
An AI Agent-Based System for Retrieving Compound Information in Traditional Chinese Medicine



Abstract
1. Introduction
2. Materials and Methods
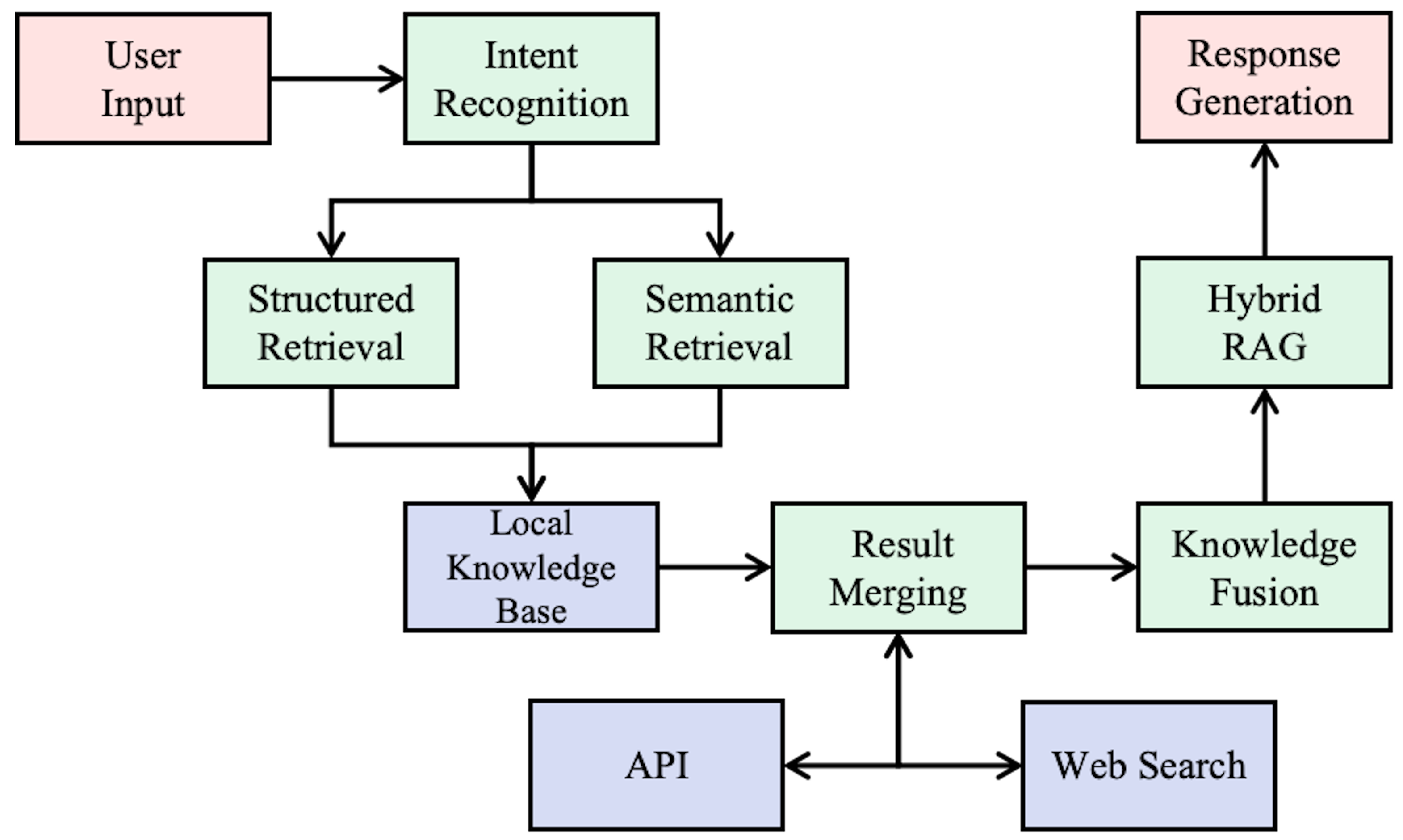
2.1. System Overview
2.2. Knowledge Base Construction and Data Sources
