
The Eyes: A Source of Information for Detecting Deepfakes †


 and
and
Abstract
1. Introduction
- We introduce a mechanism to identify forged images by leveraging two robust physiological techniques, such as pupil shape and identical corneal reflections in both eyes.
- We present a novel deepfake detection framework that focuses on the unique properties of the eyes, which are among the most challenging facial features for GANs to replicate accurately. The dual detection layers work in an end-to-end manner to produce comprehensive and effective detection outcomes.
- Our extensive experiments showcase the superior effectiveness of our method in terms of detection accuracy, generalization, and robustness when compared to other existing approaches.
2. Related Work
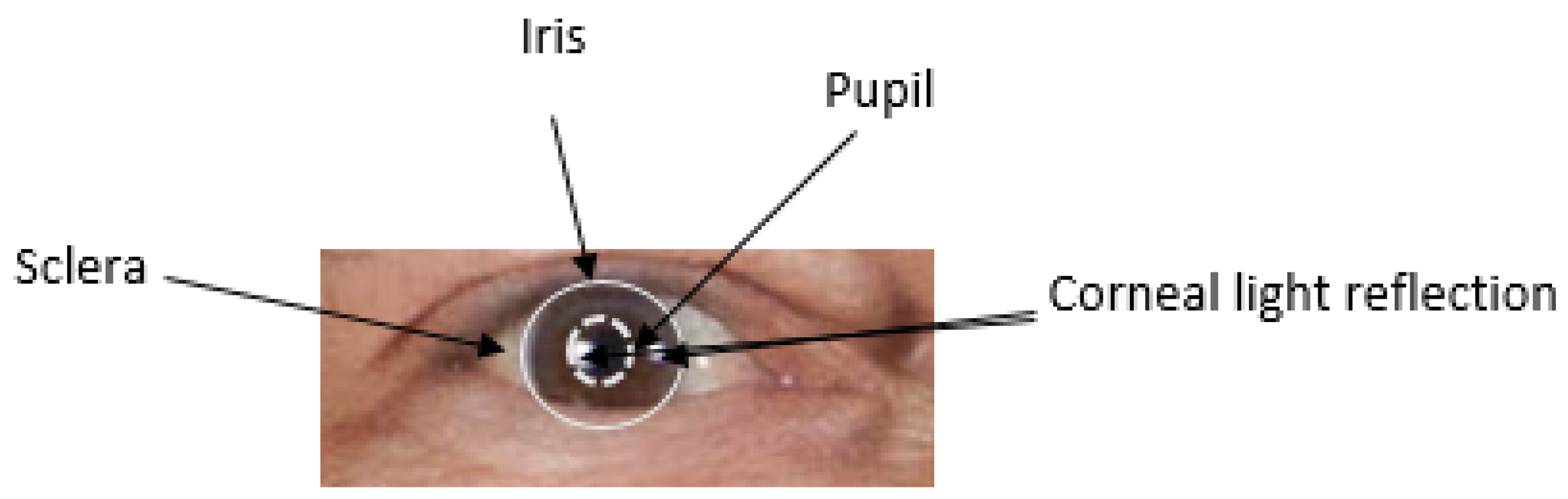
2.1. Structure of the Human Eyes
2.2. Generation of Human Faces Using GAN
2.3. Detection Method Based on Physical Properties
3. Motivation
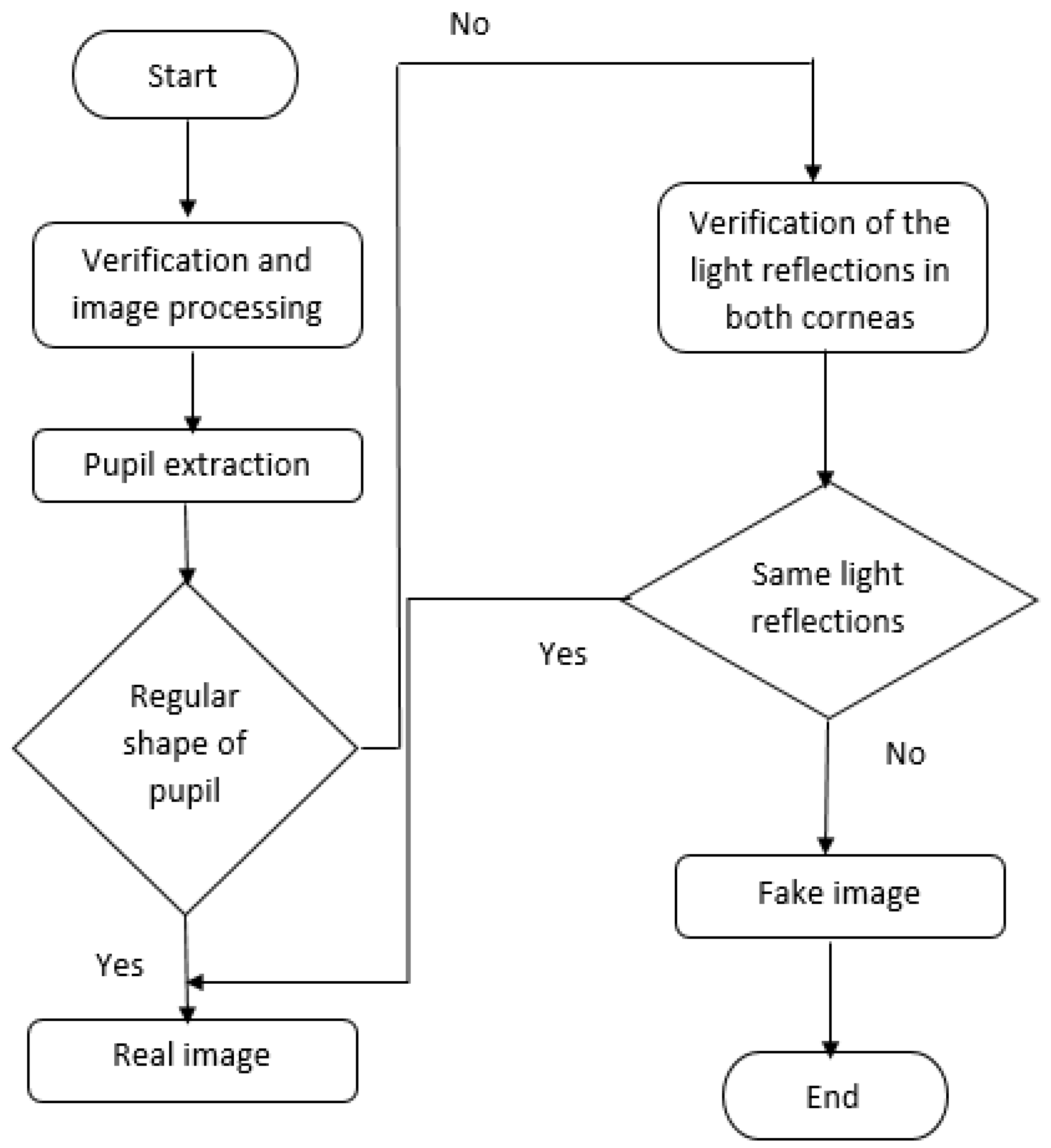
4. Proposed Method
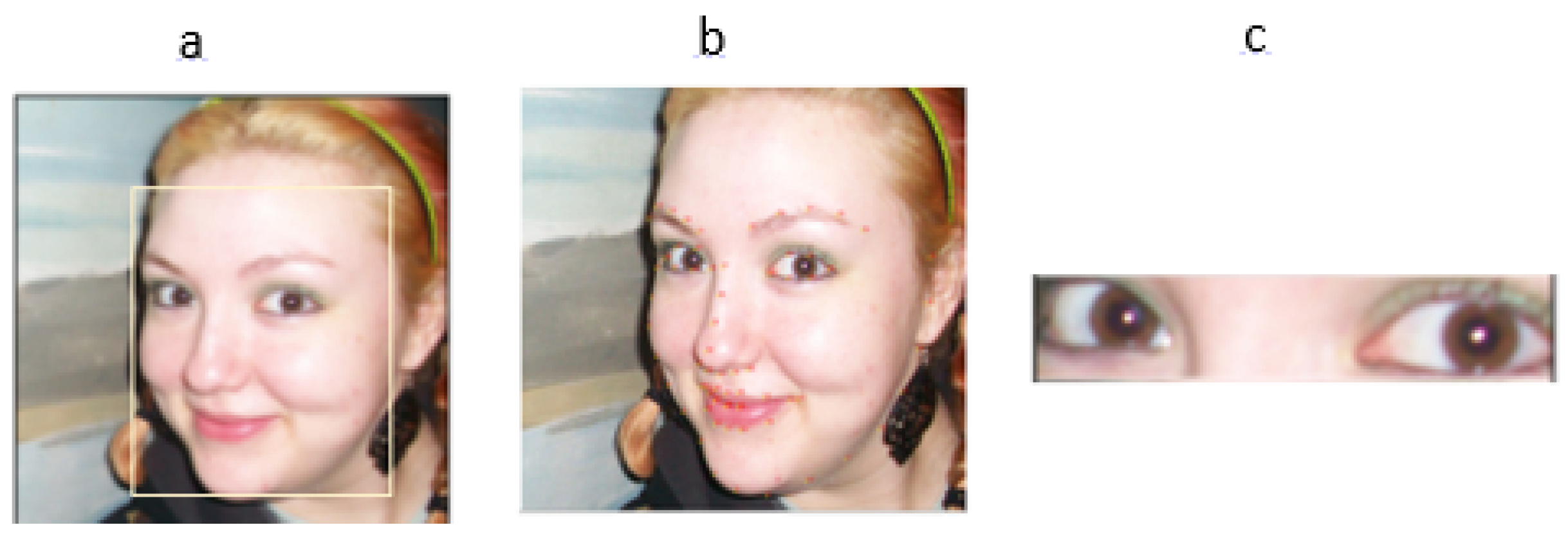
4.1. Processing and Verification Step
4.2. Detection Step
4.2.1. Verification of Pupil Shape
| Algorithm 1 Sum of squared distances |
| Require: Ensure: 1: for i in range (epochs) do 2: , 3: 4: end for 5: return |
4.2.2. Verification of Corneal Light Reflections
- The eyes are pointed straight ahead, ensuring that the line joining the centers of both eyes is parallel to the camera.
