1. Introduction
Natural language processing (NLP) has evolved dramatically over recent years, leading to significant advancements in various applications. Among these, text classification stands out due to its fundamental role across different domains. Text classification, a core task in NLP, involves categorizing text into predefined labels and is crucial for a variety of applications [
1]. The process entails analyzing textual data and assigning them to categories based on its content, significantly enhancing the efficiency of information retrieval models and content management platforms [
2,
3]. This increase in capability is largely attributed to breakthroughs in machine learning techniques and the introduction of deep learning models, which have revolutionized the ways in which machines understand and process human languages [
4]. These models can grasp nuanced language patterns and contextual variations, enabling more accurate and dynamic classification systems.
However, while these advancements have greatly improved the accuracy of text classification tasks, challenges remain. As the volume and variety of textual data continue to grow, driven by digitalization and the expansion of online platforms, the importance of sophisticated text classification mechanisms becomes even more pronounced [
1]. However, many models still struggle to capture deeper grammatical structures, which can be pivotal for more complex tasks such as question answering, sentiment analysis, or even automated summarization [
5]. These models often rely on implicit, context-dependent embeddings, which can fail to explicitly represent grammatical cues. This limitation highlights the need for approaches that explicitly incorporate grammar-based features, providing a more structured understanding of the text.
Historically, text classification relied on simpler statistical methods and feature-based models, such as the bag-of-words approach [
6,
7]. These methods lacked the ability to capture deeper grammatical or syntactic structures. Moreover, not all text used in various application tasks carries a specific, clear meaning. Text can often be short and ambiguous, with many phrases or words potentially holding multiple interpretations. This ambiguity presents a challenge in distinguishing context from limited information [
8]. Consequently, classifying content based solely on the text itself could lead to misleading results.
The shift toward integrating more complex features, including semantic and syntactic features, has addressed some of these issues [
9,
10,
11]. Recent research has increasingly focused on incorporating grammatical features [
12,
13], which provide a structured understanding of sentence syntax and semantics. This structured approach is particularly valuable in domains such as question–answer systems, where specific grammatical cues often point to distinct types of answers. Despite the potential of these grammar-based features, their integration into modern deep learning models remains underexplored.
The advent of deep learning models [
14,
15], particularly transformer-based architectures such as BERT, RoBERTa, and GPT [
16,
17,
18], has dramatically improved text classification performance. These models leverage dense contextual embeddings to achieve state-of-the-art performance across a variety of tasks. However, while these models capture semantic and syntactic relationships, they often do so implicitly within their embeddings. The question remains whether explicitly integrating grammatical features could further enhance classification performance, especially in the context of syntactic understanding.
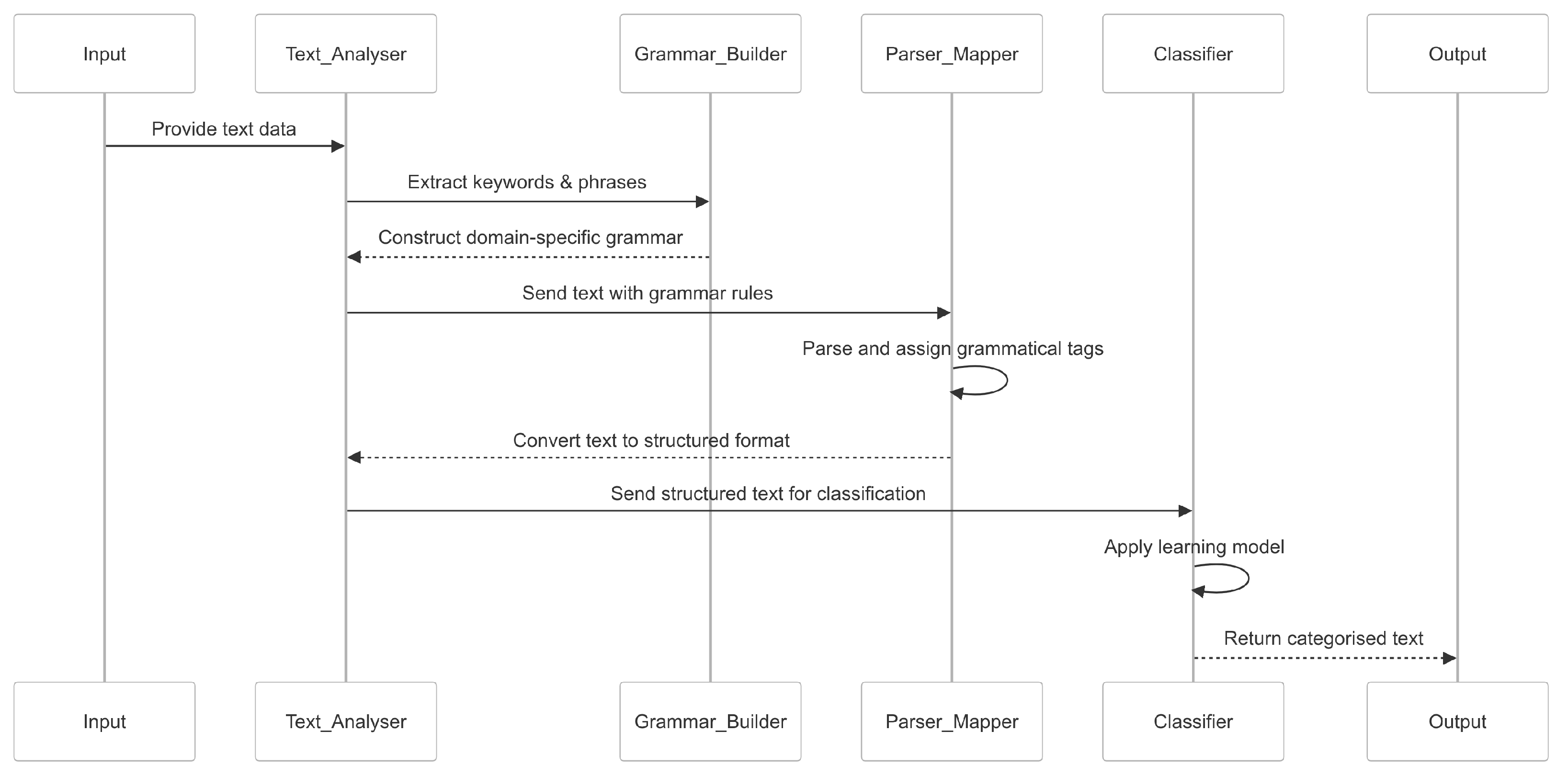
This paper investigates the impact of incorporating grammatical structures into text classification models. The study focuses on a dataset composed of questions aggregated from multiple question–answer systems, assessing whether explicit grammatical features contribute to improved classification accuracy and robustness. We argue that grammar-based feature engineering, when explicitly integrated, can provide valuable insights into the structure and meaning of text that go beyond the capabilities of traditional embeddings.
