
DefAn: Definitive Answer Dataset for LLM Hallucination Evaluation

 , and
, and
Abstract
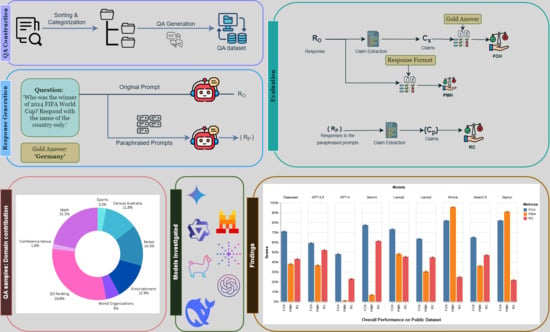
1. Introduction
- Factual Accuracy: This facet assesses the LLM’s ability to generate information grounded in verifiable reality.
- Faithfulness to the Prompt: Here, the focus shifts to evaluating how well the LLM adheres to the intent and style of the provided prompt.
- Consistency of Generated Responses: This dimension assesses the LLM’s ability to maintain consistency within its generated outputs, ensuring a logical and coherent flow of information.
2. Related Works
3. Proposed DefAn Dataset
3.1. Dataset Overview
3.2. Design Basics
3.3. Factuality Domains
3.4. Question Generation
4. Experiment
Experimental Setup
5. Result Analysis
5.1. Performance Comparison for Specific Domains
5.2. Overall Performance
5.3. Closed-Source Large Models vs. Open-Source Small Models
5.4. Ablation Study
5.5. Possible Use Cases of DefAn
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| BERT | Bidirectional Encoder Representations from Transformers |
| DefAn | Definitive Answer based dataset |
| FCH | Fact Contradicting Hallucinations |
| FELM | Factuality Evaluation of Large Language Models |
| FIFA | Fédération Internationale de Football Association |
| LFPQ | Long-Form Generation Questions |
| LLM | Large Language Model |
| MCQ | Multiple-Choice Question |
| NLP | Natural Language Processing |
| NER | Named Entity Recognition |
| OIC | Organisation of Islamic Cooperation |
| PMH | Prompt Misalignment Hallucinations |
| QA | Question Answering |
| QS | Question Set |
| RAG | Retrieval-Augmented Generation |
| RC | Response Consistency |
| SoTA | State of the Art |
| UN | United Nations |
References
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Akhtar, N.; Barnes, N.; Mian, A. A Comprehensive Overview of Large Language Models. ACM Trans. Intell. Syst. Technol. 2025, 16, 1–72. [Google Scholar] [CrossRef]
- Rawte, V.; Sheth, A.; Das, A. A survey of hallucination in large foundation models. arXiv 2023, arXiv:2309.05922. [Google Scholar] [CrossRef]
- Perković, G.; Drobnjak, A.; Botički, I. Hallucinations in llms: Understanding and addressing challenges. In Proceedings of the 2024 47th MIPRO ICT and Electronics Convention (MIPRO), Opatija, Croatia, 20–24 May 2024; IEEE: New York, NY, USA, 2024; pp. 2084–2088. [Google Scholar]
- Lan, W.; Chen, W.; Chen, Q.; Pan, S.; Zhou, H.; Pan, Y. A Survey of Hallucination in Large Visual Language Models. arXiv 2024, arXiv:2410.15359. [Google Scholar] [CrossRef]
- Hao, G.; Wu, J.; Pan, Q.; Morello, R. Quantifying the uncertainty of LLM hallucination spreading in complex adaptive social networks. Sci. Rep. 2024, 14, 16375. [Google Scholar] [CrossRef] [PubMed]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Tonmoy, S.; Zaman, S.; Jain, V.; Rani, A.; Rawte, V.; Chadha, A.; Das, A. A comprehensive survey of hallucination mitigation techniques in large language models. arXiv 2024, arXiv:2401.01313. [Google Scholar] [CrossRef]