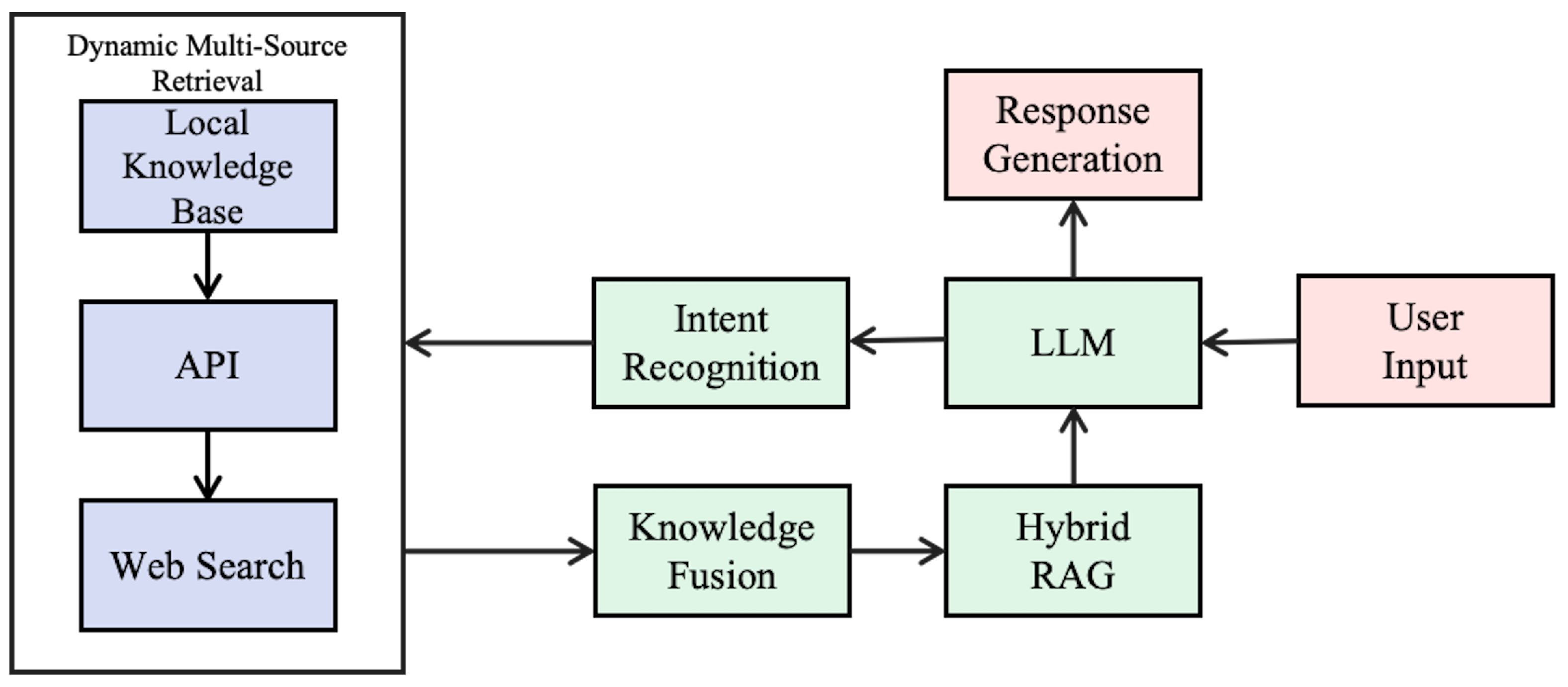
2.3. Dynamic Multi-Source Retrieval Mechanism
2.4. Knowledge Fusion
2.5. Hybrid Retrieval-Augmented Generation Technique
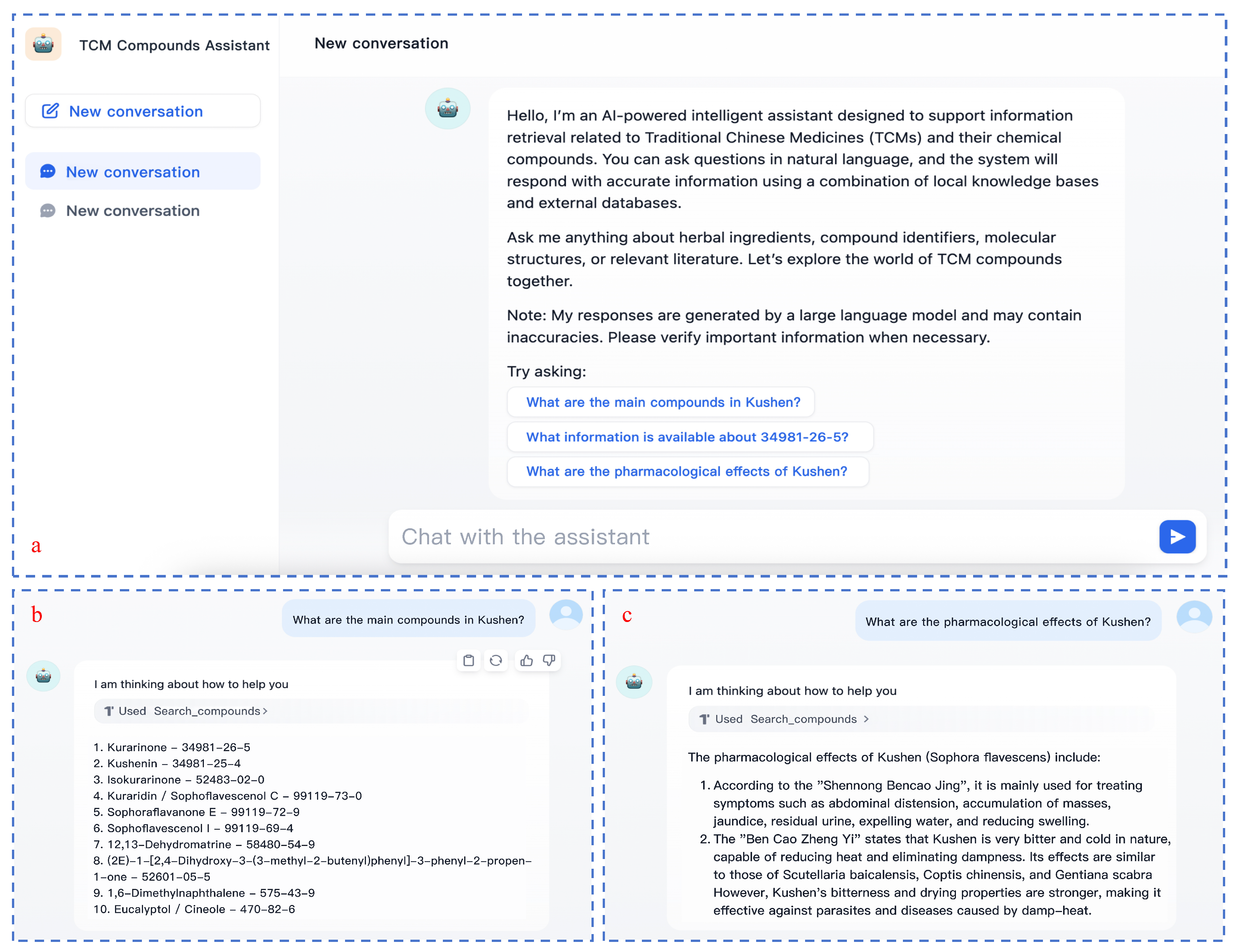
2.6. System Implementation
3. Results
3.1. Evaluation Dataset
- The recognition of herb names;
- The accuracy of compound-level information retrieval and matching;
- The completeness and fault tolerance of responses under semantically ambiguous expressions.
