
MLRec: A Machine Learning-Based Recommendation System for High School Students Context of Bangladesh


Abstract
1. Introduction
- We implemented an MLRec model that focuses on improving generalization and simplifying the discovery of significant academic impact factors in students using social media.
- We split our study into two separate sections. In the first section, we use fifteen ML models for predictions. In addition, according to the model performance, we have selected the ETC ML model for the subsequent evaluation. The ensuing experiment highlighted the fundamental factors influencing student achievement.
- LIME is an approach that provides precise estimations of the predictions made by any classifier via a locally interpretable model. This enables the generation of accurate and reliable explanations.
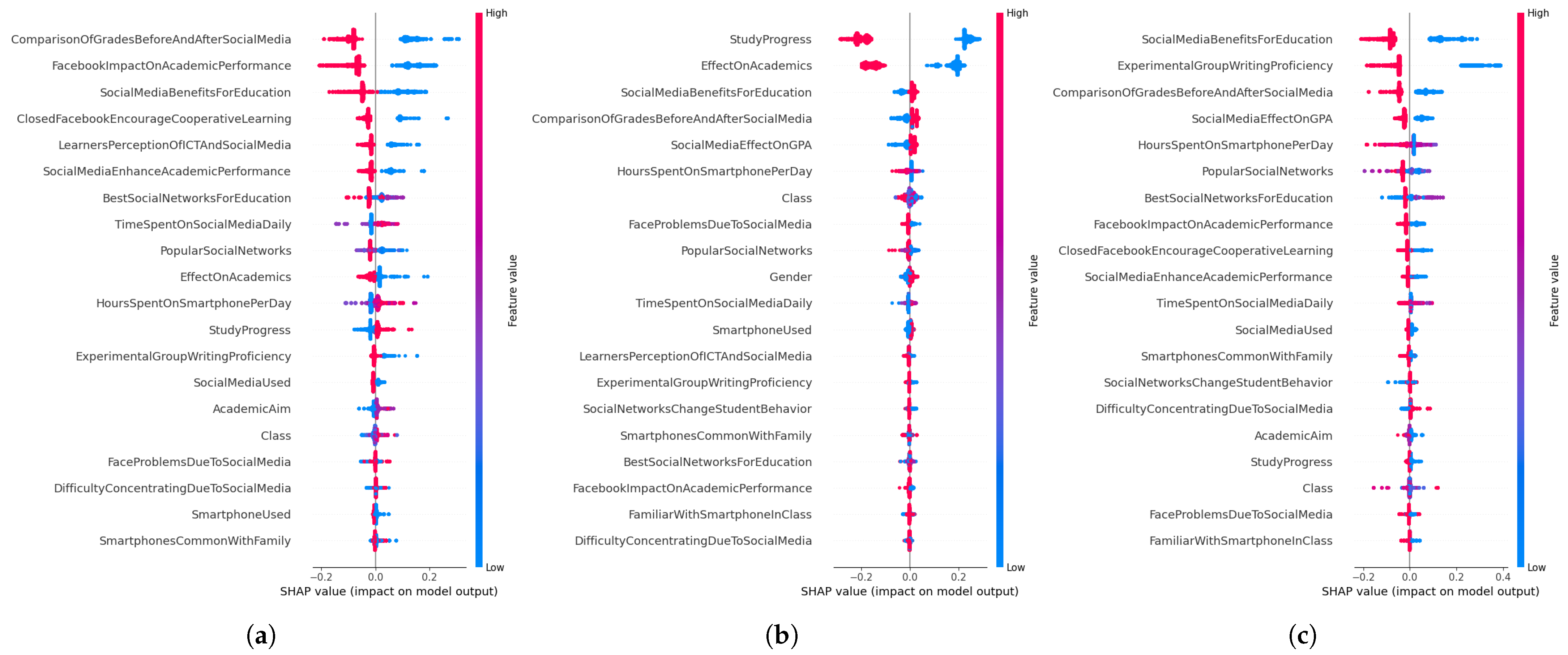
- We present an approach based on SHAP, which improves the interpretability of ML models and provides a more transparent understanding of the value of features.
- In conclusion, we have determined that the XAI techniques of LIME and SHAP provide us with a precise comprehension of the underlying factors influencing student performance and provide recommendations to parents, educators, and society. However, when comparing the two, we discovered that LIME yielded superior outcomes compared to SHAP.
- RQ1: What is the current level of awareness and utilization of socimedevices among Bangladeshi high school students, and how does it influence their interaction with Explainable AI?
- RQ2: How does the MLRec model influence the learning outcomes and academic performance of Bangladeshi high school students when integrated into their educational environment?
- RQ3: What are the social and cultural implications of integrating Explainable AI, specifically MLRec, into the educational experience of Bangladeshi high school students, and how do socimedevices mediate these implications?
- RQ4: How do privacy and ethical considerations manifest in the implementation of MLRec within the educational context for high school students in Bangladesh, taking into account the use of socimedevices?
