1. Introduction
Accurate and fast feature selection is a useful tool of data analysis. In particular, feature selection on categorical data is important in real world applications. Features, or attributes, and, in particular, features to specify class labels, which represent the phenomena to explain, and/or the targets to predict are often categorical. In this paper, we propose two new feature selection algorithms that are as accurate as, and drastically faster than, any other methods represented in the literature. In fact, our algorithms are the first accurate feature selection algorithms that scale well to big data.
The importance of feature selection can be demonstrated with an example.
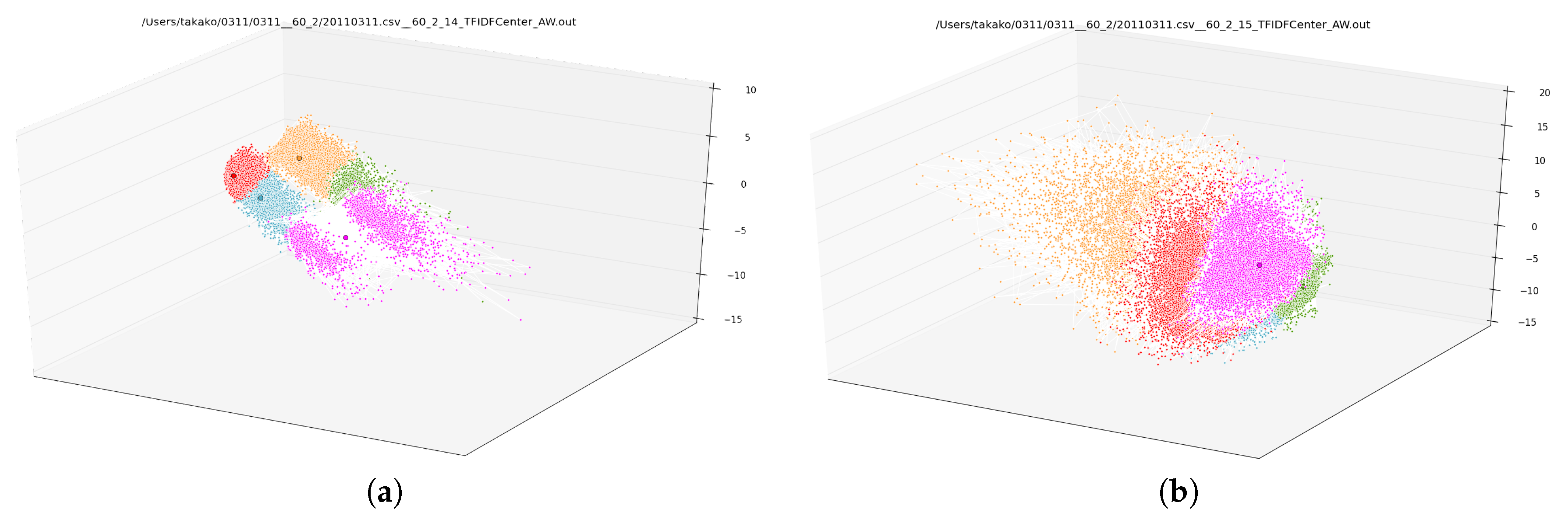
Figure 1 depicts the result of clustering tweets posted to Twitter during two different one-hour windows on the day of the Great East Japan Earthquake, which hit Japan at 2:46 p.m. on 11 March 2011 and inflicted catastrophic damage.
Figure 1a plots 97,977 authors who posted 351,491 tweets in total between 2:00 p.m. and 3:00 p.m. on the day of the quake (the quake occurred in the midst of this period of time), while
Figure 1b plots 161,853 authors who posted 978,155 tweets between 3:00 p.m. and 4:00 p.m. To plot, we used word-count-based distances between authors and a multidimensional scaling algorithm. Moreover, we grouped the authors into different groups using the
k-means clustering algorithm based on the same distances. Dot colors visualize that clustering. We observe a big change in clustering between the hour during which the quake occurred, and the hour after the quake.
Two questions naturally arise: first, what do the clusters mean? Second, what causes the change from
Figure 1a to
Figure 1b? Answering these questions requires a method for selecting words that best characterize each cluster; in other words, a method for feature selection.
To illustrate, we construct two datasets, one for the timeframe represented in
Figure 1a and one for the time-frame represented in
Figure 1b, called dataset A and dataset B, respectively. Each dataset consists of a word count vector for each author that reflects all words in all of their tweets. Dataset A has 73,543 unique words, and dataset B has 71,345 unique words, so datasets A and B have 73,543 and 71,345 features, respectively. In addition, each author was given a class label reflecting the category he or she was assigned to from the
k-means clustering process.
It was our goal to select a relatively small number of features (words) that were relevant to class labels. We say that a set of features is relevant to class labels, if the values of the features uniquely determine class labels with high likelihood.
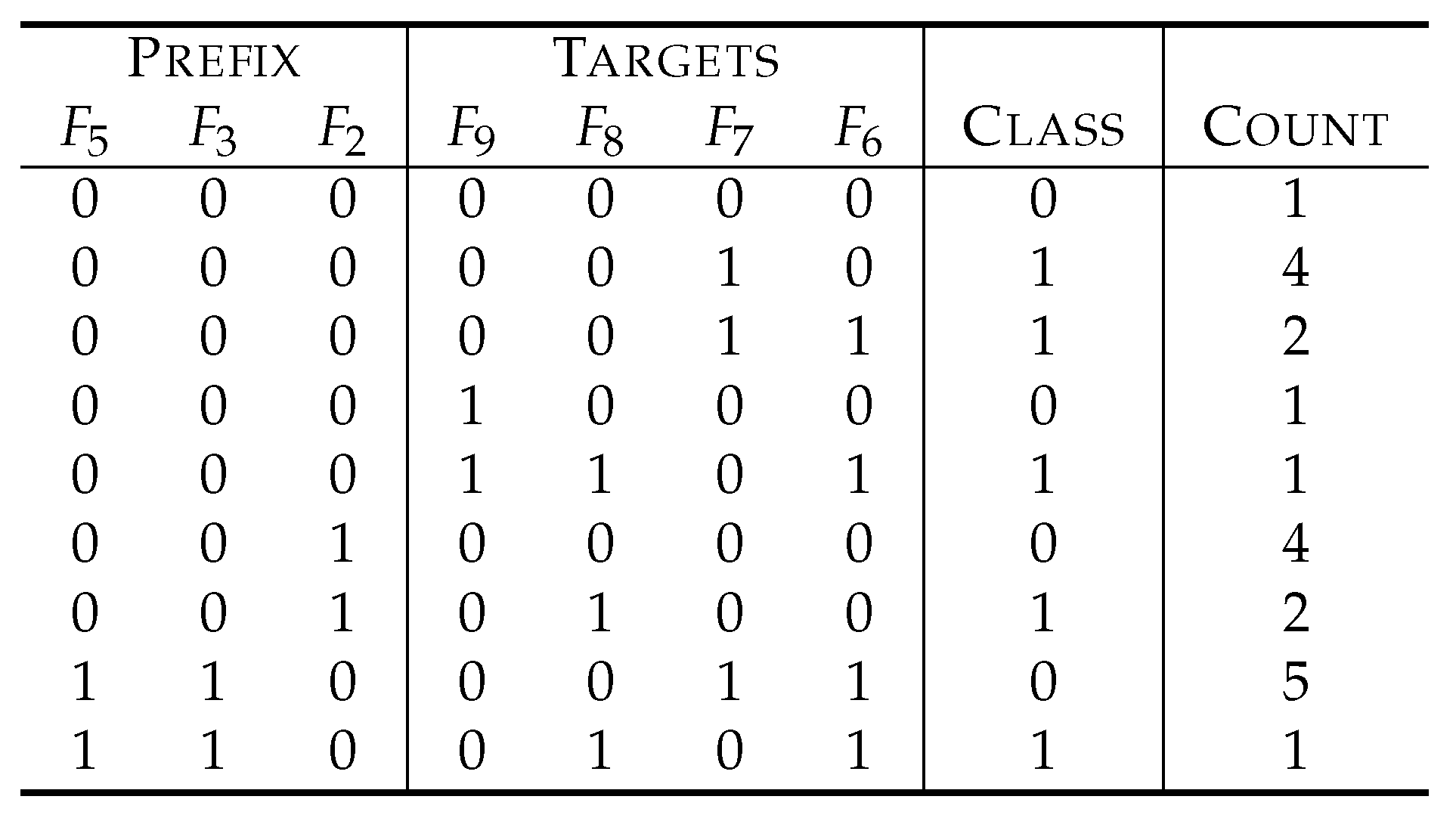
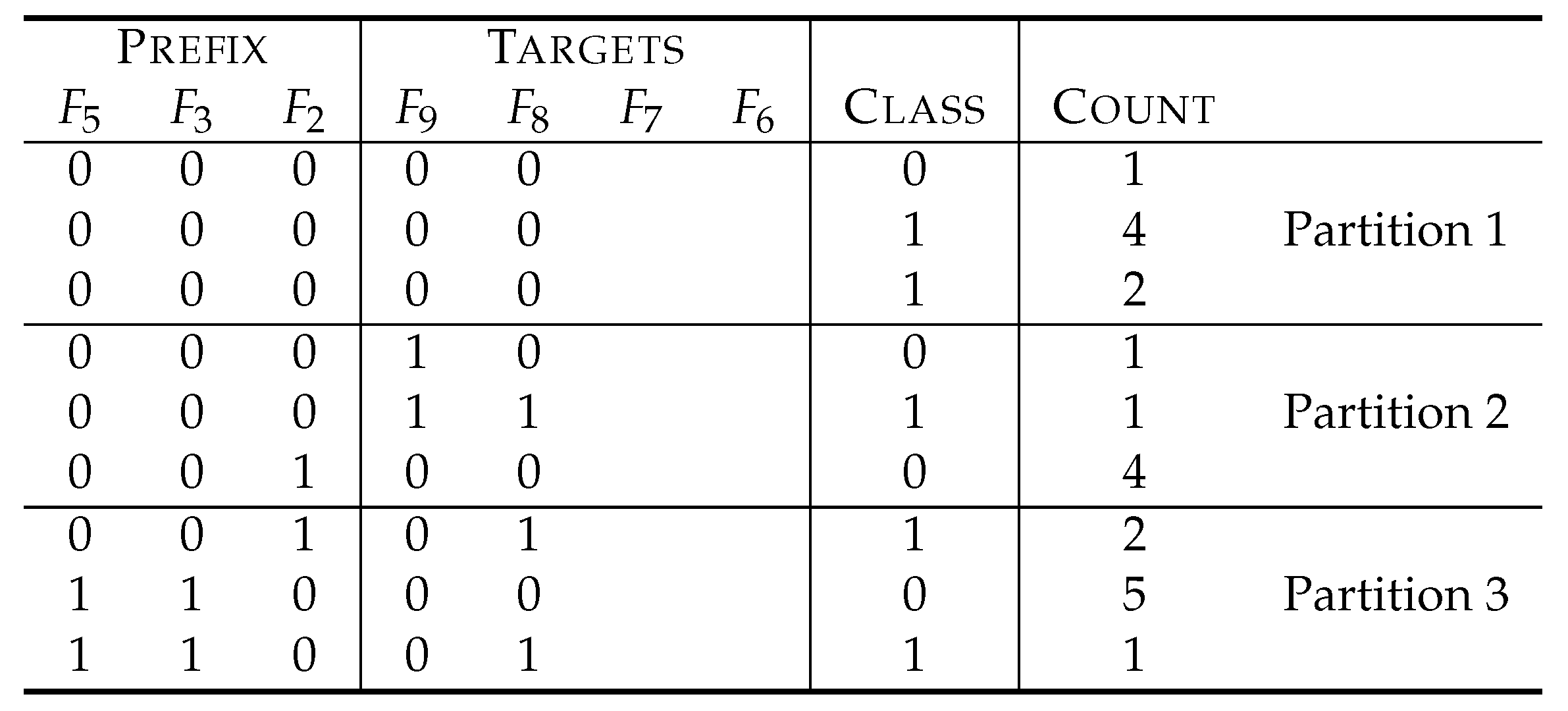
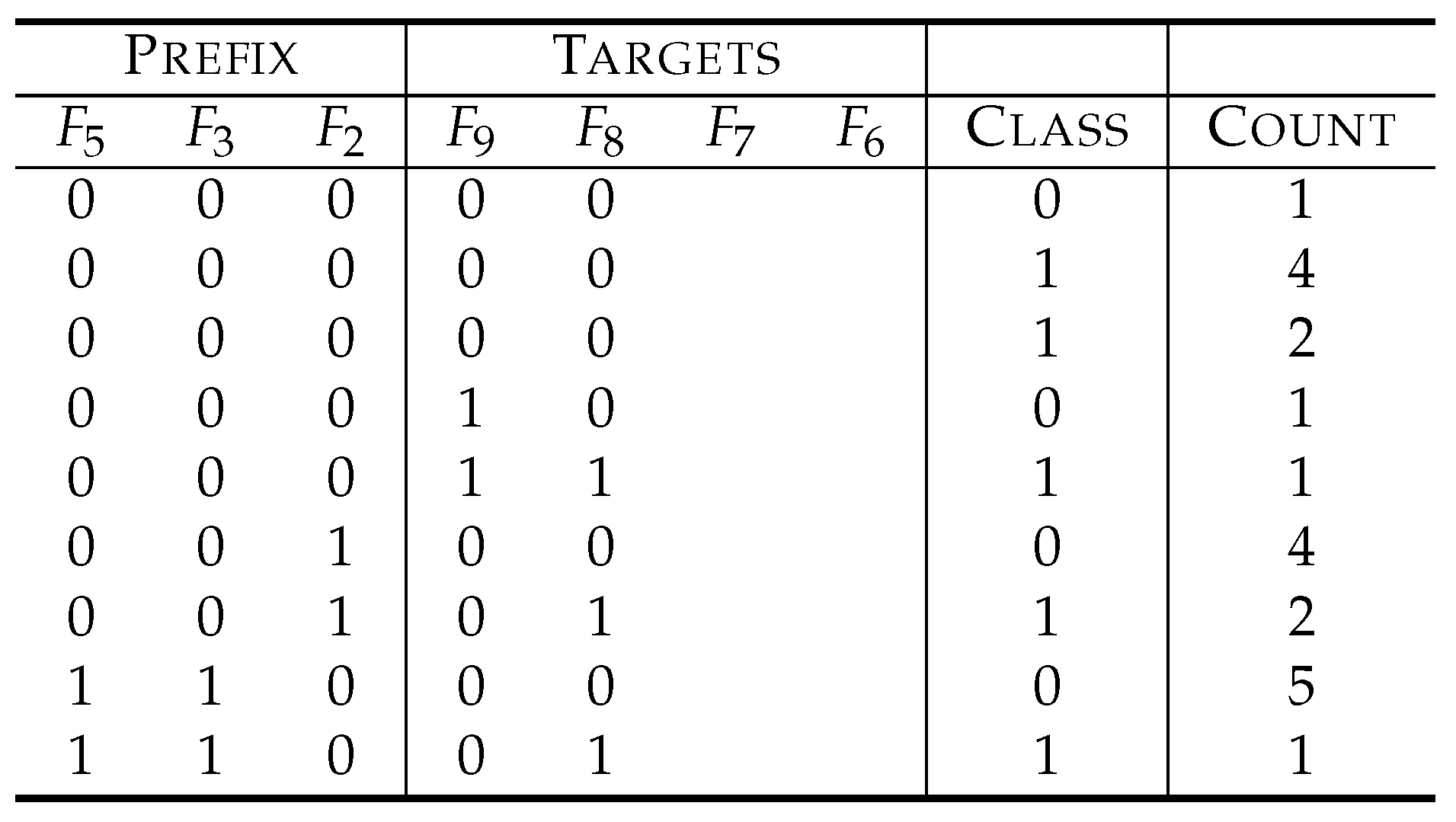
Table 1 depicts an example of a dataset for explanation.
are features, and the symbol
C denotes a variable to represent class labels. The feature
, for example, is totally
irrelevant to class labels. In fact, we have four instances with
, and a half of them have the class label 0, while the other half have the class label 1. The same holds true for the case of