3.2. Experimental Setup and Evaluation Metrics
- For compound identification questions: whether the system correctly listed the major chemical constituents of the queried herb;
- For field-specific extraction tasks: whether the system returned accurate attribute values, such as molecular formula, CAS number, or Chinese compound name;
- For logical reasoning questions: whether the system’s output exhibited factual correctness and reasonable inference based on known data.
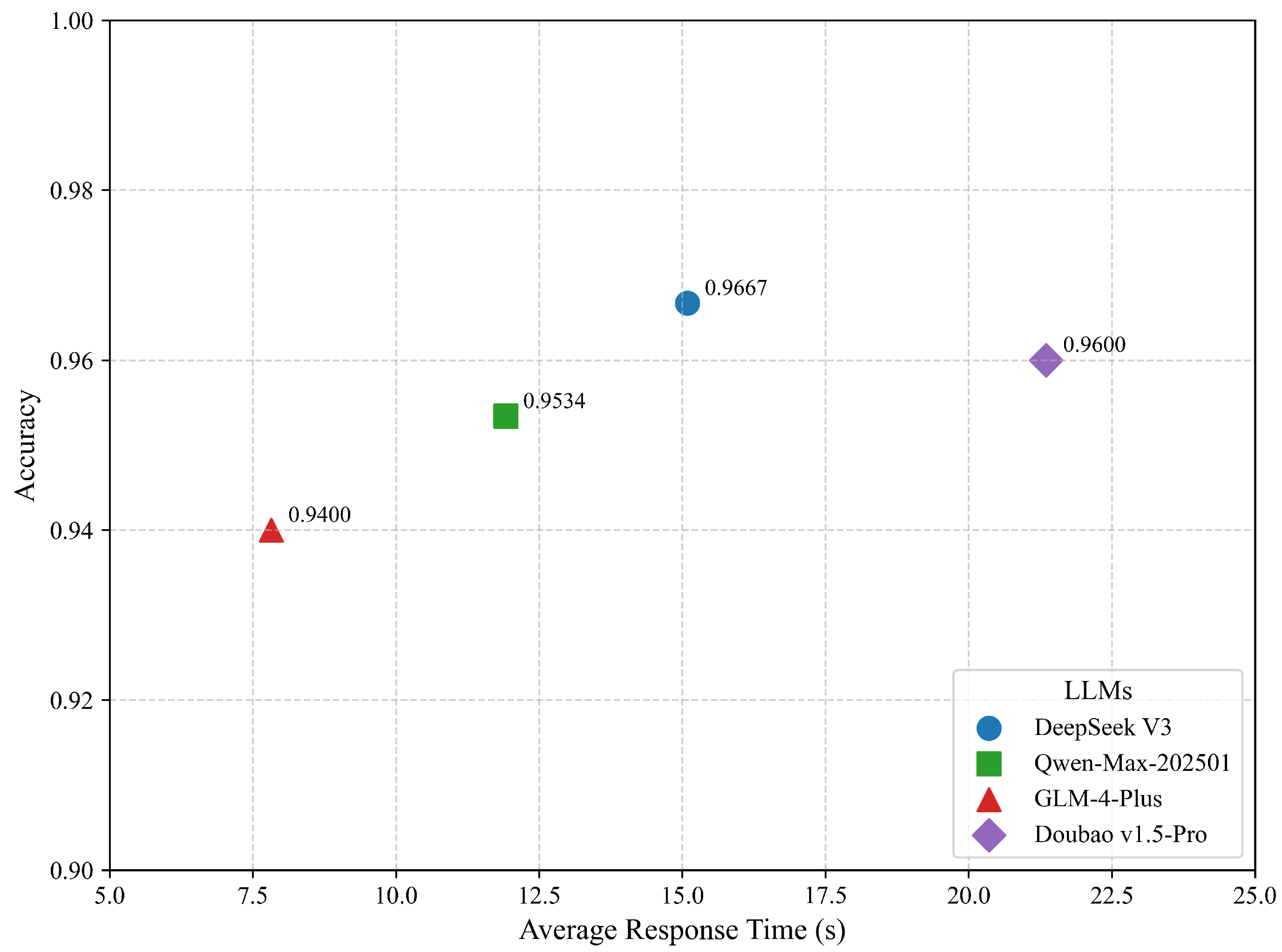
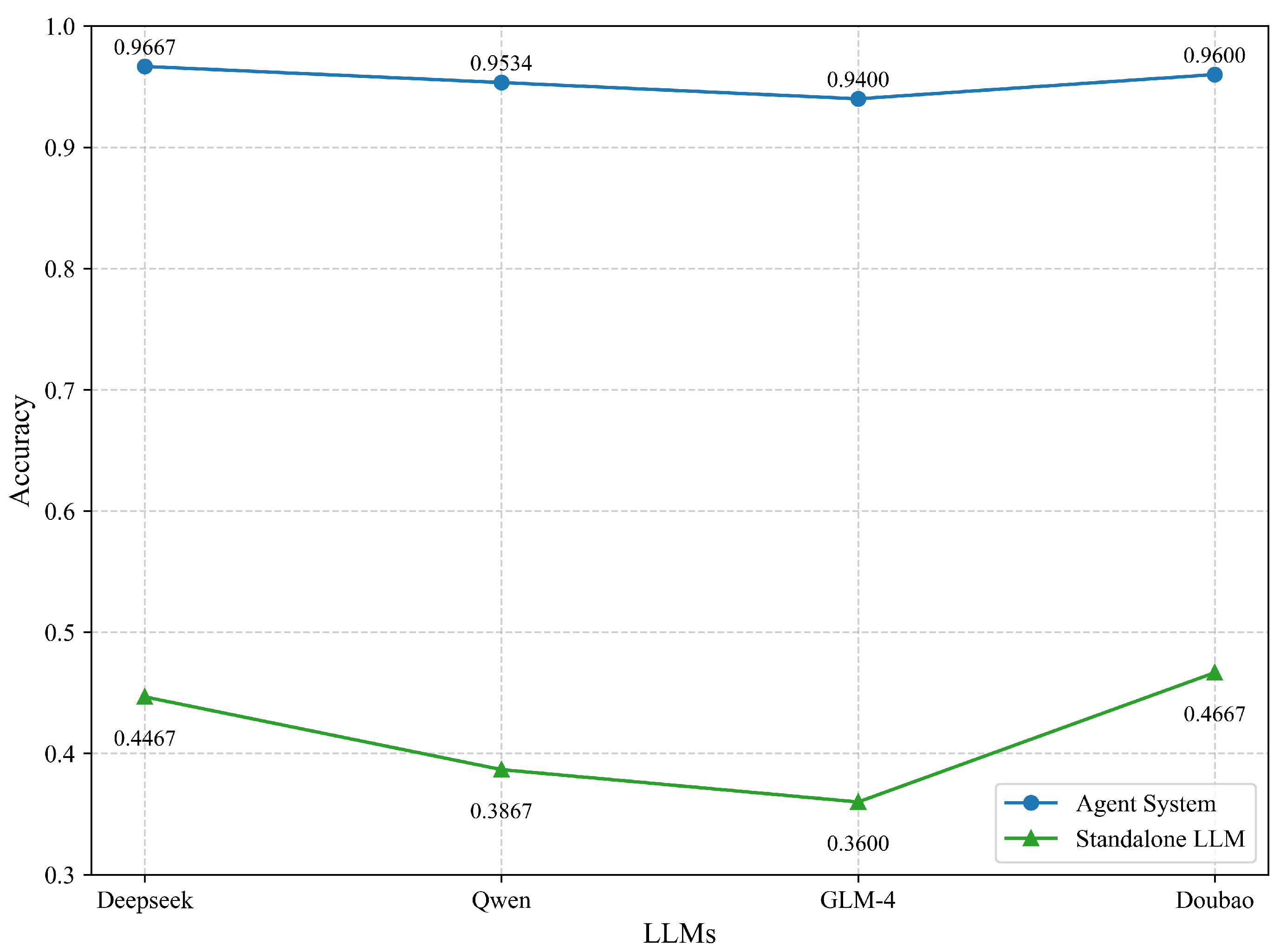
3.3. Experimental Results
3.4. Ablation Study
- A1: Disables intent recognition, directing all queries to the hybrid RAG pipeline without identifier-based structured routing.
