Deep Web Search Interface Identification: A Semi-Supervised Ensemble Approach

Abstract
:1. Introduction
2. Related Work
2.1. Search Interface Identification


2.2. Semi-Supervised Ensemble Learning
3. A Semi-Supervised Co-Training Ensemble
3.1. Diversity Generation from Data
| Algorithm 1 Diversity data creation. |
| Input: , labeled data , unlabeled data BaseLearn, base learning algorithm pconf, confidence probability threshold Dfra, factor that determines number of diversity data. Procedure: 1: train BaseLearn on L; 2: use BaseLearn to calculate class probability pi, for example ui in U; 3: label ui with class opposite to the prediction if its pi > pconf; 4: add all uis in Steps 2 and 3 to the diversity data pool; 5: select Dfra most confident examples in the pool to form D. Output: D, diversity data |
3.2. Diversity Obtained from Base Classification Algorithms
3.3. Aggregating the Base Classifiers
3.4. The Algorithm
| Algorithm 2 A semi-supervised co-training ensemble (SSCTE) learning algorithm. |
| Input: L, U, pconf, Dfra F, feature space f1, … , fp of examples in L Fi, subset of features of F used in the i-th iteration BaseTree, decision tree learning algorithm BaseNet, neural net learning algorithm Di, diversity data obtained in the i-th iteration using Algorithm 1 K, number of iterations Initialization: C = Ø; D0 = Ø 1: for () do 2: generate a bootstrapped sample Li of L 3: if i is odd then 4: draw Fi from F using random subspace to form from Li 5: use to