
Big Five Personality Trait Prediction Based on User Comments




Abstract
1. Introduction
1.1. The Background
1.2. Problem Definition
1.3. Research Contributions
- Continuous Trait Prediction: We investigate the effectiveness of transformer-based language models, specifically BERT and RoBERTa, in predicting continuous Big Five personality trait scores, a regression task that remains under-explored in personality computing compared to classification approaches;
- Evaluation on Real-World Data: We assess the model performance under challenging conditions, including large-scale, noisy, real-world data and scenarios with limited supervision, reflecting practical deployment challenges;
- Trait Intercorrelation Analysis: We examine how intercorrelations among personality traits affect the prediction performance by comparing a multi-trait transformer model with independently fine-tuned single-trait models, providing empirical insights to guide future research on transformer-based personality predictions.
2. The Literature Review
2.1. The Big Five
- Openness: Characterised by a keen intellectual curiosity and a desire for new experiences and diversity;
- Conscientiousness: Demonstrated through traits such as discipline, organisation, and achievement orientation;
- Extraversion: Marked by increased sociability, assertiveness, and talkativeness;
- Agreeableness: Refers to being helpful, cooperative, and sympathetic towards others;
- Neuroticism: Refers to the degree of emotional stability, impulse control, and susceptibility to anxiety.
2.2. Intercorrelation of the Big Five Personality Traits
2.3. Personality Computing
3. Methodology
3.1. The Dataset
3.2. Data Cleaning and Preprocessing
3.3. Experiments
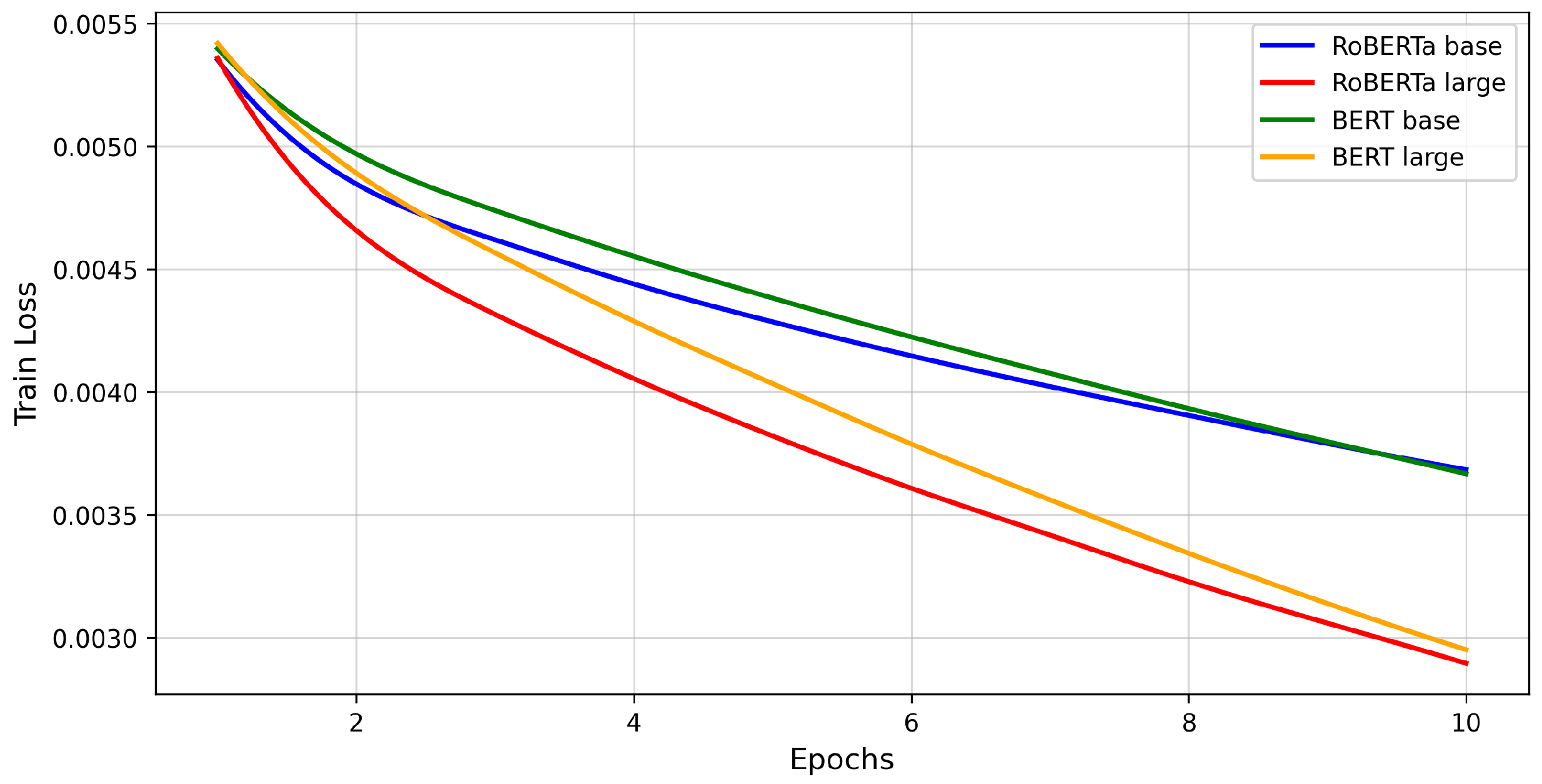
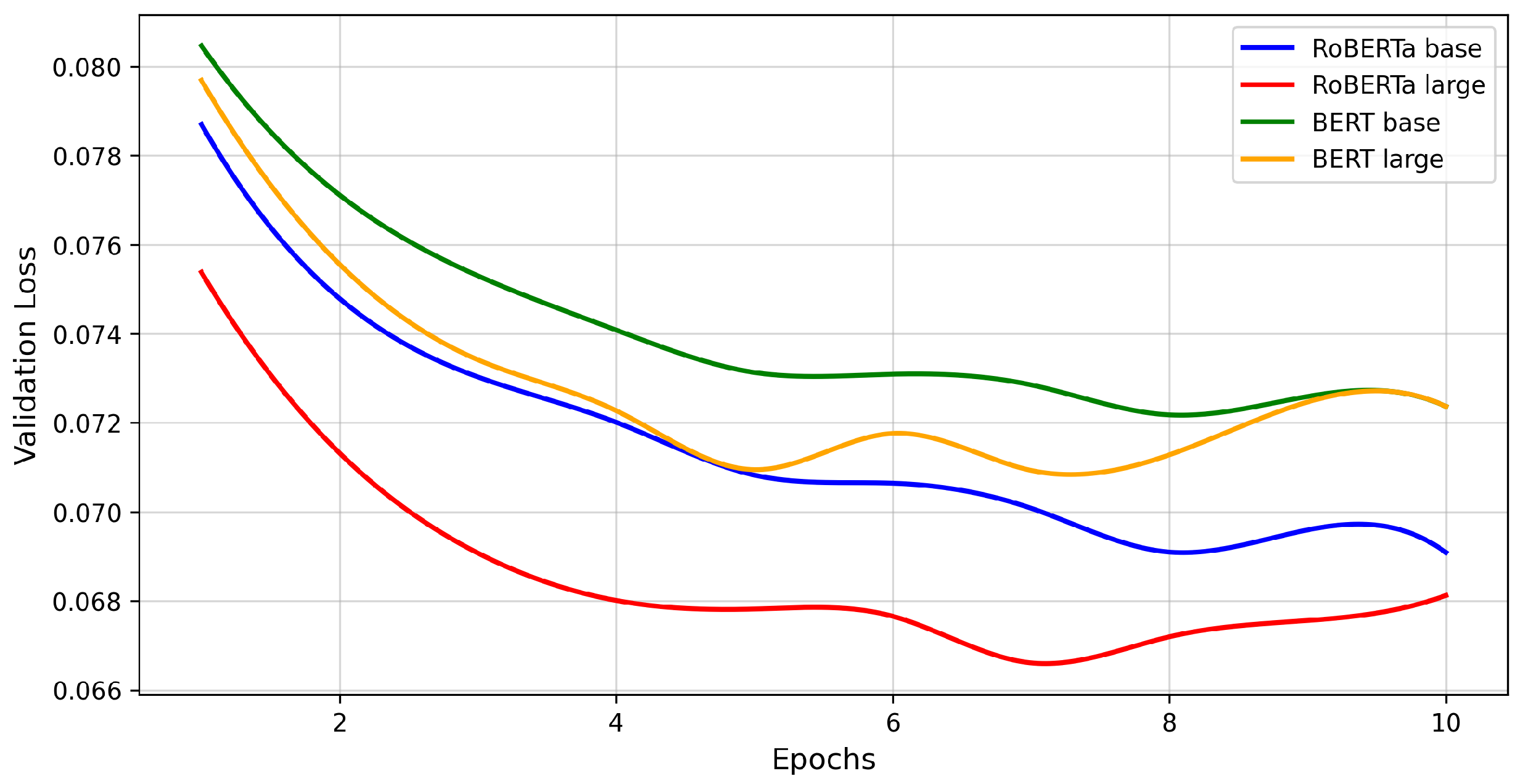
3.3.1. A Comparative Analysis of the RoBERTa and BERT Models for Predicting Big Five Personality Trait Scores
3.3.2. Investigating the Impact of Intercorrelations Among Big Five Personality Traits
4. Results
4.1. Evaluation Metrics
- n: Number of data points;
- : The actual value for the i-th data point;
- : The predicted value for the i-th data point;
- : The mean of the actual values.
4.2. A Comparative Analysis of the RoBERTa and BERT Models for Predicting Big Five Personality Trait Scores
4.3. Investigating the Impact of Intercorrelations Among Big Five Personality Traits
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AGR | Agreeableness |
| BERT | Bidirectional Encoder Representations from Transformers |
| BFI | Big Five Inventory |
| Bi-LSTM | Bidirectional Long Short-Term Memory |
