
A Systematic Review of Large Language Models in Medical Specialties: Applications, Challenges and Future Directions

 , ,
, ,  , , , and
, , , and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Search Strategy
| Listing 1. Categories and terms applied in the search queries. |
| Search concepts combined using “AND” |
|
| Search terms combined using “OR” |
|
2.2. Inclusion and Exclusion Criteria
2.3. Data Extraction
2.4. Quality Assessment
3. Results
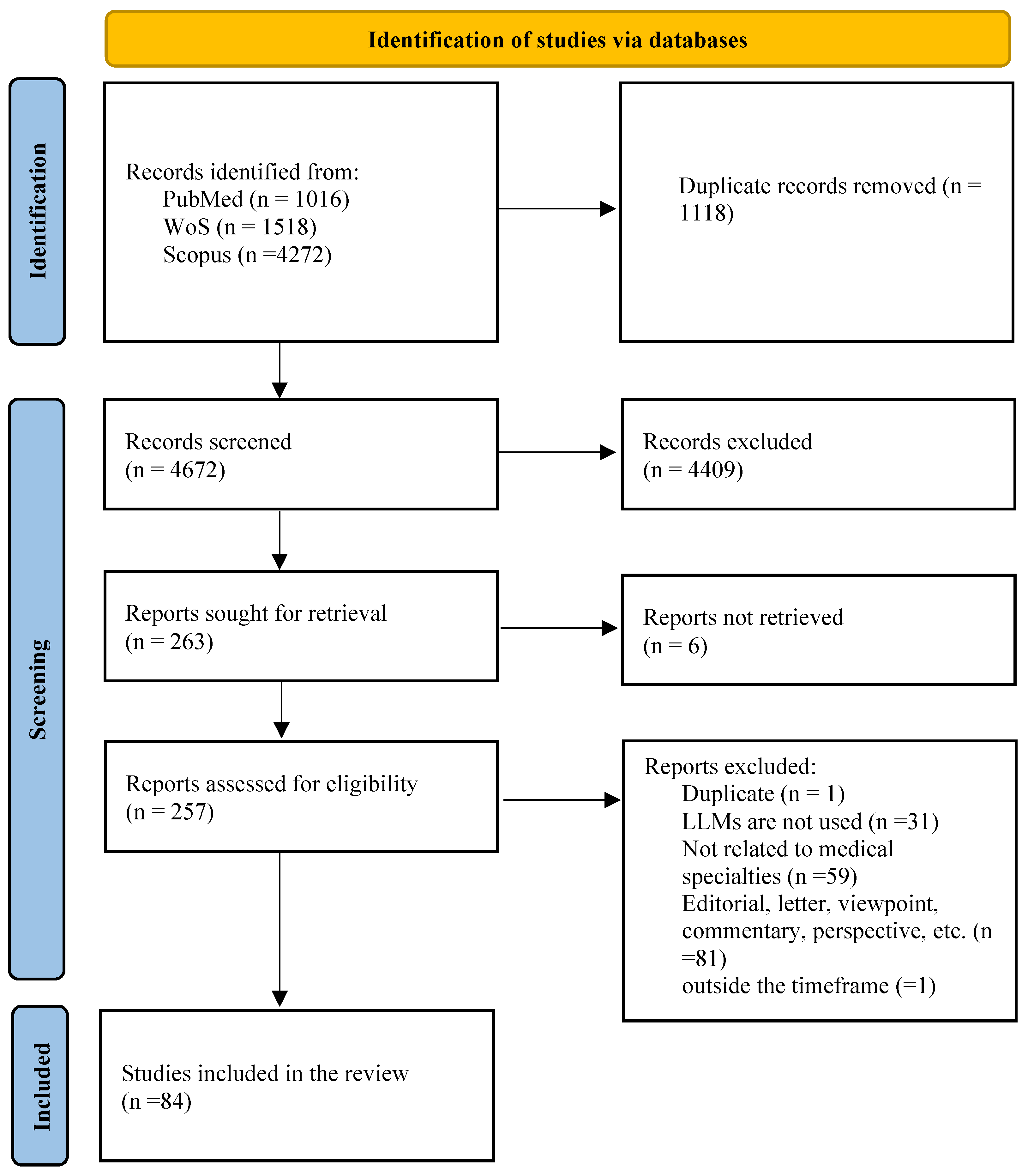
3.1. Study Selection
3.2. Study Characteristics
3.3. Medical Specialties
3.4. Application of LLMs
3.5. LLMs Used
3.6. Type of LLMs
3.7. Reported Impact
3.8. Performance Evaluation
3.9. Validation Approach
3.10. Quality Assessment Results
4. Discussion
4.1. Principal Findings
4.1.1. Overview and Scope of the Review
4.1.2. Performance Comparison Across Specialties
4.1.3. Key Areas of Utilization of LLMs
4.1.4. Dominant LLMs and Training Approaches
4.1.5. Impact Assessment
4.1.6. Evaluation Metrics and Performance Assessment
4.1.7. Validation Approaches
4.1.8. Reported Challenges
5. Future Directions
6. Limitations
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| BERT | Bidirectional Encoder Representations from Transformers |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| EHR | Electronic Health Records |
| FRS | Fundamentals of Robotic Surgery |
| LLM | Large Language Model |
| NLP | Natural Language Processing |
| PRISMA | Preferred Reporting Items for a Systematic Review and Meta-Analyses |
| PROSPERO | International Prospective Register of Systematic Reviews |
| QUADAS-AI | Quality Assessment of Diagnostic Accuracy Studies tailored for Artificial Intelligence |
| WoS | Web of Science |
References
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. arXiv 2018, arXiv:2012.11747v3. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sandmann, S.; Riepenhausen, S.; Plagwitz, L.; Varghese, J. Systematic analysis of ChatGPT, Google search and Llama 2 for clinical decision support tasks. Nat. Commun. 2024, 15, 2050. [Google Scholar] [CrossRef]
- Vrdoljak, J.; Boban, Z.; Vilović, M.; Kumrić, M.; Božić, J. A review of large language models in medical education, clinical decision support, and healthcare administration. Healthcare 2025, 13, 603. [Google Scholar] [CrossRef]
- Mishra, T.; Sutanto, E.; Rossanti, R.; Pant, N.; Ashraf, A.; Raut, A.; Uwabareze, G.; Oluwatomiwa, A.; Zeeshan, B. Use of large language models as artificial intelligence tools in academic research and publishing among global clinical researchers. Sci. Rep. 2024, 14, 31672. [Google Scholar] [CrossRef]
- Wang, X.; Gong, Z.; Wang, G.; Jia, J.; Xu, Y.; Zhao, J.; Fan, Q.; Wu, S.; Hu, W.; Li, X. ChatGPT Performs on the Chinese National Medical Licensing Examination. J. Med. Syst. 2023, 47, 86. [Google Scholar] [CrossRef]
- de Oliveira, J.M.; Antunes, R.S.; da Costa, C.A. SOAP classifier for free-text clinical notes with domain-specific pre-trained language models. Expert Syst. Appl. 2024, 245, 123046. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, J.H.; Kim, Y.M.; Song, S.; Joo, H.J. Predicting medical specialty from text based on a domain-specific pre-trained BERT. Int. J. Med. Inform. 2023, 170, 104956. [Google Scholar] [CrossRef]
