1. Introduction
The exponential growth of academic publications poses a significant challenge for researchers trying to keep up-to-date with developments in numerous fields. More than 2.5 million papers are published annually in approximately 30,000 accredited journals worldwide, making it increasingly challenging to filter relevant research efficiently. This is particularly evident in rapidly evolving domains such as artificial intelligence, virtual reality, and blockchain technologies [
1]. As the research landscape becomes saturated, the visibility of new and impactful studies diminishes, complicating the synthesis of existing knowledge [
2]. SLRs provide a structured approach to summarizing and synthesizing research, offering essential information on specific topics. However, traditional manual SLR approaches are labor-intensive, prone to human error, and increasingly unsustainable due to the overwhelming data volume.
Recent work has advanced automation in systematic literature reviews using transformer-based models. Nanggala et al. [
3] review how transformers like BERT enable tasks such as document classification and semantic clustering in literature reviews. Scherbakov et al. [
4] survey transformer models adapted for automated screening, summarization, and topic modeling, highlighting their growing role in streamlining review workflows.
Despite advances in AI-driven tools for literature searches and summarization, a significant gap remains in fully automating the systematic review process. Individual tools exist for searching, filtering, and summarizing content; however, they often operate in isolation, leaving researchers to handle other crucial stages manually, such as selecting relevant literature, extracting insights, and generating coherent reports. Additionally, practitioners face persistent challenges in SLRs, such as manual screening burden, reproducibility gaps, and reviewer fatigue. The scientific community lacks a fully integrated, scalable solution that automates the SLR pipeline. Such a solution must ensure accuracy and efficiency while reducing the manual burden on researchers.
In response to this need, we propose PROMPTHEUS: process optimization and management of papers using emerging technologies for high efficiency in updated systematic reviews. PROMPTHEUS is an automated framework that integrates large language models (LLMs) to automate key phases of the SLR process: systematic search and screening, data extraction, synthesis, and summarization. While the critical planning phase remains in the hands of researchers, PROMPTHEUS significantly reduces the manual workload, improving the final outputs’ precision, accuracy, and relevance, allowing researchers to focus more on the innovative aspects of their work.
The contributions of this work are the following:
Novel Integration of SLR Phases: We present a fully automated approach to SLRs, combining multiple stages, search, extraction, and synthesis, into an end-to-end process powered by advanced natural language processing (NLP) techniques.
Precision in Literature Retrieval: We leverage state-of-the-art language models to enhance the precision of literature searches. This ensures that researchers receive high-quality and relevant studies, addressing a critical need for accurate literature filtering.
Structured Topic Modeling: PROMPTHEUS employs BERTopic, a topic modeling technique that structures the extraction and organization of information, allowing for clear, well-organized reviews.
Comprehensive Evaluation: We present a robust evaluation using several metrics, including ROUGE scores, Flesch readability scores, cosine similarity, and topic coherence. These evaluations demonstrate the effectiveness of PROMPTHEUS in automating the SLR process while maintaining high accuracy and improving the readability of generated content.
By automating the most time-consuming aspects of SLRs, PROMPTHEUS aims to make SLRs more accessible, efficient, and comprehensive. This will ultimately enable researchers to devote more time to innovative, high-impact research while ensuring they remain up-to-date with critical developments. In addition, such tools may reduce the increasing mistrust in science by making summarization more accessible to laypeople.
By automating the most labor-intensive stages of systematic literature reviews, PROMPTHEUS enhances the accessibility, efficiency, and rigor of the review process. This enables researchers to focus more on creative and high-impact work while remaining current with field developments. Furthermore, by improving the clarity and accessibility of synthesized knowledge, PROMPTHEUS may help bridge the gap between academic research and public understanding, thereby addressing growing concerns about scientific mistrust.
The remainder of this paper is organized as follows:
Section 2 reviews related work and outlines current limitations in automated SLR systems.
Section 3 presents the PROMPTHEUS framework in detail, including its architectural components and underlying NLP techniques.
Section 4 describes the experimental setup and evaluation metrics, followed by the results and analysis.
Section 5 discusses the implications, limitations, and potential future enhancements.
Section 6 presents the main technical limitations of our approach, while
Section 7 discusses ethical implications.
Section 8 presents the link with our open-source framework. Finally,
Section 9 concludes the paper.
3. PROMPTHEUS: A Framework for AI-Driven SLRs
Despite significant advancements in AI-assisted SLRs, challenges remain in ensuring automated systems’ accuracy, scalability, and relevance. Our proposed framework, PROMPTHEUS, introduces an integrated and fully automated SLR framework that enhances SLRs’ selection, extraction, and synthesis phases while maintaining human oversight during the planning phase. PROMPTHEUS leverages advanced NLP techniques such as BERTopic for topic modeling and Sentence-BERT for sentence similarity to improve the precision and relevance of selected studies. Our system also integrates LLMs like GPT and T5 for summarization and post-editing, ensuring the generated summaries are accurate and coherent.
By introducing early stage inclusion and exclusion criteria, PROMPTHEUS improves the rigor of study selection and reduces the likelihood of including irrelevant papers. This approach addresses the shortcomings identified by O’Connor et al. [
29] and de la Torre-López et al. [
30], who emphasized the importance of integrating AI tools that improve efficiency without compromising the accuracy and comprehensiveness of systematic reviews, and also the challenges highlighted by Affengruber et al. [
31] and Shaheen et al. [
32] who stressed the importance of balancing efficiency with comprehensive, high-quality reviews.