| CLS | Classification Token |
| CON | Conscientiousness |
| CSV | Comma-Separated Values |
| DNN | Deep Neural Network |
| EXT | Extraversion |
| GRU | Gated Recurrent Unit |
| LIWC | Linguistic Inquiry and Word Count |
| LLaMA | Large Language Model Meta AI |
| LLM | Large Language Model |
| LSTM | Long Short-Term Memory |
| MBTI | Myers–Briggs Type Indicator |
| ML | Machine Learning |
| MSE | Mean Squared Error |
| NEO | Neuroticism, Extraversion, Openness |
| NEU | Neuroticism |
| NLP | Natural Language Processing |
| OCEAN | Openness, Conscientiousness, Extraversion, Agreeableness, Neuroticism |
| OPE | Openness |
| PC | Personality Computing |
| RoBERTa | Robustly Optimized BERT Pretraining Approach |
| RMSE | Root Mean Square Error |
| RNN | Recurrent Neural Network |
| Coefficient of Determination | |
| SEP | Separator Token |
| 1-DCNN | One-Dimensional Convolutional Neural Network |
References
- Kang, W.; Steffens, F.; Pineda, S.; Widuch, K.; Malvaso, A. Personality traits and dimensions of mental health. Sci. Rep. 2023, 13, 7091. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Donnellan, M.B.; Mendoza, A.M. Five-factor personality domains and job performance: A second order meta-analysis. J. Res. Personal. 2019, 82, 103848. [Google Scholar] [CrossRef]
- Caliskan, A. Applying the right relationship marketing strategy through big five personality traits. J. Relatsh. Mark. 2019, 18, 196–215. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Recommender systems: Techniques, applications, and challenges. In Recommender Systems Handbook; Springer Nature: Berlin/Heidelberg, Germany, 2021; pp. 1–35. [Google Scholar]
- Costa, P.T., Jr.; McCrae, R.R. The five-factor model of personality and its relevance to personality disorders. J. Personal. Disord. 1992, 6, 343–359. [Google Scholar] [CrossRef]
- Myers, I.B. The Myers-Briggs Type Indicator: Manual (1962); PsycInfo Database Record (c) 2025 APA; American Psychological Association (APA): Washington, DC, USA, 1962. [Google Scholar]
- Ching, C.M.; Church, A.T.; Katigbak, M.S.; Reyes, J.A.S.; Tanaka-Matsumi, J.; Takaoka, S.; Zhang, H.; Shen, J.; Arias, R.M.; Rincon, B.C.; et al. The manifestation of traits in everyday behavior and affect: A five-culture study. J. Res. Personal. 2014, 48, 1–16. [Google Scholar] [CrossRef]
- Fang, Q.; Giachanou, A.; Bagheri, A.; Boeschoten, L.; van Kesteren, E.J.; Kamalabad, M.S.; Oberski, D. On text-based personality computing: Challenges and future directions. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 10861–10879. [Google Scholar]