- Adlakha, V.; BehnamGhader, P.; Lu, X.H.; Meade, N.; Reddy, S. Evaluating correctness and faithfulness of instruction-following models for question answering. arXiv 2023, arXiv:2307.16877. [Google Scholar] [CrossRef]
- Muhlgay, D.; Ram, O.; Magar, I.; Levine, Y.; Ratner, N.; Belinkov, Y.; Abend, O.; Leyton-Brown, K.; Shashua, A.; Shoham, Y. Generating benchmarks for factuality evaluation of language models. arXiv 2023, arXiv:2307.06908. [Google Scholar]
- Zhang, Y.; Li, Y.; Cui, L.; Cai, D.; Liu, L.; Fu, T.; Huang, X.; Zhao, E.; Zhang, Y.; Chen, Y.; et al. Siren’s song in the AI ocean: A survey on hallucination in large language models. arXiv 2023, arXiv:2309.01219. [Google Scholar] [CrossRef]
- Li, J.; Consul, S.; Zhou, E.; Wong, J.; Farooqui, N.; Ye, Y.; Manohar, N.; Wei, Z.; Wu, T.; Echols, B.; et al. Banishing LLM hallucinations requires rethinking generalization. arXiv 2024, arXiv:2406.17642. [Google Scholar] [CrossRef]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv 2023, arXiv:2311.05232. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, J.; Chern, I.; Gao, S.; Liu, P.; He, J. Felm: Benchmarking factuality evaluation of large language models. Adv. Neural Inf. Process. Syst. 2024, 36, 4502–44523. [Google Scholar]
- Li, J.; Cheng, X.; Zhao, W.X.; Nie, J.Y.; Wen, J.R. Halueval: A large-scale hallucination evaluation benchmark for large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 6449–6464. [Google Scholar]
- Zhu, Z.; Yang, Y.; Sun, Z. HaluEval-Wild: Evaluating Hallucinations of Language Models in the Wild. arXiv 2024, arXiv:2403.04307. [Google Scholar]
- Thakur, A.S.; Choudhary, K.; Ramayapally, V.S.; Vaidyanathan, S.; Hupkes, D. Judging the judges: Evaluating alignment and vulnerabilities in llms-as-judges. arXiv 2024, arXiv:2406.12624. [Google Scholar] [CrossRef]
- Chen, X.; Wang, C.; Xue, Y.; Zhang, N.; Yang, X.; Li, Q.; Shen, Y.; Liang, L.; Gu, J.; Chen, H. Unified hallucination detection for multimodal large language models. arXiv 2024, arXiv:2402.03190. [Google Scholar] [CrossRef]
- Luo, J.; Li, T.; Wu, D.; Jenkin, M.; Liu, S.; Dudek, G. Hallucination detection and hallucination mitigation: An investigation. arXiv 2024, arXiv:2401.08358. [Google Scholar] [CrossRef]
- Valentin, S.; Fu, J.; Detommaso, G.; Xu, S.; Zappella, G.; Wang, B. Cost-effective hallucination detection for llms. arXiv 2024, arXiv:2407.21424. [Google Scholar] [CrossRef]
- Mishra, A.; Asai, A.; Balachandran, V.; Wang, Y.; Neubig, G.; Tsvetkov, Y.; Hajishirzi, H. Fine-grained hallucination detection and editing for language models. arXiv 2024, arXiv:2401.06855. [Google Scholar] [CrossRef]
- Hu, X.; Ru, D.; Qiu, L.; Guo, Q.; Zhang, T.; Xu, Y.; Luo, Y.; Liu, P.; Zhang, Y.; Zhang, Z. RefChecker: Reference-based Fine-grained Hallucination Checker and Benchmark for Large Language Models. arXiv 2024, arXiv:2405.14486. [Google Scholar]
- Yang, S.; Sun, R.; Wan, X. A new benchmark and reverse validation method for passage-level hallucination detection. arXiv 2023, arXiv:2310.06498. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Z.; Das, K.; Malin, B.A.; Kumar, S. SAC3: Reliable Hallucination Detection in Black-Box Language Models via Semantic-aware Cross-check Consistency. arXiv 2023, arXiv:2311.01740. [Google Scholar]
