
Image Generation and Super-Resolution Reconstruction of Synthetic Aperture Radar Images Based on an Improved Single-Image Generative Adversarial Network

Abstract
1. Introduction
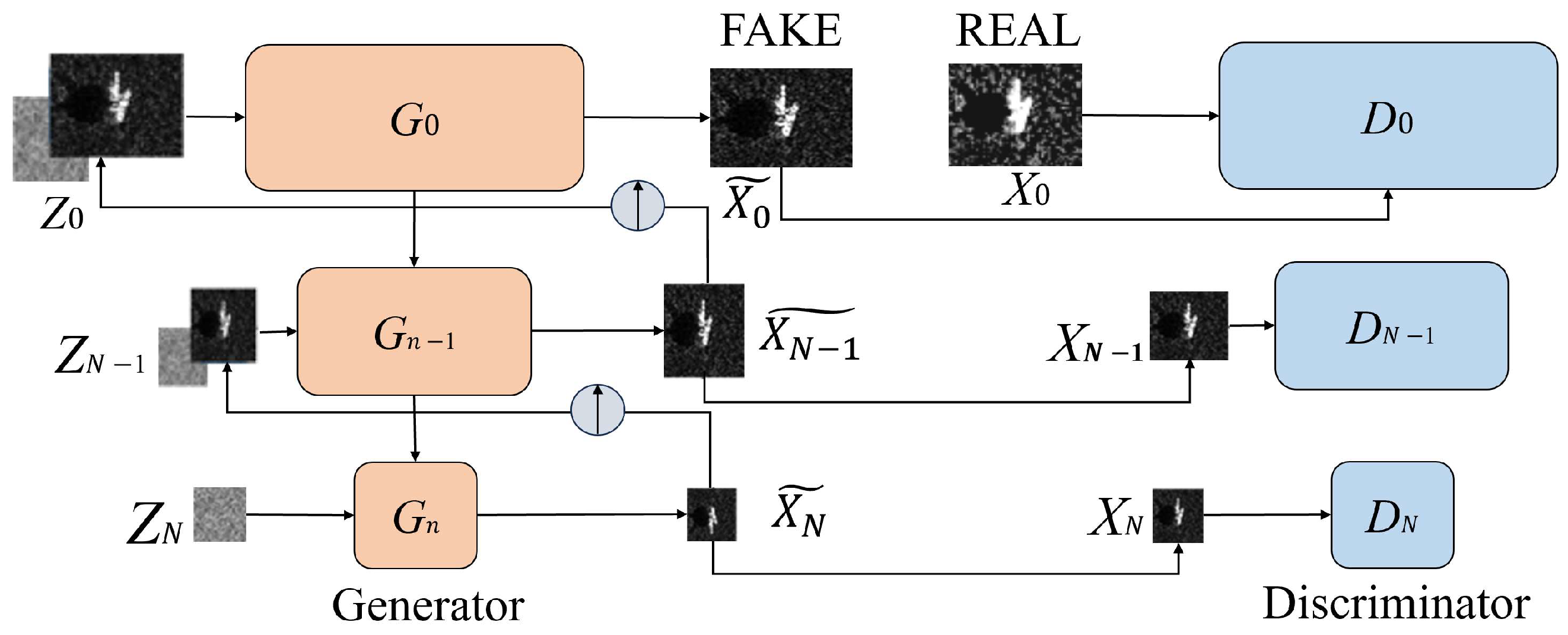
2. The Proposed Methods
2.1. The Related Theory of SinGAN
2.2. Incorporating the SAR Noise Model
3. Results
3.1. Target Recognition
3.2. Single-Image Fréchet Inception Distance Assessment
3.3. SSIM and PSNR Assessment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cerutti-Maori, D.; Sikaneta, I.; Gierull, C.H. Optimum SAR/GMTI Processing and Its Application to the Radar Satellite RADARSAT-2 for Traffic Monitoring. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3868–3881. [Google Scholar] [CrossRef]
- Zhang, M.; Lu, H.; Li, S.; Li, Z. High-resolution wide-swath sar imaging with multifrequency pulse diversity mode in azimuth multichannel system. Int. J. Remote Sens. 2024, 45, 29. [Google Scholar] [CrossRef]
- Xu, W.; Hu, J.; Huang, P.; Tan, W.; Dong, Y. Azimuth phase center adaptive adjustment upon reception for high-resolution wide-swath imaging. Sensors 2019, 19, 4277. [Google Scholar] [CrossRef]
- Tang, T.; Cui, Y.; Feng, R.; Xiang, D. Vehicle Target Recognition in SAR Images with Complex Scenes Based on Mixed Attention Mechanism. Information 2024, 15, 159. [Google Scholar] [CrossRef]
- Sanderson, J.; Mao, H.; Abdullah, M.A.M.; Al-Nima, R.R.O.; Woo, W.L. Optimal Fusion of Multispectral Optical and SAR Images for Flood Inundation Mapping through Explainable Deep Learning. Information 2023, 14, 660. [Google Scholar] [CrossRef]
- Zeng, H.; Ma, P.; Shen, H.; Su, C.; Wang, H.; Wang, Y.; Yang, W.; Liu, W. A Coarse-to-Fine Scene Matching Method for High-Resolution Multiview SAR Images. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–14. [Google Scholar] [CrossRef]
- Arai, K.; Nakaoka, Y.; Okumura, H. Method for Landslide Area Detection Based on EfficientNetV2 with Optical Image Converted from SAR Image Using pix2pixHD with Spatial Attention Mechanism in Loss Function. Information 2024, 15, 524. [Google Scholar] [CrossRef]
- Zha, Y.; Pu, W.; Chen, G.; Huang, Y.; Yang, J. A Minimum-Entropy Based Residual Range Cell Migration Correction for Bistatic Forward-Looking SAR. Information 2016, 7, 8. [Google Scholar] [CrossRef]
- Franceschetti, G.; Migliaccio, M.; Riccio, D. On ocean SAR raw signal simulation. IEEE Trans. Geosci. Remote Sens. 1998, 36, 84–100. [Google Scholar] [CrossRef]
- Jia, Y.; Liu, S.; Liu, Y.; Zhai, L.; Gong, Y.; Zhang, X. Echo-Level SAR Imaging Simulation of Wakes Excited by a Submerged Body. Sensors 2024, 24, 1094. [Google Scholar] [CrossRef]
- Wu, M.; Zhang, L.; Niu, J.; Wu, Q.J. Target detection in clutter/interference regions based on deep feature fusion for hfswr. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5581–5595. [Google Scholar] [CrossRef]
- Schmitt, A. Multiscale and multidirectional multilooking for SAR image enhancement. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5117–5134. [Google Scholar] [CrossRef]
- Gleich, D.; Datcu, M. Wavelet-based SAR image despeckling and information extraction, using particle filter. IEEE Trans. Image Process. 2009, 18, 2167–2184. [Google Scholar] [CrossRef] [PubMed]
