
Lazy Management for Frequency Table on Hardware-Based Stream Lossless Data Compression



Abstract
:1. Introduction
2. Backgrounds and Definitions
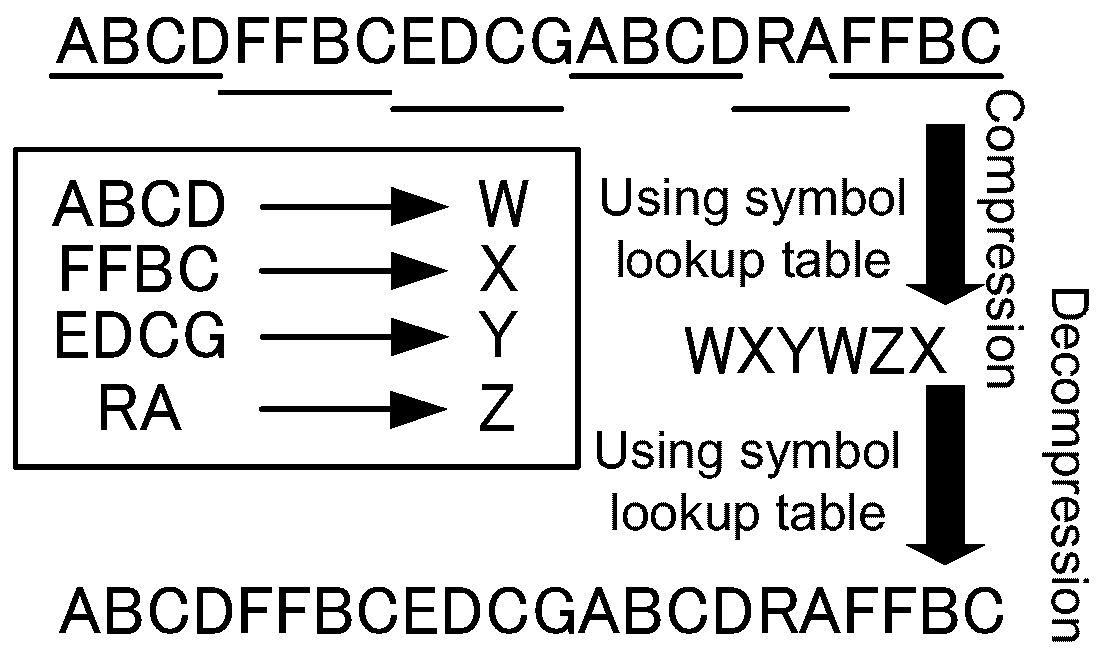
2.1. Data Compression Techniques