2. Literature Review
3. Proposed Methodology
| Algorithm 1 MLRec—Machine Learning-Based Recommendation Workflow |
|
3.1. Dataset
3.1.1. Participant Distribution and Categories
3.1.2. Features Description
3.2. Prepossessing
3.3. ML Models
3.3.1. Linear Regression (LR) [57]
3.3.2. Ridge Regression (RR)
3.3.3. Random Forest Regression (RFR)
3.3.4. Decision Tree Classifier (DTC) and Decision Tree Regression (DTR) [58]
3.3.5. Support Vector Machine (SVM) and Support Vector Classifier (SVC) [59]
3.3.6. Naive Bayes (NB)
3.3.7. Adaptive Boosting (AdaBoost) [60]
3.3.8. Gradient Boosting Classifier (GBC) [61] and Gradient Boosting Regression (GBR) [62]
3.3.9. Extreme Gradient Boosting (XGBoost) [63]
3.3.10. Extra Tree Classifier (ETC) [64]
3.3.11. K-Nearest Neighbors (KNN) [65]
3.3.12. Isotonic Regression (IR)
3.3.13. Gaussian Naive Bayes (GNB)
3.3.14. Multinomial Naive Bayes (MNB)
4. Experiment Result and Analysis
4.1. Performance Metrics
4.1.1. Mean Absolute Error (MAE)
4.1.2. Root Mean Square Error (RMSE)
4.1.3. Explained Variance (EV)
4.1.4. Coefficient of Determination Score ()
4.1.5. Tweedie Deviance Score ()
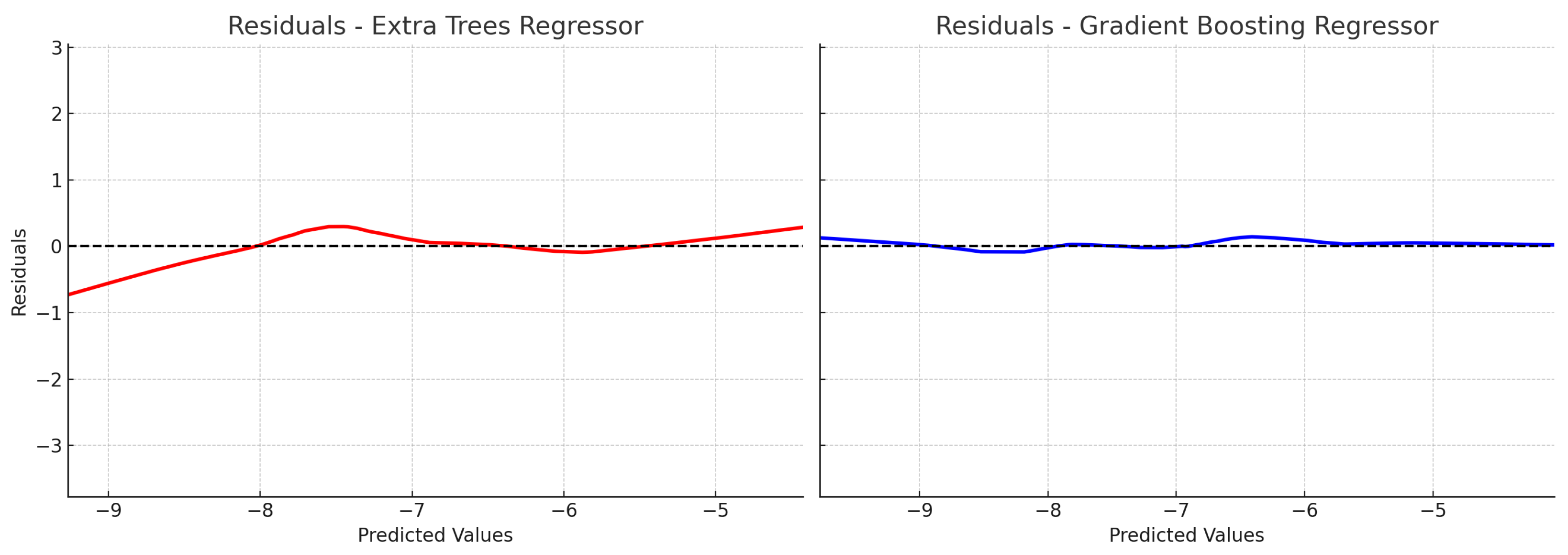
4.2. Performance Analysis
4.3. Explainable Artificial Intelligence (XAI)
4.3.1. Shapley Additive Explanations (SHAP)
4.3.2. Local Interpretable Model-Agnostic Explanations (LIME)
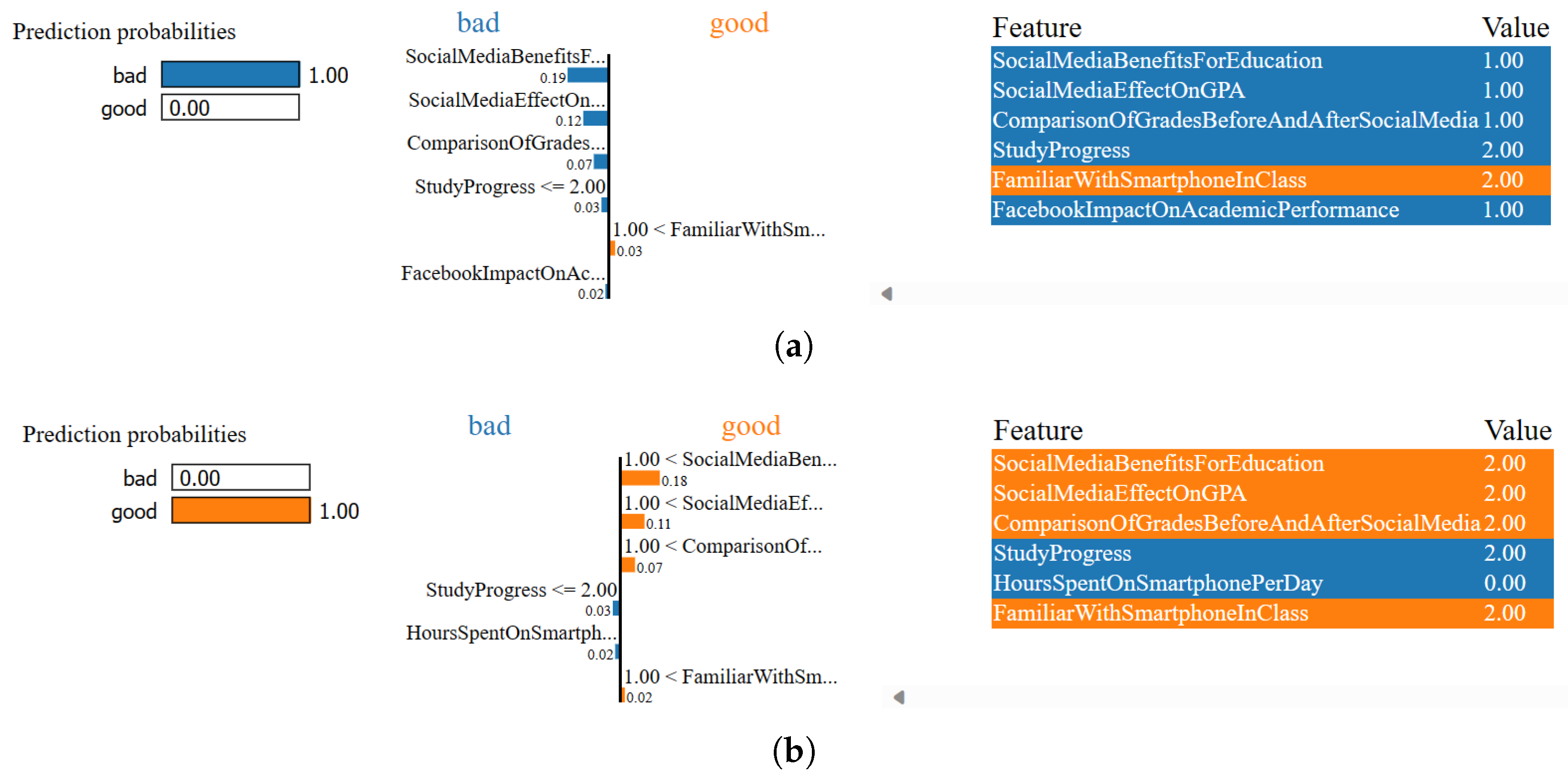
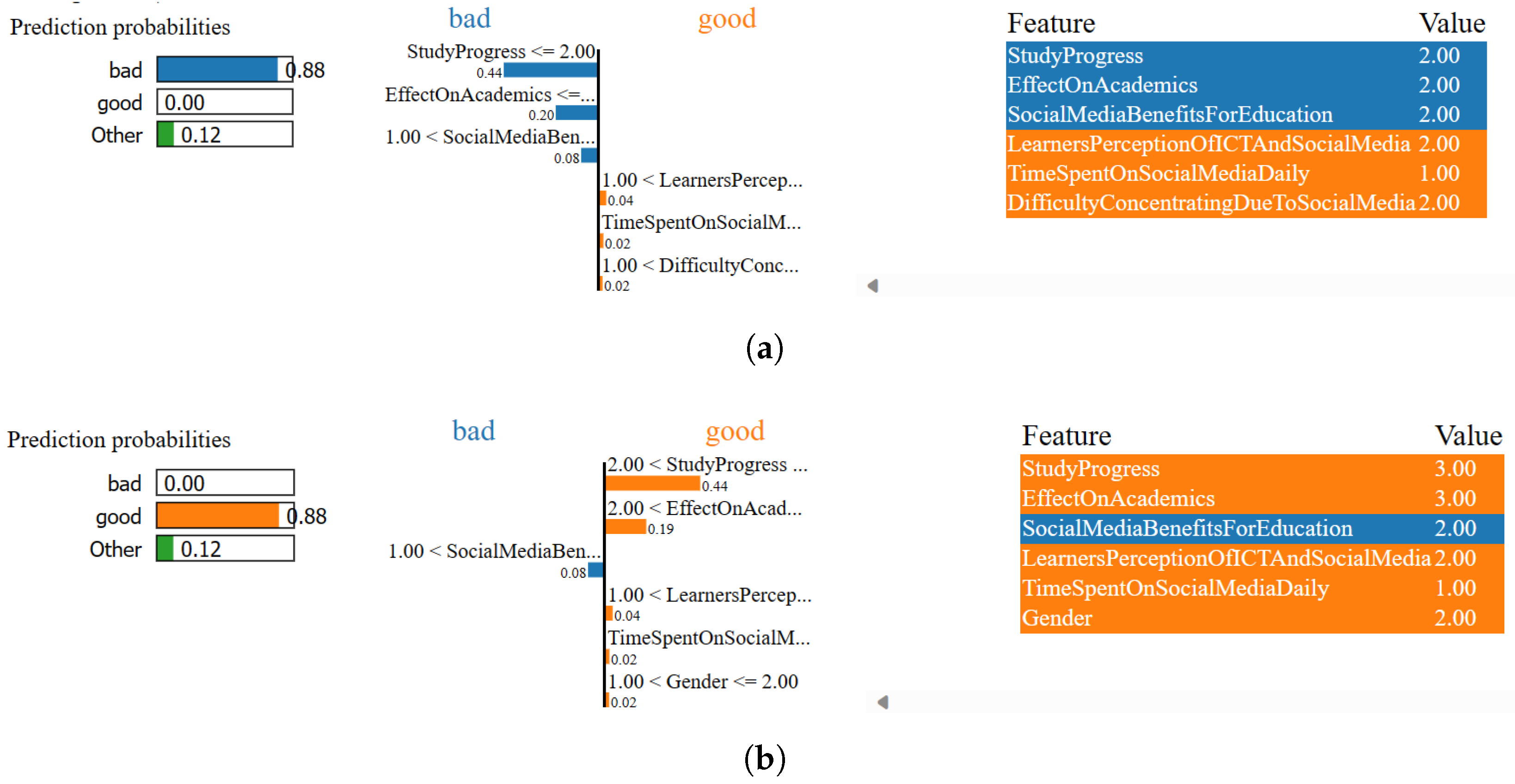
4.3.3. Result Analysis of LIME
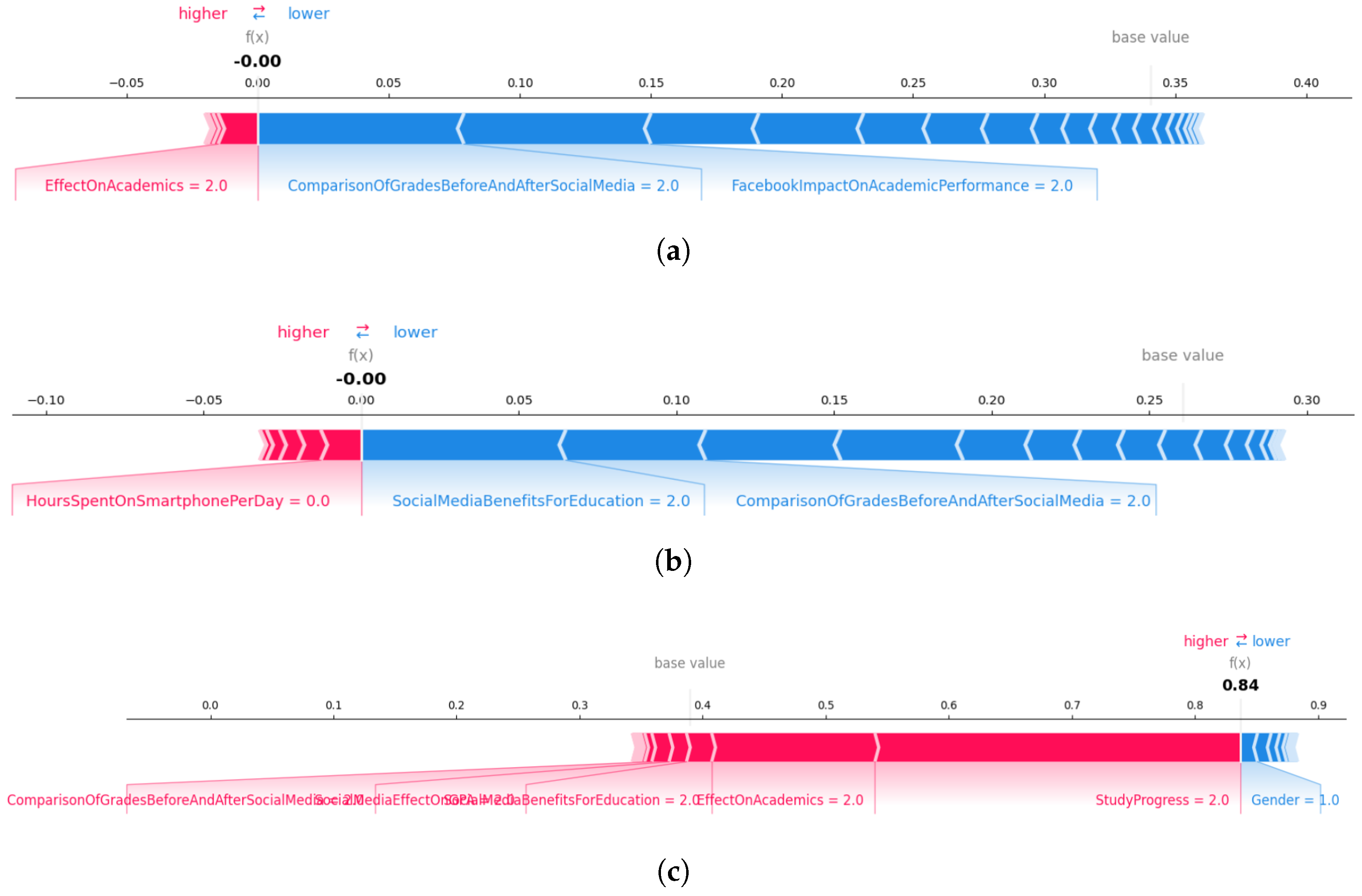
4.3.4. Result Analysis of SHAP
4.3.5. Evaluation of LIME and SHAP in Comparison
4.3.6. Recommendation of Authorities
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| List of Abbreviations | |
| MLRec | Machine Learning Recommender |
| socimedevice | social media networks or devices |
| NN | neural network |
| ML | machine learning |
| DL | deep learning |
| XAI | Explainable AI |
| LIME | Local Interpretable Model |
| SHAP | SHapley Additive exPlanations |
| MSE | Mean Squared Error |
| RMSE | Root Mean Squared Error |
