
Computer-Aided Identification and Validation of Privacy Requirements


Abstract
:1. Introduction
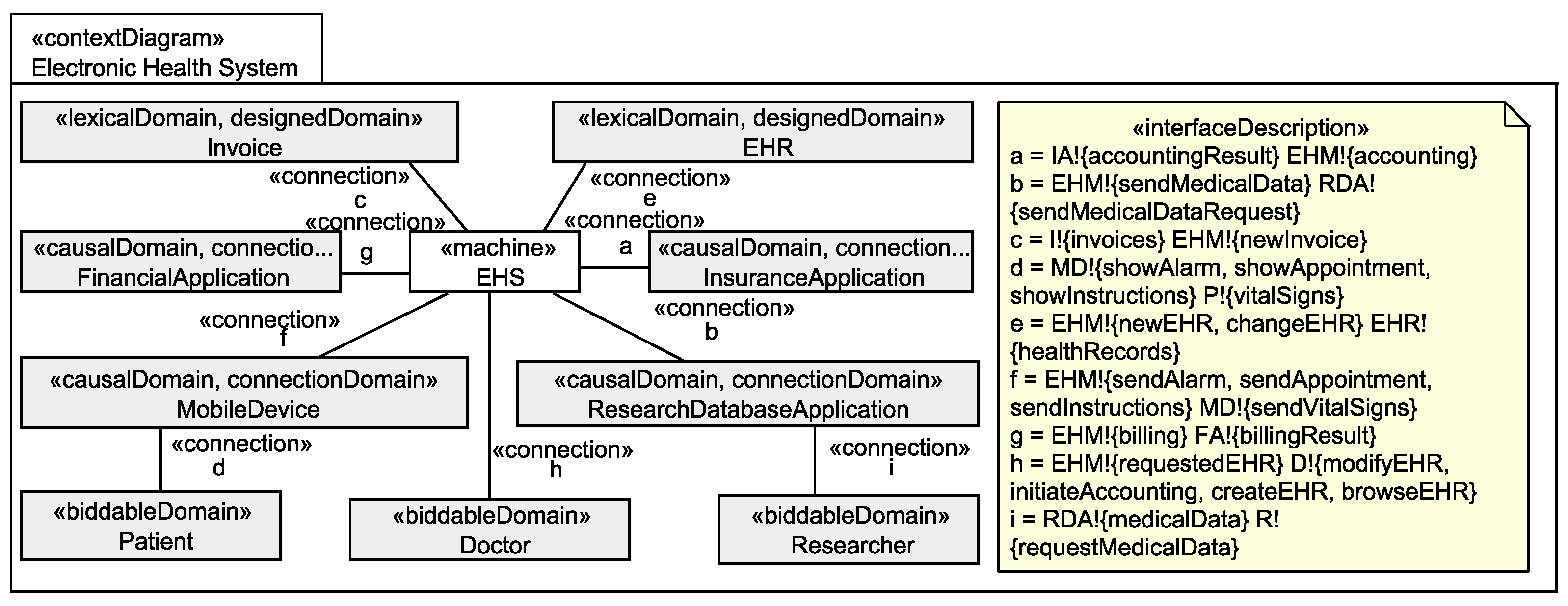
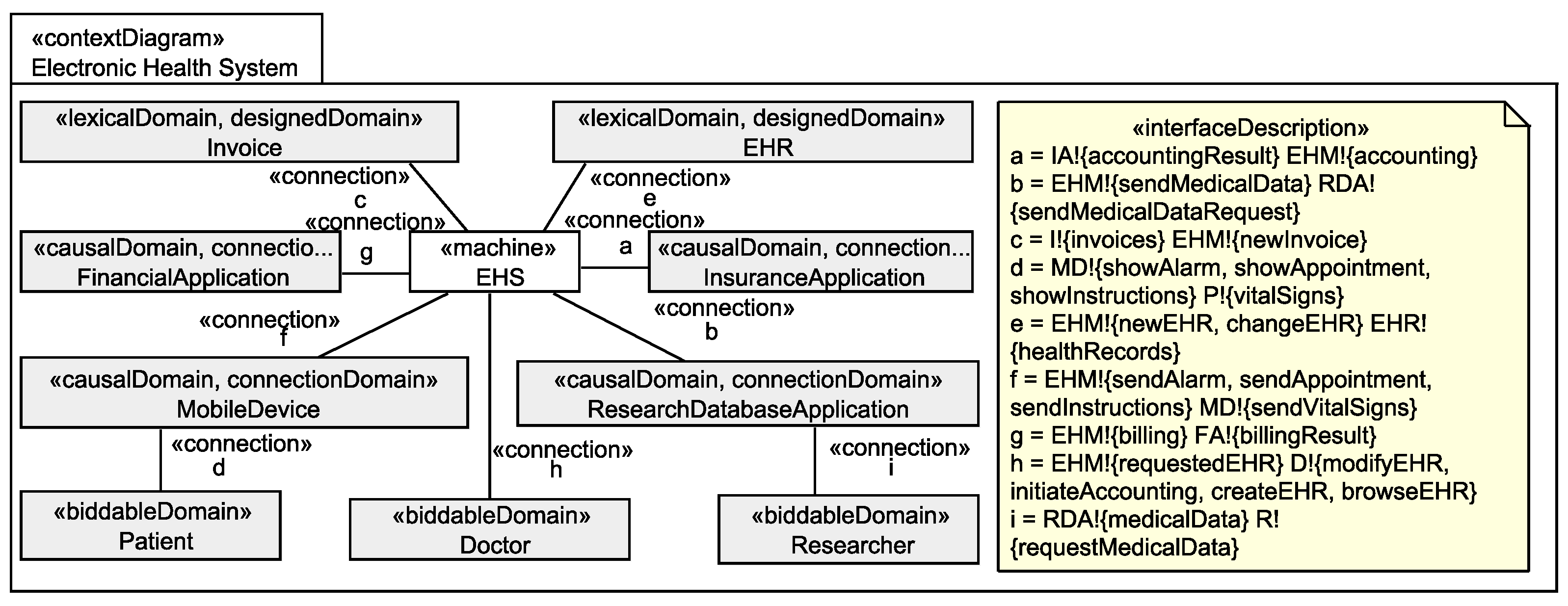
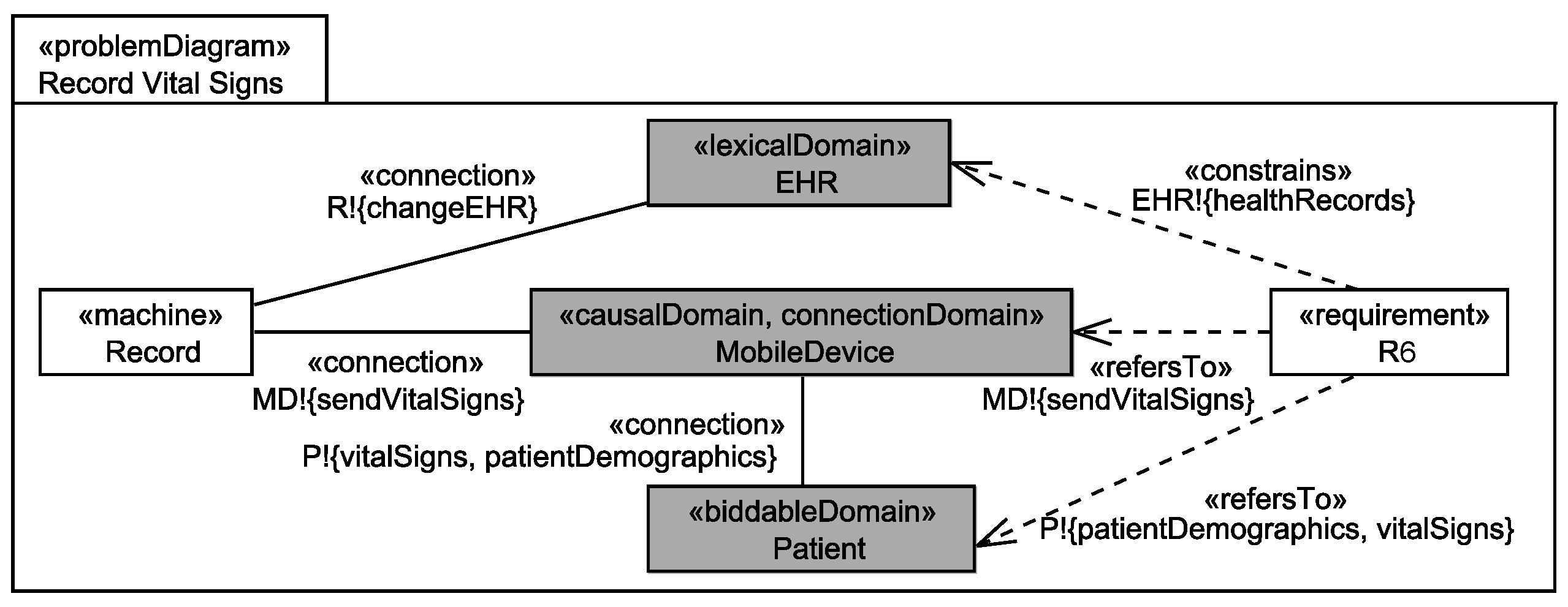
2. Running Example
3. Background
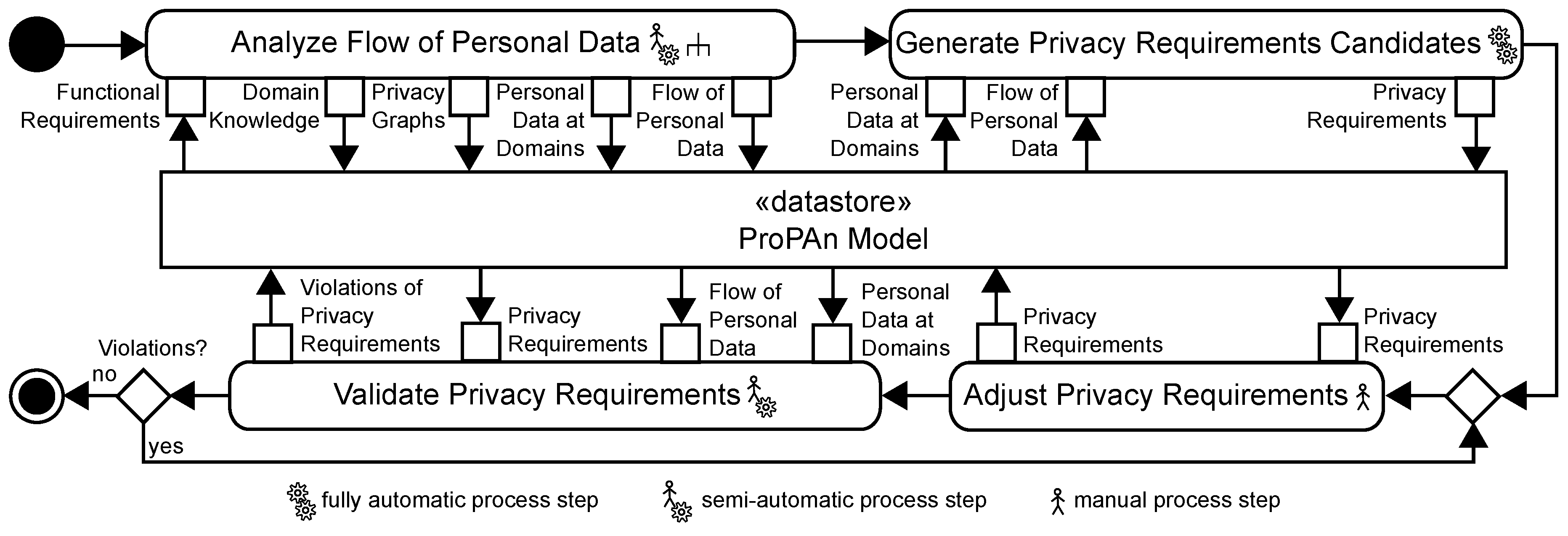
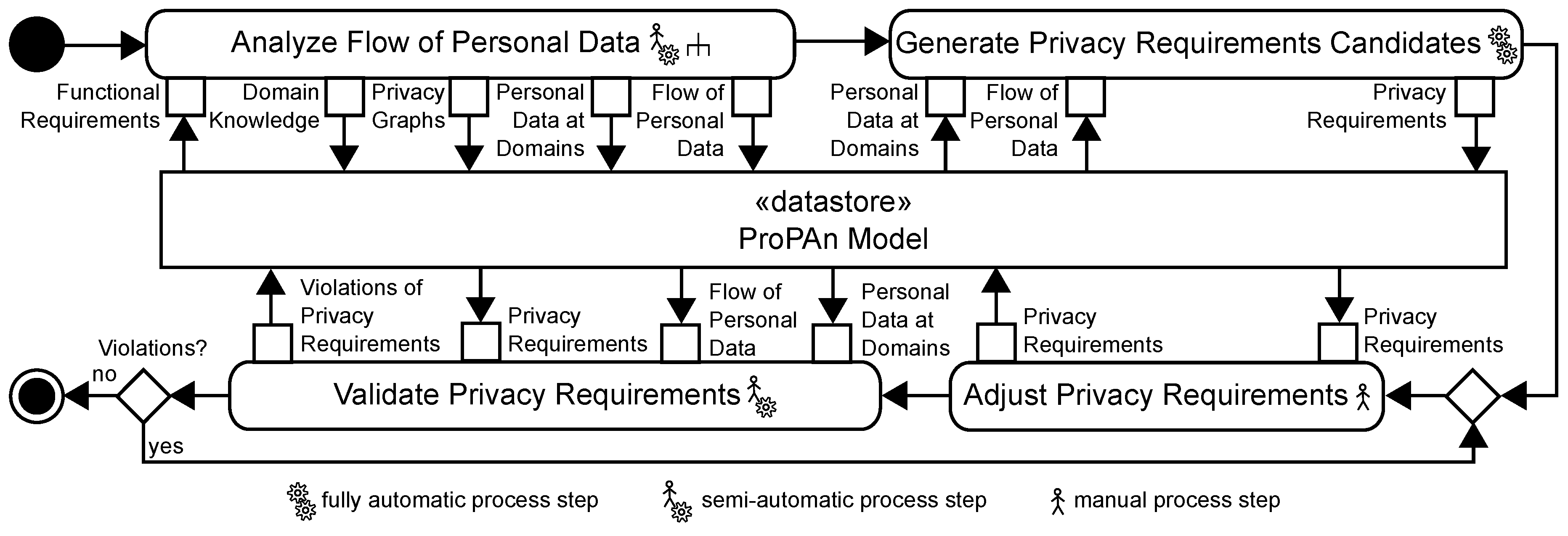
4. Overview of our Method
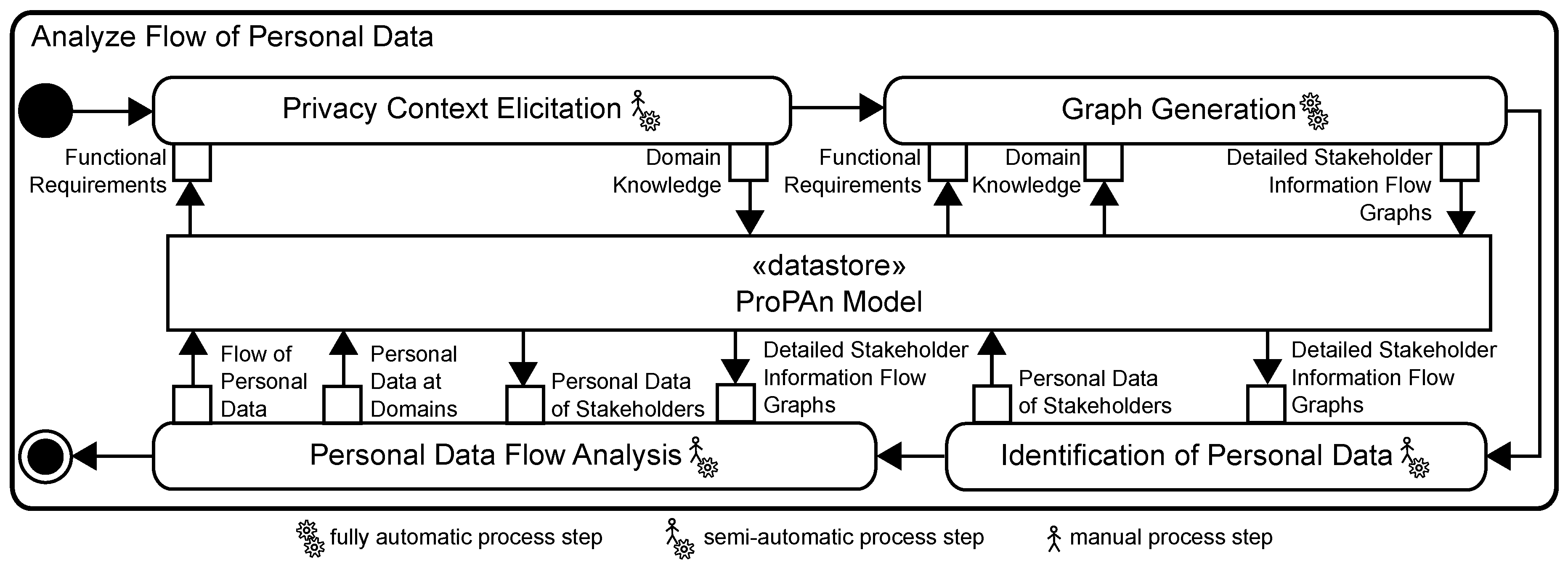
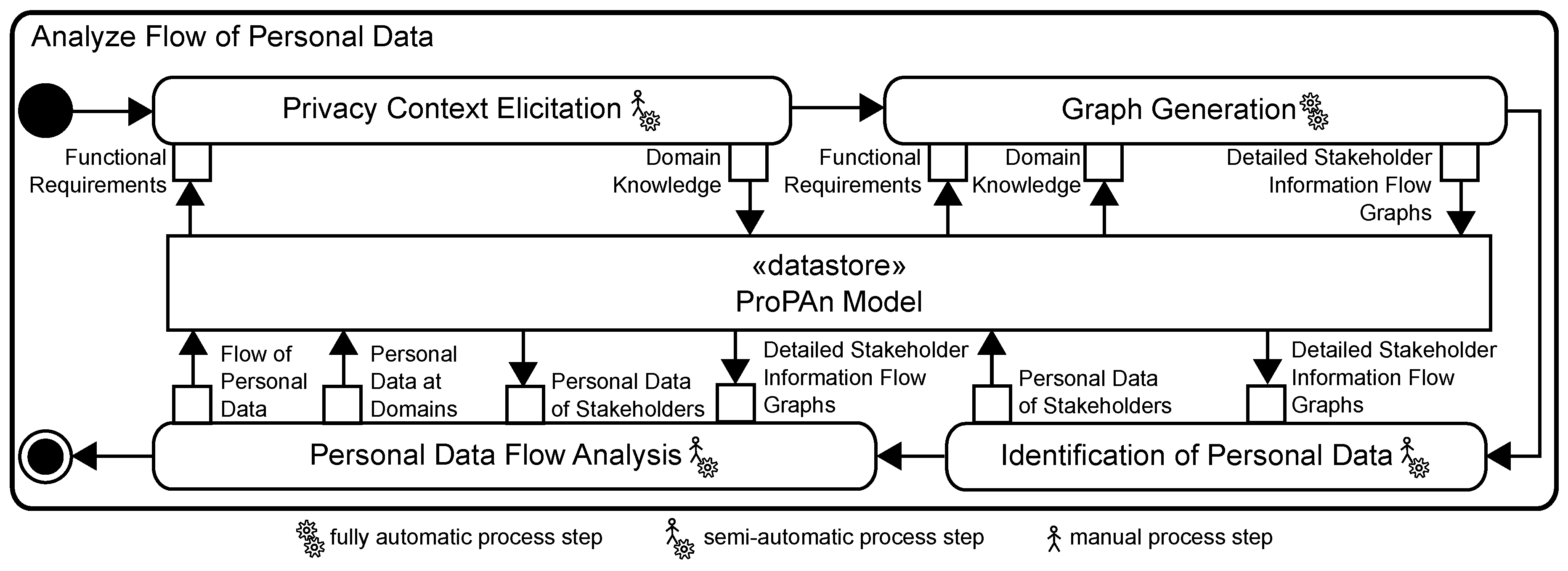
5. Analyze Flow of Personal Data
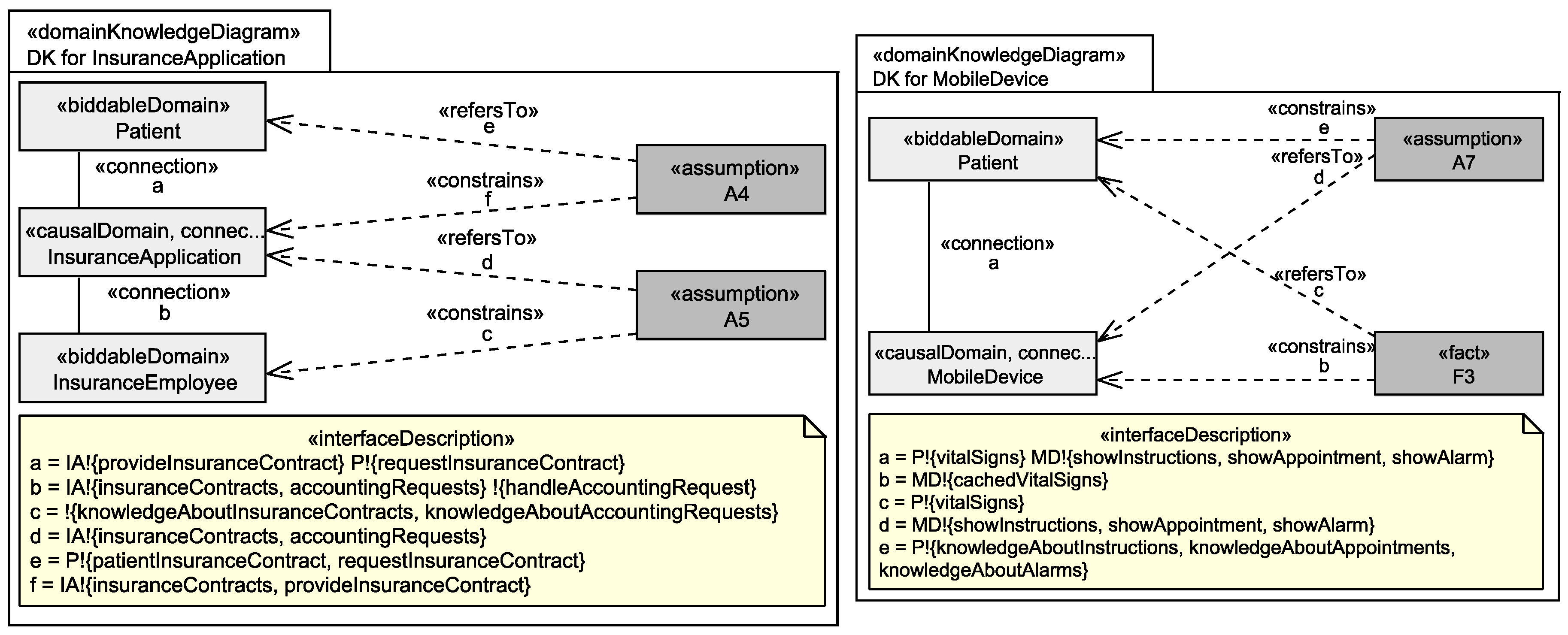
