
Explainable Machine Learning Model for Source Type Identification of Mine Inrush Water



Abstract
1. Introduction
- A novel Conv1d-GRU network is developed for accurate source type identification of mine inrush water.
- The Spearman coefficient analysis and interpretability experiments quantify the impact of key features on model performance.
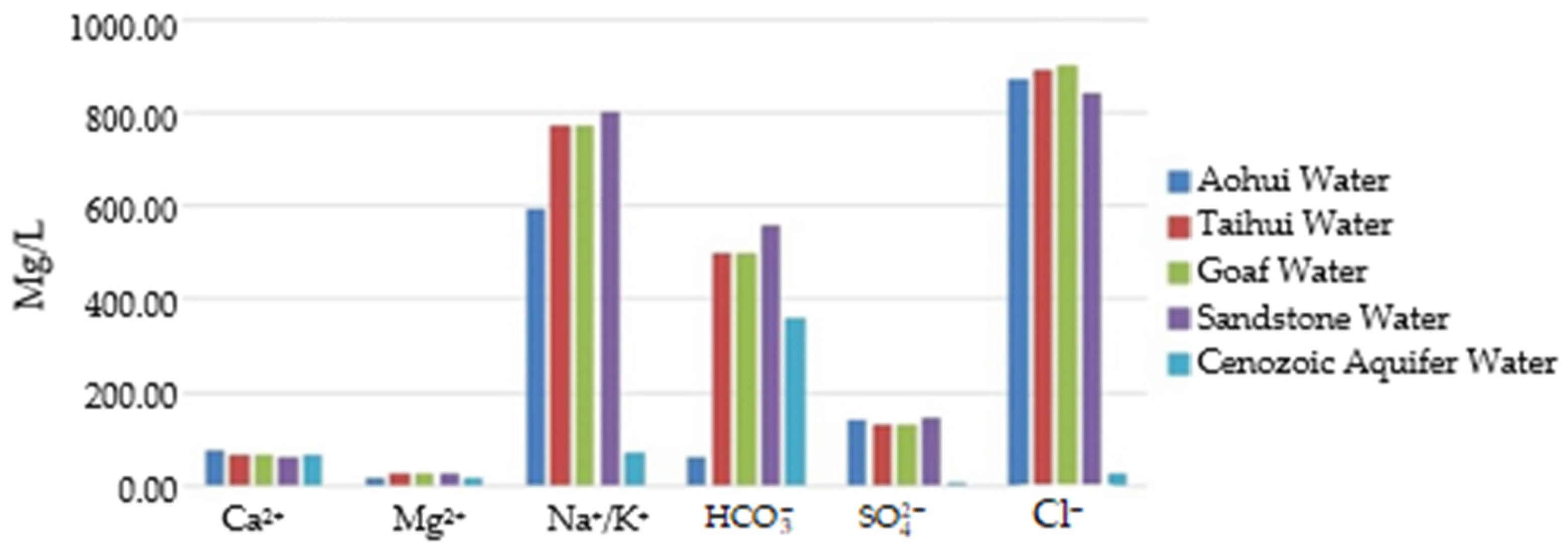
2. Hydrochemical Characteristics of Hydrogeological Mines
3. Methodology
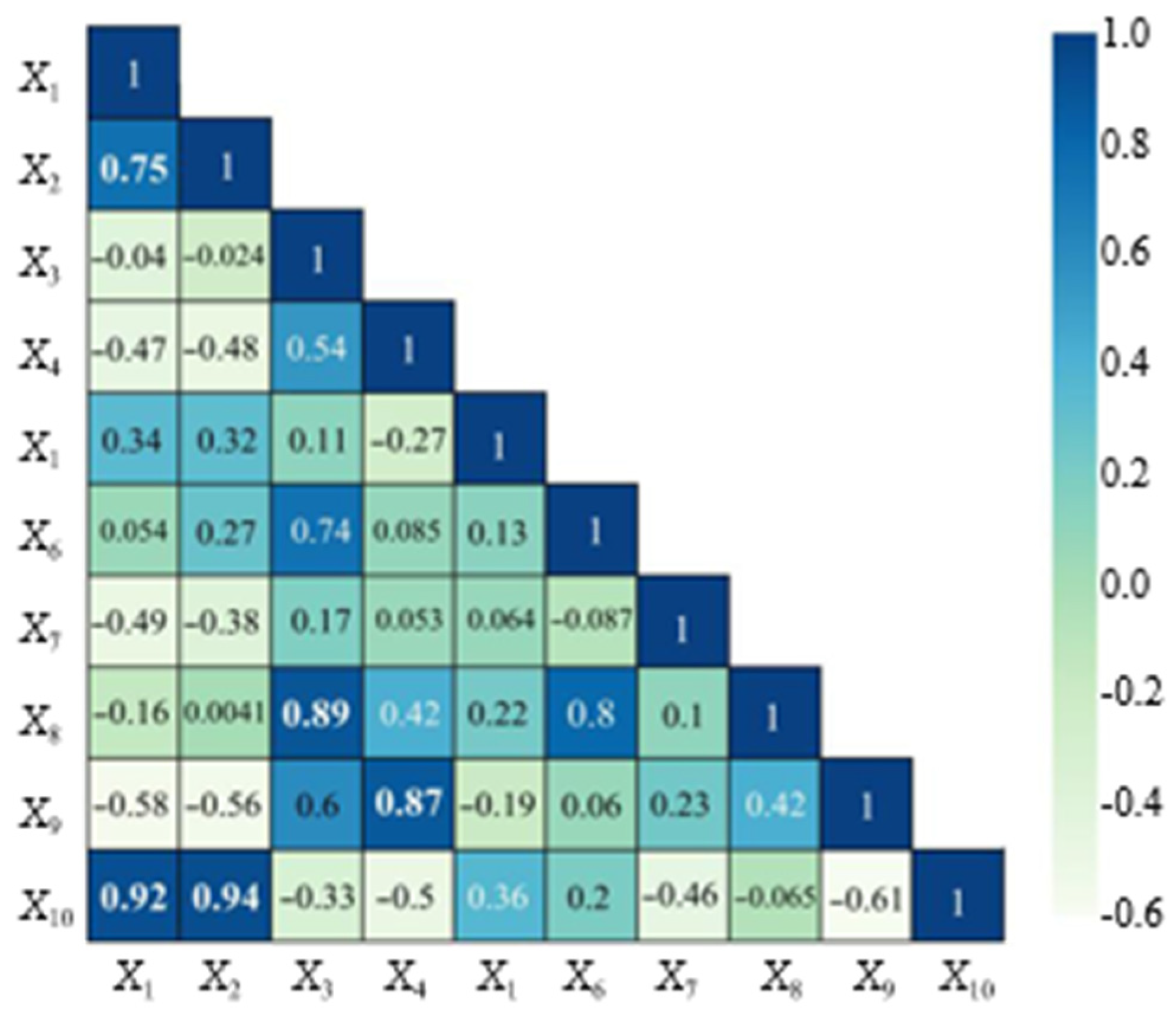
3.1. Correlation Analysis
3.2. LSTM Network
3.3. GRU Network
3.4. Conv1d Network
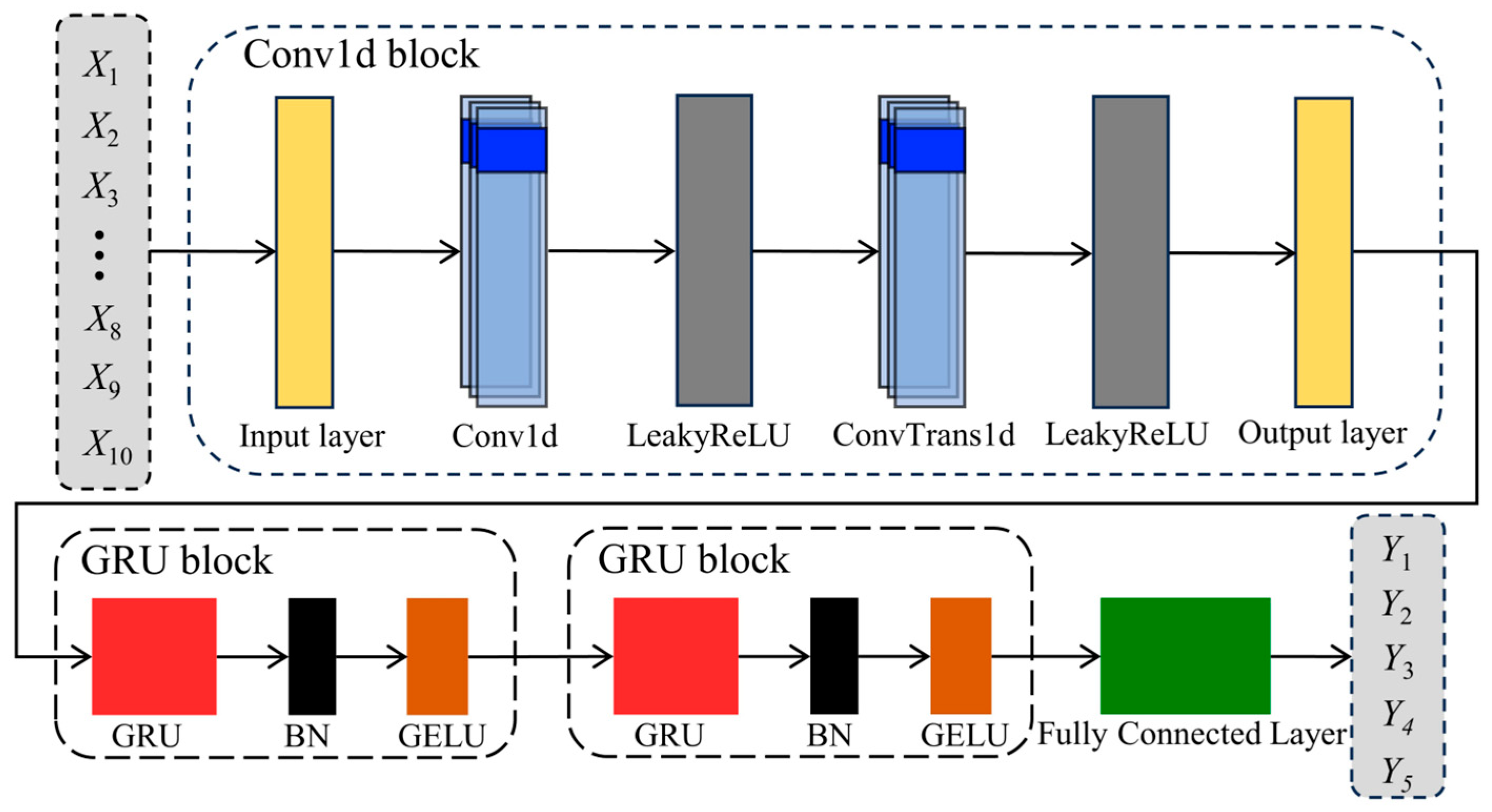
3.5. Conv1d-GRU Network
4. Experiments and Results
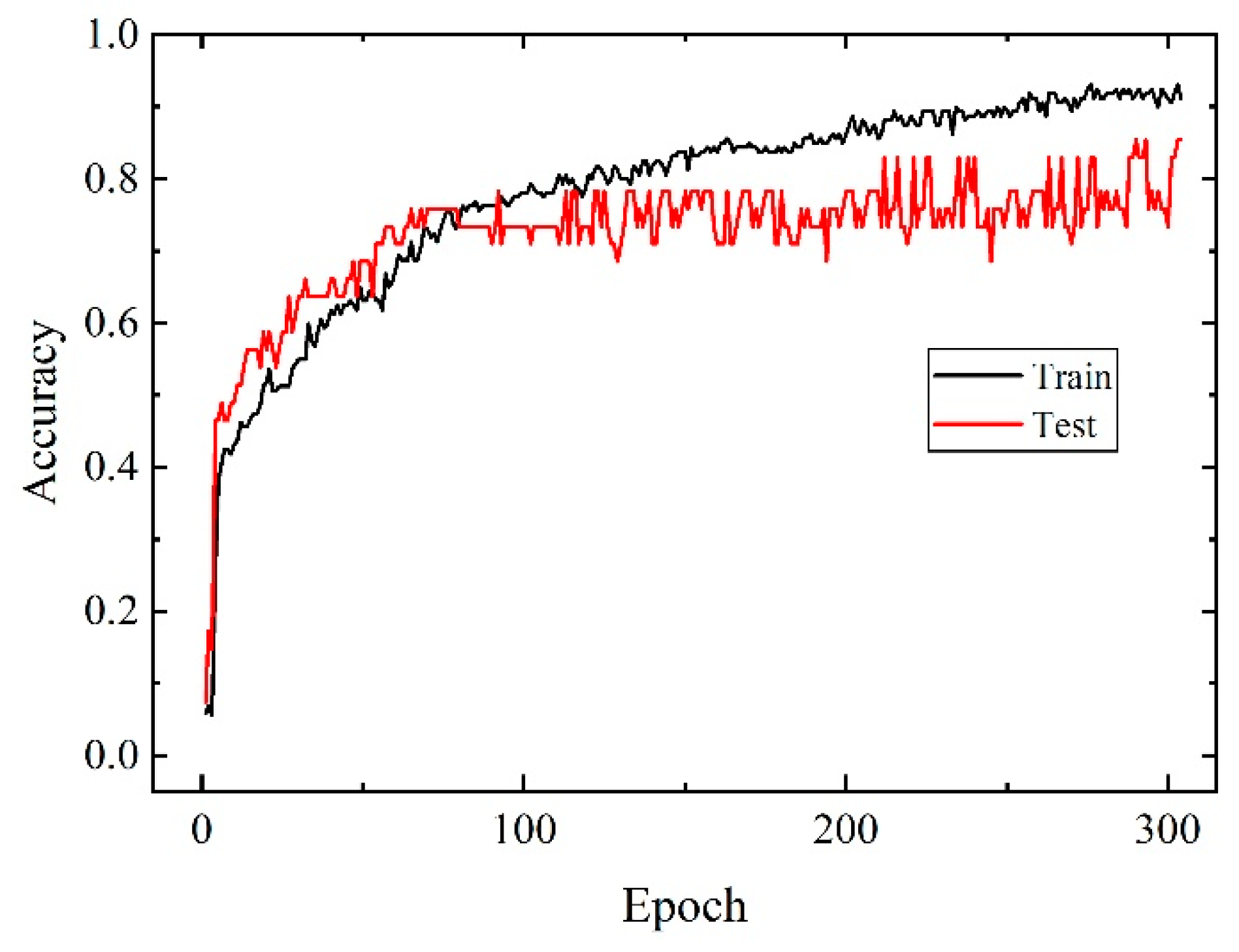
4.1. Experiment Setup
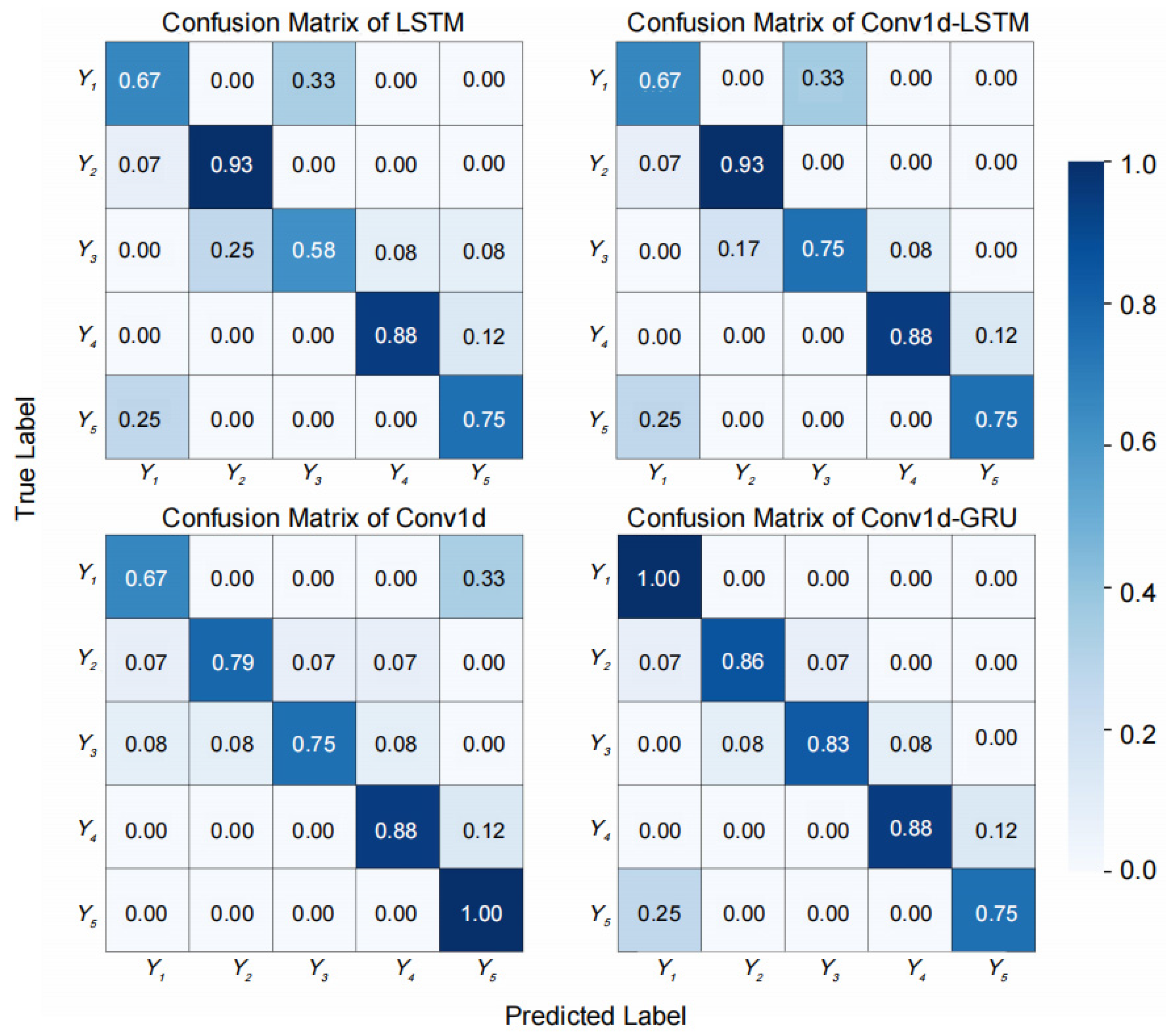
4.2. Comparative Analysis of Conv1d-GRU, GRU, LSTM, Conv1d, and Conv1d-LSTM Models
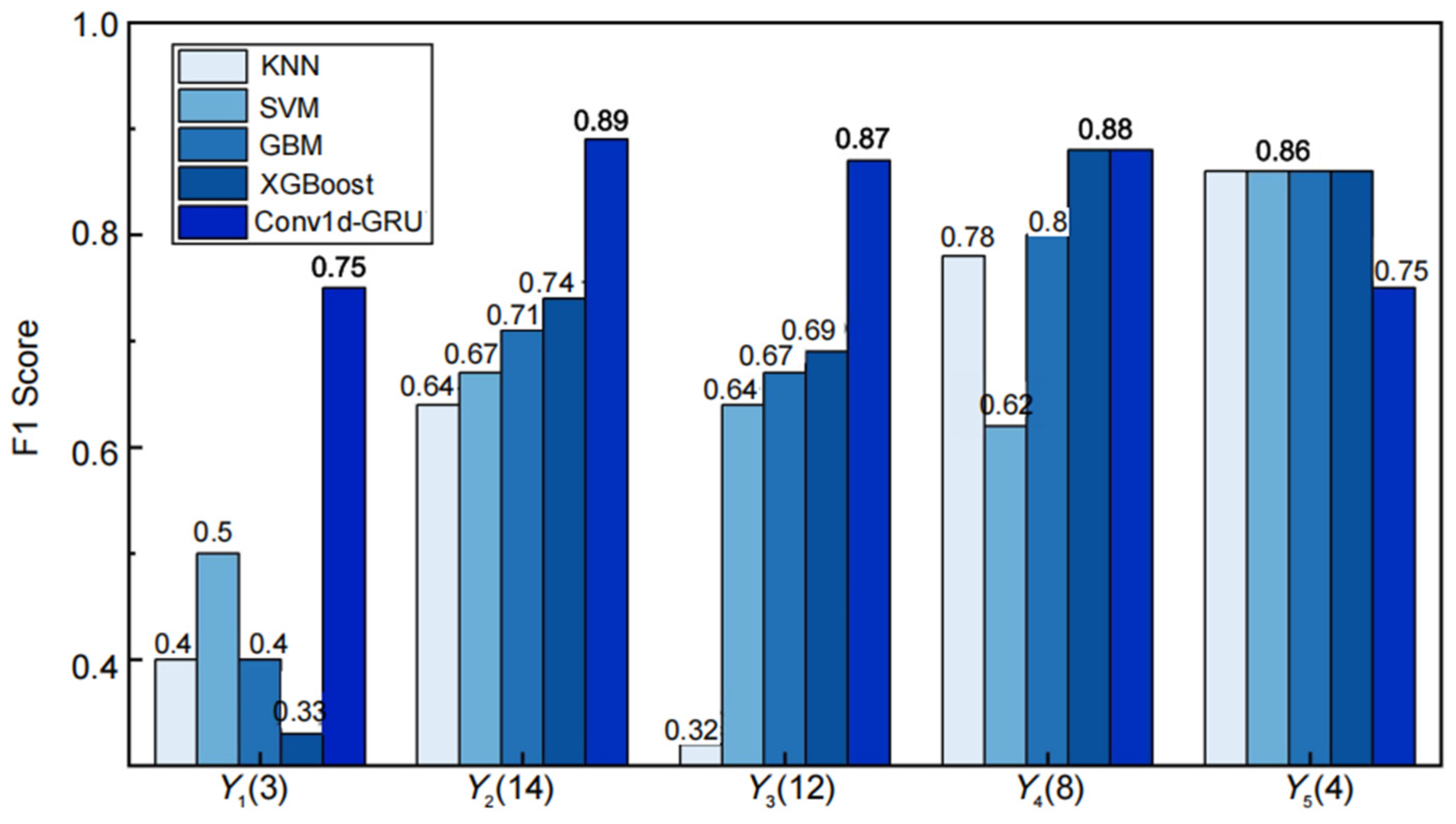
4.3. Comparative Analysis of Conv1d-GRU and Traditional Machine Learning Models
5. Explainable Machine Learning Model for Source Type Identification of Mine Inrush Water
