
Correction of Outliers in Temperature Time Series Based on Sliding Window Prediction in Meteorological Sensor Network

Abstract
:1. Introduction
2. Related Work
2.1. Error Correction in Meteorological Sensor Networks
2.2. Outlier Detection
- (1)
- (2)
- Distance based method [24,25]. In this method, the feature points are used to represent the series. Then, using the two order regression model to realize the unequal division of series. Based on the dynamic time warping distance, the abnormal scores of subsequence are calculated. Then, select the largest k values of the abnormal score to determine whether it is an outlier.
- (3)
- (4)
- Support Vector Machine (SVM) based method [28,29]. In this method, the support vector regression is used to establish the regression model of the historical time series. Then, the matching degree between the new series and the model is judged. In addition, One-Class SVM technology has been widely used in the field of outlier detection.
- (5)
- Clustering based method [30,31]. The method first divides the data set into several clusters, and the data points that do not belong to any cluster are outliers. In the field of anomaly detection, clustering technology is used for unsupervised detection and semi-supervised detection. However, anomaly detection is usually a by-product of the clustering algorithm.
3. Time Series Outlier Detection Based on Sliding Window Prediction
3.1. Relevant Definition
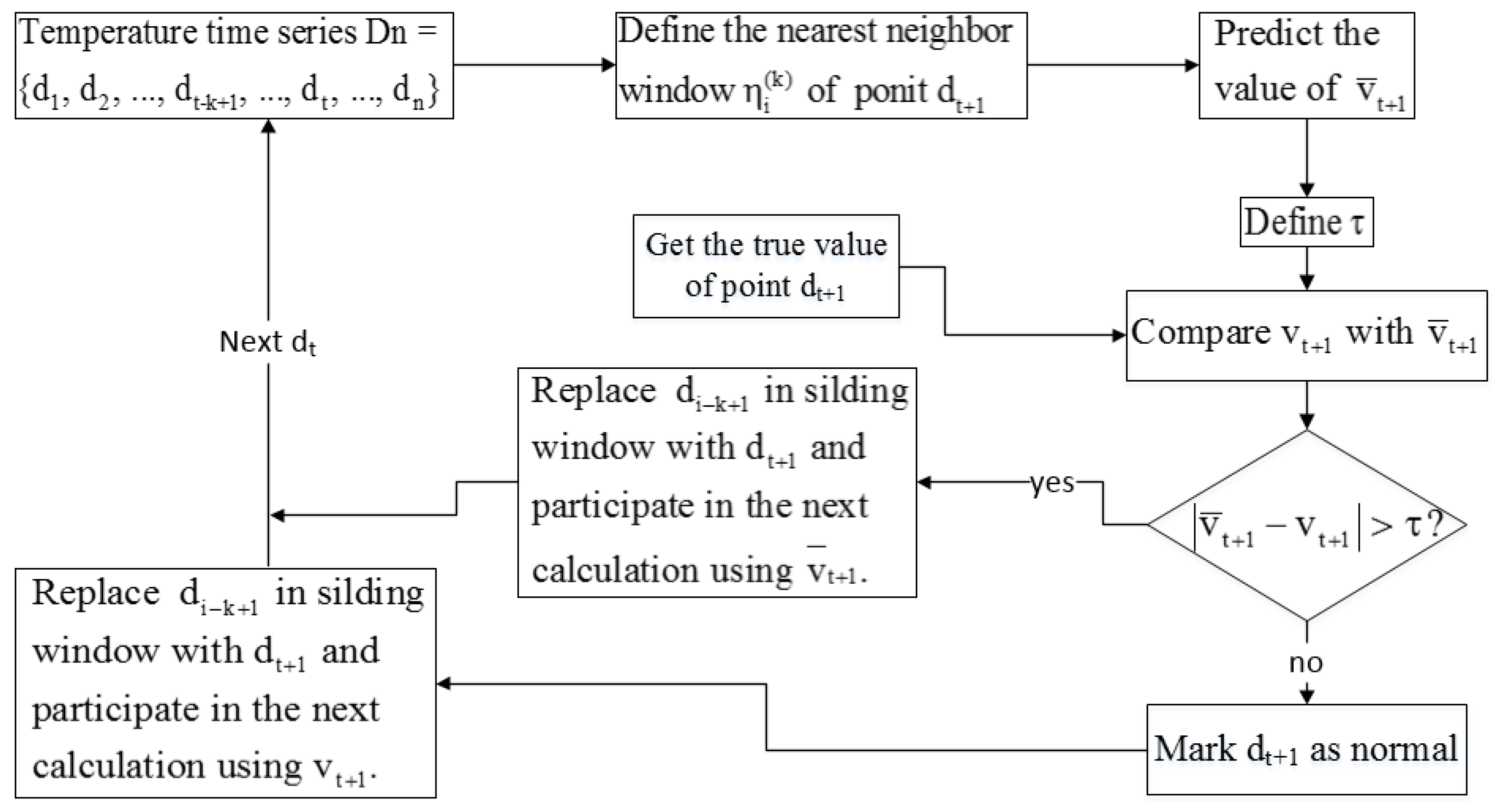
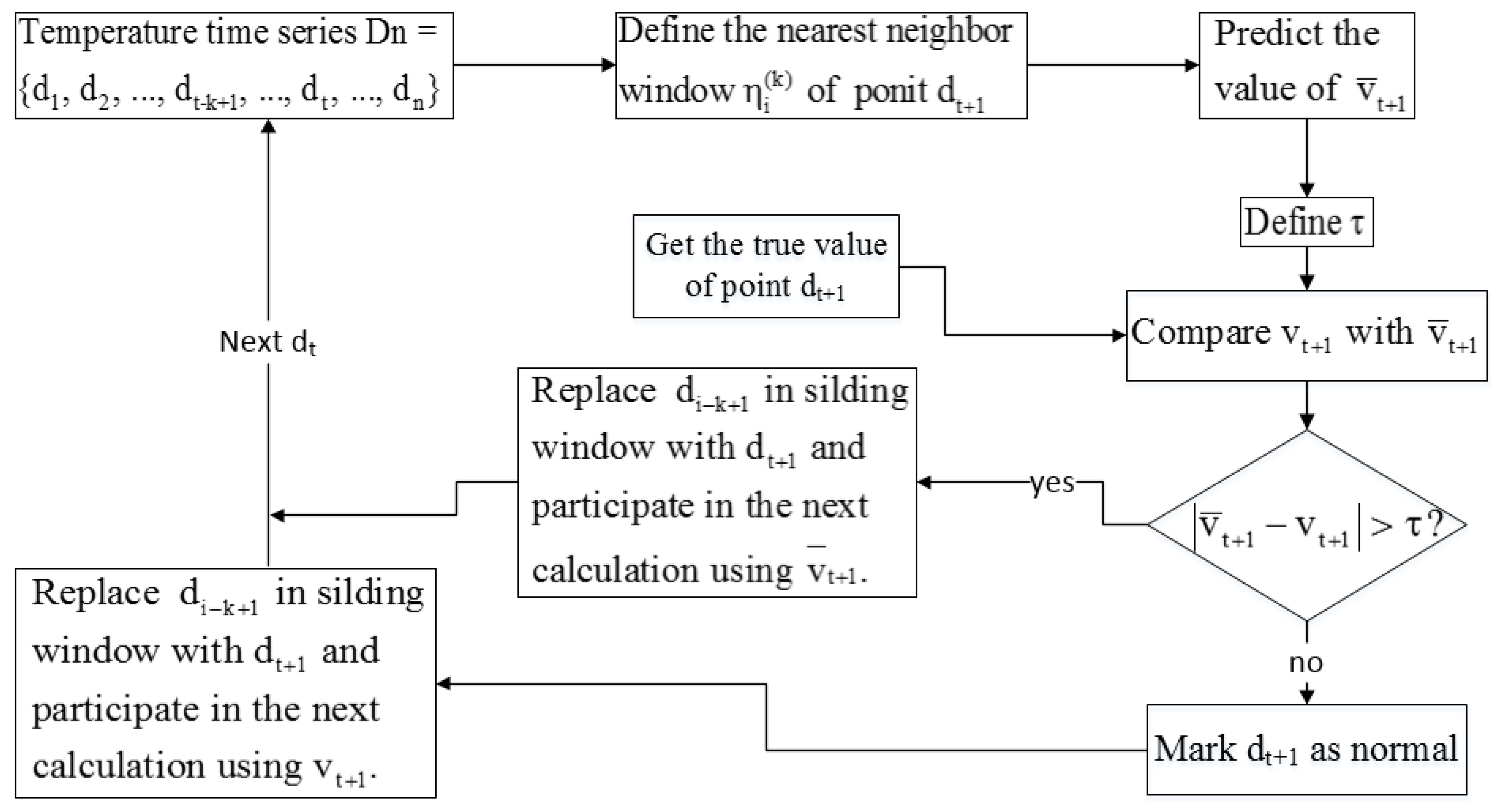
3.2. Algorithm Description
3.2.1. Sliding Window Definition
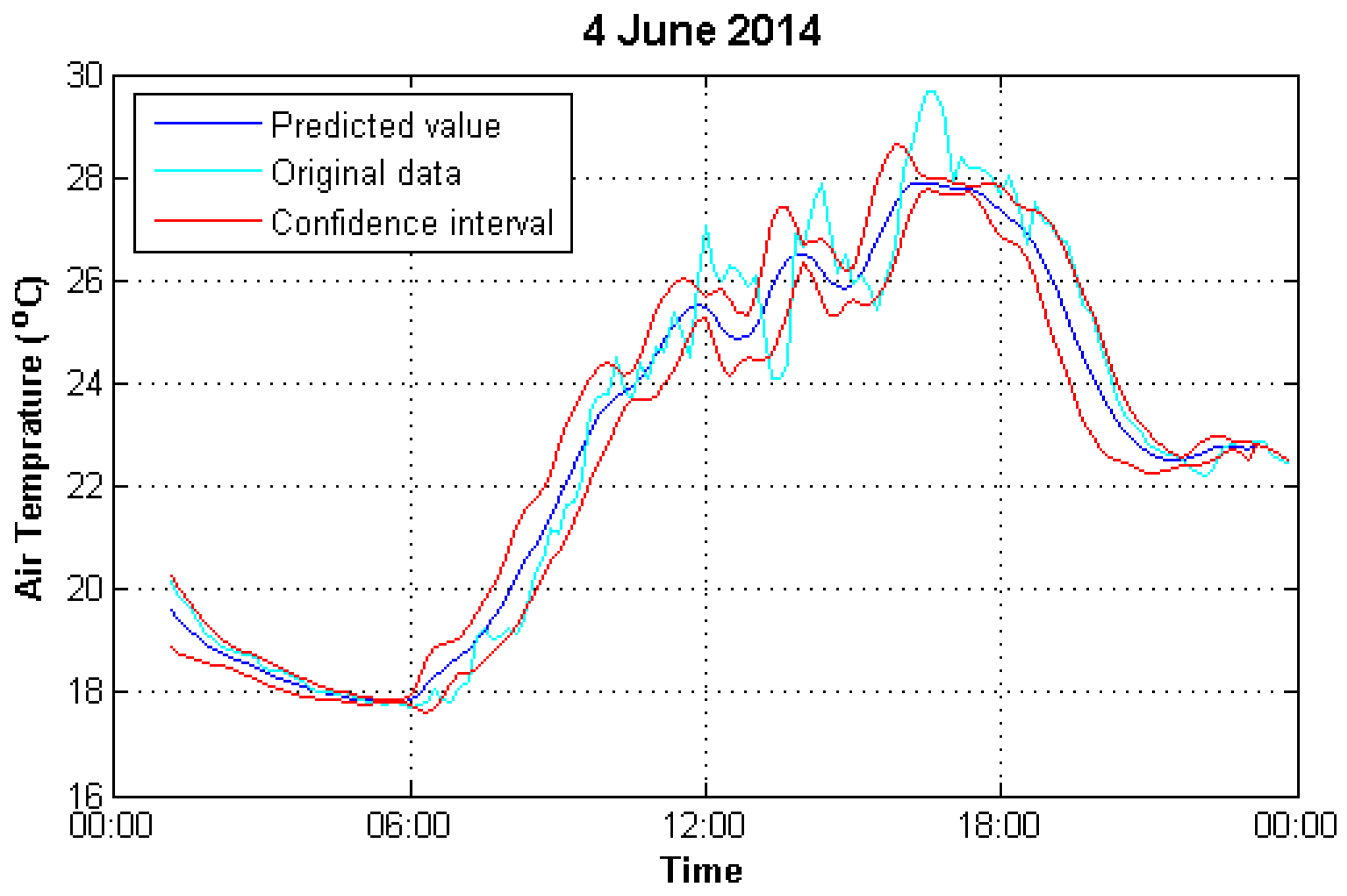
3.2.2. Prediction Model
3.2.3. Outlier Determination and Correction
3.3. Parameter Selection
- (1)
- Window width k. k determines the number of neighboring points involved in the prediction. The larger the k value is, the more adjacent points are involved in the computation, and the computational complexity is increased accordingly. In order to select the optimal sliding window width, it varies k from 3 to 15 with an increment of 1, i.e., .
