
A Novel Deep Learning Model for Motor Imagery Classification in Brain–Computer Interfaces
 ,
,  ,
,
Abstract
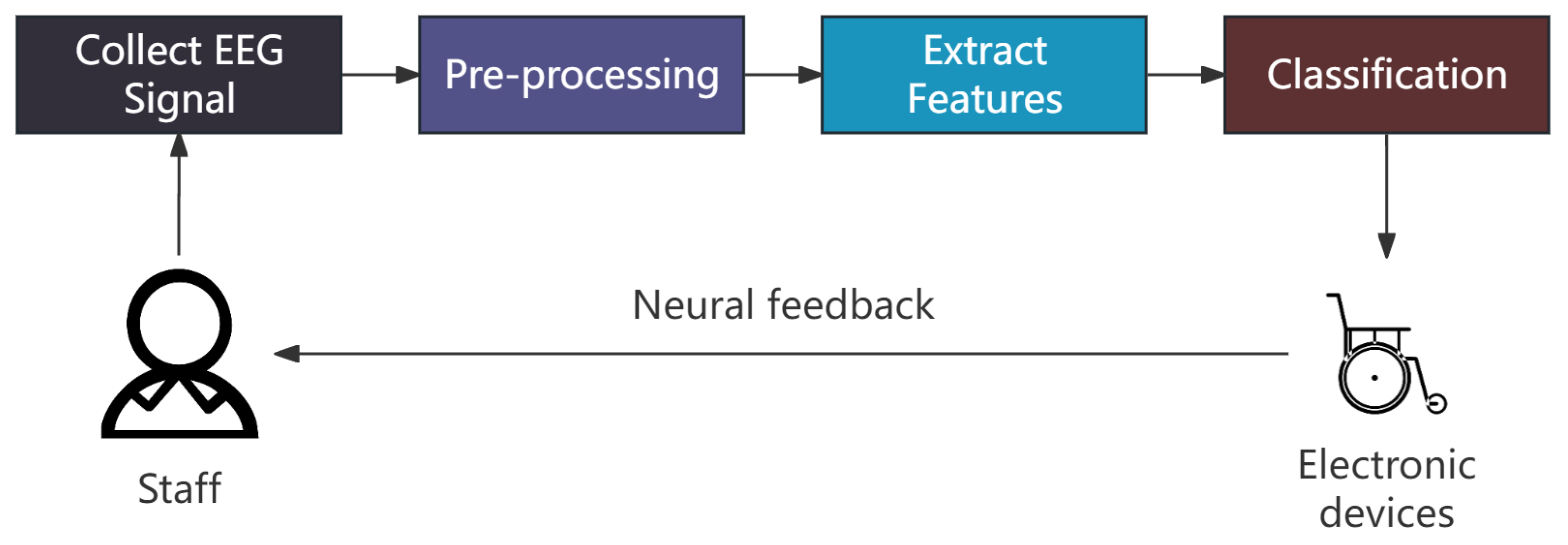
1. Introduction
- A Dual-Branch Feature Extraction Module is introduced to capture multi-scale spatio-temporal features, thereby addressing the limitations of traditional methods in extracting informative representations from EEG motor imagery signals.
- A Blocked-Integration Self-Attention Mechanism is proposed to improve model efficiency while preserving essential spatial dependencies within EEG data, resulting in more efficient and discriminative feature representations.
2. Related Work
2.1. EEG Motor Imagery
2.2. Attention Mechanism
3. Method
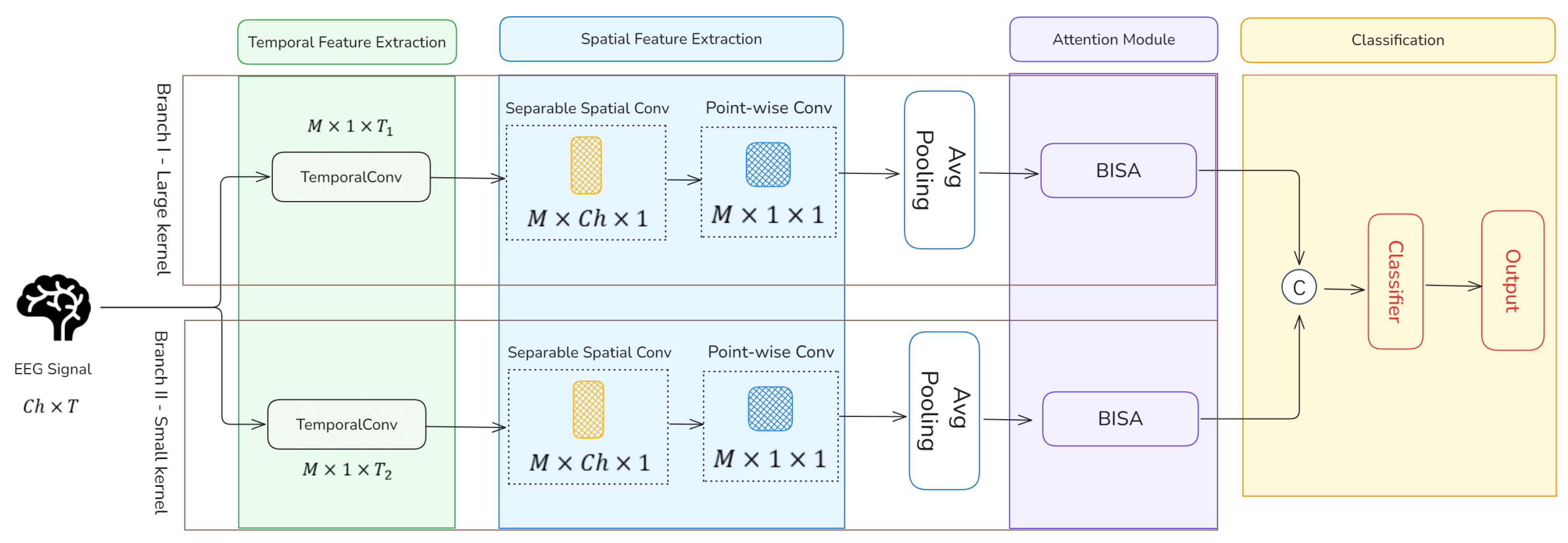
3.1. Model Overview
3.2. Dual-Branch Feature Extraction Module
3.3. Blocked-Integration Self-Attention Module
3.4. Feature Fusion Module
4. Experiment
4.1. Dataset Description
4.2. Data Processing and Experimental Setting
4.3. Validation of Classification
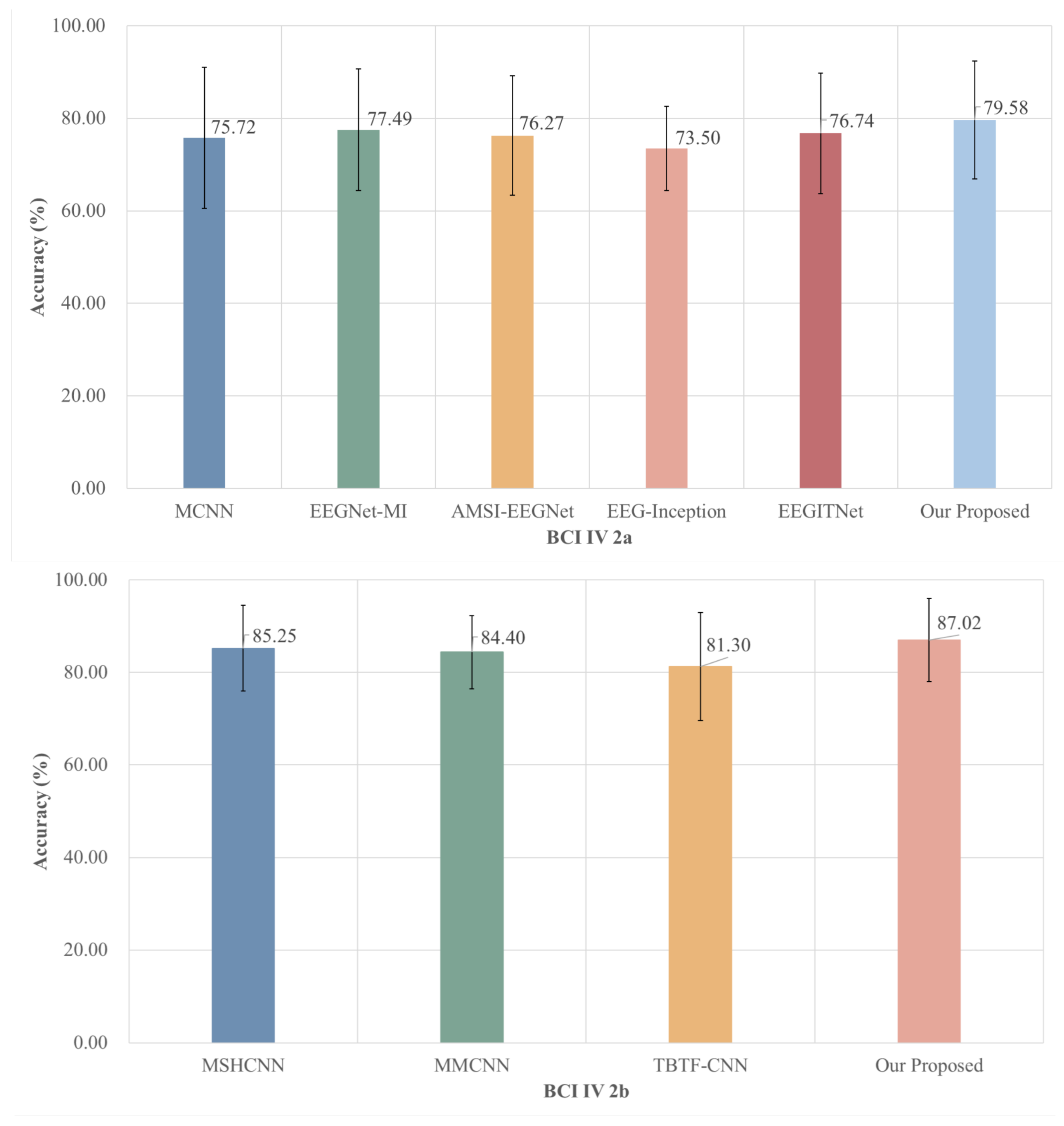
4.3.1. Comparison with Mainstream Baseline Deep Learning Methods
4.3.2. Comparison with Deep Learning Model Based on Multi-Scale Feature Fusion
4.3.3. Several State-of-the-Art Deep Learning Methods
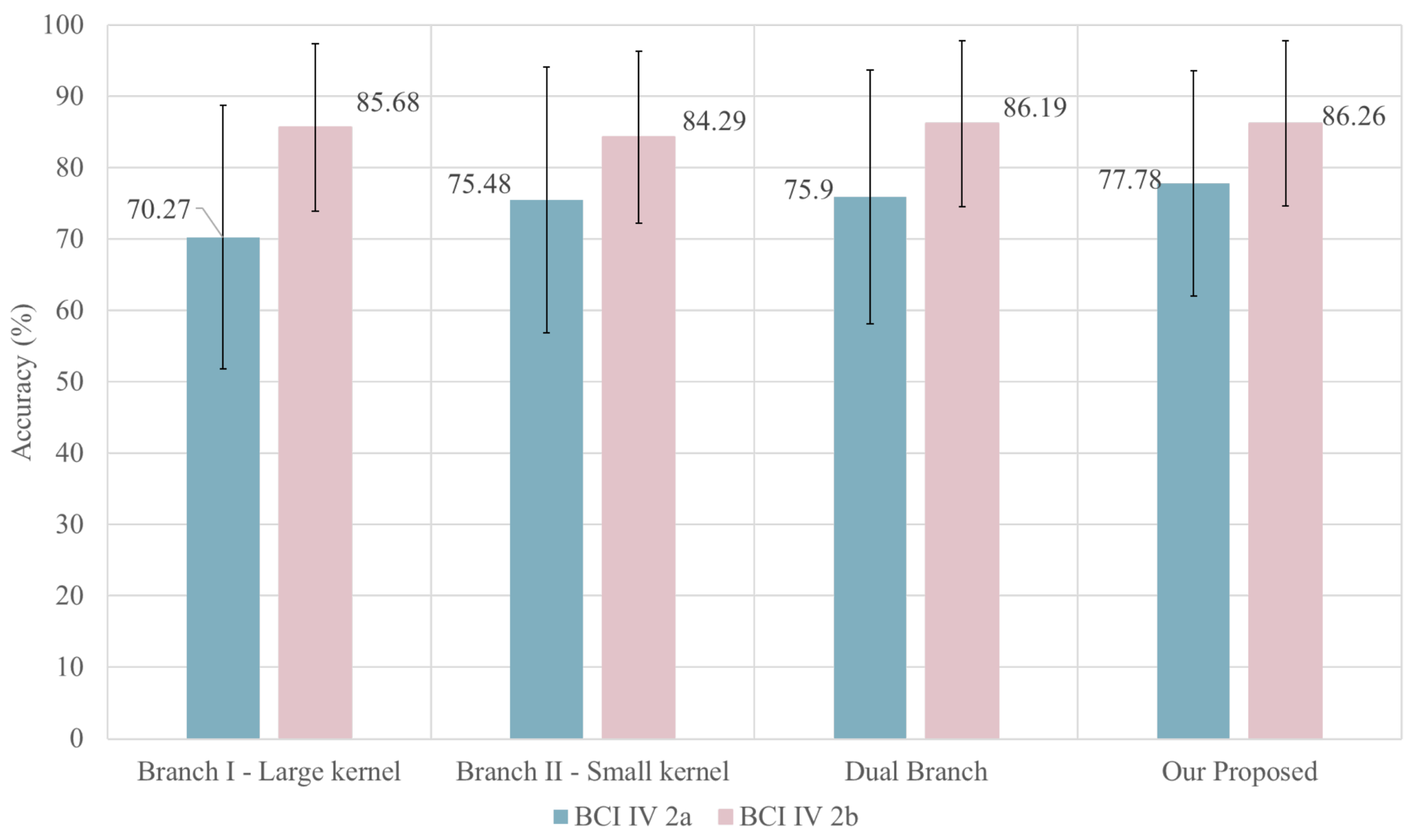
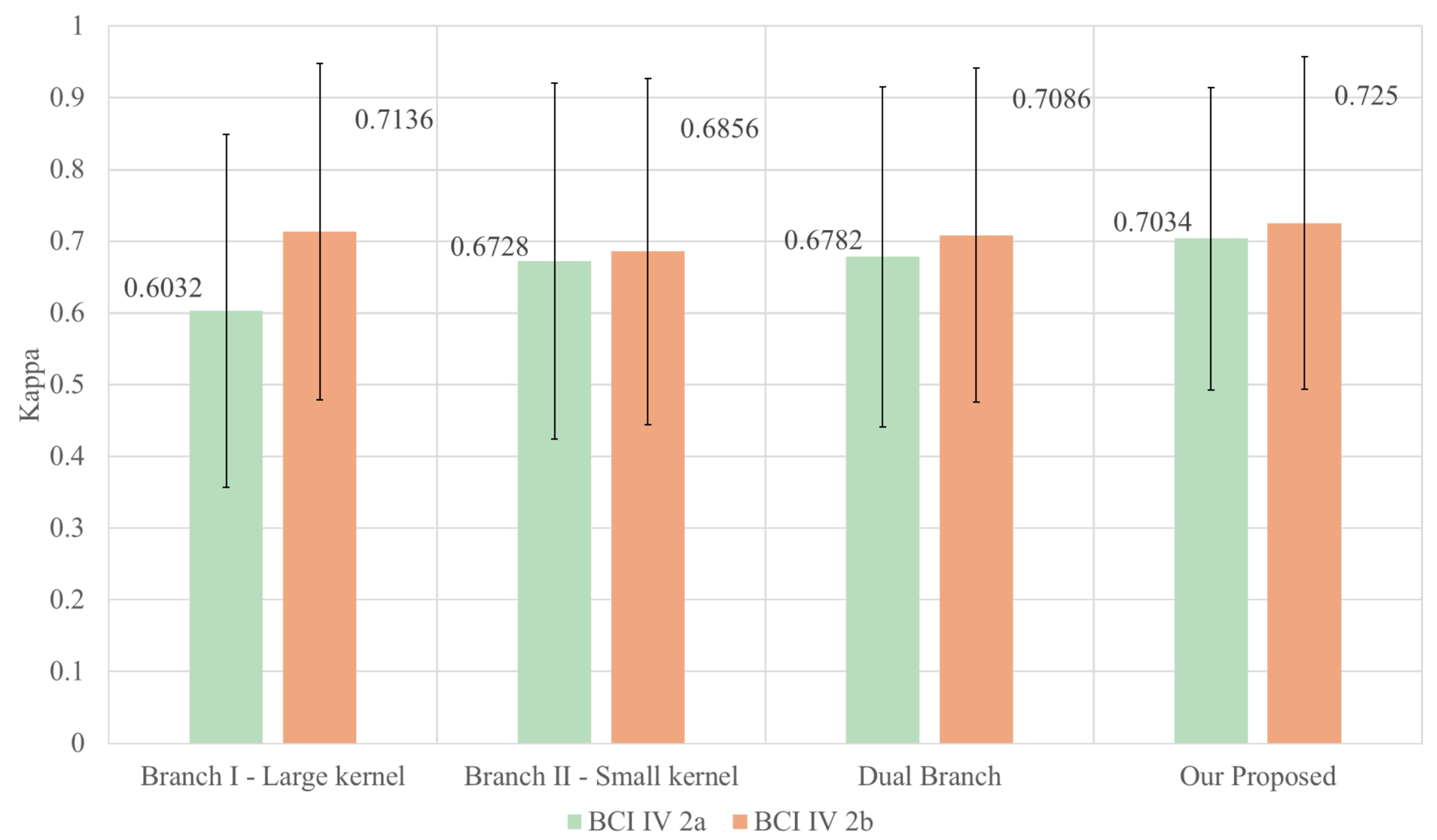
4.4. Ablation Experiment
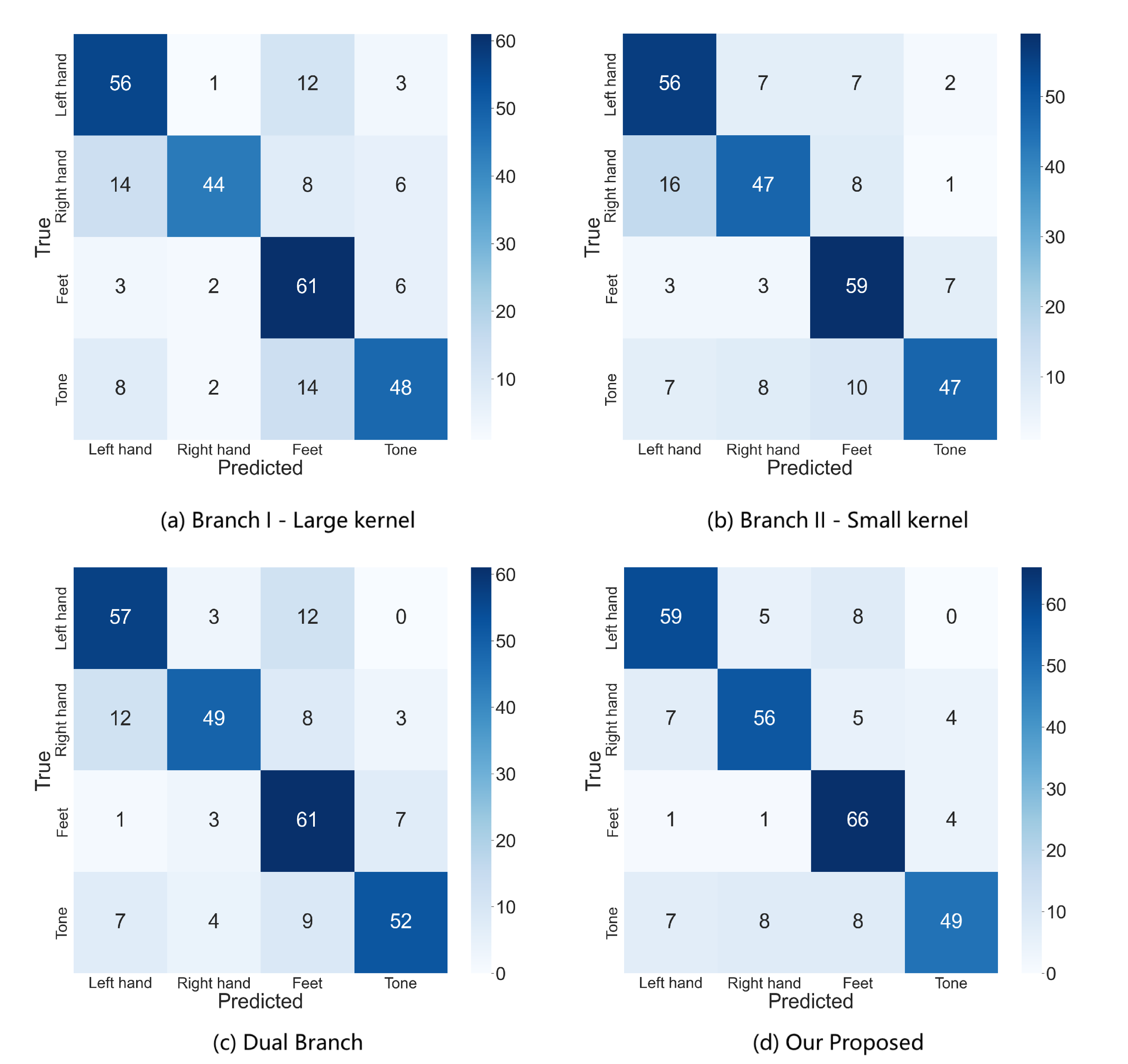
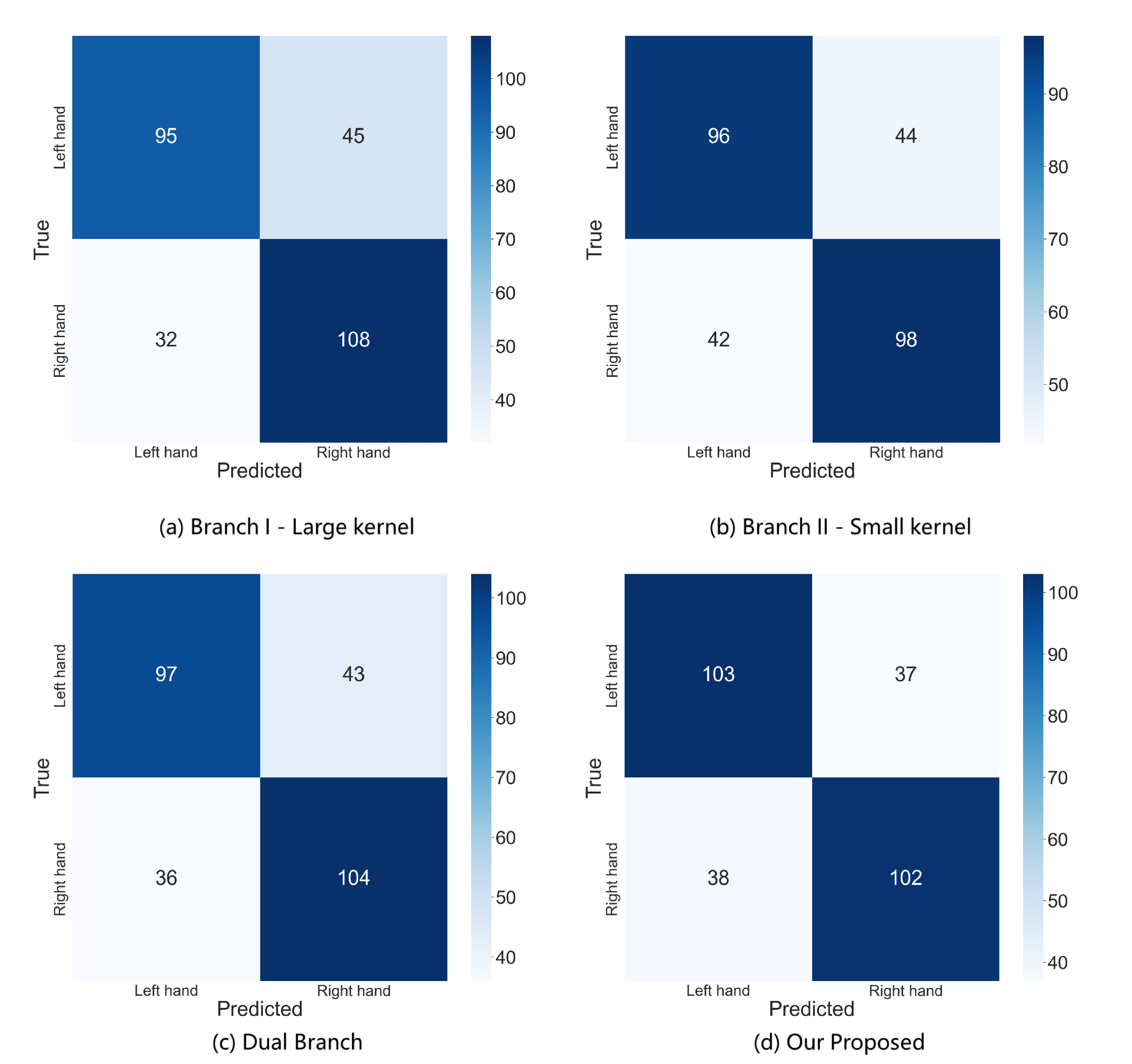
4.5. Confusion Matrix
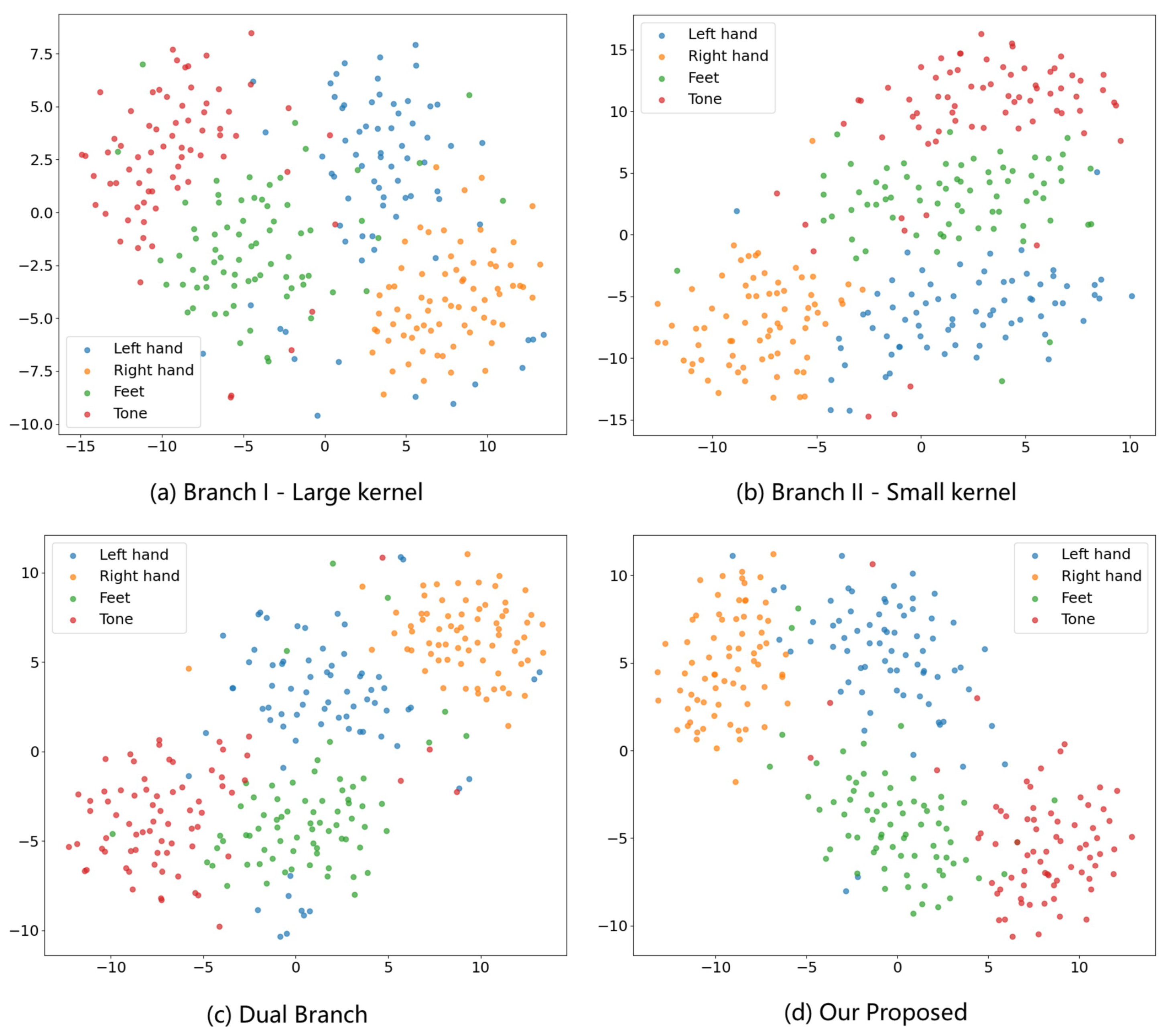
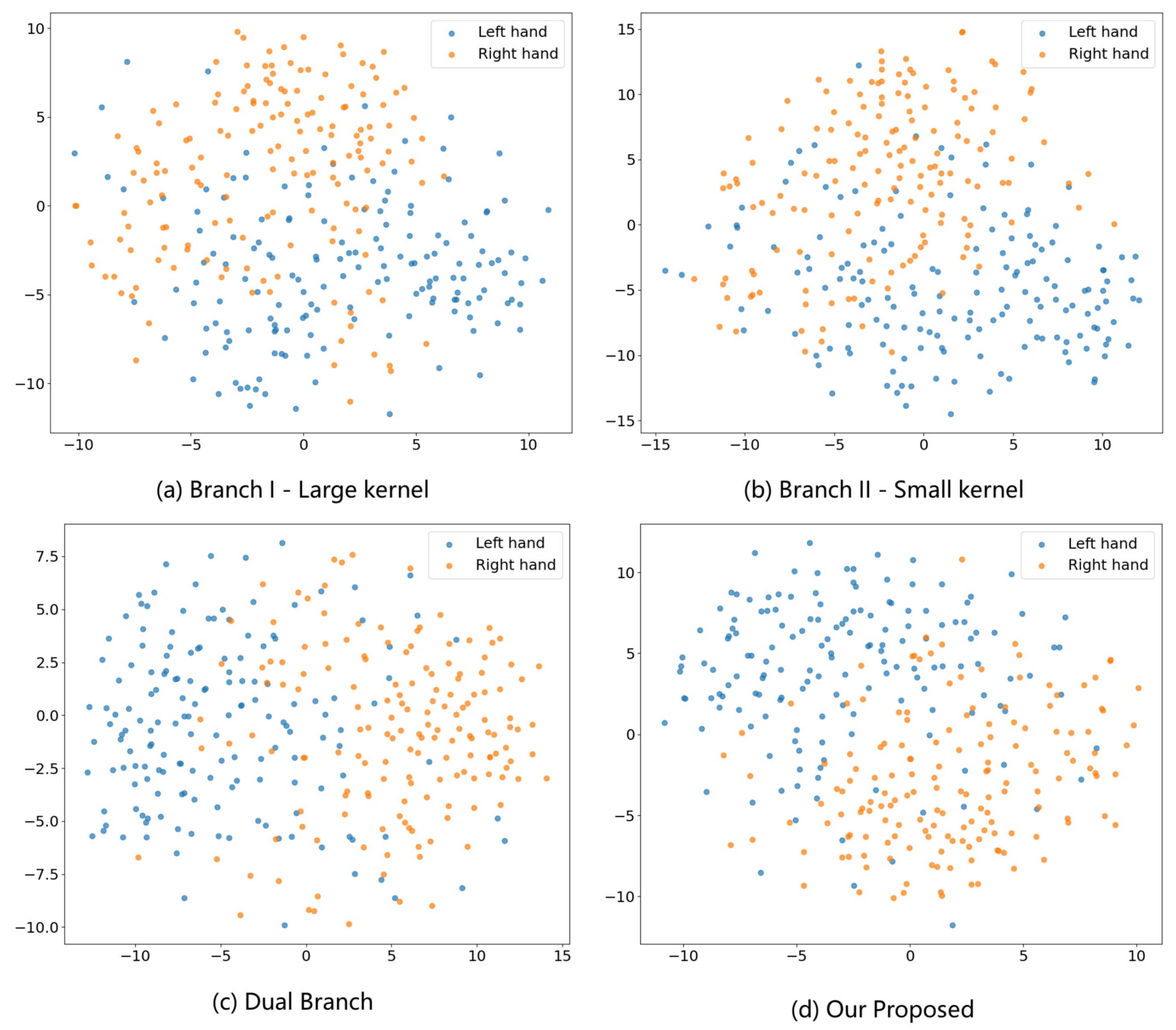
4.6. Feature Visualization
4.7. Attention Visualization
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Amin, S.U.; Altuwaijri, G.A.; Abdul, W.; Bencherif, M.A.; Faisal, M. Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: A review. Neural Comput. Appl. 2023, 35, 14681–14722. [Google Scholar]
- Al-Saegh, A.; Dawwd, S.A.; Abdul-Jabbar, J.M. Deep learning for motor imagery EEG-based classification: A review. Biomed. Signal Process. Control 2021, 63, 102172. [Google Scholar]
- Craik, A.; González-España, J.J.; Alamir, A.; Edquilang, D.; Wong, S.; Sánchez Rodríguez, L.; Feng, J.; Francisco, G.E.; Contreras-Vidal, J.L. Design and validation of a low-cost mobile eeg-based brain–computer interface. Sensors 2023, 23, 5930. [Google Scholar] [PubMed]