create diversity data Di in U 6: end if 7: if i is even then 8: use to create diversity data Di in U 9: use Ci to predict OOB data and record the prediction accuracy oobi 10: U = U − Di, remove the diversity data from U 11: end if 12: if U is empty then 13: break 14: end if 15: 16: end for 17: calculate weights w[i]s for all classifiers based on their oobis according to formula (1) Output: the learning ensemble C. In prediction, a sample (x, y) is assigned with class label y* as the one receiving the weighted majority of the votes: |
4. Experimental Results
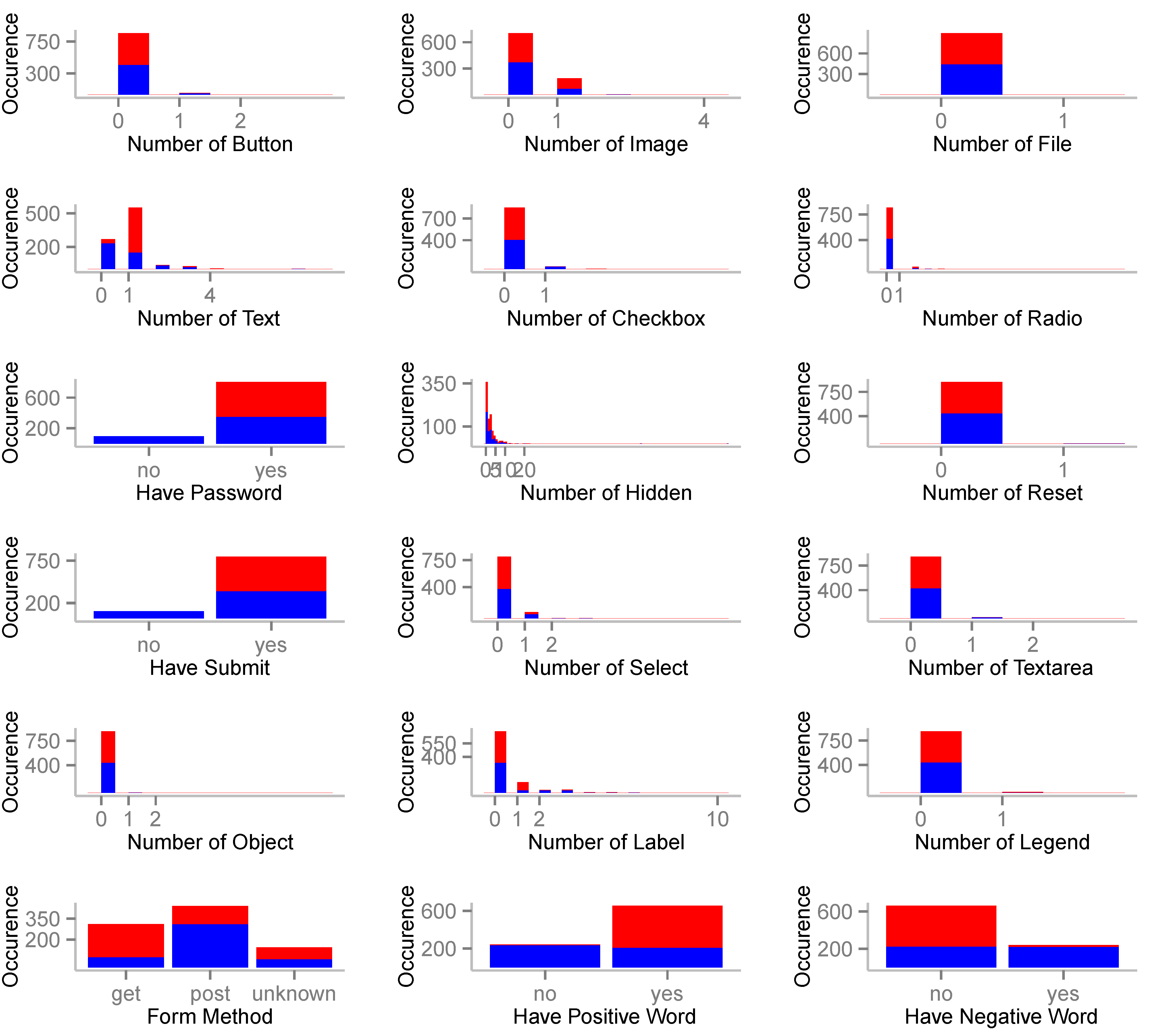
4.1. Dataset Description

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Search Forms | Non-Search Forms | |
|---|---|---|