- Costa, P.T.; McCrae, R.R. The revised neo personality inventory (neo-pi-r). SAGE Handb. Personal. Theory Assess. 2008, 2, 179–198. [Google Scholar]
- John, O.P.; Srivastava, S. The Big-Five trait taxonomy: History, measurement, and theoretical perspectives. In Handbook of personality: Theory and Research; Guilford Press: New York, NY, USA, 1999. [Google Scholar]
- Azucar, D.; Marengo, D.; Settanni, M. Predicting the Big 5 personality traits from digital footprints on social media: A meta-analysis. Personal. Individ. Differ. 2018, 124, 150–159. [Google Scholar] [CrossRef]
- Phan, L.V.; Rauthmann, J.F. Personality computing: New frontiers in personality assessment. Soc. Personal. Psychol. Compass 2021, 15, e12624. [Google Scholar] [CrossRef]
- Feizi-Derakhshi, A.R.; Feizi-Derakhshi, M.R.; Ramezani, M.; Nikzad-Khasmakhi, N.; Asgari-Chenaghlu, M.; Akan, T.; Ranjbar-Khadivi, M.; Zafarni-Moattar, E.; Jahanbakhsh-Naghadeh, Z. Text-based automatic personality prediction: A bibliographic review. J. Comput. Soc. Sci. 2022, 5, 1555–1593. [Google Scholar] [CrossRef]
- Harari, G.M.; Vaid, S.S.; Müller, S.R.; Stachl, C.; Marrero, Z.; Schoedel, R.; Bühner, M.; Gosling, S.D. Personality sensing for theory development and assessment in the digital age. Eur. J. Personal. 2020, 34, 649–669. [Google Scholar] [CrossRef]
- Lukac, M. Speech-based personality prediction using deep learning with acoustic and linguistic embeddings. Sci. Rep. 2024, 14, 30149. [Google Scholar] [CrossRef] [PubMed]
- Quwaider, M.; Alabed, A.; Duwairi, R. Shooter video games for personality prediction using five factor model traits and machine learning. Simul. Model. Pract. Theory 2023, 122, 102665. [Google Scholar] [CrossRef]
- Kosan, M.A.; Karacan, H.; Urgen, B.A. Predicting personality traits with semantic structures and LSTM-based neural networks. Alex. Eng. J. 2022, 61, 8007–8025. [Google Scholar] [CrossRef]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Chen, Y. Exploring the Intercorrelations of Big Five Personality Traits: Comparing Questionnaire-Based Methods and Automated Personality Assessment using BERT and RNN Models. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2023. [Google Scholar]
- Liu, Y. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Li, M.; Liu, H.; Wu, B.; Bai, T. Language style matters: Personality prediction from textual styles learning. In Proceedings of the 2022 IEEE International Conference on Knowledge Graph (ICKG), Orlando, FL, USA, 30 November–1 December 2022; pp. 141–148. [Google Scholar]
- Cattell, R.B. The description of personality. I. Foundations of trait measurement. Psychol. Rev. 1943, 50, 559. [Google Scholar] [CrossRef]