- Naser, M.Y.M.; Bhattacharya, S. Towards practical BCI-driven wheelchairs: A systematic review study. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 1030–1044. [Google Scholar] [PubMed]
- Al-Qaysi, Z.T.; Ahmed, M.A.; Hammash, N.M.; Hussein, A.F.; Albahri, A.S.; Suzani, M.S.; Al-Bander, B.; Shuwandy, M.L.; Salih, M.M. Systematic review of training environments with motor imagery brain–computer interface: Coherent taxonomy, open issues and recommendation pathway solution. Health Technol. 2021, 11, 783–801. [Google Scholar]
- Buerkle, A.; Eaton, W.; Lohse, N.; Bamber, T.; Ferreira, P. EEG based arm movement intention recognition towards enhanced safety in symbiotic Human-Robot Collaboration. Robot. Comput.-Integr. Manuf. 2021, 70, 102137. [Google Scholar]
- Aung, H.W.; Li, J.J.; Shi, B.; An, Y.; Su, S.W. EEG_GLT-Net: Optimising EEG graphs for real-time motor imagery signals classification. Biomed. Signal Process. Control 2025, 104, 107458. [Google Scholar]
- Bouchane, M.; Guo, W.; Yang, S. Hybrid CNN-GRU Models for Improved EEG Motor Imagery Classification. Sensors 2025, 25, 1399. [Google Scholar] [CrossRef]
- Lazarou, I.; Nikolopoulos, S.; Petrantonakis, P.C.; Kompatsiaris, I.; Tsolaki, M. EEG-based brain–computer interfaces for communication and rehabilitation of people with motor impairment: A novel approach of the 21st Century. Front. Hum. Neurosci. 2018, 12, 14. [Google Scholar]
- Yang, J.; Yao, S.; Wang, J. Deep fusion feature learning network for MI-EEG classification. IEEE Access 2018, 6, 79050–79059. [Google Scholar]
- Gu, H.; Chen, T.; Ma, X.; Zhang, M.; Sun, Y.; Zhao, J. CLTNet: A Hybrid Deep Learning Model for Motor Imagery Classification. Brain Sci. 2025, 15, 124. [Google Scholar] [PubMed]
- Shiam, A.A.; Hassan, K.M.; Islam, M.R.; Almassri, A.M.; Wagatsuma, H.; Molla, M.K.I. Motor imagery classification using effective channel selection of multichannel EEG. Brain Sci. 2024, 14, 462. [Google Scholar]
- Xie, Y.; Oniga, S. Enhancing Motor Imagery Classification in Brain–Computer Interfaces Using Deep Learning and Continuous Wavelet Transform. Appl. Sci. 2024, 14, 8828. [Google Scholar]
- Huang, W.; Liu, X.; Yang, W.; Li, Y.; Sun, Q.; Kong, X. Motor imagery EEG signal classification using distinctive feature fusion with adaptive structural LASSO. Sensors 2024, 24, 3755. [Google Scholar] [CrossRef]
- Hwaidi, J.F.; Chen, T.M. Classification of motor imagery EEG signals based on deep autoencoder and convolutional neural network approach. IEEE Access 2022, 10, 48071–48081. [Google Scholar]