- The eyes are positioned at a specific distance from the light source.
- Both eyes have a clear line of sight to all the light sources or reflective surfaces within the environment.
4.2.3. Global Approch of the Method
5. Experiments
5.1. Real Images Dataset
5.2. Fake Images Dataset
6. Result and Discussion
Comparison with Current Physiological Techniques
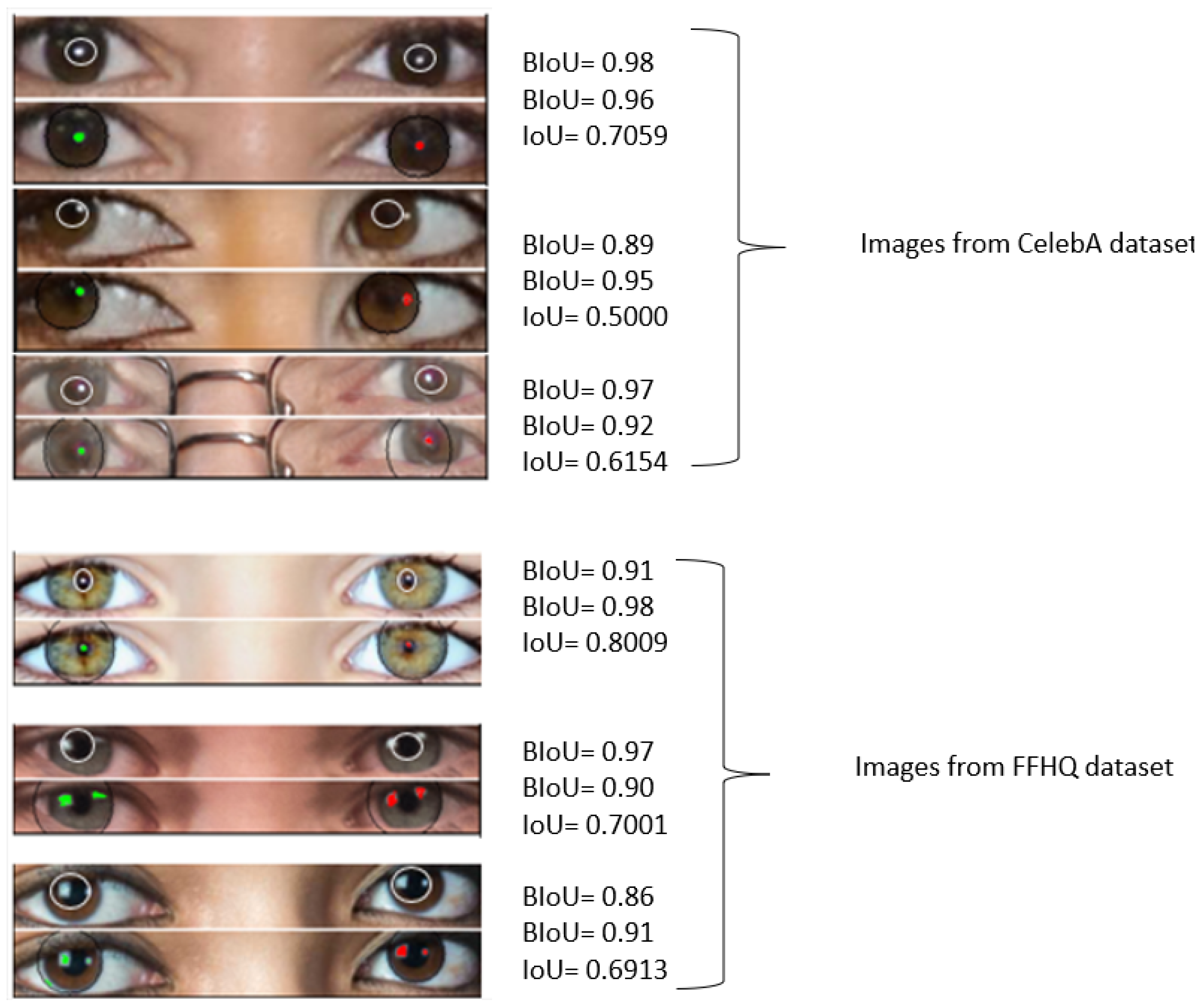
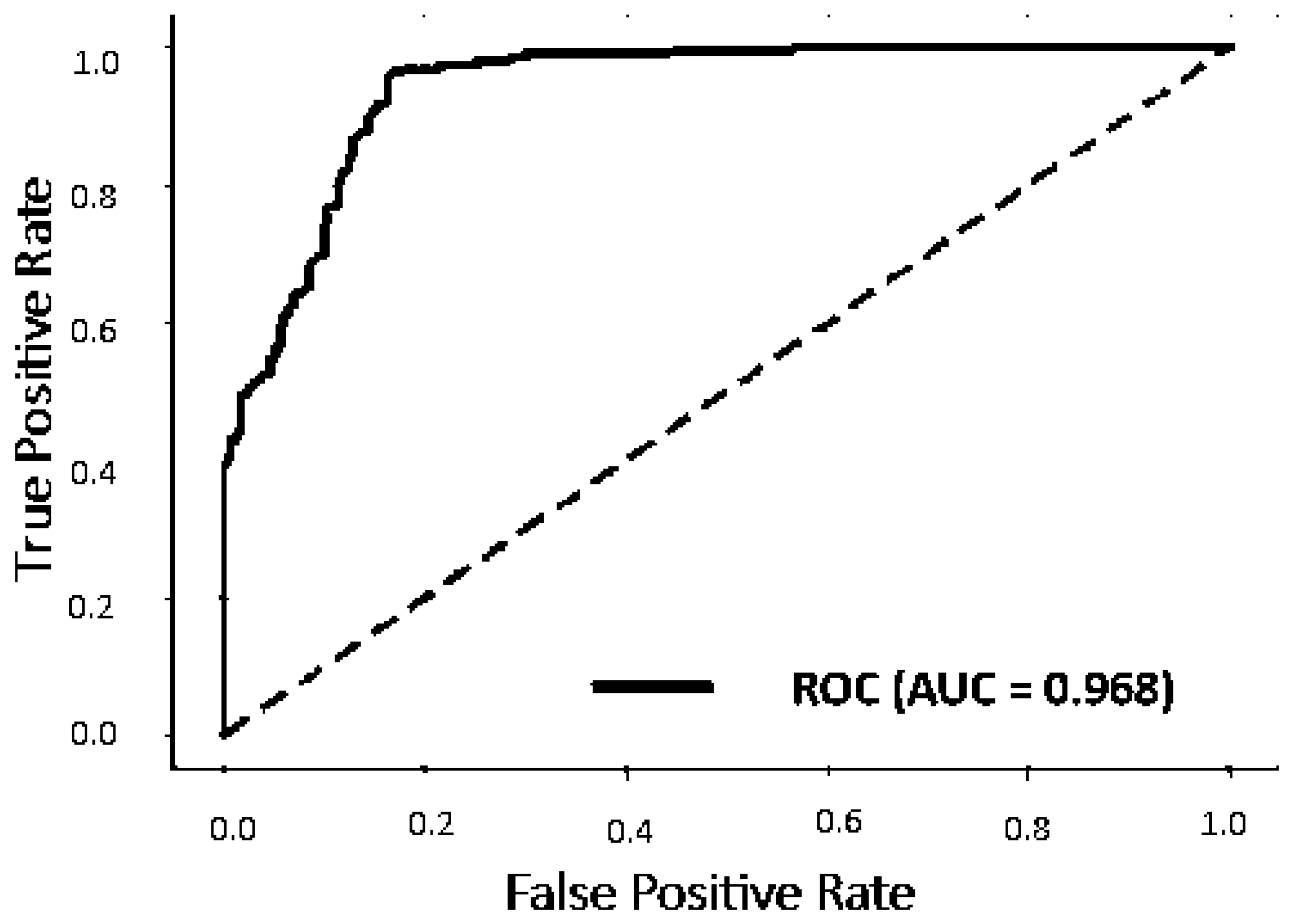
- FFHQ and StyleGAN2: The high performance of our model is demonstrated by a mean IoU of 0.85 with a low variance of 0.03, and a mean BIoU of 0.75 with a low variance of 0.02, indicating its effectiveness, stability, precision, and reliability in identifying similarities and differentiating real images from deepfakes.
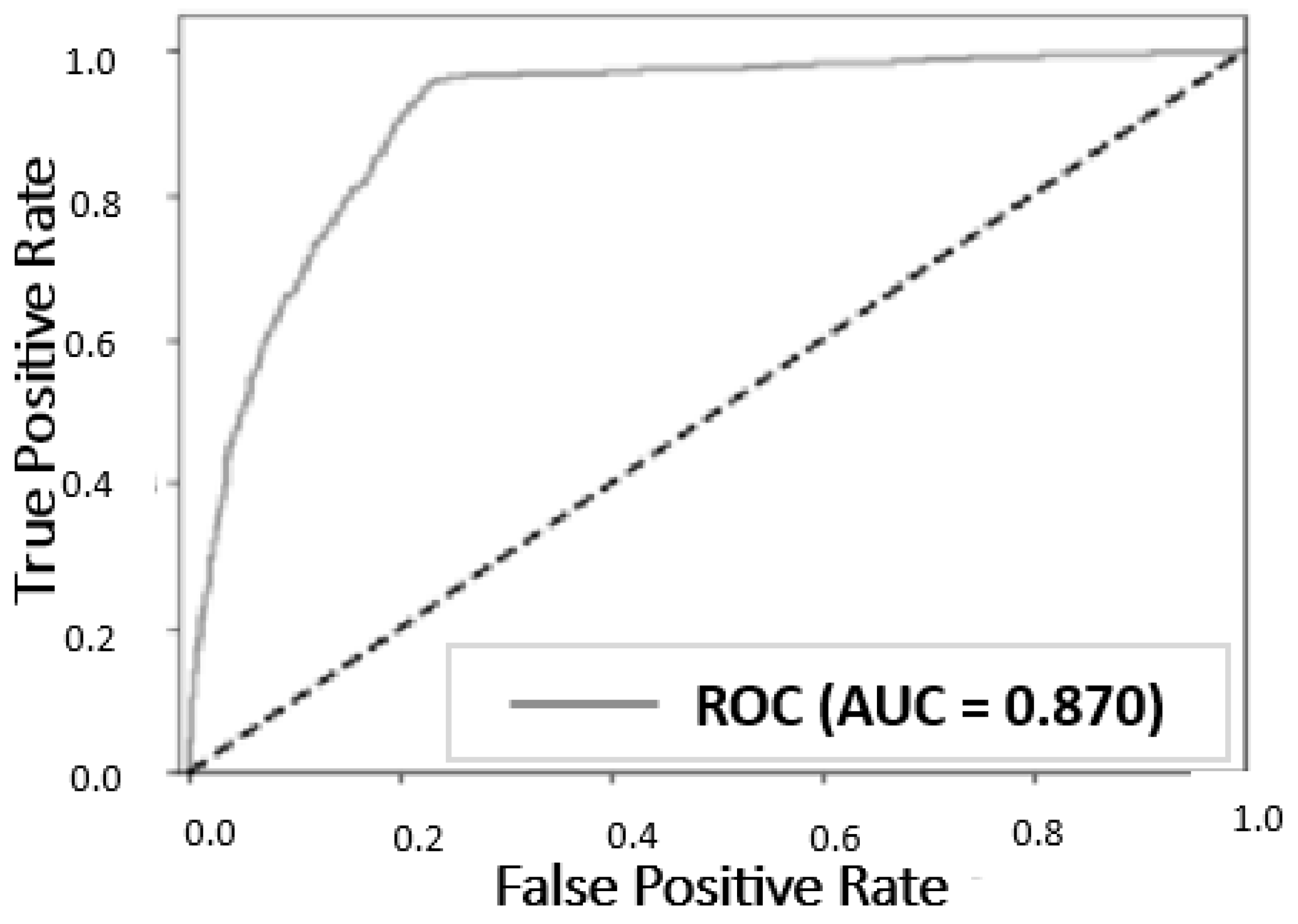
- CELEBA and PROGAN: The mean IoU of 0.72 suggests that the model performs reasonably well in capturing the similarity between corneal reflections, but there is room for improvement; the higher variance of 0.08 indicates some variability in the model’s performance across different samples, while the mean BIoU of 0.78 demonstrates fairly accurate performance in capturing the elliptical shape of the pupil, though not as effective as in (FFHQ and StyleGAN 2), and the variance of 0.09 shows some inconsistency, suggesting a need for further refinement.