
A Big Network Traffic Data Fusion Approach Based on Fisher and Deep Auto-Encoder


Abstract
:1. Introduction
2. Related Work
3. Preliminaries
3.1. Fisher Score
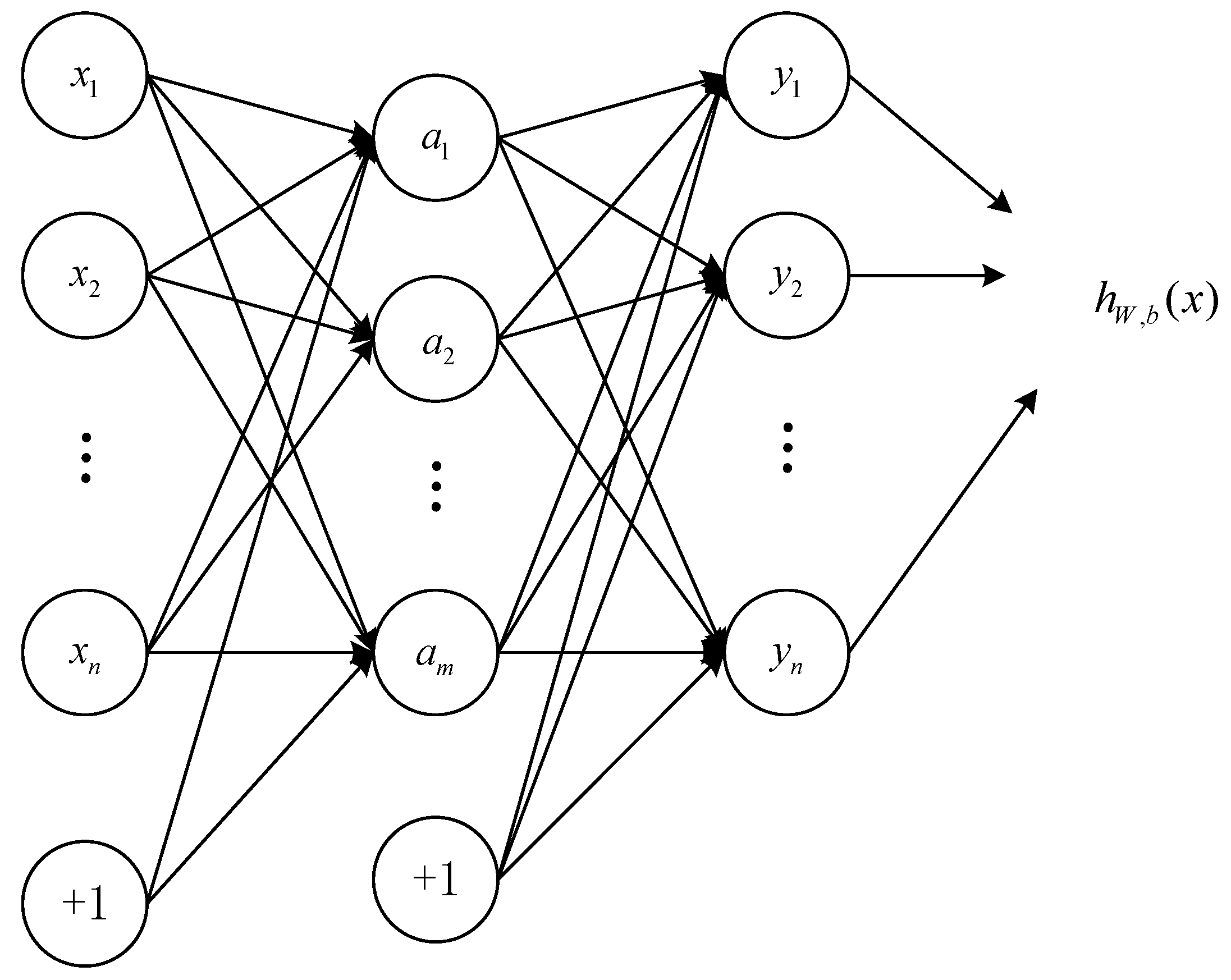
3.2. Deep Auto-Encoder
3.3. Fine-Tune
- Firstly, compute the error term:
- Secondly, compute the desired partial derivatives:
- Thirdly, update , :
- Finally, reset , :where is the learning rate.
