Abstract
Whisper is a transformer-based multilingual model that has illustrated state-of-the-art behavior in numerous languages. However, the efficiency remains persistent with the limited computational resources. To address this issue, an experiment was performed on librispeech-train-clean-100 for training purposes. The test-clean set was utilized to evaluate its performance. To enhance efficiency and to cater the computational needs, a parameter-efficient fine-tuning technique, i.e., Low-Rank Adaptation, was employed to add a limited number of trainable parameters into the frozen layers of the model. The results showed that Low-Rank Adaptation attained excellent Automatic Speech Recognition results while using fewer computational resources, showing its effectiveness for resource-saving adaptation. The research work emphasizes the promise of Low-Rank Adaptation as a lightweight and scalable fine-tuning strategy for large speech models using a transformer architecture. The baseline Whisper Small model achieved a word error rate of 16.7% without any parameter-efficient adaptation. In contrast, the Low-Rank Adaptation enhanced fine-tuned model achieved a lower word error rate of 6.08%, demonstrating the adaptability of the proposed parameter-efficient approach.
1. Introduction
ASR stands as a quick-evolving technological platform which unites signal processing with machine learning and linguistic usage methods. Through text generation from spoken input, the system enables users to access applications, which include voice assistants, transcription tools, and accessibility aids along with real-time translation applications. ASR features consist of analytical components, i.e., acoustic segments, linguistic segments, and computational segments. The acoustic model takes speech as an input and identifies useful features and maps the features to the desired phonetic units through a distinctive deep learning technique. The linguistic module uses language model in order to provide grammatical structure, contextual dependencies and word probabilities, hence promoting high-quality levels of transcribed texts. The computational component works on specified strong operations that are demanded by ASR systems, using high-performance hardware and guarantee a real-time operation and prompt functioning. The computational segment utilizes large processors [1,2].
Early ASR systems functioned via modular pipelines, such as Hidden Markov Model (HMM)- and Gaussian Mixture Model (GMM)-based acoustic models. Language modeling used statistical methods like n-gram probabilities, followed by lexicon-based approaches and handcrafted features like Mel-Frequency Cepstral Coefficients (MFCCs) and Perceptual Linear Predictive (PLP). The advent of deep learning has opened the door to end-to-end models that integrate these modules. One key development is Wav2Vec 2.0, which introduced a self-supervised learning method to learn strong speech representations from raw audio without transcriptions. The architecture includes a feature encoder that maps audio to latent representations via convolutional layers and a context network founded on transformers that learns temporal dependencies to encode long-range patterns in speech. Taking a cue from BERT, Wav2Vec 2.0 uses masked prediction during training, in order to predict the missing part of speech through their context. This strategy highly boosts performance while reducing reliance on labeled data [3,4,5].
Additionally, the feature encoder foundation from Wav2Vec received additional capabilities through vector quantization approaches, i.e., VQ-Wav2Vec. The feature encoder passed the output to a finite set of learnable codebook entries instead of keeping continuous features in VQ-Wav2Vec. The quantization operation turns continuous audio into token sequences, which allows BERT-like sequence-to-sequence models to perform downstream audio processing tasks. The training technique for VQ-Wav2Vec consists of two stages, i.e., contrastive loss-based self-supervised learning and fine-tuning. These techniques have enhanced robustness and generalization in learned representations. However, the effective use of codebook management in the context of the vector quantization models is highly important in order to make sure that the significant acoustic features, like phonetic and prosodic information, are maintained even after compression [6].
Parallel progress in sequence modeling architectures such as RNNs and transformer-based models has significantly improved ASR performance through better temporal representation of speech. The transformer architecture illustrated an ability to capture the dependencies of long-range in sequences making the system to connect remote components in the spoken input through its exceptional ability to identify distant connections across sequential data. The self-attention framework enables the system to perform efficient global contextual relationship extraction across entire sequence units. The self-attention transformer-based frameworks enables effective modeling of interactions among elements within a sequence, allowing the system to capture global context and meaning. Moreover, the transformers demonstrated strong capabilities, but they struggle to handle local structures needed to properly recognize fine phonetic sounds in speech. A solution to this challenge came with the overview of Conformer architecture, which incorporates convolutional elements inside transformer structures. The use of self-attention and convolutional operations within Conformers leads to improved accuracy combined with consistent performance stability during ASR operations. The addition of Conformers brings higher performance and resource demands in standard transformer models [7,8].
In contrast, the recurrent neural network architecture processes input data step-by-step. The transformer architectures leverage parallel computation, significantly enhancing their efficiency and scalability. However, central to the transformer’s design is the self-attention mechanism, a process that evaluates the interdependence among all input elements simultaneously. The mechanism enables the model to effectively grasp both short-range and long-range contextual relationships within the data [9].
The development of ASR led OpenAI to create Whisper by training the model in multilingual and multitasking functions using 680,000 h of internet-sourced noisy audio data. The combination of Wav2Vec self-supervision with transformer-based architecture and massive diverse training practices in Whisper produces an extremely reliable ASR system. The system demonstrates exceptional performance in speech transcription together with multilingual translation and language identification features under diverse acoustic conditions, i.e., dialects and languages. The Whisper system, which is identified as a cutting-edge solution for ASR, combines breakthroughs, i.e., supervised learning, sequential data modelling, and large-scale multilingual training [10,11].