- Khademi, Z.; Ebrahimi, F.; Kordy, H.M. A transfer learning-based CNN and LSTM hybrid deep learning model to classify motor imagery EEG signals. Comput. Biol. Med. 2022, 143, 105288. [Google Scholar]
- Wei, Y.; Liu, Y.; Li, C.; Cheng, J.; Song, R.; Chen, X. TC-Net: A Transformer Capsule Network for EEG-based emotion recognition. Comput. Biol. Med. 2023, 152, 106463. [Google Scholar]
- Gong, L.; Li, M.; Zhang, T.; Chen, W. EEG emotion recognition using attention-based convolutional transformer neural network. Biomed. Signal Process. Control 2023, 84, 104835. [Google Scholar]
- Ahmadi, H.; Mesin, L. Enhancing motor imagery electroencephalography classification with a correlation-optimized weighted stacking ensemble model. Electronics 2024, 13, 1033. [Google Scholar] [CrossRef]
- Brunner, C.; Leeb, R.; Müller-Putz, G.; Schlögl, A.; Pfurtscheller, G. BCI Competition 2008–Graz Data Set A; Graz University of Technology: Styria, Austria, 2008; Volume 16, pp. 1–6. [Google Scholar]
- Leeb, R.; Brunner, C.; Müller-Putz, G.; Schlögl, A.; Pfurtscheller, G. BCI Competition 2008–Graz Data Set B; Graz University of Technology: Styria, Austria, 2008; Volume 16, pp. 1–6. [Google Scholar]
- Jia, Z.; Lin, Y.; Wang, J.; Yang, K.; Liu, T.; Zhang, X. MMCNN: A multi-branch multi-scale convolutional neural network for motor imagery classification. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2020, Ghent, Belgium, 14–18 September 2020; Proceedings, Part III. Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 736–751. [Google Scholar]
- Chatterjee, R.; Maitra, T.; Islam, S.K.H.; Hassan, M.M.; Alamri, A.; Fortino, G. A novel machine learning based feature selection for motor imagery EEG signal classification in Internet of medical things environment. Future Gener. Comput. Syst. 2019, 98, 419–434. [Google Scholar]
- Antony, M.J.; Sankaralingam, B.P.; Mahendran, R.K.; Gardezi, A.A.; Shafiq, M.; Choi, J.-G.; Hamam, H. Classification of EEG using adaptive SVM classifier with CSP and online recursive independent component analysis. Sensors 2022, 22, 7596. [Google Scholar] [CrossRef] [PubMed]
- Buzzell, G.A.; Niu, Y.; Aviyente, S.; Bernat, E. A practical introduction to EEG time-frequency principal components analysis (TF-PCA). Dev. Cogn. Neurosci. 2022, 55, 101114. [Google Scholar]
