
Automatic Reading Method for Analog Dial Gauges with Different Measurement Ranges in Outdoor Substation Scenarios

Abstract
1. Introduction
2. An Adaptive Framework for Automated Reading of Pointer-Type Meters with Diverse Ranges in Substations
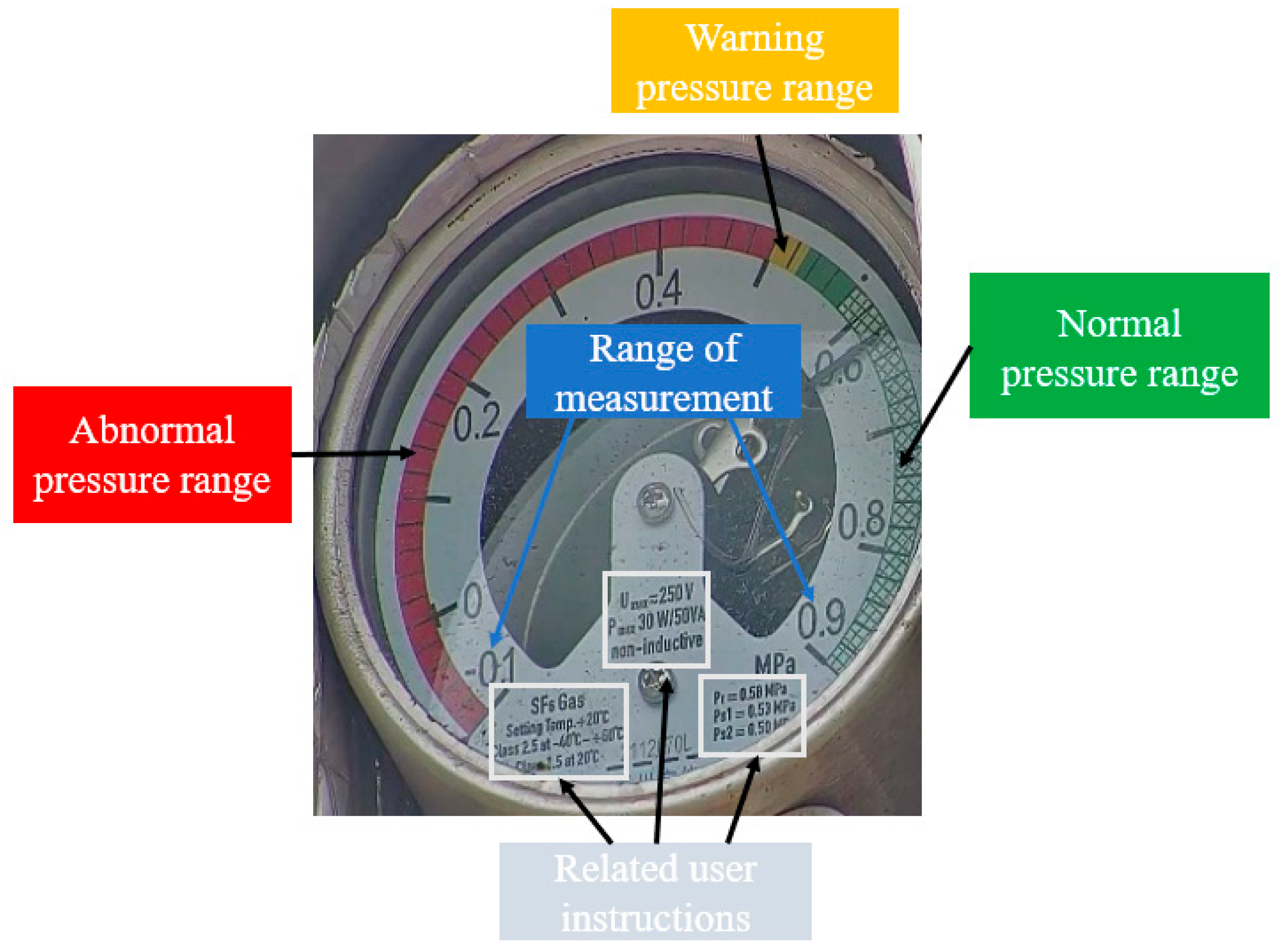