- Walker, H.L.; Ghani, S.; Kuemmerli, C.; Nebiker, C.A.; Müller, B.P.; Raptis, D.A.; Staubli, S.M. Reliability of Medical Information Provided by ChatGPT: Assessment Against Clinical Guidelines and Patient Information Quality Instrument. J. Med. Internet Res. 2023, 25, e47479. [Google Scholar] [CrossRef]
- Wilhelm, T.I.; Roos, J.; Kaczmarczyk, R. Large Language Models for Therapy Recommendations Across 3 Clinical Specialties: Comparative Study. J. Med. Internet Res. 2023, 25, e49324. [Google Scholar] [CrossRef]
- Mihalache, A.; Huang, R.S.; Popovic, M.M.; Muni, R.H. ChatGPT-4: An assessment of an upgraded artificial intelligence chatbot in the United States Medical Licensing Examination. Med. Teach. 2023, 46, 366–372. [Google Scholar] [CrossRef] [PubMed]
- Alkamli, S.; Al-Yahya, M.; Alyahya, K. Ethical and Legal Considerations of Large Language Models: A Systematic Review of the Literature. In Proceedings of the 2024 2nd International Conference on Foundation and Large Language Models (FLLM), Dubai, United Arab Emirates, 26–29 November 2024; pp. 576–586. [Google Scholar]
- Ilias, L.; Askounis, D. Context-aware attention layers coupled with optimal transport domain adaptation and multimodal fusion methods for recognizing dementia from spontaneous speech. Knowl. Based Syst. 2023, 277, 110834. [Google Scholar] [CrossRef]
- Pashangpour, S.; Nejat, G. The Future of Intelligent Healthcare: A Systematic Analysis and Discussion on the Integration and Impact of Robots Using Large Language Models for Healthcare. Robotics 2024, 13, 112. [Google Scholar] [CrossRef]
- Artsi, Y.; Sorin, V.; Konen, E.; Glicksberg, B.S.; Nadkarni, G.; Klang, E. Large language models for generating medical examinations: Systematic review. BMC Med. Educ. 2024, 24, 354. [Google Scholar] [CrossRef]
- Pressman, S.M.; Borna, S.; Gomez-Cabello, C.A.; Haider, S.A.; Haider, C.R.; Forte, A.J. Clinical and Surgical Applications of Large Language Models: A Systematic Review. J. Clin. Med. 2024, 13, 3041. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, S.; Zhou, X.; Zhou, S.; Tian, Y.; Wang, S.; Xu, N.; Li, W. Examining the Role of Large Language Models in Orthopedics: Systematic Review. J. Med. Internet Res. 2024, 26, e59607. [Google Scholar] [CrossRef]
- Moglia, A.; Georgiou, K.; Cerveri, P.; Mainardi, L.; Satava, R.M.; Cuschieri, A. Large language models in healthcare: From a systematic review on medical examinations to a comparative analysis on fundamentals of robotic surgery online test. Artif. Intell. Rev. 2024, 57, 231. [Google Scholar] [CrossRef]
- Liu, M.; Okuhara, T.; Chang, X.; Shirabe, R.; Nishiie, Y.; Okada, H.; Kiuchi, T. Performance of ChatGPT across different versions in medical licensing examinations worldwide: Systematic review and meta-analysis. J. Med. Internet Res. 2024, 26, e60807. [Google Scholar] [CrossRef]
- Wang, L.; Wan, Z.; Ni, C.; Song, Q.; Li, Y.; Clayton, E.; Malin, B.; Yin, Z. Applications and Concerns of ChatGPT and Other Conversational Large Language Models in Health Care: Systematic Review. J. Med. Internet Res. 2024, 26, e22769. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Specialty Profiles. Available online: https://careersinmedicine.aamc.org/ (accessed on 1 April 2024).