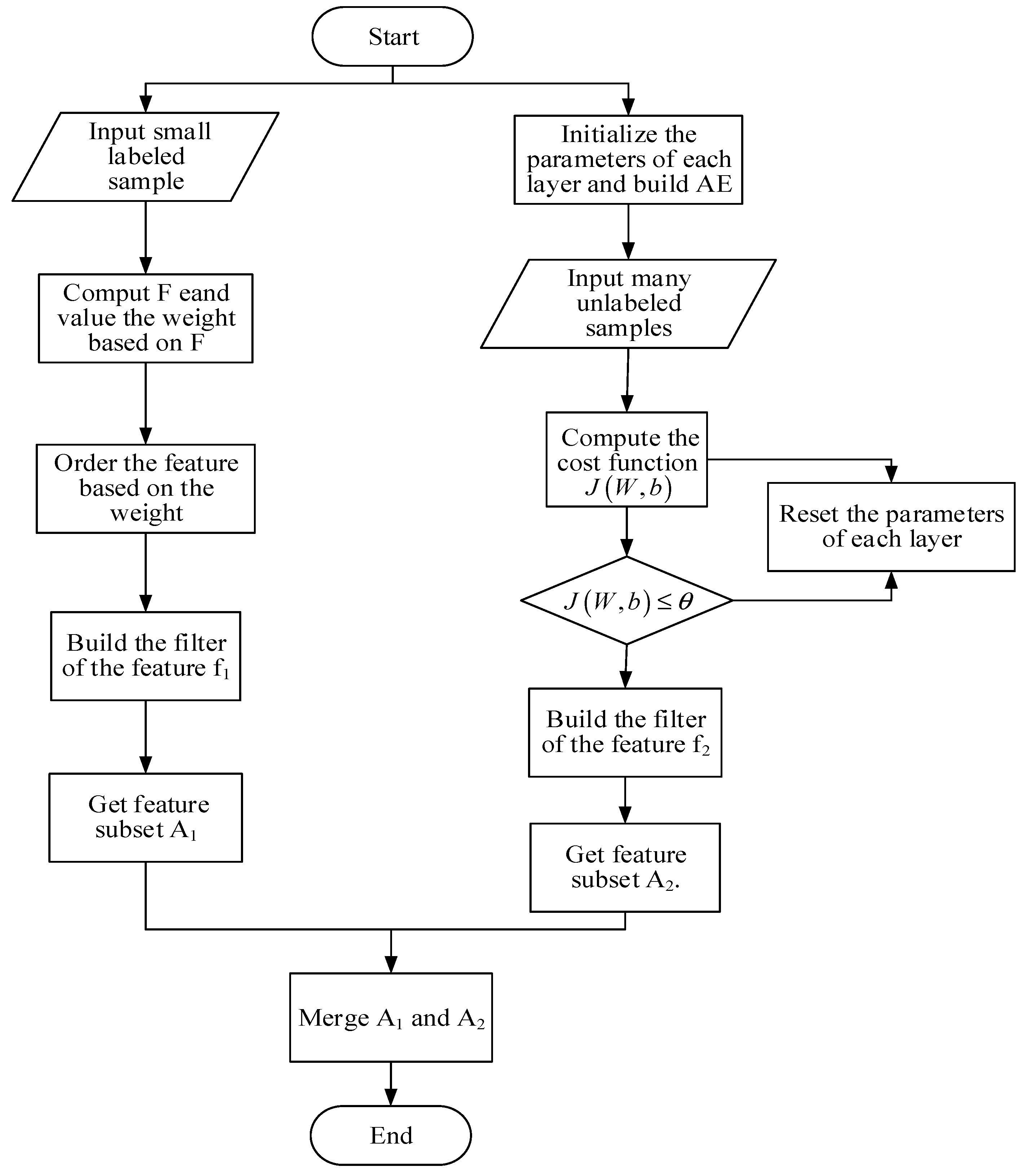
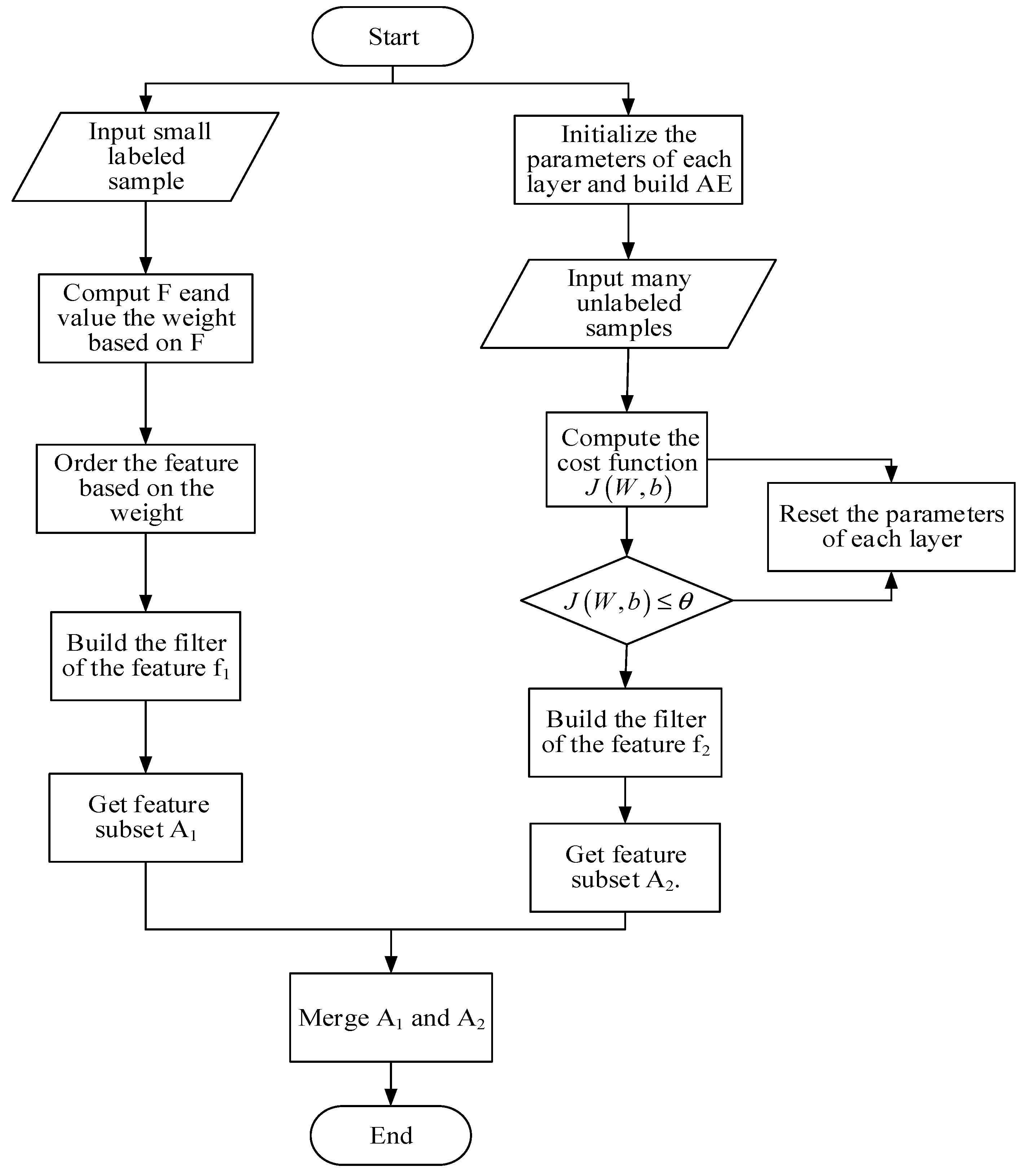
4. Data Fusion Approach Based on Fisher and Deep Auto-Encoder (DFA-F-DAE)
- Input small labeled set sample.
- Use the Formula (1) to compute and value the weight based on .
- Order the feature based on the weight.
- Build the filter of the feature f1 and get feature subset A1.
- Initialize the parameters of each layer and build the model of AE.
- Input a large number of unlabeled samples.
- Set up the threshold value , then compute the cost function according to Formula (6).
- If , the process continues. However, if , reset the parameters of each layer until .
- Build the filter of the feature f2 and get feature subset A2.
- Merge A1 and A2.
