A Hybrid Swarm Intelligent Neural Network Model for Customer Churn Prediction and Identifying the Influencing Factors

Abstract
1. Introduction
- A new model for churn prediction that exploits the predictive power of neural network and utilizes it as a base classifier is proposed. To our knowledge, the random weight neural network has not been well-investigated for the problem of churn prediction.
- The model gives insight into the importance of churn factors by assigning a weight for each input feature. This will help decision makers in their strategic plans.
2. Previous Works
3. Preliminaries
3.1. Particle Swarm Optimization
3.2. Feedforward Neural Networks
3.3. Random Weight Networks
3.4. Adaptive Synthetic Sampling (ADASYN)
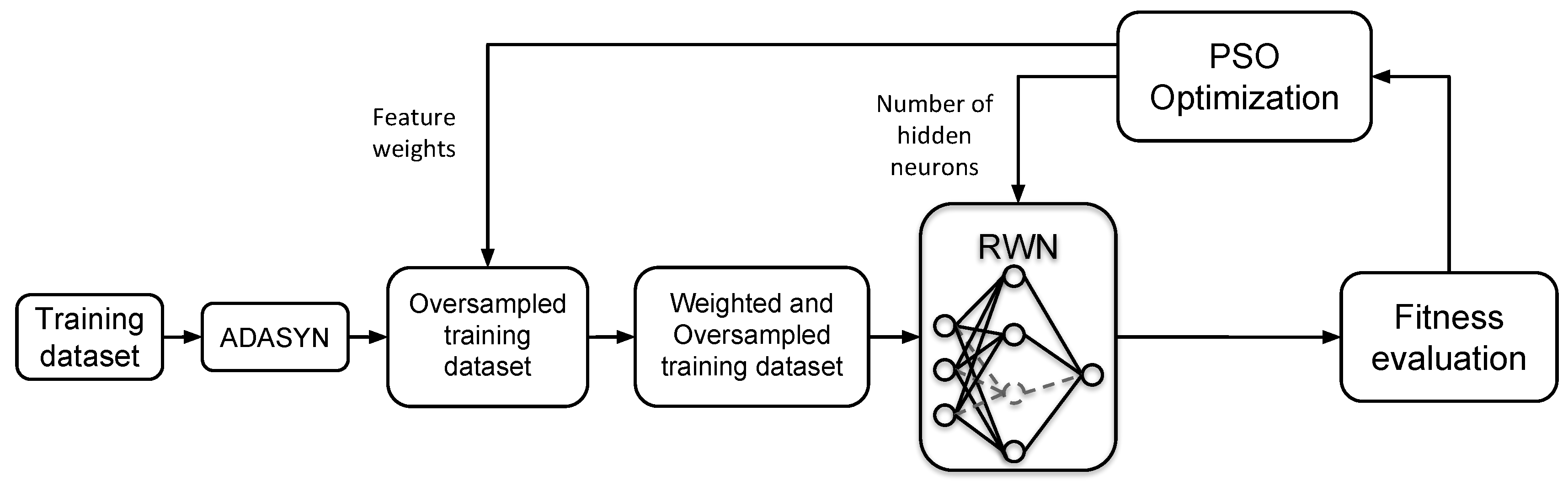
4. Proposed Approach
4.1. Components
- An oversampling algorithm: The main task of this process is to lessen the problem of the imbalanced class distribution in the dataset by re-sampling the minority class. ADASYN algorithm is selected for this task. It is an improved version of the popular SMOTE algorithm and it has shown its efficiency in various complex imbalanced datasets.
- An optimization algorithm: PSO is utilized to simultaneously optimize the weights of the input features in the training dataset, and the structure of the RWN classifier.
- Inductive algorithm: To evaluate the prediction power of the weighted features, an inductive algorithm, which is a learning classifier, is used. RWN is selected for this task due its simplicity and its extreme learning speed.
