
Improved Genetic Algorithm Optimization for Forward Vehicle Detection Problems

Abstract
:1. Introduction
2. System Overview
2.1. On-Board System Setup

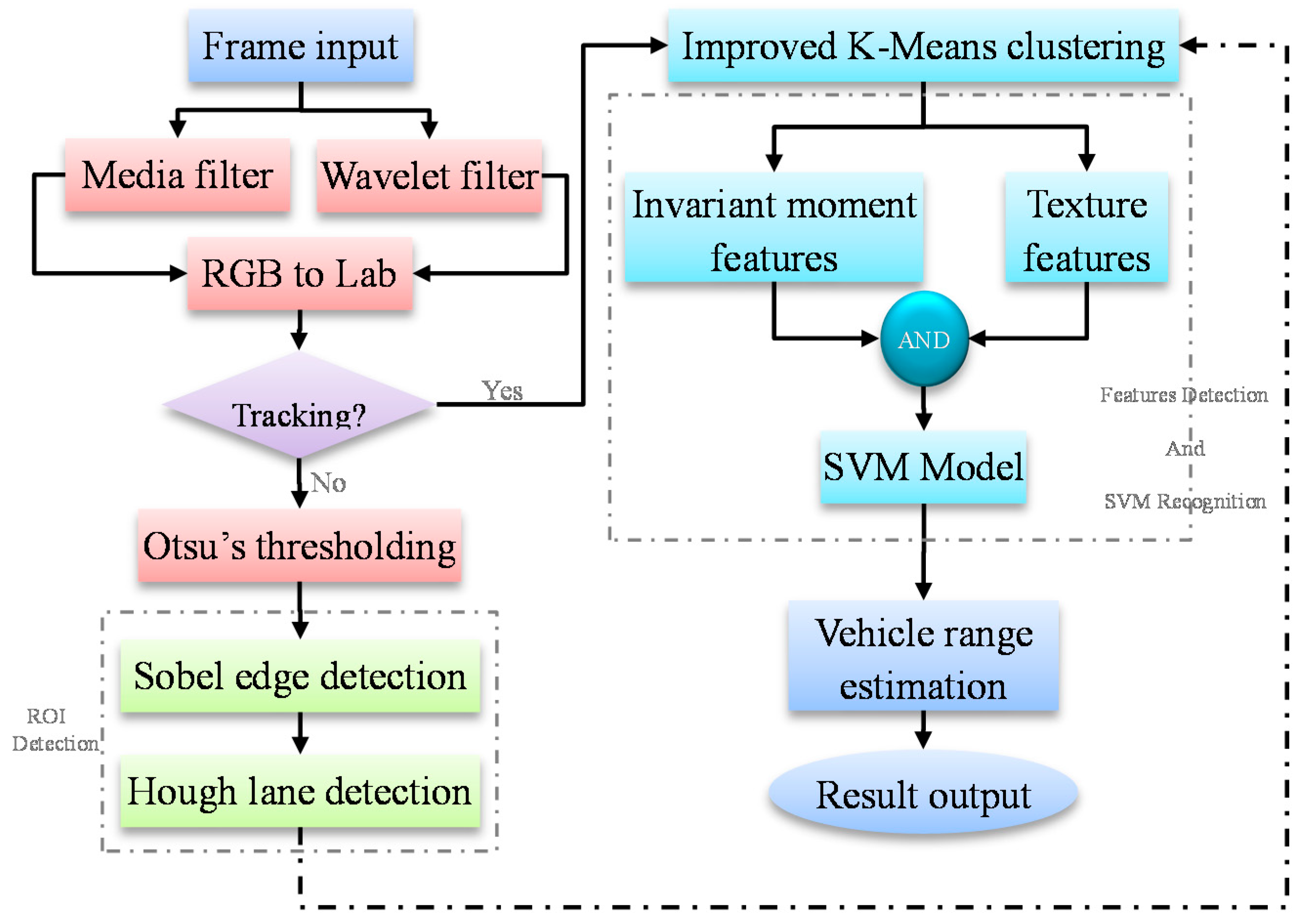
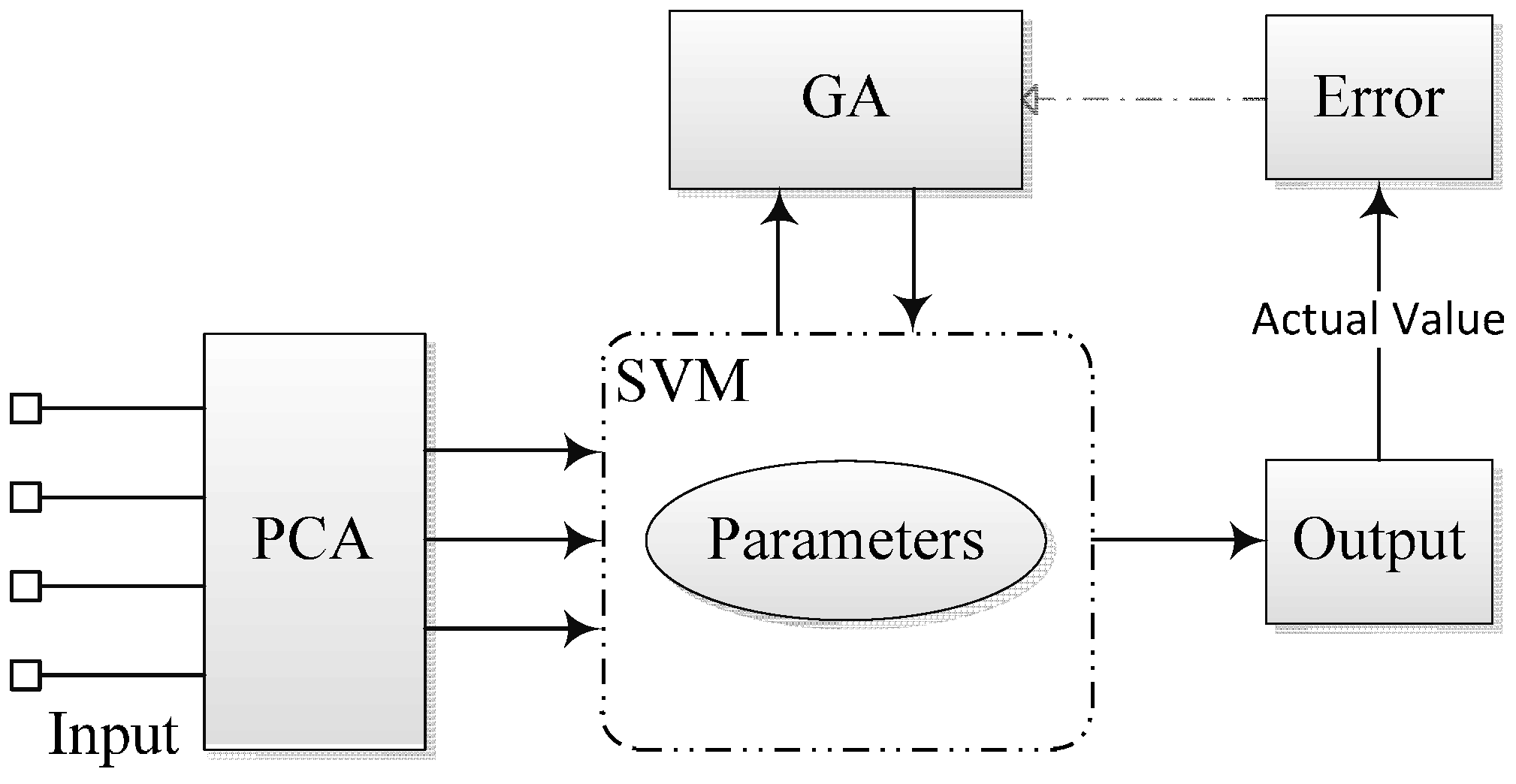
2.2. Overview of the Proposed Method
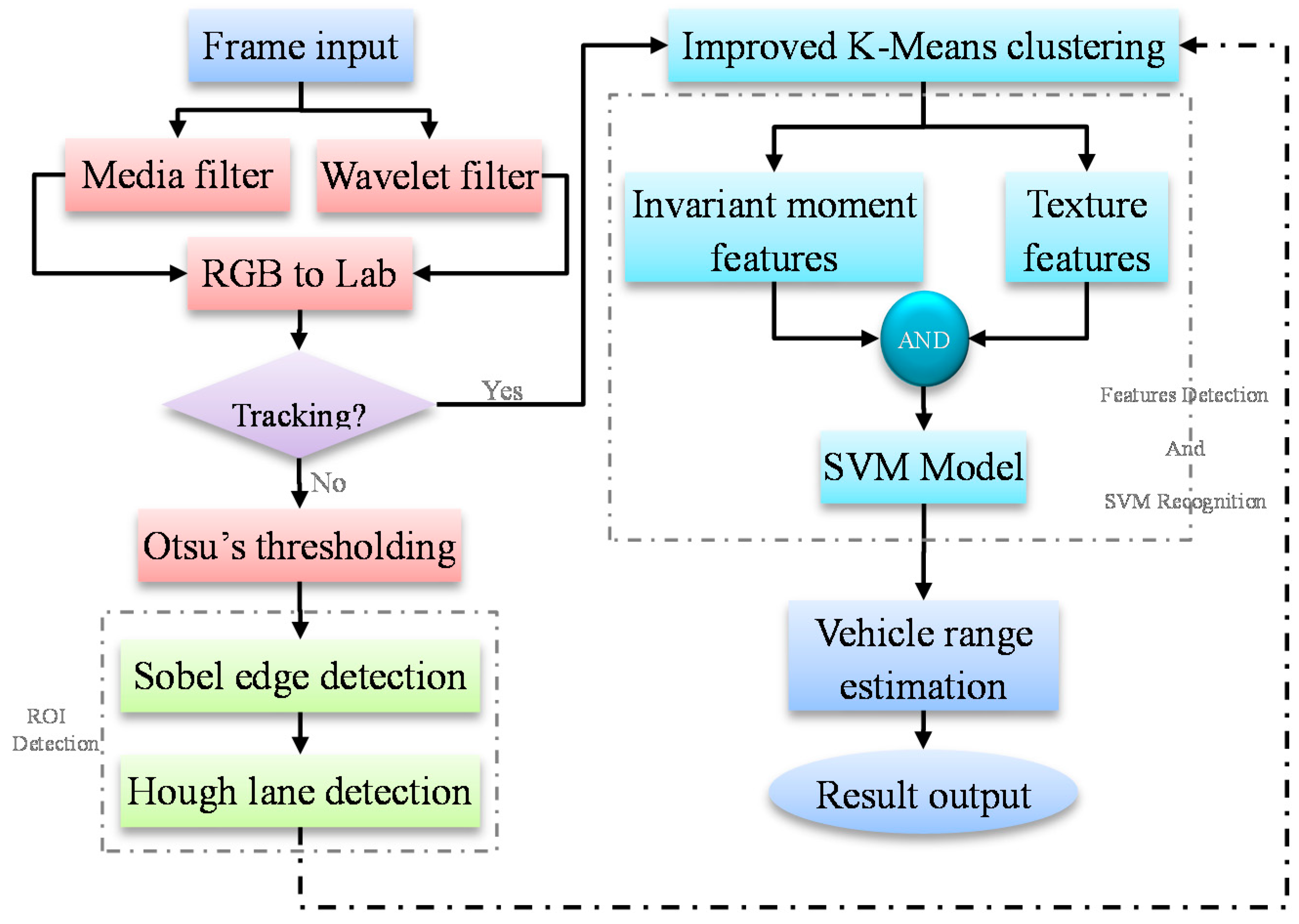
3. Vehicle Detection Using SVM
3.1. Hypothesis Generation

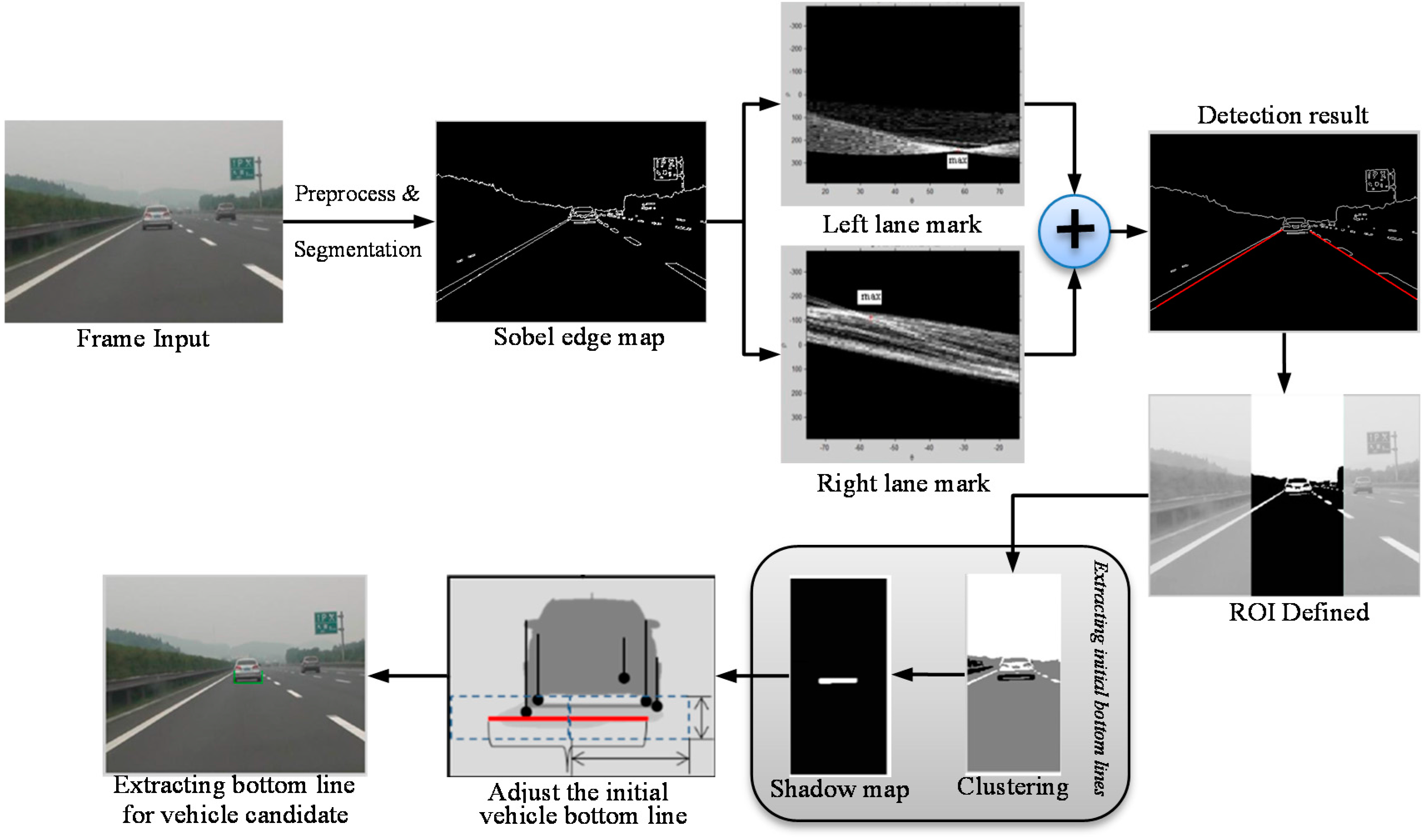
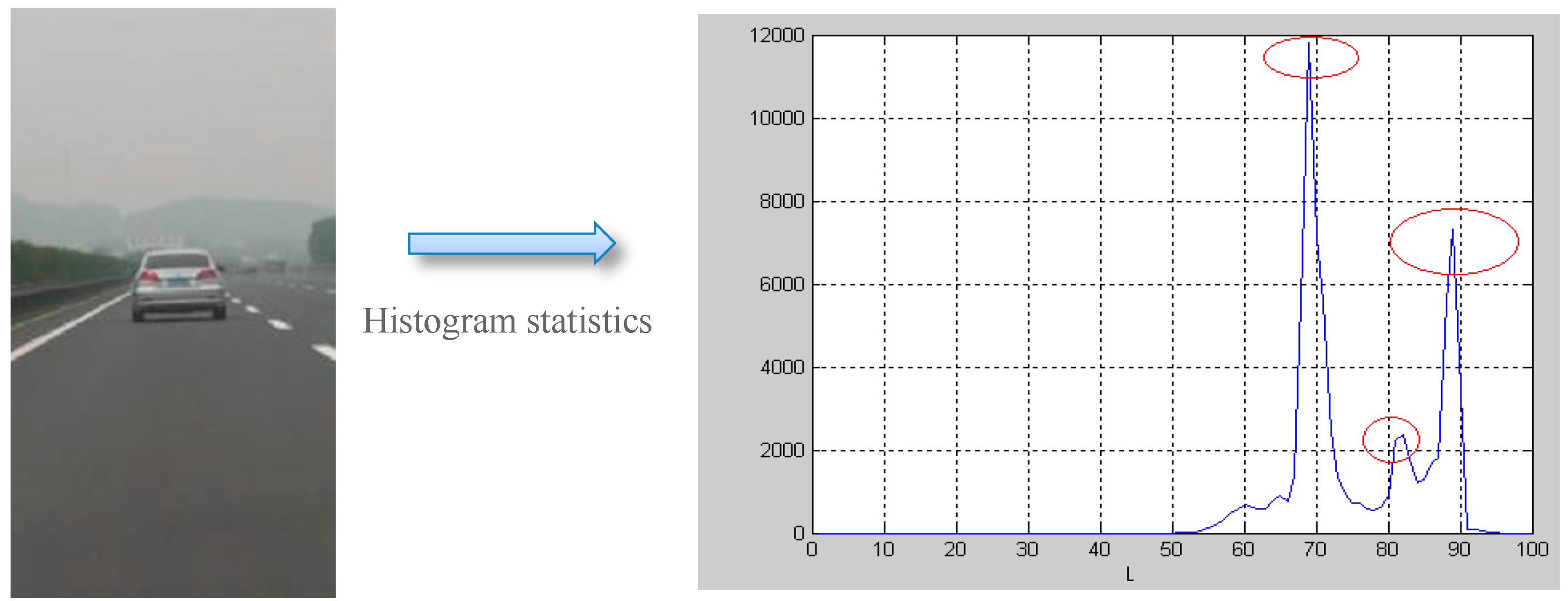
3.1.1. Hypothesis Generation: Image Preprocess and Segmentation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filter | Mask size | SNR (db) | RMSE |
|---|---|---|---|
| Original image | —— | 5.51 | 0.24 |
| Median filter | 3 × 3 | 5.94 | 0.22 |
| Mean filter | 3 × 3 | 5.54 | 0.23 |
| Wiener filter | 3 × 3 | 5.98 | 0.22 |
| Wavelet filter | Soft threshold | 7.83 | 0.31 |
| Hard threshold | 12.37 | 0.19 | |
| Compromise threshold | 31.07 | 0.02 |
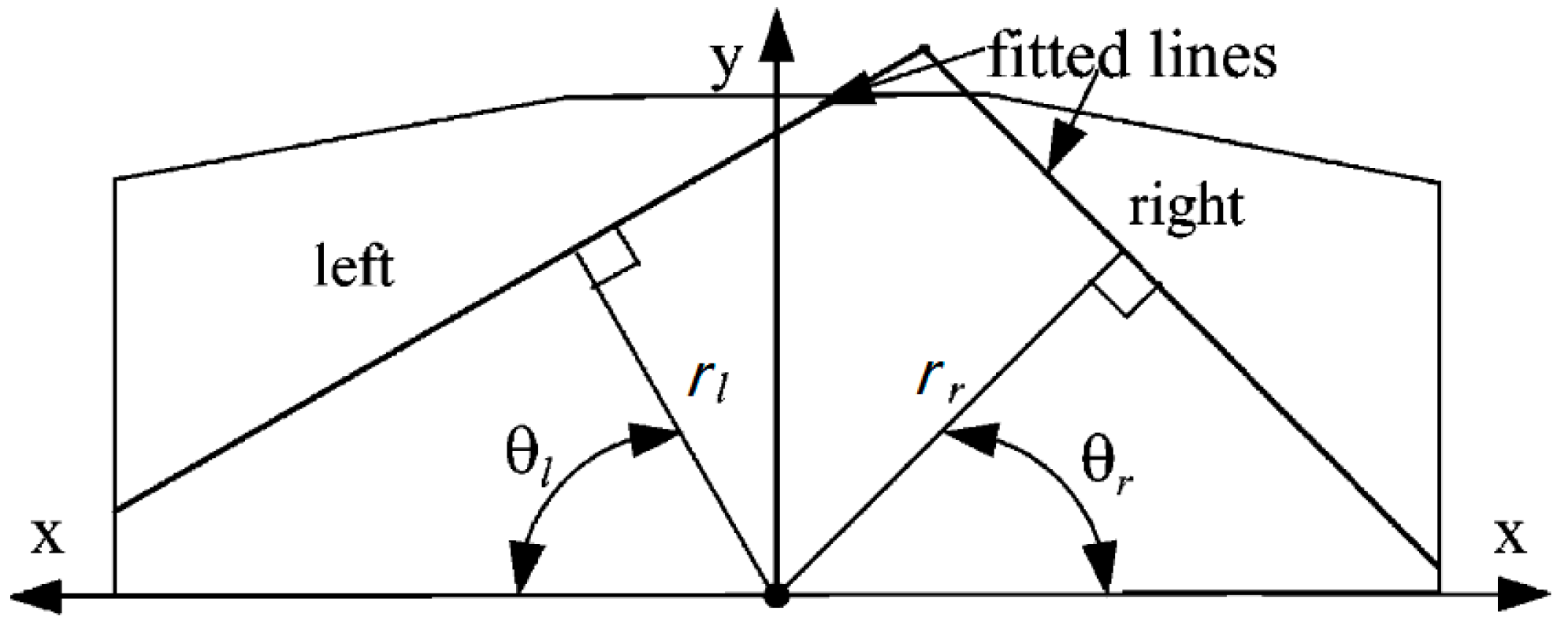
3.1.2. Hypothesis Generation: Lane Detection and ROI Defining

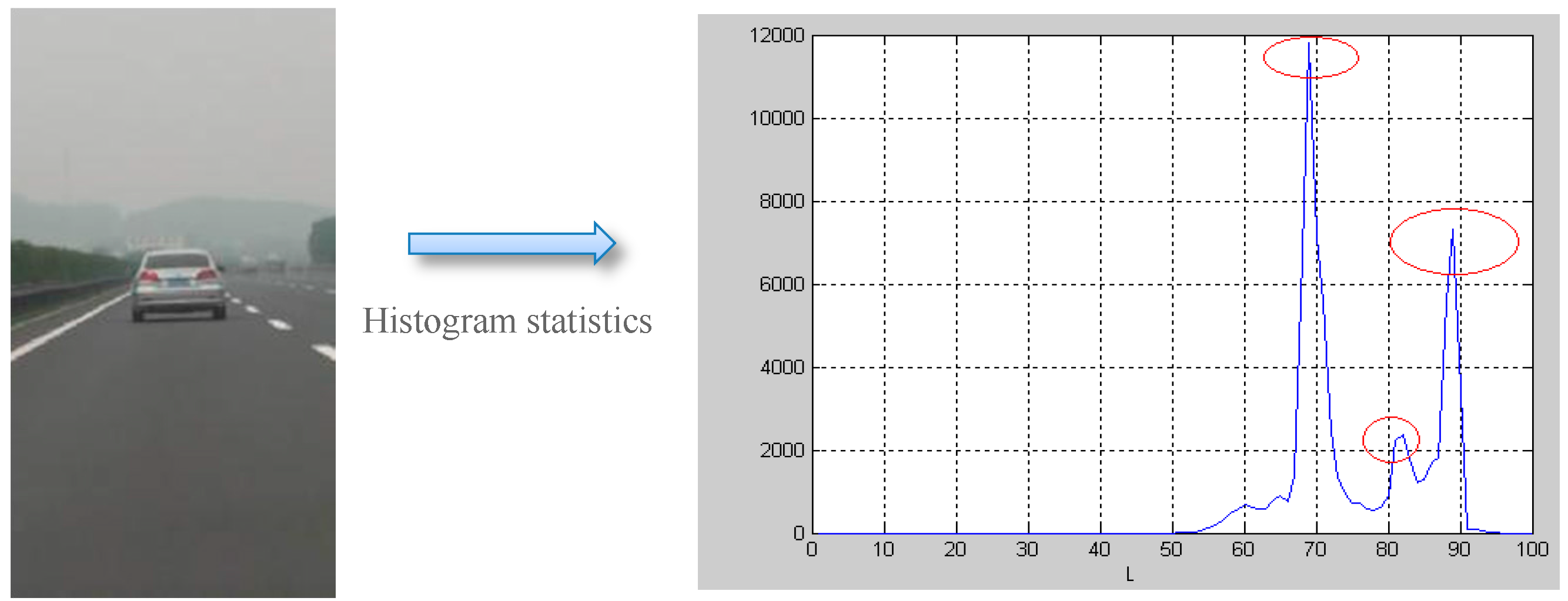
