
A Multi-Domain Enhanced Network for Underwater Image Enhancement

Abstract
1. Introduction
- 1.
- A novel hybrid backbone network is proposed, in which a vision transformer sub-net is embedded between the CNN-based encoder and decoder phases, enhancing the network’s utilization of global features.
- 2.
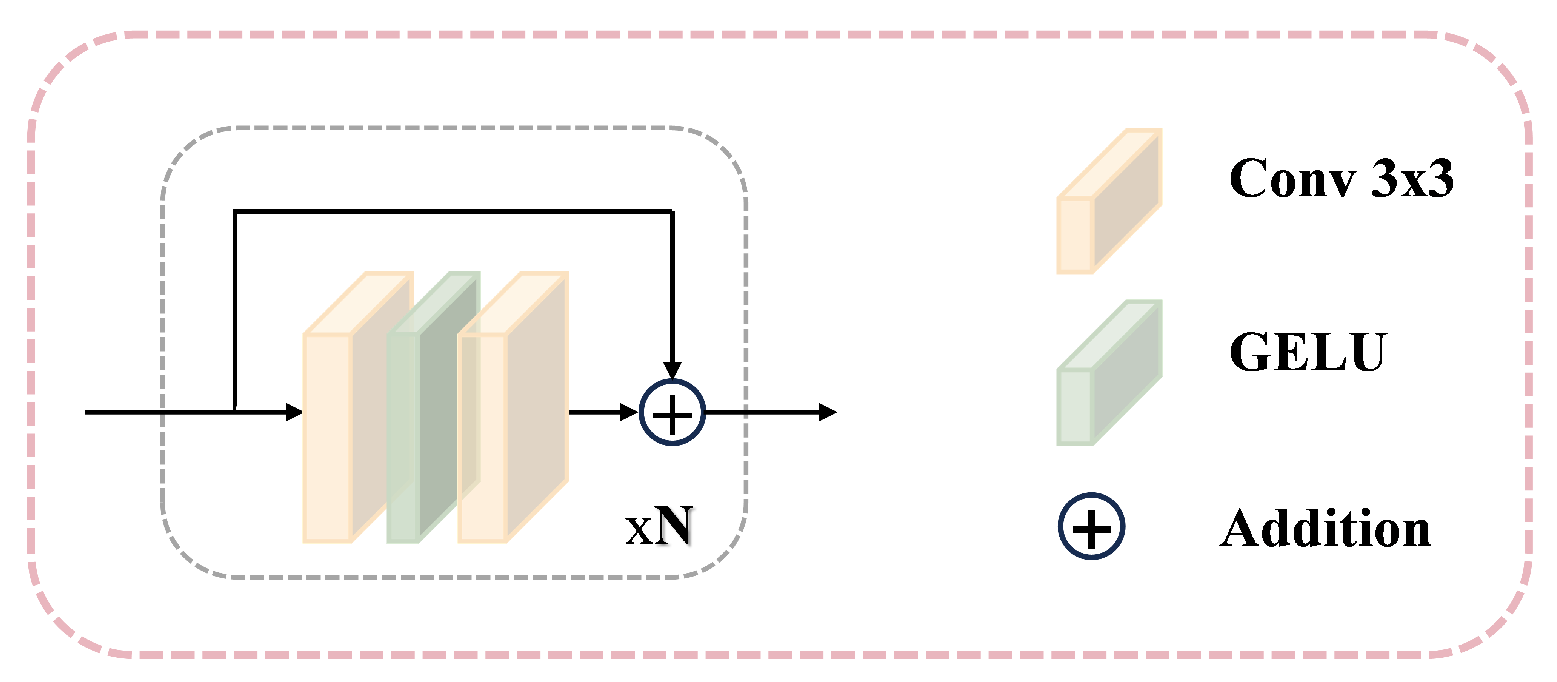
- In both encoder and decoder phases, by replacing the original encoder–decoder component in the CNN architecture, a multi-scale hybrid attention (MHA) module is proposed, which is next to the customized residual convolutional (RC) blocks. This design achieves bi-domain bidirectional attention, effectively enhancing representation learning for multi-scale image restoration.
- 3.