- A2: Disables dynamic multi-source knowledge retrieval, restricting retrieval to the local knowledge base.
- A3: Disables both A1 and A2, simulating a minimal RAG setup based solely on vector retrieval from the local database.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| TCM | Traditional Chinese medicine |
| LLM | Large Language Model |
| RAG | Retrieval-augmented generation |
| CAS | Chemical Abstracts Service |
| API | Application Programming Interface |
References
- Li, L.; Yao, H.; Wang, J.; Li, Y.; Wang, Q. The Role of Chinese Medicine in Health Maintenance and Disease Prevention: Application of Constitution Theory. Am. J. Chin. Med. 2019, 47, 495–506. [Google Scholar] [CrossRef]
- Luo, Y.; Wang, C.Z.; Hesse-Fong, J.; Lin, J.G.; Yuan, C.S. Application of Chinese Medicine in Acute and Critical Medical Conditions. Am. J. Chin. Med. 2019, 47, 1223–1235. [Google Scholar] [CrossRef]
- Zhang, N.D.; Han, T.; Huang, B.K.; Rahman, K.; Jiang, Y.P.; Xu, H.T.; Qin, L.P.; Xin, H.L.; Zhang, Q.Y.; Li, Y.m. Traditional Chinese medicine formulas for the treatment of osteoporosis: Implication for antiosteoporotic drug discovery. J. Ethnopharmacol. 2016, 189, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Liu, J.; Luo, X.; Hu, L.; Lu, H. Functional metabolomics innovates therapeutic discovery of traditional Chinese medicine derived functional compounds. Pharmacol. Ther. 2021, 224, 107824. [Google Scholar] [CrossRef] [PubMed]
- Xiang, Y.; Guo, Z.; Zhu, P.; Chen, J.; Huang, Y. Traditional Chinese medicine as a cancer treatment: Modern perspectives of ancient but advanced science. Cancer Med. 2019, 8, 1958–1975. [Google Scholar] [CrossRef]
- Tu, Y. The discovery of artemisinin (qinghaosu) and gifts from Chinese medicine. Nat. Med. 2011, 17, 1217–1220. [Google Scholar] [CrossRef] [PubMed]
- Li, W.F.; Jiang, J.G.; Chen, J. Chinese Medicine and Its Modernization Demands. Arch. Med. Res. 2008, 39, 246–251. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, Y.; Lin, W.; Wu, Q. How Can We Design a Standardized and Efficient Health Data Management System for Large-Scale Heterogeneous TCM Data? In Proceedings of the 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Lisbon, Portugal, 3–6 December 2024; pp. 4848–4853. [Google Scholar] [CrossRef]
- Gao, K.; Liu, L.; Lei, S.; Li, Z.; Huo, P.; Wang, Z.; Dong, L.; Deng, W.; Bu, D.; Zeng, X.; et al. HERB 2.0: An updated database integrating clinical and experimental evidence for traditional Chinese medicine. Nucleic Acids Res. 2025, 53, D1404–D1414. [Google Scholar] [CrossRef]
- Huang, L.; Xie, D.; Yu, Y.; Liu, H.; Shi, Y.; Shi, T.; Wen, C. TCMID 2.0: A comprehensive resource for TCM. Nucleic Acids Res. 2018, 46, D1117–D1120. [Google Scholar] [CrossRef]
- Xu, H.Y.; Zhang, Y.Q.; Liu, Z.M.; Chen, T.; Lv, C.Y.; Tang, S.H.; Zhang, X.B.; Zhang, W.; Li, Z.Y.; Zhou, R.R.; et al. ETCM: An encyclopaedia of traditional Chinese medicine. Nucleic Acids Res. 2019, 47, D976–D982. [Google Scholar] [CrossRef]
