1. Introduction
Part-of-speech (POS) tagging, which is a fundamental task in natural language understanding, has attracted considerable attention from researchers for various languages. In computational linguistics, this task involves labeling words in sentences with a unique POS tag according to their syntactic function in context. It plays an important role in natural language processing (NLP) and has been widely applied to a few high-level NLP tasks such as syntactic analysis, named entity recognition, and machine translation [
1]. With the creation of social media and the development of electronic communication in Xinjiang, China, a large quantity of digital text in Uyghur is produced currently. The information extracted from these texts can be used for different NLP tasks such as POS tagging for Uyghur. Uyghur is an agglutinative and morphologically rich language. Therefore, this is an extremely challenging and interesting task. At present, state-of-the-art POS tagging accuracy is approximately 97% for English [
2,
3,
4,
5], approximately 96% for Chinese [
6,
7,
8,
9] on news text, and approximately 96.85% for Uyghur [
10].
In Uyghur, words can be broadly divided into independent words, function words, and exclamatory words. Independent words include verbs and substantive words. Nouns, adjectives, numerals, quantifiers, pronouns, adverbs, and mimetic words belong to the class of substantive words [
11]. Function words include three kinds of words: conjunctions, prepositions, and particles. Uyghur is an agglutinative language, meaning that potentially several affixes (e.g., denoting person, number, case, or mood) are frequently attached to one word stem. Independent word affixes are divided into two main types: verbal affixes and substantive affixes. There are 150 verbal affixes and 65 different substantive affixes, which includes 49 noun affixes, 57 numeral affixes, and 55 adjective affixes. In theory, the number of various combinations of nominal affixes is 1502. However, according to recent statistical analysis [
10], only 368 combinations appear in practice. For instance, there are 21 different affix variants of the word
weqe (“accident,” “event,” or “incident”) in the corpus used in this paper (as shown in
Table 1).
It is necessary to perform morphological analysis of Uyghur words before POS tagging. If POS tagging is performed without stemming, different variants of the same word will be identified as different words, and a large number of unknown words will appear, instead of different morphosyntactic variants (as shown in
Table 1). To fully understand this issue, consider the following sentence (in Latin script):
alimjan ulugh alimimiz mehmud qeshqeri tughulghinining 1000-yilliqini xatirilesh ilmiy muhakime yighinida söz qildi.
Translation: Speech delivered by Alimjan at the 1000th anniversary conference of great scholar and lexicographer Mahmud al-Kashgari.