5. The Experiment Design and the Result Analysis
5.1. Dataset
5.2. Experimental Environment
5.3. Experimental Results
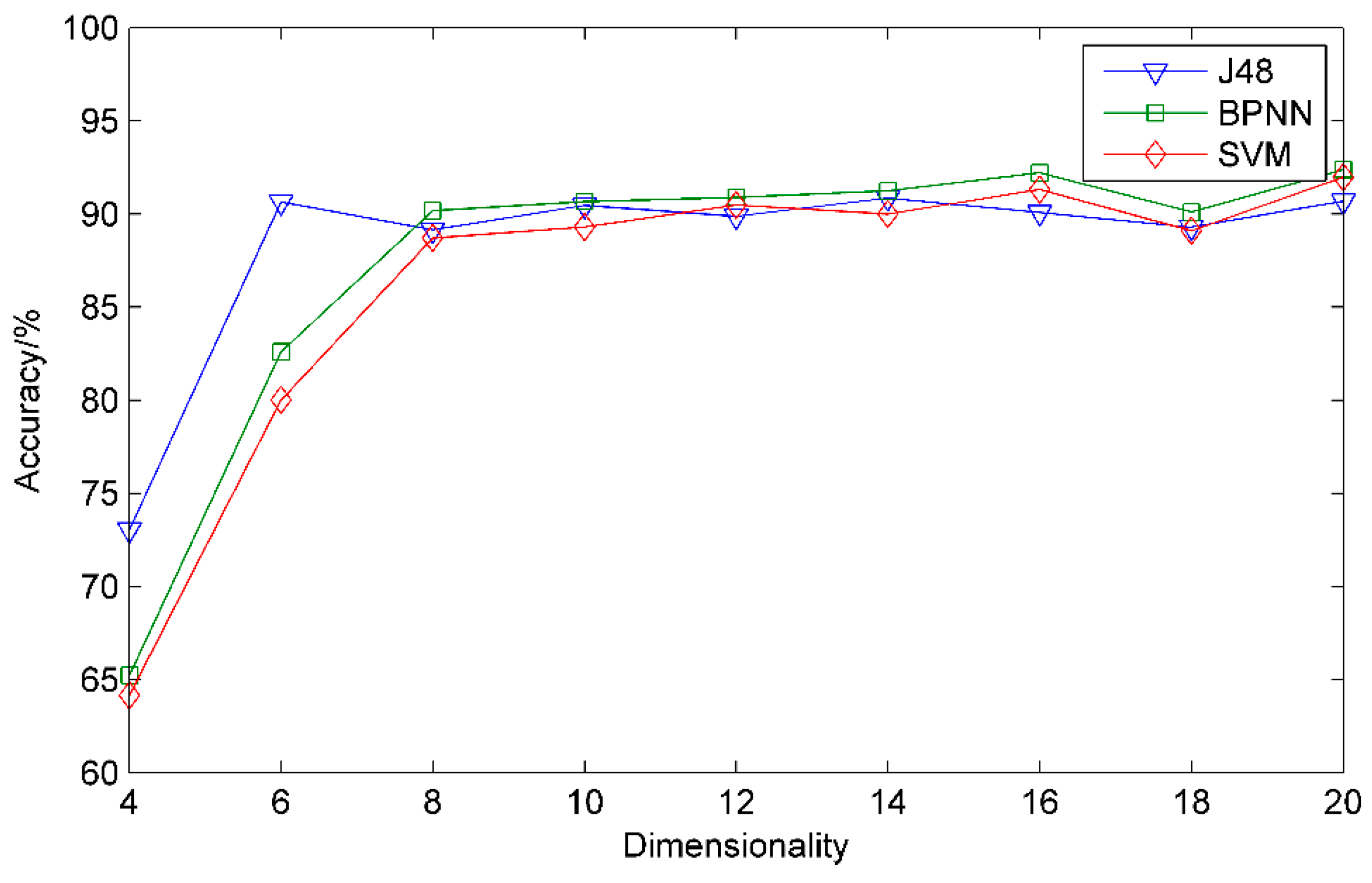
5.3.1. Classification Accuracy under Different Dimensionalities
5.3.2. Classification Time
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Li, X.; Pang, Y.; Yuan, Y. L1-Norm-Based 2DPCA. IEEE Trans. Syst. Man Cybern. 2010, 40, 1170–1175. [Google Scholar]
- Lu, G.; Zou, J.; Wang, Y. Incremental complete LDA for face recognition. Pattern Recognit. 2012, 45, 2510–2521. [Google Scholar] [CrossRef]
- Wang, Y. Fisher scoring: An interpolation family and its Monte Carlo implementations. Comput. Stat. Data Anal. 2010, 54, 1744–1755. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Tan, X. Label-Denoising Auto-encoder for Classification with Inaccurate Supervision Information. In Proceedings of the Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 3648–3653.
