10. Discussion
The findings from this study reveal a nuanced picture of how learners interact with AI and human partners in speaking tasks and how those interactions shape both linguistic performance and user experience. This section synthesizes key insights across the retelling, game, and perception tasks to offer broader pedagogical and design implications.
Author Contributions
Conceptualization, M.P., M.T., Y.M. and J.S.W.; data curation, M.P.; formal analysis, M.P.; funding acquisition, J.S.W. and M.P.; investigation, M.P. and M.T.; methodology, M.P., M.T. and Y.M.; project administration, M.T.; resources, J.S.W.; software, M.P.; supervision, Y.M.; validation, M.P.; visualization, M.P.; writing—original draft preparation, M.P.; writing—review and editing, M.P., M.T., Y.M. and J.S.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Japan Society for the Promotion of Science (JSPS) KAKENHI, Grant-in-Aid for Early-Career Scientists, Project Number 21K17794, and by the AY2024 Grassroots Practice Support Program of Ritsumeikan University.
Institutional Review Board Statement
Ethical review and approval were waived for this study due to the nature of the research, which involved voluntary participation by university students in a non-invasive language learning activity. The study did not collect sensitive personal data and posed minimal risk to participants. It was conducted in accordance with institutional guidelines at Ritsumeikan University.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study. Participants received written information and consented to data collection and analysis. They were compensated at the standard hourly minimum wage of Osaka Prefecture in the form of gift cards.
Data Availability Statement
The data supporting the findings of this study—including annotated Taboo game logs, CAF scores, and questionnaire responses—are available from the corresponding author upon reasonable request. Due to participant privacy considerations, public sharing is restricted.
Acknowledgments
Special thanks to Barry Condon, at Ritsumeikan University, for refining and adapting the taboo word dataset used in this study.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial intelligence |
| CALL | Computer-assisted language learning |
| ESL | English as a second language |
| H–AI | Human–AI (Human interacting with AI) |
| H–H | Human–human (Human interacting with human) |
| CAF | Complexity, accuracy, and fluency |
| LLM | Large language model |
| TAM | Technology acceptance model |
| TOEIC | Test of English for international communication |
| UI | User interface |
References
- Elbashir, E.E. The Challenges of Spoken English Fluency among EFL Learners in Saudi Universities. Sch. Int. J. Linguist. Lit. 2023, 6, 280–282. [Google Scholar] [CrossRef]
- Xiao, F.; Zhao, P.; Sha, H.; Yang, D.; Warschauer, M. Conversational agents in language learning. J. China-Comput.-Assist. Lang. Learn. 2024, 4, 300–325. [Google Scholar] [CrossRef]
- Nadeem, M.; Oroszlanyova, M.; Farag, W. Effect of Digital Game-Based Learning on Student Engagement and Motivation. Computers 2023, 12, 177. [Google Scholar] [CrossRef]
- Pituxcoosuvarn, M.; Radhapuram, S.C.T.; Murakami, Y. Taboo Talks: Enhancing ESL Speaking Skills through Language Model Integration in Interactive Games. Procedia Comput. Sci. 2024, 246, 3674–3683. [Google Scholar] [CrossRef]