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of GANs for improved quality, stability, and variation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Guo, H.; Hu, S.; Wang, X.; Chang, M.-C.; Lyu, S. Eyes tell all: Irregular pupil shapes reveal gan-generated faces. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 2904–2908. [Google Scholar]
- Hu, S.; Li, Y.; Lyu, S. Exposing gan-generated faces using inconsistent corneal specular highlights. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2500–2504. [Google Scholar]
- Tchaptchet, E.; Tagne, E.F.; Acosta, J.; Danda, R.; Kamhoua, C. Detecting Deepfakes Using GAN Manipulation Defects in Human Eyes. In Proceedings of the 2024 International Conference on Computing, Networking and Communications (ICNC), Big Island, HI, USA, 19–22 February 2024; pp. 456–462. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Verdoliva, L.; Poggi, G. Do gans leave artificial fingerprints? In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 506–511. [Google Scholar]
- Wang, S.-Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. Cnngenerated images are surprisingly easy to spot... for now. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8695–8704. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 83–92. [Google Scholar]
- Nirkin, Y.; Wolf, L.; Keller, Y.; Hassner, T. Deepfake detection based on discrepancies between faces and their context. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6111–6121. [Google Scholar] [CrossRef]
- Wang, J.; Wu, Z.; Ouyang, W.; Han, X.; Chen, J.; Jiang, Y.-G.; Li, S.-N. M2tr: Multi-modal multi-scale transformers for deepfake detection. In Proceedings of the 2022 International Conference on Multimedia Retrieval, Newark, NJ, USA, 27– 30 June 2022; pp. 615–623. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Yang, X.; Li, Y.; Qi, H.; Lyu, S. Exposing gan-synthesized faces using landmark locations. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security (IHMMSec), Paris, France, 3–5 July 2019. [Google Scholar]
- Cozzolino, D.; Verdoliva, L. Noiseprint: A CNN-based camera model fingerprint. IEEE Trans. Inf. Forensics Secur. 2019, 15, 144–159. [Google Scholar] [CrossRef]
- Verdoliva, D.C.G.P.L. Extracting camera-based fingerprints for video forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cozzolino, D.; Verdoliva, L. Camera-based Image Forgery Localization using Convolutional Neural Networks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5001–5010. [Google Scholar]
- Ciftci, U.A.; Demir, I.; Yin, L. Fakecatcher: Detection of synthetic portrait videos using biological signals. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, S.; Farid, H.; El-Gaaly, T.; Lim, S.N. Detecting deep-fake videos from appearance and behavior. In Proceedings of the 2020 IEEE International Workshop on Information Forensics and Security (WIFS), New York, NY, USA, 6–11 December 2020; pp. 1–6. [Google Scholar]
- Peng, B.; Fan, H.; Wang, W.; Dong, J.; Lyu, S. A Unified Framework for High Fidelity Face Swap and Expression Reenactment. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3673–3684. [Google Scholar] [CrossRef]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. Emotions don’t lie: An audio-visual deepfake detection method using affective cues. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2823–2832. [Google Scholar]
- Zhang, Y.; Goh, J.; Win, L.L.; Thing, V.L. Image Region Forgery Detection: A Deep Learning Approach. In Proceedings of the Singapore Cyber-Security Conference (SG-CRC), Singapore, 14–15 January 2016; Volume 2016, pp. 1–11. [Google Scholar]
- Salloum, R.; Ren, Y.; Kuo, C.C.J. Image splicing localization using a multi-task fully convolutional network (MFCN). J. Vis. Commun. Image Represent. 2018, 51, 201–209. [Google Scholar] [CrossRef]
- Cheng, B.; Girshick, R.; Doll´ar, P.; Berg, A.C.; Kirillov, A. Boundary iou: Improving object-centric image segmentation evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15334–15342. [Google Scholar]