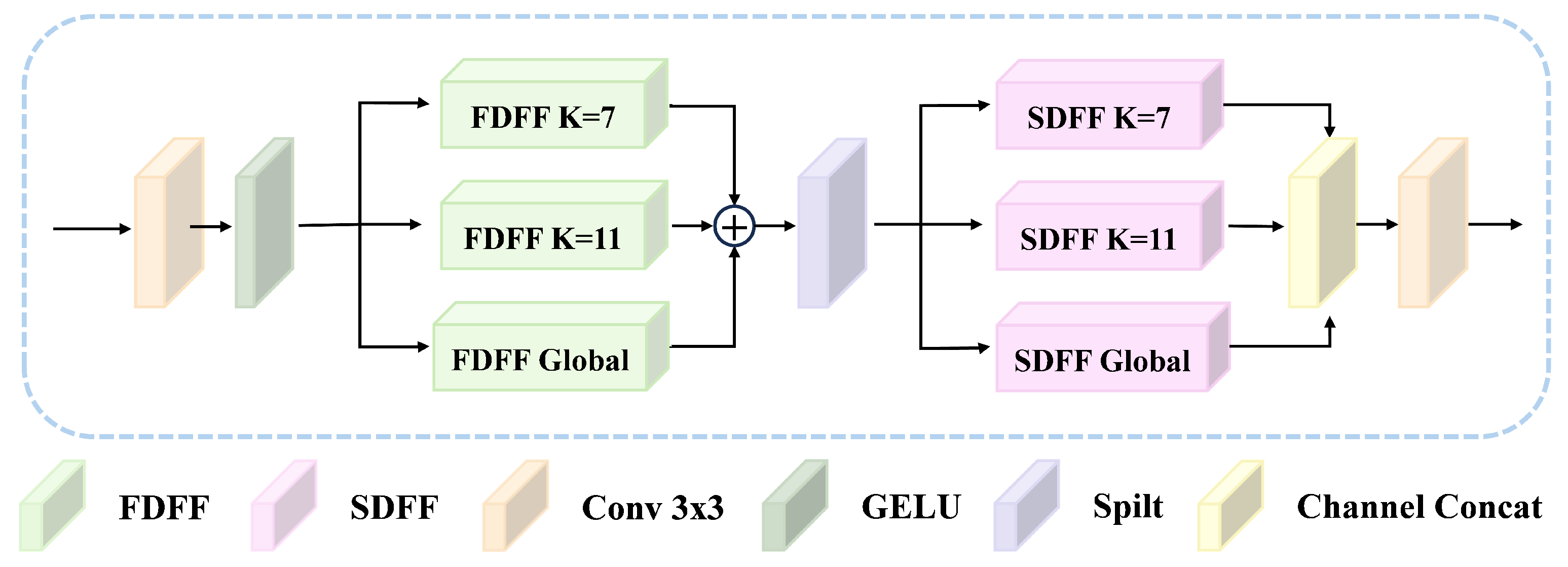
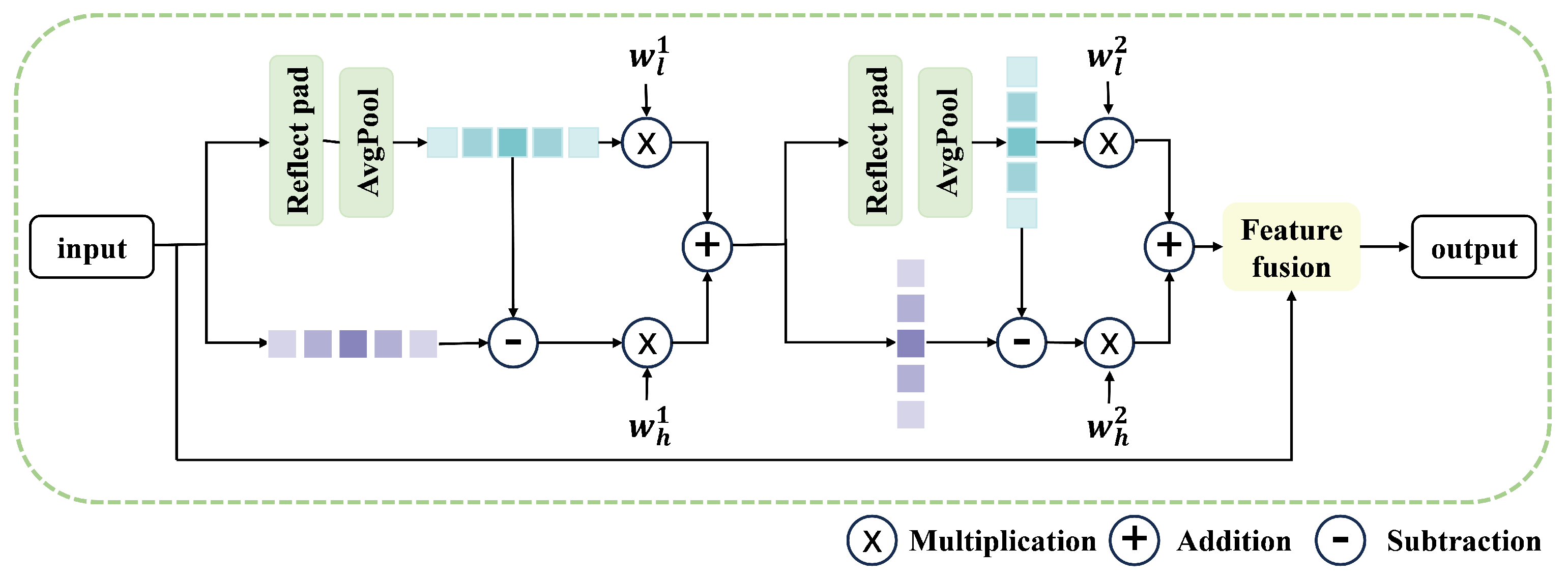
- By integrating the spatial domain feature fusion (SDFF) module and frequency domain feature fusion (FDFF) module, a dual domain attention mechanism is proposed in the multi-scale hybrid attention module, making it dynamically learnable and greatly enhancing the adaptability of the network.