| DMOZ labeled | 451 | 446 |
| DMOZ unlabeled | 18,624 | |
4.2. Evaluation Metrics and Statistical Tests
4.3. Results and Analysis
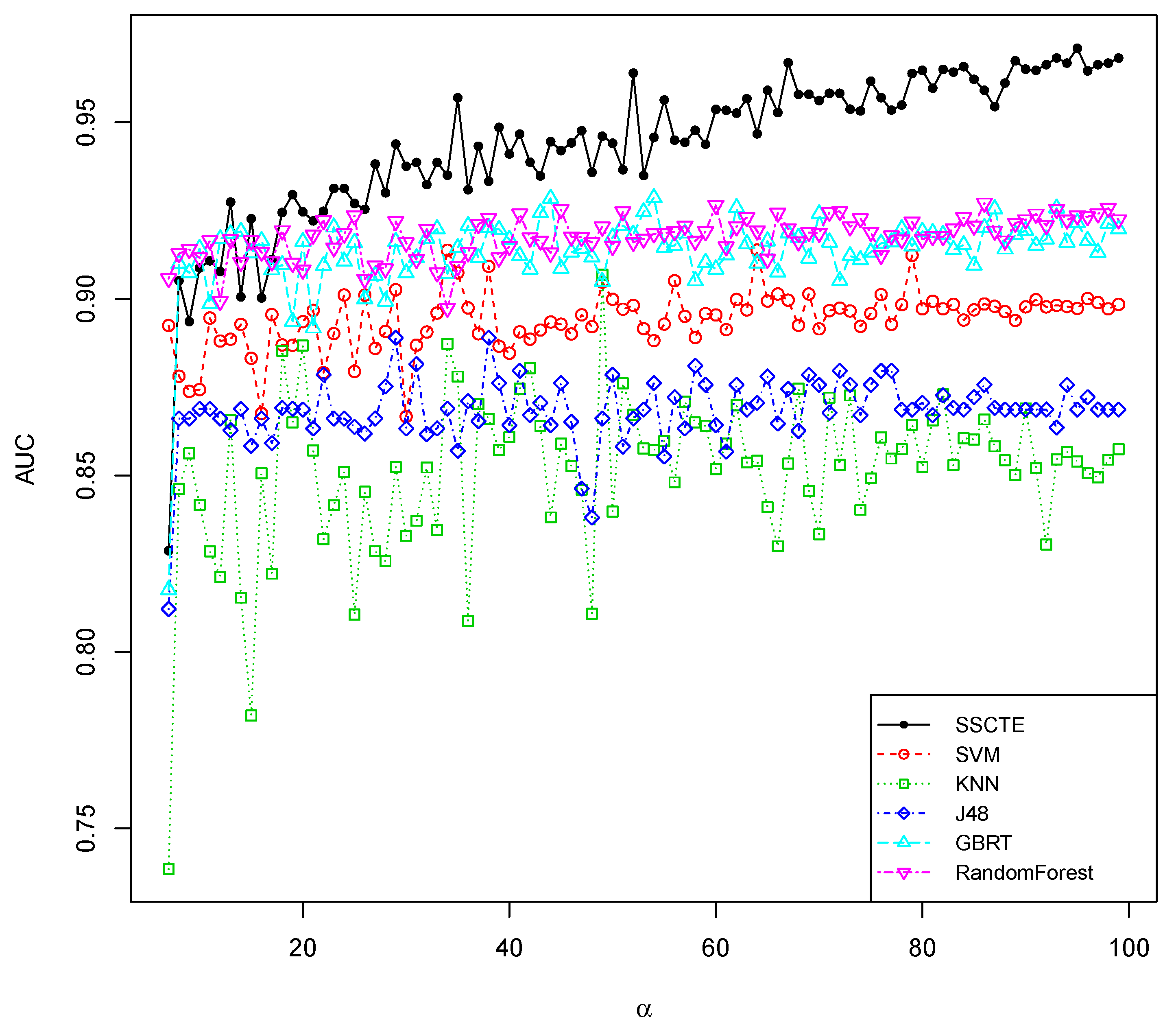
4.3.1. Parameter Sensitivity
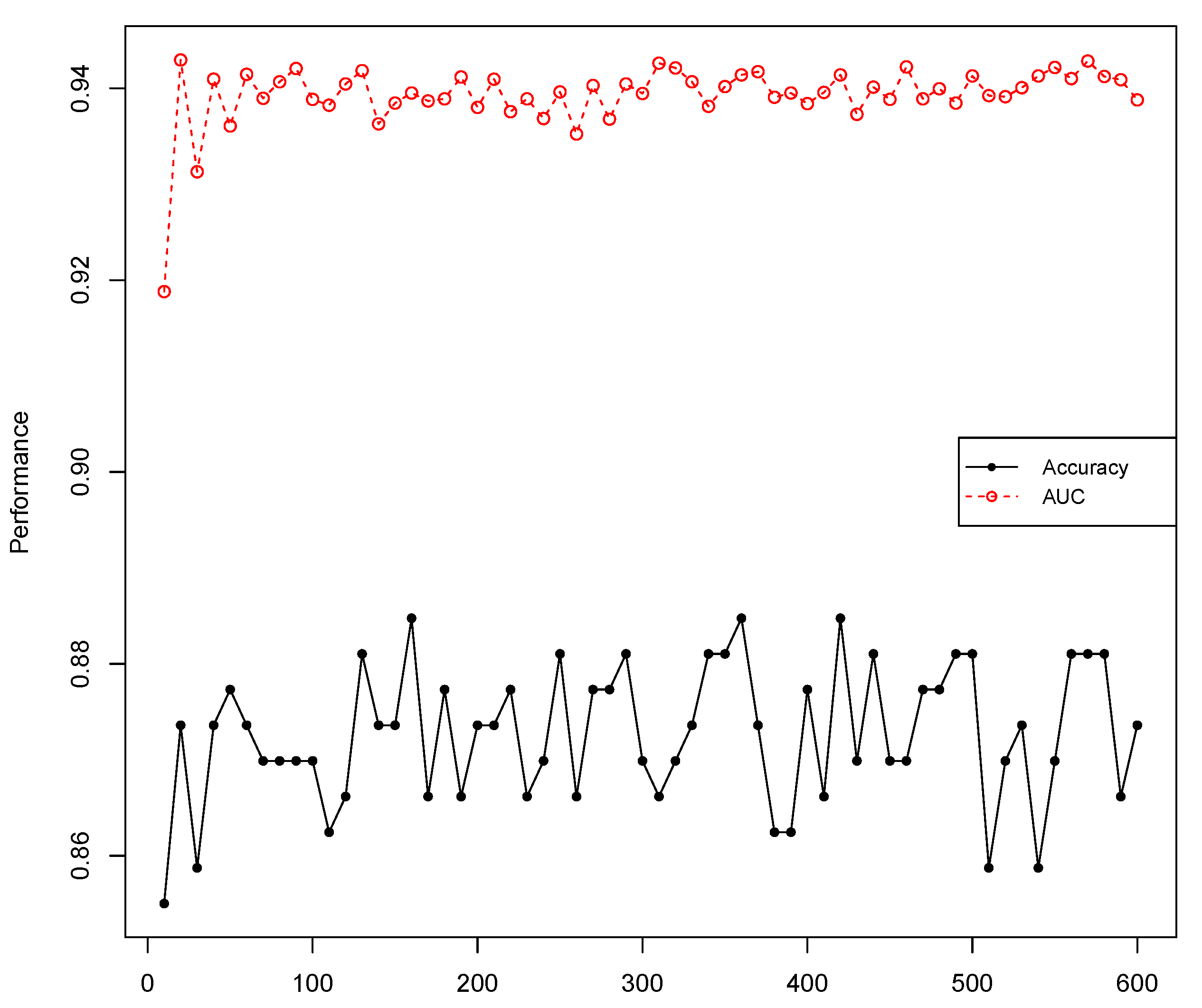
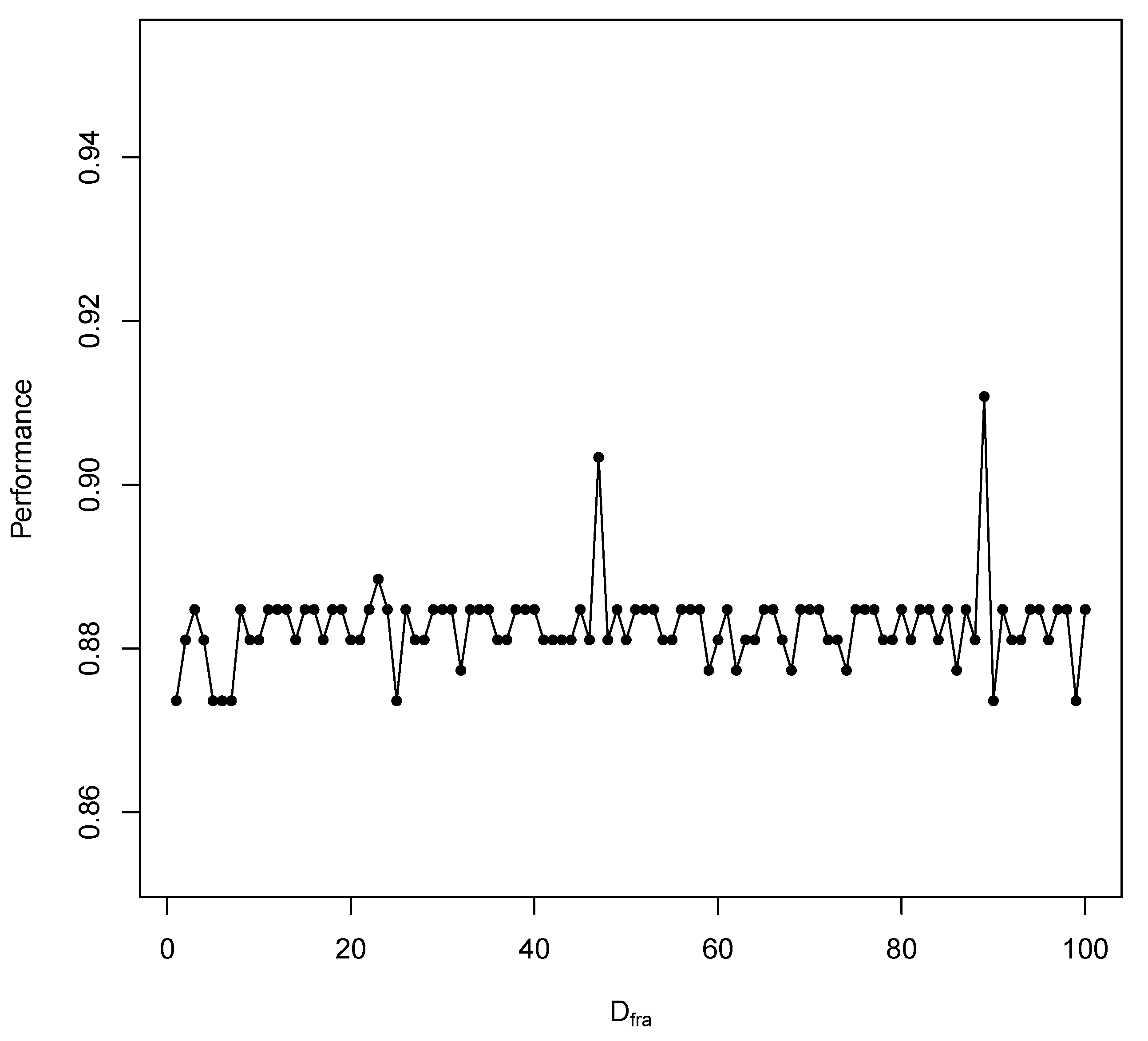
4.3.2. One versus Two
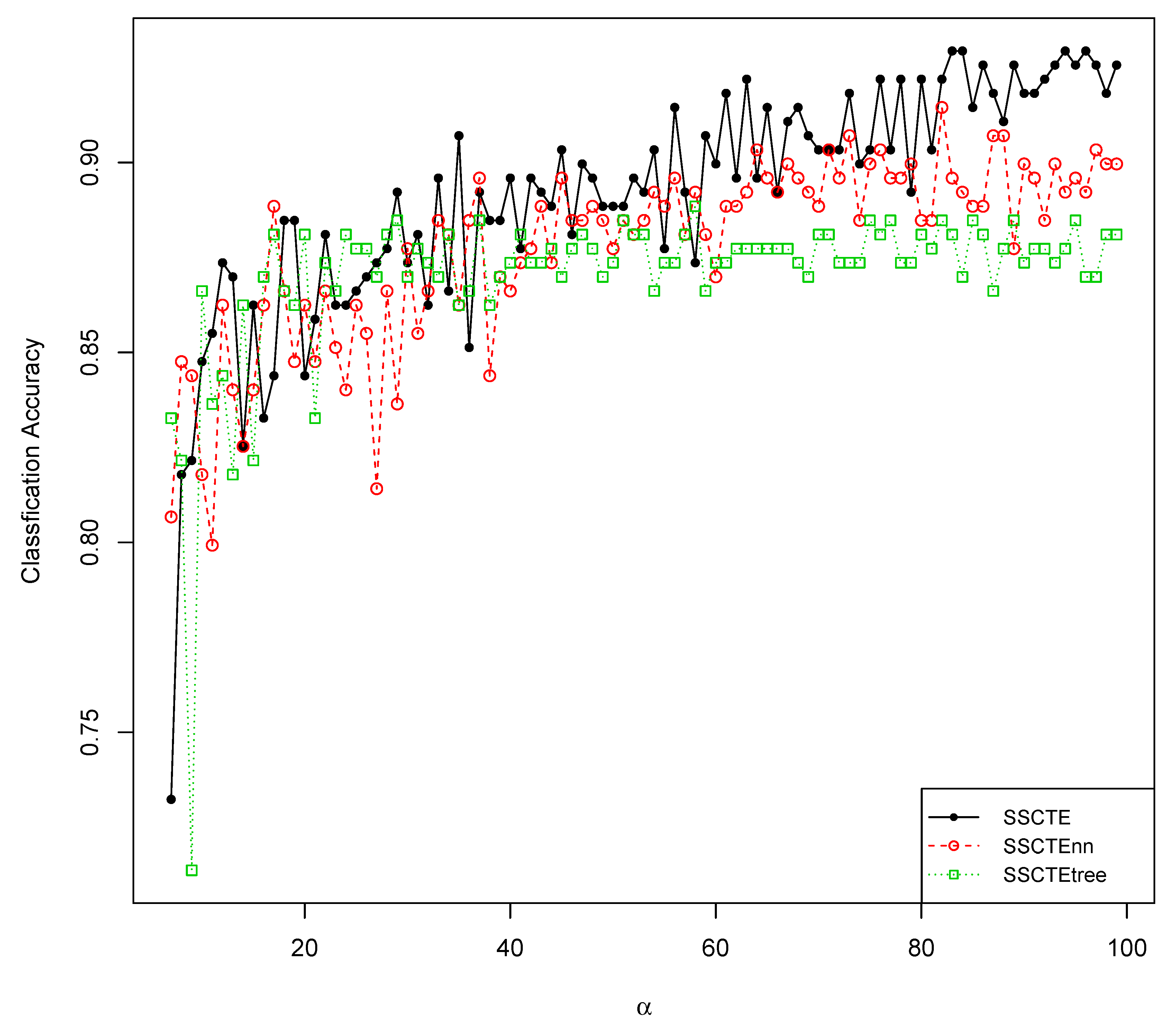
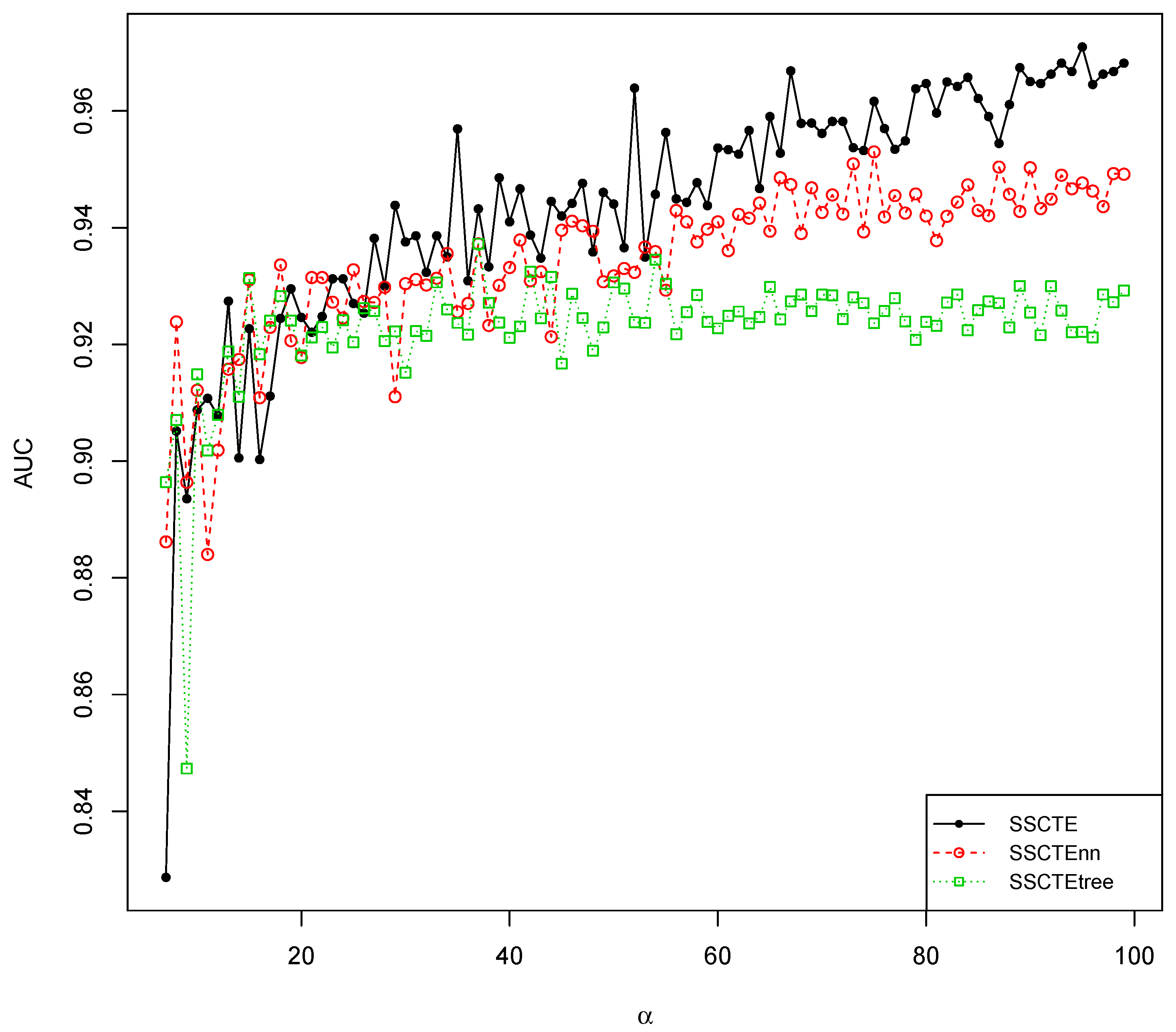
4.3.3. Comparisons
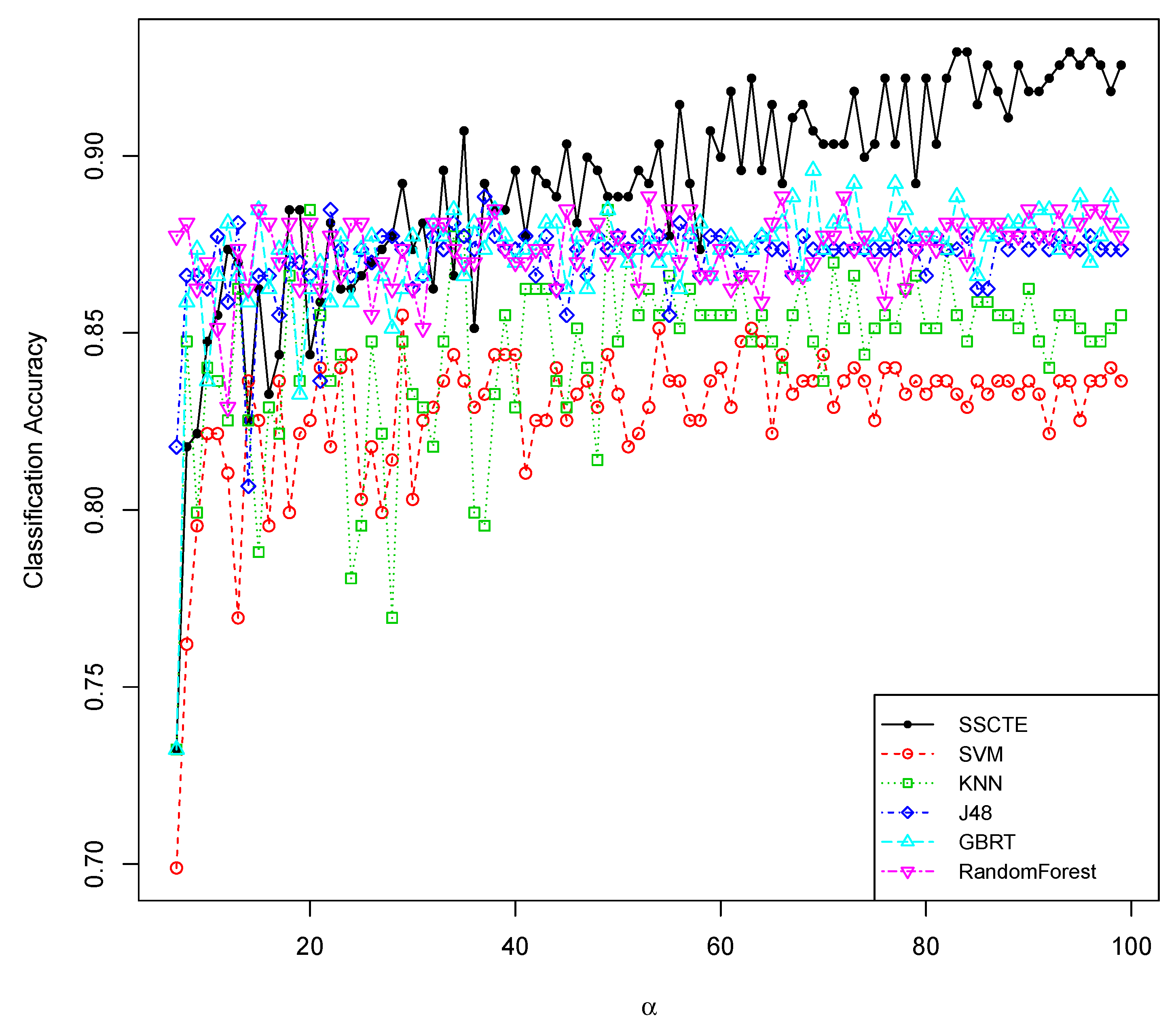
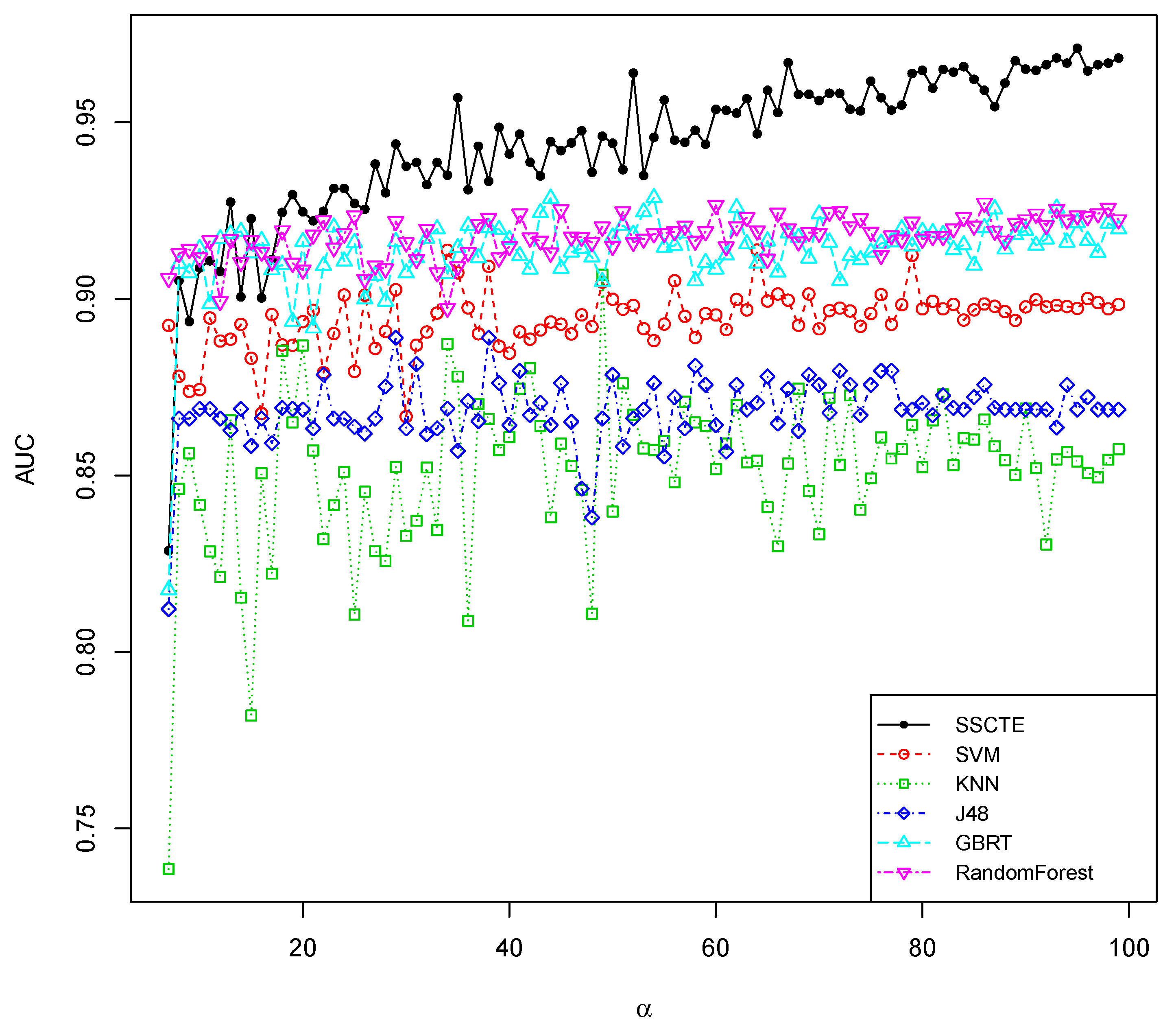
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bergman, M.K. White Paper: The deep web: Surfacing hidden value. J. Electron. Publ. 2001, 7. [Google Scholar] [CrossRef]