3.2. Systematic Search and Screening Module
The systematic search and screening module is the foundation of the automated systematic literature review process, which automates retrieving and filtering academic papers based on a user-defined research question or topic. This module addresses the limitations of traditional literature search methods, which often require extensive manual effort, by using LLMs and advanced NLP techniques to enhance the efficiency and precision of the search process.
While PROMPTHEUS supports the automation of literature retrieval and initial filtering using semantic similarity and topic modeling techniques, it currently does not include explicit mechanisms for defining and enforcing inclusion or exclusion criteria. These criteria are foundational to systematic review methodology, ensuring the transparency and consistency of selection decisions. In its current version, PROMPTHEUS approximates relevance via document embeddings and topic relevance, which serve as proxies for human judgment. In future iterations, we plan to incorporate rule-based modules that allow users to define customizable inclusion/exclusion filters based on attributes such as publication type, methodological approach, or domain-specific keywords.
Research Topic Expansion: The module begins with the user providing a research question or topic as input. The system leverages an LLM (GPT-3.5, GPT-4, or GPT-4o) to expand the initial input into a more detailed and semantically rich set of keywords and phrases to ensure the search captures a comprehensive range of relevant studies. This expansion is guided by a carefully crafted prompt that instructs the model to retain the core focus of the research topic while adding appropriate keywords and terms to cover variations and related concepts. Part of the prompt used for this task is the following:
System: “You are a knowledgeable AI specializing in generating expanded titles for research topics. Your expanded titles should be concise and focus on capturing the core semantic meaning of a topic, suitable for creating informative embeddings for tasks like similarity comparisons.”
User: “Task: Generate a slightly expanded title for the following research topic, keeping the core focus while potentially adding 1–2 highly relevant terms for improved semantic representation.
Topic: title
Guidelines:
* Include essential keywords directly related to the topic.
* If necessary, add 1–2 closely related terms to capture topic variations.
* Avoid introducing new concepts or significantly altering the original title’s meaning.
* Keep the expanded title concise and focused on the core meaning.
Output format:
* Provide the expanded title only. Do not include any additional explanations or commentary.” |
For instance, given the input topic “AI-based literature review”, the LLM might generate an expanded version such as “AI-based literature review, automated systematic reviews, natural language processing for academic research synthesis”. This expanded set of keywords ensures that the subsequent search covers a broader scope, capturing essential variations and closely related studies that might be overlooked.
Automated Query Generation: After expanding the research topic, the system constructs a structured search query tailored to the arXiv repository. This step is guided by another prompt instructing the LLM to craft a precise and targeted search query incorporating all relevant keywords and phrases. The model is asked to include fields such as title and abstract to refine the search further, ensuring that the retrieved literature aligns closely with the expanded topic. The prompt used for generating the search query is shown in the box below:
System: “You are a skilled research assistant specializing in crafting precise and effective search queries for the arXiv scientific paper repository.”
User: “Task: Craft an effective search query tailored for the arXiv database, specifically designed to retrieve research papers on the following topic:
Topic: ‘expanded_title’
Guidelines:
1. Concise and Precise: The query should be succinct yet accurately represent the core concept of the topic.
2. Key Terms: Incorporate the most relevant keywords or phrases directly associated with the topic.
3. Synonyms and Variants (Optional): If applicable, include synonyms or alternative terms to broaden the search scope and capture nuanced variations of the topic.
4. Specificity: Prioritize terms specific to the field or subfield to minimize irrelevant results.
5. arXiv Compatibility: Utilize operators like ‘ti:’ (title) and ‘abs:’ (abstract) to target specific fields within the arXiv entries.
Output format:
* Provide the ArXiv query only. Do not include any additional explanations or commentary." |
The output of this prompt might produce a query such as (ti:“AI-based literature review” OR abs:(“AI-based literature review” OR “automated systematic reviews”)) AND (ti:“NLP” OR abs:“NLP”). This structured query is then used to search the arXiv database through its API, retrieving up to 3000 academic papers that match the specified criteria. Once the search results are obtained, the module pre-processes the retrieved papers by extracting essential details such as paper ID, title, and abstract. The text is cleaned to ensure consistency and readability by removing unnecessary symbols and normalizing the format. This clean text is then used in the next stage of the module, where relevance filtering is performed.
Relevance Filtering Using Sentence Similarity: The module employs a similarity-based mechanism using Sentence-BERT embeddings to filter the most pertinent papers from the initial search results. It computes vector embeddings for both the expanded research topic and the cleaned abstracts of the retrieved papers. The cosine similarity between these embeddings is then calculated to assess the relevance of each paper. The top 200 papers with the highest similarity scores are selected for further analysis, ensuring the final literature set is focused and comprehensive. This structured approach significantly reduces manual effort while improving the quality and relevance of the selected studies, providing a robust foundation for subsequent stages.
Once the relevant papers are identified through a systematic search and screening, the next step is to organize these documents into coherent themes using the data extraction and topic modeling module.
3.3. Data Extraction and Topic Modeling Module
The data extraction and topic modeling module automates organizing and categorizing selected academic papers into meaningful topics based on semantic content. The module leverages topic modeling and language generation techniques to create a structured literature representation, making identifying key research themes and subtopics easier. The module’s core components include topic modeling and document clustering, keyword extraction and title generation, and topic report generation.
PROMPTHEUS distinguishes between two modes of information retrieval in the automated SLR pipeline: quantitative and qualitative. Quantitative retrieval refers to the extraction of structured metadata such as publication years, venues, author affiliations, or keyword frequencies. These elements are reliably parsed from bibliographic entries and document metadata using regular expressions or semantic filters. In contrast, qualitative retrieval, such as identifying key contributions, theoretical framing, or methodological limitations, requires interpretive reasoning. PROMPTHEUS employs transformer-based summarization and topic modeling to approximate this interpretive synthesis. While these tools offer scalable generation of thematic overviews, we acknowledge their current limitations in replicating the nuanced judgment of domain experts. As such, PROMPTHEUS is best viewed as an augmentative tool that can expedite preliminary synthesis, rather than fully substitute human interpretation.