. Therefore,
cannot explain class labels at all and is useless to predict class labels. In fact, predicting class labels based on
has the same success probability as guessing them by tossing a fair coin (the Bayesian risk of
to
C is 0.5, which is the theoretical worst). On the other hand,
is more relevant than
because the values of
explain 75% of the class labels, and, in other words, the prediction based on
will be right with a probability of 0.75 (that is, the Bayesian risk is 0.25).
The relevance of individual features can be estimated using statistical measures such as mutual information, symmetrical uncertainty, Bayesian risk and Matthew’s correlation coefficients. For example, at the bottom row of
Table 1, the mutual information score
of each feature
to class labels is described. We see that
is more relevant than
, since
.
To our knowledge, the most common method deployed in big data analysis to select features that characterize class labels is to select features that show higher relevance in some statistical measure. For example, in the example of
Table 1,
and
will be selected to explain class labels.
However, when we look into the dataset of
Table 1 more closely, we understand that
and
cannot determine class labels uniquely. In fact, we have two instances with
, whose class labels are 0 and 1. On the other hand,
and
as a combination uniquely determine the class labels by the formula of
, where ⊕ denotes the addition modulo two. Therefore, the traditional method based on relevance scores of individual features misses the right answer.
This problem is well known as the problem of feature interaction in feature selection research. Feature selection has been intensively studied in machine learning research. The literature describes a class of feature selection algorithms that can solve this problem, referred to as consistency-based feature selection (for example, [
1,
2,
3,
4,
5]).
Figure 2 shows the result of feature selection using one of the consistency-based algorithms, namely, C
wc (Combination of Weakest Components) [
5]. The dataset used was one generated in the aforementioned way from the tweets of the day when the quake hit Japan and includes 161,425 instances (authors) and 38,822 features (words). The figure shows not only the 40 words selected but also their scores and ranks measured by the symmetrical uncertainty (in parentheses).
This result contains two interesting findings. First, the word ranked 141th is translated as “Mr.”, “Mrs.”, or “Ms.”, which is a polite form of address in Japanese. This form of address is common in Japanese writing, so it seems odd that the word would identify a cluster of authors well. In fact, the relevance of the word is as low as 0.028. However, if we understand the nature of Cwc, we can guess that the word must interact with other features to determine which cluster the author falls inside. In fact, it turns out that the word interacts with the 125th-ranked word, “worry“. Hence, we realize that a portion of those tweets must have been asking about the safety of someone who was not an author’s family member—in other words, someone who the author would have addressed with the polite form of their name.
