
Multi-Scale Feature Fusion GANomaly with Dilated Neighborhood Attention for Oil and Gas Pipeline Sound Anomaly Detection


Abstract
1. Introduction
- By training exclusively on normal pipeline audio data, this method effectively learns the distribution of normal data, enhances detection performance under complex working conditions, and avoids overfitting that could occur when using limited anomalous data for training.
- A Multi-scale Feature Fusion module is proposed, which is deployed between the convolutional layers of different dimensions in the encoder and decoder. This module preserves channel features across various dimensions and captures rich detail and semantic features, assisting the model in recalibrating the feature maps.
- A Dilated Neighborhood Attention module is introduced in the bottleneck layer of the generator to manage channel interactions and spatial relationships in the intermediate feature maps. This module also accounts for neighborhoods with varying participation rates, enhancing cross-dimensional information interaction between channels and spatial dimensions.
- The reconstruction loss function is redesigned based on the Structure Similarity Index Measure to address inconsistencies in the structure of generated feature maps. This enhancement strengthens the network’s ability to evaluate spectral differences.
2. Related Work
2.1. Reconstruction-Based Anomalous Sound Detection Work
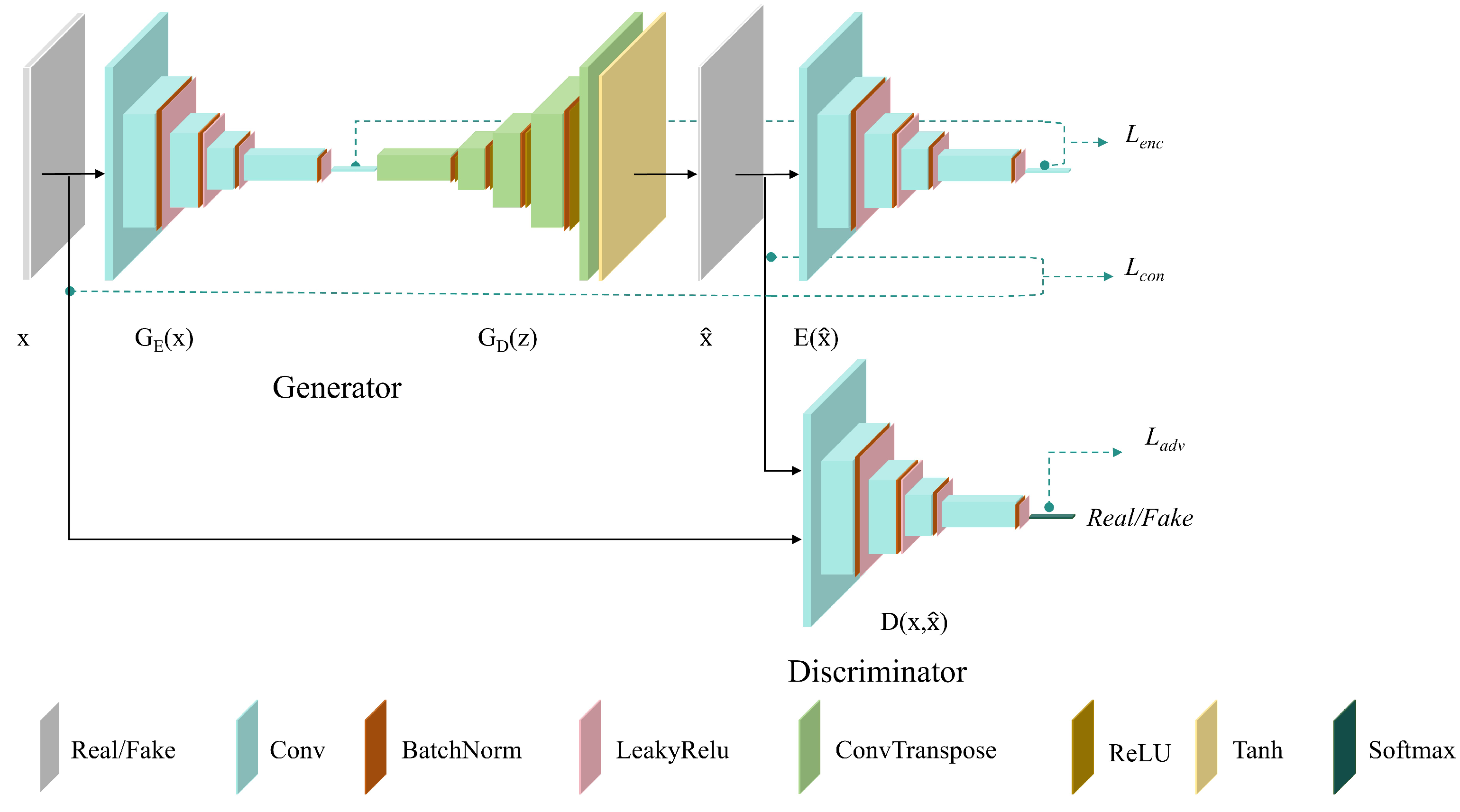
2.2. GANomaly
2.3. Feature Fusion
2.4. Attention Mechanism
3. Methods
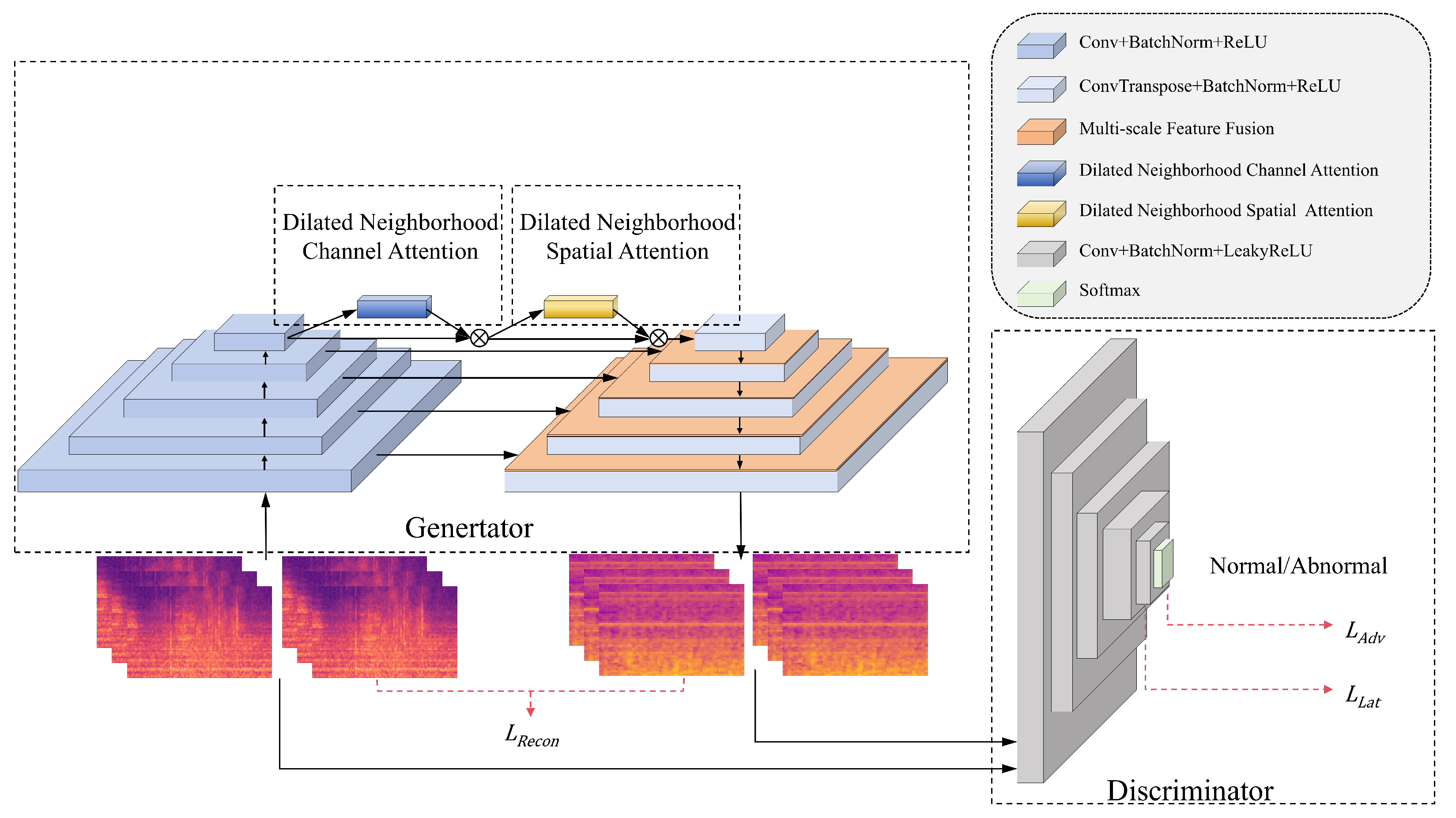
3.1. Overall Architecture of MFDNA-GANomaly
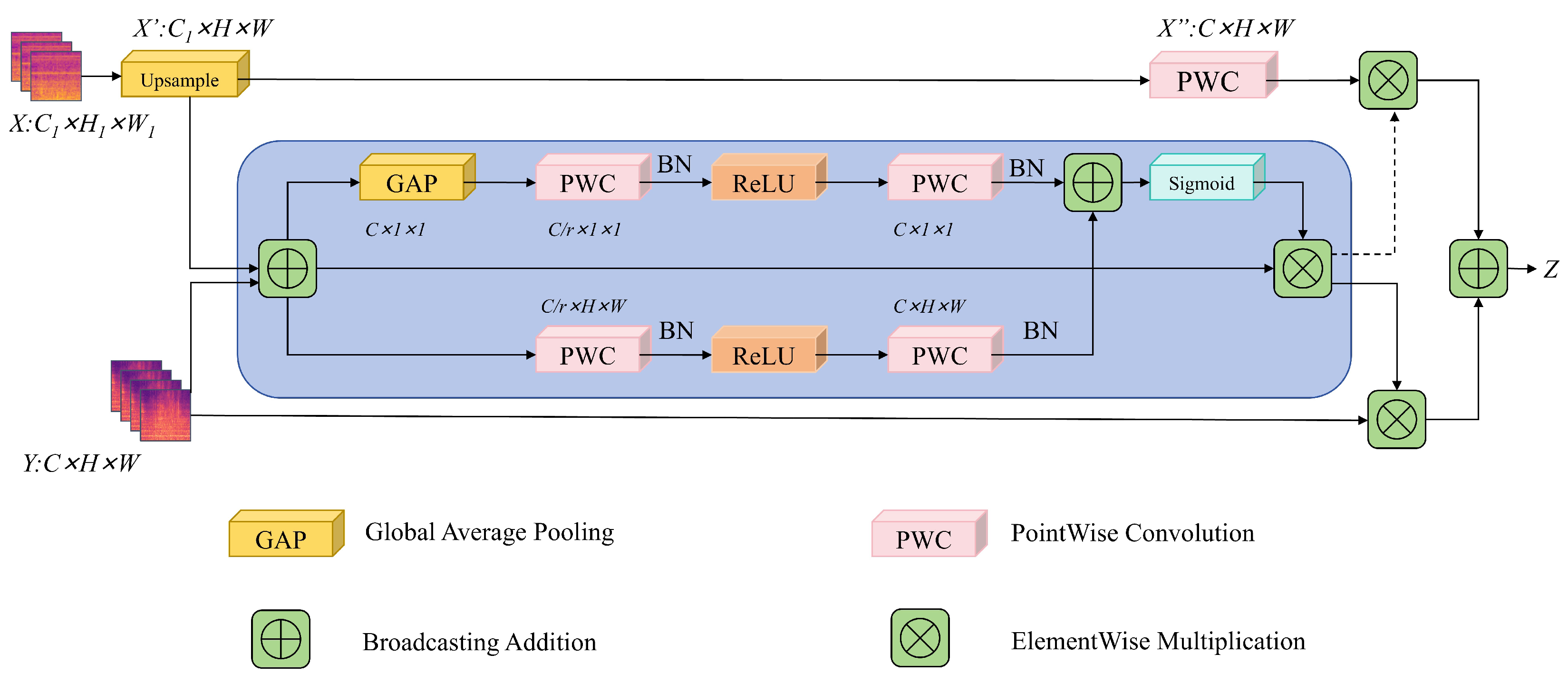
3.2. Multi-Scale Feature Fusion Module
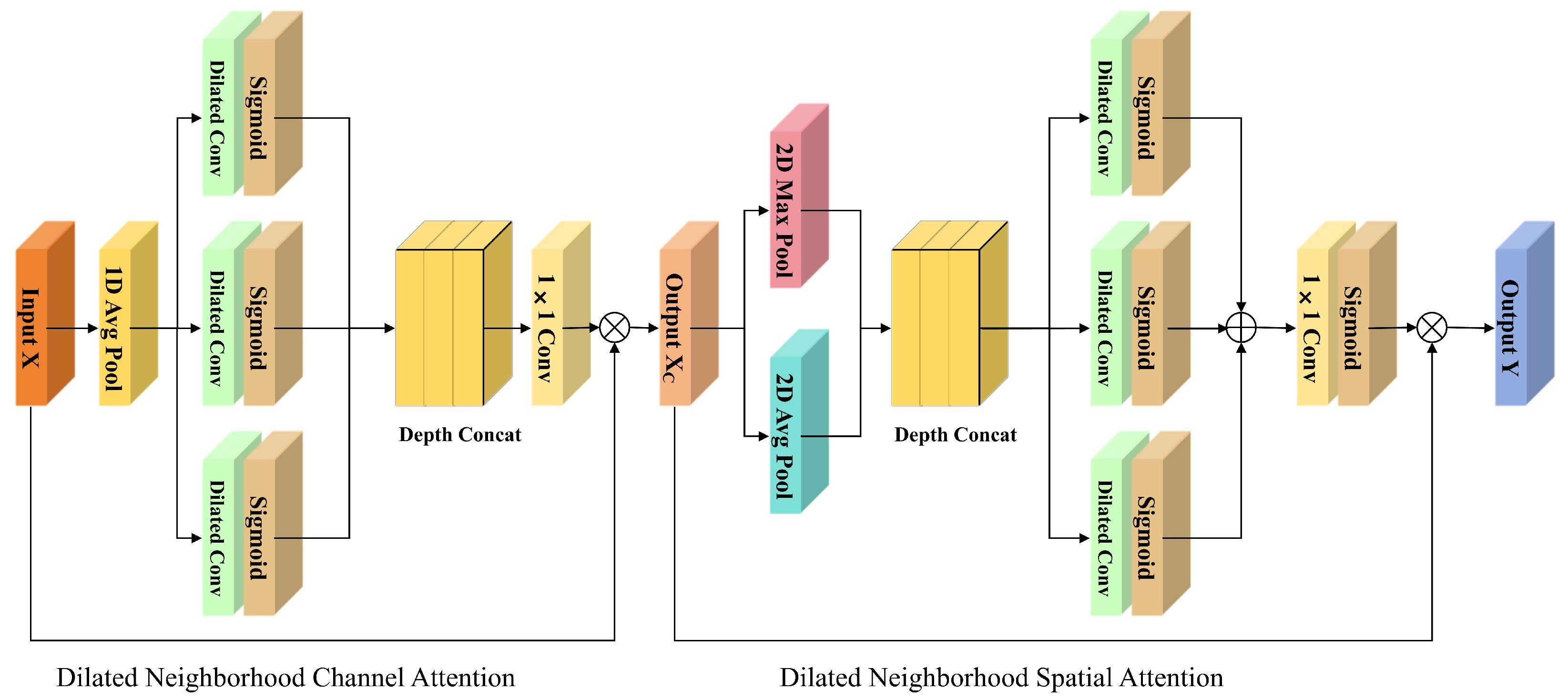
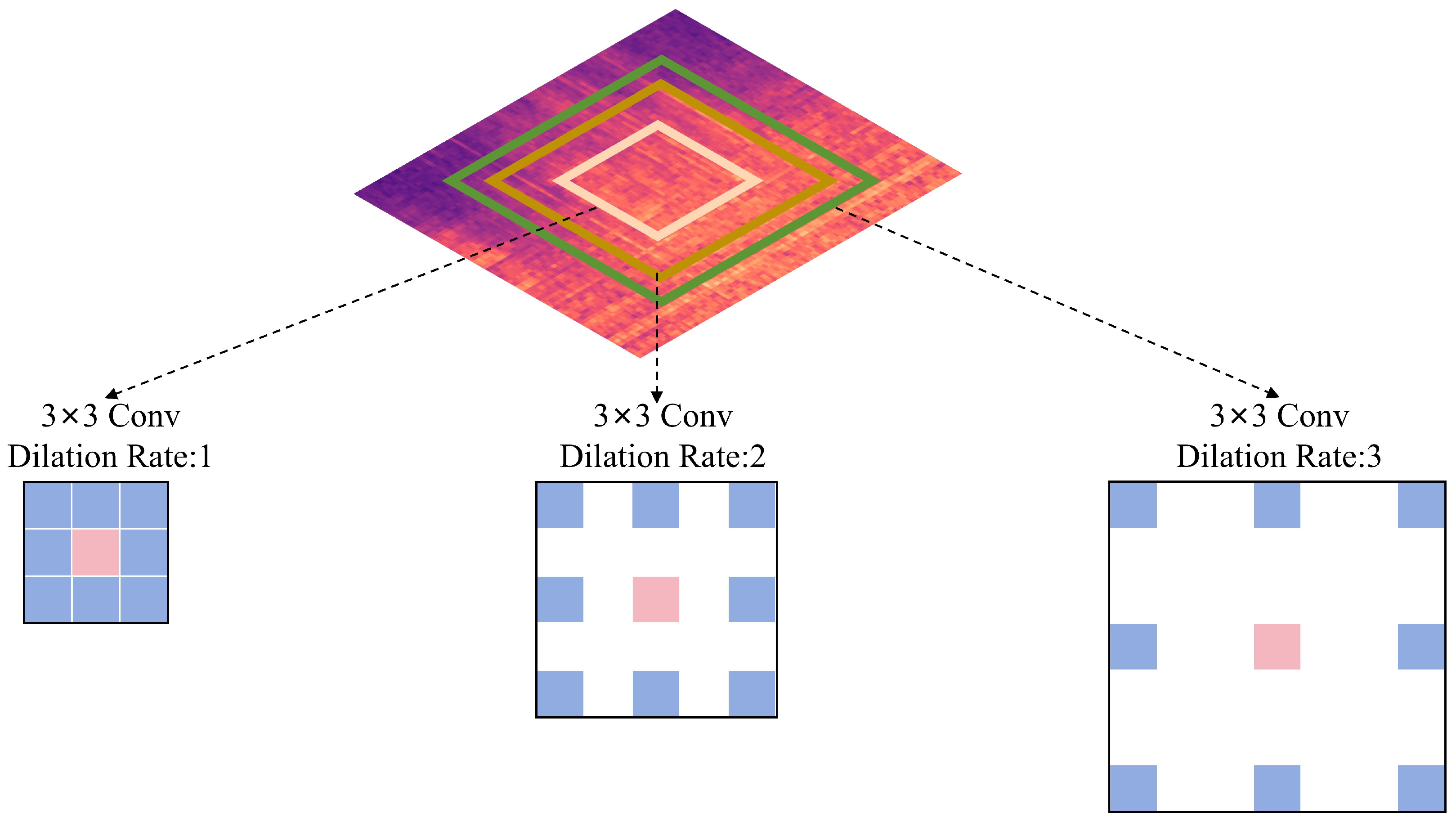
3.3. Dilated Neighborhood Attention Module
3.4. Improved Loss Function
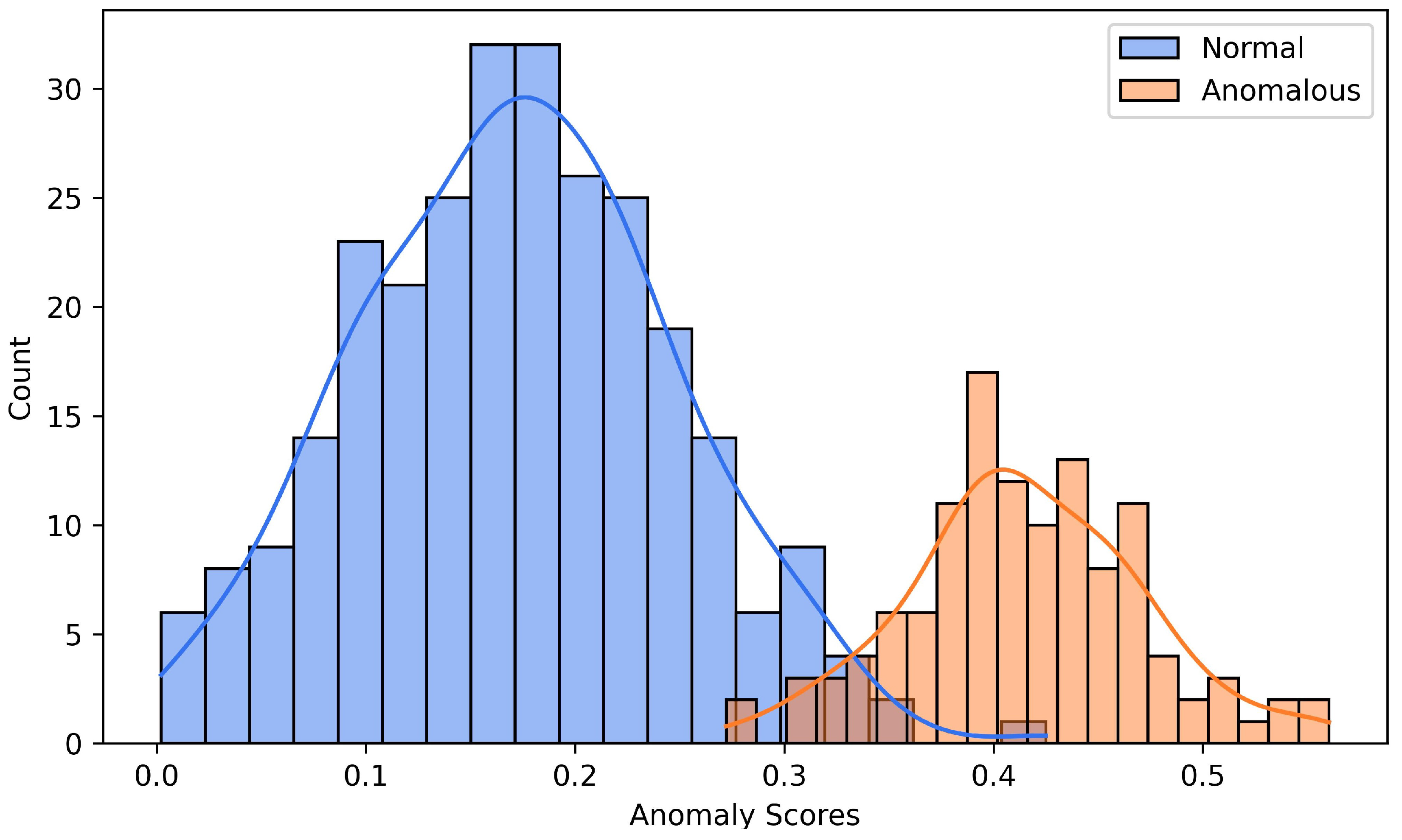
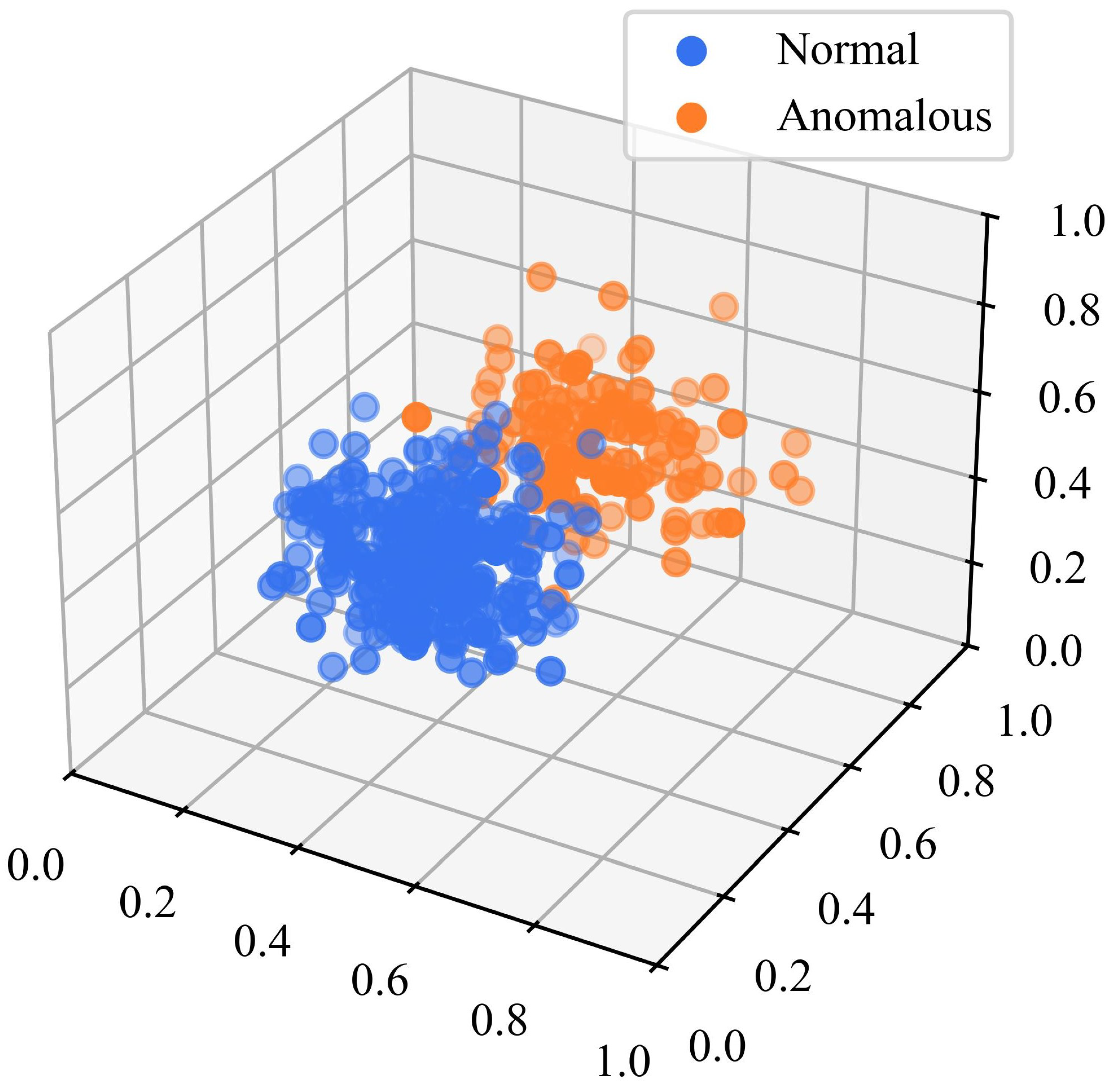
3.5. Anomaly Score
4. Experiments and Result Analysis
4.1. Experimental Introduction
4.2. Experimental Data
4.3. Experimental Setup
4.4. Evaluation Metrics
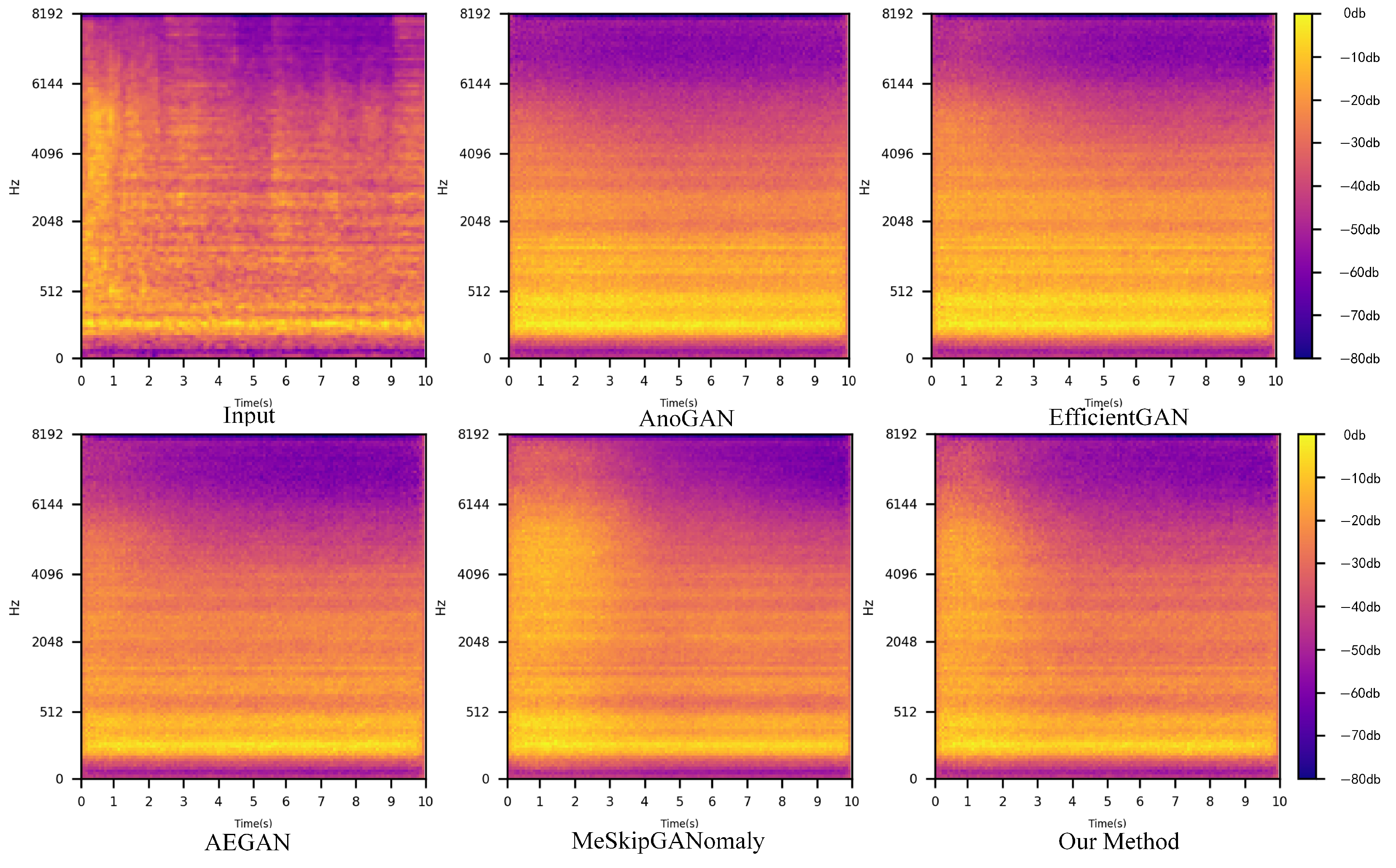
4.5. Comparative Experiment
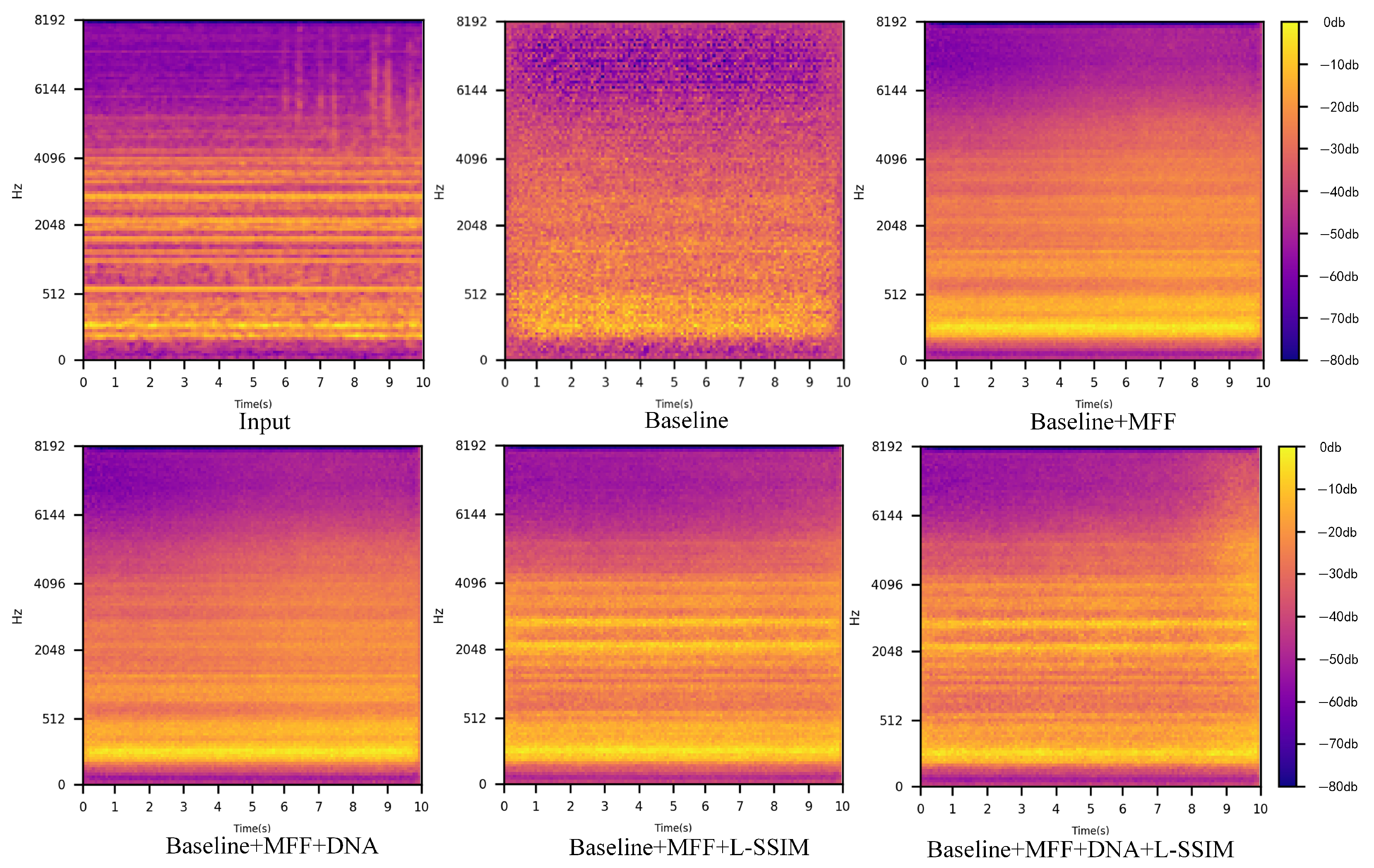
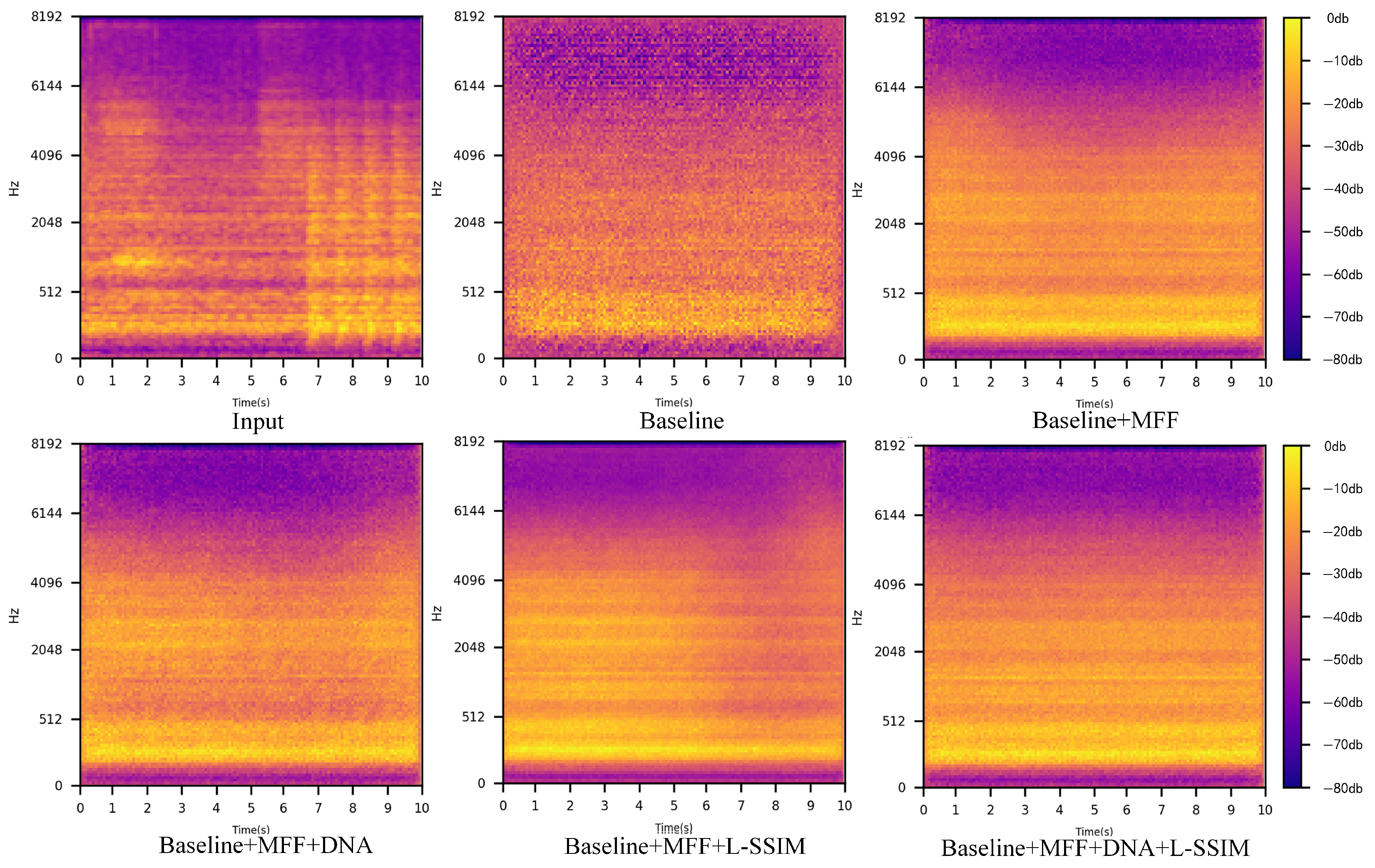
4.6. Ablation Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MFF | Multi-scale Feature Fusion |
| DNA | Dilated Neighborhood Attention |