Topic Modeling and Document Clustering: Once the most relevant documents are selected from the initial screening phase, this module initiates by creating embeddings for the textual content of each document using a Sentence-BERT model. These embeddings capture the semantic information of the documents, allowing for an effective clustering of papers based on their conceptual similarities. Topic modeling uses the BERTopic algorithm, which groups documents into coherent clusters reflecting the selected literature’s primary themes. The number of topics and the minimum topic size are dynamically adjusted based on the size and content of the dataset to ensure that the generated topics are both meaningful and interpretable.
Keyword Extraction and Title Generation: After clustering the documents into distinct topics, the system extracts keywords for each topic, summarizing the main themes in that cluster. The keywords are input into a language model, such as GPT-3.5, GPT-4, or GPT-4o, to generate concise and descriptive titles for each topic. This process is guided by a structured prompt instructing the language model to create topic titles that accurately represent the essence of the keywords while maintaining clarity and relevance. The prompt used for this task is as follows:
System: “You are an experienced researcher specializing in literature reviews. You are adept at crafting concise, informative, and engaging topic names for subsections that accurately reflect the content and guide the reader.”
User: “Task: Create a clear and concise topic name for a subsection in a literature review. The subsection covers the following keywords: topic_keywords:”
Guidelines:
* Length: Aim for 1–5 words.
* Accuracy: Ensure the topic name precisely reflects the keywords’ meaning.
* Relevance: The name should fit within the broader context of a literature review.
* Informativeness: Clearly indicate the subsection’s focus to the reader.
* Engagement: Make the topic name interesting and inviting to read.
Optional: If the keywords are too broad or ambiguous, suggest a more specific or narrowed-down focus within the topic.
Output format:
* Provide the topic title only. Do not include any additional explanations or commentary. |
For instance, if the extracted keywords for a topic are “deep learning, neural networks, image recognition”, the generated title might be “Deep Learning for Image Recognition”. This descriptive title provides an overview of the underlying theme of the clustered documents, making it easier for researchers to navigate through the literature.
Topic Report Generation: After generating the titles, the system compiles a comprehensive report that includes the list of documents under each topic, the topic keywords, and the generated titles. This hierarchical organization of literature enhances the comprehensiveness and accessibility of the review, as it delineates different research themes and subtopics, making it easier for researchers to identify key trends and gaps in the literature. The module’s process is further supported by a series of iterations and parameter adjustments to refine the topic modeling. If the initial number of topics is too few or too many, the system dynamically tunes the parameters, such as the number of issues or the minimum size of a topic, to achieve optimal clustering.
In general, this module significantly improves the efficiency and effectiveness of the systematic literature review process by automating the categorization of papers and generating meaningful insights into the core themes of the literature. Automates document categorization, offering researchers valuable insights into the core themes of the literature and simplifying the identification of key trends and gaps.
3.4. Synthesis and Summarization Module
The synthesis and summarization module generates concise and coherent summaries for each identified topic cluster, significantly reducing the manual effort typically required in literature review processes. This module utilizes transformer-based models, such as T5, to summarize abstracts and GPT-based models for post-editing, ensuring that the resulting content is well-structured and easy to understand.
Abstract Summarization with T5: The process begins by generating summaries for individual abstracts within each topic cluster using a transformer-based model like T5. This model is specifically configured to produce short yet comprehensive summaries that capture each document’s key contributions and findings. The generated summaries retain essential details while significantly reducing the length of the original abstracts, making it easier to synthesize large volumes of research.
Topic-Level Summarization and Aggregation: After individual summaries are generated, they are aggregated into a comprehensive summary for each identified topic. This step synthesizes the insights from multiple papers within the same topic, offering a holistic view of the research contributions, trends, and open questions. The aggregated summaries provide a structured narrative highlighting the most significant findings across multiple studies.
Our method proceeds in four distinct steps:
Cluster Identification: We first group documents into thematic clusters using BERTopic. This step ensures that related studies are analyzed together, forming the basis for coherent summaries.
Extractive Summary Generation: For each cluster, we apply GPT-4o in extractive mode to select representative sentences. By focusing on key sentences, we preserve the most salient findings with minimal noise.
Abstractive Refinement: The extracted sentences are then fed into GPT-4o with chain-of-thought prompting to produce concise, fluent summaries. This refinement enhances readability and integrates insights across papers.
Aggregation into Narrative: Finally, we combine the abstractive summaries into the review’s thematic narrative, adding signposting and context.
This aggregation step transforms discrete summaries into a cohesive section suitable for publication.
Post-Editing and Refinement with GPT: To enhance the clarity, coherence, and flow of the aggregated summaries, a GPT-based model is employed for post-editing. The refinement process involves using a predefined prompt instructing GPT to improve readability and structure while preserving critical information. This step ensures that the final summaries are well-organized and suitable for inclusion in a structured literature review document. The following prompt is used for post-editing:
System: “You are an expert researcher specializing in literature reviews in the field of title. Your task is to meticulously refine and enhance machine-generated summaries of multiple research papers.”
User: Refine the following machine-generated summary for the section “section_name” in a literature review titled “title”
The original summary is a compilation of various papers. Please focus on retaining the most relevant information for this literature review section.
