Leveraging Degradation Events for Enhanced Remaining Useful Life Prediction

 , , , and
, , , and
Abstract
1. Introduction
- We introduce a degradation event-based approach that prioritizes abrupt sensor variations (DEs), improving both interpretability and performance in RUL estimation.
- We propose a motif-based reference selection technique that eliminates unnecessary comparisons, reducing computational cost while preserving accuracy.
- To make the reference RUL more appropriate, we proposed the initial wear-based adjustment and degradation rate-based adjustment strategies.
- An end-to-end DERUL framework is proposed and evaluated on C-MAPSS and XJTU datasets, outperforming several competitive RUL estimation models.
2. Literature Review
2.1. Global Similarity-Based Approaches
2.2. Local Similarity-Based Approaches
2.3. Event-Aware RUL Estimation Methods
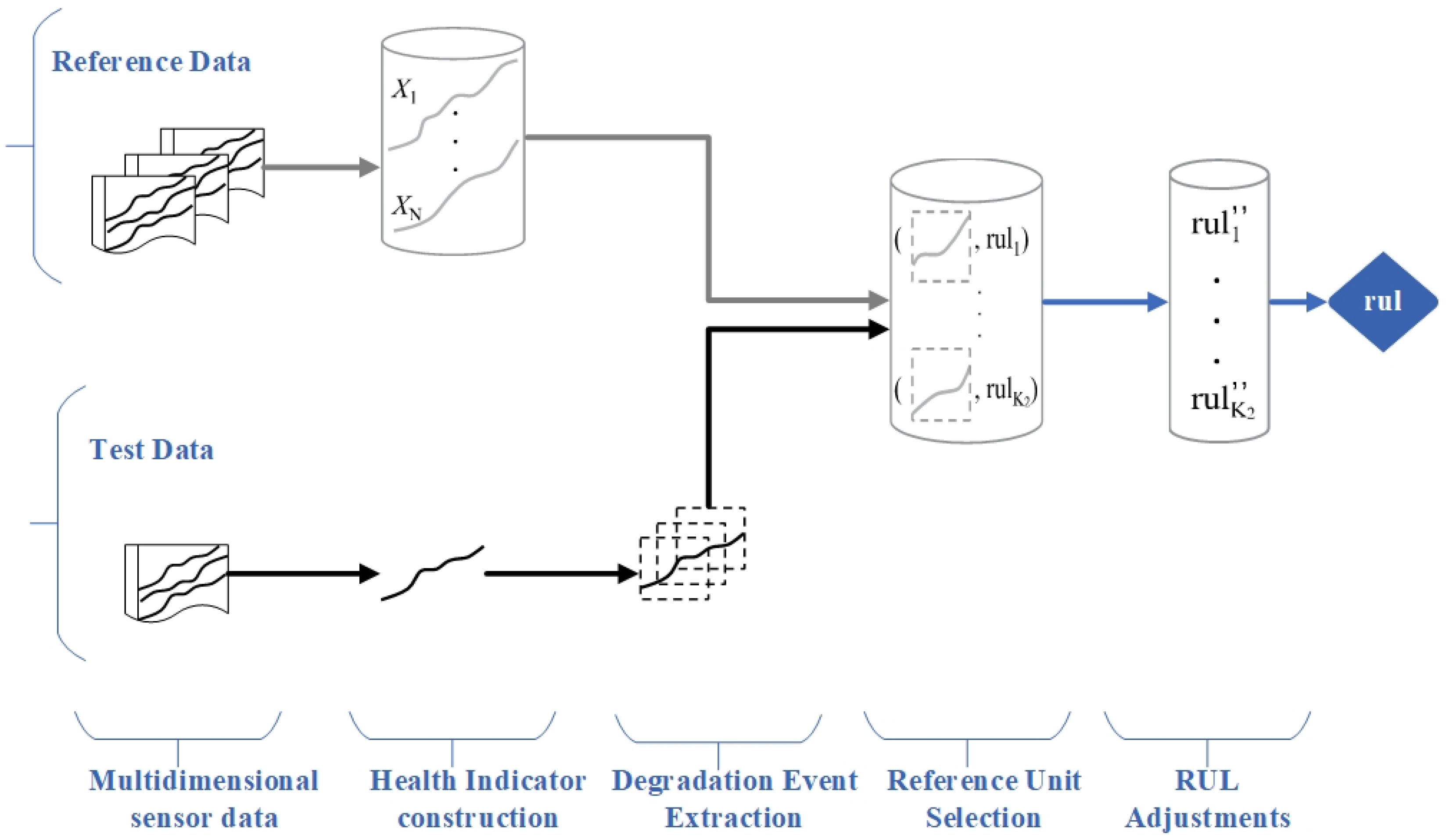
3. Methodology
| Algorithm 1 DERUL algorithm. |
|
3.1. Health Indicator Construction
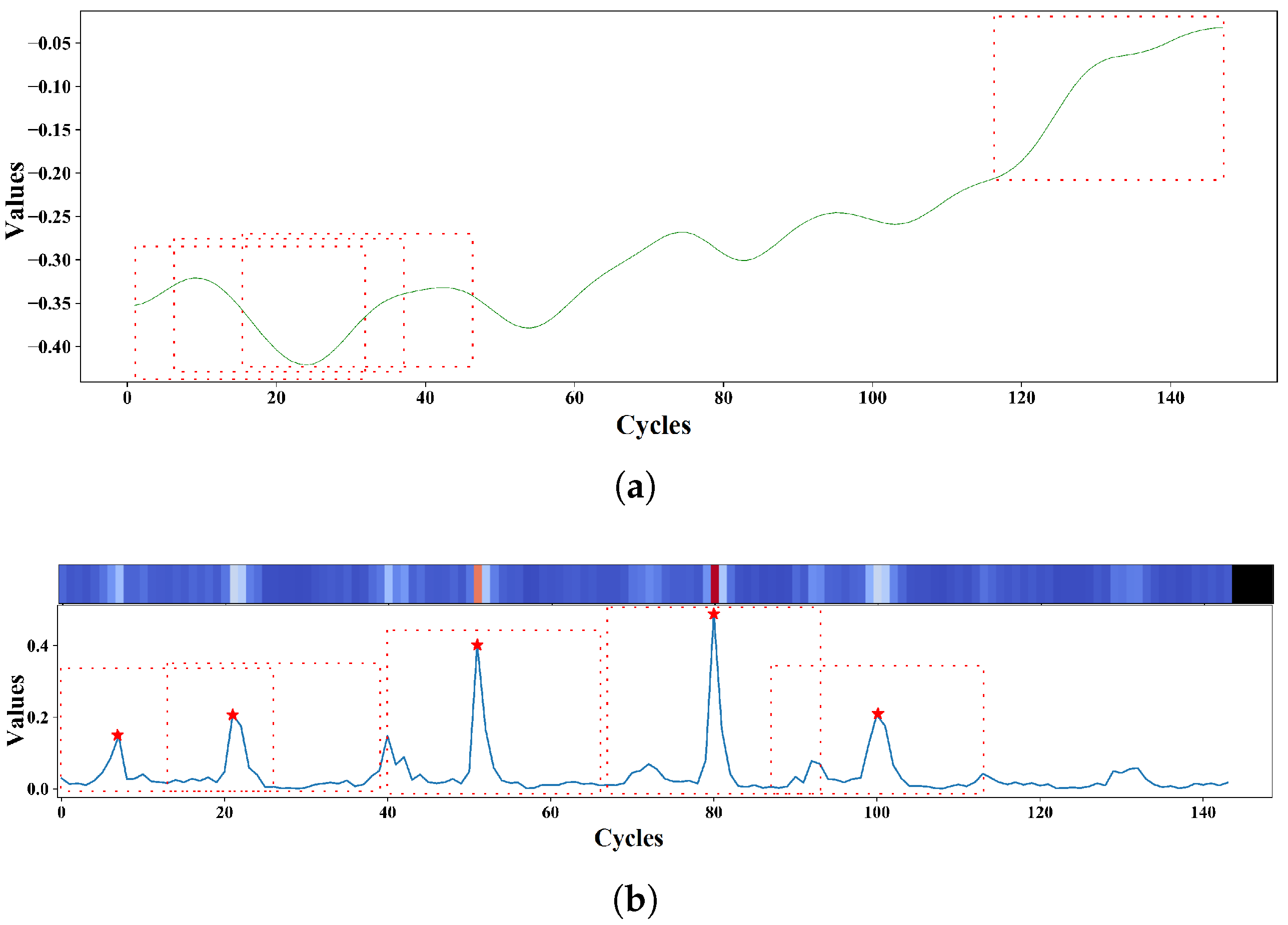
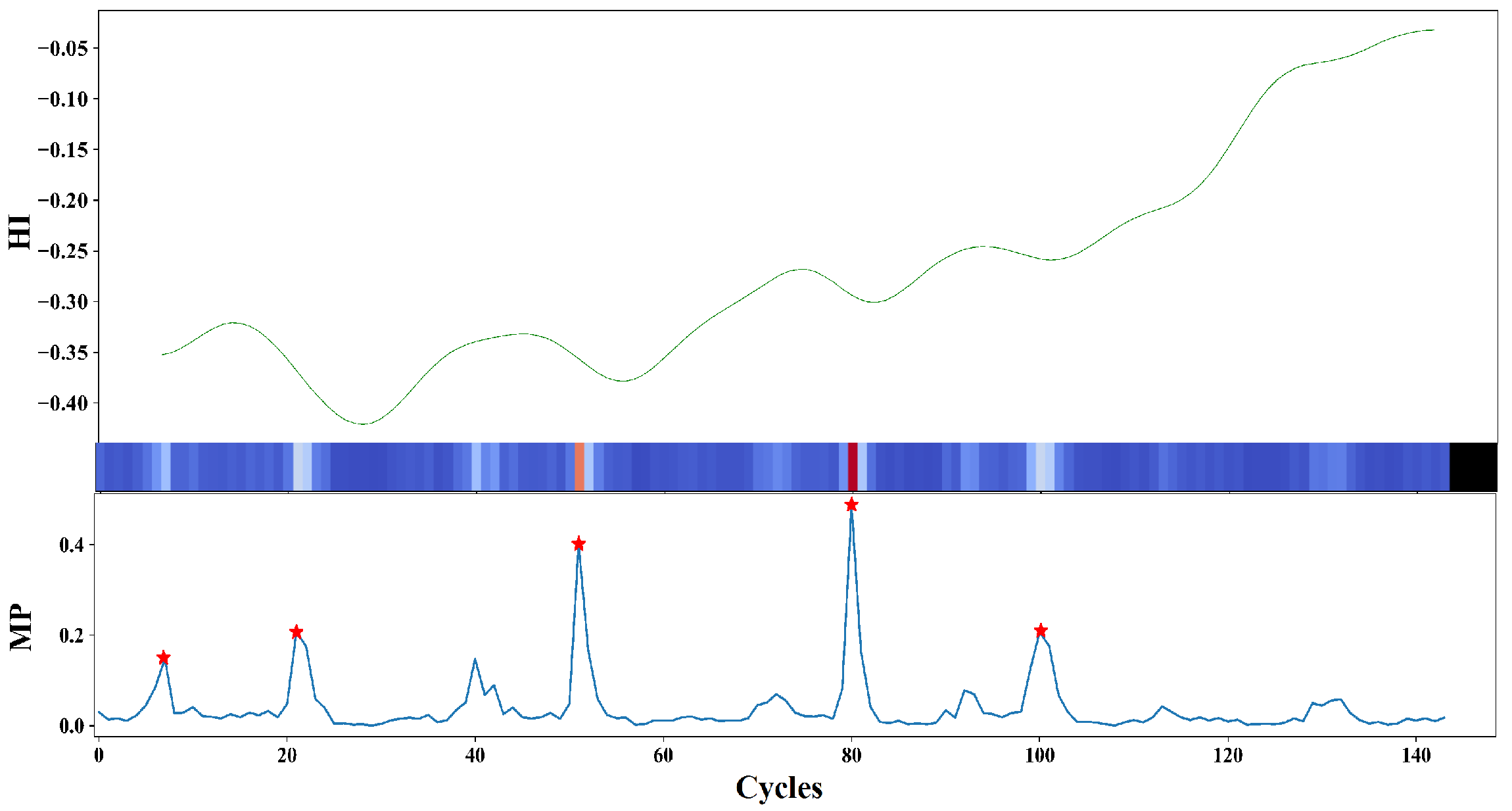
3.2. Degradation Event Extraction Using Matrix Profile
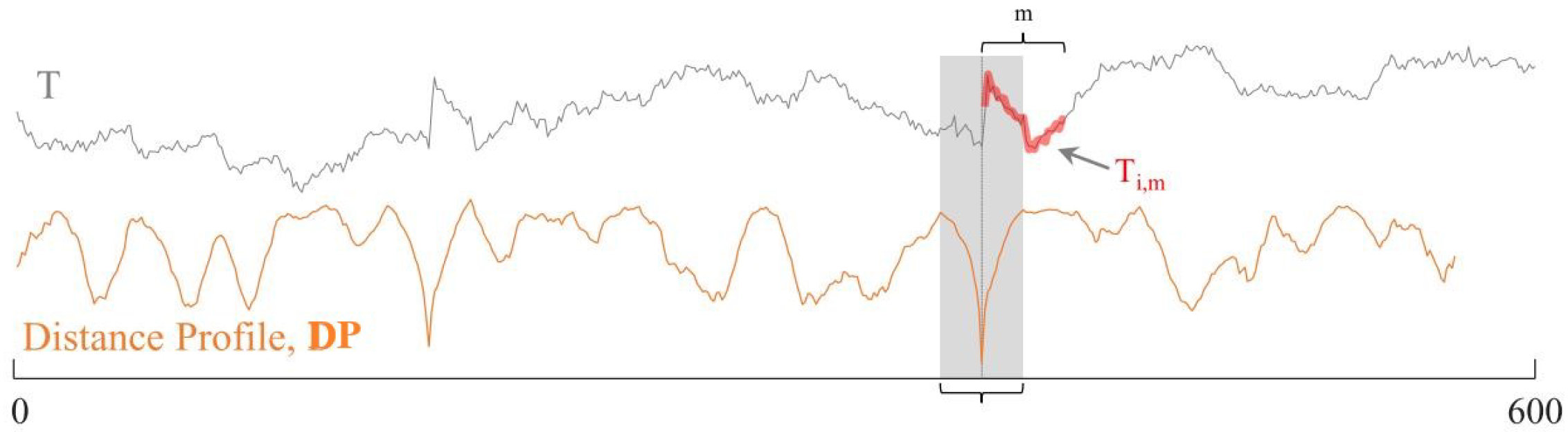
3.2.1. Distance Profile
3.2.2. Matrix Profile
| Algorithm 2 Degradation event extraction. |
|
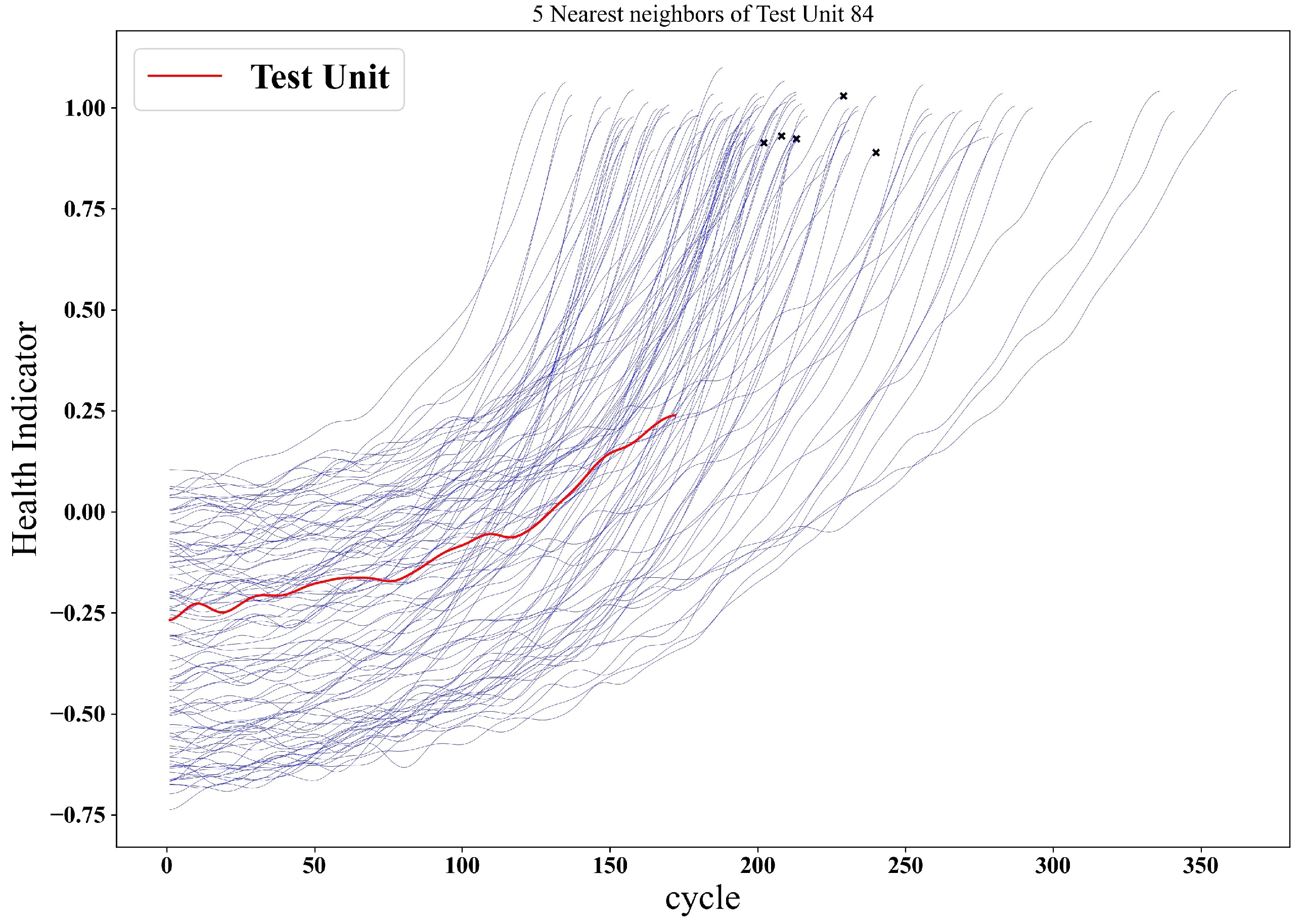
3.3. Reference System Selection
| Algorithm 3 Motif-based reference selection. |
|
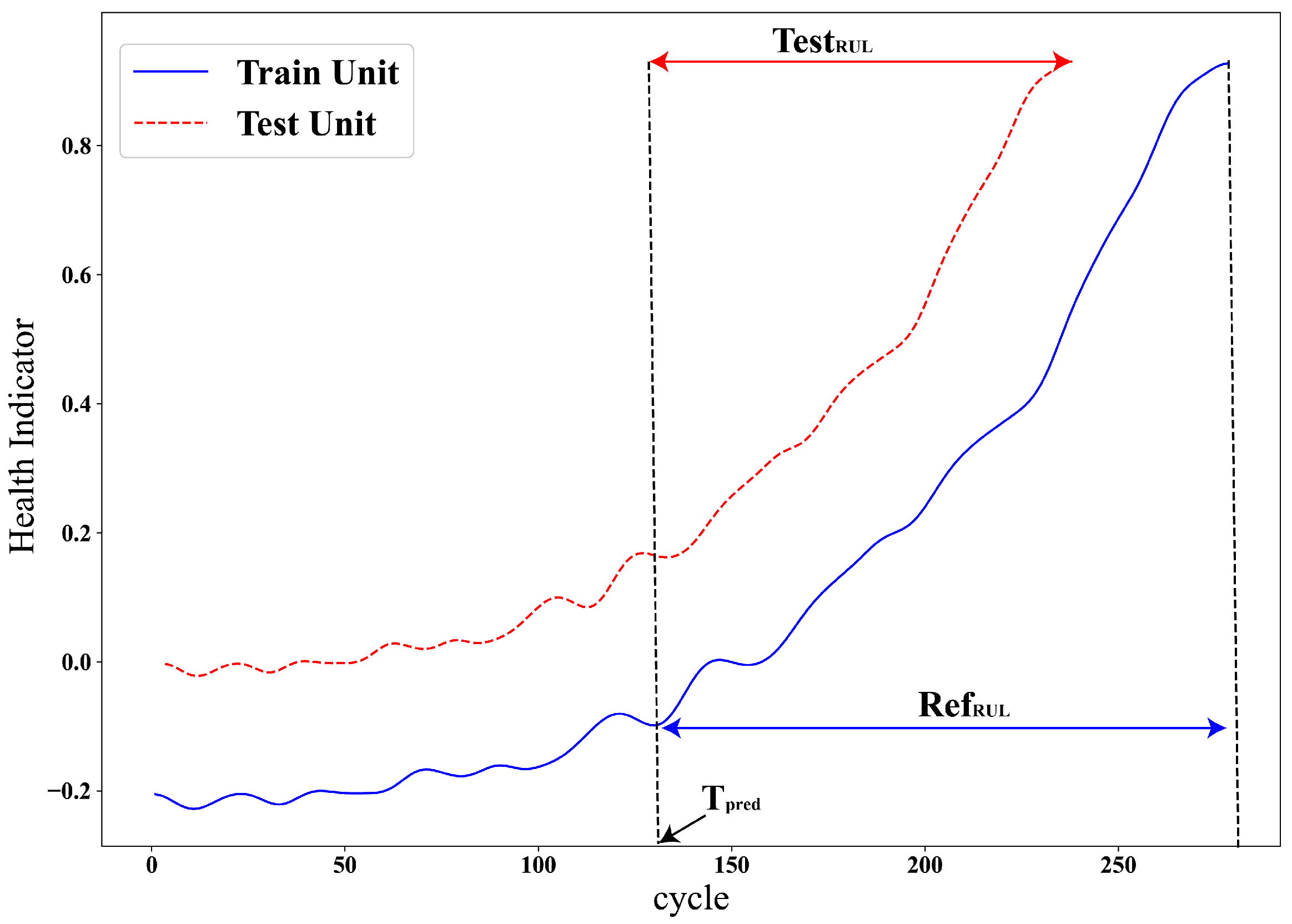
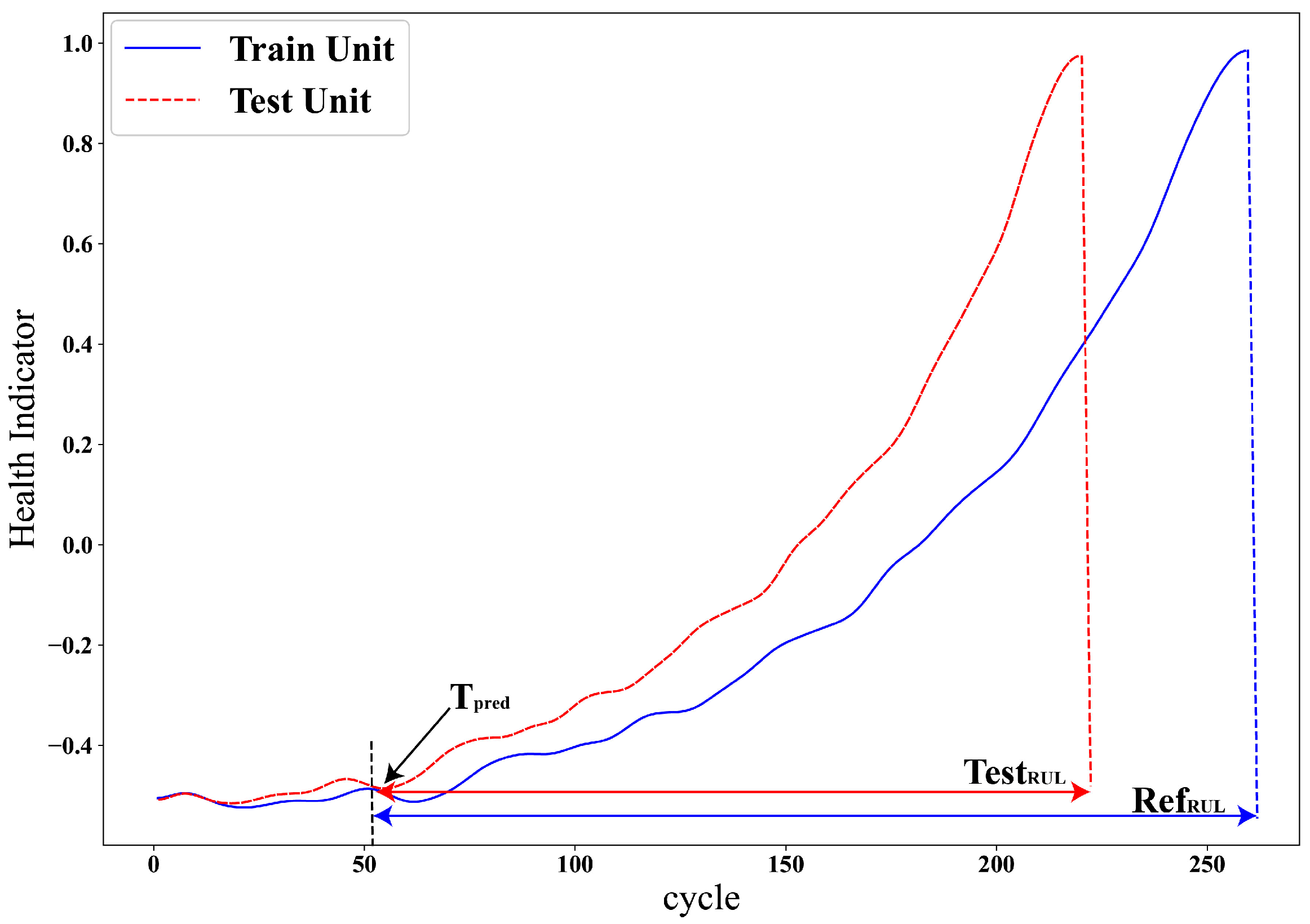