- (2)
- Confidence coefficient p. It defines the expected probability that the measured values fall within the confidence interval. The greater the confidence coefficient is, the larger the range of confidence interval is. It varies the p range from 80% to 100% with an increment of 2%, i.e., .
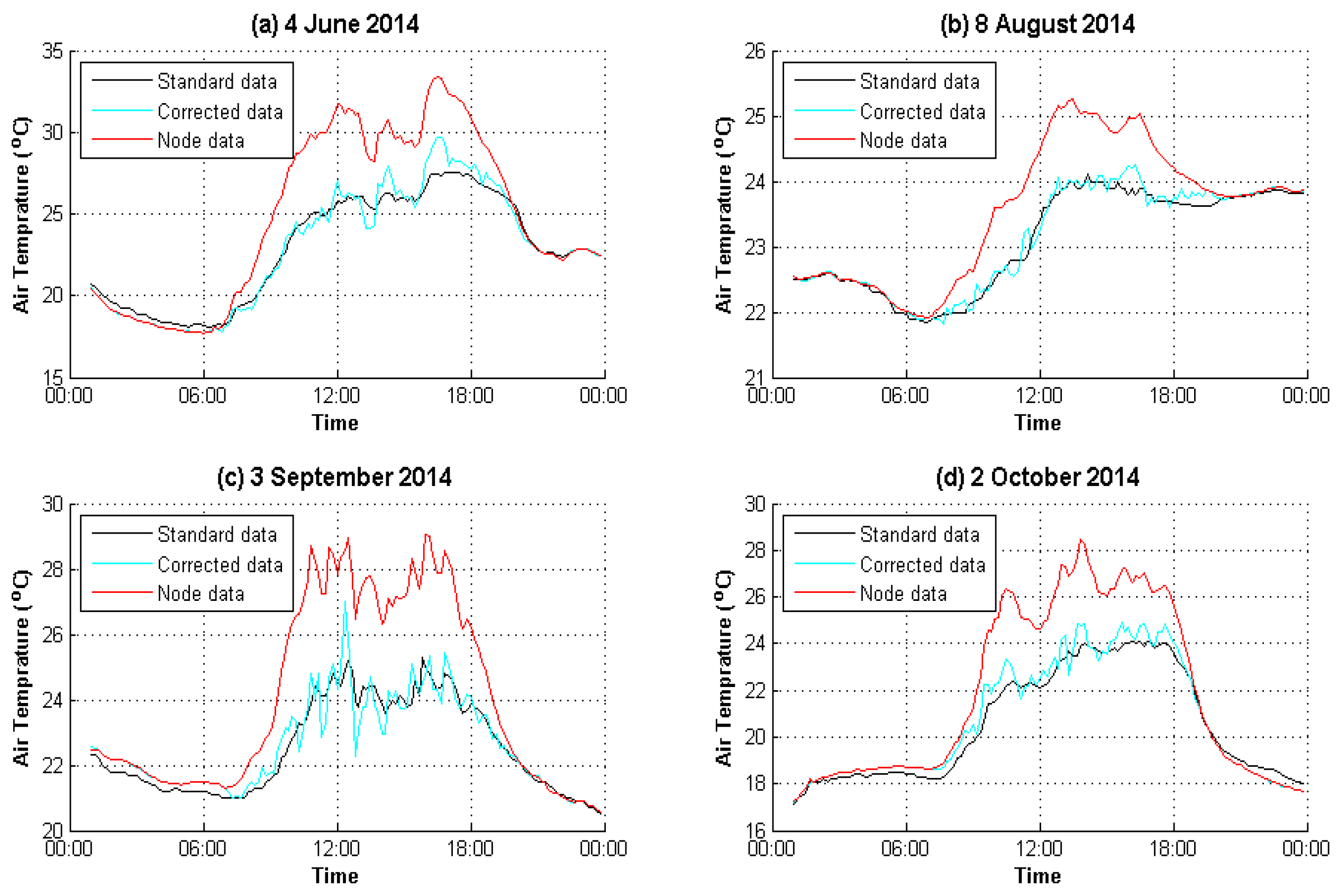
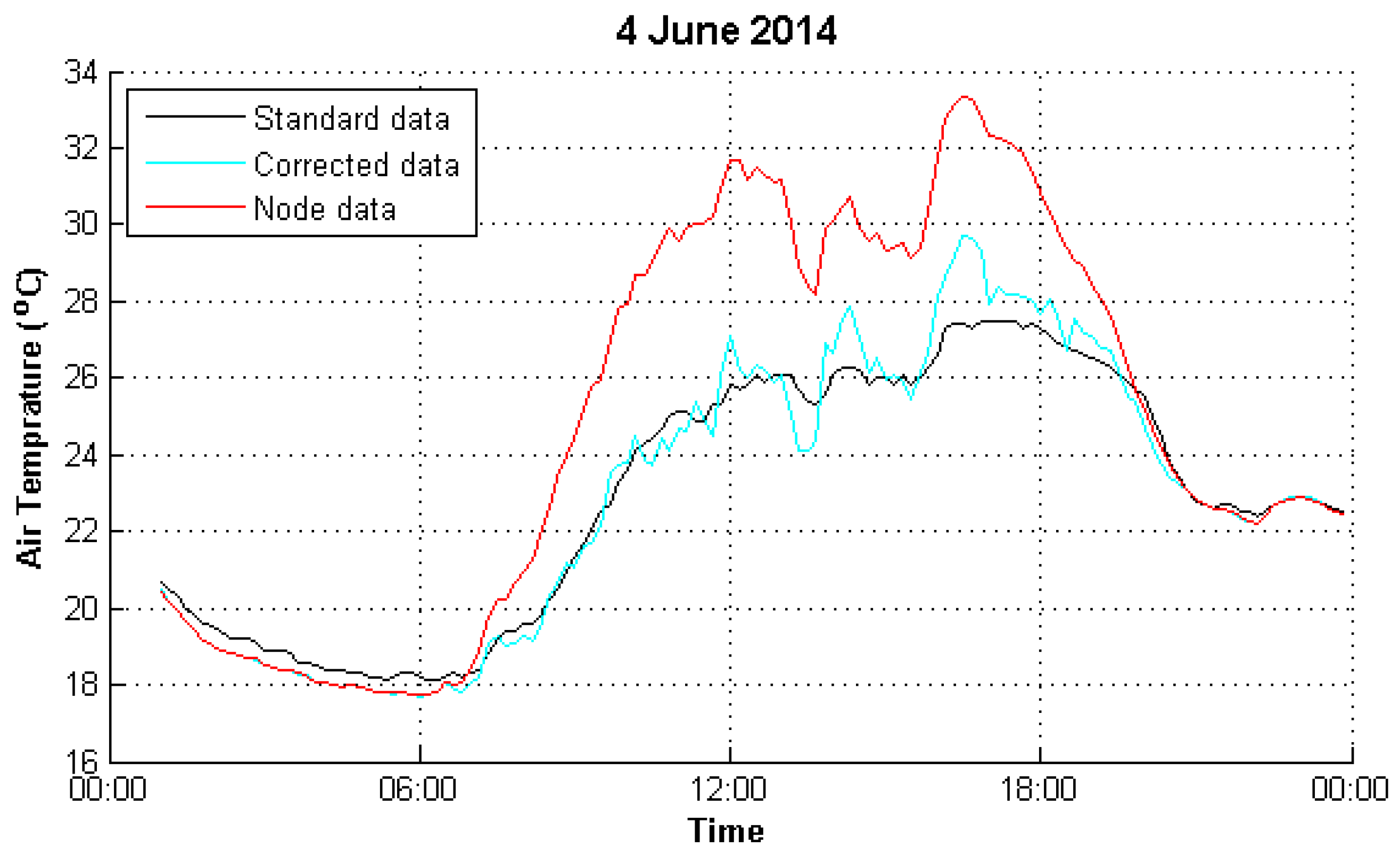
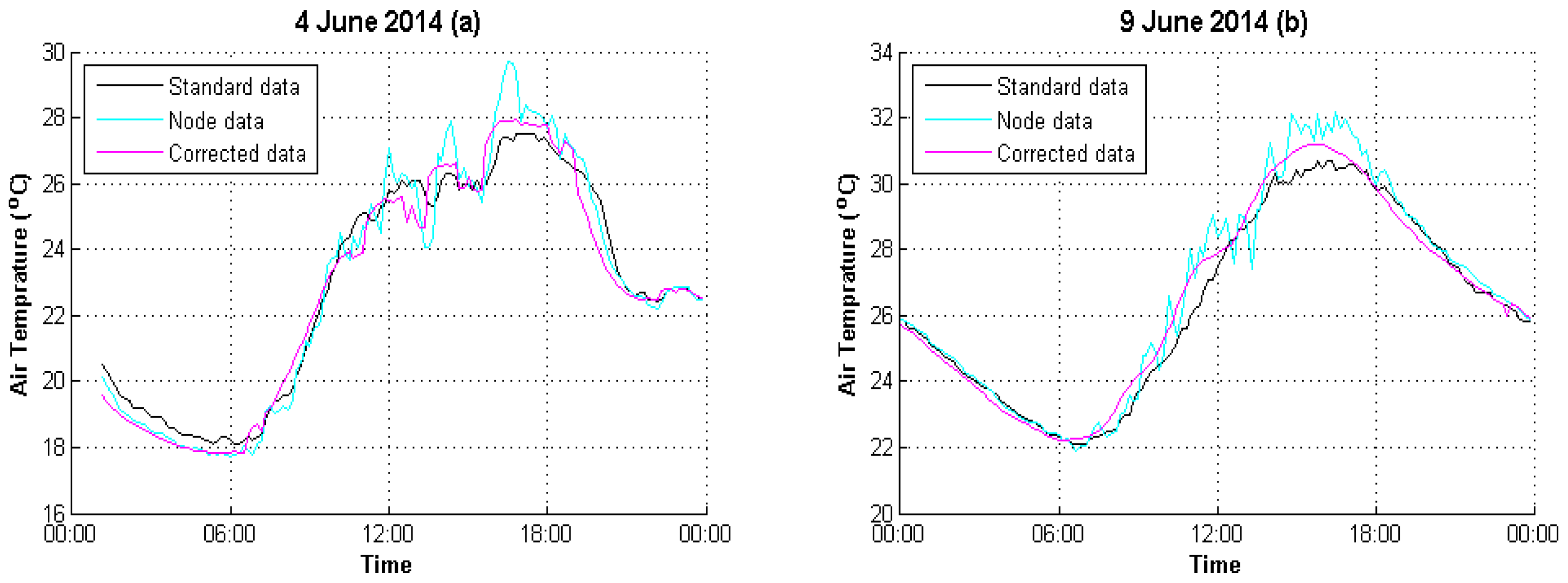
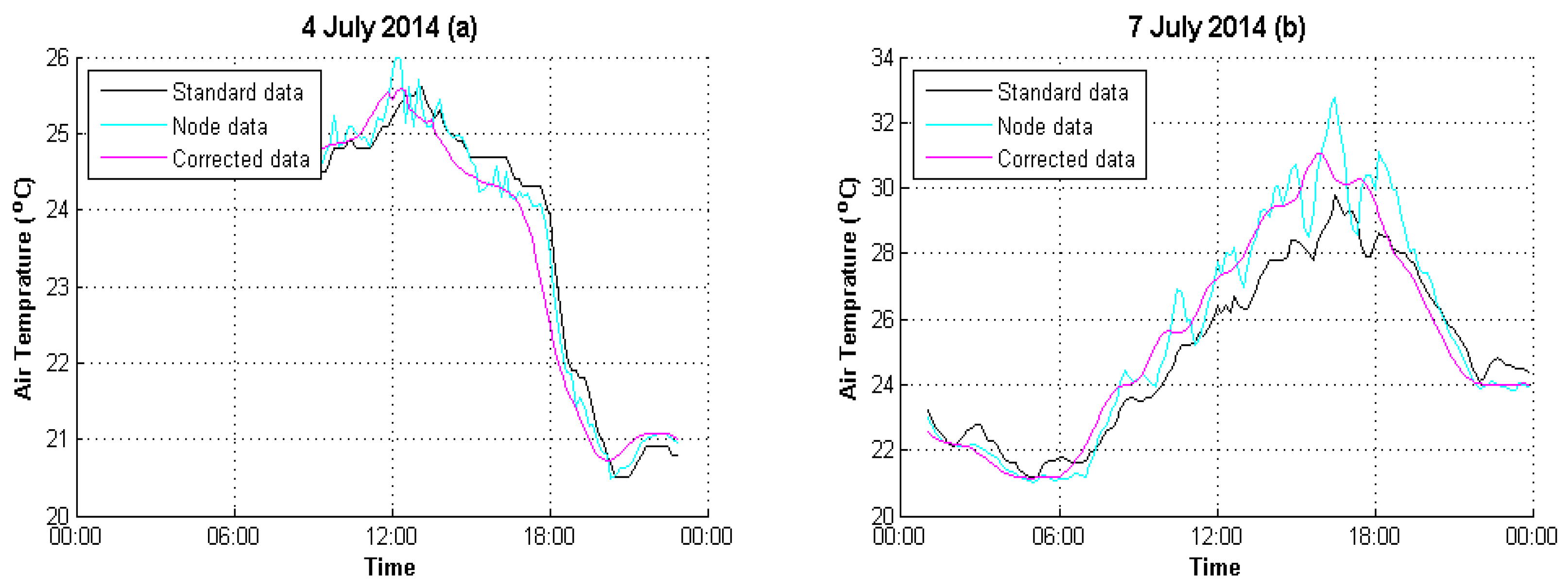
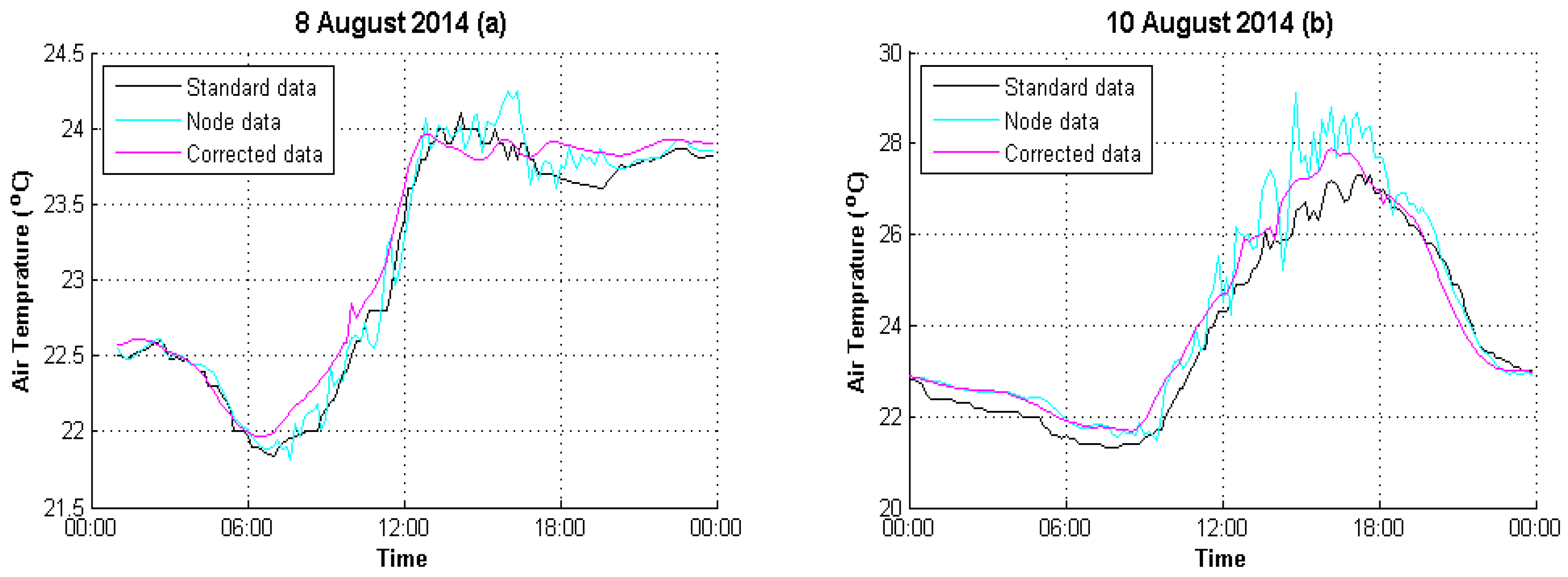
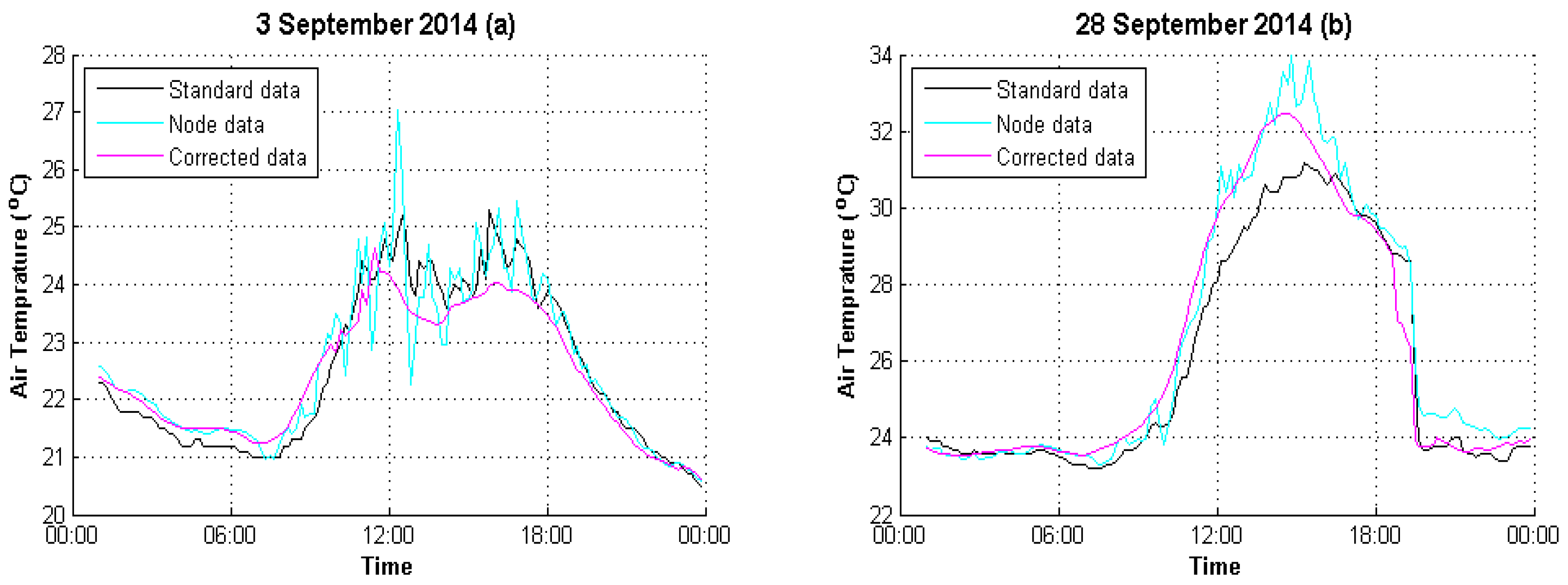
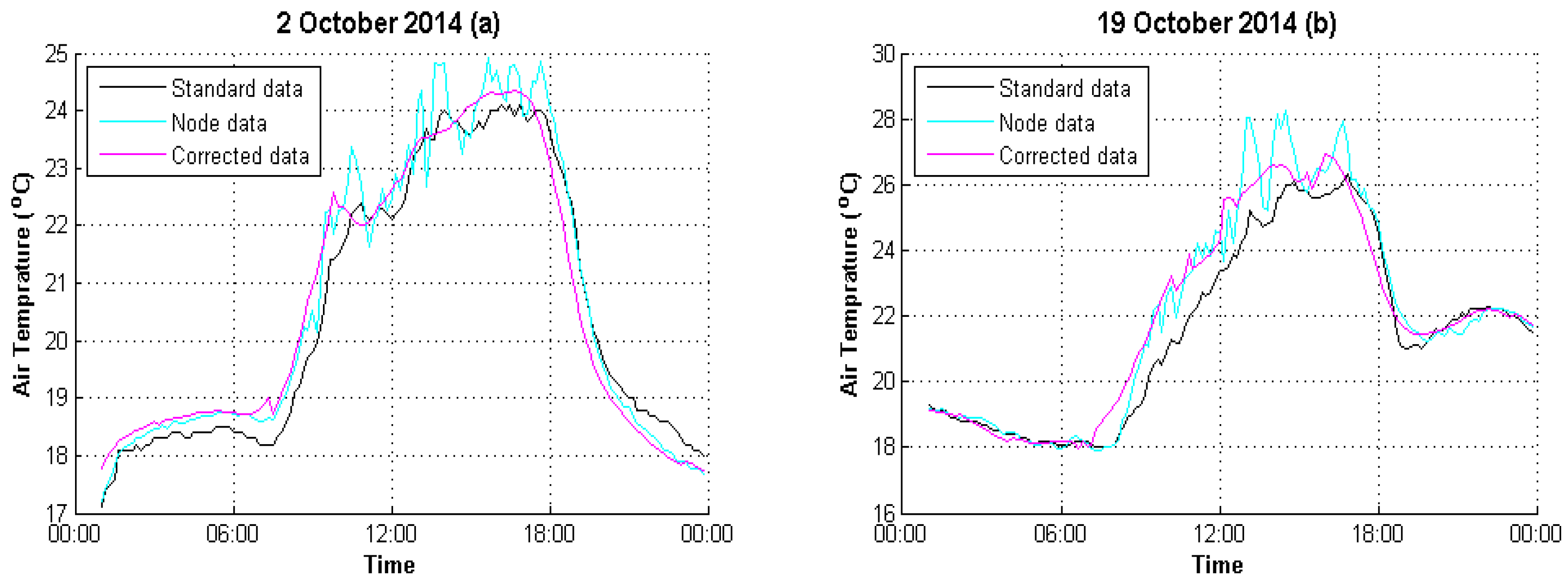
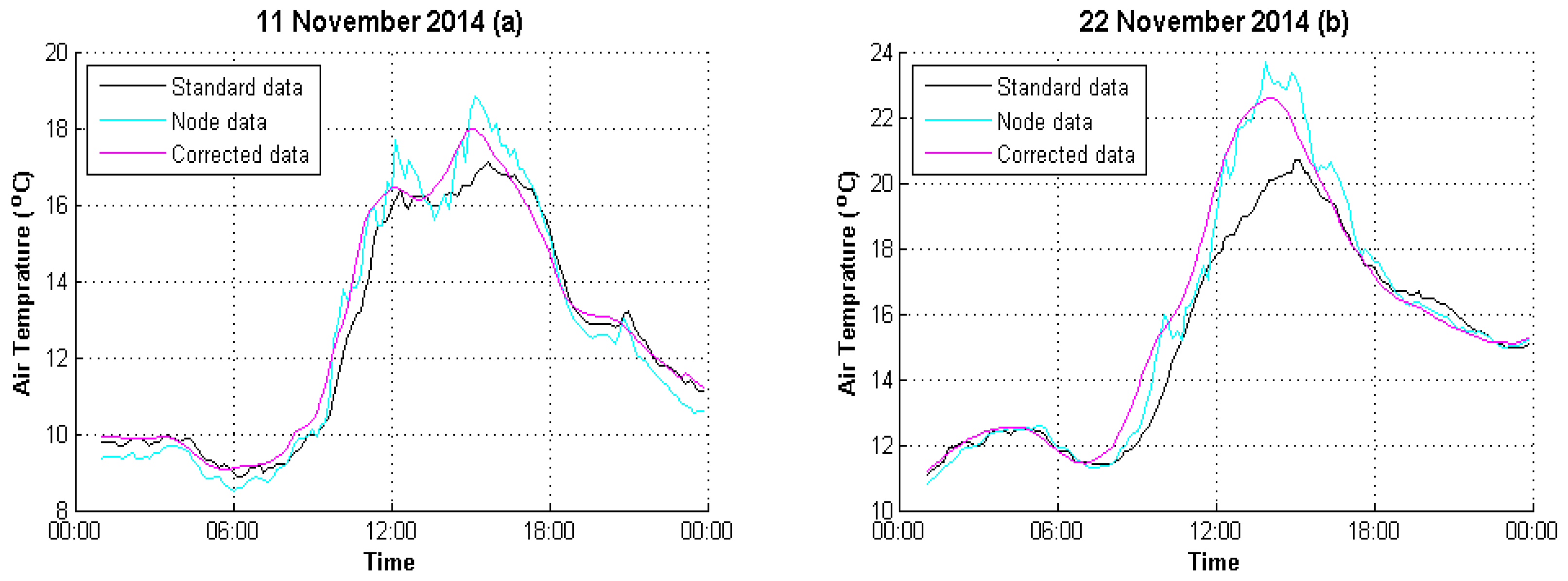
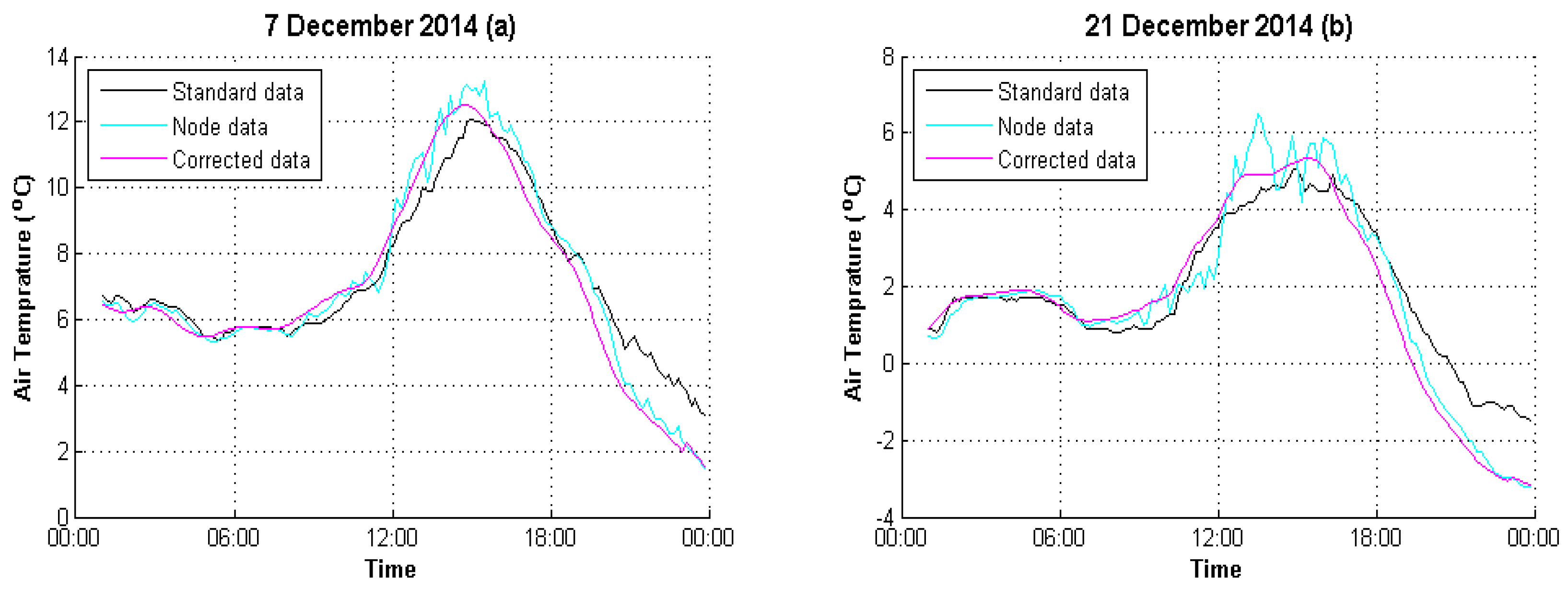
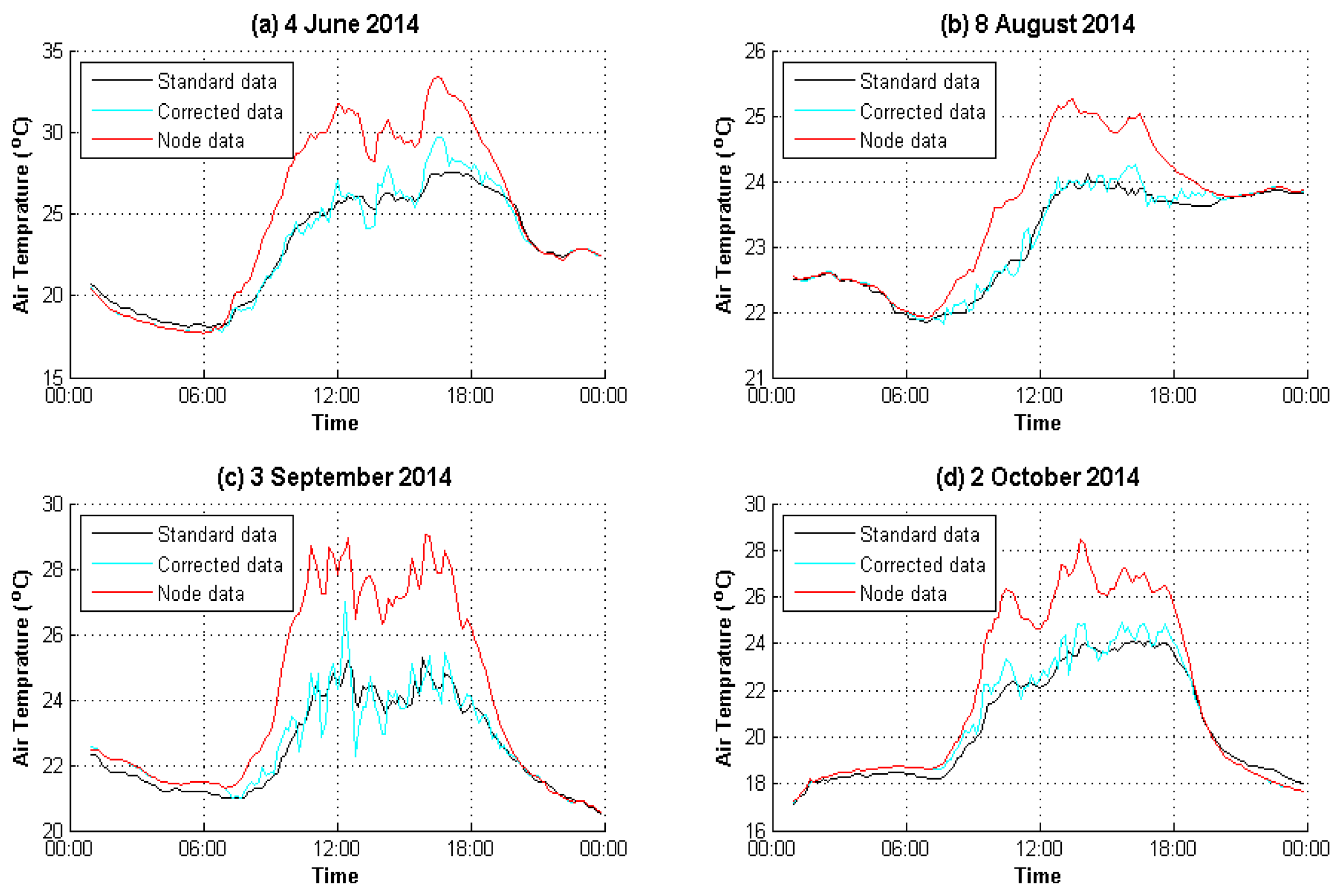
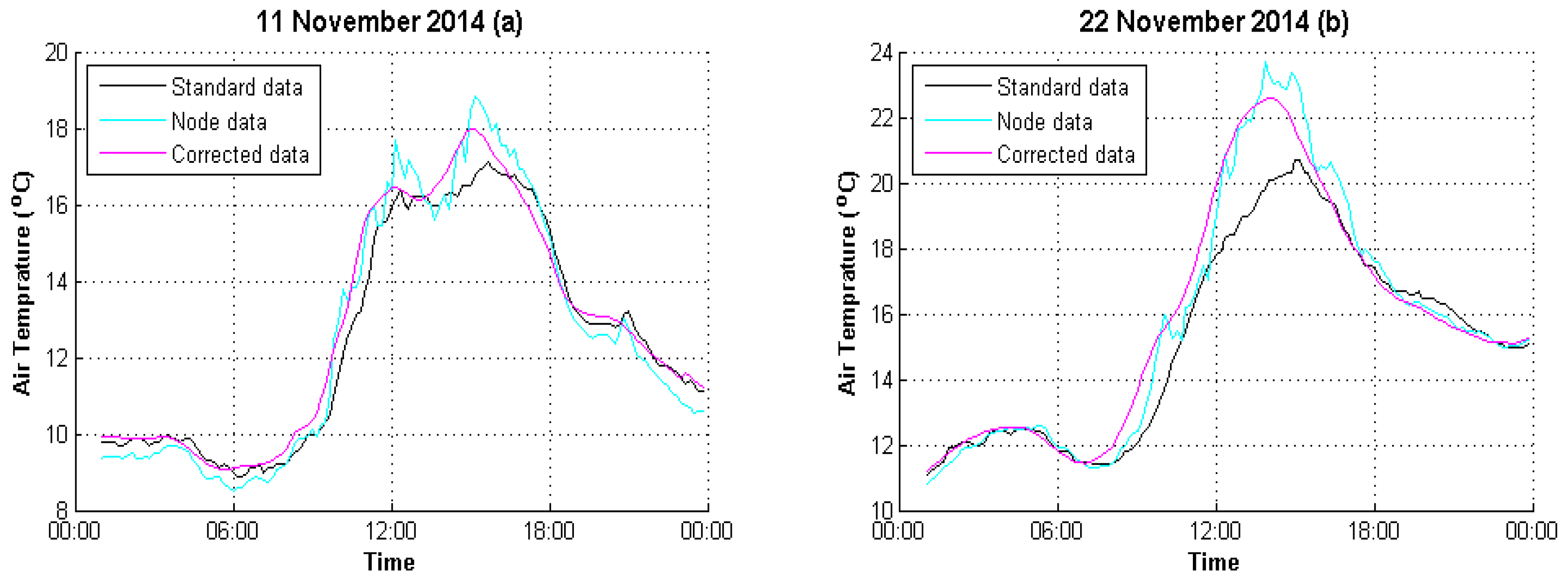
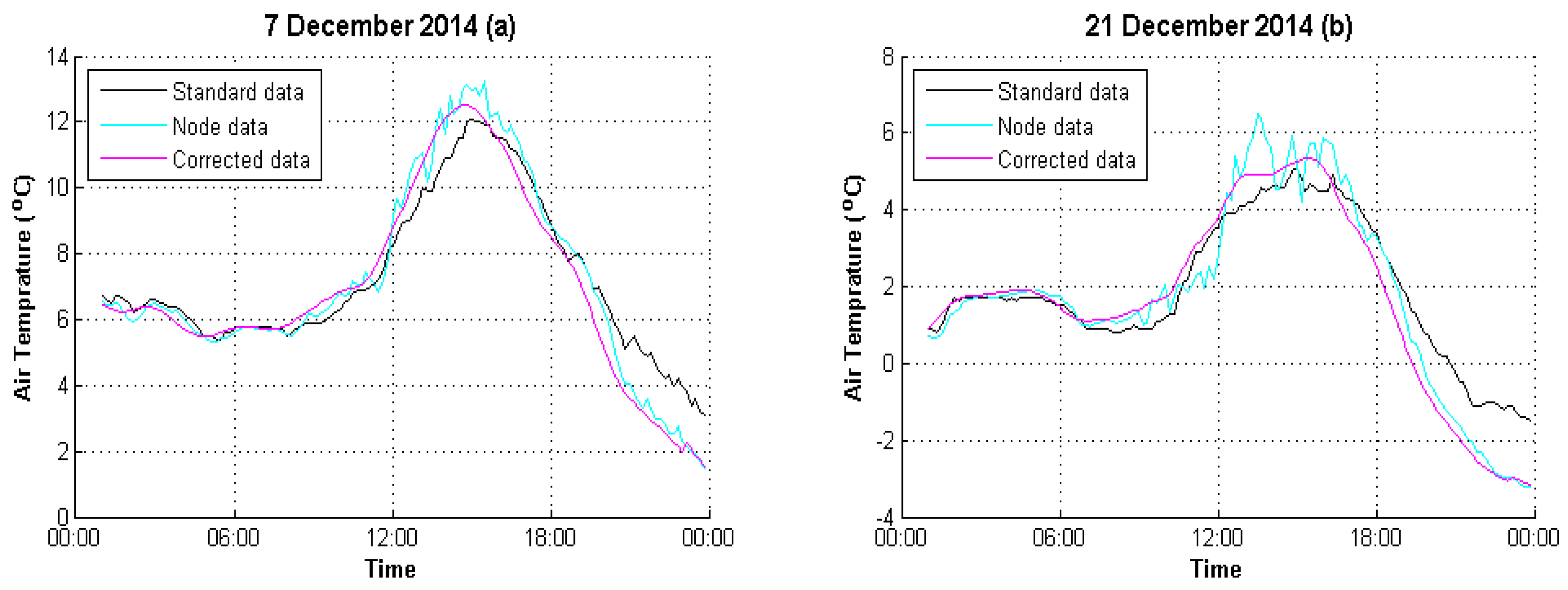
4. Experimental Analysis
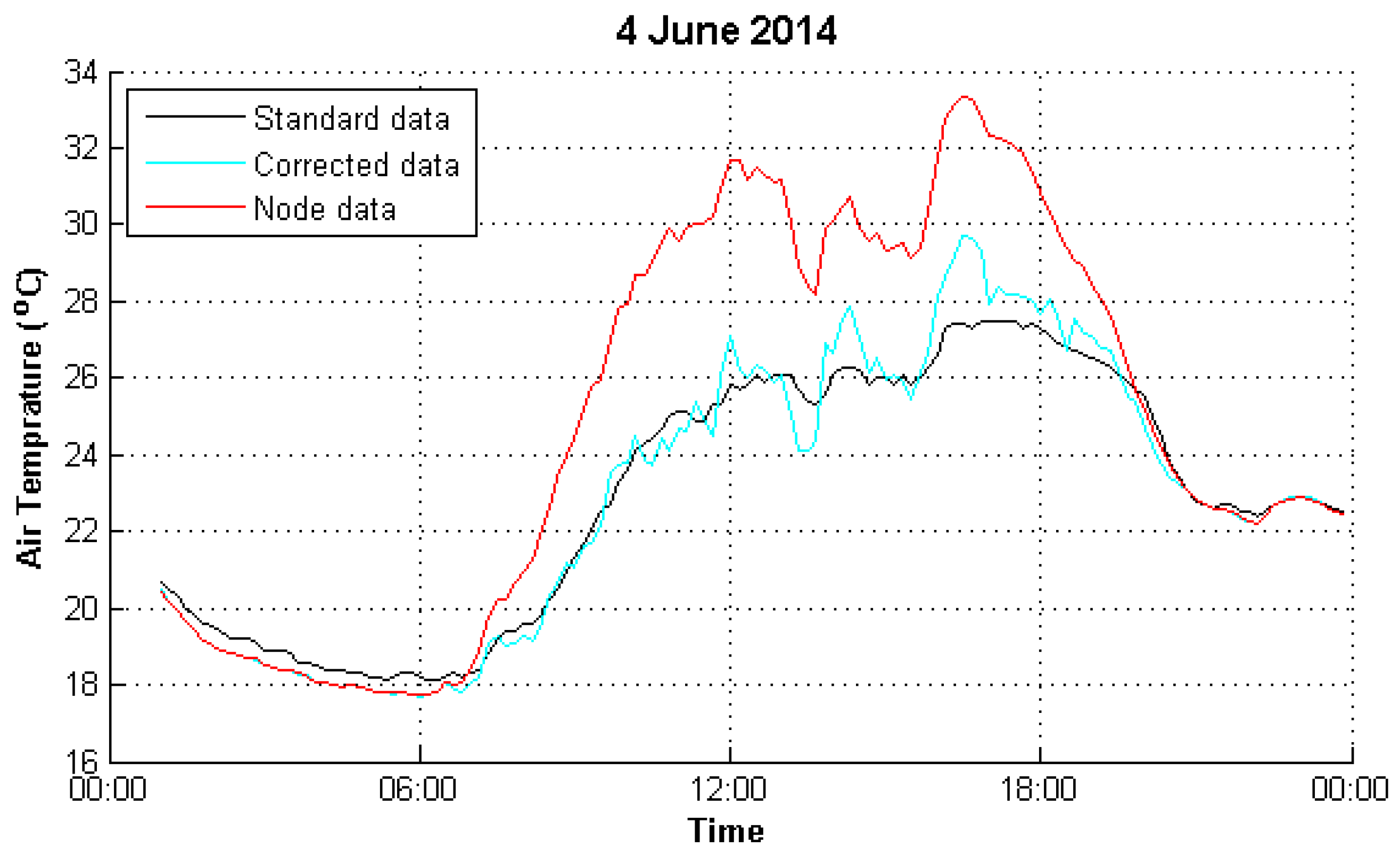
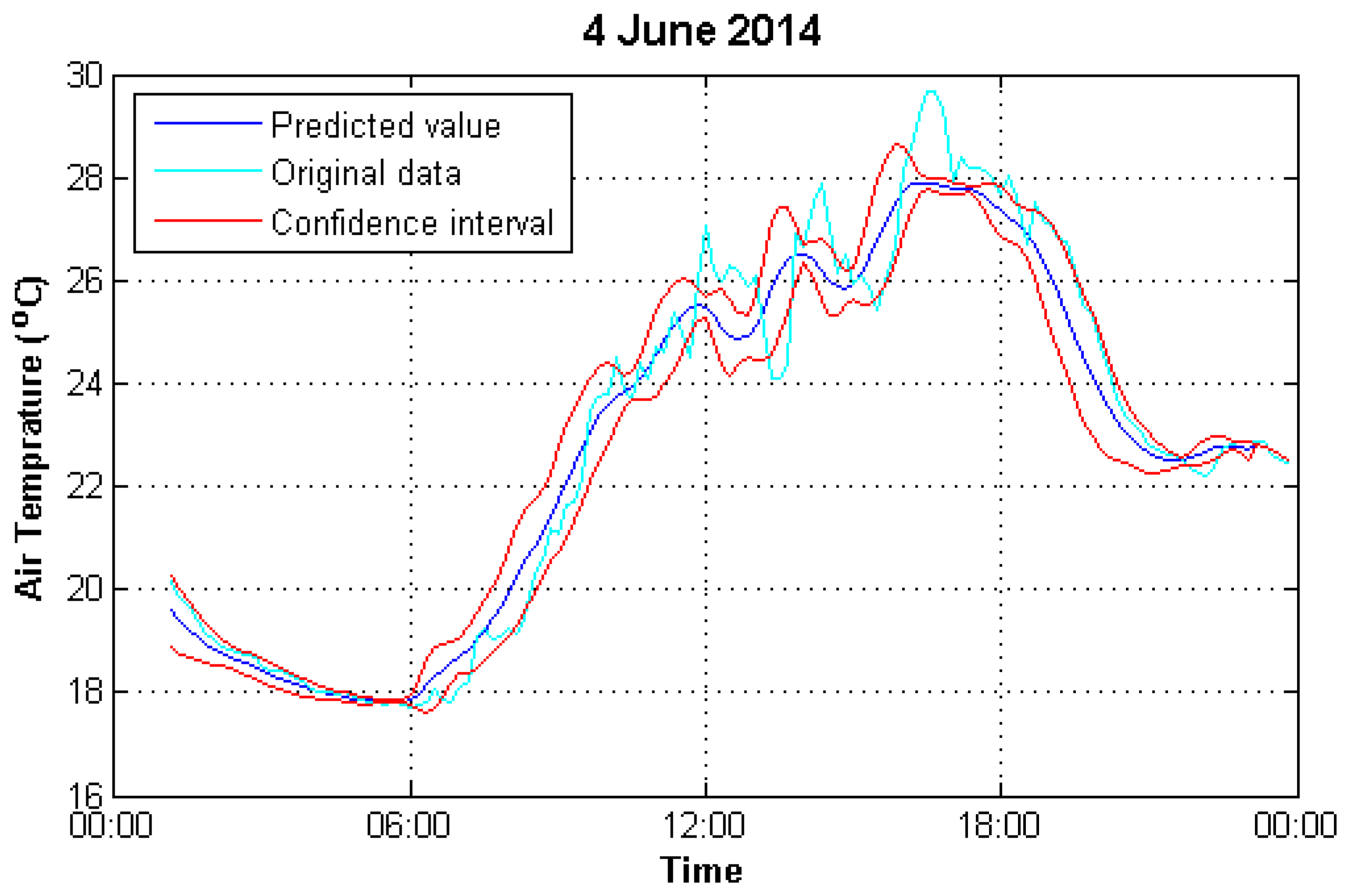
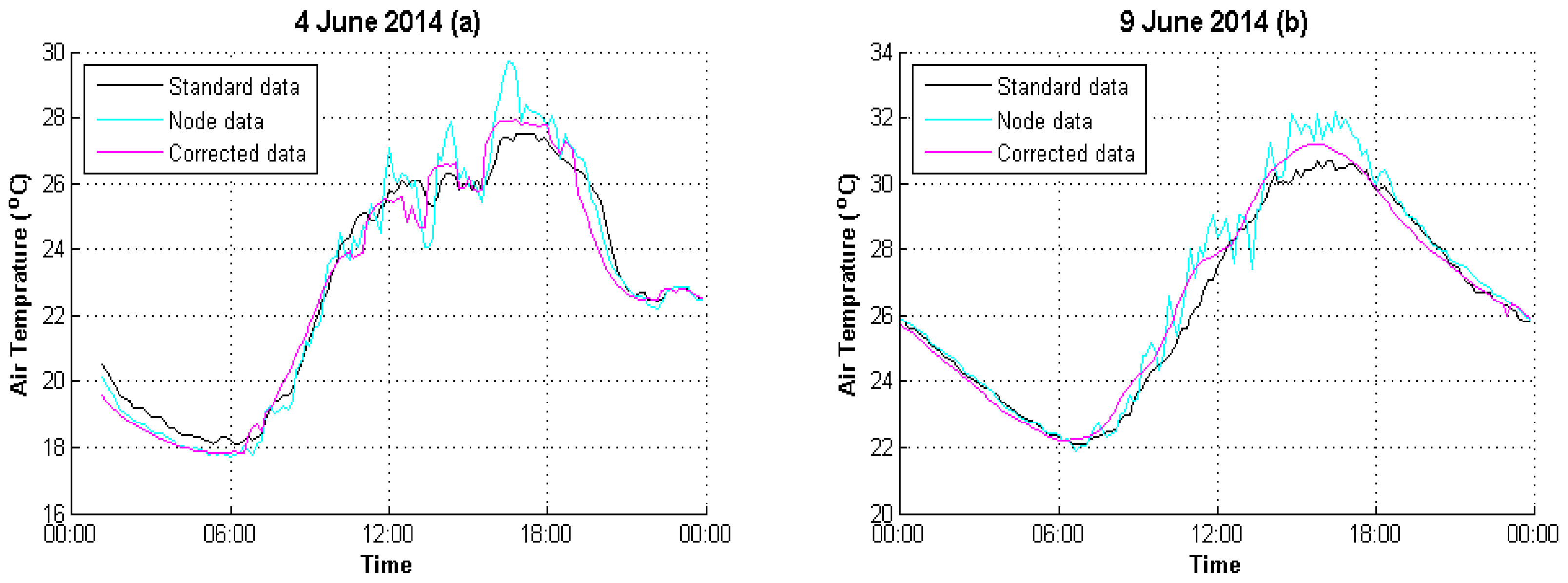
4.1. Data Preparation
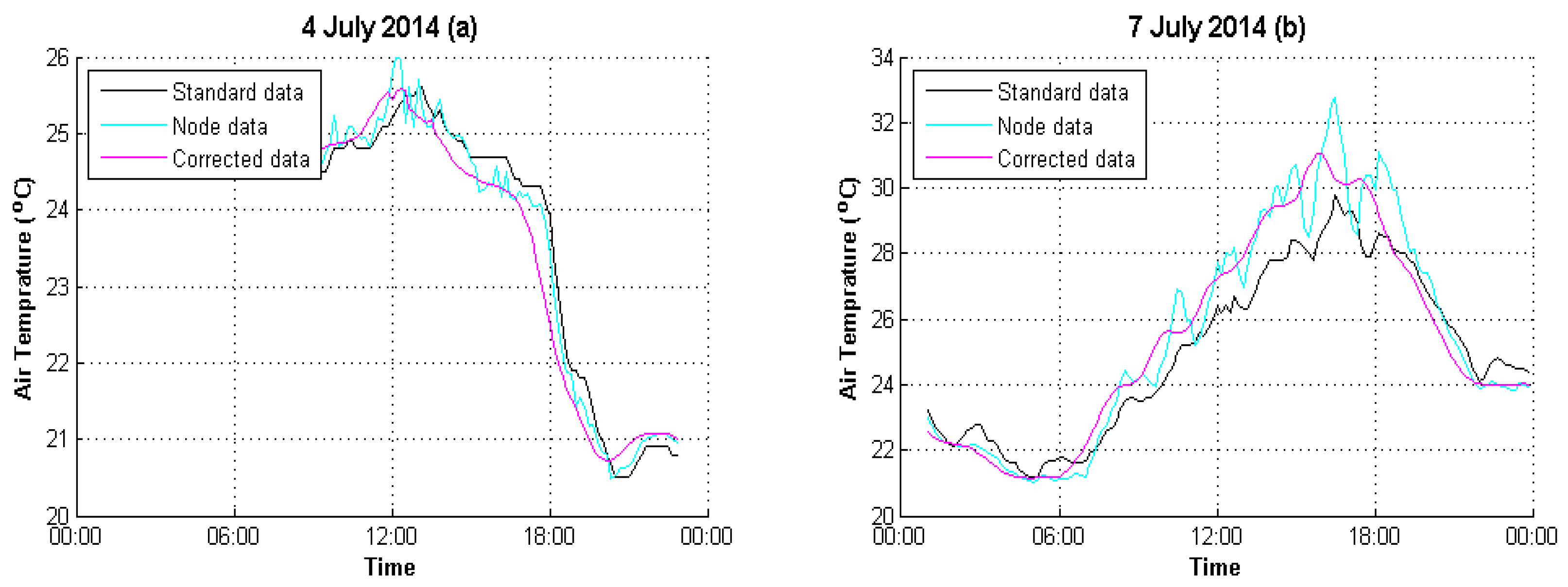
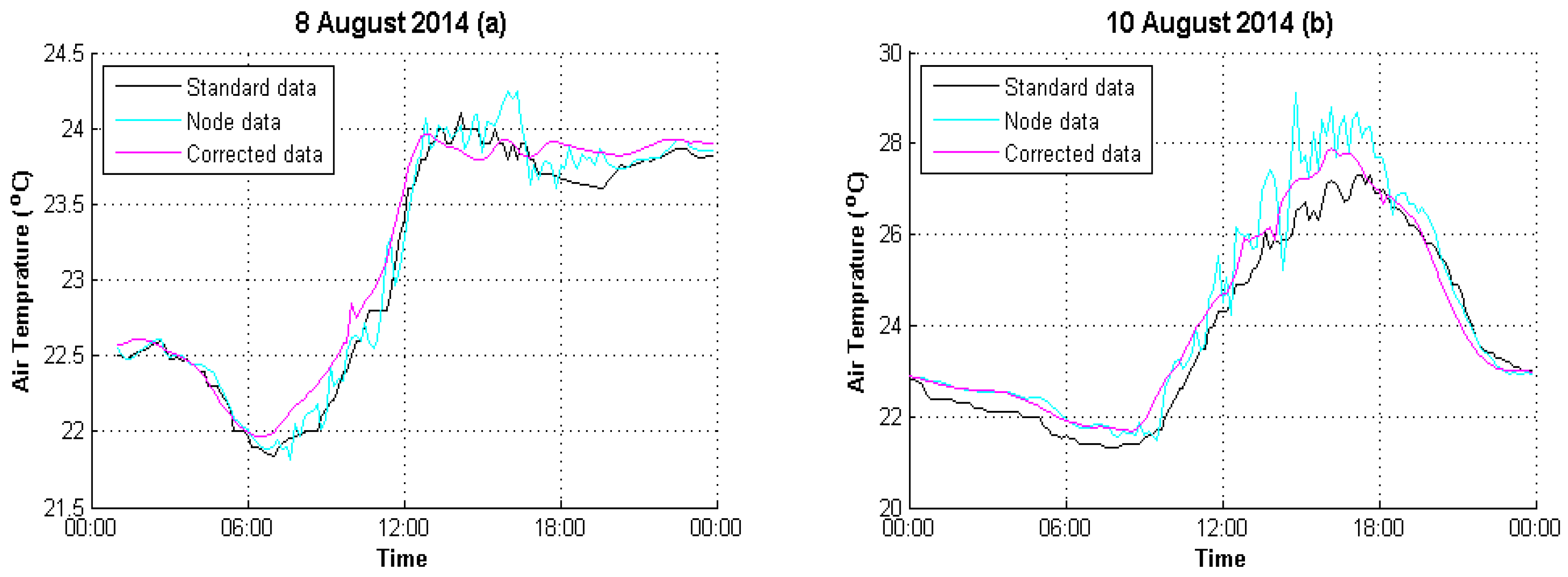
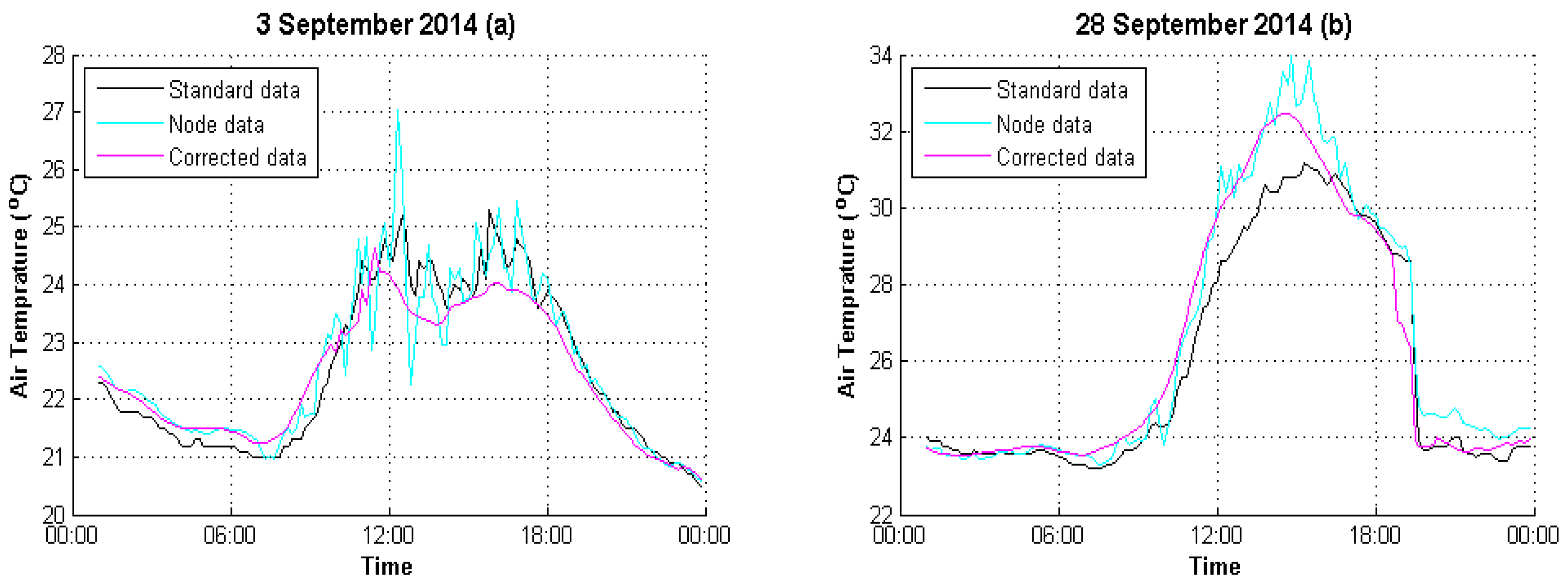
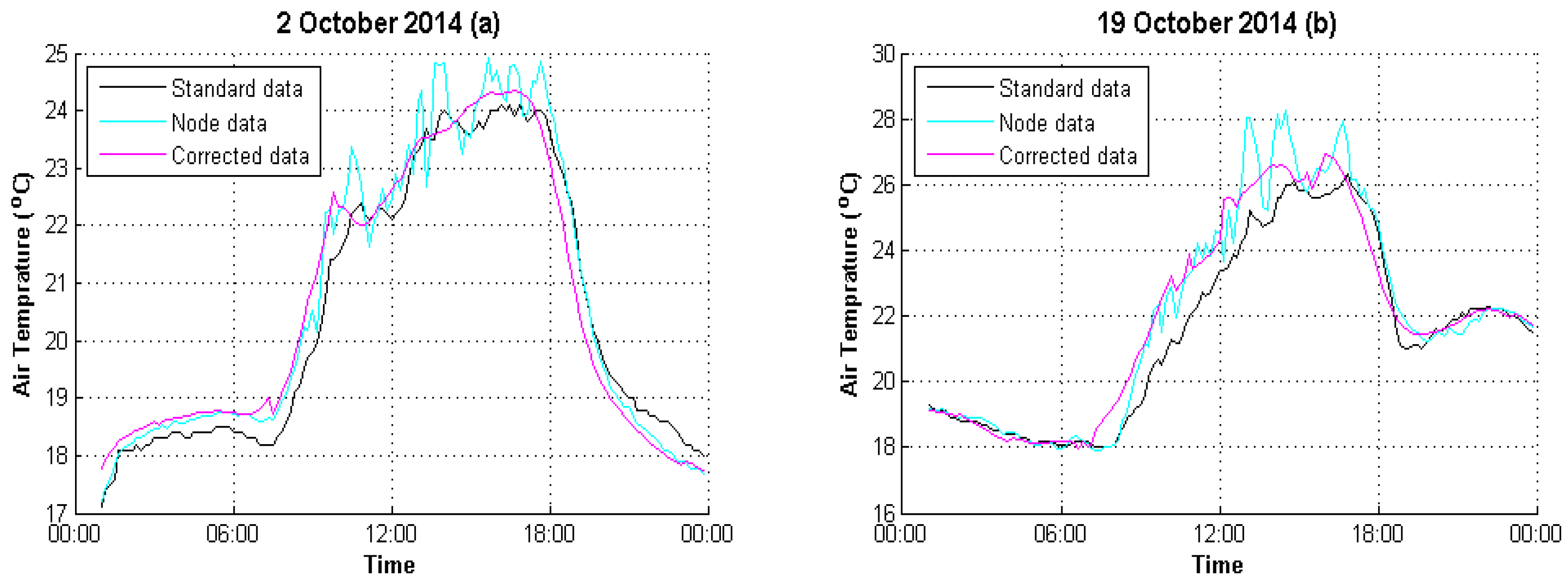
4.2. Result Evaluation
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tan, J.; Yang, L.; Grimmond, C.S.B.; Shi, J.; Gu, W.; Chang, Y.; Hu, P.; Sun, J.; Ao, X.; Han, Z. Urban Integrated Meteorological Observations: Practice and Experience in Shanghai, China. Bull. Am. Meteorol. Soc. 2015, 96, 197–210. [Google Scholar] [CrossRef]