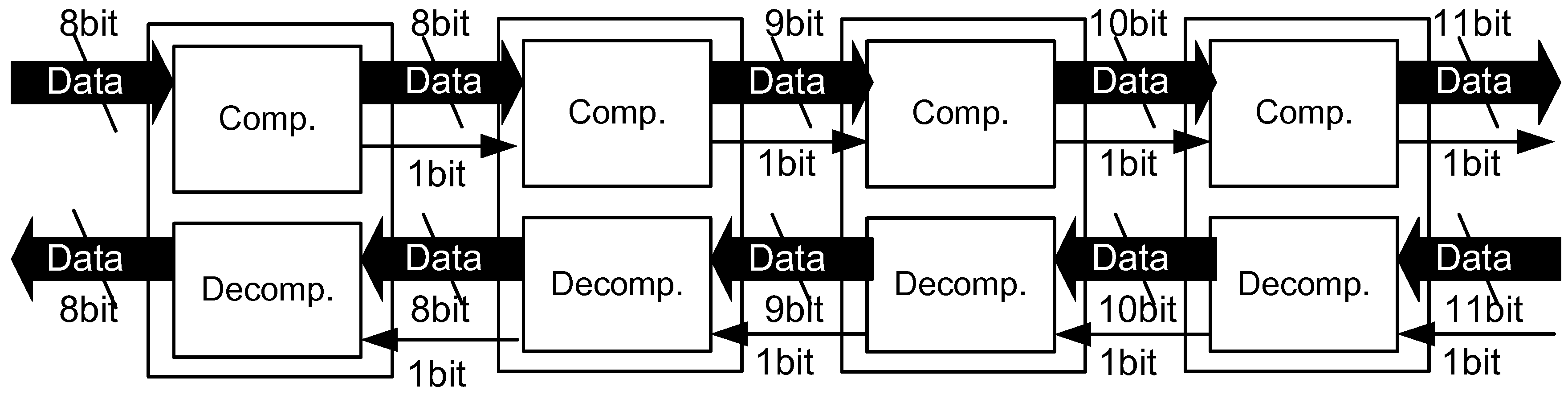
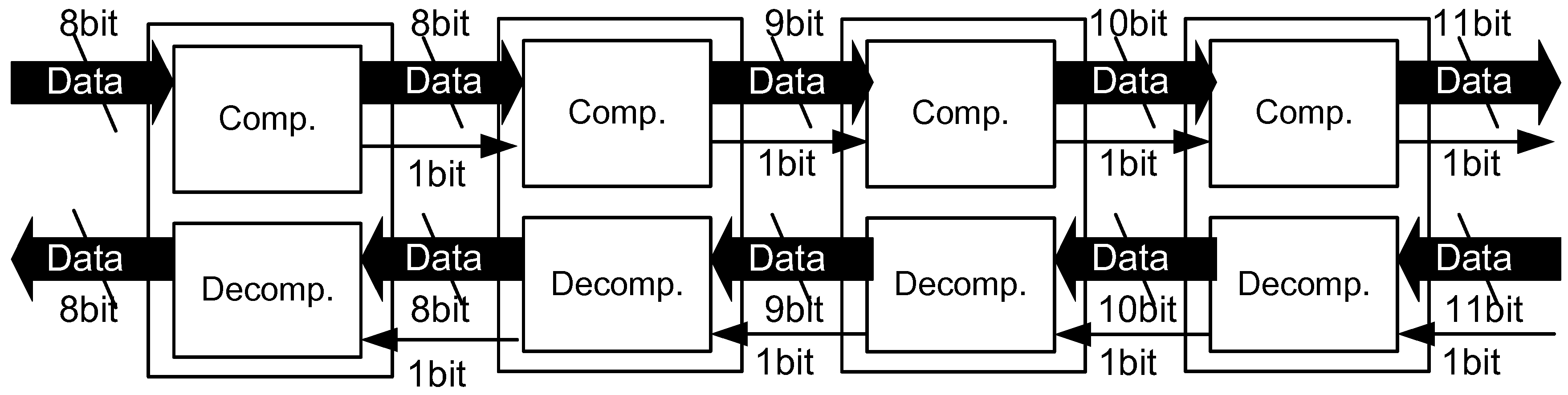
2.2. Stream-Based Data Compression on Hardware
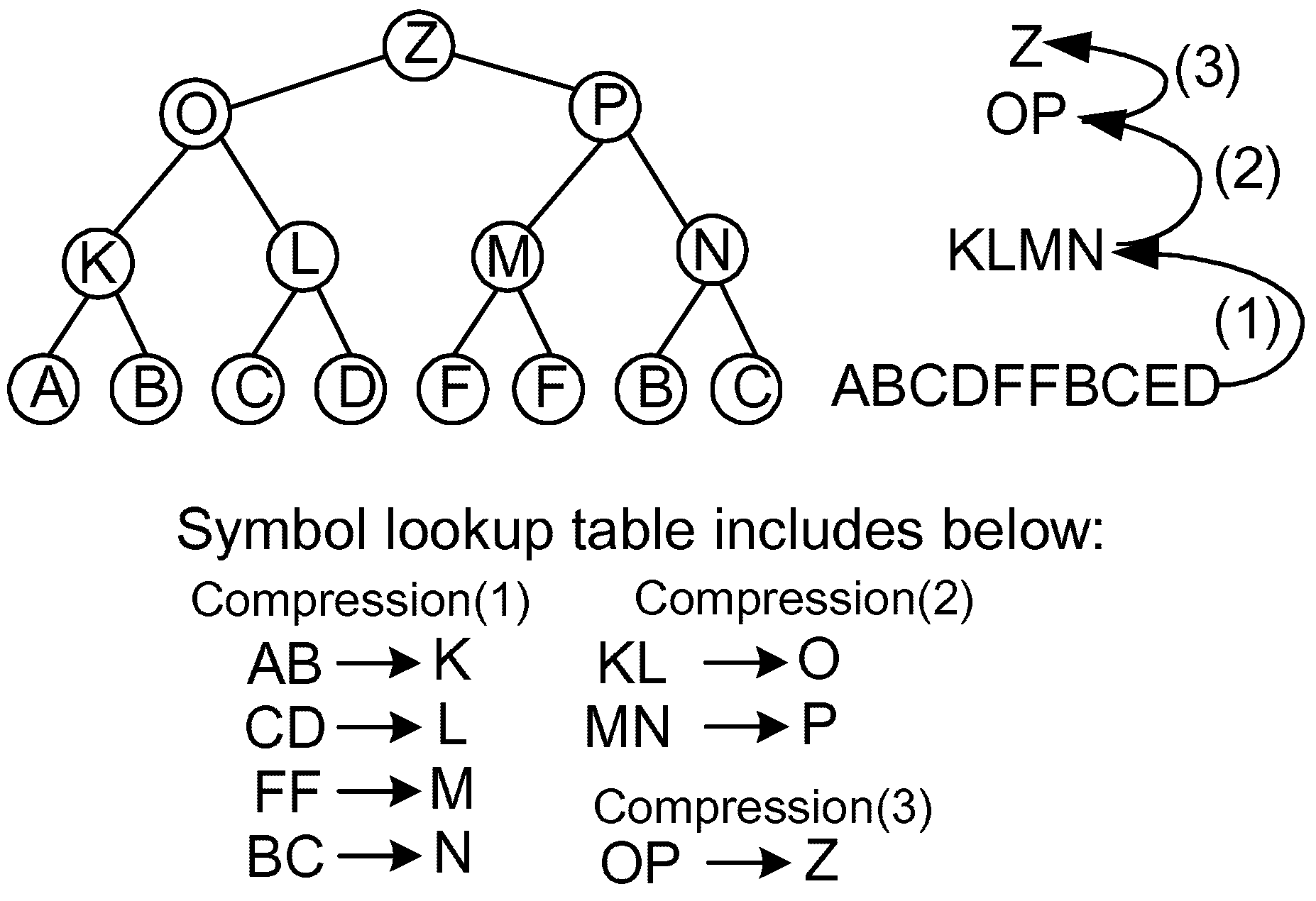
3. Related Works
4. Dynamic Histogram Management in Stream-Based Lossless Data Compression