- Xue, Z.; Jiang, X.; Liu, Q.; Wei, Z. Global–local facial fusion based gan generated fake face detection. Sensors 2023, 23, 616. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Yu, N.; Keuper, M.; Fritz, M. Beyond the spectrum: Detecting deepfakes via re-synthesis. arXiv 2021, arXiv:2105.14376. [Google Scholar]
- Luo, Y.; Zhang, Y.; Yan, J.; Liu, W. Generalizing face forgery detection with high-frequency features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16317–16326. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale gan training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Bulat, A.; Yang, J.; Tzimiropoulos, G. To learn image super-resolution, use a gan to learn how to do image degradation first. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 185–200. [Google Scholar]
- Alqahtani, H.; Kavakli-Thorne, M.; Kumar, G. Applications of generative adversarial networks (gans): An updated review. Arch. Comput. Methods Eng. 2021, 28, 525–552. [Google Scholar] [CrossRef]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Wang, C.; Wang, Y.; Zhang, K.; Muhammad, J.; Lu, T.; Zhang, Q.; Tian, Q.; He, Z.; Sun, Z.; Zhang, Y.; et al. Nir iris challenge evaluation in non-cooperative environments: Segmentation and localization. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; pp. 1–10. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Yen, J.-C.; Chang, F.-J.; Chang, S. A new criterion for automatic multilevel thresholding. IEEE Trans. Image Process. 1995, 4, 370–378. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Real Images (FFHQ) | Fake Images (StyleGAN2) | Result (AUC) |
