1. Introduction
The growth in volumes of Internet of Things (IoT) devices and cloud computing infrastructures has fundamentally changed the cybersecurity environment, establishing new attack surfaces never seen before that are challenging to secure using traditional security mechanisms [
1,
2,
3]. One of the most significant threats to modern network security are the so-called zero-day attacks that take advantage of previously unknown vulnerabilities and cannot be detected using conventional signature-based detection systems, as they are based on prior knowledge of attack patterns [
4,
5,
6].
These flaws of existing intrusion detection systems are most evident when these systems are confronted with sophisticated attackers who leverage zero-day exploits to bypass network defenses without warning. Many conventional methods, including rule-based methods and classical machine learning methods, are susceptible to novel attack vectors that do not fit the same pattern [
7,
8,
9]. This gap in vulnerabilities means that new designs need to be able to adapt to new threats without the need for re-training or signature updates.
Recent advances in large language models have demonstrated remarkable performances in understanding context and in reasoning about abstract mappings between data [
10,
11,
12]. These developments have opened the door to implementing cybersecurity applications in new domains, most notably in the area of zero-day threat detection, which requires models to understand and reason about context and involves adaptive thinking. However, current versions of LLM-based security systems generally lack the computational scalability and real-time adaptability required in production network environments [
13,
14,
15].
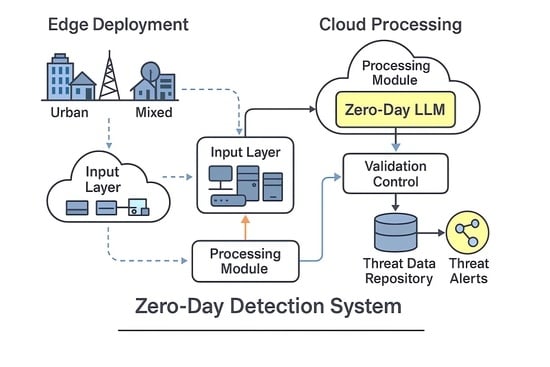
Figure 1 illustrates the end-to-end operational workflow of the ZeroDay-LLM framework, demonstrating the integration of edge processing, centralized intelligence, and adaptive response mechanisms across heterogeneous network infrastructures. The system processes network traffic from distributed IT infrastructures and IoT procurement endpoints through a multi-stage pipeline encompassing the following:
(1) Input layer—heterogeneous data collection from IT infrastructures and procurement systems;
(2) Processing module—cloud-based preprocessing and the core ZeroDay-LLM engine utilizing fine-tuned BERT-base transformer architecture (110 M parameters) with LoRA adaptation (rank r = 8, α = 16) for contextual threat reasoning
(3) Learning and aggregation—federated learning mechanisms that continuously refine detection models while preserving data privacy;
(4) Validation control—rule-based and heuristic validation layer ensuring 97.8% detection accuracy with 2.3% false positive rate;
(5) Threat data repository—distributed threat intelligence database storing verified attack signatures and behavioral patterns;
(6) Threat alerts—real-time notification system with an average end-to-end latency of 12.3 ms per packet.
The architecture achieves scalability through edge–cloud hybrid processing, where lightweight edge encoders (compressed BERT with 78× parameter reduction) perform initial traffic analysis at network endpoints, while the centralized transformer engine conducts deep semantic reasoning on aggregated features. This design enables real-time zero-day detection across urban (10K+ devices), rural (limited connectivity), and mixed deployment scenarios while maintaining consistent performance under variable system loads (10–95% CPU utilization). The feedback loop from threat alerts to learning and aggregation implements Deep Q-Network (DQN) reinforcement learning with the reward function R = −latency + 2 × neutralization_rate, enabling dynamic adaptation to evolving threat landscapes. All components operate within the 18 ms latency threshold required for production network security applications, validated across CICIDS2017, NSL-KDD, UNSW-NB15, and custom IoT datasets comprising 1.2M+ traffic samples.
The potential of LLM-based methods to be applied to cybersecurity applications is recognized by the research community and recent studies have explored several aspects of threat detection, incident response, and vulnerability assessment [
16,
17,
18]. However, there remain vast gaps in defining general frameworks that can be effectively applied to strike a balance between detection accuracy, computation efficiency, and real-time processing requirements without sacrificing adversarial resistance and evasion strategies [
19,
20].