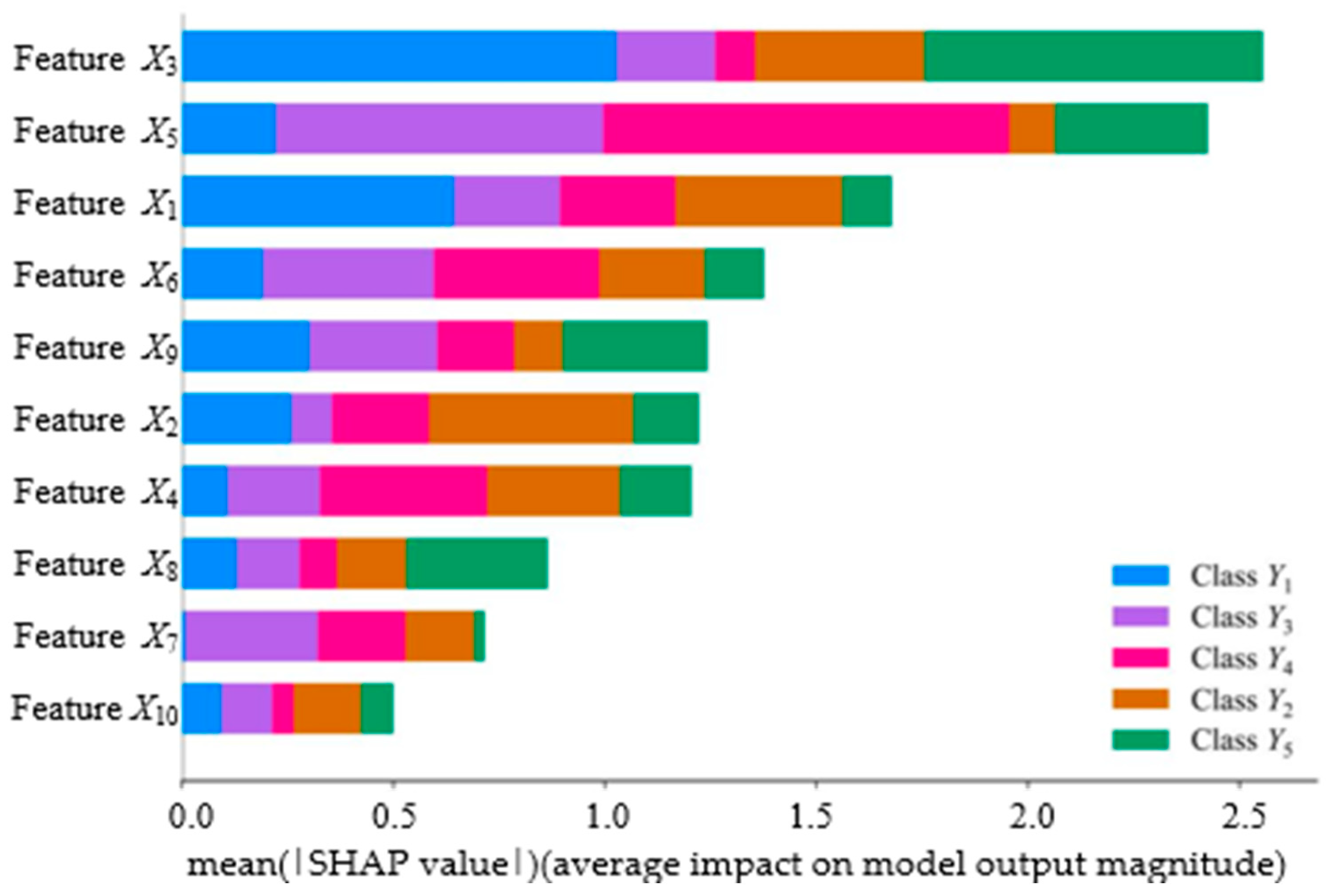
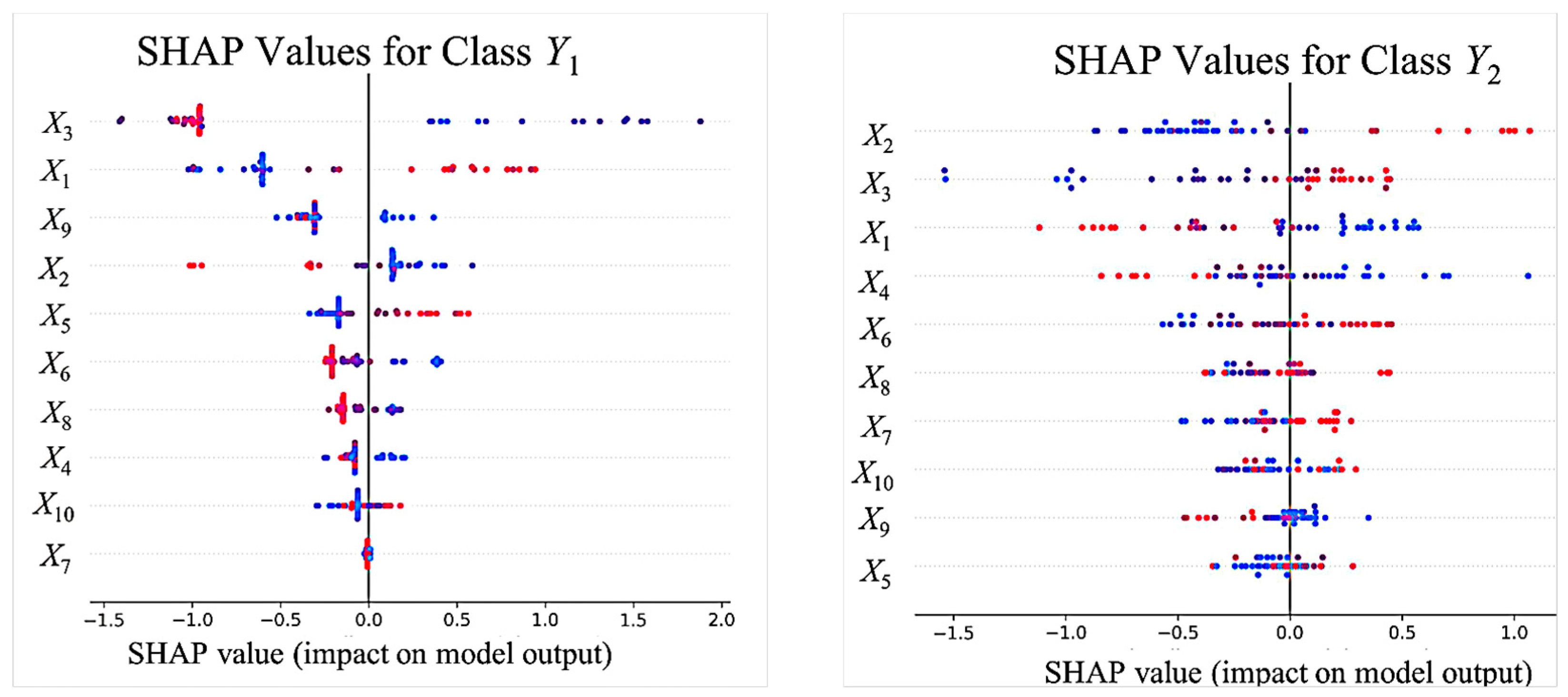
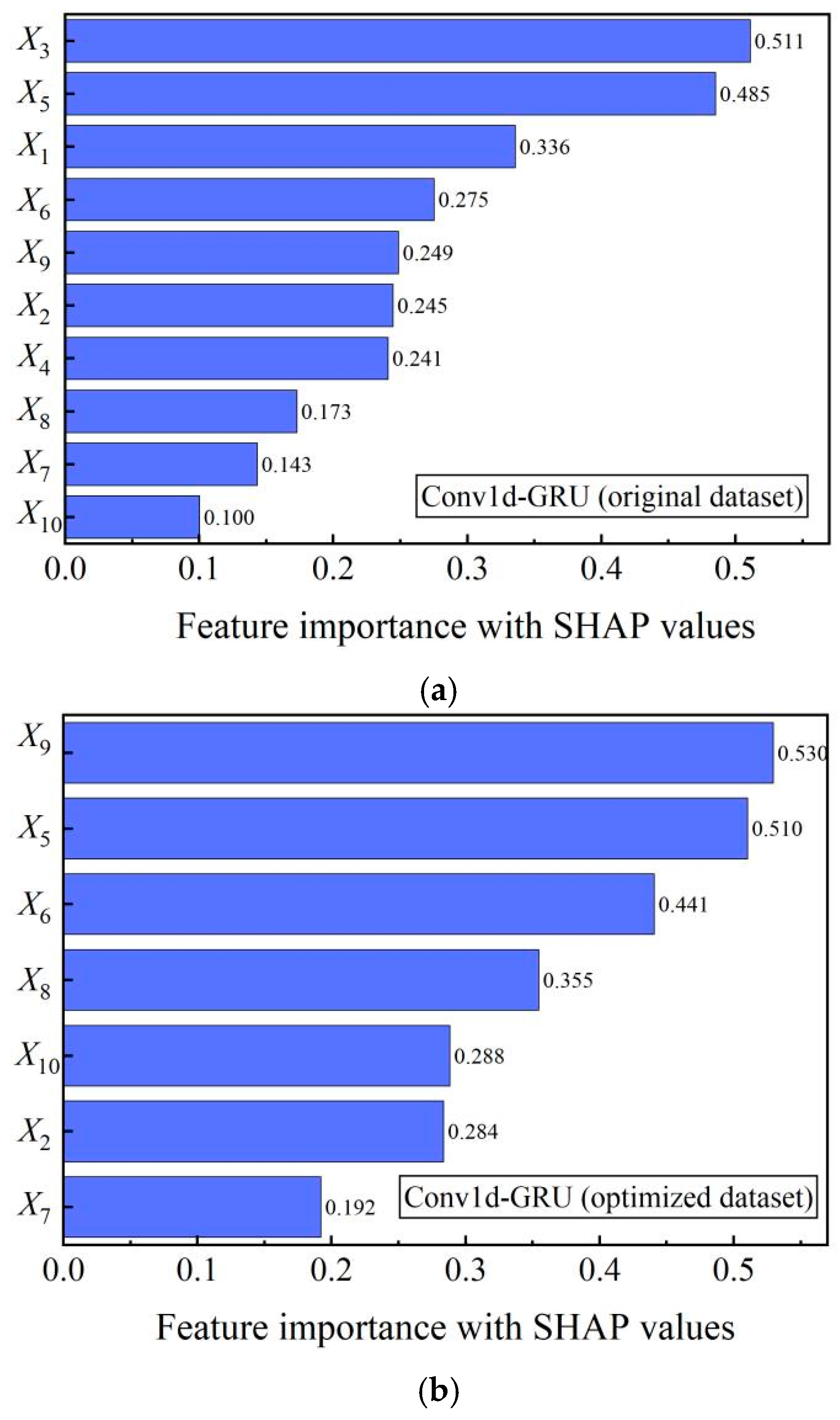
5.1. Interpretability Analysis Using SHAP Values
5.2. Comparative Analysis of the Interpretability of Feature Importance When Selecting Features
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, Q.; Liu, Q.; Liu, Y.; Chai, H.; Zhu, J. Groundwater chemical characteristic analysis and water source identification model study in Gubei coal mine, Northern Anhui Province, China. Heliyon 2024, 10, 26925. [Google Scholar] [CrossRef] [PubMed]
- Chitsazan, M.; Heidari, M.; Ghobadi, M. The Study of the Hydrogeological Setting of the Chamshir Dam Site with Special Emphasis on the Cause of Water Salinity in the Zohreh River Downstream from the Chamshir Dam (Southwest of Iran). Environ. Earth Sci. 2012, 67, 1605–1617. [Google Scholar] [CrossRef]
- Zhang, J. Investigations of water inrushes from aquifers under coal seams. Int. J. Rock Mech. Min. Sci. 2005, 42, 350–360. [Google Scholar] [CrossRef]
