1. Introduction
Epilepsy affects approximately 50 million people worldwide, making it one of the most common neurological disorders [
1]. The disability rate in epilepsy patients ranges from 0.2 to 5.8%, with patients facing significant risks of social maladjustment and stigmatization [
2,
3]. The accurate detection and classification of epileptic seizures is essential for diagnosis, treatment planning, and evaluating therapeutic efficacy [
4].
The interpretation of electroencephalography (EEG) for epileptic events presents substantial challenges. Around 25% of patients are misdiagnosed with epilepsy due to the over-reading of benign EEG features [
3,
5]. Manual review by neurologists is time-consuming, subjective, and prone to inter-rater variability. These limitations have motivated significant research into automated seizure detection and classification systems using machine learning approaches.
Automated EEG analysis for epilepsy faces several key challenges. First, the spatial resolution of EEG is often too low to accurately specify the location of epileptogenic foci [
6]. Second, data preprocessing depends heavily on artifact and noise removal techniques, which can significantly impact subsequent analysis [
7]. Third, scalp EEG, while non-invasive and clinically prevalent, is less sensitive than intracranial EEG for detecting certain seizure types [
8]. Additionally, EEG findings are difficult to interpret and visualize due to the large volume of data [
9].
Recent reviews by Roy et al. [
9] and Craik et al. [
10] highlight the growing application of deep learning for EEG analysis. These approaches range from convolutional neural networks (CNNs) that exploit the spatial and spectral characteristics of EEG signals, to recurrent architectures that capture temporal dependencies [
11], and graph-based models that leverage the topological structure of electrode placements [
12].