2. Related Works
2.1. Traditional Methods
2.2. Deep Learning-Based Approaches
3. Proposed Method
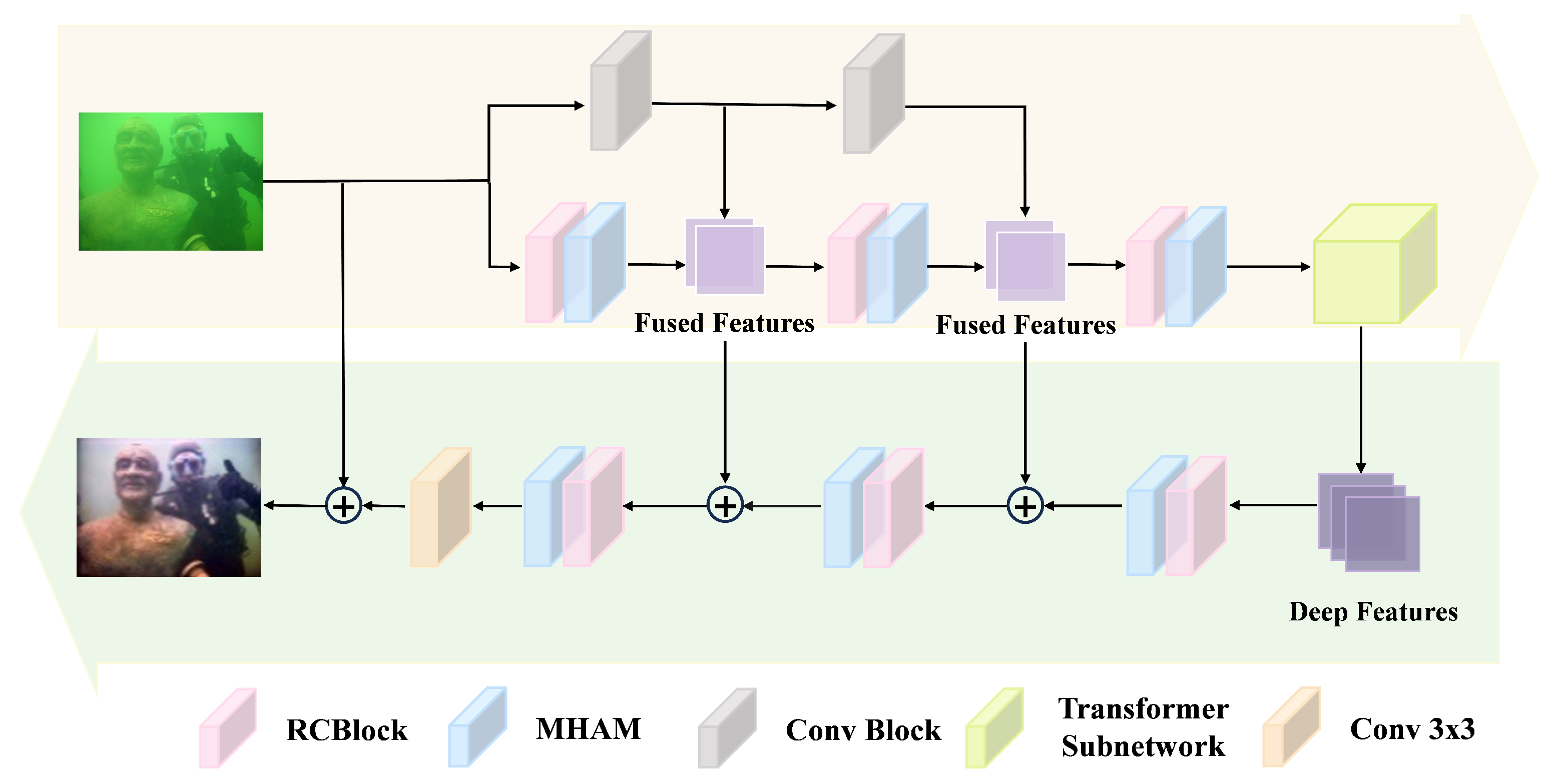
3.1. Method Overview
3.2. Multi-Scale Hybrid Attention Mechanism
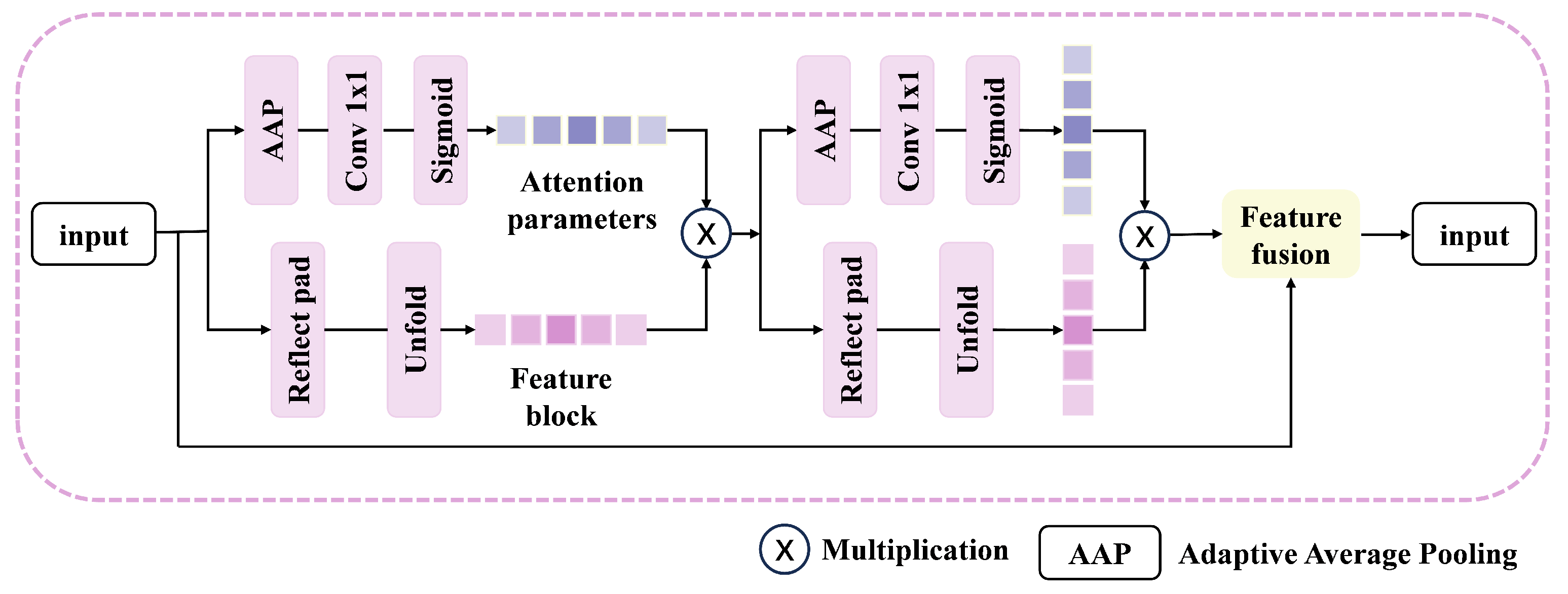
3.2.1. Spatial Domain Feature Fusion Module