- Tijani, M.N. Contamination of shallow groundwater system and soil–plant transfer of trace metals under amended irrigated fields. Agric. Water Manag. 2009, 96, 437–444. [Google Scholar] [CrossRef]
- Shi, L.Q. Summary of research on mechanism of water inrush from seam floor. J. Shandong Univ. Sci. Technol. 2009, 28, 17–23. [Google Scholar]
- Fazzino, F.; Roccaro, P.; Di Bella, A. Use of fluorescence for real-time monitoring of contaminants of emerging concern in (waste) water: Perspectives for sensors implementation and process control. J. Environ. Chem. Eng. 2025, 13, 115916. [Google Scholar] [CrossRef]
- Milinovic, J.; Santos, P.; Marques, J.E. Spectroscopic signatures for expeditious monitoring of contamination risks at abandoned coal mine sites. Geochemistry 2025, 85, 126292. [Google Scholar] [CrossRef]
- Dong, F.; Yin, H.; Cheng, W.; Zhang, C.; Zhang, D.; Ding, H.; Lu, C.; Wang, Y. Quantitative prediction model and prewarning system of water yield capacity (WYC) from coal seam roof based on deep learning and joint advanced detection. Energy 2024, 290, 130200. [Google Scholar] [CrossRef]
- He, C.Y.; Zhou, M.R.; Yan, P.C. Application of the Identification of Mine Water Inrush with LIF Spectrometry and KNN Algorithm Combined with PCA. Spectrosc. Spectr. Anal. 2016, 36, 2234–2237. [Google Scholar]
- Yao, D.; Chen, S.; Qin, D.J. Modeling abrupt changes in mine water inflow trends: A CEEMDAN-based multi-model prediction approach. J. Clean. Prod. 2024, 439, 140809. [Google Scholar] [CrossRef]
- Yin, H.; Wu, Q.; Yin, S.; Dong, S.; Dai, Z.; Soltanian, M.R. Predicting mineinrush water accidents based on water level anomalies of borehole groups using long short-term memory and isolation forest. J. Hydrol. 2023, 616, 128813. [Google Scholar] [CrossRef]
- Shi, L.; Qu, X.; Han, J.; Qiu, M.; Gao, W.; Qin, D.; Liu, H. Multi-model fusion for assessing risk of inrush of limestone karst water through the mine floor. Energy Rep. 2021, 7, 1473–1487. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, Y. A New Dynamic Assessment for Multi-parameters Information ofinrush water in Coal Mine*. Energy Procedia 2012, 16, 1586–1592. [Google Scholar]
