2. Literature Review
A growing body of recent research highlights both the significance and complexity of assessing MT and outputs generated by LLMs through metrical analysis. In general, these studies reveal a marked progression from conventional lexical-based evaluation metrics toward more sophisticated neural-based approaches, thereby emphasizing the necessity for comprehensive and multidimensional evaluation frameworks. Two distinct studies by Munková et al. [
14,
15] extensively investigated MT quality assessment across different language pairs and contexts. Munkova et al. [
14], for instance, examine the effectiveness of various automatic evaluation metrics for MT quality between Slovak and English. The study uses many metrics, including BLEU, precision, recall, word error rate (WER), and position-independent error rate (PER) to investigate the output. The study underscores the significance of the use of multiple measures to comprehensively assess MT quality. The findings of the study suggest that some metrics provide unique insights into translation accuracy and error rates. It also suggests that a multifaceted evaluation approach for accurate MT quality assessment is necessary. The second study by Munková et al. [
15] examines the effectiveness of automatic evaluation metrics in assessing machine-translated and post-edited MT sentence-level translations from Slovak to German. The study compares various accuracy and error-rate metrics such as BLEU, precision, recall, WER, and PER. Significant quality improvements have been documented in post-edited output compared to raw MT. Some sentences show higher scores for accuracy and lower error rates.
Juraska et al. [
16] further advanced MT evaluation by introducing Google’s MetricX-23 framework. The study deals with three submissions: MetricX-23, MetricX-23-b, and MetricX-23-c. These three submissions employ different configurations of pretrained language models (mT5 and PaLM 2) and fine-tuning data (Direct Assessment and MQM). The study highlights the importance of synthetic data, two-stage fine-tuning, and model size in improving evaluation metrics. The findings of the study demonstrate the significant correlation between MetricX-23 and human ratings. That is, this metric has great potential as a robust MT evaluation tool. Supporting this shift, López-Caro [
17] analyzed the transition from traditional metrics like BLEU and metric for evaluation of translation with explicit ordering (METEOR) to neural-based metrics such as crosslingual optimized metric for evaluation of translation (COMET) and bilingual evaluation understudy with representations from transformers (BLEURT). The study demonstrated the superior correlation between neural-based metrics and human judgment, especially in evaluating complex and domain-specific texts, advocating their broader adoption for future assessments. Critically engaging with traditional evaluation methods, Perrella et al. [
18] critique traditional evaluation methods that are mainly based on correlation with human judgment as lacking in actionable insights. The study proposes alternative measures using precision, recall, and F-score. The study argues that this novel evaluation framework can improve the interpretability of MT metrics. This framework assesses two metrical scenarios, namely data filtering and translation re-ranking, and thus it aims to align metric scores more closely with practical use cases. In addition, the study highlights the limitations of manually curated datasets and the potential for metrics like COMET and MetricX-23 to outperform others under specific conditions. Lee et al. [
19] categorized existing metrics into lexical-based, embedding-based, and supervised types, underscoring the limitations of traditional metrics like BLEU, particularly their failure to adequately capture semantic similarity. They recommend developing universal, language-agnostic metrics to ensure robust evaluations across different languages, addressing the current disparity in evaluation capabilities. From a practical standpoint, van Toledo et al. [
20] investigate the quality of Dutch translations produced by Google, Azure, and IBM MT systems. The study enriches MT evaluation by integrating readability metrics such as T-Scan, revealing GT’s superiority in readability and coherence over other MT systems. Their findings suggest that readability metrics may significantly complement traditional quality assessment methods. Lastly, Munkova et al. [
21] investigate the use of automated evaluation metrics in training future translators in an online environment. The study proposed OSTPERE, an online system for translation, post-editing, and assessment, which enables students to collaboratively practice and evaluate translations. Residuals of accuracy and error-rate metrics (e.g., BLEU, WER, TER) were used to identify translation errors and assess student performance. The study concludes that automated metrics effectively support formative assessment. They highlight critical, major, and minor errors in post-edited machine translations, and thus they can enhance teaching efficiency and translation competence. In short, these studies illustrate a clear trend towards integrating neural-based and multifaceted metric evaluations to promote more accurate, practical translation quality assessments in both research and educational contexts. While these studies have addressed evaluations of translation across various directionalities, to date, no prior research has comprehensively employed these diverse metrics to assess translation quality between Arabic and English using MT systems and LLMs. This study represents an original endeavor aimed at filling this gap, and contributing unique insights specifically tailored to Arabic–English translation evaluation.