- Sounderajah, V.; Ashrafian, H.; Rose, S.; Shah, N.H.; Ghassemi, M.; Golub, R.; Kahn, C.E., Jr.; Esteva, A.; Karthikesalingam, A.; Mateen, B.; et al. A quality assessment tool for artificial intelligence-centered diagnostic test accuracy studies: QUADAS-AI. Nat. Med. 2021, 27, 1663–1665. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Chen, K.; Weng, Y.; Chen, Z.; Zhang, J.; Hubbard, R. An intelligent early warning system of analyzing Twitter data using machine learning on COVID-19 surveillance in the US. Expert Syst. Appl. 2022, 198, 116882. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, J.R.; Szepietowski, P.; Howard, R.; Reisman, P.; Jones, J.D.; Lewis, P.; Fridley, B.L.; Rollison, D.E. A Question-and-Answer System to Extract Data From Free-Text Oncological Pathology Reports (CancerBERT Network): Development Study. J. Med. Internet Res. 2022, 24, e27210. [Google Scholar] [CrossRef]
- Li, D.; Kao, Y.; Tsai, S.; Bai, Y.; Yeh, T.; Chu, C.; Hsu, C.; Cheng, S.; Hsu, T.; Liang, C.; et al. Comparing the performance of ChatGPT GPT-4, Bard, and Llama-2 in the Taiwan Psychiatric Licensing Examination and in differential diagnosis with multi-center psychiatrists. Psychiatry Clin. Neurosci. 2024, 78, 347–352. [Google Scholar] [CrossRef]
- Ayoub, N.F.; Lee, Y.J.; Grimm, D.; Divi, V. Head-to-head comparison of ChatGPT versus Google search for medical knowledge acquisition. Otolaryngol. Neck Surg. 2024, 170, 1484–1491. [Google Scholar] [CrossRef]
- Wang, H.; Wu, W.; Dou, Z.; He, L.; Yang, L. Performance and exploration of ChatGPT in medical examination, records and education in Chinese: Pave the way for medical AI. Int. J. Med. Inform. 2023, 177, 105173. [Google Scholar] [CrossRef]
- Wang, C.; Liu, S.; Li, A.; Liu, J. Text Dialogue Analysis for Primary Screening of Mild Cognitive Impairment: Development and Validation Study. J. Med. Internet Res. 2023, 25, e51501. [Google Scholar] [CrossRef]
- Oon, M.L.; Syn, N.L.; Tan, C.L.; Tan, K.; Ng, S. Bridging bytes and biopsies: A comparative analysis of ChatGPT and histopathologists in pathology diagnosis and collaborative potential. Histopathology 2023, 84, 601–613. [Google Scholar] [CrossRef]
- Yun, J.Y.; Kim, D.J.; Lee, N.; Kim, E.K. A comprehensive evaluation of ChatGPT consultation quality for augmentation mammoplasty: A comparative analysis between plastic surgeons and laypersons. Int. J. Med. Inform. 2023, 179, 105219. [Google Scholar] [CrossRef]
- Scquizzato, T.; Semeraro, F.; Swindell, P.; Simpson, R.; Angelini, M.; Gazzato, A.; Sajjad, U.; Bignami, E.G.; Landoni, G.; Keeble, T.R.; et al. Testing ChatGPT ability to answer laypeople questions about cardiac arrest and cardiopulmonary resuscitation. Resuscitation 2024, 194, 110077. [Google Scholar] [CrossRef]
- Maillard, A.; Micheli, G.; Lefevre, L.; Guyonnet, C.; Poyart, C.; Canouï, E.; Belan, M.; Charlier, C. Can Chatbot Artificial Intelligence Replace Infectious Diseases Physicians in the Management of Bloodstream Infections? A Prospective Cohort Study. Clin. Infect. Dis. 2023, 78, 825–832. [Google Scholar] [CrossRef] [PubMed]
- Bushuven, S.; Bentele, M.; Bentele, S.; Gerber, B.; Bansbach, J.; Ganter, J.; Trifunovic-Koenig, M.; Ranisch, R. “ChatGPT, can you help me save my child’s life?”-Diagnostic Accuracy and Supportive Capabilities to lay rescuers by ChatGPT in prehospital Basic Life Support and Paediatric Advanced Life Support cases–an in-silico analysis. J. Med. Syst. 2023, 47, 123. [Google Scholar] [CrossRef] [PubMed]
- Mulyar, A.; Uzuner, O.; McInnes, B. MT-clinical BERT: Scaling clinical information extraction with multitask learning. J. Am. Med. Inform. Assoc. 2021, 28, 2108–2115. [Google Scholar] [CrossRef] [PubMed]
- Cai, X.; Liu, S.; Han, J.; Yang, L.; Liu, Z.; Liu, T. Chestxraybert: A pretrained language model for chest radiology report summarization. IEEE Trans. Multimed. 2021, 25, 845–855. [Google Scholar] [CrossRef]
- Wang, S.Y.; Huang, J.; Hwang, H.; Hu, W.; Tao, S.; Hernandez-Boussard, T. Leveraging weak supervision to perform named entity recognition in electronic health records progress notes to identify the ophthalmology exam. Int. J. Med. Inform. 2022, 167, 104864. [Google Scholar] [CrossRef]