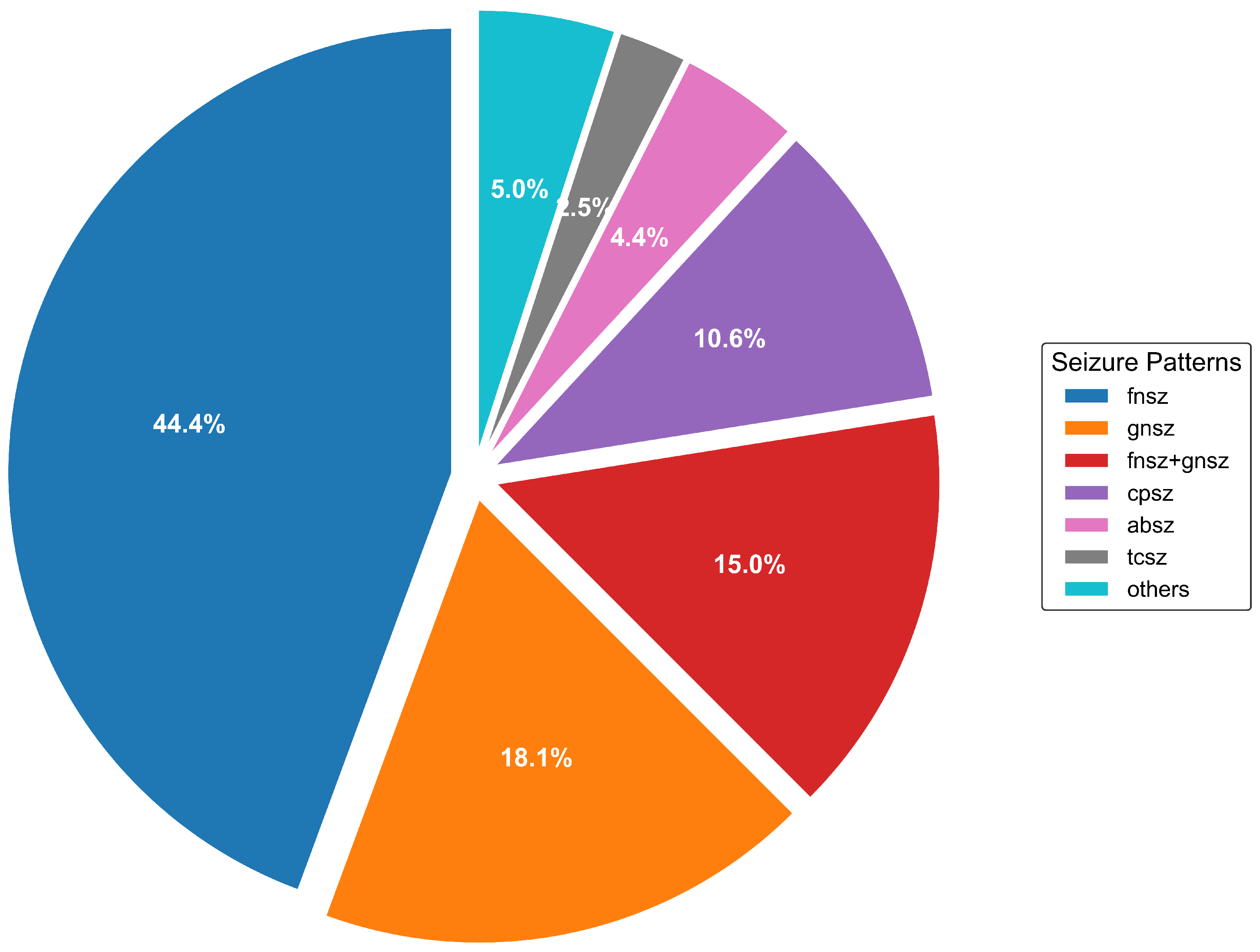
Despite these advances, a particularly significant challenge—and the focus of this paper—is the inherent and severe class imbalance that characterizes epileptic EEG data. This imbalance manifests at multiple levels: (1) temporal imbalance, where seizure events typically constitute less than 1% of the total EEG recording time [
13]; (2) categorical imbalance, as certain seizure types occur much more frequently than others, creating significant disparities in class representation [
14]; and (3) duration heterogeneity since seizure durations vary greatly, from brief events lasting seconds to prolonged episodes spanning minutes [
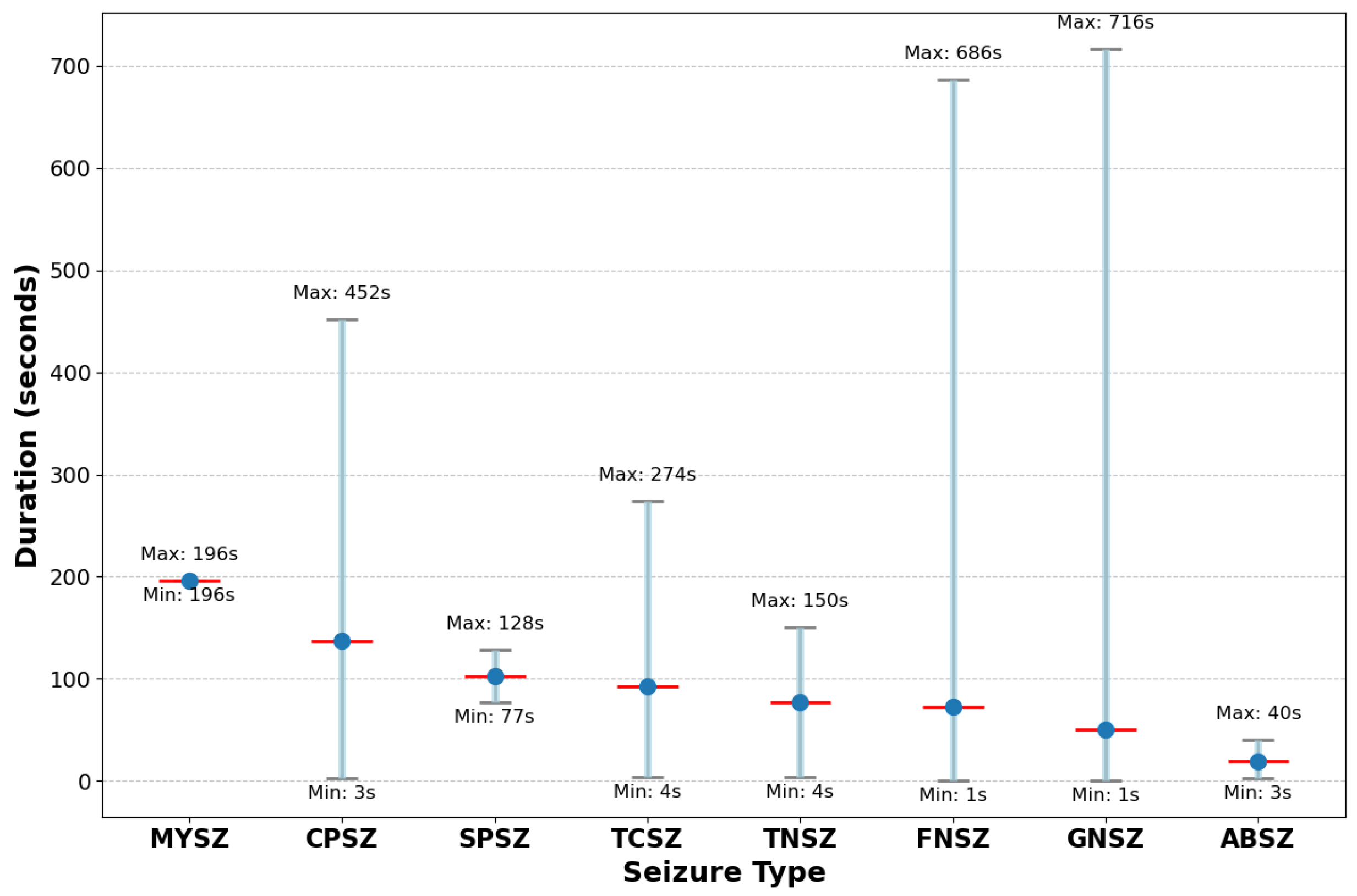
15].
Raut and Rathee [
14] demonstrated that this multi-level imbalance significantly impacts classifier performance, with most algorithms showing bias toward majority classes. Li et al. [
16] observed that even advanced deep learning methods tend to underperform on rare seizure categories, which are often the most clinically significant.
The machine learning literature offers several strategies for addressing class imbalance. He and Garcia [
17] categorized these approaches into data-level methods, algorithm-level methods, and hybrid approaches. Data-level methods include undersampling majority classes, oversampling minority classes, or generating synthetic samples. The Synthetic Minority Over-sampling Technique (SMOTE) [
18] is widely used but often struggles with complex signal patterns like EEG. Algorithm-level methods include cost-sensitive learning, which assigns higher penalties to misclassifying minority classes, and ensemble methods that combine multiple classifiers [
19]. Hybrid approaches combine data preprocessing with specialized algorithms to achieve better performance on imbalanced datasets [
17].
While these approaches have shown success in various domains, Johnson and Khoshgoftaar [
