Abstract
Power equipment anomaly detection is essential for ensuring the stable operation of power systems. Existing models have high false and missed detection rates in complex weather and multi-scale equipment scenarios. This paper proposes a YOLO-SRSA-based anomaly detection algorithm. For data enhancement, geometric and color transformations and rain-fog simulations are applied to preprocess the dataset, improving the model’s robustness in outdoor complex weather. In the network structure improvements, first, the ACmix module is introduced to reconstruct the SPPCSPC network, effectively suppressing background noise and irrelevant feature interference to enhance feature extraction capability; second, the BiFormer module is integrated into the efficient aggregation network to strengthen focus on critical features and improve the flexible recognition of multi-scale feature images; finally, the original loss function is replaced with the MPDIoU function, optimizing detection accuracy through a comprehensive bounding box evaluation strategy. The experimental results show significant improvements over the baseline model: mAP@0.5 increases from 89.2% to 93.5%, precision rises from 95.9% to 97.1%, and recall improves from 95% to 97%. Additionally, the enhanced model demonstrates superior anti-interference performance under complex weather conditions compared to other models.
1. Introduction
1.1. Related Work
With the rapid development of China’s electric power industry, the intelligent operation and maintenance of power systems has gained increasing significance. The reliability of critical components such as insulators and instrument panels directly impacts grid safety, as evidenced by multiple grid accidents caused by equipment anomalies in insulators, meters, and other devices. This underscores the importance of regular anomaly detection in images acquired through intelligent inspection [1]. The advancement of deep learning in image detection has enabled extensive applications of object detection algorithms in power equipment defect identification. Current detection models primarily consist of one-stage architectures (e.g., SSD [2], RetinaNet [3], YOLO series) and two-stage frameworks (e.g., Faster R-CNN [4], SPPNet [5], Mask R-CNN [6]). While one-stage models demonstrate superior detection speed and better suitability for real-time defect detection in power equipment, existing algorithms still exhibit insufficient accuracy when addressing complex weather conditions, background interference, and multi-scale equipment defects. These limitations hinder their effectiveness in outdoor intelligent inspection scenarios, necessitating further optimization of detection algorithms.
Extensive research has been conducted in this field. For instance, MA Qiaohui et al. [7] proposed a fault detection algorithm based on umbrella skirt morphological features to address the challenge of insulator defect identification in power equipment. While this method establishes a foundation for intelligent insulator detection, its capability remains insufficient in determining insulator integrity. WANG Daolei et al. [8] developed a detection algorithm featuring a lightweight backbone network and cross-level feature fusion module for aerial insulator defects. However, this approach exhibits limited robustness under varying weather conditions. TAO et al. [9] designed a cascaded convolutional network structure for defect localization and detection in power equipment insulators. Nevertheless, this cascaded architecture can only identify self-explosion defects, and its restricted defect category recognition diminishes algorithmic robustness. ZHAO et al. [10] enhanced detection accuracy by optimizing anchor generation and non-maximum suppression (NMS) in the region proposal network of Faster R-CNN, though their method incurs substantial computational overhead. SONG Zhiwei et al. [11] improved YOLOv7 by integrating a global attention mechanism to amplify salient features, achieving partial success in insulator damage detection while remaining inadequate for comprehensive intelligent inspection requirements. ZHAO Wenqing et al. [12] incorporated the CBAM attention mechanism into Faster R-CNN to address insulator localization challenges, enhancing detection precision but struggling with accurate defect positioning in complex backgrounds. WANG Yuanbin et al. [13] developed a lightweight YOLOv5 network for precise substation equipment recognition in cluttered environments. By implementing Ghost convolutions for backbone simplification and an enhanced C3 self-attention module for feature extraction, their network achieves accelerated detection speed while maintaining accuracy. BAO Wenxia et al. [14] introduced attention mechanisms and EDIoU loss functions to improve meter anomaly recognition amidst complex backgrounds and varying meter sizes. XIAO Canjun et al. [15] enhanced insulator defect detection accuracy in complex environments through data augmentation, GAM attention mechanisms, and ASFF feature fusion strategies. Reference [16] addresses the issues of missed detections, false detections, and low detection accuracy in substation equipment infrared image target detection by proposing an improved YOLOv8n-based detection algorithm. This algorithm enhances the model’s ability to extract relevant equipment features by integrating deformable convolutions with the C2f module, and introduces a multi-scale convolutional attention module to improve the model’s capability in capturing multi-scale information, ultimately leading to improved detection accuracy. Reference [17] tackles the challenge of insufficient fine-grained recognition caused by blurred defect image features in existing detection algorithms by proposing a self-reducing multi-head attention module. This module not only reduces computational complexity but also seamlessly integrates with convolutional neural networks (CNNs), enabling the simultaneous computation of local and global features, thus significantly enhancing defect recognition performance for power equipment. Reference [18] addresses the real-time performance limitations of existing corrosion detection methods, proposing a two-stage detection approach that combines YOLOv8 and DDRNet to achieve real-time detection of corrosion defects in substation equipment. Reference [19] proposes an improved YOLOv7-Tiny-based algorithm for substation equipment infrared image recognition to address the problems of low accuracy and slow detection speed under complex backgrounds. By employing a lightweight network and replacing the loss function, the algorithm effectively reduces the number of parameters while improving detection accuracy. Reference [20] proposes an improved YOLOv8n-based algorithm for detecting the wearing of personal protective equipment (PPE) by substation workers. By enhancing the algorithm’s feature extraction capabilities and optimizing the Path Aggregation Network (PANet) structure, the algorithm effectively identifies PPE in complex substation environments, providing reliable technical support for smart grid development.