2.1. Analysis of Meter Reading Solutions
2.2. Framework for Meter Reading
3. Method
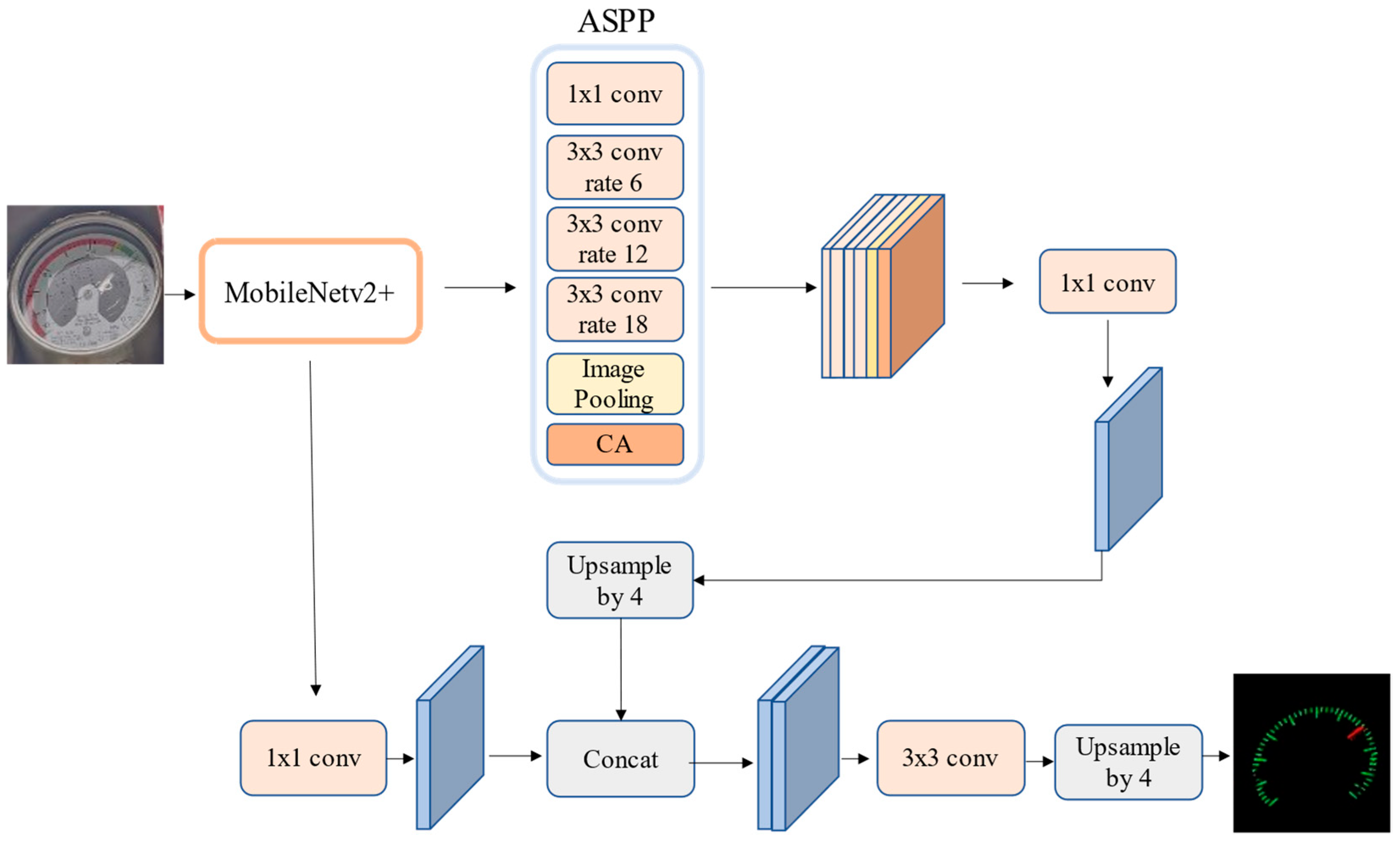
3.1. Improvement of the Dial Pointer Segmentation Model for Pointer-Type Instruments
3.1.1. Replacement of the Feature Extraction Network
3.1.2. CA Module
- Embedding of Coordinate Information
- 2.