3. Theoretical and Conceptual Framework
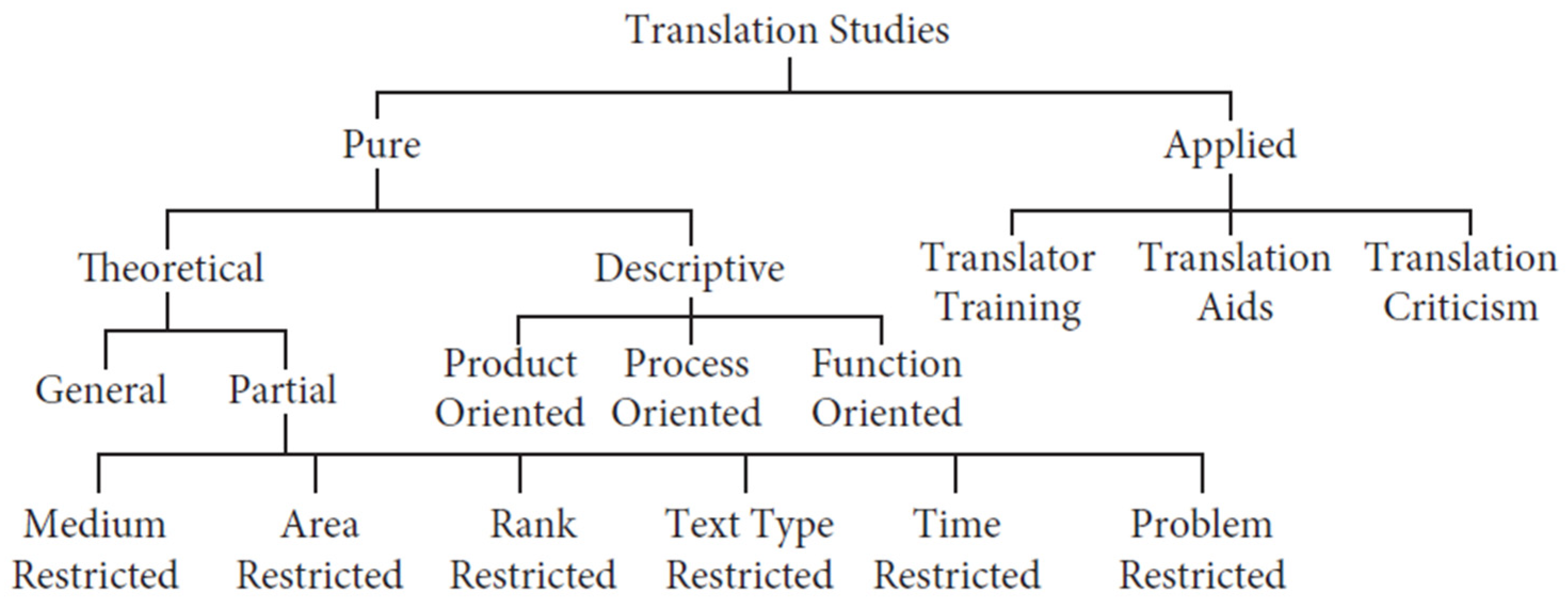
Translation quality has been given adequate attention in translation studies. Holmes’s map of translation studies (
Figure 1) sketched a scope and structure for the field in which translation criticism appears as a branch of applied translation studies [
22].
