

Deriving Empirically Grounded NFR Specifications from Practitioner Discourse: A Validated Methodology Applied to Trustworthy APIs in the AI Era


Abstract
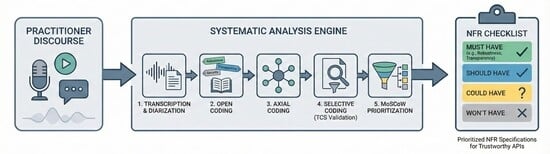
1. Introduction
2. Materials and Methods
2.1. Research Domain and Goal Definition (Initial Step)
2.2. Task 1: Data Collection
2.2.1. Video Source and Selection Strategy
2.2.2. Inclusion and Exclusion Criteria
2.2.3. Sampling Strategy and Saturation Criterion
2.2.4. Metadata Documentation
2.3. Task 2: Automated Transcription with Speaker Diarization
2.4. Task 3: Grounded Theory Coding with TCS Validation
2.4.1. Grounded Theory Foundation
2.4.2. Step 1: Open Coding
2.4.3. Step 2: Axial Coding
2.4.4. Step 3: Selective Coding and TCS Calculation
2.5. Task 4: MoSCoW Prioritization
2.5.1. MoSCoW Framework and Threshold Derivation
2.5.2. Priority Assignment Procedure
2.6. Task 5: NFR Specification with Coverage Score Evaluation
2.6.1. NFR Specification Template
2.6.2. Weighted Coverage Score Validation
3. Results
3.1. Research Domain and Goal Specification
3.1.1. Domain Selection: Trustworthy APIs in the AI Era
3.1.2. Quality Framework: Five Trustworthiness Dimensions
3.1.3. Stakeholder Perspectives
3.1.4. Research Goals
3.2. Task 1 Results: Data Collection Outcomes
3.3. Task 2 Results: Transcription Outcomes
3.4. Task 3 Results: Grounded Theory Coding Findings
3.5. Task 4 Results: MoSCoW Prioritization Outcomes
3.6. Task 5 Results: NFR Specifications and Validation
3.6.1. Derived Non-Functional Requirements
3.6.2. Must Have Requirements (TCS ≥ 85%)
- Robustness (six requirements)
- NFR-R-001: The API provider MUST implement comprehensive security frameworks with AI-specific threat modeling achieving the detection and mitigation of prompt injection, model extraction, data poisoning, and adversarial attacks for Robustness.
- NFR-R-002: The API provider MUST design modular API architectures enabling independent scaling, updating, and the replacement of AI model components without system-wide disruption for Robustness.
- NFR-R-003: The API provider MUST implement behavioral anomaly detection systems identifying model extraction attempts, membership inference attacks, and systematic probing patterns for Robustness.
- NFR-R-004: The API consumer MUST establish infrastructure readiness including adequate computational resources, network capacity, and failover mechanisms achieving high availability before production AI API integration for Robustness.
- NFR-R-005: The API consumer MUST implement hard budget caps and automated spending controls preventing runaway costs from unpredictable AI API token consumption for Robustness.
- NFR-R-006: The API consumer MUST conduct comprehensive integration testing validating edge cases, error handling, rate limit scenarios, and cost predictions before production deployment for Robustness.
- Transparency (four requirements)
- NFR-T-001: The API provider MUST implement progressive observability systems enabling drill down from high-level metrics to detailed distributed traces for operational investigation for Transparency.
- NFR-T-002: The API provider MUST publish comprehensive OpenAPI 3.0+ specifications with semantic annotations enabling both human developers and AI agents to understand the capabilities and constraints for Transparency.
- NFR-T-003: The API consumer MUST implement token tracking systems monitoring the input and output token consumption per request, per user, and per application feature for Transparency.
- NFR-T-004: The API consumer MUST provide cost monitoring dashboards displaying cumulative spend, cost trends, and predictive alerts before budget thresholds exceeded for Transparency.
- Data Privacy (one requirement)
- NFR-P-001: The API consumer MUST validate data access permissions ensuring zero unauthorized data exposure by verifying authorization policies before every API call containing user data for Data Privacy.
3.6.3. Should Have Requirements (65% ≤ TCS < 85%)
- Transparency (two requirements)
- NFR-T-005: The API provider SHOULD maintain audit trails logging all API requests, configuration changes, and access control modifications with tamper-evident storage for Transparency.
