

Intelligent Teaching Recommendation Model for Practical Discussion Course of Higher Education Based on Naive Bayes Machine Learning and Improved k-NN Data Mining Algorithm

Abstract
1. Introduction
- (1)
- We analyze the research background of “artificial intelligence plus education” and the current status and existing problems of practical teaching methods. In response to these problems, we propose the advantages of the intelligent teaching recommendation model based on naive Bayes machine learning and improved k-NN data mining algorithm.
- (2)
- We construct the student grouping algorithm based on naive Bayes machine learning. Firstly, we establish the training set model for the naive Bayes machine learning algorithm and collect the training dataset from the previous classes. Secondly, we set up a naive Bayes machine learning model to group the students in a class, so that each group of students has the closest interests.
- (3)
- We build a teaching recommendation model based on the improved k-NN data mining algorithm by implementing the class grouping. Firstly, an optimal complete binary encoding tree for the discussion topic is constructed, and the feature attributes of the discussion topic are matched based on the interests of each group of students. The binary encoding tree is established based on the spatial coordinate system of the discussion topic, and the recommendation model is established on the coordinate system.
- (4)
- We design the experiments to validate the proposed algorithm, demonstrating its feasibility from three aspects as detailed in the following sections: “Results and Analysis on the Naive Bayes Grouping”, “Results and Analysis on the Proposed Teaching Recommendation Algorithm”, and “Results and Analysis of the Comparative Experiment”. Compared with the traditional collaborative filtering algorithms, the proposed algorithm has higher accuracy, recall rate, precision, and F1 value.
2. Related Works and the Advantages, Application Purpose, Formulated Requirements, and Constraints of the Proposed Model
2.1. Related Works
2.2. The Advantages, Application Purpose, Formulated Requirements, and Constraints of the Proposed Model
2.2.1. The Innovations and Advantages of the Proposed Model
2.2.2. The Application Purpose, Formulated Requirements, and Constraints of the Proposed Model
- The Application Purpose and Formulated Requirements
- 2.
- The Model Features in Practical Teaching Case
- Primary feature labels of the recommended objects: the designed discussion topic for the course;
- Secondary feature labels of recommended objects: the grouped discussion topics determined by the discussion topic, with each group representing an interest tendency;
- Primary feature labels for students: based on the secondary feature labels of recommended objects, we design the labels that students are interested in, and let the students judge their degree of preference for the labels;