3.3.1. Reference RUL Adjustments
3.3.2. Initial Wear Based Adjustment
3.3.3. Degradation Rate-Based Adjustment
3.3.4. RUL Estimation
4. Experimental Evaluation
4.1. Experimental Data
4.1.1. Aero Engine Degradation Dataset (C-MAPSS)
4.1.2. Bearing Degradation Dataset (XJTU-SY)
4.2. Data Normalization
4.3. Evaluation Metrics
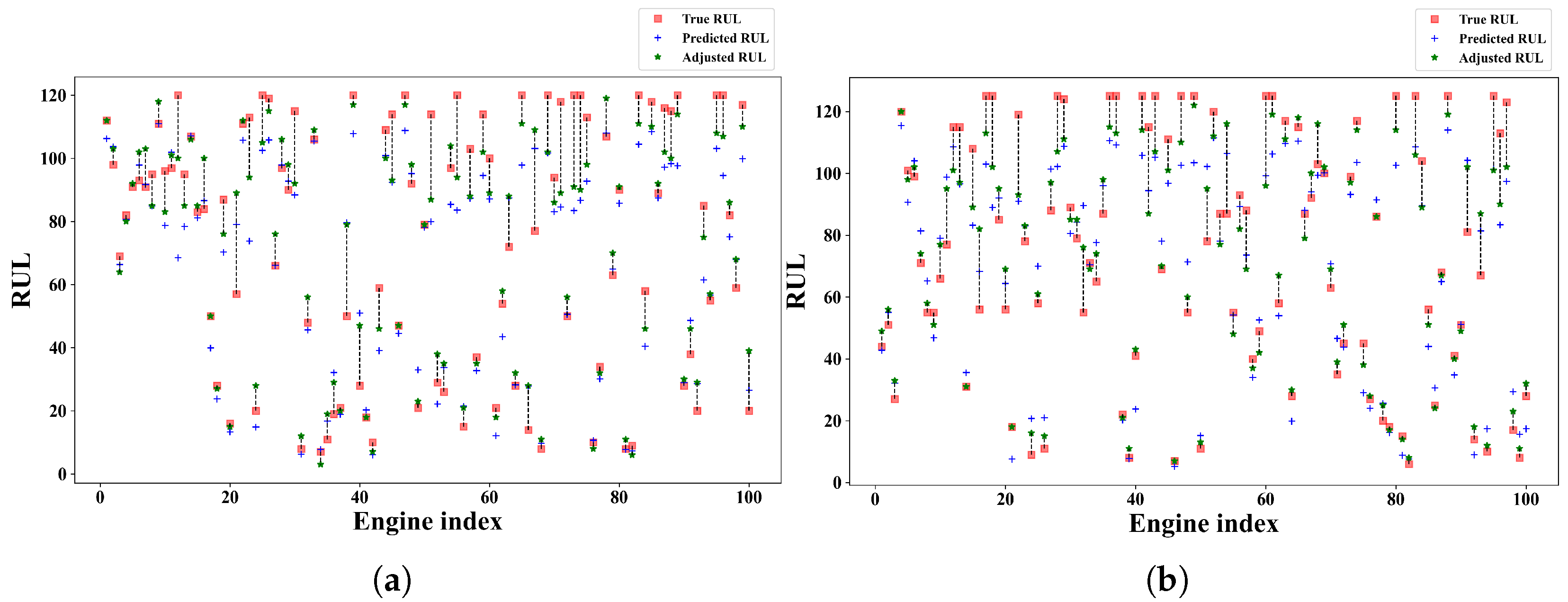
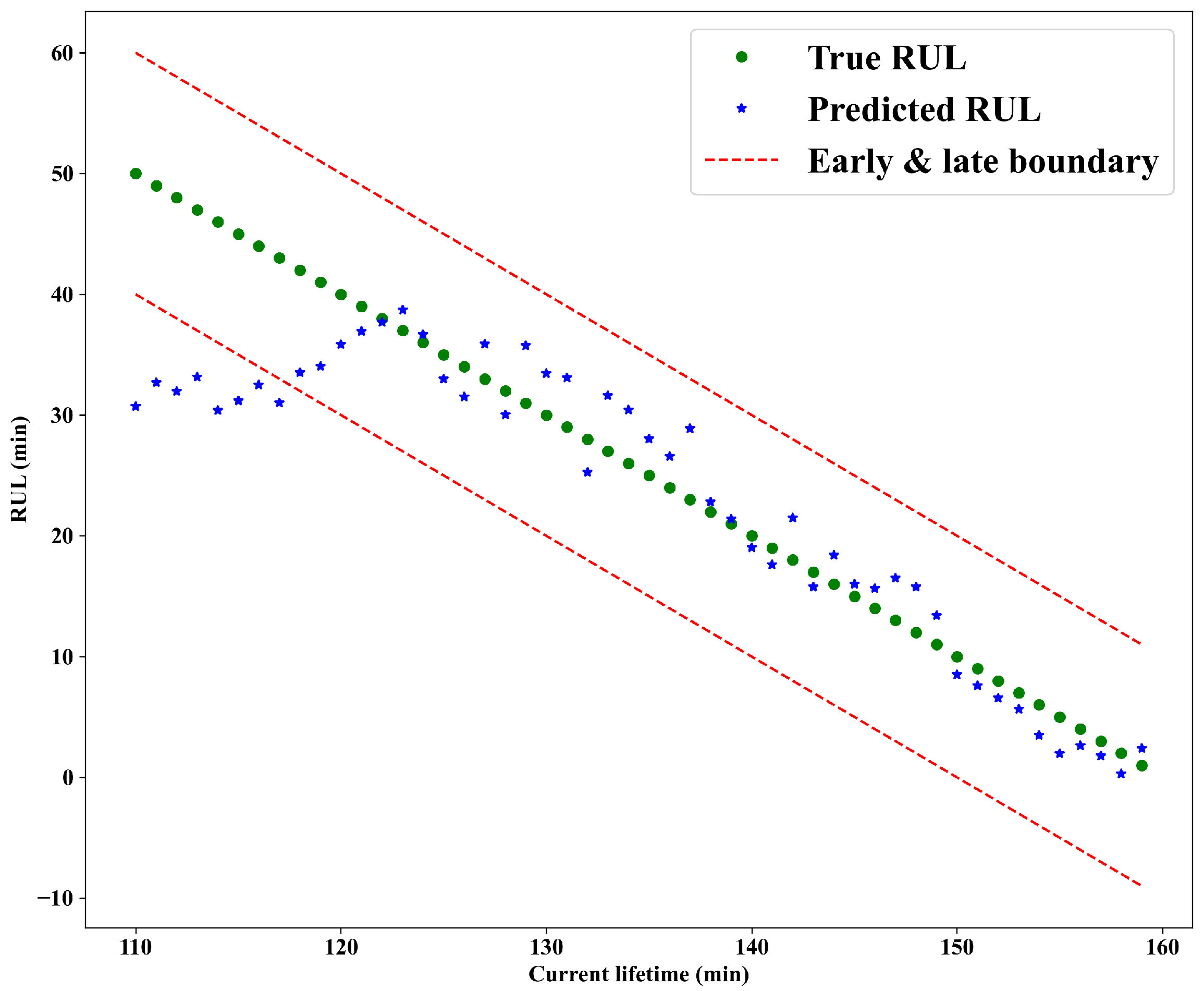
4.4. Experimental Result
4.4.1. Experimentation on C-MAPSS
4.4.2. Experimentation on XJTU-SY
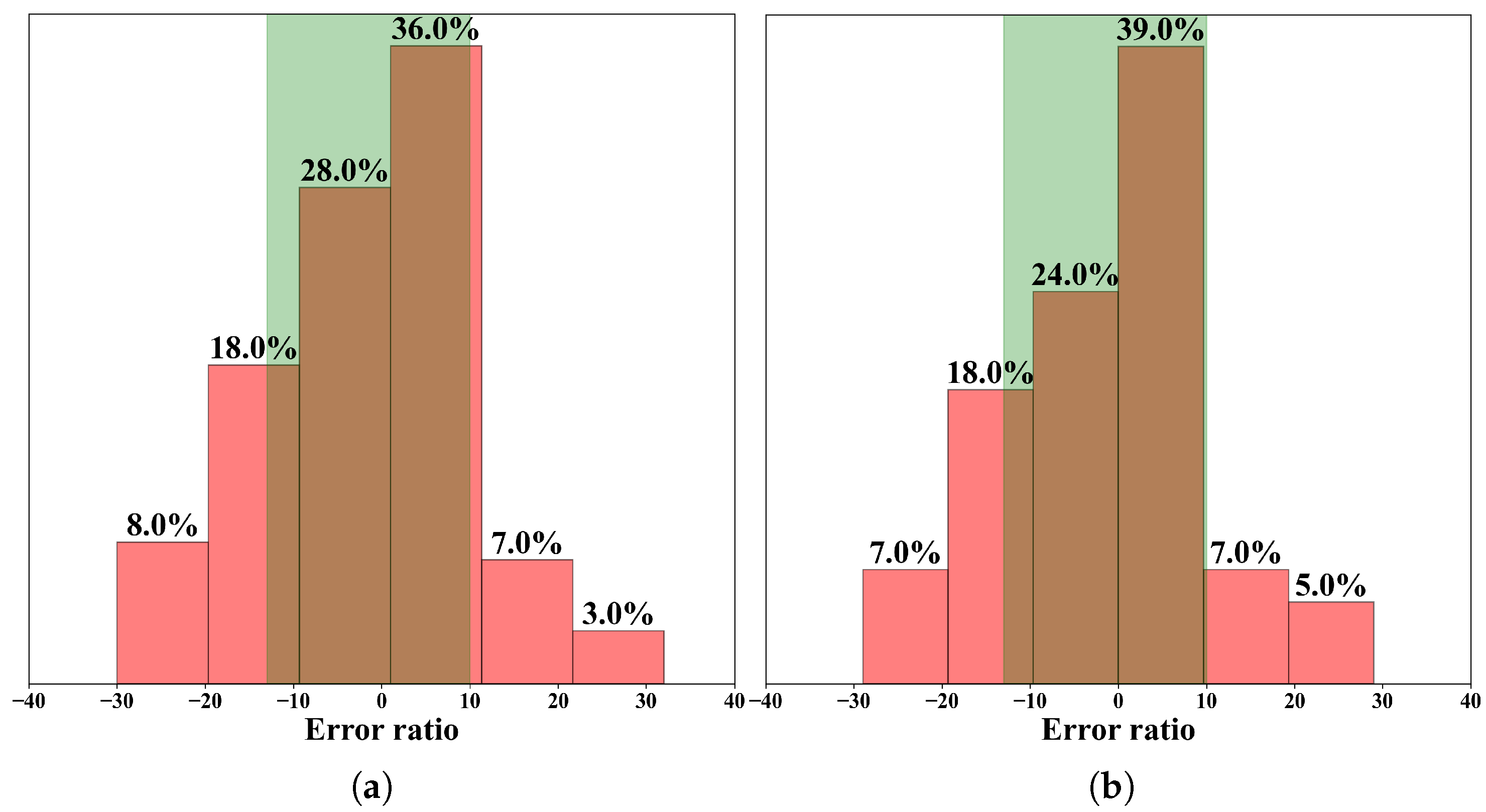
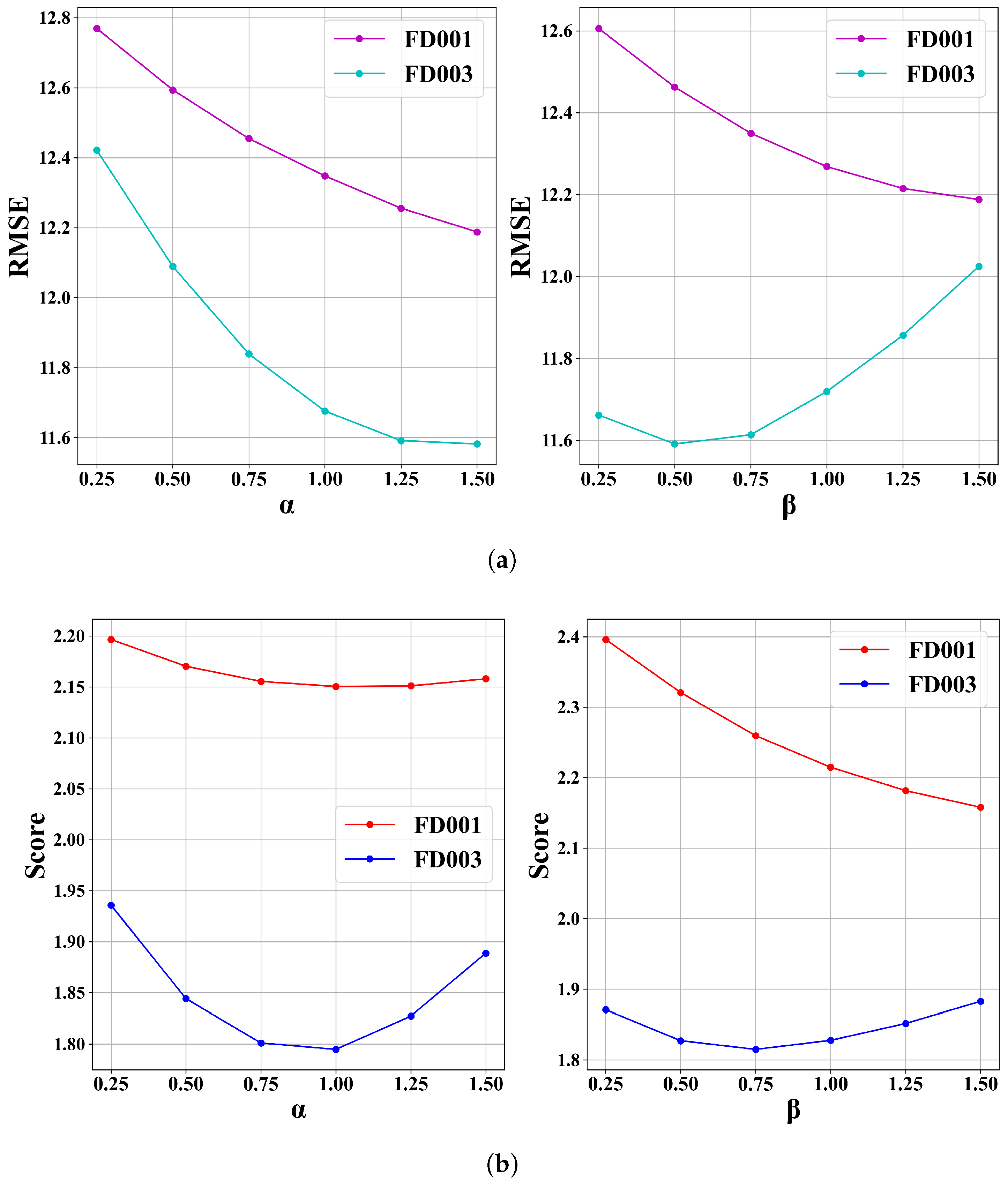
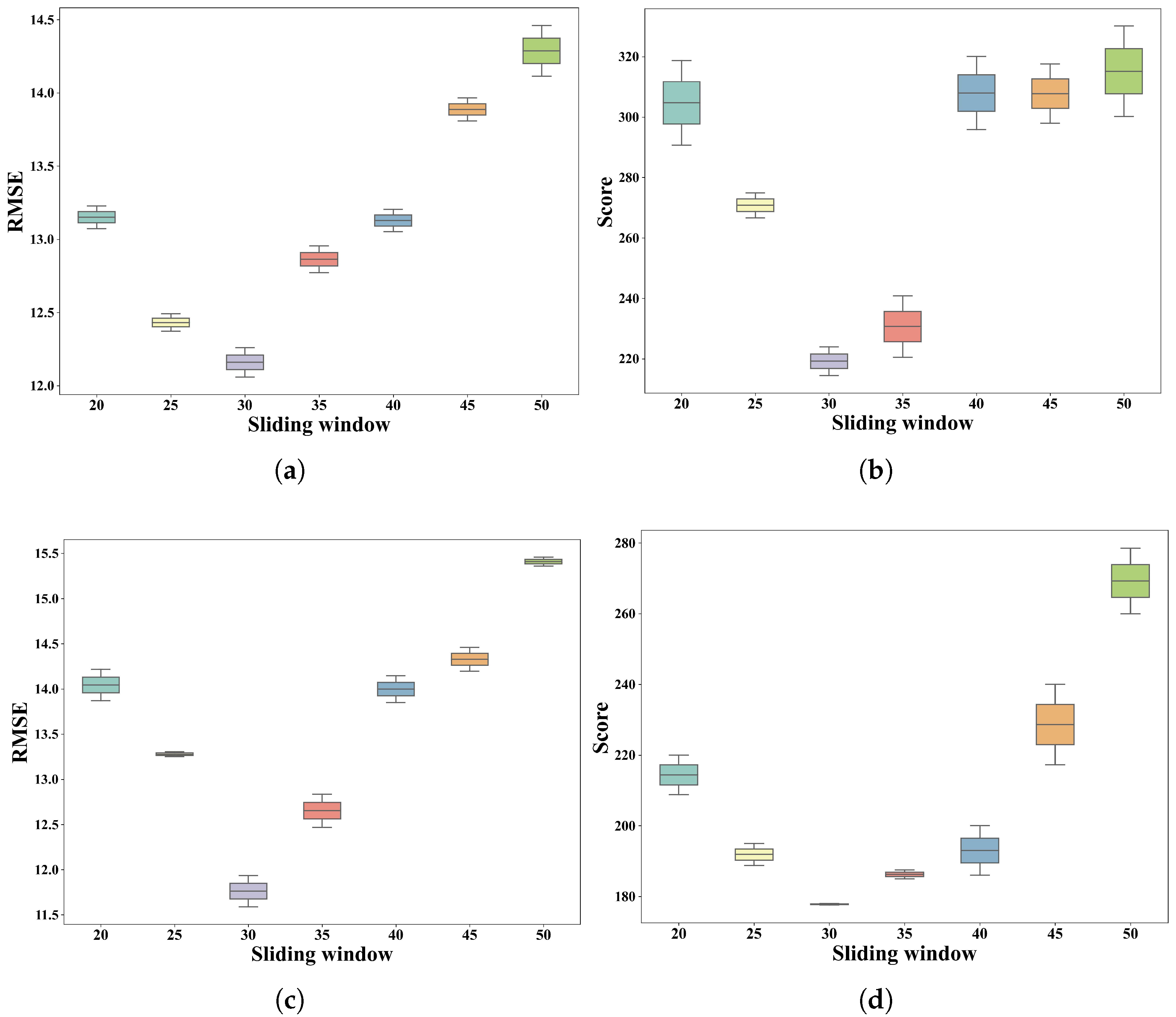
4.5. Further Analysis
4.5.1. Impact of Adjustment Parameters and
4.5.2. Effect of the Window Size
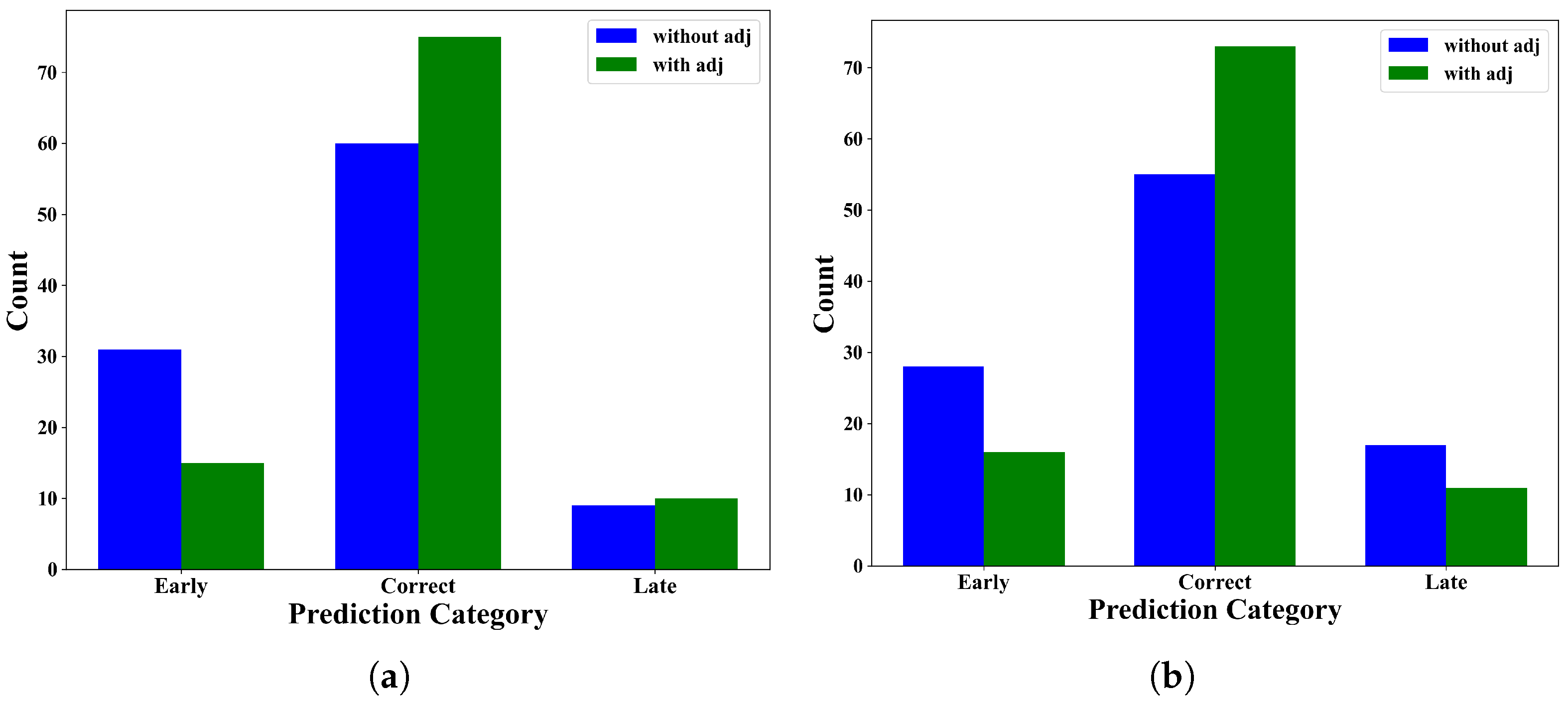
4.5.3. Effect of Adjustment Strategies
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, B.; Liu, R.; Zio, E. Remaining useful life prediction based on a double-convolutional neural network architecture. IEEE Trans. Ind. Electron. 2019, 66, 9521–9530. [Google Scholar] [CrossRef]
- Lyu, J.; Ying, R.; Lu, N.; Zhang, B. Engineering Applications of Artificial Intelligence Remaining useful life estimation with multiple local similarities. Eng. Appl. Artif. Intell. 2020, 95, 103849. [Google Scholar] [CrossRef]
- Calabrese, M.; Cimmino, M.; Fiume, F.; Manfrin, M.; Romeo, L.; Ceccacci, S.; Paolanti, M.; Toscano, G.; Ciandrini, G.; Carrotta, A.; et al. SOPHIA: An Event-Based IoT and Machine Learning Architecture for Predictive Maintenance in Industry 4.0. Information 2020, 11, 202. [Google Scholar] [CrossRef]
