
User in the Loop: Adaptive Smart Homes Exploiting User Feedback—State of the Art and Future Directions


Abstract
:1. Introduction
2. State-of-the-Art
2.1. Smart Homes
2.2. Activity Recognition
- Offline classification algorithms, such as K-Nearest-Neighbors (K-NN) [12], Artificial Neural Networks (ANNs) [13] , Decision Trees (DTs) [14] or Support Vector Machines (SVMs) [15]. These algorithms rely on the creation of “frames” of data of a chosen length that will try to find the closest example(s) in the database for a test frame. These algorithms are based only on statistical evaluation of the dispersion of the data in a given space. Using ontologies, [16] defines the context and the Activities of Daily Living for a further recognition with rules-based algorithms.
- Sequential algorithms, such as Hidden Markov Models (HMMs) [17], Conditional Random Fields (CRFs) [18] or also Markov Logic Networks (MLNs) [19]. Those methods add to the previously cited algorithms a notion of dependence between the different events of the frame or of the activity. This allows to identify spatio-temporal relationships between the data that are totally absent in the classical methods. HMMs have been, for a long time, a reference method for activity recognition.
2.3. User Feedback for Smarter Homes
3. Adaptive and Personalized Smart Home Behavior
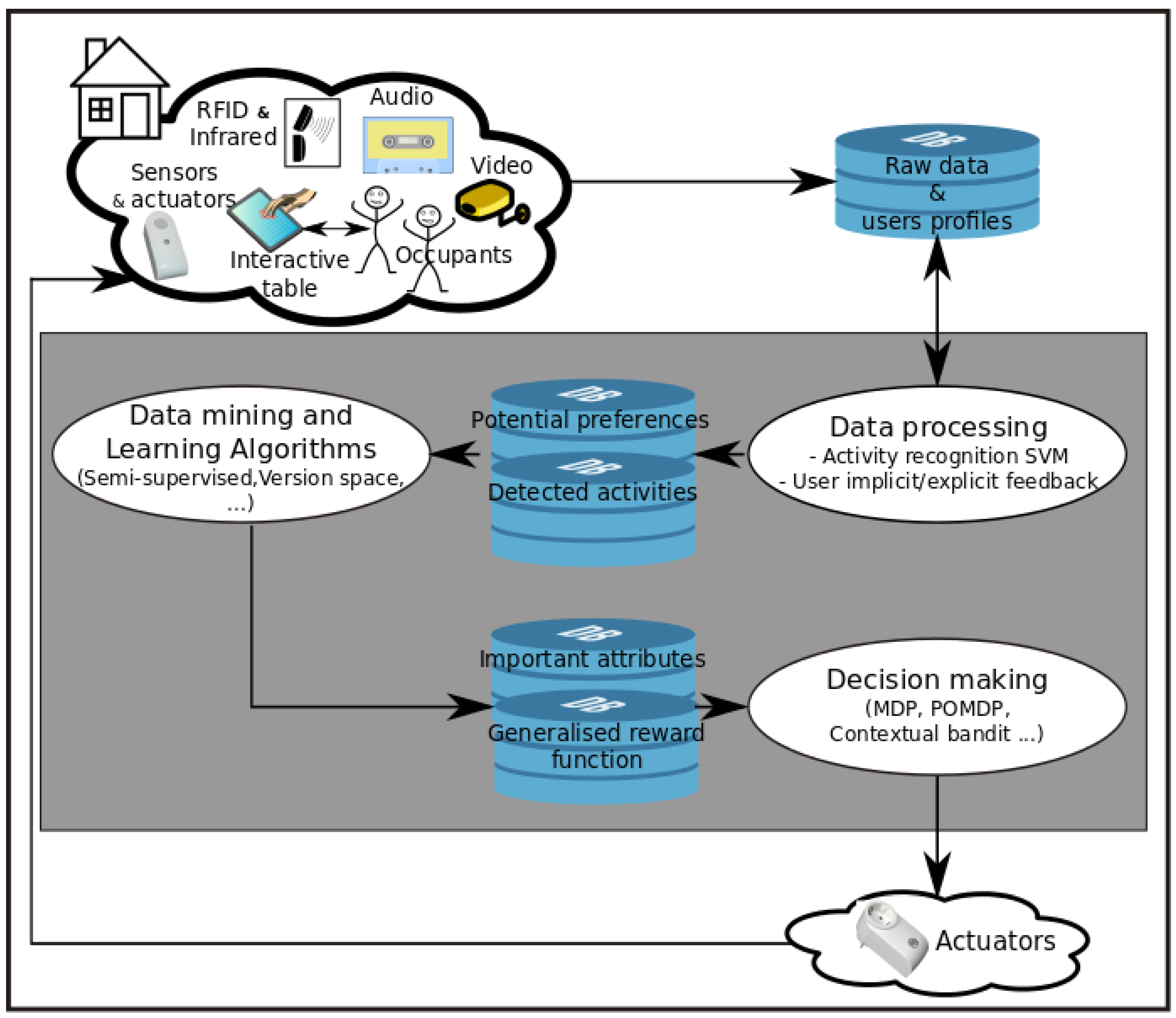
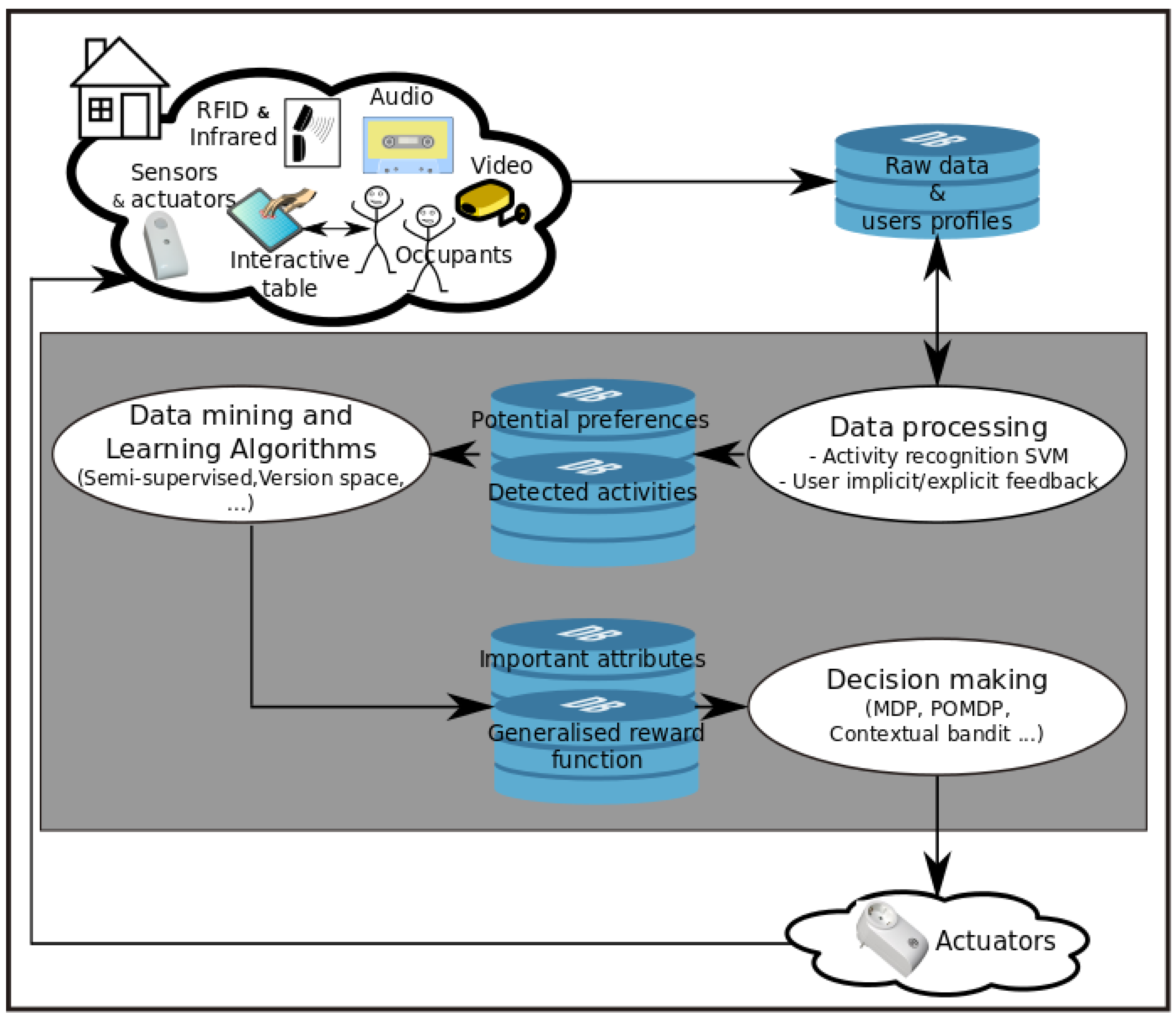
3.1. Global Architecture
- activity recognition,
- detecting implicit feedback, and exporting potential preferences through analyzing each received explicit feedback and each detected implicit feedback, and
- updating users profile using the detected new habits.
- an automated action by the smart home followed by a user explicit feedback is encountered, and
- when implicit feedback is encountered (a change of an actuator value by the user him/herself).
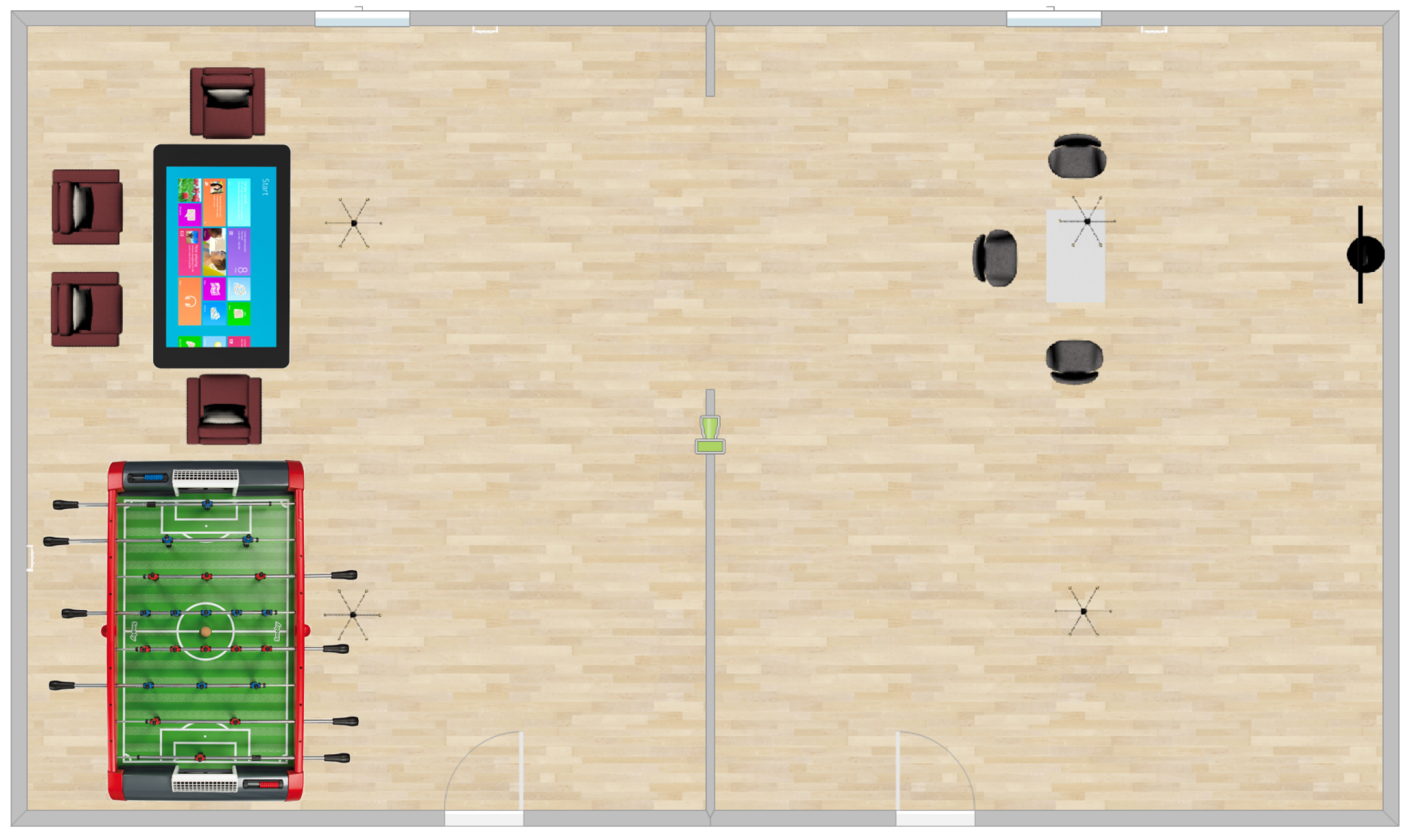
