1. Introduction
We are interested in modeling some of the basic cognitive mechanisms that may favor or hinder the spreading of fake news when coupled to the action of recommender systems [
1]. The spreading of fake news can affect many aspects of democracy [
2] and its modeling needs a multidisciplinary approach [
3]. A common explication for this diffusion is the laziness of readers [
4], but we think that there are also cognitive motivations, coupled with the non-neutral role of recommender systems.
We first present the cognitive psychology background (i.e., the concept of cognitive heuristics) and then the motivation for developing a model that tries to incorporate these aspects and their interplay with a recommender system.
1.1. The Cognitive Background: From Gossip to Heuristics
Cognitive heuristics and their indirect effects, namely cognitive biases, evolved under ancestral conditions and include phenomena such as majority bias, shared information bias, and status generalization [
5,
6,
7,
8]. In contemporary digital environments, these mechanisms interact with technologically mediated biases, such as filter bubbles, echo chambers, de-individuation and phantom emotions [
9,
10,
11,
12], whose effects are best understood by jointly considering bounded rationality [
13], the social brain hypothesis [
14] and social locomotion [
15] within networked informational environments. At the group level, the coordinated interaction of these mechanisms gives rise to emergent collective outcomes.
From this perspective, collective intelligence [
16,
17] can be defined as a group’s capacity to maximize the fitness of its members. However, the rapid transformation of the human informational ecosystem has rendered many evolutionarily tuned cognitive mechanisms systematically imperfect under contemporary conditions.
The regulatory systems governing human communities emerged in small-scale social environments, as suggested by archaeological evidence associated with early nomadic Homo sapiens populations [
18]. Although these systems have undergone adaptation and refinement, many mechanisms structuring contemporary social life, such as gossip, social dominance, stigma, and misinformation, remain deeply rooted in evolutionary contexts that predate modern technological environments by millennia.
Within these communities, social norms, roles, status systems, and group cohesion played a central regulatory role [
19], supported by strong pressures toward conformity and coordinated goal pursuit (social locomotion) [
15]. Among the mechanisms supporting norm enforcement and group cohesion, gossip plays a central role and can be broadly defined as communication about an absent or unaware third party [
20]. From a functional perspective, gossip has been interpreted as an evolutionarily grounded, prosocial mechanism supporting cohesion and cooperation [
21,
22].
While such mechanisms evolved under conditions of bounded relational density, contemporary digital environments profoundly alter the scale, visibility, and accountability of social interaction. As a consequence, prosocial gossip extends into computer-mediated communication, where reduced social costs coexist with preserved or amplified reputational benefits. Under these conditions, the diffusion of false or unverified pieces of information may become an efficient strategy for social positioning, helping to explain the persistence and social salience of gossip and misinformation in large-scale digital environments.
Reputational and visibility dynamics extend beyond informal exchanges to institutional actors, notably professional news agencies, which continue to be widely spread within contemporary media ecosystems [
23,
24].
Although formally governed by norms of verification and editorial accountability, news agencies operate under competitive performance pressures shaped by audience metrics and engagement optimization. These factors may influence news selection and potentially affect informational quality [
25,
26].
In principle, reputational risk should function as a deterrent against the deliberate dissemination of false information. However, the persistence of clickbait and sensationalist editorial strategies [
27] suggests that, under certain competitive conditions, short-term traffic and visibility gains [
28] may partially offset long-term credibility considerations [
29]. While such practices do not necessarily constitute disinformation in a strict legal or normative sense, they may nonetheless contribute to a gradual erosion of informational standards and public trust [
30].
At the regulatory level, the European Union has framed disinformation as a systemic challenge to be addressed primarily through multi-stakeholder and predominantly non-legislative approaches, rather than through a general legal definition of “fake news” [
31]. This approach is consistent with the protection of freedom of expression and media pluralism [
32], as articulated in Article 11 of the Charter of Fundamental Rights of the European Union.