- Zhang, R.; Zhu, X.; Bai, H.; Ning, K. Network Pharmacology Databases for Traditional Chinese Medicine: Review and Assessment. Front. Pharmacol. 2019, 10, 123. [Google Scholar] [CrossRef] [PubMed]
- Xi, Z.; Chen, W.; Guo, X.; He, W.; Ding, Y.; Hong, B.; Zhang, M.; Wang, J.; Jin, S.; Zhou, E.; et al. The rise and potential of large language model based agents: A survey. Sci. China Inf. Sci. 2025, 68, 121101. [Google Scholar] [CrossRef]
- Zhang, A.; Deng, Y.; Lin, Y.; Chen, X.; Wen, J.R.; Chua, T.S. Large Language Model Powered Agents for Information Retrieval. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024; SIGIR ’24, Washington, DC, USA, 14–18 July 2024; ACM: New York, NY, USA; pp. 2989–2992. [Google Scholar] [CrossRef]
- Singh, A.; Ehtesham, A.; Kumar, S.; Khoei, T.T. Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG. arXiv 2025, arXiv:2501.09136. [Google Scholar] [CrossRef]
- Feng, Y.; Zhou, L.; Ma, C.; Zheng, Y.; He, R.; Li, Y. Knowledge graph-based thought: A knowledge graph-enhanced LLM framework for pan-cancer question answering. GigaScience 2025, 14, giae082. [Google Scholar] [CrossRef] [PubMed]
- Duan, Y.; Zhou, Q.; Li, Y.; Qin, C.; Wang, Z.; Kan, H.; Hu, J. Research on a traditional Chinese medicine case-based question-answering system integrating large language models and knowledge graphs. Front. Med. 2024, 11, 1512329. [Google Scholar] [CrossRef]
- Ahmed, M.; Dorrah, M.; Ashraf, A.; Adel, Y.; Elatrozy, A.; Mohamed, B.E.; Gomaa, W. CodeQA: Advanced programming question-answering using LLM agent and RAG. In Proceedings of the 2024 6th Novel Intelligent and Leading Emerging Sciences Conference (NILES), Giza, Egypt, 19–21 October 2024; pp. 494–499. [Google Scholar] [CrossRef]
- Vakayil, S.; Juliet, D.S.; J, A.; Vakayil, S. RAG-based LLM chatbot using llama-2. In Proceedings of the 2024 7th International Conference on Devices, Circuits and Systems (ICDCS), Coimbatore, India, 19–20 April 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Suresh, K.; Kackar, N.; Schleck, L.; Fanelli, C. Towards a RAG-based summarization for the electron ion collider. J. Instrum. 2024, 19, C07006. [Google Scholar] [CrossRef]
- Kim, S.; Chen, J.; Cheng, T.; Gindulyte, A.; He, J.; He, S.; Li, Q.; Shoemaker, B.A.; Thiessen, P.A.; Yu, B.; et al. PubChem 2023 update. Nucleic Acids Res. 2023, 51, D1373–D1380. [Google Scholar] [CrossRef]
- Commission, C.P. Pharmacopoeia of the People’s Republic of China, Volume I; China Medical Science and Technology Press: Beijing, China, 2020. [Google Scholar]
- Kim, S.; Thiessen, P.A.; Bolton, E.E.; Bryant, S.H. PUG-SOAP and PUG-REST: Web services for programmatic access to chemical information in PubChem. Nucleic Acids Res. 2015, 43, W605–W611. [Google Scholar] [CrossRef]
- Tavily Search API. 2025. Available online: https://tavily.com/ (accessed on 15 March 2025).