- Lin, S.; Hilton, J.; Evans, O. Truthfulqa: Measuring how models mimic human falsehoods. arXiv 2021, arXiv:2109.07958. [Google Scholar]
- Cheng, Q.; Sun, T.; Zhang, W.; Wang, S.; Liu, X.; Zhang, M.; He, J.; Huang, M.; Yin, Z.; Chen, K.; et al. Evaluating hallucinations in chinese large language models. arXiv 2023, arXiv:2310.03368. [Google Scholar] [CrossRef]
- Kasai, J.; Sakaguchi, K.; Le Bras, R.; Asai, A.; Yu, X.; Radev, D.; Smith, N.A.; Choi, Y.; Inui, K. RealTime QA: What’s the Answer Right Now? Adv. Neural Inf. Process. Syst. 2024, 36, 49025–49043. [Google Scholar]
- Li, W.; Li, L.; Xiang, T.; Liu, X.; Deng, W.; Garcia, N. Can multiple-choice questions really be useful in detecting the abilities of LLMs? arXiv 2024, arXiv:2403.17752. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, S.; Qiang, Z.; Xi, N.; Qin, B.; Liu, T. LLMs May Perform MCQA by Selecting the Least Incorrect Option. arXiv 2024, arXiv:2402.01349. [Google Scholar]
- Bang, S.; Kim, M.; Lee, H.; Choi, Y. HalluLens: A Fine-Grained Benchmark for Evaluating Intrinsic and Extrinsic Hallucinations in Large Language Models. arXiv 2025, arXiv:2504.17550. [Google Scholar]
- Wang, X.; Sun, R.; Li, T.; He, J.; Wan, X. HALoGEN: Fantastic LLM Hallucinations and Where to Find Them. arXiv 2025, arXiv:2501.08292. [Google Scholar] [CrossRef]
- Bao, J.; Zhang, X.; Wang, S.; Liu, T.; Li, Z. FaithBench: A Diverse Hallucination Benchmark for Summarization Models. arXiv 2024, arXiv:2410.13210. [Google Scholar]
- Molfese, F.M.; Moroni, L.; Gioffrè, L.; Scirè, A.; Conia, S.; Navigli, R. Right Answer, Wrong Score: Uncovering the Inconsistencies of LLM Evaluation in Multiple-Choice Question Answering. arXiv 2025, arXiv:2503.14996. [Google Scholar] [CrossRef]
- Li, N.; Li, Y.; Liu, Y.; Shi, L.; Wang, K.; Wang, H. HalluVault: A Novel Logic Programming-aided Metamorphic Testing Framework for Detecting Fact-Conflicting Hallucinations in Large Language Models. arXiv 2024, arXiv:2405.00648. [Google Scholar]
- Li, J.; Chen, J.; Ren, R.; Cheng, X.; Zhao, W.X.; Nie, J.Y.; Wen, J.R. The dawn after the dark: An empirical study on factuality hallucination in large language models. arXiv 2024, arXiv:2401.03205. [Google Scholar] [CrossRef]
- Fourrier, C.; Habib, N.; Lozovskaya, A.; Szafer, K.; Wolf, T. Performances Are Plateauing, Let’s Make the Leaderboard Steep Again. 2024. Available online: https://huggingface.co/spaces/open-llm-leaderboard/blog (accessed on 5 September 2025).
- Tunstall, L.; Beeching, E.; Lambert, N.; Rajani, N.; Huang, S.; Rasul, K.; Rush, A.M.; Wolf, T. The Alignment Handbook. 2023. Available online: https://github.com/huggingface/alignment-handbook (accessed on 25 July 2025).
- Jiang, A.Q.; Sablayrolles, A.; Roux, A.; Mensch, A.; Savary, B.; Bamford, C.; Chaplot, D.S.; Casas, D.d.l.; Hanna, E.B.; Bressand, F.; et al. Mixtral of experts. arXiv 2024, arXiv:2401.04088. [Google Scholar] [CrossRef]
- OpenAI. ChatGPT. 2021. Available online: https://openai.com/ (accessed on 5 June 2024).