The main objectives of this study are as follows:
To design and validate a grammar-based feature engineering framework for text classification. This framework integrates both grammatical structures (e.g., part-of-speech tags and question types) and domain-specific features (e.g., named entities) to construct enriched, structured input representations that go beyond conventional word embeddings.
To evaluate and compare the effectiveness of deep learning and transformer-based models, including CNN, BiLSTM, MLP, BERT, DistilBERT, ELECTRA, and GPT-2, using these grammar-informed inputs. The goal is to assess how well each architecture leverages structured syntactic features for classification.
To assess model performance in both binary and multi-class settings, distinguishing between factoid and non-factoid questions in binary classification, and categorizing complex question types (causal, choice, confirmation, hypothetical, and list) in the multi-class scenario.
To analyze the impact of class imbalance and the application of the SMOTE oversampling technique, particularly in enhancing the recognition of under-represented classes such as choice and hypothetical, and to determine how oversampling affects the balance between precision and recall in each model.
The remainder of this paper is structured as follows.
Section 2 presents a detailed review of prior work in text classification, covering traditional machine learning, deep learning, and transformer-based approaches, with a focus on the use of grammatical and syntactic features.
Section 3 introduces the proposed grammar-based classification framework, including its components for text parsing, feature extraction, and classification, along with examples and feature mapping tables.
Section 4 outlines the experimental setup, detailing the dataset characteristics, model architectures, evaluation metrics, and the design of binary and multi-class classification experiments, including a SMOTE-enhanced setting to address class imbalance.
Section 5 presents and analyzes the experimental results, comparing the performance of grammar-based deep learning and transformer models across all tasks. Finally,
Section 6 concludes the paper by summarizing key findings and outlining future directions for grammar-informed NLP systems.
2. Related Work
This section provides a comprehensive overview of prior research in text classification, focusing on traditional machine learning approaches, neural networks, transformer-based models, and large language models.
Table 1 summarizes key techniques and representative works.
Traditional text classification methods rely heavily on machine learning algorithms such as naive Bayes, support vector machines (SVM), and decision trees. These models typically employ simple text representation techniques like bag-of-words and TF-IDF [
20]. Early research explored a wide range of features for classification, including unigram features, word shape patterns, and semantic and syntactic cues [
7,
21,
25,
26,
47]. Feature selection algorithms were used to optimize these features for specific question types, enhancing accuracy. Further improvements were achieved by incorporating headword features and leveraging external resources like WordNet to refine semantic representations [
48]. Studies showed that integrating such complex feature sets helped capture deeper linguistic structures [
21,
25,
49].
To improve model robustness and generalizability, ensemble techniques such as random forests and AdaBoost were adopted [
19,
22,
24]. K-nearest neighbor (KNN) classifiers were also widely used for baseline comparisons in short-text and question classification tasks [
23,
27]. In parallel, distributional semantic models such as latent semantic analysis (LSA) and latent dirichlet allocation (LDA) were employed to enhance feature representation beyond sparse encodings like TF-IDF [
28,
30].
The emergence of deep learning brought significant advances in text classification [
50]. Neural architectures such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) replaced manual feature engineering with automatic representation learning. These models, coupled with word embeddings like Word2Vec and GloVe, enabled a more nuanced understanding of semantic relationships between words [
29,
31]. Feature selection techniques such as chi-square, information gain, and mutual information remained important for managing model complexity and improving performance [
32,
51].
CNNs and RNNs demonstrated strong results in general text classification as well as domain-specific tasks such as question classification [
33,
34,
52]. These models were instrumental in shifting from static features to context-aware learning. LSTM networks, in particular, proved effective for handling sequential dependencies in text, achieving high performance across tasks [
35,
36].
More recently, large language models (LLMs) have reshaped the landscape of text classification through transfer learning and extensive pre-training. Ref. [
38] explored the integration of LLMs with deep learning architectures, demonstrating improved accuracy in question classification via fine-tuning of pre-trained models. Models such as GPT-4 and LLaMA3 have shown considerable success in capturing nuanced language patterns due to their scale and generalization capabilities [
37]. In addition, prompting techniques like clue and reasoning prompting (CARP) have been developed to enhance LLM reasoning and classification ability [
39].
Beyond general-purpose LLMs, several domain-specific transformer-based frameworks have been proposed. CoBerTC, introduced in [
42], is a Covid-19-specific classification model consisting of three main components: fine-tuning, model inference, and optimal model selection. The study evaluated six transformer models, mBERT, XML-RoBERTa, mDistilBERT, IndicBERT, MuRIL, and mDeBERTa-V3, on the ECovC dataset, with XML-RoBERTa achieving 94.22% accuracy.
Scalability and label sparsity have also been addressed through transformer innovations. Chang et al. [
40] proposed X-transformer, a scalable framework for extreme multi-label text classification (XMC), which combines semantic label indexing, transformer fine-tuning, and ensemble ranking to outperform models such as Parabel and AttentionXML. Similarly, Guo et al. [
41] introduced the multi-scale transformer, which integrates multi-scale multi-head self-attention (MSMSA) to capture both local and global context, yielding better performance than standard transformer architectures, particularly on smaller datasets.
Comparative evaluation remains central to understanding model efficacy. Petridis [
43] compared pre-trained transformer models (BERT, RoBERTa, and DistilBERT) with classical machine learning algorithms (SVM, random forest, and logistic regression) and traditional neural networks (MLP, RNN, and TransformerEncoder). Using TF-IDF and GloVe embeddings for non-transformer baselines, their results confirmed the consistent superiority of transformer-based models, with BERT and RoBERTa achieving up to 85.16% accuracy on level-1 classification tasks.
Comprehensive surveys [
45,
46] documented the evolution from traditional pipelines to neural and transformer-based models, highlighting their improved contextual awareness and generalization. Foundational contributions such as BERT [
53], a deep bidirectional transformer pre-trained on large corpora, and ULMFiT [
44], a transfer learning approach for fine-tuning language models, set new benchmarks in text classification.
