
Dependency Parsing with Transformed Feature


Abstract
:1. Introduction
2. Related Works
3. Graph-Based Dependency Parsing
3.1. Feature Similarity Information
3.2. Transform-Based Parsing
3.3. Optimizing Influence
3.4. Fusion Decoding
4. Implementation of Transform-Based Parsing
- Building Feature Lookup Map: An indexed set of feature strings is generated by enumerating the feature strings, where occurrence frequency is more than five, in a training corpus and assigning their indexes in occurring order. Then, they form a lookup map to identify the indexed feature string.
- Caching Sentence Transformed Features: The feature strings of every sentence in the training corpus and its possible dependency trees are extracted. Then, for each feature string (indexed or un-indexed), the column of θ is constructed and cached, where the similarity between words and is defined as the dot product of their embeddings.
- Training: The parameters are learned with MIRA, and it is known that the graph-based dependency parsing is time-consuming.
5. Experiments
5.1. Experiments Setup
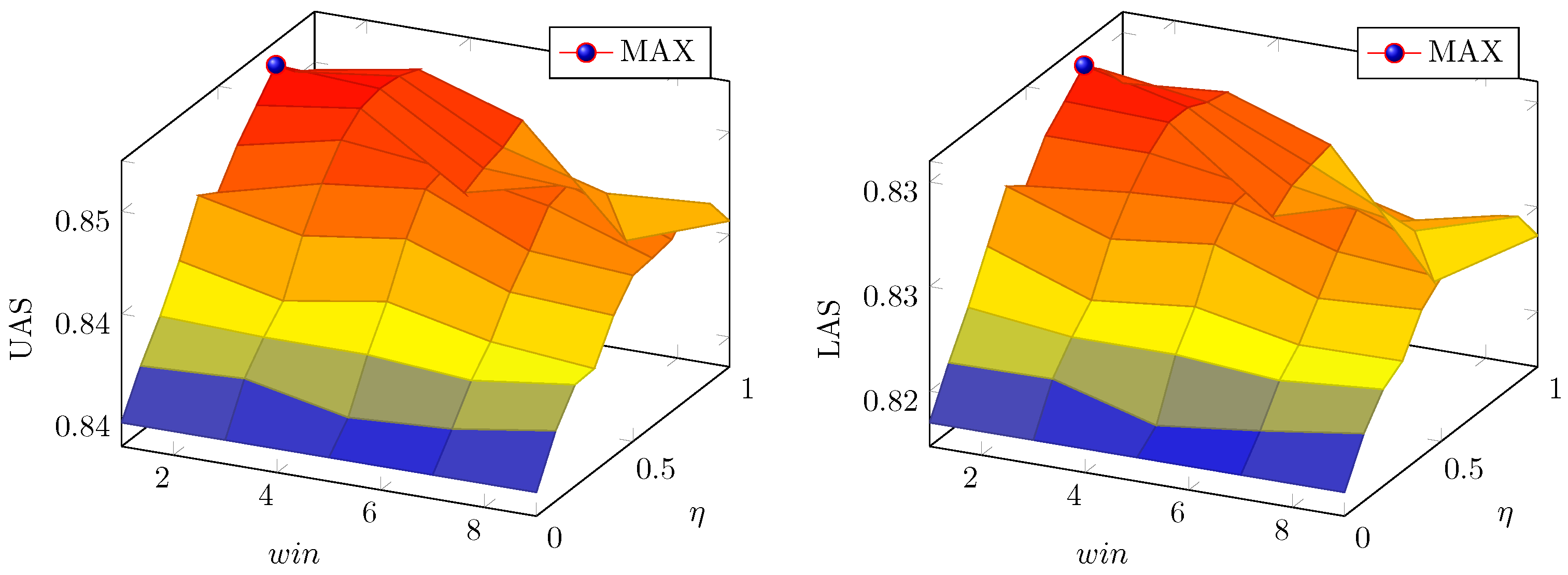
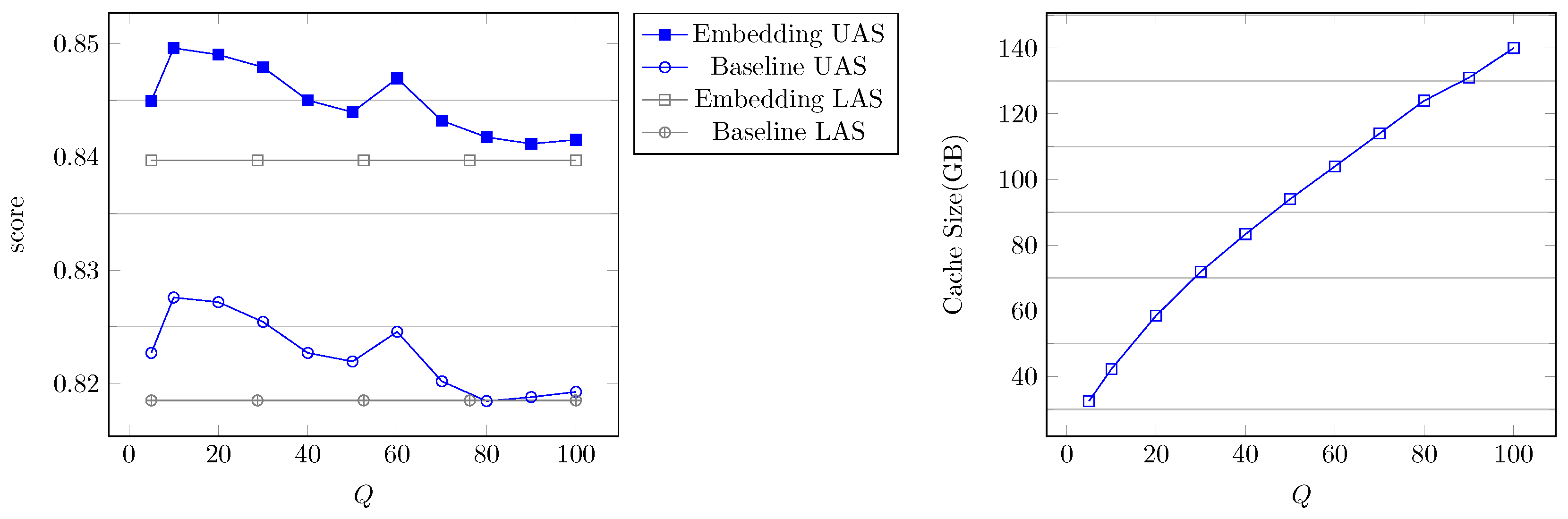
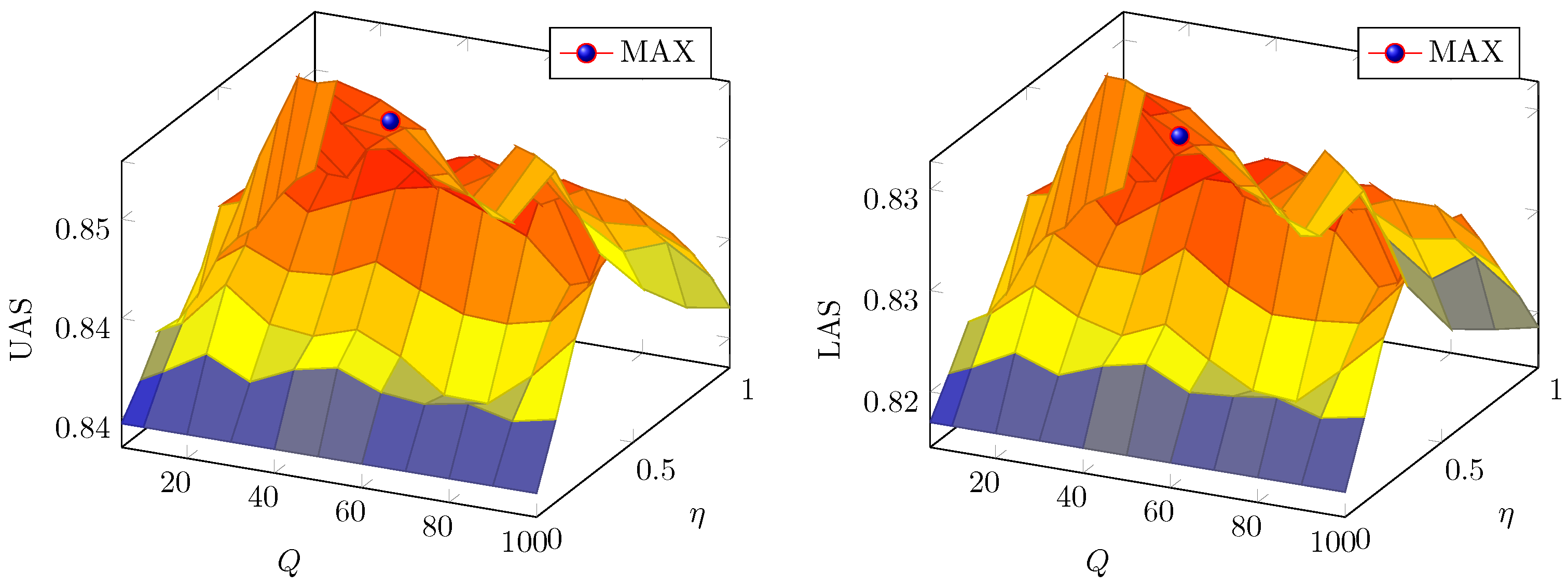
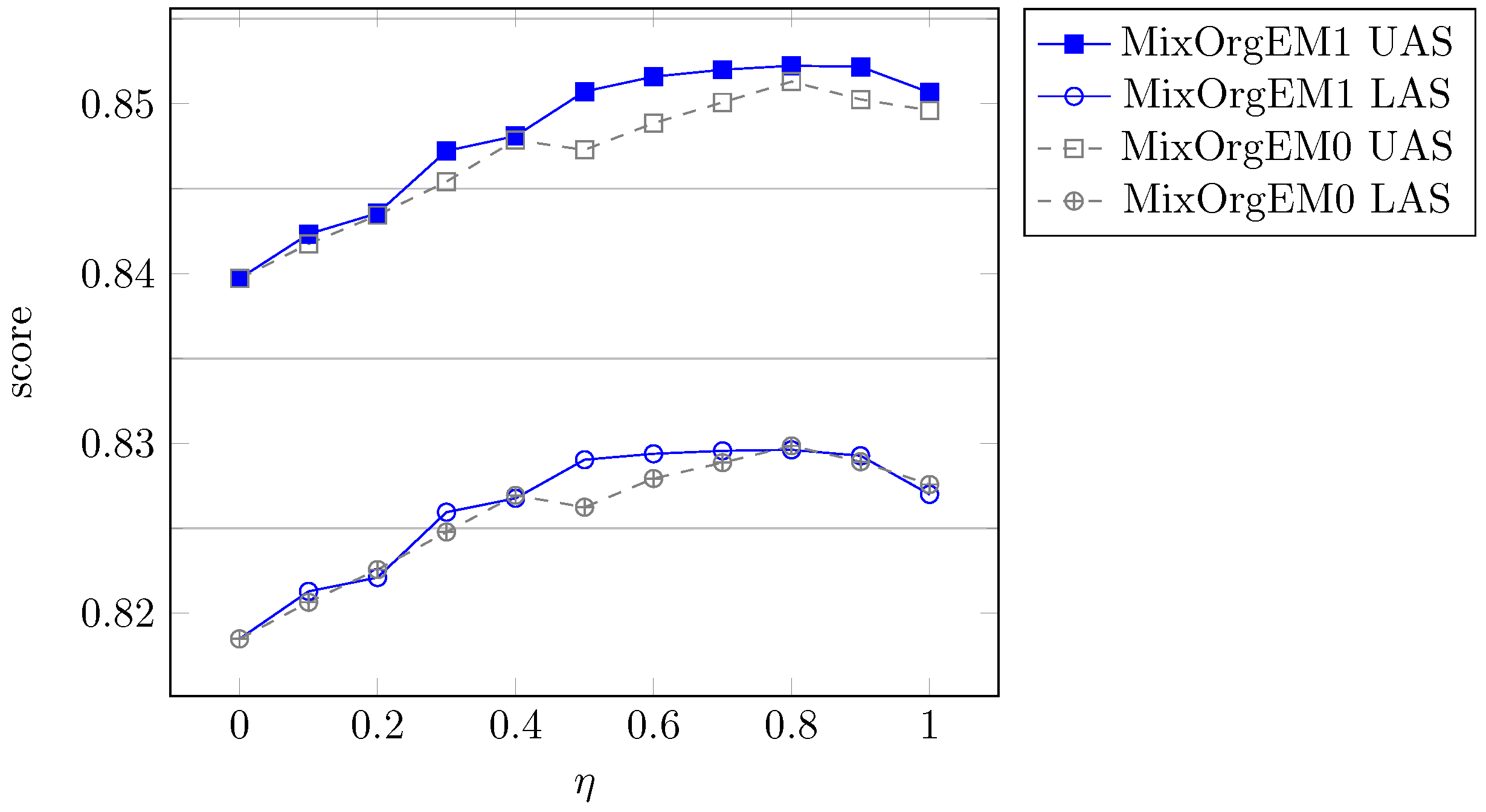
5.2. Results and Analysis
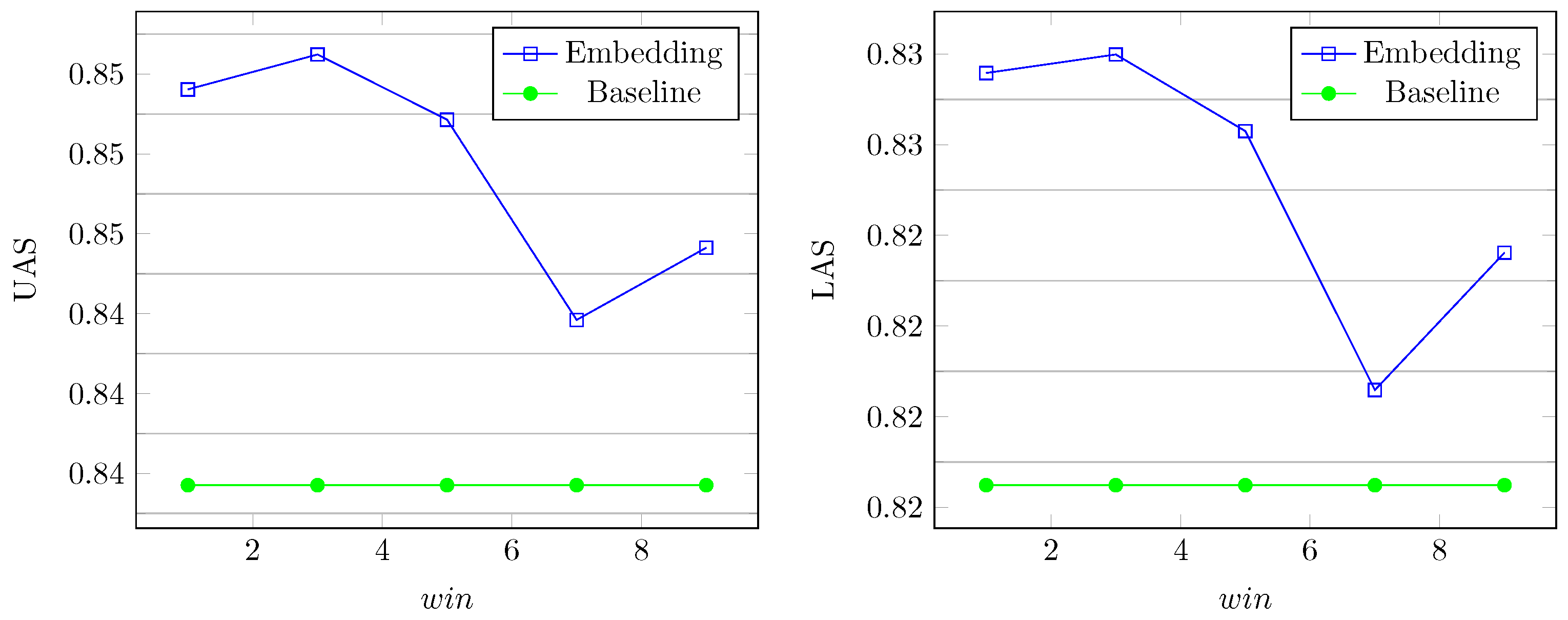
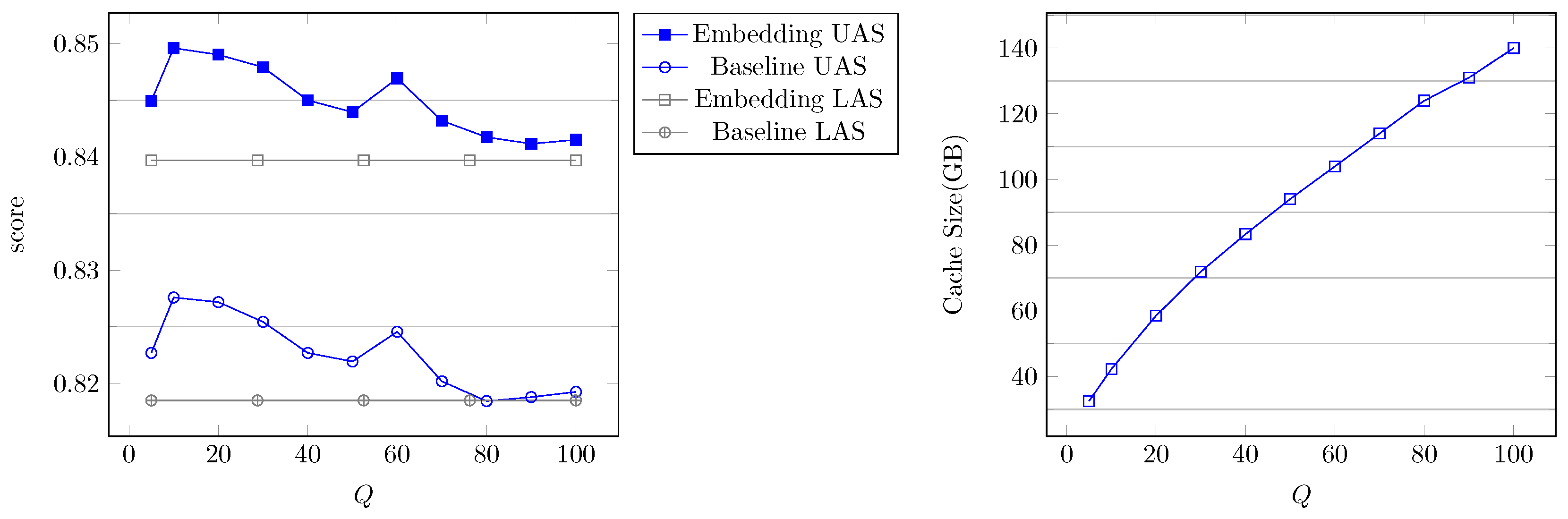
5.2.1. Parsing Accuracy
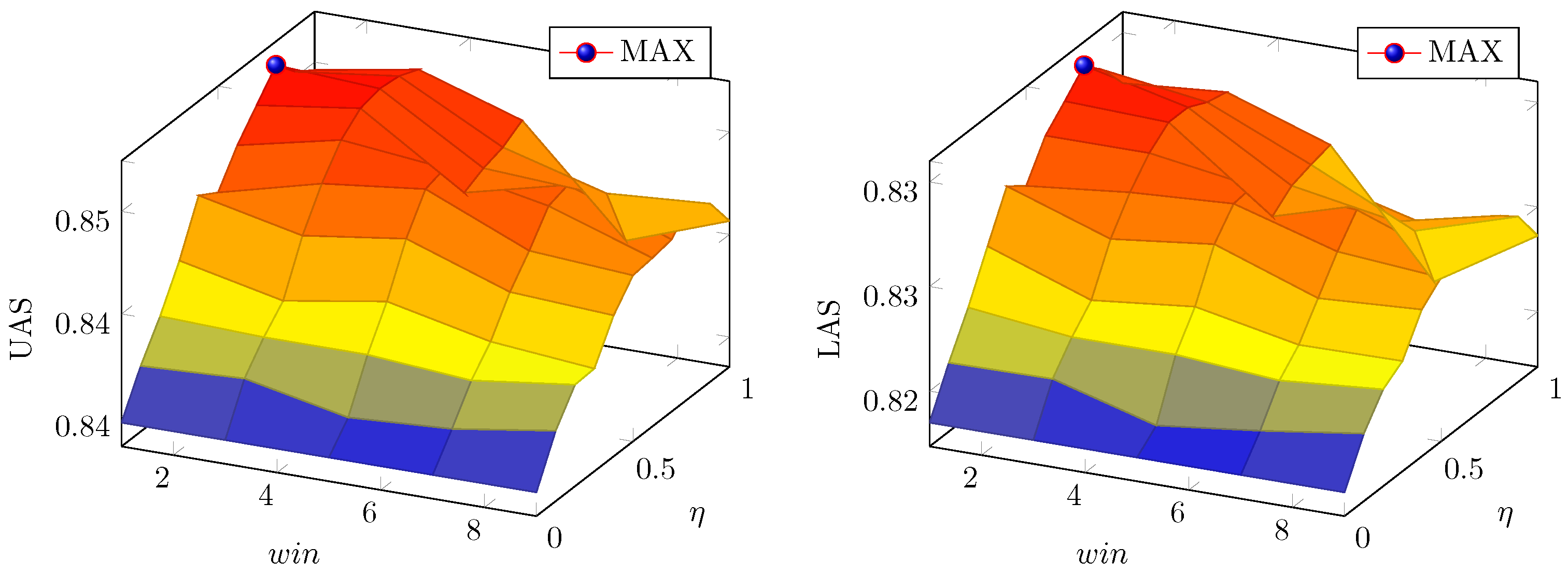
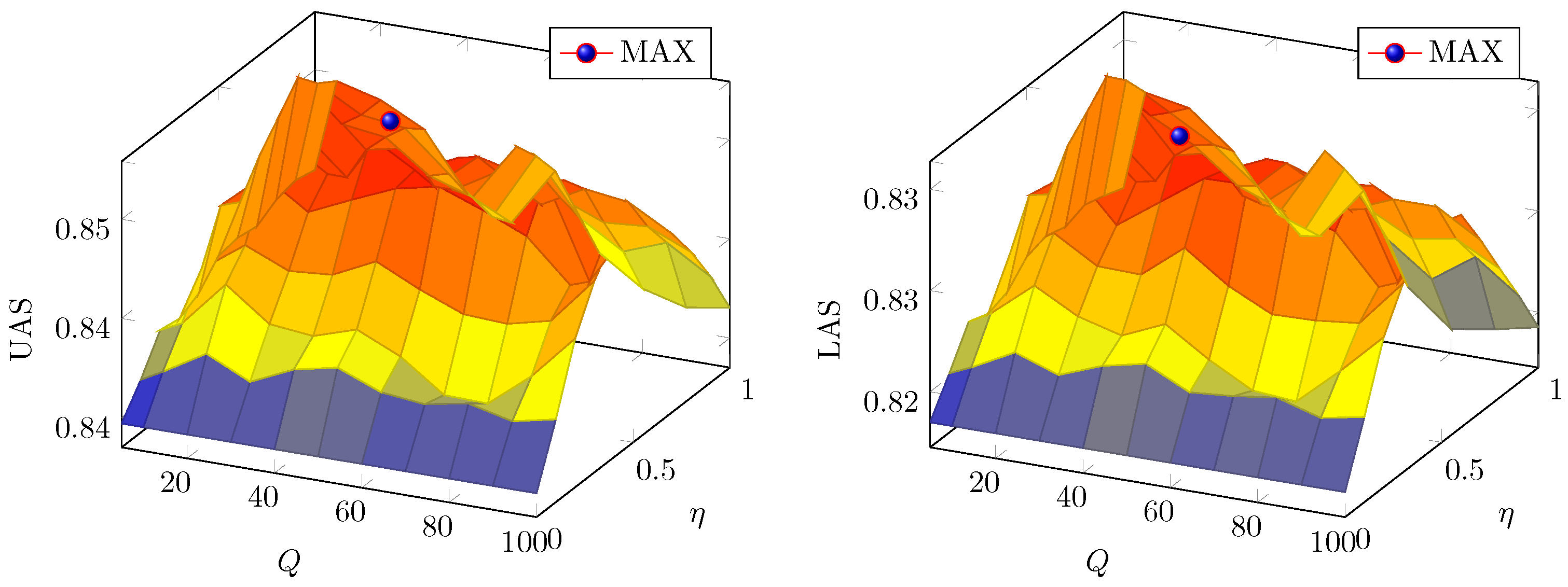
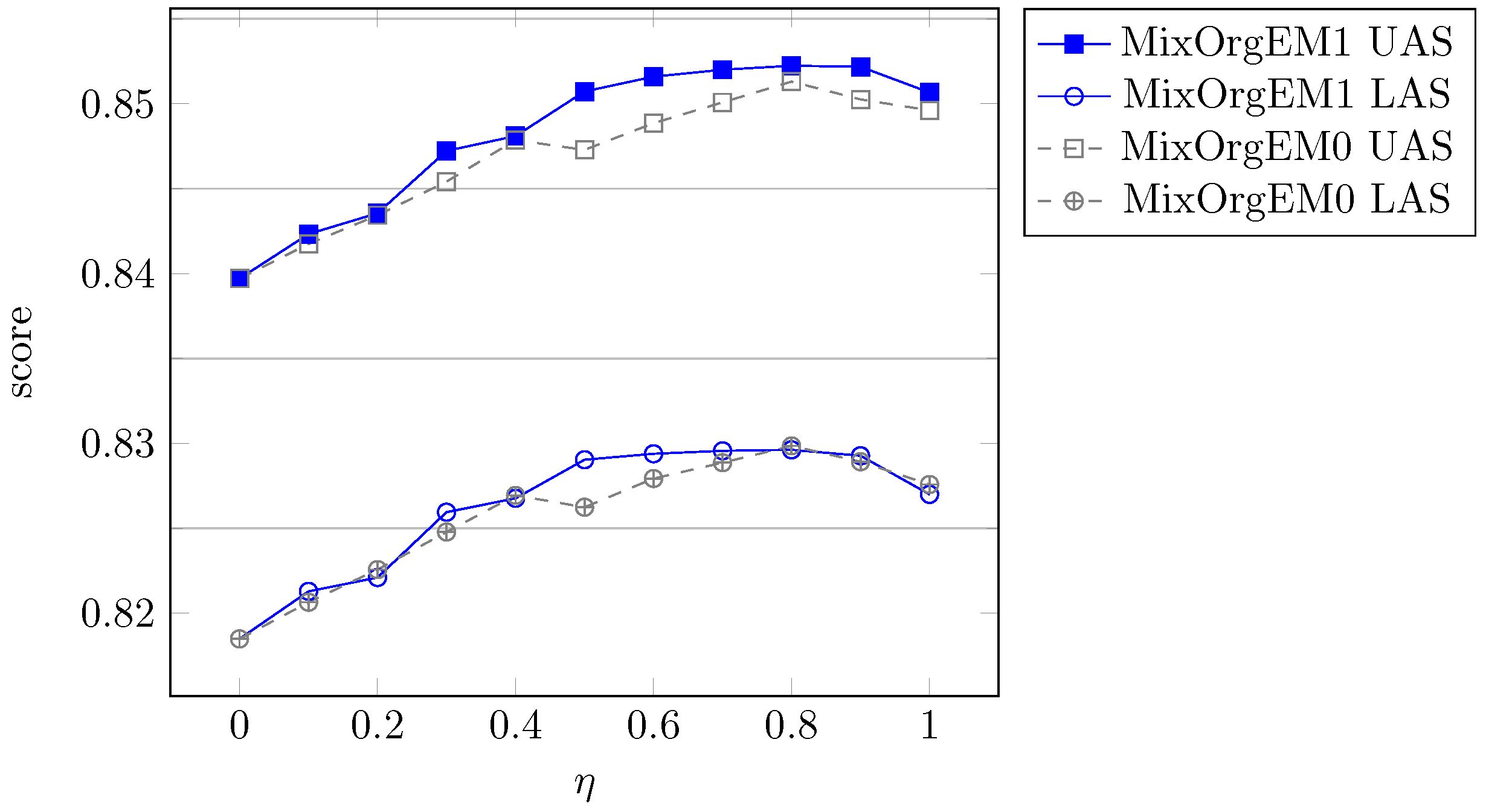
5.2.2. Parameter Selection
6. Conclusions
Conflicts of Interest
References
