
Feature Engineering for Recognizing Adverse Drug Reactions from Twitter Posts




Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Preprocessing
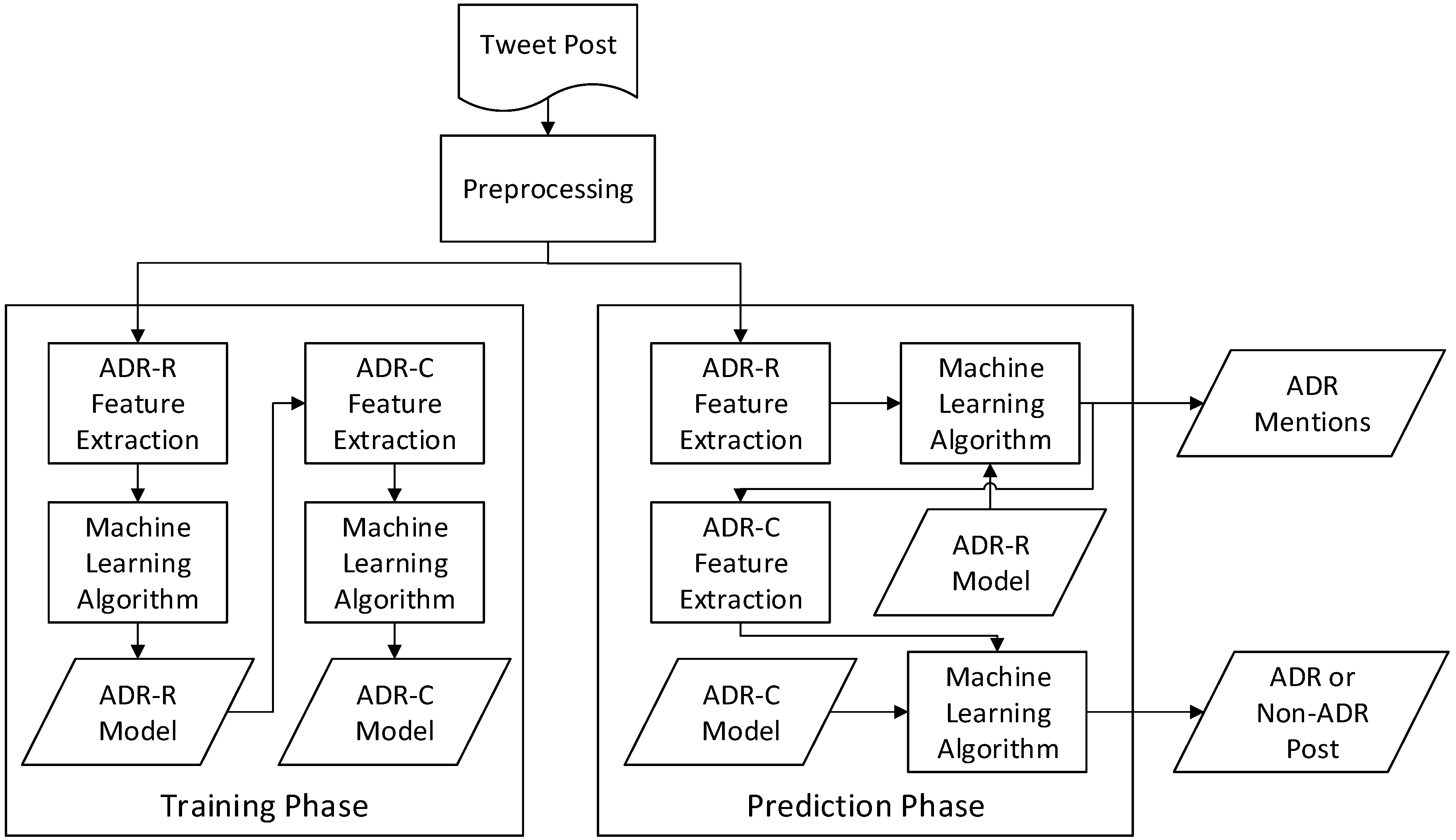
3.2. Development of the ADR Mention Recognizer
3.2.1. Machine Learning Algorithm and Formulation
3.2.2. Feature Extraction
- Contextual features: For every token, its surrounding token is referred to as its context. For a target token, its context is described as the token itself (denoted as w0) with its preceding tokens (denoted as w−n, w−n + 1, …, w−1) and its following tokens (denoted as w1, w2, …, wn). In our implementation, the contextual features were extracted for the original tokens and the spelling checked tokens. All of the tokens were transformed into more compact representation with the process of normalization and stemming. As described later in the Results section, after the feature selection procedure, the context window was set to three, including w−1, w0, and w1.
- Morphology features: The feature set represents more information extracted from the current token. In our implementation, the prefixes and the suffixes of both the normalized and the spelling checked normalized tokens were extracted as features. The lengths of the prefix/suffix features were set to 3 to 4 within one-length context window.
- PoS features: The PoS information generated by Twokenizer for every token was encoded as features.
- Lexicon features: Three lexicon features were implemented to indicate a matching between the spelling corrected tokens with the entry in a lexicon. The first lexicon feature was implemented as a binary feature to indicate whether or not the current token partially matches with an entry in a given lexicon; the second feature further combines the matched token with the first feature to create a conjunction feature. Note that the conjunct spelling checked token may not be the same as the original token used for matching. The spelling checker may generate several suggestions for a misspelled token. In our implementation, the spelling checked contextual feature always uses the first suggestion generated by the checker, which may not match with the ADR lexicon. However, in the implementation of the lexicon feature, the matching procedure will match all suggestions against the ADR lexicon until a match is found, which may result in unmatched cases. The last lexicon feature encoded a match by using the IOB scheme that represents the matched position of the current token in the employed ADR lexicon. In some circumstances, especially when the post contains unique symbols such as hashtagged terms and nonstandard compound words, the spelling checker used in this study could decompose the tokens from the compound words. For example, “cant sleep” will be decomposed from the compound word “cantsleep”. Each of the token will be matched with all of the entries in a lexicon. The ADR lexicon created by Leaman et al. [37] was employed as the lexicon for matching ADR terms. The sources of the lexicon include the UMLS Metathesaurus [38], the SIDER side effect resource [39], and other databases. The tokens annotated with the “Drug” tag were collected to form the lexicon for drugs. Take the Twitter post “Seroquel left me with sleep paralysis” as an example. The compound noun “sleep paralysis” matched with the ADR lexicon and their corresponding feature values are listed as follows.
