1. Introduction
The Kurdish language, characterized by its diverse scripts, extensive lexicon, and unique grammatical structure, is spoken by over 40 million people across multiple countries [
1,
2]. Among its dialects, Badini, predominantly used in the Duhok province of Iraqi Kurdistan and the Hakkari region of southeastern Turkey, holds significant importance [
3]. Employing an Arabic-based script, Badini is classified as a low-resource dialect with complex morphological features, including the extensive use of prefixes, suffixes, and vocabulary separation [
4]. Linguistic resources, essential for language technology and natural language processing (NLP), represent the culture and civilization of a language’s speakers, providing lexical and semantic definitions [
5]. While the Kurdish language is composed of multiple dialects, the development of resources for one dialect can contribute to the enrichment of resources for others. However, the computational analysis of such languages requires substantial time and attention [
6].
Part-of-speech (POS) tagging, a fundamental task in NLP, involves assigning syntactic categories to words within a sentence. Its applications span question-answering systems, information extraction, information retrieval, machine translation, text-to-speech, and preprocessing for parsers [
7]. POS tagging techniques have evolved from rule-based to machine learning and deep learning models, remaining a focal point of NLP research [
8,
9]. The Kurdish Badini dialect presents specific challenges for POS tagging, including lexical ambiguity and the presence of unknown words. These challenges are exacerbated by the dialect’s limited available resources and complex morphological structure [
10]. To address these challenges, three primary approaches have been employed: rule-based, statistical, and hybrid methods. Rule-based systems rely on linguistically defined rules, while statistical approaches utilize machine learning models trained on tagged corpora. Hybrid methods combine elements of both approaches [
11].
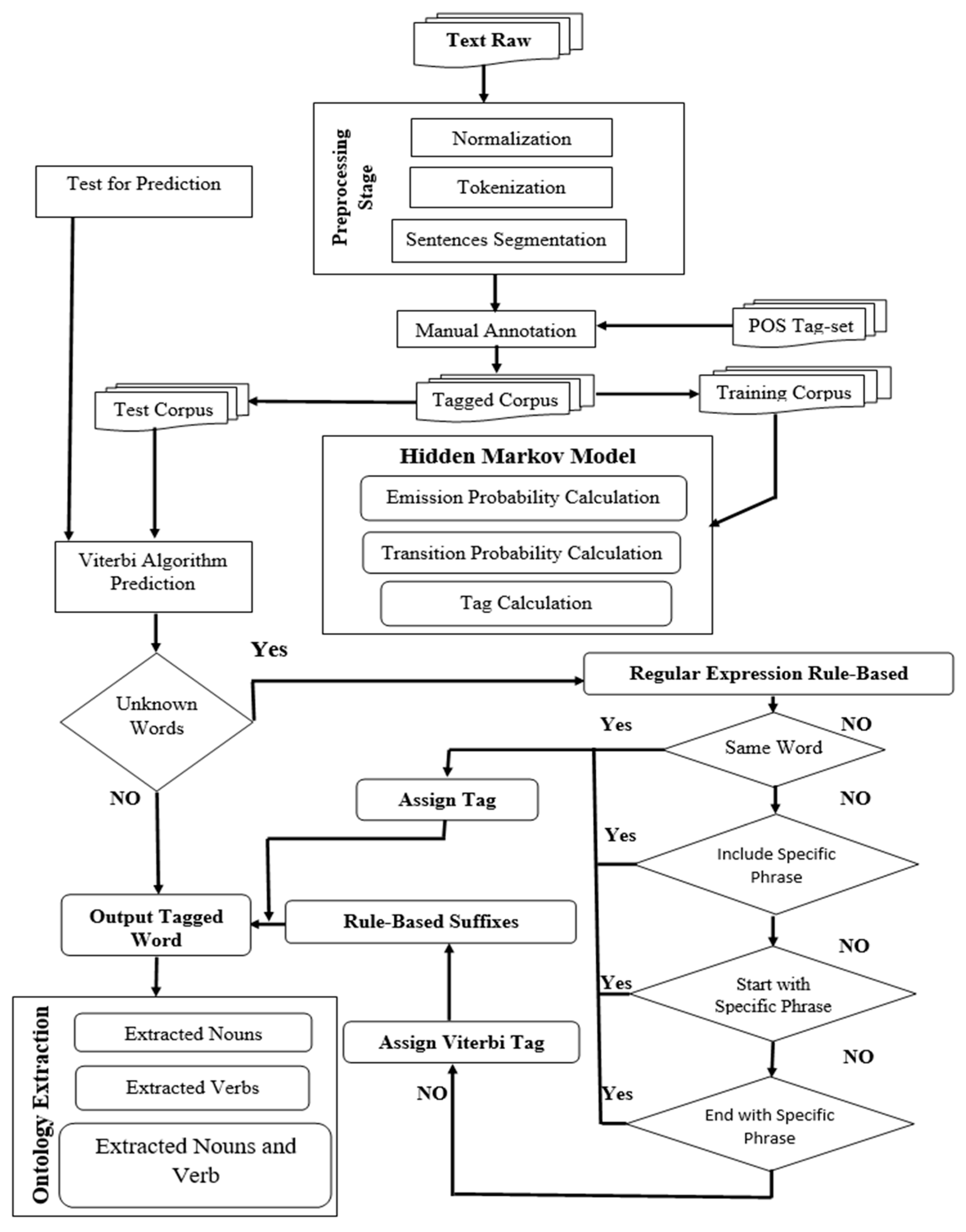
This study adopted a hybrid approach used in Maulud’s method [