- Cho, H.C.; Okazaki, N.; Miwa, M.; Tsujii, J. Named entity recognition with multiple segment representations. Inf. Process. Manag. 2013, 49, 954–965. [Google Scholar] [CrossRef]
- Sun, X.; Zhang, Y.; Matsuzaki, T.; Tsuruoka, Y.; Tsujii, J. Probabilistic Chinese word segmentation with non-local information and stochastic training. Inf. Process. Manag. 2013, 49, 626–636. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhang, X.; Tang, Y.; Nie, R. Feature-based approaches to semantic similarity assessment of concepts using Wikipedia. Inf. Process. Manag. 2015, 51, 215–234. [Google Scholar] [CrossRef]
- Zhang, Y.; Clark, S. Syntactic Processing Using the Generalized Perceptron and Beam Search. Comput. Linguist. 2011, 37, 105–151. [Google Scholar] [CrossRef]
- Chen, W.; Kazama, J.; Uchimoto, K.; Torisawa, K. Exploiting Subtrees in Auto-Parsed Data to Improve Dependency Parsing. Comput. Intell. 2012, 28, 426–451. [Google Scholar] [CrossRef]
- McDonald, R.; Crammer, K.; Pereira, F. Online Large-Margin Training of Dependency Parsers. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics (ACL ’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 91–98.
- McDonald, R.; Pereira, F.; Ribarov, K.; Hajič, J. Non-Projective Dependency Parsing using Spanning Tree Algorithms. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing (HLT ’05), Vancouver, BC, Canada, 6–8 October 2005; pp. 523–530.
- Wu, F.; Zhou, F. Hybrid dependency parser with segmented treebanks and reparsing. In Chinese Intelligent Automation Conference; Springer: Berlin/Heidelberg, Germany, 2015; Volume 336, pp. 53–60. [Google Scholar]