- ○
- Binary: 1, 1.
- ○
- Conjunction: sleep/1, paralysis/1.
- ○
- IOB: B-ADR, I-ADR.
- Word representation feature: The large unlabeled data from the Twitter website was utilized to generate word clusters for all of the unique tokens with the vector representation method [30]. The feature value for a token is then assigned based on its associated cluster number. If the current token does not have a corresponding cluster, its normalized and stemmed result will be used. The feature adds a high level abstraction by assigning the same cluster number to similar tokens. In order to create the unlabeled data, we searched the Twitter website for a predefined query to collect 7 days of tweets including 97,249 posts. The query was compiled by collecting each of the entries listed in the lexicon used for generating the lexicon feature, the described ADRs, their related drugs collected from the training set of the SMM shared task, as well as the hashtags annotated as ADRs in the training set. The final query contains 14,608 unique query terms. After the query was defined, the Twitter REST API was used to search for Twitter posts related to the collected ADR-drug pairs and hashtagged terms. Afterwards, Twokenizer was used on the collected dataset to generate tokens. The word2vec toolkit (open source tool, https://code.google.com/archive/p/word2vec/) was then used to learn a vector representation for all tokens based on their contexts in different tweets. The neural network behind the toolkit was set to use the continuous bag of words scheme, which can predict the word given its context. In our implementation, the size of context window was set to 5 with 200 dimension, and a total of 200 clusters were generated.
3.3. Development of the ADR Post Classifier
3.3.1. Machine Learning Algorithm
3.3.2. Feature Extraction
- Linguistic features: We extracted common linguistic information like bag of words, bigrams, trigrams, PoS tags, token-PoS pairs, and noun phrases as features.
- Polarity features: The polarity cues developed by Niu et al. [40] were implemented to extract four binary features that can be categorized as “more-good”, “less-good”, “more-bad”, and “less-bad”. The categories are inferred based on the presence of polarity keywords in a tweet, which were then encoded as binary features for a tweet. For example, considering the tweet “could you please address evidence abuutcymbalta being less effective than TCAs”, the value of the feature “less good” would be 1 and the rest would take the value 0 because the token “less” and “effective” matched with the “less-good” polarity cue.
- Lexicon based features: The features were generated by using the recognition results of a string matching algorithm combined with the developed ADR mention recognizer. Tweets were processed to find exact matches of lexical entries from the existing ADR and drug name lexicons [18]. The presence of lexical entries were engineered as two binary features with the value of either 0 or 1. For example, in the Twitter post “Antipsychotic drugs such as Zyprexa, Risperdal & Seroquel place the elderly at increased risk of strokes & death”, both the ADR and the drug name lexical features take the value of 1.
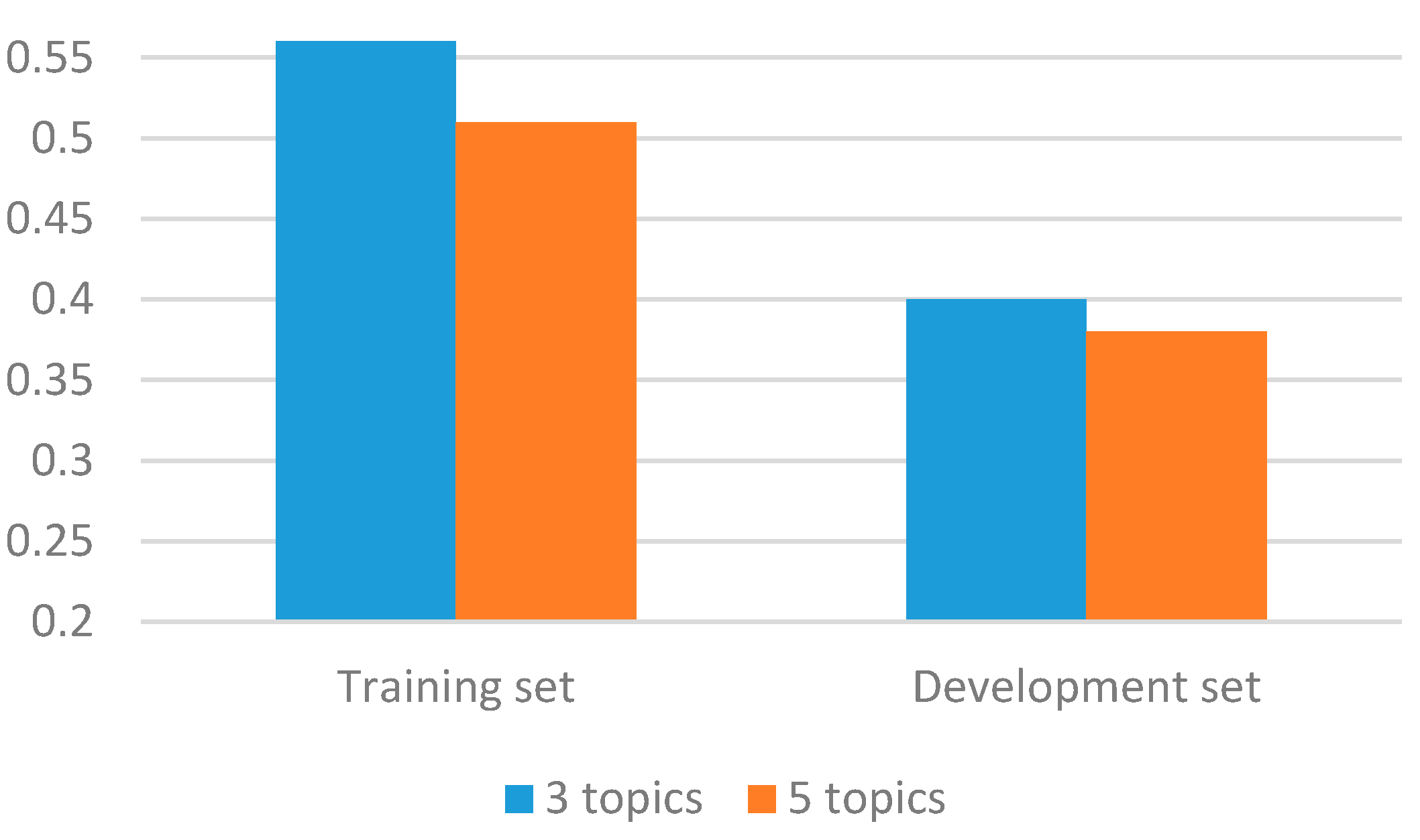
- Topic modeling features: In our system, the topic distribution weights per tweet were extracted as features. The Stanford Topic Modelling Toolbox (version 0.4, The Stanford NLP Group, Stanford, CA, USA, http://nlp.stanford.edu/software/tmt/tmt-0.4/) was used to extract these features. The number of features depends on the number of topics to be obtained from the dataset. For example, if the topic model is configured to extract five topics, then the weights corresponding to the five topics are represented as the topic modeling features.