3.1.3. Hypothesis Generation: Shadow Detection
| Traditional method | Improved method | ||||
|---|---|---|---|---|---|
| Experiment No. | 1 | 2 | 3 | 4 | 5 |
| Iterations times | 28 | 25 | 18 | 23 | 9 |
| Time consuming (s) | 1.9 | 1.7 | 1.3 | 1.5 | 0.15 |
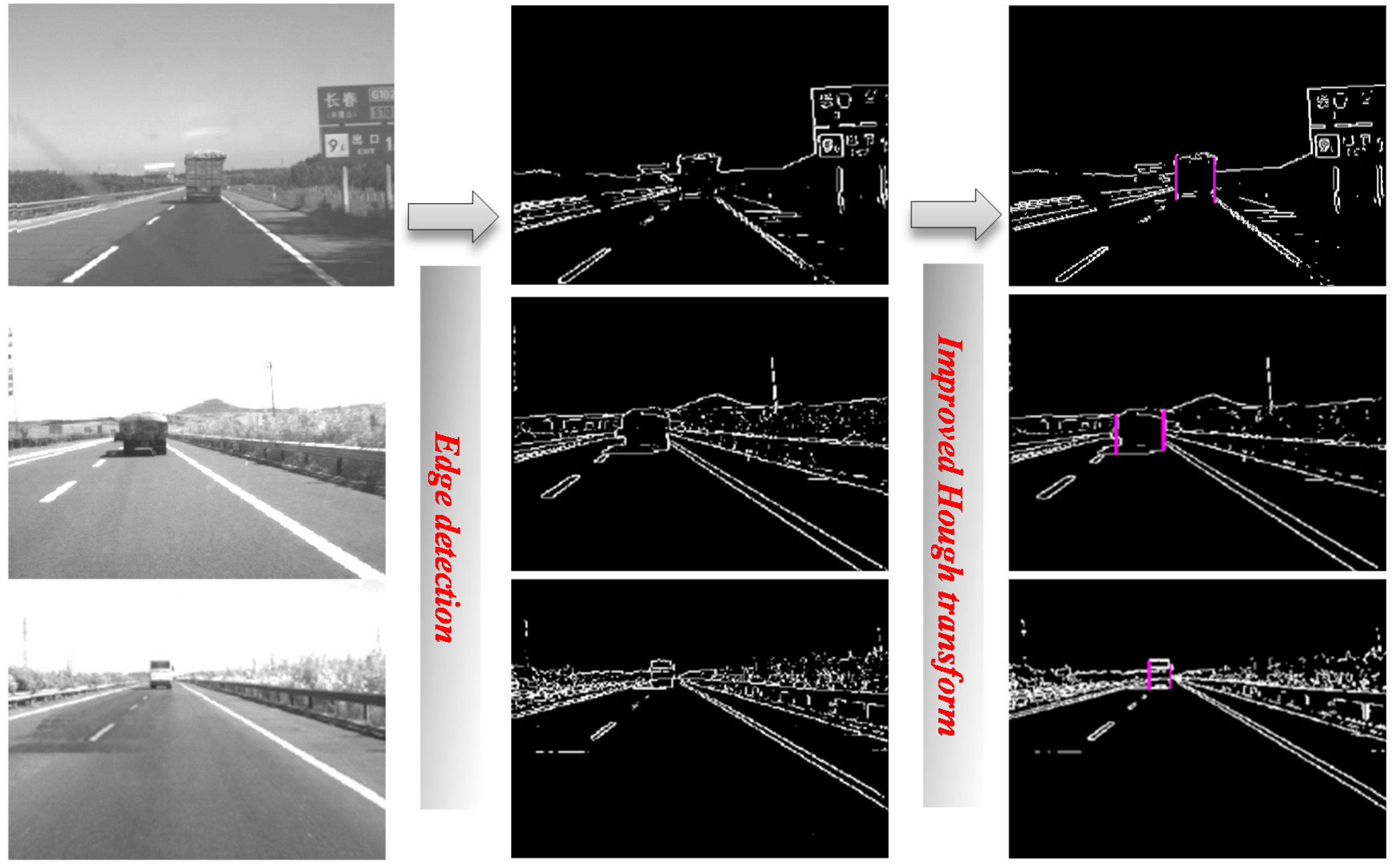
3.1.4. Hypothesis Generation: Extracting Bottom Lines for Vehicle Candidates

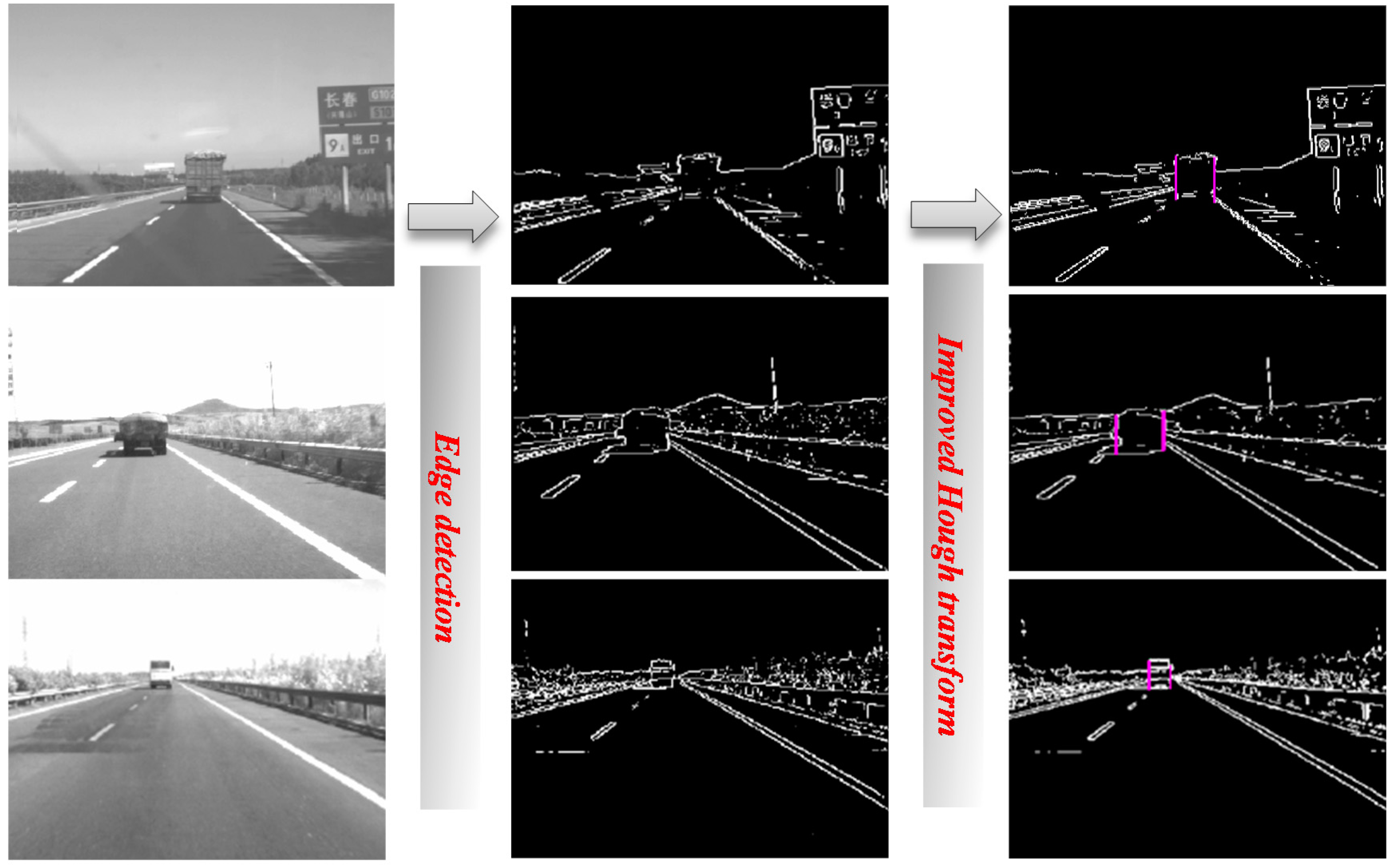
3.1.5. Hypothesis Generation: Extracting Bounding box for Vehicle Candidates
3.2. Hypothesis Verification
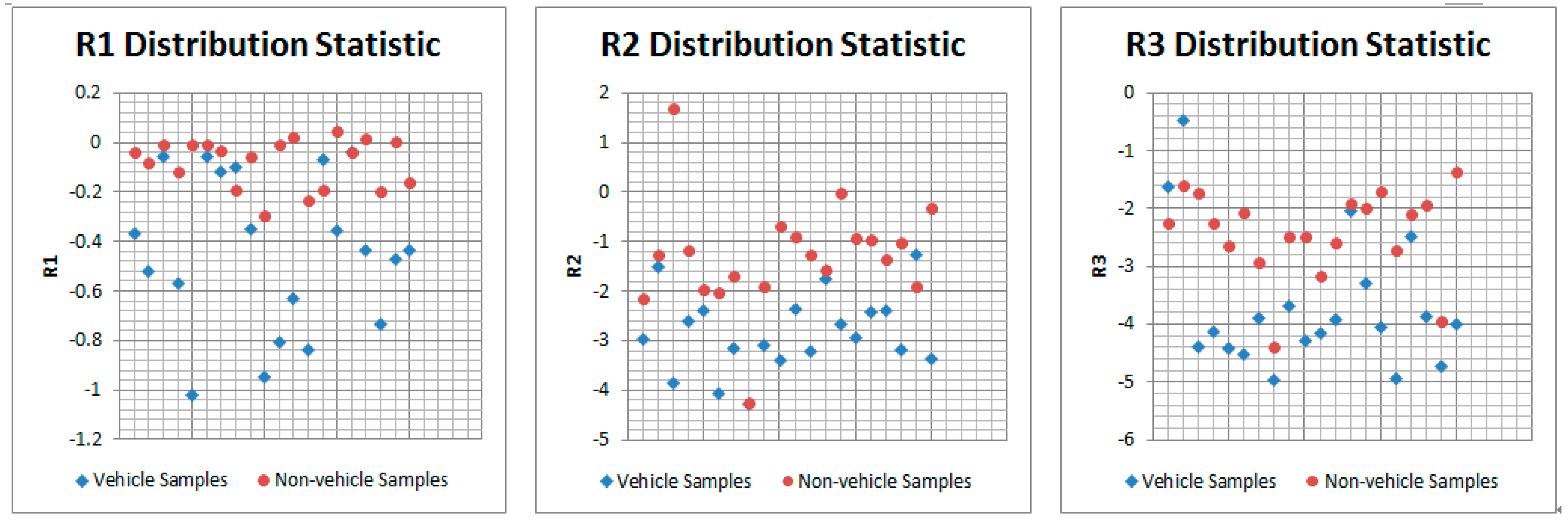
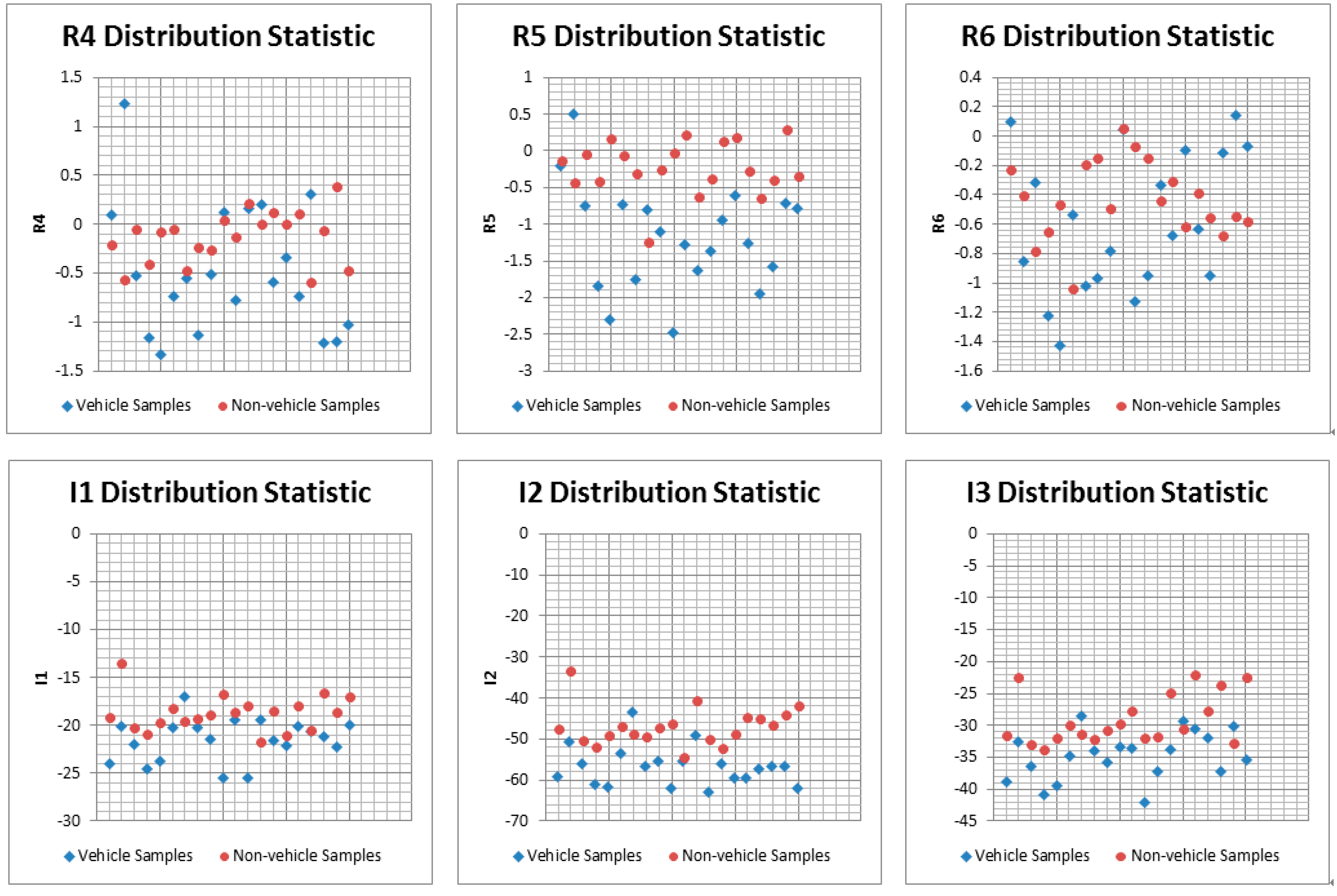
3.2.1. Hypothesis Verification: Features Extraction
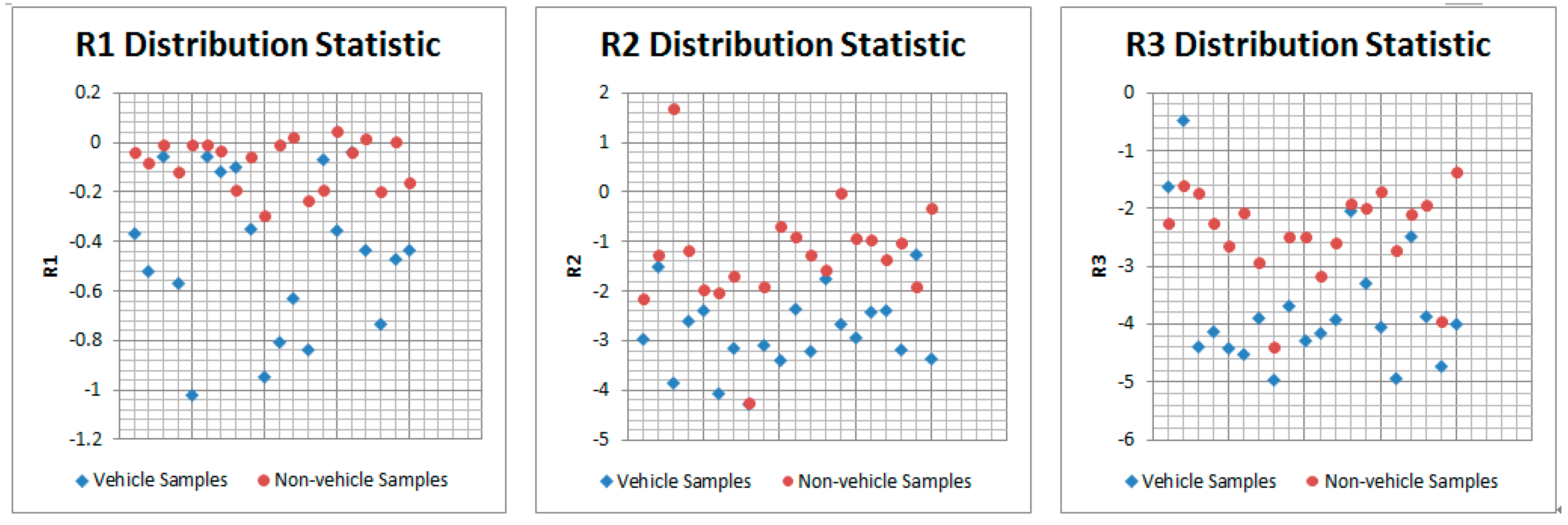
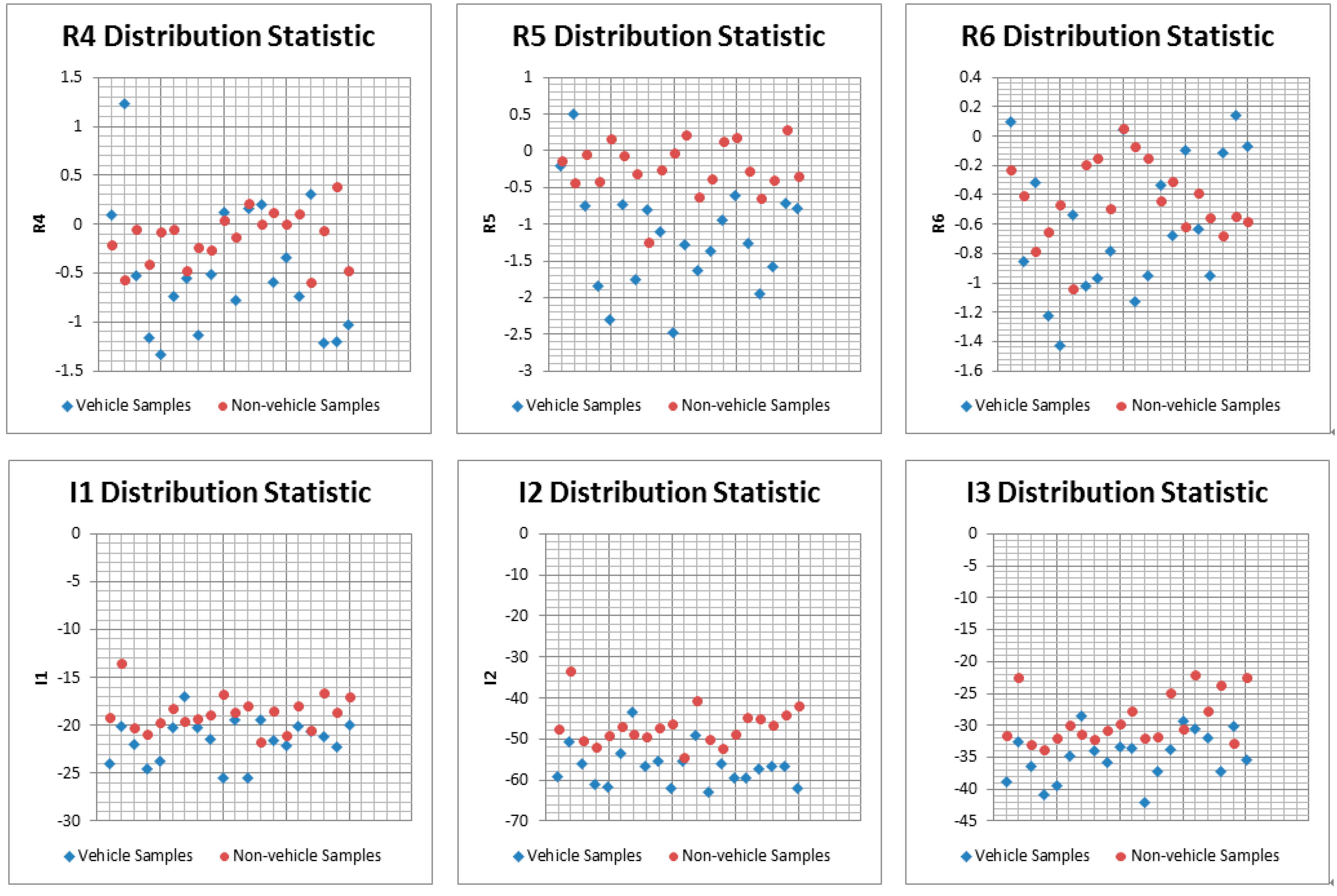


3.2.2. Hypothesis Verification: Vehicle Candidate Verification by SVM
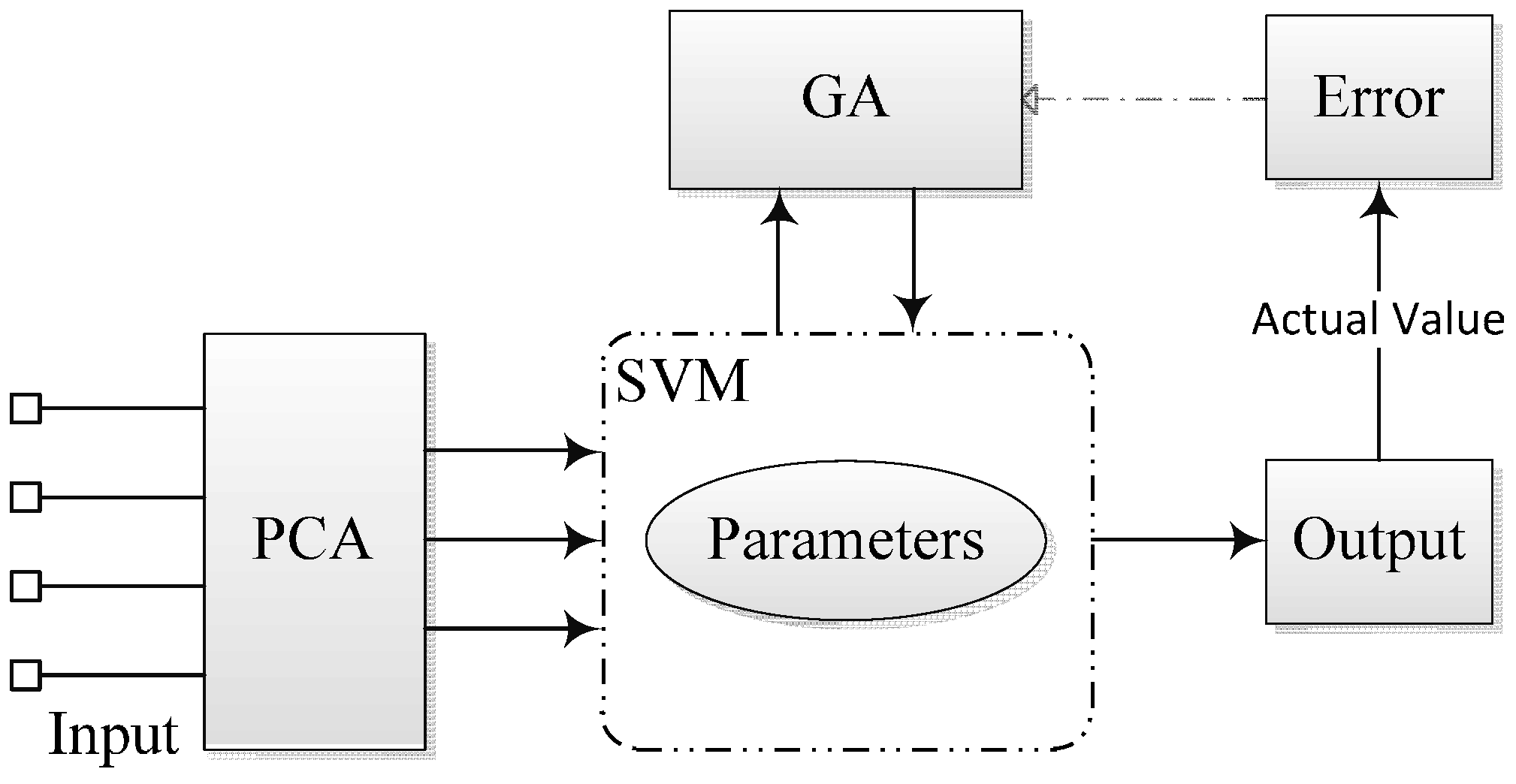
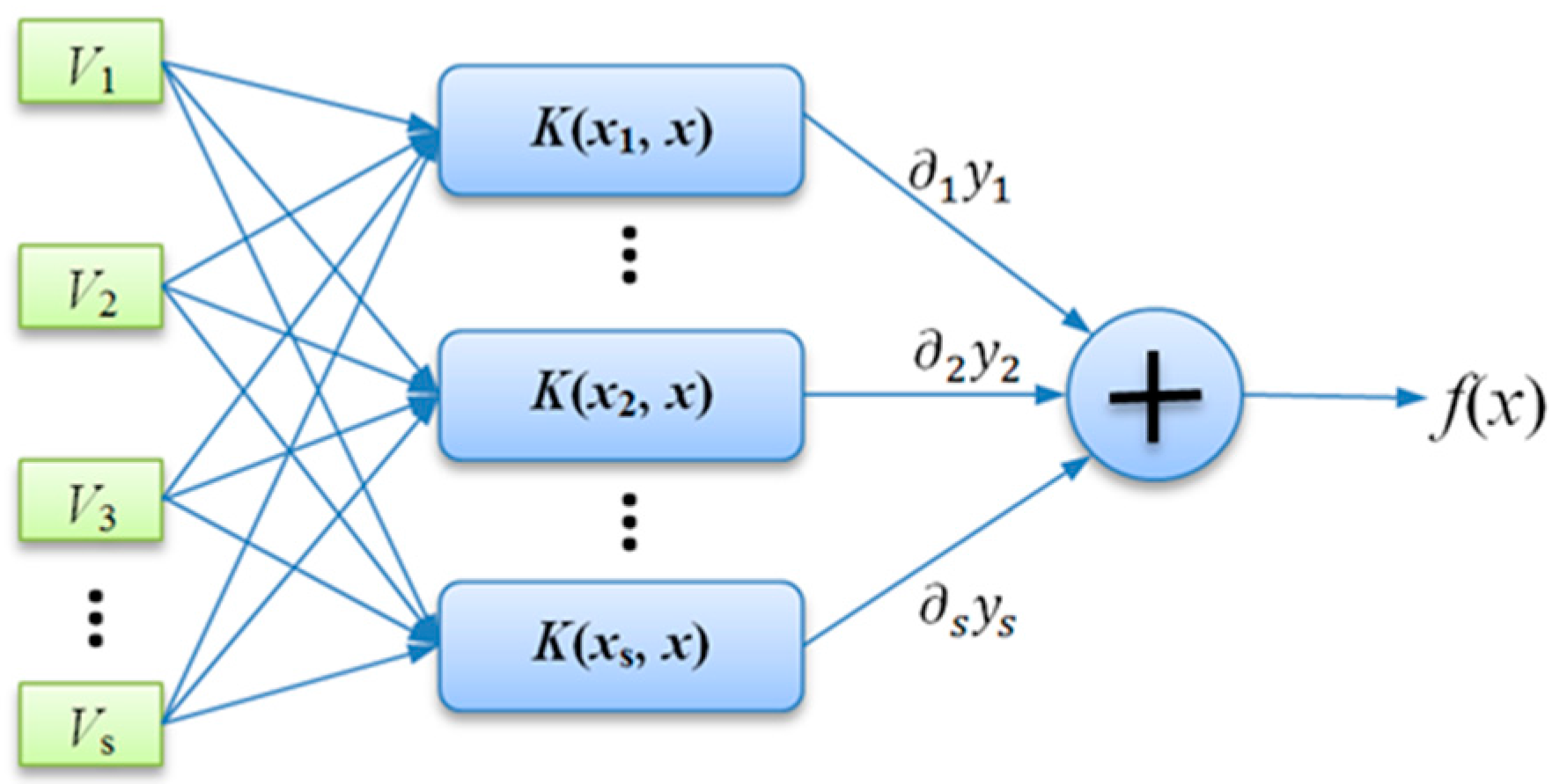