Crucially, ensure the inclusion of in-text citations (e.g.,
citepkadir2024revealing) for all information directly sourced from the referenced documents. Feel free to shorten the section summary if it enhances clarity and conciseness, but prioritize keeping essential details and all relevant citations.
Original Summary: summary
Output format:
* Provide only the revised summary. Do not include any additional explanations or commentary. |
This refinement results in a more precise and cohesive summary that better communicates the core literature of the topic.
Document Compilation and Report Generation: The final step is compiling the generated summaries and topics into a coherent literature review document. This module integrates all the synthesized content into a structured LaTeX document, which includes an introduction, background information, detailed literature synthesis for each topic, and a conclusion. The system also generates a BibTeX file with the references for all included papers, ensuring proper citation and academic integrity.
The document generation process uses GPT, ensuring the final output is professionally formatted and adheres to the desired layout and style. The module supports various formats for exporting the final report, including LaTeX and PDF, providing researchers with a polished, ready-to-use literature review.
4. Experimental Setup
The proposed automated SLR framework was evaluated using a comprehensive experimental setup to assess its performance across different stages of the review process. We used five distinct research topics for the experiments: “Explainable Artificial Intelligence (XAI)”, “Virtual Reality (VR)”, “Blockchain”, “Large Language Models (LLMs)”, and “Neural Machine Translation (NMT)”. Each experiment focused on a specific phase of the proposed SLR framework: systematic search and screening, data extraction and topic modeling, and synthesis and summarization.
Datasets: We conducted experiments using five different research topics, each representing a unique area of academic research: explainable artificial intelligence, virtual reality, blockchain, large language models, and neural machine translation. We collected the papers for each research topic from the arXiv database. We retrieved papers based on search queries generated by GPT-3.5 and GPT-4o models, with a maximum limit of 3000 papers per query.
Experiments: We designed four experiments to assess the system’s performance across different phases: systematic search and screening, data extraction and topic modeling, synthesis and summarization, and document compilation and report generation. We reported the results using various metrics, including topic coherence, ROUGE scores, readability scores, and cosine similarity.
Readability Analysis: We evaluated the readability of the generated summaries and final LaTeX documents using the Flesch Reading Ease Score (FRES). The Flesch Reading Ease Score [
33] provides insight into how easily a text can be read and understood. Higher FRES scores indicate simpler reading material, while lower scores denote more complex and challenging passages. We computed FRES at different stages of the summarization and document generation process to assess how readability changes as the content is processed through T5 summarization, GPT post-editing, and final document generation.
Metrics: To evaluate the quality and robustness of the proposed framework, we used the following metrics:
Topic coherence measures the semantic similarity between words in a topic, indicating how well the generated topics represent coherent and interpretable concepts. A higher coherence score suggests that the words within each topic are more closely related, making the topics more useful and understandable for further analysis [
34].
ROUGE stands for recall-oriented understudy for gisting evaluation. It compares an automatically produced summary or translation against a set of reference summaries (typically human-produced). ROUGE evaluates various aspects, such as the overlap of n-grams, word sequences, and word pairs between the machine-generated output and the reference.
ROUGE-1 measures the overlap of unigrams (single words) between the generated and reference abstracts. ROUGE-1 is particularly useful for evaluating summarization techniques because it captures the essential content and ensures that key information from the original text is retained in the summary.
Precision for ROUGE-1 measures the fraction of relevant instances among the retrieved cases, indicating how much of the generated summary is present in the reference text, which is the abstract in our case.
Recall for ROUGE-1 measures the fraction of instances retrieved over the total number of cases in the reference, indicating how much of the reference abstract is covered by the generated summary.
F1-score for ROUGE-1 is the harmonic mean of precision and recall, providing a balance between the two metrics.
Cosine similarity measures the similarity between two non-zero vectors of an inner product space, effectively capturing the semantic closeness between the generated text and the reference text. Cosine similarity was used to evaluate the semantic alignment of abstracts with expanded topics during the systematic search and screening phase.
Flesch Reading Ease Score (FRES) [
33] provides insight into how easily a piece of text can be read and understood. The FRES formula considers sentence length and syllable count, with higher scores indicating simpler and more accessible text. We computed the FRES for three stages: T5-generated summaries, GPT post-edited sections, and the final LaTeX document. The formula is as follows:
This formula provides a measure of how easy a text is to read. Higher scores indicate easier-to-read material, while lower scores denote more difficult passages.
The number of papers retrieved indicates the coverage of the search query and its ability to find relevant literature.
The number of papers filtered reflects the number of papers that passed an initial relevance filter based on the research topic.
The total CPU time is the computational time required for generating queries, retrieving papers, and filtering results.
Hardware: Experiments were conducted in a Google Colab environment using an Intel Xeon CPU @ 2.20 GHz (2 cores, 56 MB cache), with 12.7 GB of RAM and 107.7 GB of disk space.
4.1. Experiment 1: Systematic Search and Screening
This experiment evaluated the effectiveness of GPT-3.5 and GPT-4o in generating queries for retrieving research papers from the arXiv repository. Given their capabilities in generating structured and contextually rich queries, we sought to compare the two models regarding their retrieval performance, efficiency, and computational cost. The experiment aimed to identify which model performs better across various research topics.
We selected five diverse research topics for this evaluation: explainable artificial intelligence, virtual reality, blockchain, large language models, and neural machine translation. For each topic, we measured three key performance indicators: the number of papers retrieved, the number of papers filtered, and the CPU time.
The five selected topics, explainable AI, virtual reality, blockchain, large language models, and neural machine translation, represent high-volume research areas within the AI and computing domains. Query generation was based on a consistent prompt template used with both GPT-3.5 and GPT-4o.