- Chen, W.; Zhang, M.; Zhang, Y. Distributed Feature Representations for Dependency Parsing. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 451–460. [Google Scholar] [CrossRef]
- Bansal, M.; Gimpel, K.; Livescu, K. Tailoring Continuous Word Representations for Dependency Parsing. Available online: http://ttic.uchicago.edu/klivescu/papers/bansal_etal_ACL2014.pdf (accessed on 18 January 2017).
- Dyer, C.; Ballesteros, M.; Ling, W.; Matthews, A.; Smith, N.A. Transition-Based Dependency Parsing with Stack Long Short-Term Memory. 2015. [Google Scholar]
- Chen, D.; Manning, C.D. A Fast and Accurate Dependency Parser Using Neural Networks. Available online: http://cs.stanford.edu/people/danqi/papers/emnlp2014.pdf (accessed on 18 January 2017).
- Le, P.; Zuidema, W. The Inside-Outside Recursive Neural Network model for Dependency Parsing. Available online: http://www.emnlp2014.org/papers/pdf/EMNLP2014081.pdf (accessed on 18 January 2017).
- Zhu, C.; Qiu, X.; Chen, X.; Huang, X. Re-Ranking Model for Dependency Parser with Recursive Convolutional Neural Network. 2015. [Google Scholar]
- Crammer, K.; Dekel, O.; Keshet, J.; Shalev-Shwartz, S.; Singer, Y. Online passive-aggressive algorithms. J. Mach. Learn. Res. 2006, 7, 551–585. [Google Scholar]
- Crammer, K.; Singer, Y. Ultraconservative online algorithms for multiclass problems. J. Mach. Learn. Res. 2003, 3, 951–991. [Google Scholar]
- Censor, Y.; Zenios, S.A. Parallel Optimization: Theory, Algorithms, and Applications; Oxford University Press: Oxford, UK, 1997. [Google Scholar]
- Zhang, Z.; Huang, D.Y.; Zhao, R.; Dong, M. Onset Detection Based on Fusion of Simpls and Superflux. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.445.6390&rep=rep1&type=pdf (accessed on 18 January 2017).
- Huang, D.Y.; Zhang, Z.; Ge, S.S. Speaker state classification based on fusion of asymmetric simple partial least squares (SIMPLS) and support vector machines. Comput. Speech Lang. 2014, 28, 392–419. [Google Scholar] [CrossRef]
- Hayashi, K.; Watanabe, T.; Asahara, M.; Matsumoto, Y. Third-Order Variational Reranking on Packed-Shared Dependency Forests. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP ’11), Edinburgh, UK, 27–31 July 2011; pp. 1479–1488.
- McDonald, R.; Pereira, F. Online Learning of Approximate Dependency Parsing Algorithms. Available online: http://www.aclweb.org/old_anthology/E/E06/E06-1011.pdf (accessed on 18 January 2017).