- Li, D.; Peng, S.; Guo, Y.; Lin, P. Development status and prospect of geological guarantee technology for intelligent coal mining in China. Green Smart Min. Eng. 2024, 1, 433–446. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, L.; Chen, Y. Water environment risk prediction method based on convolutional neural network-random forest. Mar. Pollut. Bull. 2024, 209, 117228. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.; Wan, Y.; Wang, K.; Zhao, Z.; Song, Y.; Guo, X.; Xiang, G. Methods for constructing scenarios of coal and gas outburst accidents: Implications for the intelligent emergency response of secondary mine accidents. Process Saf. Environ. Prot. 2025, 199, 107236. [Google Scholar] [CrossRef]
- Tong, X.; Zheng, X.; Jin, Y.; Dong, B.; Liu, Q.; Li, Y. Prevention and control strategy of coal mine water inrush accident based on case-driven and Bow-tie-Bayesian model. Energy 2025, 320, 135312. [Google Scholar] [CrossRef]
- Ouifak, H.; Idri, A. A comprehensive review of fuzzy logic based interpretability and explainability of machine learning techniques across domains. Neurocomputing 2025, 647, 130602. [Google Scholar] [CrossRef]
- Moghaddas, S.A.; Bao, Y. Explainable machine learning framework for predicting concrete abrasion depth. Case Stud. Constr. Mater. 2025, 22, e04686. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Name |
|---|---|
| Ca2+ | X1 |
| Mg2+ | X2 |
| Na+/K+ | X3 |
| HCO3− | X4 |
| SO42− | X5 |
| Cl− | X6 |
| pH | X7 |
| TDS | X8 |
| Alkalinity | X9 |
| Hardness | X10 |
| Aohui Water | Y1 |
| Sandstone Water | Y2 |
| Goaf Water | Y3 |
| Taihui Water | Y4 |
| Cenozoic Aquifer Water | Y5 |
| Names | Input Shape | Output Shape |
|---|---|---|
| CNN Input | (8, 10) | (8, 7, 1) |
| Conv1d-1 | (8, 7, 1) | (8, 7, 1) |
| Conv1d-2 | (8, 7, 1) | (8, 7, 16) |
| Conv1d-3 | (8, 7, 16) | (8, 7, 16) |
| CNN Output | (8, 7, 1) | (8, 7) |
| GRU | (8, 7) | (8, 18) |
| GRU | (8, 18) | (8, 18) |
| Output | (8, 18) | (8, 5) |
| Names | Layers | Output Shape |
|---|---|---|
| Input | Input layer | 8 × 10 |
| GRU/LSTM block | GRU/LSTM | 8 × 18 |
| BatchNormalization | 8 × 18 | |
| ELU Activity Function | 8 × 18 | |
| Output | Fully Connected | 8 × 5 |
| Models | Hyperparameter |
|---|---|