- Tupes, E.C.; Christal, R.E. Recurrent personality factors based on trait ratings. J. Personal. 1992, 60, 225–251. [Google Scholar] [CrossRef]
- Komarraju, M.; Karau, S.J.; Schmeck, R.R.; Avdic, A. The Big Five personality traits, learning styles, and academic achievement. Personal. Individ. Differ. 2011, 51, 472–477. [Google Scholar] [CrossRef]
- Wilmot, M.P.; Ones, D.S. A century of research on conscientiousness at work. Proc. Natl. Acad. Sci. USA 2019, 116, 23004–23010. [Google Scholar] [CrossRef]
- Oh, V.; Tong, E.M. Negative emotion differentiation and long-term physical health—The moderating role of neuroticism. Health Psychol. 2020, 39, 127. [Google Scholar] [CrossRef]
- Digman, J.M. Higher-order factors of the Big Five. J. Personal. Soc. Psychol. 1997, 73, 1246. [Google Scholar] [CrossRef] [PubMed]
- van der Linden, D.; te Nijenhuis, J.; Bakker, A.B. The General Factor of Personality: A meta-analysis of Big Five intercorrelations and a criterion-related validity study. J. Res. Personal. 2010, 44, 315–327. [Google Scholar] [CrossRef]
- Kachur, A.; Osin, E.; Davydov, D.; Shutilov, K.; Novokshonov, A. Assessing the Big Five personality traits using real-life static facial images. Sci. Rep. 2020, 10, 8487. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; King, L.A. Linguistic styles: Language use as an individual difference. J. Personal. Soc. Psychol. 1999, 77, 1296. [Google Scholar] [CrossRef]
- Mairesse, F.; Walker, M.A.; Mehl, M.R.; Moore, R.K. Using linguistic cues for the automatic recognition of personality in conversation and text. J. Artif. Intell. Res. 2007, 30, 457–500. [Google Scholar] [CrossRef]
- Oberlander, J.; Nowson, S. Whose thumb is it anyway? Classifying author personality from weblog text. In Proceedings of the COLING/ACL 2006 Main Conference Poster Sessions, Sydney, Australia, 17–18 July 2006; pp. 627–634. [Google Scholar]
- Stillwell, D.J.; Kosinski, M. myPersonality project: Example of successful utilization of online social networks for large-scale social research. Am. Psychol. 2004, 59, 93–104. [Google Scholar]
- Meta Platforms, Inc. Facebook. 2004. Available online: https://www.facebook.com/ (accessed on 18 January 2025).
- Ren, Z.; Shen, Q.; Diao, X.; Xu, H. A sentiment-aware deep learning approach for personality detection from text. Inf. Process. Manag. 2021, 58, 102532. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Boyd, R.L.; Jordan, K.; Blackburn, K. LIWC2015 User’s Manual; LIWC.net: Austin, TX, USA, 2015; Available online: www.liwc.net (accessed on 18 January 2025).