Qualitative translation quality assessment (TQA) methods, such as House’s model, adopt a functional, pragmatic approach to assessing translations. House’s model in its various versions [
11,
12,
13] considers the text as a unit of translation, assessing translation quality based on the concept of textual equivalence. That is, the original text’s meaning, register, and stylistic features must be preserved in the translation. House’s model distinguishes between two types of translations, namely overt and covert translations. A translation is overt when the cultural and contextual elements of the source text are highlighted, and it is covert when the text is adapted to the target audience’s cultural norms [
13].
To ensure the functional equivalence of a translation within its specific communicative context, House’s model provides a systematic framework for analyzing translations beyond numerical scores. Aspects such as field, tenor, and mode are duly considered to ensure the functional equivalence of the translation.
Metrics-based TQA has also been given considerable attention in the translation industry. Like descriptive TQA models, it also aims to evaluate a translated text based on linguistic, semantic, contextual, and technical standards. In metrics-based TQA, machine translations are often benchmarked against human reference translations. Common metrics for TQAs include BLEU, which measures n-gram overlap between the candidate and reference translations. BLEU may offer consistency, but it is often criticized for overlooking semantic adequacy and fluency [
23]. METEOR, on the other hand, incorporates stemming, synonyms, and word order, and thus it provides better semantic alignment [
24]. TER quantifies the number of edits needed to match the reference, focusing on effort-based evaluation [
25]. Advanced methods such as COMET and bidirectional encoder representations from transformers (BERT) leverage neural networks and contextual embeddings to capture semantic and contextual nuances [
26,
27].
Hence, metric models are essential for efficiency and objectivity, particularly in MT evaluations. However, the choice of metric depends on the language pair, translation objectives, and the type of text. Hybrid or neural-based metrics are recommended for comprehensive evaluation. Hybridity may imply the use of more than one metric or human feedback.
Unlike quantitative metrics, House’s model allows for a deeper understanding of cultural, stylistic, and functional fidelity, making it particularly useful for assessing translations where nuance, tone, and cultural alignment are critical [
12]. Qualitative methods like House’s model are often paired with quantitative metrics to provide a comprehensive evaluation, addressing not only measurable accuracy but also the contextual and interpretive quality of translations.
5. Data Analysis
To assess the translation of older rule-based MT systems and recent neural-based systems like GT, this study compared the output of 14 short Arabic idiomatic expressions. The translation quality was assessed using the chrF metric along with a qualitative evaluation of the translation. ChrF works at the character level, making it ideal for morphologically rich languages like Arabic. It evaluates character-level similarity to capture minor structural differences. In order to mitigate potential distortion of Arabic fonts, this study employs the International Phonetic Alphabet (IPA) system for linguistic representation. The original Arabic source texts and their corresponding translations are provided in the appendices.
Table 1 lists the Arabic expressions, their two machine translations, as well as a reference translation.
The chrF scores for both the earlier MT and GT outputs are presented in
Table 2. As stated earlier, chrF is a character-level metric that evaluates translation quality based on the overlap of character n-grams between the candidate and reference translations. This approach is especially useful for morphologically rich languages like Arabic. It also offers greater sensitivity to minor lexical or inflectional variations than word-based metrics such as BLEU. Given the fragmented, idiomatic, and colloquial nature of the short Arabic expressions examined in this section, chrF was selected as the most appropriate quantitative measure, as it better captures nuanced similarities that surface-level word matches may overlook. However, this study acknowledges that chrF scores alone may not fully capture the semantic or cultural fidelity of the translations. To address this, this study’s analysis extends beyond the numeric scores to include qualitative evaluations that consider idiomatic equivalence, contextual meaning, and the pragmatic appropriateness of the translations in each segment.
