
Deep Learning-Enhanced Ocean Acoustic Tomography: A Latent Feature Fusion Framework for Hydrographic Inversion with Source Characteristic Embedding

Abstract
1. Introduction
- A Paraformer-based sound source classification method is proposed, achieving a balance between high accuracy and real-time performance in complex underwater environments;
- A causal inference mechanism is introduced to construct physically interpretable environmental embedding vectors, enhancing the interpretability and generalization ability of the inversion model;
- A causal analysis-driven latent feature fusion network is designed and implemented, integrating source attributes, acoustic data, and causal environmental information, and employing a classification-based strategy instead of regression to achieve high-precision inference of key physical parameters, with GPU acceleration improving inference speed by over sixfold.
Related Works
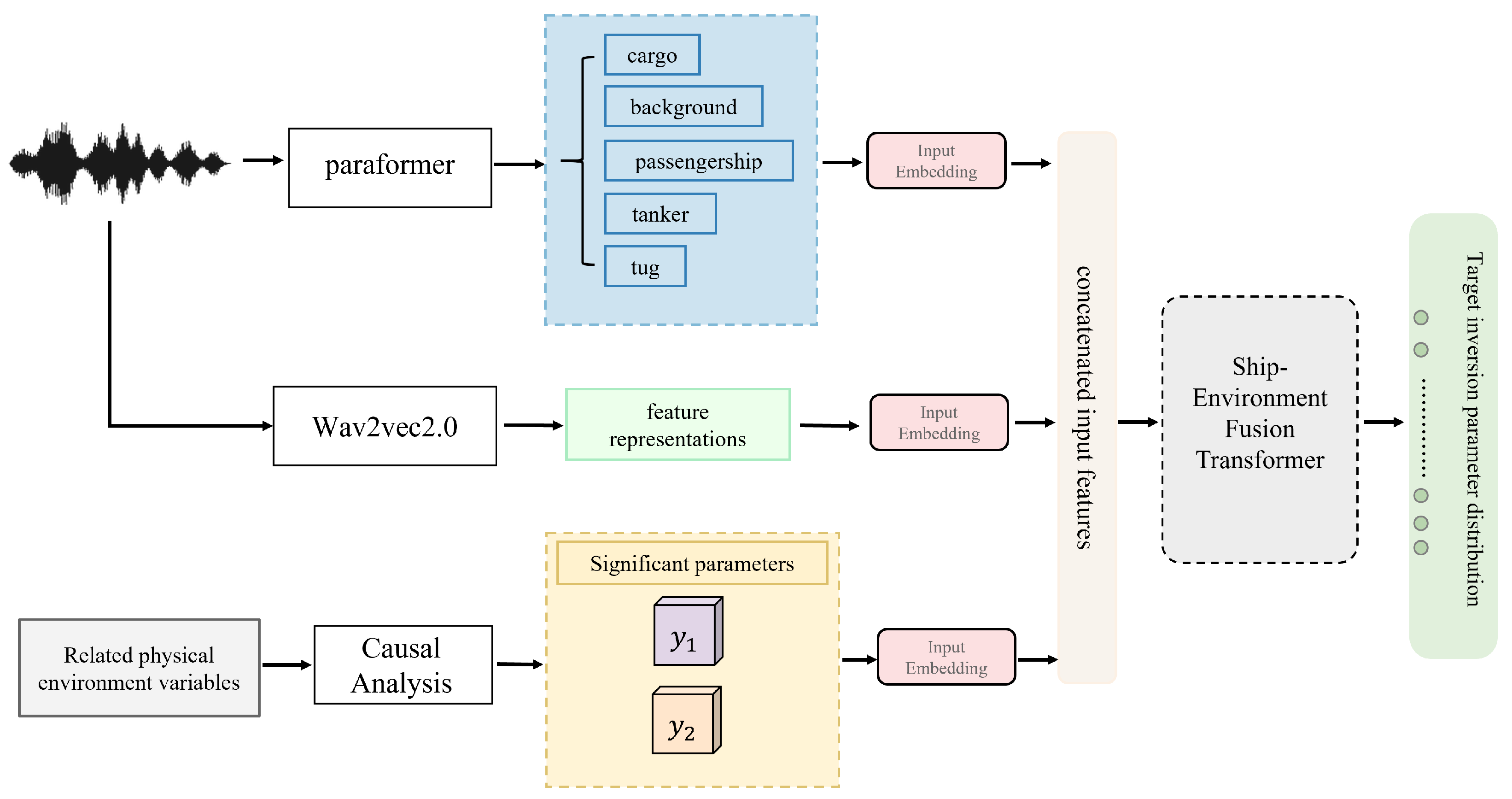
2. Methodologies
2.1. Oceanic Hydrological Parameter Inversion
2.2. Source Target Detection via Fine-Tuning of the Paraformer Model
2.3. Causal Analysis
2.4. Latent Causal Feature Fusion and Framework
3. Neural Networks
3.1. Ocean Hydrographic Parameter Inversion
| Algorithm 1 Causal Analysis of Environmental Parameters |
| Require: Observational dataset , causal graph , treatment variable set , outcome variable set Ensure: Causal graph visualization, ATE estimates, key feature set 1: Initialize the causal graph based on marine domain knowledge 2: for each treatment variable do 3: for each outcome variable do 4: Construct a CausalModel, setting t as treatment and y as outcome 5: Apply the backdoor criterion to identify the adjustment set Z 6: Estimate the intervention distribution using linear regression 7: Compute ATE: 8: Perform sensitivity analysis using the random common cause method 9: end for 10: end for 11: Select the top k key features for each outcome variable based on magnitude 12: return Causal graph , ATE values, selected features |
3.2. Latent Causal Feature Fusion and Joint Modeling
3.2.1. Physically-Informed Embedding Generation
3.2.2. Multimodal Fusion Network Architecture
4. Experimental Configuration
4.1. Dataset Description
4.2. Loss Functions
4.3. Experimental Setup
5. Results
Experiment of Model
Inference Speed Comparison Experiment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Le Gac, J.C.; Asch, M.; Stephan, Y.; Demoulin, X. Geoacoustic inversion of broad-band acoustic data in shallow water on a single hydrophone. IEEE J. Ocean. Eng. 2003, 28, 479–493. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, Y.; Kan, G.; Liu, B.; Zhou, X.; Zhang, X. An Inversion Method for Geoacoustic Parameters in Shallow Water Based on Bottom Reflection Signals. Remote Sens. 2023, 15, 3237. [Google Scholar] [CrossRef]