- Hristidis, V.; Ruggiano, N.; Brown, E.L.; Ganta, S.R.R.; Stewart, S. ChatGPT vs Google for Queries Related to Dementia and Other Cognitive Decline: Comparison of Results. J. Med. Internet Res. 2023, 25, e48966. [Google Scholar] [CrossRef]
- Ghanem, Y.K.; Rouhi, A.D.; Al-Houssan, A.; Saleh, Z.; Moccia, M.C.; Joshi, H.; Dumon, K.R.; Hong, Y.; Spitz, F.; Joshi, A.R.; et al. Dr. Google to Dr. ChatGPT: Assessing the content and quality of artificial intelligence-generated medical information on appendicitis. Surg. Endosc. 2024, 38, 2887–2893. [Google Scholar] [CrossRef]
- Parker, G.; Spoelma, M.J. A chat about bipolar disorder. Bipolar Disord. 2023, 26, 249–254. [Google Scholar] [CrossRef]
- Mishra, A.; Begley, S.L.; Chen, A.; Rob, M.; Pelcher, I.; Ward, M.; Schulder, M. Exploring the Intersection of Artificial Intelligence and Neurosurgery: Let us be Cautious With ChatGPT. Neurosurgery 2023, 93, 1366–1373. [Google Scholar] [CrossRef]
- Shang, J.; Tang, X.; Sun, Y. PhaTYP: Predicting the lifestyle for bacteriophages using BERT. Briefings Bioinform. 2023, 24, bbac487. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, G.; Li, K.; Li, F.; Huang, L.; Duan, M.; Zhou, F. HLAB: Learning the BiLSTM features from the ProtBert-encoded proteins for the class I HLA-peptide binding prediction. Briefings Bioinform. 2022, 23, bbac173. [Google Scholar] [CrossRef] [PubMed]
- Klein, A.Z.; Magge, A.; O’Connor, K.; Flores Amaro, J.I.; Weissenbacher, D.; Gonzalez Hernandez, G. Toward using Twitter for tracking COVID-19: A natural language processing pipeline and exploratory data set. J. Med. Internet Res. 2021, 23, e25314. [Google Scholar] [CrossRef] [PubMed]
- Percha, B.; Pisapati, K.; Gao, C.; Schmidt, H. Natural language inference for curation of structured clinical registries from unstructured text. J. Am. Med. Inform. Assoc. 2021, 29, 97–108. [Google Scholar] [CrossRef]
- Wong, M.; Lim, Z.W.; Pushpanathan, K.; Cheung, C.Y.; Wang, Y.X.; Chen, D.; Tham, Y.C. Review of emerging trends and projection of future developments in large language models research in ophthalmology. Br. J. Ophthalmol. 2023, 108, 1362–1370. [Google Scholar] [CrossRef]
- Klang, E.; Sourosh, A.; Nadkarni, G.N.; Sharif, K.; Lahat, A. Evaluating the role of ChatGPT in gastroenterology: A comprehensive systematic review of applications, benefits, and limitations. Ther. Adv. Gastroenterol. 2023, 16, 17562848231218618. [Google Scholar] [CrossRef]
- Younis, H.A.; Eisa, T.A.E.; Nasser, M.; Sahib, T.M.; Noor, A.A.; Alyasiri, O.M.; Salisu, S.; Hayder, I.M.; Younis, H.A. A Systematic Review and Meta-Analysis of Artificial Intelligence Tools in Medicine and Healthcare: Applications, Considerations, Limitations, Motivation and Challenges. Diagnostics 2024, 14, 109. [Google Scholar] [CrossRef]
- Levin, G.; Horesh, N.; Brezinov, Y.; Meyer, R. Performance of ChatGPT in medical examinations: A systematic review and a meta-analysis. BJOG Int. J. Obstet. Gynaecol. 2024, 131, 378–380. [Google Scholar] [CrossRef] [PubMed]
- Schopow, N.; Osterhoff, G.; Baur, D. Applications of the natural language processing tool ChatGPT in clinical practice: Comparative study and augmented systematic review. JMIR Med. Inform. 2023, 11, e48933. [Google Scholar] [CrossRef]
- Kao, H.J.; Chien, T.W.; Wang, W.C.; Chou, W.; Chow, J.C. Assessing ChatGPT’s capacity for clinical decision support in pediatrics: A comparative study with pediatricians using KIDMAP of Rasch analysis. Medicine 2023, 102, e34068. [Google Scholar] [CrossRef]
- Zhou, S.; Wang, N.; Wang, L.; Liu, H.; Zhang, R. CancerBERT: A cancer domain-specific language model for extracting breast cancer phenotypes from electronic health records. J. Am. Med. Inform. Assoc. 2022, 29, 1208–1216. [Google Scholar] [CrossRef]
- Shool, S.; Adimi, S.; Saboori Amleshi, R.; Bitaraf, E.; Golpira, R.; Tara, M. A systematic review of large language model (LLM) evaluations in clinical medicine. BMC Med. Inform. Decis. Mak. 2025, 25, 117. [Google Scholar] [CrossRef] [PubMed]
- Ali, R.; Tang, O.Y.; Connolly, I.D.; Zadnik Sullivan, P.L.; Shin, J.H.; Fridley, J.S.; Asaad, W.F.; Cielo, D.; Oyelese, A.A.; Doberstein, C.E.; et al. Performance of ChatGPT and GPT-4 on Neurosurgery Written Board Examinations. Neurosurgery 2023, 93, 1353–1365. [Google Scholar] [CrossRef] [PubMed]