While the above subsections outline the technical evolution of classification models, it is also important to acknowledge their practical deployments in applied research. Transformer models like BERT have been successfully applied in biomedical document classification [
54], legal document analysis [
55], and educational question answering [
56]. Similarly, CNN and BiLSTM architectures have been widely used in sentiment analysis [
46], social media content classification [
57], and multi-label news categorization. These applications illustrate the versatility of these models across domains, while also revealing a gap in the integration of grammatical or syntactic feature engineering. Our work addresses this gap by incorporating linguistically grounded features that improve classification robustness, particularly in imbalanced and semantically diverse question classification tasks.
Despite these advancements, the explicit integration of grammar-based feature engineering in deep learning and transformer models remains underexplored. While many models implicitly capture syntactic and semantic structures, few studies incorporate structured grammatical features directly.
5. Experimental Results
This section presents the results of the experimental study, analyzing the performance of grammar-based classification models across binary and multi-class settings. The evaluation compares deep learning and transformer-based models, assessing their ability to leverage structured grammatical features. Results are reported for both baseline and SMOTE-enhanced configurations, with particular focus on classification accuracy, class-wise F1-scores, and the impact of class imbalance mitigation techniques.
5.1. Grammar-Based Model Performance for Binary Classification
This subsection presents and analyzes the performance of grammar-based models in a binary classification task, distinguishing between factoid and non-factoid questions.
Table 5 provides the precision, recall, and F1-scores for each model across both classes, along with overall accuracy, macro, and weighted averages.
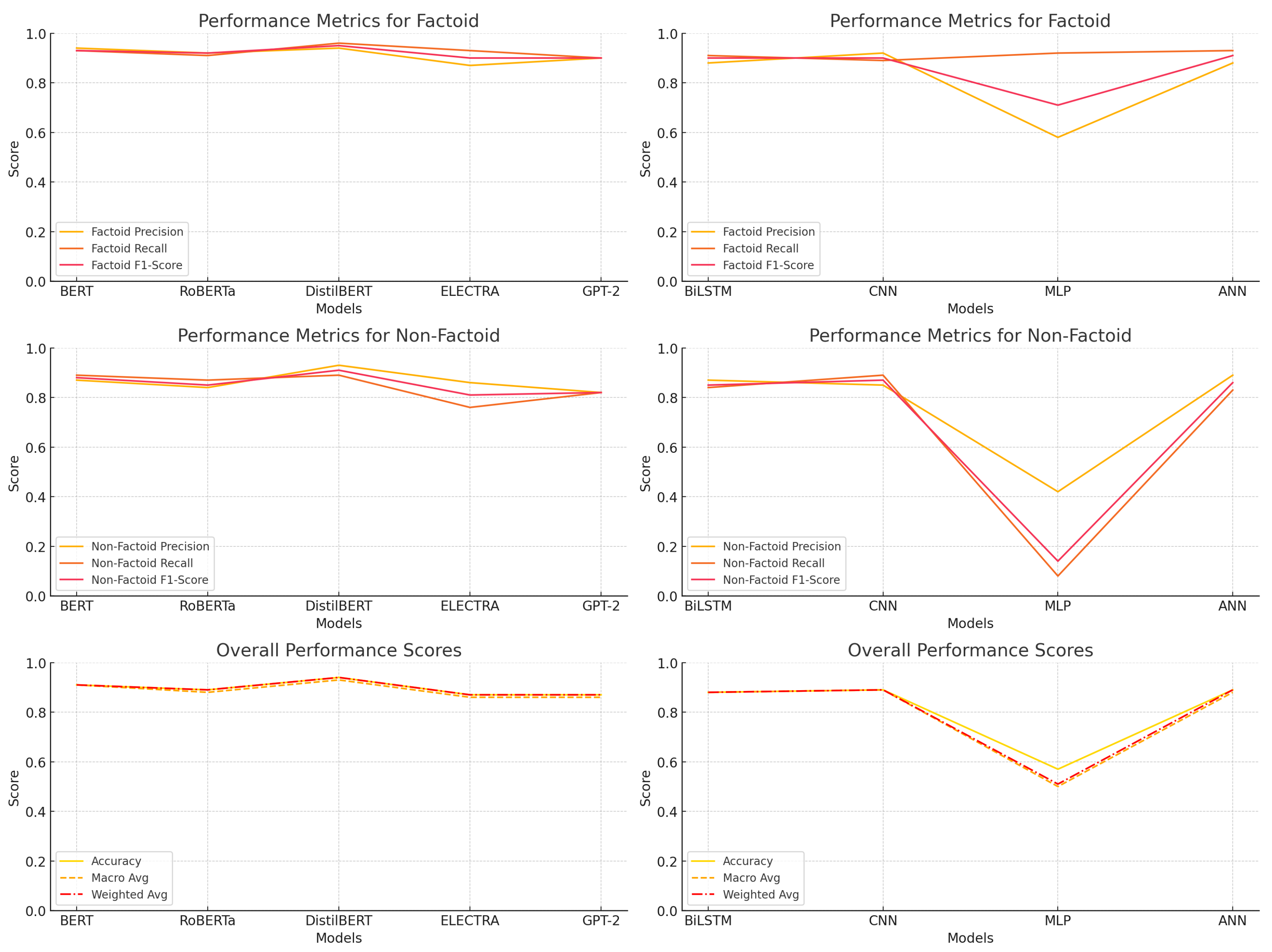
As shown in the table, transformer-based models outperformed traditional deep learning models. DistilBERT achieved the highest overall accuracy (0.94), factoid recall (0.96), and F1-score (0.95), confirming its superior capability in capturing grammatical and contextual features. BERT and RoBERTa also demonstrated high performance with accuracies of 0.91 and 0.89, respectively. GPT-2 and ELECTRA yielded solid but slightly lower results, especially in precision and recall for non-factoid questions.
Among deep learning models, BiLSTM and CNN showed competitive performance. BiLSTM achieved an F1-score of 0.90 and recall of 0.91 for factoid questions, indicating its effectiveness in handling sequential grammatical dependencies. CNN excelled in precision (0.92) but had slightly lower recall (0.89), reflecting its strength in local feature detection. In contrast, the MLP model underperformed, with an accuracy of only 0.57 and a non-factoid recall of just 0.08, highlighting its limitations in capturing complex grammatical relationships. The ANN provided a more balanced profile, achieving an accuracy of 0.89 and robust scores across both classes.
Figure 2 further illustrates these trends, showing the individual precision, recall, and F1-score values for factoid and non-factoid questions.
It is evident that transformer-based models, especially DistilBERT, maintain consistent high performance across all metrics, whereas MLP demonstrates significant drops, particularly in non-factoid recall and F1-score. BiLSTM and CNN maintain high metric scores, but with more variation between precision and recall.