12], which integrated a bi-gram Hidden Markov Model (HMM), with a modified rule-based system tailored for Badini. Maximum likelihood estimation was used for parameter estimation, and the Viterbi algorithm was employed for HMM implementation. A module has been developed to refine tag assignments. In addition, the UOZBDN annotated corpus was created, comprising five categories, 51,761 manually annotated words, and 230 articles. The Kurdish Badini tagset, derived from the Stanford POS tagset, consists of 38 tags and was constructed here. Ontologies, abstract models representing concepts and their relationships, provide a structured approach to information retrieval [
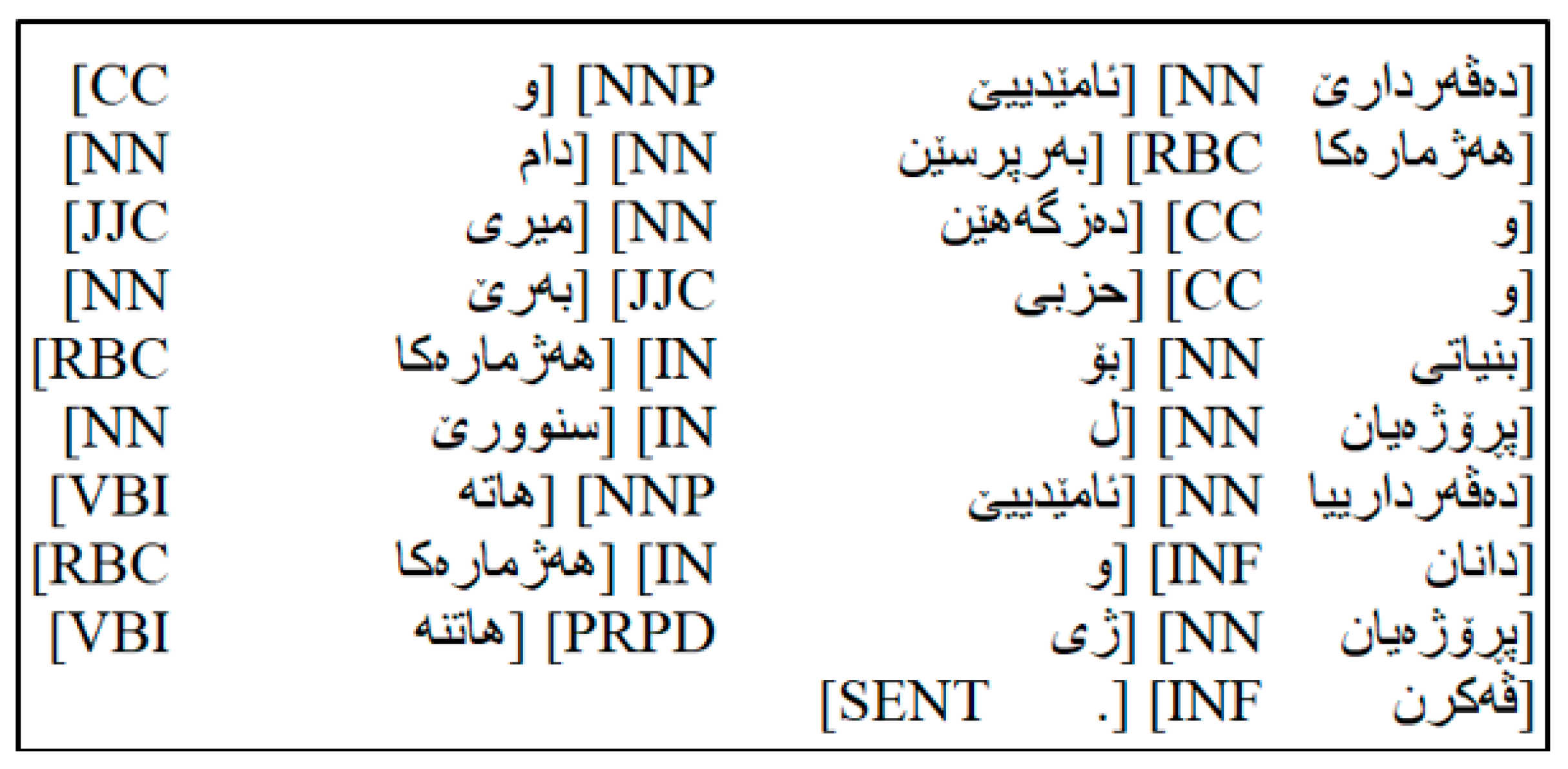
13]. This paper presents a methodology for developing a Badini-dialect ontology using the UOZBDN annotated corpus. Due to the scarcity of Kurdish language resources, particularly ontologies, this work contributes to the field of Kurdish content annotation. The proposed ontology automatically extracts relationships between words and phrases, providing insights into their semantic connections. A significant advancement in natural language processing for low-resource languages is presented through the development of the first semantic web ontology for the Badini dialect of Kurdish. A notable gap in linguistic research has been addressed by creating a Badini annotated corpus (UOZBDN), which was used to develop a bi-gram Hidden Markov Model (HMM)-based POS tagger. This tagger, combined with a modified rule-based system, enabled the automatic extraction of semantic relationships, achieving an accuracy rate of 97%, as validated by Badini language experts. The field of semantic web technologies is enriched by this work, which also lays the groundwork for further research into other underrepresented dialects.
The paper is structured as follows:
Section 2 provides a comprehensive literature review on Kurdish language processing, encompassing POS tagging, corpus development, and ontology extraction. This section also includes a detailed analysis of the existing literature.
Section 3 outlines the methodology employed for this research, including the creation of the UOZBDN corpus, preprocessing, tokenization, sentence splitting, POS tagging, and ontology extraction.
Section 4 presents the evaluation of the extracted ontology.
Section 5 offers a discussion of the results, highlighting key findings and their implications. Finally,