The scores listed in
Table 2 reflect the character-level similarity between the translations and the reference, offering insights into how well each system captures nuances. Hence, in segment 1, both translations are literal and fail to capture the idiomatic phrase. The small chrF scores reflect slight character overlap (e.g., “my sky”), but neither conveys the intended meaning. In segment 2, both translations are literal, resulting in low chrF scores. GT’s slightly higher score is due to minor improvements in phrasing at the character level, but the idiomatic meaning is still missed. In segment 3, both translations fail to capture the colloquial meaning. GT’s higher score reflects better character alignment, but both remain literal and do not convey the intended meaning. In segment 4, GT significantly outperforms earlier MT, with a much closer translation. The chrF score for GT reflects a substantial improvement in capturing the intended meaning at the character level. In segment 5, both scores are low, indicating neither translation captures the imperative tone of the expression. Earlier MT scores were slightly higher due to character overlap, but both miss the intended directive nature of the phrase. In segment 6, both translations are close but fail to fully capture the idiomatic tone. Earlier MT scores are slightly higher due to better character overlap, but the meaning conveyed by GT is more aligned. In segment 7, GT significantly outperforms earlier MT, capturing the intended meaning better. Earlier MT misinterprets
maːlek as “money”, resulting in poor alignment. In segment 8, both translations are literal and fail to capture the idiomatic expression. GT’s higher score reflects better character-level alignment. In segment 9, GT captures the meaning perfectly, resulting in a significantly higher score. Earlier MT’s literal translation leads to a nonsensical result. In segment 10, GT provides a semantically accurate translation, aligning well with the reference. Earlier MT misinterprets
qaːhira as “Cairo”, producing a nonsensical result. In segment 11, GT provides a more contextually appropriate translation. Earlier MT’s translation is literal and misses the idiomatic nuance. In segment 12, GT captures the emotional sentiment better, providing a more meaningful translation. Earlier MT fails to convey the intended sentiment. In segment 13, GT aligns closely with the reference, capturing the intended meaning. The literal translation of the earlier MT system distorts the phrase. Finally, in segment 14, both translations struggle, but GT performs slightly better. Neither captures the cultural nuance of getting engaged/married.
GT consistently provides better translations at the character level, aligning more closely with the references in both meaning and form. However, both systems exhibit significant limitations in capturing idiomatic and cultural nuances, which require contextual understanding beyond direct translation.
To confirm whether a statistically significant relation exists in the performance of the two systems, a normality test using the Shapiro–Wilk test was conducted as shown in
Table 3:
The Shapiro–Wilk test confirms that neither dataset follows a normal distribution. Since the normality assumption is violated, a Wilcoxon signed-rank test (non-parametric alternative to the paired
t-test) should be used to assess paired differences. (See
Table 4).
Results of the Wilcoxon signed-rank test show that the test statistic is 19.0 and the p-value is 0.035 (p < 0.05). That is, the Wilcoxon signed-rank test indicates a statistically significant difference between the chrF scores of the earlier MT system and GT renderings (p < 0.05). This suggests that the two systems differ in their performance. The hypothesis that there is no significant relation at (p < 0.05) between the performance of the earlier MT system and GT while translating the above idiomatic expressions from Arabic into English can therefore be rejected. The chrF scores reveal GT’s advantage in certain segments, especially those involving short, direct phrases. However, both systems struggle significantly with idiomatic and colloquial expressions, which require more than character-level alignment to capture meaning accurately.
While the first section of analysis in this study dealt with the quantitative metric-based and qualitative analyses of translation quality of some machine translations of Arabic allegorical, proverbial, and idiomatic expressions and clichés, the following section is devoted to the translation quality assessment of longer texts. The machine neural-based translation using GT and the LLM translation with ChatGPT of a technical text is examined. Both translations are analyzed quantitatively and qualitatively by comparing them with a human reference translation. The text, its GT rendering, its ChatGPT rendering, and the reference translation are given in
Appendix A.