1.2. Research Work in This Paper
The aforementioned algorithms have achieved certain improvements; however, they still exhibit limitations in detecting multi-scale power equipment anomalies under complex outdoor weather conditions, and their detection performance requires further enhancement. In addition, most current power equipment defect detection algorithms primarily focus on insulator-related defects, especially insulator breakage, while paying limited attention to flashover defects in insulators and defects in other equipment, such as meters, encountered during power system inspections.
To address these issues and improve the accuracy of anomaly detection for power equipment under complex weather conditions while reducing false detection and missed detection rates, this paper proposes a YOLO-SRSA-based anomaly detection algorithm for power equipment. The proposed method is compared with several other target detection algorithms, and the results demonstrate its superior performance in detecting power equipment anomalies under various outdoor weather conditions. The main contributions of this work are as follows:
- (1)
- To enable the network to better extract features of different anomaly targets, the Attention and Convolution Mixed module (ACmix) is integrated into the Spatial Pyramid Pooling Cross-Stage Partial Channel (SPPCSPC) structure. Meanwhile, convolutional layer pruning is performed to reduce the number of parameters and computational complexity. In addition, the original parallel pooling layers are reconfigured into a cascaded structure, where feature maps from the cascaded pooling layers are fused again to expand the receptive field. The reconstructed SPPCSPC structure enhances the network’s ability to extract features from various anomaly targets.
- (2)
- To improve the network’s flexible recognition of multi-scale feature images, a BiFormer module is added to the efficient aggregation network. The BiFormer module strengthens attention to key features by dynamically adjusting feature weights, highlighting important features while reducing interference from irrelevant data. Unlike traditional global self-attention mechanisms, BiFormer’s sparse attention mechanism selectively focuses on the most relevant parts, resulting in more efficient feature processing and improved feature representation capabilities while reducing computational overhead.
- (3)
- To more comprehensively evaluate the relationship between predicted and ground-truth bounding boxes, the original loss function is replaced with the MPDIoU (Multi-Point Distance Intersection over Union) function. MPDIoU not only considers the area and shape of the bounding boxes but also takes into account the distance between the center points of the bounding boxes, using this information to adjust the IoU calculation. In this way, MPDIoU achieves higher robustness in complex scenarios.
In this paper, Section 2 introduces the proposed YOLO-SRSA anomaly detection model. Section 3 analyzes the experimental performance of the YOLO-SRSA detection model, demonstrating the improved detection results of the enhanced model and its robust performance under various weather conditions. Section 5 concludes the paper.
2. The Proposed Approach
This chapter details the baseline network architecture selected for this study, the improved network structure, and the principles underlying the proposed modifications. The YOLOv7 network serves as the foundational framework for our enhancements. As illustrated in Figure 1, the YOLOv7 backbone primarily comprises CBS (Convolution-BatchNorm-SiLU) convolutional layers, an Efficient Layer Aggregation Network (ELAN), MP-1 modules, and SPPCSPC modules. Specifically, the CBS convolutional layers perform preliminary feature extraction from input images. The ELAN enriches feature representations by managing connection paths of varying lengths. The MP-1 module employs dual-branch processing: the upper branch conducts max-pooling operations, while the lower branch executes convolutional operations, with features from both branches fused via concatenation to enhance information extraction efficiency. The SPPCSPC module integrates multi-scale receptive field features to minimize redundant feature extraction and strengthen feature map expressiveness. For the neck structure, the Path Aggregation Feature Pyramid Network (PAFPN) extracts semantic features through a top-down pathway and integrates them with precise localization information [21].
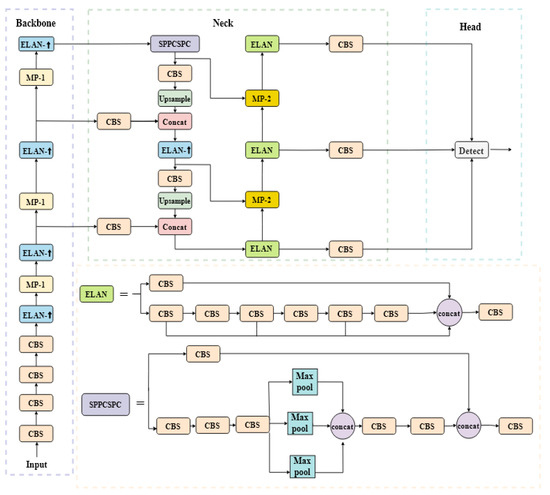
Figure 1.
YOLOv7 network architecture [21].
The defect detection of power equipment in this study involves significant size variations across anomaly types, particularly for small-scale insulator defects. The original YOLOv7 network struggles to accurately localize and characterize such anomalies due to these scale disparities. To address this limitation, the YOLOv7 architecture was modified as follows:
First, the original feature extraction structure was replaced with an AC-SPPCSPC module. This enhancement integrates the ACmix mechanism into the conventional SPPCSPC framework to improve multi-scale feature extraction. Convolutional layers were pruned to reduce parameter redundancy while preserving the fine-grained details of small targets. Additionally, the pooling strategy was optimized to strengthen feature fusion, collectively enhancing the network’s discriminative capability.