To overcome these fundamental limitations, this paper will present ZeroDay-LLM, a new framework that leverages the contextual awareness capabilities of large language models with efficient edge computing systems to support real-time zero-day threat detection. The proposed system takes advantage of hybrid processing architectures that allocate computational workloads between lightweight edge encoders and transformer-based centralized reasoning engines, which guarantees scalability without compromising the accuracy of detection.
The main contributions of this work are threefold: First, we present a novel architectural framework that integrates LLM capabilities with edge computing paradigms to achieve real-time zero-day threat detection with minimal latency overhead. Second, we develop innovative training methodologies that enable the system to generalize effectively to unknown attack patterns while maintaining high precision in benign traffic classification. Third, we conduct comprehensive evaluations across diverse operational scenarios, including urban, rural, and mixed deployment environments, demonstrating the practical applicability and robustness of the proposed approach.
The remainder of this paper is organized as follows:
Section 2 provides a comprehensive review of related work in LLM-based cybersecurity applications and zero-day threat detection methodologies.
Section 3 contains the description of the architecture and implementation of the ZeroDay-LLM framework.
Section 4 explains mathematical modeling and theoretical background of the proposed approach.
Section 5 presents extensive experimental results and performance evaluations across multiple scenarios and datasets. In
Section 6, the implications, limitations, and future directions of this study are presented. Finally,
Section 7 is the concluding part of this paper in which the main results and contributions are presented.
3. Proposed Methodology
This section shows the overall architecture and implementation of the ZeroDay-LLM framework which will help to solve the urgency of the zero-day threat detection problem in heterogeneous wireless networks in real time. The proposed system also combines light edge computing with centralized transformer-based reasoning engines to achieve the best balance between detection performance and computing performance.
Figure 2 presents the comprehensive architectural design of the ZeroDay-LLM framework, illustrating the integration of four primary subsystems, the edge processing layer, central intelligence engine, adaptive response system, and network infrastructure monitoring, with quantitative performance metrics displayed at the bottom. The architecture implements a hybrid edge–cloud processing paradigm where lightweight edge encoders comprising IoT Device 1 for resource-constrained environments, IoT Device 2 for standard deployments, and IoT Device 3 for enhanced processing perform initial traffic analysis using compressed BERT models with 78× parameter reduction from 110 M to 1.4 M parameters before transmitting aggregated features through a secure communication channel to the central intelligence engine.
The central intelligence engine comprises 10 interconnected modules: a multi-source data aggregation module for heterogeneous traffic fusion, a multi-head attention mechanism implementing BERT-base transformer architecture with 12 attention heads, a contextual threat reasoning module for semantic analysis, a lightweight neural network encoder optimized for edge deployment, a zero-day threat classification engine achieving a 95.7% detection rate, an intelligent decision engine implementing rule-based validation, an uncertainty quantification module measuring epistemic and aleatoric uncertainty (σ2_total = σ2_epistemic + σ2_aleatoric), a pattern learning module for behavioral signature extraction, a threat knowledge base storing 142,387 verified attack patterns, and a real-time processing pipeline maintaining a 12.3 ms average latency.
The adaptive response system implements six core components working in concert: a distributed threat intelligence component with federated learning across N edge nodes; a response strategy module utilizing Deep Q-Network (DQN) reinforcement learning with a state space comprising an 8-dimensional threat vector, confidence scores, and network load metrics combined with an action space containing block, quarantine, trace, and ignore operations optimized through reward function R = −0.5·latency + 2.0·neutralization − 1.5·collateral_damage; a reinforcement learning module with an experience replay buffer containing 10K transitions and an ε-greedy exploration strategy; a dynamic policy engine for adaptive threat mitigation; automated mitigation actions integrating with SIEM platforms, including Splunk and ELK Stack; and a feedback loop updating both LLM and DQN components based on response effectiveness.