- Hu, J.; Xiao, D.; Mu, Z. Application of energy entropy in motor imagery EEG classification. Int. J. Digit. Content Technol. Its Appl. 2009, 3, 83–90. [Google Scholar]
- Ang, K.K.; Chin, Z.Y.; Wang, C.; Guan, C.; Zhang, H. Filter bank common spatial pattern algorithm on BCI competition IV datasets 2a and 2b. Front. Neurosci. 2012, 6, 39. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Lance, B.J.; Lawhern, V.J.; Gordon, S.; Jung, T.-P.; Lin, C.-T. EEG-based user reaction time estimation using Riemannian geometry features. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 2157–2168. [Google Scholar]
- Chen, J.; Yu, Z.; Gu, Z.; Li, Y. Deep temporal-spatial feature learning for motor imagery-based brain–computer interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 2356–2366. [Google Scholar]
- Luo, T.; Zhou, C.; Chao, F. Exploring spatial-frequency-sequential relationships for motor imagery classification with recurrent neural network. BMC Bioinform. 2018, 19, 1–18. [Google Scholar]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar]
- Zhang, R.; Zong, Q.; Dou, L.; Zhao, X. A novel hybrid deep learning scheme for four-class motor imagery classification. J. Neural Eng. 2019, 16, 066004. [Google Scholar]
- Garcia-Moreno, F.M.; Bermudez-Edo, M.; Rodríguez-Fórtiz, M.J.; Garrido, J.L. A CNN-LSTM deep learning classifier for motor imagery EEG detection using a low-invasive and low-cost BCI headband. In Proceedings of the 2020 16th International Conference on Intelligent Environments (IE), Madrid, Spain, 20–23 July 2020; pp. 84–91. [Google Scholar]
- Wang, J.; Cheng, S.; Tian, J.; Gao, Y. A 2D CNN-LSTM hybrid algorithm using time series segments of EEG data for motor imagery classification. Biomed. Signal Process. Control 2023, 83, 104627. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 4–9. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Liu, X.; Wang, K.; Liu, F.; Zhao, W.; Liu, J. 3D convolution neural network with multiscale spatial and temporal cues for motor imagery EEG classification. Cogn. Neurodyn. 2023, 17, 1357–1380. [Google Scholar] [CrossRef]
- Altuwaijri, G.A.; Muhammad, G.; Altaheri, H.; Alsulaiman, M. A multi-branch convolutional neural network with squeeze-and-excitation attention blocks for EEG-based motor imagery signals classification. Diagnostics 2022, 12, 995. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Zhang, J.; Sun, J.; Ma, Z.; Qin, L.; Li, G.; Zhou, H.; Zhan, Y. A transformer-based approach combining deep learning network and spatial-temporal information for raw EEG classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 2126–2136. [Google Scholar] [CrossRef]