The second interesting finding is that the words with the highest relevance to class labels have not been selected. For example, the word that means “quake” was ranked at the top but not selected. This is because the word was likely to be used in the tweets with other selected words such as words that translated to “tsunami alert” (ranked 19th), “the Hanshin quake” (55th), “fire” (66th), “tsunami” (75th) and “the Chu-Etsu quake” (106th), so that Cwc judged the word “quake” to be redundant once the co-occurring words had been selected. Our interpretation is that these co-occurring words represent the contexts in which the word “quake” was used, and selecting these words gave us more information than selecting “quake”, which is too general in this case.
Thus, the consistency-based algorithms do not simply select features with higher relevance; instead, they give us knowledge that we cannot obtain from selection based on the relevance of individual features. In spite of these advantages, however, consistency-based feature selection is seldom used in big data analysis. Consistency-based algorithms require heavy computation and the amount of computation increases as the size of data increases so greatly as to make application to large data sets unfeasible.
This paper’s contribution is to improve the run-time performance of two consistency-based algorithms that are known the most accurate, namely C
wc and L
cc (Linear Consistency Constrained feature selection) [
4]. We introduce two algorithms that perform well on big data:
sC
wc and
sL
cc. They always select the same features as C
wc and L
cc, respectively, and, therefore, perform with the same accuracy.
sL
cc accepts a threshold parameter to control the number of features to select and has turned out to be as fast as
sC
wc on average in our experiments.
2. Feature Selection on Categorical Data in Machine Learning Research
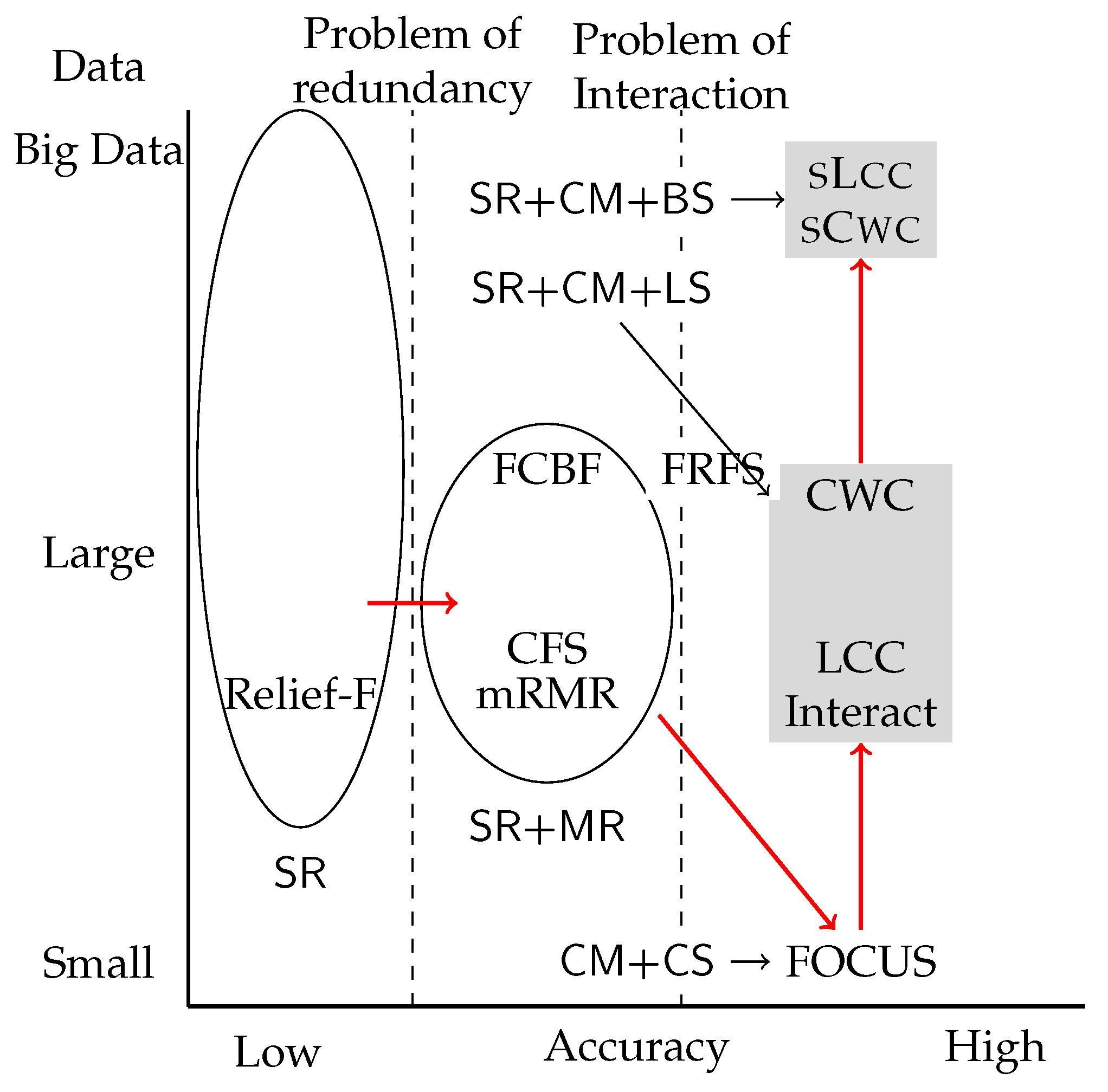
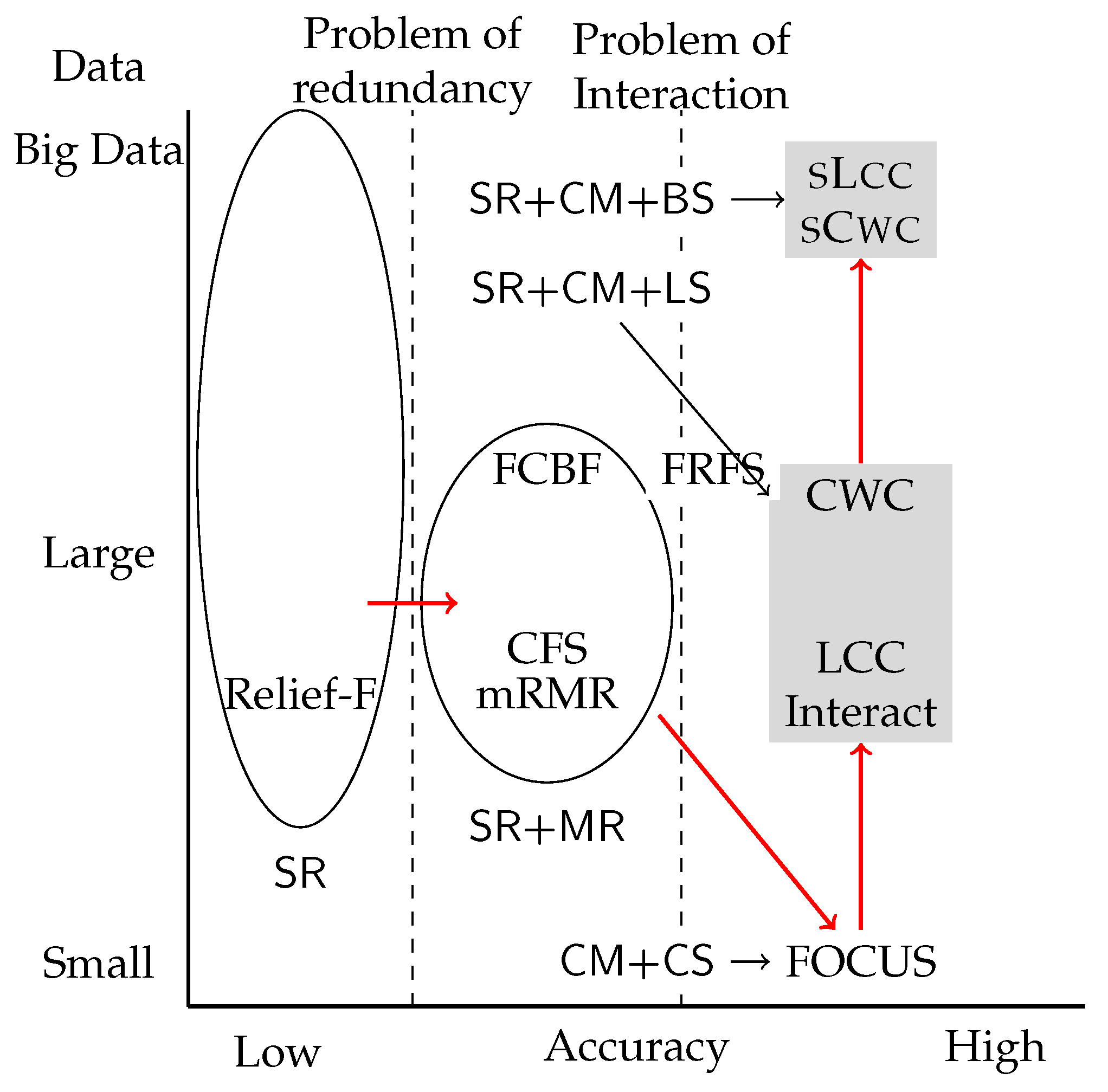
In this section, we give a brief review of feature selection research focusing on categorical data. The literature describes three broad approaches: filter, wrapper and embedded. Filter approaches aim to select features based on the intrinsic properties of datasets leveraging statistics and information theory, while wrapper and embedded approaches aim to optimize the performance of particular classification algorithms. We are interested in the filter approach in this paper. We first introduce a legacy feature selection framework and identify two problems in that framework. Then, we introduce the consistency-based approach to solve these problems. For convenience, we will describe a feature or a feature set that is relevant to class labels simply as relevant.