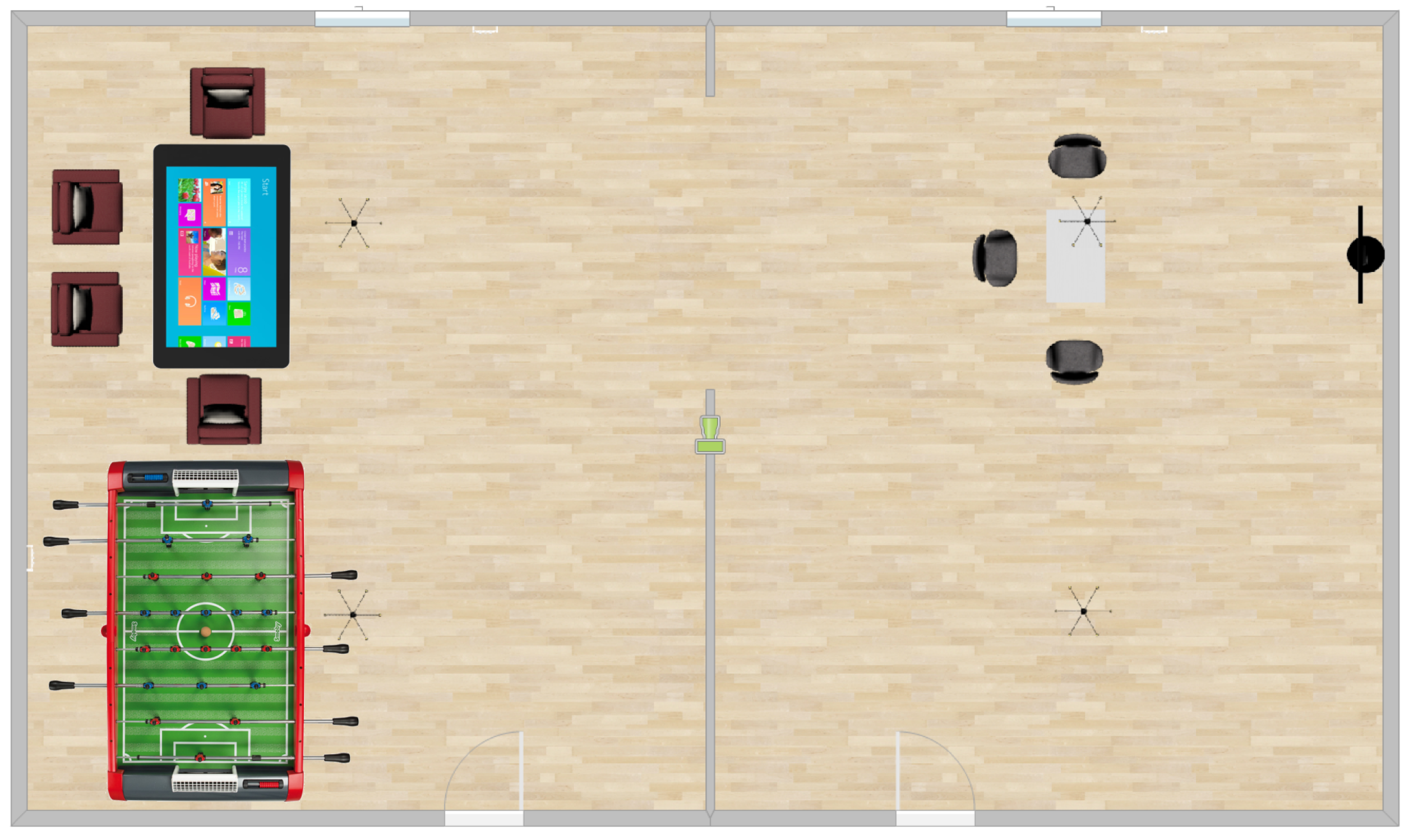
3.2. Description of the Installation of Sensors
- Sensors for all the possible electrical plugs of both rooms,
- Light, humidity and temperature sensors at different positions of the lab, and others for the outside,
- Sensors to measure the position of the shutter, the opening/closing of the doors and of the windows,
- Infra-red sensors, positioned at strategic locations in the rooms, to know where the person is (for activity recognition purpose, for instance),
- Actuators to command the different heaters of the rooms,
- Actuators to command the light (in four sets of lights distributed in the room),
- Actuators to turn on/off the different electrical outlets/plugs,
- Actuators to change the positions of the windows shutters,
- A sensor on the door that will, with an access card, recognize the person entering the room so that the system can load his/her profile (if already filled).