Results and Analysis: The results are summarized in
Table 1. GPT-4o consistently retrieved more papers than GPT-3.5 across all topics, indicating that GPT-4o generates comprehensive and relevant queries more effectively. For instance, GPT-4o retrieved 2833 papers for “Virtual Reality” compared to 1986 papers retrieved by GPT-3.5. Similarly, for “Explainable Artificial Intelligence”, GPT-4o retrieved 1712 papers, surpassing the 1287 papers retrieved by GPT-3.5.
While GPT-4o demonstrated superior retrieval capability, it also required significantly more computational time than GPT-3.5. For instance, the “Explainable Artificial Intelligence” topic took 1555 seconds to process using GPT-4o, whereas GPT-3.5 completed the same task in 1213 seconds, a difference of nearly 6 minutes. Similarly, GPT-4o required 2115 seconds to process the “Large Language Models” topic, which is approximately 10 minutes longer than GPT-3.5.
These results suggest that GPT-4o is more effective at generating queries that yield a more extensive set of relevant papers, making it well-suited for scenarios where comprehensive literature coverage is a priority. However, this increased retrieval capability comes at the cost of longer computational time, making GPT-4o less ideal for scenarios where efficiency and speed are critical considerations.
In conclusion, GPT-4o is preferable for use cases prioritizing comprehensive retrieval over computational efficiency, while GPT-3.5 may be better for time-sensitive applications. This insight provides a basis for selecting the appropriate LLM based on the specific requirements of different phases in the systematic literature review process.
4.3. Experiment 3: Synthesis and Summarization
This experiment assessed the performance of the synthesis and summarization phase of our automated literature review framework. We evaluated the quality of the generated summaries using ROUGE scores to determine their relevance and content retention. Additionally, the readability of each summary was analyzed using the Flesch Reading Ease metric. The primary goal was to determine how effectively the system condenses and synthesizes information from multiple research papers while maintaining coherence and relevance.
ROUGE Score Analysis: We used the ROUGE-1 metric to compare the content overlap between the machine-generated summaries and the abstracts of the selected research papers, which served as reference texts. ROUGE-1 measures the degree of overlap in unigrams (single words) between the generated summaries and reference texts, making it suitable for evaluating content retention and relevance.
The evaluation was conducted in three stages:
Abstract Generated Summaries using T5: These serve as the baseline summaries generated by the T5 model, which captures the core content of the abstracts.
Post-Edited Generate Summaries using GPT: GPT-based models refine these summaries to enhance readability, coherence, and overall structure.
Document Compilation and Report Generation using LaTeX: Comprehensive sections formatted as LaTeX documents that integrate information from multiple summaries, providing a cohesive and structured literature overview.
We computed ROUGE-1 precision, recall, and F1-scores for each stage. While all three metrics provide valuable insights, we focused primarily on precision. High precision indicates that the summaries retain the most pertinent information from the reference abstracts, minimizing irrelevant details.
The results in
Table 3 indicate that both GPT-3.5 and GPT-4o models achieved high precision (P) scores across all inputs, demonstrating that the generated summaries contain a significant proportion of relevant content present in the reference abstracts. However, the recall scores are relatively lower, reflecting that not all content from the reference abstracts is captured in the summaries. This is expected since we want to capture only the relevant information in the abstracts. In this table, there is no significant benefit in choosing GPT-4o instead of GPT-3.5, as the T5 model computes the summary. GPT, at this stage, was only used to gather documents by creating the ArXiv query.
Post-Editing Stage Results: The post-editing phase is crucial in refining the machine-generated summaries produced by the T5 model. This stage utilizes GPT-based models to enhance the initial summaries’ clarity, coherence, and structure. The objective is to condense and reorganize the content while preserving the most relevant information. Post-editing is essential for transforming raw summaries into well-structured sections that align with the broader context of an SLR.
Table 4 presents the ROUGE-1 scores for the summaries after being refined by GPT-based models.
The results show a clear drop in recall after post-editing compared to the initial T5-generated summaries, reflecting the focus on refining and condensing content. This reduction is expected as the goal is to produce well-structured, concise sections for the systematic literature review (SLR). Despite the decrease in recall, precision scores remain high, ensuring the retained information is relevant and concise.
GPT-4o demonstrates higher recall than GPT-3.5, indicating its ability to retain more content during post-editing. However, the F1-scores, which balance precision and recall, show only a slight advantage for GPT-4o, suggesting that both models perform similarly in maintaining a good balance between content relevance and retention.
Post-editing with GPT significantly improved the precision of the summaries, ensuring that the most relevant information was retained, even though recall slightly decreased. GPT-4o showed a slight edge in content retention, making it more suitable for comprehensive literature reviews.
Final LaTeX Document Evaluation: The system’s final LaTeX documents were evaluated to determine their effectiveness in creating cohesive literature review sections that integrate information from multiple sources.
As presented in
Table 5, both GPT-3.5 and GPT-4o achieved exceptionally high precision scores (e.g., 0.991 for GPT-3.5 and 0.989 for GPT-4o in the “Explainable Artificial Intelligence” topic), indicating that the final documents are highly aligned with the reference abstracts in terms of relevance. However, the recall scores for these documents were relatively low, which is expected given that the final LaTeX documents are designed to provide comprehensive literature review sections, not direct summaries of the abstracts. These documents incorporate additional background information, contextual insights, and synthesized content from various sources, which broadens the scope and naturally reduces recall scores.