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar] [CrossRef]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Meta Llama 3. 2024. Available online: https://github.com/meta-llama/llama3 (accessed on 5 June 2024).
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Deepmind, G. Google AI for Developers. 2023. Available online: https://ai.google.dev/gemini-api/docs/models/gemini (accessed on 5 June 2024).
- Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; Bi, X.; et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv 2025, arXiv:2501.12948. [Google Scholar]
- Yang, A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Li, C.; Liu, D.; Huang, F.; Wei, H.; et al. Qwen2. 5 Technical Report. arXiv 2024, arXiv:2409.12186. [Google Scholar]
- He, H.; Lab, T.M. Defeating Nondeterminism in LLM Inference. Thinking Machines Lab: Connectionism. 2025. Available online: https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/ (accessed on 5 September 2025).
- Sharma, M.; Tong, M.; Korbak, T.; Duvenaud, D.; Askell, A.; Bowman, S.R.; Cheng, N.; Durmus, E.; Hatfield-Dodds, Z.; Johnston, S.R.; et al. Towards understanding sycophancy in language models. arXiv 2023, arXiv:2310.13548. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Aspect | Task Type | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Benchmark | Dataset | Language | Size | Factuality | Faithfulness | Consistency | Granularity | Metric | Detection | Evaluation |
| Truthful QA [24] | - | English | 817 | ✓ | Answer | LLM judge, Human | ✓ | |||
| REALTIMEQA [26] | - | English | Dynamic | ✓ | Answer | Acc, F1 | ✓ | |||
| HaluEval [14] | Task-specific | English | 30,000 | ✓ | ✓ | Answer | Acc | |||
| General | 5000 | ✓ | ✓ | Answer | Acc | ✓ | ||||
| HaluQA [25] | Misleading | 175 | ✓ | Answer | LLM judge | ✓ | ||||
| Misleading-hard | Chinese | 69 | ✓ | ✓ | ||||||
| Knowledge | 206 | ✓ | ✓ | |||||||
| FELM [13] | - | English | 3948 | ✓ | ✓ | Response | Balanced acc & F1 | ✓ | ||
| PHD [22] | PHD-Low | English | 100 | ✓ | ✓ | Passage | P, R, F1 | ✓ | ||
| PHD-Medium | 100 | ✓ | ✓ | P, R, F2 | ✓ | |||||
| PHD-High | 100 | ✓ | ✓ | P, R, F3 | ✓ | |||||
| SAC3 [23] | Prime Numbers | 500 | Answer | AUROC | ✓ | |||||
| Seanator Search | 500 | ✓ | ||||||||
| HotpotQA | English | 250 | ✓ | ✓ | ✓ | |||||
| NQ-Open | 250 | ✓ | ||||||||
| HaluEval-wild [15] | - | English | 6505 | ✓ | Response | Acc | ✓ | |||
| HalluVault [33] | - | English | 14,000 | ✓ | Response | Structural similarity | ✓ | |||
| DefAn (Proposed) | Public | English | 68,093 | ✓ | ✓ | ✓ | Response | Hallucination Rate | ✓ | |
| Hidden | English | 7485 | ✓ | ✓ | ✓ | ✓ | ||||
| Original Prompt | Which Team Was the Runner up of 2010 FIFA World Cup? |
|---|---|
| 1. Who was the second-place finisher in the 2010 FIFA World Cup? | |