- Amin, S.U.; Altaheri, H.; Muhammad, G.; Abdul, W.; Alsulaiman, M. Attention-inception and long-short-term memory-based electroencephalography classification for motor imagery tasks in rehabilitation. IEEE Trans. Ind. Inform. 2021, 18, 5412–5421. [Google Scholar] [CrossRef]
- Riyad, M.; Khalil, M.; Adib, A. A novel multi-scale convolutional neural network for motor imagery classification. Biomed. Signal Process. Control 2021, 68, 102747. [Google Scholar] [CrossRef]
- Wang, C.; Wu, Y.; Wang, C.; Ren, Y.; Shen, J.; Pang, T.; Chan, C.S.; Ren, W.; Yu, Y. MSFNet: A Multi-Scale Space-Time Frequency Fusion Network for Motor Imagery EEG Classification. IEEE Access 2024, 12, 8325–8336. [Google Scholar] [CrossRef]
- Li, M.; Li, J.; Zheng, X.; Ge, J.; Xu, G. MSHANet: A multi-scale residual network with hybrid attention for motor imagery EEG decoding. Cogn. Neurodyn. 2024, 18, 3463–3476. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part I. Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.-S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Chen, J.; Han, Z.; Qiao, H.; Li, C.; Peng, H. EEG-based sleep staging via self-attention based capsule network with Bi-LSTM model. Biomed. Signal Process. Control 2023, 86, 105351. [Google Scholar] [CrossRef]
- Zhang, R.; Liu, G.; Wen, Y.; Zhou, W. Self-attention-based convolutional neural network and time-frequency common spatial pattern for enhanced motor imagery classification. J. Neurosci. Methods 2023, 398, 109953. [Google Scholar] [CrossRef]
- Zhang, D.; Li, H.; Xie, J. MI-CAT: A transformer-based domain adaptation network for motor imagery classification. Neural Netw. 2023, 165, 451–462. [Google Scholar] [CrossRef] [PubMed]
- Chaudhary, P.; Dhankhar, N.; Singhal, A.; Rana, K. A two-stage transformer based network for motor imagery classification. Med. Eng. Phys. 2024, 128, 104154. [Google Scholar] [CrossRef] [PubMed]
- Amin, S.U.; Alsulaiman, M.; Muhammad, G.; Mekhtiche, M.A.; Hossain, M.S. Deep Learning for EEG motor imagery classification based on multi-layer CNNs feature fusion. Future Gener. Comput. Syst. 2019, 101, 542–554. [Google Scholar] [CrossRef]