Section 6 concludes the paper by summarizing the research contributions, addressing limitations, and outlining potential avenues for future work.
2. Literature Review
The development of natural language processing applications for the Kurdish language is hindered by a paucity of lexical resources and corpora. Existing Kurdish dictionaries often lack lexicographical rigor, with inconsistent part-of-speech tagging and the inclusion of terms from various dialects. Moreover, the prevalence of physical formats limits digital accessibility, impeding the efficient creation of ontological term lists [
2]. Research efforts have focused on addressing the challenges posed by the Kurdish language’s complex morphology, low-resource nature, and multi-dialectal characteristics [
14]. Preprocessing, tokenization, POS tagging, and ontology extraction have been investigated as potential solutions.
Effective textual analysis requires robust preprocessing techniques. Although data annotation is labor-intensive, it remains essential for model development. In 2021, Amini introduced Awta, the first comprehensive parallel corpus consisting of Central Kurdish and English translations. This corpus, comprising 229,222 meticulously aligned sentence pairs from various text genres and domains, was designed to facilitate the development of robust and practical machine translation systems. However, a comprehensive examination of error types encountered by the machine translation system and their treatment was not included, which could assist in identifying areas where the system faces challenges [
15].
Badawi et al. (2023) noted that a significant challenge with existing datasets is the prevalence of grammatical and dictation errors. They emphasized the necessity of having a sufficient dataset to better understand the syntactic and semantic characteristics of the Kurdish language. In their study, headlines from the Kurdish News Dataset (KNDH) were collected for text categorization. The dataset consists of 50,000 news headlines evenly distributed across five categories: social, sport, health, economics, and technology. The Kurdish Language Processing Toolkit (KLPT) was employed for tokenization, spell-checking, stemming, and general preprocessing [
15].