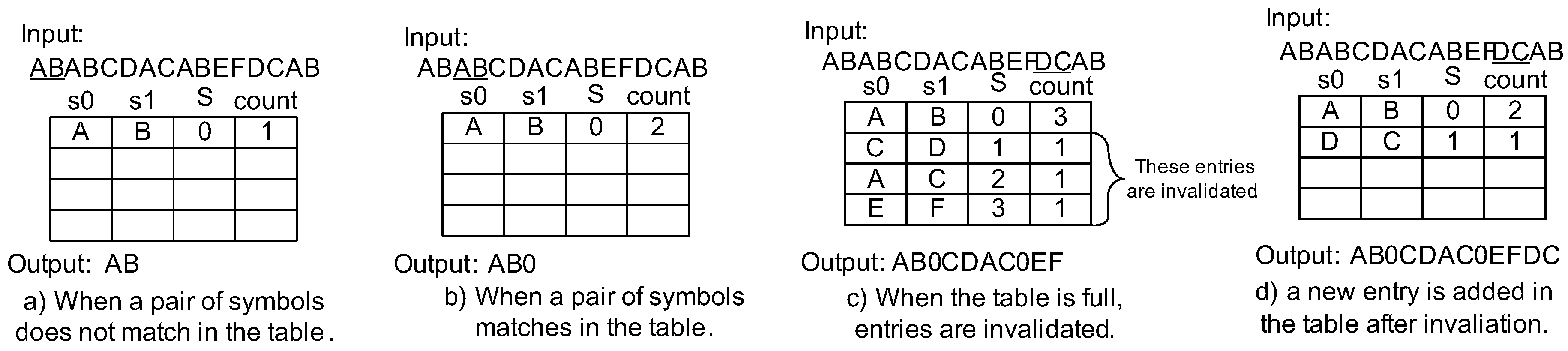
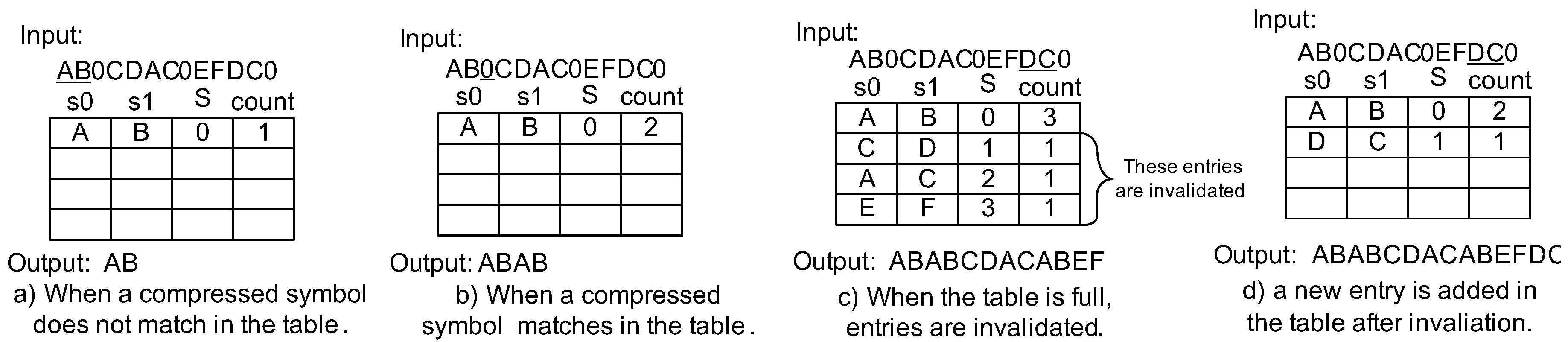
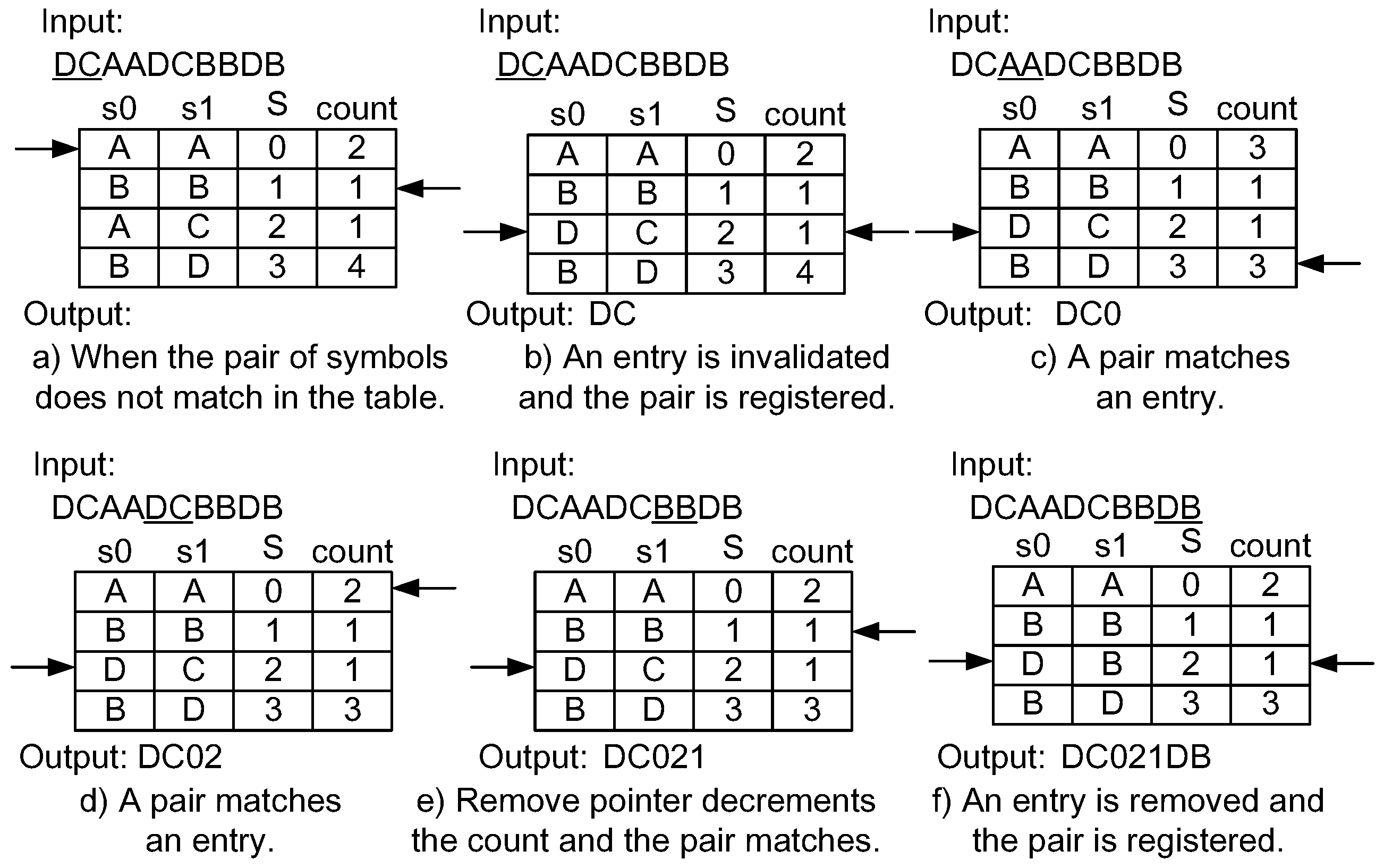
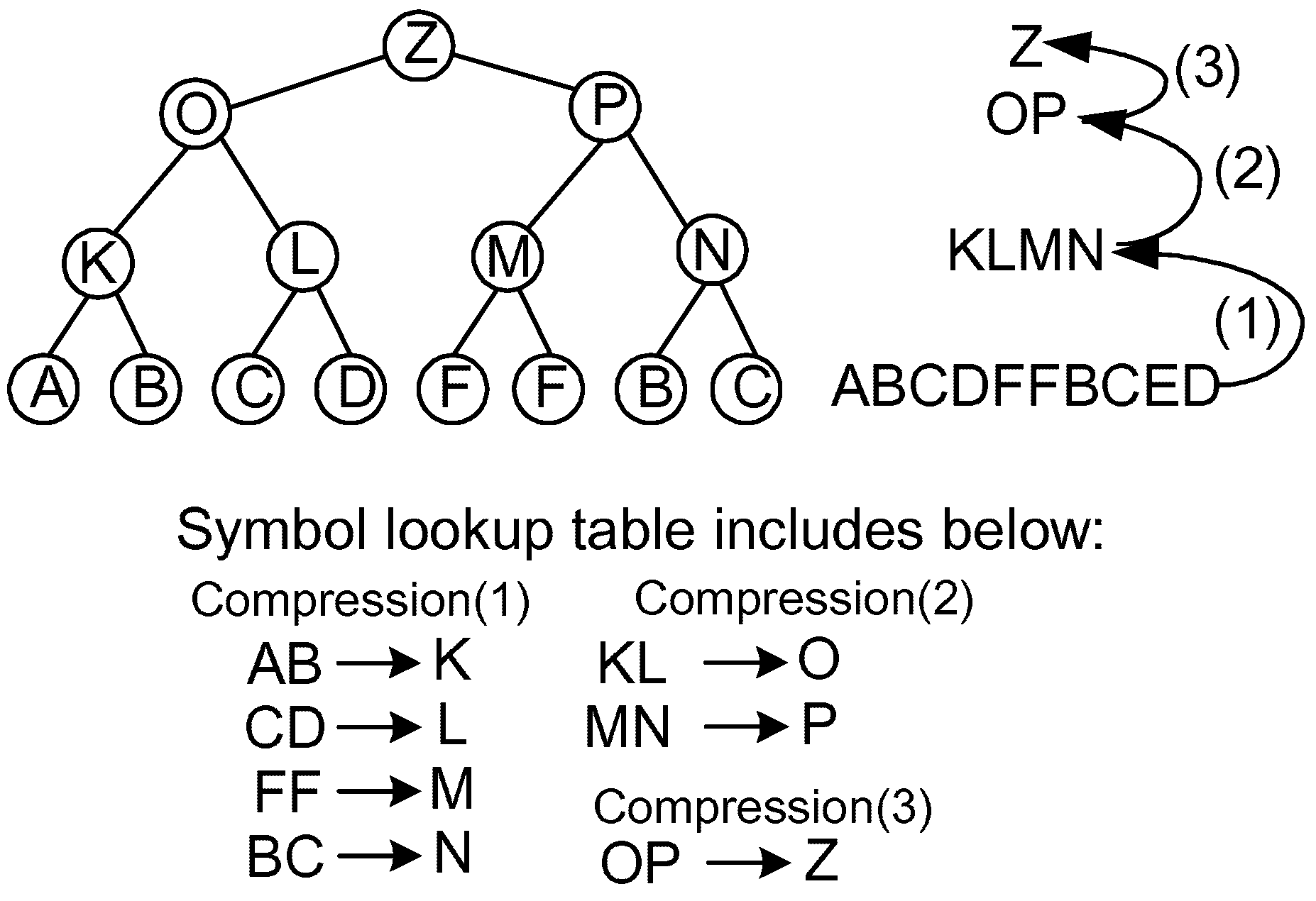
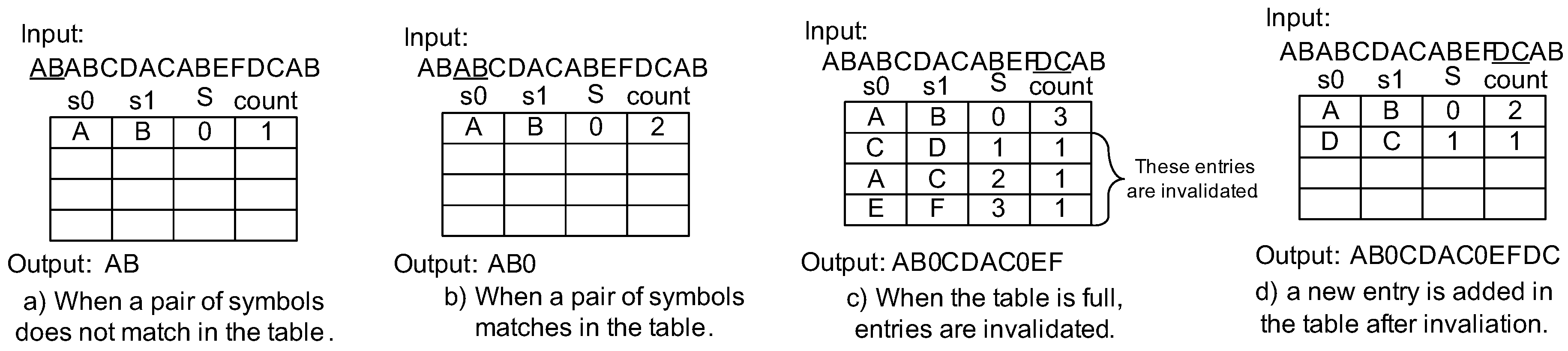