To assess the quality of the Arabic translations provided by GT and ChatGPT against the reference translation, BLEU is used. In addition, a qualitative analysis of the translation quality is provided as well. BLEU is a metric that evaluates the overlap between the candidate and reference translations, considering n-gram precision. The BLEU scores for both GT and ChatGPT translations, sentence by sentence, are given in
Table 5.
In sentence 1, GT adheres closely to the reference, with minimal variation. However, ChatGPT uses ʔanˈðˤɪma watadafːuˈlaːt ʕaˈmal ‘systems and workflows’ instead of alˈʔanðˤɪma wˈsajr alˈʕamal ‘the systems and workflow’, which is slightly more verbose but maintains the meaning. The GT scores are higher due to closer n-gram matches, and ChatGPT scores are slightly lower due to different word choices and order. Similarly, in sentence 2, GT is concise and closer to the reference. ChatGPT, on the other hand, uses ʔad͡ʒˈzaːʔ min nuˈsˤuːs ‘parts of texts’ which diverges more from the reference but still conveys the meaning accurately. The translation is also semantically correct. Likewise, in sentence 3, GT is more aligned with the reference and ChatGPT uses haːðaː alʔusˈluːb ‘this method/style’ instead of haːðiːhi alʕamaˈlijja ‘this process’, which is a better stylistic choice but changes the nuance slightly. The scenario is not too different in sentence 4, where GT matches the reference more closely, whereas ChatGPT uses anːuˈsˤuːs almutagajˈjira ‘the variable texts’ with a comma for clarity. This is a minor stylistic change, which returns lower scores but is still accurate. In sentence 5, GT matches the reference translation more closely while ChatGPT uses tuˈtiːħ ‘enable’ instead of tasmaħ ‘allow’, which has a slight semantic shift. Finally, in sentence 6, GT has a closer match with the reference while ChatGPT includes commas and uses alˈhadar ‘the waste’ instead of annifaːˈjaːt ‘the garbage/trash’, slightly changing the tone.
To quantify how far GT and ChatGPT translations structurally deviate from the reference, TER was used, which measures the number of edits needed to transform the candidate translations into the reference translations. As shown in
Table 5 above, the TER results for GT translations were [0.222, 0.450, 0.429, 0.167, 0.391, 0.435] for the six sentences, respectively. The average TER Score is 0.349. As for ChatGPT renderings, the sentence TER scores are [0.556, 0.650, 0.571, 0.222, 0.609, 0.783] and the average TER score is 0.565.
Figure 2 below provides the BLUE vs. TER scores for GT and ChatGPT renderings.
In TER, lower scores indicate closer alignment with the reference. This shows that GT achieved better TER scores overall, with smaller deviations from the reference. ChatGPT, on the other hand, demonstrated higher TER scores, indicating more edits are needed to align the translations with the reference.
To statistically test the significance of the differences between BLEU and TER scores, normality is first assessed using the Shapiro–Wilk test for both BLEU and TER scores. (See
Table 6).
Since normality is not rejected, the data are approximately normal. However, to remain conservative with small sample sizes, the Wilcoxon signed-rank test was used to assess paired differences between BLEU and TER scores. (See
Table 7).
The results show that the p-value for GT BLEU vs. TER is 0.437 (not significant). The same is applicable to ChatGPT BLEU vs. TER, as the p-value = 0.093 (not significant, though closer to the threshold).
The differences between BLEU and TER scores for both GT and ChatGPT translations are not statistically significant. This suggests that the variations between BLEU and TER metrics are not large enough to warrant meaningful differences in performance evaluations for these translations. Hence, the second hypothesis asserts that “there is no statistically significance relation between the translations of GT and ChatGPT of the text” is accepted. This suggests that despite some stylistic differences in ChatGPT translation, this does not necessarily suggest the translation is poor or non-communicative. (See
Table 8).