- Skehan, P. A Cognitive Approach to Language Learning; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Ellis, R. Task-Based Language Learning and Teaching; Oxford University Press: Oxford, UK, 2003. [Google Scholar]
- Tessmer, M. Planning and Conducting Formative Evaluations; Routledge: Oxfordshire, UK, 2013. [Google Scholar]
- Long, M.H. The Role of the Linguistic Environment in Second Language Acquisition. In Handbook of Second Language Acquisition; Ritchie, W.C., Bhatia, T.K., Eds.; Academic Press: Cambridge, MA, USA, 1996; pp. 413–468. [Google Scholar]
- Swain, M. Communicative competence: Some roles of comprehensible input and comprehensible output in its development. In Input in Second Language Acquisition; Gass, S., Madden, C., Eds.; Newbury House: Cork, Ireland, 1985; pp. 235–253. [Google Scholar]
- Leeming, P.; Aubrey, S.; Lambert, C. Collaborative Pre-Task Planning Processes and Second-Language Task Performance. RELC J. 2022, 53, 534–550. [Google Scholar] [CrossRef]
- Rassaei, E. The Interplay between Corrective Feedback Timing and Foreign Language Anxiety in L2 Development. Lang. Teach. Res. 2023. [Google Scholar] [CrossRef]
- Aubrey, S.; King, J.; Almukhaild, H. Language Learner Engagement During Speaking Tasks: A Longitudinal Study. RELC J. 2022, 53, 519–533. [Google Scholar] [CrossRef]
- Elverici, S.E. Mobile Assisted Language Learning: Investigating English Speaking Performance and Satisfaction. Rumelide Dil Edeb. Araştırmaları Derg. 2023, Ö13, 1305–1317. [Google Scholar] [CrossRef]
- Wachowicz, K.A.; Scott, B. Software That Listens. CALICO J. 2013, 16, 253–276. [Google Scholar] [CrossRef]
- Tsai, S.C. Implementing Interactive Courseware into EFL Business Writing: Computational Assessment and Learning Satisfaction. Interact. Learn. Environ. 2018, 27, 46–61. [Google Scholar] [CrossRef]
- Kim, H.K. Beyond Motivation. CALICO J. 2013, 25, 241–259. [Google Scholar] [CrossRef]
- Parmaxi, A.; Zaphiris, P. Web 2.0 in Computer-Assisted Language Learning: A Research Synthesis and Implications for Instructional Design and Educational Practice. Interact. Learn. Environ. 2016, 25, 704–716. [Google Scholar] [CrossRef]
- Mohsen, M.A. The Use of Help Options in Multimedia Listening Environments to Aid Language Learning: A Review. Br. J. Educ. Technol. 2015, 47, 1232–1242. [Google Scholar] [CrossRef]
- Yigci, D.; Eryilmaz, M.; Yetisen, A.K.; Tasoglu, S.; Ozcan, A. Large Language Model-Based Chatbots in Higher Education. Adv. Intell. Syst. 2024, 7, 2400429. [Google Scholar] [CrossRef]
- Zou, B.; Li, Q.; Luo, W. Supporting Speaking Practice by Social Network-Based Interaction in Artificial Intelligence (AI)-Assisted Language Learning. Sustainability 2023, 15, 2872. [Google Scholar] [CrossRef]
- Gao, Y.; Nuchged, B.; Li, Y.; Peng, L. An Investigation of Applying Large Language Models to Spoken Language Learning. Appl. Sci. 2023, 14, 224. [Google Scholar] [CrossRef]
- Rusmiyanto, R.; Huriati, N.; Fitriani, N.; Tyas, N.; Rofi’i, A.; Sari, M. The Role Of Artificial Intelligence (AI) In Developing English Language Learner’s Communication Skills. J. Educ. 2023, 6, 750–757. [Google Scholar] [CrossRef]
- Lucas, H.C.; Singh, A.; Kim, M.J.; Al-Twijri, R.; Chuang, T.H. A Systematic Review of Large Language Models and Their Implications in Medical Education. Med. Educ. 2024, 58, 1276–1285. [Google Scholar] [CrossRef]
- Park, Y.J.; Pillai, A.; Deng, J.; Guo, E.; Gupta, M.; Paget, M.; Naugler, C. Assessing the Research Landscape and Clinical Utility of Large Language Models: A Scoping Review. BMC Med. Inform. Decis. Mak. 2024, 24, 72. [Google Scholar] [CrossRef]