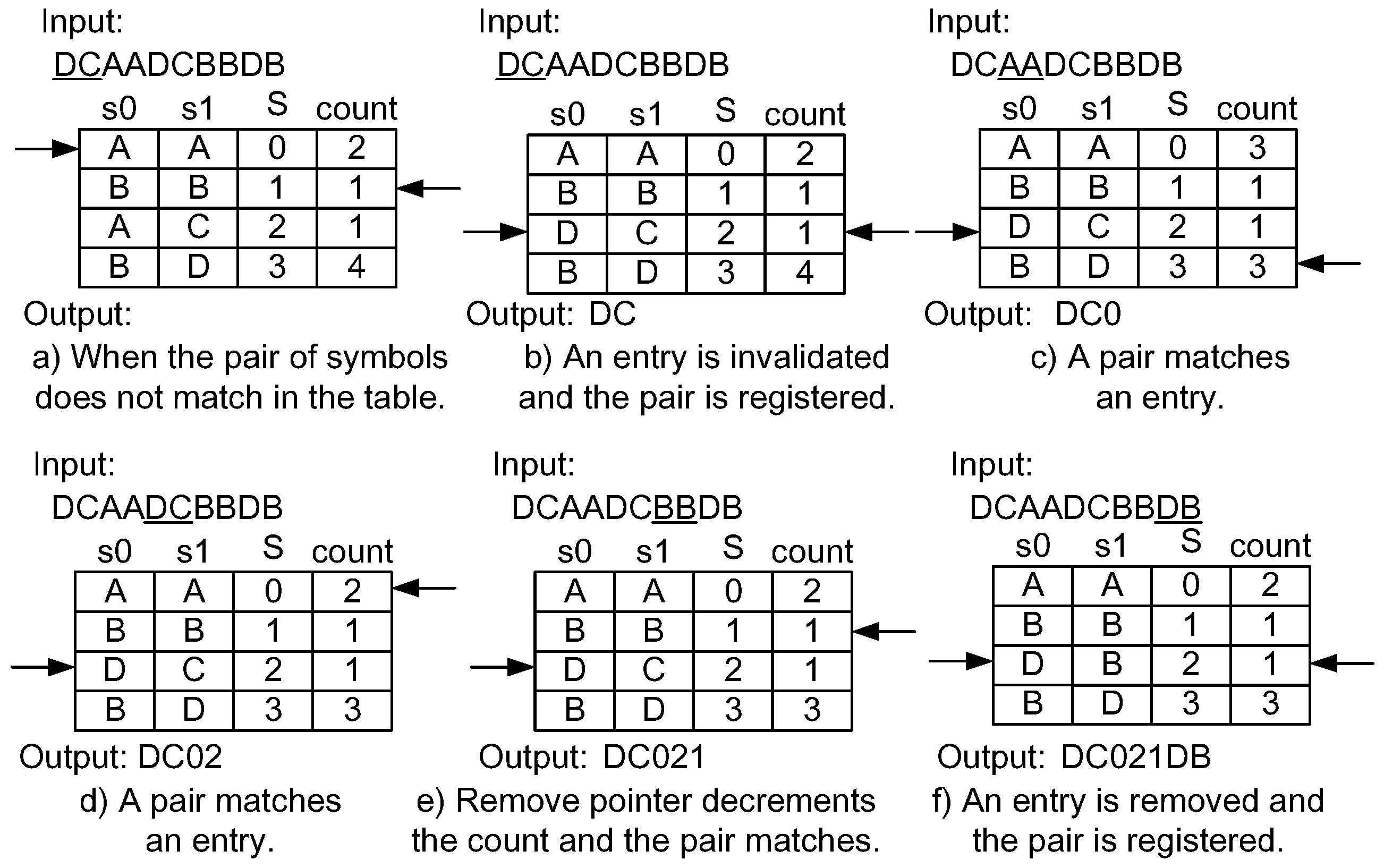
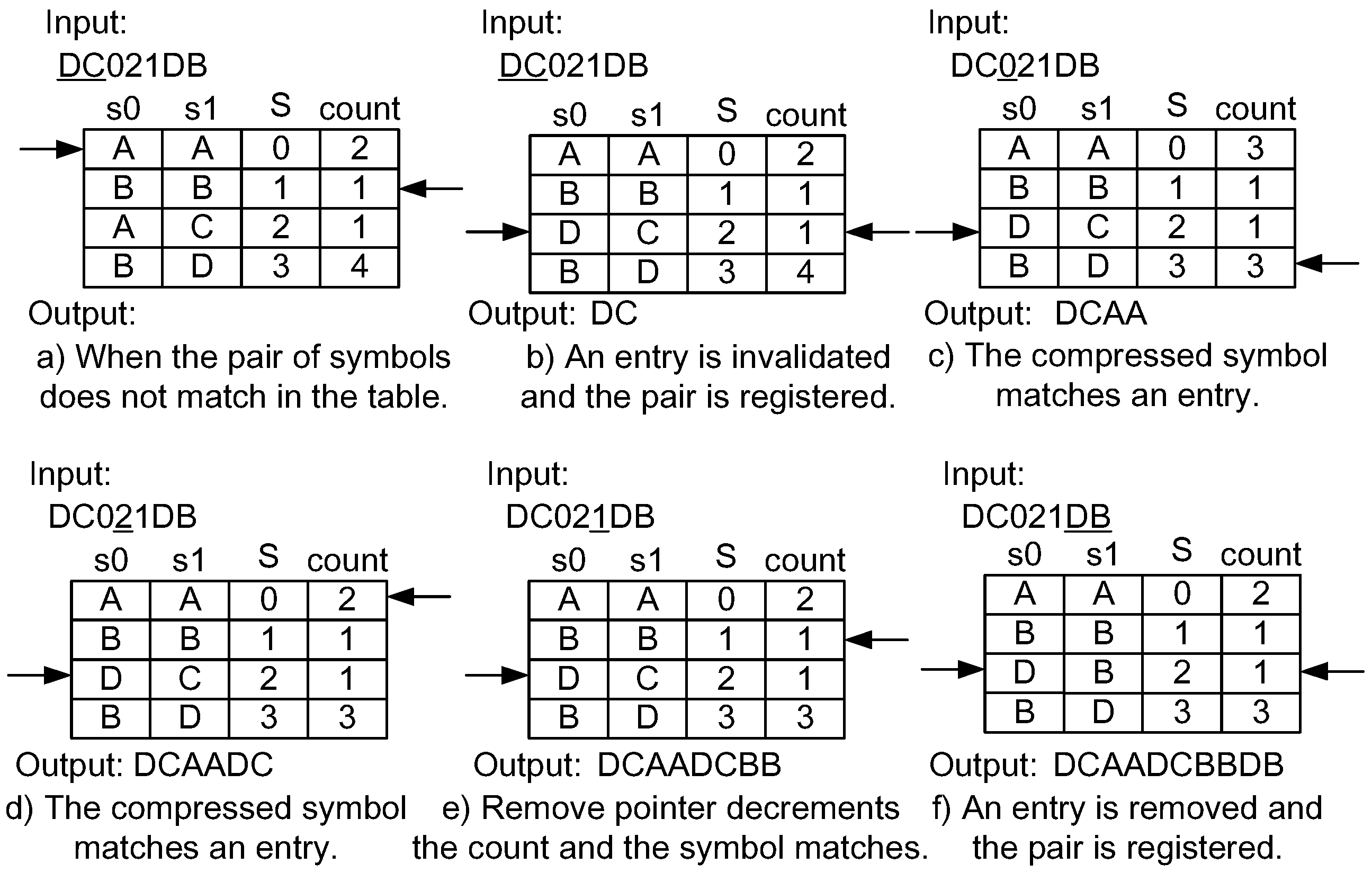
4.1. Dynamic Invalidation for Symbol Lookup Table Management
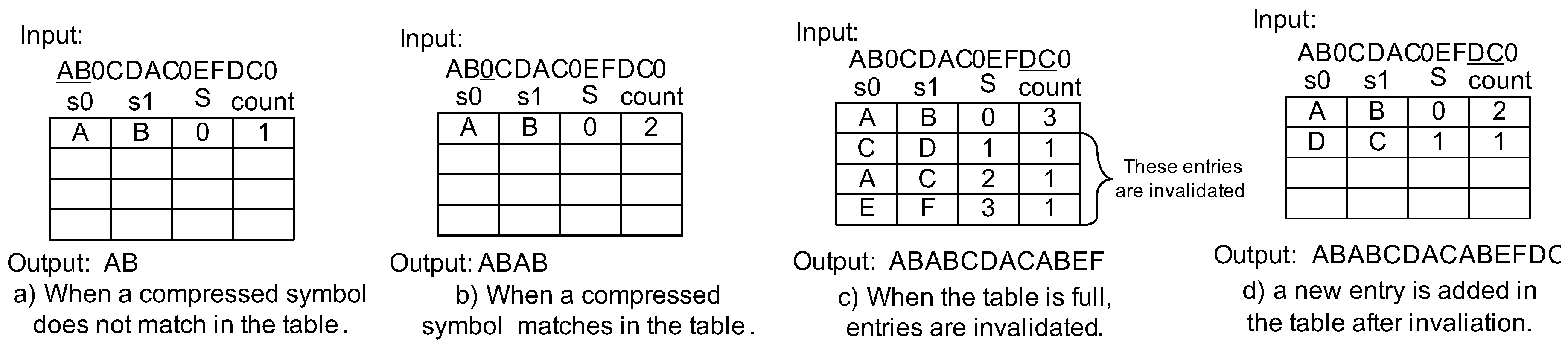
4.2. Lazy Compression
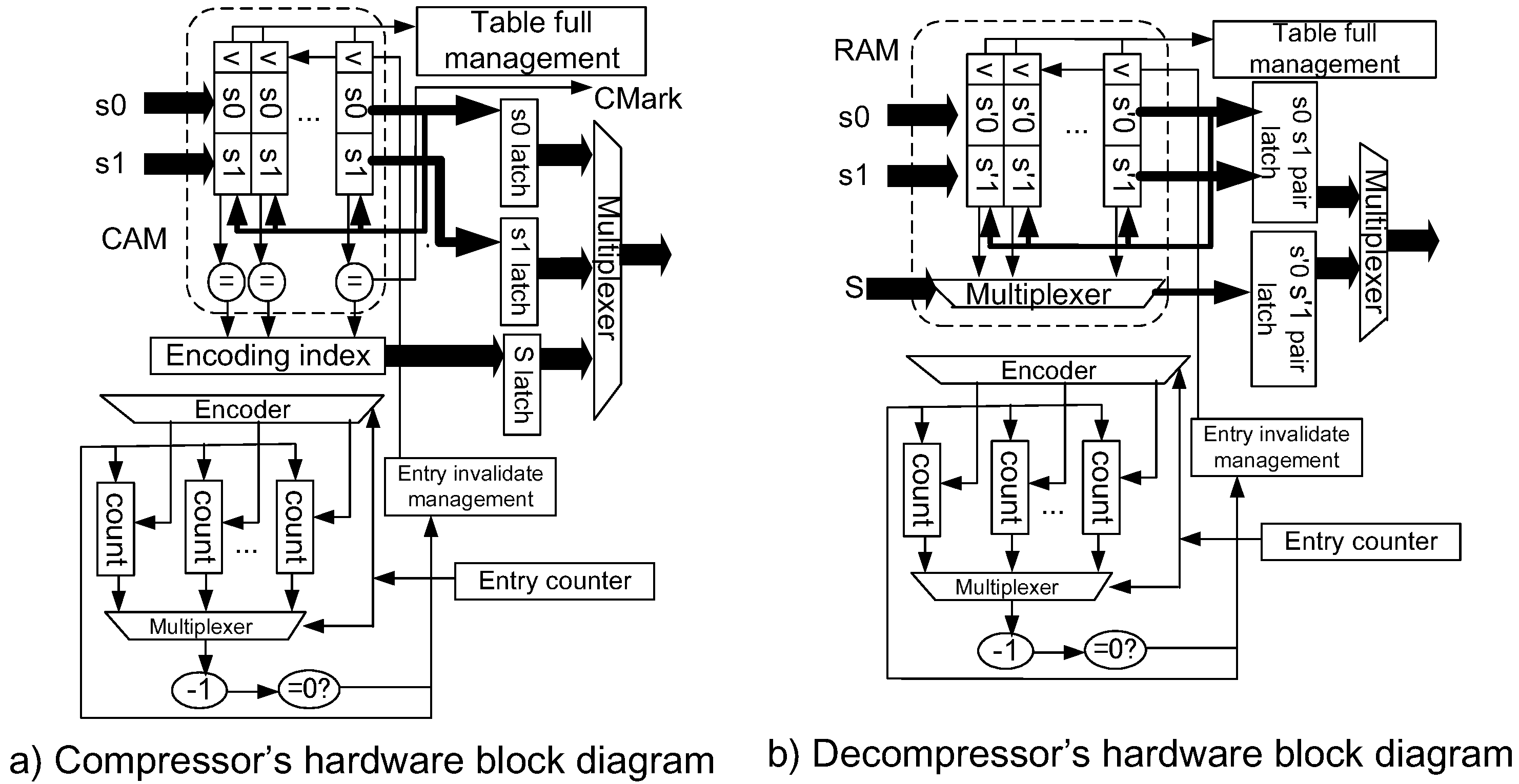