Second, the BiFormer sparse attention mechanism [18] was embedded into the efficient aggregation network. BiFormer dynamically adjusts the balance between local and global attention based on task requirements, enabling the flexible recognition of heterogeneous features.
Finally, the original loss function was replaced with MPDIoU to mitigate bounding box misalignment during prediction. The architecture of the improved network is depicted in Figure 2.
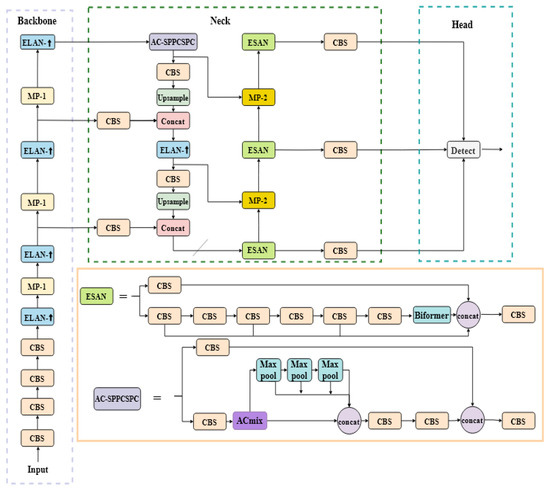
Figure 2.
YOLO-SRSA network architecture proposed in this paper.
2.1. Reconstructed SPPCSPC Module
2.1.1. ACmix Module
The ACmix (Convolutional Mixed Self-Attention) module integrates traditional convolutional operations with a self-attention mechanism in a hybrid architecture, aiming to enhance feature representation by leveraging the complementary advantages of both convolution and attention mechanisms. This fusion enables the effective capture of both local and global contextual information, thereby improving feature discriminability. As illustrated in Figure 3, the module operates through two distinct phases.
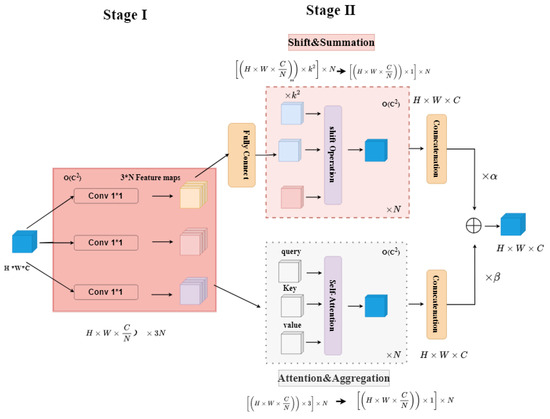
Figure 3.
ACmix architecture [22].
In the initial phase, three parallel 1 × 1 convolutional layers project the input features to generate intermediate feature maps with combined dimensions of 3 × N, forming a subset of intermediate representations. In the subsequent phase, these features are processed through two parallel branches.
The upper branch follows a convolutional pathway: A convolutional layer with a kernel size of k aggregates local spatial information by operating within local receptive fields. The resulting features are then transformed into feature maps via a fully connected layer. These maps undergo further transformations to produce refined convolutional features.
The lower branch implements a self-attention mechanism: The intermediate features are partitioned into N groups, each containing query, a key, and value tensors. These tensors are processed through shift and summation operations to derive attention-aware feature maps.
The outputs of both branches are combined through a learnable weighted summation, governed by two trainable scalar parameters [22]. The final output is expressed as
where denotes the aggregated output, represents the self-attention branch output, corresponds to the convolutional branch output, and and are trainable coefficients that dynamically balance the contributions of the two pathways.
2.1.2. AC-SPPCSPC Module Structure
The original YOLOv7 architecture employs the SPPCSPC (Spatial Pyramid Pooling Cross-Stage Partial Channel) structure to enhance feature extraction. This structure processes input feature maps with multi-scale pooling kernels to aggregate hierarchical features, which are subsequently concatenated into a composite feature map to improve representational capacity. However, the original SPPCSPC design suffers from two limitations: (1) the extensive use of convolutional layers introduces significant computational overhead, and (2) repeated convolutions may degrade fine-grained spatial details, thereby compromising detection performance. To address these challenges and improve multi-scale feature extraction for diverse power equipment anomaly detection scenarios, this paper proposes an enhanced AC-SPPCSPC module, as illustrated in Figure 4.
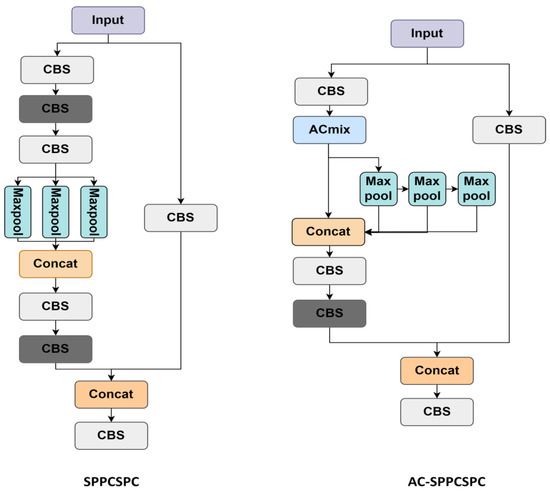
Figure 4.
Comparison of SPPCSPC structures before and after improvement.