6. Qualitative Analysis
In addition to metric-based quantitative analysis of the text under investigation, this study attempts a qualitative TQA based on House’s model [
11,
12,
13]. A register analysis of the GT and ChatGPT translations of the text shows that both reflect the same tone, level of formality, and technical precision of the source text to a great extent. However, a few inconsistencies are noted in phrases like
wataʃmal haːðiː alˈʔanðˤima alˈqaːʔima ʕalaː alˈmantˤiq ‘these logic-based systems include’ in GT and
taʃmal haːðiː alˈʔanðˤima alˈʔanðˤima alˈqaːʔima ʕalaː alˈmantˤiq ‘these systems include the systems based on logic’ in ChatGPT. Both clauses are technically correct but lack a natural tone in technical contexts. An alternative translation could be
taʃmal haːðiː alˈʔanðˤima alˈʔanðˤima allatiː taˈquːm ʕalaː alˈmantˤiq ‘these systems include the systems that are based on logic’.
Similarly, GT uses correct terminology but lacks sophistication. For example,
anːuˈsˤuːs aʃʃarˈtˤijja wa anːuˈsˤuːs almutagajˈjira ‘conditional texts and variable texts’ appears slightly repetitive and unrefined, and the same applies to the ChatGPT version, even though the latter tried to use some punctuation marks (,) to show that the terms are different. A more appropriate translation may consider more contextual information, as shown in
Table 9.
The genre remains constant to a great extent in the two translations. The text is technical, and the function of this text includes ideational clauses of being and doing. In both translations, the lexical items are technical and concise and in line with the conventions of Arabic professional discourse. However, the repetition of taqˈliːl ‘reduction or minimization’ in segment 5 could be streamlined by restructuring the sentence. In addition, lists need to be formatted for clarity, and transitions between ideas could be smoother, which could be achieved by adding some expressions in Arabic, such as maː ˈjaliː ‘What follows’, ataːˈliː ‘the following’, and alˈʔaːtiː ‘the following’.
As a technical text, the tenor indicates that the author’s personal stance is formal. As for the mode, the text is written to be read. Even though both translations are grammatically and syntactically acceptable, the translation is primarily overt. Overt errors in House’s model are direct linguistic errors, including grammar, lexis, syntax, or textual omissions/additions. In GT, grammatical structures are mostly accurate, but the translation exhibits minor awkwardness in phrasing. Lexical issues are few in both translations. Some lexical choices lack precision, e.g., anːuˈsˤuːs aʃʃarˈtˤijja ‘the conditional texts’ is correct but does not differentiate enough from anːuˈsˤuːs almutagajˈjira ‘the variable texts’ (both terms feel redundant without nuanced distinction). The use of proper punctuation, as is the case in the ChatGPT translation (i.e., anːuˈsˤuːs aʃʃarˈtˤijja, wa anːuˈsˤuːs almutagajˈjira), ‘the conditional texts, and the variable texts’ ensures clarity and logical segmentation.
As for textual additions or omissions, few instances are found in both translations. albaˈriːd/ /aʃʃaħn ‘mail/shipping’ is accurate but could have been localized better with ʔirsaːl albaˈriːd ʔaw aʃʃaħn ‘sending the mail or the shipment’ for fluidity. While there are no significant omissions or additions, some subtle rephrasing enhances clarity: wataʃmal alfaːwaːʔid alʔiḍaːfiːja maː ˈjalɪː: tawfiːr alwaqt wa alˈmaːl bisabab taqliːl attaʕaːmul maʕ alwaraq ‘additional benefits include the following: saving time and money by reducing paper handling’ is more readable and stylistically appropriate.
The use of alʔaxˈtˤaːʔ albaʃaˈrijja ‘human errors’ instead of alˈxatˤaʔ alˈbaʃariː ‘the human error’ in the ChatGPT translation is not wrong but shifts the meaning slightly to imply multiple errors rather than the concept of human error. Similarly, alˈhaːtɪf ‘the phone’ in GT in sentence 6 should be almukaːlɑˈmaːt alhaːtɪˈfijja ‘the phone calls’ for clarity and parallelism with alfaːkˈsaːt ‘the faxes’. Similarly, alˈhadr ‘the waste’ is more ambiguous than an.ni.faːˈjaːt ‘trash/garbage’ and could create ambiguity in ChatGPT translation.