| R2 | R-Squared |
| EV | Explained Variance |
| D2 | D2 Tweedie Score |
| SMOTTech | Synthetic Minority Oversampling Technique |
| LE | label encoding |
| SSR | Sum of Squared Residuals |
| SST | Total Sum of Squares |
| LR | Linear Regression |
| DTR | Decision Tree Regression |
| DTC | Decision Tree Classifier |
| RR | Ridge Regression |
| GBC | Gradient Boosting Classifier |
| GBR | Gradient Boosting Regression |
| KNN | K-Nearest Neighbors |
| IR | Isotonic Regression |
| AdaBoost | AdaBoost Classifier |
| ETC | Extra Trees Classifier |
| RFR | Random Forest Regression |
| RFC | Random Forest Classifier |
| SVR | Support Vectors Regression |
| SVC | Support Vectors Classifier |
| GNB | Gaussian Naïve Bayes |
| MNB | Multinomial Naïve Bayes |
| List of used symbols | |
| R | a random number that ranges from 0 to 1. |
| n | total number of data points. |
| i | Number of iteration. |
| feature vector of the under-investigated minority class sample. | |
| ’s is K closest neighbors. | |
| average learner that exhibits an individual performance. | |
| scaling factor that accounts for the effect of a tree on the overall model. | |
| actual value of Y. | |
| predicted value of Y. | |
| mean of actual value. | |
References
- Anjum, R.; Naeem, Z.; Chaudhary, A.A.; Asif, Q.-u.-a.; Rehman, A. The Impact of Social Media Use on Adolescent Well-Being and Academic Performance. J. Educ. Soc. Stud. 2024, 5, 426–434. [Google Scholar] [CrossRef]
- Henderson, J.; Social Media Use and Academic Achievement. UDaily 12 March 2024. Available online: https://www.udel.edu/udaily/2024/march/social-media-academic-achievement-research (accessed on 28 February 2025).
- Ashraf, M.A.; Khan, M.N.; Chohan, S.R.; Khan, M.; Rafique, W.; Farid, M.F.; Khan, A.U. Social Media Improves Students’ Academic Performance: Exploring the Role of Social Media Adoption in the Open Learning Environment among International Medical Students in China. Healthcare 2021, 9, 1272. [Google Scholar] [CrossRef] [PubMed]
