
Dynamic Mixture of Experts for Adaptive Computation in Character-Level Transformers

Abstract
1. Introduction
- We challenge the widely held assumption that MoE improves computational efficiency by providing systematic empirical evidence that MoE’s computational benefits are highly dependent on the model scale and task type [32].
- We provide the first detailed quantitative analysis of the trade-offs between performance and computational cost for MoE across different routing strategies, revealing significant increases in training time and reductions in inference speed.
- We conduct an in-depth analysis of routing behavior and expert utilization patterns, finding that even with load-balancing techniques, specific patterns still lead to uneven expert utilization.
- We provide empirical guidance for the application of conditional computation in neural networks, articulating key considerations for balancing performance and efficiency under different computational constraints [33].
2. Related Works
2.1. Transformer Models and Efficiency
2.2. Mixture-of-Experts Approaches
2.3. Character-Level Language Modeling
2.4. Positioning of Our Work
- The application of MoE specifically within the MLP component of character-level Transformer models.
- The comparative performance of different MoE configurations (basic, top-k, capacity-factored) in this context.
- A detailed analysis of performance–efficiency trade-offs, considering both training and inference metrics.
- The behavior of routing mechanisms and expert specialization patterns in character-level modeling.
3. Background
3.1. Transformer Architecture
- Embedding dimension (d): 384.
- Number of layers: 6.
- Number of attention heads: 6.
- Dropout rate: 0.2.
- Context length (block size): 256 characters.
3.2. Mixture of Experts (MoE)
- A set of N expert networks, each specialized for different inputs.
- A router or gating network that determines which expert(s) to use for each input.
- A mechanism to combine the outputs of the selected experts.
3.3. Problem Setting
4. Methodology/MoE-Based FFN Modifications
4.1. Baseline Model Architecture
- Embedding dimension (d): 384.
- Number of layers: 6.
- Number of attention heads: 6.
- Dropout rate: 0.2.
- Context length (block size): 256 characters.
4.2. MoE FFN Architecture
- A Router Network: A simple linear layer () that takes the input token representation and outputs logits indicating the affinity of the token for each of the N experts. In our case, .
- N Expert Networks: A set of N smaller, independent linear layers ( for ). Each expert network has the same input and output dimension as the original embedding dimension d. The total parameters across all experts () are equivalent to the baseline’s expansion layer ().
4.3. Routing Mechanisms and Expert Combination
4.3.1. Base MoE (Run 1)
4.3.2. Top-k Routing (Run 2)
4.3.3. Top-k Routing with Capacity Factors (Runs 3 and 4)
4.4. Implementation Details and Design Considerations
- Parameter Count Equivalence: We designed our MoE variants to maintain approximately the same parameter count as the baseline model to ensure a fair comparison. The four expert networks with dimension match the parameter count of the single expansion layer in the baseline FFN.
- Expert Granularity: We chose to have four experts based on the standard practice of using a 4× expansion factor in Transformer MLPs. This allows each expert to specialize in a distinct aspect of the input space while maintaining a reasonable computational profile.
- Progressive Complexity: Our sequence of experiments (Runs 1–4) follows a progression of increasing sophistication in the routing mechanism, allowing us to isolate the effects of each modification.
- Computational Considerations: While MoE can theoretically improve computational efficiency through sparse activation, the overhead of routing and expert selection can outweigh these benefits in smaller models. Our experiments quantify these trade-offs to inform practical implementation decisions.
Pseudocode Comparison
| Algorithm 1 FFN forward pass comparison. |
|
5. Experimental Setup
5.1. Dataset
5.2. Training Configuration
- Optimizer: AdamW with weight decay of 0.1.
- Learning rate: with cosine decay.
- Batch size: 64.
- Context length: 256 characters.
- Training iterations: 5000.
- Gradient clipping: 1.0.
5.3. Evaluation Metrics
- Training and validation loss (cross-entropy);
- Training time (seconds);
- Inference speed (tokens processed per second);
- Expert utilization patterns (for MoE variants);
- Router behavior (for MoE variants).
5.4. Experimental Runs
- Baseline: Standard Transformer with conventional FFN.