- Encoding of chromosome: In GA, a standard representation of each candidate solution is as a chromosome that is composed of “genes”. For the SVM parameters optimization problem in this paper, the real encodings were adopted since the parameters are continuous-valued. Each chromosome consists of , and , which represent the three parameters, respectively. Here, g is the current generation. In order to reduce the search space, the previous literature has given out the recommended searching space which respectively attribute to the range , and .
- Fitness function: A fitness function is a particular type of objective function that is used to summarise how close the possible solution is to achieving the set aims. For the SVM parameters optimization problem in this paper, considering that GA is always finding the maximum fitness of the individual chromosome, mean squared error (MSE) is adopted.where, is the prediction value by the SVM model; is the observed value; is the number of observation variables.
- Selection operation: During each successive generation, a proportion of the existing population is selected to breed a new generation. Individual solutions are selected through a fitness-based process, where fitter solutions (as measured by a fitness function) are typically more likely to be selected. In this paper, the roulette selection strategy is adopted. Based on the fitness calculation results, the sum fitness value of the entire population and then the ratio corresponding to each chromosome are obtained. In the next step, a random number (range from 0 to 1) is used for determining the range of the cumulative probability. The chromosome falling within the expected range is selected out.
- Genetic operators: For each new solution to be produced, a pair of “parent” solutions is selected for breeding from the pool selected previously. A second generation population of solutions is generated from those selected through a combination of genetic operators: crossover (also called recombination), and mutation. Crossover is a genetic operator used to vary the programming of a chromosome or chromosomes from one generation to the next. It is analogous to reproduction and biological crossover. Cross over is a process of taking more than one parent solution and producing a child solution from them. In literature [28], an arithmetic crossover operator is used.where, is the “parent” chromosomes; is the “child” chromosomes; is a random probability value with range (0,1).Mutation is a genetic operator used to maintain genetic diversity from one generation chromosome to the next. Mutation occurs during evolution according to a user-definable mutation probability. A very small mutation rate may lead to premature convergence of the genetic algorithm and a very high rate may lead to loss of good solutions unless there is elitist selection. In general, the mutation rate is defined with the range [0.001, 0.1]. In this paper, according to the previous literature, the mutation rate is set to 0.05.
- Termination: This generational process is repeated until a termination condition has been reached. In this paper, the search loop continues until or the number of generation reaches the maximum number of generations .