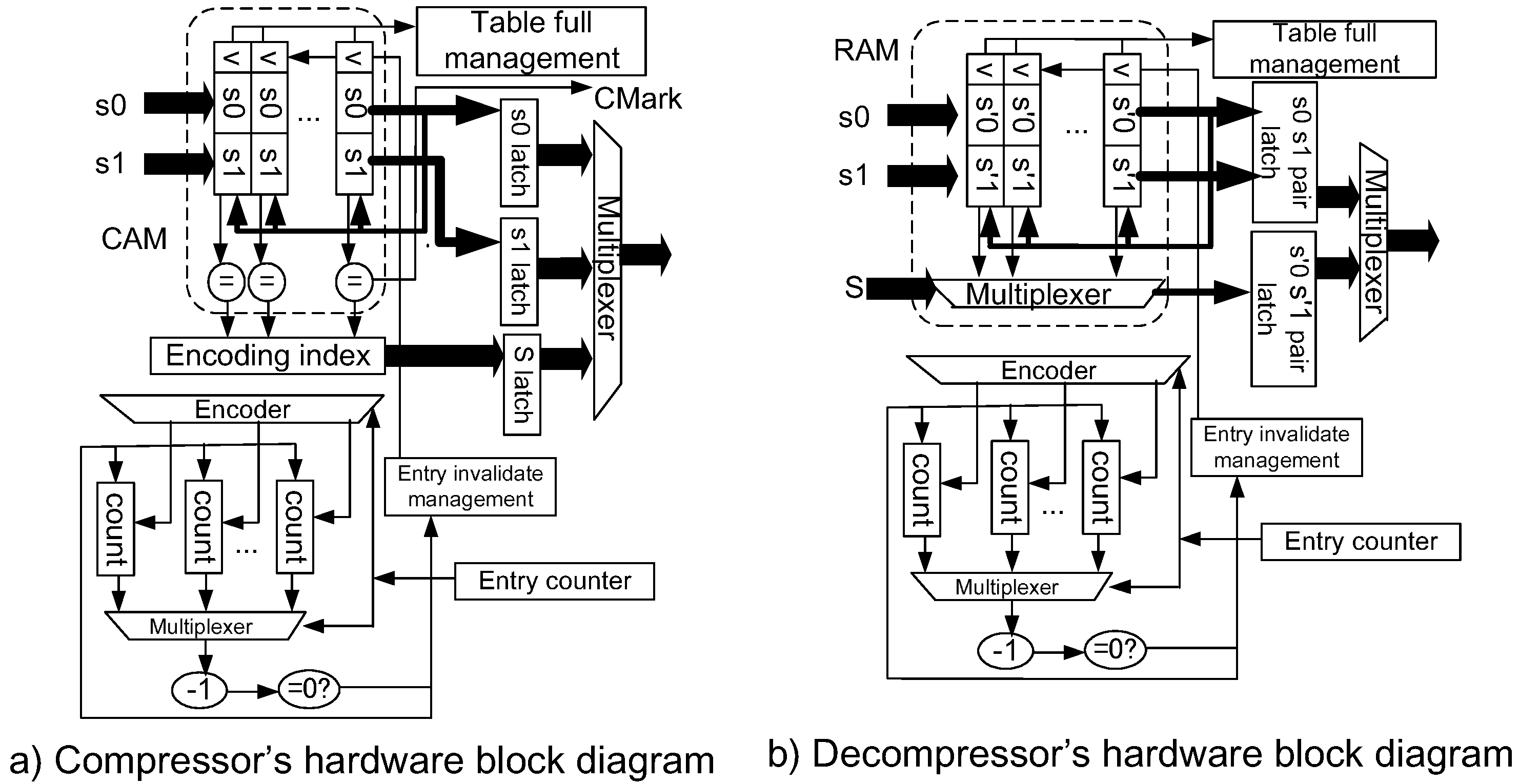
4.3. Implementation
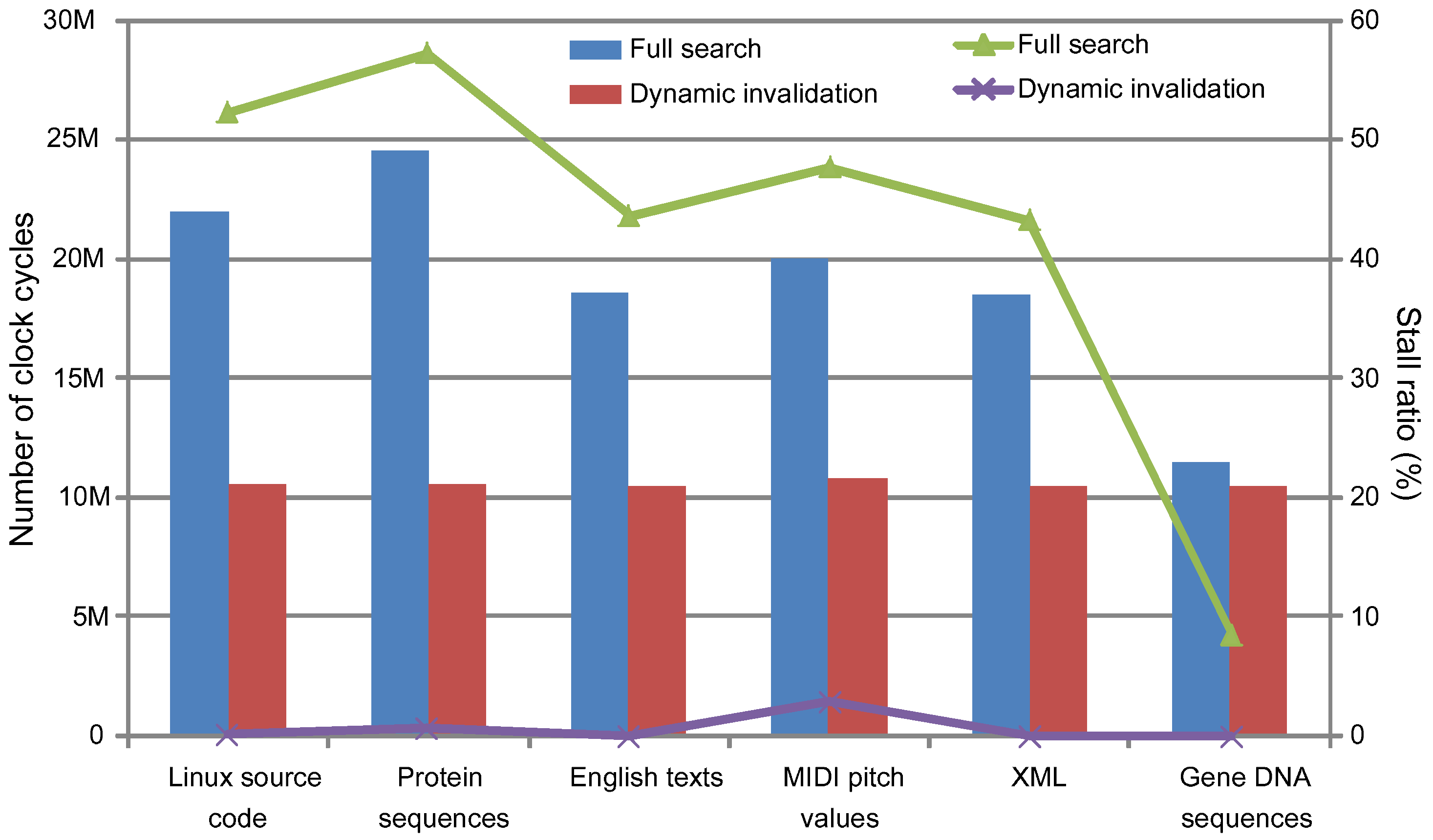
5. Performance Evaluation
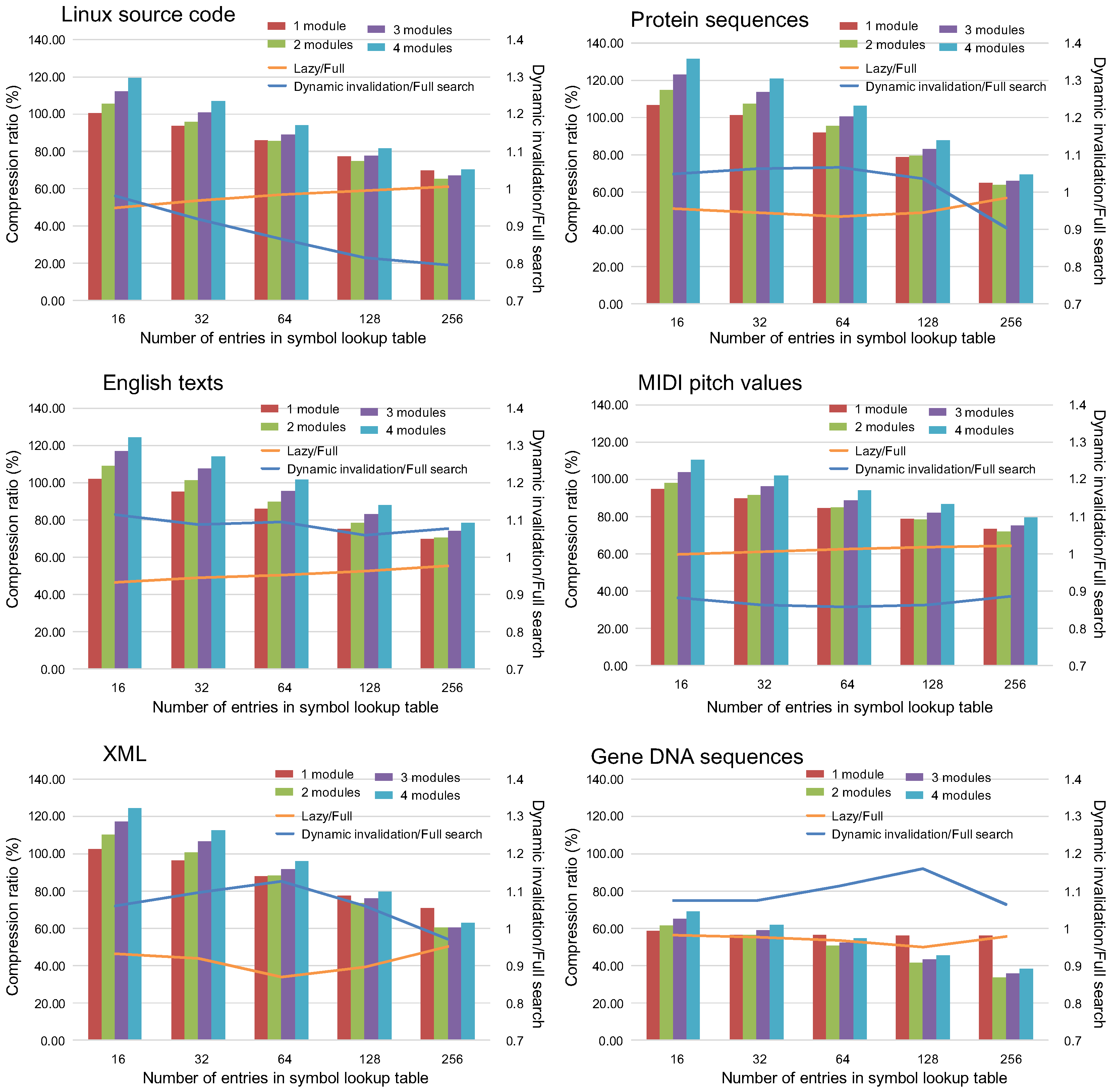
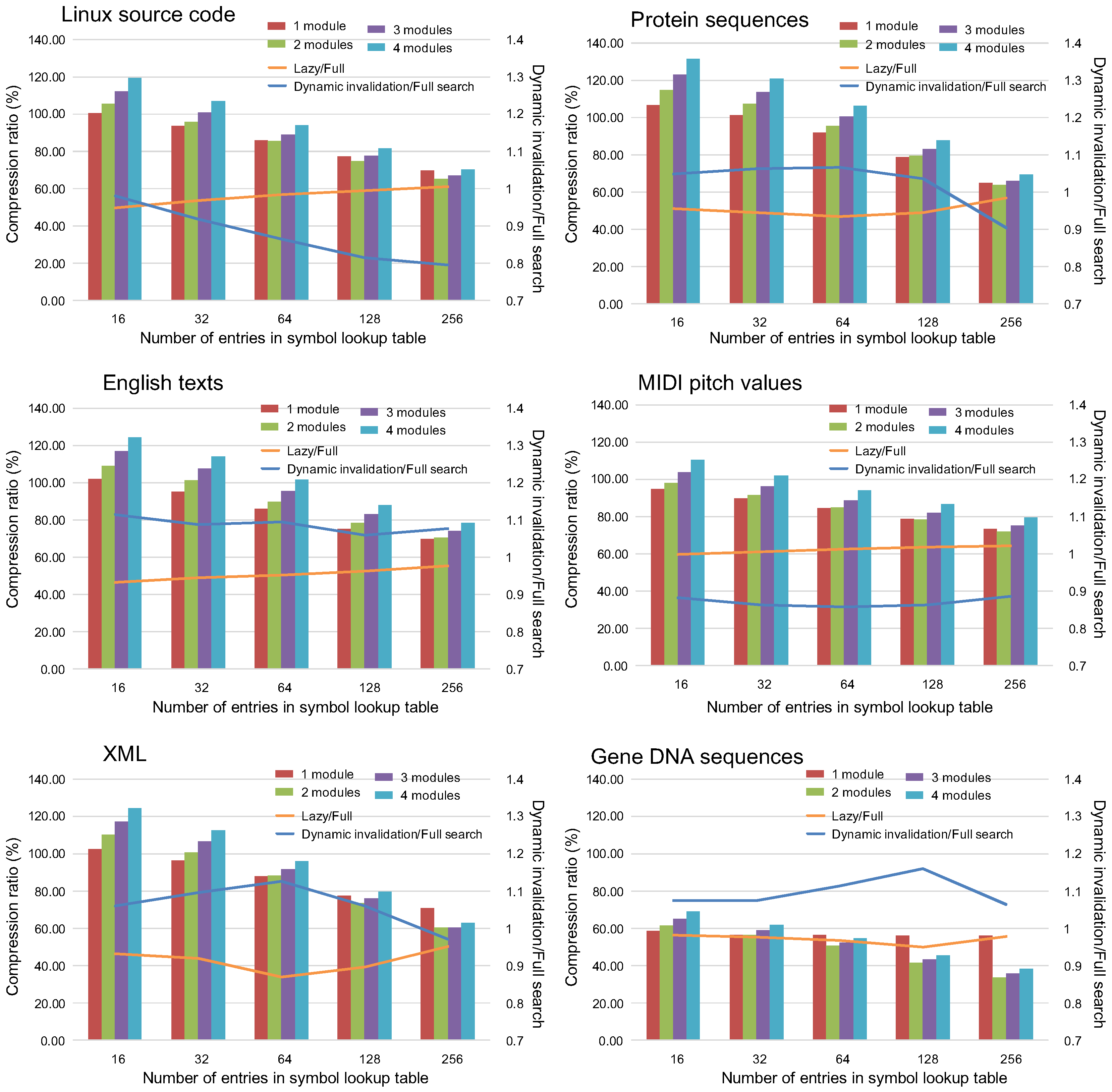
5.1. Effect on the Compression Ratio