- Martins, N.E.; Jesus, S.M. Bayesian acoustic prediction assimilating oceanographic and acoustically inverted data. J. Mar. Syst. 2009, 78, S349–S358. [Google Scholar] [CrossRef]
- Li, H.; Liu, Y.; Li, M.; Wang, P.; Zhu, Y.; Mao, K.; Chen, X. A Deep Learning-Based Reconstruction Model for 3d Sound Speed Field Combining Underwater Vertical Information. Available online: https://www.ssrn.com/abstract=5012577 (accessed on 25 April 2025).
- Jin, J.; Saha, P.; Durofchalk, N.; Mukhopadhyay, S.; Romberg, J.; Sabra, K.G. Machine learning approaches for ray-based ocean acoustic tomography. J. Acoust. Soc. Am. 2022, 152, 3768–3788. [Google Scholar] [CrossRef] [PubMed]
- Saha, P.; Touret, R.X.; Ollivier, E.; Jin, J.; McKinley, M.; Romberg, J.; Sabra, K.G. Leveraging sound speed dynamics and generative deep learning for ray-based ocean acoustic tomography. JASA Express Lett. 2025, 5, 040801. [Google Scholar] [CrossRef] [PubMed]
- Song, T.; Wei, W.; Meng, F.; Wang, J.; Han, R.; Xu, D. Inversion of Ocean Subsurface Temperature and Salinity Fields Based on Spatio-Temporal Correlation. Remote Sens. 2022, 14, 2587. [Google Scholar] [CrossRef]
- Xu, P.; Xu, S.; Shi, K.; Ou, M.; Zhu, H.; Xu, G.; Gao, D.; Li, G.; Zhao, Y. Prediction of Water Temperature Based on Graph Neural Network in a Small-Scale Observation via Coastal Acoustic Tomography. Remote Sens. 2024, 16, 646. [Google Scholar] [CrossRef]
- Bornstein, G.; Biescas, B.; Sallarès, V.; Mojica, J.F. Direct temperature and salinity acoustic full waveform inversion. Geophys. Res. Lett. 2013, 40, 4344–4348. [Google Scholar] [CrossRef]
- Zhang, C.; Zhu, Z.N.; Xiao, C.; Zhu, X.H.; Liu, Z.J. Acoustic tomographic inversion of 3D temperature fields with mesoscale anomaly in the South China Sea. Front. Mar. Sci. 2024, 11, 1350337. [Google Scholar] [CrossRef]
- Ye, H.; Wang, W.; Zhang, X. GC-MT: A Novel Vessel Trajectory Sequence Prediction Method for Marine Regions. Information 2025, 16, 311. [Google Scholar] [CrossRef]
- Domingos, L.; Skelton, P.; Santos, P. VTUAD: Vessel Type Underwater Acoustic Data. IEEE Dataport 2022. [Google Scholar] [CrossRef]
- Gao, Z.; Zhang, S.; McLoughlin, I.; Yan, Z. Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition. arXiv 2023, arXiv:2206.08317. [Google Scholar]
- Jiang, X.; Liu, T.; Song, T.; Cen, Q. Optimized Marine Target Detection in Remote Sensing Images with Attention Mechanism and Multi-Scale Feature Fusion. Information 2025, 16, 332. [Google Scholar] [CrossRef]
- Vardi, A.; Bonnel, J. End-to-End Geoacoustic Inversion With Neural Networks in Shallow Water Using a Single Hydrophone. IEEE J. Ocean. Eng. 2024, 49, 380–389. [Google Scholar] [CrossRef]