- Massey, P.A.; Montgomery, C.; Zhang, A.S. Comparison of ChatGPT–3.5, ChatGPT-4, and orthopaedic resident performance on orthopaedic assessment examinations. JAAOS-J. Am. Acad. Orthop. Surg. 2023, 31, 1173–1179. [Google Scholar] [CrossRef]
- Butler, J.J.; Puleo, J.; Harrington, M.C.; Dahmen, J.; Rosenbaum, A.J.; Kerkhoffs, G.M.M.J.; Kennedy, J.G. From technical to understandable: Artificial Intelligence Large Language Models improve the readability of knee radiology reports. Knee Surgery Sport. Traumatol. Arthrosc. 2024, 32, 1077–1086. [Google Scholar] [CrossRef]
- Mika, A.P.; Martin, J.R.; Engstrom, S.M.; Polkowski, G.G.; Wilson, J.M. Assessing ChatGPT Responses to Common Patient Questions Regarding Total Hip Arthroplasty. J. Bone Jt. Surg. 2023, 105, 1519–1526. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, Z.; Xu, Y.; Wang, N.; Huang, Y.; Yang, Z.; Jiang, R.; Chen, H. Use of BERT (Bidirectional Encoder Representations from Transformers)-Based Deep Learning Method for Extracting Evidences in Chinese Radiology Reports: Development of a Computer-Aided Liver Cancer Diagnosis Framework. J. Med. Internet Res. 2021, 23, e19689. [Google Scholar] [CrossRef]
- Datta, S.; Roberts, K. Fine-grained spatial information extraction in radiology as two-turn question answering. Int. J. Med. Inform. 2022, 158, 104628. [Google Scholar] [CrossRef] [PubMed]
- Tan, R.S.Y.C.; Lin, Q.; Low, G.H.; Lin, R.; Goh, T.C.; Chang, C.C.E.; Lee, F.F.; Chan, W.Y.; Tan, W.C.; Tey, H.J.; et al. Inferring cancer disease response from radiology reports using large language models with data augmentation and prompting. J. Am. Med. Inform. Assoc. 2023, 30, 1657–1664. [Google Scholar] [CrossRef]
- Mohamad, E.; Boutoleau-Bretonnière, C.; Chapelet, G. ChatGPT’s Dance with Neuropsychological Data: A case study in Alzheimer’s Disease. Ageing Res. Rev. 2023, 92, 102117. [Google Scholar]
- Otsuka, N.; Kawanishi, Y.; Doi, F.; Takeda, T.; Okumura, K.; Yamauchi, T.; Yada, S.; Wakamiya, S.; Aramaki, E.; Makinodan, M. Diagnosing psychiatric disorders from history of present illness using a large-scale linguistic model. Psychiatry Clin. Neurosci. 2023, 77, 597–604. [Google Scholar] [CrossRef]
- Zaboli, A.; Brigo, F.; Sibilio, S.; Mian, M.; Turcato, G. Human intelligence versus Chat-GPT: Who performs better in correctly classifying patients in triage? Am. J. Emerg. Med. 2024, 79, 44–47. [Google Scholar] [CrossRef]
- Lee, S.; Lee, J.; Park, J.; Park, J.; Kim, D.; Lee, J.; Oh, J. Deep learning-based natural language processing for detecting medical symptoms and histories in emergency patient triage. Am. J. Emerg. Med. 2024, 77, 29–38. [Google Scholar] [CrossRef] [PubMed]
- CB, A.; Mahesh, K.; Sanda, N. Ontology-based semantic data interestingness using BERT models. Connect. Sci. 2023, 35. [Google Scholar] [CrossRef]
- Qiao, Y.; Zhu, X.; Gong, H. BERT-Kcr: Prediction of lysine crotonylation sites by a transfer learning method with pre-trained BERT models. Bioinformatics 2021, 38, 648–654. [Google Scholar] [CrossRef] [PubMed]
- Vithanage, D.; Zhu, Y.; Zhang, Z.; Deng, C.; Yin, M.; Yu, P. Extracting Symptoms of Agitation in Dementia from Free-Text Nursing Notes Using Advanced Natural Language Processing. In MEDINFO 2023—The Future Is Accessible; IOS Press: Amsterdam, The Netherlands, 2024; pp. 700–704. [Google Scholar]
- Guo, Q.; Cao, S.; Yi, Z. A medical question answering system using large language models and knowledge graphs. Int. J. Intell. Syst. 2022, 37, 8548–8564. [Google Scholar] [CrossRef]
- Acharya, A.; Shrestha, S.; Chen, A.; Conte, J.; Avramovic, S.; Sikdar, S.; Anastasopoulos, A.; Das, S. Clinical risk prediction using language models: Benefits and considerations. J. Am. Med. Inform. Assoc. 2024, 31, 1856–1864. [Google Scholar] [CrossRef]
- Chen, Y.P.; Lo, Y.H.; Lai, F.; Huang, C.H. Disease Concept-Embedding Based on the Self-Supervised Method for Medical Information Extraction from Electronic Health Records and Disease Retrieval: Algorithm Development and Validation Study. J. Med. Internet Res. 2021, 23, e25113. [Google Scholar] [CrossRef]
- Haze, T.; Kawano, R.; Takase, H.; Suzuki, S.; Hirawa, N.; Tamura, K. Influence on the accuracy in ChatGPT: Differences in the amount of information per medical field. Int. J. Med. Inform. 2023, 180, 105283. [Google Scholar] [CrossRef]