- Cope, J.; Craswell, N.; Hawking, D. Automated Discovery of Search Interfaces on the Web. In Proceedings of the 14th Australasian Database Conference (ADC2003), Adelaide, Australia, 4–7 February 2003; pp. 181–189.
- Madhavan, J.; Ko, D.; Kot, L.; Ganapathy, V.; Rasmussen, A.; Halevy, A. Google’s Deep Web crawl. Proc. VLDB Endow. 2008, 1, 1241–1252. [Google Scholar] [CrossRef]
- Khare, R.; An, Y.; Song, I.Y. Understanding deep web search interfaces: A survey. ACM SIGMOD Rec. 2010, 39, 33–40. [Google Scholar] [CrossRef]
- Hedley, Y.L.; Younas, M.; James, A.; Sanderson, M. Sampling, information extraction and summarisation of hidden web databases. Data Knowl. Eng. 2006, 59, 213–230. [Google Scholar] [CrossRef]
- Noor, U.; Rashid, Z.; Rauf, A. TODWEB: Training-Less ontology based deep web source classification. In Proceedings of the 13th International Conference on Information Integration and Web-based Applications and Services, Bali, Indonesia, 5–7 December 2011; ACM: New York, NY, USA, 2011; pp. 190–197. [Google Scholar]
- Balakrishnan, R.; Kambhampati, S. Factal: Integrating deep web based on trust and relevance. In Proceedings of the 20th international conference companion on World wide web, Hyderabad, India, 28 March–1 April 2011; ACM: New York, NY, USA, 2011; pp. 181–184. [Google Scholar]
- Palmieri Lage, J.; da Silva, A.; Golgher, P.; Laender, A. Automatic generation of agents for collecting hidden web pages for data extraction. Data Knowl. Eng. 2004, 49, 177–196. [Google Scholar] [CrossRef]
- Chang, K.; He, B.; Li, C.; Patel, M.; Zhang, Z. Structured databases on the web: Observations and implications. ACM SIGMOD Rec. 2004, 33, 61–70. [Google Scholar] [CrossRef]
- Ye, Y.; Li, H.; Deng, X.; Huang, J. Feature weighting random forest for detection of hidden web search interfaces. Comput. Linguist. Chin. Lang. Process. 2009, 13, 387–404. [Google Scholar]
- Barbosa, L.; Freire, J. Combining classifiers to identify online databases. In Proceedings of the 16th international conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; ACM: New York, NY, USA, 2007; pp. 431–440. [Google Scholar]
- Barbosa, L.; Freire, J. Searching for hidden-web databases. In Proceedings of the Eighth International Workshop on the Web and Databases (WebDB 2005), Baltimore, MD, USA, 16–17 June 2005; pp. 1–6.