3.4. Dataset
- Drug: A medicine or other substance which has a physical effect when ingested or otherwise introduced into the body. For example, “citalopram”, “lexapro”, and “nasal spray”.
- Indication: A specific circumstance that indicates the advisability of a special medical treatment or method to describe the reason to use the drug. For example, “anti-depressant”, “arthritis”, and “autoimmune disease”.
- ADR: A harmful or unpleasant reaction to the use of a drug. For instance, Warfarin (Coumadin, Jantoven) is used to prevent blood clots and is usually well tolerated, but a serious internal hemorrhage may occur. Therefore, the occurrence of serious internal bleeding is an ADR for Warfarin.
3.5. Evaluation Scheme
4. Results
4.1. Feature Engineering for the ADR Mention Recognizer
4.1.1. Local Contextual Features
4.1.2. External Knowledge Features
4.1.3. Word Representation Features
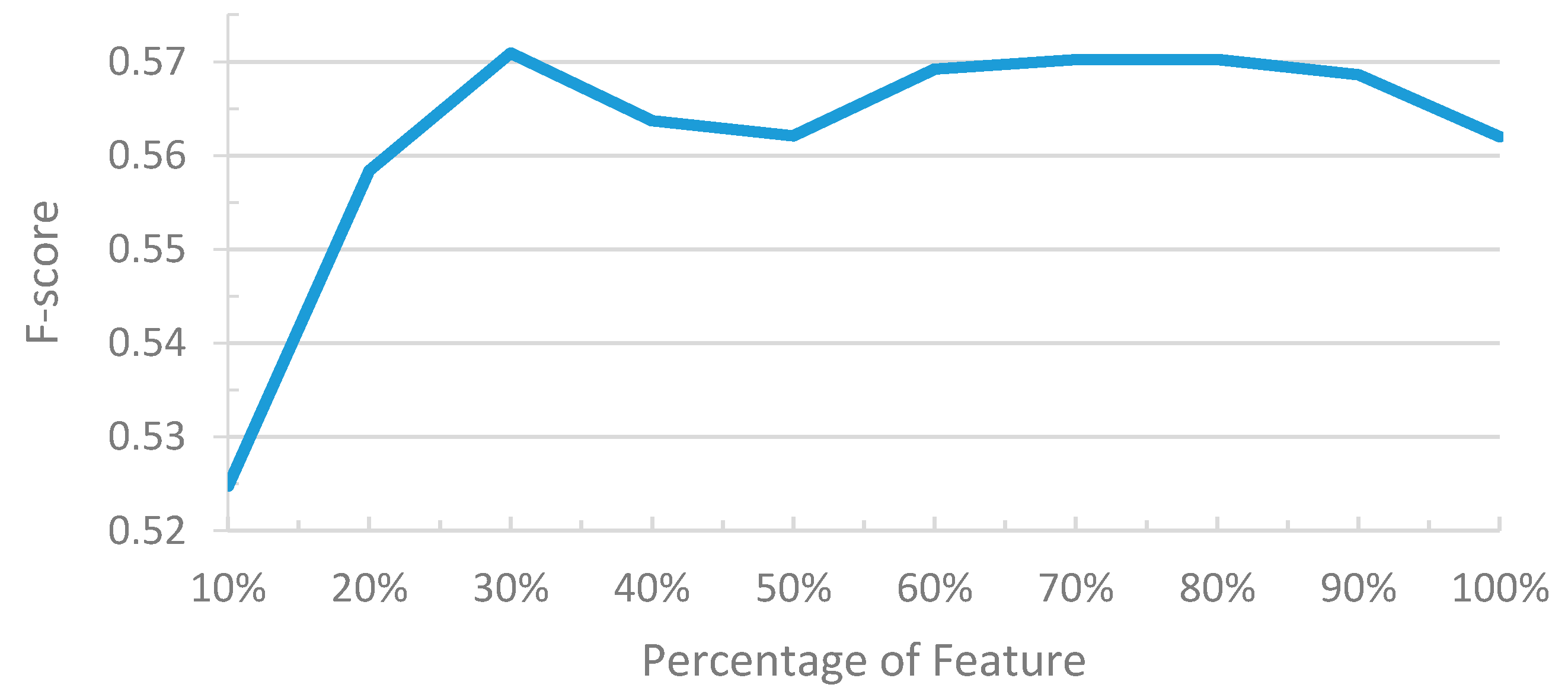
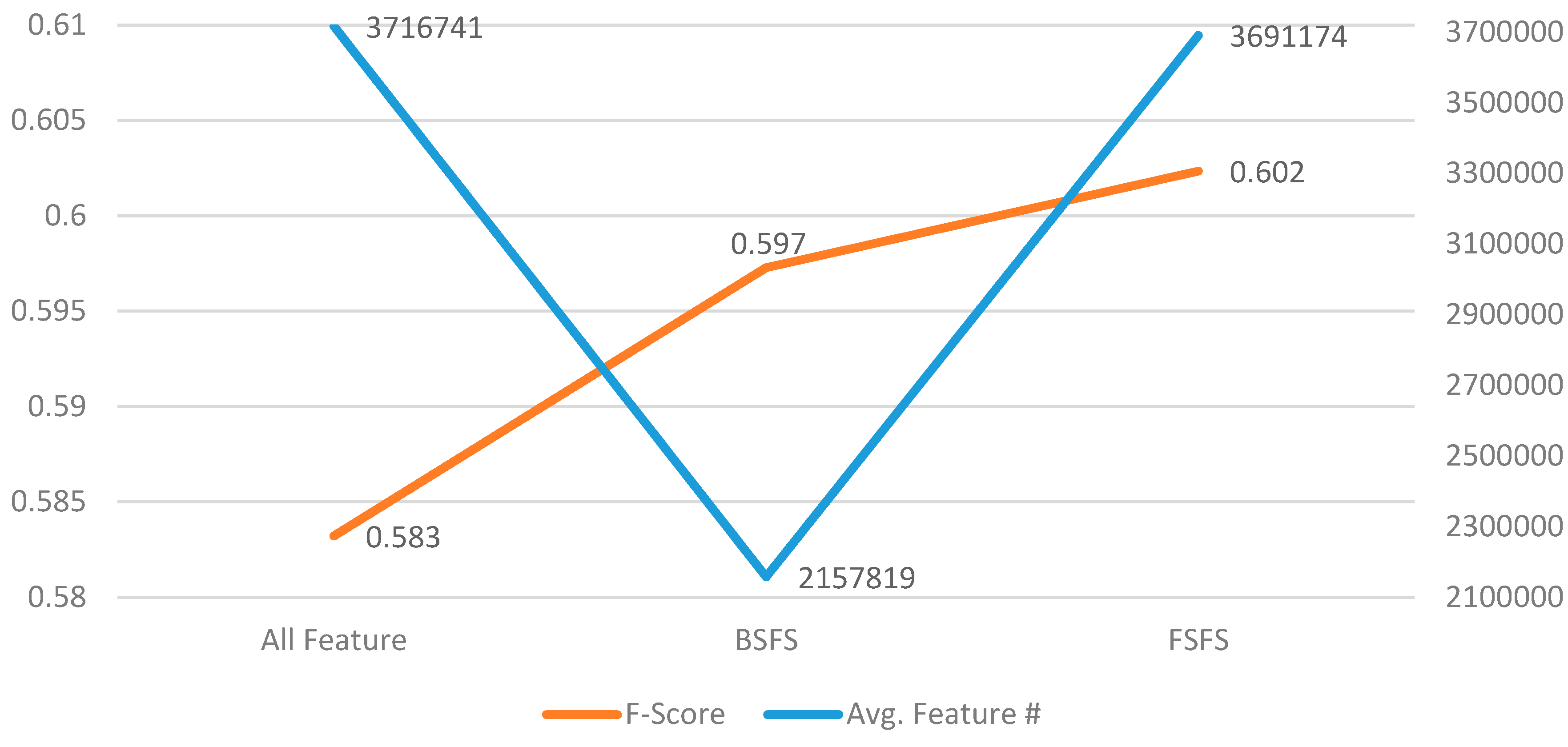
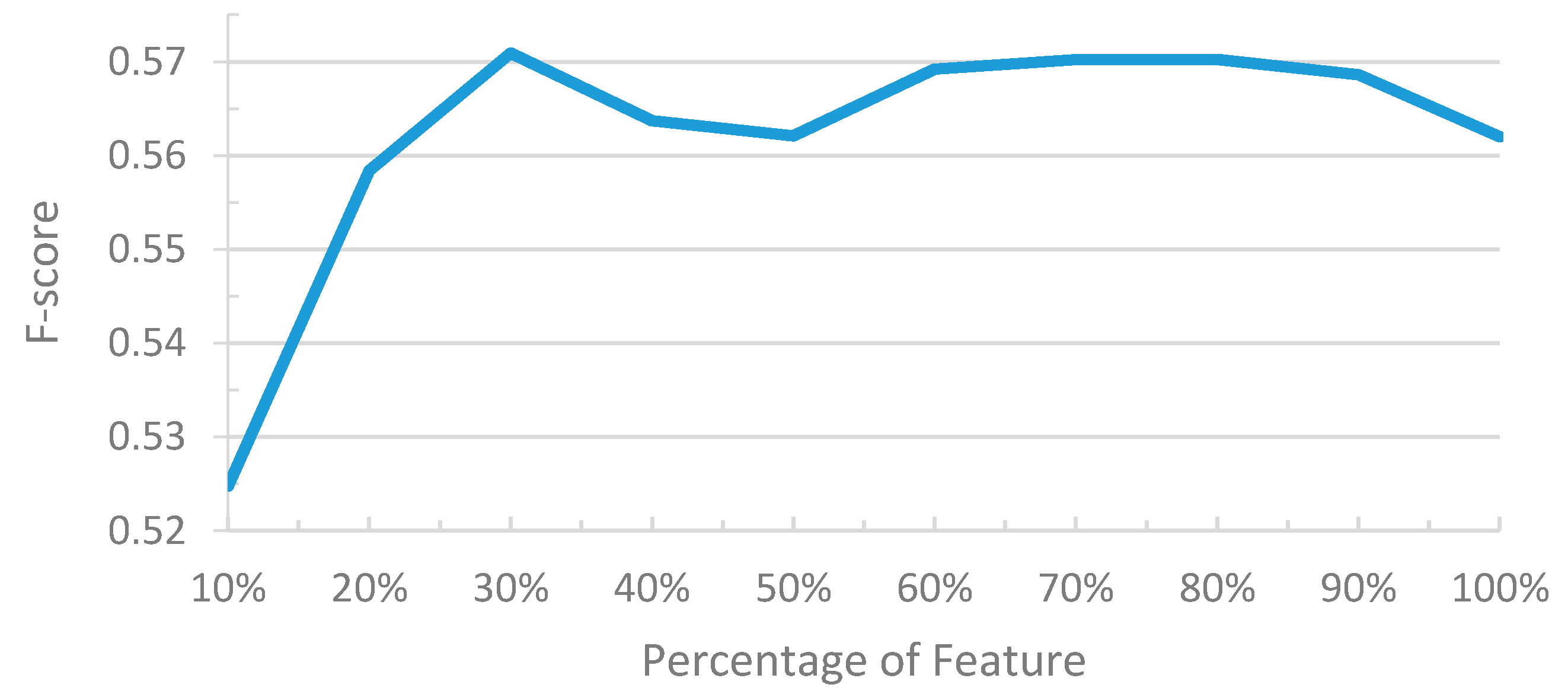
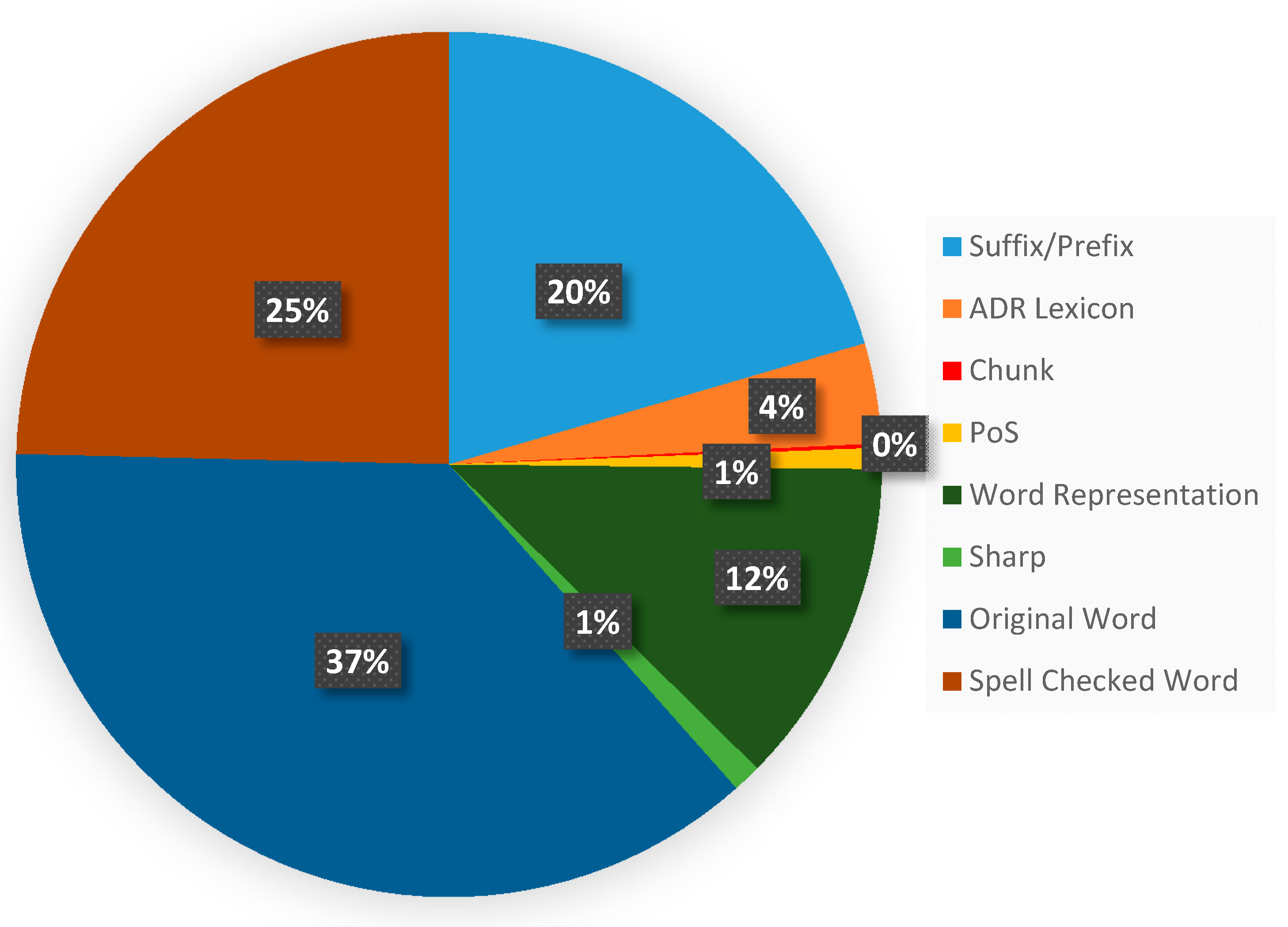
4.1.4. Backward/Forward Sequential Feature Selection Results
4.2. Performance of the ADR Post Classifier
4.3. Availability
5. Discussion
5.1. ADR Mention Recognition
5.2. ADR Post Classification
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| ADR | Adverse Drug Reaction |