Despite this, the F1-scores, which balance precision and recall, show that the final documents maintain a strong balance between relevance and content coverage. GPT-4o generally achieved higher recall scores than GPT-3.5, suggesting it is more effective at incorporating additional relevant content while maintaining overall coherence. This makes GPT-4o particularly useful in scenarios where comprehensive literature coverage is essential.
While GPT-4o offers advantages in retaining more comprehensive content, GPT-3.5 remains a competitive option for generating concise and highly relevant summaries. Future efforts could focus on improving recall without sacrificing precision, allowing for even more comprehensive and well-rounded literature review sections.
4.4. Experiment 4: Readability Score
We used the Flesch Reading Ease Score to evaluate the readability of the generated summaries and final documents at different stages of the document generation process. This metric provides insights into how accessible the text is to a general audience, with higher scores indicating easier-to-read content. Readability was evaluated for the T5-generated summaries, GPT post-edited summaries, and the final LaTeX documents.
Table 6 outlines the interpretation of Flesch Reading Ease scores, with lower scores indicating text that requires a higher level of education to comprehend. In our evaluation, we compared these scores across the stages of the automated SLR process to assess how the readability evolved from the initial summarization to the final document creation.
Table 7 presents the Flesch Reading Ease scores for each stage of the document generation process. These scores provide an overview of how readability changes as the content is transformed from initial summaries to refined, structured documents.
T5-generated summaries exhibit low readability scores, indicating that the content is quite challenging to read. This outcome is expected due to the highly condensed nature of the T5-generated summaries, which prioritize brevity over readability, often lacking the narrative structure required for easier comprehension.
The readability of the summaries significantly improves after the GPT post-edited sections. The post-editing process refines the content by enhancing clarity, improving sentence structure, and providing a more coherent flow. This results in more accessible and readable sections, reflected in the enhanced Flesch scores.
The final LaTeX generated documents show further improvements in readability. The additional structuring, formatting, and content synthesis contribute to easier-to-read documents than the earlier stages. However, while the readability has improved, it remains lower than the baseline.
Baseline summaries exhibit the highest readability scores, demonstrating that maintaining readability while summarizing and synthesizing content remains a challenge. The baseline scores highlight the gap between the generated summaries and the clarity of the original abstracts.
The Flesch Reading Ease Scores improved progressively from T5-generated summaries to GPT post-edited sections and final LaTeX documents. However, despite these improvements, the readability of the generated documents remains lower than that of the original abstracts. This outcome underscores the challenge of maintaining high readability while compressing and synthesizing content, particularly in automated systems.
4.5. Experiment 5: Sentence Similarity
To further evaluate the effectiveness of our automated systematic literature review (SLR) system, we computed cosine similarity scores at various stages of document generation. This analysis quantifies how closely the generated summaries and final documents align with the original input queries, providing a measure of content retention and relevance. For comparison, a baseline (Random) was included, representing a document generated with random words, to serve as a control.
Cosine similarity measures the cosine of the angle between two vectors in a multidimensional space; here, these vectors represent text embeddings derived from the documents. Higher cosine similarity scores indicate greater alignment between the generated texts and the original input queries.
Table 8 presents the cosine similarity scores for each stage of the document generation process, offering insights into how well the system preserves content relevance across different stages:
Abstract Filtering: The filtered abstracts generated by GPT-3.5 and GPT-4o exhibit high cosine similarity scores, demonstrating that the initial search and screening phase effectively identifies documents closely related to the input queries. Both models perform well at this stage, confirming the robustness of the search process.
T5-Generated Summaries: The cosine similarity scores decrease slightly for the T5-generated summaries, which is expected. Summarization inherently condenses content and may omit some details, leading to a lower similarity with the full abstracts. However, the core information relevant to the input query remains retained, ensuring that the generated summaries focus on the main topics.
GPT Post-Edited Summaries: The cosine similarity scores increase after the post-editing process by GPT. This improvement suggests that the GPT-based post-editing refines the structure and readability and enhances alignment with the original input. The post-editing process ensures that the key content is retained while improving the coherence of the generated sections. GPT-4o generally outperforms GPT-3.5 in maintaining content similarity, indicating that GPT-4o is more effective at preserving relevant information.
Final LaTeX Documents: The final documents generated by GPT continue to exhibit high similarity scores, indicating that the synthesis and summarization process effectively retains the relevance of the content. The structured nature of LaTeX documents ensures that core themes from the input queries are well-represented. GPT-4o again shows slightly better performance than GPT-3.5, further suggesting that it is better at understanding and incorporating relevant content throughout the document generation process.
Random Baseline: As expected, the cosine similarity scores for the randomly generated document are very low. This serves as a control, validating the significance of the similarity scores observed for the generated summaries and final documents.
Overall, the system demonstrates robustness in generating documents that remain closely aligned with the original input queries, ensuring that the synthesized literature reviews preserve essential information while improving readability and structure.