- NFR-T-006: The API consumer SHOULD implement usage analytics tracking API call patterns, performance metrics, and feature adoption for Transparency.
- Data Privacy (three requirements)
- NFR-P-002: The API provider SHOULD enforce logical data separation ensuring that different customers’ data, requests, and model interactions remain isolated for Data Privacy.
- NFR-P-003: The API provider SHOULD implement end-to-end encryption using TLS 1.3+ for data in transit and AES-256 for data at rest for Data Privacy.
- NFR-P-004: The API consumer SHOULD implement data minimization sending only necessary information by removing or redacting sensitive fields for Data Privacy.
- Explainability (four requirements)
- NFR-E-001: The API provider SHOULD provide OpenAPI specifications with semantic annotations describing parameter meanings, usage contexts, and constraints for Explainability.
- NFR-E-002: The API provider SHOULD implement automated documentation generation maintaining synchronization between API specifications, code examples, and implementation for Explainability.
- NFR-E-003: The API provider SHOULD provide natural language descriptions explaining API behavior, parameter effects, and common use cases complementing technical specifications for Explainability.
- NFR-E-006: The API consumer SHOULD provide code examples covering common use cases, error scenarios, and integration patterns in multiple programming languages for Explainability.
3.6.4. Could Have Requirements (45% ≤ TCS < 65%)
- Data Privacy (one requirement)
- NFR-P-005: The API provider COULD implement row-level security mechanisms enforcing fine-grained access control at data element level for Data Privacy.
- Explainability (two requirements)
- NFR-E-004: The API consumer COULD evaluate API documentation quality by assessing completeness, accuracy, example coverage, and maintenance frequency as a trust signal for Explainability.
- NFR-E-005: The API consumer COULD implement error handling translating API error responses into actionable guidance for developers and end users for Explainability.
- Fairness (3 requirements)
- NFR-F-001: The API provider COULD offer special pricing tiers for verified educational institutions and non-profit organizations for Fairness.
- NFR-F-002: The API consumer COULD advocate for pricing models considering regional economic differences and organizational size for Fairness.
- NFR-F-003: The API provider COULD provide free sandbox environments with realistic capabilities enabling evaluation without financial commitment for Fairness.
3.6.5. Won’t Have Classifications (TCS < 45%)
- Data Privacy (one classification)
- NFR-P-006: Advanced Privacy-Preserving Patterns—Won’t Have (TCS: 0%; one source with no substantive discussion). Insufficient practitioner attention to extract an actionable requirement for privacy-preserving patterns such as federated learning or differential privacy.
- Fairness (three classifications)
- NFR-F-004: Free Tier Access Standardization—Won’t Have (TCS: 25.0%; two sources with brief mentions). This is discussed as a business strategy rather than fairness requirement with insufficient consensus.
- NFR-F-005: Equal Access Guarantees—Won’t Have (TCS: 25.0%; four sources with minimal discussion). Scattered conceptual mentions without concrete implementation guidance.
- NFR-F-006: Proportional Rate Limiting by Organization Size—Won’t Have (TCS: 25.0%; two sources with brief mentions). Theoretical consideration without technical implementation guidance.
3.6.6. Distribution Summary
- Must Have: eleven requirements (36.7%)—six Robustness, four Transparency, and one Data Privacy.
- Should Have: nine requirements (30.0%)—two Transparency, three Data Privacy, and four Explainability.
- Could Have: six requirements (20.0%)—one Data Privacy, two Explainability, and three Fairness.
- Won’t Have: four classifications (13.3%)—one Data Privacy and three Fairness.
3.7. Summary of Findings
4. Discussion
4.1. Methodological Validation: Viability of Practitioner Discourse Analysis
4.2. Trustworthy API Priorities: Gap Between Frameworks and Practice
4.3. Stakeholder Perspective Differences: Providers Versus Consumers
4.4. Implications for Practice and Policy
4.5. Threats to Validity
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Scaled Agile, Inc. Nonfunctional Requirements. Scaled Agile Framework. 2025. Updated November 2025. Available online: https://framework.scaledagile.com/nonfunctional-requirements (accessed on 20 February 2026).
- Dongmo, C. A Review of Non-Functional Requirements Analysis Throughout the SDLC. Computers 2024, 13, 308. [Google Scholar] [CrossRef]
- ISO/IEC 25010:2023; Systems and Software Engineering—Systems and Software Quality Requirements and Evaluation (SQuaRE)—Product Quality Model. International Organization for Standardization: Geneva, Switzerland, 2023.