- Table and chairs to sit comfortably,
- A large smart TV to have access to different media such as music, TV, radio, YouTube channels, Internet, etc.,
- A baby foot table to play (several persons can be present in the living lab at the same time),
- A smart table using Microsoft Windows to allow people to use internet, read, etc. but also to give a feedback regarding smart home automation (see following sections).
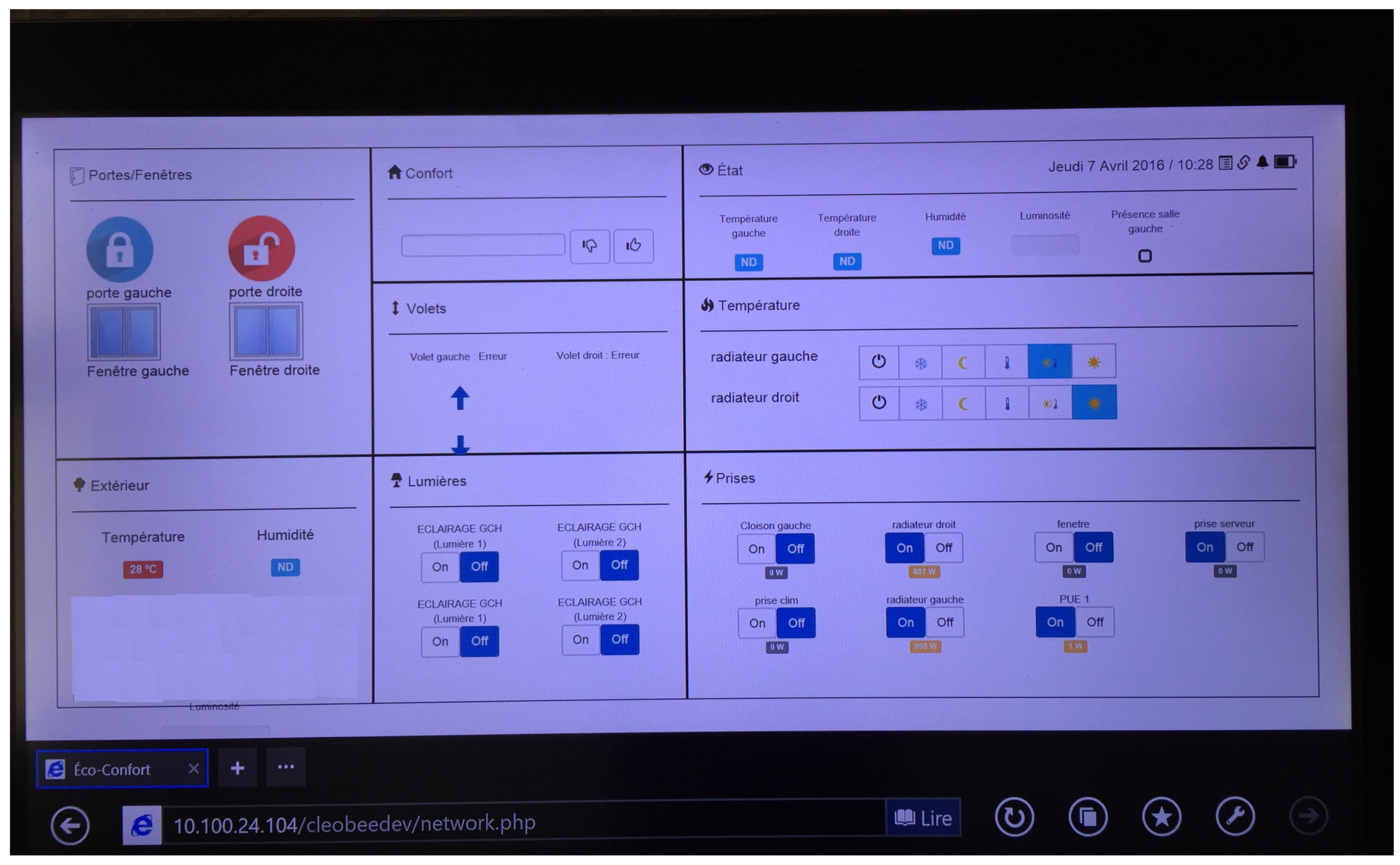
3.3. Data Processing and Acquisition
- id is the identifier of the RDE in the database,
- type is the description of the type of the RDE,
- value describes the value of the RDE,
- timestamp is the timestamp describing the time that the changing of the RDE value took place.
- Check the state of the different sensors of the room and have information on the environment,
- Perform actions on the room such as turn on/off lights, power outlets, etc.
- Give an opinion on an action that just occurred in the room. For instance, if the smart home turns on the lights after sensing a decrease in the ambient luminosity and the user does not agree for some reason, he/she can notify it on the screen (thumbs up, thumbs down buttons).
3.4. Activity Recognition
3.5. Adaptive Decision Making
3.6. Learning from User Feedback
4. Preliminary Results
4.1. Parameters and Simulation of Situations
4.2. Simulation of Potential Preferences
4.3. Procedure
- Re/Calculate the MDP policy.
- Generate n potential preferences.
- Evaluate the actions in the n potential preferences by counting the number of actions followed by a negative feedback called negative actions.
- Learn/Generalize and update the MDP reward function using the n new potential preferences.
- Repeat from step 1 until reaching number of traces.