| BSFS | Backward Sequential Feature Selection |
| CRF | Conditional Random Field |
| F | F-measure |
| FN | False Negative |
| FP | False Positive |
| FSFS | Forward Sequential Feature Selection |
| NER | Name Entity Recognition |
| NLP | Natural Language Processing |
| OOV | Out-Of-Vocabulary |
| P | Precision |
| PSB | Pacific Symposium on Biocomputing |
| PoS | Part of Speech |
| R | Recall |
| SMM | Social Media Mining |
| SVM | Support Vector Machine |
| TP | True Positive |
| UMLS | Unified Medical Language System |
References
- Lardon, J.; Abdellaoui, R.; Bellet, F.; Asfari, H.; Souvignet, J.; Texier, N.; Jaulent, M.C.; Beyens, M.N.; Burgun, A.; Bousquet, C. Adverse Drug Reaction Identification and Extraction in Social Media: A Scoping Review. J. Med. Internet Res. 2015, 17, e171. [Google Scholar] [CrossRef] [PubMed]
- Sarker, A.; Ginn, R.; Nikfarjam, A.; O’Connor, K.; Smith, K.; Jayaraman, S.; Upadhaya, T.; Gonzalez, G. Utilizing social media data for pharmacovigilance: A review. J. Biomed. Inform. 2015, 54, 202–212. [Google Scholar] [CrossRef] [PubMed]
- Blenkinsopp, A.; Wilkie, P.; Wang, M.; Routledge, P.A. Patient reporting of suspected adverse drug reactions: a review of published literature and international experience. Br. J. Clin. Pharmacol. 2007, 63, 148–156. [Google Scholar] [CrossRef] [PubMed]