| MFFDNA-GANomaly | Multi-scale Feature Fusion GANomaly with Dilated Neighborhood |
| Attention | |
| SVM | Support Vector Machine |
| 1DCNN | One-dimensional Convolutional Neural Network |
| SSIM | Structural Similarity Index Measure |
| AUC | Area Under the Curve |
| pAUC | partial Area Under the Curve |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
| GAN | Generative Adversarial Networks |
References
- Li, F.; Zheng, H.; Li, X.; Yang, F. Day-ahead city natural gas load forecasting based on decomposition-fusion technique and diversified ensemble learning model. Appl. Energy 2021, 303, 117623. [Google Scholar]
- Chen, J.; Wang, S.; Liu, Z.; Guo, Y. Network-based optimization modeling of manhole setting for pipeline transportation. Transp. Res. E Logist. Transp. Rev. 2018, 113, 38–55. [Google Scholar]
- Bian, X.; Li, Y.; Feng, H.; Wang, J.; Qi, L.; Jin, S. A location method using sensor arrays for continuous gas leakage in integrally stiffened plates based on the acoustic characteristics of the stiffener. Sensors 2015, 15, 24644–24661. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Li, Y.; Xu, M. An integrated detection and location model for leakages in liquid pipelines. J. Pet. Sci. Eng. 2019, 175, 852–867. [Google Scholar]