2.4. Consistency-Based Feature Selection
The consistency-based approach solves the problem of feature interaction by leveraging consistency measures. A consistency measure is a function that takes sets of features as input rather than individual features. Furthermore, a consistency measure is a function that represents collective irrelevance of the feature set input, and, hence, the smaller a value of a consistency measure is, the more relevant the input feature set is.
Moreover, a consistency measure is required to have the determinacy property: its measurement is zero, if, and only if, the input feature set uniquely determines classes.
Definition 1. A feature set of a dataset is consistent, if, and only if, it uniquely determines classes, that is, any two instances of the dataset that are identical with respective to the values of the features of the feature set have the identical class label as well.
Hence, a consistency measure function returns the value zero, if, and only if, its input is a consistent feature set. An important example of the consistency measure is the Bayesian risk, also known as the
inconsistency rate [
2]:
The variable
moves in the sample space of
, while the variable
y moves in the sample space of
C. It is evident that the Bayesian risk is non-negative, and determinacy follows from
Another important example of the consistency measure is the
binary consistency measure, defined as follows:
F
ocus [
1], the first consistency-based algorithms in the literature, performs an exhaustive search to find the smallest feature set
with
.
Apparently, Focus cannot be practically fast. In general, consistency-based feature selection has problems in time-efficiency because of the broadness of the search space. In fact, the search space should be the power set of the entire set of features, and its size is an exponential function of the number of features.
Problem of consistency measures
When N features describe a dataset, the number of the possible input to a consistency measure is as large as .
The
monotonicity property of consistency measures helps to solve this problem. The Bayesian risk, for example, has this property: if
,
holds, where
and
are feature subsets of a dataset. Almost all of the known consistency measures such as the binary consistency measure and the conditional entropy
have this property as well. In [
5], the consistency measure is formally defined as a non-negative function that has the determinacy and monotonicity properties.
Although some of the algorithms in the literature such as A
bb (Automatic Branch and Bound) [
2] took advantage of the monotonicity property to narrow their search space, the real breakthrough was yielded by Zhao and Liu in their algorithm I
nteract [
3]. I
nteract uses the combination of the sum-of-relevance function based on the symmetrical uncertainty and the Bayesian risk. The symmetrical uncertainty is a harmonic mean of the ratios of
and
and hence turns out to be
The basic idea of I
nteract is to narrow down the search space boldly and to take SR values of the symmetrical uncertainty into account to cover the caused decrease of relevance. Although the search space of I
nteract is very narrow, the combination of the SR function and the consistency measure keeps the accuracy performance good. L
cc [
4] improves I
nteract and can exhibit better accuracy. Although I
nteract and L
cc are much faster than previous consistency-based algorithms described in the literature, they are not fast enough to apply to large datasets with thousands of instances and features.
C
wc [
5] is a further improvement and replaces the Bayesian risk with the binary consistency measure, which can be computed faster. C
wc is reported to be about 50 times faster than I
nteract and L
cc on average. In fact, C
wc performs feature selection for a dataset with 800 instances and 100,000 features in 544 s, while L
cc does it in 13,906 s. Although the improvement was remarkable, C
wc is not fast enough to apply to big data analysis.
3. sCwc and sLcc
sCwc and sLcc improve the time efficiency of Cwc and Lcc significantly. The letter “s” of sCwc and sLcc represents “scalable”, “swift” and “superb”.
3.1. The Algorithms
We start by explaining the C
wc algorithm.
Figure 1 depicts the algorithm. Given a dataset described by a feature set
, C
wc aims to output a
minimal consistent subset .
Definition 2. A minimal consistent subset S satisfies and for any proper subset .
Achieving this goal is, however, impossible if holds, since always holds by the monotonicity property of . Therefore, the preliminary step of Cwc is to remove the cause of . To be specific, if , there exists at least one inconsistent pair of instances, which are identical with respect to the feature values but with different class labels. The process of denoising is thus to modify the original dataset so that it includes no inconsistent pairs. To denoise, we have two approaches as follows:
We can add a dummy feature to and can assign a value of to an instance so that, if the instance is not included in any inconsistent pair, the assigned value is zero; otherwise, the assigned value is determined depending on the class label of the instance.
We can eliminate at least a part of the instances that are included in inconsistent pairs.
Although both of the approaches can result in , the former seems better because useful information may be lost by eliminating instances. Fortunately, high-dimensional data usually have the property of from the beginning since N is very large. When , denoising is benign and does nothing.
On the other hand, to incorporate sum-of-relevance into consistency-based feature selection, we sort features in the incremental order of their symmetrical uncertainty scores, that is, we renumber s so that if . The symmetrical uncertainty, however, is not the mandatory choice, and we can use any measure to evaluate relevance of an individual feature so that, the greater a value of the measure is, the more relevant the feature is. For example, we can replace the symmetrical uncertainty with the mutual information .
Cwc deploys a backward elimination approach: it first sets a variable S to the entire set and then investigates whether each can be eliminated from S without violating the condition of . That is, S is updated by , if, and only if, . Hence, Cwc continues to eliminate features until S becomes a minimal consistent subset. Algorithm 1 describes the algorithm of Cwc.
The order of investigating is the incremental order of i, and, hence, the incremental order of . Since is more likely to be eliminated than with , we see that Cwc stochastically outputs minimal consistent subsets with higher sum-of-relevance scores.
| Algorithm 1 The algorithm of Cwc [5] |
Require: A dataset described by with .
Ensure: A minimal consistent subset .
- 1:
Sort in the incremental order of . - 2:
Let . - 3:
for do - 4:
if then - 5:
update S by . - 6:
end if - 7:
end for
|
To improve the time efficiency of C
wc, we restate the algorithm of C
wc as follows. To illustrate, let
be a snapshot of
S immediately after C
wc has selected
. In the next step, C
wc investigates whether
holds. If so, C
wc investigates whether
holds. C
wc continues the same procedure, until it finds
with
. This time, C
wc does not eliminate
.
S is set to
, and C
wc investigate
next. Thus, to find
to be selected, C
wc solves the problem to find
ℓ such that
To solve the problem, Cwc relies on linear search.
On the other hand, the idea of improving C
wc is obtained by looking at the same problem from a different direction. By the monotonicity property of Bn,
holds for any
, and, therefore, the formula
also characterizes
ℓ.
This characterization of ℓ indicates that we can take advantage of binary search instead of linear search to find ℓ (Algorithm 2). Since the average time complexity of the binary search is , we can expect significant improvement compared with the time complexity of of the linear search used in Cwc. Algorithm 3 depicts our improved algorithm, sCwc.
| Algorithm 2 Binary search to find ℓ |
Require: and such that and .
Ensure: such that . |
| 1: | if then | |
| 2: | . | ▹ No such ℓ exists. |
| 3: | else | |
| 4: | Let . | |
| 5: | repeat | |
| 6: | if then | |
| 7: | Let . | |
| 8: | else | |
| 9: | Let . | |
| 10: | end if | |
| 11: | Let . | |
| 12: | until holds. | |
| 13: | . | |
| 14: | end if | |
In addition, Algorithm 4 depicts the algorithm of L
cc [
4]. In contrast to C
wc, L
cc accepts a threshold parameter
. The parameter determines the strictness of its elimination criteria. The greater
is, the looser the criteria is, and, therefore, the smaller features L
cc selects.
There are two major differences between Lcc and Cwc: first, Lcc does not require that the entire feature set is consistent. Therefore, denoization to make is not necessary. Secondly, the elimination criteria of of Cwc is replaced with . By the determinacy property, , if, and only if, . Hence, with , Lcc selects the same features as Cwc does.
| Algorithm 3 The algorithm of sCwc |
Require: A dataset described by with .
Ensure: A minimal consistent subset . |
| 1: | Sort in the incremental order of . |
| 2: | Let . |
| 3: | Let . |
| 4: | repeat |
| 5: | Find by binary search. |
| 6: | if ℓ does not exist then |
| 7: | Let . |
| 8: | end if |
| 9: | Update S by . |
| 10: | Let . |
| 11: | until holds. |
| Algorithm 4 The algorithm of Lcc [4] |
Require: A dataset described by and a non-negative threshold .
Ensure: A minimal -consistent subset .
- 1:
Sort in the incremental order of . - 2:
Let . - 3:
for do - 4:
if then - 5:
update S by . - 6:
end if - 7:
end for
|
Since the Bayesian risk has the monotonicity property as well,
compose an increasing progression, and, hence, we can find
ℓ such that
very efficiently by means of binary search. Algorithm 5 describes the improved algorithm of
sL
cc based on binary search.
| Algorithm 5 The algorithm of sLcc |
Require: A finite dataset and a non-negative threshold .