- Carreras, X. Experiments with a Higher-Order Projective Dependency Parser. Available online: http://www.aclweb.org/old_anthology/D/D07/D07-1.pdf#page=991 (accessed on 18 January 2017).
- Xue, N.; Xia, F.; Chiou, F.D.; Palmer, M. The Penn Chinese TreeBank: Phrase structure annotation of a large corpus. Nat. Lang. Eng. 2005, 11, 207–238. [Google Scholar] [CrossRef]
- Zhang, Y.; Clark, S. A Tale of Two Parsers: Investigating and Combining Graph-Based and Transition-Based Dependency Parsing Using Beam-Search. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP ’08), Honolulu, HI, USA, 25–27 October 2008; pp. 562–571.
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; pp. 1532–1543.
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. 2013. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations ofwords and phrases and their compositionality. In Proceedings of the Neural Information Processing Systems Foundation, Stateline, NV, USA, 5–10 December 2013; pp. 3111–3119.
- Ling, W.; Dyer, C.; Black, A.W.; Trancoso, I. Two/Too Simple Adaptations of Word2Vec for Syntax Problems. Available online: http://www.aclweb.org/anthology/N/N15/N15-1142.pdf (accessed on 18 January 2017).
- Suzuki, J.; Nagata, M. A Unified Learning Framework of Skip-Grams and Global Vectors. Available online: http://www.aclweb.org/anthology/P/P15/P15-2031.pdf (accessed on 18 January 2017).
- Tseng, H.; Chang, P.; Andrew, G.; Jurafsky, D.; Manning, C. A conditional random field word segmenter for sighan bakeoff 2005. In Proceedings of the Fourth SIGHAN Workshop on Chinese Language Processing, Jeju Island, Korea, 14–15 October 2005.
- Toutanova, K.; Klein, D.; Manning, C.D.; Singer, Y. Feature-Rich Part-of-Speech Tagging with a Cyclic Dependency Network. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology (NAACL ’03), Edmonton, AB, Canada, 27 May–1 June 2003; Volume 1, pp. 173–180.
- Ma, X.; Zhao, H. Fourth-Order Dependency Parsing. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.378.9297&rep=rep1&type=pdf#page=799 (accessed on 18 January 2017).
- Goldberg, Y.; Nivre, J. A Dynamic Oracle for Arc-Eager Dependency Parsing. Available online: https://www.cs.bgu.ac.il/yoavg/publications/coling2012dynamic.pdf (accessed on 18 January 2017).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x | : segmented sentence | y | : dependency tree for a sentence |
| : training treebank | : number of words in x | ||
| : the ith word of a sentence x | T | : feature template | |
| C | : feature string | : the ith indexed feature string | |
| : index of the feature template generating | : set of indexed feature strings extracted from T, | ||
| : set of all feasible dependency trees of x | : loss function for from y | ||
| : transformed feature vector function | : transformed feature indicating function corresponding to | ||
| : feature vector function | : feature indicating function corresponding to | ||
| N | : number of indexed feature strings | U | : number of total feature strings. |
| c | : window size for word embedding | η | : hyper-parameter for fusion decoding |
| Q | : number of nearest transformed features for a feature | ω | : weight vector for features |
| : weight vector for transformed features | Θ | : feature weight matrix | |
| : ith row of Θ | : similarity between two words via embeddings | ||
| : similarity between two feature strings |
| Training | Testing | Development | |
|---|---|---|---|
| PTB | One-Fifth of {2–21} | 22 | 23 |
| CTB | One-Fifth of {001–815, 1001–1136} | 816–885, 1137–1147 | 886–931, 1148–1151 |
| Trans | Baseline | OrgEM0 | MixOrgEM0 | OrgEM1 | MixOrgEM1 | ||
|---|---|---|---|---|---|---|---|
| CTB | UAS | 84.13% | 83.952% | 84.709% | 85.127% | 84.730% | 84.948% |
| LAS | 82.25% | 81.770% | 82.574% | 83.054% | 82.602% | 82.905% | |
| PTB | UAS | 91.12% | 90.982% | 91.599% | 92.017% | 91.52% | 91.828% |
| LAS | 89.87% | 89.59% | 90.135% | 90.603% | 90.122% | 90.325% |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, F. Dependency Parsing with Transformed Feature. Information 2017, 8, 13. https://doi.org/10.3390/info8010013
Wu F. Dependency Parsing with Transformed Feature. Information. 2017; 8(1):13. https://doi.org/10.3390/info8010013
Chicago/Turabian StyleWu, Fuxiang. 2017. "Dependency Parsing with Transformed Feature" Information 8, no. 1: 13. https://doi.org/10.3390/info8010013
APA StyleWu, F. (2017). Dependency Parsing with Transformed Feature. Information, 8(1), 13. https://doi.org/10.3390/info8010013