- Generation of Coordinate Attention
3.1.3. Improvement of the Loss Function
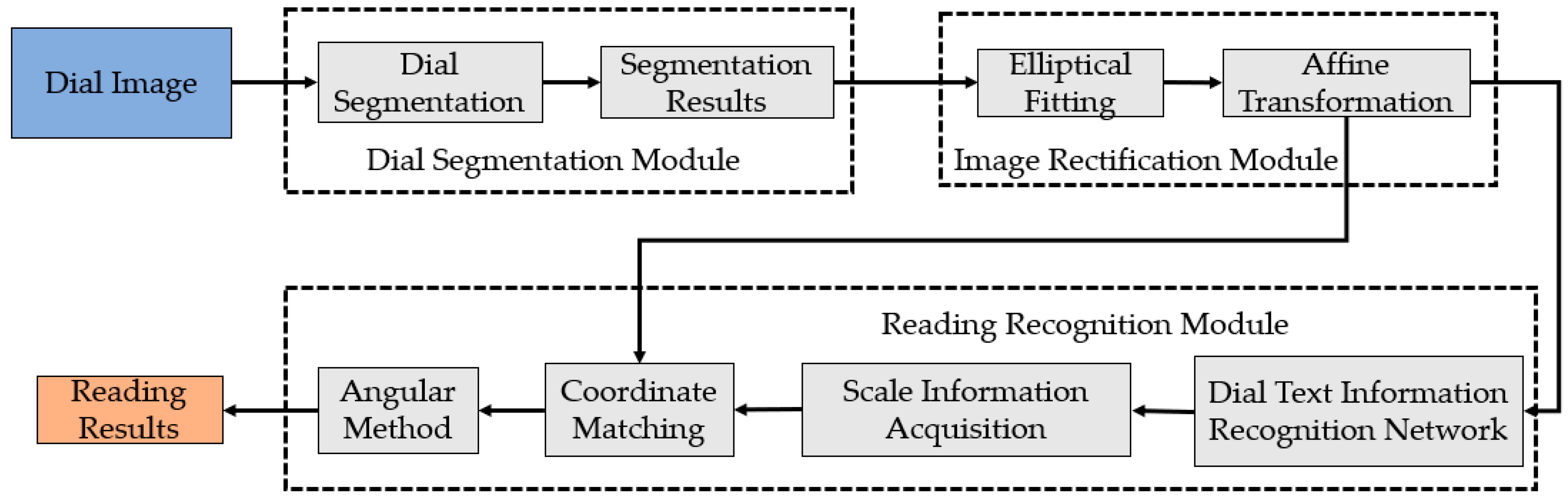
3.2. Automatic Recognition of Pointer-Type Instrument Dial Readings
3.2.1. Distortion Image Rectification
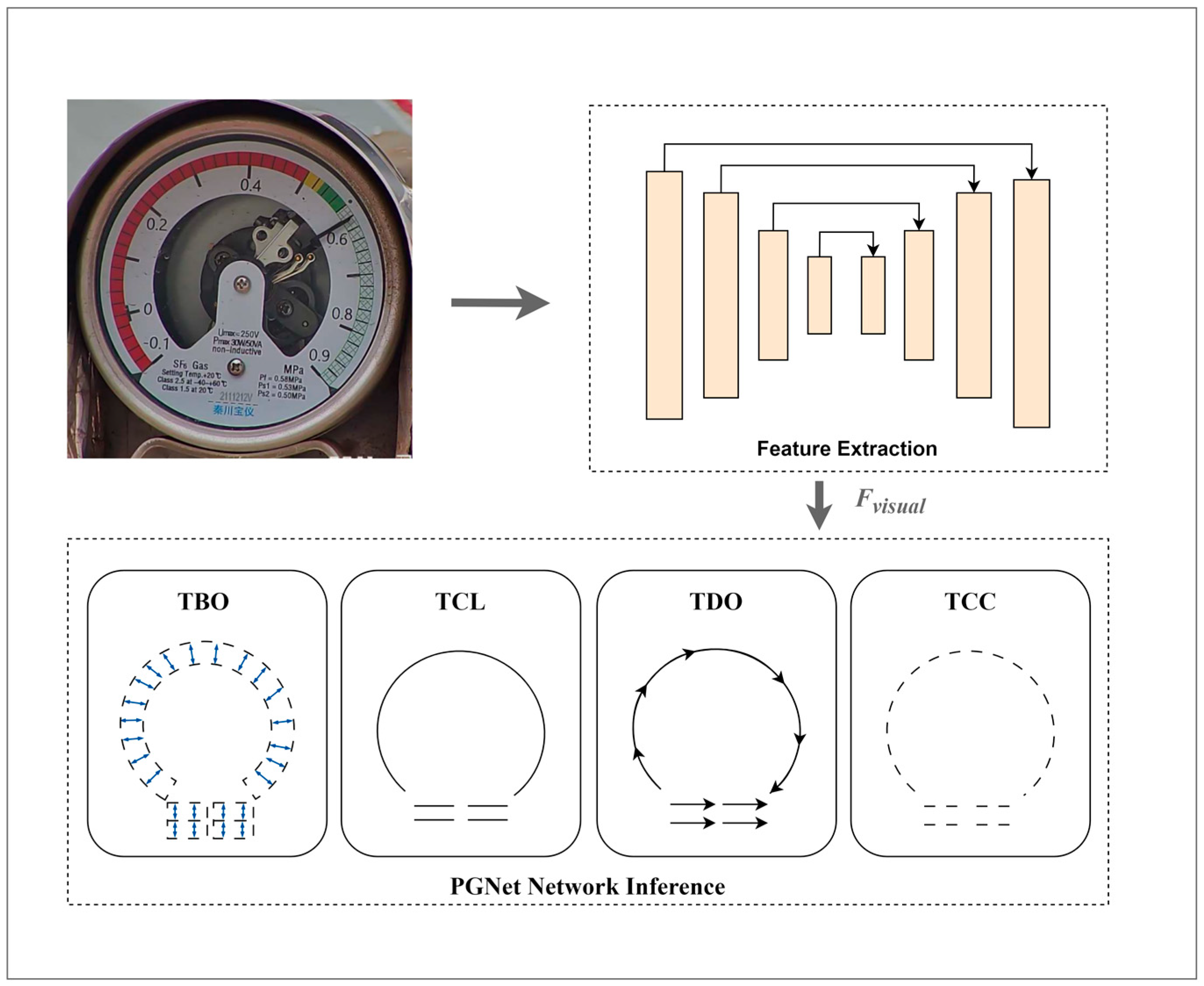
3.2.2. Identification of Scale Information on Pointer-Type Instrument Dials
3.2.3. Coordinate Matching
- Initialize the matching set following the acquisition of the set of pixel coordinates for the segmented dial scales and the set of center coordinates for the dial numerical text;
- Traverse each text center to identify the nearest scale point, computing the Euclidean distance between the current scale point and the text center;
- If the computed distance is less than the established minimum distance, update the minimum distance and designate the current scale point as the nearest scale point;
- Document each text center and its nearest scale point, along with their distance, in the matching pairs, and sort these pairs in ascending order of distance;
- Extract the two matching pairs with the smallest distances.