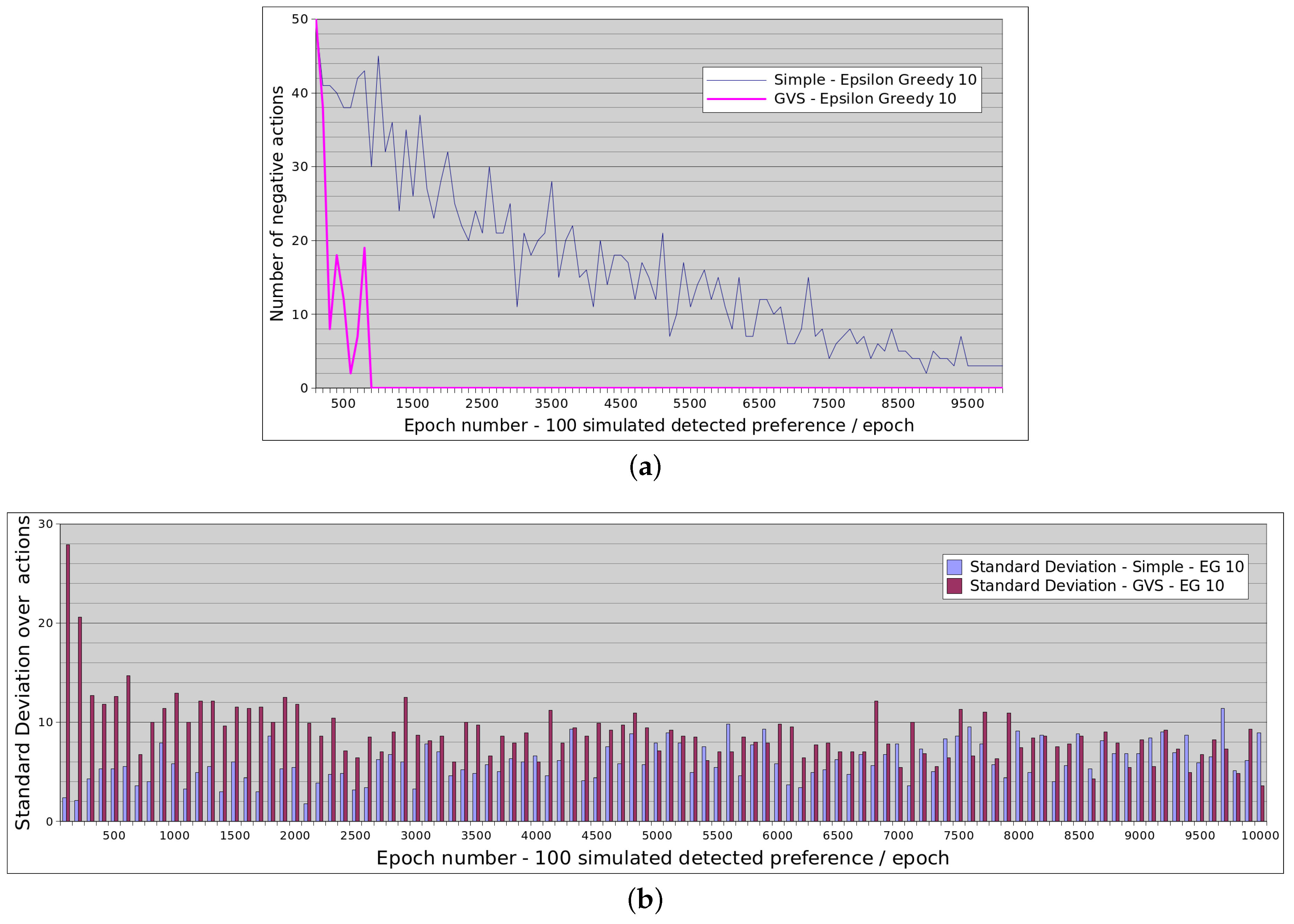
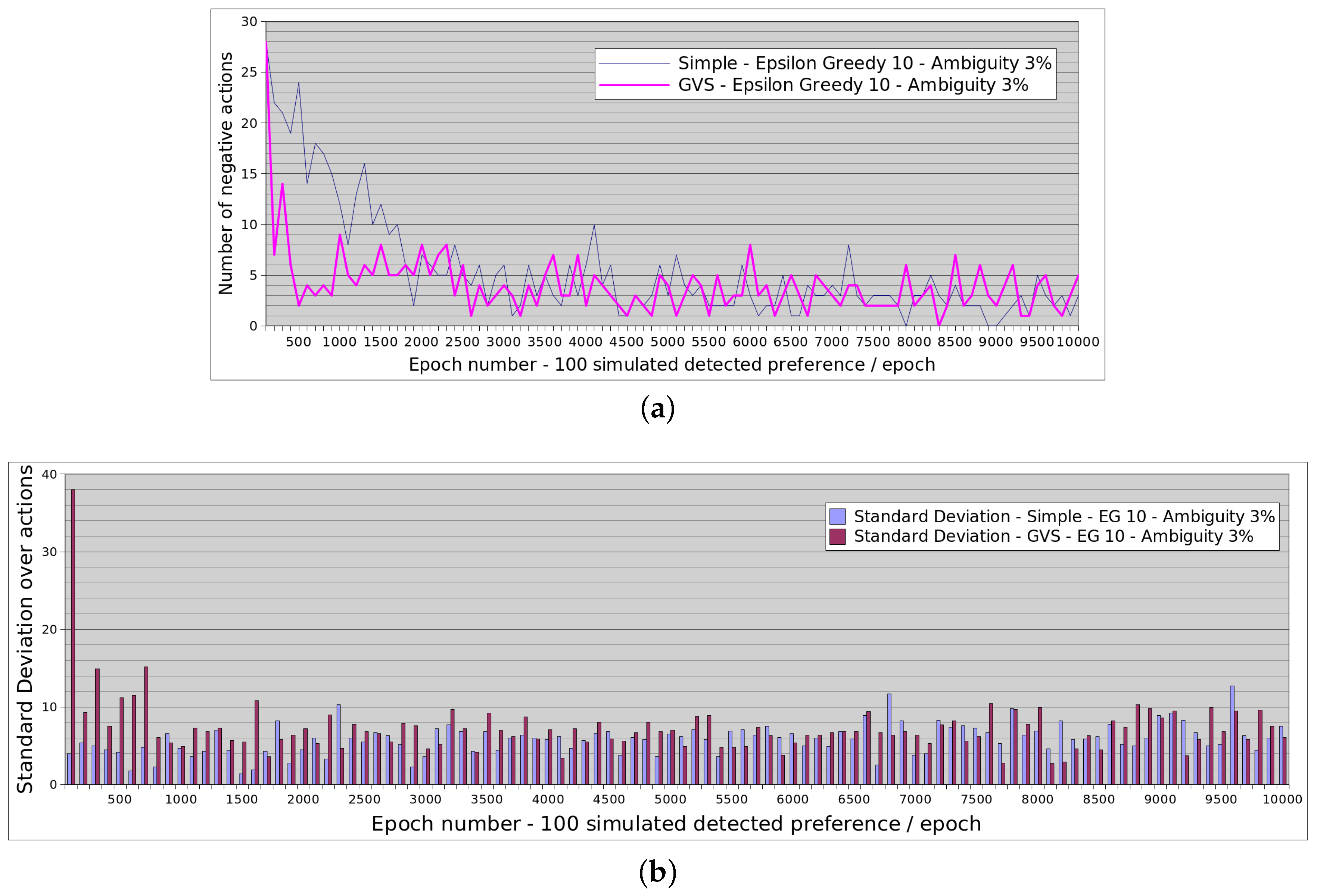
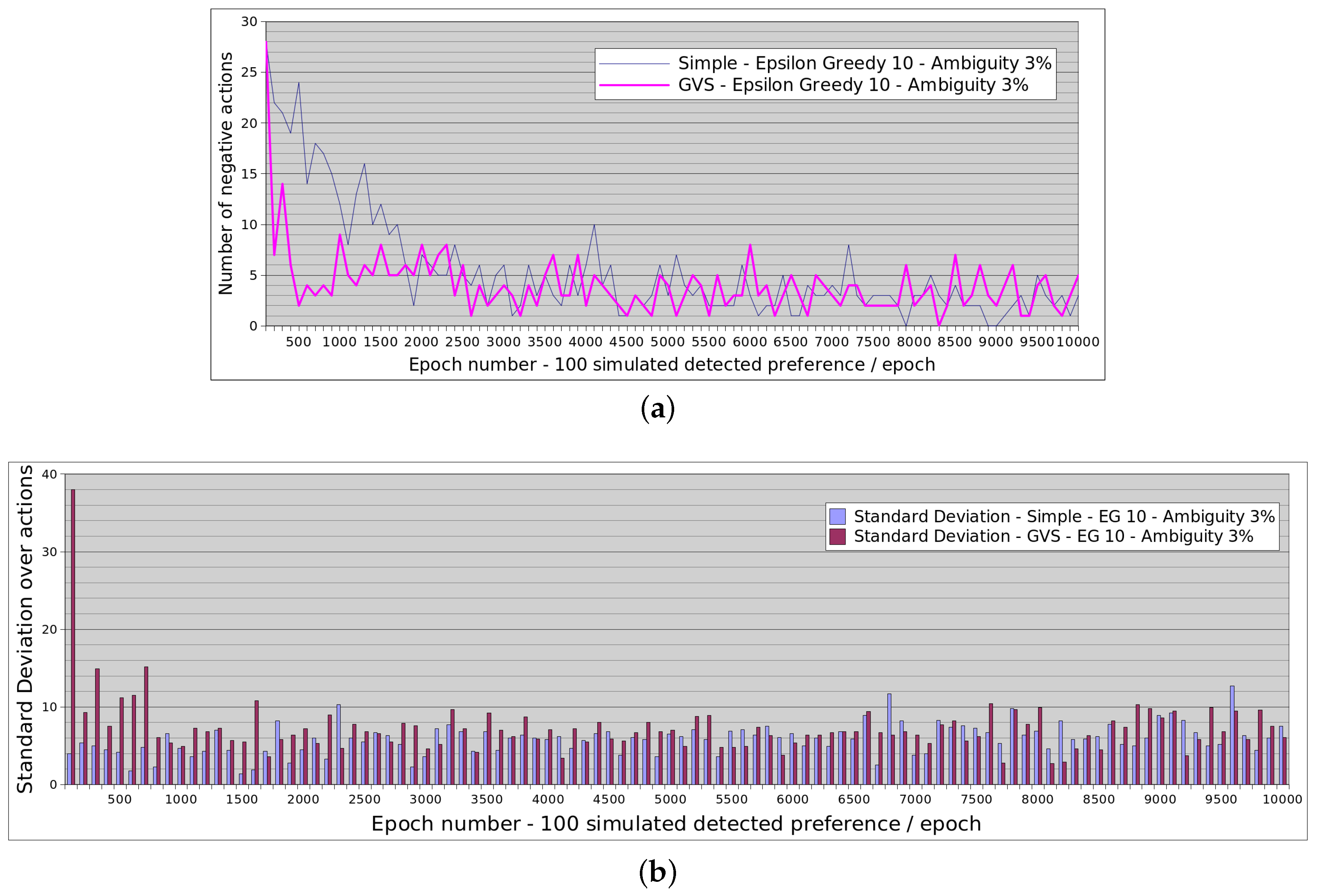
4.4. Convergence Results
5. Future Orientations
5.1. Learning and Adaptation
5.2. Experimental Design
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- GhaffarianHoseini, A.; GhaffarianHoseini, A.; Tookey, J.; Omrany, H.; Fleury, A.; Naismith, N.; Ghaffarianhoseini, M. The essence of smart homes: Application of intelligent technologies towards smarter urban future. In Handbook of Research on Creative Technologies for Multidisciplinary Applications; IGI Global: Hershey, PA, USA, 2016; Chapter 14; pp. 334–376. [Google Scholar]
- Zhu, N.; Diethe, T.; Camplani, M.; Tao, L.; Burrows, A.; Twomey, N.; Kaleshi, D.; Mirmehdi, M.; Flach, P.; Craddock, I. Bridging e-Health and the Internet of Things: The SPHERE project. IEEE Intell. Syst. 2015, 30, 39–46. [Google Scholar] [CrossRef]
- Chan, M.; Estève, D.; Escriba, C.; Campo, E. A review of smart homes—Present state and future challenges. Comput. Methods Progr. Biomed. 2008, 91, 55–81. [Google Scholar] [CrossRef] [PubMed]