- Garousi, V.; Felderer, M.; Mäntylä, M.V.; Rainer, A. Benefitting from the gray Literature in Software Engineering Research. In Contemporary Empirical Methods in Software Engineering; Felderer, M., Travassos, G.H., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 385–413. [Google Scholar] [CrossRef]
- Garousi, V.; Felderer, M.; Mäntylä, M.V. Guidelines for including gray literature and conducting multivocal literature reviews in software engineering. Inf. Softw. Technol. 2019, 106, 101–121. [Google Scholar] [CrossRef]
- Dieste, O.; Juristo, N. Systematic review and aggregation of empirical studies on elicitation techniques. IEEE Trans. Softw. Eng. 2011, 37, 283–304. [Google Scholar] [CrossRef]
- Pacheco, C.; García, I.; Reyes, M. Requirements elicitation techniques: A systematic literature review based on the maturity of the techniques. IET Softw. 2018, 12, 365–378. [Google Scholar] [CrossRef]
- MacLeod, L.; Bergen, A.; Storey, M.A. Documenting and sharing software knowledge using screencasts. Empir. Softw. Eng. 2017, 22, 1478–1507. [Google Scholar] [CrossRef]
- Treude, C.; Barzilay, O.; Storey, M.A. How do programmers ask and answer questions on the web?: NIER track. In Proceedings of the 2011 33rd International Conference on Software Engineering (ICSE); Association for Computing Machinery: New York, NY, USA, 2011; pp. 804–807. [Google Scholar] [CrossRef]
- Aniche, M.; Treude, C.; Steinmacher, I.; Wiese, I.; Pinto, G.; Storey, M.A.; Gerosa, M.A. How Modern News Aggregators Help Development Communities Shape and Share Knowledge. In Proceedings of the 2018 IEEE/ACM 40th International Conference on Software Engineering (ICSE); Association for Computing Machinery: New York, NY, USA, 2018; pp. 499–510. [Google Scholar] [CrossRef]
- Hata, H.; Novielli, N.; Baltes, S.; Kula, R.G.; Treude, C. GitHub Discussions: An exploratory study of early adoption. Empir. Softw. Eng. 2022, 27, 3. [Google Scholar] [CrossRef]
- Fang, H.; Vasilescu, B.; Herbsleb, J. Understanding information diffusion about open-source projects on Twitter, HackerNews, and Reddit. In Proceedings of the 2023 IEEE/ACM 16th International Conference on Cooperative and Human Aspects of Software Engineering (CHASE); Association for Computing Machinery: New York, NY, USA, 2023; pp. 56–67. [Google Scholar] [CrossRef]
- Stol, K.J.; Ralph, P.; Fitzgerald, B. Grounded theory in software engineering research: A critical review and guidelines. In ICSE ’16: Proceedings of the 38th International Conference on Software Engineering; Association for Computing Machinery: New York, NY, USA, 2016; pp. 120–131. [Google Scholar] [CrossRef]
- Hoda, R. Socio-Technical Grounded Theory for Software Engineering. IEEE Trans. Softw. Eng. 2022, 48, 3808–3832. [Google Scholar] [CrossRef]
- Charmaz, K. Grounded theory in global perspective: Reviews by international researchers. Qual. Inq. 2014, 20, 1074–1084. [Google Scholar] [CrossRef]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology, 4th ed.; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2019. [Google Scholar] [CrossRef]
- Seaman, C.B.; Hoda, R.; Feldt, R. Qualitative Research Methods in Software Engineering: Past, Present, and Future. IEEE Trans. Softw. Eng. 2025, 51, 783–788. [Google Scholar] [CrossRef]
- Wutich, A.; Beresford, M.; Bernard, H.R. Sample Sizes for 10 Types of Qualitative Data Analysis: An Integrative Review, Empirical Guidance, and Next Steps. Int. J. Qual. Methods 2024, 23, 16094069241296206. [Google Scholar] [CrossRef]
- Singjai, A.; Simhandl, G.; Zdun, U. On the practitioners’ understanding of coupling smells — A gray literature based Grounded-Theory study. Inf. Softw. Technol. 2021, 134, 106539. [Google Scholar] [CrossRef]