- An evaluation measure: To quantify the prediction power of the induction algorithm, an appropriate evaluation measure should be selected. F-measure is used in our developed approach, as it balances between the precision and recall of the class of interest, which is, in our case, the churners class. This point is further explained in the following subsection.
4.2. Formulation
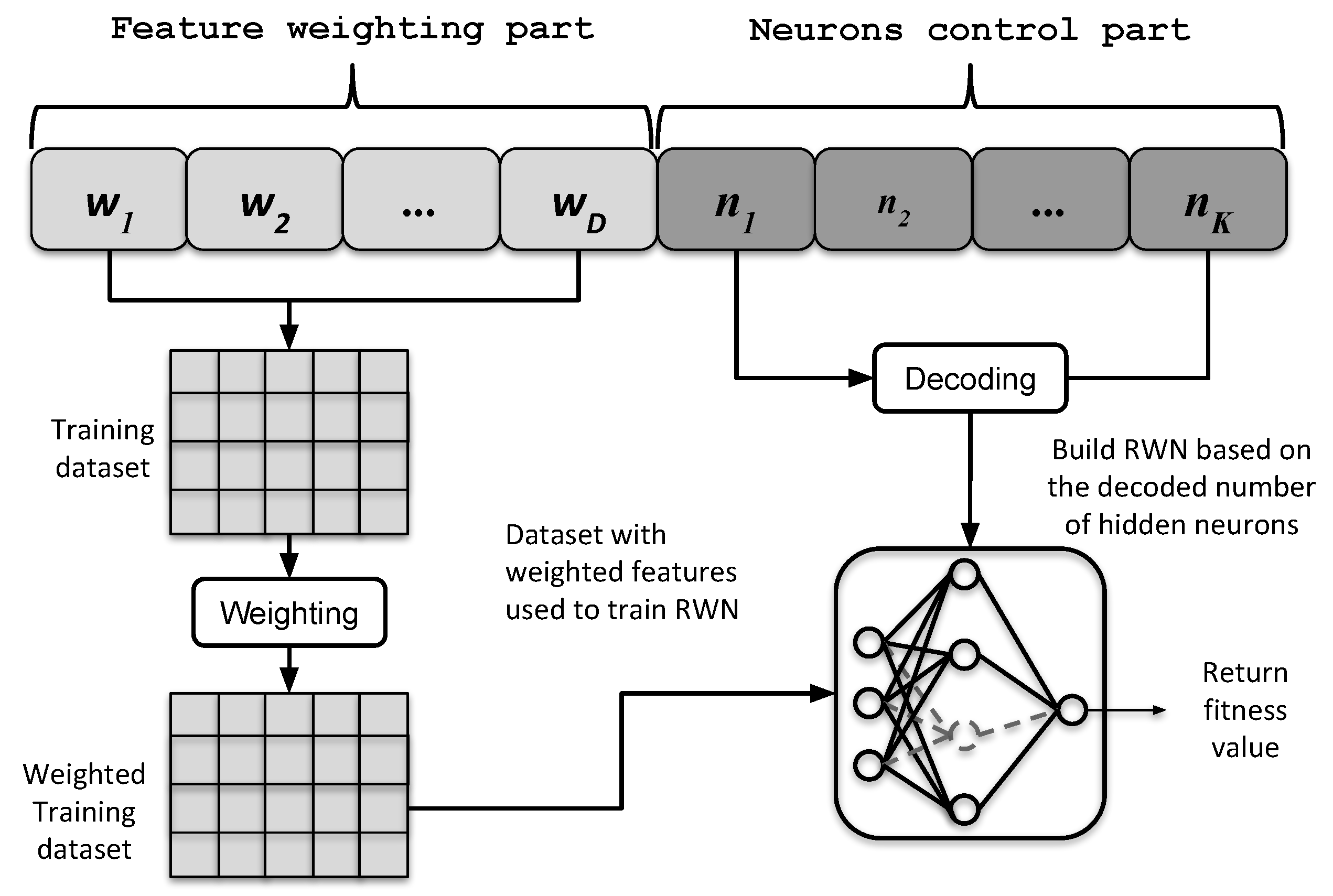
- Solution representation: A particle in PSO represents a candidate solution for the targeted problem. A solution in our case consists of two parts: the weights of the input features and the number of hidden nodes in RWN. In the implementation of the proposed approach, a single individual is encoded as a one-dimensional array of real elements where their values fall between 0 and 1. The first D variables are the weights of their corresponding features, where D is the number of features in the dataset. The second part of the individual consists of K variables to encode the number of hidden nodes. This array can be expressed as follows:The part of the hidden neurons is mapped to a binary representation as given in Equation (13), where is the resulted ith element of a sequence of binary flags that encode the number of selected hidden neurons in RWN.
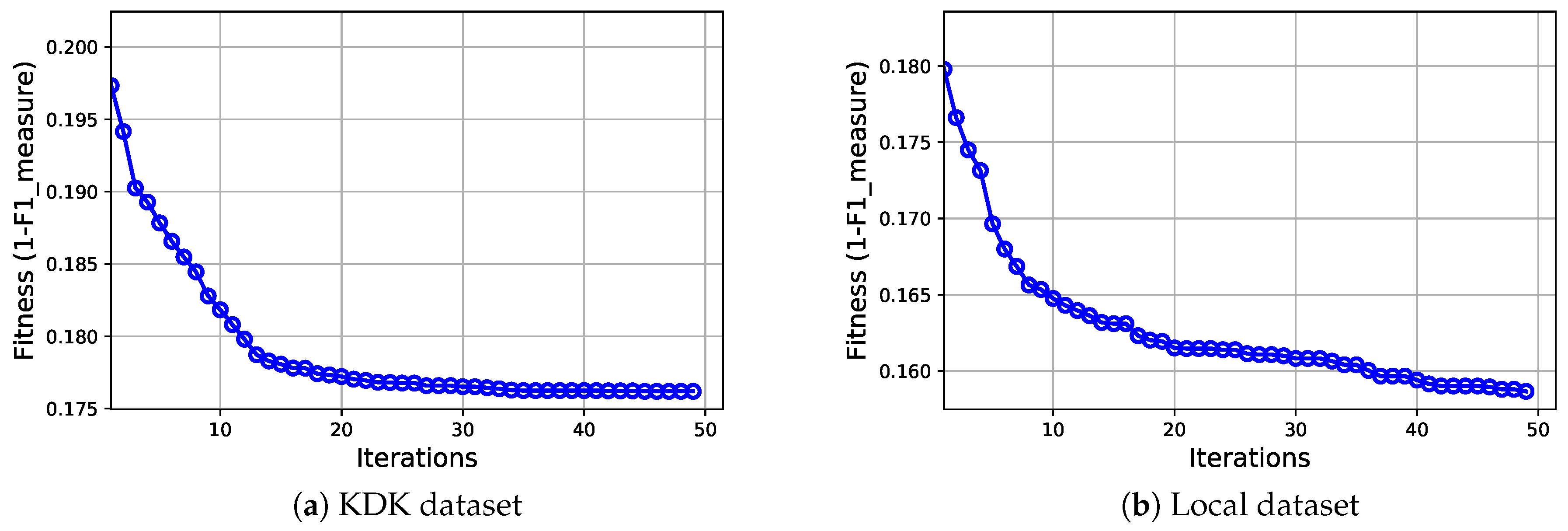
- Fitness evaluation: The merit of the particles/solutions should be evaluated based on a predefined fitness criterion. In this work, the fitness is based on the harmonic mean of precision and recall of the class of interest that is the churn class. This measurement is called F-measure, and it can be calculated as given in Equation (16). The fitness value is calculated based on the predictions of the RWN model that is trained using the weighted features of the training dataset.