4.6. Experiment 6: Finding the Optimal Number of Papers for SLR
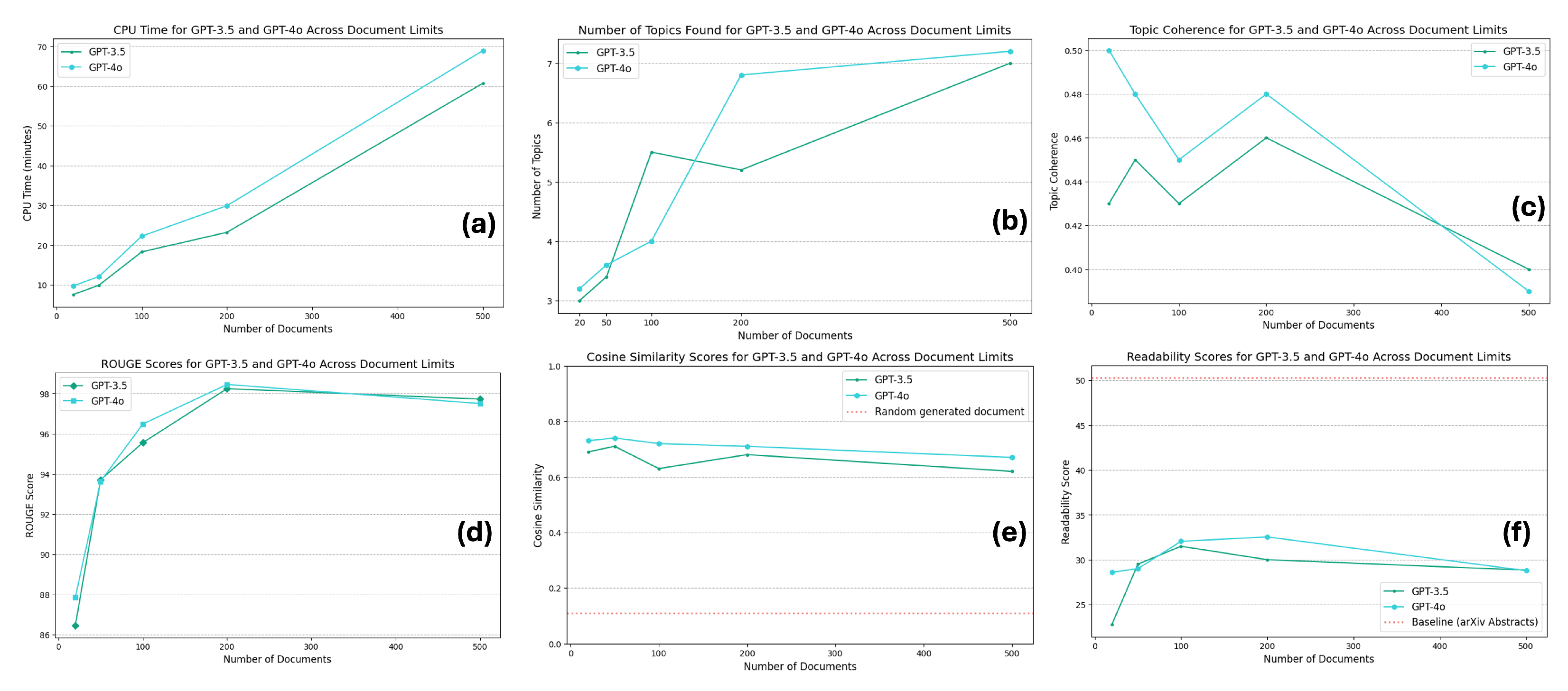
This section explores several key performance metrics to determine the optimal number of papers to include in the SLR process. The metrics analyzed include CPU time, number of topics identified, topic coherence, ROUGE scores, readability scores, and cosine similarity scores. These metrics are used to assess the impact of different document limits on the quality and efficiency of the SLR. We recommend the most effective document limit that balances performance and computational resources based on the analysis results.
Figure 2 presents the results obtained.
CPU Time: Figure 2a shows the CPU time shows how computational requirements scale with the number of documents processed. As the document count increases, CPU time rises significantly, with GPT-4o consistently requiring more time than GPT-3.5. This indicates that although GPT-4o can potentially offer more accurate results, it demands more computational resources, which is a trade-off to consider when processing large volumes of documents.
Number of Topics Found: In
Figure 2b, BERTopic identifies an increasing number of topics as more documents are processed. GPT-4o consistently identifies more topics than GPT-3.5 across all document limits. This suggests that GPT-4o is more adept at detailed clustering, potentially offering a more nuanced breakdown of the literature. However, after a certain threshold, the increase in topics may not necessarily translate to better quality but rather more fragmented groupings.
Topic Coherence: The topic coherence metric measures the semantic similarity within the topics identified, providing insight into the quality of the generated clusters.
Figure 2c illustrates the quality of the topics generated based on the semantic similarity of words within them. GPT-3.5 and GPT-4o maintain relatively stable topic coherence scores of up to 200 documents. Beyond this point, coherence begins to drop slightly for both models, likely due to overfitting or noise introduced by an excessive number of documents. This reinforces that 200 documents strike an optimal balance between quality and quantity regarding topic coherence.
ROUGE Scores for Summarization Quality: The ROUGE scores measure how well the generated summaries align with reference abstracts, focusing on content retention.
Figure 2d shows that as the number of documents increases, the ROUGE scores improve, peaking around 200. This suggests that the system becomes better at generating summaries that capture the core content of the papers as more documents are processed. However, beyond the 200-document threshold, the improvement in ROUGE scores plateaus, indicating that additional documents do not contribute significantly to better summarization. This implies that while increasing the document count improves the system’s ability to summarize effectively, there is little benefit to going beyond 200 documents regarding content retention and quality.
Cosine Similarity for Content Alignment: The cosine similarity scores measure how closely the generated documents align with the input queries, indicating relevance and focus.
Figure 2e shows that GPT-3.5 and GPT-4o achieve high similarity scores across all document limits, stabilizing around 200 documents. This indicates that 200 documents provide sufficient information to produce outputs well-aligned with the original research query without overwhelming the system with excess data. The plateau in similarity scores beyond this threshold suggests that additional documents do not significantly enhance the relevance of the generated summaries. Therefore, 200 documents appear to be the most efficient choice for maintaining high alignment with the research objectives while minimizing computational overhead.