| 2. Who was the runner-up in the 2010 FIFA World Cup? | |
| 3. What country came in second in the 2010 FIFA World Cup? | |
| 4. Which team ended up as the runner-up in the 2010 FIFA World Cup? | |
| 5. Give me the name of the country who was the runner up in the 2010 FIFA World Cup? | |
| 6. Who clinched the runner-up spot in the 2010 FIFA World Cup? | |
| 7. Which country was the second-place holder in the 2010 FIFA World Cup? | |
| Paraphrased | 8. Which team secured the second position in the 2010 FIFA World Cup? |
| 9. What nation finished as the runner-up in the 2010 FIFA World Cup? | |
| 10. In the 2010 FIFA World Cup, which team came in second? | |
| 11. Who ended up as the runner-up in the 2010 FIFA World Cup? | |
| 12. Which country attained the runner-up position in the 2010 FIFA World Cup? | |
| 13. Who was the second-best team in the 2010 FIFA World Cup? | |
| 14. Which nation was the runner-up in the 2010 FIFA World Cup? | |
| 15. What team took second place in the 2010 FIFA World Cup? |
| # of Samples | Response Type | ||||||
|---|---|---|---|---|---|---|---|
| Domains | Public (Unique) | Hidden (Unique) | Date | Numeric | Name | Location | Paraphrased |
| Sports | 1305 (87) | 1005 (67) | ✓ | ✓ | ✓ | ✓ | ✓ |
| Census Australia | 7905 (527) | 1005 (67) | ✓ | ✓ | |||
| Nobel Prize | 9795 (653) | 1005 (67) | ✓ | ✓ | |||
| Entertainment | 8715 (581) | 1005 (67) | ✓ | ✓ | ✓ | ||
| World Organizations | 2745 (183) | 1005 (67) | ✓ | ✓ | |||
| QS Ranking | 21,495 (1433) | 1005 (67) | ✓ | ✓ | |||
| Conference Venue | 915 (61) | 450 (30) | ✓ | ✓ | |||
| Math | 15,218 (15,218) | 1005 (1005) | ✓ | ||||
| Total | 68,093 (18,743) | 7485 (1437) | |||||
| Metric | Average Similarity |
|---|---|
| Cosine similarity | 0.967 |
| BERTScore | 0.945 |
| LLM-judge (GPT-4.5) | 0.913 |
| LLMs | Developer | Parameters | Context Window | Accessibility |
|---|---|---|---|---|
| Zephyr 7B Beta [36] | Webpilot.ai | 7 B | 8 K | Lemonfox API |
| Mixtral-8x7b [37] | Mistral AI | 7 B | 8 K | Lemonfox API |
| Llama 3 8B [40] | Meta AI | 8 B | 8 K | Lemonfox API |
| Llama 2 7B [39] | Meta AI | 7 B | 4 K | Llama API |
| GPT-3.5 [38] | OpenAI | 175 B * | 4 K | OpenAI API |
| Gemini 1.0 pro [42] | Google DeepMind | Unrevealed | 33 K | Google Gemini API |
| GPT-4o [41] | OpenAI | 1.8 trillion * | 4 K | OpenAI API |
| DeepSeek-r1-7b [43] | DeepSeek | 7 B | 128 k | HuggingFace |
| Qwen2.5-14B [44] | Alibaba Cloud | 14 B | 128 k | HuggingFace |
| Prompts | Answer | LLM Response |
|---|---|---|
| What was the position of Kobe University in the QS rankings for 2022? | 386 | 334 |
| In 2022, where did Kobe University stand in the QS ranking? | 386 | 62 |
| What was the QS ranking of Kobe University for 2022? | 386 | 334 |
| How did Kobe University fare in the QS rankings for 2022? | 386 | Kobe University is located in Japan. |
