LICIC: Less Important Components for Imbalanced Multiclass Classification



Abstract
1. Introduction
2. Literature Review
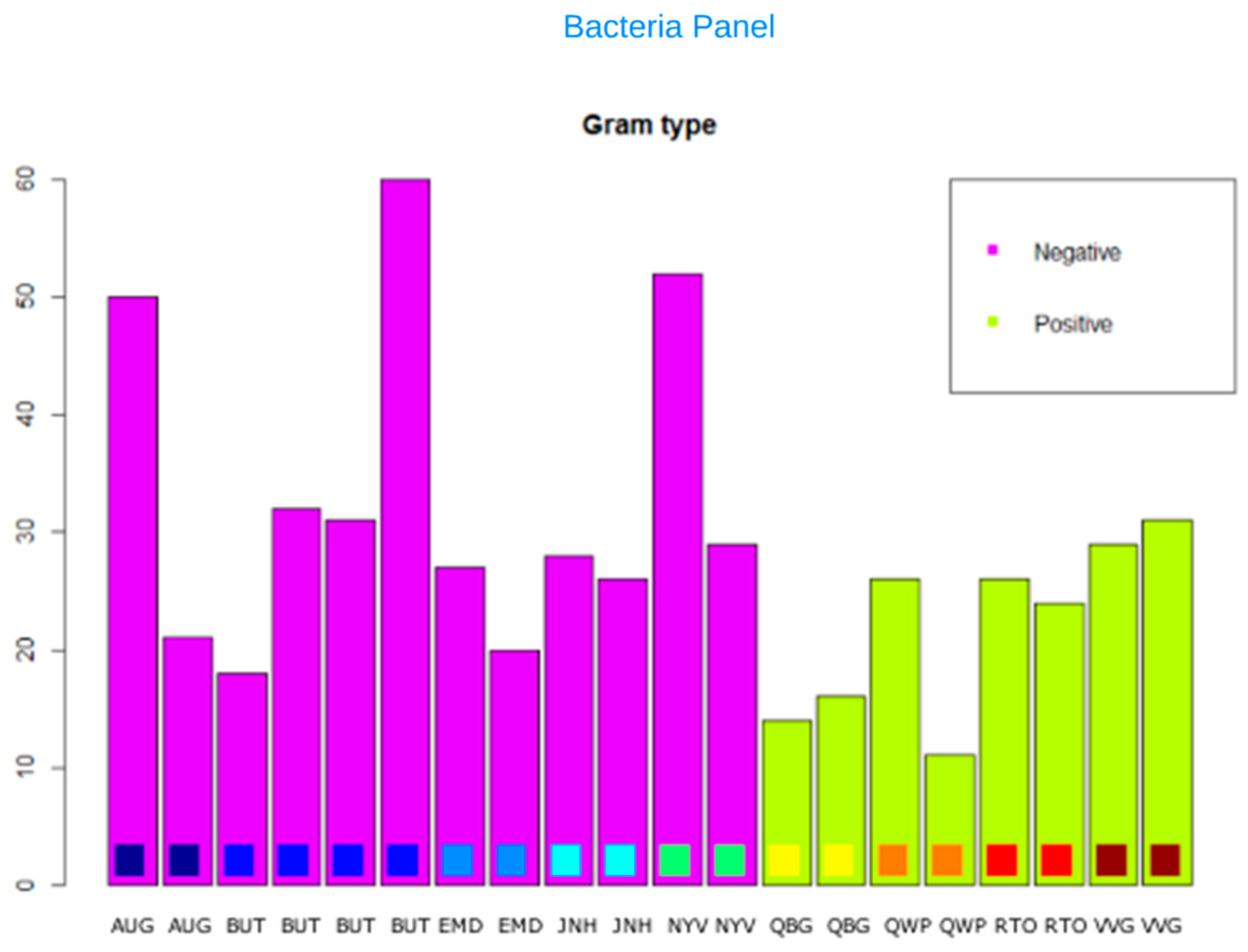
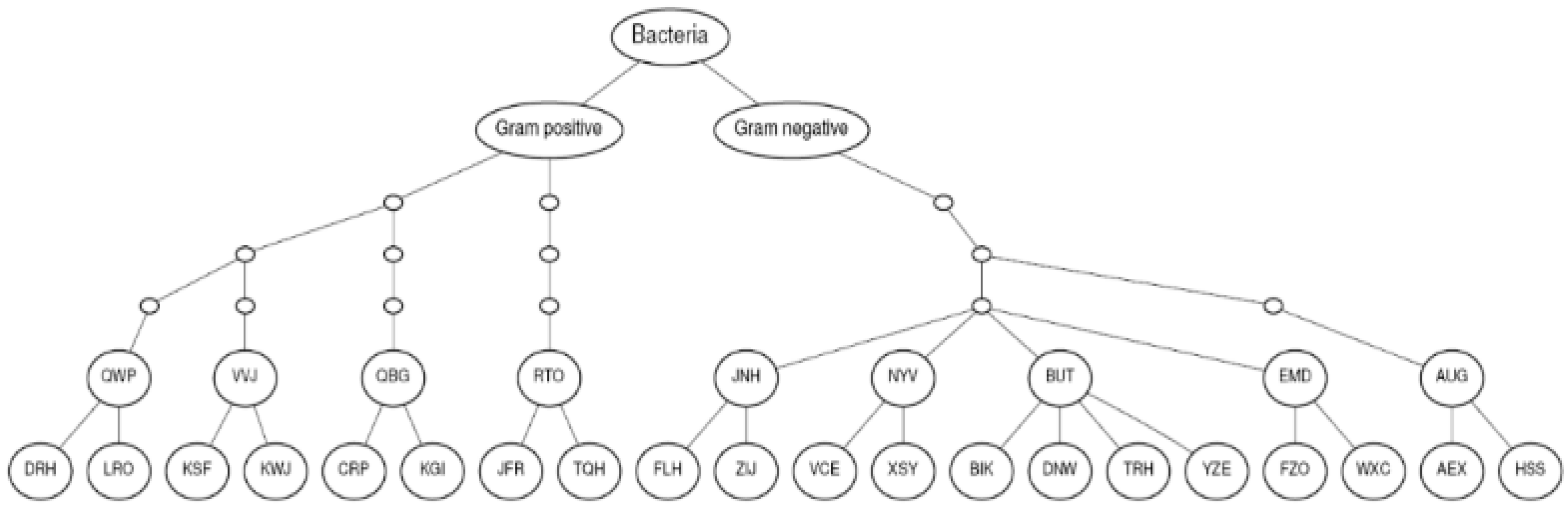
3. Dataset Description
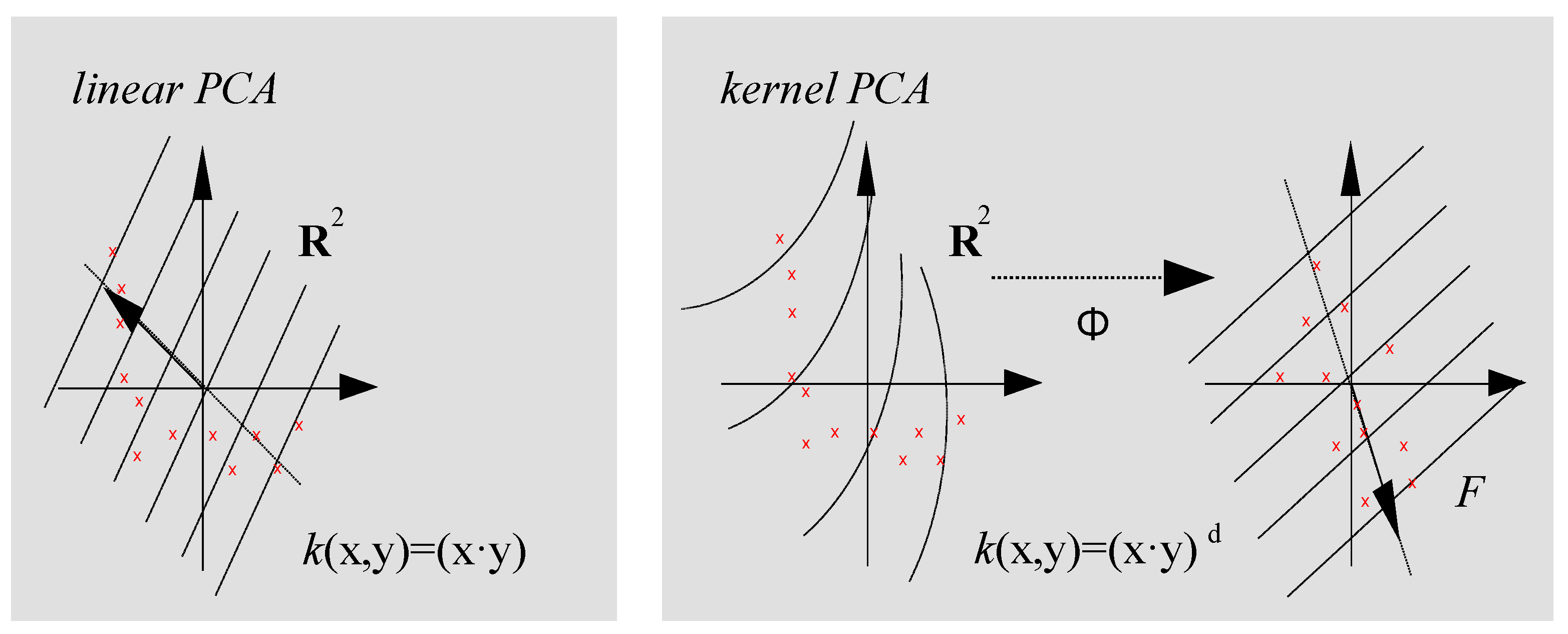
4. Kernel Principal Components Analysis with Pre-Image Computation
5. LICIC Algorithm

6. Experiments and Results
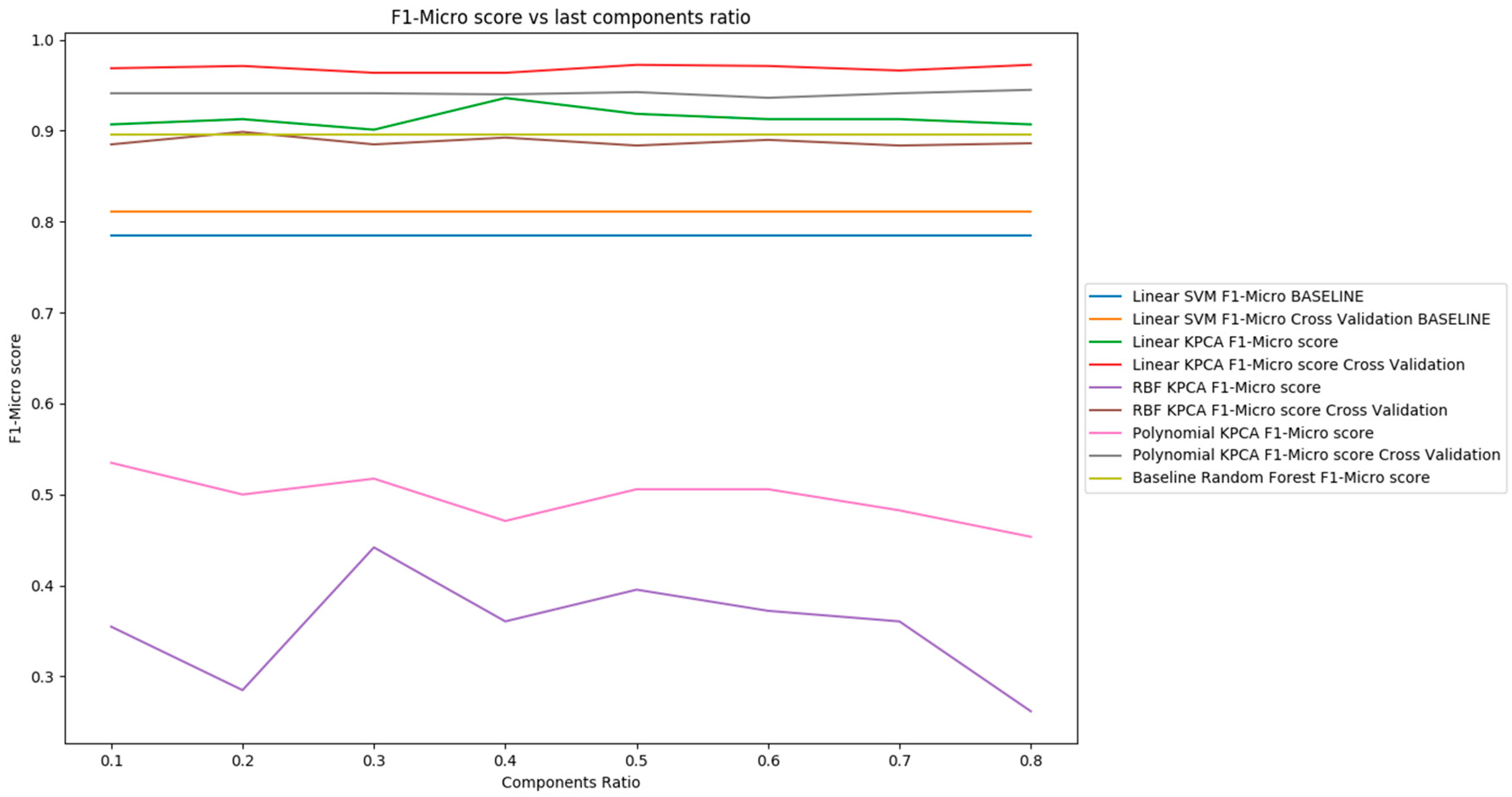
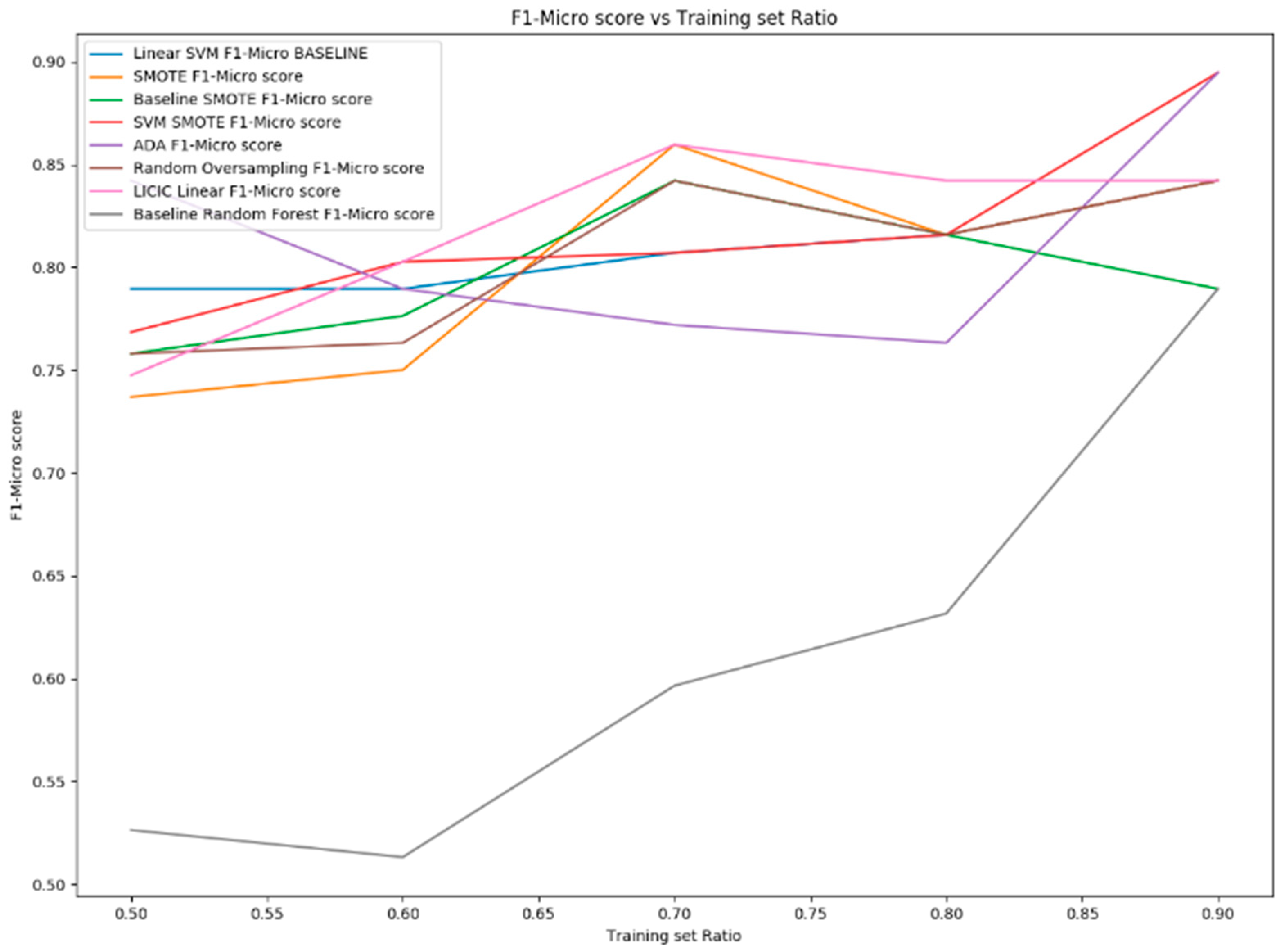
6.1. MicroMass Dataset Results
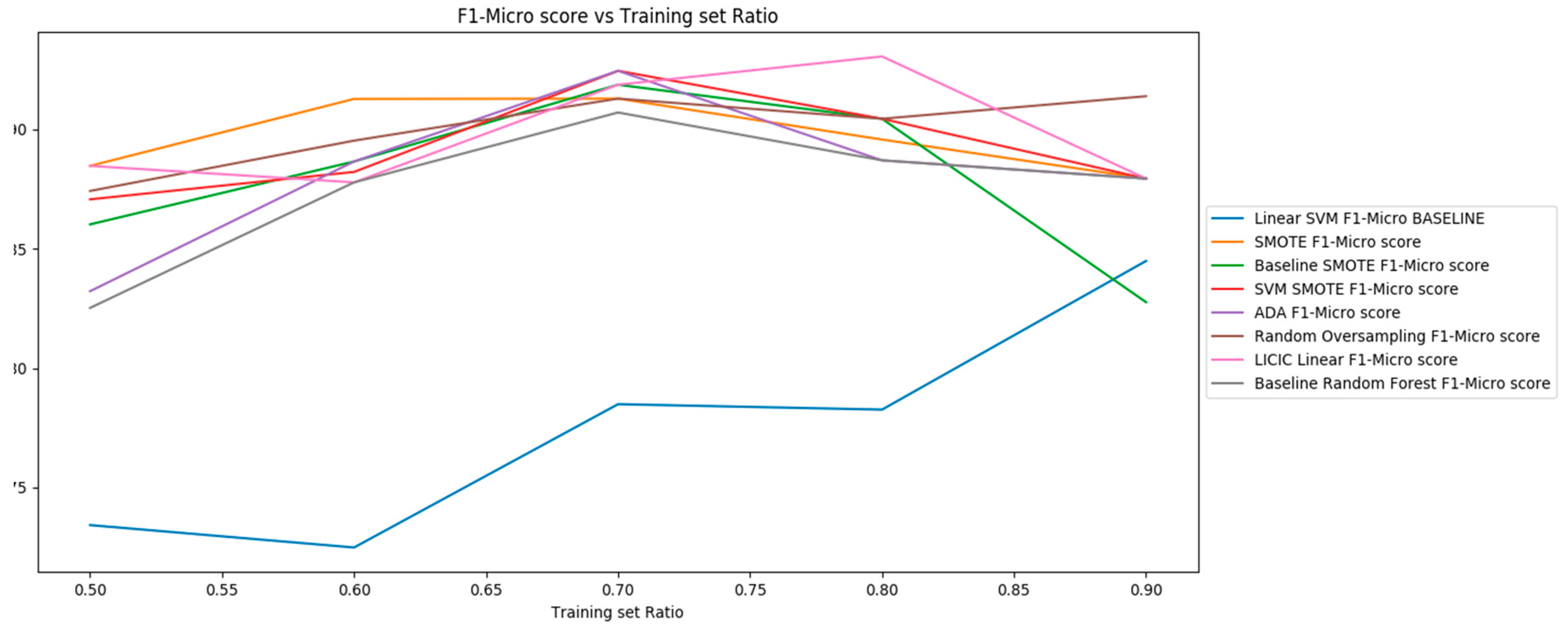
6.2. GCM Dataset Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bellman, R.E. Adaptive Control Processes: A Guided Tour; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Han, H.; Wang, W.; Mao, B. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Nguyen, H.M.; Cooper, E.W.; Kamei, K. Borderline over-sampling for imbalanced data classification. In Proceedings of the Fifth International Workshop on Computational Intelligence & Applications, Milano, Italy, 7–10 September 2009; pp. 24–29. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. JAIR 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Schölkopf, B.; Smola, A.; Müller, K.R. Kernel principal component analysis. In Proceedings of the International Conference on Artificial Neural Networks, Lausanne, Switzerland, 8–10 October 1997; pp. 583–588. [Google Scholar]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-level-smote: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Bangkok, Thailand, 27–30 April 2009; pp. 475–482. [Google Scholar]
- Guo, H.; Viktor, H.L. Learning from Imbalanced Data Sets with Boosting and Data Generation: The DataBoost-IM Approach. ACM Sigkdd Explor. Newslett. 2004, 6, 30–39. [Google Scholar] [CrossRef]
- Guo, H.; Zhou, J.; Wu, C.-A. Imbalanced Learning Based on Data-Partition and SMOTE. Information 2018, 9, 238. [Google Scholar] [CrossRef]
- Feng, S.; Fu, P.; Zheng, W. A Hierarchical Multi-Label Classification Algorithm for Gene Function Prediction. Algorithms 2017, 10, 138. [Google Scholar] [CrossRef]
- Impedovo, D.; Pirlo, G. Updating knowledge in feedback-based multi-classifier systems. In Proceedings of the 2011 International Conference on Document Analysis and Recognition (ICDAR), Beijing, China, 18–21 September 2011; pp. 227–231. [Google Scholar]
- Pirlo, G.; Trullo, C.A.; Impedovo, D. A feedback-based multi-classifier system. In Proceedings of the 10th International Conference on Document Analysis and Recognition, ICDAR’09, Barcelona, Spain, 26–29 July 2009; pp. 713–717. [Google Scholar]