- Sigsgaard, E.E.; Carl, H.; Møller, P.R.; Thomsen, P.F. Monitoring the near-extinct European weather loach in Denmark based on environmental DNA from water samples. Biol. Conserv. 2015, 183, 46–52. [Google Scholar] [CrossRef]
- Chandran, M.A.S.; Rao, A.V.M.S.; Sandeep, V.M.; Pramod, V.P.; Pani, P.; Rao, V.U.M.; Kumari, V.V.; Rao, C.S. Indian summer heat wave of 2015: A biometeorological analysis using half hourly automatic weather station data with special reference to Andhra Pradesh. Int. J. Biometeorol. 2016, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Wang, C.L.; Chen, X.G.; Chen, H.H. Characteristics of heat resource in mountainous region of northern Guangdong, South China based on three-dimensional climate observation. Chin. J. Appl. Ecol. 2013, 24, 2571–2580. (In Chinese) [Google Scholar]
- Xie, S.; Wang, Y. Construction of Tree Network with Limited Delivery Latency in Homogeneous Wireless Sensor Networks. Wirel. Pers. Commun. 2014, 78, 231–246. [Google Scholar] [CrossRef]
- Wang, L.; Xu, L.D.; Bi, Z.; Xu, Y. Data Cleaning for RFID and WSN Integration. IEEE Trans. Ind. Inform. 2014, 10, 408–418. [Google Scholar] [CrossRef]
- Padmavathi, G.; Shanmugapriya, D.; Kalaivani, M. A Study on Vehicle Detection and Tracking Using Wireless Sensor Networks. Wirel. Sens. Netw. 2010, 2, 173–185. [Google Scholar] [CrossRef]
- Nijak, G. M.J.; Geary, J.R.; Larson, S.L.; Talley, J.W. Autonomous, wireless in-situ sensor (AWISS) for rapid warning of Escherichia coli outbreaks in recreational and source waters. Environ. Eng. Sci. 2012, 29, 64–69. [Google Scholar] [CrossRef]