- Cieliebak, M.; Egger, D.; Uzdilli, F. Twitter can Help to Find Adverse Drug Reactions. Available online: http://ercim-news.ercim.eu/en104/special/twitter-can-help-to-find-adverse-drug-reactions (accessed on 20 May 2016).
- Benton, A.; Ungar, L.; Hill, S.; Hennessy, S.; Mao, J.; Chung, A.; Leonard, C.E.; Holmes, J.H. Identifying potential adverse effects using the web: A new approach to medical hypothesis generation. J. Biomed. Inform. 2011, 44, 989–996. [Google Scholar] [CrossRef] [PubMed]
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning (ICML), Williamstown, MA, USA, 28 June 2001.
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Liu, S.; Tang, B.; Chen, Q.; Wang, X.; Fan, X. Feature engineering for drug name recognition in biomedical texts: Feature conjunction and feature selection. Comput. Math. Methods Med. 2015, 2015, 913489. [Google Scholar] [CrossRef] [PubMed]
- Dai, H.J.; Lai, P.T.; Chang, Y.C.; Tsai, R.T. Enhancing of chemical compound and drug name recognition using representative tag scheme and fine-grained tokenization. J. Cheminform. 2015, 7, S14. [Google Scholar] [CrossRef] [PubMed]
- Tkachenko, M.; Simanovsky, A. Named entity recognition: Exploring features. In Proceedings of The 11th Conference on Natural Language Processing (KONVENS 2012), Vienna, Austria, 19–21 September 2012; pp. 118–127.