- MoE Base: MoE with softmax routing across all four experts.
- MoE Top-2: MoE with top-2 routing selection.
- MoE Capacity 0.5: MoE with top-2 routing and a capacity factor of 0.5.
- MoE Capacity 1.0: MoE with top-2 routing and a capacity factor of 1.0.
6. Results
6.1. Computational Efficiency
6.2. Model Architecture and Performance Trade-Offs
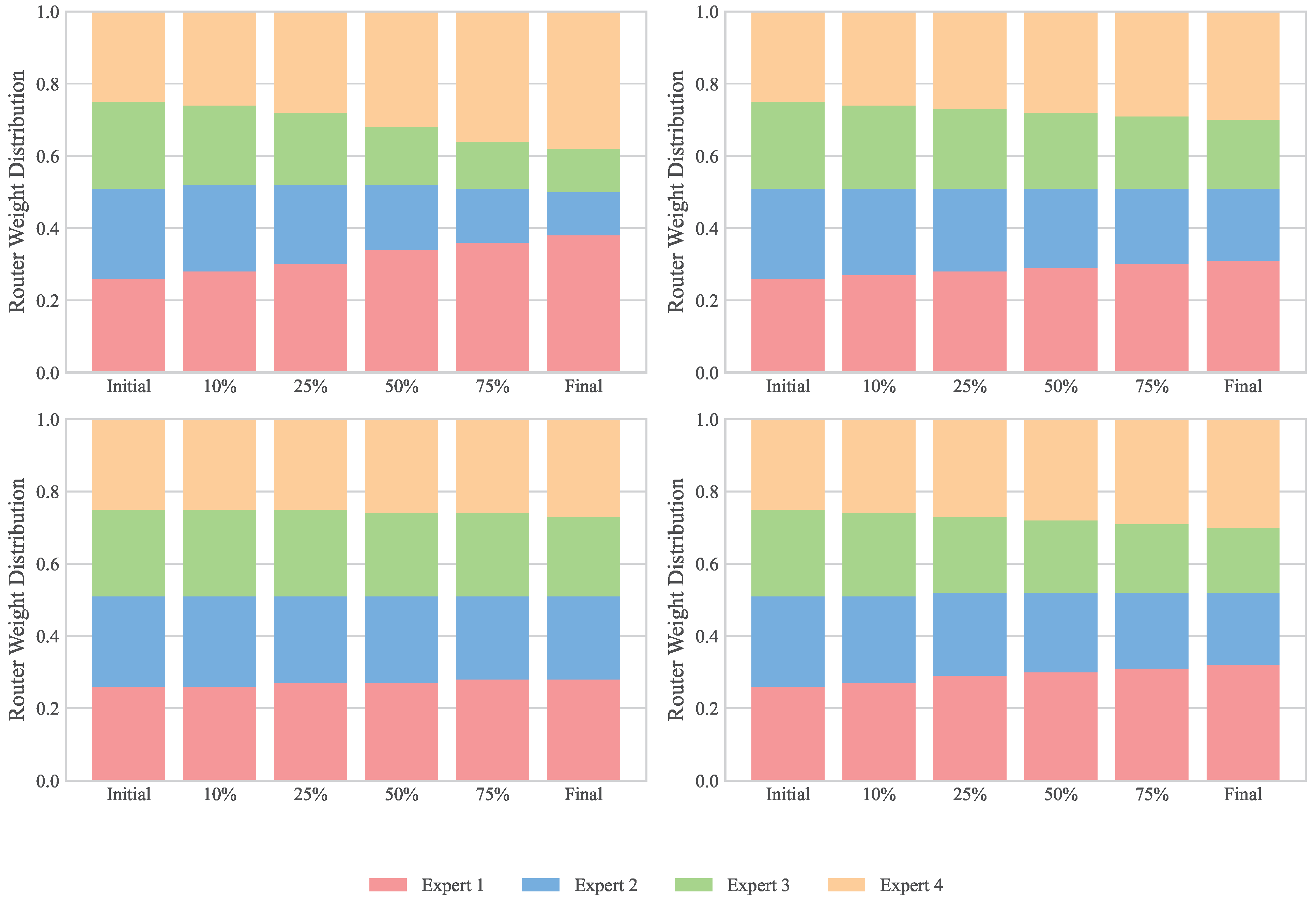
6.3. Router Analysis and Expert Utilization
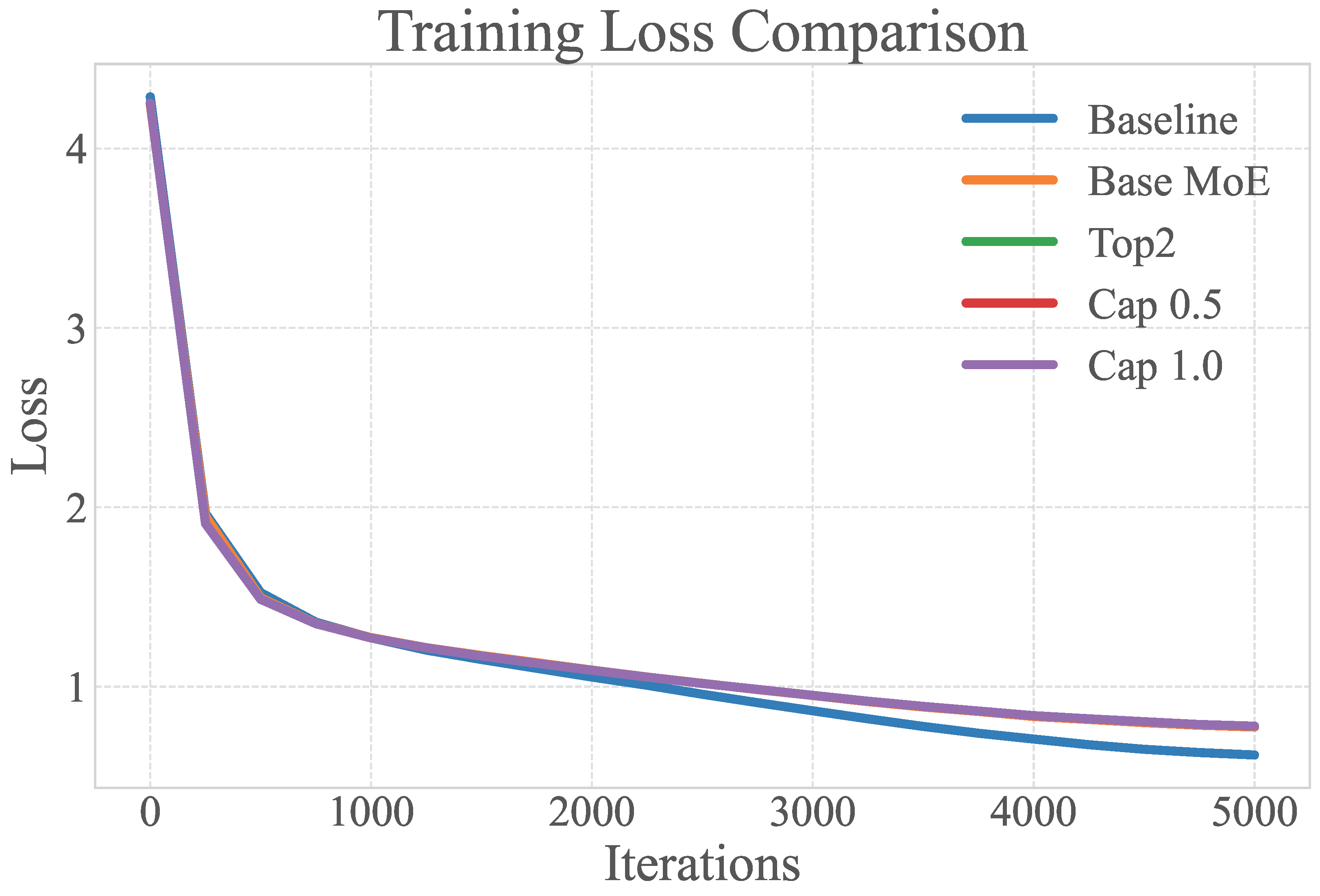
6.4. Training Loss vs. Generalization Analysis
6.5. Discussion of Limitations
- Computational Overhead: Despite the theoretical potential for computational efficiency through sparse activation, all MoE variants showed significant overhead in both training and inference. This suggests that the benefits of MoE may only be realized in larger models, where the computational savings from activating a subset of parameters outweigh the routing overhead. The overhead is also hardware-dependent; our evaluations were performed on standard GPU hardware, and results might differ on specialized hardware.