3.2.2. Frequency Domain Feature Fusion Module
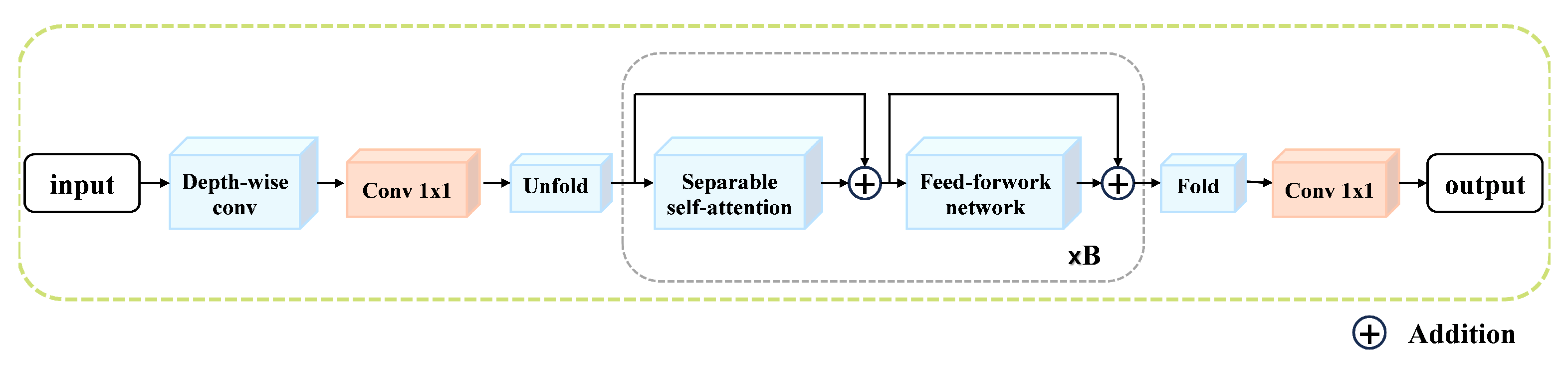
3.3. Transformer Sub-Network
3.4. Loss Function
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
- (1)
- Warm-up phase (first 500 steps): The learning rate increases linearly from 1% of the initial value to 100%.