In GT, some phrasing feels overtly literal, e.g., ʔinxɪˈfaːdˤ attaʕaːˈmul maʕ alˈwaraq ‘a decrease in handling paper’ translates accurately but does not fully capture the nuanced benefit implied in the source text. In addition, the translation lacks the subtlety of professional Arabic texts, especially in technical and formal contexts. ChatGPT translation is somewhat more localized. For example, taqliːl attaʕaːˈmul maʕ alˈwaraq ‘reducing paper handling’ subtly shifts the emphasis in a way that feels more natural and professional. On the other hand, more idiomatic phrasing is needed in both translations; wajutam ʔistixˈdaːm haːðihi alʕamalijˈjaː biʃaklin mutazaːjid ‘this process is increasingly being used’, is smoother and aligns with Arabic formal writing norms better than juːstaχdam haːðaː alʔusˈluːb biʃaklin mutazaːjid ‘this style is increasingly used’ from ChatGPT and tustaxdam haːðiː alʕamalijˈjaː biʃaklin mutazaːjid ‘this process is increasingly used’ from GT. In addition, alʔusˈluːb ‘the style’ is less precise than alʕamalijˈja ‘the process’ because the text focuses on the automation process rather than a general method or style.
As for cohesion, textual cohesion and flow are somewhat lacking in both translations. Sentence divisions occasionally feel disconnected, e.g., taʃmal haːðiː alʔanðˤima alqaːʔima ʕalaː alˈmantˤiq walˈlatiː tastaʕmil ʔadʒˈzaːʔ min anˈnˤaṣˤ ‘these systems include those based on logic and that use parts of the text’ has an awkward structure and the repetition of phrases like taqliːl ʔidˈxɑːl alˌbajaːnaːt ‘reducing data entry’ without slight variation impacts the fluency of the text. Smooth transitions and appropriate use of conjunctions make translations easier to read.
Even though metrics-based data may imply that the GT is far better than ChatGPT, the qualitative analysis shows that ChatGPT translations may outperform GT in some respects, including enhanced lexico-grammatical precision, greater textual cohesion and flow, and a more professional stylistic register. However, for improvement, both systems could focus on refining phrasing for enhanced readability and tone.
7. Discussion
This study has attempted quantitative metric-based and qualitative translation assessments of texts translated by early MT systems, GT and ChatGPT between Arabic and English. The findings of this study have shown that early MT systems (i.e., rule-based MT systems) as well as neural-based systems still encounter many problems in the translation of idioms, proverbs, clichés, and colloquial expressions. This finding is consistent with the findings of Alzeebaree [
37], who concludes that GT, which is more advanced than most earlier MT systems, fails to render culture-specific aspects of most idioms. In addition, GT renders some collocations literally and the results are non-standard collocations in the target language. This finding is in line with the findings of Abdullah Naeem’s study [
38] that show the translated collocations are not adapted to the beliefs and experiences of the target audience. In addition, the findings of this study show that GT generally fails to achieve adequate translations of complex colloquial and informal expressions, a finding confirmed in other studies [
39]. The performance of other MT systems is similar to that of GT. Findings from other studies show that Microsoft Bing and other systems also encounter problems in the rendering of idiomatic expressions [
40,
41]. The qualitative analysis of Arabic–English translations shows that LLMs, and in this case ChatGPT, work well in the translation of these expressions, and it outperforms earlier MT systems and GT in terms of accuracy, fluency, and cultural sensitivity [
42].