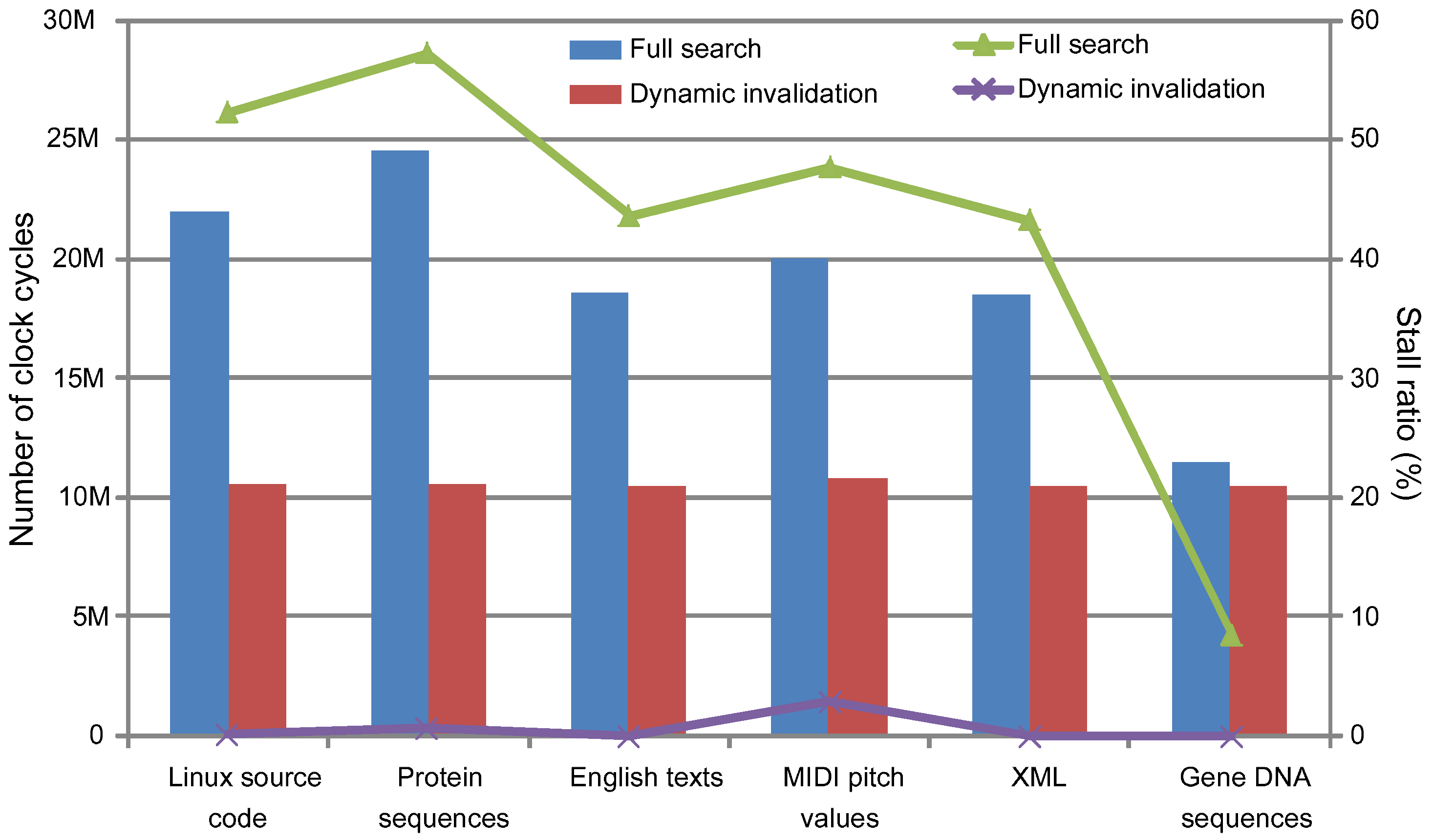
5.2. Dynamic Hardware Performance
5.3. Application Example Using Image Data
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yamagiwa, S.; Aoki, K.; Wada, K. Performance Enhancement of Inter-Cluster Communication with Software-based Data Compression in Link Layer. In Proceedings of the International Conference on Parallel and Distributed Computing Systems (PDCS 2005), Phoenix, AZ, USA, 14–16 November 2005; pp. 325–332.