- (2)
- Main training phase: This uses a cosine annealing learning rate of .
- (3)
- Fine-tuning phase: This uses a fixed learning rate of for 50 epochs of fine-tuning. This is combined with automatic mixed precision (AMP) and gradient clipping (max_norm = 1.0).
4.4. Quantitative Evaluation
4.5. Quantitative Evaluation
4.6. Ablation Studies
4.6.1. The Design Selection of FDFF and SDFF
4.6.2. Selection of Different Strip Sizes
4.6.3. Design Choice of MHA
4.6.4. Design–Selection of Transform
5. Conclusions
6. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
References
- Li, C.; Anwar, S.; Hou, J.; Cong, R.; Guo, C.; Ren, W. Underwater Image Enhancement via Medium Transmission-Guided Multi-Color Space Embedding. IEEE Trans. Image Process. 2021, 30, 4985–5000. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, Y.; Ding, X.; Fu, X. Underwater Image Enhancement via L2 based Laplacian Pyramid Fusion. In Proceedings of the OCEANS 2019 MTS/IEEE SEATTLE, Seattle, WA, USA, 27–31 October 2019; pp. 1–4. [Google Scholar]
- Dai, C.; Lin, M. Adaptive contrast enhancement for underwater image using imaging model guided variational framework. Multimed. Tools Appl. 2024, 83, 83311–83338. [Google Scholar] [CrossRef]
- Zhang, W.; Pan, X.; Xie, X.; Li, L.; Wang, Z.; Han, C. Color correction and adaptive contrast enhancement for underwater image enhancement. Comput. Electr. Eng. 2021, 91, 106981. [Google Scholar] [CrossRef]
- Zhang, W.; Dong, L.; Xu, W. Retinex-inspired color correction and detail preserved fusion for underwater image enhancement. Comput. Electron. Agric. 2022, 192, 106585. [Google Scholar] [CrossRef]
- Zhang, D.; Zhou, J.; Guo, C.; Zhang, W.; Li, C. Synergistic Multiscale Detail Refinement via Intrinsic Supervision for Underwater Image Enhancement. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 7033–7041. [Google Scholar]
- Guan, M.; Xu, H.; Jiang, G.; Yu, M.; Chen, Y.; Luo, T.; Zhang, X. DiffWater: Underwater Image Enhancement Based on Conditional Denoising Diffusion Probabilistic Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 2319–2335. [Google Scholar] [CrossRef]
- Lu, S.; Guan, F.; Zhang, H.; Lai, H. Underwater image enhancement method based on denoising diffusion probabilistic model. J. Vis. Commun. Image Represent. 2023, 96, 103926. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Volume 9351. [Google Scholar]
- Chiang, J.Y.; Chen, Y.C. Underwater Image Enhancement by Wavelength Compensation and Dehazing. IEEE Trans. Image Process. 2012, 21, 1756–1769. [Google Scholar] [CrossRef]
- Galdran, A.; Pardo, D.; Picón, A.; Alvarez-Gila, A. Automatic Red-Channel Underwater Image Restoration. J. Vis. Commun. Image Represent. 2015, 26, 132–145. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1956–1963. [Google Scholar]
- Peng, Y.T.; Cosman, P.C. Underwater Image Restoration Based on Image Blurriness and Light Absorption. IEEE Trans. Image Process. 2017, 26, 1579–1594. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, H.; Chau, L.P. Single Underwater Image Restoration Using Adaptive Attenuation-Curve Prior. IEEE Trans. Circuits Syst. Video Technol. 2018, 65, 992–1002. [Google Scholar] [CrossRef]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised Generative Network to Enable Real-Time Color Correction of Monocular Underwater Images. IEEE Robot. Autom. Lett. 2017, 2, 1944–1950. [Google Scholar] [CrossRef]