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential Deep Learning for Human Action Recognition. In Human Behavior Understanding; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7065, pp. 29–39. [Google Scholar]
- Tamilselvan, P.; Wang, Y.; Wang, P. Deep Belief Network Based State Classification for Structural Health Diagnosis. In Proceedings of the Aerospace Conference, Big Sky, MT, USA, 3–10 March 2012; pp. 1–11.
- Liu, Z.; Yang, S. A Hybrid Intelligent Optimization Algorithm to Assess the NSS Based on FNN Trained by HPS. J. Netw. 2010, 5, 1076–1083. [Google Scholar] [CrossRef]
- Tim, B. Intrusion detection systems and multi-sensor data fusion: Creating cyberspace situational awareness. Commun. ACM 2000, 43, 99–105. [Google Scholar]
- Kokar, M.; Endsley, M. Situation awareness and cognitive modeling. IEEE Intell. Syst. 2012, 27, 91–96. [Google Scholar] [CrossRef]
- Parvar, H.; Fesharaki, M.; Moshiri, B. Shared Situation Awareness System Architecture for Network Centric Environment Decision Making. In Proceedings of the Second International Conference on Computer and Network Technology (ICCNT), Bangkok, Thailand, 23–25 April 2010; pp. 372–376.
- Gamba, P. Human settlements: A global challenge for EO data processing and interpretation. Proc. IEEE 2013, 101, 570–581. [Google Scholar] [CrossRef]
- Delalieux, S.; Zarco-Tejada, P.J.; Tits, L.; Jimenez-Bello, M.A.; Intrigliolo, D.S.; Somers, B. Unmixing-based fusion of hyperspatial and hyperspectral airborne imagery for early detection of vegetation stress. Sel. Top. Appl. Earth Obs. Remote Sen. 2014, 7, 2571–2582. [Google Scholar] [CrossRef]
- Fingas, M.; Brown, C. Review of oil spill remote sensing. Mar. Pollut. Bull. 2014, 83, 9–23. [Google Scholar] [CrossRef] [PubMed]
- Dell, A.F.; Gamba, P. Remote sensing and earthquake damage assessment: Experiences, limits, perspectives. Proc. IEEE 2012, 100, 2876–2890. [Google Scholar] [CrossRef]
- Dalla, M.M.; Prasad, S.; Pacifici, F.; Gamba, P.; Chanussot, J.; Benediktsson, J.A. Challenges and opportunities of multimodality and data fusion in remote sensing. Proc. IEEE 2015, 103, 1585–1601. [Google Scholar] [CrossRef]
- Li, F.; Nie, Y.; Liu, F.; Zhu, J.; Zhang, H. Event-centric situation trust data aggregation mechanism in distributed wireless network. Int. J. Distrib. Sens. Netw. 2014, 2014, 585302. [Google Scholar] [CrossRef]
- Papadopoulos, S.; Kiayisa, A.; Papadias, D. Exact in-network aggregation with integrity and confidentiality. Comput. Inf. Syst. 2012, 24, 1760–1773. [Google Scholar] [CrossRef]
- Akselrod, D.; Sinha, A.; Kirubarajan, T. Information flow control for collaborative distributed data fusion and multisensory multitarget tracking. IEEE Syst. Man Cybern. Soc. 2012, 42, 501–517. [Google Scholar] [CrossRef]
- Zeng, M.; Wang, X.; Nguyen, L.T.; Mengshoel, O.J.; Zhang, J. Adaptive Activity Recognition with Dynamic Heterogeneous Sensor Fusion. In Proceedings of the 6th International Conference on Mobile Computing, Applications and Services (MobiCASE), Austin, TX, USA, 6–7 November 2014; pp. 189–196.
- Chen, Y.; Wei, D.; Neastadt, G.; DeGraef, M.; Simmons, J.; Hero, A. Statistical Estimation and Clustering of Group-Invariant Orientation Parameters. In Proceedings of the 18th International Conference on Information Fusion (Fusion), Washington, DC, USA, 6–9 July 2015; pp. 719–726.
- Bu, S.; Cheng, S.; Liu, Z.; Han, J. Multimodal feature fusion for 3D shape recognition and retrieval. IEEE MultiMed. 2014, 21, 38–46. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, X.; Xu, J. Traffic data fusion research based on numerical optimization BP neural network. Appl. Mech. Mater. 2014, 513–517, 1081–1087. [Google Scholar] [CrossRef]
- Yu, D.; Seltzer, M.L. Improved bottleneck features using pretrained deep neural networks. Interspeech 2011, 237, 234–240. [Google Scholar]
- Felix, W.; Shigetaka, W.; Yuuki, T.; Schuller, B. Deep Recurrent De-noising Auto-encoder and Blind De-Reverberation for Reverberated Speech Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4623–4627.