- Li, X.; Zhao, T.; Sun, Q.; Chen, Q. Frequency response function method for dynamic gas flow modeling and its application in pipeline system leakage diagnosis. Appl. Energy 2022, 324, 119720. [Google Scholar]
- Zhou, Y.; Zhang, Y.; Yang, D.; Lu, J.; Dong, H.; Li, G. Pipeline signal feature extraction with improved VMD and multi-feature fusion. Syst. Sci. Control Eng. 2020, 8, 318–327. [Google Scholar]
- Liu, C.W.; Li, Y.X.; Yan, Y.K.; Fu, J.T.; Zhang, Y.Q. Technical analysis and research suggestions for long-distance oil pipeline leakage monitoring. J. Loss Prev. Process Ind. 2015, 35, 236–246. [Google Scholar]
- Wang, W.; Gao, Y. Pipeline leak detection method based on acoustic-pressure information fusion. Measurement 2023, 212, 112691. [Google Scholar]
- Wu, Y.; Ma, X.; Guo, G.; Huang, Y.; Liu, M.; Liu, S.; Zhang, J.; Fan, J. Hybrid method for enhancing acoustic leak detection in water distribution systems: Integration of handcrafted features and deep learning approaches. Process Saf. Environ. Prot. 2023, 177, 1366–1376. [Google Scholar]
- Wang, C.; Han, F.; Zhang, Y.; Lu, J. An SAE-based resampling SVM ensemble learning paradigm for pipeline leakage detection. Neurocomputing 2020, 403, 237–246. [Google Scholar]