- Giunchiglia, F.; Zeni, M.; Gobbi, E.; Bignotti, E.; Bison, I. Mobile social media usage and academic performance. Comput. Hum. Behav. 2018, 82, 177–185. [Google Scholar] [CrossRef]
- Singh, M.; Amiri, M.; Sabbarwal, S. Social media usage: Positive and negative effects on the life style of Indian youth. Iran. J. Soc. Sci. Humanit. Res. 2017, 5, 123–127. [Google Scholar]
- Ali, A.; Iqbal, K.; Iqbal, A. EFFECTS OF SOCIAL MEDIA ON YOUTH: A CASE STUDY IN UNIVERSITY OF SARGODHA. Int. J. Adv. Res. 2016, 4, 369–372. [Google Scholar] [CrossRef]
- Barkhuus, L.; Tashiro, J. Student Socialization in the Age of Facebook. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; Volume 1, pp. 133–142. [Google Scholar] [CrossRef]
- Phauk, S.; Okazaki, T. Developing Web-based Support Systems for Predicting Poor-performing Students using Educational Data Mining Techniques. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 23–32. [Google Scholar] [CrossRef]
- Stollak, M.; Vandenberg, A.; Burklund, A.; Weiss, S. Getting Social: The Impact of Social Networking Usage on Grades Amongst College Students. Proc. ASBBS Annu. Conf. 2011, 18, 859–865. [Google Scholar]
- Charoensukmongkol, P. The Impact of Social Media on Social Comparison and Envy in Teenagers: The Moderating Role of the Parent Comparing Children and In-group Competition among Friends. J. Child. Fam. Stud. 2018, 27, 69–79. [Google Scholar] [CrossRef]
- Mushroor, S.; Haque, S.; Amir, R.A. The impact of smart phones and mobile devices on human health and life. Int. J. Community Med. Public Health 2019, 7, 9–15. [Google Scholar] [CrossRef]
- Boyd, D.M.; Ellison, N.B. Social Network Sites: Definition, History, and Scholarship. J. Comput.-Mediat. Commun. 2007, 13, 210–230. [Google Scholar] [CrossRef]
- Dabbagh, N.; Reo, R. Back to the Future: Tracing the Roots and Learning Affordances of Social Software. Web 2.0-Based E-Learn. Appl. Soc. Inform. Tert. Teach. 2010, 1–20. Available online: https://www.igi-global.com/gateway/chapter/45014 (accessed on 3 February 2025).