- Limited Performance Improvement: While MoE variants matched or slightly improved validation performance compared to the baseline, the magnitude of improvement was minimal (less than 0.2%). Given the significant computational overhead, this raises questions about the practical value of MoE in this context.
- Limited Scope: Our study focused on a single dataset (Shakespeare) and a relatively small model architecture. The findings may not generalize to larger models or different tasks.
- Absence of Qualitative Evaluation: While we analyzed quantitative metrics and router behavior, our study lacked a systematic qualitative evaluation of the generated text. Future work could explore whether MoE models produce qualitatively different outputs despite similar validation losses.
- Focus on MLP-MoE: We explored a specific implementation of MoE within the FFN component of Transformer blocks. Alternative implementations (e.g., applying MoE to attention layers or using different expert architectures) might yield different results and represent an area for future work.
7. Conclusions
7.1. Summary of Findings
- MoE variants maintain validation performance comparable to the baseline model (within ±0.2%) despite exhibiting significantly higher training losses (+18%). This discrepancy suggests a potential regularization effect or different learning dynamics [27].
- MoE implementations incur substantial computational costs, with the training time increasing by approximately 50% and the inference speed decreasing by up to 56% compared to the baseline model.
- Different routing strategies influence both model performance and computational efficiency. Top-k selection slightly improves validation performance but further reduces inference speed, while capacity factors improve load balancing but at the cost of additional computational overhead.
- Routing patterns evolve during training, with experts gradually developing specialization for different aspects of the input space. Capacity constraints appear to encourage diverse forms of specialization, including both character-level and sequence-level patterns.
7.2. Limitations
- Our experiments were conducted on a single dataset (Shakespeare) with a relatively small model architecture, and the findings may not generalize to larger models or different tasks. The specific hardware used also influenced the computational results.
- Our analysis lacked a systematic qualitative evaluation of the generated text, focusing instead on quantitative metrics and router behavior. Explainability methods could also be explored [49].
7.3. Future Work
- Lightweight routing mechanisms: Developing hash-based or learned index routing that reduces computational overhead while maintaining specialization benefits, potentially using techniques similar to locality-sensitive hashing for expert assignment.
- Hierarchical expert architectures: Implementing two-tier expert systems in which a fast primary router directs to expert clusters, followed by fine-grained routing within clusters, which could reduce routing overhead while maintaining specialization granularity.
- Dynamic expert capacity: Designing adaptive capacity-allocation mechanisms that adjust expert sizes based on task difficulty or input complexity, potentially using techniques from dynamic neural networks.
- Cross-layer expert sharing: Exploring expert networks that span multiple Transformer layers to amortize routing costs across the entire model depth.
- Pattern-aware routing: Developing routing mechanisms that explicitly consider character n-gram patterns or linguistic structures rather than learned embeddings alone.
- Sequence-length adaptive MoE: Implementing routing strategies that adapt expert selection based on local sequence complexity or position within longer contexts.
- Multi-granularity experts: Designing expert architectures that specialize in different linguistic levels (character, morpheme, and word boundaries) simultaneously.
- Approximate routing: Developing probabilistic or approximate expert selection methods that trade routing precision for computational efficiency.
- Expert pruning strategies: Implementing dynamic expert removal or merging techniques that eliminate underutilized experts during training.
- Hardware-aware MoE: Designing routing and expert architectures specifically optimized for the target hardware (e.g., mobile GPUs or edge devices) rather than using general-purpose implementations.