- Singjai, A.; Zdun, U.; Zimmermann, O. Practitioner Views on the Interrelation of Microservice APIs and Domain-Driven Design: A gray Literature Study Based on Grounded Theory. In Proceedings of the 2021 IEEE 18th International Conference on Software Architecture (ICSA); IEEE: Piscataway, NJ, USA, 2021; pp. 25–35. [Google Scholar] [CrossRef]
- Rodríguez, P. Grounded Theory in Software Engineering: Challenges and Lessons Learned from the Trenches. In WSESE ’24: Proceedings of the 1st IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engineering; Association for Computing Machinery: New York, NY, USA, 2024; pp. 21–26. [Google Scholar] [CrossRef]
- Saldaña, J. The Coding Manual for Qualitative Researchers, 5th ed.; SAGE Publications: London, UK, 2025. [Google Scholar]
- Corbin, J.; Strauss, A. Basics of Qualitative Research: Techniques and Procedures for Developing Grounded Theory, 4th ed.; SAGE Publications: Thousand Oaks, CA, USA, 2015. [Google Scholar]
- Clegg, D.; Barker, R. CASE Method Fast-Track: A RAD Approach; Addison-Wesley: Reading, MA, USA, 1994. [Google Scholar]
- Vijayakumar, S.; Prasad, K.K.; Holla, M.R. Assessing the Effectiveness of MoSCoW Prioritization in Software Development: A Holistic Analysis across Methodologies. EAI Endorsed Trans. Internet Things 2024, 10, 1. [Google Scholar]
- Treblle Webinars. Rethinking API Architecture for the AI Era|Treblle Webinars. YouTube. 2025. Available online: https://www.youtube.com/watch?v=-dSKp-saIt0 (accessed on 19 August 2025).
- Permit. API Development in the AI Era. YouTube. 2024. Available online: https://www.youtube.com/watch?v=5sglo4e1SLs (accessed on 19 August 2025).
- Wilde, E. How Does AI Affect APIs? Expert Opinions from Erik Wilde. YouTube. 2025. Available online: https://www.youtube.com/watch?v=6ekEQR45IIo (accessed on 19 August 2025).
- Sharma, A.; Freeman, J. Securing APIs in the Age of AI: New Risks and Opportunities. YouTube. 2025. Available online: https://www.youtube.com/watch?v=tpsq3LoP67Y (accessed on 19 August 2025).
- Budzynski, M.; Kasper, J. Effective API Governance in the Era of AI. YouTube. 2024. Available online: https://www.youtube.com/watch?v=SfFe2e-9u5M (accessed on 19 August 2025).
- Cindric, V. 7 Key Lessons to Make Your APIs Work. YouTube. 2025. Available online: https://www.youtube.com/watch?v=1iw5Ywz0TLE (accessed on 19 August 2025).
- Pilarinos, D. Building Trust in the AI Era. YouTube. 2025. Available online: https://www.youtube.com/watch?v=j9zzX-dO-x0 (accessed on 19 August 2025).
- Sitaraman, M. AI and APIs, A Powerful Duo! YouTube. 2025. Available online: https://www.youtube.com/watch?v=EajW4HuS7zQ (accessed on 19 August 2025).
- Sitbon, R. Securely Boosting Any Product with Generative AI. YouTube. 2024. Available online: https://www.youtube.com/watch?v=FZTq_8Iwj2A (accessed on 19 August 2025).
- Harmon, J. API-as-a-Product: The Key to a Successful API Strategy. YouTube. 2024. Available online: https://www.youtube.com/watch?v=G3UZ_oiIw6I (accessed on 19 August 2025).
- Gunatilaka, P.; Wijesekara, N. AI Driven API Design, Development, and Consumption. YouTube. 2025. Available online: https://www.youtube.com/watch?v=9WkuTw9NFcg (accessed on 19 August 2025).
- Bhartiya, S.; Websbecher, A. How Traceable AI Is Approaching API Security. YouTube. 2022. Available online: https://www.youtube.com/watch?v=R59zciw679c (accessed on 19 August 2025).
- Wilhelm, A.; Deng, S. Merge’s Unified API Bet in the AI Era. YouTube. 2024. Available online: https://www.youtube.com/watch?v=7owvVCVEDXk (accessed on 19 August 2025).
- Park, S.; Segal, T. Five Ways AI-Assisted API Automation Can Supercharge Integration. YouTube. 2024. Available online: https://www.youtube.com/watch?v=gNWd6tlrhcI (accessed on 19 August 2025).
- a16z. The API Economy—The Why, What and How. YouTube. 2019. Available online: https://www.youtube.com/watch?v=HNBDxRhc9PU (accessed on 19 August 2025).