- Adi, G.Y.N.; Tandio, M.H.; Ong, V.; Suhartono, D. Optimization for automatic personality recognition on Twitter in Bahasa Indonesia. Procedia Comput. Sci. 2018, 135, 473–480. [Google Scholar] [CrossRef]
- Ptaszynski, M.; Zasko-Zielinska, M.; Marcinczuk, M.; Leliwa, G.; Fortuna, M.; Soliwoda, K.; Dziublewska, I.; Hubert, O.; Skrzek, P.; Piesiewicz, J.; et al. Looking for razors and needles in a haystack: Multifaceted analysis of suicidal declarations on social media—A pragmalinguistic approach. Int. J. Environ. Res. Public Health 2021, 18, 11759. [Google Scholar] [CrossRef]
- Schwartz, H.A.; Eichstaedt, J.C.; Kern, M.L.; Dziurzynski, L.; Ramones, S.M.; Agrawal, M.; Shah, A.; Kosinski, M.; Stillwell, D.; Seligman, M.E.; et al. Personality, gender, and age in the language of social media: The open-vocabulary approach. PLoS ONE 2013, 8, e73791. [Google Scholar] [CrossRef]
- Eichstaedt, J.C.; Kern, M.L.; Yaden, D.B.; Schwartz, H.A.; Giorgi, S.; Park, G.; Hagan, C.A.; Tobolsky, V.A.; Smith, L.K.; Buffone, A.; et al. Closed-and open-vocabulary approaches to text analysis: A review, quantitative comparison, and recommendations. Psychol. Methods 2021, 26, 398. [Google Scholar] [CrossRef] [PubMed]
- Xue, D.; Wu, L.; Hong, Z.; Guo, S.; Gao, L.; Wu, Z.; Zhong, X.; Sun, J. Deep learning-based personality recognition from text posts of online social networks. Appl. Intell. 2018, 48, 4232–4246. [Google Scholar] [CrossRef]
- Tadesse, M.M.; Lin, H.; Xu, B.; Yang, L. Personality predictions based on user behavior on the facebook social media platform. IEEE Access 2018, 6, 61959–61969. [Google Scholar] [CrossRef]
- Tanwijaya, J.; Suhartono, D. Towards Personality Identification from Social Media Text Status Using Machine Learning and Transformer. ICIC Express Lett. 2022, 13, 233–240. [Google Scholar]
- Arijanto, J.E.; Geraldy, S.; Tania, C.; Suhartono, D. Personality prediction based on text analytics using bidirectional encoder representations from transformers from english twitter dataset. Int. J. Fuzzy Log. Intell. Syst. 2021, 21, 310–316. [Google Scholar] [CrossRef]
- Mehta, Y.; Fatehi, S.; Kazameini, A.; Stachl, C.; Cambria, E.; Eetemadi, S. Bottom-up and top-down: Predicting personality with psycholinguistic and language model features. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 1184–1189. [Google Scholar]
- Gjurković, M.; Karan, M.; Vukojević, I.; Bošnjak, M.; Šnajder, J. PANDORA talks: Personality and demographics on Reddit. arXiv 2020, arXiv:2004.04460. [Google Scholar]
- Inc., R. Reddit. 2005. Available online: https://www.reddit.com/ (accessed on 18 January 2025).