The specific modifications are as follows:
- (1)
- Integration of Convolutional Mixed Attention Module: A convolutional mixed attention mechanism (ACmix) is introduced prior to the pooling layers to enhance discriminative feature extraction for heterogeneous anomaly patterns. This enables the network to better distinguish between anomaly types while preserving critical spatial information. Additionally, redundant convolutional layers are pruned to reduce computational complexity and parameter volume, thereby mitigating the excessive filtering of spatial features from defective targets.
- (2)
- Sequential Pooling Configuration: The original parallel pooling layers are replaced with a sequential arrangement. Unlike parallel pooling, which processes multi-scale features independently, the sequential design cascades pooling operations of varying kernel sizes. This enables the progressive aggregation of multi-scale contextual information, which is particularly advantageous for detecting objects in complex, multi-scale scenarios. By concatenating the outputs of sequentially applied pooling operations, the network synthesizes discriminative features across scales, thereby strengthening its representational capacity and improving detection accuracy.
2.2. Introduction of BiFormer in ESAN Module
2.2.1. BiFormer Module
The core of the BiFormer module lies in its Bi-level Routing Attention (BRA) mechanism, as illustrated in Figure 5. The BRA mechanism operates as follows:
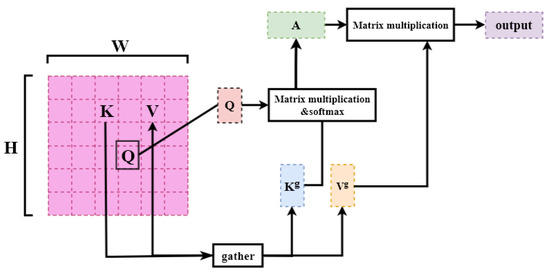
Figure 5.
BRA construction diagram.
- Input Partitioning and Transformation: The input feature map is first partitioned into non-overlapping regions. These regions undergo linear transformations to generate query (Q), key (K), and value (V) tensors.
- Region Affinity Computation: For each region, the similarity matrix A is computed by evaluating the affinity between its query (Q) and all keys (K) across regions.
- Sparse Routing: To enforce sparsity, the algorithm retains only the top-S most relevant regions for each row in A, generating a sparse routing matrix .
- Feature Aggregation: Using the routing indices , the corresponding S regions in K and V are aggregated via a gather operation, producing condensed tensors and .
- Output Synthesis: The BRA mechanism updates the input features by combining the attention output with a Local Context Enhancement (LCE) term applied to V. The final output is formulated as
Here, gather(·) denotes the tensor indexing operation that selectively aggregates features based on the routing indices . This hierarchical routing strategy ensures efficient computation while preserving critical long-range dependencies and local details, enhancing the model’s adaptability to complex spatial patterns [23].
Based on the BRA module, BiFormer adopts a four-level pyramid structure, as shown on the left side of Figure 6. In each BiFormer block, a 3 × 3 depth-wise convolution is first applied to implicitly encode relative positional information. Then, the BRA module and two MLP modules are sequentially applied to model cross-position relationships and perform per-position embedding, respectively, as illustrated on the right side of Figure 6.
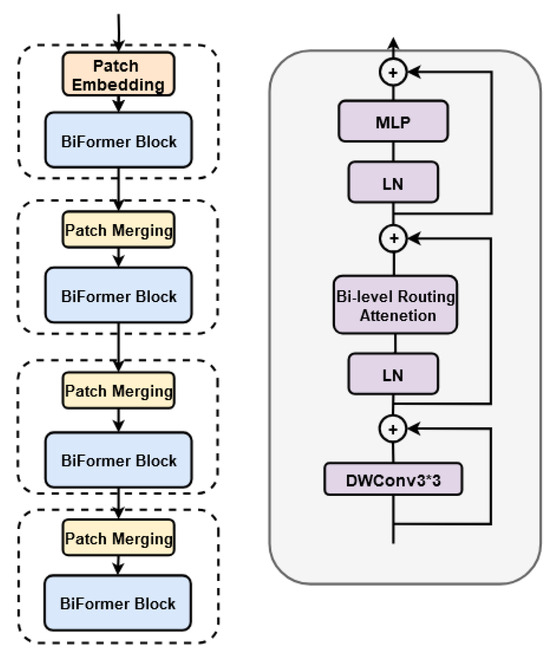
Figure 6.
Overall structure of BiFormer.
2.2.2. ESAN Module
As illustrated in YOLOv7, the efficient aggregation network employs a multi-branch architecture to decompose and integrate features, effectively enhancing feature diversity and representational capacity. By processing input features through distinct branches followed by feature aggregation operations, this design ensures the effective fusion of multi-level features. The BiFormer sparse attention mechanism emphasizes critical information while mitigating interference from irrelevant data through its sparse selection mechanism, which dynamically adjusts feature weights to amplify salient features and suppress redundant ones. Additionally, it captures both long-range dependencies and local details to achieve richer feature representations. Furthermore, the sparse attention mechanism demonstrates adaptability to varying input sizes and types, thereby improving the network’s flexibility in handling multi-scale features. For object detection tasks, robust feature representation is crucial for the accurate localization and detection of anomalous objects, particularly when they are occluded by larger irrelevant targets or background noise. BiFormer enhances scene understanding by strengthening feature expressiveness, thereby improving detection accuracy for anomalous objects. Its inherent adaptability also enables its flexible deployment across detection scenarios involving anomalies of diverse scales.