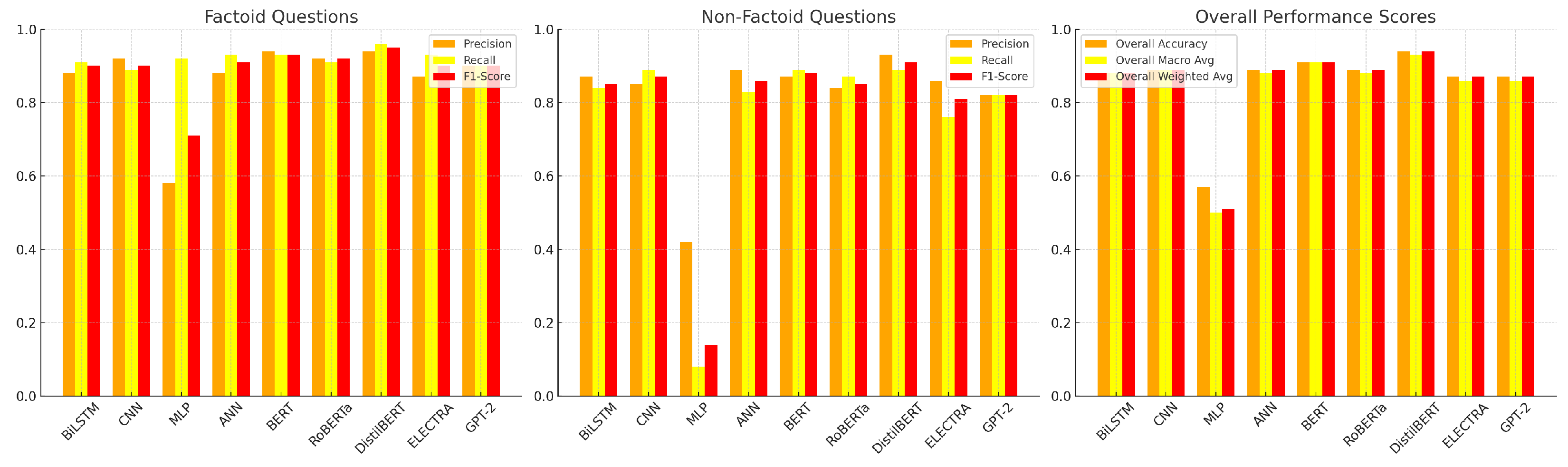
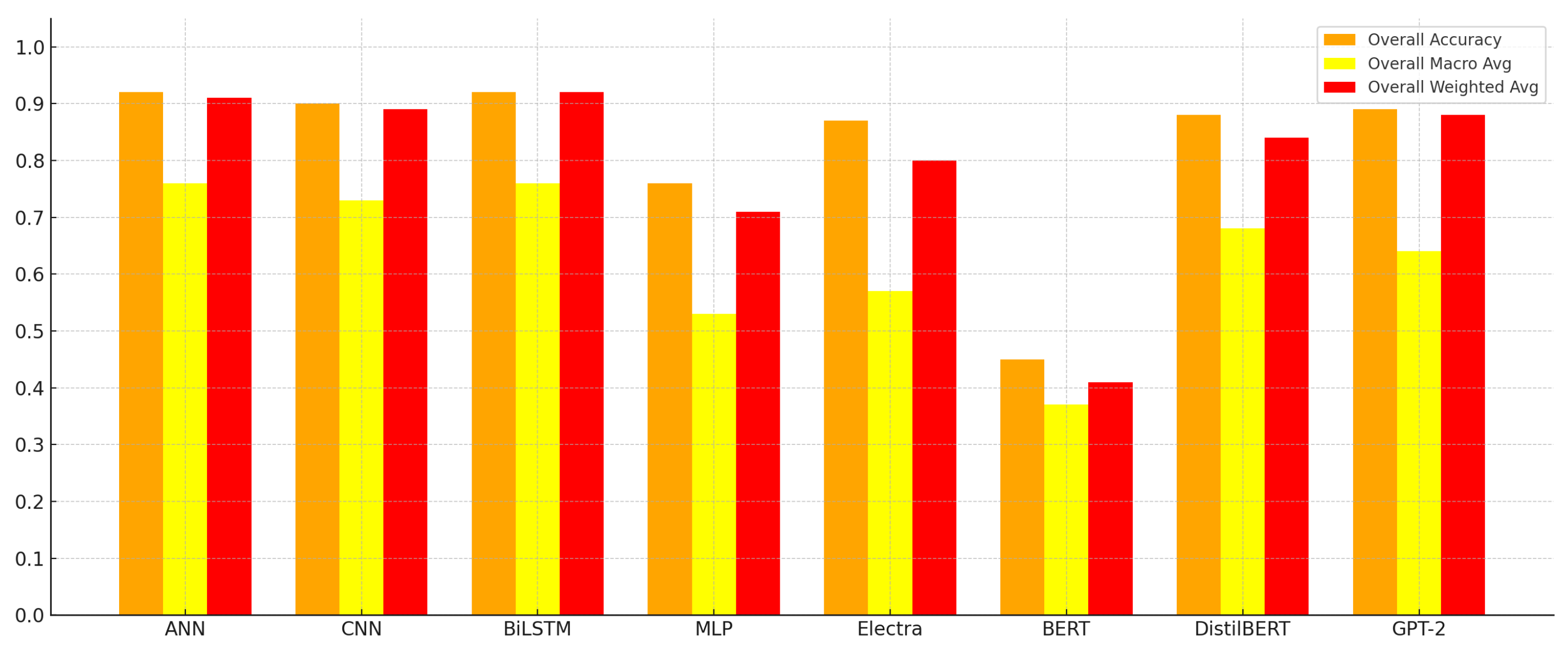
Figure 3 presents a comparative summary across all models using bar charts, facilitating clearer visual analysis of the overall accuracy, macro average, and weighted average.
As shown in the chart, DistilBERT leads across all overall metrics, while BERT, RoBERTa, and CNN form the next tier. The visualization also highlights the underperformance of MLP across all dimensions, underscoring the need for more expressive architectures for binary classification based on grammatical structures.
Overall, transformer-based models demonstrated superior generalization, particularly for factoid questions, while BiLSTM and CNN remained competitive among deep learning models. DistilBERT emerged as the most balanced and effective model for grammar-based binary classification tasks.