5.1. Privacy Context Elicitation
Application to Running Example
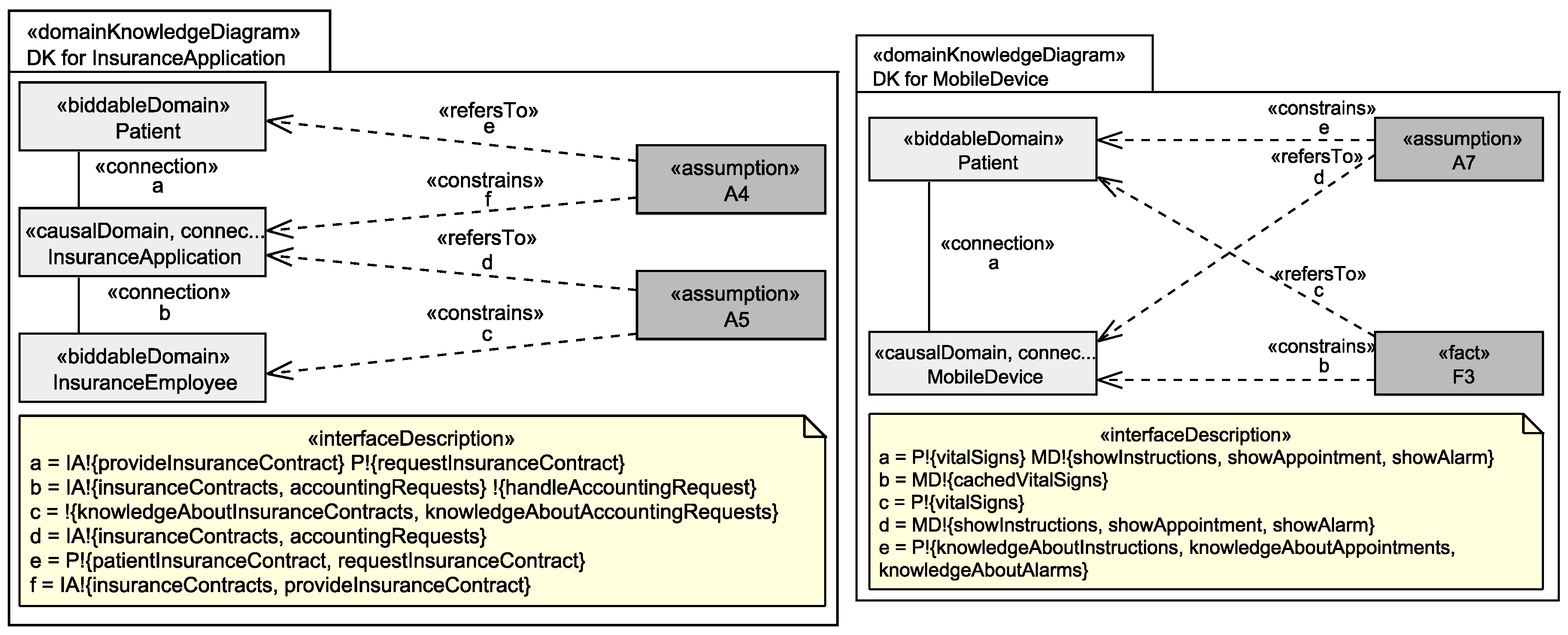
5.2. Graph Generation
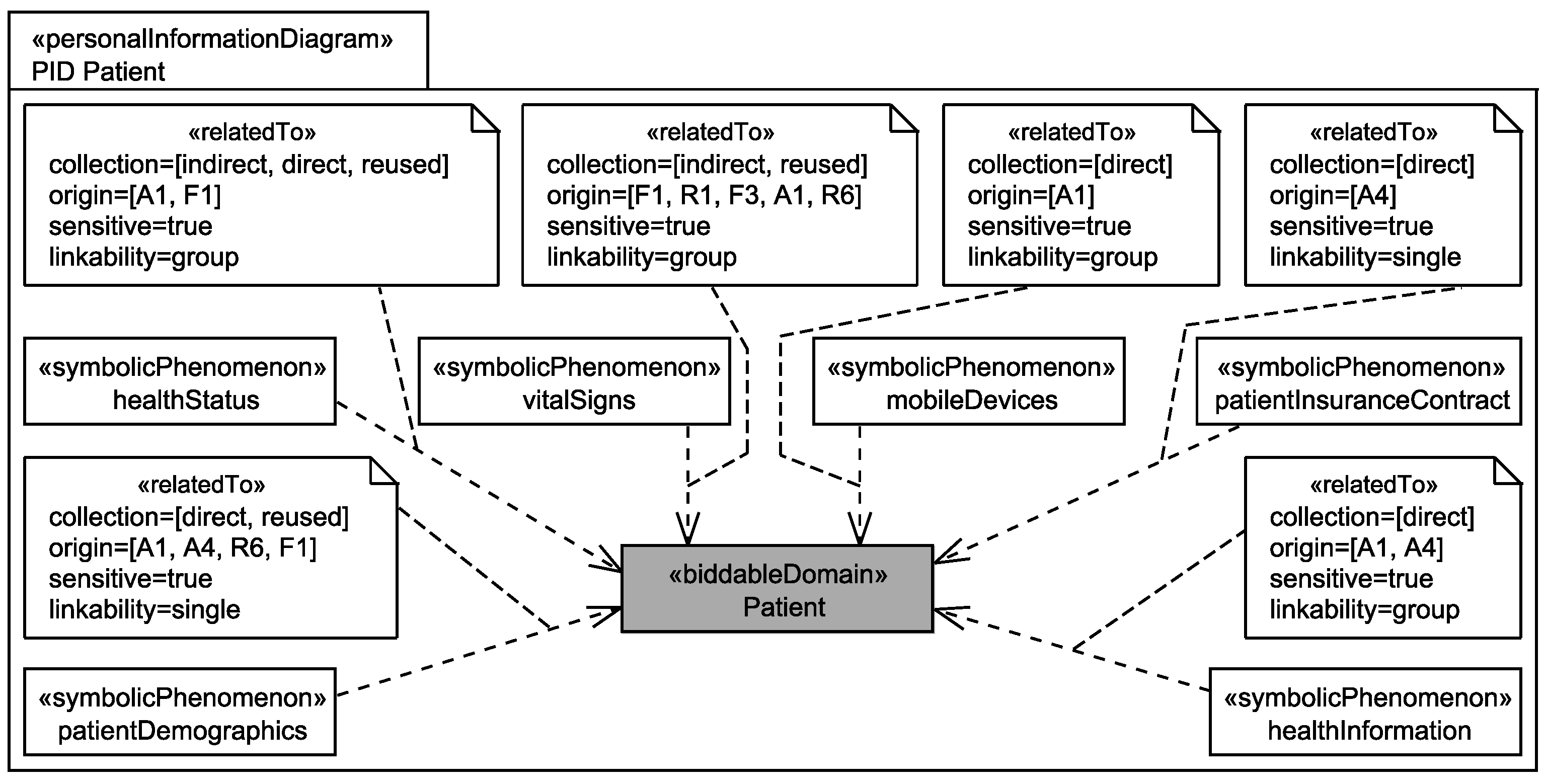
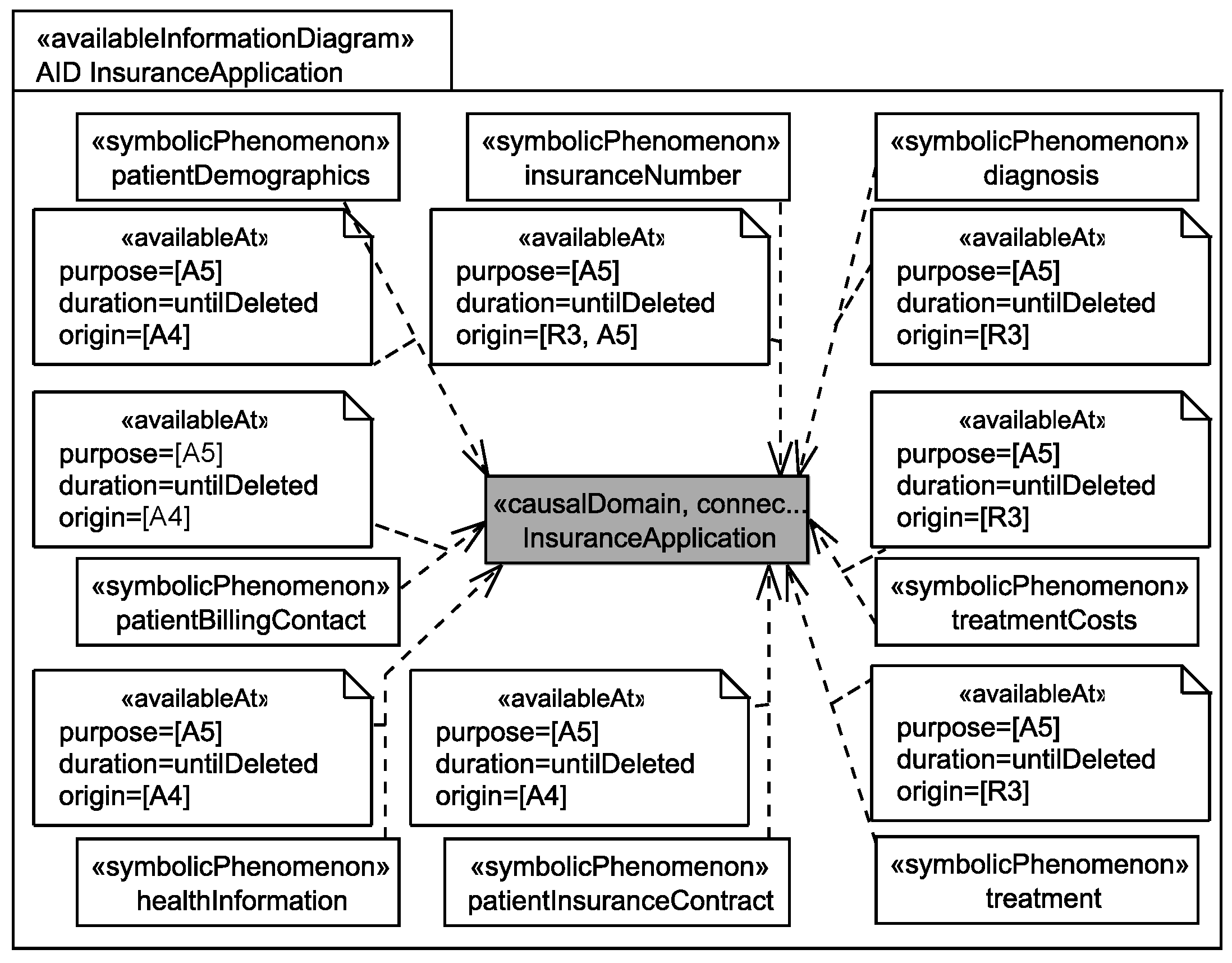
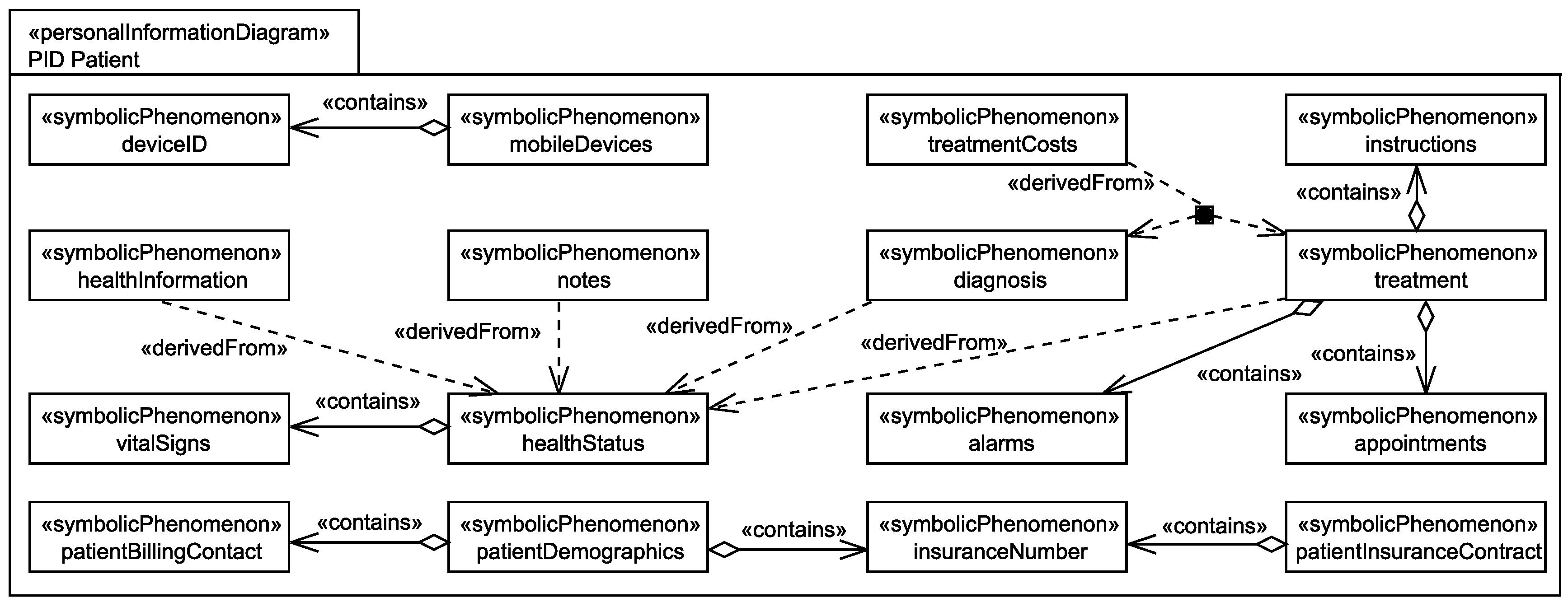
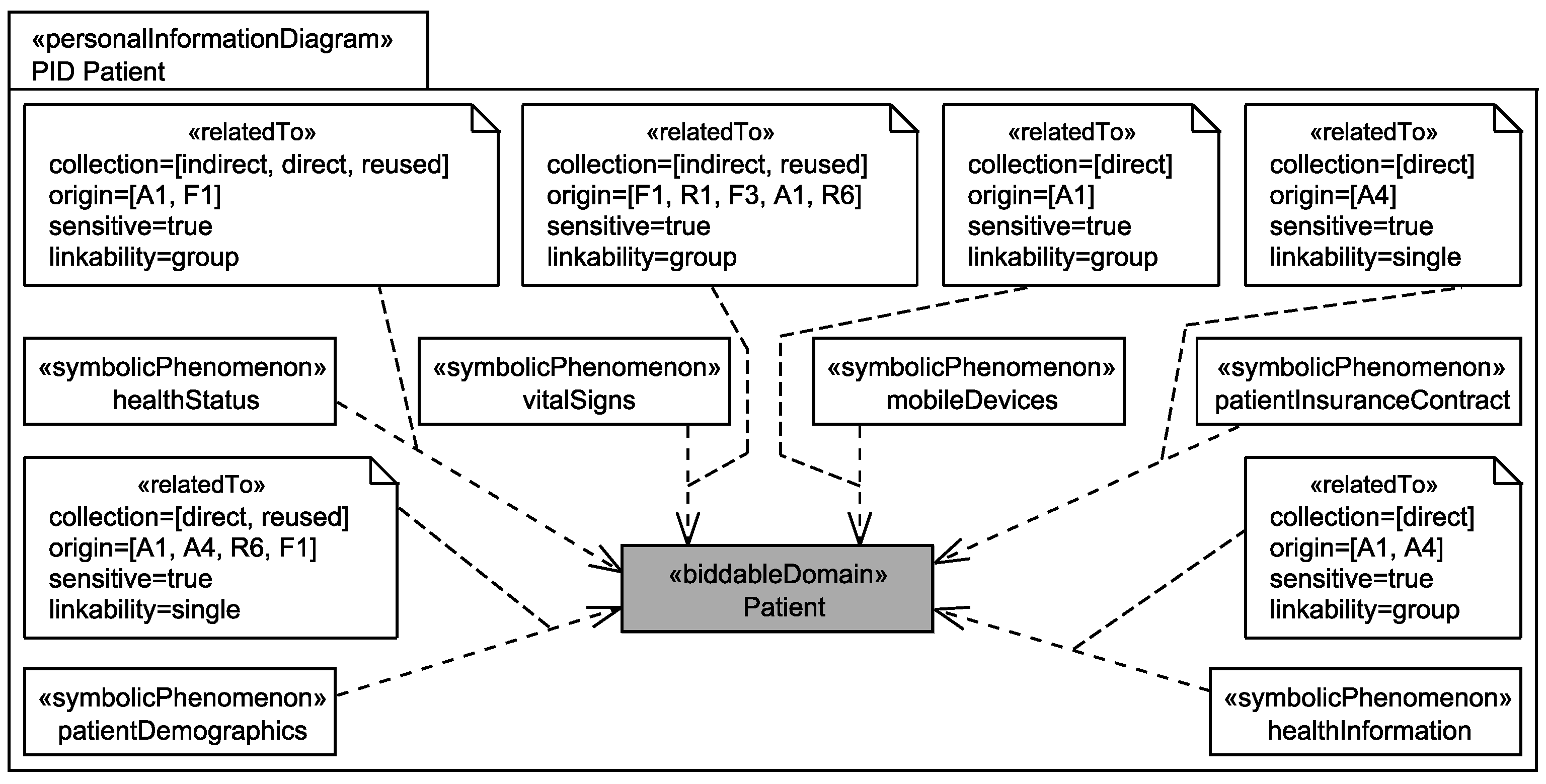
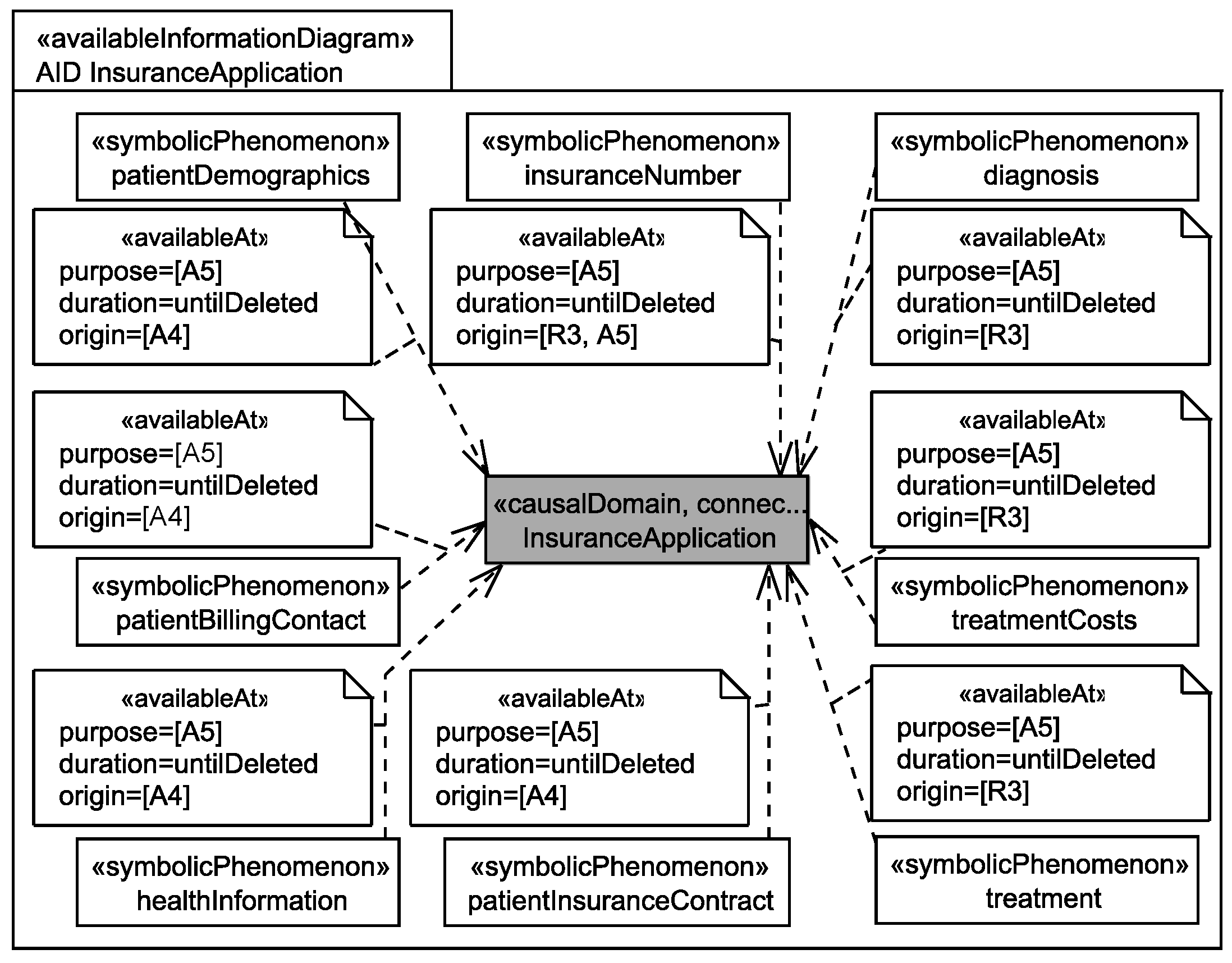
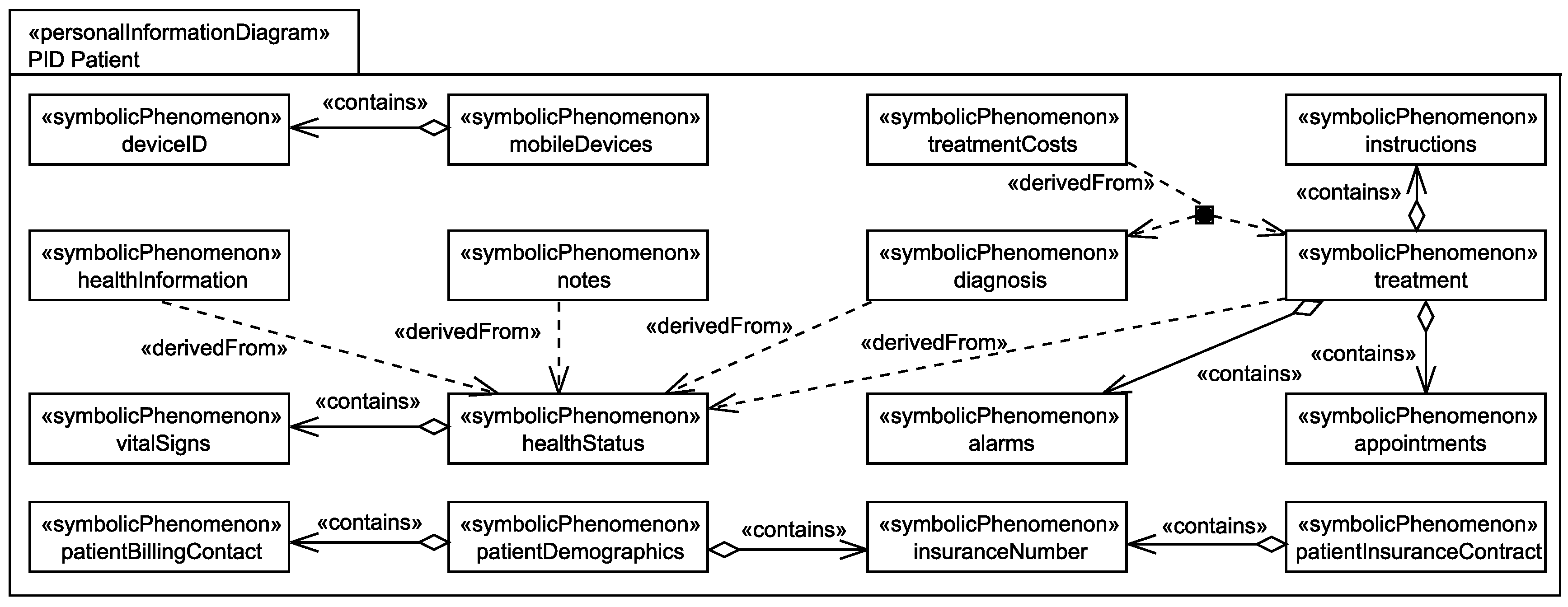
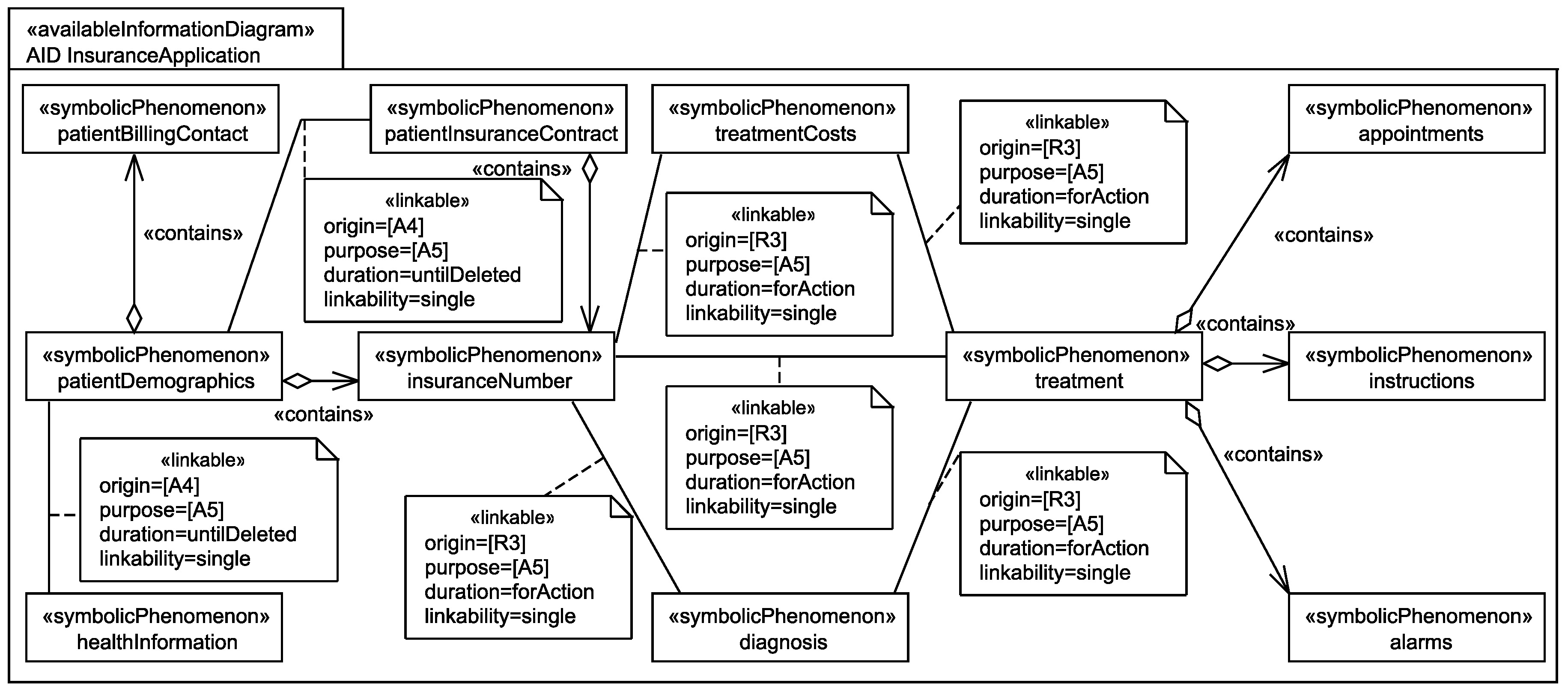
5.3. Identification of Personal Data
Application to Running Example
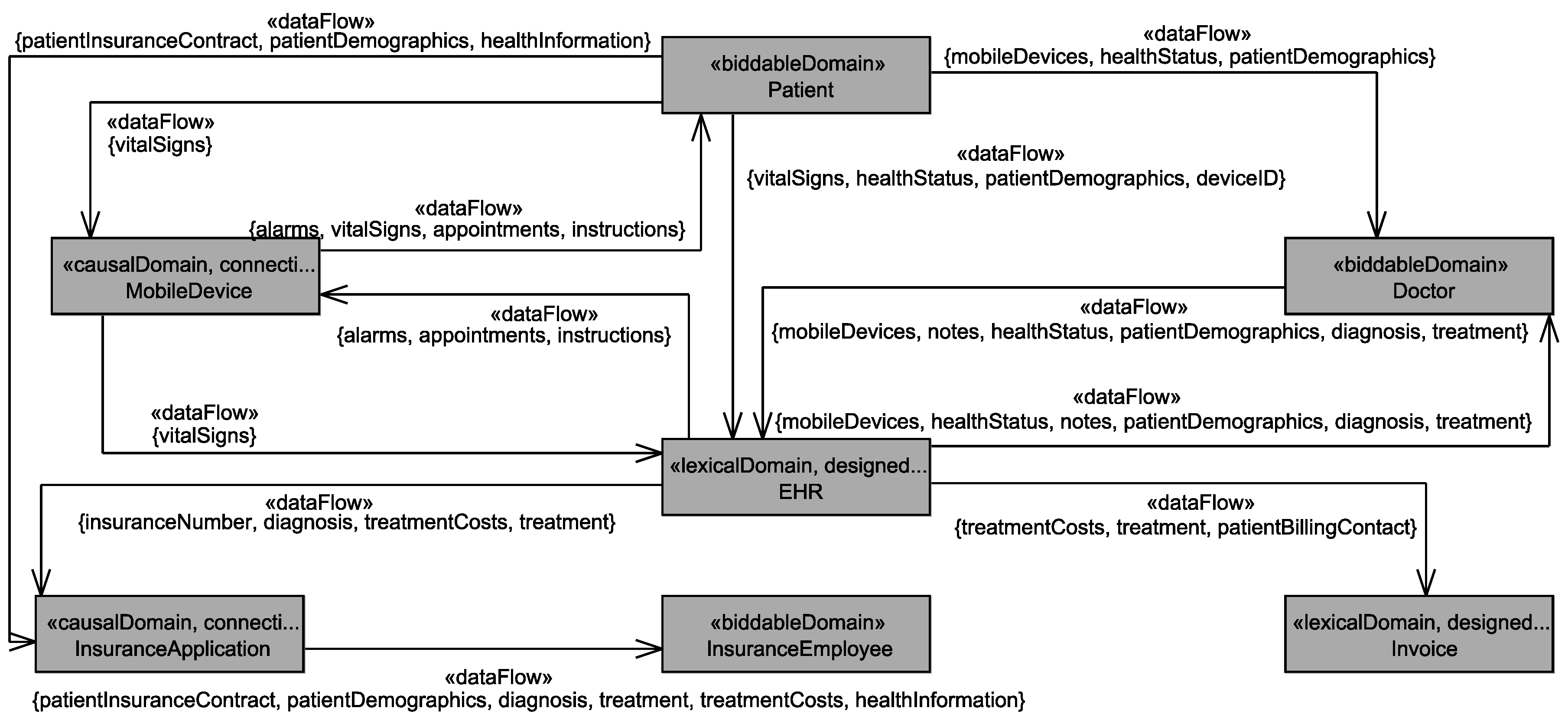
- The healthStatus that contains all data that is related to the patient’s health and that is processed by the EHS. The health status is considered to be sensitive personal data and it can itself not directly be linked to the single individuals it belongs to, but due to the contained information, it can be linked to a group of individuals it possibly belongs to. The health status is collected in different ways from the patient, it is collected directly from the patient, e.g., during interviews with a doctor, it is indirectly collected by observation of his/her vital signs, and it is also reused from already existing data bases (cf. Figure 6).
- The patientDemographics summarize details of the patient such as contact information, insurance number, and billing contact. This information suffices to identify the single individual it belongs to, it is considered as sensitive information, and it is collected directly from the patient, e.g., during interviews with a doctor, and by reuse of already existing data sets (cf. Figure 6).