- Bouchard, L.F. APIs 101: From Concept to Deployment for AI Engineers. YouTube. 2025. Available online: https://www.youtube.com/watch?v=5atR70lV1fs (accessed on 19 August 2025).
- Dalley, A. Why API Architecture Is the Missing Key to AI Success. YouTube. 2025. Available online: https://www.youtube.com/watch?v=vZEN9PZf2cw (accessed on 19 August 2025).
- Amir; Brid, A. The Brutal Truth About Enterprise AI Adoption. YouTube. 2025. Available online: https://www.youtube.com/watch?v=VzNmynLu0e0 (accessed on 19 August 2025).
- Karpathy, A. Software Is Changing (Again). YouTube. 2025. Available online: https://www.youtube.com/watch?v=LCEmiRjPEtQ (accessed on 19 August 2025).
- Petruzzelli, V.; Rivera, G. The Rise of Agentic Checkout and AI Agents. YouTube. 2025. Available online: https://www.youtube.com/watch?v=_7SkxySh2tY (accessed on 19 August 2025).
- Grover, K. The Price of Intelligence—AI Agent Pricing in 2025. YouTube. 2025. Available online: https://www.youtube.com/watch?v=In7K-4JZKR4 (accessed on 19 August 2025).
- Sinha, S.; Fronza, E.M.; Gajula, S. Transparent and Trustworthy AI Governance. YouTube. 2025. Available online: https://www.youtube.com/watch?v=bbXqqmvppnI (accessed on 19 August 2025).
- Runeson, P.; Höst, M.; Rainer, A.; Regnell, B. Case Study Research in Software Engineering: Guidelines and Examples; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Title | Speaker(s) | Date | Ref. |
|---|---|---|---|---|
| TWAI-1 | Rethinking API Architecture for the AI Era | Treblle Webinars | 17 April 2025 | [26] |
| TWAI-2 | API Development in the AI Era | Permal | 22 May 2024 | [27] |
| TWAI-3 | How does AI affect APIs? Expert Opinions from API Days NY 2025 | Erik Wilde | 22 May 2025 | [28] |
| TWAI-4 | Securing APIs in the Age of AI: New Risks and Threat Models | Anubhav Sharma Freeman | 28 May 2025 | [29] |
| TWAI-5 | Effective API governance in the era of AI with Azure API Management | Mike Budzynski, Julia Kasper | 25 September 2024 | [30] |
| TWAI-6 | 7 Key Lessons to Make Your APIs Work Efficiently | Vedran Cindric | 15 March 2025 | [31] |
| TWAI-7 | Building Trust In The AI Era | Dennis Pilarinos | 10 July 2025 | [32] |
| TWAI-8 | AI & APIs: A Powerful Duo | Mulari Sitaraman | 5 March 2025 | [33] |
| TWAI-9 | Securely Boosting Any Product with Generative AI APIs | Ruben Sitbon | 30 October 2024 | [34] |
| TWAI-10 | API-as-a-product: The Key to a Successful API Program | Jason Harmon | 13 November 2024 | [35] |
| TWAI-11 | AI Driven APIAI-Drivenh Enhanced Governance | Natasha Wiesekara | 4 April 2025 | [36] |
| TWAI-12 | How Traceable AI Is Approaching API Security Differently | Weichao Li | 18 August 2022 | [37] |
| TWAI-13 | Merge’s Unified API Bet in the AI Era | Alex Wilhelm, Shensi Deng | 25 October 2024 | [38] |
| TWAI-14 | Five ways AI-assisted API automation can supercharge platform engineering | Sujin Park, Todd Segal | 1 July 2024 | [39] |
| TWAI-15 | The API Economy: The Why, What, and How | a16z Podcast | 2 January 2019 | [40] |
| TWAI-16 | APIs 101: From Concept to Deployment for AI Engineers | Louis-Francois Bouchard | 11 January 2025 | [41] |