Readability Scores: We use the Flesch Reading Ease [
33] metric to evaluate how accessible and easy to read the generated summaries are.
Figure 2f indicates that the readability scores increase as more documents are processed, reaching their highest point, around 200. This suggests that the generated summaries become clearer and easier to read as the system processes more documents, possibly due to having a more comprehensive pool of content to draw from. However, readability scores decline slightly after 200 documents, indicating that the system might introduce more complex or fragmented language as the document count grows. This highlights that 200 documents offer the best balance for generating summaries that are both informative and easy to read.
Optimal Number of Papers: Based on the analysis of the above metrics, 200 documents emerge as the optimal document limit for the SLR process. At this threshold, the system provides high-quality summaries, maintains strong topic coherence, and produces readable and relevant outputs without excessive computational resources. Using over 200 documents leads to diminishing returns, particularly regarding topic coherence, readability, and cosine similarity. Thus, we recommend 200 documents as the ideal balance between performance and efficiency for conducting automated systematic literature reviews.
5. Discussion
The results presented in this study demonstrate the potential of the proposed automated SLR framework to streamline and enhance the process of conducting literature reviews. By integrating advanced NLP techniques and LLMs such as GPT-3.5 and GPT-4o, the framework automates systematic search, data extraction, topic modeling, and summarization stages. However, a critical analysis of the results reveals both strengths and areas for improvement.
GPT-4o retrieves more papers than GPT-3.5: The experiments revealed that GPT-4o consistently outperformed GPT-3.5 in retrieving a larger number of papers across all research topics. This suggests that GPT-4o is better at generating more comprehensive and contextually rich search queries. The ability of GPT-4o to retrieve more papers is beneficial in scenarios where exhaustive literature coverage is important, such as systematic reviews and meta-analyses, as it ensures that a wider array of relevant research is considered. However, this improved retrieval capacity may also introduce more irrelevant or low-quality papers, necessitating more robust filtering mechanisms.
High ROUGE-1 precision scores for both models: Both GPT-3.5 and GPT-4o demonstrated high ROUGE-1 precision scores during the summarization phase, indicating that the generated summaries retained a significant amount of relevant content from the reference abstracts. This suggests that the models effectively focus on the most important information when creating summaries, which is critical in systematic reviews where maintaining the relevance of summarized content is paramount. However, the relatively lower recall scores reflect that some content was omitted during summarization, which may be intentional to avoid overwhelming the reader with excessive detail. The high precision with lower recall suggests a bias toward conciseness, which can be advantageous in certain contexts but may require adjustment depending on the goals of the review.
Post-editing improved precision but reduced recall: The post-editing phase significantly improved the precision of the generated summaries but reduced recall, indicating that while the content became more concise and focused, some relevant details were omitted. This aligns with the goal of post-editing, which is to refine and streamline the summaries for clarity and coherence. GPT-4o demonstrated higher recall than GPT-3.5 in this phase, suggesting it more effectively retained content during post-editing. This slight advantage highlights GPT-4o’s ability to balance relevance and conciseness better, making it more suitable for generating comprehensive yet readable summaries in systematic reviews.
GPT-4o achieved higher recall in final LaTeX documents: The final LaTeX documents generated by GPT-4o achieved higher recall scores than those generated by GPT-3.5, indicating that GPT-4o was more successful in incorporating additional relevant content while maintaining coherence. This makes GPT-4o particularly advantageous for use cases that require comprehensive literature coverage, as the final documents generated by GPT-4o were better at synthesizing information from multiple sources. However, this increase in recall may come at the cost of readability, as the additional content could make the final documents more complex and challenging to navigate. Future work could explore optimizing the balance between recall and readability in final document generation.
Readability improved through post-editing and final document generation: The Flesch Reading Ease Scores demonstrated a clear improvement in readability from the initial T5-generated summaries to the GPT post-edited sections and final LaTeX documents. This suggests that the post-editing process significantly enhanced the clarity and coherence of the summaries, making them easier to read and understand. However, despite these improvements, the readability of the generated documents remained lower than the baseline abstracts. This outcome reflects the inherent difficulty in maintaining high readability while condensing and synthesizing technical content. Future work could explore more advanced techniques to improve readability, especially in the post-editing phase, to close the gap with the original abstracts.
Cosine similarity confirms robust content retention: Cosine similarity scores across all stages of document generation were high, confirming that the system retained key content from the original input queries. The post-editing and final document generation stages further improved content alignment, particularly with GPT-4o, which generally outperformed GPT-3.5 in maintaining content relevance. These results suggest that both models effectively ensure the generated summaries and documents stay focused on the core topics of the input queries, making them reliable tools for systematic literature reviews. The consistently high similarity scores also validate the robustness of retrieval, summarization, and synthesis, ensuring that essential information is not lost throughout the stages.
The findings from this study underscore the utility of combining GPT models and NLP techniques to automate key phases of systematic literature reviews, from retrieval to summarization. While GPT-4o demonstrates superior performance in content retrieval and recall, GPT-3.5 remains competitive for tasks prioritizing efficiency and conciseness. The framework shows promise in automating extensive literature reviews with relatively high precision and robust content retention. However, challenges remain, particularly in optimizing readability and balancing recall with document complexity. Future work should focus on refining the post-editing processes, improving the coherence and accessibility of generated documents, and ensuring that the system remains adaptable to diverse academic domains. Enhancing the framework’s ability to filter irrelevant or lower-quality content will strengthen its applicability in high-demand, resource-intensive reviews.








{kind=link}
{kind=link}
{kind=link}