While this framework addresses systemic risks mainly at the level of online intermediaries, it does not introduce a general prohibition on the production of misleading news. Instead, it focuses on the responsibilities of intermediaries, leaving them space to monitor and manage the content they disseminate. As a result, the economic and visibility-driven incentives shaping competition among professional newspapers remain only indirectly addressed within the current regulatory architecture.
1.2. Cognitive Heuristics
In many cases of ordinary life, we humans (and presumably all animals) are forced to make decisions in the absence of a sufficient quantity of information and often in short times. In addition, we are generally reluctant to invest cognitive resources in elaborating the available information. We therefore often rely on “quick and dirty” procedures called heuristics, which are sometimes prone to errors (and exploited by scammers) but can also provide effective decision techniques [
33].
In the early 1970s, Daniel Kahneman and Amos Tversky (K&T) started investigating how humans make decisions in uncertain conditions [
5,
34,
35,
36,
37]. Their main result was that
“people rely on a limited number of heuristic principles which reduce the complex tasks of assessing probabilities and predicting values to simpler judgmental operations”.
Although K&T claimed that, as a general rule, heuristics are quite valuable, in some cases, they can lead
“to severe and systematic errors”. What is important (and what has already been noted by scammers) is that these errors follow certain statistics and, therefore, they could be described and predicted. It is therefore important to include these aspects in any model aiming at representing typical human behavior (i.e., the algorithmic understanding of human logic [
37]).
K&T described three general-purpose heuristics: representativeness, availability and anchoring.
People exploit the availability heuristic when dealing with a probabilistic problem by relying upon the knowledge that is readily available (i.e., when examples are easily recalled) rather than examining all possible alternatives. For example, one may assess the risk of a flight accident by how easily an instance of an accident is retrieved from memory.
Availability is, however, an useful proxy for assessing frequency or probability because instances of common events are usually recalled better and faster than instances belonging to less frequent classes. The problem is that this heuristic can lead to excessive fear of small risks, neglecting large ones.
The representativeness heuristic occurs when assessing the degree of correspondence between a sample and a population, an instance and a category, an act and an actor or, more generally, an outcome and a model. Representativeness is composed of categorization and generalization: in order to forecast the behavior of an unknown subject, we first identify the group to which it belongs (categorization) and them we associate the “typical” behavior of the group with the item. It is apparent that the representativeness heuristic will produce problems whenever people are ignoring base rates.
K&T also suggested that estimates are often made from an initial value, or anchoring, which is then adjusted to produce a final answer. In one investigation, K&T asked participants to estimate whether the following number that was going to be (randomly) extracted would be higher or lower than the relevant percentage. It turned out that the starting point, though clearly random, greatly affected people’s answers. If the starting point was above the average, so was the estimate, and vice versa.
Another important heuristics is the
confirmation one, which is the tendency to seek out and trust information that affirms already existing expectations, avoiding or ignoring information that contradicts them [
38]. This heuristic is related to the representativeness one, since both are based on previous knowledge.
We also have to consider that, according to time constraints, stress and the importance of the context, human thinking exhibits a “dual-process” character [
33,
39,
40,
41,
42]. According to these investigations, people have two systems for making decisions. System I is rapid, intuitive, but sometimes error-prone, while system II involves more reasoning (and more cognitive load) and is therefore slower. We can assume that the less time available for making a decision, the more probable the use of a fast (and somewhat stereotyped) heuristic with respect to rational reasoning.
We shall try to include some of these concepts to model autonomous agents that have the task of processing messages from sources that are not always trustable [
43,
44,
45,
46,
47].
Our main goal is to develop a simple model of the diffusion of hoaxes, gossip, and fake news to be compared with data coming out of a real experiment that is under way in this period.
1.3. Modeling Human and Recommender System Interplay
We model here a society of agents who exchange messages through a recommender system. Agents do not corresponds to individuals, but rather to homogeneous communities, grouped together following the representativeness heuristic. We therefore use the pronoun “it” when referring to agents.