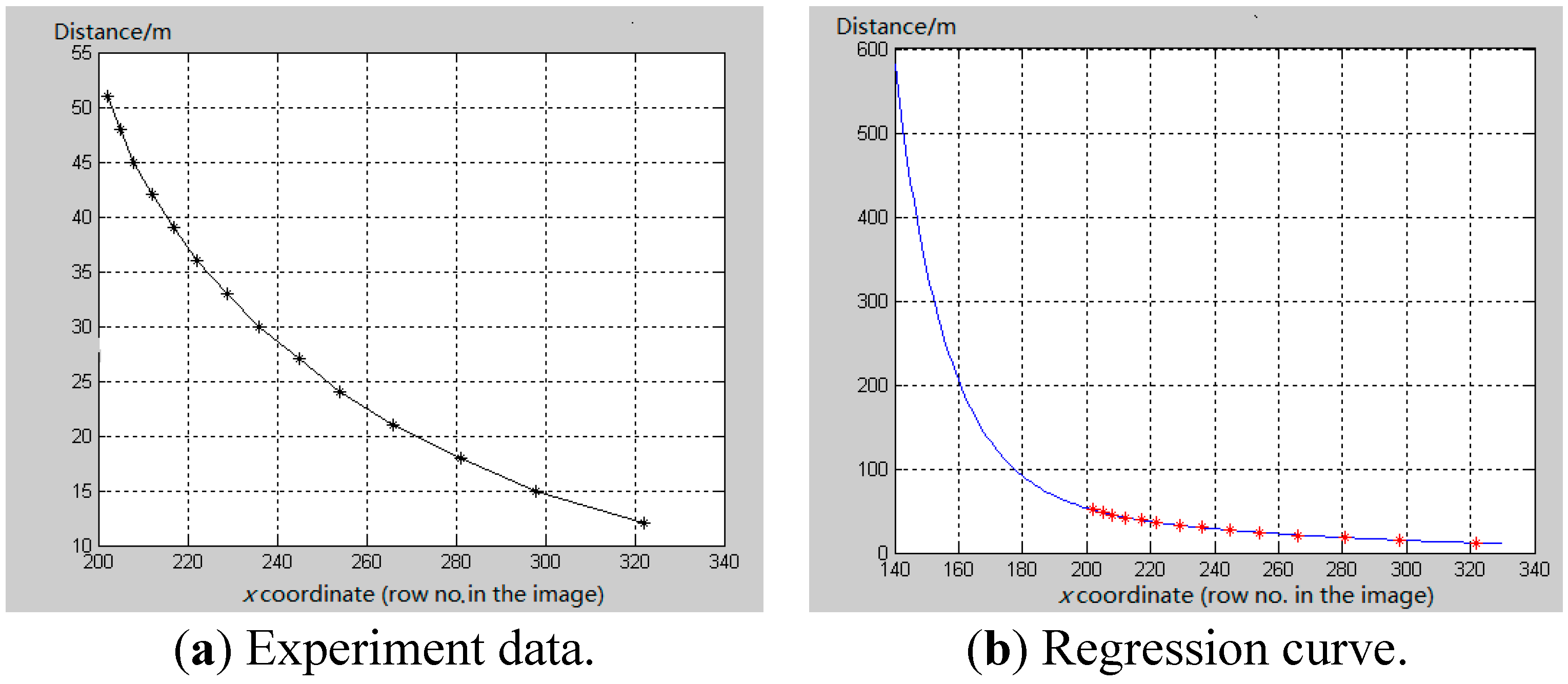
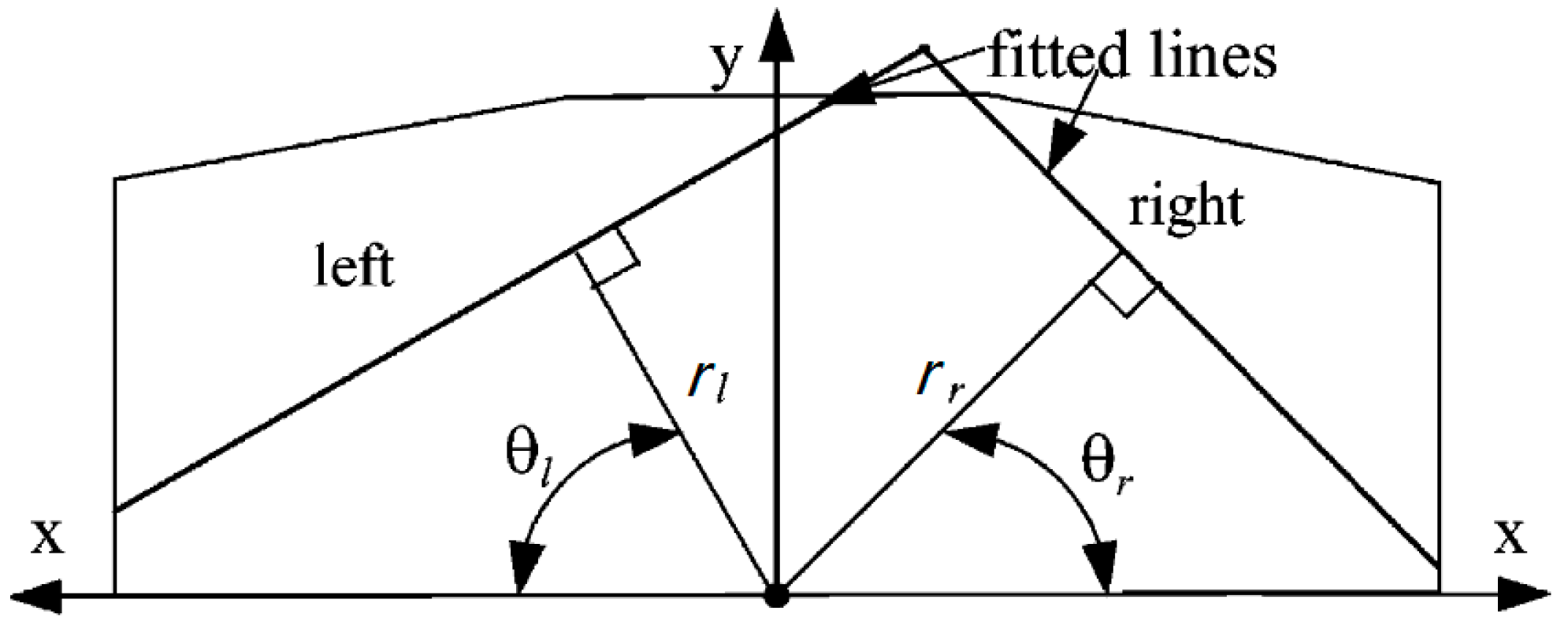
4. Range Estimation

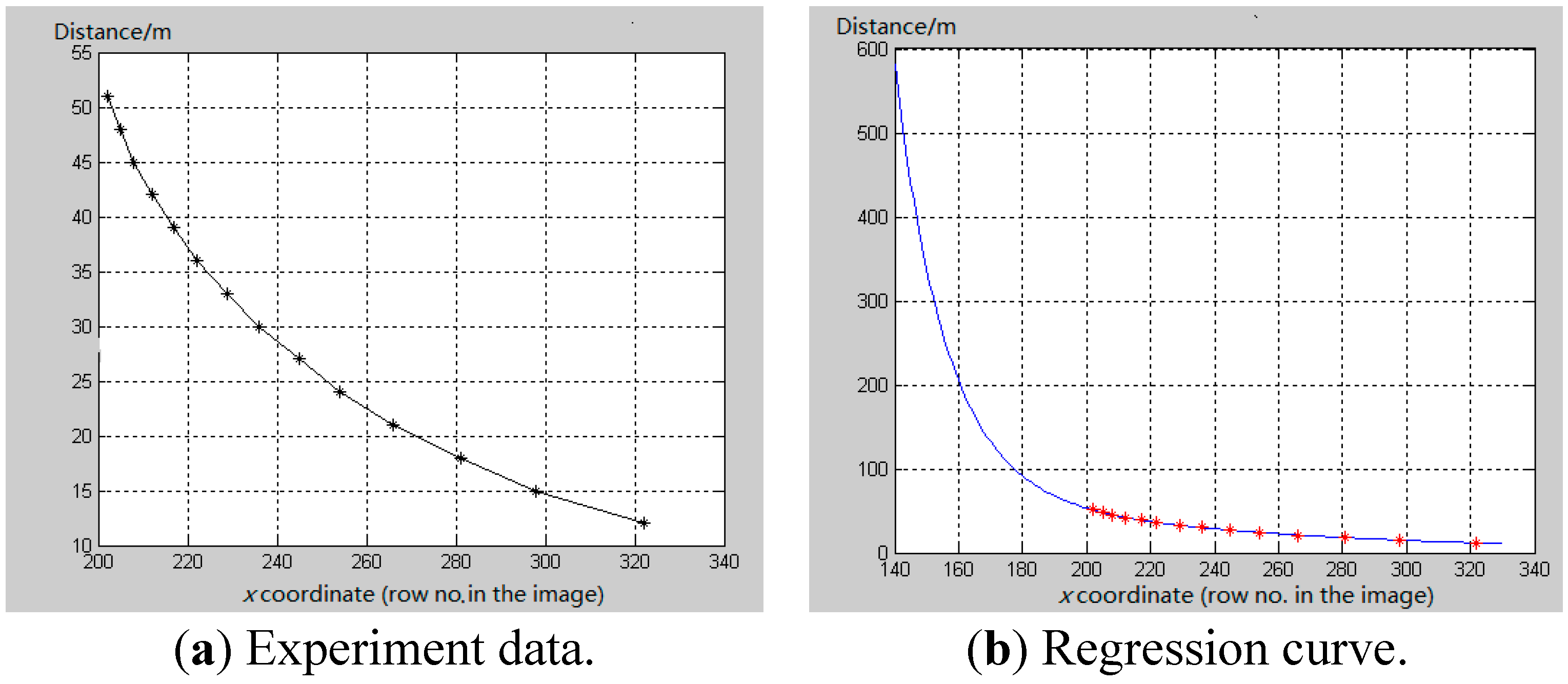
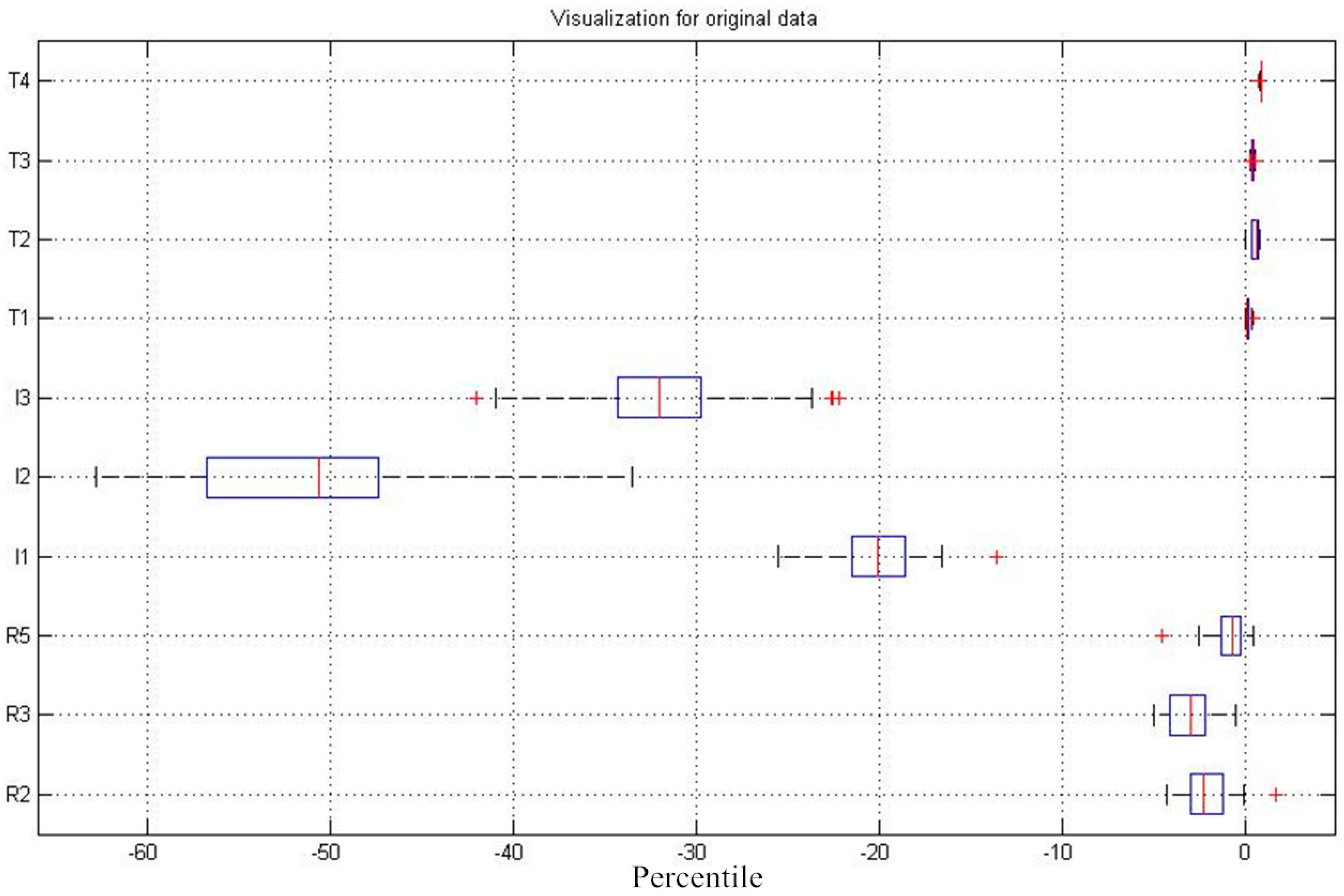
5. Experimental Results
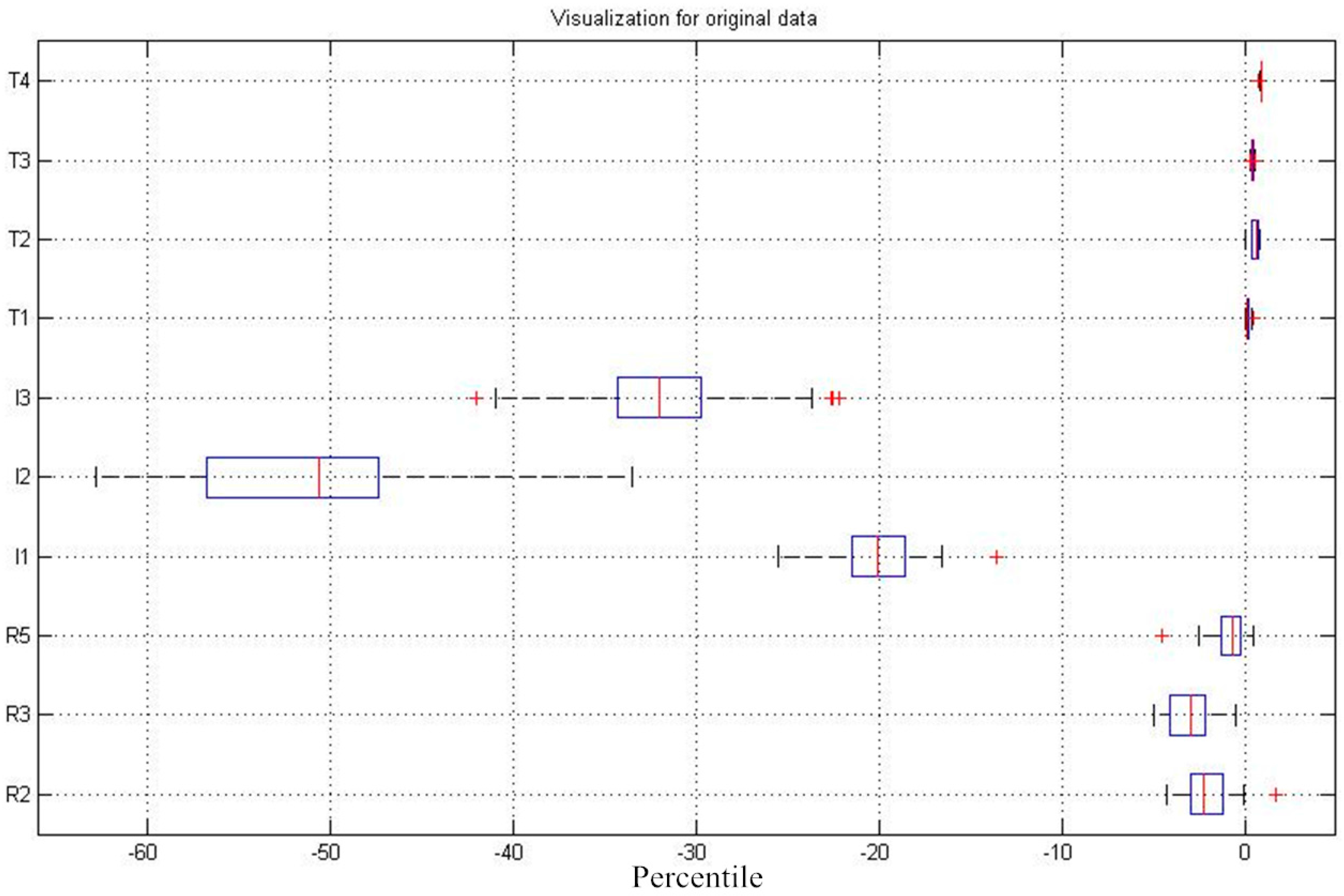
5.1. Performance Evaluation of Improved SVM
| Method | Best c | Best g | Accuracy | Testing time | Tmax | SVTotal | |
|---|---|---|---|---|---|---|---|
| Train | Test | ||||||
| CG-SVM | 9.1896 | 0.1088 | 99.22% | 96.8% | 5.3 ms | -- | 16 |
| GA-SVM | 4.0338 | 0.1859 | 99.22% | 96.8% | 0.42 ms | 50 | 19 |
| PSO-SVM | 0.1 | 2.2778 | 98.44% | 96.8% | 2.47 ms | 50 | 71 |
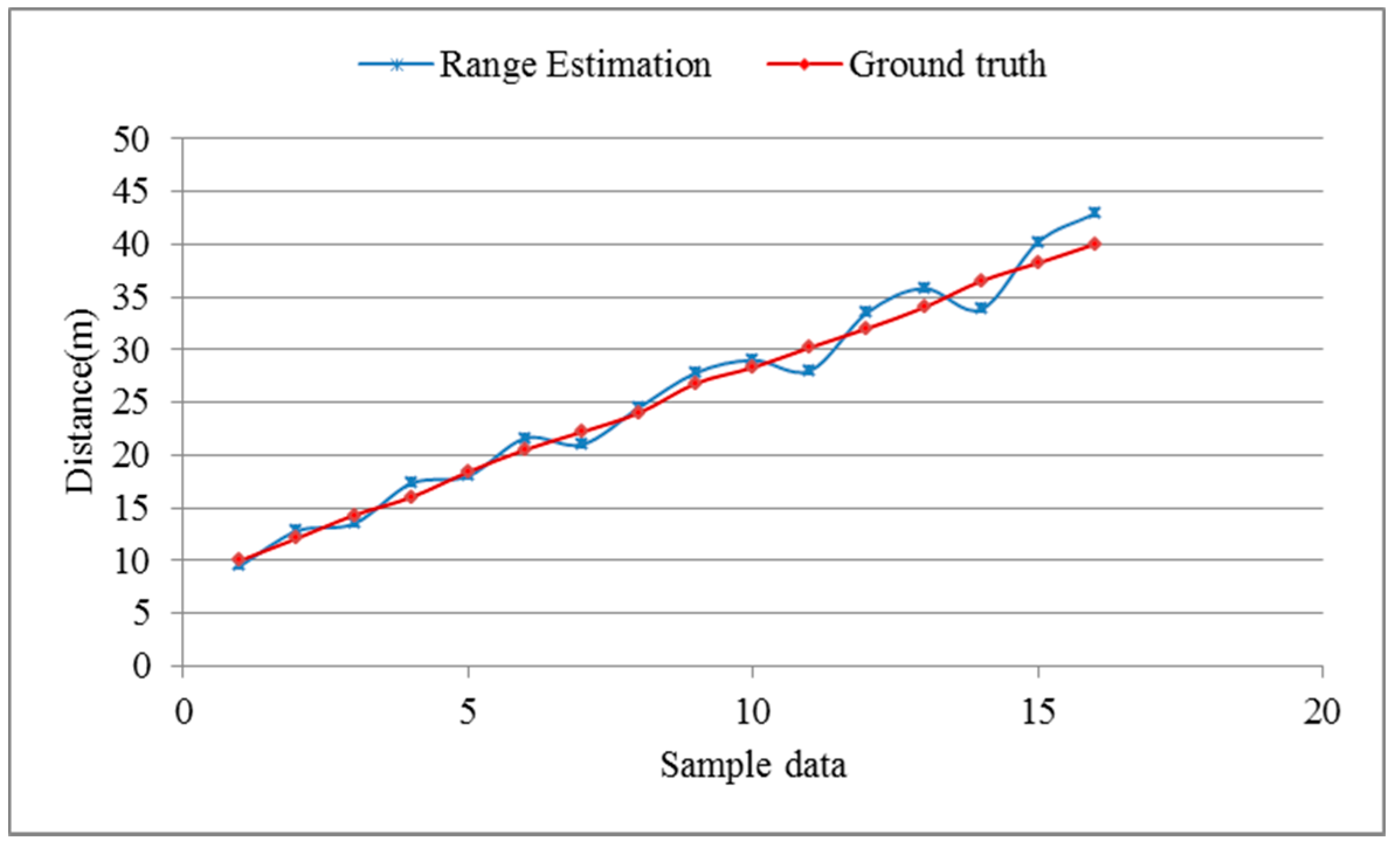
5.2. Performance Evaluation of Range Estimation

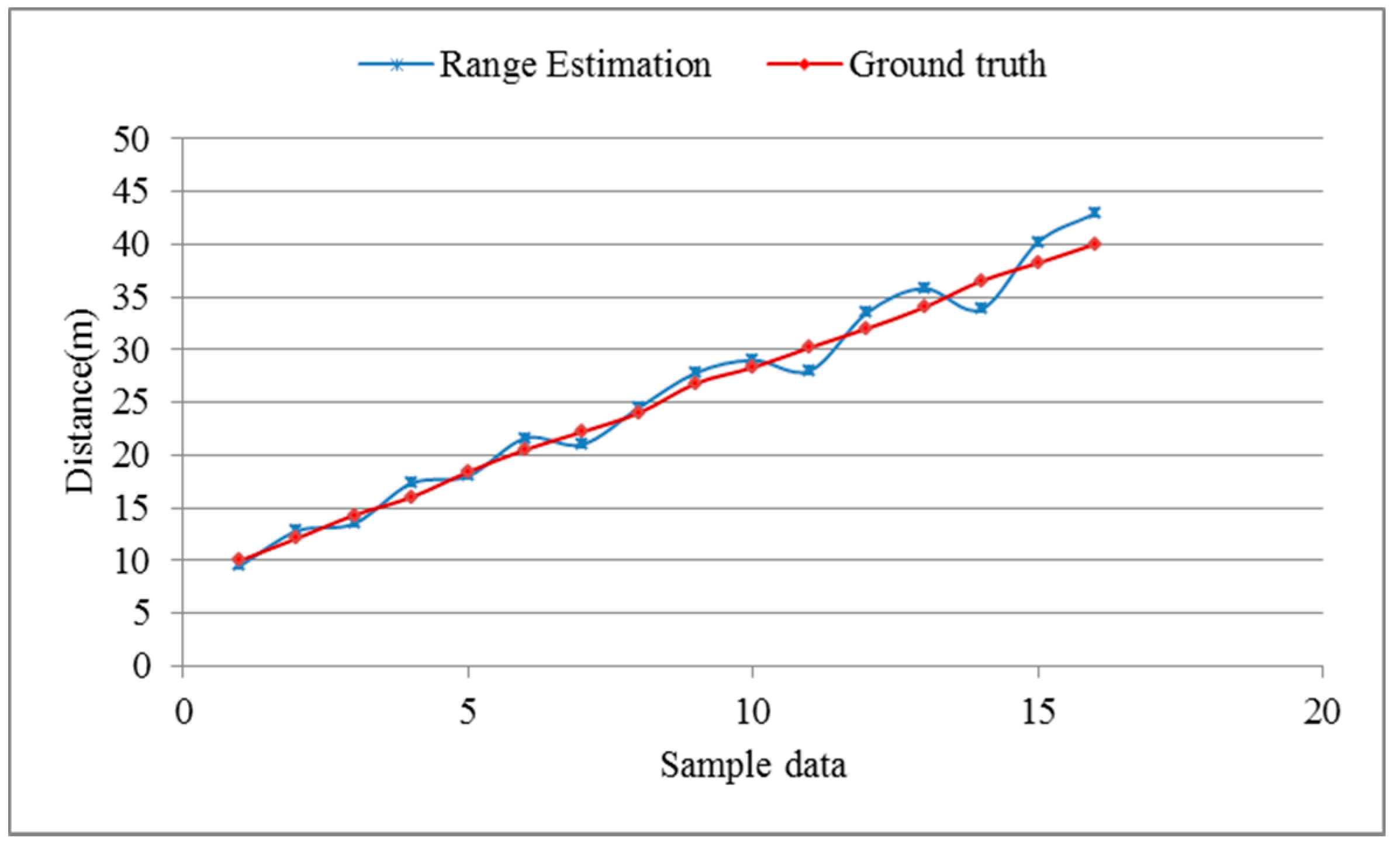
5.3. Model Verification in a Real-Driving Environment
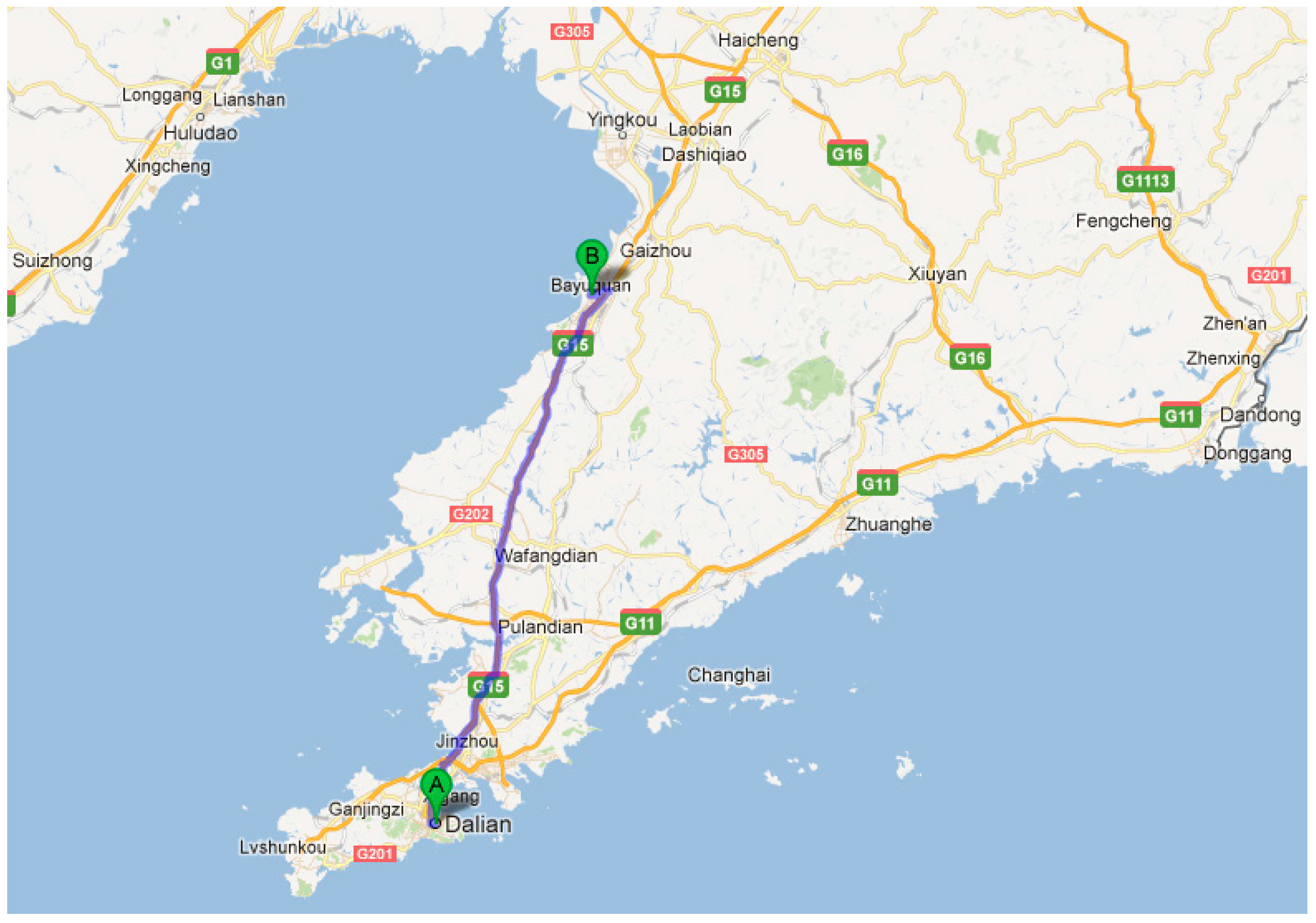
| Weather | Sunlit | Rainy | ||||
|---|---|---|---|---|---|---|
| Vehicle type | Sedan | Minivan | Truck | Sedan | Minivan | Truck |
| # of sampled frame | 1450 | 1080 | 1260 | 1150 | 980 | 1100 |
| # of detection | 1408 | 1030 | 1190 | 1108 | 949 | 1020 |
| # of false positive | 72 | 65 | 58 | 35 | 27 | 52 |
| Detection rate (%) | 97.1 | 95.37 | 94.44 | 96.34 | 96.83 | 92.73 |

6. Conclusion and Perspective
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Dagan, E.; Mano, O.; Stein, G.P.; Shashua, A. Forward collision warning with a single camera. In Proceedings of the 2004 IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 37–42.
- Park, S.J.; Kim, T.Y.; Kang, S.M.; Koo, K.H. A novel signal processing technique for vehicle detection radar. In Proceedings of the 2003 IEEE MTT-S International Microwave Symposium Digest, Philadelphia, PA, USA, 8–13 June 2003; Vol. 601, pp. 607–610.
- Wang, C.C.; Thorpe, C.; Suppe, A. Ladar-based detection and tracking of moving objects from a ground vehicle at high speeds. In Proceedings of the 2003 IEEE Intelligent Vehicles Symposium, Columbus, OH, USA, 9–11 June 2003; pp. 416–421.
- Baek, Y.M.; Kim, W.Y. Forward vehicle detection using cluster-based adaboost. Opt. Eng. 2014, 53. [Google Scholar] [CrossRef]
- Zhan, W.; Ji, X. Algorithm research on moving vehicles detection. Procedia Eng. 2011, 15, 5483–5487. [Google Scholar] [CrossRef]
- Aytekin, B.; Altug, E. Increasing driving safety with a multiple vehicle detection and tracking system using ongoing vehicle shadow information. In Proceedings of the 2010 IEEE International Conference on Systems Man and Cybernetics (SMC), Istanbul, Turkey, 10–13 October 2010; pp. 3650–3656.