- Riyad, M.; Khalil, M.; Adib, A. MI-EEGNET: A novel convolutional neural network for motor imagery classification. J. Neurosci. Methods 2021, 353, 109037. [Google Scholar] [CrossRef]
- Riyad, M.; Khalil, M.; Adib, A. Incep-eegnet: A convnet for motor imagery decoding. In Proceedings of the Image and Signal Processing: 9th International Conference, ICISP 2020, Marrakesh, Morocco, 4–6 June 2020; Proceedings. Springer International Publishing: Cham, Switzerland, 2020; pp. 103–111. [Google Scholar]
- Salami, A.; Andreu-Perez, J.; Gillmeister, H. EEG-ITNet: An explainable inception temporal convolutional network for motor imagery classification. IEEE Access 2022, 10, 36672–36685. [Google Scholar] [CrossRef]
- Tang, X.; Yang, C.; Sun, X.; Zou, M.; Wang, H. Motor imagery EEG decoding based on multi-scale hybrid networks and feature enhancement. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 1208–1218. [Google Scholar] [CrossRef]
- Yang, J.; Gao, S.; Shen, T. A two-branch CNN fusing temporal and frequency features for motor imagery EEG decoding. Entropy 2022, 24, 376. [Google Scholar] [CrossRef]
- Luo, T. Parallel genetic algorithm based common spatial patterns selection on time–frequency decomposed EEG signals for motor imagery brain-computer interface. Biomed. Signal Process. Control 2023, 80, 104397. [Google Scholar] [CrossRef]
- Liu, C.; Jin, J.; Daly, I.; Li, S.; Sun, H.; Huang, Y.; Wang, X.; Cichocki, A. SincNet-based hybrid neural network for motor imagery EEG decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 540–549. [Google Scholar] [CrossRef]
- Phunruangsakao, C.; Achanccaray, D.; Hayashibe, M. Deep adversarial domain adaptation with few-shot learning for motor-imagery brain-computer interface. IEEE Access 2022, 10, 57255–57265. [Google Scholar] [CrossRef]
- Yan, Y.; Zhou, H.; Huang, L.; Cheng, X.; Kuang, S. A novel two-stage refine filtering method for EEG-based motor imagery classification. Front. Neurosci. 2021, 15, 657540. [Google Scholar] [CrossRef]
- Chen, X.; Teng, X.; Chen, H.; Pan, Y.; Geyer, P. Toward reliable signals decoding for electroencephalogram: A benchmark study to EEGNeX. Biomed. Signal Process. Control 2024, 87, 105475. [Google Scholar] [CrossRef]
- Sudalairaj, S. Spatio-Temporal Analysis of EEG Using Deep Learning. Ph.D. Thesis, University of Cincinnati, Cincinnati, OH, USA, 2022. [Google Scholar]