19] note their limitations when dealing with extreme imbalance (ratios exceeding 100:1) or multi-level imbalance as found in the EEG data. Most existing methods address only a single dimension of imbalance, failing to account for the complex, hierarchical nature of the imbalance in seizure classification.
Recent work by Statsenko et al. [
20] proposed a system architecture for precise seizure detection and classification using deep learning models for binary and multigroup classifications, also using the TUSZ dataset. While they achieved good results (87.7% sensitivity, 91.16% specificity for detection and 95–100% accuracy for classification), their approach did not specifically address the multi-level imbalance challenge through a specialized framework.
The Temple University Hospital Seizure (TUSZ) dataset [
21] has emerged as a benchmark for seizure detection algorithms. It contains 2012 EEG sessions from 264 patients, with 1046 seizure events annotated by expert neurologists. Our analysis of this dataset reveals previously uncharacterized extreme imbalance ratios exceeding 150:1 between common and rare seizure types, with substantial temporal heterogeneity in seizure duration (ranging from 1 s to 1638 s).
Recent work on the TUSZ dataset includes Asif et al. [
22], who proposed a multi-spectral CNN that achieved 94.8% accuracy for seizure detection but struggled with rare seizure types. Hussein et al. [
23] implemented an optimized RNN architecture reaching 95.7% accuracy but showed significant performance disparities across different seizure categories. Covert et al. [
12] applied temporal graph convolutional networks to capture spatial–temporal EEG patterns, achieving 97.2% for binary seizure detection, but did not address type classification.
These approaches, while advancing the state of the art, have not adequately addressed the fundamental challenge of multi-level imbalance in seizure classification.