- Xie, K.; Gallagher, R.S.; Conrad, E.C.; Garrick, C.O.; Baldassano, S.N.; Bernabei, J.M.; Galer, P.D.; Ghosn, N.J.; Greenblatt, A.S.; Jennings, T.; et al. Extracting seizure frequency from epilepsy clinic notes: A machine reading approach to natural language processing. J. Am. Med. Inform. Assoc. 2022, 29, 873–881. [Google Scholar] [CrossRef]
- Alkouz, B.; Al Aghbari, Z.; Al-Garadi, M.A.; Sarker, A. Deepluenza: Deep learning for influenza detection from Twitter. Expert Syst. Appl. 2022, 198, 116845. [Google Scholar] [CrossRef]
- Lu, Z.H.; Wang, J.X.; Li, X. Revealing opinions for COVID-19 questions using a context retriever, opinion aggregator, and question-answering model: Model development study. J. Med. Internet Res. 2021, 23, e22860. [Google Scholar] [CrossRef] [PubMed]
- Truhn, D.; Loeffler, C.M.; Müller-Franzes, G.; Nebelung, S.; Hewitt, K.J.; Brandner, S.; Bressem, K.K.; Foersch, S.; Kather, J.N. Extracting structured information from unstructured histopathology reports using generative pre-trained transformer 4 (GPT-4). J. Pathol. 2023, 262, 310–319. [Google Scholar] [CrossRef]
- Karakas, C.; Brock, D.; Lakhotia, A. Leveraging ChatGPT in the Pediatric Neurology Clinic: Practical Considerations for Use to Improve Efficiency and Outcomes. Pediatr. Neurol. 2023, 148, 157–163. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Wright, A.P.; Patterson, B.L.; Wanderer, J.P.; Turer, R.W.; Nelson, S.D.; McCoy, A.B.; Sittig, D.F.; Wright, A. Using AI-generated suggestions from ChatGPT to optimize clinical decision support. J. Am. Med. Inform. Assoc. 2023, 30, 1237–1245. [Google Scholar] [CrossRef]
- Xue, Z.; Zhang, Y.; Gan, W.; Wang, H.; She, G.; Zheng, X. Quality and Dependability of ChatGPT and DingXiangYuan Forums for Remote Orthopedic Consultations: Comparative Analysis. J. Med. Internet Res. 2024, 26, e50882. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Gao, K.; Liu, Q.; Wu, Y.; Zhang, K.; Zhou, W.; Guo, C. Potential and Limitations of ChatGPT 3.5 and 4.0 as a Source of COVID-19 Information: Comprehensive Comparative Analysis of Generative and Authoritative Information. J. Med. Internet Res. 2023, 25, e49771. [Google Scholar] [CrossRef]
- Ji, S.; Hölttä, M.; Marttinen, P. Does the magic of BERT apply to medical code assignment? A quantitative study. Comput. Biol. Med. 2021, 139, 104998. [Google Scholar] [CrossRef]
- Nimmi, K.; Janet, B.; Selvan, A.K.; Sivakumaran, N. Pre-trained ensemble model for identification of emotion during COVID-19 based on emergency response support system dataset. Appl. Soft Comput. 2022, 122, 108842. [Google Scholar] [CrossRef]
- Hartman, V.C.; Bapat, S.S.; Weiner, M.G.; Navi, B.B.; Sholle, E.T.; Campion, T.R. A method to automate the discharge summary hospital course for neurology patients. J. Am. Med. Inform. Assoc. 2023, 30, 1995–2003. [Google Scholar] [CrossRef]
- Kim, S.; Cha, J.; Kim, D.; Park, E. Understanding Mental Health Issues in Different Subdomains of Social Networking Services: Computational Analysis of Text-Based Reddit Posts. J. Med. Internet Res. 2023, 25, e49074. [Google Scholar] [CrossRef]
- Hu, D.; Liu, B.; Zhu, X.; Lu, X.; Wu, N. Zero-shot information extraction from radiological reports using ChatGPT. Int. J. Med. Inform. 2024, 183, 105321. [Google Scholar] [CrossRef]
- Datta, S.; Lee, K.; Paek, H.; Manion, F.J.; Ofoegbu, N.; Du, J.; Li, Y.; Huang, L.C.; Wang, J.; Lin, B.; et al. AutoCriteria: A generalizable clinical trial eligibility criteria extraction system powered by large language models. J. Am. Med. Inform. Assoc. 2023, 31, 375–385. [Google Scholar] [CrossRef]
- Bombieri, M.; Rospocher, M.; Ponzetto, S.P.; Fiorini, P. Machine understanding surgical actions from intervention procedure textbooks. Comput. Biol. Med. 2023, 152, 106415. [Google Scholar] [CrossRef] [PubMed]
- Laison, E.K.E.; Hamza Ibrahim, M.; Boligarla, S.; Li, J.; Mahadevan, R.; Ng, A.; Muthuramalingam, V.; Lee, W.Y.; Yin, Y.; Nasri, B.R. Identifying Potential Lyme Disease Cases Using Self-Reported Worldwide Tweets: Deep Learning Modeling Approach Enhanced With Sentimental Words Through Emojis. J. Med. Internet Res. 2023, 25, e47014. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.F.; Yu, C.Q.; You, Z.H.; Qiao, Y.; Li, Z.W.; Huang, W.Z. An efficient circRNA-miRNA interaction prediction model by combining biological text mining and wavelet diffusion-based sparse network structure embedding. Comput. Biol. Med. 2023, 165, 107421. [Google Scholar] [CrossRef]