- Coates, A.; Ng, A.Y.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. J. Mach. Learn. Res. 2011, 15, 215–223. [Google Scholar]
- Chen, B.; Wang, S.; Jiao, L.; Stolkin, R.; Liu, H. A three-component Fisher-based feature weighting method for supervised PolSAR image classification. Geosci. Remote Sens. Lett. 2015, 12, 731–735. [Google Scholar] [CrossRef]
- Marney, L.C.; Siegler, W.C.; Parsons, B.A. Tile-based Fisher-ratio software for improved feature selection analysis of comprehensive two-dimensional gas chromatography–time-of-flight mass spectrometry data. Talanta 2013, 115, 887–895. [Google Scholar] [CrossRef] [PubMed]
- Lange, S.; Riedmiller, M. Deep Auto-Encoder Neural Networks in Reinforcement Learning. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN 2010), Barcelona, Spain, 18–23 July 2010; pp. 1–8.
- Muller, X.; Glorot, X.; Bengio, Y.; Rifai, S.; Vincent, P. Contractive auto-encoders: Explicit invariance during feature extraction. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 833–840.
- KDD Cup 1999 Data. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 11 October 2015).



{kind=link}
{kind=link}
{kind=link}
| Attacks Types | Train-Set | Test-Set | ||
|---|---|---|---|---|
| Number | Percentage | Number | Percentage | |
| Normal (0) | 2146 | 21.46% | 348,413 | 69.6826% |
| Probe (1) | 2092 | 20.92% | 19,395 | 3.879% |
| DOS (2) | 5164 | 51.64% | 131,605 | 26.321% |
| U2R (3) | 25 | 0.25% | 25 | 0.005% |
| R2L (4) | 573 | 5.73% | 562 | 0.1124% |
| Information | |
|---|---|
| CPU | Intel i7-3770@ 3.40 GHz |
| Memory | 16 GB |
| Hard Drive | 256 G SSD |
| Operating System | Windows 7 64-bit |
| Java Environment | JDK 1.7.0 |
| Matlab | version 8.0.0 |
| Weka | version 3.7.13 |
| Algorithm | J48 | BPNN | SVM | |
|---|---|---|---|---|
| 500,000 | B-time | 7.8 s | 43.23 s | 51.04 s |
| A-time | 2.71 s | 3.42 s | 2.73 s | |
| 1,000,000 | B-time | 15.68 s | 86.32 s | 104.47 s |
| A-time | 5.12 s | 6.91 s | 5.75 s | |
| 1,500,000 | B-time | 24.96 s | 130.48 s | 158.81 s |
| A-time | 7.86 s | 10.08 s | 7.98 s | |
| 2,000,000 | B-time | 30.73 s | 169.65 s | 214.39 s |
| A-time | 10.47 s | 14.12 s | 10.78 s | |
| 2,500,000 | B-time | 39.83 s | 217.42 s | 256.76 s |
| A-time | 13.81 s | 17.46 s | 15.52 s | |
| 3,000,000 | B-time | 47.9 s | 263.03 s | 319.53 s |
| A-time | 16.58 s | 20.41 s | 18.41 s |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, X.; Kong, D.; Wei, Y.; Wang, Y. A Big Network Traffic Data Fusion Approach Based on Fisher and Deep Auto-Encoder. Information 2016, 7, 20. https://doi.org/10.3390/info7020020
Tao X, Kong D, Wei Y, Wang Y. A Big Network Traffic Data Fusion Approach Based on Fisher and Deep Auto-Encoder. Information. 2016; 7(2):20. https://doi.org/10.3390/info7020020
Chicago/Turabian StyleTao, Xiaoling, Deyan Kong, Yi Wei, and Yong Wang. 2016. "A Big Network Traffic Data Fusion Approach Based on Fisher and Deep Auto-Encoder" Information 7, no. 2: 20. https://doi.org/10.3390/info7020020
APA StyleTao, X., Kong, D., Wei, Y., & Wang, Y. (2016). A Big Network Traffic Data Fusion Approach Based on Fisher and Deep Auto-Encoder. Information, 7(2), 20. https://doi.org/10.3390/info7020020