A recommender system can be seen as a device to extract hidden information from a database (also denoted knowledge network or knowledge graph) [
48,
49,
50].
Let us assume that we can represent a good, e.g., a book or a movie, by a vector of characteristics, expressing, for instance, the genre, the author/director, actors/characters, and so on. Customers are also represented as complementary (dual) vectors of preferences, corresponding to goods’ characteristics.
The opinion of a customer about a good is assumed to be given by the scalar product of the corresponding vectors (with some nonlinear threshold), i.e., essentially a perceptron model. The similarity between two users is given by the overlap of their preferences, and that of two goods is given by the overlap of their characteristics.
The goal of a recommender systems is that of recommending goods that are expected to be appreciated by a customer (but more on this in the following).
It can be shown that if a matchmaker knows an large enough fraction of the overlaps between customers, above a “rigidity percolation” threshold, then it can anticipate, from this database, the unknown overlaps [
48]. However, the direct overlap between customers is not accessible to direct measurements, but a recommender system may have access to the (partial) database of opinions expressed by customers on goods, either by their direct evaluation or indirectly by their behavior. For instance, in a social network, the appreciation of customers with respect to received messages can be evaluated by their propensity to forward them.
It can be shown that the opinion database can also be used as a proxy for the overlap one [
51] in the case of slight nonlinearities in the matching functions [
52,
53]. The effect of a recommender system is also that of promoting the formation of filter bubbles and artificial communities [
54], which here correspond to agents.
This paper is structured as follows. In
Section 2, we introduce the model and results are presented. Suggestions for incorporating human cognitive mechanisms into modern recommender systems are reported in
Section 3. A discussion of these results and conclusions are drawn in
Section 4.
2. The Model
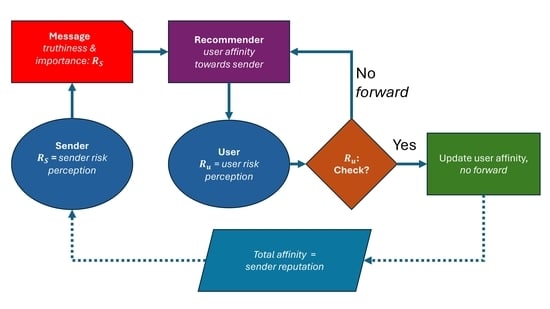
Let us apply a similar model to the case of a social network confronted with the diffusion of fake news; see
Figure 1 for the working scheme of the model.
We assume that agents can emit messages, which can be fake or not. A message is successful (and the sender gains in reputation) if it is forwarded, according to its perceived importance. We also assume that this importance is proportional to the probability of being fake. The extreme cases are those of surely true messages, of limited importance, and breakthrough news that is perceived as extremely important and popular, which, however, has a high probability of being fake.
We assume that the affinity network is available to the recommender system (for instance by the analysis of forwarded and checked messages), so that a message is preferably sent to the agents with higher affinity with respect to the sender. This assumption also constitutes a simplification of the simulation structure.
The receiver is confronted with two opportunities: either trust the message, accept the risk of passing false pieces of information and process it in a short time, or contact a central database (for instance looking for related information on the Internet) and be sure of the correctness of the message but also waste some time in this task. The problem is similar to that of detecting forged information in automatic trading [
55].
Since in social networks news quickly loses its importance, we assume that the fact of checking hinders or makes useless the possibility of forwarding the message, even in the case of a true one. Therefore, in our model, the diffusion of fake news is not due to the laziness of users, but rather to the “pressure” related to the need to increase one’s own social importance.
An agent’s affinity towards a receiver is increased whenever a message is checked and revealed to be true and lowered whenever the message is checked and revealed to be fake.
We finally assume that the propensity to emit fake messages is inversely proportional to one’s risk perception. This can be seen as an implementation of the confirmation heuristic, since it implies stereotyped actions.