In this example, alim appears twice, as alimjan (“a person name”) and alimimiz (“our scholar,” or “our scientist”), and both instances are nouns. If alim, which is the more frequently used form, is the only form that appears in the training corpus, POS tagging would identify alimimiz as out of vocabulary (OOV). Unfortunately, (i) there is no open source stemming tool, (ii) the development cost of such a tool is high because the Uyghur language is a low-resource language and it has agglutinative and rich morphological features, and iii) the performance of stemming affects the performance of POS tagging.
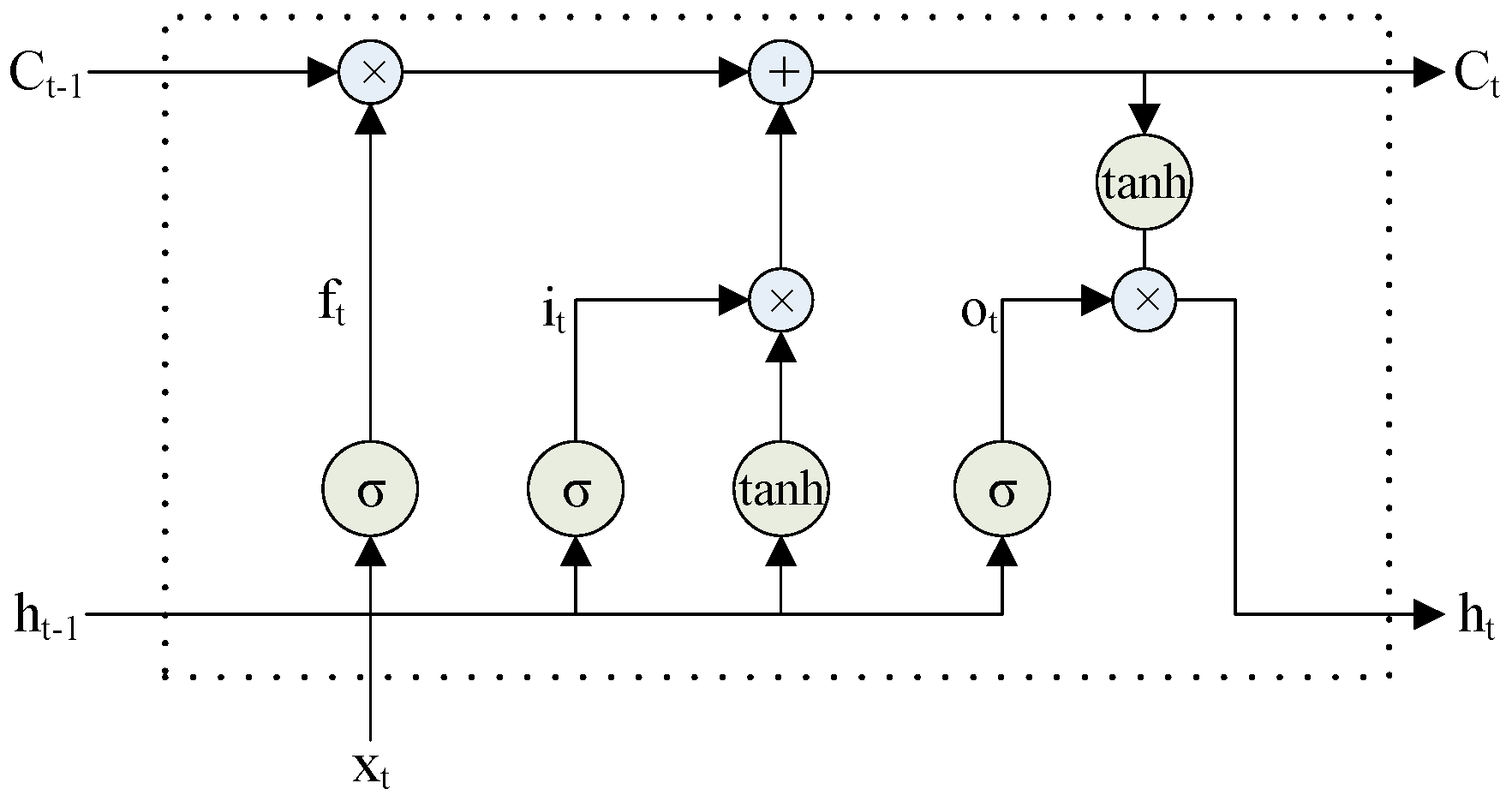
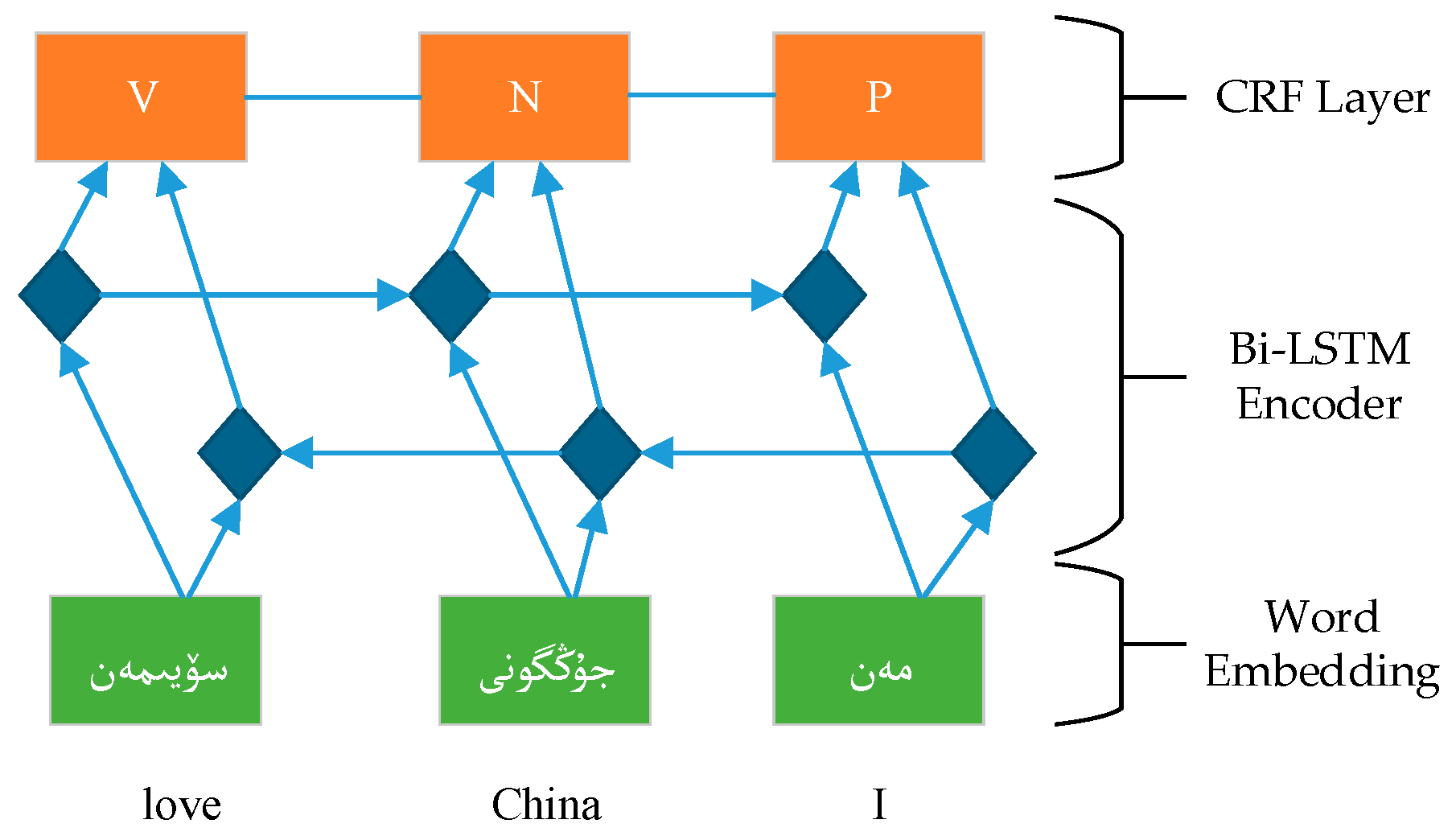
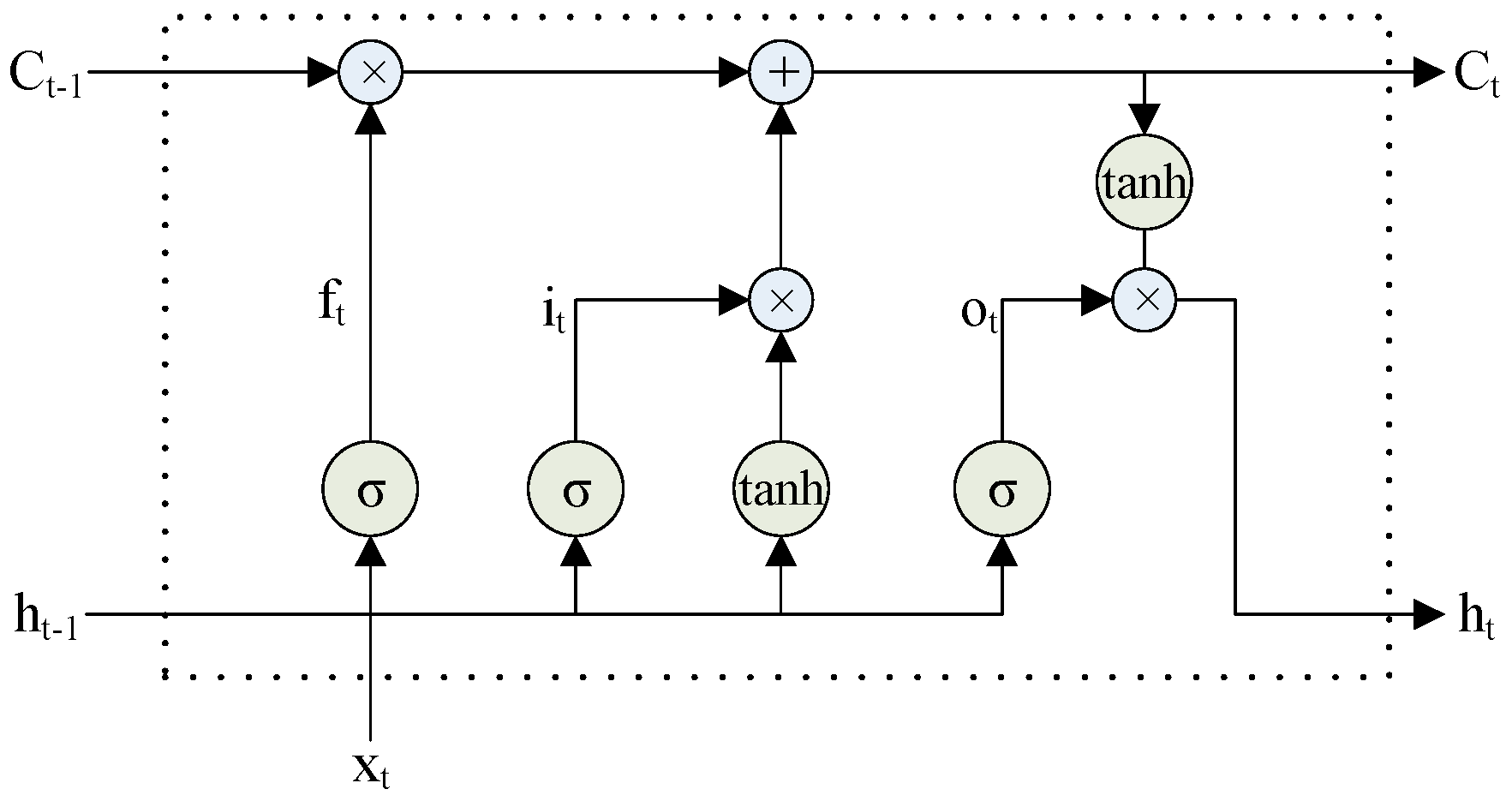
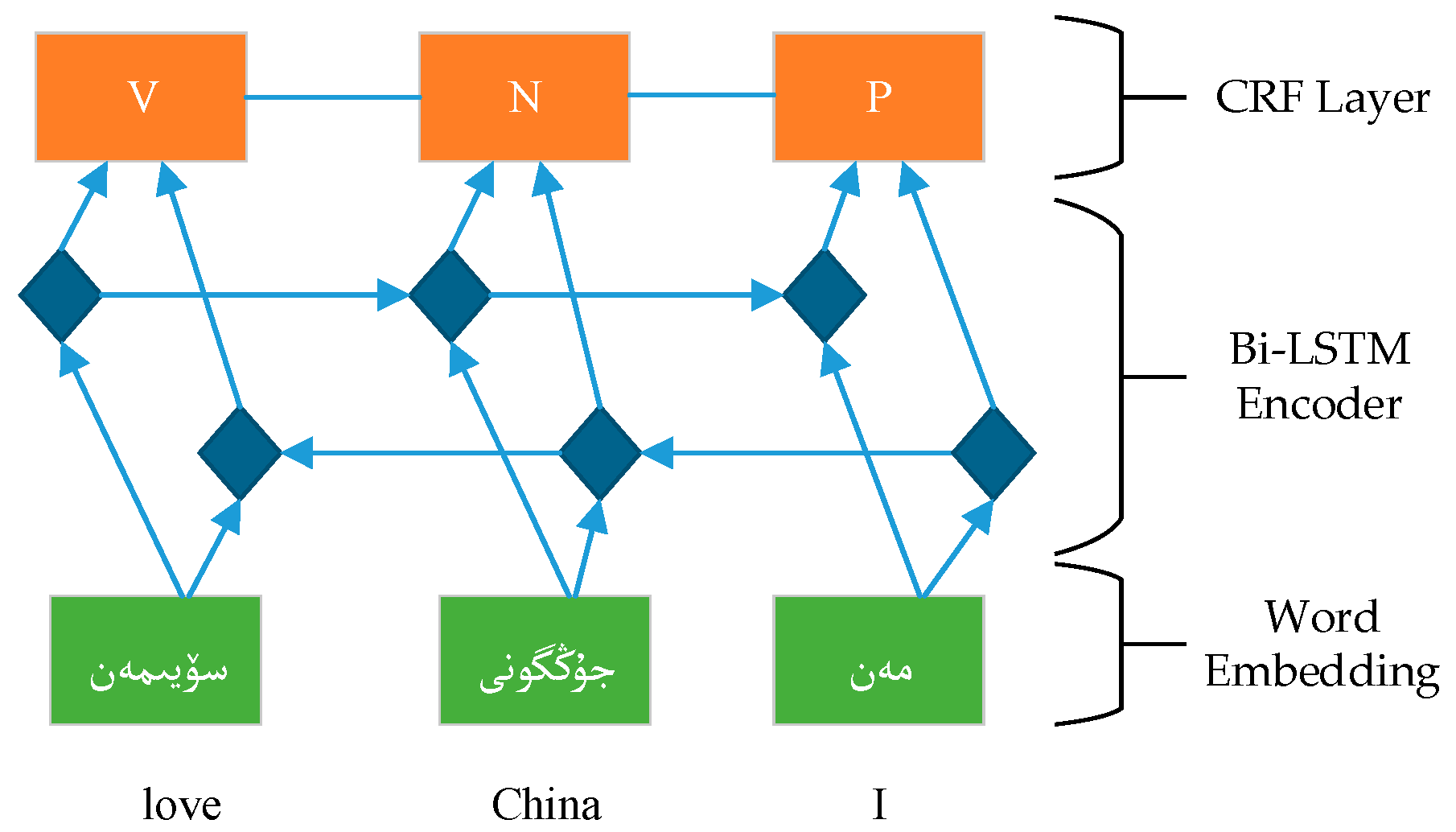
To address this problem, we propose embedding words and characters and using syllable features in a bidirectional long short-term memory network with a conditional random field layer (BI-LSTM-CRF). This method combines handcrafted features with a neural network model and is described in
Section 3.5. The experimental results are described in
Section 4.
However, when morphological analysis is performed, the number of ambiguous phenomena may increase. For example,
at means “name”, “horse”, or “shoot” and is either a verb or a noun,
atqin means “shoot it” and is a verb, and