- Sivaraman, S.; Trivedi, M.M. Looking at vehicles on the road: A survey of vision-based vehicle detection, tracking, and behavior analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1795. [Google Scholar] [CrossRef]
- Ming, Q.; Jo, K.-H. Vehicle detection using tail light segmentation. In Proceeding of the 6th International Forum on Strategic Technology (IFOST), Harbin, China, 22–24 August 2011; pp. 729–732.
- O’Malley, R.; Jones, E.; Glavin, M. Rear-lamp vehicle detection and tracking in low-exposure color video for night conditions. IEEE Trans. Intell. Transp. Syst. 2010, 11, 453–462. [Google Scholar] [CrossRef]
- Mithun, N.C.; Rashid, N.U.; Rahman, S.M.M. Detection and classification of vehicles from video using multiple time-spatial images. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1215–1225. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, X.; Qu, B. Three-frame difference algorithm research based on mathematical morphology. Procedia Eng. 2012, 29, 2705–2709. [Google Scholar] [CrossRef]
- Mandellos, N.A.; Keramitsoglou, I.; Kiranoudis, C.T. A background subtraction algorithm for detecting and tracking vehicles. Expert Syst. Appl. 2011, 38, 1619–1631. [Google Scholar] [CrossRef]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Yao, B.; Yao, J.; Zhang, M.; Yu, L. Improved support vector machine regression in multi-step-ahead prediction for rock displacement surrounding a tunnel. Sci. Iran. 2014, 21, 1309–1316. [Google Scholar]
- Yao, B.; Yu, B.; Hu, P.; Gao, J.; Zhang, M. An improved particle swarm optimization for carton heterogeneous vehicle routing problem with a collection depot. Ann. Oper. Res. 2015. [Google Scholar] [CrossRef]
- Cao, L.J.; Tay, F.E.H. Support vector machine with adaptive parameters in financial time series forecasting. IEEE Trans. Neural Netw. 2003, 14, 1506–1518. [Google Scholar] [CrossRef] [PubMed]
- Yao, B.; Hu, P.; Zhang, M.; Jin, M. A support vector machine with the tabu search algorithm for freeway incident detection. Int. J. Appl. Math. Comput. Sci. 2014, 24, 397–404. [Google Scholar] [CrossRef]
- Liu, W.; Wen, X.; Duan, B.; Yuan, H.; Wang, N. Rear vehicle detection and tracking for lane change assist. In Proceedings of the 2007 IEEE Intelligent Vehicles Symposium, Istanbul, Turkey, 13–15 June 2007; pp. 252–257.