- Gui, Y.; Gao, Z.; Li, R.; Yang, X. Hierarchical Text Classification for News Articles Based-on Named Entities. In Advanced Data Mining and Applications, Proceedings of the 8th International Conference, ADMA 2012, Nanjing, China, 15–18 December 2012; Zhou, S., Zhang, S., Karypis, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 318–329. [Google Scholar]
- Tsai, R.T.-H.; Hung, H.-C.; Dai, H.-J.; Lin, Y.-W. Protein-protein interaction abstract identification with contextual bag of words. In Proceedings of the 2nd International Symposium on Languages in Biology and Medicine (LBM 2007), Singapore, 6–7 December 2007.
- Sarker, A.; Nikfarjam, A.; Gonzalez, G. Social media mining shared task workshop. In Proceedings of the Pacific Symposium on Biocomputing 2016, Big Island, HI, USA, 4–8 January 2016.
- Gimpel, K.; Schneider, N.; O’Connor, B.; Das, D.; Mills, D.; Eisenstein, J.; Heilman, M.; Yogatama, D.; Flanigan, J.; Smith, N.A. Part-of-speech tagging for Twitter: Annotation, features, and experiments. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011.
- Ritter, A.; Clark, S.; Etzioni, O. Named entity recognition in tweets: an experimental study. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011.
- Finkel, J.R.; Grenager, T.; Manning, C. Incorporating non-local information into information extraction systems by Gibbs sampling. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005.
- Eisenstein, J. What to do about bad language on the internet. In Proceedings of the North American Chapter of the Association for Computational Linguistics (NAACL), Atlanta, GA, USA, 9–15 June 2013.
- Nikfarjam, A.; Sarker, A.; O’Connor, K.; Ginn, R.; Gonzalez, G. Pharmacovigilance from social media: Mining adverse drug reaction mentions using sequence labeling with word embedding cluster features. J. Am. Med. Inform. Assoc. 2015, 22, 671–681. [Google Scholar] [CrossRef] [PubMed]
- Harpaz, R.; DuMochel, W.; Shah, N.H. Big Data and Adverse Drug Reaction Detection. Clin. Pharmacol. Ther. 2016, 99, 268–270. [Google Scholar] [CrossRef] [PubMed]
- Dai, H.-J.; Syed-Abdul, S.; Chen, C.-W.; Wu, C.-C. Recognition and Evaluation of Clinical Section Headings in Clinical Documents Using Token-Based Formulation with Conditional Random Fields. BioMed Res. Int. 2015. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Yang, Z.; Lin, H.; Li, Y. Drug name recognition in biomedical texts: A machine-learning-based method. Drug Discov. Today 2014, 19, 610–617. [Google Scholar] [CrossRef] [PubMed]
- Kazama, J.I.; Torisawa, K. Exploiting Wikipedia as external knowledge for named entity recognition. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Prague, Czech Republic, 28–30 June 2007; pp. 698–707.
- Zhang, T.; Johnson, D. A robust risk minimization based named entity recognition system. In Proceedings of the Seventh Conference on Natural language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May–1 June 2003.
- Tsai, R.T.-H.; Sung, C.-L.; Dai, H.-J.; Hung, H.-C.; Sung, T.-Y.; Hsu, W.-L. NERBio: Using selected word conjunctions, term normalization, and global patterns to improve biomedical named entity recognition. BMC Bioinform. 2006, 7, S11. [Google Scholar] [CrossRef] [PubMed]
- Cohen, W.W.; Sarawagi, S. Exploiting dictionaries in named entity extraction: combining semi-Markov extraction processes and data integration methods. In Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004.
- Turian, J.; Ratinov, L.; Bengio, Y. Word representations: A simple and general method for semi-supervised learning. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 384–394.
- Brown, P.F.; de Souza, P.V.; Mercer, R.L.; Pietra, V.J.D.; Lai, J.C. Class-based n-gram models of natural language. Comput. Linguist. 1992, 18, 467–479. [Google Scholar]
- Ratinov, L.; Roth, D. Design challenges and misconceptions in named entity recognition. In Proceedings of the 19th Conference on Computational Natural Language Learning, Boulder, CO, USA, 4–5 June 2009.
- Lin, W.-S.; Dai, H.-J.; Jonnagaddala, J.; Chang, N.-W.; Jue, T.R.; Iqbal, U.; Shao, J.Y.-H.; Chiang, I.J.; Li, Y.-C. Utilizing Different Word Representation Methods for Twitter Data in Adverse Drug Reactions Extraction. In Proceedings of the 2015 Conference on Technologies and Applications of Artificial Intelligence (TAAI), Tainan, Taiwan, 20–22 November 2015.
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of Advances in Neural Information Processing Systems (NIPS 2013), Lake Taheo, NV, USA, 5–10 December 2013; pp. 3111–3119.
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; Volume 12, pp. 1532–1543.
- Yates, A.; Goharian, N.; Frieder, O. Extracting Adverse Drug Reactions from Social Media. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence (AAAI-15), Austin, TX, USA, 25–30 Jaunary 2015; pp. 2460–2467.
- Sarker, A.; Gonzalez, G. Portable automatic text classification for adverse drug reaction detection via multi-corpus training. J. Biomed. Inform. 2015, 53, 196–207. [Google Scholar] [CrossRef] [PubMed]
- Sarker, A.; O’Connor, K.; Ginn, R.; Scotch, M.; Smith, K.; Malone, D.; Gonzalez, D. Social Media Mining for Toxicovigilance: Automatic Monitoring of Prescription Medication Abuse from Twitter. Drug Saf. 2016, 39, 231–240. [Google Scholar] [CrossRef] [PubMed]
- Paul, M.J.; Dredze, M. You Are What You Tweet: Analyzing Twitter for Public Health. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media (ICWSM-11), Barcelona, Spain, 17–21 July 2011.
- Owoputi, O.; O’Connor, B.; Dyer, C.; Gimpel, K.; Schneider, N.; Smith, N.A. Improved part-of-speech tagging for online conversational text with word clusters. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics, Atlanta, GA, USA, 9–14 June 2013.