To leverage these advantages, this study integrates the BiFormer sparse attention mechanism into the efficient aggregation network module, proposing an Efficient Layer Sparse Attention Aggregation Network (ESAN). The detailed architecture is depicted in Figure 7.
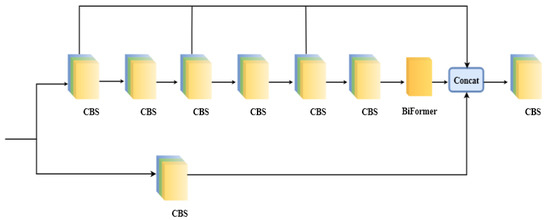
Figure 7.
ESAN architecture diagram.
2.3. Improvement of Loss Function
The original loss function in YOLOv7 is the Complete Intersection over Union (CIoU). This loss function accounts for the overlapping area, the distance between bounding box centers, and the aspect ratio of width and height between predicted and ground-truth boxes. However, CIoU inadequately addresses variations in target bounding box dimensions during image processing. For instance, when bounding boxes share the same aspect ratio but exhibit significant differences in width and height, CIoU struggles to effectively optimize the alignment between predicted and ground-truth boxes. Additionally, during optimization, the aspect ratio penalty term in CIoU may lead to an increase in one dimension while reducing the other, thereby compromising bounding box alignment accuracy and hindering model convergence efficiency [24].
To address these limitations, this study replaces the CIoU loss function with the Minimum Point Distance Intersection over Union (MPDIoU) loss function. MPDIoU introduces a more flexible similarity metric for bounding boxes, enabling improved handling of aspect ratios and rotational variations, which enhances alignment precision. Furthermore, MPDIoU simultaneously considers both the area and shape of bounding boxes, ensuring robust detection performance in complex scenarios. By incorporating the distance between bounding box centers and adjusting IoU calculations based on this distance, MPDIoU provides a more accurate evaluation of similarity between targets [25]. The computation method is as follows:
In this formulation, A and B denote the input images, where w and h represent their width and height, respectively. The coordinates () and () correspond to the top-left and bottom-right corners of input image A, while () and () specify the top-left and bottom-right corners of input image B.
3. Experimental Work
3.1. Experimental Environment Setup
The experimental hardware configuration consisted of a GeForce GTX GPU, an Intel Core i7-12700H CPU, and 16 GB of RAM. The software environment included Windows 11, PyTorch 2.1, Torchvision 0.16, and CUDA 12.2. For ablation studies, the model was trained for 100 epochs using stochastic gradient descent (SGD) with an initial learning rate of 0.01, a minimum learning rate of 0.0001, and a batch size of 8. The momentum parameter and weight decay were set to 0.937 and 0.0005, respectively.
3.2. Data Augmentation
This study focuses on insulators and meter dials within substation systems. The dataset were derived from historical field-collected data provided by a power company. Prior to training, data augmentation was performed. In addition, to enhance the model’s robustness against outdoor weather conditions, rain and fog simulation operations were applied to the images. The visual results of the data augmentation techniques are shown in Figure 8. After augmentation, the dataset comprised a total of 2932 images, including 1688 images of insulator equipment and 1244 images of meter equipment.

Figure 8.
Data Augmentation Effects with Different Methods.
3.3. Data Annotation
The augmented dataset of defective power equipment was utilized for model training. Prior to training, the constructed anomaly dataset was annotated using the LabelImg 1.8.6. Representative samples of each defect category are shown in Figure 9, with the annotation labels defined as follows: insulator breakage (jyz_sh, 1260 samples), insulator flashover (jyz_sl, 2723 samples), meter blur (bj_mh, 459 samples), meter breakage (bj_ps, 605 samples), and normal meters (bj, 406 samples). The annotations were stored in .xml files, and the labeling process is illustrated in Figure 10. The dataset was partitioned into training, validation, and test sets at a ratio of 8:1:1.

Figure 9.
Defect sample diagram.
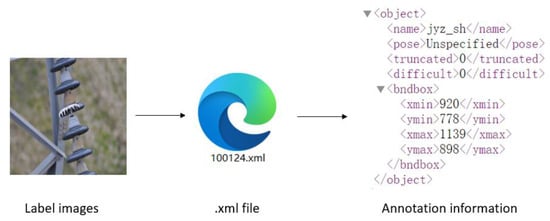
Figure 10.
Illustration of annotated labels.
4. Experimental Results and Comparative Analysis
4.1. Ablation Studies
4.1.1. Impacts of Different Attention Mechanisms
To investigate the effects of various attention mechanisms, ablation experiments were conducted by integrating four mechanisms: SimAm [26], SE [27], CBAM [28], and BiFormer [23]. The experimental results are summarized in Table 1. The BiFormer attention mechanism introduced in this work achieved the highest mean average precision (mAP) of 92.6%, surpassing SimAm, SE, and CBAM by 1.3%, 2.7%, and 2.1%, respectively. Furthermore, BiFormer attained the highest average precision (AP) values across all anomaly categories in the dataset compared to the other three mechanisms, validating the effectiveness of the proposed BiFormer integration.

Table 1.
Comparison of accuracy results for different attention mechanisms.