7.4. Significance
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4128–4141. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. In Proceedings of the Workshop on Energy Efficient Machine Learning and Cognitive Computing-NeurIPS 2019, Vancouver, BC, Canada, 13 December 2019. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling Language Modeling with Pathways. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 9411–9431. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 34302–34321. [Google Scholar]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient transformers: A survey. ACM Comput. Surv. 2022, 55, 109. [Google Scholar] [CrossRef]
- Schwartz, R.; Dodge, J.; Smith, N.A.; Etzioni, O. Green AI. Commun. ACM 2020, 63, 54–63. [Google Scholar] [CrossRef]
- Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.; Hinton, G.; Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch Transformers: Scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res. 2022, 23, 1–39. [Google Scholar]
- Jacobs, R.A.; Jordan, M.I.; Nowlan, S.J.; Hinton, G.E. Adaptive mixtures of local experts. Neural Comput. 1991, 3, 79–87. [Google Scholar] [CrossRef] [PubMed]
- Lepikhin, D.; Lee, H.; Xu, Y.; Chen, D.; Firat, O.; Huang, Y.; Krikun, M.; Shazeer, N.; Chen, Z. GShard: Scaling giant models with conditional computation and automatic sharding. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; Casas, D.d.l.; Bressand, F.; Lengyel, G.; Lachaux, M.A.; Lavril, T.; et al. Mixture-of-Experts with Expert Choice Routing. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Volume 36. [Google Scholar]
- Liu, Z.; Rajbhandari, S.; Li, Y.; Yao, Z.; Zhang, C.; Aminabadi, R.Y.; He, Y.; Zheng, E.; Yan, S.; Chen, M.; et al. DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale. In Proceedings of the 40th International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 22729–22744. [Google Scholar]
- Rajbhandari, S.; Li, C.; Liu, Z.; Chen, M.; Li, Y.; Aminabadi, R.Y.; He, A.A.A.Y.; Yan, S.; Zheng, E. DeepSpeed-MoE: Advancing mixture-of-experts inference and training to power next-generation AI scale. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 18332–18346. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N. Revisiting Mixture-of-Experts Model Parallelism. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 3206–3216. [Google Scholar]
- Yuan, H.; Wu, C.; Jiang, N.; Liu, X. Understanding and Improving Mixture-of-Experts Training via Annealed Importance Sampling. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Zoph, B.; Bello, I.; Chen, S.; Cheng, N.; Zou, J.; Liu, L.C.; Liu, T.Y.; Fedus, W.; Chowdhery, A.; Li, X.; et al. Designing Effective Sparse Expert Models. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 14174–14186. [Google Scholar]
- Shen, S.; Ghahramani, Z.; Le, Q.V.; Zhou, Y.; Han, S.; Kumar, S.; Jiang, J.; Shakeri, S.; Kuo, A.; Yuan, Z.; et al. Mixture-of-Experts with Expert Choice Routing. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Volume 36. [Google Scholar]
- He, J.; Jiang, J.; Sellentin, B.; Gupta, S.; Zhou, W.; Zhang, X.; Xu, D.; Liu, D.; Deng, L.; Li, S.Z.; et al. Fastmoe: A fast mixture-of-expert training system. In Proceedings of the 30th International Symposium on High-Performance Parallel and Distributed Computing, Stockholm, Sweden, 21–25 June 2021; pp. 183–185. [Google Scholar]
- Riquelme, C.; Puigcerver, J.; Mustafa, B.; Neumann, M.; Jenatton, R.; Pinto, A.M.; Keysers, D.; Houlsby, N. Scaling Vision with Sparse Mixture of Experts. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 8583–8593. [Google Scholar]
- Chen, Z.; Wang, Y.; Liu, T.; Liu, Y.; Li, S.; Wang, Z. Towards understanding mixture of experts in deep learning. Adv. Neural Inf. Process. Syst. 2022, 35, 36158–36170. [Google Scholar]
- Lewis, M.; Bhosale, S.; Dettmers, T.; Goyal, N.; Zettlemoyer, L. Base Layers: Simplifying Training of Large, Sparse Models. In Proceedings of the International Conference on Machine Learning, Shenzhen, China, 26 February–1 March 2021; pp. 6265–6274. [Google Scholar]
- Liu, M.; Huang, X.; Yang, Y.; Hu, X. Structured Pruning for Efficient Mixture-of-Experts. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 8798–8811. [Google Scholar]