The contribution of the study is the fine-tuning of the Whisper Small model 244 M, which strikes a good balance between speed and accuracy. The Adam and Adam W optimizers are used to obtain efficient gradient updates and generalization performance. Whisper models, even though effective, are computationally intensive at the time of fine-tuning. An efficient approach to solve this bottleneck is LoRA, which is a parameter-efficient fine-tuning method specifically designed for pre-trained large-scale models. The main mechanism of LoRA is to freeze the original weights of the model. The approach adds small, trainable, low-rank matrices to particular layers usually in the attention and feed-forward parts. Additionally, the significant advantages of LoRA are the reduction of trainable parameters by a substantial margin. The optimization leads to much lower GPU memory usage and faster convergence training. Moreover, the method maintains the performance normally obtained using full fine-tuning and enables deployment in systems with limited computational resources. The mostly adopted method LoRA has made it convenient to convert large models such as Whisper to domain-specific tasks without full fine-tuning [12].
1.1. Research Gap
Whisper has made tremendous strides in automated speech recognition (ASR). Most of the existing research work relies on full-model fine-tuning, which is computationally demanding and impractical in resource-constrained settings. In order to address growing computational needs, LoRA has been utilized. Low-Rank Adaptation (LoRA) is one of the most recent developments in parameter-efficient fine-tuning (PEFT) techniques which has demonstrated potential in lowering the training footprint while preserving competitive performance. The research addresses the challenges of high computational cost using LoRA alongside Whisper Small. Firstly, there is a dearth of systematic evaluation of LoRA in ASR. In this regard, there are few studies which have explored the usage of LoRA with respect to Whisper Small model. Secondly, the use of optimizers such as Adam and AdamW have been used to fine-tune entire models in the review of the literature. However, their behavior under LoRA-based adaptation has not been thoroughly examined. Thirdly, the role of training granularity, which mainly highlights the differences between sample-wise and batch-wise approaches, is underreported. Therefore, the current research focuses to propose the solution for above mentioned challenges which have not been explored.
1.2. Novelty of the Research Work
The research work provides the detailed comparisons of optimizers, i.e., Adam and AdamW, with the utilization of the LoRA-based ASR framework, emphasizing their impacts on training dynamics and model efficacy. Additionally, a detailed comparison between batch-wise and sample-wise training methods is presented, which shows how these comparisons affect convergence and error rates. The research work has shown that large-scale ASR models can be optimized using reduced computational resources which makes them well-suited for resource-constrained environment. Moreover, the train-clean-100 subset of LibriSpeech experiments provides in-depth evaluations, which can be used as a guide for further studies on the adaptation of parameter-efficient ASR models.
2. Literature Review
Whisper’s capabilities have been expanded in recent research work to handle a variety of ASR difficulties, notably those involving overlapping speech, resource-limited environments, and oral proficiency assessment. For example, SQ-Whisper attained up to 15% lower WER than preceding models by incorporating a dynamic SQ-Former block and speaker-querying procedure to handle multi-speaker input [13]. Similarly, Whisper has been employed to automate assessments of oral competency in educational settings. A WER of 12.1% was achieved, demonstrating a strong correlation to human raters. However, the performance tended to decline for speakers with lower proficiency levels [14]. In terms of Persian speakers, a combination of augmentation and hyper-parameter optimization has been performed to fine-tune Whisper Small while lowering the WER from 32.93% to 27.15%, exceeding baseline models [15]. In addition, Whisper obtained up to a 41% WER reduction in Chinese dialects through the use of Speech-based In-Context Learning (SICL), which allows Whisper to adapt to new accents and domains without fine-tuning [16]. Whisper was employed to generate huge auto-labeled datasets for Visual Speech Recognition, yielding 12% WER while retaining 99% of the linguistic content [17].
A key component of Whisper’s advancement for low-resource speech primarily depends on parameter-efficient fine-tuning techniques. S2-LoRA and other techniques illustrated strong performance, achieving a CER of 8.67% while lowering trainable parameters to 0.02% [18]. Similarly, the catastrophic forgetting in Tibetan and Uyghur people was effectively dealt with by orthogonal fine-tuning techniques, i.e., O-LoRA and O-AdaLoRA. O-AdaLoRA had a WER of 50.45% using only 1.36 M parameters [19]. Notable WER reductions (from 56.94% to ~17–21%) improved effectiveness through rapid training, which were demonstrated by additional comparative experiments that investigated vanilla fine-tuning, bottleneck adapters, and LoRA on FLEURS [20]. The agglutinative morphology and complex orthography of Turkish ASR have resulted in variations in LoRA adaptation across different datasets [21].
However, scalability to larger models like Whisper-244 M remained limited. LoRA’s competence examined in Whisper’s Chinese adaptation was examined. For instance, Whisper-74 M needed only 8.69 GB with LoRA, whereas full fine-tuning required 14.99 GB [22]. In NLP benchmarks like GLUE and SAMSum, LoRA outperformed full fine-tuning and decreased training costs, despite challenges with rank selection and batch processing beyond ASR [23]. These results highlighted the effectiveness of LoRA-based fine-tuning, Whisper’s adaptability, and the need for further research on language-specific adaptation strategies, dataset augmentation, and multilingual resilience.