- Dabbagh, N.; Kitsantas, A. Personal Learning Environments, social media, and self-regulated learning: A natural formula for connecting formal and informal learning. Internet High. Educ. 2012, 15, 3–8. [Google Scholar] [CrossRef]
- Solomon, G.; Schrum, L. Web 2.0: New Tools, New Schools. 2007. Available online: https://www.slideshare.net/slideshow/web-20-new-tools-new-schools/51473705 (accessed on 3 February 2025).
- Selwyn, N. Faceworking: Exploring students’ education-related use of Facebook. Learn. Media Technol. 2009, 34, 157–174. [Google Scholar] [CrossRef]
- Hosen, M.; Uddin, M.N.; Hossain, S.; Islam, M.A.; Ahmad, A. The impact of COVID-19 on tertiary educational institutions and students in Bangladesh. Heliyon 2022, 8, e08806. [Google Scholar]
- Saha, B.; Atiqul Haq, S.M.; Ahmed, K.J. How does the COVID-19 pandemic influence students’ academic activities? An explorative study in a public university in Bangladesh. Humanit. Soc. Sci. Commun. 2023, 10, 1–10. [Google Scholar]
- Sakib, F. Online Education Trajectory during the COVID-19 Pandemic Among the Bangladeshi Adolescent Children. Res. Sq. 2022. [Google Scholar] [CrossRef]
- Arefin, A.S.; Chowdhury, S.A.; Roy, R.C.; Rahaman, M.M.; Cross, B. Education system in Bangladesh amid COVID-19: Traditional scenario, emergency protocols, challenges and a proposed sustainable conceptual framework. Sustainability 2023, 15, 8126. [Google Scholar] [CrossRef]
- Al Masud, A.; Hossain, M.A.; Biswas, S.; Ruma, A.P.; Rahman, K.S.; Tagore, S. The emergence of digital learning in higher education: A lesson from the COVID-19 pandemic. Int. J. Inf. Learn. Technol. 2023, 40, 202–224. [Google Scholar] [CrossRef]
- Islam, M.R.; Apu, M.M.H.; Akter, R.; Tultul, P.S.; Anjum, R.; Nahar, Z.; Shahriar, M.; Bhuiyan, M.A. Internet addiction and loneliness among school-going adolescents in Bangladesh in the context of the COVID-19 pandemic: Findings from a cross-sectional study. Heliyon 2023, 9, e13340. [Google Scholar]
- Chowdhury, M.K.; Behak, F.B.P. Online higher education in Bangladesh during Covid-19: Its challenges and prospects. Utamax: J. Ultim. Res. Trends Educ. 2022, 4, 15–28. [Google Scholar]
- Islam, M.T.; Habib, T.I. Barriers of adopting online learning among the university students in Bangladesh during COVID-19. Indones. J. Learn. Adv. Educ. (IJOLAE) 2022, 4, 71–91. [Google Scholar] [CrossRef]
- Sayeed, A.; Islam, M.S.; Christopher, E.; Zubayer, A.A.; Kundu, S.; Tariq, M.R.; Sultana, M.S.; Banna, M.H.A.; Rahman, M.H.; Khan, M.S.I.; et al. Investigating problematic uses of Facebook and other Internet activities among university students in Bangladesh during the COVID-19 pandemic. Sci. Rep. 2023, 13, 1307. [Google Scholar] [CrossRef] [PubMed]
- Rahman, Z.; Haque, M.A.; Aziz, D.A.B. Internet Usage During and Post COVID-19 Pandemic: A Study on the Students of Information Science and Library Management in the University of Rajshahi, Bangladesh. Bangladesh. Libr. Philos. Pract. 2023, 1–15. [Google Scholar]
- Lukose, J.M.; Agbeyangi, A.O. Is social media hindering or helping Academic Performance? A case study of Walter Sisulu University Buffalo City Campus. arXiv 2025, arXiv:2501.03611. [Google Scholar]
- Tabasum, T.; Jabeen, M. Effects of Social Media Engagement and Romantic Relationships on Academic Distraction with Emotional Attachment as a Mediator. J. Child. Lit. Soc. Issues 2024, 3, 17–37. [Google Scholar]
- Srivastava, R.; Srivastava, A.K. TO STUDY THE IMPACT OF SOCIAL MEDIA ON THE ACADEMIC ACHIEVEMENT OF SECONDARY SCHOOL STUDENT. Int. J. Nov. Res. Dev. (IJNRD) 2022, 7, 51–60. [Google Scholar]
- Sharma, S.; Behl, R. Analysing the Impact of Social Media on Students’ Academic Performance: A Comparative Study of Extraversion and Introversion Personality. Psychol. Stud. 2022, 67, 549–559. [Google Scholar] [CrossRef]
- Hemal, S.H.; Khan, M.A.R.; Ahammad, I.; Rahman, M.; Khan, M.A.S.; Ejaz, S. Predicting the impact of internet usage on students’ academic performance using machine learning techniques in Bangladesh perspective. Soc. Netw. Anal. Min. 2024, 14, 66. [Google Scholar]
- Tariq, M.B.; Habib, H.A. A Reinforcement Learning Based RecommendationSystem to Improve Performance of Students in Outcome Based Education Model. IEEE Access 2024, 12, 36586–36605. [Google Scholar] [CrossRef]
- Sagabala, M.O.; Regidor, S.M.A.; Torre, M.C.M.D.; Monteza, A.M.M. A qualitative inquiry on the behavior of english major students towards social media distractions. Eur. J. Educ. Stud. 2023, 10, 77–98. [Google Scholar]
- Panchanathan, S.; Raj, K. A Study on Impact of Social Media Among Students of Adolescent Age Group on Individual Performance. Int. J. Prof. Bus. Rev. 2022, 7, e0505. [Google Scholar] [CrossRef]
- Thelma, C.C.; Mubemba, B.N.; Chitondo, L. Social media and pupils’ academic performance: A case of selected secondary schools in Lusaka District, Zambia. World J. Adv. Res. Rev. 2023, 20, 1028–1035. [Google Scholar] [CrossRef]
- Muslikah, M.; Mulawarman, M.; Andriyani, A. Social Media User Students’ Academic Procrastination. PSIKOPEDAGOGIA J. Bimbing. Konseling 2018, 7, 53–57. [Google Scholar]
- Jamil, M.; ul Ain, Q.; Batool, S.; Saadat, S.; Malik, S.; Arshad, M.; Nagra, R.N.; Haider, M.; Shameem, R.; Latif, B. Impact of social media on academic performance. Eur. J. Med. Health Sci. 2020, 2. Available online: https://www.ej-med.org/index.php/ejmed/article/view/512 (accessed on 3 February 2025).