- De Silva, L.C.; Morikawa, C.; Petra, I.M. State of the art of smart homes. Eng. Appl. Artif. Intell. 2012, 25, 1313–1321. [Google Scholar] [CrossRef]
- Solaimani, S.; Keijzer-Broers, W.; Bouwman, H. What we do-and don’t-know about the Smart Home: An analysis of the Smart Home literature. Indoor Built Environ. 2013. [Google Scholar] [CrossRef]
- Alam, M.R.; Reaz, M.B.I.; Ali, M.A.M. A review of smart homes—Past, present, and future. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2012, 42, 1190–1203. [Google Scholar] [CrossRef]
- Wilson, C.; Hargreaves, T.; Hauxwell-Baldwin, R. Smart homes and their users: A systematic analysis and key challenges. Pers. Ubiquitous Comput. 2014, 19, 463–476. [Google Scholar] [CrossRef]
- Vischer, J.C. The concept of environmental comfort in workplace performance. Ambient. Constr. 2007, 7, 21–34. [Google Scholar]
- Allameh, E.; Heidari Jozam, M.; Vries, B.D.; Timmermans, H.; Beetz, J. Smart Home as a smart real estate: A state-of-the-art review. In Proceedings of the 18th International Conference of European Real Estate Society, ERES 2011, Eindhoven, The Netherlands, 16–18 June 2011.