The review of the literature highlights two main perspectives. The first perspective deals with the full fine-tuning of Whisper model which demands significant memory and computational resources making it challenging for deployment in resource-limited environments. The second perspective explores parameter-efficient approaches, i.e., LoRA, that mitigate the previously mentioned challenges by reducing the number of trainable parameters and diminishing memory utilization. While synthesizing the review of the literature, the importance of resource-efficient fine-tuning method has been highlighted, which can produce promising results in comparison with full fine-tuning of the Whisper model.
3. Materials and Methods
This section provides a general overview of the various components employed in the methodology as shown in Figure 1.
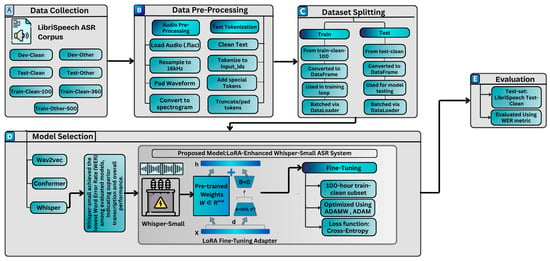
Figure 1.
Proposed methodology.
3.1. Data Workflow and Processing Stages
The methodology is divided into five major components, i.e., dataset collection, data pre-processing, dataset splitting, model selection, proposed model, and fine-tuning and model evaluation, as shown in Figure 1.
3.1.1. Dataset Collection
A well-organized benchmark dataset, i.e., LibriSpeech, was utilized for the assessment of model performance. LibriSpeech is an English audio transcript corpus, derived from public domain audiobooks. The dataset contains approximately 1000 h of correctly segmented and human-transcribed speech of 16 kHz [24].
The transcriptions and segmentation of every audio file is given, enabling to perform extremely well for model training and evaluation. The distinguishing features of LibriSpeech is that it has a strong structure and resilient framework.
The subset is divided into several divisions, i.e., the “clean” and “other” categories that represent different levels of background noise and speaker enunciation. The “clean” subset contain speech with low levels of background noise and higher enunciation therefore, ideal for model development. The “other” subsets contain complex audio with higher acoustic variability and are best used for robust evaluation of ASR systems. The experimental setup utilized the LibriSpeech Corpus with its standard partition configuration, where train-clean-100 subset is used for model training, while the test-clean subset is employed for evaluation.
In addition, the separate portions are made for training, development, and testing, allowing for rigorous evaluation of model generalization. Furthermore, LibriSpeech provides human-aligned, word-level, time-stamped transcriptions to enable accurate supervision of model training. Furthermore, the speaker metadata, like gender and speaker_id, make it more suitable for speaker adaptation.
3.1.2. Data Pre-Processing
The data pre-processing stage involves a two-sided synchronized workflow in which one pipeline was for the audio pre-processing, while the second was geared toward text tokenization. In addition, the audio stream was pre-processed by loading the ‘.flac’ file into the model. Additionally, in order to handle audio of different lengths in a batch, dynamic padding was used, where each waveform was padded to have the same duration as the longest sample in the batch. The padded waveforms were subsequently fed into Log-Mel spectrogram conversion with the Whisper feature extractor so that the model could decode the acoustic signal in an appropriate format for transformer-based models. Moreover, the respective textual transcripts were normalized by reducing all characters to lowercase, removing punctuation, and reducing textual variation. The cleaned text was tokenized with Whisper’s tokenizer, which converted the cleaned sentences into numerical token IDs. The padding and truncation were also performed as necessary, and special tokens were inserted to mark the start and end of each sequence. However, the pre-processing was performed in two parallel paths, which dealt with two different streams of data output, which were ready to feed into the chosen models for a consistent process.
3.1.3. Dataset Splitting
After following the pre-processing step, the dataset was logically divided into two separate parts, i.e., training and testing. The train-clean-100 portion of the LibriSpeech corpus, which includes about 100 h of labelled speech, was chosen exclusively for training the model. The subset offered a balanced compromise between adequate volume of data and computational tractability for fine-tuning. However, the test-clean subset was used as the evaluation set to estimate the model performance, providing a clean and standardized reference point for transcription accuracy on unseen samples. In addition, the learning of the model was strictly limited to the training set via supervised optimization, whereas the evaluation set was left unaltered until after training to measure generalization performance. The rigorous separation protected against overfitting and allowed for valid measurement of model performance.
3.1.4. Model Selection: Whisper Architecture
A several state-of-the-art (SOTA) speech recognition models such as Conformer and Wav2Vec 2.0 have shown promising transcription accuracy. The research work uses the OpenAI Whisper Small model, which has strong zero-shot capabilities and covers many languages. Due to multilingual support, it can be used for new languages and tasks without optimizing for specific tasks.
Whisper architecture is based on a transformer encoder-decoder design that breaks the input audio into 30 s chunks and turns into Log-Mel spectrograms in the form of features. The overlapping chunks are made to keep things consistent while processing longer sentences. Subsequently, while going through positional encodings and convolutional layers, the transformer encoder achieves higher-level contextual and linguistic representations from the spectrogram features as shown in Figure 2. Furthermore, the decoder uses self-attention on the tokens and cross-attention on the encoded features to make transcriptions in an autoregressive way [9,10]. Table 1 provides the configuration details for various Whisper architectures used in this study.
