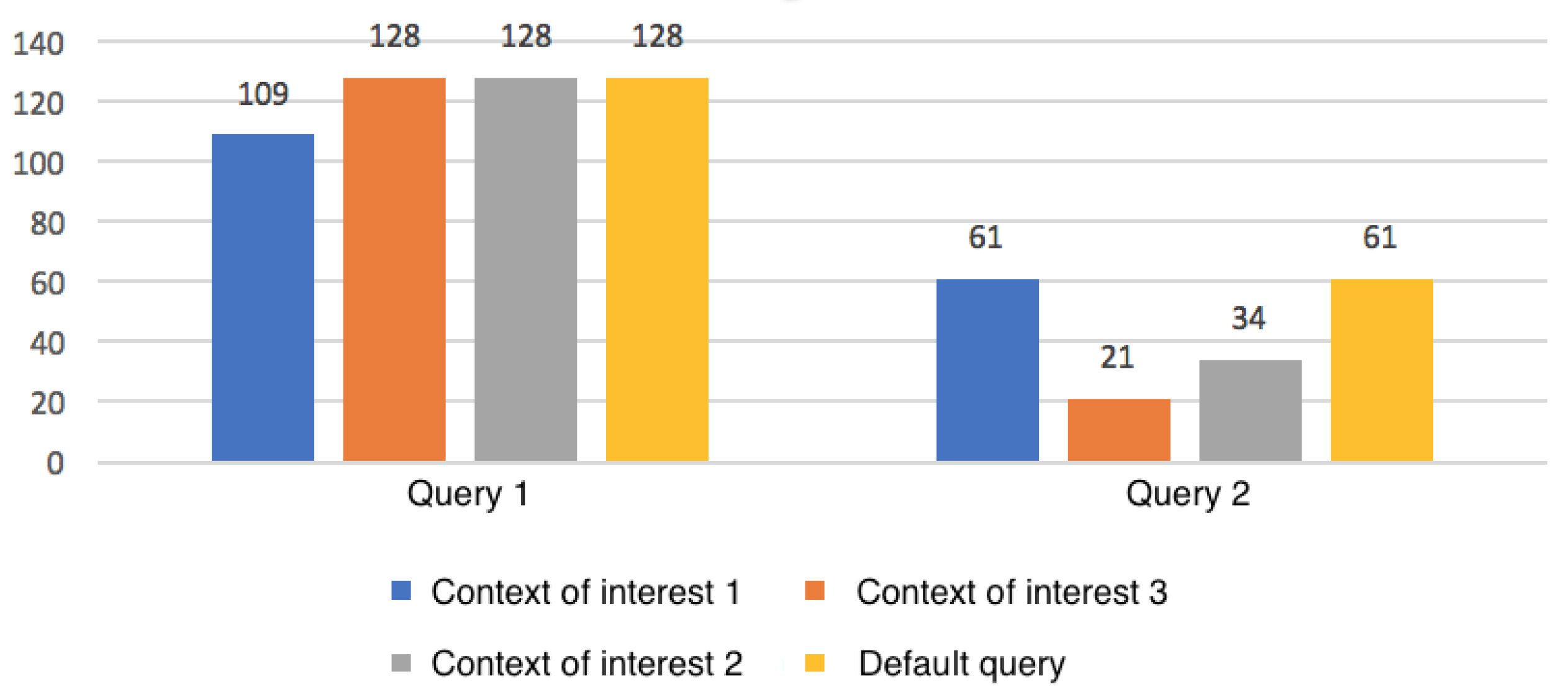
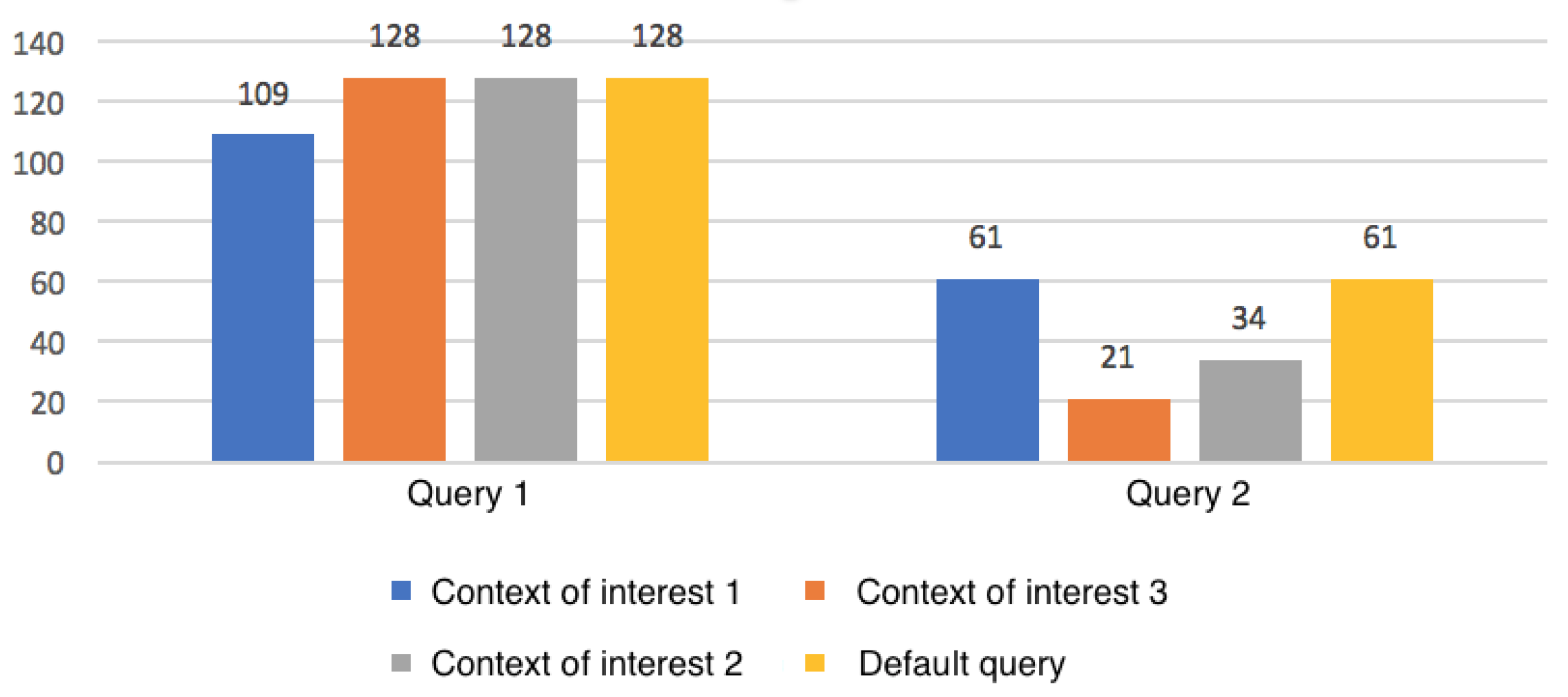
| QC1, QC2 | Query 1 | Context of Interest (a) | All video-type modules that have a duration greater than 600 were not included in the query. |
| QC3 | Query 2 | Context of Interest (c) | Only the modules and sub-modules of the course associated with the interests of physical activity promotion and smoking control were returned in the consultation. |
| QC4, QC5 | Query 2 | Context of Interest (b) | Only the course modules that present the basic structure of the course (overview and discussion) or that are associated with the generic learning of MI techniques were returned in the query. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maran, V.; Medeiros Machado, G.; Machado, A.; Augustin, I.; Palazzo M. de Oliveira, J. UPCaD: A Methodology of Integration Between Ontology-Based Context-Awareness Modeling and Relational Domain Data. Information 2018, 9, 30. https://doi.org/10.3390/info9020030
Maran V, Medeiros Machado G, Machado A, Augustin I, Palazzo M. de Oliveira J. UPCaD: A Methodology of Integration Between Ontology-Based Context-Awareness Modeling and Relational Domain Data. Information. 2018; 9(2):30. https://doi.org/10.3390/info9020030
Chicago/Turabian StyleMaran, Vinícius, Guilherme Medeiros Machado, Alencar Machado, Iara Augustin, and José Palazzo M. de Oliveira. 2018. "UPCaD: A Methodology of Integration Between Ontology-Based Context-Awareness Modeling and Relational Domain Data" Information 9, no. 2: 30. https://doi.org/10.3390/info9020030
APA StyleMaran, V., Medeiros Machado, G., Machado, A., Augustin, I., & Palazzo M. de Oliveira, J. (2018). UPCaD: A Methodology of Integration Between Ontology-Based Context-Awareness Modeling and Relational Domain Data. Information, 9(2), 30. https://doi.org/10.3390/info9020030