- Novitzky, P.; Smeaton, A.F.; Chen, C.; Irving, K.; Jacquemard, T.; O’Brolcháin, F.; O’Mathúna, D.; Gordijn, B. A review of contemporary work on the ethics of ambient assisted living technologies for people with Dementia. Sci. Eng. Ethics 2014, 21, 707–765. [Google Scholar] [CrossRef] [PubMed]
- Cook, D.J.; Krishnan, N.C. Activity Learning: Discovering, Recognizing, and Predicting Human Behavior from Sensor Data; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Fahad, L.G.; Ali, A.; Rajarajan, M. Learning models for activity recognition in smart homes. In Information Science and Applications; Kim, J.K., Ed.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 819–826. [Google Scholar]
- Bourobou, S.T.M.; Yoo, Y. User activity recognition in smart homes using pattern clustering applied to temporal ANN algorithm. Sensors 2015, 15, 11953–11971. [Google Scholar] [CrossRef] [PubMed]
- Mckeever, S.; Ye, J.; Coyle, L.; Bleakley, C.; Dobson, S. Activity recognition using temporal evidence theory. J. Ambient Intell. Smart Environ. 2010, 2, 253–269. [Google Scholar]
- Fleury, A.; Vacher, M.; Noury, N. SVM-based multimodal classification of activities of daily living in health smart homes: Sensors, algorithms, and first experimental results. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 274–283. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Nugent, C.D.; Wang, H. A knowledge-driven approach to activity recognition in smart homes. IEEE Trans. Knowl. Data Eng. 2012, 24, 961–974. [Google Scholar] [CrossRef]
- Duong, T.; Phung, D.; Bui, H.; Venkatesh, S. Efficient duration and hierarchical modeling for human activity recognition. Artif. Intell. 2009, 173, 830–856. [Google Scholar] [CrossRef]
- Nazerfard, E.; Das, B.; Holder, L.B.; Cook, D.J. Conditional random fields for activity recognition in smart environments. In Proceedings of the 1st ACM International Health Informatics Symposium, IHI ’10, New York, NY, USA, 11–12 November 2010; ACM: New York, NY, USA, 2010; pp. 282–286. [Google Scholar]
- Chahuara, P.; Fleury, A.; Portet, F.; Vacher, M. On-line human activity recognition from audio and home automation sensors: Comparison of sequential and non-sequential models in realistic Smart Homes. J. Ambient Intell. Smart Environ. 2016, in press. [Google Scholar]
- Hoque, E.; Stankovic, J. AALO: Activity recognition in smart homes using Active Learning in the presence of Overlapped activities. In Proceedings of the 6th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), San Diego, CA, USA, 21–24 May 2012.
- Yala, N.; Fergani, B.; Fleury, A. Feature extraction and incremental learning to improve activity recognition on streaming data. In Proceedings of the 2015 IEEE International Conference on Evolving and Adaptive Intelligent Systems (EAIS), Douai, France, 1–3 December 2015.
- Rashidi, P. Smart Home Adaptation Based on Explicit and Implicit User Feedback. Master’s Thesis, Washington State University, Pullman, WA, USA, 2007. [Google Scholar]
- Aztiria, A.; Izaguirre, A.; Basagoiti, R.; Augusto, J.C. Learning about Preferences and Common Behaviours of the User in an Intelligent Environment; Book Manufacturers’ Institue: Palm Coast, FL, USA, 2009; pp. 289–315. [Google Scholar]
- Vainio, A.M.; Valtonen, M.; Vanhala, J. Proactive fuzzy control and adaptation methods for smart homes. IEEE Intell. Syst. 2008, 23, 42–49. [Google Scholar] [CrossRef]
- Herczeg, M. The smart, the intelligent and the wise: Roles and values of interactive technologies. In Proceedings of the First International Conference on Intelligent Interactive Technologies and Multimedia, Allahabad, India, 27–30 December 2010; ACM: New York, NY, USA, 2010; pp. 17–26. [Google Scholar]
- Knox, W.B.; Stone, P. Interactively shaping agents via human reinforcement: The TAMER framework. In Proceedings of the Fifth International Conference on Knowledge Capture, K-CAP ’09, Redondo Beach, CA, USA, 1–4 September 2009; ACM: New York, NY, USA, 2009; pp. 9–16. [Google Scholar]
- Knox, W.B.; Stone, P.; Breazeal, C. Training a robot via human feedback: A case study. In Social Robotics; Springer: Berlin/Heidelberg, Germany, 2013; pp. 460–470. [Google Scholar]
- Akrour, R.; Schoenauer, M.; Sebag, M. APRIL: Active Preference-Learning Based Reinforcement Learning. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7524, pp. 116–131. [Google Scholar]
- Nick, M. Reducing the Case acquisition and maintenance bottleneck with user-feedback-driven case base maintenance. In Proceedings of the FLAIRS Conference, Melbourne Beach, FL, USA, 11–13 May 2006; pp. 376–382.