Furthermore, the findings of this study are in conformity with those of other studies that tackled MT in various directionalities, between English and other languages such as French, Swedish, Farsi, and Chinese. Some weaknesses, irregularities, and limitations in MT in general are reported in many studies in the literature [
43,
44,
45,
46,
47,
48].
Another important finding of this study is that while MT metrics are important in the assessment of translation quality, their scores might be misleading. Findings from the translation of Task 2 show that GT translations are consistently closer to the reference translation, both in structure and terminology. ChatGPT’s translations are accurate, but generally deviate stylistically, introducing unnecessary changes that lower fidelity to the reference, but are ultimately more professional. This finding confirms those of other studies that tackled various language pairs, including [
19,
49,
50]. In general, these studies and this one highlight that a higher BLEU score does not always correlate with human judgment of translation quality. Traditional metrics (e.g., BLEU, TER) over-reward lexical similarity while ignoring deeper aspects of translation quality, such as fluency and context-appropriateness.
The qualitative translation assessment shows that ChatGPT has produced better overall translation outputs. This finding is in line with those of a recent study on the translation of expressive genres such as poetry [
51] that ChatGPT outperformed GT and DeepL Translator across various evaluation criteria, which highlights its potential in handling complex literary translations. However, while ChatGPT-4 may achieve competitive translation quality in the translation of specific genres and high-resource languages, as is the case for English–Arabic translations, it may have limited capabilities for other genres or low-resource languages, a finding that has been highlighted in some recent studies including [
10,
52].
While this study relies primarily on traditional metrics such as chrF, BLEU, and TER, it is increasingly clear that these may not adequately reflect semantic fidelity, especially in expressive or idiomatic translations. Recent work on generative AI evaluation, such as the Pass@k metric developed by OpenAI [
53], highlights alternative frameworks for assessing meaning preservation across multiple plausible outputs. Though originally designed for code generation, Pass@k’s underlying logic, capturing whether a correct or acceptable output is produced among a set of completions, could be adapted to translation tasks, particularly for languages with high variability or nuance like Arabic. Incorporating such probable metrics could provide richer insights into the strengths and limitations of LLM outputs beyond deterministic match scores.
Moreover, the growing use of RLHF, as demonstrated in recent studies [
54], suggests a promising pathway for refining translation evaluation. Crowd-sourced or expert human ratings on fluency, semantic accuracy, and cultural appropriateness can be used not only to validate model outputs but to inform weighting schemes in hybrid metrics. These insights open important future possibilities for integrating structured human judgments with automatic evaluation tools to produce more context-appropriate and functionally relevant translation assessments.
This study has several limitations. Firstly, it has evaluated the translation quality of specific text types and genres, necessitating further research to examine the performance of MT systems and LLMs across other text types and genres. Secondly, this study has focused on GT and ChatGPT. The performance outcomes of these systems may differ slightly or significantly from other neural-based MT systems and generative AI models. Additionally, the scope of this study is restricted to certain metrics and language pairs, which complicates the generalization of its findings. Future research should incorporate new metrics, language pairs, MT systems, and LLMs. Another limitation is the reliance on standard automatic evaluation metrics, which, while useful, may not fully capture nuanced aspects of meaning, idiomatic accuracy, or cultural appropriateness in translations. As noted in recent generative AI research, alternative frameworks like Pass@k and RLHF offer more robust methods for evaluating meaning preservation in flexible output scenarios [
53,
54]. Future work should consider integrating these frameworks and employing structured human evaluations to augment metric-based assessments.
Future studies may also explore more comprehensive integration of human evaluative feedback, potentially crowd-sourced or expert-based, to refine or adjust automatic metrics like chrF. It is also possible to explore dynamic evaluation strategies based on transfer learning principles, where meaning transfer and contextual adaptation are assessed through targeted translation tasks. Such hybrid frameworks would not only evaluate output accuracy but also model learning behaviors and generalizations, offering more scalable and human-aligned metrics for LLM evaluation in translation.




{kind=link}
{kind=link}