4.1.2. Impact of Modified Feature Extraction Module
To validate the effect of the improved feature extraction module on detection accuracy, heatmap visualizations were compared between the original and modified modules. The color intensity in the heatmaps reflects the network’s attention to defective regions, with darker hues indicating higher focus on target anomalies [29]. As illustrated in Figure 11, the heatmap of the proposed AC-SPPCSPC module exhibits significantly denser and deeper coloration concentrated on defective areas compared to the original SPPCSPC module. This demonstrates that the AC-SPPCSPC-enhanced network prioritizes defect regions more effectively and localizes anomalies with greater precision. These results confirm that the modified SPPCSPC module enhances the network’s focus on defect-related features while suppressing interference from complex backgrounds, thereby improving defect detection capability.
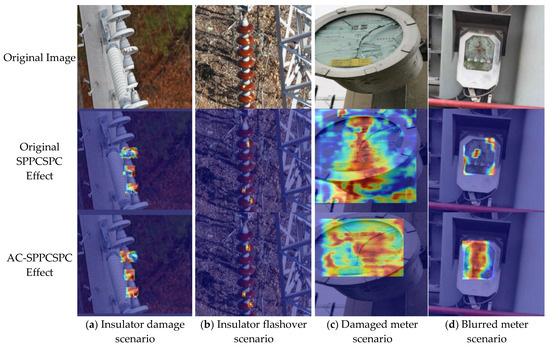
Figure 11.
Comparison of heatmap results before and after improvement.
4.1.3. Impact of Different Loss Functions
To validate the superiority of the proposed MPDIoU loss function over the original YOLOv7 loss, its performance was compared with that of three alternatives: CIoU, EIoU, and SIoU. As illustrated in Figure 12, MPDIoU demonstrates significant advantages in loss reduction, convergence speed, and mAP50-95 accuracy, outperforming SIoU, EIoU, and CIoU. These results indicate that MPDIoU achieves higher efficiency and precision in bounding box optimization. Unlike conventional IoU-based loss functions, MPDIoU incorporates multi-point distance information, which not only evaluates the overlap between bounding boxes but also refines their positional alignment through multi-reference point matching. This mechanism comprehensively captures spatial relationships between predicted and ground-truth boxes, thereby accelerating convergence and minimizing error accumulation during training. Additionally, the multi-point matching strategy enhances adaptability to multi-scale object detection, improving both accuracy and robustness in complex scenarios.
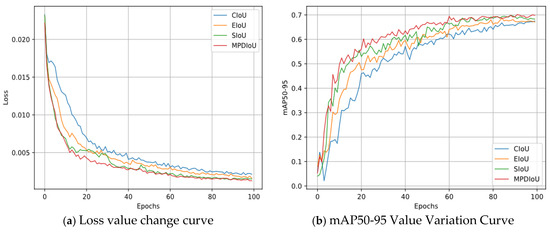
Figure 12.
Comparative diagram of different loss functions.
4.1.4. Ablation Study of Different Improvement Modules
To validate the impact of individual modifications on detection performance, ablation experiments were conducted by incrementally integrating the following components into the baseline YOLOv7 network: the AC-SPPCSPC module, BiFormer attention mechanism, and optimized MPDIoU loss function. A checkmark (√) in Table 2 indicates the use of combined modifications. The experimental results reveal that the baseline network achieved a precision of 95.9%, recall of 95.9%, and mAP@0.5 of 89.2%. Replacing the original loss function with MPDIoU improved mAP@0.5 by 1.0%, with precision and recall increasing by 1.1% and 1.0%, respectively. Individually integrating the AC-SPPCSPC and BiFormer modules further enhanced mAP@0.5 by 2.7% and 3.2%, respectively. The proposed YOLO-SRSA network, which combines all three modifications, achieved a 4.3% improvement in mAP@0.5 over the baseline, alongside higher precision and recall. Notably, the parameter count decreased from 70.8 M to 67.3 M, demonstrating enhanced efficiency. These results confirm that each proposed modification positively contributes to detection accuracy, with the combined application of all three modules yielding the best performance.
Table 2.
Comparison of ablation experiment results for the improved model.
To further validate the effectiveness of the proposed network improvements, the detection results from the baseline and modified networks were visually compared, as shown in Figure 12. In the first three comparison groups, the baseline network exhibited misdetections in scenarios with complex backgrounds and densely distributed insulator defects. Specifically, in Groups 1 and 2, non-defective regions were incorrectly identified as insulator breakage (jyz_sh), while in Group 3, non-flashover regions were falsely detected as insulator flashover (jyz_sl). In contrast, the proposed network achieved accurate detections with notably higher confidence scores. In Group 4, the baseline network misclassified a meter breakage (bj_ps) as meter blur (bj_mh), and in Group 5, it erroneously detected non-blurred regions as (bj_mh). These errors were absent in the proposed network.
The results in Figure 13 demonstrate that the enhanced SPPCSPC structure improves feature extraction capabilities, while the integration of the BiFormer sparse attention mechanism within the efficient aggregation network strengthens the flexible recognition of multi-scale targets. These modifications collectively reduce false positives and misdetections, significantly boosting precision in multi-scale anomaly detection for power equipment.

Figure 13.
Visualization of the comparison of detection performance before and after network improvement.