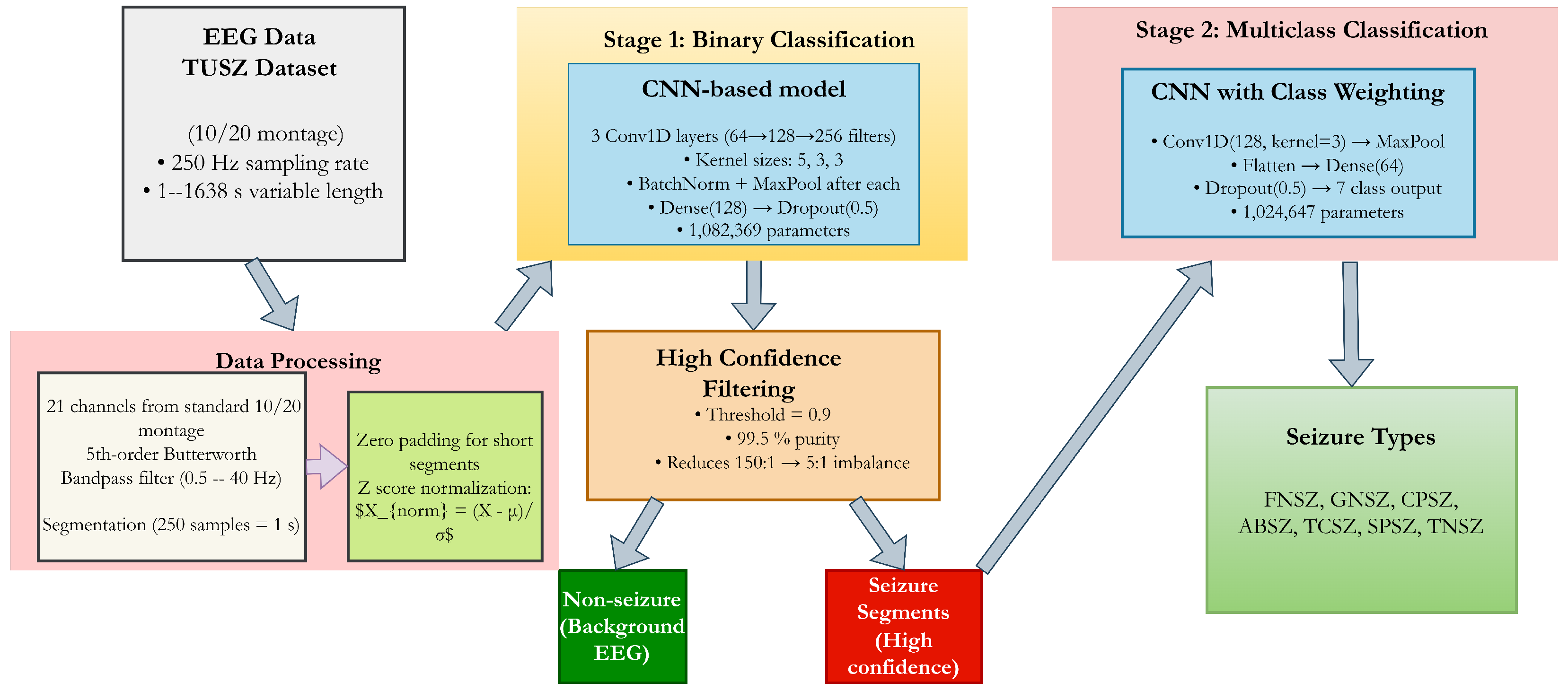
In this paper, we introduce a cascaded deep learning architecture specifically designed to address multi-level imbalance in seizure classification. Our approach decomposes the complex multi-class problem into a sequence of more tractable sub-problems: first distinguishing seizure from non-seizure activity, then classifying the specific seizure type among those segments identified as seizures.