| What was Kobe University’s QS rank in 2022? | 386 | 386 |
| In 2022, what position did Kobe University secure in the QS rankings? | 386 | 195 |
| What was Kobe University’s standing in the QS rankings for 2022? | 386 | Kobe University is located in Japan and was ranked 334th. |
| In 2022, what was the QS ranking of Kobe University? | 386 | 801–1000 |
| Where did Kobe University place in the QS rankings for 2022? | 386 | Kobe University is not ranked in the QS rankings for 2022. |
| What QS ranking did Kobe University achieve in 2022? | 386 | 334th |
| QS ranking of Kobe University in 2022? | 386 | 467 |
| What position did Kobe University attain in the QS rankings for 2022? | 386 | Kobe University is highly ranked university in the world and was ranked 386th in 2022. |
| What was Kobe University’s QS rating for 2022? | 386 | Kobe University was not ranked in the QS World University Rankings for 2022. |
| Give the specific QS rank of Kobe University in 2022 | 386 | 386th |
| what place did Kobe University achieved in 2022 QS ranking? | 386 | 601–650 |
| Sports | Census | Nobel | Entertainment | World Org. | QS Ranking | Conf. Venue | Math | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | |
| Zephyr | 0.50 | 0.29 | 1.00 | 1.00 | 0.91 | 0.93 | 0.68 | 0.20 | 0.95 | 0.92 | 0.94 | 0.98 | 0.82 | 0.95 | 0.99 | 0.99 |
| Mixtral | 0.20 | 0.13 | 1.00 | 1.00 | 0.59 | 0.60 | 0.56 | 0.11 | 0.69 | 0.44 | 0.88 | 0.98 | 0.52 | 0.63 | 0.98 | 0.97 |
| Llama3 | 0.44 | 0.30 | 1.00 | 1.00 | 0.63 | 0.70 | 0.29 | 0.19 | 0.71 | 0.73 | 0.97 | 0.99 | 0.65 | 0.87 | 1.00 | 0.99 |
| Llama2 | 0.15 | 0.09 | 1.00 | 1.00 | 0.90 | 0.90 | 0.33 | 0.17 | 0.85 | 0.74 | 0.93 | 0.99 | 0.85 | 0.88 | 0.98 | 0.98 |
| GPT-3.5 | 0.17 | 0.11 | 1.00 | 1.00 | 0.35 | 0.52 | 0.10 | 0.19 | 0.57 | 0.38 | 0.93 | 0.98 | 0.31 | 0.60 | 0.98 | 0.98 |
| Gemini | 0.21 | 0.09 | 1.00 | 1.00 | 0.35 | 0.52 | 0.42 | 0.14 | 0.54 | 0.31 | 0.97 | 0.96 | 0.47 | 0.51 | 0.99 | 0.99 |
| GPT-4o | 0.06 | 0.04 | 1.00 | 1.00 | 0.06 | 0.07 | 0.03 | 0.24 | 0.34 | 0.07 | 0.55 | 0.29 | 0.09 | 0.24 | 0.62 | 0.63 |
| DeepSeek | 0.37 | 0.32 | 1.00 | 1.00 | 0.53 | 0.58 | 0.24 | 0.20 | 0.51 | 0.53 | 0.87 | 0.89 | 0.54 | 0.62 | 0.82 | 0.79 |
| Qwen2.5 | 0.34 | 0.26 | 1.00 | 1.00 | 0.56 | 0.60 | 0.23 | 0.15 | 0.64 | 0.65 | 0.93 | 0.94 | 0.59 | 0.68 | 0.92 | 0.89 |
| Sports | Census | Nobel | Entertainment | World Org. | QS Ranking | Conf. Venue | Math | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | |
| Zephyr | 0.87 | 0.98 | 1.00 | 1.00 | 0.96 | 0.98 | 0.76 | 0.41 | 0.99 | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Mixtral | 0.95 | 0.89 | 1.00 | 1.00 | 0.94 | 0.99 | 0.87 | 0.71 | 1.00 | 1.00 | 1.00 | 1.00 | 0.97 | 0.99 | 0.98 | 0.98 |
| Llama3 | 0.18 | 0.34 | 0.98 | 0.99 | 0.16 | 0.26 | 0.01 | 0.03 | 0.78 | 0.74 | 0.52 | 0.56 | 0.24 | 0.26 | 0.04 | 0.04 |