5.2. Grammar-Based Model Performance for Multi-Class Classification (Baseline)
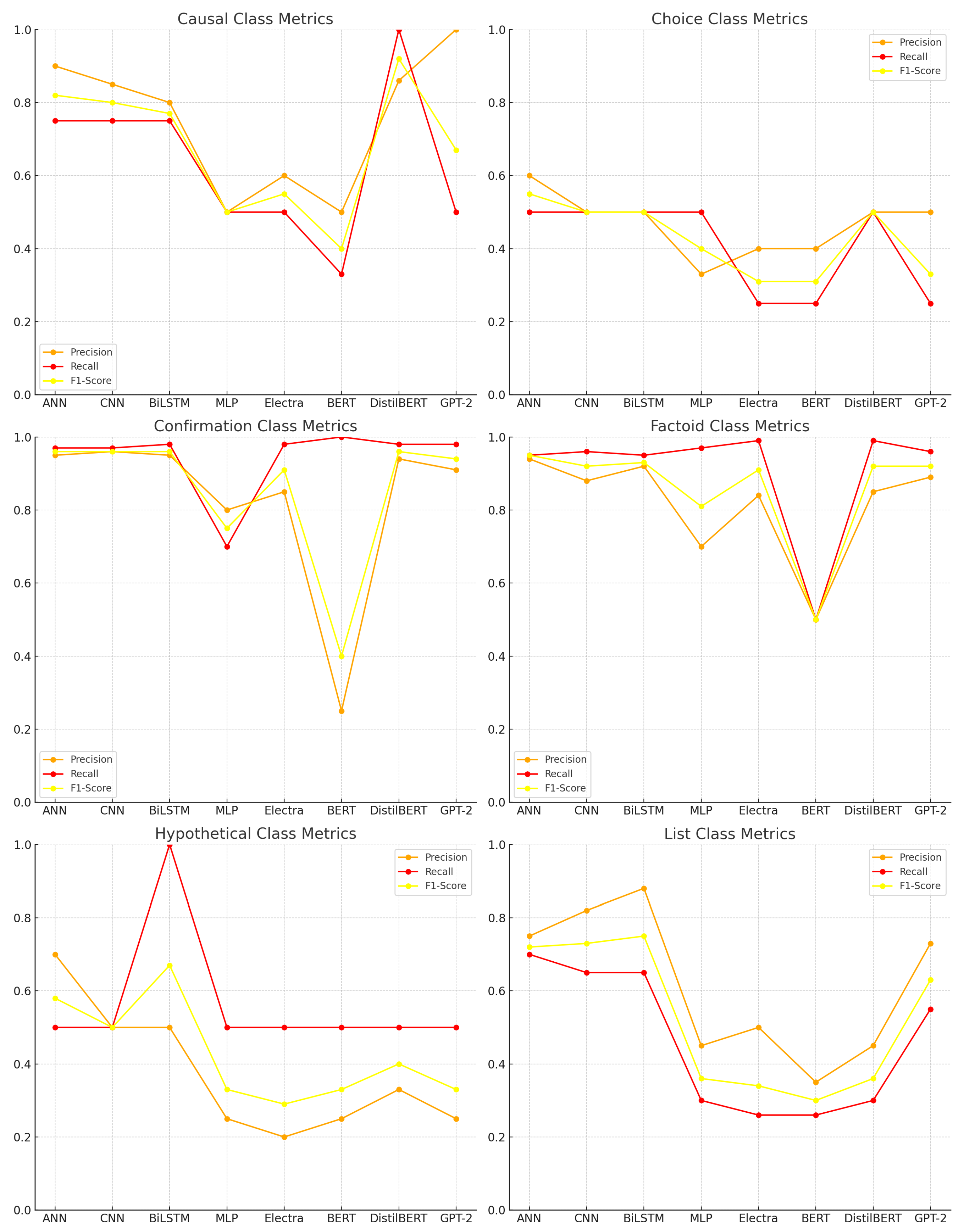
This subsection evaluates the performance of grammar-based models in a multi-class classification task, categorizing questions into six distinct classes: causal, choice, factoid, confirmation, hypothetical, and list.
Table 6 provides a detailed breakdown of model performance across these classes, including precision, recall, and F1-score per class, as well as overall accuracy, macro average, and weighted average scores.
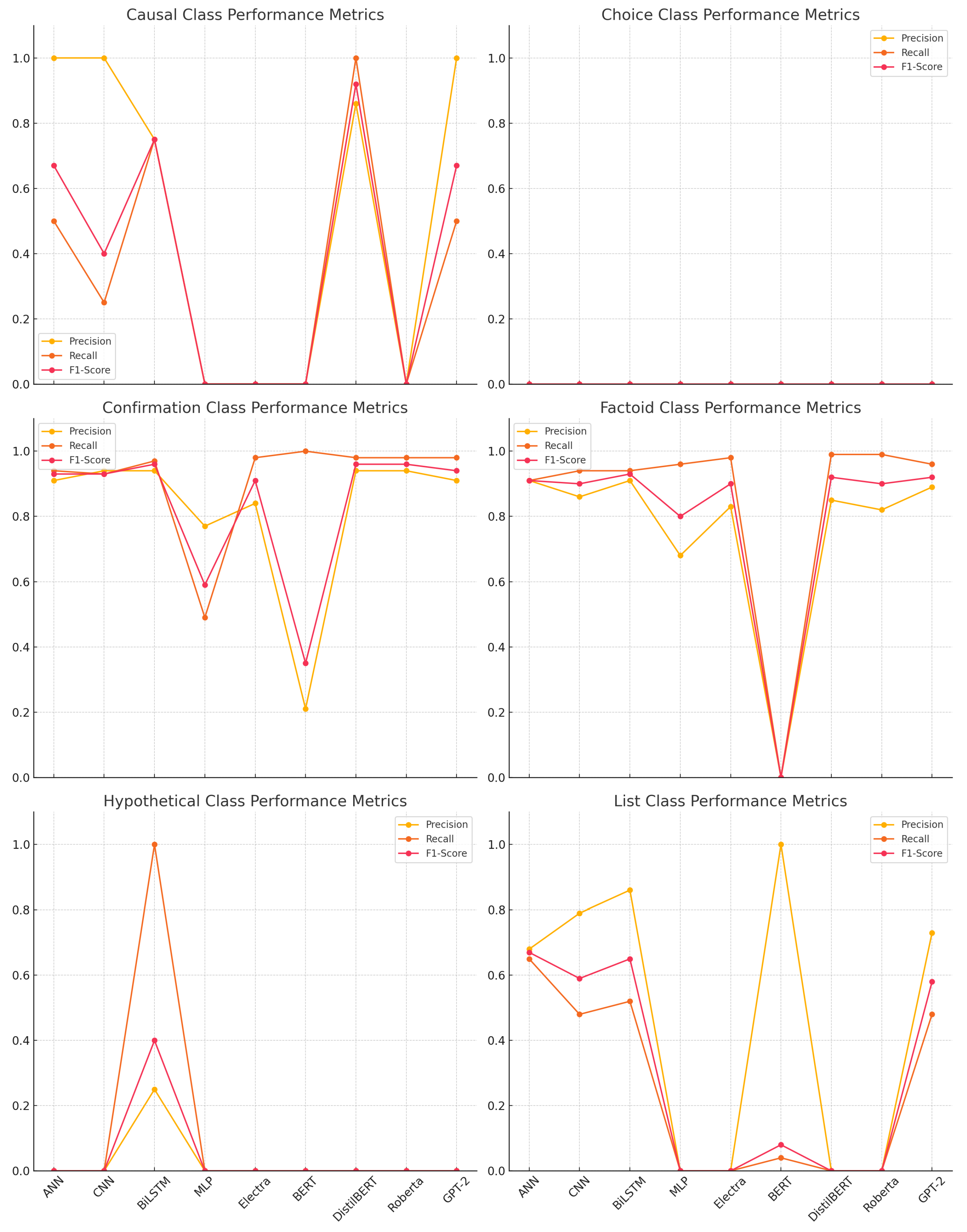
Among the deep learning models, BiLSTM achieved the highest overall accuracy (0.90), along with the best macro average (0.61) and weighted average (0.90), indicating balanced performance across both frequent and infrequent classes. It demonstrated particularly strong results in the confirmation (F1 = 0.96) and factoid (F1 = 0.93) categories. ANN followed closely with an overall accuracy of 0.88 and strong performance in confirmation (F1 = 0.93) and list (F1 = 0.67) questions. CNN also performed robustly (accuracy = 0.87), though its macro average (0.47) suggests slightly less balanced effectiveness across all categories.
In contrast, MLP displayed the weakest performance among neural models. It yielded near-zero scores in several classes, including causal, choice, and hypothetical, resulting in an overall accuracy of 0.70 and a macro average of 0.23. These shortcomings are clearly visualized in
Figure 4, where MLP’s F1-scores approach zero for these under-represented classes.
Among transformer-based models, DistilBERT delivered promising results, achieving excellent performance in the causal (F1 = 0.92), confirmation (F1 = 0.96), and factoid (F1 = 0.92) classes. However, it failed to identify any instances from the choice, hypothetical, or list classes, likely due to class imbalance. GPT-2 showed competitive performance (accuracy = 0.88), with strong results in confirmation (F1 = 0.94) and factoid (F1 = 0.92), and moderate success in causal (F1 = 0.67), but similarly struggled with the low-frequency classes.
Electra and RoBERTa exhibited inconsistent performance. Electra achieved a reasonable accuracy (0.84), but its class-wise scores fluctuated significantly, particularly in the hypothetical and list categories. BERT was the weakest overall performer, with an accuracy of just 0.21 and minimal contribution across all classes, indicating difficulties in adapting to grammar-based, structured input.
From a class-wise perspective, the confirmation class was the easiest to classify, with nearly all models achieving F1-scores above 0.90. The factoid class followed closely, with strong performance from most models except BERT and MLP. The causal class posed moderate difficulty; while some models achieved perfect precision (e.g., ANN, CNN, and GPT-2), only a few attained high recall.
In contrast, the choice and hypothetical classes were the most challenging, with no model successfully identifying examples from these categories. This underscores the impact of class imbalance in the dataset and highlights the need for enhanced augmentation or contextual modeling strategies.