- Leaman, R.; Wojtulewicz, L.; Sullivan, R.; Skariah, A.; Yang, J.; Gonzalez, G. Towards internet-age pharmacovigilance: extracting adverse drug reactions from user posts to health-related social networks. In Proceedings of the 2010 Workshop on Biomedical Natural Language Processing, Uppsala, Sweden, 15 July 2010; pp. 117–125.
- Bodenreider, O. The unified medical language system (UMLS): Integrating biomedical terminology. Nucleic Acids Res. 2004, 32, D267–D270. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, M.; Campillos, M.; Letunic, I.; Jensen, L.J.; Bork, P. A side effect resource to capture phenotypic effects of drugs. Mol. Syst. Biol. 2010, 6. [Google Scholar] [CrossRef] [PubMed]
- Niu, Y.; Zhu, X.; Li, J.; Hirst, G. Analysis of Polarity Information in Medical Text. AMIA Ann. Symp. Proc. 2005, 2005, 570–574. [Google Scholar]
- Tsai, R.T.-H.; Wu, S.-H.; Chou, W.-C.; Lin, C.; He, D.; Hsiang, J.; Sung, T.-Y.; Hsu, W.-L. Various criteria in the evaluation of biomedical named entity recognition. BMC Bioinform. 2006, 7. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.-D.; Ohta, T.; Tsuruoka, Y.; Tateisi, Y. Introduction to the bio-entity recognition task at JNLPBA. In Proceedings of the International Workshop on Natural Language Processing in Biomedicine and its Applications (JNLPBA-04), Geneva, Switzerland, 28–29 August 2004; pp. 70–75.
- Tsuruoka, Y.; Tateishi, Y.; Kim, J.D.; Ohta, T.; McNaught, J.; Ananiadou, S.; Tsujii, J.I. Developing a robust part-of-speech tagger for biomedical text. In Advances in Informatics, Proceedings of the 10th Panhellenic Conference on Informatics, PCI 2005, Volas, Greece, 11–13 November 2005; Bozanis, P., Houstis, E.N., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2005; Volume 3746, pp. 382–392. [Google Scholar]
- Aha, D.W.; Bankert, R.L. A comparative evaluation of sequential feature selection algorithms. In Learning from Data: Artificial Intelligence and Statistics V; Fisher, D., Lenz, H.-J., Eds.; Springer: New York, NY, USA, 1995; pp. 199–206. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Klinger, R.; Friedrich, C.M. Feature Subset Selection in Conditional Random Fields for Named Entity Recognition. In Proceedings of the International Conference RANLP 2009, Borovets, Bulgaria, 14–16 September 2009.
- Brody, S.; Diakopoulos, N. Cooooooooooooooollllllllllllll!!!!!!!!!!!!!!: Using word lengthening to detect sentiment in microblogs. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–29 July 2011.
- Wang, C.-K.; Singh, O.; Dai, H.-J.; Jonnagaddala, J.; Jue, T.R.; Iqbal, U.; Su, E.C.-Y.; Abdul, S.S.; Li, J.Y.-C. NTTMUNSW system for adverse drug reactions extraction in Twitter data. In Proceedings of the Social Media Mining Shared Task Workshop at the Pacific Symposium on Biocomputing, Big Island, HI, USA, 4–8 January 2016.
- Lai, S.; Liu, K.; Xu, L.; Zhao, J. How to Generate a Good Word Embedding? 2015; arXiv:1507.05523. [Google Scholar]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. In IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews; IEEE: New York, NY, USA, 2012; Volume 42, pp. 463–484. [Google Scholar]
- Jonnagaddala, J.; Dai, H.-J.; Ray, P.; Liaw, S.-T. A preliminary study on automatic identification of patient smoking status in unstructured electronic health records. ACL-IJCNLP 2015, 2015, 147–151. [Google Scholar]
- Jonnagaddala, J.; Jue, T.R.; Dai, H.-J. Binary classification of Twitter posts for adverse drug reactions. In Proceedings of the Social Media Mining Shared Task Workshop at the Pacific Symposium on Biocomputing, Big Island, HI, USA, 4–8 January 2016.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Precision | Recall | F-Measure |
|---|---|---|---|
| (1) w0 | 0.219 | 0.423 | 0.289 |
| (2) w0 (Normalized) | 0.261 | 0.418 | 0.321 |
| (3) w0 (Normalized + Stemmed) | 0.353 | 0.429 | 0.387 |
| (4) (3) + w−1, w1 (Normalized + Stemmed) | 0.743 | 0.377 | 0.500 |
| (5) (4) + w−2, w2 (Normalized + Stemmed) | 0.791 | 0.353 | 0.489 |
| (6) (5) + w−3, w3 (Normalized + Stemmed) | 0.790 | 0.322 | 0.457 |
| (7) (4) + w−1/w0, w0/w1(Normalized + Stemmed) 1 | 0.810 | 0.358 | 0.496 |
| (8) (3) + Prefix0, Suffix0 2 | 0.629 | 0.441 | 0.518 |
| (9) (4) + Prefix0, Suffix0 2 | 0.735 | 0.451 | 0.559 |
| (10) (4) + Shape0 | 0.793 | 0.356 | 0.491 |
| Configuration | P | R | F |
|---|---|---|---|
| (1) w0 (Normalized) | 0.261 | 0.418 | 0.321 |
| (2) w0 (Normalized + Spelling Checked) | 0.277 | 0.418 | 0.333 |
| (3) w0 (Normalized + Stemmed) | 0.353 | 0.429 | 0.387 |
| (4) w0 (Normalized + SpellingChecked + Stemmed) | 0.377 | 0.439 | 0.406 |
| (5) (3) + w−1, w1 (Normalized + Stemmed) | 0.743 | 0.377 | 0.500 |
| (6) (4) + w−1, w1 (Normalized + SpellingChecked + Stemmed) | 0.718 | 0.368 | 0.487 |