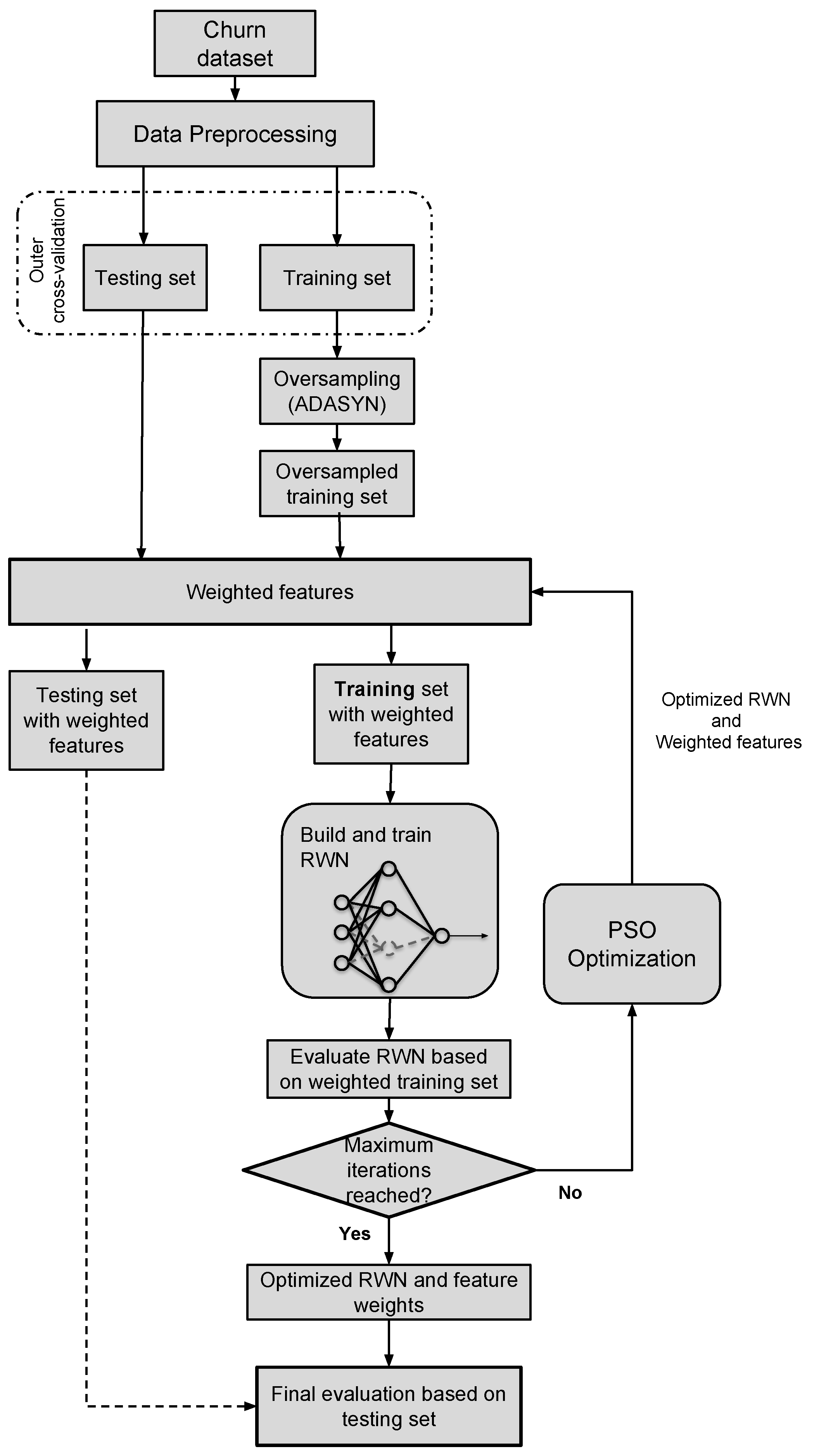
4.3. Procedure
- Initialization: The procedure of ADASYN-wPSO-NN begins by generating a random swarm of particles/candidate solutions where each solution is composed of a set of feature weights and a set of elements that control the number of hidden neurons, as shown in the previous subsection.
- Update: The updating mechanisms of PSO that were described previously in Section 3.1 are utilized at this stage to create a new swarm of particles (possible classification networks).
- Mapping and RWN training: Before calculating the fitness value, the individual is split into two main parts. The first part is used to weight the features of the training data. For example, suppose that we have a set of features such asthen the training process of RWN is performed based onwhere is the ith element of the weights part and associated with the ith feature. has a real of value between 0 and 1.On the other hand, the part that controls the neurons is used to determine the number of hidden nodes in RWN. The resulted RWN is trained based on the weighted training data as explained in Section 3. For example, suppose that we reserve four elements for this part, and there is an individual that has values of [0.2, 0.6, 0.1, 0.7] for these elements, then these values will be rounded as given in Equation (13) to obtain [0, 1, 0, 1]. By converting the resulted binary string to decimal format, five neurons are used in the hidden layer in the RWN.The process of feature weighting and determining the number of hidden neurons is illustrated in Figure 2.
- Fitness evaluation: The merit of every generated particle (candidate network) in the swarm is assessed using the F-measure, as given by Equation (16).
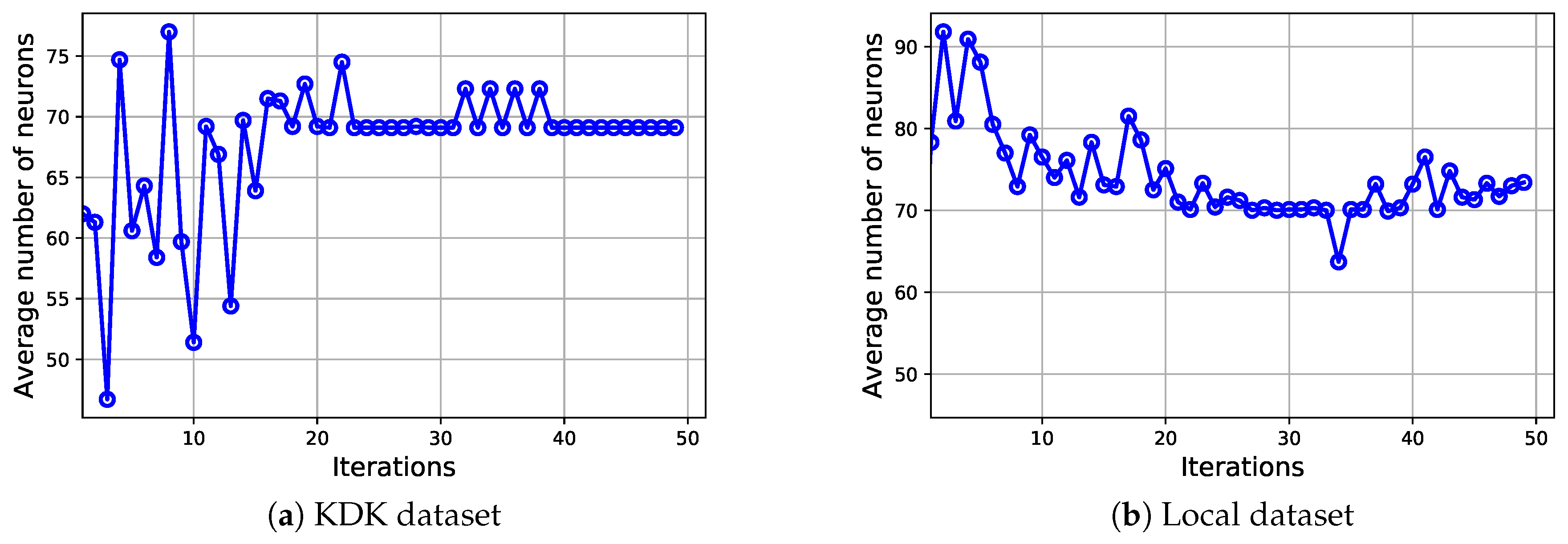
- End of procedure: The search process for the best RWN network terminates when a predefined maximum number of iterations is reached. Then, the ADASYN-wPSO-NN model returns the feature weights and the number of hidden nodes required to construct the RWN network that achieved the best fitness quality.