- Hu, Q.; Zhao, Y.; Wang, Y.; Peng, P.; Ren, L. Remaining Useful Life Estimation in Prognostics Using Deep Reinforcement Learning. IEEE Access 2023, 11, 32919–32934. [Google Scholar] [CrossRef]
- Solís-Martín, D.; Galán-Páez, J.; Borrego-Díaz, J. On the Soundness of XAI in Prognostics and Health Management (PHM). Information 2023, 14, 256. [Google Scholar] [CrossRef]
- Arunan, A.; Qin, Y.; Li, X.; Yuen, C. A change point detection integrated remaining useful life estimation model under variable operating conditions. Control Eng. Pract. 2024, 144. [Google Scholar] [CrossRef]
- Behera, S.; Patel, Y.S.; Choubey, A.; Misra, R.; Kanani, C.S.; Sillitti, A. Ensemble trees learning based improved predictive maintenance using IIoT for turbofan engines. In Proceedings of the 34th ACM Symposium on Applied Computing, New York, NY, USA, 8–12 April 2019; pp. 842–850. [Google Scholar] [CrossRef]
- Xu, F.; Yang, F.; Fan, X.; Huang, Z.; Tsui, K.L. Extracting degradation trends for roller bearings by using a moving-average stacked auto-encoder and a novel exponential function. Measurement 2020, 152, 107371. [Google Scholar] [CrossRef]
- Liang, Z.; Gao, J.; Jiang, H.; Gao, X.; Gao, Z.; Wang, R. A Degradation Degree Considered Method for Remaining Useful Life Prediction Based on Similarity. Comput. Sci. Eng. 2019, 21, 50–64. [Google Scholar] [CrossRef]
