
EHMQA-GPT: A Knowledge Augmented Large Language Model for Personalized Elderly Health Management



Abstract
1. Introduction
- (1)
- We proposed EHMQA-GPT, a large language model for elderly health management. It can understand users’ intentions in asking questions and provide accurate responses. This model can offer practical assistance to the elderly population and their caregivers.
- (2)
- The data collection strategy and the constructed special corpus in this paper can serve as the research foundation for large language models in the field of elderly health management.
- (3)
- Through a large number of experiments on the evaluation dataset, the effectiveness of EHMQA-GPT and the corpus was verified. The experimental results confirmed the feasibility of the research ideas in this paper and provided a practical and feasible method for future researchers.
2. Related Work
2.1. General LLMs
2.2. Med-LLMs
2.3. Summary of LLMs in EHM
2.4. Comparison with Knowledge-Graph-Based Methods
2.4.1. Methodological Contrast
- (1)
- Knowledge Representation
- (2)
- Reasoning Mechanisms
- (3)
- Operational Flexibility
2.4.2. Novelty and Synergy
- (1)
- Handling Unstructured Data
- (2)
- Cost-Efficiency
- (3)
- Dynamic Adaptation
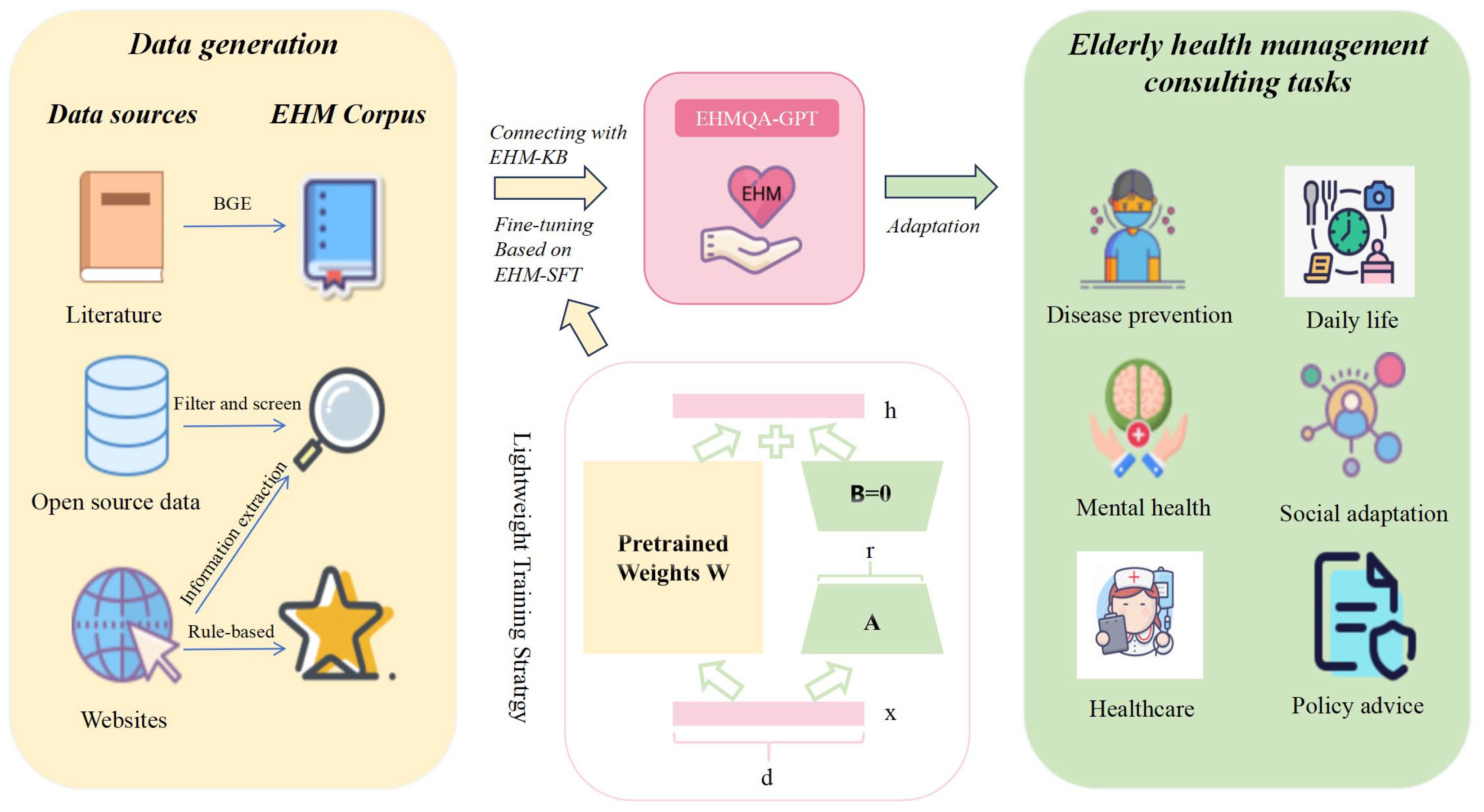
3. EHMQA-GPT Data Collection and Processing
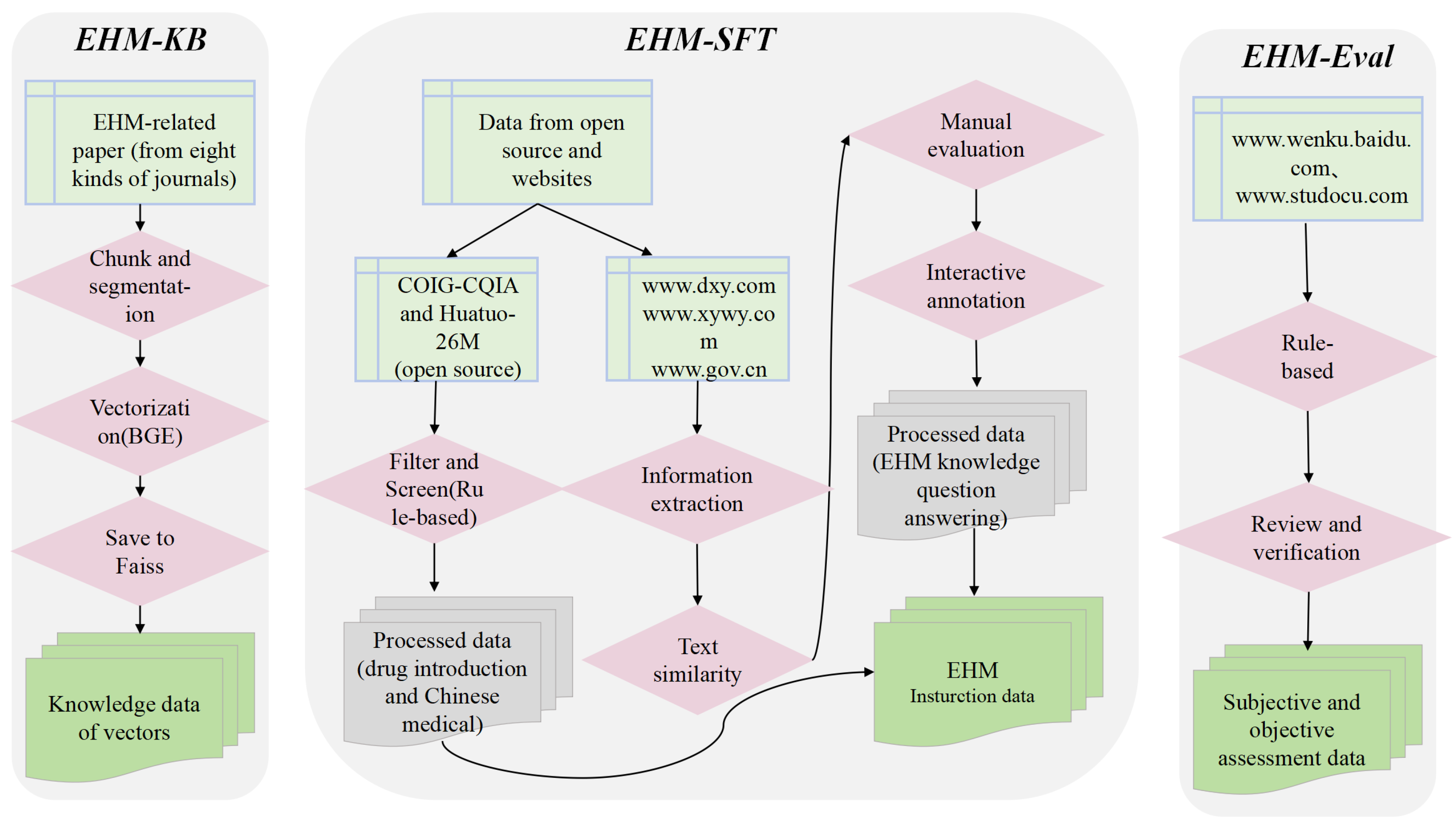
3.1. EHM Corpus: EHM-KB
3.2. Instruction Tuning Corpus: EHM-SFT
3.2.1. Dataset Overview
3.2.2. Professional Instruction Tuning Data
- (1)
- Construction of the dataset based on information extraction using LLMs
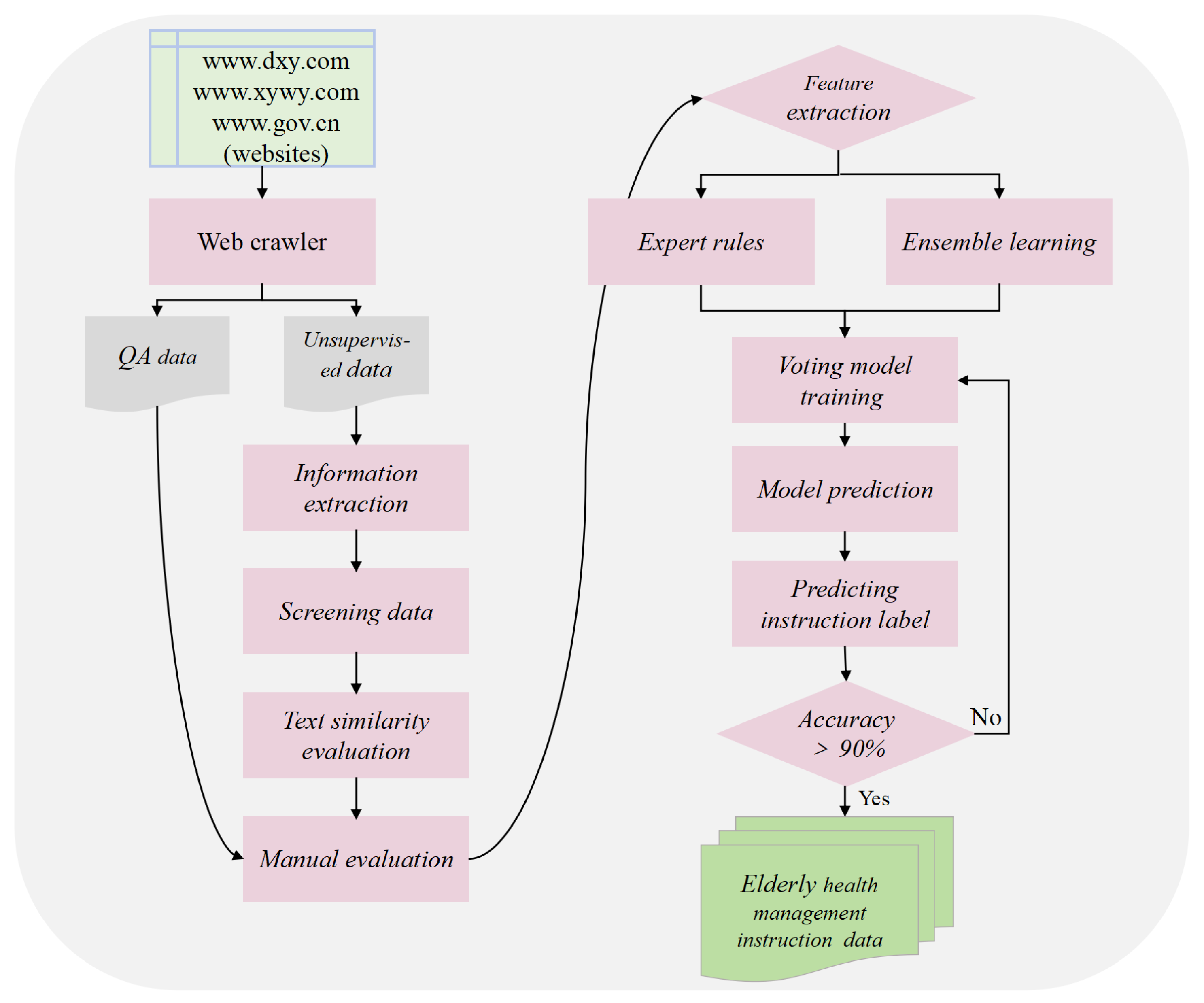
- Data crawling: This step used web crawlers to collect question–answer data and unsupervised data (i.e., unstructured text data) related to elderly health management from authoritative websites such as www.dxy.com, www.xywy.com, and www.gov.cn. The crawled data cover aspects including professional knowledge of elderly diseases, common health questions, health care and wellness, prevention and nursing, and medical insurance service policies. The question–answer data pairs will be stored in JSON format, while the unsupervised data will be logically divided by the delimiter “@@@@@” into each piece of data and saved as txt files.