- Park, P.; Marco, P.D.; Johansson, K. Cross-Layer Optimization for Industrial Control Applications using Wireless Sensor and Actuator Mesh Networks. IEEE Trans. Ind. Electron. 2017, 64, 3250–3259. [Google Scholar] [CrossRef]
- Kong, D.; Li, T.; You, X.; Sun, X.; Wang, B.; Liu, Q. The Research of Long-Distance Data Transmission Based on Meteorological Sensor Network. Int. J. Future Gener. Commun. Netw. 2014, 7, 59–70. [Google Scholar] [CrossRef]
- Nagy, Z.; Rossi, D.; Hersberger, C.; Irigoyen, S.D.; Miller, C.; Schlueter, A. Balancing envelope and heating system parameters for zero emissions retrofit using building sensor data. Appl. Energy 2014, 131, 56–66. [Google Scholar] [CrossRef]
- Sun, X.; Yan, S.; Wang, B.; Li, X.; Liu, Q.; Zhang, H. Air Temperature Error Correction Based on Solar Radiation in an Economical Meteorological Wireless Sensor Network. Sensors 2015, 15, 18114–18139. [Google Scholar] [CrossRef] [PubMed]
- Dai, H.J.; Touray, M.; Jonnagaddala, J.; Syed-Abdul, S. Feature Engineering for Recognizing Adverse Drug Reactions from Twitter Posts. Information 2016, 7, 27. [Google Scholar] [CrossRef]
- Esling, P.; Agon, C. Time-series data mining. ACM Comput. Surv. 2012, 45, 12. [Google Scholar] [CrossRef]
- Sun, W.; Ishidaira, H.; Bastola, S.; Yu, J. Estimating daily time series of streamflow using hydrological model calibrated based on satellite observations of river water surface width: Toward real world applications. Environ. Res. 2015, 139, 36–45. [Google Scholar] [CrossRef] [PubMed]