- Dentamaro, V.; Impedovo, D.; Pirlo, G.; Vessio, G. A new ConvNet architecture for heartbeat classification. In Proceedings of the ICPRAI, Montréal, QC, Canada, 14–17 May 2018. [Google Scholar]
- Mahé, P.; Arsac, M.; Chatellier, S.; Monnin, V.; Perrot, N.; Mailler, S.; Girard, V.; Ramjeet, M.; Surre, J.; Lacroix, B.; et al. Automatic identification of mixed bacterial species fingerprints in a MALDI-TOF mass-spectrum. Bioinformatics 2014, 30, 1280–1286. [Google Scholar] [CrossRef] [PubMed]
- Vervier, K.; Mahé, P.; Veyrieras, J.B.; Vert, J.P. Benchmark of structured machine learning methods for microbial identification from mass-spectrometry data. arXiv, 2015; arXiv:1506.07251. [Google Scholar]
- Dua, D.; Karra Taniskidou, E. UCI Machine Learning Repository; University of California: Irvine, CA, USA, 2017; Available online: http://archive.ics.uci.edu/ml (accessed on 9 December 2018).
- Ramaswamy, S.; Tamayo, P.; Rifkin, R.; Mukherjee, S.; Yeang, C.-H.; Angelo, M.; Ladd, C.; Reich, M.; Latulippe, É.; Mesirov, J.P.; et al. Multiclass cancer diagnosis using tumor gene expression signatures. Proc. Natl. Acad. Sci. USA 2001, 98, 15149–15154. [Google Scholar] [CrossRef] [PubMed]
- Simple Blood Test Detects Eight Different Kinds of Cancer, Nature. 18 January 2018. Available online: https://www.nature.com/articles/d41586-018-00926-5 (accessed on 9 December 2018).