|---|---|---|---|
| Hu et al. [5] | 500 | 500 | 0.94 |
| Guo et al. [4] | 1000 | 1000 | 0.91 |
| Yang et al. [13] | 50,000 (CelebA) | 25,000 (ProGAN) | 0.94 |
| Xue et al. [25] | 1000 | 1000 | 0.96 |
| Xue et al. [25] | 1000 (CelebA) | 1000 (ProGAN) | 0.88 |
| Our method | 1000 | 1000 | 0.968 |
| Our method | 1000 (CelebA) | 1000 (ProGAN) | 0.870 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tchaptchet, E.; Tagne, E.F.; Acosta, J.; Rawat, D.B.; Kamhoua, C. The Eyes: A Source of Information for Detecting Deepfakes. Information 2025, 16, 371. https://doi.org/10.3390/info16050371
Tchaptchet E, Tagne EF, Acosta J, Rawat DB, Kamhoua C. The Eyes: A Source of Information for Detecting Deepfakes. Information. 2025; 16(5):371. https://doi.org/10.3390/info16050371
Chicago/Turabian StyleTchaptchet, Elisabeth, Elie Fute Tagne, Jaime Acosta, Danda B. Rawat, and Charles Kamhoua. 2025. "The Eyes: A Source of Information for Detecting Deepfakes" Information 16, no. 5: 371. https://doi.org/10.3390/info16050371
APA StyleTchaptchet, E., Tagne, E. F., Acosta, J., Rawat, D. B., & Kamhoua, C. (2025). The Eyes: A Source of Information for Detecting Deepfakes. Information, 16(5), 371. https://doi.org/10.3390/info16050371