- Nick, M.; Becker, M. A hybrid approach to intelligent living assistance. In Proceedings of the 7th International Conference on Hybrid Intelligent Systems, HIS 2007, Kaiserlautern, Germany, 17–19 September 2007.
- Khalili, A.; Wu, C.; Aghajan, H. Autonomous learning of user’s preference of music and light services in smart home applications. In Proceedings of the Behavior Monitoring and Interpretation Workshop at German AI Conference, Paderborn, Germany, 15–18 September 2009.
- Gil, M.; Pelechano, V. Exploiting user feedback for adapting mobile interaction obtrusiveness. In Ubiquitous Computing and Ambient Intelligence; Springer: Berlin/Heidelberg, Germany, 2012; pp. 274–281. [Google Scholar]
- Rashidi, P.; Cook, D.J. Keeping the resident in the loop: Adapting the smart home to the user. IEEE Trans. Syst. Man Cybern. A Syst. Hum. 2009, 39, 949–959. [Google Scholar] [CrossRef]
- ZigBee. Available online: https://en.wikipedia.org/wiki/ZigBee (accessed on 14 June 2016).
- Cleobee. Available online: http://www.cleode.fr/en/produits.php?page=cleobee (accessed on 14 June 2016).
- Hockley, W.E. Analysis of response time distributions in the study of cognitive processes. J. Exp. Psychol. Learn. Mem. Cognit. 1984, 10, 598–615. [Google Scholar] [CrossRef]
- Fleury, A.; Vacher, M.; Portet, F.; Chahuara, P.; Noury, N. A french corpus of audio and multimodal interactions in a health smart home. J. Multimodal User Interfaces 2013, 7, 93–109. [Google Scholar] [CrossRef]
- Vacher, M.; Lecouteux, B.; Chahuara, P.; Portet, F.; Meillon, B.; Bonnefond, N. The Sweet-Home speech and multimodal corpus for home automation interaction. In Proceedings of the 9th Edition of the Language Resources and Evaluation Conference (LREC), Reykjavik, Iceland, 26–31 May 2014; pp. 4499–4506.
- Kaelbling, L.P.; Littman, M.L.; Cassandra, A.R. Planning and acting in partially observable stochastic domains. Artif. Intell. 1998, 101, 99–134. [Google Scholar] [CrossRef]
- Loftin, R.; MacGlashan, J.; Peng, B.; Taylor, M.E.; Littman, M.L.; Huang, J.; Roberts, D.L. A strategy-aware technique for learning behaviors from discrete human feedback. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-14), Québec City, QC, Canada, 27–31 July 2014.
- Bellman, R. A Markovian Decision Process. Indiana Univ. Math. J. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Howard, R.A. Dynamic Programming and Markov Processes; The MIT Press: Cambridge, MA, USA, 1960. [Google Scholar]
- Karami, A.B.; Sehaba, K.; Encelle, B. Adaptive artificial companions learning from users’ feedback. Adapt. Behav. 2016, 24, 69–86. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach, 2nd ed.; Pearson Education: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Langford, J.; Zhang, T. The epoch-greedy algorithm for multi-armed bandits with side information. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008; pp. 817–824.
- Isbell, C.L., Jr.; Kearns, M.; Singh, S.; Shelton, C.R.; Stone, P.; Kormann, D. Cobot in LambdaMOO: An adaptive social statistics agent. Auton. Agents Multi-Agent Syst. 2006, 13, 327–354. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | SH Dataset | HIS Corpus | ||||
|---|---|---|---|---|---|---|
| Without Unknown | With Unknown | diff. | Without Unknown | With Unknown | diff. | |
| SVM | 75.00 | 71.90 | 3.10 | 74.86 | 64.90 | 9.96 |
| Random Forest | 82.96 | 80.14 | 2.82 | 70.72 | 62.32 | 8.40 |
| MLN naive | 79.20 | 76.73 | 2.47 | 75.45 | 66.81 | 8.64 |
| HMM | 74.76 | 72.45 | 2.31 | 77.26 | 67.11 | 10.15 |
| CRF | 85.43 | 83.57 | 1.86 | 75.85 | 69.29 | 6.56 |
| MLN | 82.22 | 78.11 | 4.11 | 75.95 | 65.82 | 10.13 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karami, A.B.; Fleury, A.; Boonaert, J.; Lecoeuche, S. User in the Loop: Adaptive Smart Homes Exploiting User Feedback—State of the Art and Future Directions. Information 2016, 7, 35. https://doi.org/10.3390/info7020035
Karami AB, Fleury A, Boonaert J, Lecoeuche S. User in the Loop: Adaptive Smart Homes Exploiting User Feedback—State of the Art and Future Directions. Information. 2016; 7(2):35. https://doi.org/10.3390/info7020035
Chicago/Turabian StyleKarami, Abir B., Anthony Fleury, Jacques Boonaert, and Stéphane Lecoeuche. 2016. "User in the Loop: Adaptive Smart Homes Exploiting User Feedback—State of the Art and Future Directions" Information 7, no. 2: 35. https://doi.org/10.3390/info7020035
APA StyleKarami, A. B., Fleury, A., Boonaert, J., & Lecoeuche, S. (2016). User in the Loop: Adaptive Smart Homes Exploiting User Feedback—State of the Art and Future Directions. Information, 7(2), 35. https://doi.org/10.3390/info7020035