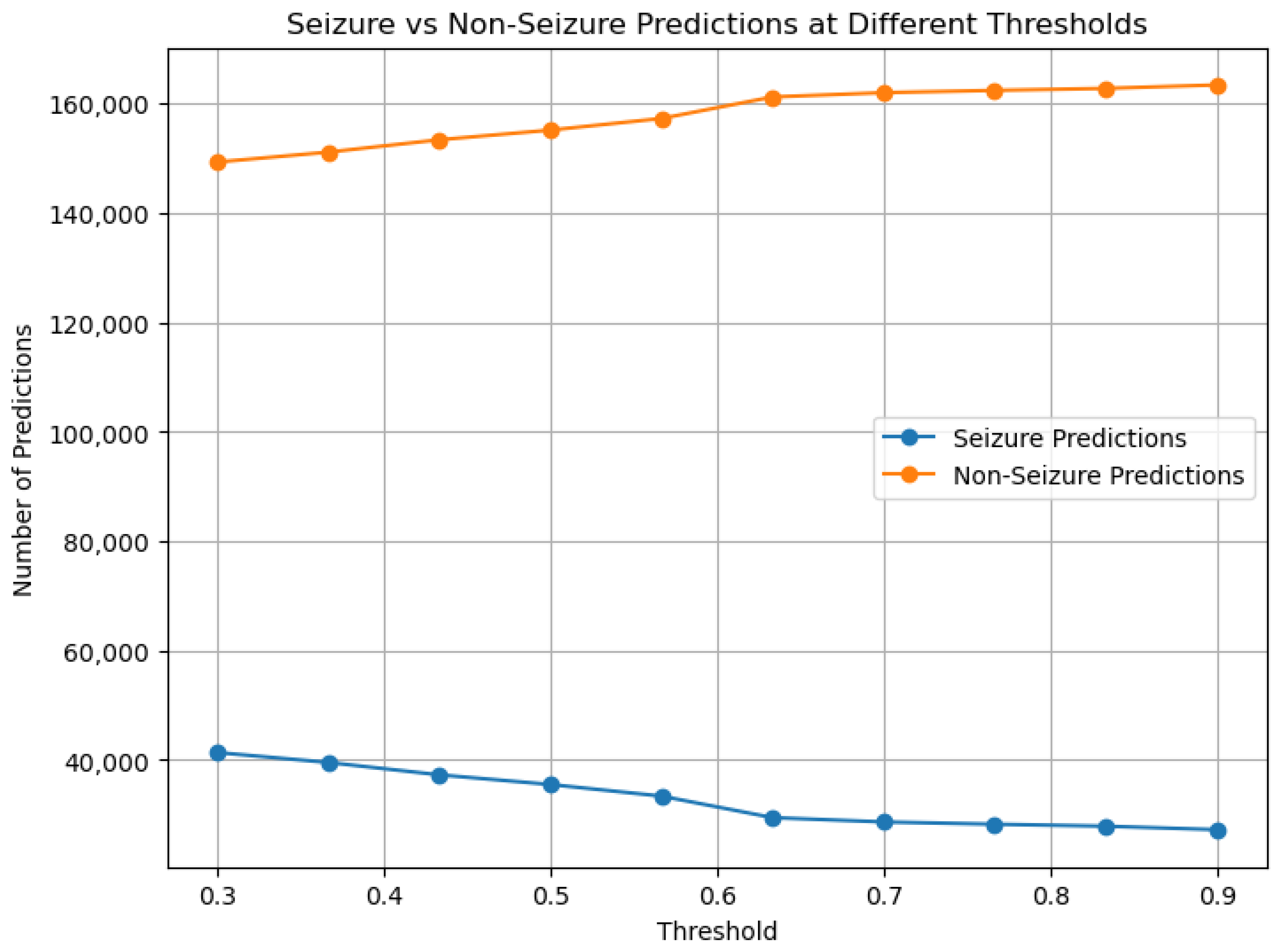
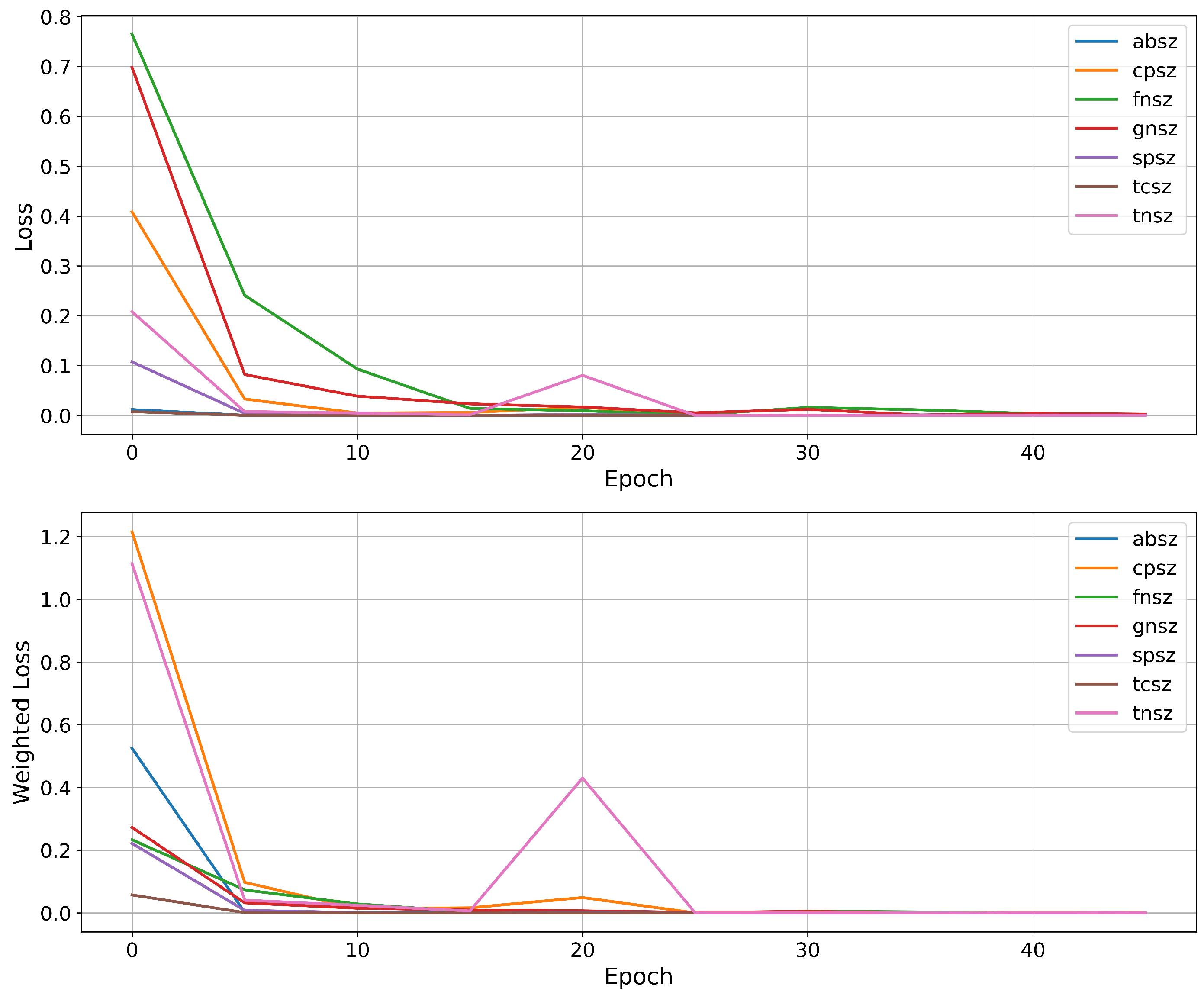
The key innovation lies in our specialized information flow between stages, with high-confidence filtering creating a purified dataset for subsequent type classification. This approach, coupled with class-weighted optimization and gradient flow balancing, enables effective learning even from severely underrepresented classes.