We consider a scenario with N agents, identified by the index . Each agent is characterized by a risk perception factor between zero and one. The affinity network is used to select the recipients of the emitted message. Finally, the total affinity with others determines one’s reputation, as illustrated below.
At each repetition step (emission of a new message), an agent i is selected at random. It emits a message with importance I, equal to , but this message can be fake with probability , F (fake propensity) being one of the parameters of the system.
The rationale is that agents with higher levels of risk perception (and, as we shall see, with more propensity to check suspicious messages) are assumed to be more reluctant to emit “fake” messages (they can, however, do it, since messages can be fake if they have not carefully checked the news). However, we also assume that the higher the importance of messages, the higher their probability of being fake. We also assume that the recommender system is able to estimate the possible importance of a message by its content (not modeled here).
The message is propagated by the recommender system to up to other agents, K being another parameter of the system. Therefore, the more important a message, the larger the number of recipients. We choose a limited number of possible recipients since otherwise the recommender system would act like a spammer. A propagation level is given by the passage of messages from all possible senders to recipients. Once an agent has processed a message it is no longer available as a receiver for the same message.
The choice of recipients is based on the affinity: an agent j is selected for receiving the message if it has not already received it, with a probability . Therefore, an agent is more likely to receive messages from those with which it has a greater affinity.
The receiver j has the option of checking the message coming from i or not, according to its own risk perception level . Clearly, in the real case, the message can also be forwarded after checking and discovering its truthiness, but probably the resulting delay would greatly diminish the relevance of this contribution to the spreading of the news.
This second function of the parameter
R can be interpreted either as another aspect of the confirmation heuristic, since this propensity does not evolve in time and does not depend on the frequency of fake messages received, or as an implementation of the representativeness one. A possible improvement of the present model would be that of allowing an evolution of the risk perception level, which may “freeze” after a few first experiences. A somewhat analogous procedure was used in Ref. [
54] to simulate community and bubble formation induced by recommender systems.
If the receiver j decides to check the incoming message and it is revealed to be fake, the affinity is decreased by an amount r, up to a minimum of ; if the message is revealed to be true is increased by an amount r, up to a maximum of 1. In the case of checking, the message is not forwarded.
On the contrary, if the message is not checked, it is forwarded with the same modality. The reputation
of the agent
i at time
t is determined by the sum of its affinity with others,
Some examples of propagation of a message among agents are shown in
Figure 2. In general, either messages reach a substantial fraction of the population or stop after a few steps because they are neither recommended nor checked. A typical distribution of reached people (for small populations) is shown in
Figure 3.
We implemented the model on a computer using the C language for simulations. Let us first examine the effect of checking the message on a variant of the model, not considering the importance of messages nor the evolution of the affinity, considered constant and equal to . One agent is randomly chosen to emit a message, which reaches K other agents. Each of them chooses to forward (without checking) the message to other K agents (not previously exposed to the message and not chosen by others) with probability or to check it (without forwarding).
As can be seen from
Figure 4, the behavior of the fraction of checked and not checked messages (whose sum is equal to one) is not monotone with
. If
is small, almost all initial messages are checked and not forwarded, and most agents are not reached. If
is large, most messaged are not checked, so many agents are reached, but fake news is not detected. Therefore, the detection of fake messages works better for intermediate values of the affinity.
A consequent nontrivial result of the model is that there is a tendency to reveal more fake messages than true ones, even when the probability of generating them is the same. Let us consider again the case in which the affinity is constant () and not evolving (), but inserting the checking mechanism in the model. Agents with high values of risk perception emit messages that are probably true, but with less importance (), while people with low values of emit more “impactful” messages, which are probably fake. The recommender system forwards more important messages to a larger number of people (the number of recipients being ), and this originates the unbalance.
When all recipients check the message, the propagation chain stops, and this happens with higher probability if the number of recipients is small. As shown in
Figure 5 (with
the probability of a fake message is
), this discrepancy is large for large values of
and smaller for intermediate values of
. For
all messages are checked and do not diffuse.