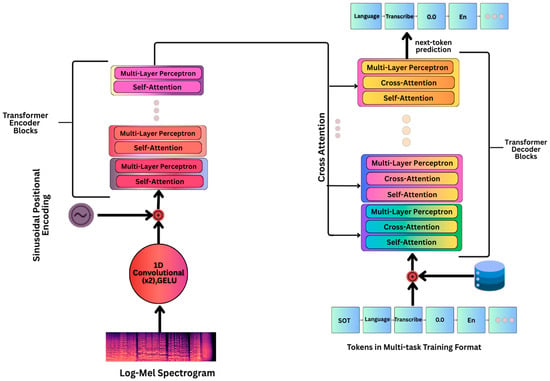
Figure 2.
Architecture of whisper model for end-to-end speech recognition adapted from [10].

Table 1.
Configuration parameters of Whisper variants.
3.1.5. Proposed Model and Fine-Tuning
In this research work, LoRA was implemented to the Whisper Small model’s multi-head attention layers, i.e., query (Q) and value (V) projection matrices. The full-rank weight matrices remained frozen, and only the low-rank adapter parameters were trained.
Mathematically, each projection matrix adds a low-rank update that is described as in Equation (1)
where .
The effective projection becomes as shown in Equation (2)
The query and value projection matrices of all attention layers had Low-Rank Adaptation to parameter-efficient fine-tuning and reproducibility. LoRA injects trainable low-rank matrices into the attention mechanism so that the model can be fine-tuned while leaving most of the pre-trained weights remained unchanged as shown in Figure 3.
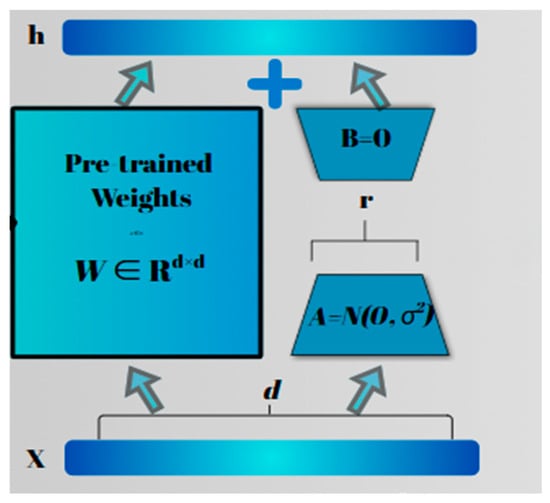
Figure 3.
LoRA fine-tuning adapter.
The modified forward pass is given by:
h = Wx + BAx
Since B = 0 at initialization, the model begins as original to pre-trained model, and only the low-rank parameters A and B are being updated through the fine-tuning, while the original weights W remain frozen as shown in Equation (3).
where
- W is the frozen pre-trained weight matrix;
- A ∈ Rd×r, B ∈ Rr×k are trainable matrices;
- ensuring a significant reduction in trainable parameters.
During fine-tuning, the audio inputs were normalized to a 16 kHz sampling rate and passed through the feature extractor to produce Log-Mel Spectrograms. To enable batching, all inputs were either padded or truncated to a constant sequence length. The transcription labels were tokenized and aligned with the input features. The Adam and AdamW optimizers (learning rate = 1 × 10−4) with cross-entropy loss were used to fine-tune the Whisper Small model. The convergence and WER were compared under batch-wise (batch size 8) and sample-wise (batch size 4) training setups. In order to handle GPU memory constraints, the fine-tuning procedure incorporated gradient accumulation along with mixed-precision training facilitated through PyTorch (v2.7.0)’s auto cast and GradScaler.
After the fine-tuning, as an evaluation measure, the model chooses to perform greedy decoding through model_generator () choosing the highest-probability token at every step without beam search or sampling. The generated transcriptions were normalized by removing punctuation and lowercasing. The performance was measured with the Word Error Rate (WER), calculated through the Jiwer library.
3.1.6. Model Evaluation
Once the fine-tuning phase was completed, the Whisper Small model had to be evaluated systematically for performance using the test-clean split of the LibriSpeech dataset for measuring transcription accuracy and determining generalization. A structured workflow was implemented to maintain reproducibility and efficiency during evaluation. However, the design of the evaluation workflow was arranged to have a high level of scalability and to perform well on the most basic computational infrastructure. In addition, the training pipeline loads every sample of the audio data dynamically and prepares it through the standardized preprocessing and feature extraction preprocessing steps outlined in the Whisper architecture. The processed inputs were batched at the input level to the model’s decoder through the generate function, which supports parallelized autoregressive transcription.
The output sequences, which were token IDs, decoded to text through the tokenizer’s batch_ decode method, set to ignore special tokens in decoding. In addition, for an unbiased evaluation against ground-truth labels, predicted and reference texts were both normalized through case folding to lowercase and removal of punctuation, apostrophes, and unnecessary spaces. However, the normalization minimized superficial differences to enable evaluation to be based exclusively on linguistic precision. In the absence of normalization, the WER was estimated to be 100 percent, implying that the test was skewed toward superficial errors, including variations in the punctuation, casing, and formatting. The WER was reduced to 6.08% after normalization, which confirmed the need to apply the procedure of normalization in order to make sure that the evaluation results were based on the actual linguistic accuracy instead of the differences in formatting.