Tokenization, a fundamental NLP process, is particularly challenging for languages with complex writing systems and spelling variations. A method for tokenizing the Sorani and Kurmanji dialects of Kurdish was proposed by S. Ahmadi in 2020. This approach, employing a lexicon and a morphological analyzer, demonstrated superior performance compared to unsupervised alternatives [
16]. Another study by the same author also contributed to the field by compiling corpora for the Zazaki and Gorani dialects of Kurdish. These corpora, comprising over 1.6 million and 194,000 word tokens, respectively, were constructed from news website content to establish foundational resources for these languages [
17].
POS tagging is essential for enhancing the utility of Kurdish corpora. Research has explored various methodologies, including rule-based and statistical approaches. In 2023, Maulud et al. introduced a Sorani Kurdish corpus annotated with POS tags. This corpus, comprising 74,258 words and 38 tags, was created using a hybrid approach combining a bigram HMM with a Kurdish rule-based system. Despite the corpus’s limited size, an accuracy rate of approximately 96% was achieved [
12]. A study by Morad et al. (2024) focused on addressing the challenges of part-of-speech (POS) tagging and tokenization for Northern Kurdish. They evaluated various statistical, neural, and fine-tuned transformer-based models specifically tailored for Northern Kurdish, utilizing both the Universal Dependency Kurmanji treebank, contributed by Memduh Gökırmak and Francis M. Tyers in 2017 [
18], and a newly developed, manually annotated, gold-standard dataset comprising 136 sentences with 2937 tokens. The findings demonstrated that the fine-tuned transformer-based model significantly outperformed the other models, achieving an accuracy of 0.87 and a macro-averaged F1 score of 0.77 [
19].
Ontology extraction aims to create structured knowledge representations from textual data. In 2017, H. Hassan presented a technique for accurately extracting proper nouns from Kurdish literature. An application was developed utilizing various name lists, rules, and procedures to identify Kurdish person names [
20]. This research contributed to advancing Kurdish information retrieval and simplifying machine translation processes. The proposed method demonstrated accuracy exceeding 95%, with recall ranging from 40% to 80% and an F-measure between 60% and 80%.
The existing works were analyzed by categorizing them into three primary areas: (1) Preprocessing and Tokenization: Preprocessing, tokenization, and POS tagging are emphasized in various Kurdish dialects, particularly Sorani and Kurmanji. These tasks are essential for the development of NLP tools but are not directly linked to ontology extraction. Existing tokenization methods, such as those proposed by Ahmadi, are valuable but fail to address the full complexity of dialectal diversity, especially within the Badini dialect. (2) POS Tagging: Significant advancements in POS tagging have been made through hybrid models and transformer-based approaches, as demonstrated by Maulud et al. and Morad et al. However, the focus remains largely on Kurmanji and Sorani dialects, leaving a gap in tailored solutions for the Badini dialect. Furthermore, these studies concentrate primarily on syntactic classification, rather than addressing the semantic relationships critical to ontology extraction. (3) Ontology Extraction: The primary research in ontology extraction, such as Hassan’s work, has been limited to extracting specific entity types, such as proper nouns. This focus omits more complex tasks, including verb–noun pair identification, which is essential for constructing a more nuanced ontology capable of representing actions, events, and relationships between entities.
The proposed method distinguishes itself from the existing works in several significant ways: (1) Dialectal Focus: While most studies have focused on Sorani and Kurmanji dialects, the proposed method prioritizes the Badini dialect, which uses an Arabic-based script and has not been extensively explored in NLP research. Existing works offer valuable frameworks but lack the specificity required to address the dialectal diversity within Badini. (2) Verb–Noun Pair Extraction: In contrast to the reviewed studies, which primarily focus on proper noun extraction or general POS tagging, the proposed method targets the extraction of verb–noun pairs. This approach provides a more comprehensive ontology that captures actions and relationships within the language, moving beyond the entity-level focus of previous research. (3) Corpus and Dataset Development: The UOZBDN corpus developed in the proposed method addresses the limitations of earlier datasets by focusing specifically on the Badini dialect. Prior corpora, such as Amini’s Awta corpus and Ahmadi’s Sorani and Kurmanji corpora, have not fully captured the linguistic nuances of Badini, particularly concerning its verb and noun structures.