- Yang, D.; Hou, N.; Lu, J.; Ji, D. Novel leakage detection by ensemble 1DCNN-VAPSO-SVM in oil and gas pipeline systems. Appl. Soft Comput. 2022, 115, 108212. [Google Scholar]
- Yao, L.; Zhang, Y.; He, T.; Luo, H. Natural gas pipeline leak detection based on acoustic signal analysis and feature reconstruction. Appl. Energy 2023, 352, 121975. [Google Scholar]
- Deng, X.; Xiao, L.; Liu, X.; Zhang, X. One-dimensional residual GANomaly network-based deep feature extraction model for complex industrial system fault detection. IEEE Trans. Instrum. Meas. 2023, 72, 3520013. [Google Scholar]
- Hu, Z.; Wang, L.; Qi, L.; Li, Y.; Yang, W. A novel wireless network intrusion detection method based on adaptive synthetic sampling and an improved convolutional neural network. IEEE Access 2020, 8, 195741–195751. [Google Scholar]
- Ma, X.; Keung, J.; He, P.; Xiao, Y.; Yu, X.; Li, Y. A semisupervised approach for industrial anomaly detection via self-adaptive clustering. IEEE Trans. Ind. Inform. 2023, 20, 1687–1697. [Google Scholar]
- Han, Y.; Chang, H. Xa-ganomaly: An explainable adaptive semi-supervised learning method for intrusion detection using ganomaly. Comput. Mater. Contin. 2023, 76, 221–237. [Google Scholar]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. GANomaly: Semi-supervised Anomaly Detection via Adversarial Training. In Proceedings of the 14th Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2018; pp. 622–637. [Google Scholar]
- Tagawa, Y.; Maskeliūnas, R.; Damaševičius, R. Acoustic anomaly detection of mechanical failures in noisy real-life factory environments. Electronics 2021, 10, 2329. [Google Scholar] [CrossRef]
- Liu, S.; Li, J.; Ke, W.; Yin, H. Multi-Attention Enhanced Discriminator for GAN-Based Anomalous Sound Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 6715–6719. [Google Scholar]
- Chen, S.; Sun, Y.; Wang, J.; Wan, M.; Liu, M.; Li, X. A multi-scale dual-decoder autoencoder model for domain-shift machine sound anomaly detection. Digit. Signal Process. 2024, 156, 104813. [Google Scholar]
- Huang, X.; Guo, F.; Chen, L. A RES-GANomaly method for machine sound anomaly detection. IEEE Access 2024, 12, 80099–80114. [Google Scholar]
- Akçay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Skip-ganomaly: Skip connected and adversarially trained encoder-decoder anomaly detection. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Wang, Y.; Jiang, Z.; Wang, Y.; Yang, C.; Zou, L. Intelligent detection of foreign objects over coal flow based on improved GANomaly. J. Intell. Fuzzy Syst. 2024, 46, 5841–5851. [Google Scholar]
- Zhang, L.; Dai, Y.; Fan, F.; He, C. Anomaly Detection of GAN Industrial Image Based on Attention Feature Fusion. Sensors 2022, 23, 355. [Google Scholar] [CrossRef] [PubMed]
- Peng, J.; Shao, H.; Xiao, Y.; Cai, B.; Liu, B. Industrial surface defect detection and localization using multi-scale information focusing and enhancement GANomaly. Expert Syst. Appl. 2024, 238, 122361. [Google Scholar] [CrossRef]
- Zhang, H.; Qiao, G.; Lu, S.; Yao, L.; Chen, X. Attention-based Feature Fusion Generative Adversarial Network for yarn-dyed fabric defect detection. Text. Res. J. 2023, 93, 1178–1195. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 14–19 September 2018; pp. 801–818. [Google Scholar]
- Bergmann, P.; Löwe, S.; Fauser, M.; Sattlegger, D.; Steger, C. Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders. Available online: https://arxiv.org/abs/1807.02011 (accessed on 5 July 2024).
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery. Available online: https://arxiv.org/abs/1703.05921 (accessed on 20 March 2024).