The primary evaluation metric is WER, a standard widely used in speech recognition which is defined as the number of word-level operations such as insertions, deletions, and substitutions required to align the predicted transcript with the reference, normalized by the total number of words in the reference. However, the metric was calculated using the Jiwer library, which is recognized for its flexibility and accuracy in evaluating ASR systems [25,26].
WER is calculated by the following Equation (4).
where
- S = number of substitutions (wrong word instead of the correct one);
- D = number of deletions (a word that was missed);
- I = number of insertions (an extra word that was not in the reference);
- N = total number of words in the reference (ground truth).
The evaluation showed that the LoRA fine-tuned Whisper model updated only a few parameters while retaining strong transcription accuracy. The final WER achieved competitive performance, which further confirms the effectiveness of Low-Rank Adaptation as a lightweight method for domain-specific tuning. The model also exhibited consistent robustness to different speaker profiles and acoustic conditions within the test-clean data, which emphasizes the resilience of the core architecture of Whisper and the adaptability introduced by efficient fine-tuning.
3.1.7. Pseudo-Code
The pseudo-code illustrates the initialization, data processing, model training, and evaluation workflow for fine-tuning Whisper Small with LoRA, utilizing Adam and AdamW in batch-wise and sample-wise configurations.
4. Experimental Results
The section summarizes the findings of fine-tuning experiments which were performed on the Whisper Small model with Low-Rank Adaptation (LoRA) with various configuration settings.
4.1. Hyper-Parameter Tuning and Optimization
The Whisper Small has been selected as the baseline architecture; LoRA was applied to the model to enhance training efficiency while minimizing the number of trainable parameters. A set of fine-tuning experiments was performed to compare the effect of various training settings on model performance. The three important hyper parameters were systematically tuned, such as the optimizer type, batch size, and training granularity, i.e., batch-wise vs. sample-wise. The LoRA configuration never changed throughout all experiments (rank = 8, α = 16, dropout = 0.1) to make a fair comparison.
4.1.1. Optimizer Analysis
The results of both optimizers, i.e., Adam and AdamW, on the training granularities are shown in Table 2. The training was performed (batch-wise) with batch size of 8, which shows that AdamW outperformed Adam. However, under a sample-wise configuration with a lower batch size, i.e., 4, Adam performed better than AdamW by achieving a lower word error rate (WER) of 6.08%.
Table 2.
WER variation across optimizers and training granularities.
The comparative analysis of the Adam and AdamW optimizers across different training granularities revealed that AdamW performs better in batch-wise training (batch-size 8), while Adam yields superior results in sample-wise training (batch size 4), achieving a lower word error rate (WER) of 6.08%. These results suggest that the choice of optimizer should be aligned with the training configuration to maximize performance.
These findings indicated that Adam is more sensitive to high-variance updates, appreciating finer-grained training steps, and AdamW performs consistently but conservatively across configurations settings. These results are found to be consistent with the research study [27].
4.1.2. Batch-Wise vs. Sample-Wise Evaluation
The two gradient update granularities, named as batch-wise and sample-wise, were evaluated with two optimizers, i.e., Adam and AdamW. The optimizers were utilized to examine the impact of training strategy on model performance. The model trained with a batch size 8 (batch-wise) resulted in a WER of 7.98% on AdamW, which was slightly better in comparison with Adam, which had a WER of 8.45% under the same configuration [28].
On the contrary, when trained with batch size 4 (sample-wise), Adam achieved better results than AdamW, with a WER of 6.08%, as opposed to 8.02% using AdamW, indicating superior adaptability to fine-grained updates. A comparative summary of these results is presented in Table 3.
Table 3.
Influence of batch size on performance under various optimizers.
The results demonstrated that smaller batch sizes add gradient noise, which enhances generalization, especially in ASR systems [28].
4.2. Visual Analysis of Training Behavior
The training behavior of the Whisper Small model was examined by tracking the loss and WER curves to gain insights into convergence behavior, optimizer sensitivity, and generalization capability.
4.2.1. Training Loss Curve
The training loss curve of both optimizers, i.e., AdamW and Adam, are explained in the section below.
AdamW Optimizer Loss
Figure 4 illustrates the training loss curves for AdamW under different update granularities. The batch size 8 (batch-wise) produced a smoother and linear loss reduction, which indicates AdamW’s stability in low-variance settings. However, in comparison, the batch size 4 (sample-wise) showed higher variance, but eventually converged, demonstrating that the batch-wise setup was more effective for AdamW in this scenario [29].
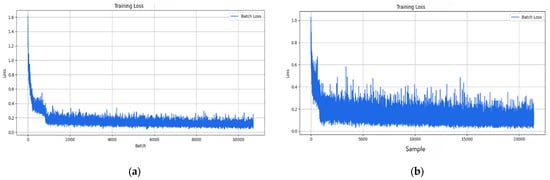
Figure 4.
Training loss curves for the AdamW optimizer: (a) loss curve batch size 8 (batch-wise), (b) loss curve batch size 4 (sample-wise).