- Chemical Abstracts Service. CAS REGISTRY. 2025. Available online: https://www.cas.org/cas-data/cas-registry (accessed on 13 May 2025).
- Heller, S.R.; McNaught, A.; Pletnev, I.; Stein, S.; Tchekhovskoi, D. InChI, the IUPAC International Chemical Identifier. J. Cheminform. 2015, 7, 23. [Google Scholar] [CrossRef]
- Xiao, S.; Liu, Z.; Zhang, P.; Muennighoff, N.; Lian, D.; Nie, J.Y. C-Pack: Packed Resources For General Chinese Embeddings. arXiv 2024, arXiv:2309.07597. [Google Scholar] [CrossRef]
- PubMed. 2025. Available online: https://pubmed.ncbi.nlm.nih.gov/ (accessed on 15 March 2025).
- CNKI (China National Knowledge Infrastructure). 2025. Available online: https://www.cnki.net/ (accessed on 15 March 2025).
- Inc, LangGenius Dify: Open-Source LLM Application Development Platform. 2025. Available online: https://github.com/langgenius/dify (accessed on 15 March 2025).
- DeepSeek-AI; Liu, A.; Feng, B.; Xue, B.; Wang, B.; Wu, B.; Lu, C.; Zhao, C.; Deng, C.; Zhang, C.; et al. DeepSeek-V3 Technical Report. arXiv 2025, arXiv:2412.19437. [Google Scholar] [CrossRef]
- Yang, A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Li, C.; Liu, D.; Huang, F.; Wei, H.; et al. Qwen2.5 Technical Report. arXiv 2025, arXiv:2412.15115. [Google Scholar] [CrossRef]
- GLM Team; Zeng, A.; Xu, B.; Wang, B.; Zhang, C.; Yin, D.; Zhang, D.; Rojas, D.; Feng, G.; Zhao, H.; et al. ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools. arXiv 2024, arXiv:2406.12793. [Google Scholar] [CrossRef]
- ByteDance. Doubao v1.5-Pro. 2025. Available online: https://seed.bytedance.com/en/special/doubao_1_5_pro/ (accessed on 15 March 2025).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Setting | Active Modules | Accuracy |
|---|---|---|
| A0—Full system | Multi-source + hybrid RAG | 0.9667 |
| A1—RAG only | Multi-source + RAG | 0.8533 |
| A2—Local only | Local DB + hybrid RAG | 0.8400 |
| A3—Minimal RAG | Local DB + RAG | 0.7133 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, F.; Li, Q.; Wang, M.; Xiong, X. An AI Agent-Based System for Retrieving Compound Information in Traditional Chinese Medicine. Information 2025, 16, 543. https://doi.org/10.3390/info16070543
Zhao F, Li Q, Wang M, Xiong X. An AI Agent-Based System for Retrieving Compound Information in Traditional Chinese Medicine. Information. 2025; 16(7):543. https://doi.org/10.3390/info16070543
Chicago/Turabian StyleZhao, Feifan, Qianjin Li, Meng Wang, and Xingchuang Xiong. 2025. "An AI Agent-Based System for Retrieving Compound Information in Traditional Chinese Medicine" Information 16, no. 7: 543. https://doi.org/10.3390/info16070543
APA StyleZhao, F., Li, Q., Wang, M., & Xiong, X. (2025). An AI Agent-Based System for Retrieving Compound Information in Traditional Chinese Medicine. Information, 16(7), 543. https://doi.org/10.3390/info16070543