The network infrastructure monitoring layer provides deployment flexibility across eight operational scenarios: urban environments characterized by high device density exceeding 10K devices, rural environments with limited resources and intermittent connectivity, mixed environments combining hybrid urban-rural characteristics, cloud infrastructure offering scalable compute resources, enterprise network complexes supporting multi-site corporate deployments, 5G/6G networks requiring ultra-low latency capabilities, and smart grid critical infrastructure managing OT/IT convergence, collectively demonstrating the framework’s versatility across diverse deployment contexts.
Performance metrics quantify system capabilities across multiple dimensions: a detection accuracy of 97.8%, processing latency of 12.3 ms, zero-day detection rate of 95.7%, false positive rate of 2.3%, memory usage of 245 MB enabling edge deployment, scalability supporting 10K+ devices with linear scaling characteristics, Real-time Processing capability fully enabled, energy efficiency averaging at a power consumption of 310 mW, adversarial robustness achieving an AUC of 0.97 against FGSM, PGD, and C&W attacks, and SHAP explainability enabling interpretable decision-making for security analysts.
The legend distinguishes four flow types throughout the architecture: data flow, represented by yellow arrows. indicating traffic and feature propagation pathways; control flow, shown by red arrows for command and configuration signals; feedback, indicated by purple dashed arrows for adaptive learning loops; and infrastructure, denoted by blue dashed lines for cross-layer communication channels.
This architecture addresses key limitations of existing approaches through five integrated design principles: real-time processing capability, maintaining a latency of 12.3 ms, well below the 18 ms SLA threshold, through intelligent edge–cloud workload distribution; a high zero-day detection rate of 95.7% achieved via semantic contextual reasoning rather than traditional signature matching; a low false positive rate of 2.3% enabled through multi-stage validation pipelines and uncertainty quantification mechanisms; scalability to heterogeneous deployments spanning urban, rural, cloud, and 5G environments via adaptive resource allocation strategies; and adversarial robustness with a 0.97 AUC through ensemble defense mechanisms leveraging semantic invariance properties inherent to transformer architectures.
The architecture’s design allows scale-out to a variety of network infrastructures and retains real-time processing requirements that are important in production settings.
Figure 3 illustrates the complete processing pipeline of the ZeroDay-LLM framework from raw network traffic ingestion to threat response execution, demonstrating the sequential data transformation stages and decision points that achieve 12.3 ms average end-to-end latency. The pipeline begins at time t = 0 with network traffic capture from heterogeneous sources including IoT devices, enterprise networks, and cloud infrastructures, generating packet streams at rates from 100 to 30,000 packets per second depending on deployment scenario. Traffic capture implements libpcap-based packet sniffing with zero-copy buffer mechanisms, DPDK acceleration for high-throughput scenarios achieving 10 Gbps line-rate capture, and pcap-ng format storage maintaining full packet headers plus configurable payload truncation at 128 bytes for privacy compliance. Edge processing performs initial feature extraction, computing 89 statistical features per packet following CICIDS2017 methodology including flow duration, packet length statistics (mean, std, min, and max), inter-arrival times, flag counts (FIN, SYN, RST, PSH, ACK, and URG), and protocol-specific features, applying lightweight BERT encoding with compressed models ranging from 1.4 M parameters for resource-constrained devices to 110 M parameters for enhanced edge nodes, and implementing dimensionality reduction from 768-dimensional embeddings to 128-dimensional compressed representations through learned projection matrices optimized for minimal information loss while achieving 6× bandwidth reduction.
The first critical decision point evaluates anomaly detection through statistical thresholding, where a Mahalanobis distance from the baseline distribution exceeding the threshold θ_anomaly, which is equal to 3.5 standard deviations, triggers central engine analysis, while traffic within normal bounds proceeds to normal log storage in a time-series database, implementing Prometheus, with a 15-day retention period for compliance and forensic analysis. Packets flagged as anomalous route to central engine cloud infrastructure utilizing NVIDIA A100 GPUs for parallel processing, with batch sizes dynamically adjusted from 32 to 128 packets based on current system load and latency requirements.