- Choudhury, A.; Chaudhry, Z. Large Language Models and User Trust: Consequence of Self-Referential Learning Loop and the Deskilling of Health Care Professionals. J. Med. Internet Res. 2024, 26, e56764. [Google Scholar] [CrossRef]
- Jošt, G.; Taneski, V.; Karakatič, S. The Impact of Large Language Models on Programming Education and Student Learning Outcomes. Appl. Sci. 2024, 14, 4115. [Google Scholar] [CrossRef]
- Haltaufderheide, J.; Ranisch, R. The Ethics of ChatGPT in Medicine and Healthcare: A Systematic Review on Large Language Models (LLMs). NPJ Digit. Med. 2024, 7, 183. [Google Scholar] [CrossRef]
- Campbell, H.; Bluck, T.; Curry, E.; Harris, D.; Pike, B.; Wright, B. Should We Still Teach or Learn Coding? A Postgraduate Student Perspective on the Use of Large Language Models for Coding in Ecology and Evolution. Methods Ecol. Evol. 2024, 15, 1767–1770. [Google Scholar] [CrossRef]
- Plass, J.L.; Homer, B.D.; Kinzer, C.K. Foundations of game-based learning. Educ. Psychol. 2015, 50, 258–283. [Google Scholar] [CrossRef]
- Chowdhury, M.; Dixon, L.Q.; Kuo, L.J.; Donaldson, J.P.; Eslami, Z.; Viruru, R.; Luo, W. Digital game-based language learning for vocabulary development. Comput. Educ. Open 2024, 6, 100160. [Google Scholar] [CrossRef]
- Zhou, S. Gamifying language education: The impact of digital game-based learning on Chinese EFL learners. Humanit. Soc. Sci. Commun. 2024, 11, 1518. [Google Scholar] [CrossRef]
- Esteban, A.J. Theories, principles, and game elements that support digital game-based language learning (DGBLL): A systematic review. Int. J. Learn. Teach. Educ. Res. 2024, 23, 1–22. [Google Scholar] [CrossRef]
- Lestari, S.D.; Damanik, E.S.D. Students’ Perceptions on the Effectiveness of the Taboo Game in Enhancing English Vocabulary Acquisition. Elsya J. Engl. Lang. Stud. 2024, 6, 172–184. [Google Scholar] [CrossRef]
- Agung, W.K.S. The Effectiveness of Taboo Game to Improve Students’ Vocabulary Mastery. ELTALL Engl. Lang. Teaching, Appl. Linguist. Lit. 2023, 4, 88–98. [Google Scholar]
- Yaacob, A.; Alsaraireh, M.Y.; Suryani, I.; Yulianeta, Y.; MdHussin, H. Effectiveness of Taboo Word Game on Augmenting Business Vocabulary Competency Through Reflective Action Research. Arab. World Engl. J. (AWEJ) 2024, 15, 267–281. [Google Scholar] [CrossRef]
- Abusahyon, A.S.E.; Alzyoud, A.; Alshorman, O.; Al-Absi, B.A. AI-driven technology and chatbots as tools for enhancing English language learning in the context of second language acquisition: A review study. Int. J. Membr. Sci. Technol. 2023, 10, 1209–1223. [Google Scholar] [CrossRef]
- Dennis, N.K. Using AI-powered speech recognition technology to improve English pronunciation and speaking skills. IAFOR J. Educ. Technol. Educ. 2024, 12, 107–123. [Google Scholar] [CrossRef]
- Du, J.; Daniel, B.K. Transforming language education: A systematic review of AI-powered chatbots for English as a foreign language speaking practice. Comput. Educ. Artif. Intell. 2024, 6, 100230. [Google Scholar] [CrossRef]
- Zhan, Z.; Tong, Y.; Lan, X.; Zhong, B. A systematic literature review of game-based learning in Artificial Intelligence education. Interact. Learn. Environ. 2024, 32, 1137–1158. [Google Scholar] [CrossRef]
- N, M.; Kumar, P.N.S. Investigating ESL Learners’ Perception and Problem towards Artificial Intelligence (AI)-Assisted English Language Learning and Teaching. World J. Engl. Lang. 2023, 13, 290. [Google Scholar] [CrossRef]