- Testing: For verification, the best constructed RWN network is tested based on a new unseen dataset. Several measurements are used to assess the final network, as explained in Section 6.
5. Datasets Description
5.1. DKD Dataset
5.2. Local Dataset
6. Model Evaluation Metrics
- Accuracy is the ratio of the correct classifications to total number of classifications.
- Recall is the ratio of relevant instances that are correctly classified to the total amount of relevant instances (i.e., coverage rate). It can be expressed for the churn and non-churn classes by the following equations, respectively.
- G-mean is the geometric mean of the recalls of each class and it can be measured by the following equation:
7. Experiment and Results
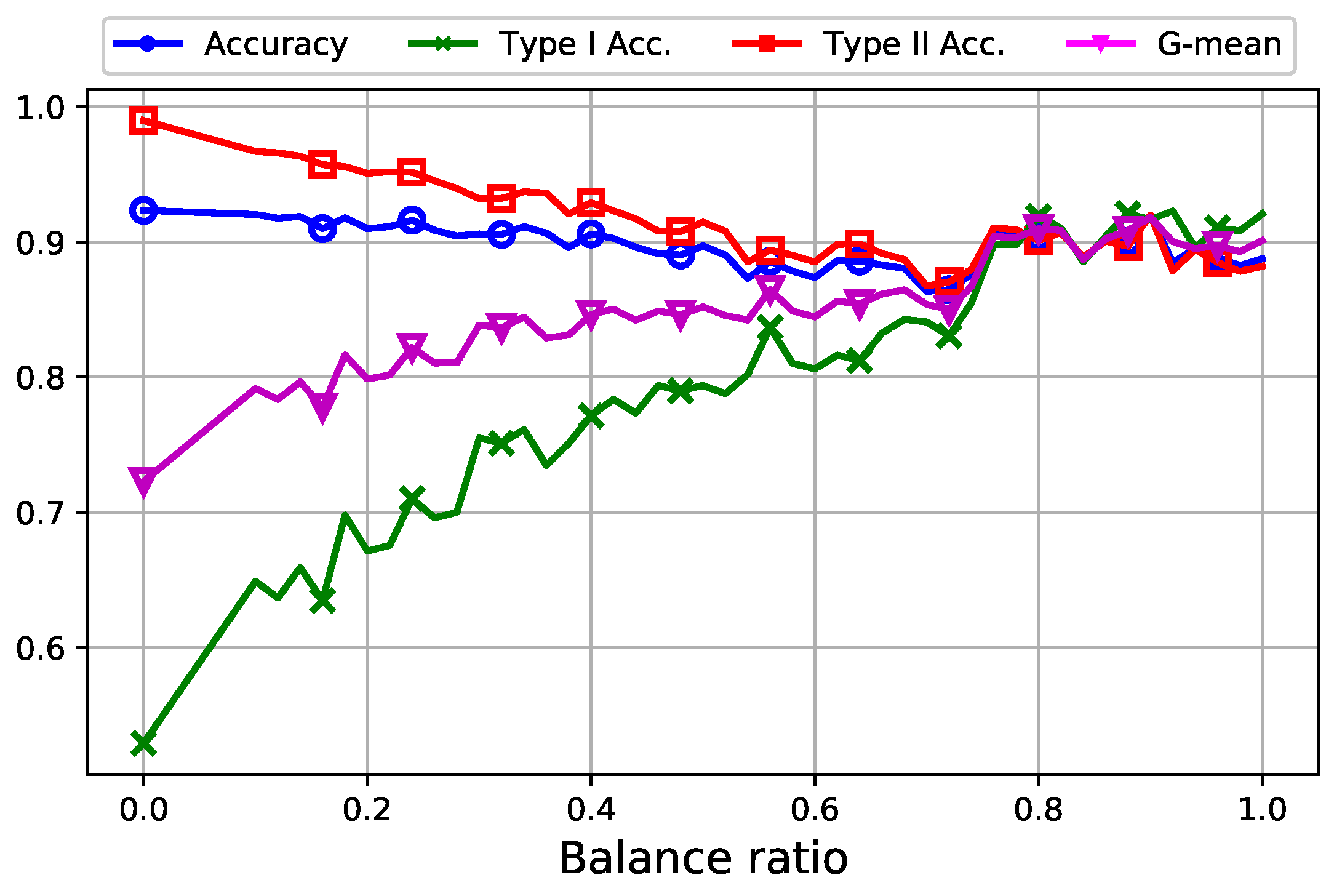
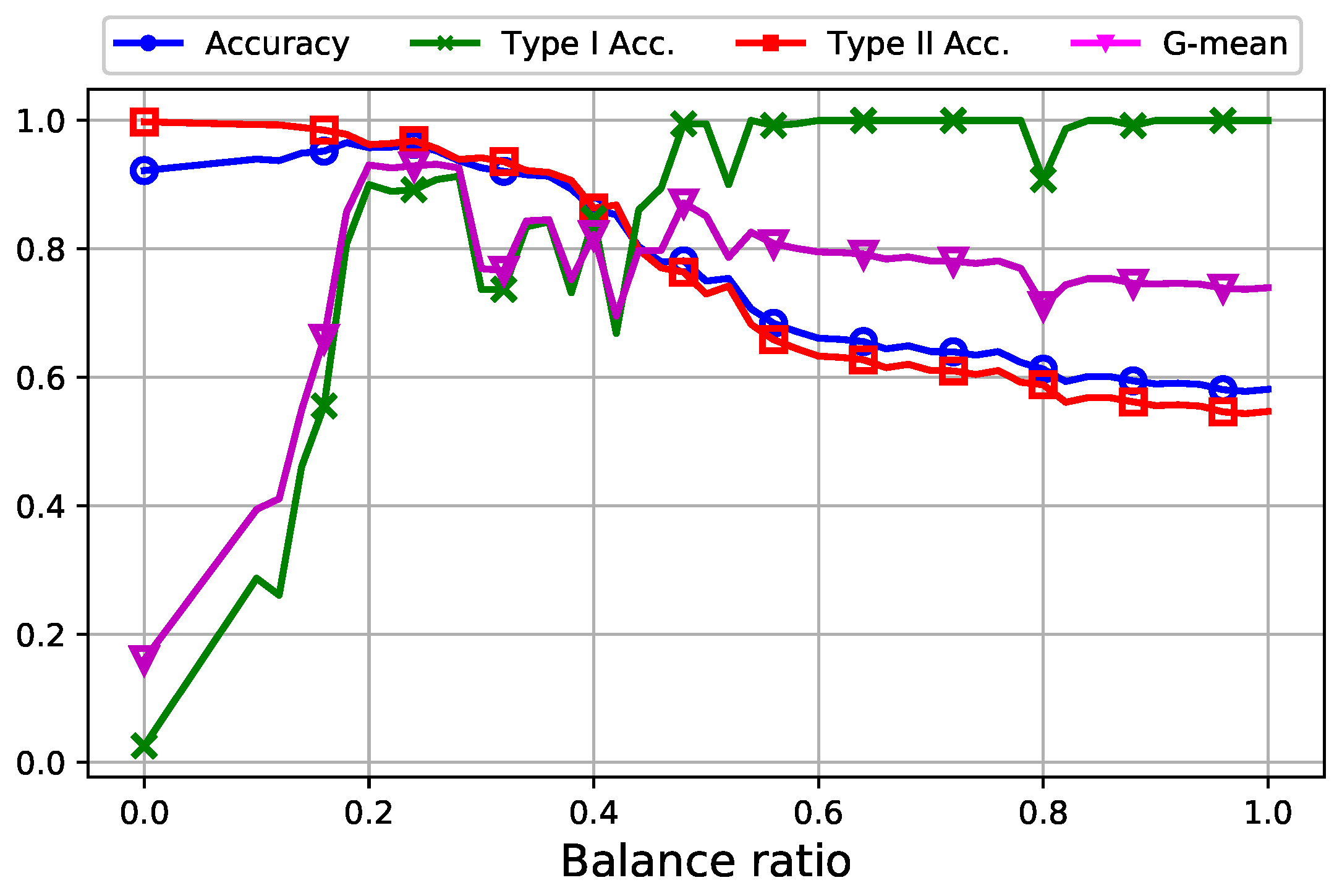
7.1. Analysis of Data Oversampling
7.2. Comparison with other Classifiers
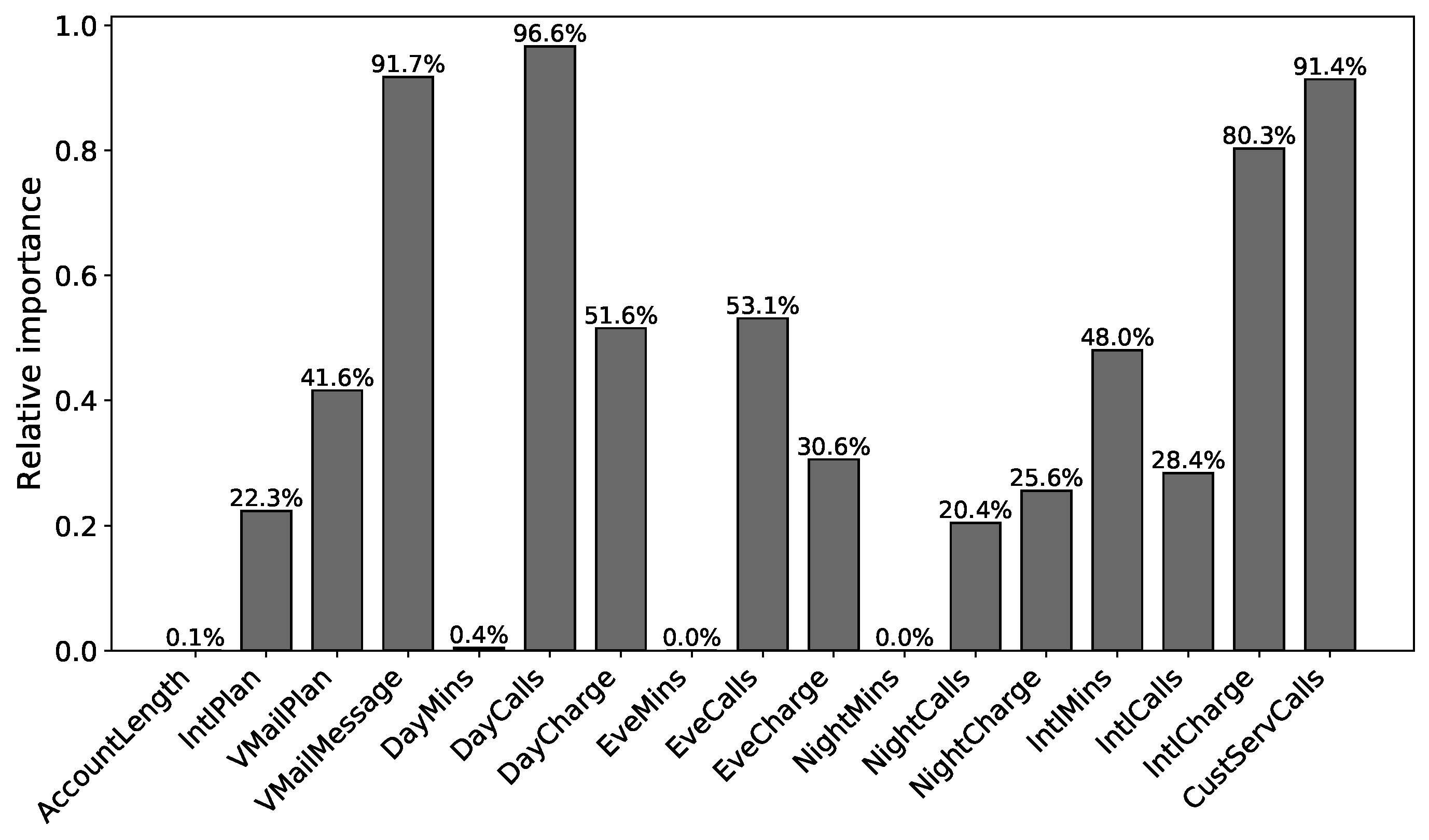
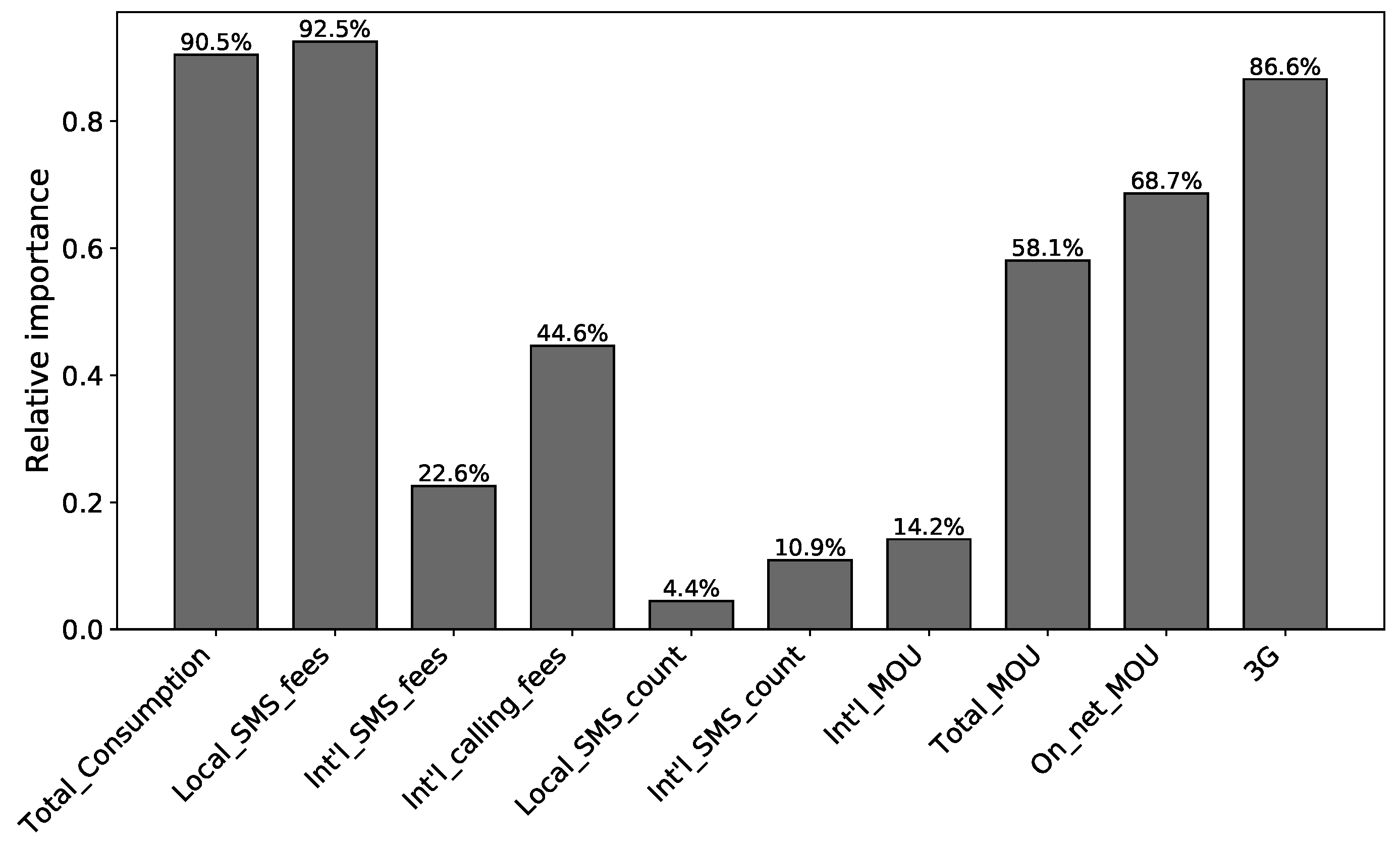
7.3. Relative Importance of Churn Features
8. Conclusions
Conflicts of Interest
References
- Wei, C.P.; Chiu, I.T. Turning telecommunications call details to churn prediction: A data mining approach. Expert Syst. Appl. 2002, 23, 103–112. [Google Scholar] [CrossRef]
- Hadden, J.; Tiwari, A.; Roy, R.; Ruta, D. Computer assisted customer churn management: State-of-the-art and future trends. Comput. Oper. Res. 2007, 34, 2902–2917. [Google Scholar] [CrossRef]
- Keramati, A.; Ardabili, S.M. Churn analysis for an Iranian mobile operator. Telecommun. Policy 2011, 35, 344–356. [Google Scholar] [CrossRef]
- Baesens, B.; Verstraeten, G.; Van den Poel, D.; Egmont-Petersen, M.; Van Kenhove, P.; Vanthienen, J. Bayesian network classifiers for identifying the slope of the customer lifecycle of long-life customers. Eur. J. Oper. Res. 2004, 156, 508–523. [Google Scholar] [CrossRef]
- García, D.L.; Nebot, À.; Vellido, A. Intelligent data analysis approaches to churn as a business problem: A survey. Knowl. Inf. Syst. 2017, 51, 719–774. [Google Scholar] [CrossRef]
- Mozer, M.C.; Wolniewicz, R.; Grimes, D.B.; Johnson, E.; Kaushansky, H. Predicting subscriber dissatisfaction and improving retention in the wireless telecommunications industry. IEEE Trans. Neural Netw. 2000, 11, 690–696. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Yang, D.; Yang, L.; Lu, Y.; Lin, X. Supervised Massive Data Analysis for Telecommunication Customer Churn Prediction. In Proceedings of the 2016 IEEE International Conferences on Big Data and Cloud Computing (BDCloud), Social Computing and Networking (SocialCom), Sustainable Computing and Communications (SustainCom) (BDCloud-SocialCom-SustainCom), Atlanta, GA, USA, 8–10 October 2016; pp. 163–169. [Google Scholar]