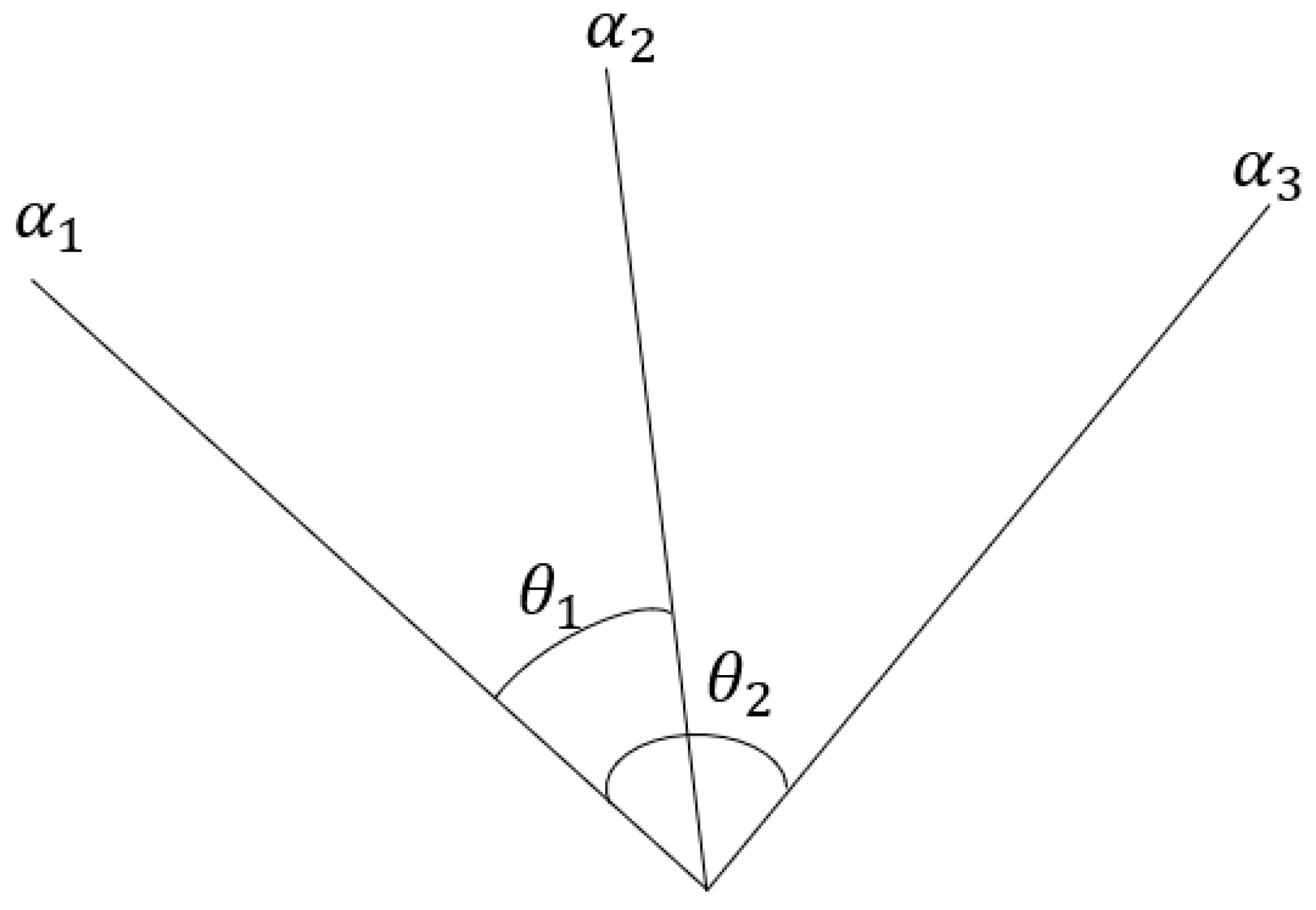
3.2.4. Angular Measurement Method for Reading
4. Experiments
4.1. Dataset
4.2. Evaluation Metrics
- Pointer-Type Instrument Dial Segmentation
- 2.