- Roberto De Oliveira Da Costa, P.; Akcay, A.; Zhang, Y.; Kaymak, U.; de Oliveira da Costa, P.R.; Akcay, A.; Zhang, Y.; Kaymak, U. Attention and Long Short-Term Memory Network for Remaining Useful Lifetime Predictions of Turbofan Engine Degradation. Int. J. Progn. Health Manag. 2019, 10, 034. [Google Scholar]
- Haque, M.S.; Choi, S.; Baek, J. Auxiliary particle filtering-based estimation of remaining useful life of IGBT. IEEE Trans. Ind. Electron. 2018, 65, 2693–2703. [Google Scholar] [CrossRef]
- Li, N.; Lei, Y.; Yan, T.; Li, N.; Han, T. A wiener-process-model-based method for remaining useful life prediction considering unit-to-unit variability. IEEE Trans. Ind. Electron. 2019, 66, 2092–2101. [Google Scholar] [CrossRef]
- Huang, C.G.; Huang, H.Z.; Li, Y.F. A Bidirectional LSTM Prognostics Method Under Multiple Operational Conditions. IEEE Trans. Ind. Electron. 2019, 66, 8792–8802. [Google Scholar] [CrossRef]
- Liu, K.; Hu, X.; Wei, Z.; Li, Y.; Jiang, Y. Modified Gaussian Process Regression Models for Cyclic Capacity Prediction of Lithium-Ion Batteries. IEEE Trans. Transp. Electrif. 2019, 5, 1225–1236. [Google Scholar] [CrossRef]
- Ma, M.; Sun, C.; Mao, Z.; Chen, X. Ensemble deep learning with multi-objective optimization for prognosis of rotating machinery. ISA Trans. 2021, 113, 166–174. [Google Scholar] [CrossRef] [PubMed]
- Bektas, O.; Jones, J.A.; Sankararaman, S.; Roychoudhury, I.; Goebel, K. A neural network framework for similarity-based prognostics. MethodsX 2019, 6, 383–390. [Google Scholar] [CrossRef] [PubMed]