Ensure: A minimal -consistent subset . |
| 1: | Sort in the incremental order of . |
| 2: | Let . |
| 3: | Let . |
| 4: | repeat |
| 5: | Find by binary search. |
| 6: | if ℓ does not exist then |
| 7: | Let . |
| 8: | end if |
| 9: | Update S by . Let . |
| 10: | until holds. |
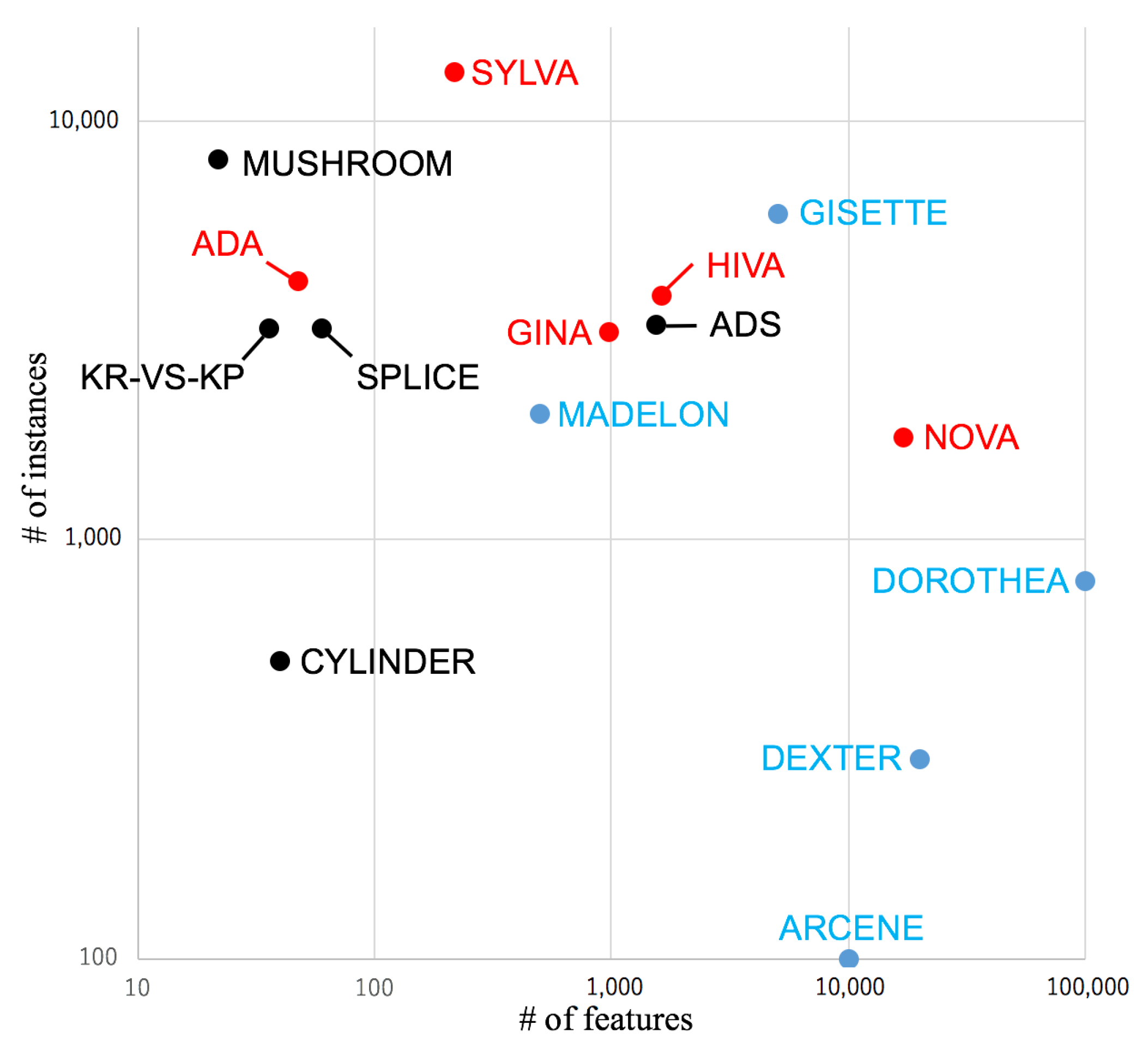
5. Performance of sLcc and sCwc for High-Dimensional Data
In this section, we look into both of the accuracy and time-efficiency performance of
sL
cc and
sC
wc when applied to high-dimensional data. We use 26 real datasets studied in social network analysis, which were described in
Section 1 as well. These datasets were generated from the large volume of tweets sent to Twitter on the day of the Great East Japan Earthquake, which hit Japan at 2:46 p.m. on 11 March 2011 and inflicted catastrophic damage. Each dataset was generated from a collection of tweets posted during a particular time window of an hour