- Li, C.; Guo, J.; Guo, C. Emerging From Water: Underwater Image Color Correction Based on Weakly Supervised Color Transfer. IEEE Signal Process. Lett. 2018, 25, 323–327. [Google Scholar] [CrossRef]
- Fu, X.; Cao, X. Underwater Image Enhancement with Global–Local Networks and Compressed-Histogram Equalization. Signal Process. Image Commun. 2020, 86, 115892. [Google Scholar] [CrossRef]
- Qi, Q.; Zhang, Y.; Tian, F.; Wu, Q.J.; Li, K.; Luan, X.; Song, D. Underwater Image Co-Enhancement With Correlation Feature Matching and Joint Learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1133–1147. [Google Scholar] [CrossRef]
- Zhou, J.; Sun, J.; Li, C.; Jiang, Q.; Zhou, M.; Lam, K.M.; Zhang, W.; Fu, X. HCLR-Net: Hybrid Contrastive Learning Regularization with Locally Randomized Perturbation for Underwater Image Enhancement. Int. J. Comput. Vis. 2024, 132, 4132–4156. [Google Scholar] [CrossRef]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7313–7322. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-Stage Progressive Image Restoration. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14816–14826. [Google Scholar]
- Chen, X.; Fan, Z.; Li, P.; Dai, L.; Kong, C.; Zheng, Z.; Huang, Y.; Li, Y. Unpaired Deep Image Dehazing Using Contrastive Disentanglement Learning. arXiv 2022, arXiv:2203.07677. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Lee, H.; Choi, H.; Sohn, K.; Min, D. KNN Local Attention for Image Restoration. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2129–2139. [Google Scholar]
- Chen, Z.; Zhang, Y.; Gu, J.; Zhang, Y.; Kong, L.; Yuan, X. Cross Aggregation Transformer for Image Restoration. arXiv 2023, arXiv:2211.13654. [Google Scholar]
- Li, Y.; Fan, Y.; Xiang, X.; Demandolx, D.; Ranjan, R.; Timofte, R.; Van Gool, L. Efficient and Explicit Modelling of Image Hierarchies for Image Restoration. arXiv 2023, arXiv:2303.00748. [Google Scholar]
- Mehta, S.; Rastegari, M. Separable Self-attention for Mobile Vision Transformers. arXiv 2022, arXiv:2206.02680. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient Transformer for High-Resolution Image Restoration. arXiv 2022, arXiv:2111.09881. [Google Scholar]
- Wang, T.; Yang, X.; Xu, K.; Chen, S.; Zhang, Q.; Lau, R.W.H. Spatial Attentive Single-Image Deraining With a High Quality Real Rain Dataset. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12262–12271. [Google Scholar]
- Li, C.; Anwar, S.; Porikli, F. Underwater Scene Prior Inspired Deep Underwater Image and Video Enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast Underwater Image Enhancement for Improved Visual Perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-World Underwater Enhancement: Challenges, Benchmarks, and Solutions Under Natural Light. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wang, W. A Fusion Adversarial Underwater Image Enhancement Network with a Public Test Dataset. arXiv 2019, arXiv:1906.06819. [Google Scholar]
- Korhonen, J.; You, J. Peak Signal-to-Noise Ratio Revisited: Is Simple Beautiful? In Proceedings of the 2012 Fourth International Workshop on Quality of Multimedia Experience, Melbourne, Australia, 5–7 July 2012; pp. 37–38. [Google Scholar]