- Student classification labels: corresponding to the secondary feature labels of the recommended objects;
- Discussion contents and feature labels: we further subdivide the group discussion topics into several discussion contents, quantify the labels of the discussion contents, and use them to match the student interest labels.
- Collection and quantification of discussion content labels: we determine the discussion contents based on the discussion topic, then collect discussion content labels, and quantify the labels;
- Collection and quantification of student interest labels: regarding the designed discussion contents of student classification, we collect interest labels and quantify the labels;
- Build the matching model: we construct the matching model between the discussion content labels and the student interest labels to achieve the personalized recommendation.
- 3.
- The Constraints of the Model
3. Methodology
3.1. Class Grouping Algorithm Based on Naive Bayes Machine Learning
- The first step is used to interpret the data collected from the previous classes to build the algorithm.
- The second step is used to interpret the data collected from the current class (a class that will be organized to have a discussion course, and its students will be grouped).
- The third step is used to interpret how the student data in the current class is used in the naive Bayes machine learning algorithm.
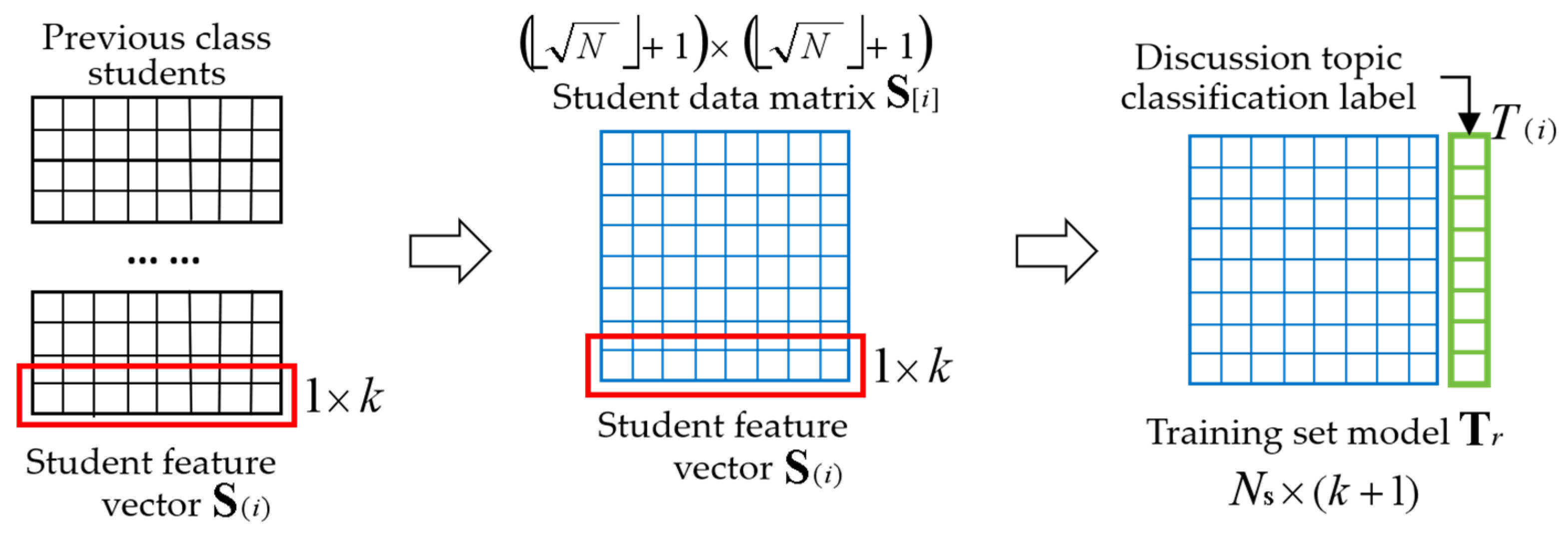
3.1.1. Training Set Model for Naive Bayes Machine Learning Algorithm
3.1.2. Class Grouping Algorithm
3.2. Teaching Recommendation Model Based on Improved k-NN Data Mining Algorithm
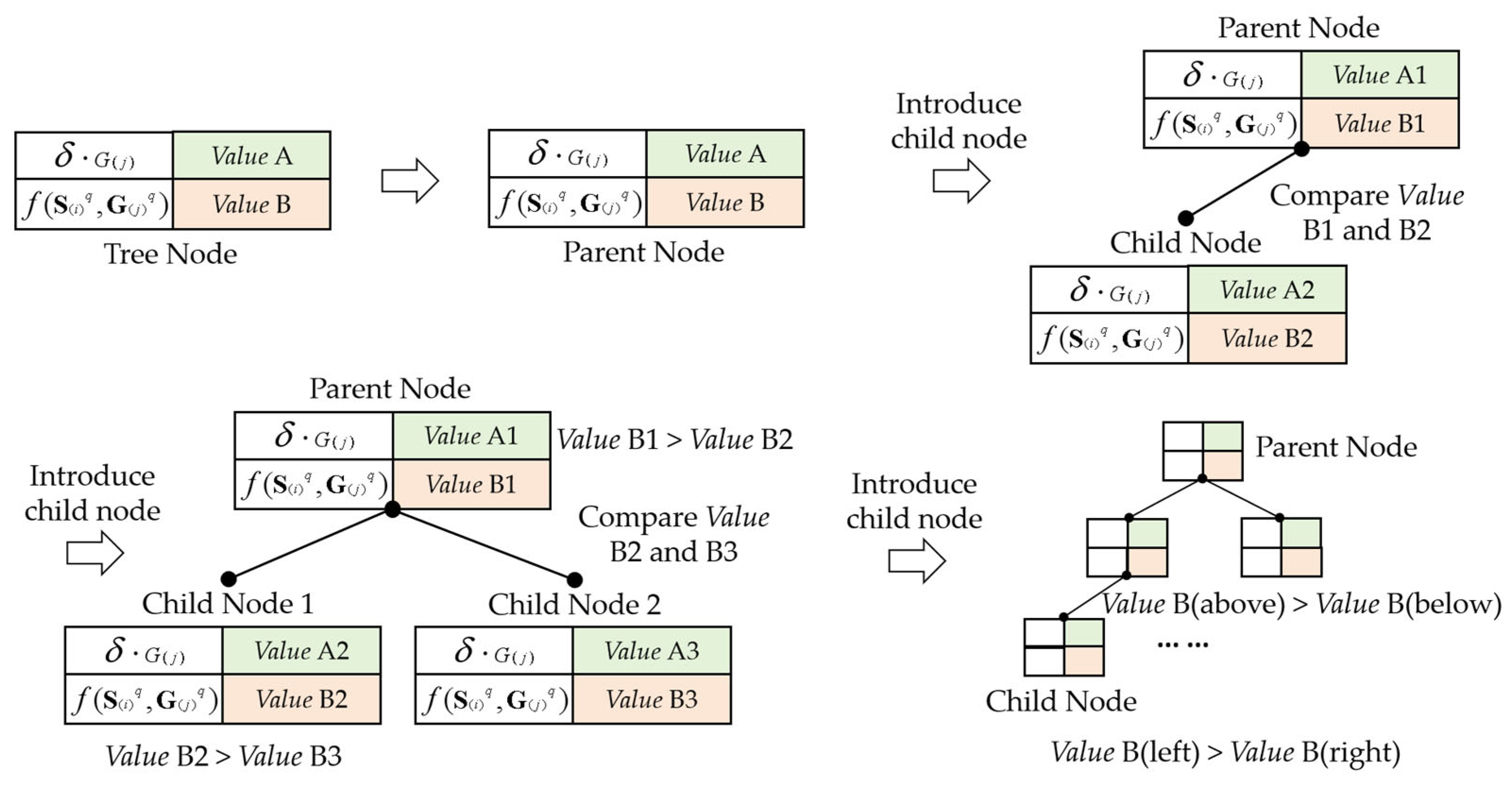
3.2.1. The Modeling of the Complete Binary Encoding Tree for Discussion Topic
3.2.2. Recommendation Model Based on the Improved k-NN Data Mining Algorithm
3.2.3. Improvement of the Constructed k-NN Recommendation Algorithm
4. Experiment and Analysis
4.1. Data Preparation
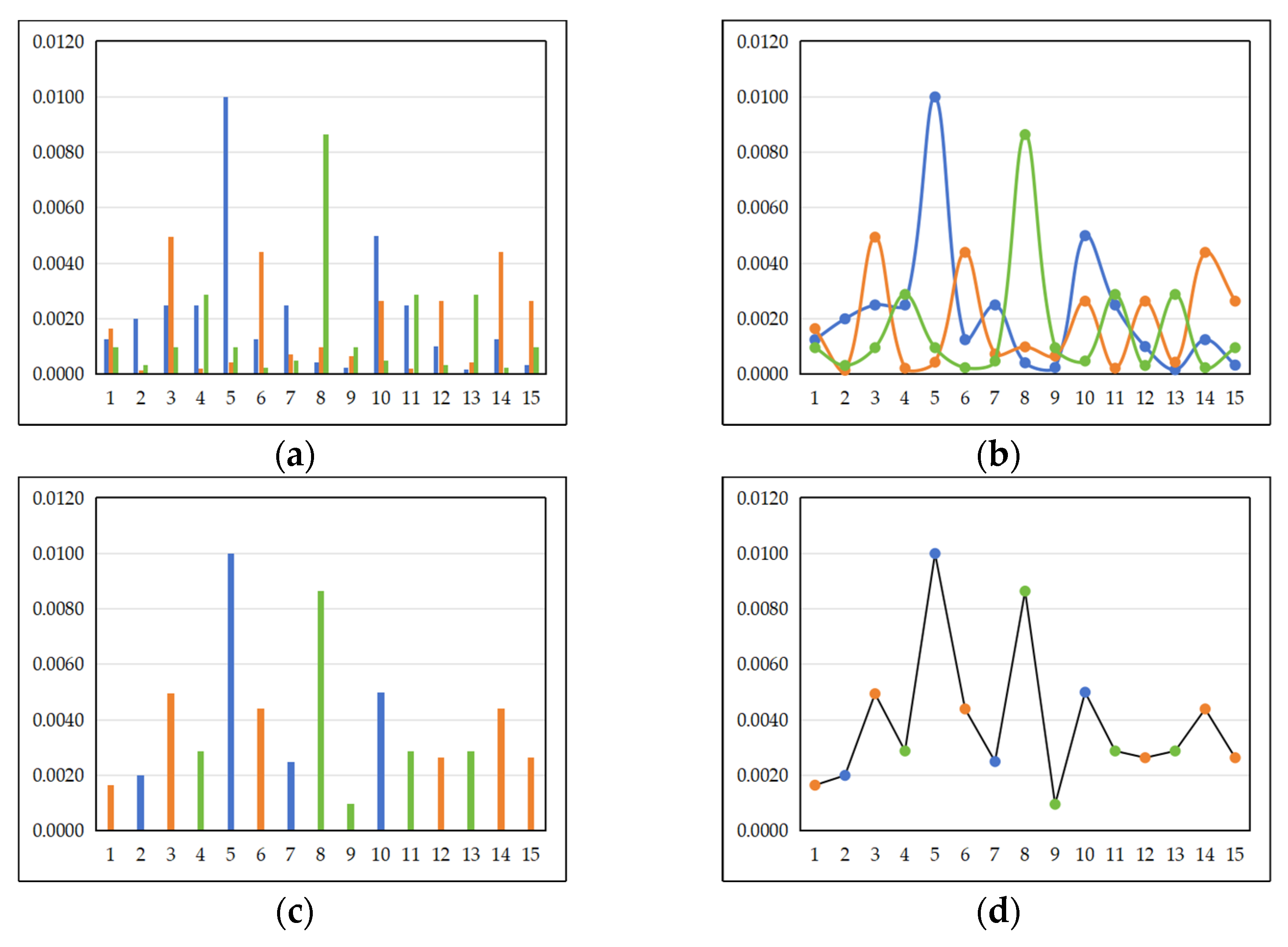
4.2. Results and Analysis on the Naive Bayes Grouping
4.3. Results and Analysis of the Proposed Teaching Recommendation Algorithm
4.4. Results and Analysis of the Comparative Experiment
4.4.1. Testing and Comparison in the Single Dataset (Class E1)
4.4.2. Testing and Comparison in the Multiple-Dataset (Class E2 and Class E3): Robustness Testing
5. Conclusions and Prospects
5.1. Conclusion of the Research Work
5.2. The Practical Applications and Implications of the Proposed Model
5.2.1. The Application Value and Implications
5.2.2. Principles for Conducting Teaching in Practical Applications
5.2.3. The Application Method and Process
- The case: in “4. Experiment and Analysis”, the discussion topic is determined as “Rural Tourism”. The data source comes from the selected students of the previous class.