- Boateng, R.O.; Amankwaa, A. The impact of social media on student academic life in higher education. Glob. J. Hum.-Soc. Sci. 2016, 16, 1–8. [Google Scholar]
- Mosharrafa, R.A.; Akther, T.; Siddique, F.K. Impact of social media usage on academic performance of university students: Mediating role of mental health under a cross-sectional study in Bangladesh. Health Sci. Rep. 2024, 7, e1788. [Google Scholar] [CrossRef]
- Hasnain, H.; Nasreen, A.; Ijaz, H. Impact of social media usage on academic performance of university students. In Proceedings of the 2nd International Research Management & Innovation Conference (IRMIC), Langkawi, Malaysia, 26–27 August 2015; pp. 26–27. [Google Scholar]
- Hershcovits, H.; Vilenchik, D.; Gal, K. Modeling engagement in self-directed learning systems using principal component analysis. IEEE Trans. Learn. Technol. 2019, 13, 164–171. [Google Scholar]
- De la Hoz Domínguez, E.J.; Fontalvo Herrera, T.J. Methodology of Machine Learning for the classification and Prediction of users in Virtual Education Environments. Inf. Tecnol. 2019, 30, 247–254. [Google Scholar]
- Khan, I.A.; Choi, J.T. An application of educational data mining (EDM) technique for scholarship prediction. Int. J. Softw. Eng. Its Appl. 2014, 8, 31–42. [Google Scholar]
- Burman, I.; Som, S. Predicting Students Academic Performance Using Support Vector Machine. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 756–759. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, W.; Liang, Y. The Effects of Social Media on College Students. MBA Student Scholarship 2011. Available online: https://scholarsarchive.jwu.edu/mba_student/5/ (accessed on 3 February 2025).
- Güney, K. Considering the Advantages and Disadvantages of Utilizing Social Media to Enhance Learning and Engagement in K-12 Education. Res. Soc. Sci. Technol. 2023, 8, 83–100. [Google Scholar] [CrossRef]
- Rostaminezhad, M.A.; Porshafei, H.; Ahamdi, A.A. Can effective study approaches mediate the negative effect of social networking on academic performance? Educ. Inf. Technol. 2019, 24, 205–217. [Google Scholar] [CrossRef]
- Nti, I.K.; Akyeramfo-Sam, S.; Bediako-Kyeremeh, B.; Agyemang, S. Prediction of social media effects on students’ academic performance using Machine Learning Algorithms (MLAs). J. Comput. Educ. 2022, 9, 195–223. [Google Scholar] [CrossRef]
- Kaspersen, M.H.; Bilstrup, K.E.K.; Mechelen, M.V.; Hjort, A.; Bouvin, N.O.; Petersen, M.G. High school students exploring machine learning and its societal implications: Opportunities and challenges. Int. J. Child-Comput. Interact. 2022, 34, 100539. [Google Scholar] [CrossRef]
- Hussain, S.; Khan, M.Q. Student-Performulator: Predicting Students’ Academic Performance at Secondary and Intermediate Level Using Machine Learning. Ann. Data. Sci. 2023, 10, 637–655. [Google Scholar] [CrossRef]
- Lai, T.; Xie, C.; Ruan, M.; Wang, Z.; Lu, H.; Fu, S. Influence of artificial intelligence in education on adolescents’ social adaptability: The mediatory role of social support. PLoS ONE 2023, 18, e0283170. [Google Scholar] [CrossRef]
- Tran, M.; Draeger, C.; Wang, X.; Nikbakht, A. Monitoring the well-being of vulnerable transit riders using machine learning based sentiment analysis and social media: Lessons from COVID-19. Environ. Plan. B Urban Anal. City Sci. 2023, 50, 60–75. [Google Scholar] [CrossRef]
- Salim, S.; Turnbull, B.; Moustafa, N. Data analytics of social media 3.0: Privacy protection perspectives for integrating social media and Internet of Things (SM-IoT) systems. Ad Hoc Netw. 2022, 128, 102786. [Google Scholar] [CrossRef]
- Shuvo, M.H.; Begum, M. Survey for Impact of social media in the context of Bangladeshi High school students. IEEE Dataport 2024. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M. Survey on categorical data for neural networks. J. Big Data 2020, 7, 28. [Google Scholar] [CrossRef]
- Maulud, D.; Abdulazeez, A.M. A Review on Linear Regression Comprehensive in Machine Learning. J. Appl. Sci. Technol. Trends 2020, 1, 140–147. [Google Scholar] [CrossRef]
- Begum, M.; Shuvo, M.H.; Ashraf, I.; Mamun, A.A.; Uddin, J.; Samad, M.A. Software Defects Identification: Results Using Machine Learning and Explainable Artificial Intelligence Techniques. IEEE Access 2023, 11, 132750–132765. [Google Scholar] [CrossRef]
- Costa-Mendes, R.; Oliveira, T.; Castelli, M.; Cruz-Jesus, F. A machine learning approximation of the 2015 Portuguese high school student grades: A hybrid approach. Educ. Inf. Technol. 2021, 26, 1527–1547. [Google Scholar] [CrossRef]
- Solomatine, D.; Shrestha, D. AdaBoost.RT: A boosting algorithm for regression problems. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No. 04CH37541), Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 1163–1168. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar]
- Otchere, D.A.; Ganat, T.O.A.; Ojero, J.O.; Tackie-Otoo, B.N.; Taki, M.Y. Application of gradient boosting regression model for the evaluation of feature selection techniques in improving reservoir characterisation predictions. J. Pet. Sci. Eng. 2022, 208, 109244. [Google Scholar] [CrossRef]
- Lee, S.; Park, J.; Kim, N.; Lee, T.; Quagliato, L. Extreme Gradient Boosting-inspired process optimization algorithm for manufacturing engineering applications. Mater. Des. 2023, 226, 111625. [Google Scholar] [CrossRef]
- Sanmorino, A.; Marnisah, L.; Sunardi, H. Feature Selection Using Extra Trees Classifier for Research Productivity Framework in Indonesia. 2023. In Proceedings of the 3rd International Conference on Electronics, Biomedical Engineering, and Health Informatics, Surabaya, Indonesia, 5–6 October 2020; pp. 13–21. [Google Scholar] [CrossRef]
- Valero-Mas, J.J.; Gallego, A.J.; Alonso-Jiménez, P.; Serra, X. Multilabel Prototype Generation for data reduction in K-Nearest Neighbour classification. Pattern Recognit. 2023, 135, 109190. [Google Scholar] [CrossRef]
- Tyagi, K.; Rane, C.; Harshvardhan; Manry, M. Chapter 4—Regression analysis. In Artificial Intelligence and Machine Learning for EDGE Computing; Academic Press: New York, NY, USA, 2022; pp. 53–63. [Google Scholar] [CrossRef]
- O’Grady, K.E. Measures of explained variance: Cautions and limitations. Psychol. Bull. 1982, 92, 766–777. [Google Scholar] [CrossRef]
- Roussel, C.; Böhm, K. Geospatial XAI: A Review. ISPRS Int. J. Geo-Inf. 2023, 12, 355. [Google Scholar] [CrossRef]
- Interpretable machine learning for imbalanced credit scoring datasets. Eur. J. Oper. Res. 2024, 312, 357–372. [CrossRef]
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Contributors | Covered Area | Methodology | Key Findings |
|---|---|---|---|