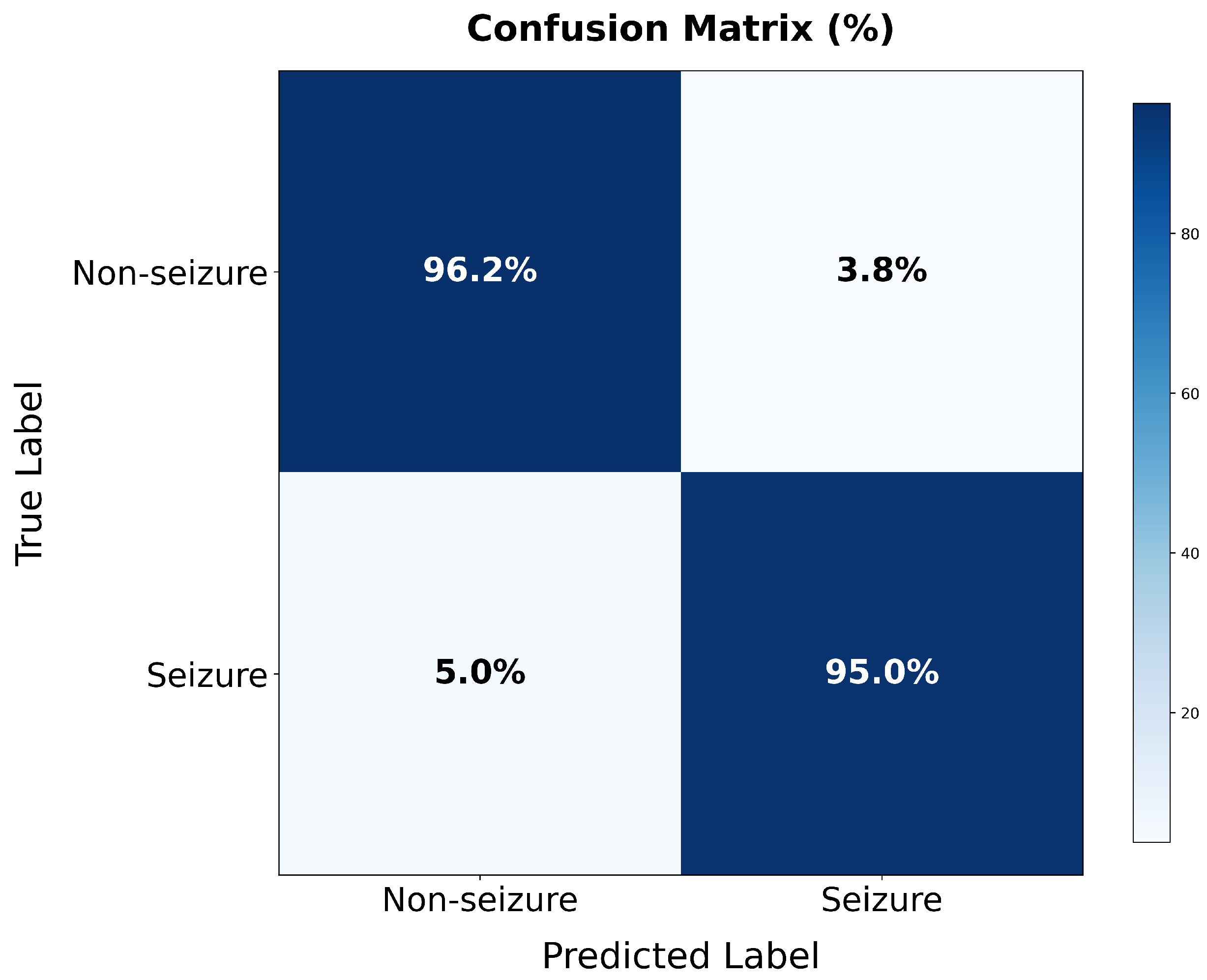
Experimental validation on the TUSZ dataset demonstrates exceptional performance: 99.64% specificity and 98.23% sensitivity for seizure detection, and >99% accuracy across seven seizure categories. Most significantly, our approach achieves consistent performance improvement across all seizure types, rather than improving majority classes at the expense of minority classes as commonly observed in prior work.
The contributions of this work are threefold:
We present a comprehensive statistical analysis of the class imbalance and heterogeneity in epileptic seizure data, quantifying the challenges at multiple levels and demonstrating why conventional approaches often underperform on this task.
We introduce a cascaded deep learning architecture that effectively addresses multi-level imbalance through problem decomposition, class-weighted optimization, and high-confidence filtering between stages.
We provide detailed gradient flow and computational complexity analyses that offer insights into why our approach succeeds where others fail, providing guidance for addressing similar imbalanced classification problems in other domains.
Our results suggest that hierarchical problem decomposition coupled with targeted imbalance mitigation strategies offers a promising approach for biomedical classification tasks characterized by severe class imbalance. The implications extend to other domains with natural hierarchical class structures, such as fault detection, medical diagnosis, and anomaly identification.
The remainder of this paper is organized as follows:
Section 2 details our dataset, preprocessing methods, and cascaded architecture;
Section 3 presents our experimental results;
Section 4 discusses the implications of our findings and limitations; and
Section 5 concludes with future research directions.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}