- The case: in “4.1. Data Preparation”, I-1, I-2, I-3, I-4, and I-5 form the label set A, while T1, T2, and T3 form the label set B.
- The case: in “4.1. Data Preparation”, Table 2 represents the training set model.
- The case: in “4.1. Data Preparation”, Table 3 represents the interest labels of students in the class to be classified.
- The case: the grouping result output in “4.2. Results and Analysis on the Naive Bayes Grouping”.
- The case: the encoding tree result output in Figure 6.
- The case: the result output in Table 9.
5.3. Work Prospect
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations and Mathematical Symbols
| K-NN | K- nearest neighbor |
| UCFA | User-based collaborative filtering recommendation algorithm |
| ICFA | Item-based collaborative filtering recommendation algorithm |
| The sample student | |
| The student feature vector | |
| The classification label for the discussion topic | |
| The student data matrix | |
| The training set model for the naive Bayes machine learning. | |
| The naive Bayes prior probability model | |
| The naive Bayes conditional probability density | |
| The naive Bayes posterior probability model | |
| The feature vector of the student to be classified | |
| The discussion topic feature vector | |
| The quantization vector based on the interests of the individual students | |
| The quantization vector based on the topic features | |
| The discussion topic weight | |
| The discussion topic matching model | |
| The discussion topic spatial coordinate system | |
| The discussion topic spatial coordinates | |
| The optimal complete binary encoding tree model for the discussion topic | |
| The optimal topic vector for the student | |
| The student optimal topic matrix for the student | |
| The discussion topic interest intensity | |
| The discussion topic recommendation vector |
Appendix A
Appendix A.1. Pseudo Code for the Training Set Algorithm for Naive Bayes Machine Learning Model
| Input: Sample set of previous class students: | |
| Output: Training set for naive Bayes machine learning model: | |
| Process: | |
| 1: | Randomly select number of student samples from : {, , …, } |
| 2: | Establish student vector , |
| 3: | Confirm number of attributes for teaching theme |
| 4: | Identify number of discussion topics and label them as classification labels , |
| 5: | Set up dimension vector , elements 1~ store , element stores |
| 6: | Establish a student matrix for the previous class, element is , |
| 7: | For do |
| 8: | For do |
| 9: | Store into , |
| 10: | If then |
| 11: | The remaining elements are stored as 0 |
| 12: | Judge the element of vector |
| 13: | If vector element: then matrix element |
| 14: | If vector element: then matrix element |
| 15: | Note element , count its number |
| 16: | End for |
| 17: | Establish dimension matrix |
| 18: | Define dimension empty matrix |
| 19: | Initialize row , , expand row of vector to |
Appendix A.2. Pseudo Code for the Class Grouping Algorithm Based on Naive Bayes Machine Learning
| Input: Student matrix to be classified: | |
| Output: Student classification: | |
| Process: | |
| 1: | Quantify vector , determine the quantified value of student labels |
| 2: | Equivalently simplify the Bayesian posterior probability model |
| 3: | Assume that student has equal probability for all classes , |
| 4: | Equivalently simplify to calculate |
| 5: | Set equivalently to calculate |
| 6: | Regarding , establish prior probability model of |
| 7: | Note |
| 8: | Initialize , |
| 9: | For do |
| 10: | If then |
| 11: | If then |
| 12: | End for |
| 13: | Calculate |
| 14: | Repeat Traversing |
| 15: | Introduce and quantified label , set up |
| 16: | Construct the conditional probability density |
| 17: | Probabilistic valuation . The is the number of students with labels appearing in the class , is the number of students in class |
| 18: | Introduce disturbance factor , calculate |
| 19: | Sort and output . The related classification is the group for student |
Appendix A.3. Pseudo Code for the Algorithm of the Complete Binary Encoding Tree for Discussion Topic
| Input: Discussion topics of classification , Individual students within the group | |
| Output: Encoding tree for student individual | |
| Process: | |
| 1: | Select individual students from the classification , quantify and output |
| 2: | Regarding the number of discussion topics for classification , quantify and output number of , encode the discussion topic |
| 3: | Determine the tree node structure: |
| 4: | : discussion topic weight: |
| 5: | : discussion topic matching value: |
| 6: | Initialize , encode the discussion topic |
| 7: | For do |
| 8: | Initialize the no. topic , generate the tree node for |
| 9: | Extract , calculate , store into the related of |
| 10: | Extract , calculate , store into the related of |
| 11: | End for |
| 12: | Initialize the complete binary encoding tree , including number of nodes. Traverse all nodes. |
| 13: | For do |
| 14: | Compare , , …, and store them |
| 15: | For any node , its left node meets |
| 16: | For any node , its right node meets: |
| 17: | If current stores the last , then the right node does not exist |
| 18: | If current is not the last , then the right node meets |
| 19: | Any node meets: |
| 20: | ①The stored of corresponds to , and the stored of child nodes and correspond to and , there is ; ② The stored of corresponds to , and the stored of left node corresponds to , the stored of right node corresponds to , there is . |
| 21: | Repeat Stop searching until the traversal is complete |