- Information extraction and data generation: Leveraging the powerful information extraction capabilities of LLMs, the acquired unsupervised data are used as background knowledge input. Prompt engineering is employed to design instruction prompts (see Figure 5a), guiding the model to generate instruction questions with strong domain characteristics that are closely related to the background knowledge. Additionally, answer generation prompts are designed (see Figure 5b) to instruct the model to generate corresponding answers based on the background knowledge and the previously generated instruction questions.
- Data cleaning and screening: A combination of regular expressions and manual review was applied to clean and filter the instruction data. Specifically, the following criteria were used: (1) eliminating duplicate QA pairs based on semantic similarity (cosine similarity threshold > 0.95); (2) discarding incomplete or empty answers; (3) filtering out formatting inconsistencies, such as missing question headers or malformed delimiters; and (4) removing out-of-domain content, including non-health-related queries or generic chatbot responses. These steps ensured that the resulting instruction dataset was consistent, medically relevant, and of high quality.
- Text similarity evaluation: The model is prompted to generate different answers based on the background knowledge and instruction questions (see Figure 5c). Text similarity evaluation prompts are designed to guide the model in assessing the text similarity between these answers. Instruction data with significant semantic differences, low accuracy, or weak domain relevance are identified and removed.
- Manual evaluation and annotation: Manual annotation, combined with semantic similarity features, provides a basis for model training and accuracy evaluation. Instruction data pairs closely related to elderly health management are assigned a label value of 0, while those with low or no relevance are assigned a label value of 1.
- Human–computer interaction annotation: During the stage of manual evaluation and annotation, 10,000 pieces of data were randomly selected for annotation to form the initial sample set. Subsequently, based on the manual evaluation criteria, an expert rule model was defined, and a voting classification model was trained on the initial sample set to enable the model to have high-accuracy data classification. In the human–computer interaction annotation stage, the remaining 27,769 pieces of data were annotated interactively. Finally, the instance labels of all data were obtained, and the dataset was completed.
- (2)
- Open-Source Professional Datasets
3.3. Evaluation Corpus: EHM-Eval
4. The Training Process of EHMQA-GPT
4.1. EHMQA-GPT Supervised Fine-Tuning
4.2. Knowledge Base Connecting
5. The Evaluation of EHMQA-GPT
5.1. Objective Task
5.2. Subjective Task
5.2.1. GPT-4 as a Judge
5.2.2. Assessment Based on Professionals
5.3. Error Analysis
- (1)
- Issues such as ambiguous subject reference in the instructions;
- (2)
- Lack of factual grounding, especially for recent policy updates not yet reflected in the knowledge base;
- (3)
- Lexical overlap-based confusion, where the model selected the distractor due to surface-level similarity.
- (1)
- Rephrased but failed to complete key factual elements;
- (2)
- Overgeneralized advice without considering an elderly-specific context.
6. Discussion
6.1. Review of Methods and Analysis of Experimental Limitations
6.2. Transferability of the Research Methods
7. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Han, L.; Wu, F. COVID-19 Drives Medical Education Reform to Promote “Healthy China 2030” Action Plan. Front. Public Health 2024, 12, 1465781. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Ye, W.; Chen, X.; Li, Y.; Zhang, L.; Li, F.; Yao, N.; Gao, C.; Wang, P.; Yi, D.; et al. Spatio-Temporal Pattern, Matching Level and Prediction of Ageing and Medical Resources in China. BMC Public Health 2023, 23, 1155. [Google Scholar] [CrossRef]
- Min, B.; Ross, H.; Sulem, E.; Veyseh, A.P.B.; Nguyen, T.H.; Sainz, O.; Agirre, E.; Heintz, I.; Roth, D. Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey. ACM Comput. Surv. 2023, 56, 1–40. [Google Scholar] [CrossRef]
- Zheng, J.; Ding, X.; Pu, J.J.; Chung, S.M.; Ai, Q.Y.H.; Hung, K.F.; Shan, Z. Unlocking the Potentials of Large Language Models in Orthodontics: A Scoping Review. Bioengineering 2024, 11, 1145. [Google Scholar] [CrossRef]
- Zhu, S.; He, C. Chinese News Classification Based on ERNIE and Attention Fusion Features. In Proceedings of the 2023 6th International Conference on Robot Systems and Applications, Wuhan, China, 22–24 September 2023; Association for Computing Machinery: New York, NY, USA, 2024; pp. 134–138. [Google Scholar]
- Che, T.-Y.; Mao, X.-L.; Lan, T.; Huang, H. A Hierarchical Context Augmentation Method to Improve Retrieval-Augmented LLMs on Scientific Papers. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 243–254. [Google Scholar]
- Liu, C.; Sun, K.; Zhou, Q.; Duan, Y.; Shu, J.; Kan, H.; Gu, Z.; Hu, J. CPMI-ChatGLM: Parameter-Efficient Fine-Tuning ChatGLM with Chinese Patent Medicine Instructions. Sci. Rep. 2024, 14, 6403. [Google Scholar] [CrossRef]
- Katz, D.M.; Bommarito, M.J.; Gao, S.; Arredondo, P. GPT-4 Passes the Bar Exam. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 2024, 382, 20230254. [Google Scholar] [CrossRef]
- Waisberg, E.; Ong, J.; Masalkhi, M.; Kamran, S.A.; Zaman, N.; Sarker, P.; Lee, A.G.; Tavakkoli, A. GPT-4: A New Era of Artificial Intelligence in Medicine. Ir. J. Med. Sci. 2023, 192, 3197–3200. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Zhou, W.; Cheng, J.; Yang, J. An Enhanced Retrieval Scheme for a Large Language Model with a Joint Strategy of Probabilistic Relevance and Semantic Association in the Vertical Domain. Appl. Sci. 2024, 14, 11529. [Google Scholar] [CrossRef]
- Yue, S.; Liu, S.; Zhou, Y.; Shen, C.; Wang, S.; Xiao, Y.; Li, B.; Song, Y.; Shen, X.; Chen, W.; et al. LawLLM: Intelligent Legal System with Legal Reasoning and Verifiable Retrieval. In Proceedings of the Database Systems for Advanced Applications, Gifu, Japan, 2–5 July 2024; Onizuka, M., Lee, J.-G., Tong, Y., Xiao, C., Ishikawa, Y., Amer-Yahia, S., Jagadish, H.V., Lu, K., Eds.; Springer Nature: Singapore, 2024; pp. 304–321. [Google Scholar]
- Wang, P.; Wei, X.; Hu, F.; Han, W. TransGPT: Multi-Modal Generative Pre-Trained Transformer for Transportation. In Proceedings of the 2024 International Conference on Computational Linguistics and Natural Language Processing (CLNLP), Yinchuan, China, 19–21 July 2024; pp. 96–100. [Google Scholar]
- Kuska, M.T.; Wahabzada, M.; Paulus, S. AI for Crop Production—Where Can Large Language Models (LLMs) Provide Substantial Value? Comput. Electron. Agric. 2024, 221, 108924. [Google Scholar] [CrossRef]
- Wen, Q.; Liang, J.; Sierra, C.; Luckin, R.; Tong, R.; Liu, Z.; Cui, P.; Tang, J. AI for Education (AI4EDU): Advancing Personalized Education with LLM and Adaptive Learning. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 6743–6744. [Google Scholar]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large Language Models in Medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef]
- Agarwal, S.; Acun, B.; Hosmer, B.; Elhoushi, M.; Lee, Y.; Venkataraman, S.; Papailiopoulos, D.; Wu, C.-J. CHAI: Clustered Head Attention for Efficient LLM Inference. arXiv 2024, arXiv:2403.08058. [Google Scholar]