4.2. Comparative Experiment
To validate the effectiveness of the proposed network, it was compared with widely used object detection networks, including SSD [2], TPH-YOLOv5 [30], YOLOv7 [21], YOLOv8 [31], and DETR [32], under identical experimental conditions. All networks were trained on the same platform using identical training and test sets. As shown in Table 3, the proposed network achieves superior mAP@0.5 values for insulator breakage (jyz_sh), flashover anomalies (jyz_sl), and meter blur (bj_mh) and breakage (bj_ps) compared to other state-of-the-art networks. Specifically, the improved network attains an mAP@0.5 of 93.5%, representing a 4.3% improvement over the baseline YOLOv7 and outperforming other comparative networks. A detailed analysis against the baseline reveals AP improvements of 3.9% for (bj_mh), 2.2% for (bj_ps), 6.9% for (jyz_sh), and 8.7% for (jyz_sl). These results conclusively demonstrate the efficacy of the proposed network in enhancing detection accuracy across critical defect categories.
Table 3.
Model comparison experiment results.
To further evaluate the robustness of the improved network in complex outdoor scenarios, the test set images were processed with simulated rain, fog, darkening, and brightening effects to mimic varying weather conditions, and detection performance was compared across networks. Table 4 presents the mAP@0.5 values of different networks under these simulated weather conditions. The results indicate that all networks experienced accuracy degradation under adverse weather, with the most significant declines observed for rain and fog simulations. This is attributed to the occlusion of anomalous targets by synthetic rain/fog effects, which severely disrupts detection. In contrast, illumination adjustments (darkening/brightening) primarily alter visual appearance without introducing occlusions or artifacts, resulting in smaller performance impacts.
Table 4.
mAP@0.5 values (%) for different models under various weather conditions.
Notably, the proposed network achieved the highest mAP@0.5 values across all weather conditions while exhibiting the smallest relative declines compared to normal scenarios. Specifically, the mAP@0.5 decreased by 3.3% for rain, 3.8% for fog, 1.9% for darkening, and 1.4% for brightening, demonstrating superior resilience to environmental interference compared to other networks.
To provide an intuitive comparison of the robustness of each detection network against varying weather conditions, bar charts were generated to visualize the mAP@0.5 values and their percentage declines under simulated weather perturbations across networks, as illustrated in Figure 14 and Figure 15.
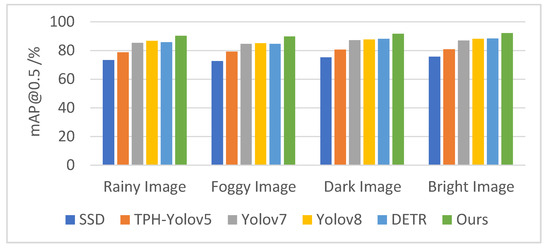
Figure 14.
mAP@0.5 Values (%) for Different Networks Under Various Weather Conditions.
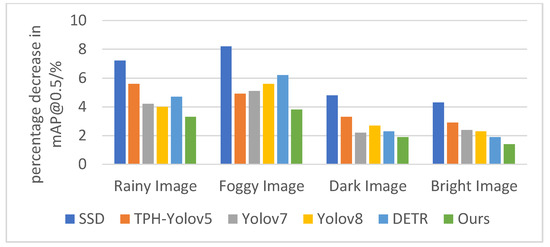
Figure 15.
Percentage decrease in mAP@0.5 values for different networks under various weather conditions (%).
To further validate the robustness of the improved network under varying weather conditions, the detection results across simulated weather scenarios were visualized and compared, as shown in Figure 16. The comparative results reveal that despite image degradation caused by weather factors, the improved network maintains stable detection performance. Although the confidence scores exhibit slight declines, the network still achieves accurate anomaly detection under all tested conditions. In summary, this study verifies that the proposed YOLO-SRSA method achieves higher detection accuracy and robustness in power equipment anomaly detection tasks by comparing its mAP@0.5 values and performance degradation rates under different weather conditions with those of other target detection models.

Figure 16.
Visualization of detection results of the improved network under different weather conditions.
5. Conclusions
This paper proposes an improved YOLO-SRSA algorithm for anomaly detection in power system equipment. The network enhancements primarily include the following modifications: First, the SPPCSPC module in the backbone network is refined by introducing the AC-SPPCSPC structure, which reduces the parameter count by trimming the number of convolutions and incorporates the ACmix convolution-based attention mechanism to improve the extraction of anomalous target features. Furthermore, the parallel pooling layers in SPPCSPC are replaced with serial pooling layers to enhance the network’s focus on anomalous targets. Second, the BiFormer sparse attention mechanism is integrated into the efficient aggregation network to construct the ESAN structure, thereby enhancing the network’s flexibility in recognizing anomalies at different scales. Finally, the original loss function is replaced with the MpDIoU function to resolve issues related to mismatched target prediction boxes.
In terms of data augmentation, geometric and color transformations, along with rain and fog simulations, are applied to preprocess the dataset, which improves the model’s robustness under various outdoor weather conditions. The experimental results validate that the improved network achieves an mAP@0.5 of 93.5%, a precision of 97.1%, and a recall of 97%. The proposed network modifications effectively reduce both missed and false detections, providing practical significance for the intelligent operation and maintenance of power systems. Although this paper effectively improves the detection accuracy of specific power equipment through enhanced network architecture, the current work mainly focuses on anomaly detection for insulators and meters. Future research should further extend generalized detection capabilities to critical equipment such as transformers and circuit breakers. Additionally, in response to the stringent real-time requirements of intelligent operation and maintenance in substations, subsequent studies could explore model lightweighting methods and attempt deployment on edge computing devices to establish an intelligent operation and maintenance system with millisecond-level response capabilities.