| 22: | End for |
| 23: | Output individual student encoding tree , with tree nodes for sorting discussion topics |
Appendix A.4. Pseudo Code for the Recommendation Algorithm Based on the Improved k-NN Data Mining
| Input: Classification and students , student interest vector and topic vector , individual student encoding tree | |
| Output: The optimal discussion topic recommended for student classification | |
| Process: | |
| 1: | For do |
| 2: | Generate individual student encoding tree |
| 3: | Output the top number of nodes of each tree |
| 4: | End for |
| 5: | Output the optimal topic vector of student |
| 6: | For do |
| 7: | Take the number of optimal topics from the student coding tree and store them in the dimensional vector |
| 8: | End for |
| 9: | Initialize matrix , counter: |
| 10: | For do |
| 11: | Take element; vector elements ~ are stored into the elements of no. row |
| 12: | |
| 13: | End for |
| 14: | Build a baseline vector containing number of discussion topics , with corresponding storage of for vector element |
| 15: | Scan matrix ; the row is encoded as , the column is encoded as ; note that is the intensity weight of |
| 16: | For row do |
| 17: | For column do |
| 18: | If , then |
| 19: | If , then |
| 20: | End for |
| 21: | End for |
| 22: | Normalize . Output the intensity weight of each element in the vector |
| 23: | Build a complete binary tree , store to nodes in descending order. The top number of and are recommended to the classification |
References
- Huang, H. The cultivation of quality and ability of environmental design professionals in universities under the digital background. Int. Educ. Res. 2025, 8, 25. [Google Scholar] [CrossRef]
- Sunardi, S.; Hermagustiana, I.; Rusmawati, D. Tension between theory and practice in literature courses at university-based educational institutions: Strategies and approaches. J. Lang. Teach. Res. 2025, 16, 666–675. [Google Scholar] [CrossRef]
- Wu, S.Y. Research on the integration of practical teaching in introduction courses under the background of inter-school cooperation. Educ. Insights 2025, 2, 45–51. [Google Scholar]
- Gong, Y.F. Innovation and practice of translation practice course teaching from the perspective of interdisciplinary integration. J. Hum. Arts Soc. Sci. 2025, 9, 103–108. [Google Scholar]
- Meng, Y.R.; Cui, Y.; Aryadoust, V. EFL teachers’ formative assessment literacy and developmental Trajectories: A comparative study of face-to-face and blended teaching modes. System 2025, 132, 103694. [Google Scholar] [CrossRef]
- Loureiro, A.; Rodrigues, M.O. Student grouping: Investigating a socio-educational practice in a public school in Portugal. Soc. Sci. 2024, 13, 141. [Google Scholar] [CrossRef]
- Fu, L.M. Construction of Vocational Education Quality Evaluation Index System from the Perspective of Digital Transformation Based on the Analytic Hierarchy Process of Higher Vocational Colleges in Hainan Province, China. J. Contemp. Educ. Res. 2025, 9, 282–289. [Google Scholar] [CrossRef]
- Wang, J.Y. Issues and Improvement Strategies in Group Teaching of Instrumental Performance Courses in Higher Normal Universities. Int. J. New Dev. Educ. 2024, 6, 31–36. [Google Scholar]
- Caskurlu, S.; Yalçın, Y.; Hur., J.; Shi, H.; Klein, J. Data-Driven Decision-Making in Instructional Design: Instructional Designers’ Practices and Strategies. TechTrends 2025, prepublish. [Google Scholar] [CrossRef]
- Ashcroft, J.; Warren, P.; Weatherby, T.; Barclay, S.; Kemp, L.; Davies, R.J.; Hook, C.E.; Fistein, E.; Soilleux, E. Using a scenario-based approach to teaching professionalism to medical students: Course description and evaluation. JMIR Med. Educ. 2021, 7, e26667. [Google Scholar] [CrossRef] [PubMed]
- Rizi, C.E.; Gholami, A.; Koulaynejad, J. The compare the affect instruction in experimental and practical approach (with emphasis on play) to verbal approach on mathematics educational progress. Procedia—Soc. Behav. Sci. 2011, 15, 2192–2195. [Google Scholar] [CrossRef]
- Porubän, J.; Nosál’, M.; Sulír, M.; Chodarev, S. Teach Programming Using Task-Driven Case Studies: Pedagogical Approach, Guidelines, and Implementation. Computers 2024, 13, 221. [Google Scholar] [CrossRef]
- Heidari-Shahreza, M.A. Pedagogy of play: Insights from playful learning for language learning. Dis. Edu. 2024, 3, 157. [Google Scholar] [CrossRef]
- Johnson, O.; Olukayode, Y.A.; Abosede, A.A.; Homero, M.; Gao, X.H.; Kereshmeh, A. Construction practice knowledge for complementing classroom teaching during site visits. Smart Sustain. Built Environ. 2025, 14, 119–139. [Google Scholar]
- Wira, G.; Oke, H.; Rizkina, A.P.; Direstu, A. Updating aircraft maintenance education for the modern era: A new approach to vocational higher education. High. Educ. Ski. Work.-Based Learn. 2025, 15, 46–61. [Google Scholar]
- Wilkinson, S.D.; Penney, D. Students’ preferences for setting and/or mixed-ability grouping in secondary school physical education in England. Br. Edu. Res. J. 2024, 50, 1804–1830. [Google Scholar] [CrossRef]
- Ren, C.J. Immersive E-learning mode application in Chinese language teaching system based on big data recommendation algorithm. Entertain. Comput. 2025, 52, 100774. [Google Scholar] [CrossRef]
- Fu, L.W.; Mao, L.J. Application of personalized recommendation algorithm based on sensor networks in Chinese multimedia teaching system. Meas. Sens. 2024, 33, 101167. [Google Scholar] [CrossRef]