- Wright, A.P.; Wright, A.T.; Mccoy, A.B.; Sittig, D.F. The use of sequential pattern mining to predict next prescribed medications. J. Biomed. Inform. 2015, 53, 73–80. [Google Scholar] [CrossRef] [PubMed]
- Ruuskanen, V.; Nerg, J.; Pyrhonen, J.; Ruotsalainen, S. Drive Cycle Analysis of a Permanent-Magnet Traction Motor Based on Magnetostatic Finite-Element Analysis. IEEE Trans. Veh. Technol. 2015, 64, 1249–1254. [Google Scholar] [CrossRef]
- Liu, H.; Wang, B.; Sun, X.; Li, T.; Liu, Q.; Guo, Y. DCSCS: A Novel Approach to Improve Data Accuracy for Low Cost Meteorological Sensor Networks. Inf. Technol. J. 2014, 13, 1640–1647. [Google Scholar]
- Hawkins, D.M. Identification of Outliers. Biometrics 1980, 37, 860. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Laber, E.B.; Zhao, Y.Q. Outlier detection for high-dimensional data. Biometrika 2015, 102, 589–599. [Google Scholar]
- Gogoi, P.; Bhattacharyya, D.K.; Borah, B.; Kalita, J.K. A Survey of Outlier Detection Methods in Network Anomaly Identification. Comput. J. 2011, 54, 570–588. [Google Scholar] [CrossRef]
- Wu, T.B.; Cheng, Y.; Hu, Z.K.; Xie, W.P.; Liu, Y.L. A New PLS and Bayesian Classification Based On-Line Outlier Detection Method. Appl. Mech. Mater. 2013, 397–400, 1362–1365. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.L.; Ma, Y.; Wilkes, D.M. A fast MST-inspired kNN-based outlier detection method. Inf. Syst. 2015, 48, 89–112. [Google Scholar] [CrossRef]