The list class showed moderate success, with BiLSTM (F1 = 0.65), ANN (F1 = 0.67), and CNN (F1 = 0.59) performing best. Transformer-based models generally underperformed in this category.
In summary, deep learning models such as BiLSTM, ANN, and CNN demonstrated stronger and more consistent performance across classes. While DistilBERT and GPT-2 were competitive in specific categories, they struggled with under-represented ones. BERT and MLP were the least effective overall. These results indicate that grammar-based deep learning architectures remain competitive for multi-class classification, particularly in scenarios involving diverse and imbalanced data.
5.3. Grammar-Based Model Performance for Multi-Class Classification (SMOTE-Enhanced)
This subsection investigates the effect of addressing class imbalance through the application of SMOTE (synthetic minority over-sampling technique) on grammar-based models for multi-class text classification. SMOTE generates synthetic examples for minority classes by interpolating between existing samples, effectively balancing class distribution without introducing noise. The aim is to enhance model performance across six question categories: causal, choice, factoid, confirmation, hypothetical, and list.
Table 7 presents a comprehensive overview of precision, recall, and F1-score per class, alongside overall accuracy, macro average, and weighted average scores for each model.
Following this,
Figure 5 visualizes per-class performance metrics, highlighting the impact of class balancing on model robustness.
Among deep learning models, ANN and BiLSTM achieved the highest classification performance, both attaining an accuracy of 0.92. CNN followed closely with an accuracy of 0.90. These models consistently achieved strong F1-scores across all classes, indicating balanced precision and recall. For example, ANN handled the causal class well with an F1-score of 0.82, precision = 0.90, and recall = 0.75, while BiLSTM maintained good recall (0.75) and an F1-score of 0.77. CNN also performed strongly in this class with precision of 0.85 and an F1-score of 0.80. GPT-2 achieved perfect precision (1.00) for causal questions but exhibited low recall (0.50), leading to an F1-score of 0.67, indicating overconfidence with reduced sensitivity.
Although performance on the choice class improved after SMOTE was applied, it remained one of the most difficult categories. ANN performed best (F1 = 0.55), while most other models hovered around 0.50. BERT and Electra achieved only 0.31, showing difficulty in learning distinguishing features for this category. GPT-2 also struggled (F1 = 0.33), pointing to the need for further fine-tuning or data augmentation.
The confirmation class showed the most consistent performance across all models. BiLSTM reached a near-perfect recall (0.98) and F1-score (0.96), closely followed by ANN and CNN. Transformer-based models such as Electra (F1 = 0.91) and DistilBERT (F1 = 0.96) also excelled. Only BERT lagged behind significantly with an F1-score of 0.40.
Factoid classification remained a strong area for most models. ANN, CNN, and BiLSTM achieved F1-scores of 0.95, 0.92, and 0.93, respectively. Transformer models such as DistilBERT (F1 = 0.92), Electra (F1 = 0.91), and GPT-2 (F1 = 0.92) also performed well. BERT again showed the weakest results with only 0.50.