in length and consists of a word count vector for each author of Twitter that reflects all words in all they sent during that time window. In addition, each author was given a class label reflecting the category he or she was assigned from the
k-means clustering process. We expect that this annotation represents the extent to which authors are related to the Great East Japan Earthquake.
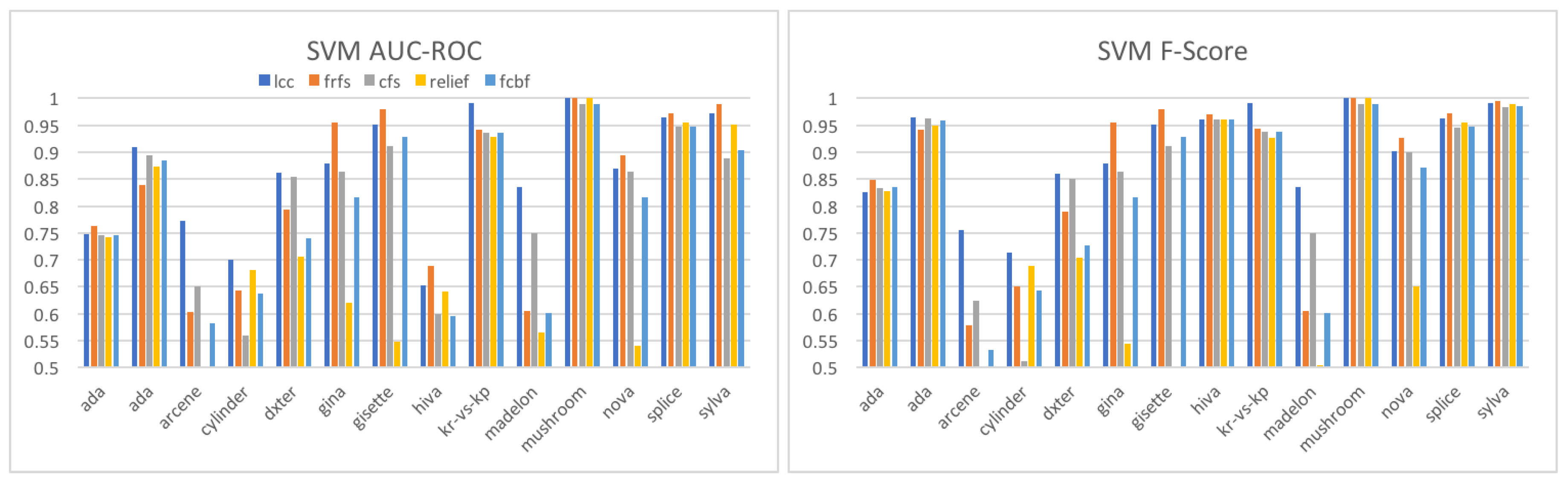
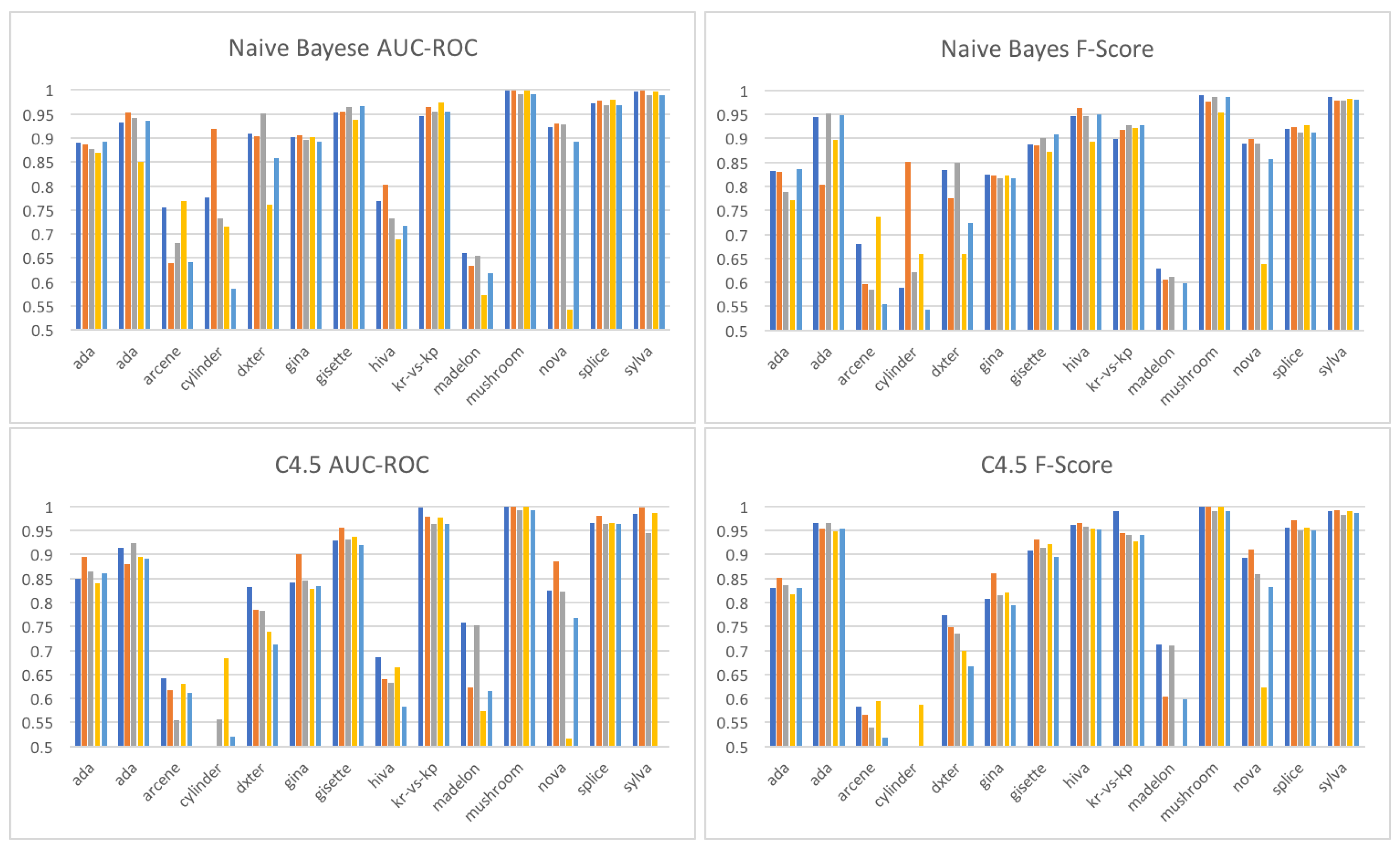
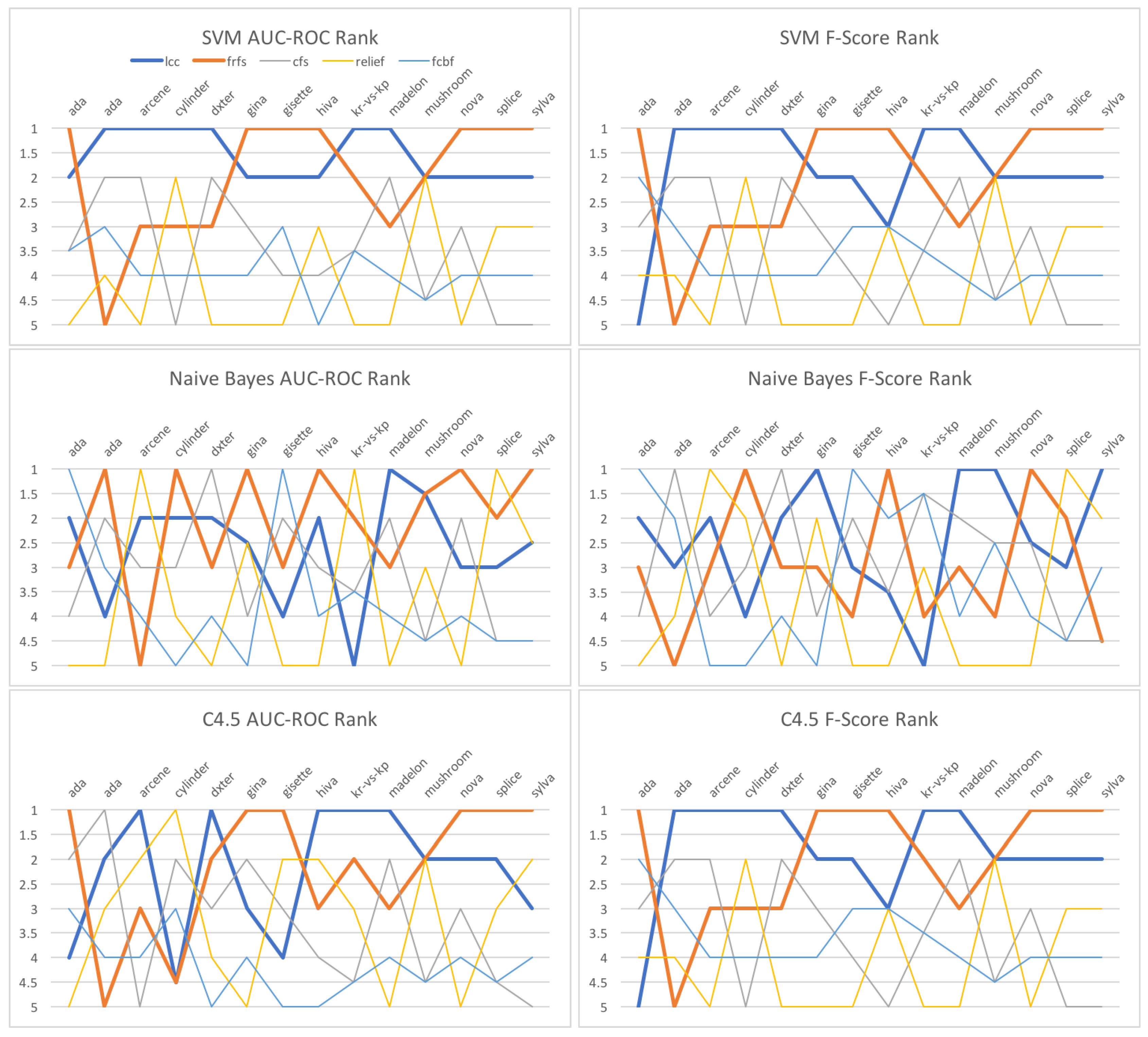
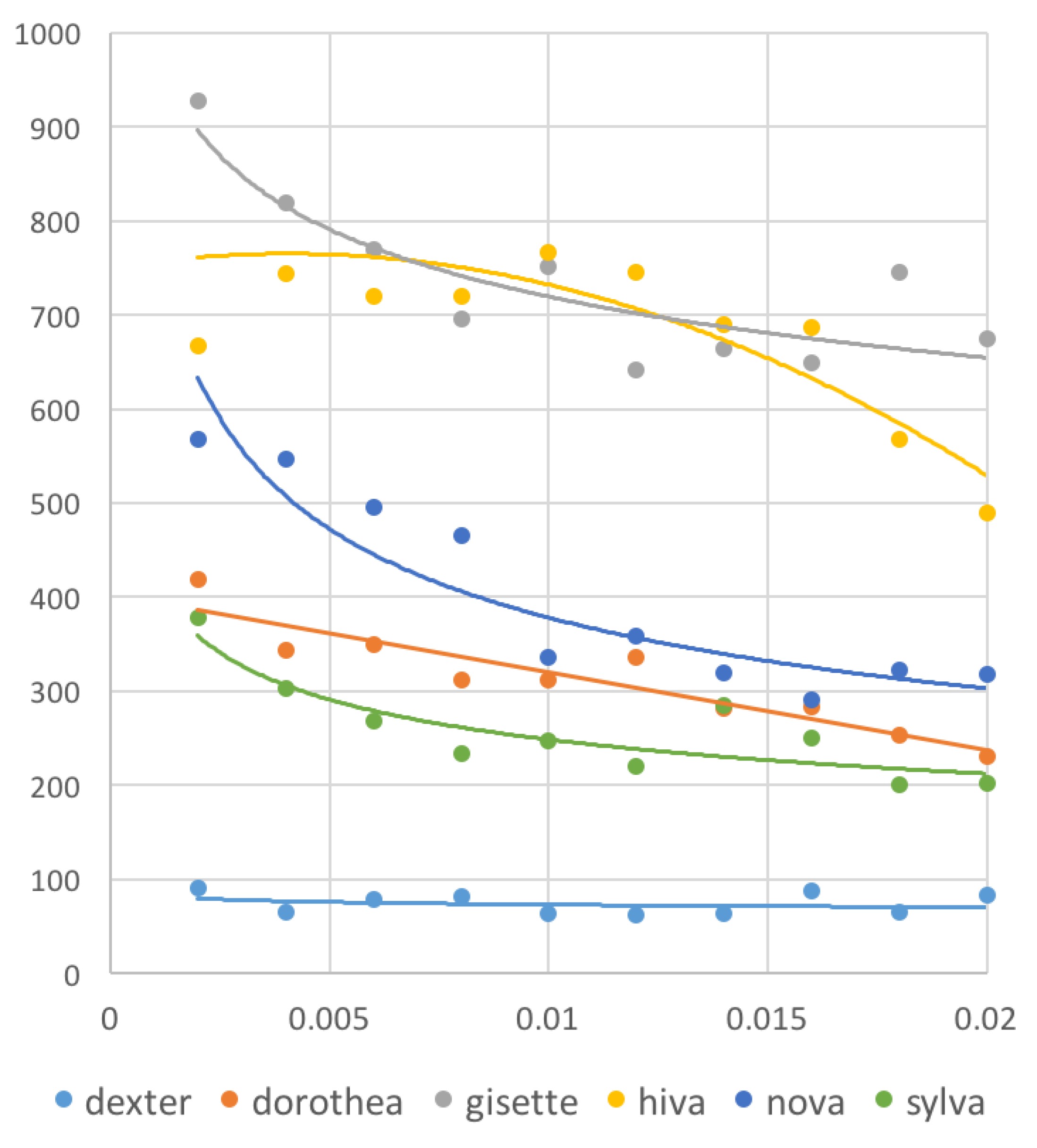
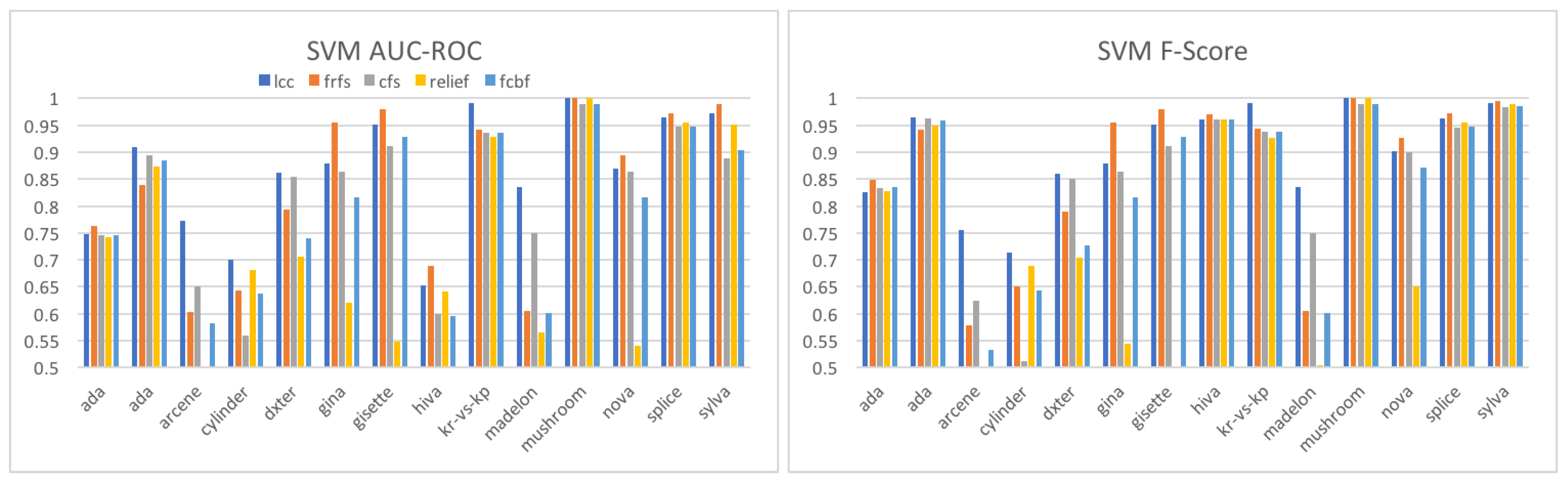
Table 13 shows the AUC-ROC scores of C-SVM that run on the features selected by
sC
wc. We measured the scores using the method described in
Section 4.2.1. Given time constraints, we use only 18 datasets out of the 26 datasets prepared. We see that the scores are significantly high, and the features selected well characterize the classes.