- Liu, Y.; Zhai, G.; Gu, K.; Liu, X.; Zhao, D.; Gao, W. Reduced-Reference Image Quality Assessment in Free-Energy Principle and Sparse Representation. IEEE Trans. Multimed. 2018, 20, 379–391. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-Visual-System-Inspired Underwater Image Quality Measures. IEEE J. Ocean. Eng. 2016, 41, 541–551. [Google Scholar] [CrossRef]
- Yang, M.; Sowmya, A. An Underwater Color Image Quality Evaluation Metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef]
- Peng, Y.T.; Cao, K.; Cosman, P.C. Generalization of the Dark Channel Prior for Single Image Restoration. IEEE Trans. Image Process. 2018, 27, 2856–2868. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An Underwater Image Enhancement Benchmark Dataset and Beyond. IEEE Trans. Image Process. 2020, 29, 4376–4389. [Google Scholar] [CrossRef]
- Zhang, W.; Zhuang, P.; Sun, H.H.; Li, G.; Kwong, S.; Li, C. Underwater Image Enhancement via Minimal Color Loss and Locally Adaptive Contrast Enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef]
- Fu, Z.; Wang, W.; Huang, Y.; Ding, X.; Ma, K.K. Uncertainty Inspired Underwater Image Enhancement. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Volume 13678, pp. 465–482. [Google Scholar]
- Zhang, D.; Wu, C.; Zhou, J.; Zhang, W.; Li, C.; Lin, Z. Hierarchical attention aggregation with multi-resolution feature learning for GAN-based underwater image enhancement. Eng. Appl. Artif. Intell. 2023, 125, 106743. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | UIEB T-90 | EUVP | UIEB C-60 | UCCS | U45 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | UIQM↑ | UCIQE↑ | UIQM↑ | UCIQE↑ | UIQM↑ | UCIQE↑ | |
| GDCP [40] | 13.38 | 0.747 | 16.38 | 0.644 | 2.250 | 0.569 | 2.699 | 0.564 | 2.248 | 0.594 |
| FUInEGAN [32] | 17.11 | 0.701 | 21.92 | 0.887 | 2.220 | 0.508 | 3.095 | 0.529 | 2.473 | 0.519 |
| UWCNN [31] | 17.95 | 0.847 | 17.73 | 0.704 | 2.546 | 0.520 | 3.025 | 0.498 | 3.079 | 0.546 |
| WaterNet [41] | 17.35 | 0.813 | 20.14 | 0.681 | 2.382 | 0.597 | 3.039 | 0.569 | 2.993 | 0.599 |
| UColor [1] | 21.90 | 0.872 | 21.89 | 0.795 | 2.482 | 0.553 | 3.019 | 0.550 | 3.159 | 0.573 |
| MLLE [42] | 19.08 | 0.825 | 15.04 | 0.632 | 2.250 | 0.569 | 2.868 | 0.570 | 2.485 | 0.595 |
| PUIE_MP [43] | 21.52 | 0.854 | 22.60 | 0.814 | 2.521 | 0.558 | 3.003 | 0.536 | 3.199 | 0.578 |
| HAAM-GAN [44] | 22.95 | 0.889 | 22.55 | 0.746 | 2.876 | 0.570 | 3.029 | 0.556 | 3.029 | 0.606 |
| HCLR-Net [20] | 24.99 | 0.925 | 26.04 | 0.915 | 2.695 | 0.586 | 3.045 | 0.579 | 3.103 | 0.610 |
| Ours | 25.96 | 0.946 | 27.92 | 0.927 | 2.635 | 0.586 | 3.107 | 0.574 | 3.067 | 0.611 |
| Methods | UIEB T-90 | EUVP | UIEB C-60 | UCCS | U45 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNRstd | SSIMstd | PSNRstd | SSIMstd | UIQMstd | UCIQEstd | UIQMstd | UCIQEstd | UIQMstd | UCIQEstd | |
| GDCP [40] | 0.21 | 0.012 | 0.25 | 0.011 | 0.035 | 0.012 | 0.045 | 0.014 | 0.041 | 0.014 |
| FUInEGAN [32] | 0.28 | 0.015 | 0.31 | 0.013 | 0.033 | 0.011 | 0.040 | 0.009 | 0.036 | 0.010 |
| UWCNN [31] | 0.26 | 0.014 | 0.29 | 0.012 | 0.037 | 0.010 | 0.041 | 0.011 | 0.044 | 0.011 |