We started all subsequent simulations with zero affinity () and risk perception uniformly distributed between 0 and 1. As we shall show, the system can exhibit extremely slow dynamics, and therefore we limited our investigation to a population of 200 agents and an affinity change rate (so that it takes roughly 100 coherent steps for affinity to saturate).
One can see two interesting effects: for large values of the fake factor
F, the reputation is larger for agents with higher values of risk perception; the opposite happens when
F is low. There is also a substantial decrease in the number of reached people for very large iteration times and high
F values. This is consistent with the results of the simplified model in
Figure 4: in this case the large number of fake messages lowers the average affinity (which takes negative values) and this implies that most messages are checked and thus stopped after a few steps.
We see also a kind of transition in the reputation–risk perception dependence, with varying values of the fake factor F. At the transition, which occurs at about for and and at about for and , the reputation first grows with risk perception and then decreases. Above this transition the percentage of reached people first increases and then drops to small values, with extremely long transients.
We can also analyze in detail the characteristics of the spreading of messages in a different situation, as can be done in experimental situations [
1].
In the simulations we first let agents evolve their affinity for a number of repetitions
, and then we blocked the evolution of the affinity (setting
) and performed measurements for a number of repetitions
T. The reputation distributions in the different cases are essentially those reported in
Figure 6.
One can see from
Figure 8a–c,g–i that, by increasing the factor
F, the distribution of reached levels shrinks, as expected, since more fake news is discovered.
The cascade size distribution (total number of reached people) in
Figure 8d–f is essentially exponential for all values of
F. By increasing values of the fake factor
F, instances of larger cascades appear. This may seem inconsistent, but one has to remember that the importance of a message (and therefore the average number of people reached by the recommender system) is proportional to the probability of a message being fake; therefore when this probability increases, messages become more impactful, so the recommender system proposes them to more people, and one observes a wide diffusion, stopped by checking and low affinity.
Indeed, the distribution of maximal depth is wider for lower values of
F,
Figure 8g–i. Notice that there are in general “bumps” in this distribution, indicating that messages are either quickly stopped or may reach a large fraction of the population, consistent with
Figure 3.
3. Discussion: Bridging Modern Recommender Systems and Cognitive Modeling
Among modern sequential recommender systems, Self-Attentive Sequential Recommendation (SASRec) represents a state-of-the-art architecture based on self-attention mechanisms, capable of capturing both short- and long-range dependencies in user interaction sequences [
56]. SASRec consistently outperforms Markovian, convolutional (CNN), and recurrent (RNN) approaches, primarily by adaptively weighting past interactions. Despite its strong empirical performance across datasets of varying sparsity, SASRec optimizes prediction accuracy under the implicit assumption that past user interactions constitute reliable signals of relevance.
This assumption is shared by most contemporary recommender systems; however, such formulations do not explicitly account for cognitive costs, risk perception, or epistemic uncertainty, nor for the downstream societal effects of recommendation-driven information propagation. Our simulation framework complements this line of work by explicitly modeling how cognitive heuristics, trust, and risk perception shape user behavior and information diffusion. From this perspective, systems such as SASRec can be interpreted as operating in a regime where behavioral regularities are leveraged without direct consideration of epistemic validity.
Based on our results, at least three fundamental architectural extensions can be envisioned. The first concerns the attention formalization used in SASRec (Equation (2) of Ref. [
56]):
where
A models the attention. The inclusion of two parameters,
R, which represents specific user or item risk perception, and
, the cognitive cost weight, results in a risk-aware attention algorithm,
where
is the attention modulated by risk.