Adam Optimizer Loss
The Adam training loss curves are illustrated in Figure 5, revealing distinct divergence behavior based on the training granularity. The training (sample-wise) with a batch size of 4 provided a faster and consistent decrease in loss, which is aligned with the fine-grained responsiveness of Adam. On the other hand, the training (batch-wise) with a batch size of 8 converged slowly and increased loss, which indicates reduced gradient variance and possible convergence to sharp minima. However, the training with large batch sizes frequently leads models convergence toward sharp minima, which are linked with sub-optimal generalization performance on the unseen test data [30].
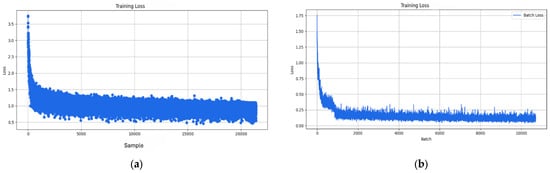
Figure 5.
Training loss curves for the AdamW optimizer: (a) loss curve batch-size 4 (sample-wise), (b) loss curve batch-size 8 (batch-wise).
4.3. WER Progression Curve
4.3.1. AdamW Optimizer WER
Figure 6 shows that AdamW had generally consistent WER trends under both training settings. The batch-wise setup (batch size 8) resulted in a WER of 7.98%, which performed significantly better than the sample-wise configuration (batch-size 4), which achieved a WER of 8.02%. In spite of its stability, AdamW performed worse than Adam when trained in sample-wise experimental conditions [31].
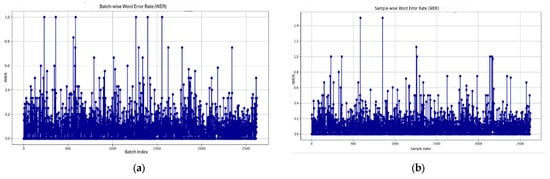
Figure 6.
WER progression for the AdamW optimizer: (a) WER graph batch size 8 (batch-wise), (b) WER graph batch size 4 (sample-wise).
4.3.2. Adam Optimizer WER
The WER improvement in Figure 7 indicated that Adam performed better under sample-wise training (batch size 4), attaining a lower WER of 6.08%. This pattern specifies that more frequent weight updates improve the generalization ability of the Adam optimizer. On the contrary, the batch-wise setting (batch size 8) led to achieving a lower WER of 8.45% [32].
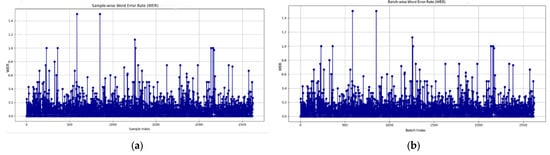
Figure 7.
WER progression for the Adam optimizer: (a) WER graph batch size 4 (sample-wise), (b) WER graph batch size 8 (batch-wise), sample-wise and batch-wise.
Table 4 presents a comparative analysis of the proposed method with existing studies. The results show that the fine-tuned Whisper-small model with LoRA outperforms previous ASR approaches in terms of WER, demonstrating its superior performance.
Table 4.
Research synthesis.
5. Discussion
The findings reflected that Adam performed better in the sample-wise configurations. However, AdamW performed better in batch-wise configurations. The behavior is due to the functional differences between optimizers, i.e., Adam and AdamW. For instance, Adam uses per-parameter adaptive learning rates to handle small-batch training’s high variation and noisy gradients. The flatter minima can be optimized by such noise, which increases the generalization [30].
However, AdamW decouples weight decay from the adaptive gradient update, while regularization directly affects weights rather than gradient estimates [31]. The gradients computed over bigger and stable batches demonstrate better convergence and generalization.
The batch size is one of the most significant aspect of model generalization. The stochastic noise in gradient updates from smaller batches prevents convergence to sharp minima and encourages smoother solutions with better generalization [30]. However, large batch sizes limit the intrinsic regularization effect, resulting in sharper minima and poorer generalization capacity without compensatory techniques like prolonged training or adjusted learning rate schedules. The findings from the experiments were found to be aligned with the theoretical arguments in the existing body of knowledge.
LoRA adapts Whisper Small in a parameter- and computationally efficient manner. The possibilities to express the complex task-specific transformations of LoRA were restricted by constraining model adaptation to low-rank updates (∆W = BA). In the cases where the target domain or task distribution is very different than the pre-training corpus, e.g., distinct languages, specialized vocabularies, or domain-specific acoustic properties, the low-rank parameterization might not be able to represent all the representational demands, leading to poor performance. The potential mitigating strategies that expand the effective parameter space available during adaptation include increasing the LoRA rank or optimizing the entire model [19,23]. These results are consistent with the prior studies highlighting that LoRA works effectively in domain-similar and low-resource environments, while it loses effectiveness when domain shift or cross-lingual adaptation is significant.
To examine the sensitivity of LoRA with respect to rank, an exploratory run was performed with a reduced rank configuration using R = 4, α = 8, dropout = 0.1 using AdamW with a batch size of 4; sample-wise updates reduced the trainable parameters to 442,368 (0.1827% of the model) but resulted in a substantial poor performance with a WER rising to 40.23%. The preliminary results already indicated that a low-rank alpha limits the model’s capacity leading to poor performance and rise in WER. Therefore, the subsequent experiments were consistently performed with increasing rank which provided a stable balance between computational efficiency and recognition accuracy. In the current research work, the results are found to be consistent with the study by [33].