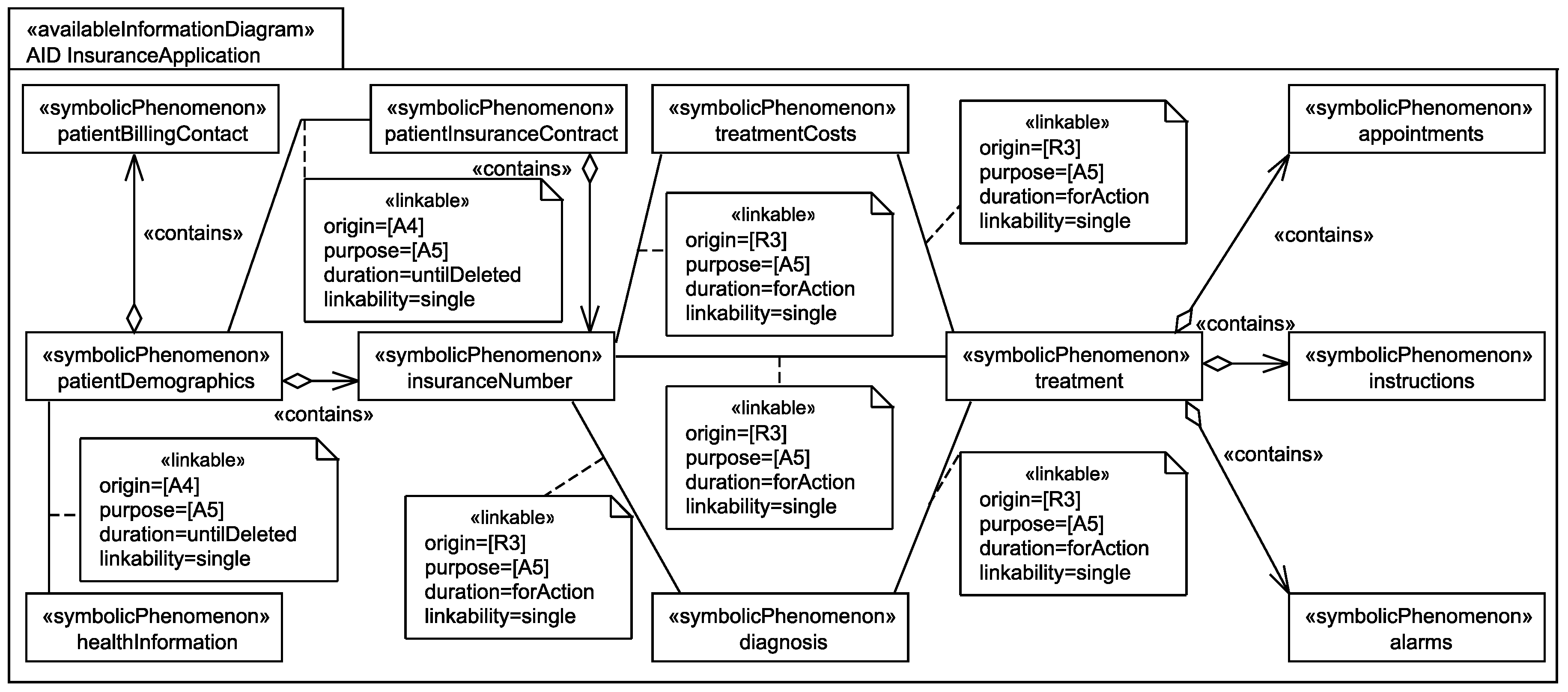
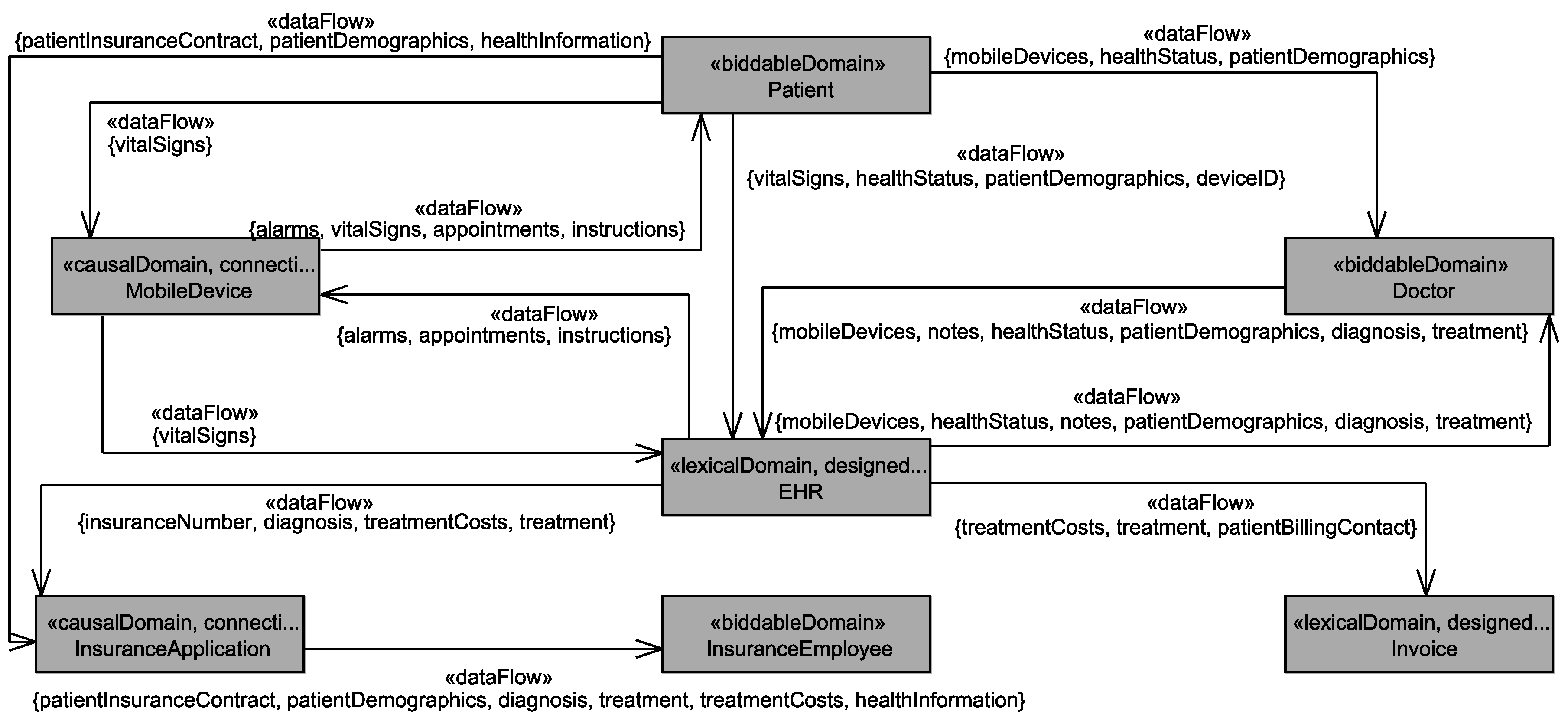
5.4. Personal Data Flow Analysis
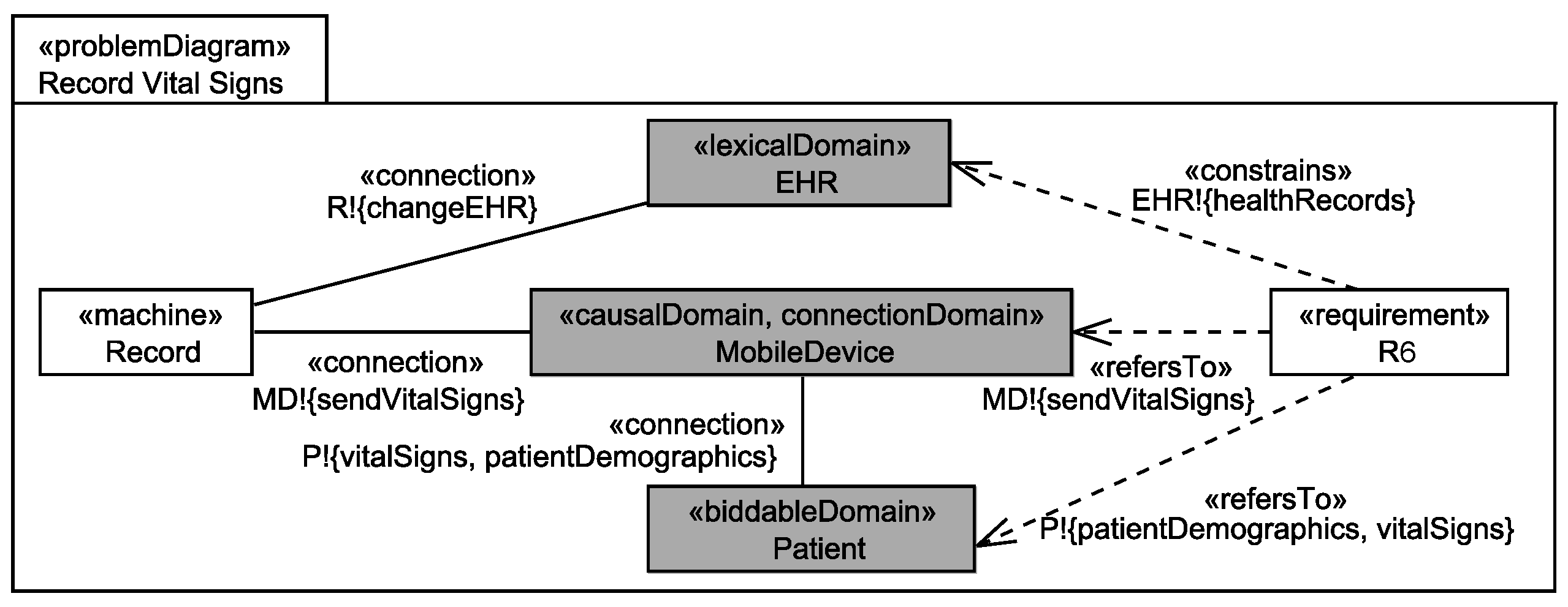
Application to Running Example
6. Generate Privacy Requirements Candidates
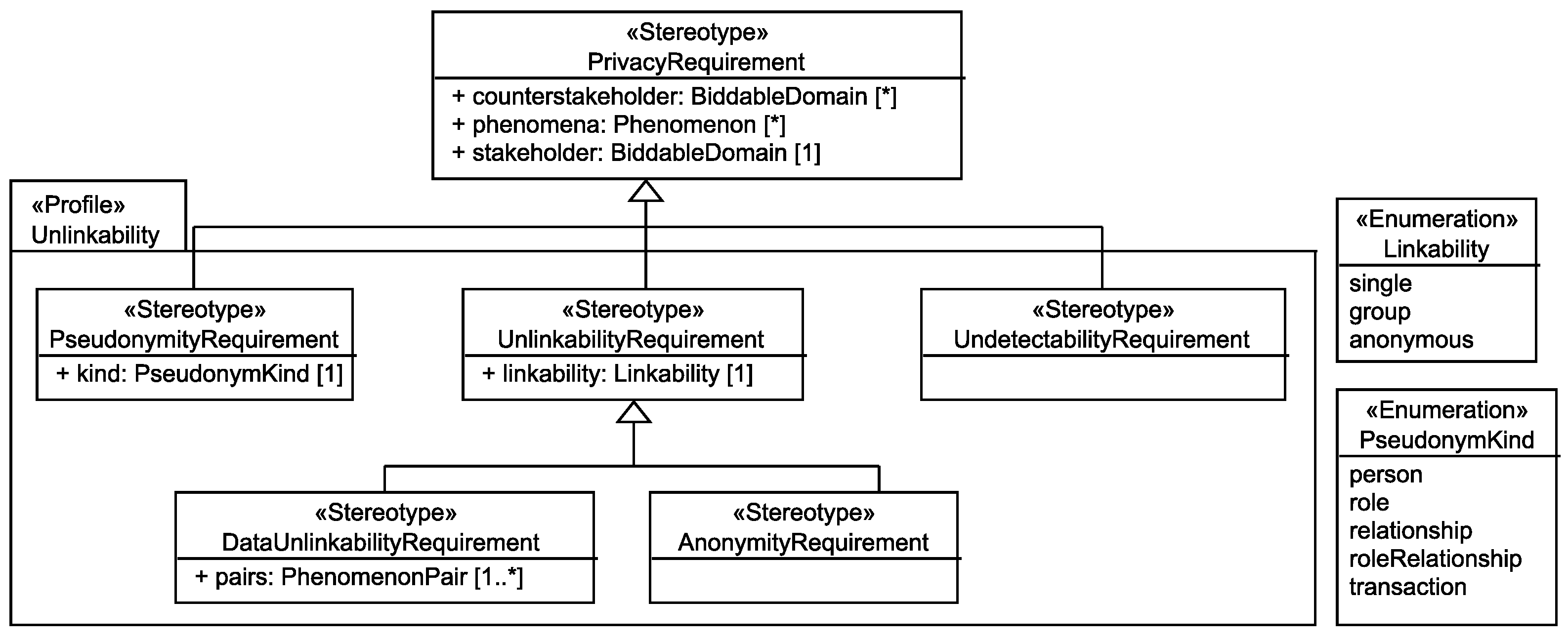
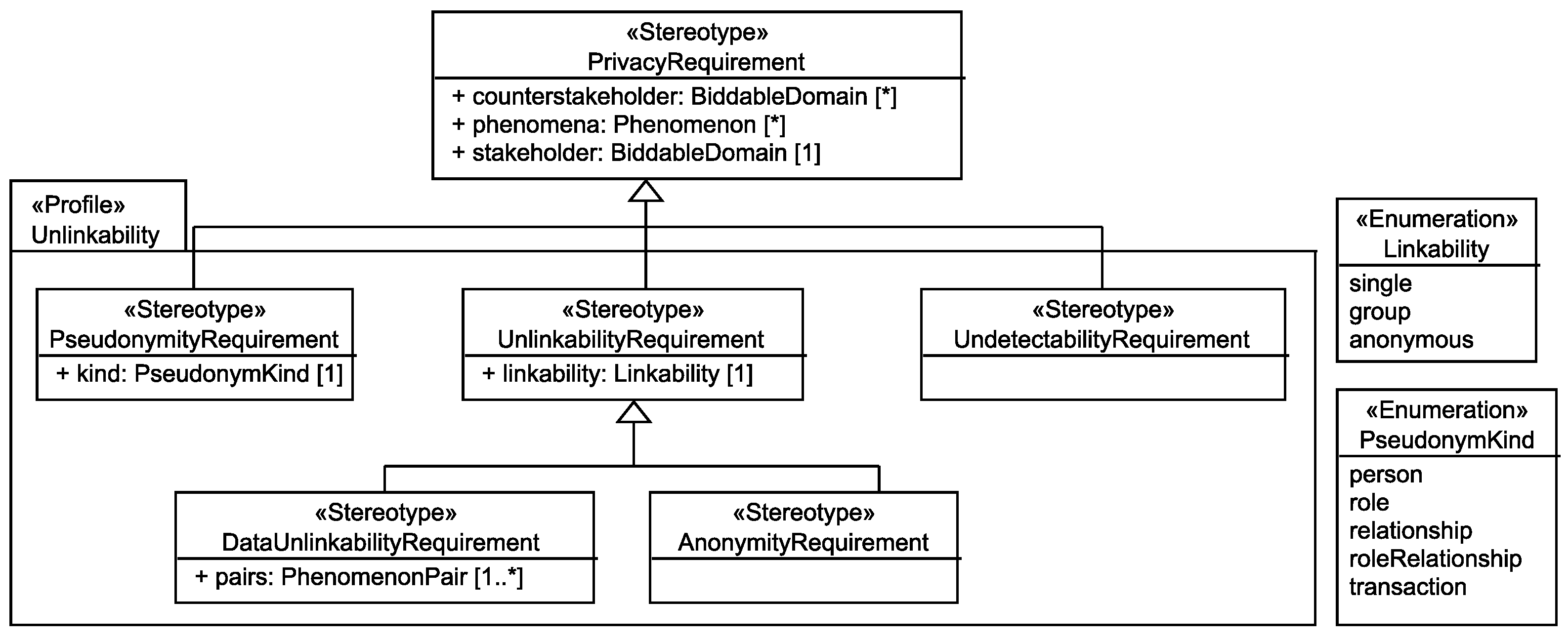
6.1. Unlinkability Requirements
- UndetectabilityRequirement Pfitzmann and Hansen define undetectability as: “Undetectability of an item of interest (IOI) from an attacker’s perspective means that the attacker cannot sufficiently distinguish whether it exists or not.”