- Ngai, E.; Xiu, L.; Chau, D. Application of data mining techniques in customer relationship management: A literature review and classification. Expert Syst. Appl. 2009, 36, 2592–2602. [Google Scholar] [CrossRef]
- Idris, A.; Khan, A. Churn Prediction System for Telecom using Filter–Wrapper and Ensemble Classification. Comput. J. 2016, 60, 410–430. [Google Scholar] [CrossRef]
- Vijaya, J.; Sivasankar, E. An efficient system for customer churn prediction through particle swarm optimization based feature selection model with simulated annealing. Cluster Comput. 2017. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Han, F.; Yao, H.F.; Ling, Q.H. An improved evolutionary extreme learning machine based on particle swarm optimization. Neurocomputing 2013, 116, 87–93. [Google Scholar] [CrossRef]
- Ding, S.; Xu, X.; Nie, R. Extreme learning machine and its applications. Neural Comput. Appl. 2014, 25, 549–556. [Google Scholar] [CrossRef]
- Xia, G.; Jin, W. Model of customer churn prediction on support vector machine. Syst. Eng. Theory Pract. 2008, 28, 71–77. [Google Scholar] [CrossRef]
- Rodan, A.; Faris, H.; Alsakran, J.; Al-Kadi, O. A Support Vector Machine Approach for Churn Prediction in Telecom Industry. Int. J. Inf. 2014, 17, 3961–3970. [Google Scholar]
- Adwan, O.; Faris, H.; Jaradat, K.; Harfoushi, O.; Ghatasheh, N. Predicting customer churn in telecom industry using multilayer preceptron neural networks: Modeling and analysis. Life Sci. J. 2014, 11, 75–81. [Google Scholar]
- Vafeiadis, T.; Diamantaras, K.I.; Sarigiannidis, G.; Chatzisavvas, K.C. A comparison of machine learning techniques for customer churn prediction. Simul. Model. Pract. Theory 2015, 55, 1–9. [Google Scholar] [CrossRef]
- Khan, I.; Usman, I.; Usman, T.; Rehman, G.U.; Rehman, A.U. Intelligent churn prediction for telecommunication industry. Int. J. Innov. Appl. Stud. 2013, 4, 165–170. [Google Scholar]
- Keramati, A.; Jafari-Marandi, R.; Aliannejadi, M.; Ahmadian, I.; Mozaffari, M.; Abbasi, U. Improved churn prediction in telecommunication industry using data mining techniques. Appl. Soft Comput. 2014, 24, 994–1012. [Google Scholar] [CrossRef]
- Tsai, C.F.; Lu, Y.H. Customer churn prediction by hybrid neural networks. Expert Syst. Appl. 2009, 36, 12547–12553. [Google Scholar] [CrossRef]
- Rodan, A.; Faris, H. Echo state network with SVM-readout for customer churn prediction. In Proceedings of the 2015 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT), The Dead Sea, Jordan, 3–5 November 2015; pp. 1–5. [Google Scholar]
- Faris, H.; Al-Shboul, B.; Ghatasheh, N. A genetic programming based framework for churn prediction in telecommunication industry. In Proceedings of the International Conference on Computational Collective Intelligence, Madrid, Spain, 21–23 September 2015; pp. 353–362. [Google Scholar]