- Flores, J. Using Gamification to Enhance Second Language Learning. Digit. Educ. Rev. 2015, 27, 32–54. [Google Scholar]
- Klimova, B.; Pikhart, M.; Al-Obaydi, L.H. Exploring the potential of ChatGPT for foreign language education at the university level. Front. Psychol. 2024, 15, 1269319. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust speech recognition via large-scale weak supervision. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 28492–28518. [Google Scholar]
- Mcnamara, T.; May, L.; Hill, K. 12. Discourse and Assessment. Annu. Rev. Appl. Linguist. 2002, 22, 221–242. [Google Scholar] [CrossRef]
- Nippold, M.A.; Frantz-Kaspar, M.W.; Vigeland, L.M. Spoken Language Production in Young Adults: Examining Syntactic Complexity. J. Speech, Lang. Hear. Res. 2017, 60, 1339–1347. [Google Scholar] [CrossRef]
- Koizumi, R.; Hirai, A. Comparing the Story Retelling Speaking Test with Other Speaking Tests. JALT J. 2012, 34, 35–56. [Google Scholar] [CrossRef]
- Uchida, S. Evaluating the Accuracy of ChatGPT in Assessing Writing and Speaking: A Verification Study Using ICNALE GRA. Learn. Corpus Stud. Asia World 2024, 6, 1–12. [Google Scholar]
- Huang, Q.; Willems, T.; Wang, P.K. The application of GPT-4 in grading design university students’ assignment and providing feedback: An exploratory study. arXiv 2023, arXiv:2409.17698. [Google Scholar]
- Hirunyasiri, D.; Thomas, D.R.; Lin, J.; Koedinger, K.R.; Aleven, V. Comparative Analysis of GPT-4 and Human Graders in Evaluating Praise Given to Students in Synthetic Dialogues. arXiv 2023, arXiv:2307.02018. [Google Scholar]
- Luger, E.; Sellen, A. “Like having a really bad PA”: The gulf between user expectation and experience of conversational agents. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 5286–5297. [Google Scholar] [CrossRef]
- Clark, L.; Radziwill, N.M. What makes a good conversation? Challenges in designing truly conversational agents. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence Testing (AITest), Newark, CA, USA, 4–9 April 2019; pp. 101–107. [Google Scholar] [CrossRef]
- Clark, H.H. Using Language; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Bowman, R.; Nadal, C.; Morrissey, K.; Thieme, A.; Doherty, G. Using thematic analysis in healthcare HCI at CHI: A scoping review. In Proceedings of the Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–18. [Google Scholar]
- Faulkner, L. Beyond the five-user assumption: Benefits of increased sample sizes in usability testing. Behav. Res. Methods Instruments Comput. 2003, 35, 379–383. [Google Scholar] [CrossRef]
- Nielsen, J. Why You only Need to Test with 5 Users. Nielsen Norman Group. 2000. Available online: https://www.nngroup.com/articles/why-you-only-need-to-test-with-5-users/ (accessed on 30 March 2025).
- Burleson, B.R.; Kunkel, A. Gender differences in communication: Implications for salespeople. J. Pers. Sell. Sales Manag. 2003, 23, 371–387. [Google Scholar]
- Derwing, T.M.; Munro, M.J. What do ESL students say about their accents? TESOL Q. 2005, 39, 379–397. [Google Scholar] [CrossRef]
Figure 1.
Interface for Describe Mode.
Figure 2.
Interface for Guess Mode.
Figure 3.
System Workflow for Describe Mode.
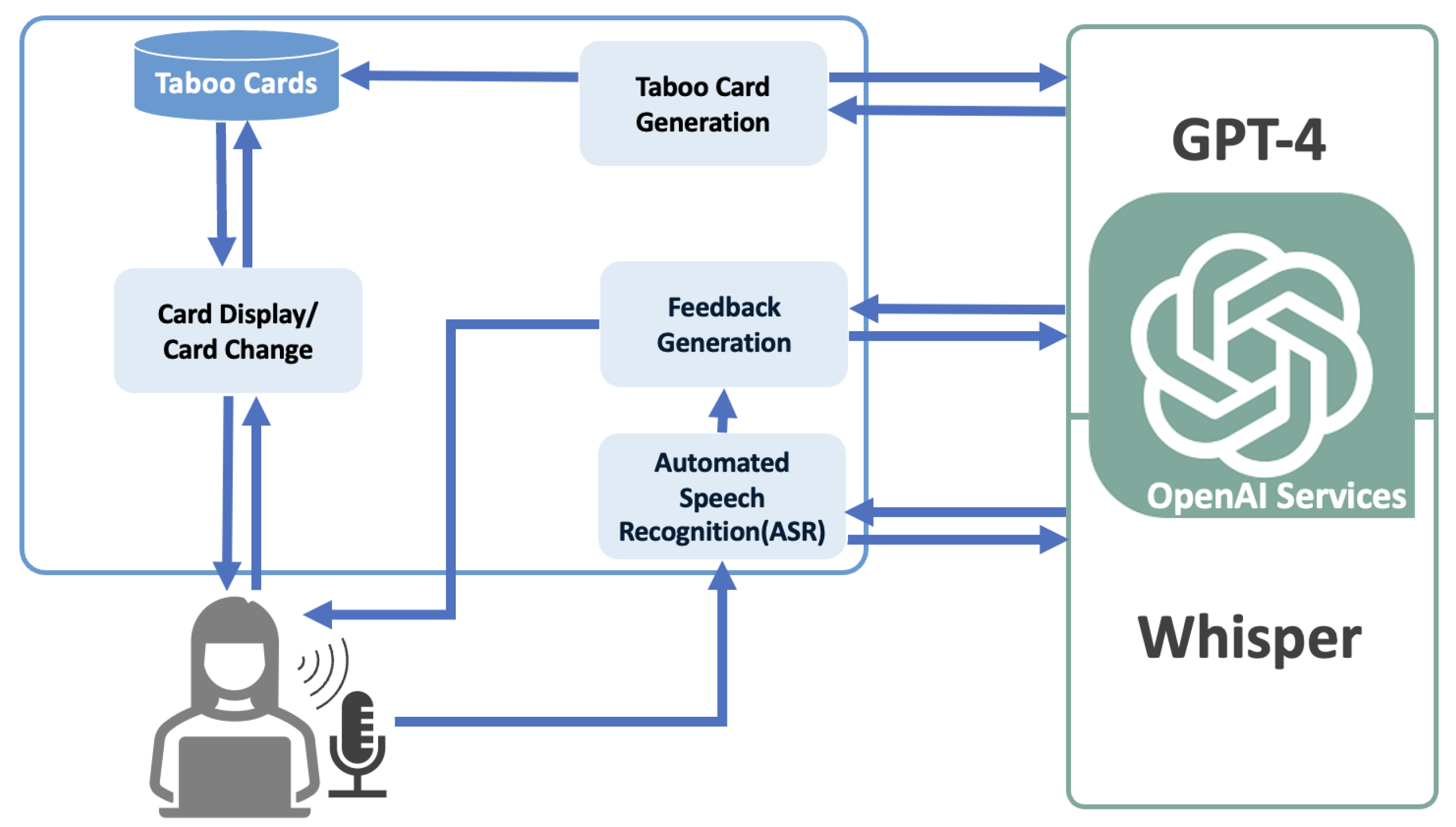
Figure 4.
System Workflow for Guess Mode.
Figure 5.
CAF Mean Scores After H–AI and H–H (Bar Chart with SD Error Bars).
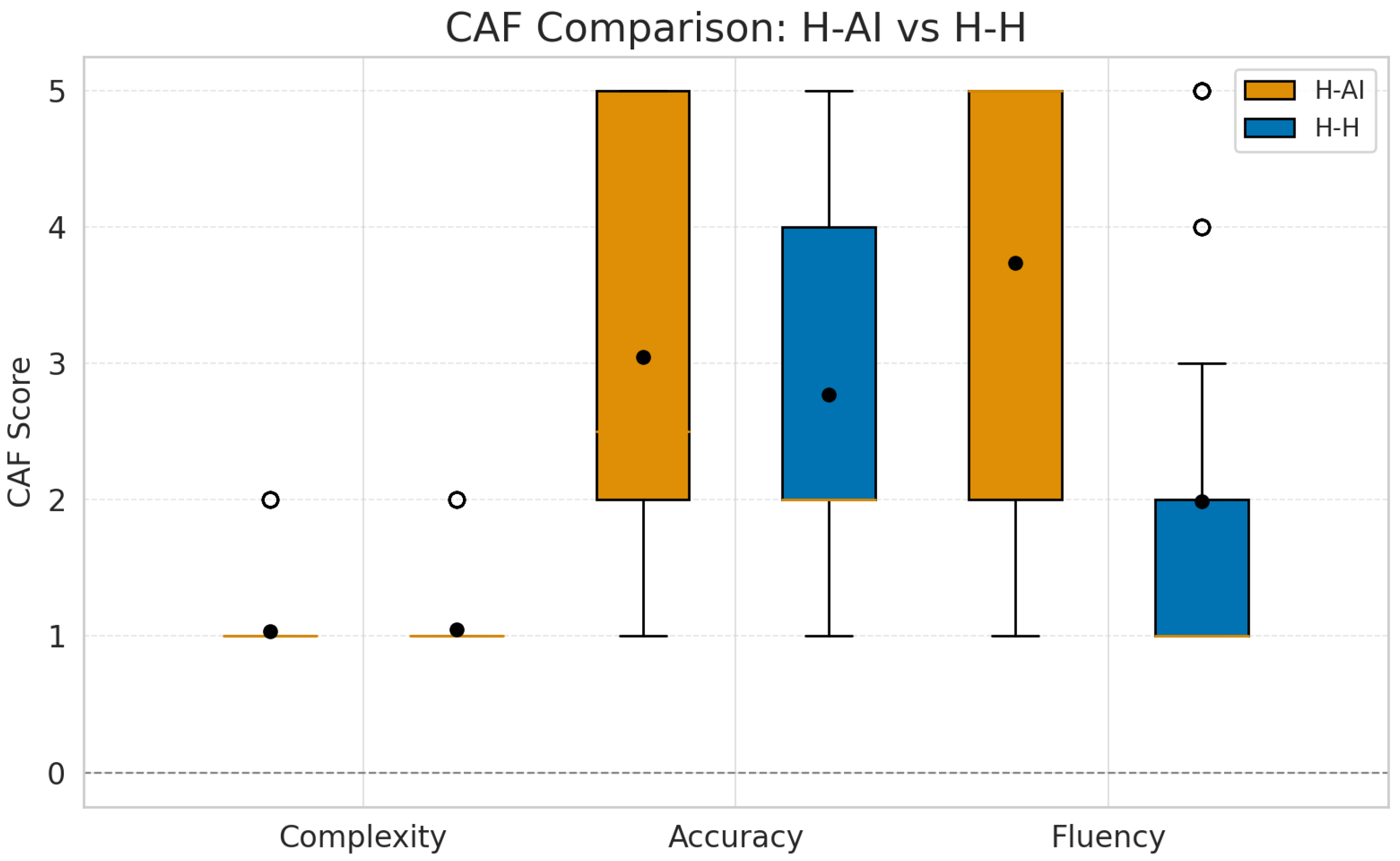
Figure 6.