- AnonymityRequirement Pfitzmann and Hansen define anonymity as: “Anonymity of a subject from an attacker’s perspective means that the attacker cannot sufficiently identify the subject within a set of subjects, the anonymity set.”
- DataUnlinkabilityRequirement Pfitzmann and Hansen define unlinkability as: “Unlinkability of two or more items of interest (IOIs, e.g., subjects, messages, actions, ...) from an attacker’s perspective means that within the system (comprising these and possibly other items), the attacker cannot sufficiently distinguish whether these IOIs are related or not.” Our data unlinkability requirements express the intended relations between messages, actions, and the like which a subject performs and do not concern the relations of these to the subject itself, as these are represented by anonymity requirements.
6.1.1. Undetectability
The <counterstakeholder>s shall not be able to sufficiently distinguish whether the personal information <phenomena> of the <stakeholder> exists or not.
Application to Running Example
The insurance employee shall not be able to sufficiently distinguish whether the personal information healthStatus, mobileDevices, deviceId, vitalSigns, and notes of the patient exist or not.
6.1.2. Data Unlinkability Requirements
For each pair of personal information <pairs> of the <stakeholder>, the <counterstakeholder>s shall at most be able to link instances of the two elements of the pair to each other with linkability <linkability>.
Application to Running Example
6.1.3. Anonymity Requirement
The <counterstakeholder>s shall at most be able to link the personal information <phenomena> to the stakeholder with linkability <linkability>.
Application to Running Example
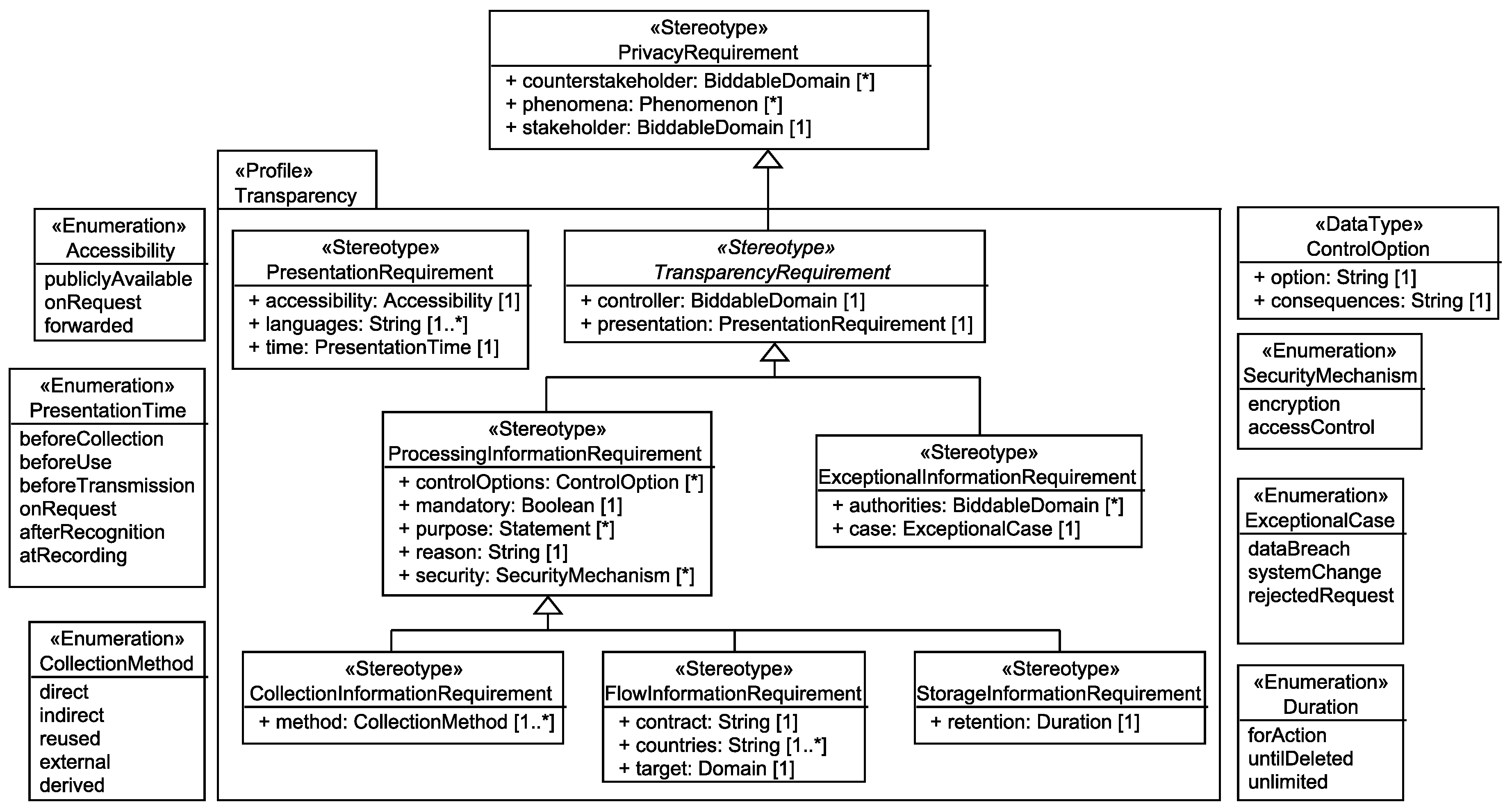
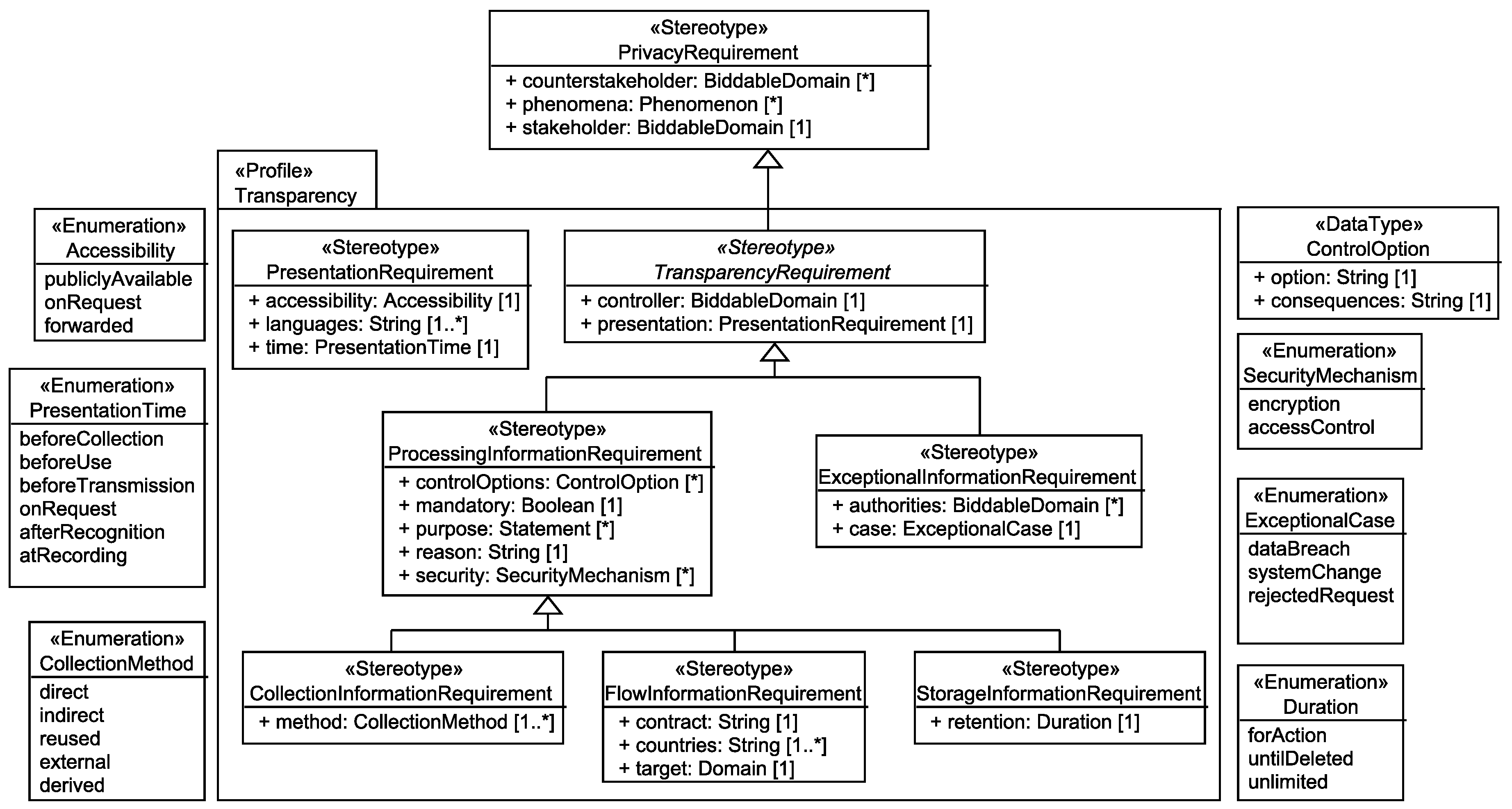
6.2. Transparency and Intervenability Requirements
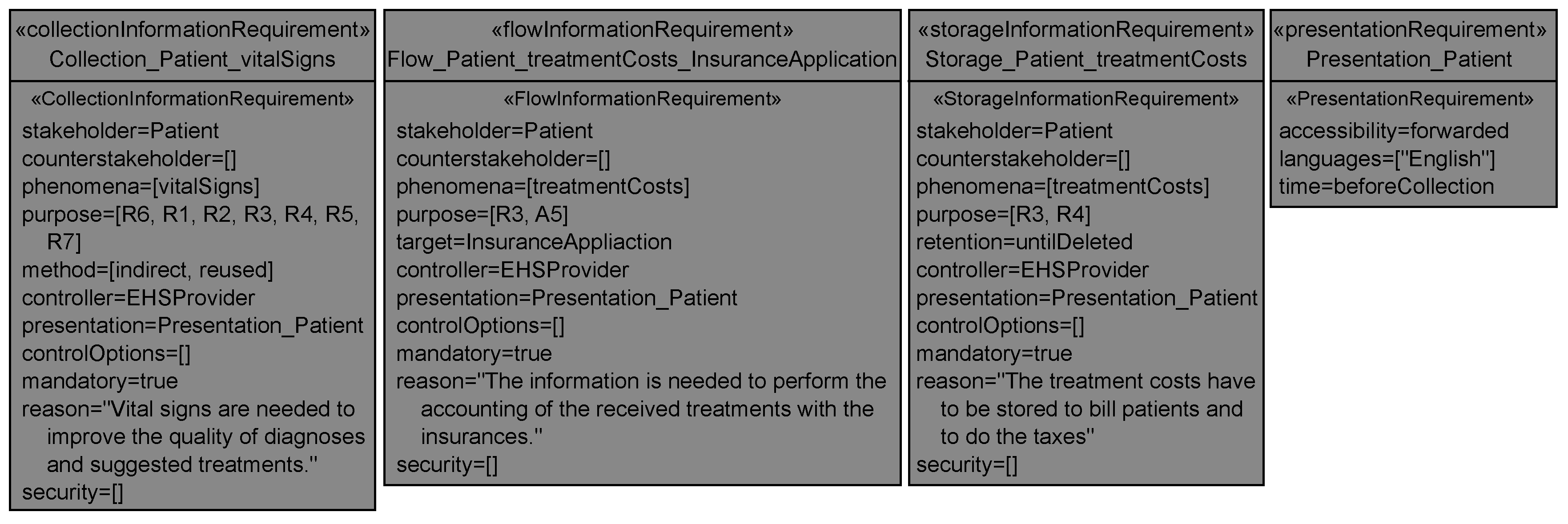
6.2.1. Collection Information Requirements
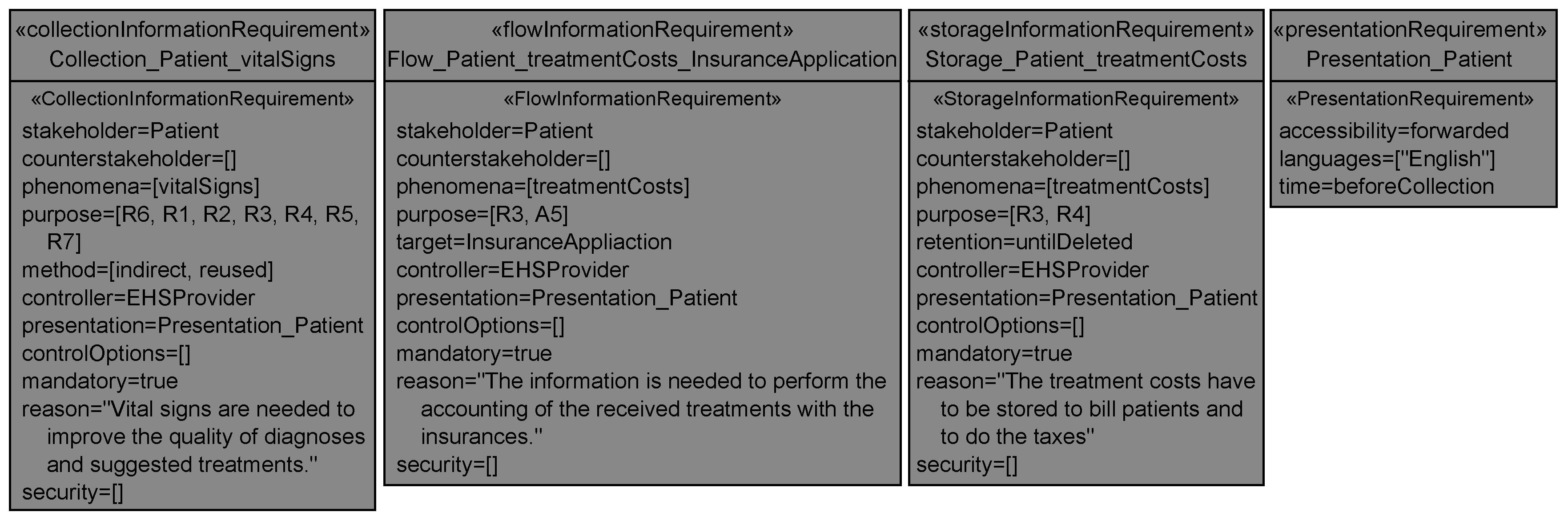
The <stakeholder> shall be informed that his/her personal data <phenomena> are <mandatory>ly collected by the system-to-be that is run by the <controller>. The applied collection methods to obtain <phenomena> from the <stakeholder> are <method>. The <stakeholder>’s possibilities to control the collection of his/her data are <controlOptions>. <phenomena> are collected for the purpose of <purpose> because <reason>. The <controller> has selected the security mechanisms <security> to protect the personal data <phenomena>. The details on how the information has to be presented to the <stakeholder> are defined in the presentation requirement <presentation>.