| KNN | n neighbors = 5, weights = ‘uniform’ |
| SVM | C = 1, kernel = ‘rbf’, gamma = ‘scale’ |
| LightGBM | num leaves = 31, learning rate = 0.05, max depth = 5, feature fraction = 0.9, verbose = −1, num class = 5 |
| RF | max depth = 10, min samples split = 5, n estimators = 200, class weight = ‘balanced’ |
| ANN | learning rate = 0.0005, batch size = 8, epoch = 600, hidden size = 64, optimizer = ‘Adam’ |
| GBM | learning rate = 0.1, max depth = 3, n estimators = 100, subsample = 0.8 |
| XGBoost | learning rate = 0.1, max mdepth = 5, n estimators = 100, Subsample = 0.8, colsample bytree = 0.8 |
| Models | Accuracy (%) | Weighted Precision (%) | Weighted Recall (%) |
|---|---|---|---|
| GRU | 78.05% | 79.94% | 78.05% |
| LSTM | 78.05% | 82.74% | 78.05% |
| Conv1d | 80.49% | 82.98% | 80.49% |
| Conv1d-LSTM | 82.93% | 83.98% | 82.93% |
| Conv1d-GRU | 85.37% | 86.91% | 85.37% |
| Models | Accuracy (%) | Weighted Precision (%) | Weighted Recall (%) |
|---|---|---|---|
| KNN | 58.54% | 60.00% | 58.54% |
| SVM | 65.85% | 68.62% | 65.85% |
| LightGBM | 65.85% | 69.91% | 65.85% |