From
Table 3, we observe that the run-times of
sC
wc on the aforementioned 26 datasets range from 1.397 s to 461.130 s, and the average is 170.017 s. Thus, this experiment shows that the time-efficiency of
sC
wc is satisfactory enough to apply it to high-dimensional data analysis.
For a more precise measurement, we compare
sC
wc with F
rfs.
Table 14 shows the results. Since running F
rfs takes much longer, we test only three datasets and use a more powerful computer with CentOS release 5.11 (The CentOS Project), Intel Xeon X5690 6-Cores 3.47 GHz processor and 192 GB memory (Santa Clara, CA, USA). Although we tested only a few datasets, the superiority of
sC
wc to F
rfs is evident:
sC
wc is more than twenty times faster than F
rfs.
In addition, we can conclude that
sC
wc remarkably improves the time-efficiency of C
wc. Running C
wc on the smallest dataset with 15,567 instances and 15,741 features in
Table 3 requires several hours to finish feature selection. Based on this, we estimate that it will take up to ten days to process the largest dataset with 200,569 instances and 99,672 features because we know the time complexity of C
wc is
. Surprisingly,
sC
wc has finished feature selection of this dataset in only 405 s.
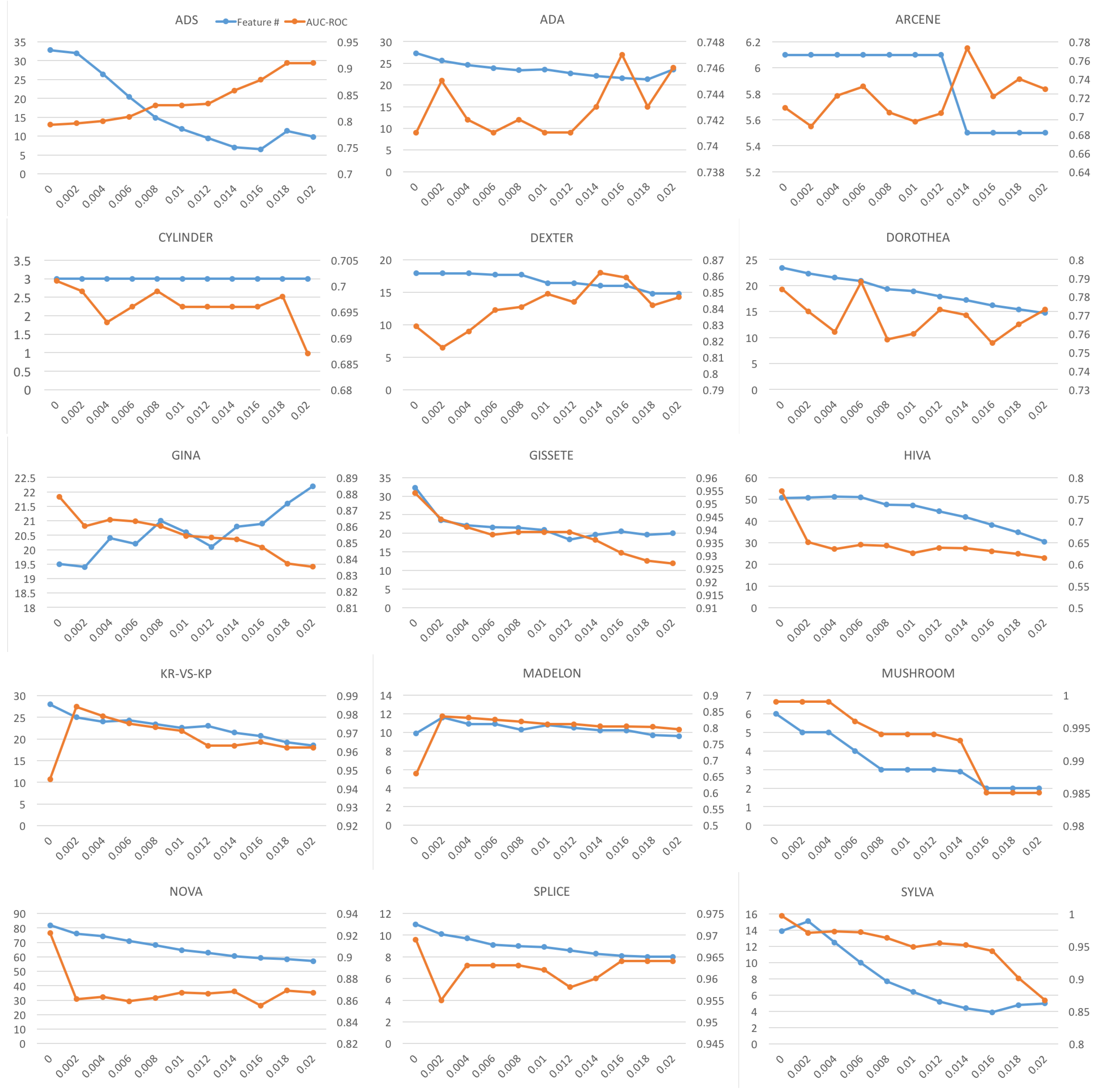
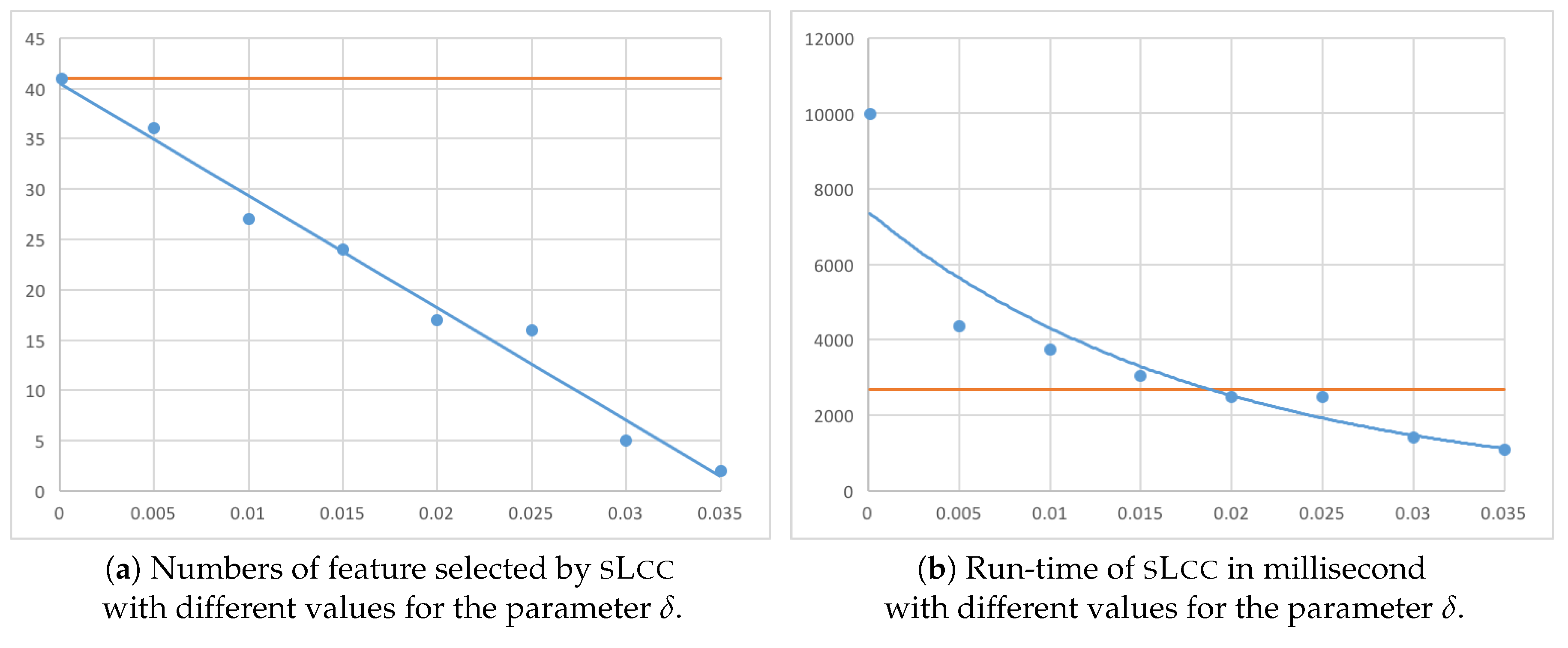
Lastly, we investigate how the parameter
can affect the performance of
sL
cc. As described in
Section 4.3, with greater
,
sL
cc will eliminate more features, and, consequently, the run-time will decrease. To verify this, we run an experiment with
sL
cc with the dataset with 161,425 instances and 38,822 features.