| Hosen et al. (2022) [17] | Bangladesh (tertiary education) | Mixed methods: content analysis (interviews) + frequency distribution (questionnaire survey) | Students faced significant challenges, including 88% having mental health issues, 79% experiencing financial hardship, 72% reporting tech problems, and 21% lacking electronic devices. Over 55% studied less during COVID-19. Online education adoption was difficult due to lack of access, training, and interaction. |
| Saha et al. (2023) [18] | Public university in Bangladesh | Qualitative: semi-structured interviews with 30 students; thematic analysis | The study identified significant disruptions in education resulting from insufficient resources, the closure of libraries and dormitories, and difficulties associated with online classes. Students encountered psychological strain, physical inactivity, financial difficulties, and diminished peer interaction. They acquired digital skills, participated in online courses (e.g., Coursera), and pursued creative and volunteer activities, demonstrating enhanced adaptability. |
| Sakib (2022) [19] | Adolescent children in Bangladesh | Mixed method: in-depth interviews, focus groups, case studies; 1013 survey responses | The COVID-19 pandemic transitioned education to digital platforms, yet it revealed disparities in access, the digital divide, and socio-emotional repercussions. Students encountered psychological stress, reliance on smartphones, impaired social interactions, and difficulties with accent and language transitions. Nevertheless, certain individuals gained advantages from adaptable access, self-directed learning, and enhanced exposure to educational technology. |
| Arefin et al. (2023) [20] | All education levels in Bangladesh | Convergent parallel mixed-methods: surveys (205 students, 50 teachers), 11 parent interviews, 12 expert KIIs | Obstacles to online education comprised inadequate training, unreliable Internet access, shortages of information and communication technology, and electricity disruptions. Recommended utilizing television/radio, learning management systems, and mobile applications. Proposed a sustainable emergency framework for formal education contingent upon educational attainment. |
| Masud et al. (2023) [21] | Higher education in Bangladesh | Quantitative: Structural Equation Modeling (SEM) with 392 university students | Faculty readiness, student preparedness, economic viability, and assessment frameworks substantially impact students’ propensity to embrace technology. The preparedness of faculty exerted the most significant positive influence, whereas challenges associated with online assessment adversely impacted technology adoption. Students from economically disadvantaged backgrounds encountered obstacles related to financial resources and digital accessibility. A blended learning model is advocated for enduring sustainability. |
| Islam et al. (2023) [22] | School-going adolescents in Bangladesh | Online cross-sectional survey (n = 502); IAT and UCLA Loneliness Scale-3 | 88.25% exhibit internet addiction, while 72.51% experience loneliness; social media users are three times more susceptible to loneliness; individuals utilizing English medium and mobile platforms are disproportionately affected. |
| Chowdhury and Behak (2022) [23] | Higher education in Bangladesh | Systematic literature review of 42 sources | Digital divide and adverse perceptions; blended learning is suggested to enhance access and equity. |
| Islam and Habib (2022) [24] | University students in Dhaka | Quantitative: semi-structured online survey with 394 responses analyzed via SPSSv30 | Barriers categorized as environmental, e-learning, and psychological; all substantially impeded learning. |
| Sayeed et al. (2023) [25] | University students in Bangladesh | Online survey (n = 1101); IAT and Facebook Addiction Scale | 39.3% exhibited problematic internet usage; 37.1% demonstrated Facebook addiction; associated with rural demographics, art majors, unsuccessful relationships, and prolonged usage durations. |
| Rahman et al. (2023) [26] | ISLM students, Rajshahi University | Quantitative survey (199 students); SPSS and Biblioshiny analysis | 57% utilized the Internet for over 4 h per day; advantages: acquisition of skills (IT, language); disadvantages: sleep disturbances; ambivalent opinions regarding online classes; Facebook is the most utilized platform. |
| Ref. | Contributions | Constraints |
|---|---|---|
| [48] | The paper’s contributions lie in its data-driven, predictive, and methodologically innovative approach to assessing social media’s effect on students’ educational performance | The choice of machine learning algorithms may not be exhaustive or may not consider the latest advancements in the field. Different algorithms have varying strengths and weaknesses, and not all of them may be suitable for the specific context of the study. |
| [49] | The paper describes the design and implementation of VotestratesML, which is a learning method that helps students explore ML and its societal implications through the lens of participatory elections. | The study was conducted with only two high school classes, which limits the generalizability of the findings |
| [50] | The author proposed a framework that educators can use to recognize risky students early on and give them the assistance they need to succeed. Policymakers can also use the framework to inform decisions about resource allocation and educational policy. | The study used two supervised learning algorithms, a regression model and a decision tree classifier, which may not be the most accurate or appropriate models for predicting student performance. |
| [51] | It provides important insights into the potential impacts of AI on social development and suggests ways to mitigate these impacts. | This limits the findings’ applicability to different countries/cultures. In addition, the small sample size may not be large enough to detect all of the possible effects of AIEd on social adaptability. |
| [52] | The paper demonstrates the feasibility of using social media sentiment analysis powered by machine learning data to monitor the security of susceptible transportation users. | The study focuses on sentiment analysis, which provides a general sense of positive or negative emotions, but it does not delve into specific well-being indicators such as stress levels, anxiety, or feelings of safety and security. |