- Yin, C.J. Application of recommendation algorithms based on social relationships and behavioral characteristics in music online teaching. Int. J. Web-Based Learn. Teach. Technol. 2024, 19, 1–18. [Google Scholar] [CrossRef]
- Liu, Y. The application of digital multimedia technology in the innovative mode of English teaching in institutions of higher education. Appl. Math. Nonlinear Sci. 2024, 9. [Google Scholar] [CrossRef]
- Zhang, Y.Y.; Guo, H.Y. Research on a recommendation model for sustainable innovative teaching of Chinese as a foreign language based on the data mining algorithm. Int. J. Knowl.-Based Dev. 2024, 14, 1–18. [Google Scholar] [CrossRef]
- Ying, F. Interactive AI Virtual Teaching Resource Intelligent Recommendation Algorithm Based on Similarity Measurement on the Internet of Things Platform. J. Test. Eval. 2024, 52, 1650–1662. [Google Scholar]
- Liu, Q.L. Construction and application of personalised classroom teaching model of college English combined with recommendation algorithm. Appl. Math. Nonlinear Sci. 2024, 9. [Google Scholar] [CrossRef]
- Lu, H. Personalized music teaching service recommendation based on sensor and information retrieval technology. Meas. Sens. 2024, 33, 101207. [Google Scholar] [CrossRef]
- Nebojsa, G.; Tatjana, S.; Dragan, D. Design and implementation of discrete Jaya and discrete PSO algorithms for automatic collaborative learning group composition in an e-learning system. Appl. Soft Comput. 2022, 129, 109611. [Google Scholar]
- Baig, D.; Nurbakova, D.; Mbaye, B.; Calabretto, S. Knowledge graph-based recommendation system for personalized e-Learning. In Proceedings of UMAP Adjunct ‘24: Adjunct Proceedings of the 32nd ACM Conference on User Modeling, Adaptation and Personalization, Cagliari, Italy, 28 June 2024; pp. 561–566. [Google Scholar]
- Sundaresan, B.; Raja, M.; Balachandran, S. Design and analysis of a cluster-based intelligent hybrid recommendation system for e-learning applications. Mathematics 2021, 9, 197. [Google Scholar]
- Nachida, R.; Benkessirat, S.; Boumahdi, F. Enhancing collaborative filtering with game theory for educational recommendations: The Edu-CF-GT Approach. J. Web Eng. 2025, 24, 57–78. [Google Scholar] [CrossRef]
- Bustos López, M.; Alor-Hernández, G.; Sánchez-Cervantes, J.L.; Paredes-Valverde, M.A.; Salas-Zárate, M.d.P.; Bickmore, T. EduRecomSys: An Educational Resource Recommender System Based on Collaborative Filtering and Emotion Detection. Interact. Comput. 2020, 32, 407–432. [Google Scholar] [CrossRef]
- Amin, S.; Uddin, M.I.; Mashwani, W.K.; Alarood, A.A.; Alzahrani, A.; Alzahrani, A.O. Developing a personalized e-learning and MOOC recommender system in IoT-enabled smart education. IEEE Access 2023, 11, 136437–136455. [Google Scholar] [CrossRef]
- Lin, P.-H.; Chen, S.-Y. Design and evaluation of a deep learning recommendation based augmented reality system for teaching programming and computational thinking. IEEE Access 2020, 8, 45689–45699. [Google Scholar] [CrossRef]
- Chen, W.Q.; Yang, T. A recommendation system of personalized resource reliability for online teaching system under large-scale user access. Mob. Netw. Appl. 2023, 28, 983–994. [Google Scholar] [CrossRef]
- Qu, Z.H. Personalized recommendation system for English teaching resources in colleges and universities based on collaborative recommendation. Appl. Math. Nonlinear Sci. 2024, 9. [Google Scholar] [CrossRef]
- Wang, T.Y.; Ge, D. Research on recommendation system of online Chinese learning resources based on multiple collaborative filtering algorithms (RSOCLR). Int. J. Hum.-Comput. Interact. 2025, 41, 177. [Google Scholar] [CrossRef]
- Luo, Y.L.; Lu, C.L. TF-IDF combined rank factor Naive Bayesian algorithm for intelligent language classification recommendation systems. Syst. Soft Comp. 2024, 6, 200136. [Google Scholar] [CrossRef]
- Soheli, F. Classification of academic performance for university research evaluation by implementing modified Naive Bayes algorithm. Procedia Comp. Sci. 2021, 194, 224–228. [Google Scholar]
- Ahmad, K.; Ali, B.M.; Hamid, B. A distributed density estimation algorithm and its application to naive Bayes classification. App. Soft Comp. 2020, prepublish. [Google Scholar]
- Li, Q.N.; Li, T.H. Research on the application of Naive Bayes and support vector machine algorithm on exercises classification. J. Phys. Conf. Ser. 2020, 1437, 012071. [Google Scholar] [CrossRef]
- Gao, H.Y.; Zeng, X.; Yao, C.H. Application of improved distributed naive Bayesian algorithms in text classification. J. Supercomp. 2019, 75, 5831–5847. [Google Scholar] [CrossRef]
- Wang, D.Q.; Yang, Q.; Wu, X.L.; Wu, Z.Z.; Zhang, J.W.; He, S.X. Multi-behavior enhanced group recommendation for smart educational services. Discov. Comp. 2025, 28, 49. [Google Scholar] [CrossRef]
- Gong, Y.J.; Shen, X.Z. An algorithm for distracted driving recognition based on pose features and an improved KNN. Electronics 2024, 13, 1622. [Google Scholar] [CrossRef]
- Bahrani, P.; Bidgoli, B.M.; Parvin, H.; Mirzarezaee, M.; Keshavarz, A.J. A new improved KNN-based recommender system. J. Supercomput. 2024, 80, 800–834. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Recommendation Model/Method | Discussion (Teaching) Topic | Group Discussion (Teaching) Topic | Student Interest Label | Student Classification Label | Group Discussion (Teaching) Sub-Topic |
|---|---|---|---|---|---|
| The constructed model | Design the overall topic for the teaching content | Design each group topic based on the grouping result | Design student interest labels based on each topic | Design student classification labels based on grouping result | Further refine the discussion content for each group based on their respective topics |