CAF score comparison between H–AI and H–H Conditions. Fluency shows a noticeable upward trend in the H–AI condition. Accuracy appears slightly higher, while complexity remains relatively stable across conditions.
Figure 7.
Clue Success Rate by Mode.
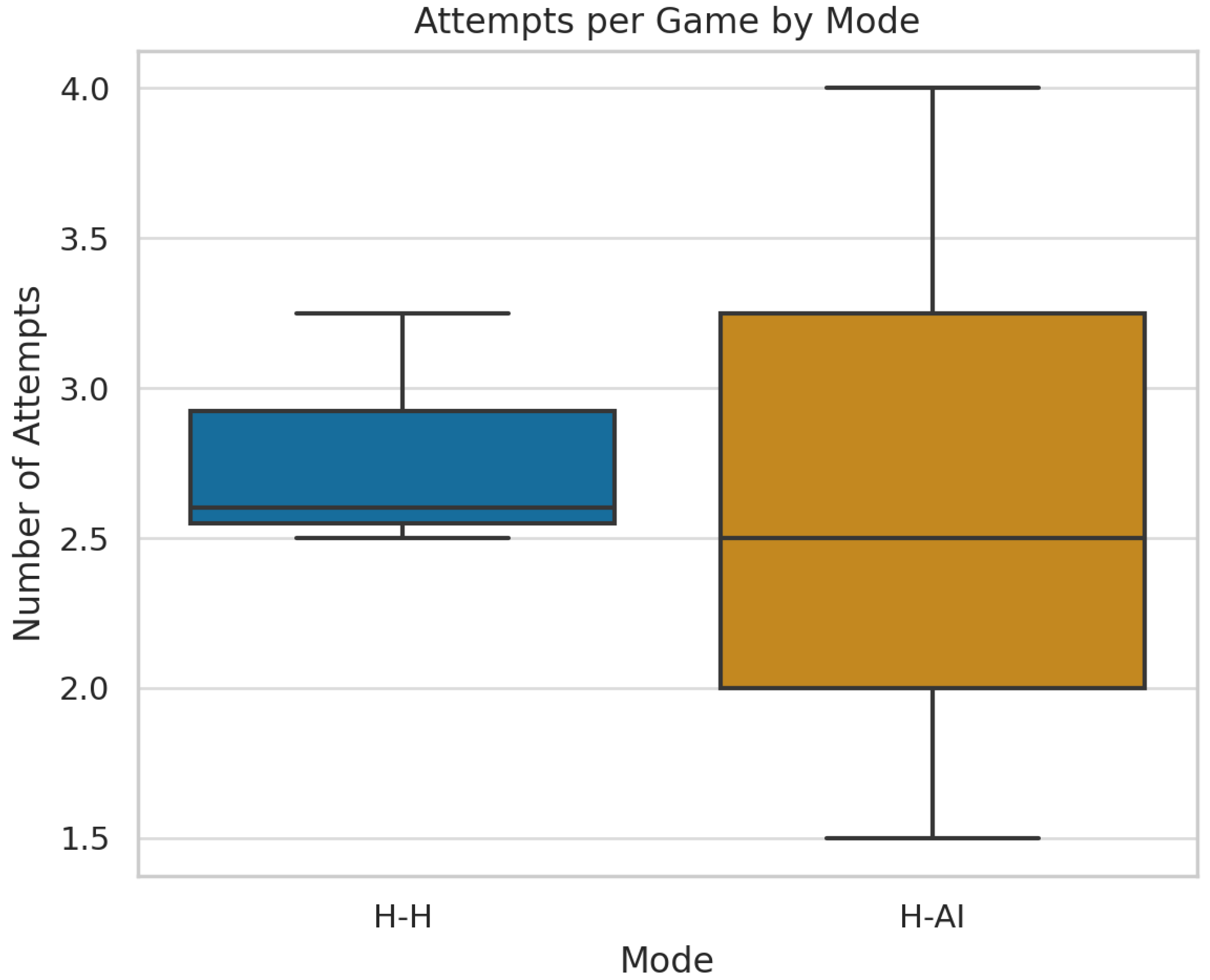
Figure 8.
Attempts per Game by Mode.