- Muqeeth, M.A.; Jin, C.; Jandaghi, P.; Thung, F.; Lo, D.; Sundaresan, V. Demystifying GPT Self-Repair for Code Generation. arXiv 2023, arXiv:2306.09896. [Google Scholar]
- Kadavath, S.; Conerly, T.; Askell, A.; Henighan, T.; Drain, D.; Mann, B.; Perez, E.; Schiefer, N.; Showk, A.; Joseph, N.; et al. Language models (mostly) know what they know. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 12653–12661. [Google Scholar]
- Dai, D.; Zhou, Y.; Xiao, G.; Cimini, J.; Yang, Z.; Li, L.; Li, S. StableMoE: Stable Routing Strategy for Mixture of Experts. Adv. Neural Inf. Process. Syst. 2022, 35, 7444–7457. [Google Scholar]
- Chi, E.A.; Sabour, S.; Sun, C.; Romps, D.; Ellis, K. Representation Engineering: A Top-Down Approach to AI Transparency. arXiv 2023, arXiv:2310.01405. [Google Scholar]
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Marinova, E.; Lespiau, J.B.; Cai, T.; Laeuchli, J.; Mirza, S.; Bapst, V.; Rutherford, A.; et al. Training compute-optimal large language models. arXiv 2022, arXiv:2203.15556. [Google Scholar]
- Kudugunta, S.; Huang, Y.; Du, N.; Chen, M.; Zhou, A.; Song, X.; Zhou, D.; Lee, H.; Joshi, R.; Yu, A.; et al. Beyond distillation: Task-level mixture-of-experts for efficient inference. arXiv 2021, arXiv:2110.03742. [Google Scholar]
- Komatsuzaki, A.; Simig, D.; Zhou, I.; Belrose, G.; Zhang, H.; Bender, G.; Noune, H.; Chhipa, H.; Chowdhery, A.; Thopalli, K.; et al. Sparse Upcycling: Training Mixture-of-Experts with Bit-level Sparsity. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Li, K.; McCarley, J.S.; Jaech, A.; Apidianaki, M.; Khabsa, M.; Graff, E.; Shen, K.D.; Roukos, S. Mixture-of-experts with adaptive computation time. arXiv 2022, arXiv:2205.13501. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2978–2988. [Google Scholar]
- Lample, G.; Conneau, A. Cross-lingual language model pretraining. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Huang, Y.; Zhang, Z.; Wu, F.; Li, Z.; Bai, T.; Zhou, H.; Dong, L.; Wei, F.; Li, Z. Dynamic Token Sparsification for Efficient Language Modeling. In Proceedings of the Thirty-Sixth Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Li, B.; Chen, H.; Zhou, Y.; Dai, P. SparseFormer: Sparse Visual Recognition via Limited Region Aggregation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6570–6580. [Google Scholar]
- Du, N.; Huang, Y.; Dai, A.M.; Tong, S.; Lepikhin, D.; Xu, Y.; Krikun, M.; Zhou, Y.; Yu, A.W.; Firat, O.; et al. GLaM: Efficient scaling of language models with mixture-of-experts. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 5547–5569. [Google Scholar]
- Roller, S.; Suleman, D.; Szlam, A.; Goyal, N.; Weston, J. Hash Layers for Large Sparse Models. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 15776–15786. [Google Scholar]
- Wang, L.; Ping, W.; Chen, Y.; Ni, Y.; He, P.; Chen, W.; Liu, X. Residual Mixture-of-Experts Layer for Training Large Language Models. In Proceedings of the Thirty-Seventh Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Chen, T.; Chen, M. Mixture-of-Tokens: Efficient Alternative to Mixture-of-Experts. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Zhou, D.; Kim, T.W.; Lee, S. Sparse MoE Layers for Continual Learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 513–530. [Google Scholar]
- Kim, L.; Lee, S.; Zhao, T.; Chilimbi, T.; Papernot, N. Memory-Efficient Differentially Private MoE Training. In Proceedings of the Thirty-Seventh Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Mustafa, B.; Dehghani, M.; Ghezloo, A.; Riquelme, C.; Puigcerver, J.; Djolonga, J.; Houlsby, N.; Beyer, L. Multimodal Contrastive Learning with LIMoE: The Language-Image Mixture of Experts. In Proceedings of the Thirty-Sixth Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Clark, A.; Ye, D.; Cohen, N.; Chung, H.W.; Zoph, B.; Wei, J.; Zhou, D. UnifiedMoE: Scaling Instruction-Tuned Language Models. In Proceedings of the Thirty-Seventh Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Sutskever, I.; Martens, J.; Hinton, G.E. Generating text with recurrent neural networks. In Proceedings of the ICML, Bellevue, WA, USA, 28 June–2 July 2011; pp. 1017–1024. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Karpathy, A. nanoGPT. GitHub Repository. 2022. Available online: https://github.com/karpathy/nanoGPT (accessed on 15 November 2024).