- Tsai, C.F.; Cheng, K.C. Simple instance selection for bankruptcy prediction. Knowl.-Based Syst. 2012, 27, 333–342. [Google Scholar] [CrossRef]
- Liu, J.; Deng, H.F. Outlier detection on uncertain data based on local information. Knowl.-Based Syst. 2013, 51, 60–71. [Google Scholar] [CrossRef]
- Cassisi, C.; Ferro, A.; Giugno, R.; Pigola, G.; Pulvirenti, A. Enhancing density-based clustering: Parameter reduction and outlier detection. Inf. Syst. 2013, 38, 317–330. [Google Scholar] [CrossRef]
- Shahid, N.; Naqvi, I.H.; Qaisar, S.B. One-class support vector machines: Analysis of outlier detection for wireless sensor networks in harsh environments. Artif. Intell. Rev. 2015, 43, 515–563. [Google Scholar] [CrossRef]
- Dufrenois, F.; Noyer, J.C. One class proximal support vector machines. Pattern Recogn. 2016, 52, 96–112. [Google Scholar] [CrossRef]
- Jiang, F.; Liu, G.; Du, J.; Sui, Y. Initialization of K-modes clustering using outlier detection techniques. Inf. Sci. 2016, 332, 167–183. [Google Scholar] [CrossRef]
- Jobe, J.M.; Pokojovy, M. A Cluster-Based Outlier Detection Scheme for Multivariate Data. J. Am. Stat. Assoc. 2015, 110, 1543–1551. [Google Scholar] [CrossRef]
- Hill, D.J.; Minsker, B.S. Anomaly detection in streaming environmental sensor data: A data-driven modeling approach. Environ. Model. Softw. 2010, 25, 1014–1022. [Google Scholar] [CrossRef]