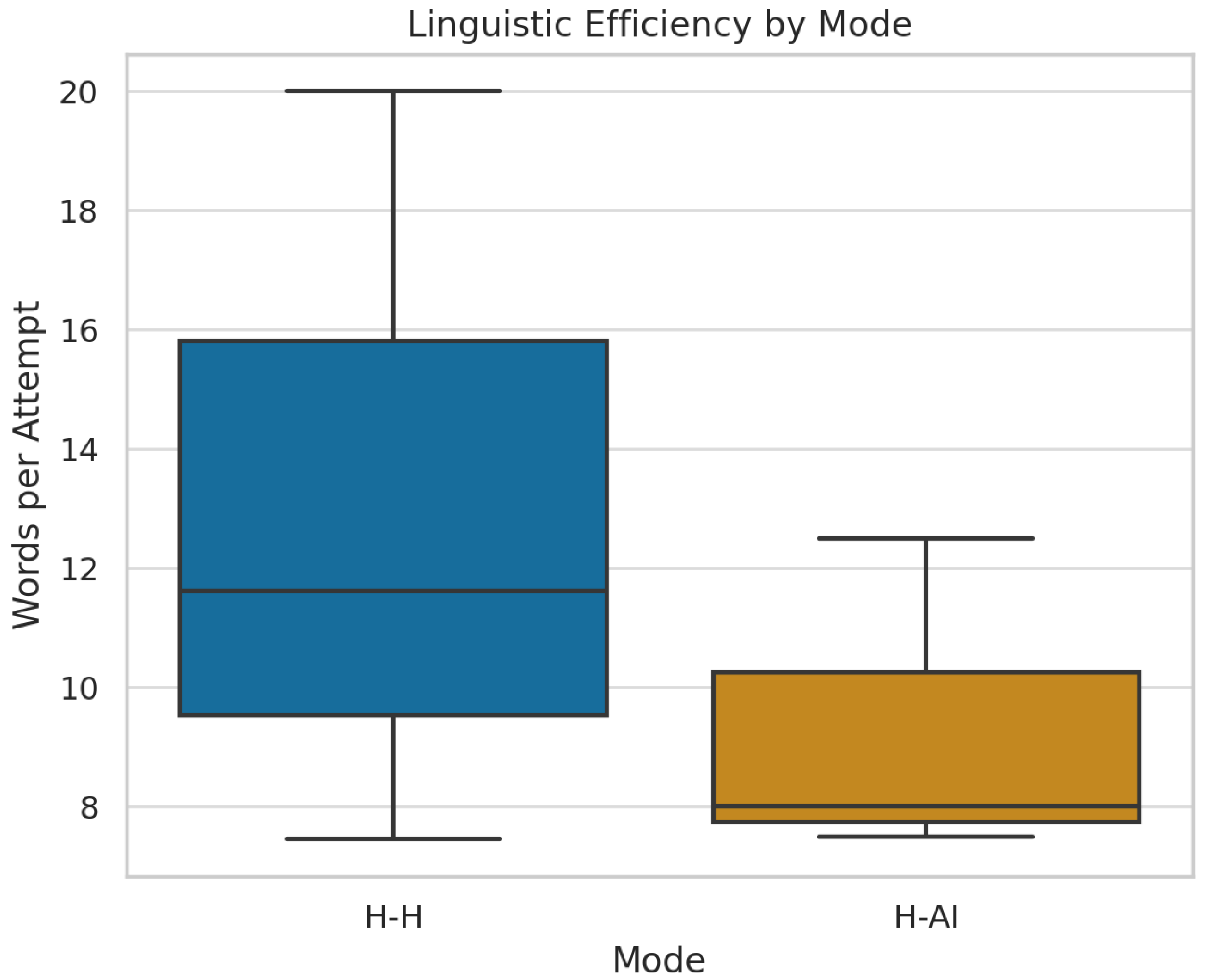
Figure 9.
Linguistic Efficiency by Mode.
Figure 10.
Utterances per game until success by mode.
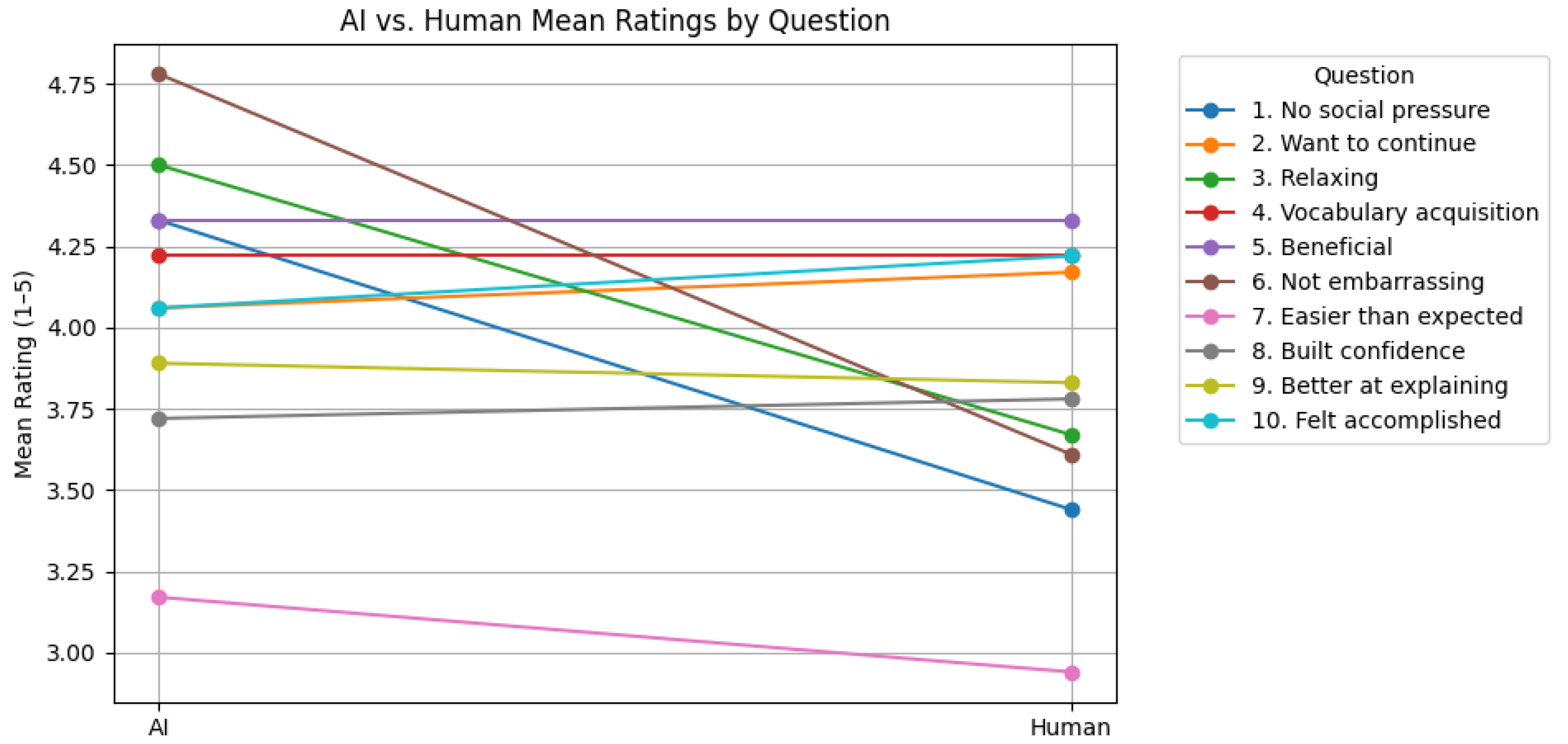
Figure 11.