In conclusion, the proposed method significantly differs from previous works through its emphasis on the Badini dialect, its focus on verb–noun pair extraction for ontology development, and the creation of a tailored corpus that directly addresses the challenges specific to this dialect. These contributions fill a critical gap in Kurdish NLP research, expanding the scope of ontology extraction for under-represented dialects.
4. Evaluation
Corpus-based techniques, also known as data-driven approaches, are employed to assess the topical coverage of an ontology. This methodology involves comparing the extracted ontology with a comprehensive corpus representing a specific domain. Unlike traditional ontology comparison methods that rely on pre-existing ontologies, this approach enables the comparison of multiple ontologies with a corpus [
33]. A data-driven approach was utilized to evaluate the developed system. The corpus, encompassing five previously unexplored domains (economics, health, politics, social, and sports), served as the evaluation basis. By analyzing the Badini-dialect corpus, a robust ontology was constructed. Nouns and verbs were identified and extracted from the text, and their correctness was calculated using data-driven methodologies. The resulting ontology contained 2249 ontological sentences and 1320 normal phrases.
The evaluation approach relied on precision, recall, and F1-measure metrics. Recall was calculated as the ratio of accurately identified ontology sentences to the total number of phrases in the sample. Precision was determined by dividing the number of accurately identified ontologies by the total number of identified ontologies. A data-driven evaluation yielded precision of 97.06%, recall of 97.78%, and F-measure of approximately 97.42%. These results represent a significant achievement in the field of Kurdish language processing, particularly for the Badini dialect, as this level of accuracy has not been previously reported.
Table 9 presents the detailed results of the evaluated ontology. The values for true positive (TP), false positive (FP), false negative (FN), and true negative (TN) were obtained by comparing the findings to the original text.
Given the importance of both precision and recall in ontology extraction, the G-measure, a metric that combines these two measures, was deemed appropriate for evaluating our system. The G-measure’s impartiality towards accuracy and recall makes it suitable for tasks where both aspects are equally critical. By considering both the proportion of correctly extracted entities (precision) and the proportion of relevant entities successfully extracted (recall), the G-measure provides a balanced assessment of the ontology extraction system’s performance.
In the evaluation of ontology extraction from textual data, confidence intervals were calculated to assess the reliability of the system’s performance in extracting ontological predicates. A 95% confidence interval was selected, corresponding to a Z-value of 1.96, as 95% of data fall within ±1.96 standard deviations of the mean in a normal distribution. With a sample size of 2249 extracted predicates, the system’s performance metrics were as follows: precision (0.9706), recall (0.9778), F1 score (0.9742), and G-measure (0.9742). The 95% confidence intervals for these metrics were calculated as precision [0.9636, 0.9776], recall [0.9717, 0.9839], F1 score [0.9677, 0.9807], and G-measure [0.9677, 0.9807]. The confidence interval for precision indicates that the true precision of the system, representing the proportion of correctly extracted predicates, lies between 96.36% and 97.76%, reflecting high reliability. The recall interval suggests that the system accurately captures between 97.17% and 98.39% of relevant predicates, demonstrating minimal omission of actual predicates. The F1 score, a harmonic mean of precision and recall, indicates a balanced performance with a likely value between 96.77% and 98.07%, further supported by the identical confidence interval for the G-measure. These consistently narrow intervals indicate a highly reliable and effective ontology extraction system, with performance metrics consistently above 96%, underscoring the system’s robustness in extracting both correct and relevant predicates from textual data.
Author Contributions
Conceptualization, M.A. and K.J.; methodology, M.A.; software, M.A.; validation, M.A., I.A. and K.J.; formal analysis, M.A.; investigation, M.A.; resources, M.A.; data curation, M.A.; writing—original draft preparation, M.A.; writing—review and editing, I.A.; visualization, M.A.; supervision, K.J.; project administration, M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This project received no external funding and was supported by internal resources from the Semantic Web Lab at the University of Zakho.
Data Availability Statement
Data can be made available upon reasonable request.