Author Contributions
Conceptualization, W.Z. and Y.J.; methodology, W.L.; validation, S.F., Y.Y. and H.T.; formal analysis, S.F.; writing—original draft preparation, H.T.; writing—review and editing, H.T., Y.Y. and J.H.; visualization, H.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the State Grid Sichuan Electric Power Company Science and Technology Program, grant number 521997230014 and the funding of Southwest Jiaotong University’s first batch of English-taught quality courses for international students in China, grant number LHJP[2023]07.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Restrictions apply to the datasets. The datasets presented in this article are not readily available due to safety considerations of substation equipment, and the data are confidential. Requests to access the datasets should be directed to liaowl2050@sc.sgcc.com.cn.
Conflicts of Interest
Authors Wan Zou and Yiping Jiang were employed by State Grid Sichuan Electric Power Company. Authors Wenlong Liao, Songhai Fan and Yueping Yang were employed by State Grid Sichuan Electric Power Research Institute. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Qi, D.L.; Han, Y.F.; Zhou, Z.Q.; Yan, Y.F. Detection technology for external defects of power transmission and transformation equipment based on video imaging and its current application status. J. Electron. Inf. 2022, 44, 3709–3720. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ma, Q.H. Insulator fault detection method based on umbrella skirt morphology. Sci. Technol. Innov. 2020, 31, 20–21. [Google Scholar]
- Wang, D.L.; Zhang, S.H.; Yuan, B.X.; Zhao, W.; Zhu, R. Research on lightweight detection of self-explosion defects in glass insulators based on improved YOLOv5. High Volt. Technol. 2023, 49, 4382–4390. [Google Scholar]
- Tao, X.; Zhang, D.; Wang, Z.; Liu, X.; Zhang, H.; Xu, D. Detection of power line insulator defects using aerial images analyzed with convolutional neural networks. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 1486–1498. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhen, Z.; Zhang, L.; Qi, Y.; Kong, Y.; Zhang, K. Insulator detection method in inspection image based on improved faster R-CNN. Energies 2019, 12, 1204. [Google Scholar] [CrossRef]
- Song, Z.W.; Huang, X.B.; Ji, C.; Zhang, Y. Insulator defect detection and fault warning method for transmission line based on Flexible YOLOv7. High Volt. Eng. 2023, 49, 5084–5094. (In Chinese) [Google Scholar]
- Zhao, W.; Cheng, X.; Zhao, Z.; Zhai, Y. Insulator recognition based on attention mechanism and Faster RCNN. J. Intell. Syst. 2020, 15, 92–98. [Google Scholar]
- Wang, Y.B.; Li, Y.Y.; Duan, Y.; Wu, H. Recognition of infrared images of substation equipment based on lightweight backbone network and attention structure. Power Grid Technol. 2023, 47, 4358–4366. [Google Scholar]
- Bao, W.; Yuan, M.; Liang, D.; Wang, N.; Du, X. Detection algorithm for substation meter defects based on improved YOLOv5. J. Anhui Univ. (Nat. Sci. Ed.) 2024, 48, 50–56. [Google Scholar]
- Xiao, C.J.; Pan, R.Z.; Li, C.; Huang, J. Research on insulator defect detection technology based on improved YOLOv5s. Electron. Meas. Technol. 2022, 45, 137–144. [Google Scholar]
- Xiang, S.; Chang, Z.; Liu, X.; Luo, L.; Mao, Y.; Du, X.; Li, B.; Zhao, Z. Infrared Image Object Detection Algorithm for Substation Equipment Based on Improved YOLOv8. Energies 2024, 17, 4359. [Google Scholar] [CrossRef]
- Han, Y.; Qi, D.; Yan, Y. Self-reduction multi-head attention module for defect recognition of power equipment in substation. Glob. Energy Interconnect. 2025, 8, 82–91. [Google Scholar] [CrossRef]
- Wang, Z.; Lan, X.; Zhou, Y.; Wang, F.; Wang, M.; Chen, Y.; Zhou, G.; Hu, Q. A Two-Stage Corrosion Defect Detection Method for Substation Equipment Based on Object Detection and Semantic Segmentation. Energies 2024, 17, 6404. [Google Scholar] [CrossRef]
- Deng, C.; Liu, M.; Fu, T.; Gong, M.; Luo, B. Infrared Image Recognition of Substation Equipment Based on Improved YOLOv7-Tiny Algorithm. Infrared Technol. 2025, 47, 44–51. [Google Scholar]
- Zhang, H.; Mu, C.; Ma, X.; Guo, X.; Hu, C. MEAG-YOLO: A Novel Approach for the Accurate Detection of Personal Protective Equipment in Substations. Appl. Sci. 2024, 14, 4766. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovshiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the integration of self-attention and convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 815–825. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W. BiFormer: Vision Transformer with Bi-Level Routing Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Siliang, M.; Yong, X. Mpdiou: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops, Montreal, BC, Canada, 11–17 October 2021; IEEE Press: New York, NY, USA, 2021; pp. 2778–2788. [Google Scholar]
- Jocher, G. YOLOv8[EB/OL]. Available online: https://github.com/ultralytics/ultralytics (accessed on 28 March 2025).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).