- Balkus, S.V.; Yan, D. Improving Short Text Classification with Augmented Data Using GPT-3. Nat. Lang. Eng. 2024, 30, 943–972. [Google Scholar] [CrossRef]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling Language Modeling with Pathways. J. Mach. Learn. Res. 2022, 24, 1–113. [Google Scholar]
- Wu, C.; Gan, Y.; Ge, Y.; Lu, Z.; Wang, J.; Feng, Y.; Shan, Y.; Luo, P. LLaMA Pro: Progressive LLaMA with Block Expansion. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; Ku, L.-W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Bangkok, Thailand, 2024; pp. 6518–6537. [Google Scholar]
- Gabber, H.A.; Hemied, O.S. Domain-Specific Large Language Model for Renewable Energy and Hydrogen Deployment Strategies. Energies 2024, 17, 6063. [Google Scholar] [CrossRef]
- Wu, S.; Peng, Z.; Du, X.; Zheng, T.; Liu, M.; Wu, J.; Ma, J.; Li, Y.; Yang, J.; Zhou, W.; et al. A Comparative Study on Reasoning Patterns of OpenAI’s O1 Model. arXiv 2024, arXiv:2410.13639. [Google Scholar]
- Hurst, A.; Lerer, A.; Goucher, A.P.; Perelman, A.; Ramesh, A.; Clark, A.; Ostrow, A.J.; Welihinda, A.; Hayes, A.; Radford, A.; et al. GPT-4o System Card. arXiv 2024, arXiv:2410.21276. [Google Scholar]
- Mondillo, G.; Frattolillo, V.; Colosimo, S.; Perrotta, A.; Di Sessa, A.; Guarino, S.; Miraglia Del Giudice, E.; Marzuillo, P. Basal Knowledge in the Field of Pediatric Nephrology and Its Enhancement Following Specific Training of ChatGPT-4 “Omni” and Gemini 1.5 Flash. Pediatr. Nephrol. Berl. Ger. 2025, 40, 151–157. [Google Scholar] [CrossRef]
- Chen, G.; Fan, Z.; Zhu, Y.; Zhang, T. Multi-Time Knowledge Distillation. Neurocomputing 2025, 623, 129377. [Google Scholar] [CrossRef]
- Huang, T.; Dong, W.; Wu, F.; Li, X.; Shi, G. Uncertainty-Driven Knowledge Distillation for Language Model Compression. IEEEACM Trans. Audio Speech Lang. Process. 2023, 31, 2850–2858. [Google Scholar] [CrossRef]
- Zhuang, R.; Wang, B.; Sun, S.; Wang, Y.; Ding, Z.; Liu, W. Unlocking Chain of Thought in Base Language Models by Heuristic Instruction. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–7. [Google Scholar]
- Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. Training Verifiers to Solve Math Word Problems. arXiv 2021, arXiv:2110.14168. [Google Scholar]
- Liu, L.; Zhang, D.; Li, S.; Zhou, G.; Cambria, E. Two Heads Are Better than One: Zero-Shot Cognitive Reasoning via Multi-LLM Knowledge Fusion. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Boise, ID, USA, 21–25 October 2024; pp. 1462–1472. [Google Scholar] [CrossRef]
- Besta, M.; Blach, N.; Kubicek, A.; Gerstenberger, R.; Podstawski, M.; Gianinazzi, L.; Gajda, J.; Lehmann, T.; Niewiadomski, H.; Nyczyk, P.; et al. Graph of Thoughts: Solving Elaborate Problems with Large Language Models. In Proceedings of the AAAI Conference on Artificial Intelligence 2024, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 17682–17690. [Google Scholar] [CrossRef]
- Xie, T.; Gao, Z.; Ren, Q.; Luo, H.; Hong, Y.; Dai, B.; Zhou, J.; Qiu, K.; Wu, Z.; Luo, C. Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning. arXiv 2025, arXiv:2502.14768. [Google Scholar]
- Cuconasu, F.; Trappolini, G.; Siciliano, F.; Filice, S.; Campagnano, C.; Maarek, Y.; Tonellotto, N.; Silvestri, F. The Power of Noise: Redefining Retrieval for RAG Systems. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 11–15 July 2024; pp. 719–729. [Google Scholar] [CrossRef]
- Huang, W.; Wu, A.; Yang, Y.; Luo, X.; Yang, Y.; Hu, L.; Dai, Q.; Dai, X.; Chen, D.; Luo, C.; et al. LLM2CLIP: Powerful Language Model Unlocks Richer Visual Representation. arXiv 2024, arXiv:2411.04997. [Google Scholar]
- Fan, W.; Ding, Y.; Ning, L.; Wang, S.; Li, H.; Yin, D.; Chua, T.-S.; Li, Q. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 6491–6501. [Google Scholar]