Despite improvements from SMOTE, the hypothetical class continued to pose challenges. BiLSTM achieved the highest F1-score (0.67) through perfect recall (1.00) but had moderate precision (0.50). ANN and CNN followed with F1-scores of 0.58 and 0.50, respectively. Transformer models such as BERT, GPT-2, and Electra scored below 0.35, reflecting difficulty in capturing abstract or less frequent hypothetical constructs.
For the list class, BiLSTM again led with an F1-score of 0.75, followed by CNN (0.73) and ANN (0.72). GPT-2 delivered moderate results (F1 = 0.63), while MLP, DistilBERT, BERT, and Electra scored below 0.40. These findings suggest that sequential models like BiLSTM and CNN are better suited to this question type.
In conclusion, addressing class imbalance with SMOTE led to measurable improvements in model performance, particularly in macro and weighted averages, which reflect the treatment of under-represented classes.
Figure 6 presents a comparative bar chart summarizing the overall accuracy, macro-average F1-score, and weighted-average F1-score for each grammar-based model after SMOTE application. Deep learning models, especially ANN, BiLSTM, and CNN, consistently delivered high accuracy (>90%) and balanced performance across classes. While transformer models such as GPT-2 and DistilBERT demonstrated competitive accuracy, their macro-average scores were slightly lower, suggesting sensitivity to class imbalance. BERT, in contrast, lagged behind in all metrics, underscoring its relative weakness in handling grammatically enriched, imbalanced multi-class datasets. Overall, the chart visually confirms the effectiveness of SMOTE in enhancing fairness and generalization across diverse model architectures.
5.4. Overall Comparison with Baseline Models
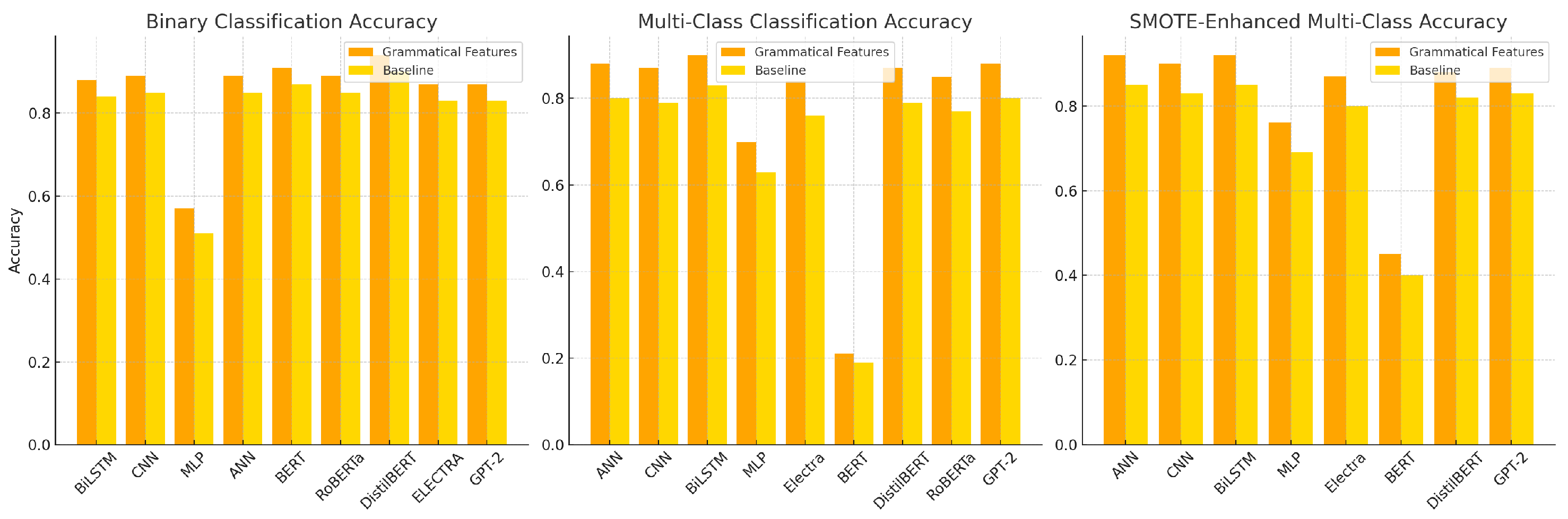
This subsection presents a comprehensive comparison between grammar-enhanced models and their baseline counterparts that do not incorporate grammatical features. The performance is evaluated across three experimental settings: binary classification, multi-class classification, and SMOTE-enhanced multi-class classification. Each task is assessed using standard metrics such as accuracy, macro average, and weighted average scores.
Table 8,
Table 9 and
Table 10 summarize the baseline results for each task. The visual summary in
Figure 7 further illustrates the accuracy differences across model types and configurations.
Table 8 presents the performance of baseline models across the factoid and non-factoid classes in the binary setting.
As shown, DistilBERT achieved the highest accuracy (0.90) and macro F1-score (0.89) among baseline models, while MLP significantly underperformed (accuracy = 0.51). Transformer models generally outperformed deep learning models, except for ANN and CNN, which demonstrated solid results. However, the lack of grammatical features limited all models’ ability to distinguish non-factoid questions, evidenced by low recall and F1-scores in this class.
Table 9 displays performance across the six-class setting without oversampling.
In this configuration, BiLSTM achieved the best macro F1-score (0.54), while MLP and BERT performed poorly across most classes. The choice and hypothetical categories remained unrecognised by all models, highlighting the impact of class imbalance. Overall, macro average scores ranged between 0.05 (BERT) and 0.54 (BiLSTM), indicating poor minority class recognition without grammar support.
Table 10 presents the performance of models after applying SMOTE.
Performance generally improved after SMOTE. BiLSTM and ANN achieved the highest accuracy (0.85), and macro F1-scores increased across all models by approximately 10–20 percentage points. However, models like MLP and BERT still struggled to generalize across low-frequency classes, and gains were modest without structural linguistic input.
Figure 7 visually summarizes the accuracy improvements across tasks. Grammar-enhanced models (orange bars) consistently outperformed baseline models (yellow bars), particularly in multi-class and SMOTE settings. The improvements are most prominent in under-represented class handling, as reflected in macro F1-score trends.
In conclusion, grammar-based features consistently improved classification performance across all tasks. The most substantial gains were observed in macro-average scores, highlighting better treatment of minority categories. While baseline models performed adequately on dominant classes, they failed to generalize under syntactic complexity and class imbalance. These findings affirm the utility of grammar-aware NLP frameworks for more robust, equitable, and contextually grounded classification.