- Cappelli, E.; Felici, G.; Weitschek, E. Combining DNA methylation and RNA sequencing data of cancer for supervised knowledge extraction. BioData Min. 2018, 11, 22. [Google Scholar] [CrossRef] [PubMed]
- Weitschek, E.; Di Lauro, S.; Cappelli, E.; Bertolazzi, P.; Felici, G. CamurWeb: A classification software and a large knowledge base for gene expression data of cancer. BMC Bioinf. 2018, 19, 354. [Google Scholar] [CrossRef] [PubMed]
- Celli, F.; Cumbo, F.; Weitschek, E. Classification of Large DNA Methylation Datasets for Identifying Cancer Drivers. Big Data Res. 2018, 13, 21–28. [Google Scholar] [CrossRef]
- Cestarelli, V.; Fiscon, G.; Felici, G.; Bertolazzi, P.; Weitschek, E. CAMUR: Knowledge extraction from RNA-seq cancer data through equivalent classification rules. Bioinformatics 2015, 32, 697–704. [Google Scholar] [CrossRef] [PubMed]
- Weitschek, E.; Cunial, F.; Felici, G. LAF: Logic Alignment Free and its application to bacterial genomes classification. BioData Min. 2015, 8, 39. [Google Scholar] [CrossRef] [PubMed]
- Weitschek, E.; Fiscon, G.; Fustaino, V.; Felici, G.; Bertolazzi, P. Clustering and Classification Techniques for Gene Expression Profiles Pattern Analysis. In Pattern Recognition in Computational Molecular Biology: Techniques and Approaches; Wiley Book Series on Bioinformatics: Computational Techniques and Engineering; Elloumi, M., Iliopoulos, C.S., Wang, J.T.L., Zomaya, A.Y., Eds.; Wiley-Blackwell: Hoboken, NJ, USA, 2015; ISBN 978-1118893685. [Google Scholar]
- Raschka, S. Kernel Tricks and Nonlinear Dimensionality Reduction via RBF Kernel PCA. Available online: http://sebastianraschka.com/Articles/2014_kernel_pca.html (accessed on 9 December 2018).
- Weston, J.; Schölkopf, B.; Bakir, G.H. Learning to find pre-images. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2004; pp. 449–456. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training-Set Ratio | 50% of Dataset as Training Set | 60% of Dataset as Training Set | 70% of Dataset as Training Set | 80% of Dataset as Training Set | 90% of Dataset as Training Set | |
|---|---|---|---|---|---|---|
| Algorithm | ||||||
| Linear SVM | 0.7736 | 0.7736 | 0.8002 | 0.80914 | 0.82361 | |
| SMOTE | 0.7368 | 0.7452 | 0.8603 | 0.80914 | 0.8746 | |
| Baseline SMOTE | 0.7574 | 0.7682 | 0.8325 | 0.80914 | 0.7732 | |
| SVM SMOTE | 0.7632 | 0.8002 | 0.8002 | 0.80914 | 0.8746 | |
| ADASYN | 0.8435 | 0.7736 | 0.7631 | 0.7547 | 0.8746 | |
| Random Oversampling | 0.7574 | 0.7532 | 0.8325 | 0.80914 | 0.8378 | |
| LICIC | 0.7463 | 0.8002 | 0.8603 | 0.8423 | 0.8378 | |
| Baseline Random Forest | 0.5321 | 0.5267 | 0.6002 | 0.6367 | 0.7732 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dentamaro, V.; Impedovo, D.; Pirlo, G. LICIC: Less Important Components for Imbalanced Multiclass Classification. Information 2018, 9, 317. https://doi.org/10.3390/info9120317
Dentamaro V, Impedovo D, Pirlo G. LICIC: Less Important Components for Imbalanced Multiclass Classification. Information. 2018; 9(12):317. https://doi.org/10.3390/info9120317
Chicago/Turabian StyleDentamaro, Vincenzo, Donato Impedovo, and Giuseppe Pirlo. 2018. "LICIC: Less Important Components for Imbalanced Multiclass Classification" Information 9, no. 12: 317. https://doi.org/10.3390/info9120317
APA StyleDentamaro, V., Impedovo, D., & Pirlo, G. (2018). LICIC: Less Important Components for Imbalanced Multiclass Classification. Information, 9(12), 317. https://doi.org/10.3390/info9120317