| Literature [17] | Design the overall topic for the teaching content | No user classification mechanism | Obtain users’ interest labels | No user classification mechanism | Efficiently screen required learning content and data |
| Literature [18] | Design the overall topic for the teaching content | No user classification mechanism | Obtain users’ interest labels | No user classification mechanism | There is no mechanism to refine the teaching topic |
| Literature [19] | Design the overall topic for the teaching content | No user classification mechanism | Obtain users’ interest labels and behavior labels | No user classification mechanism | Teaching labels can be further subdivided |
| Literature [20] | Design the overall topic for the teaching content | The experimental group and the control group use the same teaching content | Obtain users’ interest labels and behavior labels | The experimental group and the control group use the same teaching content | Efficiently screen required learning content and data |
| Literature [21] | Design the overall topic for the teaching content | No user classification mechanism | Mine user interest’s similarity | No user classification mechanism | Recommend different teaching resources for different learners |
| Literature [22] | Design the overall topic for the teaching content | Classify learners and identify learning resources | Explore learners’ behavioral patterns | Classify learners and identify learning resources | Recommend different teaching resources for different learners |
| Literature [23] | Design the overall topic for the teaching content | No user classification mechanism, conducting research on individual learners | Obtain student portraits and interests | No user classification mechanism, conducting research on individual learners | Implement the personalized teaching content recommendations |
| Literature [24] | Design the overall topic for the teaching content | Personalized recommendations for individual learners | Establish interest labels based on users’ preference | Personalized recommendations for individual learners | Realize personalized recommendation of teaching resources |
| Literature [25] | Design the overall topic for the teaching content | Automatically create student interest groups and recommend teaching content based on group recommendations | Obtain students’ interest labels | Automatically create student interest groups and recommend teaching content based on group recommendations | Implement teaching content recommendations for different groups of students |
| Literature [26] | Design the overall topic for the teaching content | Personalized recommendations for individual learners | Obtain student interests based on knowledge graphs | Personalized recommendations for individual learners | Realize personalized recommendation of teaching resources |
| Literature [27] | Design the overall topic for the teaching content | Automatically analyze and learn learners’ styles and features to determine different topics | Obtain users’ interest labels | Automatically analyze and learn learners’ styles and features to determine different topics | Recommend teaching contents for students in different groups |
| Literature [28] | Design the overall topic for the teaching content | No user classification mechanism, conducting research on individual learners | Obtain users’ interest labels | No user classification mechanism, conducting research on individual learners | Implement the personalized teaching content recommendations |
| Literature [29] | Design the overall topic for the teaching content | No user classification mechanism, conducting research on individual learners | Obtain users’ interest labels | No user classification mechanism, conducting research on individual learners | Implement the personalized teaching content recommendations |
| Literature [30] | Design the overall topic for the teaching content | No user classification mechanism, conducting research on individual learners | Obtain users’ interest labels | No user classification mechanism, conducting research on individual learners | Implement the personalized teaching content recommendations |
| Literature [31] | Design the overall topic for the teaching content | Divide students into two groups and recommend them by using different methods | Obtain interest data from different groups of students | Divide students into two groups and recommend them by using different methods | Recommend different teaching resources for different learners |
| Literature [32] | Design the overall topic for the teaching content | No grouping, used for recommendation in large-scale user base | Establish a thematic interest model and explore students’ interests | No grouping, used for recommendation in large-scale user base | Implement the personalized teaching content recommendations |
| Literature [33] | Design the overall topic for the teaching content | No user classification mechanism | Explore and mine user interests | No user classification mechanism | Recommend different teaching resources for different learners |
| Literature [34] | Design the overall topic for the teaching content | No user classification mechanism | Explore and mine user interests and demands | No user classification mechanism | Recommend different teaching resources for different learners |
| I-1 | I-2 | I-3 | I-4 | I-5 | I-1 | I-2 | I-3 | I-4 | I-5 | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LL | FL | FL | LL | MFL | T1 | LL | MFL | MFL | MFL | FL | T2 | ||