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage propagation modeling for aircraft engine run-to-failure simulation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, PHM 2008, Denver, CO, USA, 6–9 October 2008; pp. 11–19. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Li, N. A Hybrid Prognostics Approach for Estimating Remaining Useful Life of Rolling Element Bearings. IEEE Trans. Reliab. 2020, 69, 401–412. [Google Scholar] [CrossRef]
- Huang, C.G.; Huang, H.Z.; Peng, W.; Huang, T. Improved trajectory similarity-based approach for turbofan engine prognostics. Mech. Syst. Signal Process. 2019, 33, 4877–4890. [Google Scholar] [CrossRef]
- Ren, Y.; Lyu, J.; Jebali, M.; Zhang, B. An AC Contactor Remaining Useful Life Prediction Method based on Degradation Event Analysis. In Proceedings of the 2023 6th International Symposium on Autonomous Systems (ISAS), Nanjing, China, 23–25 June 2023; pp. 1–6. [Google Scholar]
- Aydemir, G.; Acar, B. Anomaly monitoring improves remaining useful life estimation of industrial machinery. J. Manuf. Syst. 2020, 56, 463–469. [Google Scholar] [CrossRef]
- Kumar, P.S.; Kumaraswamidhas, L.A.; Laha, S.K.; Shankar, P.; Kumaraswamidhas, L.A.; Laha, S.K. Selection of efficient degradation features for rolling element bearing prognosis using Gaussian Process Regression method. ISA Trans. 2021, 112, 386–401. [Google Scholar] [CrossRef]