- Pavlopoulos, J.; Malakasiotis, P.; Androutsopoulos, I. Explainability for natural language processing: A survey on methods and evaluation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4499–4514. [Google Scholar]
- Malinova, A.; Golev, A.; Iliev, A.; Kyurkchiev, N. A family of recurrence generating activation functions based on Gudermann function. Int. J. Eng. Res. Manag. Stud. 2017, 4, 58–72. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | MoE | Character-Level Modeling | Small-Scale Models | Performance–Efficiency Trade-Off Analysis |
|---|---|---|---|---|
| GShard [13] | ✓ | ✓ | ||
| Switch Transformer [11] | ✓ | ✓ | ||
| Character Transformers | ✓ | ✓ | ||
| DeepSpeed-MoE | ✓ | ✓ | ||
| Mixtral [14] | ✓ | ✓ | ||
| Our Work | ✓ | ✓ | ✓ | ✓ |
| Model | Training Time (s) | Inference Speed (tokens/s) |
|---|---|---|
| Baseline (Original FFN) | 287.9 | 441.3 |
| MoE Base (4 experts) | 434.0 | 250.9 |
| MoE Top-2 Experts | 460.5 | 224.7 |
| MoE Capacity 0.5 | 463.3 | 196.9 |
| MoE Capacity 1.0 | 463.3 | 195.0 |
| Model | Best Val. Loss | Training Time (s) | Inference Speed (tokens/s) |
|---|---|---|---|
| Baseline | 1.4739 | 287.9 | 441.3 |
| MoE Base | 1.4764 (+0.17%) | 434.0 (+50.7%) | 250.9 (−43.1%) |
| MoE Top-2 | 1.4718 (−0.14%) | 460.5 (+60.0%) | 224.7 (−49.1%) |
| MoE Capacity 0.5 | 1.4718 (−0.14%) | 463.3 (+60.9%) | 196.9 (−55.4%) |
| MoE Capacity 1.0 | 1.4718 (−0.14%) | 463.3 (+60.9%) | 195.0 (−55.8%) |
| Model | Final Training Loss | Final Validation Loss | Training–Val. Gap |
|---|---|---|---|
| Baseline | 1.387 | 1.474 | +0.087 |
| MoE Base | 1.634 | 1.476 | −0.158 |
| MoE Top-2 | 1.612 | 1.472 | −0.140 |
| MoE Capacity 0.5 | 1.618 | 1.472 | −0.146 |
| MoE Capacity 1.0 | 1.615 | 1.472 | −0.143 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Chen, M.; Zheng, S. Dynamic Mixture of Experts for Adaptive Computation in Character-Level Transformers. Information 2025, 16, 483. https://doi.org/10.3390/info16060483
Huang Z, Chen M, Zheng S. Dynamic Mixture of Experts for Adaptive Computation in Character-Level Transformers. Information. 2025; 16(6):483. https://doi.org/10.3390/info16060483
Chicago/Turabian StyleHuang, Zhigao, Musheng Chen, and Shiyan Zheng. 2025. "Dynamic Mixture of Experts for Adaptive Computation in Character-Level Transformers" Information 16, no. 6: 483. https://doi.org/10.3390/info16060483
APA StyleHuang, Z., Chen, M., & Zheng, S. (2025). Dynamic Mixture of Experts for Adaptive Computation in Character-Level Transformers. Information, 16(6), 483. https://doi.org/10.3390/info16060483