- Recognition of Readings
4.3. Results of Pointer-Type Instrument Dial Segmentation Experiments
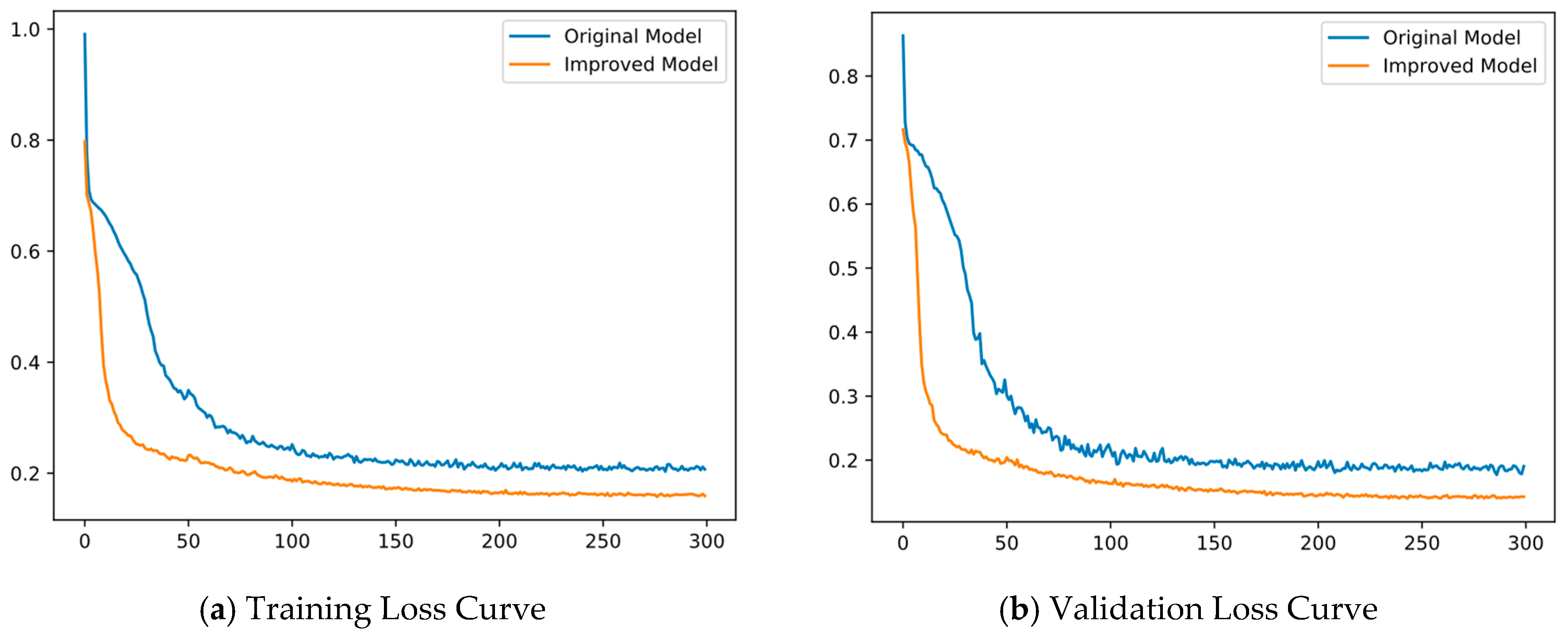
4.3.1. Comparative Analysis of Segmentation Network Performance: Pre- and Post-Improvement
4.3.2. Comparative Analysis of Segmentation Network Performance
4.4. Experimental Results of Distortion Image Rectification
4.5. Experimental Results of Pointer-Type Instrument Dial Reading Recognition
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.F.; Huang, S. Research on pointer identifying and number reading of multiple pointer instruments. Electr. Meas. Instrum. 2020, 57, 147–152. [Google Scholar]
- Zhai, Y.J.; Zhao, Z.Y.; Wang, Q.M.; Bai, K. Pointer meter detection method based on artificial-real sample metric learning. Electr. Meas. Instrum. 2022, 59, 174–183. [Google Scholar]
- Hu, X.; Ouyang, H.; Yin, Y.; Hou, Z.C. An improved method for recognizing readings of pointer meters. Electron. Meas. Technol. 2021, 44, 132–137. [Google Scholar]
- Yang, Y.Q.; Zhao, Y.Q.; He, X.Y. Automatic Calibration of Analog Measuring Instruments Using Computer Vision; North China Electric Power University: Beijing, China, 2001; p. 3. [Google Scholar]
- Xu, P.; Zeng, W.M.; Shi, Y.H.; Zhang, Y. A reading recognition algorithm of pointer type oil-level meter. Comput. Technol. Dev. 2018, 28, 189–193. [Google Scholar]
- Shi, W.; Wang, C.L.; Chen, J.S.; Hou, X.H. Substation pointer instrument reading based on image processing. Electron. Sci. Technol. 2016, 29, 118–120. [Google Scholar]
- Fang, Y.X.; Dai, Y.; He, G.L.; Qi, D. A mask RCNN based automatic reading method for pointer meter. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8466–8471. [Google Scholar]
- Geng, L.; Shi, R.Z.; Liu, Y.B.; Xiao, Z.; Wu, J.; Zhang, F. Instrument image segmentation method based on UNet with multi-scale receptive field. Comput. Eng. Des. 2022, 43, 771–777. [Google Scholar]
- Jin, A.P.; Yuan, L.; Zhou, D.Q.; Yang, K. Identification Method for Reading of Pointer Instruments Based on YOLOv5 and U-net. Instrum. Tech. Sens. 2022, 11, 29–33. [Google Scholar]
- Mao, A.K.; Liu, X.M.; Chen, W.Z.; Song, S.L. Improved substation instrument target detection method for YOLOv5 algorithm. J. Graph. 2023, 44, 448–455. [Google Scholar]
- Wang, K.; Lu, S.H.; Chen, C.; Chen, Z.B.; Qiang, S.; Chen, B. Research on Detection and Reading Recognition Algorithm of Pointer Instrument Based on YOLOv5. J. China Three Gorges Univ. (Nat. Sci.) 2022, 44, 42–47. [Google Scholar]
- Yang, S.Q.; Wu, J.Y.; Chen, M.N.; Fu, C.X.; Zhao, N.; Wang, J. Automatic identification for reading of pointer-type meters based on deep learning. Electron. Meas. Technol. 2023, 46, 149–156. [Google Scholar]