- Zhao, N.; Yu, F.R.; Sun, H.; Yin, H.; Nallanathan, A.; Wang, G. Interference alignment with delayed channel state information and dynamic AR-model channel prediction in wireless networks. Wirel. Netw. 2015, 21, 1227–1242. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Root Mean Square Error | |
|---|---|---|
| Raw Data | Corrected Data | |
| 4 June 2014 | 2.9706 | 0.4432 |
| 9 June 2014 | 3.4410 | 0.2883 |
| 4 July 2014 | 0.8766 | 0.1910 |
| 7 July 2014 | 3.4376 | 0.8598 |
| 8 August 2014 | 0.6496 | 0.1199 |
| 10 August 2014 | 2.6665 | 0.3984 |
| 3 September 2014 | 2.1479 | 0.4458 |
| 28 September 2014 | 3.2044 | 0.5826 |
| 2 October 2014 | 1.9883 | 0.3169 |
| 19 October 2014 | 2.6907 | 0.5654 |
| 11 November 2014 | 2.0904 | 0.3317 |
| 22 November 2014 | 2.6658 | 0.9391 |
| 7 December 2014 | 2.1044 | 0.6247 |
| 21 December 2014 | 2.0193 | 0.6711 |
| Average | 2.1634 | 0.4811 |
| Date | Correlation Coefficient | |
|---|---|---|
| Raw Data | Corrected Data | |
| 4 June 2014 | 0.9565 | 0.9935 |
| 9 June 2014 | 0.9024 | 0.9968 |
| 4 July 2014 | 0.9437 | 0.9931 |
| 7 July 2014 | 0.9454 | 0.9855 |
| 8 August 2014 | 0.9099 | 0.9917 |
| 10 August 2014 | 0.9254 | 0.9932 |
| 3 September 2014 | 0.9685 | 0.9725 |
| 28 September 2014 | 0.9494 | 0.9944 |
| 2 October 2014 | 0.9763 | 0.9922 |
| 19 October 2014 | 0.9333 | 0.9911 |
| 11 November 2014 | 0.9564 | 0.9972 |
| 22 November 2014 | 0.9448 | 0.9843 |
| 7 December 2014 | 0.9705 | 0.9863 |
| 21 December 2014 | 0.9688 | 0.9773 |
| Average | 0.9465 | 0.9892 |
| Date | Symmetric Mean Absolute Percentage Error (SMAPE) | |