- Karacan, E. Evaluating the Quality of Postpartum Hemorrhage Nursing Care Plans Generated by Artificial Intelligence Models. J. Nurs. Care Qual. 2024, 39, 206–211. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A Pre-Trained Biomedical Language Representation Model for Biomedical Text Mining. Bioinforma. Oxf. Engl. 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Bian, J.; Huang, X.; Zhou, H.; Zhu, S. PubLabeler: Enhancing Automatic Classification of Publications in UniProtKB Using Protein Textual Description and PubMedBERT. IEEE J. Biomed. Health Inform. 2024, 29, 3782–3791. [Google Scholar] [CrossRef]
- Cervera, M.R.; Bermejo-Peláez, D.; Gómez-Álvarez, M.; Hidalgo Soto, M.; Mendoza-Martínez, A.; Oñós Clausell, A.; Darias, O.; García-Villena, J.; Benavente Cuesta, C.; Montoro, J.; et al. Assessment of Artificial Intelligence Language Models and Information Retrieval Strategies for QA in Hematology. Blood 2023, 142, 7175. [Google Scholar] [CrossRef]
- Li, Y.; Li, Z.; Zhang, K.; Dan, R.; Jiang, S.; Zhang, Y. ChatDoctor: A Medical Chat Model Fine-Tuned on a Large Language Model Meta-AI (LLaMA) Using Medical Domain Knowledge. Cureus 2023, 15, e40895. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Zhao, S.; Qiang, Z.; Li, Z.; Liu, C.; Xi, N.; Du, Y.; Qin, B.; Liu, T. Knowledge-Tuning Large Language Models with Structured Medical Knowledge Bases for Trustworthy Response Generation in Chinese. ACM Trans. Knowl. Discov. Data 2025, 19, 1–17. [Google Scholar] [CrossRef]
- Zhang, P.; Shi, J.; Kamel Boulos, M.N. Generative AI in Medicine and Healthcare: Moving Beyond the ‘Peak of Inflated Expectations’. Future Internet 2024, 16, 462. [Google Scholar] [CrossRef]
- Kim, Y.; Xu, X.; McDuff, D.; Breazeal, C.; Park, H.W. Health-LLM: Large Language Models for Health Prediction via Wearable Sensor Data. arXiv 2024, arXiv:2401.06866. [Google Scholar]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large Language Models Encode Clinical Knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Toma, A.; Lawler, P.R.; Ba, J.; Krishnan, R.G.; Rubin, B.B.; Wang, B. Clinical Camel: An Open Expert-Level Medical Language Model with Dialogue-Based Knowledge Encoding. arXiv 2023, arXiv:2305.12031. [Google Scholar]
- Wu, C.; Lin, W.; Zhang, X.; Zhang, Y.; Xie, W.; Wang, Y. PMC-LLaMA: Toward Building Open-Source Language Models for Medicine. J. Am. Med. Inform. Assoc. JAMIA 2024, 31, 1833–1843. [Google Scholar] [CrossRef]
- Varshney, D.; Zafar, A.; Behera, N.K.; Ekbal, A. Knowledge Graph Assisted End-to-End Medical Dialog Generation. Artif. Intell. Med. 2023, 139, 102535. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Chen, A.; PourNejatian, N.; Shin, H.C.; Smith, K.E.; Parisien, C.; Compas, C.; Martin, C.; Costa, A.B.; Flores, M.G.; et al. A Large Language Model for Electronic Health Records. NPJ Digit. Med. 2022, 5, 194. [Google Scholar] [CrossRef]
- Gupta, R.; Bhongade, A.; Gandhi, T.K. Multimodal Wearable Sensors-Based Stress and Affective States Prediction Model. In Proceedings of the 2023 9th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 17–18 March 2023; Volume 1, pp. 30–35. [Google Scholar]
- Yin, X.; Zhu, Y.; Hu, J. A Comprehensive Survey of Privacy-Preserving Federated Learning: A Taxonomy, Review, and Future Directions. ACM Comput. Surv. 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Alghamdi, H.; Mostafa, A. Advancing EHR Analysis: Predictive Medication Modeling Using LLMs. Inf. Syst. 2025, 131, 102528. [Google Scholar] [CrossRef]
- Marziali, R.A.; Franceschetti, C.; Dinculescu, A.; Nistorescu, A.; Kristály, D.M.; Moșoi, A.A.; Broekx, R.; Marin, M.; Vizitiu, C.; Moraru, S.-A.; et al. Reducing Loneliness and Social Isolation of Older Adults Through Voice Assistants: Literature Review and Bibliometric Analysis. J. Med. Internet Res. 2024, 26, e50534. [Google Scholar] [CrossRef]