| Llama2 | 0.07 | 0.09 | 0.96 | 0.99 | 0.48 | 0.85 | 0.04 | 0.01 | 0.74 | 0.72 | 1.00 | 0.99 | 0.64 | 0.57 | 0.02 | 0.01 |
| GPT-3.5 | 0.17 | 0.16 | 0.55 | 0.49 | 0.14 | 0.41 | 0.31 | 0.33 | 0.75 | 0.88 | 0.55 | 0.62 | 0.17 | 0.22 | 0.38 | 0.36 |
| Gemini | 0.06 | 0.05 | 0.01 | 0.00 | 0.12 | 0.36 | 0.06 | 0.01 | 0.57 | 0.80 | 0.04 | 0.00 | 0.27 | 0.20 | 0.01 | 0.02 |
| GPT-4o | 0.01 | 0.02 | 0.00 | 0.00 | 0.01 | 0.02 | 0.03 | 0.02 | 0.03 | 0.04 | 0.02 | 0.03 | 0.03 | 0.02 | 0.01 | 0.01 |
| DeepSeek | 0.21 | 0.31 | 0.92 | 0.90 | 0.26 | 0.31 | 0.16 | 0.23 | 0.53 | 0.54 | 0.42 | 0.47 | 0.34 | 0.29 | 0.18 | 0.14 |
| Qwen2.5 | 0.16 | 0.32 | 0.95 | 0.96 | 0.18 | 0.28 | 0.03 | 0.03 | 0.70 | 0.64 | 0.50 | 0.46 | 0.29 | 0.30 | 0.10 | 0.11 |
| Sports | Census | Nobel | Entertainment | World Org. | QS Ranking | Conf. Venue | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | Public | Hidden | |
| Zephyr | 0.19 | 0.15 | 0.00 | 0.00 | 0.10 | 0.11 | 0.43 | 0.59 | 0.13 | 0.15 | 0.13 | 0.10 | 0.47 | 0.43 |
| Mixtral | 0.19 | 0.28 | 0.00 | 0.00 | 0.12 | 0.09 | 0.38 | 0.26 | 0.13 | 0.22 | 0.00 | 0.00 | 0.78 | 0.74 |
| Llama3 | 0.60 | 0.62 | 0.00 | 0.00 | 0.46 | 0.52 | 0.81 | 0.84 | 0.50 | 0.46 | 0.11 | 0.08 | 0.58 | 0.50 |
| Llama2 | 0.94 | 0.97 | 0.00 | 0.00 | 0.36 | 0.21 | 0.96 | 0.97 | 0.28 | 0.31 | 0.09 | 0.0 | 0.47 | 0.43 |
| GPT-3.5 | 0.77 | 0.86 | 0.00 | 0.00 | 0.80 | 0.62 | 0.67 | 0.66 | 0.28 | 0.23 | 0.21 | 0.15 | 0.84 | 0.73 |
| Gemini | 0.82 | 0.91 | 0.00 | 0.00 | 0.79 | 0.74 | 0.89 | 0.93 | 0.79 | 0.72 | 0.15 | 0.16 | 0.78 | 0.42 |
| GPT-4o | 0.71 | 0.56 | 0.00 | 0.00 | 0.32 | 0.09 | 0.64 | 0.94 | 0.64 | 0.76 | 0.10 | 0.09 | 0.73 | 0.43 |
| DeepSeek | 0.64 | 0.67 | 0.00 | 0.00 | 0.49 | 0.62 | 0.78 | 0.82 | 0.60 | 0.51 | 0.17 | 0.12 | 0.68 | 0.59 |
| Qwen2.5 | 0.68 | 0.64 | 0.00 | 0.00 | 0.49 | 0.58 | 0.85 | 0.89 | 0.58 | 0.56 | 0.18 | 0.16 | 0.52 | 0.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahman, A.B.M.A.; Anwar, S.; Usman, M.; Ahmad, I.; Mian, A. DefAn: Definitive Answer Dataset for LLM Hallucination Evaluation. Information 2025, 16, 937. https://doi.org/10.3390/info16110937
Rahman ABMA, Anwar S, Usman M, Ahmad I, Mian A. DefAn: Definitive Answer Dataset for LLM Hallucination Evaluation. Information. 2025; 16(11):937. https://doi.org/10.3390/info16110937
Chicago/Turabian StyleRahman, A. B. M. Ashikur, Saeed Anwar, Muhammad Usman, Irfan Ahmad, and Ajmal Mian. 2025. "DefAn: Definitive Answer Dataset for LLM Hallucination Evaluation" Information 16, no. 11: 937. https://doi.org/10.3390/info16110937
APA StyleRahman, A. B. M. A., Anwar, S., Usman, M., Ahmad, I., & Mian, A. (2025). DefAn: Definitive Answer Dataset for LLM Hallucination Evaluation. Information, 16(11), 937. https://doi.org/10.3390/info16110937