5.5. Discussion
The results across the experimental phases (baseline, class-balanced, and binary classification) demonstrate the substantial impact of data imbalance and the effectiveness of oversampling through SMOTE in grammar-based question classification.
Initially, in the baseline multi-class classification setting, deep learning models such as ANN and CNN demonstrated high precision but notably low recall for under-represented classes. For example, ANN recorded perfect precision of 1.00 for the causal class but recall of only 0.50, highlighting the tendency of the model to favor majority classes while neglecting minority ones. This trend was consistent across several low-frequency categories, such as hypothetical and choice, where many models failed to identify any instances. Such discrepancies reflect the skewed distribution of the dataset and the inherent challenges in learning from imbalanced data.
Following the introduction of SMOTE, all models showed marked improvements in minority class recognition, particularly in F1-score, which balances both precision and recall. ANN and CNN improved their F1-scores in the causal class to 0.82 and 0.80, respectively. BiLSTM also showed a notable gain, with an F1-score of (0.77), while even transformer models such as DistilBERT improved from complete failure to achieving moderate performance in several classes. This shift illustrates SMOTE’s ability to augment the feature space and alleviate class imbalance without sacrificing the quality of learned representations.
However, the degree of improvement varied across models. Traditional deep learning models, i.e., ANN, CNN, and BiLSTM, consistently outperformed their transformer-based counterparts, particularly in under-represented categories. For instance, while GPT-2 achieved perfect precision (1.00) in the CausF1 score post-balancing, its recall dropped to 0.50, resulting in a moderate F1-score of 0.67, suggesting sensitivity to data augmentation and potential overfitting. Similarly, while BERT showed some improvement, it remained the weakest model overall, often underperforming in both precision and recall even after balancing. This highlights limitations in certain transformer architectures when applied to domain-specific or grammatically enriched classification tasks.
Additionally, the new comparative analysis with baseline models, e.g., those that do not incorporate grammar-based features, further validates the effectiveness of grammar-informed representations. Across all tasks, grammar-enhanced models achieved consistently higher macro-average scores, particularly in SMOTE-enhanced settings, where macro F1 improvements ranged from 4% to 10% compared to baseline equivalents. These gains were most pronounced in previously under-represented classes, such as hypothetical and choice. Transformer-based models like DistilBERT and RoBERTa, while strong in binary tasks, particularly benefited from grammar-based features in complex multi-class scenarios, where baseline models often failed to detect minority classes altogether.
The contrast between binary and multi-class classification performance further reinforces the importance of class balance. In binary settings, where class distribution is naturally less skewed, models generally achieved higher accuracy and balanced performance without requiring oversampling. This suggests that the complexity of the multi-class scenario, combined with data imbalance, significantly contributes to model degradation, and balancing techniques like SMOTE are essential for fair and accurate classification.
Beyond data augmentation, another key contributor to performance was the integration of grammatical and domain-specific features. These enriched representations enabled models to capture structural, syntactic, and semantic cues that are critical for fine-grained question classification. Even when model architecture was limited, such as in MLP or BERT, the addition of these features offered modest gains. For example, classification in the list and confirmation categories improved across nearly all models, demonstrating the discriminative power of grammar-informed features.
In summary, the findings underscore the importance of both data-centric and model-centric strategies in NLP classification tasks. Class balancing techniques like SMOTE substantially mitigate the adverse effects of skewed distributions, while grammar-based feature engineering enhances the expressiveness of the input data. The added comparison with baseline results further illustrates that grammar-aware architectures significantly enhance robustness and generalisability across both balanced and imbalanced scenarios. Together, these approaches contribute to improved generalization, fairer treatment of minority classes, and more reliable multi-class classification, paving the way for more interpretable and equitable NLP systems.
6. Conclusions and Future Work
This study explored a novel grammar-based classification framework that integrates grammatical and domain-specific features into both deep learning and transformer-based architectures. The framework was rigorously evaluated across binary and multi-class classification tasks using a syntactically rich question dataset. Three experimental settings were considered: baseline classification, class-balanced classification via SMOTE, and binary classification. The primary goals were to assess the utility of grammar-enhanced feature representations, compare the effectiveness of traditional and transformer models, and quantify the impact of class balancing techniques.
The experimental results revealed that integrating structured grammatical features significantly improves model performance, particularly when linguistic cues are critical for label discrimination. In the binary classification task, where data distribution was naturally balanced, transformer-based models such as DistilBERT and BERT outperformed deep learning alternatives, achieving accuracies between 88–94% and macro F1-scores between 88–93%. In contrast, baseline models without grammatical features reached lower values (accuracy: 83–90% and macro F1: 82–89%).
In the multi-class setting, grammar-enhanced models achieved accuracy scores ranging from 70–90% and macro averages from 23–61%, whereas their baseline counterparts reached 63–83% and 21–54%, respectively. For SMOTE-enhanced multi-class classification, grammar-informed models reached up to 92% accuracy and macro averages up to 76%, outperforming baseline models, which plateaued at 85% accuracy and 69% macro average. These results confirm that grammar-based features provide a substantial boost in handling minority classes, as evidenced by consistent improvements in macro-average metrics across all configurations.
Additionally, the comparative analysis highlighted that grammar-based deep learning models remained highly competitive with transformer architectures, particularly in scenarios involving syntactically structured input. While transformer models excelled in capturing context, they often struggled with under-represented classes, even after oversampling. This suggests that transformer-based models may benefit from further adaptation to grammar-informed input formats or from hybrid approaches that incorporate both local structure and global context.
For future work, several promising directions may be pursued. First, exploring adaptive oversampling strategies or cost-sensitive loss functions could further address class imbalance [
69]. Second, the integration of attention-based mechanisms over structured grammatical features may enhance interpretability and performance. Third, extending the grammar-based framework to other domains, such as legal, biomedical, or multilingual datasets, would test its generalizability and robustness. Finally, ensemble models that combine syntactic, semantic, and contextual representations may yield additional performance improvements and offer better generalization across diverse text types [
70,
71].
In conclusion, this work demonstrates the tangible benefits of integrating grammatical structure and domain knowledge into modern text classification pipelines. By bridging traditional feature engineering with state-of-the-art learning models, the proposed framework not only advances performance metrics but also enhances the interpretability and adaptability of NLP systems. These findings pave the way for future innovations in grammar-aware text analytics, offering a promising direction for more equitable, accurate, and linguistically informed natural language understanding.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}