| RF | 70.73% | 75.85% | 70.73% |
| ANN | 70.73% | 71.40% | 70.73% |
| GBM | 70.73% | 71.75% | 70.73% |
| XGBoost | 73.17% | 74.35% | 73.17% |
| Conv1d-GRU | 85.37% | 86.91% | 85.37% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Li, J.; Tao, H.; Cheng, Y.; Zhao, L. Explainable Machine Learning Model for Source Type Identification of Mine Inrush Water. Information 2025, 16, 648. https://doi.org/10.3390/info16080648
Yang Y, Li J, Tao H, Cheng Y, Zhao L. Explainable Machine Learning Model for Source Type Identification of Mine Inrush Water. Information. 2025; 16(8):648. https://doi.org/10.3390/info16080648
Chicago/Turabian StyleYang, Yong, Jing Li, Huawei Tao, Yong Cheng, and Li Zhao. 2025. "Explainable Machine Learning Model for Source Type Identification of Mine Inrush Water" Information 16, no. 8: 648. https://doi.org/10.3390/info16080648
APA StyleYang, Y., Li, J., Tao, H., Cheng, Y., & Zhao, L. (2025). Explainable Machine Learning Model for Source Type Identification of Mine Inrush Water. Information, 16(8), 648. https://doi.org/10.3390/info16080648