- Zhang, H.; Zhang, D.X.; Chen, P. Application of Parallel Attention Mechanism in Image Semantic Segmentation. Comput. Eng. Appl. 2022, 58, 151–160. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhou, D.; Hou, Q.; Chen, Y.; Feng, J.; Yan, S. Rethinking Bottleneck Structure for Efficient Mobile Network Design. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 680–697. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Li, B.; Yao, Y.; Tan, J.; Zhang, G.; Yu, F.; Lu, J. Equalized focal loss for dense long-tailed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6990–6999. [Google Scholar]
- Wang, P.; Zhang, C.; Qi, F.; Liu, S.; Zhang, X.; Lyu, P.; Han, J.; Liu, J.; Ding, E.; Shi, G. PGNet: Real-time Arbitrarily-Shaped Text Spotting with Point Gathering Network. Proc. AAAI Conf. Artif. Intell. 2021, 35, 2782–2790. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kwon, I. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. FCANet: Frequency Channel Attention Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wang, H.; Jiang, X.; Ren, H.; Hu, Y.; Bai, S. SwiftNet: Real-time Video Object Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1296–1305. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Li, D.; Li, W.; Yu, X.; Gao, Q.; Song, Y. Automatic reading algorithm of substation dial gauges based on coordinate positioning. Appl. Sci. 2021, 11, 6059. [Google Scholar] [CrossRef]
- Zheng, C.; Wang, S.; Zhang, Y.; Zhang, P.; Zhao, Y. A robust and automatic recognition system of analog instruments in power system by using computer vision. Measurement 2016, 92, 413–420. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | t | c | n | s |
|---|---|---|---|---|---|
| 256 × 256 × 3 | Conv2d | — | 32 | 1 | 2 |
| 128 × 128 × 32 | SG-block | 1 | 16 | 1 | 1 |
| 128 × 128 × 16 | SG-block | 6 | 24 | 2 | 2 |
| 64 × 64 × 24 | SG-block | 6 | 32 | 3 | 2 |
| 32 × 32 × 32 | SG-block | 6 | 64 | 4 | 2 |
| 3 × 32 × 64 | SG-block | 6 | 96 | 3 | 1 |
| 16 × 16 × 96 | SG-block | 6 | 160 | 3 | 2 |
| 8 × 8 × 160 | SG-block | 6 | 320 | 1 | 1 |
| Attention Mechanism | MIoU% | MPA% | Precision | Recall | Parameters/M |
|---|---|---|---|---|---|
| SE | 76.9 | 88.4 | 79.5 | 89.8 | 5.99 |
| CBAM | 77.9 | 90.2 | 80.3 | 90.7 | 6.02 |
| FcaNet | 77.4 | 89.8 | 79.9 | 90.5 | 5.97 |
| CA | 78.3 | 91.1 | 80.7 | 91.1 | 5.97 |
| Loss Fuction | MIoU% | MPA% | Precision | Recall |
|---|---|---|---|---|
| CE | 76.7 | 90.4 | 79.6 | 89.9 |
| FL | 77.1 | 90.8 | 80.1 | 90.4 |
| EFL | 77.8 | 91.1 | 80.4 | 90.9 |
| Ablation Experiments | Backbone | CA | EFL | MIoU% | MPA% | Parameters/M |
|---|---|---|---|---|---|---|