- Lv, X.; Gao, Z.; Yuan, C.; Li, M.; Chen, C. Hybrid Real-Time Fall Detection System Based on Deep Learning and Multi-Sensor Fusion. In Proceedings of the 2020 6th International Conference on Big Data and Information Analytics (BigDIA), Shenzhen, China, 4–6 December 2020; pp. 386–391. [Google Scholar]
- Wang, B.; Chang, J.; Qian, Y.; Chen, G.; Chen, J.; Jiang, Z.; Zhang, J.; Nakashima, Y.; Nagahara, H. DiReCT: Diagnostic Reasoning for Clinical Notes via Large Language Models. arXiv 2024, arXiv:2408.01933. [Google Scholar]
- Gao, Y.; Li, R.; Croxford, E.; Caskey, J.; Patterson, B.W.; Churpek, M.; Miller, T.; Dligach, D.; Afshar, M. Leveraging Medical Knowledge Graphs Into Large Language Models for Diagnosis Prediction: Design and Application Study. Jmir Ai 2025, 4, e58670. [Google Scholar] [CrossRef]
- Xiao, S.; Liu, Z.; Zhang, P.; Muennighoff, N.; Lian, D.; Nie, J.-Y. C-Pack: Packed Resources For General Chinese Embeddings. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 641–649. [Google Scholar]
- Douze, M.; Guzhva, A.; Deng, C.; Johnson, J.; Szilvasy, G.; Mazaré, P.-E.; Lomeli, M.; Hosseini, L.; Jégou, H. The Faiss Library. arXiv 2025, arXiv:2401.08281. [Google Scholar]
- Song, Y.; Liu, C.; Zhang, R.; Zhu, D.; Wang, Z. An Efficient FPGA Implementation of Approximate Nearest Neighbor Search. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2025, 33, 1705–1714. [Google Scholar] [CrossRef]
- Bai, Y.; Du, X.; Liang, Y.; Jin, Y.; Zhou, J.; Liu, Z.; Fang, F.; Chang, M.; Zheng, T.; Zhang, X.; et al. COIG-CQIA: Quality Is All You Need for Chinese Instruction Fine-Tuning. arXiv 2024, arXiv:2403.18058. [Google Scholar]
- Wang, X.; Li, J.; Chen, S.; Zhu, Y.; Wu, X.; Zhang, Z.; Xu, X.; Chen, J.; Fu, J.; Wan, X.; et al. Huatuo-26M, a Large-Scale Chinese Medical QA Dataset. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2025, Albuquerque, NM, USA, 29 April–4 May 2025; Chiruzzo, L., Ritter, A., Wang, L., Eds.; Association for Computational Linguistics: Troutsburg, PA, USA, 2025; pp. 3828–3848. [Google Scholar]
- Han, Z.; Gao, C.; Liu, J.; Zhang, J.; Zhang, S.Q. Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey. arXiv 2024, arXiv:2403.14608. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. ICLR 2022, 1, 3. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Generation Method or Source | Task | Count of Final Instruction QA Pairs | |
|---|---|---|---|
| Information extraction | Elderly health management knowledge question answering | 37,769 | |
| Open-source | COIG-CQIA | Drug introduction QA | 6971 |
| Open-source | Huatuo-26M | Chinese medical QA | 49,899 |
| Category | Disease Prevention | Daily Life | Mental Health | Social Adaptation | Healthcare | Policy Advice | Total |
|---|---|---|---|---|---|---|---|
| Objective Questions | 180 | 150 | 90 | 110 | 120 | 70 | 720 |
| Subjective Questions | 41 | 35 | 26 | 25 | 29 | 24 | 180 |
| Model | Disease Prevention | Daily Life | Mental Health | Social Adaptation | Healthcare | Policy Advice | Average |
|---|---|---|---|---|---|---|---|
| ChatGLM3-6B | 0.583 ± 0.0318 | 0.633 ± 0.0336 | 0.511 ± 0.0356 | 0.555 ± 0.0359 | 0.608 ± 0.0357 | 0.457 ± 0.0379 | 0.558 ± 0.0209 |
| DeepSeek R1-7B | 0.711 ± 0.0323 | 0.787 ± 0.0318 | 0.689 ± 0.0355 | 0.700 ± 0.0340 | 0.733 ± 0.0340 | 0.614 ± 0.0377 | 0.706 ± 0.0208 |
| DoctorGLM | 0.761 ± 0.0302 | 0.707 ± 0.0341 | 0.689 ± 0.0356 | 0.682 ± 0.0343 | 0.808 ± 0.0301 | 0.657 ± 0.0360 | 0.717 ± 0.0208 |
| EHMQA-GPT | 0.822 ± 0.0276 | 0.767 ± 0.0318 | 0.789 ± 0.0341 | 0.773 ± 0.0321 | 0.792 ± 0.0322 | 0.743 ± 0.0340 | 0.781 ± 0.0198 |
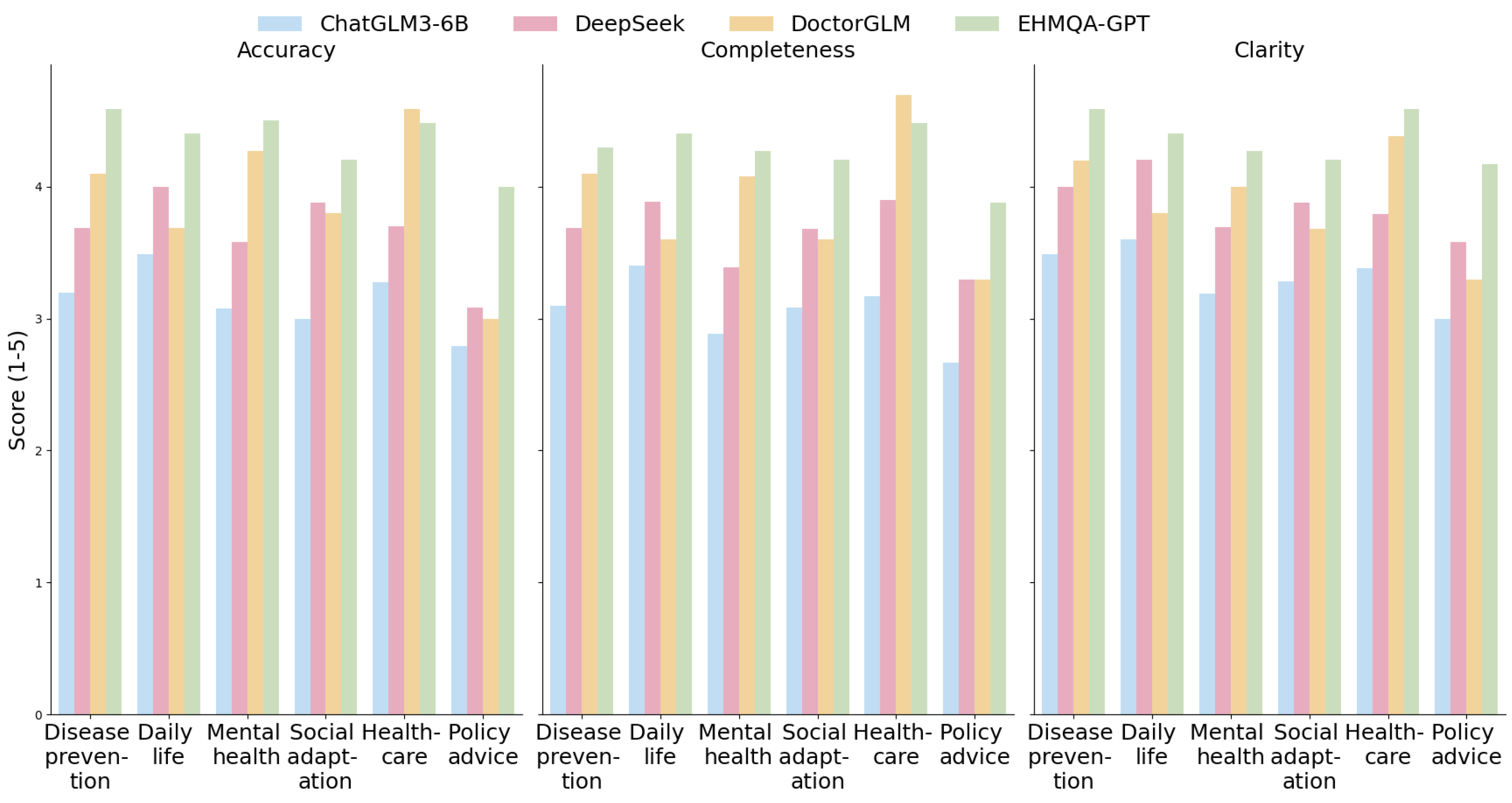
| Index | Category | ChatGLM3-6B | DeepSeek R1-7B | DoctorGLM | EHMQA-GPT |
|---|---|---|---|---|---|