- Al-Shboul, B.; Faris, H.; Ghatasheh, N. Initializing genetic programming using fuzzy clustering and its application in churn prediction in the telecom industry. Malays. J. Comput. Sci. 2015, 28, 213–220. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man Cybern. C 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Zhu, B.; Baesens, B.; vanden Broucke, S.K. An empirical comparison of techniques for the class imbalance problem in churn prediction. Inf. Sci. 2017, 408, 84–99. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, B.; Li, X.; Liu, W.; Ren, S. Customer churn prediction using improved one-class support vector machine. In Proceedings of the International Conference on Advanced Data Mining and Applications, ADMA 2005, Wuhan, China, 22–24 July 2005; pp. 300–306. [Google Scholar]
- Idris, A.; Rizwan, M.; Khan, A. Churn prediction in telecom using Random Forest and PSO based data balancing in combination with various feature selection strategies. Comput. Electr. Eng. 2012, 38, 1808–1819. [Google Scholar] [CrossRef]
- Faris, H. Neighborhood Cleaning Rules and Particle Swarm Optimization for Predicting Customer Churn Behavior in Telecom Industry. Int. J. Adv. Sci. Technol. 2014, 68, 11–22. [Google Scholar] [CrossRef]
- Ahmed, A.A.; Maheswari, D. An enhanced ensemble classifier for telecom churn prediction using cost based uplift modelling. Int. J. Inf. Technol. 2018. [Google Scholar] [CrossRef]
- Idris, A.; Khan, A.; Lee, Y.S. Genetic Programming and Adaboosting based churn prediction for Telecom. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, SMC 2012, Seoul, Korea, 14–17 October 2012; pp. 1328–1332. [Google Scholar]
- Lu, N.; Lin, H.; Lu, J.; Zhang, G. A Customer Churn Prediction Model in Telecom Industry Using Boosting. IEEE Trans. Ind. Inf. 2014, 10, 1659–1665. [Google Scholar] [CrossRef]
- Bock, K.W.D.; den Poel, D.V. An empirical evaluation of rotation-based ensemble classifiers for customer churn prediction. Expert Syst. Appl. 2011, 38, 12293–12301. [Google Scholar] [CrossRef]
- Xie, Y.; Li, X.; Ngai, E.; Ying, W. Customer churn prediction using improved balanced random forests. Expert Syst. Appl. 2009, 36, 5445–5449. [Google Scholar] [CrossRef]
- Rodan, A.; Fayyoumi, A.; Faris, H.; Alsakran, J.; Al-Kadi, O. Negative correlation learning for customer churn prediction: A comparison study. Sci. World J. 2015, 2015, 473283. [Google Scholar] [CrossRef] [PubMed]
- Ismail, M.R.; Awang, M.K.; Rahman, M.N.A.; Makhtar, M. A multi-layer perceptron approach for customer churn prediction. Int. J. Multimed. Ubiquitous Eng. 2015, 10, 213–222. [Google Scholar] [CrossRef]
- Sharma, A.; Panigrahi, D.; Kumar, P. A Neural Network based Approach for Predicting Customer Churn in Cellular Network Services. Int. J. Comput. Appl. 2011, 27, 26–31. [Google Scholar] [CrossRef]