- Riso, D. Personality Types: Using the Enneagram for Self-Discovery; Houghton Mifflin Company: Boston, MA, USA, 1996. [Google Scholar]
- Ma, W.; Cui, Y.; Si, C.; Liu, T.; Wang, S.; Hu, G. CharBERT: Character-aware pre-trained language model. arXiv 2020, arXiv:2011.01513. [Google Scholar]
- Chaumond, J.; Sanseviero, O.; Debut, L. BERT Base Model (Cased). 2018. Available online: https://huggingface.co/google-bert/bert-base-cased (accessed on 13 June 2024).
- Chaumond, J.; Sanseviero, O.; Debut, L. BERT Large Model (Cased). 2018. Available online: https://huggingface.co/google-bert/bert-large-cased (accessed on 13 June 2024).
- Chaumond, J.; Debut, L. RoBERTa Base Model. 2019. Available online: https://huggingface.co/FacebookAI/roberta-base (accessed on 13 June 2024).
- Chaumond, J.; Debut, L. RoBERTa Large Model. 2019. Available online: https://huggingface.co/FacebookAI/roberta-large (accessed on 13 June 2024).
- Uma, A.N.; Fornaciari, T.; Hovy, D.; Paun, S.; Plank, B.; Poesio, M. Learning from disagreement: A survey. J. Artif. Intell. Res. 2021, 72, 1385–1470. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Attributes | Details |
|---|---|
| Source | |
| Period | 2015–2020 |
| Total authors | 10,295 |
| Total comments | 17,640,979 |
| Demographic labels | Age, Gender, Location * |
| Language | English, Spanish, French * |
| Personality Taxonomy | Number of Authors | Number of Comments |
|---|---|---|
| MBTI | 9067 | 15,555,974 |
| Big Five | 1568 | 3,006,567 |
| Enneagram | 794 | 1,458,816 |
| Big Five + MBTI | 377 | 1,045,375 |
| Big Five + Enneagram | 64 | 235,883 |
| MBTI + Enneagram | 793 | 1,457,625 |
| Big Five + MBTI + Enneagram | 63 | 234,692 |
| Body | Agr | Ope | Con | Ext | Neu |
|---|---|---|---|---|---|
| I admit having fallen into the trap myself… | 0.3 | 0.7 | 0.15 | 0.15 | 0.5 |
| thats a great business idea, why didn’t i… | 0.09 | 0.59 | 0.05 | 0.73 | 0.07 |
| Hey, at least you lost something that’s… | 0.09 | 0.61 | 0.13 | 0.04 | 0.72 |
| Body | Agr |
|---|---|
| I admit having fallen into the trap myself. As much as I know… | 0.3 |
| thats a great business idea, why didn’t i think of that!! | 0.09 |
| Hey, at least you lost something that’s still currently made. I’ve… | 0.09 |
| Big Five Personality Traits | RoBERTa (Base) | RoBERTa (Large) | BERT (Base) | BERT (Large) | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | RMSE | RMSE | RMSE | |||||
| Openness | 0.2345 | 0.2201 | 0.2315 | 0.2403 | 0.2391 | 0.1895 | 0.2386 | 0.1926 |
| Conscientiousness | 0.2669 | 0.2161 | 0.2653 | 0.2255 | 0.2739 | 0.1743 | 0.2730 | 0.1797 |