| TWAI-17 | Why API Architecture Is the Missing Key to AI Success | Alan Dailey | 27 May 2025 | [42] |
| TWAI-18 | The Brutal Truth About Enterprise AI Adoption | Amir, Ameya Brid | 29 May 2025 | [43] |
| TWAI-19 | Andrej Karpathy: Software Is Changing (Again) | Andrej Karpathy | 19 June 2025 | [44] |
| TWAI-20 | The Rise of Agentic Checkout and AI Agents in Ecommerce | Vito Petruzzelli, Gena Rivera | 26 June 2025 | [45] |
| TWAI-21 | The Price of Intelligence: AI Agent Pricing in 2025 | Kashif Grover | 23 February 2025 | [46] |
| TWAI-22 | Transparent and trustworthy AI governance with watsonx | Monich Fronza, Sunil | 18 February 2025 | [47] |
| Video Source | Avg | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dimension | TWAI-1 | TWAI-2 | TWAI-3 | TWAI-4 | TWAI-5 | TWAI-6 | TWAI-7 | TWAI-8 | TWAI-9 | TWAI-10 | TWAI-11 | TWAI-12 | TWAI-13 | TWAI-14 | TWAI-15 | TWAI-16 | TWAI-17 | TWAI-18 | TWAI-19 | TWAI-20 | TWAI-21 | TWAI-22 | |
| Provider Perspective | |||||||||||||||||||||||
| Explainability | 75 | 75 | 75 | 75 | 75 | 50 | 50 | 50 | 50 | 75 | 75 | 50 | 50 | 75 | 75 | 50 | 50 | 50 | 75 | 100 | 50 | 100 | 65.91% |
| Fairness | 25 | 25 | 25 | 25 | 50 | 25 | 0 | 0 | 25 | 25 | 50 | 0 | 0 | 50 | 25 | 0 | 0 | 25 | 25 | 75 | 50 | 75 | 27.27% |
| Robustness | 100 | 75 | 100 | 100 | 100 | 100 | 100 | 75 | 100 | 50 | 100 | 100 | 100 | 100 | 50 | 75 | 100 | 75 | 100 | 100 | 75 | 75 | 88.64% |
| Data Privacy | 50 | 75 | 25 | 100 | 75 | 75 | 100 | 75 | 25 | 25 | 25 | 50 | 50 | 75 | 25 | 25 | 75 | 50 | 50 | 50 | 0 | 100 | 54.55% |
| Transparency | 100 | 100 | 100 | 75 | 100 | 75 | 75 | 100 | 75 | 75 | 100 | 75 | 75 | 100 | 100 | 50 | 75 | 50 | 75 | 100 | 75 | 100 | 84.09% |
| Consumer Perspective | |||||||||||||||||||||||
| Explainability | 75 | 75 | 75 | 50 | 50 | 50 | 50 | 50 | 25 | 75 | 75 | 25 | 25 | 75 | 25 | 50 | 50 | 25 | 25 | 75 | 50 | 75 | 52.27% |
| Fairness | 25 | 25 | 25 | 25 | 25 | 50 | 0 | 0 | 25 | 25 | 25 | 0 | 0 | 25 | 25 | 0 | 0 | 25 | 25 | 50 | 50 | 75 | 23.86% |
| Robustness | 100 | 100 | 100 | 100 | 100 | 75 | 100 | 75 | 100 | 25 | 50 | 100 | 75 | 75 | 50 | 50 | 75 | 50 | 100 | 100 | 75 | 100 | 80.68% |
| Data Privacy | 25 | 100 | 25 | 75 | 50 | 50 | 100 | 50 | 25 | 25 | 0 | 100 | 50 | 50 | 25 | 25 | 50 | 25 | 25 | 0 | 0 | 75 | 43.18% |
| Transparency | 75 | 100 | 75 | 100 | 100 | 75 | 75 | 100 | 50 | 75 | 75 | 50 | 75 | 75 | 75 | 25 | 75 | 25 | 50 | 75 | 100 | 100 | 73.86% |
| Dimension | Stakeholder | Theme | Source IDs | n | TCS | Classification |
|---|---|---|---|---|---|---|
| Robustness | Provider | R1: Security frameworks | 2, 3, 4, 5, 6, 7, 11, 14, 18, 22 | 10 | 92.5% | Must Have |
| R2: Modular architecture | 1, 2, 17, 18 | 4 | 87.5% | Must Have | ||
| R3: Behavioral detection | 4, 12, 14 | 3 | 100% | Must Have | ||
| Provider Average | 3 | 93.3% | ||||
| Consumer | R1: Infrastructure readiness | 3, 5, 9, 12, 13, 19 | 6 | 95.8% | Must Have | |
| R2: Budget caps | 2, 5, 8, 21 | 4 | 87.5% | Must Have | ||
| R3: Integration testing | 2, 4, 7, 13, 20, 22 | 6 | 95.8% | Must Have | ||
| Consumer Average | 3 | 93.0% | ||||
| Dimension Average | 6 | 93.2% | ||||