- Lu, Z.; Sim, J.A.; Wang, J.X.; Forrest, C.B.; Krull, K.R.; Srivastava, D.; Hudson, M.M.; Robison, L.L.; Baker, J.N.; Huang, I.C. Natural language processing and machine learning methods to characterize unstructured patient-reported outcomes: Validation study. J. Med. Internet Res. 2021, 23, e26777. [Google Scholar] [CrossRef]
- Bressem, K.K.; Papaioannou, J.M.; Grundmann, P.; Borchert, F.; Adams, L.C.; Liu, L.; Busch, F.; Xu, L.; Loyen, J.P.; Niehues, S.M.; et al. medBERT.de: A comprehensive German BERT model for the medical domain. Expert Syst. Appl. 2024, 237, 121598. [Google Scholar] [CrossRef]
- Chizhikova, M.; López-Úbeda, P.; Collado-Montañez, J.; Martín-Noguerol, T.; Díaz-Galiano, M.C.; Luna, A.; Ureña-López, L.A.; Martín-Valdivia, M.T. CARES: A Corpus for classification of Spanish Radiological reports. Comput. Biol. Med. 2023, 154, 106581. [Google Scholar] [CrossRef]
- Kaplar, A.; Stošović, M.; Kaplar, A.; Brković, V.; Naumović, R.; Kovačević, A. Evaluation of clinical named entity recognition methods for Serbian electronic health records. Int. J. Med. Inform. 2022, 164, 104805. [Google Scholar] [CrossRef]
- Karthikeyan, S.; de Herrera, A.G.S.; Doctor, F.; Mirza, A. An OCR Post-Correction Approach Using Deep Learning for Processing Medical Reports. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 2574–2581. [Google Scholar] [CrossRef]
- Homburg, M.; Meijer, E.; Berends, M.; Kupers, T.; Olde Hartman, T.; Muris, J.; de Schepper, E.; Velek, P.; Kuiper, J.; Berger, M.; et al. A Natural Language Processing Model for COVID-19 Detection Based on Dutch General Practice Electronic Health Records by Using Bidirectional Encoder Representations From Transformers: Development and Validation Study. J. Med. Internet Res. 2023, 25, e49944. [Google Scholar] [CrossRef] [PubMed]
- Fonseca, Ă.; Ferreira, A.; Ribeiro, L.; Moreira, S.; Duque, C. Embracing the future—Is artificial intelligence already better? A comparative study of artificial intelligence performance in diagnostic accuracy and decision-making. Eur. J. Neurol. 2024, 31. [Google Scholar] [CrossRef]
- Gan, R.K.; Ogbodo, J.C.; Wee, Y.Z.; Gan, A.Z.; González, P.A. Performance of Google bard and ChatGPT in mass casualty incidents triage. Am. J. Emerg. Med. 2024, 75, 72–78. [Google Scholar] [CrossRef] [PubMed]
- Caruccio, L.; Cirillo, S.; Polese, G.; Solimando, G.; Sundaramurthy, S.; Tortora, G. Can ChatGPT provide intelligent diagnoses? A comparative study between predictive models and ChatGPT to define a new medical diagnostic bot. Expert Syst. Appl. 2024, 235, 121186. [Google Scholar] [CrossRef]
- Cuthbert, R.; Simpson, A.I. Artificial intelligence in orthopaedics: Can chat generative pre-trained transformer (ChatGPT) pass Section 1 of the fellowship of the royal college of surgeons (trauma & orthopaedics) examination? Postgrad. Med J. 2023, 99, 1110–1114. [Google Scholar]
- Fu, S.; Thorsteinsdottir, B.; Zhang, X.; Lopes, G.S.; Pagali, S.R.; LeBrasseur, N.K.; Wen, A.; Liu, H.; Rocca, W.A.; Olson, J.E.; et al. A hybrid model to identify fall occurrence from electronic health records. Int. J. Med. Inform. 2022, 162, 104736. [Google Scholar] [CrossRef]
- Kaarre, J.; Feldt, R.; Keeling, L.E.; Dadoo, S.; Zsidai, B.; Hughes, J.D.; Samuelsson, K.; Musahl, V. Exploring the potential of ChatGPT as a supplementary tool for providing orthopaedic information. Knee Surg. Sport. Traumatol. Arthrosc. 2023, 31, 5190–5198. [Google Scholar] [CrossRef]
- Liu, J.; Gupta, S.; Chen, A.; Wang, C.K.; Mishra, P.; Dai, H.J.; Wong, Z.S.Y.; Jonnagaddala, J. OpenDeID Pipeline for Unstructured Electronic Health Record Text Notes Based on Rules and Transformers: Deidentification Algorithm Development and Validation Study. J. Med. Internet Res. 2023, 25, e48145. [Google Scholar] [CrossRef]
- Liu, S.; McCoy, A.B.; Wright, A.P.; Nelson, S.D.; Huang, S.S.; Ahmad, H.B.; Carro, S.E.; Franklin, J.; Brogan, J.; Wright, A. Why do users override alerts? Utilizing large language model to summarize comments and optimize clinical decision support. J. Am. Med. Inform. Assoc. 2024, 31, 1388–1396. [Google Scholar] [CrossRef]