- Yu, R.; An, X.; Jin, B.; Shi, J.; Move, O.A.; Liu, Y. Particle classification optimization-based BP network for telecommunication customer churn prediction. Neural Comput. Appl. 2018, 29, 707–720. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R.C. Particle Swarm Optimization. In Proceedings of the IEEE International Conference on Neural Networks, Piscataway, NJ, USA, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Schmidt, W.F.; Kraaijveld, M.A.; Duin, R.P. Feedforward neural networks with random weights. In Proceedings of the 11th IAPR International Conference on Pattern Recognition, Vol. II. Conference B: Pattern Recognition Methodology and Systems, The Hague, The Netherlands, 30 August–3 September 1992; pp. 1–4. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the IEEE International Joint Conference on Neural Networks, IJCNN 2008, Hong Kong, China, 1–6 June 2008; pp. 1322–1328. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Larose, D.T.; Larose, C.D. Discovering Knowledge in Data: An Introduction to Data Mining; John Wiley & Sons: New York, NY, USA, 2014. [Google Scholar]
- Simon, D. Biogeography-based optimization. IEEE Trans. Evol. Comput. 2008, 12, 702–713. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Let a biogeography-based optimizer train your multi-layer perceptron. Inf. Sci. 2014, 269, 188–209. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: an update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Lemmens, A.; Croux, C. Bagging and boosting classification trees to predict churn. J. Mark. Res. 2006, 43, 276–286. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Description |
|---|---|
| State | The US state, in which, the customer resides |
| Account Length | The number of days that this account has been active |
| Area Code | Area code of the corresponding customer’s phone number |
| Phone | The remaining seven-digit phone number |
| Int’l Plan | Whether the customer has an international calling plan (yes/no) |
| VMail Plan | Whether the customer has a voice mail feature (yes/no) |
| VMail Message | Presumably, the average number of voice mail messages per month |
| Day Mins | Total number of calling minutes used during the day |
| Day Calls | Total number of calls placed during the day |
| Day Charge | The billed cost of daytime calls |
| Eve Mins | Total number of calling minutes used during the evening |
| Eve Calls | Total number of calls placed during the evening |
| Eve Charge | The billed cost for calls placed during the evening |
| Night Mins | Total number of calling minutes used during the nighttime |
| Night Calls | Total number of calls placed during the nighttime |
| Night Charge | The billed cost for the calls placed during nighttime |
| Intl Mins | Total number of international calling minutes |
| Intl Calls | Total number of international calls |
| Intl Charge | The billed cost for international calls |