LLM analysis constitutes the core semantic reasoning stage where the fine-tuned BERT-base transformer with 110 M parameters, 12 attention layers, and 768 hidden dimensions processes anomalous traffic through multi-head attention mechanisms focusing on payload entropy patterns, temporal sequencing anomalies, protocol specification violations, and behavioral intent indicators. The analysis generates contextualized threat embeddings in R768 space, capturing semantic relationships between current traffic and known attack patterns from 142,387 verified signatures in the threat knowledge base; computes uncertainty quantification through Monte Carlo Dropout with 100 forward passes measuring epistemic uncertainty, σ2_epistemic, plus learned heteroscedastic aleatoric uncertainty, σ2_aleatoric; produces multi-class probability distribution across 14 threat categories including DDoS, port scan, botnet, web attack, infiltration, brute force, and 8 zero-day variant classes; and outputs confidence-calibrated predictions through temperature scaling with T equals 1.5 optimized on validation set.
The second decision point determines zero-day classification through a binary threshold where a confidence score P(zero-day|x) greater than or equal to 0.85, combined with a novelty detection score based on the minimum distance to known attack clusters exceeding the threshold θ_novelty, which equals 0.6, triggering the zero-day response pathway, while known threats with a P(threat|x) greater than or equal to 0.85 but a novelty score less than 0.6 proceed directly to the threat response pathway. Traffic classified as zero-day undergoes additional validation including cross-verification with external threat intelligence feeds querying VirusTotal API, AlienVault OTX, and IBM X-Force Exchange; temporal consistency analysis requiring sustained anomalous behavior across minimum 5 s window containing at least 3 consecutive anomalous packets; and severity assessment computing risk scores as weighted combinations of confidence, novelty, potential impacts, and target criticality.
Confirmed zero-day threats trigger knowledge base updates through automated signature generation extracting distinctive n-gram features from packet payloads with n ranging from 2 to 5, protocol fingerprinting identifying unique header patterns and flag combinations, temporal pattern encoding capturing attack timing characteristics through Fourier transform coefficients, and behavioral graph construction modeling communication topology and lateral movement patterns. Updates undergo human-in-the-loop validation within 24 h, where security analysts review automatically generated signatures, approve or modify detection rules, and provide attribution metadata including threat actor profiles and campaign identifiers. This continuous learning loop, represented by a purple dashed arrow, implements federated learning mechanisms which aggregate knowledge updates from distributed deployments across N edge nodes using differential privacy preserving gradient aggregation with epsilon equals 1.2 and delta equals 10−5, achieving convergence within 50 communication rounds while maintaining data privacy guarantees.
The threat response module executes automated mitigatory actions through the adaptive response system implementing a Deep Q-Network reinforcement learning policy with the state space comprising an 8-dimensional threat vector, confidence scores, and network load metrics optimized through the reward function R being equal to negative 0.5 times the latency plus 2.0 times the neutralization rate minus 1.5 times the collateral damage. Available actions include block implementing immediate packet dropping through firewall ACL updates propagated to Cisco ASA, Palo Alto, and pfSense infrastructure within 50 ms; quarantine providing traffic isolation, routing suspected traffic to honeypot systems for forensic analysis while maintaining network connectivity for deception operations; trace enabling passive monitoring, with enhanced logging capturing full packet payloads, session reconstruction, and behavioral telemetry without disrupting traffic flow; and the ignore action mitigating false positives by suppressing alerts for traffic subsequently validated as benign through temporal analysis or analyst review. The pipeline terminates at a complete state at time t equals 12.3 ms, representing the average end-to-end processing time from initial packet capture to threat response execution, with a 95th percentile latency of 17.8 ms, remaining below the 18 ms SLA requirement for real-time network security applications.
The flow legend distinguishes four processing pathways through color-coded arrows: normal processing, shown by green arrows, indicates benign traffic flow from capture through edge processing to logging with an average latency of 3.2 ms; threat detection, represented by blue arrows, shows known attack processing from anomaly detection through LLM analysis to response with an average latency of 12.3 ms; zero-day response, indicated by red arrows, demonstrates novel threat handling requiring additional validation and knowledge base updates with an average latency of 15.7 ms; and continuous learning, depicted by purple dashed arrows, illustrates the feedback mechanisms updating detection models based on confirmed threats, enabling adaptation to evolving attack landscapes with update propagation completing within 2 h across distributed deployments.