| Experiment 1 | Xception | — | — | 74.2 | 88.8 | 41.20 |
| Experiment 2 | MobileNetV2+ | — | — | 76.7 | 90.6 | 4.09 |
| Experiment 3 | MobileNetV2+ | √ | — | 78.3 | 91.7 | 4.25 |
| Experiment 4 | MobileNetV2+ | — | √ | 77.8 | 91.1 | 4.09 |
| Experiment 5 | MobileNetV2+ | √ | √ | 79.7 | 92.7 | 4.25 |
| Network Model | Backbone | MIoU% | MPA% | Parameters/M | FPS |
|---|---|---|---|---|---|
| DeepLabV3+ | Xception | 74.2 | 88.8 | 41.20 | 22.2 |
| PSPNet | ResNet-50 | 77.1 | 90.8 | 28.50 | 30.0 |
| SwiftNet | ResNet-18 | 77.8 | 91.1 | 11.80 | 39.9 |
| Mask2Former | ViT | 78.8 | 91.9 | 105 | 15.2 |
| Ours | MobileNetV2+ | 79.7 | 92.7 | 4.25 | 52.6 |
| Sample | Manual Reading Results | Before Correction | After Correction | ||||
|---|---|---|---|---|---|---|---|
| Reading Results | Absolute Error | Relative Error/% | Reading Results | Absolute Error | Relative Error/% | ||
| Sample 1 | 0.450 | 0.415 | 0.035 | 7.7 | 0.449 | 0.001 | 0.2 |
| Sample 2 | 0.610 | 0.658 | 0.038 | 6.2 | 0.613 | 0.003 | 0.5 |
| Sample 3 | 0.630 | 0.601 | 0.029 | 4.6 | 0.639 | 0.009 | 1.4 |
| Sample 4 | 0.600 | 0.514 | 0.082 | 13.6 | 0.592 | 0.008 | 1.3 |
| Sample 5 | 0.620 | 0.526 | 0.094 | 15.1 | 0.615 | 0.005 | 0.8 |
| Accuracy | Time/ms | |
|---|---|---|
| Detection | 97.8 | 85 |
| Recognition | 96.4 | 19 |
| Partial Dial | Reading by Human | Reading by Our Method | Absolute Error | Relative Error/% | Time/s |
|---|---|---|---|---|---|
| dial 1 | 0.450 | 0.449 | 0.001 | 0.2 | 2.04 |
| dial 2 | 0.610 | 0.613 | 0.003 | 0.5 | 1.95 |
| dial 3 | 0.630 | 0.639 | 0.009 | 1.4 | 1.99 |
| dial 4 | 0.600 | 0.592 | 0.008 | 1.3 | 2.02 |
| dial 5 | 0.620 | 0.615 | 0.005 | 0.8 | 2.04 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Liao, W.; Fan, S.; Hou, J.; Tang, H. Automatic Reading Method for Analog Dial Gauges with Different Measurement Ranges in Outdoor Substation Scenarios. Information 2025, 16, 226. https://doi.org/10.3390/info16030226
Yang Y, Liao W, Fan S, Hou J, Tang H. Automatic Reading Method for Analog Dial Gauges with Different Measurement Ranges in Outdoor Substation Scenarios. Information. 2025; 16(3):226. https://doi.org/10.3390/info16030226
Chicago/Turabian StyleYang, Yueping, Wenlong Liao, Songhai Fan, Jin Hou, and Hao Tang. 2025. "Automatic Reading Method for Analog Dial Gauges with Different Measurement Ranges in Outdoor Substation Scenarios" Information 16, no. 3: 226. https://doi.org/10.3390/info16030226
APA StyleYang, Y., Liao, W., Fan, S., Hou, J., & Tang, H. (2025). Automatic Reading Method for Analog Dial Gauges with Different Measurement Ranges in Outdoor Substation Scenarios. Information, 16(3), 226. https://doi.org/10.3390/info16030226