| WaterNet [41] | 0.24 | 0.013 | 0.27 | 0.011 | 0.034 | 0.010 | 0.043 | 0.012 | 0.042 | 0.010 |
| UColor [1] | 0.32 | 0.015 | 0.30 | 0.014 | 0.036 | 0.010 | 0.044 | 0.011 | 0.046 | 0.010 |
| MLLE [42] | 0.25 | 0.014 | 0.22 | 0.010 | 0.033 | 0.010 | 0.040 | 0.011 | 0.034 | 0.009 |
| PUIE_MP [43] | 0.31 | 0.015 | 0.033 | 0.014 | 0.037 | 0.010 | 0.043 | 0.011 | 0.047 | 0.010 |
| HAAM-GAN [44] | 0.34 | 0.016 | 0.32 | 0.013 | 0.042 | 0.011 | 0.044 | 0.012 | 0.044 | 0.011 |
| HCLR-Net [20] | 0.20 | 0.011 | 0.38 | 0.016 | 0.032 | 0.006 | 0.041 | 0.011 | 0.038 | 0.008 |
| Ours | 0.12 | 0.004 | 0.15 | 0.005 | 0.020 | 0.005 | 0.025 | 0.006 | 0.022 | 0.005 |
| Methods | #Params (M) | MACs (G) | GPU Mem (GB) | Inference Time (ms) |
|---|---|---|---|---|
| GDCP [40] | 0.02 | 0.15 | 0.8 | 35.2 |
| FUInEGAN [32] | 2.3 | 5.7 | 1.5 | 22.5 |
| UWCNN [31] | 0.12 | 1.8 | 1.2 | 18.7 |
| WaterNet [41] | 0.34 | 4.2 | 1.8 | 25.4 |
| UColor [1] | 3.1 | 15.3 | 2.7 | 32.1 |
| MLLE [42] | 0.08 | 0.9 | 1.1 | 15.8 |
| PUIE_MP [43] | 4.7 | 21.6 | 3.4 | 41.3 |
| HAAM-GAN [44] | 5.2 | 24.8 | 3.8 | 45.6 |
| HCLR-Net [20] | 3.8 | 18.3 | 3.1 | 38.2 |
| Ours | 3.5 | 16.7 | 2.9 | 29.3 |
| No. | Method | PSNR↑ | SSIM↑ |
|---|---|---|---|
| 1 | Base | 23.06 | 0.891 |
| 2 | SDFF-W | 25.25 | 0.931 |
| 3 | SDFF-H | 25.15 | 0.924 |
| 4 | SDFF- Parallel | 25.13 | 0.918 |
| 5 | SDFF-W-H | 25.35 | 0.926 |
| 6 | SDFF-H-W | 25.78 | 0.928 |
| 7 | FDFF-W+SDFF | 25.42 | 0.925 |
| 8 | FDFF-H+SDFF | 25.53 | 0.929 |
| 9 | FDFF- Parallel+SDFF | 25.61 | 0.927 |
| 10 | FDFF-W-H+SDFF | 25.45 | 0.924 |
| 11 | FDFF-H-W+SDFF | 25.96 | 0.946 |
| Method | PSNR↑ | SSIM↑ |
|---|---|---|
| SDFF | 25.78 | 0.928 |
| SDFF+FDFF-K7 | 25.35 | 0.927 |
| SDFF+FDFF-K11 | 25.55 | 0.928 |
| SDFF+FDFF-K7-K11 | 25.13 | 0.923 |
| SDFF+FDFF-K7-K11-Global | 25.96 | 0.946 |
| Method | PSNR↑ | SSIM↑ |
|---|---|---|
| SDFF+SDFF | 25.38 | 0.866 |
| FDFF+FDFF | 25.47 | 0.926 |
| SDFF+FDFF-Parallel | 25.21 | 0.918 |
| SDFF+FDFF | 25.31 | 0.827 |
| FDFF+SDFF | 25.96 | 0.946 |
| Method | N = 0 | N = 4 | N = 5 | N = 6 | N = 10 | N = 12 | N = 16 |
|---|---|---|---|---|---|---|---|
| PSNR↑ | 23.76 | 25.64 | 25.78 | 25.96 | 25.75 | 25.14 | 24.92 |
| Placement Configuration | PSNR↑ | SSIM↑ |
|---|---|---|
| MHA before Encoder (Serial) | 25.42 | 0.913 |
| MHA between Enc–Dec (Serial) | 25.96 | 0.932 |
| MHA after Decoder (Serial) | 25.18 | 0.908 |
| MHA in Parallel | 25.67 | 0.925 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, T.; Zhang, Y.; Hu, J.; Cui, H.; Yu, T. A Multi-Domain Enhanced Network for Underwater Image Enhancement. Information 2025, 16, 627. https://doi.org/10.3390/info16080627
Sun T, Zhang Y, Hu J, Cui H, Yu T. A Multi-Domain Enhanced Network for Underwater Image Enhancement. Information. 2025; 16(8):627. https://doi.org/10.3390/info16080627
Chicago/Turabian StyleSun, Tianmeng, Yinghao Zhang, Jiamin Hu, Haiyuan Cui, and Teng Yu. 2025. "A Multi-Domain Enhanced Network for Underwater Image Enhancement" Information 16, no. 8: 627. https://doi.org/10.3390/info16080627
APA StyleSun, T., Zhang, Y., Hu, J., Cui, H., & Yu, T. (2025). A Multi-Domain Enhanced Network for Underwater Image Enhancement. Information, 16(8), 627. https://doi.org/10.3390/info16080627