Mean ratings for each item comparing AI and human learning partners. Error bars represent ± 1 SD.
Table 1.
Counterbalanced Task Orders for the Two Conditions.
| Phase | Condition 1 (AI-First) | Condition 2 (Human-First) |
|---|
| 1 | Explanation | Explanation |
| 2 | Retelling 1 (Pre) | Retelling 1 (Pre) |
| 3 | Human–AI Taboo Game | Human–Human Taboo Game |
| 4 | Retelling 2 (Mid) | Retelling 2 (Mid) |
| 5 | Human–Human Taboo Game | Human–AI Taboo Game |
| 6 | Retelling 3 (Post) | Retelling 3 (Post) |
| 7 | Free Talk Session (Peer Discussion) | Free Talk Session (Peer Discussion) |
| 8 | Questionnaire | Questionnaire |
Table 2.
CAF Evaluation Rubric (1–5 scale).
| CAF Dimension | Descriptor |
|---|
| Complexity (Lexical and Grammatical Range) | - 5:
Wide range of vocabulary and complex sentence structures (e.g., subordination, embedded clauses) - 4:
Good range of vocabulary and some complex structures - 3:
Moderate variety; mostly simple structures with some variation - 2:
Limited vocabulary and repetitive patterns - 1:
Very basic vocabulary; minimal variation in sentence form
|
| Accuracy (Grammatical and Lexical Correctness) | - 5:
Virtually no errors; message consistently clear - 4:
Minor errors that do not hinder meaning - 3:
Occasional errors; mostly understandable - 2:
Frequent errors that obscure meaning - 1:
Persistent errors; difficult to comprehend
|
| Fluency (Flow, Pausing, Self-correction) | - 5:
Smooth delivery with minimal hesitation - 4:
Generally fluent with minor disruptions - 3:
Noticeable pauses or repetition, but message remains followable - 2:
Frequent hesitation or reformulation - 1:
Very disfluent; hard to follow due to disrupted flow
|
Table 3.
Paired-Subset Comparison of CAF Score Changes.
| Metric | Mean | Mean | p-Value | Cohen’s d |
|---|
| Complexity | +0.60 | −0.40 | 0.142 | 0.82 |
| Accuracy | +0.40 | +0.40 | 1.000 | 0.00 |
| Fluency | +1.00 | +0.64 | 0.551 | 0.29 |
Table 4.
Clue-Giving Utterances by Condition (Excerpt).
| User | Partner | Words | Fluency | Transcript (Excerpt) |
|---|
| user16 | H–H | 52 | 1.0 | This, this, this, this question, this question, okay? This question. I say this… |
| user12 | H–H | 44 | 1.0 | This is a kind of act. Often this is used for windows. Window. And… Small… M… |
| user16 | H–H | 42 | 1.0 | No, no, no, no, no, no. Touch. Ah. Ah, so. No, no, no, no, no, no. No, no, no, n… |
| user1 | H–AI | 7 | 5.0 | A car which can ride many person. |
| user11 | H–AI | 9 | 5.0 | This is a thing to clear the brown environment. |
| user13 | H–AI | 6 | 5.0 | We can carry this more power. |
Table 5.
Comparison of explainer performance across interaction modes.
| Metric | Mean (H–H) | Mean (H–AI) | t-Test p-Value |
|---|
| Clue Success Rate | 0.36 | 0.44 | 0.044 |
| Attempts | 2.78 | 2.67 | 0.038 |
| Linguistic Efficiency | 13.03 | 9.33 | 0.205 |
Table 6.
Average number of utterances until successful guess.
| Metric | Mean (H–H) | Mean (H–AI) | t-Test p-Value |
|---|
| Utterances | 2.62 | 1.98 | 0.033 |
Table 7.
Partner-Specific Clue Strategies: Shared vs. Explicit References.
| User | Condition | Transcript |
|---|
| user17 | H–H | Miss K. and Mr. T. like this. |
| user16 | H–H | People ride this when they go to BKC campus. |
| user1 | H–AI | A car which can ride many person. |
| user4 | H–AI | It is used when people play baseball and to catch balls. |
Table 8.
CAF Scores by Game Type and Condition Order.
| Game Type | Condition Order | Complexity | Accuracy | Fluency |
|---|
| H–AI | H–AI First | 1.02 | 2.95 | 3.85 |
| H–AI | H–H First | 1.05 | 3.13 | 3.64 |
| H–H | H–AI First | 1.10 | 2.68 | 2.07 |
| H–H | H–H First | 1.03 | 2.80 | 1.95 |
Table 9.