Application to Running Example
6.2.2. Flow Information Requirements
The <stakeholder> shall be informed that his/her personal data <phenomena> flow <mandatory>ly to the <target> due to the system-to-be that is run by the <controller>. The <target> is located in <countries> and contractual obligations <contract> exist between the <target> and the <controller>. The <stakeholder>’s possibilities to control the flow of his/her data are <controlOptions>. <phenomena> flow to the <target> for the purpose of <purpose> because <reason>. The <controller> has selected the security mechanisms <security> to protect the personal data <phenomena>. The details on how the information has to be presented to the <stakeholder> are defined in the presentation requirement <presentation>.
Application to Running Example
6.2.3. Storage Information Requirements
The <stakeholder> shall be informed that his/her personal data <phenomena> are stored <mandatory>ly by the system-to-be that is run by the <controller>. The <phenomena>’s retention in the system-to-be is <retention>. The <stakeholder>’s possibilities to control the storage of his/her data are <controlOptions>. <phenomena> are stored for the purpose of <purpose> because <reason>. The <controller> has selected the security mechanisms <security> to protect the personal data <phenomenon>. The details on how the information has to be presented to the <stakeholder> are defined in the presentation requirement <presentation>.
Application to Running Example
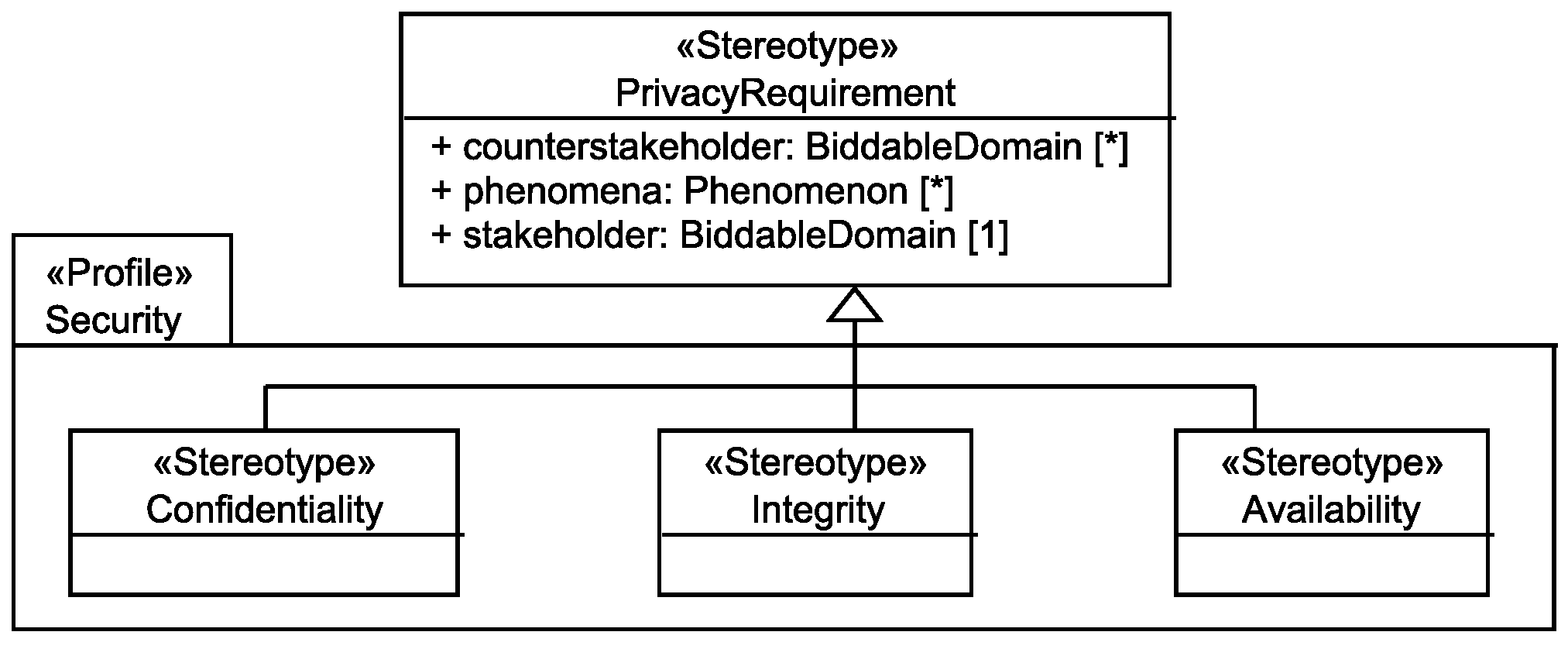
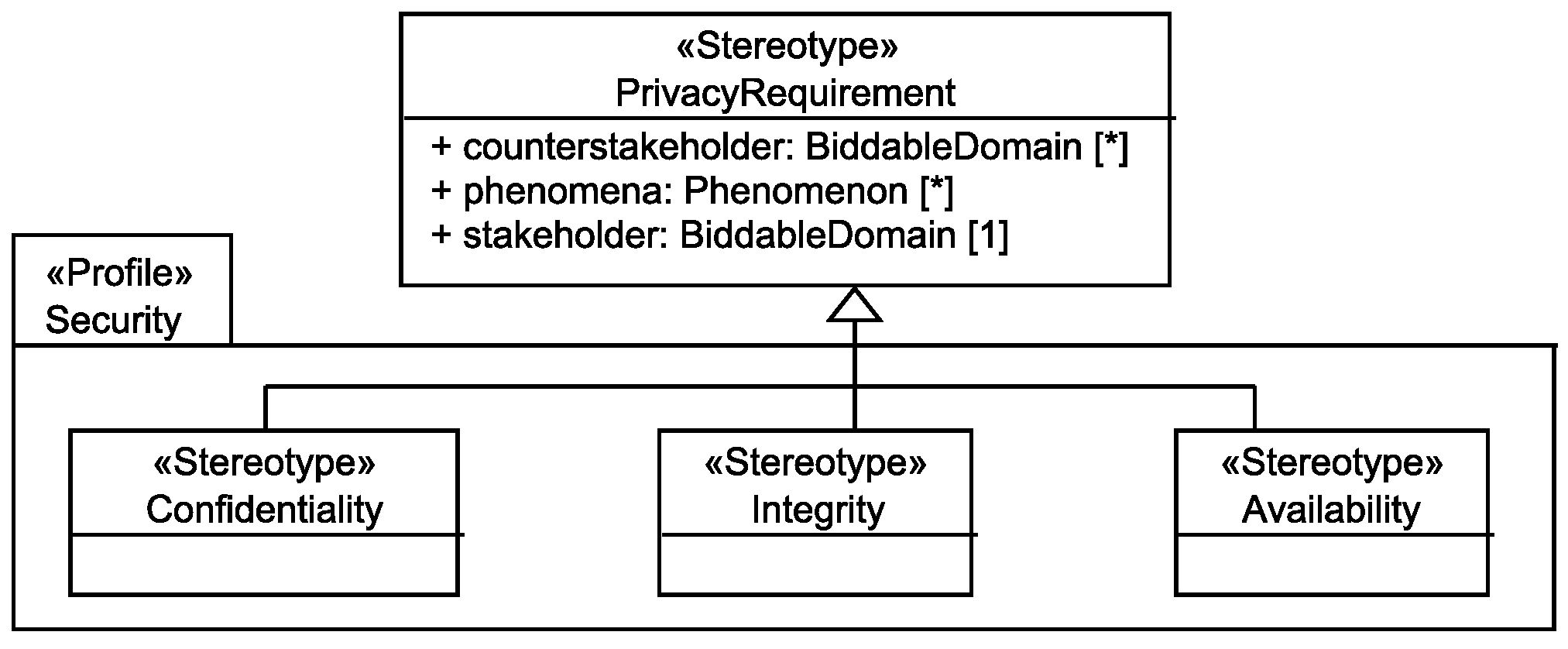
6.3. Security Requirements
The personal data <phenomena> of the <stakeholder> shall be kept confidential from <counterstakeholder>.
Random faults of the system and <counterstakeholder> shall not be able to negatively influence the consistency and correctness of the personal data <phenomena> of the <stakeholder>.
Random faults of the system and <counterstakeholder> shall not be able to negatively influence the availability of the personal data <phenomena> to the corresponding <stakeholder>.
Application to Running Example
7. Adjust Privacy Requirements
7.1. Unlinkability Requirements
7.1.1. Undetectability Requirements
Application to the Running Example
7.1.2. Anonymity and Data Unlinkability Requirements
For the personal information <phenomena> of the <stakeholder> the <counterstakeholder> shall only be able to relate it to a <kind> pseudonym and not to the <stakeholder> himself/herself.
Application to the Running Example
7.2. Transparency Requirements
Application to the Running Example
The information contained in the related transparency requirements has to be presented before the data is collected from the stakeholder in English and made accessible to stakeholders by forwarding the information to them.
7.3. Security Requirements
Application to the Running Example
8. Validate Privacy Requirements
8.1. Privacy Requirements
- VP1
- Raise an error for every privacy requirement if the following condition is not satisfied. Every p in phenomena has to be personal information of the stakeholder.
Application to the Running Example
8.2. Unlinkability Requirements
- VU1
- Raise an error for every undetectability, anonymity, and confidentiality if the following condition is not satisfied. Every p in phenomena must not be contained in another undetectability, anonymity (with a different linkability), or confidentiality requirement for the same stakeholder and counterstakeholder.
- By deciding that the counterstakeholder shall only be able to link the personal information with a weaker linkability to the stakeholder.
- By changing an anonymity requirement (or a part of it) to an undetectability requirement.
- By changing an anonymity requirement (or a part of it) to a confidentiality requirement.
- VU2
- For every undetectability and confidentiality requirement do the following. Raise an error if a phenomenon exists in phenomena that is available to the counterstakeholder.
- VU3
- For every anonymity requirement do the following. Raise an error if personal information exists in phenomena that is linkable to the stakeholder with a greater linkability than linkability for the counterstakeholder.
- VU4
- For every data unlinkability requirement do the following. Raise an error if a pair of personal information exists in pairs that is linkable to each other with a greater linkability than linkability for the counterstakeholder.
- VU5
- For every combination of stakeholder s and counterstakeholder c, warn the user when a personal information of s exists that does not occur in the phenomena of any of the undetectability, anonymity, or confidentiality requirements for s and c.
- VU6
- For every combination of stakeholder s and counterstakeholder c, warn the user when a pair of personal information of s exists for which both elements are available at c, but that does not occur in the pairs of any of the data unlinkability requirements for s and c.
Application to the Running Example
8.3. Transparency Requirements
- VT1
- Raise an error for every transparency requirement where an attribute is unset.
- VT2
- For every transparency requirement, warn the user if an attribute with a multiplicity greater than 1 (except counterstakeholder) is empty.
- VT3
- Raise an error for every collection and storage information requirement if a p in phenomena exists that is not available at a designed domain.
- VT4
- Raise an error for every flow information requirement if a p in phenomena exists that is not available at the target.
- VT5
- Warn the user if a personal information flows from a given domain to a designed domain, but no corresponding collection information requirement exists.
- VT6
- Warn the user if a personal information is available at a designed domain, but no corresponding storage information requirement exists.
- VT7
- Warn the user if a personal information flows from a designed domain to a given domain, or between two given domains due to a functional requirement, but no corresponding flow information requirement exists.
Application to the Running Example
8.4. Security Requirements
- VS1
- Warn the user if a personal information of a stakeholder that is available at a designed domain is not contained in the corresponding availability and integrity requirements.
- VS2
- Raise an error if not all phenomena contained in an availability or integrity requirement are available at a designed domain.