- Mane, R.; Chew, E.; Chua, K.; Ang, K.K.; Robinson, N.; Vinod, A.P.; Lee, S.-W.; Guan, C. FBCNet: A multi-view convolutional neural network for brain-computer interface. arXiv 2021, arXiv:2104.01233. [Google Scholar]
- Zhao, H.; Zheng, Q.; Ma, K.; Li, H.; Zheng, Y. Deep representation-based domain adaptation for nonstationary EEG classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 535–545. [Google Scholar] [CrossRef]
- Song, Y.; Zheng, Q.; Liu, B.; Gao, X. EEG conformer: Convolutional transformer for EEG decoding and visualization. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 31, 710–719. [Google Scholar] [CrossRef]
- Yang, L.; Song, Y.; Ma, K.; Xie, L. Motor imagery EEG decoding method based on a discriminative feature learning strategy. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 368–379. [Google Scholar] [CrossRef]
- Malan, N.S.; Sharma, S. Motor imagery EEG spectral-spatial feature optimization using dual-tree complex wavelet and neighbourhood component analysis. IRBM 2022, 43, 198–209. [Google Scholar] [CrossRef]
- Song, Y.; Jia, X.; Yang, L.; Xie, L. Transformer-based spatial-temporal feature learning for EEG decoding. arXiv 2021, arXiv:2106.11170. [Google Scholar]
- Hu, B.; Gao, B.; Woo, W.L.; Ruan, L.; Jin, J.; Yang, Y.; Yu, Y. A lightweight spatial and temporal multi-feature fusion network for defect detection. IEEE Trans. Image Process. 2020, 30, 472–486. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | S01 | S02 | S03 | S04 | S05 | S06 | S07 | S08 | S09 | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| TSFBCSP-MRPGA | 86.11% | 61.81% | 86.81% | 71.18% | 62.85% | 56.25% | 90.28% | 80.56% | 78.47% | 74.92% |
| SincNet | 82.76% | 68.97% | 79.31% | 65.52% | 58.62% | 48.28% | 86.21% | 89.66% | 89.87% | 74.26% |
| DAFS | 81.94% | 64.58% | 88.89% | 73.61% | 70.49% | 56.67% | 85.42% | 79.15% | 81.60% | 75.85% |
| C2CMe | 83.3% | 53.7% | 87.0% | 55.6% | 50.0% | 27.3% | 86.1% | 77.8% | 72.70% | 65.9% |
| EEGNext | 86.25% | 60.71% | 93.38% | 70.27% | 67.14% | 70.63% | 88.84% | 85.89% | 86.16% | 78.81% |
| Spatio-Temporal | 82.99% | 56.25% | 93.06% | 84.03% | 68.75% | 58.34% | 79.72% | 87.67% | 86.81% | 77.51% |
| FBCNet | 85.42% | 60.42% | 90.63% | 76.39% | 74.31% | 53.82% | 84.38% | 79.51% | 80.90% | 76.20% |
| DRDA | 83.19% | 55.14% | 87.43% | 75.28% | 62.29% | 57.15% | 86.18% | 83.31% | 82.00% | 74.74% |