Sample H–H Game Transcripts by Condition Order.
| User | Condition | Transcript | C | A | F |
|---|
| user6 | H–AI First | Ok. We can use the AI in that way. To eat bread, to toast… | 2.0 | 3.0 | 4.0 |
| user7 | H–AI First | It’s used in Thailand. This is ride. Not place. | 1.0 | 3.0 | 4.0 |
| user17 | H–H First | place | 1.0 | 1.0 | 1.0 |
| user11 | H–H First | No. Uh… Give in… Uh… Body… Inside. | 1.0 | 1.0 | 1.0 |
Table 10.
Paired questionnaire items comparing AI-based and human-based language learning.
| No. | AI-Based Learning | Human-Based Learning |
|---|
| Q1 | AI-based language learning required no concern for politeness. | Human-based language learning required no concern for politeness. |
| Q2 | I want to continue AI-based language learning. | I want to continue human-based language learning. |
| Q3 | AI-based language learning was relaxing. | Human-based language learning was relaxing. |
| Q4 | Using the AI game helped me acquire related vocabulary. | Learning with a person helped me acquire related vocabulary. |
| Q5 | AI-based language learning was beneficial. | Human-based language learning was beneficial. |
| Q6 | I was not embarrassed to make mistakes during AI-based learning. | I was not embarrassed to make mistakes during human-based learning. |
| Q7 | The AI game was easier than expected. | Learning with a person was easier than expected. |
| Q8 | I gained confidence in learning language through the AI game. | I gained confidence in learning language through the human partner. |
| Q9 | I became better at explaining through the AI game. | I became better at explaining through learning with a person. |
| Q10 | I felt a sense of accomplishment from the AI game. | I felt a sense of accomplishment from learning with a person. |
Table 11.
Mean Ratings and Wilcoxon Signed-Rank Results for AI- vs. Human-Partner Learning Items .
| Question (Q1–Q10) | AI Mean | Human Mean | W | p-Value |
|---|
| Q1. No social pressure | 4.33 | 3.44 | 15 | 0.036 |
| Q2. Want to continue | 4.06 | 4.17 | 39.5 | 0.701 |
| Q3. Feel relaxed | 4.50 | 3.67 | 17 | 0.050 |
| Q4. Vocabulary acquisition | 4.22 | 4.22 | 9 | 0.834 |
| Q5. Beneficial | 4.33 | 4.33 | 9 | 0.834 |
| Q6. Not embarrassing | 4.78 | 3.61 | 2 | 0.007 |
| Q7. Easier than expected | 3.17 | 2.94 | 23 | 0.398 |
| Q8. Built confidence | 3.72 | 3.78 | 9 | 0.834 |
| Q9. Better at explaining | 3.89 | 3.83 | 12 | 0.441 |
| Q10. Felt accomplished | 4.06 | 4.22 | 12 | 0.441 |
Table 12.
Theme Analysis of Q1 Responses with Representative Examples (N = 18).
| Theme | Explanation and Representative Comments (English) | # of Users |
|---|
| Cognitive | Learners reflected on language learning (grammar, vocabulary, clarity, thinking time, noticing). | |
“I tried harder to explain in sentences with the AI.” (User 5) “The AI used vocabulary well, which helped me learn grammar.” (User 11) “The AI used concise and clear structures. Just memorizing those helps.” (User 12)
| 7 |
| Emotional | Emotions such as fun, surprise, shock, enjoyment, or embarrassment. | |
“It felt like a game, so it was fun.” (User 3) “It felt relaxed, but I was shocked at how poorly I performed.” (User 17) “I was surprised how smart the AI was.” (User 1)
| 8 |
| Social | Social comparison with human interaction, freedom from embarrassment, communication freedom. | |
“I could speak freely without worrying.” (User 10) “I felt bad when I couldn’t lead a human to the answer.” (User 13) “It felt like I was chatting.” (User 18)
| 5 |
| Technical | Comments on AI accuracy, speech recognition, system praise/feedback. | |
“It didn’t catch my pronunciation well.” (User 8) “The AI understood even my incorrect English.” (User 16) “Its responses were harder to understand than a human’s.” (User 4)
| 6 |
Table 13.
Theme Analysis of Q2 Responses with Representative Examples (N = 18).
| Theme | Explanation and Representative Comments (English) | # of Users |
|---|
| Cognitive | Learners reflected on grammar awareness, sentence planning, learning strategies, and skill development. | |
“With the AI, I had to form correct sentences. That made me think more carefully.” (User 7) “To convey meaning precisely, grammar is really important.” (User 12) “From the second round, I wanted to increase the number of sentences.” (User 13)
| 9 |
| Emotional | Users expressed enjoyment, pressure, embarrassment, motivation, or low anxiety. | |
“It was easier with AI and felt less stressful.” (User 3) “With humans, I felt nervous around strangers.” (User 4) “I felt guilty when my English wasn’t understood.” (User 18)
| 6 |
| Social | Comparison between human–human and AI interactions; comments on shared understanding, gestures, feedback, and naturalness. | |
“With people, we share gestures and common knowledge, which made it easier.” (User 16) “Facial expressions helped when playing with humans.” (User 18) “AI lacked the sense of accomplishment I got with people.” (User 8)
| 10 |
| Technical | Feedback on AI prediction, hints, understanding, or rigid behavior. | |
“AI guessed easily, which made it convenient.” (User 3) “Sometimes the AI didn’t give strong enough hints.” (User 2) “AI needed accurate language, while people could understand even rough speech.” (User 9)
| 6 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}