- Shestakov, D. On building a search interface discovery system. In Proceedings of the 2nd International Conference on Resource Discovery, Lyon, France, 28 August 2009; pp. 81–93.
- Fang, W.; Cui, Z.M. Semi-Supervised Classification with Co-Training for Deep Web. Key Eng. Mater. 2010, 439, 183–188. [Google Scholar] [CrossRef]
- Chang, K.C.C.; He, B.; Zhang, Z. Metaquerier over the deep web: Shallow integration across holistic sources. In Proceedings of the 2004 VLDB Workshop on Information Integration on the Web, Toronto, Canada, 29 August 2004; pp. 15–21.
- Wang, Y.; Li, H.; Zuo, W.; He, F.; Wang, X.; Chen, K. Research on discovering deep web entries. Comput. Sci. Inf. Syst. 2011, 8, 779–799. [Google Scholar] [CrossRef]
- Marin-Castro, H.; Sosa-Sosa, V.; Martinez-Trinidad, J.; Lopez-Arevalo, I. Automatic discovery of Web Query Interfaces using machine learning techniques. J. Intell. Inf. Syst. 2013, 40, 85–108. [Google Scholar] [CrossRef]
- Bergholz, A.; Childlovskii, B. Crawling for domain-specific hidden Web resources. In Proceedings of the Fourth International Conference on Web Information Systems Engineering, WISE 2003, Roma, Italy, 10–12 December 2003; pp. 125–133.
- Lin, L.; Zhou, L. Web database schema identification through simple query interface. In Proceedings of the 2nd International Conference on Resource Discovery, Lyon, France, 28 August 2009; pp. 18–34.
- Chapelle, O.; Schölkopf, B.; Zien, A. Semi-Supervised Learning; MIT press: Cambridge, MA, USA, 2006. [Google Scholar]
- Zhu, X. Semi-Supervised Learning Literature Survey. Available online: http://pages.cs.wisc.edu/jerryzhu/research/ssl/semireview.html (accessed on 28 November 2014).
- Roli, F. Semi-supervised multiple classifier systems: Background and research directions. Mult. Classif. Syst. 2005, 3541, 674–676. [Google Scholar]
- Zhou, Z.; Li, M. Semi-supervised learning by disagreement. Knowl. Inf. Syst. 2010, 24, 415–439. [Google Scholar] [CrossRef]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45. [Google Scholar] [CrossRef]
- Zhou, Z. When semi-supervised learning meets ensemble learning. Mult. Classif. Syst. 2009, 5519, 529–538. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- d’Alchè, F.; Grandvalet, Y.; Ambroise, C. Semi-supervised marginboos. In Advances in Neural Information Processing Systems 14; MIT Press: Cambridge, MA, USA, 2002; pp. 553–560. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. ICML 1996, 96, 148–156. [Google Scholar]
- Bennett, K.; Demiriz, A.; Maclin, R. Exploiting unlabeled data in ensemble methods. In Proceedings of the eighth ACM SIGKDD international conference on knowledge discovery and data mining, Edmonton, AB, Canada, 23–25 July 2002; ACM: New York, NY, USA, 2002; pp. 289–296. [Google Scholar]
- Mallapragada, P.; Jin, R.; Jain, A.; Liu, Y. SemiBoost: Boosting for Semi-Supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2000–2014. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Zhou, Z.H. Improve Computer-Aided Diagnosis With Machine Learning Techniques Using Undiagnosed Samples. IEEE Trans. Syst. Man Cybern. 2007, 37, 1088–1098. [Google Scholar] [CrossRef]
- Melville, P.; Mooney, R.J. Constructing diverse classifier ensembles using artificial training examples. In Proceedings of the 18th International Joint Conference on Artificial Intelligence, Acapulco, Mexico, 9–15 August 2003; pp. 505–510.
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, X. Ensemble learning via negative correlation. Neural Netw. 1999, 12, 1399–1404. [Google Scholar] [CrossRef]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; ACM: New York, NY, USA, 1998; pp. 92–100. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recogn. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2012; ISBN 3-900051-07-0. [Google Scholar]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Xu, Q.; Zhou, L. Deep Web Search Interface Identification: A Semi-Supervised Ensemble Approach. Information 2014, 5, 634-651. https://doi.org/10.3390/info5040634
Wang H, Xu Q, Zhou L. Deep Web Search Interface Identification: A Semi-Supervised Ensemble Approach. Information. 2014; 5(4):634-651. https://doi.org/10.3390/info5040634
Chicago/Turabian StyleWang, Hong, Qingsong Xu, and Lifeng Zhou. 2014. "Deep Web Search Interface Identification: A Semi-Supervised Ensemble Approach" Information 5, no. 4: 634-651. https://doi.org/10.3390/info5040634
APA StyleWang, H., Xu, Q., & Zhou, L. (2014). Deep Web Search Interface Identification: A Semi-Supervised Ensemble Approach. Information, 5(4), 634-651. https://doi.org/10.3390/info5040634