| Transparency | Provider | T1: Progressive observability | 1, 5, 8, 22 | 4 | 100% | Must Have |
| T2: OpenAPI specifications | 1, 2, 3, 11, 14, 15, 19 | 7 | 96.4% | Must Have | ||
| T3: Audit trails | 10, 13, 15 | 3 | 83.3% | Should Have | ||
| Provider Average | 3 | 93.2% | ||||
| Consumer | T1: Token tracking | 2, 5, 8, 21 | 4 | 100% | Must Have | |
| T2: Cost monitoring | 2, 4, 7, 13, 20, 22 | 6 | 87.5% | Must Have | ||
| T3: Usage analytics | 6, 10, 11, 17 | 4 | 75.0% | Should Have | ||
| Consumer Average | 3 | 87.5% | ||||
| Dimension Average | 6 | 90.4% | ||||
| Data Privacy | Provider | P1: Logical separation | 2, 3, 4, 5, 6, 7, 11, 14, 18, 22 | 10 | 70.0% | Should Have |
| P2: Encryption | 7 | 1 | 100% * | Should Have | ||
| P3: Row-level security | 12, 20 | 2 | 50.0% | Could Have | ||
| Provider Average | 3 | 73.3% | ||||
| Consumer | P1: Validate permissions | 4, 7, 12, 22 | 4 | 87.5% | Must Have | |
| P2: Data minimization | 2, 4, 7, 13, 20, 22 | 6 | 66.7% | Should Have | ||
| P3: Privacy patterns | 20 | 1 | 0% | Won’t Have | ||
| Consumer Average | 3 | 51.4% | ||||
| Dimension Average | 6 | 62.4% | ||||
| Explainability | Provider | E1: Machine-readable docs | 1, 2, 3, 11, 14, 15, 19 | 7 | 75.0% | Should Have |
| E2: Automated generation | 10, 15, 19 | 3 | 75.0% | Should Have | ||
| E3: Natural language | 11 | 1 | 75.0% | Should Have | ||
| Provider Average | 3 | 75.0% | ||||
| Consumer | E1: Doc quality signal | 6, 10, 11, 17 | 4 | 62.5% | Could Have | |
| E2: Error messages | 1, 16 | 2 | 62.5% | Could Have | ||
| E3: Examples | 2, 3, 8, 14 | 4 | 68.8% | Should Have | ||
| Consumer Average | 3 | 64.6% | ||||
| Dimension Average | 6 | 69.8% | ||||
| Fairness | Provider | F1: Tiered access | 13, 21 | 2 | 25.0% | Won’t Have |
| F2: Educational pricing | 11 | 1 | 50.0% | Could Have | ||
| F3: Proportional limiting | 13, 21 | 2 | 25.0% | Won’t Have | ||
| Provider Average | 3 | 33.3% | ||||
| Consumer | F1: Pricing equity | 6 | 1 | 50.0% | Could Have | |
| F2: Access fairness | 9, 15, 18, 20 | 4 | 31.25% | Won’t Have | ||
| F3: Sandbox access | 6 | 1 | 50.0% | Could Have | ||
| Consumer Average | 3 | 43.75% | ||||
| Dimension Average | 6 | 38.5% | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Share and Cite
Singjai, A. Deriving Empirically Grounded NFR Specifications from Practitioner Discourse: A Validated Methodology Applied to Trustworthy APIs in the AI Era. Information 2026, 17, 304. https://doi.org/10.3390/info17030304
Singjai A. Deriving Empirically Grounded NFR Specifications from Practitioner Discourse: A Validated Methodology Applied to Trustworthy APIs in the AI Era. Information. 2026; 17(3):304. https://doi.org/10.3390/info17030304
Chicago/Turabian StyleSingjai, Apitchaka. 2026. "Deriving Empirically Grounded NFR Specifications from Practitioner Discourse: A Validated Methodology Applied to Trustworthy APIs in the AI Era" Information 17, no. 3: 304. https://doi.org/10.3390/info17030304
APA StyleSingjai, A. (2026). Deriving Empirically Grounded NFR Specifications from Practitioner Discourse: A Validated Methodology Applied to Trustworthy APIs in the AI Era. Information, 17(3), 304. https://doi.org/10.3390/info17030304