| CustServ Calls | Number of calls placed to Customer Service |
| Churn | Did the customer leave the service? (true/false) |
| Feature Name | Description |
|---|---|
| 3G | Subscriber is provided with 3G service (Yes, No) |
| Total Consumption | Total monthly fees spent by the customer (calling+SMS) (in JD) |
| Int’l calling fees | Monthly fees spent by the customer for international calling (in JD) |
| Int’l MOU | Total minutes of international outgoing calls |
| Int’l SMS fees | Monthly fees spent by the customer for international SMS (in JD) |
| Int’l SMS count | Number of monthly international SMS |
| Local SMS fees | The total monthly local SMS fees spent by the customer (in JD) |
| Local SMS count | The total number of monthly local SMS |
| Total MOU | Total minutes of use for all outgoing calls |
| On net MOU | Total minutes of use for on-net-outgoing calls |
| Churn | Did the customer leave the service? (true/false) |
| Actual | ||
|---|---|---|
| Churners | nonChurners | |
| Predicted churners | TP | FP |
| Predicted nonChurners | FN | TN |
| G-mean | Type I Accuracy | Type II Accuracy | Accuracy | |
|---|---|---|---|---|
| ADASYN-PSO-wNN | 0.918 | 0.917 | 0.920 | 0.920 |
| PSO-wNN | 0.723 | 0.529 | 0.990 | 0.923 |
| Bagging | 0.862 | 0.752 | 0.987 | 0.953 |
| AdaBoost | 0.863 | 0.756 | 0.985 | 0.952 |
| Random Forest | 0.876 | 0.776 | 0.989 | 0.959 |
| Grid-SVM | 0.893 | 0.849 | 0.941 | 0.931 |
| MLP(17-10-2) | 0.850 | 0.735 | 0.982 | 0.946 |
| MLP(17-10-10-2) | 0.849 | 0.731 | 0.986 | 0.949 |
| G-mean | Type I Accuracy | Type II Accuracy | Accuracy | |
|---|---|---|---|---|
| ADASYN-PSO-wNN | 0.929 | 0.892 | 0.968 | 0.963 |
| PSO-wNN | 0.160 | 0.026 | 0.998 | 0.922 |
| Bagging | 0.838 | 0.703 | 0.998 | 0.976 |
| AdaBoost | 0.841 | 0.714 | 0.991 | 0.970 |
| Random Forest | 0.845 | 0.717 | 0.995 | 0.974 |
| Grid-SVM | 0 | 0 | 0.924 | 0.924 |
| MLP(10-10-2) | 0.493 | 0.249 | 0.977 | 0.9216 |
| MLP(10-10-10-2) | 0.281 | 0.079 | 0.997 | 0.927 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faris, H. A Hybrid Swarm Intelligent Neural Network Model for Customer Churn Prediction and Identifying the Influencing Factors. Information 2018, 9, 288. https://doi.org/10.3390/info9110288
Faris H. A Hybrid Swarm Intelligent Neural Network Model for Customer Churn Prediction and Identifying the Influencing Factors. Information. 2018; 9(11):288. https://doi.org/10.3390/info9110288
Chicago/Turabian StyleFaris, Hossam. 2018. "A Hybrid Swarm Intelligent Neural Network Model for Customer Churn Prediction and Identifying the Influencing Factors" Information 9, no. 11: 288. https://doi.org/10.3390/info9110288
APA StyleFaris, H. (2018). A Hybrid Swarm Intelligent Neural Network Model for Customer Churn Prediction and Identifying the Influencing Factors. Information, 9(11), 288. https://doi.org/10.3390/info9110288