|---|---|---|
| Raw Data | Corrected Data | |
| 4 June 2014 | 8.1% | 1.56% |
| 9 June 2014 | 7.76% | 0.77% |
| 4 July 2014 | 2.59% | 0.64% |
| 7 July 2014 | 8.85% | 2.41% |
| 8 August 2014 | 1.93% | 0.43% |
| 10 August 2014 | 6.74% | 1.42% |
| 3 September 2014 | 6.13% | 1.44% |
| 28 September 2014 | 6.79% | 1.34% |
| 2 October 2014 | 6.05% | 1.38% |
| 19 October 2014 | 7.02% | 1.83% |
| 11 November 2014 | 8.71% | 1.63% |
| 22 November 2014 | 8.12% | 3.32% |
| 7 December 2014 | 17.09% | 8.33% |
| 21 December 2014 | 15.17% | 13.06% |
| Average | 7.93% | 2.83% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, L.; Gu, X.; Wang, B. Correction of Outliers in Temperature Time Series Based on Sliding Window Prediction in Meteorological Sensor Network. Information 2017, 8, 60. https://doi.org/10.3390/info8020060
Ma L, Gu X, Wang B. Correction of Outliers in Temperature Time Series Based on Sliding Window Prediction in Meteorological Sensor Network. Information. 2017; 8(2):60. https://doi.org/10.3390/info8020060
Chicago/Turabian StyleMa, Li, Xiaodu Gu, and Baowei Wang. 2017. "Correction of Outliers in Temperature Time Series Based on Sliding Window Prediction in Meteorological Sensor Network" Information 8, no. 2: 60. https://doi.org/10.3390/info8020060
APA StyleMa, L., Gu, X., & Wang, B. (2017). Correction of Outliers in Temperature Time Series Based on Sliding Window Prediction in Meteorological Sensor Network. Information, 8(2), 60. https://doi.org/10.3390/info8020060