| FL | MFL | MFL | MFL | FL | T1 | MFL | MFL | FL | LL | MFL | T2 | ||
| FL | MFL | B | MFL | FL | T1 | FL | FL | LL | FL | MFL | T2 | ||
| LL | MFL | LL | MFL | FL | T1 | FL | FL | LL | MFL | LL | T2 | ||
| MFL | MFL | FL | MFL | LL | T1 | LL | FL | FL | MFL | LL | T2 | ||
| FL | FL | FL | MFL | MFL | T1 | MFL | LL | MFL | MFL | LL | T3 | ||
| LL | LL | MFL | FL | FL | T1 | FL | LL | MFL | FL | LL | T3 | ||
| MFL | FL | LL | FL | FL | T2 | LL | MFL | LL | MFL | FL | T3 | ||
| MFL | FL | FL | FL | LL | T2 | MFL | LL | FL | MFL | FL | T3 | ||
| FL | LL | LL | FL | FL | T2 | MFL | FL | FL | LL | MFL | T3 |
| I-1 | I-2 | I-3 | I-4 | I-5 | I-1 | I-2 | I-3 | I-4 | I-5 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| FL | FL | MFL | MFL | LL | MFL | MFL | FL | LL | LL | ||
| LL | MFL | MFL | LL | FL | FL | MFL | LL | MFL | FL | ||
| FL | FL | FL | MFL | LL | LL | LL | MFL | MFL | FL | ||
| LL | LL | MFL | MFL | FL | FL | MFL | FL | FL | LL | ||
| LL | MFL | MFL | MFL | FL | MFL | LL | MFL | FL | FL | ||
| FL | FL | LL | MFL | MFL | FL | FL | LL | MFL | MFL | ||
| LL | FL | MFL | MFL | MFL | MFL | MFL | FL | FL | LL | ||
| MFL | LL | FL | MFL | LL |
| Classification | ||||||
|---|---|---|---|---|---|---|
| Quantization interval | ||||||
“Rural Preservation” | : Leisure Walk | : Physical Exercise | : Medical Health Preservation | : Swimming Fitness | : Cycling Experience | : Climbing Mountain Experience |
“Rural Cuisine” | : Food Making | : Food Tasting | : Food Science Popularization | : Food Expo | : Food Festival | : Food and Health Preservation |
“Rural Farming” | : Picking Experience | : Fertilization Experience | : Fishing Experience | : Planting Experience | : Harvesting Experience | : Drying Experience |
| Emei Yequan Valley | Niuhua Ancient Town | Jiajiang Fengshan, New Year’s Painting Village | Suji Ancient Town | Bagou Ancient Town | Zi Ai Tianyuan Family Farm | ||
| Jiayang Suoluo Lake | Suji Ancient Town | Jia’e Tea Valley | Kashasha Rural Resort | Qingxi Town | Tianye Farm | ||
| Luomu Ancient Town | Muyu Mountain Villa | Qinghe Village | Fanshen Village, Wutongqiao | Xiba Ancient Town | Tangjiaba Village | ||
| Pingqiang Xiaosanxia | Jinying Mountain Villa | Guihuaqiao Town, Agricultural Park | Shuangshan Village, Zhenxi Town | Huatou Ancient Town | Tianfu Sightseeing Tea Garden | ||
| Futian Village | Lianggou, Gaoqiao Town | Xinhua Village | Black Bamboo Gully | Luocheng Ancient Town | Si’e Mountain Terraced Fields |
| 1.249 × 10−3 | 1.648 × 10−3 | 0.960 × 10−3 | 0.249 × 10−3 | 0.659 × 10−3 | 0.960 × 10−3 | ||
| 2.000 × 10−3 | 0.146 × 10−3 | 0.320 × 10−3 | 4.998 × 10−3 | 2.637 × 10−3 | 0.480 × 10−3 | ||
| 2.499 × 10−3 | 4.944 × 10−3 | 0.960 × 10−3 | 2.499 × 10−3 | 0.220 × 10−3 | 2.880 × 10−3 | ||
| 2.499 × 10−3 | 0.220 × 10−3 | 2.880 × 10−3 | 1.000 × 10−3 | 2.637 × 10−3 | 0.320 × 10−3 | ||
| 9.996 × 10−3 | 0.439 × 10−3 | 0.960 × 10−3 | 0.167 × 10−3 | 0.439 × 10−3 | 2.880 × 10−3 | ||
| 1.249 × 10−3 | 4.395 × 10−3 | 0.240 × 10−3 | 1.249 × 10−3 | 4.395 × 10−3 | 0.240 × 10−3 | ||
| 2.499 × 10−3 | 0.732 × 10−3 | 0.480 × 10−3 | 0.333 × 10−3 | 2.637 × 10−3 | 0.960 × 10−3 | ||
| 0.416 × 10−3 | 0.989 × 10−3 | 8.640 × 10−3 |
| Class | Degree of Satisfaction | Grouping Satisfaction | Interest Matching Satisfaction | Team Collaboration Satisfaction | Discussion Process Satisfaction |
|---|---|---|---|---|---|
| E1 | very satisfied and satisfied | 0.867 | 0.867 | 0.800 | 0.800 |
| dissatisfied | 0.133 | 0.133 | 0.200 | 0.200 | |
| E2 | very satisfied and satisfied | 0.800 | 0.667 | 0.667 | 0.600 |
| dissatisfied | 0.200 | 0.333 | 0.333 | 0.400 | |
| E3 | very satisfied and satisfied | 0.600 | 0.533 | 0.667 | 0.600 |
| dissatisfied | 0.400 | 0.467 | 0.333 | 0.400 |
| Class | Grouping Accuracy | Interest Matching Accuracy | Team Collaboration Accuracy | Discussion Process Accuracy |
|---|---|---|---|---|
| E1 | 0.667 | 0.600 | 0.533 | 0.667 |
| E2 | 0.533 | 0.400 | 0.467 | 0.400 |
| E3 | 0.400 | 0.333 | 0.400 | 0.333 |
| 0.150 | 0.150 | 0.050 | 0.150 | 0.100 | 0.050 | 0.050 | 0.050 | 0.150 | 0.100 | |
| 0.100 | 0.033 | 0.033 | 0.067 | 0.133 | 0.100 | 0.133 | 0.200 | 0.100 | 0.100 | |
| 0.160 | 0.000 | 0.160 | 0.120 | 0.120 | 0.040 | 0.000 | 0.120 | 0.080 | 0.200 | |
| 0.167 | 0.125 | 0.042 | 0.125 | 0.083 | 0.083 | 0.125 | 0.042 | 0.125 | 0.083 | |
| 0.083 | 0.056 | 0.028 | 0.083 | 0.111 | 0.083 | 0.111 | 0.167 | 0.139 | 0.139 | |
| 0.133 | 0.000 | 0.167 | 0.167 | 0.133 | 0.033 | 0.000 | 0.133 | 0.067 | 0.167 | |
| 0.143 | 0.107 | 0.071 | 0.107 | 0.107 | 0.071 | 0.143 | 0.071 | 0.107 | 0.071 | |
| 0.095 | 0.048 | 0.048 | 0.095 | 0.119 | 0.071 | 0.143 | 0.143 | 0.119 | 0.119 | |
| 0.114 | 0.057 | 0.143 | 0.143 | 0.114 | 0.086 | 0.029 | 0.114 | 0.057 | 0.143 | |
| 0.125 | 0.125 | 0.063 | 0.094 | 0.125 | 0.063 | 0.125 | 0.094 | 0.125 | 0.063 | |
| 0.104 | 0.063 | 0.063 | 0.104 | 0.104 | 0.083 | 0.125 | 0.125 | 0.104 | 0.125 | |
| 0.100 | 0.050 | 0.125 | 0.125 | 0.125 | 0.100 | 0.050 | 0.125 | 0.075 | 0.125 | |
| PRA | 0.300 | 0.400 | 0.500 | 0.500 | |
| 0.233 | 0.267 | 0.450 | 0.300 | ||
| 0.260 | 0.300 | 0.300 | 0.500 | ||
| UCFA | 0.200 | 0.350 | 0.500 | 0.475 | |
| 0.217 | 0.250 | 0.417 | 0.300 | ||
| 0.200 | 0.220 | 0.300 | 0.480 | ||
| ICFA | 0.250 | 0.350 | 0.450 | 0.425 | |
| 0.167 | 0.217 | 0.383 | 0.283 | ||
| 0.180 | 0.240 | 0.260 | 0.480 | ||
| PRA | 0.600 | 0.667 | 0.714 | 0.625 | |
| 0.467 | 0.444 | 0.643 | 0.594 | ||
| 0.520 | 0.500 | 0.429 | 0.531 | ||
| UCFA | 0.400 | 0.583 | 0.714 | 0.375 | |
| 0.433 | 0.417 | 0.595 | 0.375 | ||