- Song, H.; Xia, Y.; Luo, Z.; Liu, H.; Song, Y.; Zeng, X.; Li, T.; Zhong, G.; Li, J.; Chen, M.; et al. Evaluating the Performance of Different Large Language Models on Health Consultation and Patient Education in Urolithiasis. J. Med. Syst. 2023, 47. [Google Scholar] [CrossRef]
- Bellinger, J.R.; De La Chapa, J.S.; Kwak, M.W.; Ramos, G.A.; Morrison, D.; Kesser, B.W. BPPV Information on Google VersusAI (ChatGPT). Otolaryngol. Neck Surg. 2023, 170, 1504–1511. [Google Scholar] [CrossRef] [PubMed]
- Koczkodaj, W.W.; Kakiashvili, T.; Szymańska, A.; Montero-Marin, J.; Araya, R.; Garcia-Campayo, J.; Rutkowski, K.; Strzałka, D. How to reduce the number of rating scale items without predictability loss? Scientometrics 2017, 111, 581–593. [Google Scholar] [CrossRef] [PubMed]
- Campbell, D.J.; Estephan, L.E.; Sina, E.M.; Mastrolonardo, E.V.; Alapati, R.; Amin, D.R.; Cottrill, E.E. Evaluating ChatGPT responses on thyroid nodules for patient education. Thyroid 2024, 34, 371–377. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Zhou, Y.; Jiang, X.; Natarajan, K.; Pakhomov, S.V.; Liu, H.; Xu, H. Are synthetic clinical notes useful for real natural language processing tasks: A case study on clinical entity recognition. J. Am. Med. Inform. Assoc. 2021, 28, 2193–2201. [Google Scholar] [CrossRef]
- Tsoutsanis, P.; Tsoutsanis, A. Evaluation of Large language model performance on the Multi-Specialty Recruitment Assessment (MSRA) exam. Comput. Biol. Med. 2024, 168, 107794. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Application | Task Examples | Dataset Characteristics | Accuracy Range | Key Findings |
|---|---|---|---|---|
| Medical Education | Performance in different medical exams | Official/practice question sets (100–861 questions) | 29.4–90% | GPT-4 significantly outperforms other LLMs [26,27,28,29]. Human experts still outperform LLMs [30,31]. |
| Diagnostic Assistance | Disease diagnosis based on various inputs | single to hundreds of questions/cases | 3–94% | Prompt design significantly impacts AI diagnostic performance [32]. LLMs are promising for primary screening but not complex cases [33,34]. Significant safety concerns exist for using current LLMs in real-time [32]. |
| Clinical decision support | Suggesting clinical risks, outcomes, and recommendations | 15 cases to 84 K patients/questions | 27–60% | Performance is highly model-dependent [35,36,37]. LLMs show potential in assisting decision support but often lack reliability, accuracy, and reasoning of human experts [31]. |
| Patient Management and Engagement | Answering patient questions | notes/reports (100–6600) sets of 10–40 questions | 56–80% | LLMs have the potential to answer medical questions but patients are challenged by medical terms [38,39]. LLMs often fabricate citations and hallucinate [40]. Overall information quality is lower than human expert [41]. |
| Clinical NLP |
| clinical notes (100 s–10 Ks) clinical trial protocols (180) | 71–>90% | Fine-tuning can improve LLMs performance substantially [42,43,44]. Handling long documents, complex reasoning, and model hallucinations limit clinical extraction tasks [45]. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkalbani, A.M.; Alrawahi, A.S.; Salah, A.; Haghighi, V.; Zhang, Y.; Alkindi, S.; Sheng, Q.Z. A Systematic Review of Large Language Models in Medical Specialties: Applications, Challenges and Future Directions. Information 2025, 16, 489. https://doi.org/10.3390/info16060489
Alkalbani AM, Alrawahi AS, Salah A, Haghighi V, Zhang Y, Alkindi S, Sheng QZ. A Systematic Review of Large Language Models in Medical Specialties: Applications, Challenges and Future Directions. Information. 2025; 16(6):489. https://doi.org/10.3390/info16060489
Chicago/Turabian StyleAlkalbani, Asma Musabah, Ahmed Salim Alrawahi, Ahmad Salah, Venus Haghighi, Yang Zhang, Salam Alkindi, and Quan Z. Sheng. 2025. "A Systematic Review of Large Language Models in Medical Specialties: Applications, Challenges and Future Directions" Information 16, no. 6: 489. https://doi.org/10.3390/info16060489
APA StyleAlkalbani, A. M., Alrawahi, A. S., Salah, A., Haghighi, V., Zhang, Y., Alkindi, S., & Sheng, Q. Z. (2025). A Systematic Review of Large Language Models in Medical Specialties: Applications, Challenges and Future Directions. Information, 16(6), 489. https://doi.org/10.3390/info16060489