| Conformer | 88.19% | 61.46% | 93.4% | 78.13% | 52.08% | 65.28% | 92.36% | 89.18% | 88.89% | 78.66% |
| Our Proposed Method | 86.8% | 51.73% | 93.05% | 79.86% | 77.43% | 70.48% | 91.31% | 78.12% | 87.50% | 79.58% |
| Method | S01 | S02 | S03 | S04 | S05 | S06 | S07 | S08 | S09 | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| TSFBCSP-MRPGA | 75.63% | 62.5% | 61.25% | 97.81% | 87.81% | 85% | 81.25% | 92.81% | 85.31% | 81.04% |
| SincNet | 83.33% | 61.76% | 58.33% | 97.3% | 91.89% | 88.89% | 86.11% | 92.11% | 91.67% | 83.49% |
| DAFS | 70.31% | 73.57% | 80.31% | 94.69% | 95.00% | 83.75% | 93.73% | 95% | 75.31% | 84.63% |
| CD-LOSS | 79.69% | 60.71% | 82.19% | 96.87% | 94.37% | 89.37% | 82.19% | 93.75% | 90.00% | 85.46% |
| NCA | 85.6% | 66.3% | 63.7% | 99.4% | 91.3% | 79.2% | 86.9% | 94.4% | 89.4% | 84.02% |
| S3T | 81.67% | 68.33% | 66.67% | 98.33% | 88.33% | 90% | 85% | 93.33% | 86.67% | 84.26% |
| DRDA | 81.37% | 62.86% | 63.63% | 95.94% | 93.56% | 88.19% | 85% | 95.25% | 90% | 83.98% |
| Conformer | 82.5% | 65.71% | 63.75% | 98.44% | 86.56% | 90.31% | 87.81% | 94.38% | 92.19% | 84.63% |
| Our Proposed Method | 76.56% | 73.21% | 82.18% | 96.56% | 99.37% | 85.37% | 94.68% | 90.62% | 84.37% | 87.01% |
| Model Name | Small Kernel | Large Kernel | Attention |
|---|---|---|---|
| Branch I—Large kernel | ✓ | ||
| Branch II—Small kernel | ✓ | ||
| Dual-Branch | ✓ | ✓ | |
| Our Proposed Model | ✓ | ✓ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Xu, S.; Hu, Q.; Peng, Y.; Zhang, H.; Zhang, J.; Chen, Z. A Novel Deep Learning Model for Motor Imagery Classification in Brain–Computer Interfaces. Information 2025, 16, 582. https://doi.org/10.3390/info16070582
Chen W, Xu S, Hu Q, Peng Y, Zhang H, Zhang J, Chen Z. A Novel Deep Learning Model for Motor Imagery Classification in Brain–Computer Interfaces. Information. 2025; 16(7):582. https://doi.org/10.3390/info16070582
Chicago/Turabian StyleChen, Wenhui, Shunwu Xu, Qingqing Hu, Yiran Peng, Hong Zhang, Jian Zhang, and Zhaowen Chen. 2025. "A Novel Deep Learning Model for Motor Imagery Classification in Brain–Computer Interfaces" Information 16, no. 7: 582. https://doi.org/10.3390/info16070582
APA StyleChen, W., Xu, S., Hu, Q., Peng, Y., Zhang, H., Zhang, J., & Chen, Z. (2025). A Novel Deep Learning Model for Motor Imagery Classification in Brain–Computer Interfaces. Information, 16(7), 582. https://doi.org/10.3390/info16070582