- Yahya, N.; Kamel, N.S.; Malik, A.S. Subspace-based technique for speckle noise reduction in SAR images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6257–6271. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, H.; Ding, C.; Wang, H. A novel approach for shadow enhancement in high-resolution SAR images using the height-variant phase compensation algorithm. IEEE Geosci. Remote Sens. Lett. 2012, 10, 189–193. [Google Scholar] [CrossRef]
- Thayaparan, T.; Stankovic, L.; Wernik, C.; Dakovic, M. Real-time motion compensation, image formation and image enhancement of moving targets in ISAR and SAR using S-method-based approach. IET Signal Process. 2008, 2, 247–264. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.-Q. Target classification using the deep convolutional networks for SAR images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Liu, P.; Li, J.; Wang, L.; He, G. Remote sensing data fusion with generative adversarial networks, State-of-the-art methods and future research directions. IEEE Geosci. Remote Sens. Mag. 2022, 10, 295–328. [Google Scholar] [CrossRef]
- Yuan, C.; Deng, K.; Li, C.; Zhang, X.; Li, Y. Improving image super-resolution based on multiscale generative adversarial networks. Entropy 2022, 24, 1030. [Google Scholar] [CrossRef]
- Xie, J.; Fang, L.; Zhang, B.; Chanussot, J.; Li, S. Super resolution guided deep network for land cover classification from remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Karwowska, K.; Wierzbicki, D. MCWESRGAN, Improving Enhanced Super-Resolution Generative Adversarial Network for Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 9459–9479. [Google Scholar] [CrossRef]
- Vitale, S.; Ferraioli, G.; Pascazio, V. Multi-objective CNN-based algorithm for SAR despeckling. IEEE Trans. Geosci. Remote Sens. 2020, 59, 9336–9349. [Google Scholar] [CrossRef]
- Li, Y.; Du, L.; Wei, D. Multiscale CNN based on component analysis for SAR ATR. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Li, H.; Huang, H.; Chen, L.; Peng, J.; Huang, H.; Cui, Z.; Mei, X.; Wu, G. Adversarial examples for CNN-based SAR image classification, An experience study. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1333–1347. [Google Scholar] [CrossRef]
- Zhu, J.; Lin, Z.; Wen, B. TM-GAN, A Transformer-Based Multi-Modal Generative Adversarial Network for Guided Depth Image Super-Resolution. IEEE J. Emerg. Sel. Top. Circuits Syst. 2024, 14, 261–274. [Google Scholar] [CrossRef]
- Hou, J.; Bian, Z.; Yao, G.; Lin, H.; Zhang, Y.; He, S.; Chen, H. Attribute Scattering Center Assisted SAR ATR Based on GNN-FiLM. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Ye, T.; Kannan, R.; Prasanna, V.; Busart, C. Adversarial attack on GNN-based SAR image classifier. Artif. Intell. Mach. Learn. Multi-Domain Oper. Appl. V SPIE 2023, 12538, 291–295. [Google Scholar]
- Shaham, T.R.; Dekel, T.; Michaeli, T. Singan, Learning a generative model from a single natural image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4570–4580. [Google Scholar]