atlar means “horses” and is a noun. After stemming, these words become the ambiguous word
at, which is quite difficult to distinguish. To our knowledge, there is no study that addresses this problem. As mentioned earlier, in the Uyghur language, different word classes take different affixes (common affixes are also present), e.g., Uyghur nouns are inflected for number (singular and plural), case (nominative, accusative, dative, locative, ablative, genitive, similitude, locative-qualitative, limitative, equivalence) [
11], and person (first, second, third), and verbs are conjugated for tense: present and past; person; voice: causative and passive; aspect: continuous; mood. In addition, these affixes are typically attached to the stem in a relatively fixed order, e.g., the general order of attachment for nouns is number, person, and case. For example, the word
atlirimning means “my horses’” and can split into affixes such as
at (stem)
+ lir (plural)
+ im (first person)
+ ning (genitive case). Therefore, the affixes and their order in a word may refer to the class that the words belong to. It is better to use intra-word information to capture syntactic and semantic information on Uyghur POS tagging. We obtain word shape information in our proposed model using character embedding, which is described in
Section 3.6.
Several studies on Uyghur POS tagging employ a small POS tag set; however, only a few studies consider a large POS tag set that can support high-level NLP tasks with richer information. Moreover, most existing Uyghur POS tagging models are linear statistical models, such as hidden Markov models (HMMs), maximum entropy models (MEMs), and n-gram models, all of which are limited to using only past and future features.
Our main contributions in this paper are as follows: (i) We apply long short-term memory (LSTM) networks, bidirectional LSTM (BI-LSTM) networks, an LSTM network with a conditional random field layer (LSTM-CRF), and the BI-LSTM-CRF model to Uyghur POS tagging. We experimentally compare the performance of the models on Uyghur POS tagging data sets and show that this task can be effectively performed by neural networks and that competitive tagging accuracy can be obtained without handcrafted features. Moreover, we show that because the BI-LSTM-CRF model considers word- and sentence-level information and can fully use past and future input features, it is an effective method of performing the POS tagging task in morphologically rich languages. (ii) For the first time, we examine the performance of easily applied engineered features, such as syllable- and suffix-based features, with character embedding and word embedding in Uyghur POS tagging and further improve the performance. (iii) We demonstrate that our approach can achieve state-of-the-art performance on small and large tag sets.


{kind=link}
{kind=link}