Acknowledgments
The authors express sincere gratitude to the language experts at the Zakho Center for Kurdish Studies, led by Abdulsalam Najimaldeen Abdullah, for their invaluable contributions to this research. Their expertise in the Badini dialect was instrumental in the creation and refinement of the UOZBDN annotated corpus.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Saeed, A.M.; Ismael, A.N.; Rasul, D.L.; Majeed, R.S.; Rashid, T.A. Hate Speech Detection in Social Media for the Kurdish Language. In Proceedings of the ICR’22 International Conference on Innovations in Computing Research, Athens, Greece, 29–31 August 2022; Daimi, K., Al Sadoon, A., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 253–260. [Google Scholar]
- Naserzade, M.; Mahmudi, A.; Veisi, H.; Hosseini, H.; MohammadAmini, M. CKMorph: A comprehensive morphological analyzer for Central Kurdish. Int. J. Digit. Humanit. 2023, 5, 187–232. [Google Scholar] [CrossRef]
- Weeden, M.J.N. Postgate (ed.): Languages of Iraq, Ancient and Modern. ix, 187 pp. London: British School of Archaeology in Iraq, 2007. ISBN 978 0 903472 21 0. Bull. Sch. Orient. Afr. Stud. 2008, 71, 397–399. [Google Scholar] [CrossRef]
- Syan, K.A.Q. Media in an Emergent Democracy: The Development of Online Journalism in the Kurdistan Region of Iraq. Ph.D. Thesis, University of Bradford, Bradford, UK, 2017. [Google Scholar]
- Azin, Z.; Ahmadi, S. Creating an Electronic Lexicon for the Under-resourced Southern Varieties of Kurdish Language. In Proceedings of the Electronic Lexicography in the 21st Century Conference, Brno, Czech Republic, 5–7 July 2021; pp. 479–488. [Google Scholar]
- Tavadze, G. Spreading of the Kurdish Language Dialects and Writing Systems Used in the Middle East. Bull. Georg. Natl. Acad. Sci. 2019, 13, 170–174. [Google Scholar]
- Hassani, H. Part of Speech Tagging (POST) of a Low-Resource Language Using Another Language (Developing a POS-Tagged Lexicon for Kurdish (Sorani) using a Tagged Persian (Farsi) Corpus). arXiv 2022, arXiv:2201.12793. [Google Scholar]
- Amri, S.; Zenkouar, L. Amazigh POS Tagging using TreeTagger: A Language Independant Model; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2019; Volume 915, ISBN 978-3-030-11927-0. [Google Scholar] [CrossRef]
- Maulud, D.H.; Ameen, S.Y.; Omar, N.; Kak, S.F.; Rashid, Z.N.; Yasin, H.M.; Ibrahim, I.M.; Salih, A.A.; Salim, N.O.; Ahmed, D.M. Review on Natural Language Processing Based on Different Techniques. Asian J. Res. Comput. Sci. 2021, 10, 1–17. [Google Scholar] [CrossRef]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. CSUR 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Ahmadi, S.; Hassani, H.; McCrae, J.P. Towards electronic lexicography for the Kurdish language. In Proceedings of the Sixth Biennial Conference on Electronic Lexicography (eLex), Sintra, Portugal, 1–3 October 2019. [Google Scholar]
- Maulud, D.; Jacksi, K.; Ali, I. A hybrid part-of-speech tagger with annotated Kurdish corpus: Advancements in POS tagging. Digit. Scholarsh. Humanit. 2023, 38, 1604–1612. [Google Scholar] [CrossRef]
- Sharipov, M.; Kuriyozov, E.; Yuldashev, O.; Sobirov, O. UzbekTagger: The Rule-Based POS Tagger for Uzbek Language. arXiv 2023, arXiv:2301.12711. [Google Scholar]
- Azzat, M.; Jacksi, K.; Ali, I. The Kurdish Language Corpus: State of the Art. Sci. J. Univ. Zakho 2023, 11, 125–131. [Google Scholar] [CrossRef]
- Badawi, S.; Saeed, A.M.; Ahmed, S.A.; Abdalla, P.A.; Hassan, D.A. Kurdish News Dataset Headlines (KNDH) through multiclass classification. Data Brief 2023, 48, 109120. [Google Scholar] [CrossRef] [PubMed]
- Ahmadi, S. A Tokenization System for the Kurdish Language. In Proceedings of the 7th VarDial Workshop on NLP for Similar Languages, Varieties and Dialects, Barcelona, Spain, 13 December 2020; pp. 114–127. [Google Scholar]
- Ahmadi, S. Building a Corpus for the Zaza–Gorani Language Family. In Proceedings of the 7th VarDial Workshop on NLP for Similar Languages, Barcelona, Spain, 13 December 2020; pp. 70–78. [Google Scholar]
- Gökırmak, M.; Tyers, F.M. A Dependency Treebank for Kurmanji Kurdish. In Proceedings of the Fourth International Conference on Dependency Linguistics (Depling 2017), Pisa, Italy, 18–20 September 2017; Montemagni, S., Nivre, J., Eds.; Linköping University Electronic Press: Pisa, Italy, 2017; pp. 64–72. Available online: https://aclanthology.org/W17-6509 (accessed on 15 April 2024).