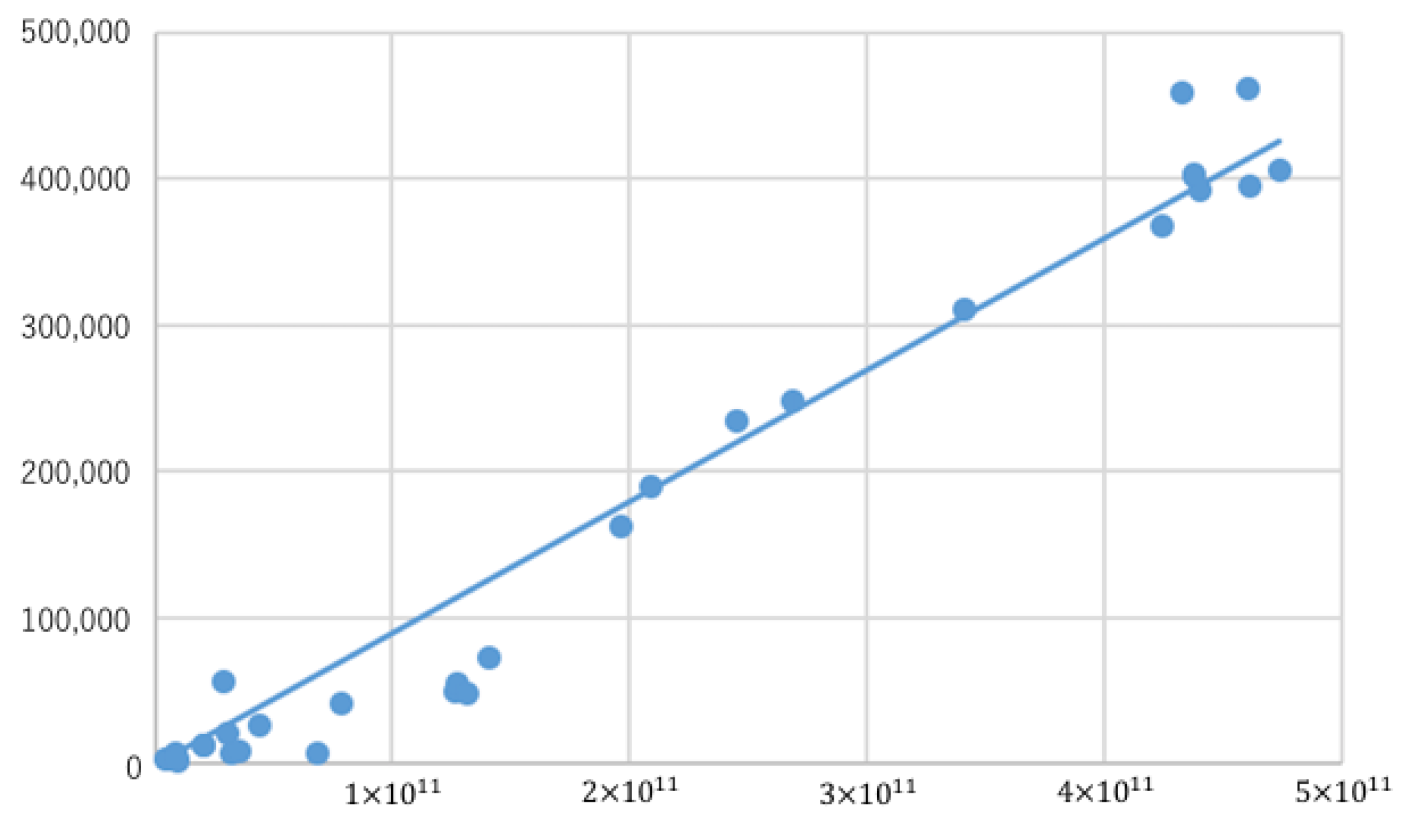
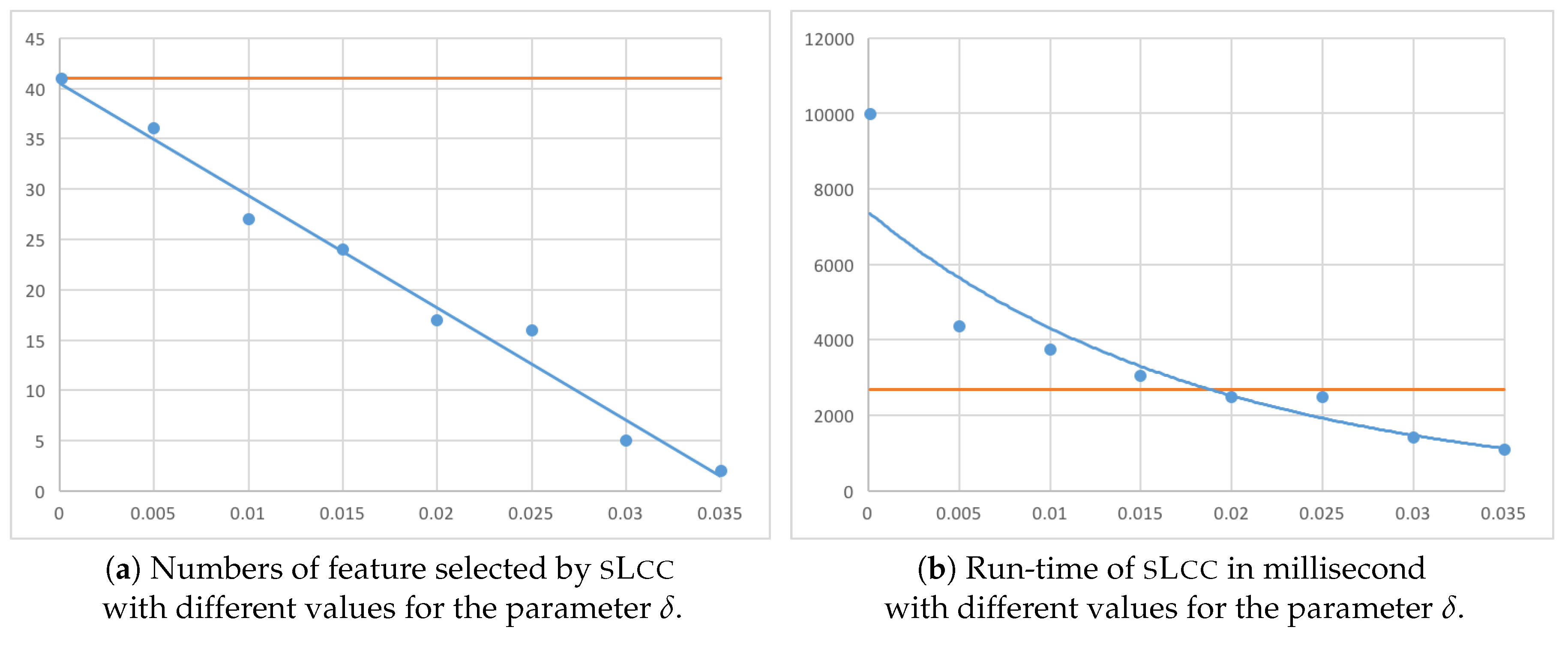
Figure 10 exhibits plots of the results. In fact, the number of features selected by and the run-time of
sL
cc decrease as the threshold
increases. In addition, we see that, although
sL
cc selects the same features as
sC
wc when
, the run-time is greater than
sC
wc. This is because computing the Bayesian risk (Br) is computationally heavier than computing the binary consistency measure (Bn). It is also interesting to note that
sL
cc becomes faster than
sC
wc for greater thresholds, and their averaged run-time performance appears comparable.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}