- Biggio, L.; Kastanis, I. Prognostics and Health Management of Industrial Assets: Current Progress and Road Ahead. Front. Artif. Intell. 2020, 3, 578613. [Google Scholar] [CrossRef]
- Bektas, O.; Jones, J.A.; Sankararaman, S.; Roychoudhury, I.; Goebel, K. A neural network filtering approach for similarity-based remaining useful life estimation. Int. J. Adv. Manuf. Technol. 2019, 101, 87–103. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, M.; Zhao, R.; Guretno, F.; Yan, R.; Li, X. Machine Remaining Useful Life Prediction via an Attention-Based Deep Learning Approach. IEEE Trans. Ind. Electron. 2021, 68, 2521–2531. [Google Scholar] [CrossRef]
- Ramasso, E. Investigating computational geometry for failure prognostics. Int. J. Progn. Health Manag. 2014, 5, 1–18. [Google Scholar] [CrossRef]
- Kang, Z.; Catal, C.; Tekinerdogan, B. Remaining useful life (Rul) prediction of equipment in production lines using artificial neural networks. Sensors 2021, 21, 932. [Google Scholar] [CrossRef]
- Fan, L.; Chai, Y.; Chen, X. Trend attention fully convolutional network for remaining useful life estimation. Reliab. Eng. Syst. Saf. 2022, 225, 108590. [Google Scholar] [CrossRef]
- Sternharz, G.; Elhalwagy, A.; Kalganova, T. Data-Efficient Estimation of Remaining Useful Life for Machinery With a Limited Number of Run-to-Failure Training Sequences. IEEE Access 2022, 10, 129443–129464. [Google Scholar] [CrossRef]