Figure 4, Figure 5, Figure 6 and Figure 7 shows the loss convergence and WER progression of the Adam and AdamW optimizers’ training. The details of training with various batch sizes are also presented. The loss curve of AdamW with the higher batch size is smoother than that of the lower batch size, which has variance and slower descent. The WER curve indicates a better generalization performance as it is more stable and decreasing continuously. The convergence behavior of Adam with a lower batch size is unpredictable, which can be observed by the irregular, non-decreasing loss and WER curves. The drop of the WER and the convergence of Adam are smoother with the higher batch size. AdamW has been preferred to fine-tune Whisper Small when the task is resource-constrained because it is efficient and has lower error rates.
The research studies have compared full fine-tuning and Low-Rank Adaptation (LoRA)-based tuning for Whisper models, highlighting trade-offs between accuracy in terms of WER and computational efficiency. In the research study, it is stated that LoRA fine-tuning significantly reduces computational cost and time while maintaining performance closer to full fine-tuning with a slight reduction in WER [34]. Another study provides the comparative evaluation of results for Whisper Small and other variants, which demonstrates that full fine-tuning yields slightly lower word error rates (WER). However, LoRA achieves comparable performance with fewer trainable parameters. These findings provide evidence which clearly states that LoRA-based adaptation can operate with approximately 1% of the model’s parameters while achieving nearly identical multilingual ASR accuracy measured through WER [20]. Conclusively, the existing body of knowledge justifies that full fine-tuning can provide marginally higher accuracy. However, LoRA-based fine-tuning provides a scientifically validated, resource-efficient alternative that achieves comparable performance with minimal trade-offs.
6. Conclusions
The research study showed that LoRA on the LibriSpeech dataset can fine-tune Whisper Small parameters efficiently. The Adam optimizer’s WER was 6.08%, and the AdamW’s WER was 7.98%, which shows that optimizer selection affects ASR performance. The results clearly indicate that simple WER improvements boost recognition accuracy and systems efficiency. The research work shows that LoRA allows scalable and resource-efficient fine-tuning without updating 244 million Whisper Small parameters, which makes it useful for ASR-related tasks.
Despite these results, the scope of this study is limited to Whisper Small with LoRA under two optimizers on the train-clean-100 and test-clean subsets of the LibriSpeech dataset. The evaluations with larger and noisy datasets, alternative optimizers, and different Whisper model variations could generate more insights. The multilingual ASR, noise-robust transcription, domain-specific adaptability, and variants of LoRA could be utilized for future use. The hybrid optimization and LoRA integration with other parameter-efficient methods may improve ASR performance.
Author Contributions
Conceptualization, H.A., T.A. and M.R.; methodology, H.A., T.A., M.R. and F.K.; software, H.A. and M.P.; validation, H.A., T.A. and M.R.; formal analysis, T.A., M.R., A.H. and F.K.; investigation, T.A. and M.R.; resources, H.A., T.A., M.R., A.H. and F.K.; data curation, H.A.; writing—original draft, H.A. and M.R.; writing—review and editing, T.A., M.R. and F.K.; visualization, H.A., T.A. and M.P.; supervision, T.A. and M.R.; project administration, H.A.; funding acquisition: there is no funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
The research work received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are openly available in OpenSLR at https://www.openslr.org/12, accessed on 10 October 2025.
Conflicts of Interest
There are no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ASR | Automatic Speech Recognition |
| MFCC | Mel-Frequency Cepstral Coefficients (MFCC) |
| PLP | Perceptual Linear Predictive (PLP) features |
| LoRA | Low-Rank Adaptation |
References
- Kheddar, H.; Hemis, M.; Himeur, Y. Automatic speech recognition using advanced deep learning approaches: A survey. Inf. Fusion 2024, 109, 102422. [Google Scholar] [CrossRef]
- Goldstein, A.; Wang, H.; Niekerken, L.; Schain, M.; Zada, Z.; Aubrey, B.; Sheffer, T.; Nastase, S.A.; Gazula, H.; Singh, A.; et al. A unified acoustic-to-speech-to-language embedding space captures the neural basis of natural language processing in everyday conversations. Nat. Hum. Behav. 2025, 9, 1041–1055. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Kaur, N.; Kukreja, V.; Kadyan, V.; Kumar, M. Computational intelligence in processing of speech acoustics: A survey. Complex Intell. Syst. 2022, 8, 2623–2661. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Google, K.T.; Language, A.I. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. Available online: https://aclanthology.org/N19-1423.pdf (accessed on 10 October 2025).