- Cai, Z.; Xiong, Z.; Xu, H.; Wang, P.; Li, W.; Pan, Y. Generative Adversarial Networks: A Survey Toward Private and Secure Applications. ACM Comput. Surv. 2021, 54, 132. [Google Scholar] [CrossRef]
- Singh, P.; Diwakar, M.; Shankar, A.; Shree, R.; Kumar, M. A Review on SAR Image and its Despeckling. Arch. Comput. Methods Eng. 2021, 28, 4633–4653. [Google Scholar] [CrossRef]
- Tarchi, D.; Lukin, K.; Fortuny-Guasch, J.; Mogyla, A.; Vyplavin, P.; Sieber, A. SAR imaging with noise radar. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 1214–1225. [Google Scholar] [CrossRef]
- Zhang, W.P.; Tong, X. Noise modeling and analysis of SAR ADCs. IEEE Trans. VLSI Syst. 2014, 23, 2922–2930. [Google Scholar] [CrossRef]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Chaabane, F.; Réjichi, S.; Tupin, F. Self-attention generative adversarial networks for times series VHR multispectral image generation. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4644–4647. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10076–10085. [Google Scholar]
- Zheng, C.; Jiang, X.; Zhang, Y.; Liu, X.; Yuan, B.; Li, Z. Self-normalizing generative adversarial network for super-resolution reconstruction of SAR images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1911–1914. [Google Scholar]
- Lee, J.S.; Wen, J.H.; Ainsworth, T.L.; Chen, K.-S.; Chen, A.J. Improved sigma filter for speckle filtering of SAR imagery. IEEE Trans. Geosci. Remote Sens. 2008, 47, 202–213. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | ACC (%) |
|---|---|
| NEDI [33] | 94.55 ± 0.32 |
| ICBI [34] | 93.15 ± 0.18 |
| Bicubic [35] | 95.22 ± 0.15 |
| SRCNN [36] | 97.07 ± 0.55 |
| SRGAN [37] | 97.26 ± 0.51 |
| SinGAN | 97.28 ± 0.42 |
| ISinGAN | 98.16 ± 0.33 |
| 1st Scale | SIFID |
|---|---|
| N | 0.08 |
| N − 1 | 0.04 |
| Methods | PSNR (dB) | SSIM |
|---|---|---|
| NEDI | 29.0815 | 0.8481 |
| ICBI | 27.8448 | 0.8499 |
| Bicubic | 30.2548 | 0.8728 |
| SRCNN | 31.5881 | 0.9055 |
| SRGAN | 32.5538 | 0.9154 |
| SinGAN | 32.5224 | 0.9166 |
| ISinGAN | 33.1741 | 0.9273 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Nie, L.; Zhang, Y.; Zhang, L. Image Generation and Super-Resolution Reconstruction of Synthetic Aperture Radar Images Based on an Improved Single-Image Generative Adversarial Network. Information 2025, 16, 370. https://doi.org/10.3390/info16050370
Yang X, Nie L, Zhang Y, Zhang L. Image Generation and Super-Resolution Reconstruction of Synthetic Aperture Radar Images Based on an Improved Single-Image Generative Adversarial Network. Information. 2025; 16(5):370. https://doi.org/10.3390/info16050370
Chicago/Turabian StyleYang, Xuguang, Lixia Nie, Yun Zhang, and Ling Zhang. 2025. "Image Generation and Super-Resolution Reconstruction of Synthetic Aperture Radar Images Based on an Improved Single-Image Generative Adversarial Network" Information 16, no. 5: 370. https://doi.org/10.3390/info16050370
APA StyleYang, X., Nie, L., Zhang, Y., & Zhang, L. (2025). Image Generation and Super-Resolution Reconstruction of Synthetic Aperture Radar Images Based on an Improved Single-Image Generative Adversarial Network. Information, 16(5), 370. https://doi.org/10.3390/info16050370