Furthermore, trust-modulated attention to interactions associated with low trust tackles the conceptual issue that past actions are not equally reliable. This can be achieved by additive logit bias, a very common weighting method in attention variants,
Such a formulation introduces
as a trust score and
, which controls the strength of the signal. Lastly, in order to penalize the propagation of high-risk or unverified content, the optimization function can be modified to a dual-objective training, which considers accuracy and epistemic safety simultaneously,
Taken together, these extensions illustrate how state-of-the-art sequential recommender systems can be conceptually augmented to account for cognitive and epistemic dimensions of user behavior. Importantly, the proposed modifications do not aim to replace existing architectures such as SASRec, but rather to highlight the principal directions through which attention-based recommenders may be aligned with models of human decision-making. By integrating risk perception, trust, and epistemic cost into the recommendation process, such systems may better capture the trade-offs between engagement, accuracy, and information reliability observed in real-world social and informational ecosystems.
Note that Equation (
1) is the scaled dot-product attention; this is not specific to recommender systems. It is exactly the same attention operator introduced in Ref. [
57]. Equation (
1) constructs a data-dependent graph and performs one step of message passing on it. Large language models (GPT, LLaMA, etc.) use exactly the same operator with a difference scale (billions of parameters and many stacked layers). In other words, LLMs are nothing more than very deep stacks of Equation (
1) with nonlinearities and residuals.
As SASRec can be viewed as a generalization of Markov chains, LLMs generalize n-gram language models in exactly the same way. The addition of the two parameters changes the semantics of attention. R is a cost/risk matrix, aligned with attention scores, while
controls the trade-off between cognitive cost and relevance. Therefore, adding
R and
turns attention from a pure similarity operator into a rational decision mechanism that trades relevance against risk or cost. By setting
the novelty of our work is that attention becomes a decision mechanism that balances relevance, trust, and risk—not just similarity.
4. Conclusions
We have presented a simple model that includes some aspects of human heuristics (availability, representativeness and confirmation ones, shaped by individual risk perception and mutual affinity) coupled to a recommender system (which is able to “sense” the level of affinity to forward messages to specific agents). The model aims at reproducing some aspects of the diffusion of fake news and is meant to be compared with the outcomes of a planned experiment.
In our model, agents face the dilemma of checking the received message for correctness. If they choose to check it (according with their risk perception and affinity with the sender), they lose the opportunity to forward it within the “importance” timing window. If agents do not check the message, it can be resubmitted to the recommender system (and thus they can increase their affinity with others), taking the risk of distributing fake messages.
We assume that the probability that a message is fake inversely depends on the risk perception of the sender. On the other hand, the estimated importance of a message by the recommender system is proportional to its probability of being fake.
The system shows unexpected complexity: people with more propensity towards checking determine the diffusion of messages, so that when the affinity is low, all messages (including fake ones) do not propagate, but when affinity is large fake messages are also not easily discovered. However, the affinity evolves in time according to the discovered “truthiness” of messages.
The final reputation of agents is based on their total affinity with others. The main result of the model is that the relation between reputation and the “fake factor” F that determines (together with the risk perception of the emitter) the truthiness of messages and reputation is not always the same.
When F is small, fewer messages are fake, and agents with low levels of risk perception can increase their reputation since the messages that they forward without checking are probably true. On the contrary, when F is large, agents with high levels of risk perception, while forwarding fewer messages (due to their propensity towards checking), get relatively higher values of reputation. In this regime, however, most messages are checked, so, when F is large, there is a decrease in the number of reached people.
This simple model can illustrate two tendencies seen in real recommender systems: their reluctance to stop or discourage fake news and the fact that in many cases there is a strong correlation between popularity (or reputation) and propensity towards the spreading of fake news.
The main result of our model is that the “slope” of reputation vs. risk perception attitude (
Figure 6 and
Figure 7) is the main indicator related to the persistence of fake news in the system. The individual level of risk perception can be derived by the propensity to check messages. Therefore, a sensible improvement in recommender systems would be that of implementing the possibility of “fact checking” in the interface.
Clearly, this checking cannot be carried out only using artificial intelligence techniques, since it is quite difficult to control the conditions of their training, which could have been based on data similar to that being checked or simply manipulated.
In any case, the inclusion of factors related to risk perception in the weighting procedures of recommender systems could improve their reliability.



 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