- Chen, Q.; Zhao, L.; Lu, J.; Kuang, G.; Wang, N.; Jiang, Y. Modified two-dimensional otsu image segmentation algorithm and fast realisation. IET Image Process. 2012, 6, 426–433. [Google Scholar] [CrossRef]
- Yang, X.; Duan, J.; Gao, D.; Zheng, B. Research on lane detection based on improved hough transform. Comput. Meas. Control 2010, 18, 292–295. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proc. of the fifth Berkeley Symposium on Mathematical Statistics and Probability; Le Cam, L.M., Neyman, J., Eds.; University of California Press: Berkeley, CA, USA, 1976; pp. 281–297. [Google Scholar]
- Hu, M.-K. Visual pattern recognition by moment invariants. IRE Trans. Inf. Theory 1962, 8, 179–187. [Google Scholar]
- Han, B.; Xu, Z.; Wang, S. Scale invariance of discrete moment. J. Data Acquis. Process. 2008, 23, 555–558. [Google Scholar]
- Flusser, J.; Suk, T. Affine moment invariants: A new tool for character recognition. Pattern Recog. Lett. 1994, 15, 433–436. [Google Scholar] [CrossRef]
- Mridula, J.; Kumar, K.; Patra, D. Combining glcm features and markov random field model for colour textured image segmentation. In Proceedings of the 2011 International Conference on Devices and Communications (ICDeCom), Mesra, India, 24–25 February 2011; pp. 1–5.
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Chang, C.-C.; Lin, C.-J. A Practical Guide to Support Vector Classication; National Taiwan University: Taipei, Taiwan, 2003. [Google Scholar]
- Yu, B.; Yang, Z.; Cheng, C. Optimizing the distribution of shopping centers with parallel genetic algorithm. Eng. Appl. Artif. Intell. 2007, 20, 215–223. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gang, L.; Zhang, M.; Zhao, X.; Wang, S. Improved Genetic Algorithm Optimization for Forward Vehicle Detection Problems. Information 2015, 6, 339-360. https://doi.org/10.3390/info6030339
Gang L, Zhang M, Zhao X, Wang S. Improved Genetic Algorithm Optimization for Forward Vehicle Detection Problems. Information. 2015; 6(3):339-360. https://doi.org/10.3390/info6030339
Chicago/Turabian StyleGang, Longhui, Mingheng Zhang, Xiudong Zhao, and Shuai Wang. 2015. "Improved Genetic Algorithm Optimization for Forward Vehicle Detection Problems" Information 6, no. 3: 339-360. https://doi.org/10.3390/info6030339
APA StyleGang, L., Zhang, M., Zhao, X., & Wang, S. (2015). Improved Genetic Algorithm Optimization for Forward Vehicle Detection Problems. Information, 6(3), 339-360. https://doi.org/10.3390/info6030339