Application to the Running Example
9. Tool Support
9.1. Technical Realization
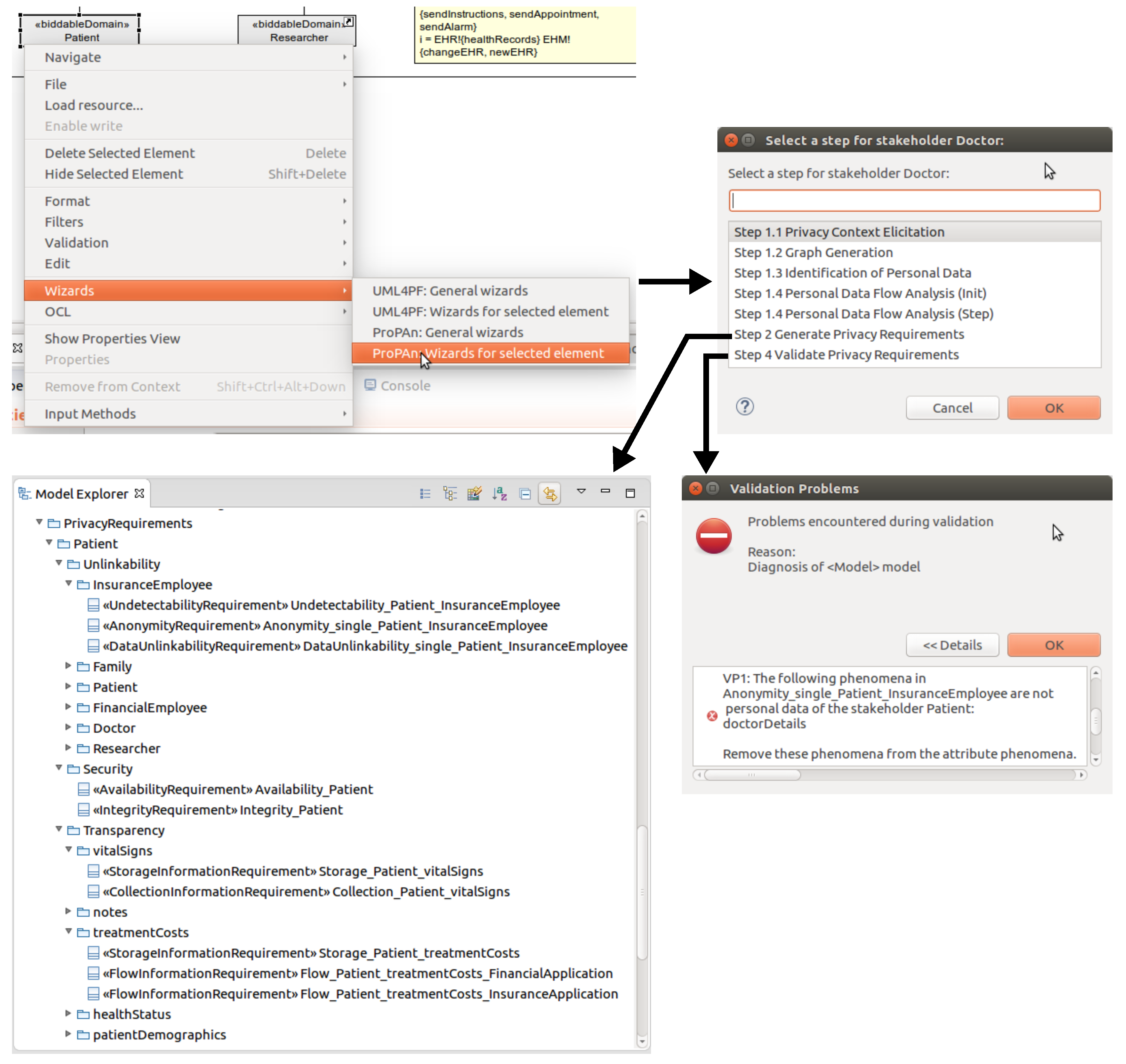
9.2. Using the ProPAn Tool
 in the case that an error was raised for it during the validation or with the symbol
in the case that an error was raised for it during the validation or with the symbol  if a was warning produced for it. In both cases a tooltip provides the information which validation condition was violated and why.
if a was warning produced for it. In both cases a tooltip provides the information which validation condition was violated and why.10. Related Work
11. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| EHR | Electronic Health Record |
| EHS | Electronic Health System |
| PET | Privacy Enhancing Technology |
| ProPAn | Problem-based Privacy Analysis |
| SDFG | Stakeholder Data Flow Graph |
References
- European Commission. Proposal for a Regulation of the European Parliament and of the Council on the Protection of Individuals with Regard to the Processing of Personal Data and on the Free Movement of Such Data (General Data Protection Regulation). 2012. Available online: http://ec.europa.eu/justice/data-protection/document/review2012/com_2012_11_en.pdf (accessed on 24 May 2016).
- Verizon. 2016 Data Breach Investigations Report. Available online: http://www.verizonenterprise.com/verizon-insights-lab/dbir/2016/ (accessed on 24 May 2016).
- Ponemon Institute. 2015 Cost of Data Breach Study: Global Analysis. Available online: http://www-03.ibm.com/security/data-breach/ (accessed on 24 May 2016).
- GSMA. MOBILE PRIVACY: Consumer Research Insights and Considerations for Policymakers. 2014. Available online: http://www.gsma.com/publicpolicy/wp-content/uploads/2014/02/MOBILE_PRIVACY_Consumer_research_insights_and_considerations_for_policymakers-Final.pdf (accessed on 24 May 2016).
- Hansen, M.; Jensen, M.; Rost, M. Protection Goals for Privacy Engineering. In Proceedings of the 2015 IEEE Symposium on Security and Privacy Workshops, SPW 2015, San Jose, CA, USA, 21–22 May 2015.
- Meis, R.; Heisel, M.; Wirtz, R. A Taxonomy of Requirements for the Privacy Goal Transparency. In Trust, Privacy, and Security in Digital Business; Springer: Cham, Switzerland, 2015; pp. 195–209. [Google Scholar]
- Cavoukian, A. The 7 Foundational Principles. 2011. Available online: https://www.ipc.on.ca/images/resources/7foundationalprinciples.pdf (accessed on 24 May 2016).
- Jackson, M. Problem Frames: Analyzing and Structuring Software Development Problems; Addison-Wesley: Boston, MA, USA, 2001. [Google Scholar]
- Beckers, K.; Faßbender, S.; Heisel, M.; Meis, R. A Problem-based Approach for Computer Aided Privacy Threat Identification; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–16. [Google Scholar]
- ProPAn: A UML4PF Extension. Available online: http://www.uml4pf.org/ext-propan/index.html (accessed on 24 May 2016).
- Network of Excellence (NoE) on Engineering Secure Future Internet Software Services and Systems. Available online: http://www.nessos-project.eu (accessed on 24 May 2016).
- Côté, I.; Hatebur, D.; Heisel, M.; Schmidt, H. UML4PF—A Tool for Problem-Oriented Requirements Analysis. In Proceedings of the 2011 IEEE 19th International Requirements Engineering Conference, Trento, Italy, 29 August–2 September 2011; pp. 349–350.
- Meis, R. Problem-Based Consideration of Privacy-Relevant Domain Knowledge. In Privacy and Identity Management for Emerging Services and Technologies; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Beckers, K.; Faßbender, S.; Gritzalis, S.; Heisel, M.; Kalloniatis, C.; Meis, R. Privacy-Aware Cloud Deployment Scenario Selection. In Trust, Privacy, and Security in Digital Business; Springer: Cham, Switzerland, 2014; pp. 94–105. [Google Scholar]
- Meis, R.; Heisel, M. Supporting Privacy Impact Assessments Using Problem-Based Privacy Analysis. In Software Technologies, Proceedings of the 10th International Joint Conference, ICSOFT 2015, Colmar, France, 20–22 July 2015; Lorenz, P., Cardoso, J., Maciaszek, L.A., van Sinderen, M., Eds.; Communications in Computer and Information Science. Springer: Cham, Switzerland, 2016; pp. 79–98. [Google Scholar]
- Pfitzmann, A.; Hansen, M. A Terminology for Talking About Privacy by Data Minimization: Anonymity, Unlinkability, Undetectability, Unobservability, Pseudonymity, and Identity Management. 2010. Available online: http://www.maroki.de/pub/dphistory/2010_Anon_Terminology_v0.34.pdf (accessed on 23 May 2016).
- Sabit, S. Consideration of Intervenability Requirements in Software Development. Master’s Thesis, University of Duisburg-Essen, Duisburg, Germany, 2015. [Google Scholar]
- UML4PF Tool. Available online: http://www.uml4pf.org (accessed on 24 May 2016).
- Papyrus. Available online: https://eclipse.org/papyrus/ (accessed on 24 May 2016).
- Eclipse IDE. Available online: http://www.eclipse.org (accessed on 24 May 2016).
- Epsilon Platform. Available online: http://www.eclipse.org/epsilon (accessed on 24 May 2016).
- EMF-Based Models. Available online: http://www.eclipse.org/modeling/emf/ (accessed on 24 May 2016).
- GMF-Based Models. Available online: http://www.eclipse.org/modeling/gmp/ (accessed on 24 May 2016).
- Deng, M.; Wuyts, K.; Scandariato, R.; Preneel, B.; Joosen, W. A privacy threat analysis framework: Supporting the elicitation and fulfillment of privacy requirements. Requir. Eng. 2011, 16, 3–32. [Google Scholar] [CrossRef]
- Howard, M.; Lipner, S. The Security Development Lifecycle; Microsoft Press: Redmond, WA, USA, 2006. [Google Scholar]
- Kalloniatis, C.; Kavakli, E.; Gritzalis, S. Addressing privacy requirements in system design: The PriS method. Requir. Eng. 2008, 13, 241–255. [Google Scholar] [CrossRef]
- Liu, L.; Yu, E.; Mylopoulos, J. Security and Privacy Requirements Analysis within a Social Setting. In Proceedings of the 11th IEEE International Conference on Requirements Engineering, Monterey Bay, CA, USA, 8–12 September 2003; pp. 151–161.
- Yu, E. Towards Modeling and Reasoning Support for Early-Phase Requirements Engineering. In Proceedings of the 3rd IEEE International Symposium on Requirements Engineering, Annapolis, MD, USA, 6–10 January 1997.
- Omoronyia, I.; Cavallaro, L.; Salehie, M.; Pasquale, L.; Nuseibeh, B. Engineering Adaptive Privacy: On the Role of Privacy Awareness Requirements. In Proceedings of the 2013 International Conference on Software Engineering, ICSE ’13, San Francisco, CA, USA, 18–26 May 2013.
- Oetzel, M.; Spiekermann, S. A systematic methodology for privacy impact assessments: A design science approach. Eur. J. Inf. Syst. 2014, 23, 126–150. [Google Scholar] [CrossRef]
- Antón, A.I.; Earp, J.B. A requirements taxonomy for reducing Web site privacy vulnerabilities. Requir. Eng. 2004, 9, 169–185. [Google Scholar] [CrossRef]
- Hoepman, J. Privacy Design Strategies (Extended Abstract). In Proceedings of the 29th IFIP TC 11 International Conference on ICT Systems Security and Privacy Protection, Marrakech, Morocco, 2–4 June 2014.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UnlinkabilityRequirement | Phenomena / Pairs |
|---|---|
| Undetectability | healthStatus, mobileDevices, deviceID, vitalSigns, notes |
| Anonymity linkability=single | patientBillingContact, patientDemographics, healthInformation, insuranceNumber, patientInsuranceContact, treatmentCosts, treatment, diagnosis, appointments, instructions, alarms |
| Data Unlinkability linkability=single | (treatmentCosts,diagnosis), (treatmentCosts,patientDemographics), |
| (treatmentCosts,healthInformation), (treatmentCosts,instructions), | |
| (treatmentCosts,alarms), (treatmentCosts,insuranceNumber), | |
| (treatmentCosts,patientBillingContact), | |
| (treatmentCosts,patientInsuranceContract), (treatmentCosts,treatment), | |
| (treatmentCosts,appointments),(diagnosis,patientDemographics), | |
| (diagnosis,healthInformation), (diagnosis,instructions), (diagnosis,alarms), | |
| (diagnosis,insuranceNumber), (diagnosis,patientBillingContact), | |
| (diagnosis,patientInsuranceContract), (diagnosis,treatment), | |
| (diagnosis,appointments), (patientDemographics,healthInformation), | |
| (patientDemographics,instructions), (patientDemographics,alarms), | |
| (patientDemographics,insuranceNumber), | |
| (patientDemographics,patientBillingContact), | |
| (patientDemographics,patientInsuranceContract), | |
| (patientDemographics,treatment), (patientDemographics,appointments), | |
| (healthInformation,instructions), (healthInformation,alarms), | |
| (healthInformation,insuranceNumber), (healthInformation,patientBillingContact), | |
| (healthInformation,patientInsuranceContract), (healthInformation,treatment), | |
| (healthInformation,appointments), (instructions,alarms), | |
| (instructions,insuranceNumber), (instructions,patientBillingContact), | |
| (instructions,patientInsuranceContract), (instructions,treatment), | |
| (instructions,appointments), (alarms,insuranceNumber), | |
| (alarms,patientBillingContact), (alarms,patientInsuranceContract), | |
| (alarms,treatment), (alarms,appointments), | |
| (insuranceNumber,patientBillingContact), | |
| (insuranceNumber,patientInsuranceContract), (insuranceNumber,treatment), | |
| (insuranceNumber,appointments), (treatment,appointments), | |
| (patientBillingContact,patientInsuranceContract), | |
| (patientBillingContact,treatment), (patientBillingContact,appointments), | |
| (patientInsuranceContract,treatment), (patientInsuranceContract,appointments) |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meis, R.; Heisel, M. Computer-Aided Identification and Validation of Privacy Requirements. Information 2016, 7, 28. https://doi.org/10.3390/info7020028
Meis R, Heisel M. Computer-Aided Identification and Validation of Privacy Requirements. Information. 2016; 7(2):28. https://doi.org/10.3390/info7020028
Chicago/Turabian StyleMeis, Rene, and Maritta Heisel. 2016. "Computer-Aided Identification and Validation of Privacy Requirements" Information 7, no. 2: 28. https://doi.org/10.3390/info7020028
APA StyleMeis, R., & Heisel, M. (2016). Computer-Aided Identification and Validation of Privacy Requirements. Information, 7(2), 28. https://doi.org/10.3390/info7020028