- Abdelghafar, S.; Khater, A.; Wagdy, A.; Darwish, A.; Hassanien, A.E. Aero engines remaining useful life prediction based on enhanced adaptive guided differential evolution. Evol. Intell. 2024, 17, 1209–1220. [Google Scholar] [CrossRef]
- Li, X.; Xu, S.; Yang, Y.; Lin, T.; Mba, D.; Li, C. Spherical-dynamic time warping—A new method for similarity-based remaining useful life prediction. Expert Syst. Appl. 2024, 238. [Google Scholar] [CrossRef]
- Wen, Z.; Fang, Y.; Wei, P.; Liu, F.; Chen, Z.; Member, S.; Wu, M. Temporal and heterogeneous graph neural network for remaining useful life prediction. arXiv 2024, arXiv:2405.04336. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Operating Conditions | Fault Modes | Training Dataset | Test Dataset | RUL Dataset |
|---|---|---|---|---|---|
| Dimension | Dimension | Dimension | |||
| FD001 | 1 | 1 | 20,631 × 24 | 13,096 × 24 | 100 |
| FD002 | 6 | 1 | 53,759 × 24 | 33,991 × 24 | 259 |
| FD003 | 1 | 2 | 24,720 × 24 | 16,596 × 24 | 100 |
| FD004 | 6 | 2 | 61,249 × 24 | 41,214 × 24 | 248 |
| Models/Datasets | Year | FD001 | FD003 | ||
|---|---|---|---|---|---|
| RMSE | M-Score | RMSE | MScore | ||
| Deep learning based models | |||||
| Anomaly-Triggered-RUL [21] | 2020 | 17.15 | 392 | 17.6 | 520 |
| LSTM-Transformer [25] | 2021 | 14.53 | 322 | - | - |
| TaFCN [28] | 2022 | 13.99 | 336 | 12.01 | 251 |
| Changepoint LSTM [6] | 2024 | 13.59 | 224 | 12.94 | 207 |
| THGNN [32] | 2024 | 13.15 | 285 | 12.61 | 255 |
| Machine learning (non-deep)-based models | |||||