- Purohit, H.; Tanabe, R.; Ichige, K.; Endo, T.; Nikaido, Y.; Suefusa, K.; Kawaguchi, Y. MIMII dataset: Sound dataset for malfunctioning industrial machine investigation and inspection. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), New York, NY, USA, 25–30 June 2019; pp. 1–19. [Google Scholar]
- Zenati, H.; Foo, C.; Lecouat, B.; Manek, G.; Chandrasekhar, V. Efficient Gan-Based Anomaly Detection. Available online: https://arxiv.org/abs/1802.06222 (accessed on 17 February 2024).
- Jiang, A.; Zhang, W.; Deng, Y.; Fan, P.; Liu, J. Unsupervised anomaly detection and localization of machine audio: A gan-based approach. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Jiang, W.; Yang, K.; Qiu, C.; Xie, L. Memory enhancement method based on Skip-GANomaly for anomaly detection. Multimed. Tools Appl. 2024, 83, 19501–19516. [Google Scholar]
- Zhao, Z.; Tan, Y.; Qian, K.; Xu, K.; Hu, B. Ensemble Systems with GAN and Auto-Encoder Models for Anomalous Sound Detection. Available online: https://dcase.community/documents/challenge2023/technical_reports/DCASE2023_QianXuHu_95_t2.pdf (accessed on 10 June 2024).
- Fujimura, T.; Kuroyanagi, I.; Hayashi, T.; Toda, T. Anomalous Sound Detection by End-to-End Training of Outlier Exposure and Normalizing Flow with Domain Generalization Techniques. Available online: https://dcase.community/documents/challenge2023/technical_reports/DCASE2023_Fujimura_75_t2.pdf (accessed on 10 June 2024).
- Wilkinghoff, K. Fraunhofer FKIE Submission for Task 2: First-Shot Unsupervised Anomalous Sound Detection for Machine Condition Monitoring. Available online: https://dcase.community/documents/challenge2023/technical_reports/DCASE2023_Wilkinghoff_4_t2.pdf?utm_source=chatgpt.com (accessed on 10 June 2024).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Chen, H.Y.; Lee, C.H. Vibration signals analysis by explainable artificial intelligence (XAI) approach: Application on bearing faults diagnosis. IEEE Access 2020, 8, 134246–134256. [Google Scholar]
- Raghavan, K.; Kamakoti, V. Attention guided grad-CAM: An improved explainable artificial intelligence model for infrared breast cancer detection. Multimed. Tools Appl. 2024, 83, 57551–57578. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Configuration Instruction |
|---|---|
| Sound Acquisition equipment | Fluke SV600 |
| GPU | NVIDIA A100-SXM |
| CPU | Intel Xeon Platinum 8375C |
| Operating System | Ubuntu 18.04.1 |
| Deep Learning Framework | PyTorch 1.9.0 + cu111 |
| Version of Python | 3.7.0 |
| Method | AUC/% | pAUC/% | Accuracy/% | F1-Score |
|---|---|---|---|---|
| AnoGAN | 71.65 | 50.58 | 74.87 | 0.809 |
| EfficientGAN | 73.84 | 57.95 | 81.40 | 0.861 |
| AEGAN | 83.19 | 60.47 | 85.92 | 0.896 |
| MeSkipGANomaly | 86.79 | 65.89 | 89.44 | 0.921 |
| Our Method | 92.06 | 64.92 | 93.96 | 0.955 |
| Method | Metric | ToyCar | ToyTrain | Fan | Gearbox | Bearing | Slider | Valve |
|---|---|---|---|---|---|---|---|---|
| AE-GAN-AD [34] | /% | 74.22 | 70.66 | 81.32 | 73.80 | 75.48 | 89.10 | 43.18 |
| /% | 54.44 | 59.04 | 62.56 | 69.74 | 67.70 | 67.38 | 43.04 | |
| /% | 49.68 | 51.26 | 59.42 | 59.84 | 58.00 | 64.11 | 49.05 | |
| Fujimural et al. [35] | /% | 62.36 | 68.88 | 78.04 | 83.72 | 74.44 | 96.14 | 97.62 |
| /% | 62.48 | 55.24 | 70.96 | 79.44 | 57.40 | 91.88 | 98.68 | |
| /% | 51.53 | 48.58 | 70.32 | 64.26 | 56.26 | 80.53 | 78.95 | |
| Wilkinghoff et al. [36] | /% | 60.66 | 58.12 | 80.22 | 82.66 | 75.48 | 94.02 | 87.98 |
| /% | 50.04 | 61.64 | 64.76 | 80.92 | 71.64 | 93.72 | 88.96 | |
| % | 48.02 | 48.37 | 52.32 | 65.21 | 51.42 | 72.68 | 87.47 | |
| Our Method | /% | 75.78 | 68.42 | 75.34 | 87.56 | 74.93 | 92.34 | 94.53 |
| /% | 63.23 | 62.45 | 58.32 | 81.92 | 72.46 | 80.68 | 92.49 | |
| /% | 55.42 | 56.74 | 62.65 | 69.97 | 59.92 | 70.90 | 76.34 |
| Baseline | MFF | DNA | L-SSIM | AUC/% | pAUC/% | Accuracy/% | F1-Score |
|---|---|---|---|---|---|---|---|
| ✓ | 74.67 | 61.46 | 73.86 | 0.810 | |||
| ✓ | ✓ | 81.51 | 61.84 | 84.92 | 0.889 | ||
| ✓ | ✓ | ✓ | 83.19 | 63.47 | 88.94 | 0.919 | |
| ✓ | ✓ | ✓ | 86.82 | 62.73 | 91.54 | 0.941 | |
| ✓ | ✓ | ✓ | ✓ | 92.06 | 64.92 | 93.96 | 0.955 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Sun, Z.; Shi, S.; Yu, H. Multi-Scale Feature Fusion GANomaly with Dilated Neighborhood Attention for Oil and Gas Pipeline Sound Anomaly Detection. Information 2025, 16, 279. https://doi.org/10.3390/info16040279
Zhang Y, Sun Z, Shi S, Yu H. Multi-Scale Feature Fusion GANomaly with Dilated Neighborhood Attention for Oil and Gas Pipeline Sound Anomaly Detection. Information. 2025; 16(4):279. https://doi.org/10.3390/info16040279
Chicago/Turabian StyleZhang, Yizhuo, Zhengfeng Sun, Shen Shi, and Huiling Yu. 2025. "Multi-Scale Feature Fusion GANomaly with Dilated Neighborhood Attention for Oil and Gas Pipeline Sound Anomaly Detection" Information 16, no. 4: 279. https://doi.org/10.3390/info16040279
APA StyleZhang, Y., Sun, Z., Shi, S., & Yu, H. (2025). Multi-Scale Feature Fusion GANomaly with Dilated Neighborhood Attention for Oil and Gas Pipeline Sound Anomaly Detection. Information, 16(4), 279. https://doi.org/10.3390/info16040279