- Imbens, G.W.; Rubin, D.B. Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Sharma, A.; Kiciman, E. DoWhy: An End-to-End Library for Causal Inference. arXiv 2020, arXiv:2011.04216. [Google Scholar]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Chen, C.; Millero, F.J. Speed of sound in seawater at high pressures. J. Acoust. Soc. Am. 1977, 62, 1129–1135. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Farahnakian, F.; Heikkonen, J. Deep Learning Based Multi-Modal Fusion Architectures for Maritime Vessel Detection. Remote Sens. 2020, 12, 2509. [Google Scholar] [CrossRef]
- Santos-Domínguez, D.; Torres-Guijarro, S.; Cardenal-López, A.; Pena-Gimenez, A. ShipsEar: An underwater vessel noise database. Applied Acoust. 2016, 113, 64–69. [Google Scholar] [CrossRef]
- Irfan, M.; Jiangbin, Z.; Ali, S.; Iqbal, M.; Masood, Z.; Hamid, U. DeepShip: An underwater acoustic benchmark dataset and a separable convolution based autoencoder for classification. Expert Syst. Appl. 2021, 183, 115270. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CPU | Intel(R) Xeon(R) Gold 6230 CPU @ 2.10 GHz (Santa Clara, CA, USA) |
| OS | Ubuntu 20.04 LTS |
| GPU | NVIDIA Tesla V100-SXM2-32 GB (Santa Clara, CA, USA) |
| CUDA Version | CUDA 12.6 |
| Model Layers | Dropout | Epochs | Learning Rate Strategy |
| 4 | 0.3 | 100 | Cosine Annealing |
| Batch Size | Initial Learning Rate | Optimizer | |
| 32 | 0.0001 | AdamW |
| Inversion Parameter | Classes | Accuracy (%) | F1 Score | Recall (%) | Precision (%) | AUC |
|---|---|---|---|---|---|---|
| Temperature | 100 | 98.61 | 0.985 | 96.95 | 97.26 | 0.99 |
| 1000 | 97.77 | 0.978 | 96.08 | 96.59 | 0.99 | |
| Salinity | 100 | 96.72 | 0.964 | 96.28 | 96.28 | 0.99 |
| 1000 | 95.52 | 0.955 | 94.54 | 94.86 | 0.99 |
| Inversion Parameter | CPU (Seconds) | GPU (Seconds) | ||
|---|---|---|---|---|
| Average Time | Speedup Ratio | Average Time | Speedup Ratio | |
| Temperature | 37.49 | 1.00 | 5.73 | 6.54 |
| Salinity | 36.85 | 1.00 | 5.73 | 6.43 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Chen, Z.; Zhu, Y.; Zheng, X. Deep Learning-Enhanced Ocean Acoustic Tomography: A Latent Feature Fusion Framework for Hydrographic Inversion with Source Characteristic Embedding. Information 2025, 16, 665. https://doi.org/10.3390/info16080665
Zhou J, Chen Z, Zhu Y, Zheng X. Deep Learning-Enhanced Ocean Acoustic Tomography: A Latent Feature Fusion Framework for Hydrographic Inversion with Source Characteristic Embedding. Information. 2025; 16(8):665. https://doi.org/10.3390/info16080665
Chicago/Turabian StyleZhou, Jiawen, Zikang Chen, Yongxin Zhu, and Xiaoying Zheng. 2025. "Deep Learning-Enhanced Ocean Acoustic Tomography: A Latent Feature Fusion Framework for Hydrographic Inversion with Source Characteristic Embedding" Information 16, no. 8: 665. https://doi.org/10.3390/info16080665
APA StyleZhou, J., Chen, Z., Zhu, Y., & Zheng, X. (2025). Deep Learning-Enhanced Ocean Acoustic Tomography: A Latent Feature Fusion Framework for Hydrographic Inversion with Source Characteristic Embedding. Information, 16(8), 665. https://doi.org/10.3390/info16080665