| (7) (5) + (4) | 0.729 | 0.426 | 0.538 |
| (8) (6) + (3) | 0.734 | 0.436 | 0.547 |
| (9) (8) + w−2, w2 (Normalized + SpellingChecked + Stemmed) | 0.728 | 0.420 | 0.532 |
| (10) (8) + w−1/w0, w0/w1 (Normalized + Stemmed) | 0.792 | 0.391 | 0.524 |
| (11) (7) + Prefix0, Suffix0 (Normalized+Stemmed) | 0.720 | 0.448 | 0.552 |
| (12) (8) + Prefix0, Suffix0 (Normalized + SpellingChecked + Stemmed) | 0.752 | 0.480 | 0.586 |
| (13) (7) + Shape0 | 0.802 | 0.402 | 0.535 |
| Configuration | P | R | F |
|---|---|---|---|
| (1) w0 (Normalized + SpellingChecked + Stemmed) | 0.377 | 0.439 | 0.406 |
| (2) (1) + PoSGENIATagger0 | 0.784 | 0.295 | 0.428 |
| (3) (1) + PoSTwokenizer0 | 0.781 | 0.326 | 0.460 |
| (4) (1) + w−1, w1 (Normalized + SpellingChecked + Stemmed) | 0.718 | 0.368 | 0.487 |
| (5) (4) + PoSGENIATagger0 | 0.794 | 0.331 | 0.467 |
| (6) (4) + PoSTwokenizer0 | 0.809 | 0.364 | 0.502 |
| (7) (6) + w−2, w2 (Normalized + SpellingChecked + Stemmed) | 0.833 | 0.346 | 0.489 |
| Configuration | P | R | F |
|---|---|---|---|
| (1) w0 (Normalized + SpellingChecked + Stemmed) | 0.377 | 0.439 | 0.406 |
| (2) (1) + Chunking0 | 0.784 | 0.301 | 0.435 |
| (3) (1) + w−1, w1 (Normalized + SpellingChecked + Stemmed) | 0.718 | 0.368 | 0.487 |
| (4) (3) + Chunking0 | 0.798 | 0.332 | 0.469 |
| (5) (3) + w0 (Normalized + Stemmed) | 0.734 | 0.436 | 0.547 |
| (6) (5) + Chunking0 | 0.815 | 0.377 | 0.516 |
| Configuration | P | R | F |
|---|---|---|---|
| (1) w0 (Normalized + SpellingChecked + Stemmed) | 0.377 | 0.439 | 0.406 |
| (2) (1) + ADR Lexicon-BIO0 | 0.764 | 0.370 | 0.498 |
| (3) (1) + ADR Lexicon-Binary0 | 0.773 | 0.323 | 0.456 |
| (4) (1) + ADR Lexicon-Binary0/Matched Token | 0.684 | 0.403 | 0.507 |
| (5) (1) + w−1, w1 (Normalized + SpellingChecked + Stemmed) | 0.718 | 0.368 | 0.487 |
| (6) (5) + ADR Lexicon-BIO0 | 0.747 | 0.409 | 0.529 |
| (7) (5) + ADR Lexicon-Binary0 | 0.771 | 0.349 | 0.480 |
| (8) (5) + ADR Lexicon-Binary0/Matched Spelling Checked Token | 0.715 | 0.392 | 0.507 |
| Configuration | P | R | F |
|---|---|---|---|
| (1) w0 (Normalized + SpellingChecked + Stemmed) | 0.377 | 0.439 | 0.406 |
| (2) (1) + Word Representation0 | 0.463 | 0.380 | 0.418 |
| (3) (1) + w−1, w1 (Normalized + SpellingChecked + Stemmed) | 0.718 | 0.368 | 0.487 |
| (4) (3) + Word Representation0 | 0.748 | 0.397 | 0.519 |
| (5) (3) + w−2, w2 (Normalized + SpellingChecked + Stemmed) | 0.785 | 0.352 | 0.486 |
| (6) (5) + Word Representation0 | 0.782 | 0.377 | 0.509 |
| Entity Type | Our Recognizer (All Features) | Our Recognizer (After Feature Selection) | Baseline System | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | P | R | F | |
| Indication | 0.600 | 0.120 | 0.200 | 0.667 | 0.160 | 0.258 | 0.000 | 0.008 | 0.000 |
| Drug | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| ADR | 0.797 | 0.490 | 0.606 | 0.800 | 0.521 | 0.631 | 0.670 | 0.394 | 0.496 |
| Overall | 0.789 | 0.437 | 0.562 | 0.788 | 0.469 | 0.588 | 0.392 | 0.579 | 0.466 |
| Configuration | P | R | F |
|---|---|---|---|
| (1) Baseline Feature Set | 0.37 | 0.31 | 0.34 |
| (2) 1 + Topic Modeling Features | 0.43 | 0.38 | 0.40 |
| Feature |
|---|
| w−1, w0,w1 (Normalized + Stemmed) |
| w0 (Normalized + Spelling Checked + Stemmed) |
| Prefix0, Suffix0 (Normalized + Stemmed) |
| Prefix0, Suffix0 (Normalized + Spelling Checked + Stemmed) |
| PoSTwokenizer0 |
| ADR Lexicon-BIO0 |
| Word Representation0 |
| Configuration | Precision | Recall | F-Measure |
|---|---|---|---|
| (1) With the Original 200 Clusters | 0.788 | 0.469 | 0.5876 |
| (2) With Nikfarjam et al.’s 150 Clusters | 0.776 | 0.469 | 0.5843 |
| (3) With Pennington et al.’s Vectors (150 Clusters) | 0.771 | 0.455 | 0.5722 |
| (4) With Pennington et al.’s Vectors (200 Clusters) | 0.767 | 0.460 | 0.5746 |
| (5) With Pennington et al.’s Vectors (400 Clusters) | 0.779 | 0.478 | 0.5922 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, H.-J.; Touray, M.; Jonnagaddala, J.; Syed-Abdul, S. Feature Engineering for Recognizing Adverse Drug Reactions from Twitter Posts. Information 2016, 7, 27. https://doi.org/10.3390/info7020027
Dai H-J, Touray M, Jonnagaddala J, Syed-Abdul S. Feature Engineering for Recognizing Adverse Drug Reactions from Twitter Posts. Information. 2016; 7(2):27. https://doi.org/10.3390/info7020027
Chicago/Turabian StyleDai, Hong-Jie, Musa Touray, Jitendra Jonnagaddala, and Shabbir Syed-Abdul. 2016. "Feature Engineering for Recognizing Adverse Drug Reactions from Twitter Posts" Information 7, no. 2: 27. https://doi.org/10.3390/info7020027
APA StyleDai, H.-J., Touray, M., Jonnagaddala, J., & Syed-Abdul, S. (2016). Feature Engineering for Recognizing Adverse Drug Reactions from Twitter Posts. Information, 7(2), 27. https://doi.org/10.3390/info7020027