| [53] | The study delves into the wider societal consequences of merging social media and IoT, contributing to the ethical and social dialogue on these technologies by examining the implications of SM-IoT systems for both individuals and society at large. | It does not adequately address the broader social, ethical, and legal implications of integrating social media and IoT data. For instance, the paper does not discuss the potential for data misuse or the lack of transparency in data collection and processing practices. |
| Principles | Category | Number of Participants | Participants(%) |
|---|---|---|---|
| Gender | Male | 152 | 55% |
| Female | 123 | 45% | |
| Academic Year | Class Six | 33 | 12% |
| Class Seven | 46 | 17% | |
| Class Eight | 50 | 18% | |
| Class Nine | 66 | 24% | |
| Class Ten | 80 | 29% |
| FN | FG | Feature Description | PV |
|---|---|---|---|
| F1 | Personal Information | Name | Text |
| F3 | Gender | Text | |
| F4 | Study in class | Text | |
| F5 | Study progress? | 2, 3, 4 | |
| F6 | Aim? | Text | |
| F7 | Digital Connectivity Metrics | Smartphones used? | 0, 1 |
| F8 | Familiar with smartphones in class? | Text | |
| F9 | Smartphone used per day (hour). | 0, 1 | |
| F10 | Smartphones are common with family? | 0, 1 | |
| F11 | Unveiling Social Media’s Educational Impact | Social media used? | Text |
| F12 | Problem face? | Text | |
| F13 | Top social platform in Bangladesh? | Text | |
| F14 | How often do you scroll? | Text | |
| F15 | Does social media aid education? | 0, 1 | |
| F16 | Top educational social networking platforms. | Text | |
| F17 | Facebook’s effect on student grades? | 0, 1 | |
| F18 | Can social media alter student behavior effectively? | 2, 3, 4 | |
| F19 | Does social media impact GPA? | 0, 1 | |
| F20 | Do social platforms boost academic performance? | 0, 1 | |
| F21 | How does the use of social networking sites affect students’ academics? | Text | |
| F22 | Does a private Facebook group promote collaborative learning and engagement? | Text | |
| F23 | Examining Online Distractions in Education | Does easy access to online games and websites hinder studying/focus? | 0, 1 |
| F24 | How many hours a day do you play online or offline games for entertainment purposes? | Text | |
| F25 | Analyzing Non-Traditional Methods for Writing Proficiency | Does the experimental group outperform the control group in writing proficiency through a non-traditional teaching approach? | 0, 1 |
| F26 | How do students in the test group view the possible gains from combining ICT and social media for improving their writing abilities? | Text |
| SL | Model Name | Score | MSE | RMSE | R2 | EV | D2 |
|---|---|---|---|---|---|---|---|
| 1 | Linear R. | 0.4077 | 0.2650 | 0.4077 | 0.5148 | 0.4086 | 0.4077 |
| 2 | Decision Tree R. | 0.3800 | 0.2774 | 0.3800 | 0.5267 | 0.3807 | 0.3800 |
| 3 | Ridge R. | 0.4077 | 0.2650 | 0.4077 | 0.5148 | 0.4086 | 0.4077 |
| 4 | Random Forest R. | 0.3863 | 0.2746 | 0.3863 | 0.5240 | 0.3870 | 0.3863 |
| 5 | Gradient Boosting R. | 0.4077 | 0.2650 | 0.4077 | 0.5148 | 0.4087 | 0.4077 |
| 6 | Kneighbors R. | 0.3111 | 0.3082 | 0.3111 | 0.5552 | 0.3111 | 0.3111 |
| 7 | Isotonic R. | 0.4073 | 0.2651 | 0.4073 | 0.5149 | 0.4083 | 0.4073 |
| 8 | Decision Tree C. | 0.8609 | 0.3112 | 0.3045 | 0.5578 | 0.3815 | 0.3045 |
| 9 | Ada Boost C. | 0.8556 | 0.3165 | 0.2925 | 0.5626 | 0.3567 | 0.2925 |
| 10 | Gradient Boosting C. | 0.8618 | 0.3103 | 0.3065 | 0.557 | 0.3828 | 0.3065 |
| 11 | Extra Trees C. | 0.8618 | 0.2576 | 0.3125 | 0.5546 | 0.4095 | 0.3125 |
| 12 | SVR | 0.3720 | 0.2810 | 0.3720 | 0.5301 | 0.3979 | 0.3720 |
| 13 | SVC | 0.8617 | 0.3094 | 0.3085 | 0.5562 | 0.3870 | 0.3085 |
| 14 | Gaussian NB | 0.8591 | 0.3130 | 0.3005 | 0.5594 | 0.3717 | 0.3005 |
| 15 | Multinomial NB | 0.5022 | 0.6807 | −0.5211 | 0.8250 | −0.3625 | −0.5211 |
| SL. | Question | Answer |
|---|---|---|
| RQ1 | What is the current level of awareness and utilization of socimedevices among Bangladeshi high school students, and how does it influence their interaction with XAI? | Investigating the extent to which high school students in Bangladesh are familiar with and actively use socimedevices such as smartphones, tablets, and laptops. Examining the relationship between their device usage patterns and engagement with Explainable AI and how this impacts their academic and social experiences. |
| RQ2 | How does the MLRec model influence the learning outcomes and academic performance of Bangladeshi high school students when integrated into their educational environment? | Assessing the impact of the MLRec model on the educational landscape in Bangladesh, particularly its effects on the academic achievements of high school students. Exploring the ways in which personalized recommendations and adaptive learning through MLRec contribute to improved learning outcomes and student performance. |
| RQ3 | What are the social and cultural implications of integrating Explainable AI, specifically MLRec, into the educational experience of Bangladeshi high school students, and how do socimedevices mediate these implications? | Analyzing the broader societal and cultural effects of incorporating MLRec into the educational system. Investigating how the use of socimedevices as intermediaries influences social interactions, cultural norms, and the overall fabric of student life both inside and outside the classroom. |
| RQ4 | How do privacy and ethical considerations manifest in the implementation of MLRec within the educational context for high school students in Bangladesh, taking into account the use of socimedevices? | Delving into the ethical dimensions of utilizing MLRec in education, particularly focusing on privacy concerns and ethical considerations. Examining how the integration of socimedevices as conduits for MLRec impacts data security, student privacy, and the ethical framework surrounding the use of AI in the educational context. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Begum, M.; Shuvo, M.H.; Uddin, J. MLRec: A Machine Learning-Based Recommendation System for High School Students Context of Bangladesh. Information 2025, 16, 280. https://doi.org/10.3390/info16040280
Begum M, Shuvo MH, Uddin J. MLRec: A Machine Learning-Based Recommendation System for High School Students Context of Bangladesh. Information. 2025; 16(4):280. https://doi.org/10.3390/info16040280
Chicago/Turabian StyleBegum, Momotaz, Mehedi Hasan Shuvo, and Jia Uddin. 2025. "MLRec: A Machine Learning-Based Recommendation System for High School Students Context of Bangladesh" Information 16, no. 4: 280. https://doi.org/10.3390/info16040280
APA StyleBegum, M., Shuvo, M. H., & Uddin, J. (2025). MLRec: A Machine Learning-Based Recommendation System for High School Students Context of Bangladesh. Information, 16(4), 280. https://doi.org/10.3390/info16040280