| Extraversion | 0.2625 | 0.2604 | 0.2602 | 0.2734 | 0.2694 | 0.2212 | 0.2702 | 0.2168 |
| Agreeableness | 0.2743 | 0.2288 | 0.2727 | 0.2379 | 0.2803 | 0.1949 | 0.2805 | 0.1939 |
| Neuroticism | 0.2737 | 0.2223 | 0.2732 | 0.2248 | 0.2796 | 0.1884 | 0.2800 | 0.1859 |
| Big Five Personality Traits | Mean Baseline | RoBERTa | RoBERTa (Large) | |||
|---|---|---|---|---|---|---|
| RMSE | RMSE | RMSE | ||||
| Openness | 0.2314 | 0.1742 | 0.4333 | 0.2315 | 0.2403 | |
| Conscientiousness | 0.2633 | 0.0000 | 0.2046 | 0.3964 | 0.2653 | 0.2255 |
| Extraversion | 0.3574 | 0.2469 | 0.5229 | 0.2602 | 0.2734 | |
| Agreeableness | 0.3036 | 0.2423 | 0.3964 | 0.2727 | 0.2379 | |
| Neuroticism | 0.3074 | 0.2527 | 0.3248 | 0.2732 | 0.2248 | |
| Big Five Personality Traits | Mean Baseline | RoBERTa | RoBERTa (Single) | RoBERTa (Multiple) | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | RMSE | RMSE | RMSE | |||||
| Openness | 0.2314 | 0.1742 | 0.4333 | 0.2345 | 0.2201 | 0.2655 | 0.0008 | |
| Conscientiousness | 0.2633 | 0.0000 | 0.2046 | 0.3964 | 0.2669 | 0.2161 | ||
| Extraversion | 0.3574 | 0.2469 | 0.5229 | 0.2625 | 0.2604 | 0.3033 | 0.0131 | |
| Agreeableness | 0.3036 | 0.2423 | 0.3964 | 0.2743 | 0.2288 | 0.3124 | ||
| Neuroticism | 0.3074 | 0.2527 | 0.3248 | 0.2737 | 0.2223 | 0.3103 | ||
| Trait Pairs | Dataset | RoBERTa Large |
|---|---|---|
| EXT-NEU | ||
| EXT-AGR | ||
| EXT-CON | 0.0689 | 0.0923 |
| EXT-OPE | 0.2344 | 0.2782 |
| NEU-AGR | 0.0491 | 0.1027 |
| NEU-CON | ||
| NEU-OPE | 0.0433 | 0.0583 |
| AGR-CON | 0.1350 | 0.1823 |
| AGR-OPE | 0.1178 | 0.1132 |
| CON-OPE |
| Trait Pairs | Dataset | RoBERTa |
|---|---|---|
| EXT-NEU | ||
| EXT-AGR | ||
| EXT-CON | ||
| EXT-OPE | 0.2428 | −0.4436 |
| NEU-AGR | 0.0309 | 0.3321 |
| NEU-CON | ||
| NEU-OPE | ||
| AGR-CON | 0.3486 | 0.6360 |
| AGR-OPE | ||
| CON-OPE |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shum, K.-M.; Ptaszynski, M.; Masui, F. Big Five Personality Trait Prediction Based on User Comments. Information 2025, 16, 418. https://doi.org/10.3390/info16050418
Shum K-M, Ptaszynski M, Masui F. Big Five Personality Trait Prediction Based on User Comments. Information. 2025; 16(5):418. https://doi.org/10.3390/info16050418
Chicago/Turabian StyleShum, Kit-May, Michal Ptaszynski, and Fumito Masui. 2025. "Big Five Personality Trait Prediction Based on User Comments" Information 16, no. 5: 418. https://doi.org/10.3390/info16050418
APA StyleShum, K.-M., Ptaszynski, M., & Masui, F. (2025). Big Five Personality Trait Prediction Based on User Comments. Information, 16(5), 418. https://doi.org/10.3390/info16050418