- Vitter, J.S. Design and Analysis of Dynamic Huffman Codes. J. ACM 1987, 34, 825–845. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. Compression of individual sequences via variable-rate coding. IEEE Trans. Inf. Theory 1978, 24, 530–536. [Google Scholar] [CrossRef]
- Leavlin, E.J.; Singh, D.A.A.G. Hardware Implementation of LZMA Data Compression Algorithm. Int. J. Appl. Inf. Syst. 2013, 5, 51–56. [Google Scholar]
- Yamagiwa, S.; Marumo, K.; Sakamoto, H. Stream-based Lossless Data Compression Hardware using Adaptive Frequency Table Management. In Big Data Benchmarks, Performance Optimization, and Emerging Hardware; Lecture Note in Computer Science; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Maruyama, S.; Sakamoto, H.; Takeda, M. An Online Algorithm for Lightweight Grammar-Based Compression. Algorithms 2012, 5, 214–235. [Google Scholar] [CrossRef]
- Qin, C.; Chang, C.C.; Chiu, Y.P. A Novel Joint Data-Hiding and Compression Scheme Based on SMVQ and Image Inpainting. IEEE Trans. Image Process. 2014, 23, 969–978. [Google Scholar]
- Qin, C.; Chang, C.C.; Chen, Y.C. Efficient reversible data hiding for VQ-compressed images based on index mapping mechanism. Signal Process. 2013, 93, 2687–2695. [Google Scholar] [CrossRef]
- Manku, G.S.; Motwani, R. Approximate Frequency Counts over Data Streams. In Proceedings of the 28th International Conference on Very Large Data Bases, Hong Kong, China, 20–23 August 2002; pp. 346–357.
- Metwally, A.; Agrawal, D.; Abbadi, A.E. An Integrated Efficient Solution for Computing Frequent and Top-k Elements in Data Streams. ACM Trans. Database Syst. 2006, 31, 1095–1133. [Google Scholar] [CrossRef]
- Karp, R.M.; Shenker, S.; Papadimitriou, C.H. A Simple Algorithm for Finding Frequent Elements in Streams and Bags. ACM Trans. Database Syst. 2003, 28, 51–55. [Google Scholar] [CrossRef]
- Fowers, J.; Kim, J.-Y.; Burger, D.; Hauck, S. A Scalable High-Bandwidth Architecture for Lossless Compression on FPGAs. In Proceedings of the 23rd IEEE International Symposium on Field-Programmable Custom Computing Machines, Vancouver, BC, Canada, 2–6 May 2015.
- Kim, J.Y.; Hauck, S.; Burger, D. A Scalable Multi-engine Xpress9 Compressor with Asynchronous Data Transfer. In Proceedings of the IEEE 22nd Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boston, MA, USA, 11–13 May 2014; pp. 161–164.
- Langdon, G.; Rissanen, J. Compression of Black-White Images with Arithmetic Coding. IEEE Trans. Commun. 1981, 29, 858–867. [Google Scholar] [CrossRef]
- Schwarz, H.; Marpe, D.; Wiegand, T. Overview of the Scalable Video Coding Extension of the H.264/AVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 1103–1120. [Google Scholar] [CrossRef]
- Osorio, R.R.; Bruguera, J.D. Arithmetic coding architecture for H.264/AVC CABAC compression system. In Proceedings of the Euromicro Symposium on Digital System Design (DSD 2004), Rennes, France, 31 August–3 September 2004; pp. 62–69.
- Chuang, T.D.; Chen, Y.J.; Chen, Y.H.; Chien, S.Y.; Chen, L.G. Architecture Design of Fine Grain Quality Scalable Encoder with CABAC for H.264/AVC Scalable Extension. J. Signal Process. Syst. 2010, 60, 363–375. [Google Scholar] [CrossRef]
- Lo, C.C.; Tsai, S.T.; Shieh, M.D. Reconfigurable architecture for entropy decoding and inverse transform in H.264. IEEE Trans. Consum. Electron. 2010, 56, 1670–1676. [Google Scholar] [CrossRef]
- Pande, A.; Zambreno, J.; Mohapatra, P. Hardware Architecture for Simultaneous Arithmetic Coding and Encryption. In Proceedings of the International Conference on Engineering of Reconfigurable Systems and Algorithms (ERSA), Las Vegas, NV, USA, 18–21 July 2011.
- Mitchell, J.L.; Pennebaker, W.B. Optimal hardware and software arithmetic coding procedures for the Q-Coder. IBM J. Res. Dev. 1988, 32, 727–736. [Google Scholar] [CrossRef]
- Zukowski, M.; Heman, S.; Nes, N.; Boncz, P. Super-Scalar RAM-CPU Cache Compression. In Proceedings of the 22nd International Conference on Data Engineering, Atlanta, GA, USA, 3–8 April 2006; p. 59.
- Tremaine, R.B.; Franaszek, P.A.; Robinson, J.T.; Schulz, C.O.; Smith, T.B.; Wazlowski, M.; Bland, P.M. IBM Memory Expansion Technology (MXT). IBM J. Res. Dev. 2001, 45, 271–285. [Google Scholar] [CrossRef]
- Alameldeen, A.R.; Wood, D.A. Adaptive Cache Compression for High-Performance Processors. In Proceedings of the 31st Annual International Symposium on Computer Architecture, München, Germany, 19–23 June 2004; p. 212.
- Pekhimenko, G.; Seshadri, V.; Mutlu, O.; Gibbons, P.B.; Kozuch, M.A.; Mowry, T.C. Base-delta-immediate Compression: Practical Data Compression for On-chip Caches. In Proceedings of the 21st International Conference on Parallel Architectures and Compilation Techniques, Minneapolis, MN, USA, 19–23 September 2012; pp. 377–388.
- Chen, X.; Yang, L.; Dick, R.P.; Shang, L.; Lekatsas, H. C-Pack: A High-Performance Microprocessor Cache Compression Algorithm. IEEE Trans. Very Large Scale Integr. Syst. 2010, 18, 1196–1208. [Google Scholar] [CrossRef]
- Arelakis, A.; Stenstrom, P. SC2: A Statistical Compression Cache Scheme. In Proceeding of the 41st Annual International Symposium on Computer Architecuture, Minneapolis, MN, USA, 14–18 June 2014; pp. 145–156.
- The Prologue. Available online: http://pizzachili.dcc.uchile.cl/ (accessed on 30 September 2016).
- Sanchez, V.; Nasiopoulos, P.; Abugharbieh, R. Efficient Lossless Compression of 4-D Medical Images Based on the Advanced Video Coding Scheme. IEEE Trans. Inf. Technol. Biomed. 2008, 12, 442–446. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Tan, D.M.; Baird, M.; DeCampo, J.; White, C.; Wu, H.R. Perceptually lossless medical image coding. IEEE Trans. Med. Imaging 2006, 25, 335–344. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Data | # of Bits after Compression | Compression Ratio (%) |
|---|---|---|
| C (direct) | 39,171,843 | 93 |
| K (direct) | 31,779,855 | 76 |
| M (direct) | 38,905,452 | 93 |
| Y (direct) | 40,220,676 | 96 |
| C (diff) | 35,230,032 | 84 |
| K (diff) | 32,065,308 | 76 |
| M (diff) | 35,911,494 | 86 |
| Y (diff) | 37,415,628 | 89 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marumo, K.; Yamagiwa, S.; Morita, R.; Sakamoto, H. Lazy Management for Frequency Table on Hardware-Based Stream Lossless Data Compression. Information 2016, 7, 63. https://doi.org/10.3390/info7040063
Marumo K, Yamagiwa S, Morita R, Sakamoto H. Lazy Management for Frequency Table on Hardware-Based Stream Lossless Data Compression. Information. 2016; 7(4):63. https://doi.org/10.3390/info7040063
Chicago/Turabian StyleMarumo, Koichi, Shinichi Yamagiwa, Ryuta Morita, and Hiroshi Sakamoto. 2016. "Lazy Management for Frequency Table on Hardware-Based Stream Lossless Data Compression" Information 7, no. 4: 63. https://doi.org/10.3390/info7040063
APA StyleMarumo, K., Yamagiwa, S., Morita, R., & Sakamoto, H. (2016). Lazy Management for Frequency Table on Hardware-Based Stream Lossless Data Compression. Information, 7(4), 63. https://doi.org/10.3390/info7040063