- Baevski, A.; Schneider, S.; Auli, M. VQ-WAV2VEC: Self-supervised learning of discrete speech representations. arXiv 2020, arXiv:2406.05745. [Google Scholar]
- Miao, H.; Cheng, G.; Gao, C.; Zhang, P.; Yan, Y. Transformer-based online CTC/attention end-to-end speech recognition architecture. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 6084–6088. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH 2020, Shanghai, China, 25–29 October 2020; pp. 5036–5040. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; Volume 202, pp. 28492–28518. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised Pre-training for Speech Recognition. arXiv 2019, arXiv:1904.05862. [Google Scholar]
- Wang, S.; Yu, L.; Li, J. LoRA-GA: Low-Rank Adaptation with Gradient Approximation. arXiv 2024, arXiv:2407.05000. [Google Scholar]
- Guo, P.; Chang, X.; Lv, H.; Watanabe, S.; Xie, L. SQ-Whisper: Speaker-Querying Based Whisper Model for Target-Speaker ASR. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 33, 175–185. [Google Scholar] [CrossRef]
- McGuire, M.; Larson-Hall, J. Assessing Whisper automatic speech recognition and WER scoring for elicited imitation: Steps toward automation. Res. Methods Appl. Linguist. 2025, 4, 100197. [Google Scholar] [CrossRef]
- Pour, M.H.R.; Rastin, N.; Kermani, M.M. Persian Automatic Speech Recognition by the Use of Whisper Model. In Proceedings of the 2024 20th CSI International Symposium on Artificial Intelligence and Signal Processing (AISP), Babol, Iran, 21–22 February 2024; pp. 1–7. [Google Scholar]
- Wang, S.; Yang, C.H.; Wu, J.; Zhang, C. Can Whisper Perform Speech-Based in-Context Learning? In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 13421–13425. [Google Scholar]
- Yeo, J.H.; Kim, M.; Watanabe, S.; Ro, Y.M. Visual Speech Recognition for Languages with Limited Labeled Data Using Automatic Labels from Whisper. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 10471–10475. [Google Scholar]
- Liu, W.; Qin, Y.; Peng, Z.; Lee, T. Sparsely Shared Lora on Whisper for Child Speech Recognition. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 11751–11755. [Google Scholar]
- Xu, T.; Huang, K.; Guo, P.; Zhou, Y.; Huang, L.; Xue, H.; Xie, L. Towards Rehearsal-Free Multilingual ASR: A LoRA-based Case Study on Whisper. arXiv 2024, arXiv:2408.10680. [Google Scholar]
- Liu, Y.; Yang, X.; Qu, D. Exploration of Whisper fine-tuning strategies for low-resource ASR. EURASIP J. Audio Speech Music Process. 2024, 2024, 29. [Google Scholar] [CrossRef]
- Polat, H.; Turan, A.K.; Koçak, C.; Ulaş, H.B. Implementation of a Whisper Architecture-Based Turkish Automatic Speech Recognition (ASR) System and Evaluation of the Effect of Fine-Tuning with a Low-Rank Adaptation (LoRA) Adapter on Its Performance. Electronics 2024, 13, 4227. [Google Scholar] [CrossRef]
- Ou, L.; Feng, G. Parameter-Efficient Fine-Tuning Large Speech Model Based on LoRA. In Proceedings of the 2024 27th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Tianjin, China, 8–10 May 2024; pp. 36–41. [Google Scholar]
- Hu, E.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-Rank Adaptation of Large Language Models. In Proceedings of the ICLR 2022—10th International Conference on Learning Representations, Virtual, 25–29 April 2022; pp. 1–26. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing—ICASSP, Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Jannet, M.A.B.; Galibert, O.; Adda-Decker, M.; Rosset, S. How to evaluate ASR output for named entity recognition? In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH 2015, Dresden, Germany, 6–10 September 2015; pp. 1289–1293. [Google Scholar]
- Arif, S.; Khan, A.J.; Abbas, M.; Raza, A.A.; Athar, A. WER We Stand: Benchmarking Urdu ASR Models. In Proceedings of the International Conference on Computational Linguistics, COLING 2025, Abu Dhabi, United Arab Emirates, 19–24 January 2025; pp. 5952–5961. [Google Scholar]
- Zhou, P.; Xie, X.; Lin, Z.; Yan, S. Towards Understanding Convergence and Generalization of AdamW. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 6486–6493. [Google Scholar] [CrossRef] [PubMed]
- Oyedotun, O.K.; Papadopoulos, K.; Aouada, D. A new perspective for understanding generalization gap of deep neural networks trained with large batch sizes. Appl. Intell. 2023, 53, 15621–15637. [Google Scholar] [CrossRef]
- Zhuang, Z.; Liu, M.; Cutkosky, A.; Orabona, F. Understanding AdamW Through Proximal Methods and Scale-Freeness. arXiv 2022, arXiv:2202.00089. [Google Scholar]
- Ramirez, P.Z.; Salti, S.; Stefano, L.D. On large-batch training for deep learning: Generalization gap and sharp minima. arXiv 2017, arXiv:1609.04836. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Hoffer, E.; Hubara, I.; Soudry, D. Train longer, generalize better: Closing the generalization gap in large batch training of neural networks. In Proceedings of the 31st Conference on Neural Information Processing Systems (NeurIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 1–12. [Google Scholar]
- Hu, J.Y.C.; Su, M.; Kuo, E.J.; Song, Z.; Liu, H. Computational Limits of Low-Rank Adaptation (Lora) Fine-Tuning for Transformer Models. In Proceedings of the 13th International Conference on Learning Representations, ICLR 2025, Singapore, 24–28 April 2025; pp. 54606–54645. [Google Scholar]
- Zhang, L.; Wu, S.; Wang, Z. LoRA-INT8 Whisper: A Low-Cost Cantonese Speech Recognition Framework for Edge Devices. Sensors 2025, 25, 5404. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).