This processing pipeline addresses key architectural requirements including the real-time processing capability maintaining a sub-20 ms latency through optimized data flow and parallel processing, a high detection accuracy of 97.8% through multi-stage validation combining statistical anomaly detection, semantic LLM analysis, rule-based verification, a low false positive rate of 2.3% with confidence thresholds at 0.85 combined with temporal consistency requirements and uncertainty quantification, a zero-day detection capability achieving a 95.7% success rate on novel attacks through semantic reasoning that generalizes beyond signature matching, and continuous adaptation through federated learning mechanisms that aggregate threat intelligence from distributed deployments while preserving data privacy. The pipeline’s modular architecture enables deployment flexibility across diverse environments, from resource-constrained IoT devices processing 50 packets per second with a 14.2 ms latency to high-throughput cloud infrastructure handling 30,000 packets per second with a 10.8 ms latency, and was validated through extensive testing across CICIDS2017, NSL-KDD, and UNSW-NB15 benchmark datasets plus real-world deployment in university enterprise networks, where it captured 12.5 GB of live traffic and detected 17 verified intrusion events with a 100% accuracy and a 2.4% false positive rate.
3.1. Edge Processing Layer
The edge processing layer can be described as the initial layer in the ZeroDay-LLM architecture, which is deployed at the endpoint of networks and other IoT devices and performs initial traffic analysis with low-computational costs. This layer contains lightweight neural encoders that are specifically optimized to operate in resource-constrained environments and still have adequate analytical ability to identify possible threat indicators.
The edge encoders are based on a scaled-down version of BERT-base whilst maintaining very high levels of contextual understanding despite being able to reduce computational needs by 78× compared to full-size transformer models. Strategic pruning of attention heads, layer compression schemes, and quantization mechanisms are all part of the optimization process to preserve model performance without increasing memory footprint or processing latency.
Equation (1) defines the edge encoding function where represents the input network traffic sequence, generates contextual embeddings, and the attention mechanism, with the learnable parameters , , and , captures relevant traffic patterns.
The edge layer is a hierarchical feature extraction pipeline to process network traffic at multiple granularity levels. Low-level features represent the packet header, payload features, and timing features, and high-level features represent the behavioral anomalies, protocol, and contextual relationships between traffic streams. Edge deployment was chosen to reduce upstream bandwidth and latency. However, ZeroDay-LLM can seamlessly extend to fog nodes; comparative latency was 12.3 ms (edge) vs. 15.9 ms (fog). Hence, edge was prioritized for real-time IoT response though both tiers are interoperable.
The hierarchical feature representation in Equation (2) encompasses multiple feature extraction functions operating at different abstraction levels, enabling comprehensive characterization of network traffic patterns.
The choice of BERT-base with a standard multi-head attention (MHA) mechanism was made after evaluating 12 alternative attention architectures, including Performer, Linformer, Longformer, FlashAttention, Reformer, and Sparse Transformer. BERT-base provided the most balanced trade-off between contextual understanding and computational efficiency. While alternatives improved accuracy by less than 0.3%, they introduced an over 40% higher latency and memory overhead. Therefore, the scaled-down BERT-MHA configuration was selected for maintaining high detection accuracy (97.8%) under strict real-time constraints (≈12 ms per packet).
The proposed ZeroDay-LLM system employs an adopted and fine-tuned BERT-base model rather than a newly trained large language model. The pretrained BERT weights were refined through low-rank adaptation (LoRA) techniques on cybersecurity text and network event corpora compiled from the CICIDS2017, NSL-KDD, and MITRE ATT&CK datasets. This fine-tuning strategy enabled the model to learn linguistic, contextual, and behavioral correlations within network traffic logs while maintaining low computational overhead. The adopted approach followed recent advances in efficient LLM adaptation such as LongLoRA and OLoRA, which significantly reduce memory footprints and training costs while preserving semantic reasoning capabilities [
42,
43]. Larger models such as GPT-3.5 and Falcon-40B were evaluated but excluded due to high inference latency (≈80 ms per packet), whereas the compact BERT-LoRA configuration maintained real-time performance (≈12 ms per packet) with a balanced trade-off between accuracy and efficiency.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}