- Morad, P.; Ahmadi, S.; Gatti, L. Part-of-Speech Tagging for Northern Kurdish. In Proceedings of the Joint Workshop on Multiword Expressions and Universal Dependencies (MWE-UD) @ LREC-COLING 2024, Torino, Italy, 25 May 2024; pp. 70–80. [Google Scholar]
- Hassani, H. A method for proper noun extraction in Kurdish. In Proceedings of the 6th Symposium on Languages, Applications and Technologies (SLATE 2017), Vila do Conde, Portugal, 26–27 June 2017. [Google Scholar] [CrossRef]
- Veisi, H.; MohammadAmini, M.; Hosseini, H. Toward Kurdish language processing: Experiments in collecting and processing the AsoSoft text corpus. Digit. Scholarsh. Humanit. 2019, 35, 176–193. [Google Scholar] [CrossRef]
- Ahmadi, S. KLPT—Kurdish Language Processing Toolkit. In Proceedings of the Second Workshop for NLP Open Source Software (NLP-OSS), Online, 19 November 2020; pp. 72–84. [Google Scholar] [CrossRef]
- Ahmad, H.A.; Rashid, T.A. Gigant-KTTS dataset: Towards building an extensive gigant dataset for Kurdish text-to-speech systems. Data Brief 2024, 55, 110753. [Google Scholar] [CrossRef]
- Maulud, D.; Jacksi, K.; Ali, I. Towards a Complete Kurdish NLP Pipeline: Challenges and Opportunities. J. Inform. 2023, 17, 1–17. [Google Scholar]
- Ahmadi, S.; Hassani, H. Towards Finite-State Morphology of Kurdish. arXiv 2020, arXiv:2005.10652. [Google Scholar]
- Salehi, A.; Jacobs, C.L. The effect of model capacity and script diversity on subword tokenization for Soranî Kurdish. In Proceedings of the 21st SIGMORPHON workshop on Computational Research in Phonetics, Phonology, and Morpholog, Mexico City, Mexico, 20 June 2024; pp. 51–56. [Google Scholar]
- Cing, D.L.; Soe, K.M. Improving accuracy of part-of-speech (POS) tagging using hidden markov model and morphological analysis for Myanmar Language. Int. J. Electr. Comput. Eng. 2020, 10, 2023–2030. [Google Scholar] [CrossRef]
- Lam Cing, D.; Mar Soe, K. Joint Word Segmentation and Part-of-Speech (POS) Tagging for Myanmar Language. In Proceedings of the 17th International Conference on Computer Application, Yangon, Myanmar, 27–28 February 2019; pp. 141–146. [Google Scholar]
- Tukur, A.; Umar, K.; Sa, A. Parts-of-Speech Tagging of Hausa-Based Texts Using Hidden Markov Model. Dutse J. Pure Appl. Sci. 2020, 6, 303–313. [Google Scholar]
- Ahmadi, S. Hunspell for Sorani Kurdish Spell Checking and Morphological Analysis. arXiv 2021, arXiv:2021.06374. [Google Scholar]
- Jain, V.; Singh, M. Ontology Based Information Retrieval in Semantic Web: A Survey. Int. J. Inf. Technol. Comput. Sci. 2013, 5, 62–69. [Google Scholar] [CrossRef]
- Al-Yahya, M.; Al-Shaman, M.; Al-Otaiby, N.; Al-Sultan, W.; Al-Zahrani, A.; Al-Dalbahie, M. Ontology-Based Semantic Annotation of Arabic Language Text. Int. J. Mod. Educ. Comput. Sci. 2015, 7, 53–59. [Google Scholar] [CrossRef]
- Raad, J.; Cruz, C. A survey on ontology evaluation methods. In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Lisbon, Portugal, 12–14 November 2015; Volume 2, pp. 179–186. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}