| 0.400 | 0.367 | 0.429 | 0.354 | ||
| ICFA | 0.500 | 0.583 | 0.643 | 0.625 | |
| 0.333 | 0.361 | 0.548 | 0.600 | ||
| 0.360 | 0.400 | 0.371 | 0.600 | ||
| Average | ||||||
| 33.33% | 12.50% | 0.00% | 5.00% | 12.71% | ||
| 6.87% | 6.37% | 7.33% | 0.00% | 5.14% | ||
| 23.08% | 26.67% | 0.00% | 4.00% | 13.44% | ||
| 16.67% | 12.50% | 10.00% | 15.00% | 13.54% | ||
| 28.33% | 18.73% | 14.89% | 5.67% | 16.90% | ||
| 30.77% | 20.00% | 13.33% | 4.00% | 17.03% |
| Average | ||||||
| 33.33% | 12.59% | 0.00% | 4.96% | 12.72% | ||
| 7.28% | 6.08% | 7.47% | 0.00% | 5.21% | ||
| 23.08% | 26.60% | 0.00% | 4.00% | 13.42% | ||
| 16.67% | 12.59% | 9.94% | 15.04% | 13.56% | ||
| 28.69% | 18.69% | 14.77% | 5.60% | 16.94% | ||
| 30.77% | 20.00% | 13.52% | 4.00% | 17.07% |
| Class 1—E2 | Class 2—E3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PRA | 0.250 | 0.350 | 0.300 | 0.600 | PRA | 0.275 | 0.350 | 0.575 | 0.600 | ||
| 0.283 | 0.350 | 0.500 | 0.700 | 0.267 | 0.283 | 0.300 | 0.500 | ||||
| 0.400 | 0.500 | 0.600 | 0.600 | 0.300 | 0.400 | 0.600 | 0.700 | ||||
| UCFA | 0.225 | 0.325 | 0.300 | 0.325 | UCFA | 0.250 | 0.300 | 0.450 | 0.425 | ||
| 0.200 | 0.267 | 0.400 | 0.300 | 0.233 | 0.267 | 0.267 | 0.317 | ||||
| 0.200 | 0.260 | 0.280 | 0.400 | 0.220 | 0.260 | 0.320 | 0.420 | ||||
| ICFA | 0.250 | 0.300 | 0.300 | 0.325 | ICFA | 0.225 | 0.325 | 0.500 | 0.300 | ||
| 0.183 | 0.217 | 0.267 | 0.283 | 0.200 | 0.233 | 0.267 | 0.300 | ||||
| 0.180 | 0.260 | 0.260 | 0.400 | 0.220 | 0.260 | 0.280 | 0.420 | ||||
| Class 1—E2 | Class 2—E3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PRA | 0.500 | 0.583 | 0.429 | 0.750 | PRA | 0.550 | 0.583 | 0.821 | 0.750 | ||
| 0.567 | 0.583 | 0.714 | 0.875 | 0.533 | 0.472 | 0.429 | 0.625 | ||||
| 0.800 | 0.833 | 0.857 | 0.750 | 0.600 | 0.667 | 0.857 | 0.875 | ||||
| UCFA | 0.450 | 0.542 | 0.429 | 0.344 | UCFA | 0.500 | 0.500 | 0.643 | 0.531 | ||
| 0.400 | 0.444 | 0.571 | 0.375 | 0.467 | 0.444 | 0.381 | 0.396 | ||||
| 0.400 | 0.433 | 0.400 | 0.500 | 0.440 | 0.433 | 0.457 | 0.525 | ||||
| ICFA | 0.500 | 0.500 | 0.429 | 0.406 | ICFA | 0.450 | 0.542 | 0.714 | 0.375 | ||
| 0.367 | 0.361 | 0.381 | 0.354 | 0.400 | 0.389 | 0.381 | 0.375 | ||||
| 0.360 | 0.433 | 0.371 | 0.500 | 0.440 | 0.433 | 0.400 | 0.525 | ||||
| Class 1—E2 | Class 2—E3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PRA | 0.714 | 0.778 | 0.667 | 0.857 | PRA | 0.647 | 0.778 | 0.852 | 0.774 | ||
| 0.895 | 0.581 | 0.833 | 0.875 | 0.696 | 0.586 | 0.514 | 0.682 | ||||
| 0.833 | 0.833 | 0.882 | 0.789 | 0.600 | 0.714 | 0.882 | 0.875 | ||||
| UCFA | 0.563 | 0.650 | 0.500 | 0.731 | UCFA | 0.556 | 0.700 | 0.833 | 0.739 | ||
| 0.500 | 0.533 | 0.632 | 0.486 | 0.538 | 0.552 | 0.432 | 0.413 | ||||
| 0.625 | 0.542 | 0.609 | 0.645 | 0.579 | 0.542 | 0.552 | 0.656 | ||||
| ICFA | 0.625 | 0.571 | 0.444 | 0.520 | ICFA | 0.529 | 0.684 | 0.741 | 0.500 | ||
| 0.579 | 0.520 | 0.533 | 0.425 | 0.500 | 0.424 | 0.500 | 0.563 | ||||
| 0.450 | 0.591 | 0.481 | 0.625 | 0.478 | 0.542 | 0.424 | 0.724 | ||||
| Class 1—E2 | Class 2—E3 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PRA | 0.588 | 0.667 | 0.522 | 0.800 | PRA | 0.595 | 0.667 | 0.836 | 0.762 | ||
| 0.694 | 0.582 | 0.769 | 0.875 | 0.604 | 0.523 | 0.468 | 0.652 | ||||
| 0.816 | 0.833 | 0.869 | 0.769 | 0.600 | 0.690 | 0.869 | 0.875 | ||||
| UCFA | 0.500 | 0.591 | 0.462 | 0.468 | UCFA | 0.527 | 0.583 | 0.726 | 0.618 | ||
| 0.444 | 0.484 | 0.600 | 0.423 | 0.500 | 0.492 | 0.405 | 0.404 | ||||
| 0.488 | 0.481 | 0.483 | 0.563 | 0.500 | 0.481 | 0.500 | 0.583 | ||||
| ICFA | 0.556 | 0.533 | 0.436 | 0.456 | ICFA | 0.486 | 0.605 | 0.727 | 0.429 | ||
| 0.449 | 0.426 | 0.444 | 0.386 | 0.444 | 0.406 | 0.432 | 0.450 | ||||
| 0.400 | 0.500 | 0.419 | 0.556 | 0.458 | 0.481 | 0.412 | 0.609 | ||||
| Class 1—Average optimization degree | |||||
| 15.74% | 17.79% | 19.34% | 19.84% | ||
| 32.55% | 32.62% | 30.25% | 31.62% | ||
| 46.17% | 46.17% | 27.28% | 38.41% | ||
| 15.03% | 15.03% | 27.96% | 21.25% | ||
| 44.88% | 44.88% | 33.31% | 40.06% | ||
| 48.25% | 48.27% | 35.32% | 42.61% | ||
| Class 2—Average optimization degree | |||||
| 18.57% | 18.55% | 7.71% | 14.02% | ||
| 16.50% | 16.54% | 20.97% | 18.66% | ||
| 37.08% | 37.11% | 22.51% | 30.70% | ||
| 22.09% | 22.06% | 19.69% | 21.09% | ||
| 23.44% | 23.43% | 18.99% | 21.88% | ||
| 38.75% | 38.77% | 28.40% | 34.24% | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Guo, L.; Li, R.; Liu, L.; Pan, J. Intelligent Teaching Recommendation Model for Practical Discussion Course of Higher Education Based on Naive Bayes Machine Learning and Improved k-NN Data Mining Algorithm. Information 2025, 16, 512. https://doi.org/10.3390/info16060512
Zhou X, Guo L, Li R, Liu L, Pan J. Intelligent Teaching Recommendation Model for Practical Discussion Course of Higher Education Based on Naive Bayes Machine Learning and Improved k-NN Data Mining Algorithm. Information. 2025; 16(6):512. https://doi.org/10.3390/info16060512
Chicago/Turabian StyleZhou, Xiao, Ling Guo, Rui Li, Ling Liu, and Juan Pan. 2025. "Intelligent Teaching Recommendation Model for Practical Discussion Course of Higher Education Based on Naive Bayes Machine Learning and Improved k-NN Data Mining Algorithm" Information 16, no. 6: 512. https://doi.org/10.3390/info16060512
APA StyleZhou, X., Guo, L., Li, R., Liu, L., & Pan, J. (2025). Intelligent Teaching Recommendation Model for Practical Discussion Course of Higher Education Based on Naive Bayes Machine Learning and Improved k-NN Data Mining Algorithm. Information, 16(6), 512. https://doi.org/10.3390/info16060512