| Accuracy | Disease prevention | 3.195 ± 0.1427 | 3.683 ± 0.1489 | 4.098 ± 0.1470 | 4.585 ± 0.1429 |
| Daily life | 3.486 ± 0.1455 | 4.000 ± 0.1457 | 3.686 ± 0.1459 | 4.400 ± 0.1455 | |
| Mental health | 3.077 ± 0.1470 | 3.577 ± 0.1470 | 4.269 ± 0.1470 | 4.500 ± 0.1458 | |
| Social adaptation | 3.000 ± 0.1455 | 3.880 ± 0.1455 | 3.800 ± 0.1455 | 4.200 ± 0.1455 | |
| Healthcare | 3.276 ± 0.1457 | 3.700 ± 0.1458 | 4.586 ± 0.1459 | 4.483 ± 0.1457 | |
| Policy advice | 2.792 ± 0.1455 | 3.083 ± 0.1455 | 3.000 ± 0.1455 | 4.000 ± 0.1455 | |
| Average | 3.138 ± 0.1058 | 3.654 ± 0.1059 | 3.907 ± 0.1059 | 4.361 ± 0.1057 | |
| Completeness | Disease prevention | 3.096 ± 0.1455 | 3.683 ± 0.1455 | 4.096 ± 0.1455 | 4.293 ± 0.1460 |
| Daily life | 3.400 ± 0.1455 | 3.886 ± 0.1455 | 3.600 ± 0.1455 | 4.400 ± 0.1453 | |
| Mental health | 2.885 ± 0.1454 | 3.385 ± 0.1456 | 4.077 ± 0.1455 | 4.269 ± 0.1456 | |
| Social adaptation | 3.080 ± 0.1456 | 3.680 ± 0.1454 | 3.600 ± 0.1454 | 4.200 ± 0.1454 | |
| Healthcare | 3.172 ± 0.1454 | 3.897 ± 0.1456 | 4.690 ± 0.1457 | 4.483 ± 0.1454 | |
| Policy advice | 2.667 ± 0.1456 | 3.292 ± 0.1454 | 3.292 ± 0.1456 | 3.875 ± 0.1457 | |
| Average | 3.050 ± 0.1055 | 3.637 ± 0.1055 | 3.893 ± 0.1057 | 4.253 ± 0.1052 | |
| Clarity | Disease prevention | 3.488 ± 0.1053 | 4.000 ± 0.1055 | 4.185 ± 0.1064 | 4.585 ± 0.1060 |
| Daily life | 3.600 ± 0.1055 | 4.200 ± 0.1056 | 3.800 ± 0.1061 | 4.400 ± 0.1056 | |
| Mental health | 3.192 ± 0.1057 | 3.692 ± 0.1054 | 4.000 ± 0.1058 | 4.269 ± 0.1058 | |
| Social adaptation | 3.280 ± 0.1054 | 3.880 ± 0.1055 | 3.680 ± 0.1056 | 4.200 ± 0.1057 | |
| Healthcare | 3.379 ± 0.1054 | 3.793 ± 0.1053 | 4.379 ± 0.1057 | 4.586 ± 0.1056 | |
| Policy advice | 3.000 ± 0.1056 | 3.583 ± 0.1057 | 3.292 ± 0.1055 | 4.167 ± 0.1055 | |
| Average | 3.323 ± 0.1053 | 3.858 ± 0.1053 | 3.891 ± 0.1057 | 4.368 ± 0.1053 |
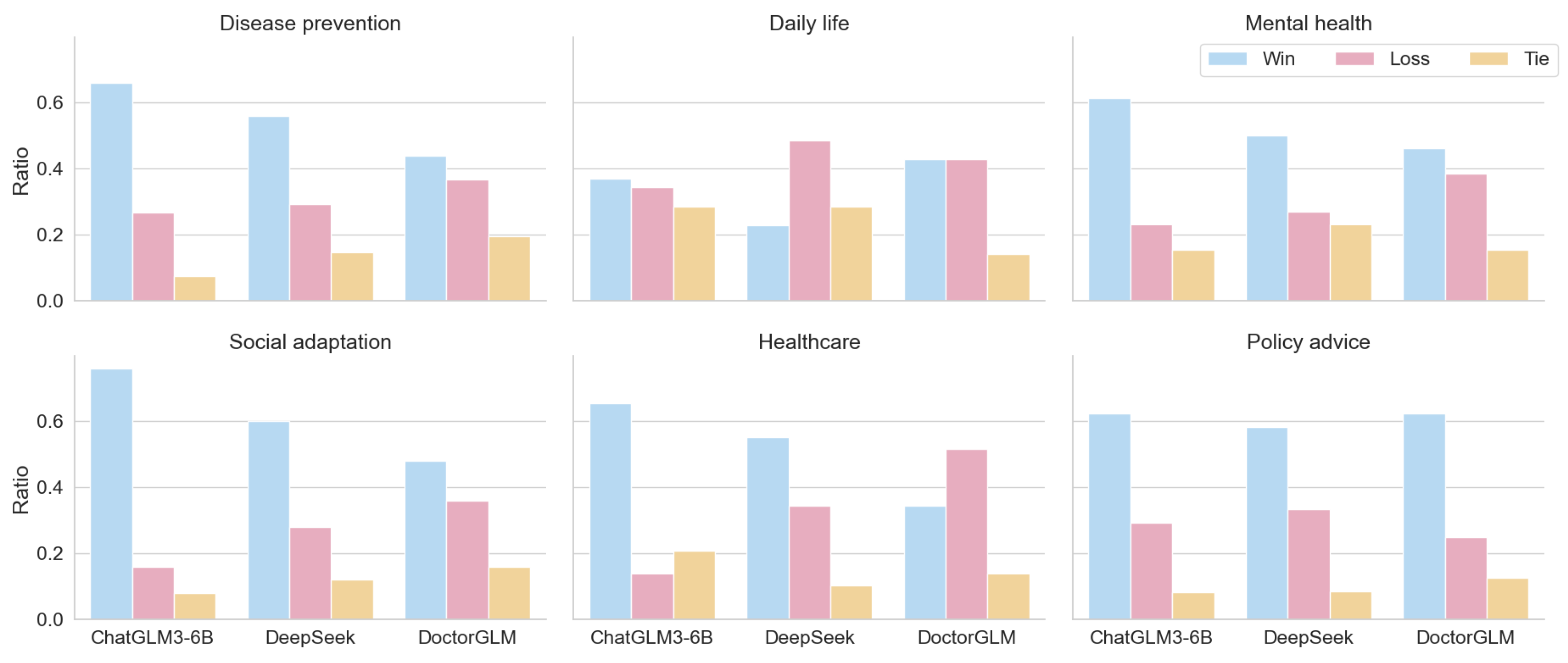
| Title 1 | Evaluation | ChatGLM3-6B | DeepSeek R1-7B | DoctorGLM |
|---|---|---|---|---|
| Disease prevention | Win | 0.659 | 0.561 | 0.439 |
| Loss | 0.268 | 0.293 | 0.366 | |
| Tie | 0.073 | 0.146 | 0.195 | |
| Daily life | Win | 0.371 | 0.228 | 0.429 |
| Loss | 0.343 | 0.486 | 0.429 | |
| Tie | 0.286 | 0.286 | 0.142 | |
| Mental health | Win | 0.615 | 0.500 | 0.462 |
| Loss | 0.231 | 0.269 | 0.384 | |
| Tie | 0.154 | 0.231 | 0.154 | |
| Social adaptation | Win | 0.760 | 0.600 | 0.480 |
| Loss | 0.160 | 0.280 | 0.360 | |
| Tie | 0.080 | 0.120 | 0.160 | |
| Healthcare | Win | 0.655 | 0.552 | 0.345 |
| Loss | 0.138 | 0.345 | 0.517 | |
| Tie | 0.207 | 0.103 | 0.138 | |
| Policy advice | Win | 0.625 | 0.583 | 0.625 |
| Loss | 0.292 | 0.333 | 0.250 | |
| Tie | 0.083 | 0.084 | 0.125 | |
| Average | Win | 0.614 | 0.504 | 0.463 |
| Loss | 0.239 | 0.334 | 0.384 | |
| Tie | 0.147 | 0.162 | 0.153 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, S.; Duan, Y.; Zhou, T.; Liu, X.; Wang, J. EHMQA-GPT: A Knowledge Augmented Large Language Model for Personalized Elderly Health Management. Information 2025, 16, 467. https://doi.org/10.3390/info16060467
Lin S, Duan Y, Zhou T, Liu X, Wang J. EHMQA-GPT: A Knowledge Augmented Large Language Model for Personalized Elderly Health Management. Information. 2025; 16(6):467. https://doi.org/10.3390/info16060467
Chicago/Turabian StyleLin, Shaofu, Yidan Duan, Tao Zhou, Xiliang Liu, and Jiaojiao Wang. 2025. "EHMQA-GPT: A Knowledge Augmented Large Language Model for Personalized Elderly Health Management" Information 16, no. 6: 467. https://doi.org/10.3390/info16060467
APA StyleLin, S., Duan, Y., Zhou, T., Liu, X., & Wang, J. (2025). EHMQA-GPT: A Knowledge Augmented Large Language Model for Personalized Elderly Health Management. Information, 16(6), 467. https://doi.org/10.3390/info16060467