| Multi-Local Similarities [2] | 2020 | 14.1 | 264 | 15.36 | 271 |
| EAGDE–SVM [30] | 2022 | 14.10 | 253 | 18.86 | 514 |
| Spherical-DTW [31] | 2024 | 26.19 | - | - | - |
| RUL-DE (Without Adj) | 2025 | 14.53 | 269 | 13.15 | 231 |
| RUL-DE (Proposed) | 2025 | 12.33 | 214 | 11.59 | 178 |
| Method (Similarity-Based) | RMSE | MScore |
|---|---|---|
| Local | 9.88 | 1.29 |
| Multi-local similarities | 8.40 | 0.76 |
| RUL-DE (without adj) | 8.17 | 0.75 |
| RUL-DE (proposed) | 7.61 | 0.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, Z.; Sharif, M.; Hussain, M.; Hussain, N.; Hussain, M.; Khan, N.A. Leveraging Degradation Events for Enhanced Remaining Useful Life Prediction. Information 2025, 16, 542. https://doi.org/10.3390/info16070542
Abbas Z, Sharif M, Hussain M, Hussain N, Hussain M, Khan NA. Leveraging Degradation Events for Enhanced Remaining Useful Life Prediction. Information. 2025; 16(7):542. https://doi.org/10.3390/info16070542
Chicago/Turabian StyleAbbas, Zeeshan, Muhammad Sharif, Musrat Hussain, Naeem Hussain, Mehboob Hussain, and Naveed Ahmad Khan. 2025. "Leveraging Degradation Events for Enhanced Remaining Useful Life Prediction" Information 16, no. 7: 542. https://doi.org/10.3390/info16070542
APA StyleAbbas, Z., Sharif, M., Hussain, M., Hussain, N., Hussain, M., & Khan, N. A. (2025). Leveraging Degradation Events for Enhanced Remaining Useful Life Prediction. Information, 16(7), 542. https://doi.org/10.3390/info16070542